Thread: check point segments leakage ?
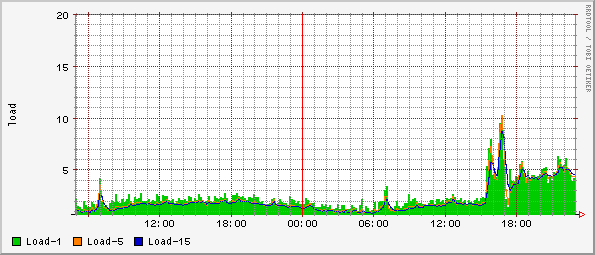
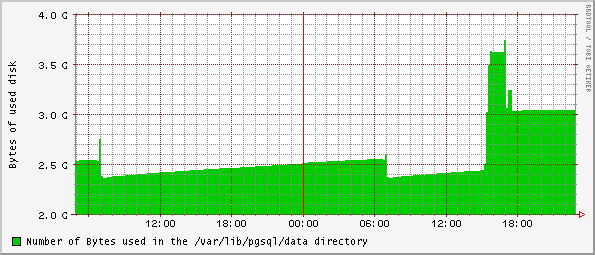
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1 Hi all, today I add 4 new columns to a table with 4E+06 rows, I also update to an initial value these new columns. The new columns are 3 INTEGER one of type DOUBLE. The table have also 5 indexes. Immediately after the operation my partition "data" had an usage increment of 1.2GB. I did a reindex and a vacuum full on that table and 600MB were freed. Now I have an increment of only 600 MB. I use a checkpoint_segments = 16 but in my pg_xlog I have 35 files. Why 35 files ? Where are lost my 600MB ? Also the load increased from 1 to 5 !! Any ideas ? I'm attaching boot graphs ( HD space usage and load ). Regards Gaetano Mendola -----BEGIN PGP SIGNATURE----- Version: GnuPG v1.2.4 (MingW32) Comment: Using GnuPG with Thunderbird - http://enigmail.mozdev.org iD8DBQFA/Ydh7UpzwH2SGd4RAuhKAKCTftBGjBLSfR+OTy5vHlYpL46TXQCfc65/ VfepMM87dQKvg3rswhGUNL8= =HWHy -----END PGP SIGNATURE-----
Attachment
{kind=link}
{kind=link}
Hello, Perhaps you have an open transaction that isn't closing and thus the pg_xlog continues to grow? Sincerely, Joshua D. Drake Gaetano Mendola wrote: > -----BEGIN PGP SIGNED MESSAGE----- > Hash: SHA1 > > Hi all, > today I add 4 new columns to a table with 4E+06 rows, > I also update to an initial value these new columns. > > The new columns are 3 INTEGER one of type DOUBLE. > The table have also 5 indexes. > > Immediately after the operation my partition "data" had > an usage increment of 1.2GB. > I did a reindex and a vacuum full on that table and 600MB > were freed. > > Now I have an increment of only 600 MB. > > I use a checkpoint_segments = 16 but in my pg_xlog I have > 35 files. Why 35 files ? > > Where are lost my 600MB ? > > Also the load increased from 1 to 5 !! > Any ideas ? > > I'm attaching boot graphs ( HD space usage and load ). > > Regards > Gaetano Mendola > > > -----BEGIN PGP SIGNATURE----- > Version: GnuPG v1.2.4 (MingW32) > Comment: Using GnuPG with Thunderbird - http://enigmail.mozdev.org > > iD8DBQFA/Ydh7UpzwH2SGd4RAuhKAKCTftBGjBLSfR+OTy5vHlYpL46TXQCfc65/ > VfepMM87dQKvg3rswhGUNL8= > =HWHy > -----END PGP SIGNATURE----- > > ------------------------------------------------------------------------ > > > ------------------------------------------------------------------------ > > > ------------------------------------------------------------------------ > > > ---------------------------(end of broadcast)--------------------------- > TIP 8: explain analyze is your friend -- Command Prompt, Inc., home of Mammoth PostgreSQL - S/ODBC and S/JDBC Postgresql support, programming shared hosting and dedicated hosting. +1-503-667-4564 - jd@commandprompt.com - http://www.commandprompt.com Mammoth PostgreSQL Replicator. Integrated Replication for PostgreSQL
Attachment
Bruce said the other day open transactions can't cause this problem. I wonder what all can? On Tue, 2004-07-20 at 16:32, Joshua D. Drake wrote: > Hello, > > Perhaps you have an open transaction that isn't closing and thus the > pg_xlog continues to grow? > > Sincerely, > > Joshua D. Drake > > > Gaetano Mendola wrote: > > -----BEGIN PGP SIGNED MESSAGE----- > > Hash: SHA1 > > > > Hi all, > > today I add 4 new columns to a table with 4E+06 rows, > > I also update to an initial value these new columns. > > > > The new columns are 3 INTEGER one of type DOUBLE. > > The table have also 5 indexes. > > > > Immediately after the operation my partition "data" had > > an usage increment of 1.2GB. > > I did a reindex and a vacuum full on that table and 600MB > > were freed. > > > > Now I have an increment of only 600 MB. > > > > I use a checkpoint_segments = 16 but in my pg_xlog I have > > 35 files. Why 35 files ? > > > > Where are lost my 600MB ? > > > > Also the load increased from 1 to 5 !! > > Any ideas ? > > > > I'm attaching boot graphs ( HD space usage and load ). > > > > Regards > > Gaetano Mendola > > > > > > -----BEGIN PGP SIGNATURE----- > > Version: GnuPG v1.2.4 (MingW32) > > Comment: Using GnuPG with Thunderbird - http://enigmail.mozdev.org > > > > iD8DBQFA/Ydh7UpzwH2SGd4RAuhKAKCTftBGjBLSfR+OTy5vHlYpL46TXQCfc65/ > > VfepMM87dQKvg3rswhGUNL8= > > =HWHy > > -----END PGP SIGNATURE----- > > > > ------------------------------------------------------------------------ > > > > > > ------------------------------------------------------------------------ > > > > > > ------------------------------------------------------------------------ > > > > > > ---------------------------(end of broadcast)--------------------------- > > TIP 8: explain analyze is your friend >
