Thanks for your comments.
My reply inserted into the following section.
> Hi,
>
> May "GB18030 server side support" deserve reconsidering, after about 15 years later than release of GB18030-2005?
> It may be the one of most green features for PostgreSQL.
Moving GB18030 to server side encoding requires a technical challenge:
currently PostgreSQL's SQL parser and perhaps in other parts of
backend assume that each byte in a string data is not confused with
ASCII byte. Since GB18030's second and fourth byte are in range of
0x40 to 0x7e, backend will be confused. How do you resolve the
technical challenge exactly?
--Parker:
I do not have an exact solution proposal yet.
Maybe an investigation on MySQL's mechanism would be of help.> 1. In this big data and mobile era, in the country with most population, 50% more disk energy consuming for Chinese characters (UTF-8 usually 3 bytes for a Chinese character, while GB180830 only 2 bytes) is indeed a harm to "Carbon Neutral", along with Polar ice melting.Really? I thought GB18030 uses up to 4 bytes.https://en.wikipedia.org/wiki/GB_18030#Encoding--Parker: More preciously description should be GB18030 use 2 or 4 bytes for Chinese characters.
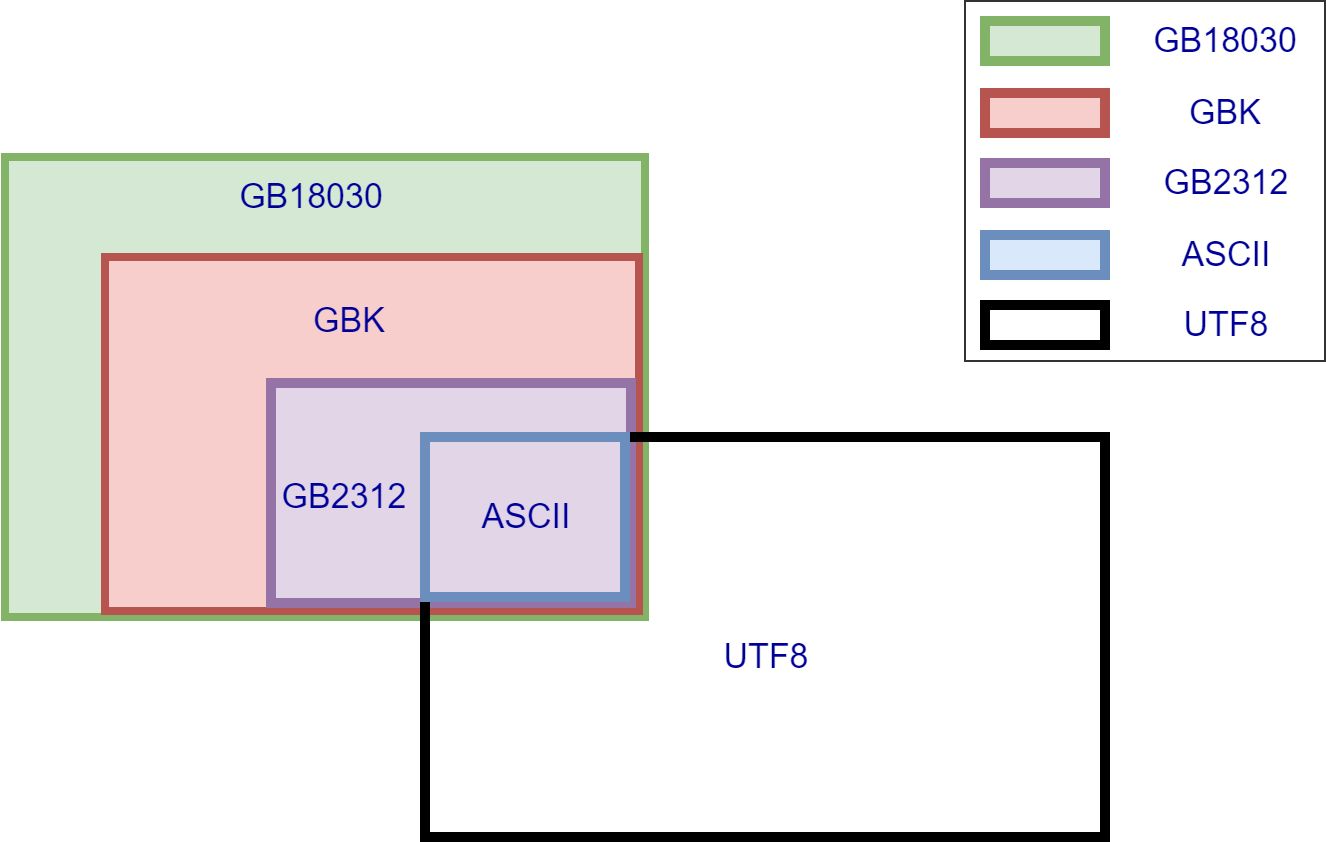
It's a bit complicated to explain with only words but easy with help of the following graph.
Most frequently used 20902 Chinese characters and 984 symbols in GBK is encoded with 2 bytes, which is a subset of GB18030.
Newly added not so frequently but indeed used characters and symbols in GB18030 use 4 bytes.
Best regards,
--
Tatsuo Ishii
SRA OSS, Inc. Japan
English:
http://www.sraoss.co.jp/index_en.php Japanese:http://www.sraoss.co.jp