Joshua D. Drake wrote: > Hello,>> Perhaps you have an open transaction that isn't closing and thus the> pg_xlog continues to grow?>> Sincerely,>>Joshua D. Drake I was thinking about it but unfortunately there is no transaction open. On my development database, were I simulate the same operation that I did in production I have the same situation: 34 files and same configuration, right now there are 5 connection and no one of them have a transaction opened: template1=# select * from pg_locks ; relation | database | transaction | pid | mode | granted ----------+----------+-------------+-------+-----------------+--------- 16759 | 1 | | 15910 | AccessShareLock| t | | 7714652 | 15910 | ExclusiveLock | t Regards Gaetano Mendola
Scott Marlowe wrote: > > > I use a checkpoint_segments = 16 but in my pg_xlog I have > > > 35 files. Why 35 files ? You have 35 because the max files in pg_xlog is 2*checkpoint_segments +1 or something like that. This is documented in the SGML. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 359-1001+ If your life is a hard drive, | 13 Roberts Road + Christ can be your backup. | Newtown Square, Pennsylvania19073
Bruce Momjian wrote: > Scott Marlowe wrote: > >>>>I use a checkpoint_segments = 16 but in my pg_xlog I have >>>>35 files. Why 35 files ? > > > You have 35 because the max files in pg_xlog is 2*checkpoint_segments +1 > or something like that. This is documented in the SGML. Ok, that explain why. And they will remain there also if not needed ? Another weird behaviour is that during the day the storage space usage increase gruadualy. Since today as the graph show the space usage is constant, it's like if some space was pre-allocated and now is used, see same yesterday period between 18:00 and 24:00. Toughts ? Regards Gaetano Mendola
Gaetano Mendola wrote: > Bruce Momjian wrote: > > > Scott Marlowe wrote: > > > >>>>I use a checkpoint_segments = 16 but in my pg_xlog I have > >>>>35 files. Why 35 files ? > > > > > > You have 35 because the max files in pg_xlog is 2*checkpoint_segments +1 > > or something like that. This is documented in the SGML. > > Ok, that explain why. And they will remain there also if not needed ? Yes, it keeps them around so it doesn't need to recreate them. > Another weird behaviour is that during the day the storage space usage > increase gruadualy. Since today as the graph show the space usage > is constant, it's like if some space was pre-allocated and now is > used, see same yesterday period between 18:00 and 24:00. > Toughts ? My guess is that you need a certain amount of free space in the tables to operate properly. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 359-1001+ If your life is a hard drive, | 13 Roberts Road + Christ can be your backup. | Newtown Square, Pennsylvania19073
Bruce Momjian wrote: > Gaetano Mendola wrote:>>>Bruce Momjian wrote:>>>>>>>Scott Marlowe wrote:>>>>>>>>>>>>I use a checkpoint_segments = 16 butin my pg_xlog I have>>>>>>35 files. Why 35 files ?>>>>>>>>>You have 35 because the max files in pg_xlog is 2*checkpoint_segments+1>>>or something like that. This is documented in the SGML.>>>>Ok, that explain why. And they willremain there also if not needed ?>>> Yes, it keeps them around so it doesn't need to recreate them.>>>>Another weirdbehaviour is that during the day the storage space usage>>increase gruadualy. Since today as the graph show the spaceusage>>is constant, it's like if some space was pre-allocated and now is>>used, see same yesterday period between 18:00and 24:00.>>Toughts ?>>> My guess is that you need a certain amount of free space in the tables> to operate properly. Well, today I stop the pg_autovacuum and I did a vacuum full and I reindexed all big tables and other 500 MB were reclamed. Could be the pg_autovacuum running yesterday the responsible for these 500MB not reclamed during a vacuum full and reindex already performed yesterday ? I'm wandering if will be possible in the 7.5 start and stop the the autovacuum integrated in the backend. I don't know if there is space for improvements but add columns to a table with milion rows is very painfull, for sure could be usefull to do the following tree operation in one shot: 1) Add column 2) Update the column 3) Set not null Regards Gaetano Mendola
Gaetano Mendola wrote: > Well, today I stop the pg_autovacuum and I did a vacuum full and I > reindexed > all big tables and other 500 MB were reclamed. Could be the pg_autovacuum > running yesterday the responsible for these 500MB not reclamed during > a vacuum full and reindex already performed yesterday ? Probably not. Most of the time pg_autovacuum is just sleeping. If you happened to fun a VACUUM FULL while pg_autovacuum was running a vacuum, there might have been a conflict on the tabke pg_autovacuum was working with at the time. Also, are you sure that the space wasn't reclaimed yesterday after the VACUUM FULL? It could be that your tables have grown 500M since then. Remember, the minimum table size (the size after a VACUUM FULL) is not necessarilly the optimial size. Postgresql will almost always need to reallocate the space that was reclaimed by VACUUM FULL. > I'm wandering if will be possible in the 7.5 start and stop the the > autovacuum integrated in the backend. Yes (at least the patch waiting to be applied to CVS HEAD does) in order to stop autovacuum you will have to edit the autovac option in postgresql.conf and HUP the postmaster. Matthew
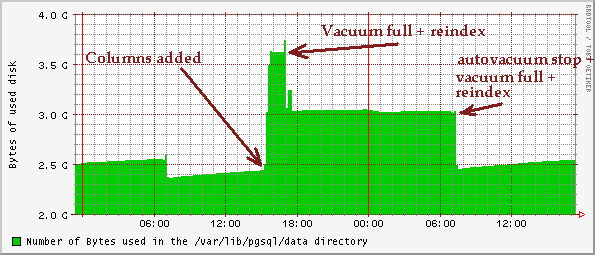
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1 Matthew T. O'Connor wrote: | Gaetano Mendola wrote: | |> Well, today I stop the pg_autovacuum and I did a vacuum full and I |> reindexed |> all big tables and other 500 MB were reclamed. Could be the pg_autovacuum |> running yesterday the responsible for these 500MB not reclamed during |> a vacuum full and reindex already performed yesterday ? | | | Probably not. Most of the time pg_autovacuum is just sleeping. If you | happened to fun a VACUUM FULL while pg_autovacuum was running a vacuum, | there might have been a conflict on the tabke pg_autovacuum was working | with at the time. | | Also, are you sure that the space wasn't reclaimed yesterday after the | VACUUM FULL? It could be that your tables have grown 500M since then. | Remember, the minimum table size (the size after a VACUUM FULL) is not | necessarilly the optimial size. Postgresql will almost always need to | reallocate the space that was reclaimed by VACUUM FULL. I'm pretty sure, see the attached graph. Each morning at 7 a script stop the autovacuum, vacuum full the database and reindex the eavy updated tables and restart of course the autovacuum. Note also that for all the day I didn't have the usual disk usage increment. |> I'm wandering if will be possible in the 7.5 start and stop the the |> autovacuum integrated in the backend. | | | Yes (at least the patch waiting to be applied to CVS HEAD does) in order | to stop autovacuum you will have to edit the autovac option in | postgresql.conf and HUP the postmaster. This is a good news. Regards Gaetano Mendola -----BEGIN PGP SIGNATURE----- Version: GnuPG v1.2.4 (MingW32) Comment: Using GnuPG with Thunderbird - http://enigmail.mozdev.org iD8DBQFA/o2Z7UpzwH2SGd4RAi38AKCO7XqClR/+X5b8szVJwbREC50HrQCg5M8n R5ODgRU05IGnnS1YaK4afIk= =ftFY -----END PGP SIGNATURE-----
Attachment
{kind=link}
Gaetano Mendola wrote: > I'm pretty sure, see the attached graph. Each morning at 7 a script stop > the autovacuum, vacuum full the database and reindex the eavy updated > tables > and restart of course the autovacuum. Note also that for all the day I > didn't > have the usual disk usage increment. I don't know why the 1st VACUUM FULL wasn't able to reclaim the same amount of space as the 2nd one, but I would guess that it wasn't able to get a lock on some table. It could have been autovac if it was doing a vacuum at that moment, but it could have been something else too. From the attached graph, it looks like your stead state database size is approx 3.0G. After the 2nd VACUUM FULL, you dropped to 2.5G, but as you can see it's creeping up back up again. If you let it continue to run without running VACUUM FULL, but with autovacuum enabled, and it climbs to 3.0G and stops growing, then I think you are fine and you don't need to run VACUUM FULL at all. If it continues to grop witout bound, then you need to up your FSM and/or make autovac more aggressive. Bottom line, you shouldn't need VACUUM FULL, if you do, I think there are people on this list that would like to hear about it. Matthew
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1 Matthew T. O'Connor wrote: | Gaetano Mendola wrote: | |> I'm pretty sure, see the attached graph. Each morning at 7 a script stop |> the autovacuum, vacuum full the database and reindex the eavy updated |> tables |> and restart of course the autovacuum. Note also that for all the day I |> didn't |> have the usual disk usage increment. | | | I don't know why the 1st VACUUM FULL wasn't able to reclaim the same | amount of space as the 2nd one, but I would guess that it wasn't able to | get a lock on some table. It could have been autovac if it was doing a | vacuum at that moment, but it could have been something else too. | | From the attached graph, it looks like your stead state database size | is approx 3.0G. After the 2nd VACUUM FULL, you dropped to 2.5G, but as | you can see it's creeping up back up again. | | If you let it continue to run without running VACUUM FULL, but with | autovacuum enabled, and it climbs to 3.0G and stops growing, then I | think you are fine and you don't need to run VACUUM FULL at all. If it | continues to grop witout bound, then you need to up your FSM and/or make | autovac more aggressive. | | Bottom line, you shouldn't need VACUUM FULL, if you do, I think there | are people on this list that would like to hear about it. I will try to disable ( I hope the management is not reading this list ) the vacuum full performed each morning, I'll leave only the reindex for a couple of table and I'll see what happen I will post another graph Regards Gaetano Mendola -----BEGIN PGP SIGNATURE----- Version: GnuPG v1.2.4 (MingW32) Comment: Using GnuPG with Thunderbird - http://enigmail.mozdev.org iD8DBQFA/p247UpzwH2SGd4RAokEAJ9+xhF9g8ZbzE3ne6qCFOuV6z3LmACg9yQR hL7LaOX8EucswifK5okQZ9g= =jKG9 -----END PGP SIGNATURE-----
> I don't know why the 1st VACUUM FULL wasn't able to reclaim the same > amount of space as the 2nd one, but I would guess that it wasn't able to > get a lock on some table. It could have been autovac if it was doing a > vacuum at that moment, but it could have been something else too. Or there was a long running transaction in the background. The oldest active transaction will place limits on what VACUUM can or cannot remove.
On Wed, 2004-07-21 at 18:54, Rod Taylor wrote: > > I don't know why the 1st VACUUM FULL wasn't able to reclaim the same > > amount of space as the 2nd one, but I would guess that it wasn't able to > > get a lock on some table. It could have been autovac if it was doing a > > vacuum at that moment, but it could have been something else too. > > Or there was a long running transaction in the background. The oldest > active transaction will place limits on what VACUUM can or cannot > remove. > What happens when a transaction fails to either commit or abort as a result of a serious error? That looks like a transaction-in-progress doesn't it? Would that prevent VACUUM from doing its work? It should be able to check the last startup xid to check that isn't the case, but suppose a backend had exited without taking down the postmaster. (...waits for thunder...) Best Regards, Simon Riggs
> What happens when a transaction fails to either commit or abort as a > result of a serious error? > > That looks like a transaction-in-progress doesn't it? > > Would that prevent VACUUM from doing its work? It should be able to > check the last startup xid to check that isn't the case, but suppose a > backend had exited without taking down the postmaster. I don't know if this is the case now or not (I imagine it's pretty good at cleaning up at the moment), but if we implemented 2 Phase Commit this logic would need to be removed as transactions need to cross database restarts.
>> ...
>> Would that prevent VACUUM from doing its work? It should be able to
>> check the last startup xid to check that isn't the case, but suppose a
>> backend had exited without taking down the postmaster.
There is no such thing as a backend crashing without the postmaster
noticing (at least not unless your kernel is seriously broken).
It is entirely possible for a backend not to log xact commit or abort,
though --- in fact I think that is the normal case for a read-only
transaction (no point in writing a clog entry if no one will ever
consult it, eh?). This is not unsafe because the actual logic for
such things is:
1. Transaction still running? (check shared memory PGPROC array to see if any backend claims to be running it)
2. Transaction committed or aborted according to pg_clog?
3. If none of the above, it must have crashed --- mark it aborted in pg_clog.
Also, VACUUM's pruning logic does not depend at all on whether individual
transactions are still running or not. The issue there is the oldest
xid that is still shown as running in the shared-memory PGPROC array.
AFAIK this is highly reliable.
regards, tom lane