Thread: can postgresql supported utf8mb4 character sets ?
can postgresql supported utf8mb4 character set?
today mobile apps support 4-byte character and utf8 can only support 1-3 bytes character
if load string to database which contain a 4-byte character will failed .
mysql since 5.5.3 support utf8mb4 character sets
I don't find some information about postgresql
thanks
On 03/05/2015 01:45 AM, lsliang wrote: > can postgresql supported utf8mb4 character set? > today mobile apps support 4-byte character and utf8 can only > support 1-3 bytes character The docs would seem to indicate otherwise: http://www.postgresql.org/docs/9.3/interactive/multibyte.html http://en.wikipedia.org/wiki/UTF-8 > if load string to database which contain a 4-byte character > will failed . Have you actually tried to load strings in to Postgres? If so and it failed what was the method you used and what was the error? > mysql since 5.5.3 support utf8mb4 character sets > I don't find some information about postgresql > thanks -- Adrian Klaver adrian.klaver@aklaver.com
2015-03-06
发件人:Adrian Klaver
发送时间:2015-03-05 21:31:39
收件人:lsliang; pgsql-general
抄送:
主题:Re: [GENERAL] can postgresql supported utf8mb4 character sets?
On 03/05/2015 01:45 AM, lsliang wrote:
> can postgresql supported utf8mb4 character set?
> today mobile apps support 4-byte character and utf8 can only
> support 1-3 bytes character
The docs would seem to indicate otherwise:
http://www.postgresql.org/docs/9.3/interactive/multibyte.html
http://en.wikipedia.org/wiki/UTF-8
> if load string to database which contain a 4-byte character
> will failed .
Have you actually tried to load strings in to Postgres?
If so and it failed what was the method you used and what was the error?
> mysql since 5.5.3 support utf8mb4 character sets
> I don't find some information about postgresql
> thanks
--
Adrian Klaver
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
thanks for your help .
postgresql can support 4-byte character
test=> select * from utf8mb4_test ;
ERROR: character with byte sequence 0xf0 0x9f 0x98 0x84 in encoding "UTF8" has no equivalent in encoding "GB18030"
test=> \encoding utf8
test=> select * from utf8mb4_test ;
content
---------
😄
😄
pcauto=>
On 03/05/2015 06:55 PM, lsliang wrote: > 2015-03-06 > * > * > ------------------------------------------------------------------------ > *发件人:*Adrian Klaver > *发送时间:*2015-03-05 21:31:39 > *收件人:*lsliang; pgsql-general > *抄送:* > *主题:*Re: [GENERAL] can postgresql supported utf8mb4 character sets? > On 03/05/2015 01:45 AM, lsliang wrote: > > can postgresql supported utf8mb4 character set? > > today mobile apps support 4-byte character and utf8 can only > > support 1-3 bytes character > The docs would seem to indicate otherwise: > http://www.postgresql.org/docs/9.3/interactive/multibyte.html > http://en.wikipedia.org/wiki/UTF-8 > > if load string to database which contain a 4-byte character > > will failed . > Have you actually tried to load strings in to Postgres? > If so and it failed what was the method you used and what was the error? > > mysql since 5.5.3 support utf8mb4 character sets > > I don't find some information about postgresql > > thanks > -- > Adrian Klaver > adrian.klaver@aklaver.com <mailto:adrian.klaver@aklaver.com> > >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> > thanks for your help . > postgresql can support 4-byte character > test=> select * from utf8mb4_test ; > ERROR: character with byte sequence 0xf0 0x9f 0x98 0x84 in encoding "UTF8" has no equivalent in encoding "GB18030" > test=> \encoding utf8 > test=> select * from utf8mb4_test ; > content > --------- > 😄 > 😄 > pcauto=> FYI, you can force the client encoding: http://www.postgresql.org/docs/9.4/interactive/app-psql.html "If both standard input and standard output are a terminal, then psql sets the client encoding to "auto", which will detect the appropriate client encoding from the locale settings (LC_CTYPE environment variable on Unix systems). If this doesn't work out as expected, the client encoding can be overridden using the environment variable PGCLIENTENCODING." -- Adrian Klaver adrian.klaver@aklaver.com
On Fri, Mar 6, 2015 at 3:55 AM, lsliang <lsliang@pconline.com.cn> wrote:
2015-03-06发件人:Adrian Klaver发送时间:2015-03-05 21:31:39收件人:lsliang; pgsql-general抄送:主题:Re: [GENERAL] can postgresql supported utf8mb4 character sets?On 03/05/2015 01:45 AM, lsliang wrote:> can postgresql supported utf8mb4 character set?> today mobile apps support 4-byte character and utf8 can only> support 1-3 bytes characterThe docs would seem to indicate otherwise:> if load string to database which contain a 4-byte character> will failed .Have you actually tried to load strings in to Postgres?If so and it failed what was the method you used and what was the error?> mysql since 5.5.3 support utf8mb4 character sets> I don't find some information about postgresql> thanks--Adrian Klaver>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>thanks for your help .postgresql can support 4-byte charactertest=> select * from utf8mb4_test ;ERROR: character with byte sequence 0xf0 0x9f 0x98 0x84 in encoding "UTF8" has no equivalent in encoding "GB18030"test=> \encoding utf8test=> select * from utf8mb4_test ;content---------😄😄pcauto=>
UTF-8 support works fine. The 3 byte limit was something mysql invented. But it only works if your client encoding is UTF-8. In your example, your terminal is not set to UTF-8.
create table test (glyph text);
insert into test values ('A'), ('馬'), ('𐁀'), ('😄'), ('🇪🇸');
select glyph, convert_to(glyph, 'utf-8'), length(glyph) FROM test;
glyph | convert_to | length
-------+--------------------+--------
A | \x41 | 1
馬 | \xe9a6ac | 1
𐁀 | \xf0908180 | 1
😄 | \xf09f9884 | 1
🇪🇸 | \xf09f87aaf09f87b8 | 2
(5 rows)
What doesn't work is GB18030:
select glyph, convert_to(glyph, 'GB18030'), length(glyph) FROM test;
ERROR: character with byte sequence 0xf0 0x90 0x81 0x80 in encoding "UTF8" has no equivalent in encoding "GB18030"
create table test (glyph text);
insert into test values ('A'), ('馬'), ('𐁀'), ('😄'), ('🇪🇸');
select glyph, convert_to(glyph, 'utf-8'), length(glyph) FROM test;
glyph | convert_to | length
-------+--------------------+--------
A | \x41 | 1
馬 | \xe9a6ac | 1
𐁀 | \xf0908180 | 1
😄 | \xf09f9884 | 1
🇪🇸 | \xf09f87aaf09f87b8 | 2
(5 rows)
What doesn't work is GB18030:
select glyph, convert_to(glyph, 'GB18030'), length(glyph) FROM test;
ERROR: character with byte sequence 0xf0 0x90 0x81 0x80 in encoding "UTF8" has no equivalent in encoding "GB18030"
I think that is a bug.
Gr. Arjen
Hi,
May "GB18030 server side support" deserve reconsidering, after about 15 years later than release of GB18030-2005?
It may be the one of most green features for PostgreSQL.
1. In this big data and mobile era, in the country with most population, 50% more disk energy consuming for Chinese characters (UTF-8 usually 3 bytes for a Chinese character, while GB180830 only 2 bytes) is indeed a harm to "Carbon Neutral", along with Polar ice melting.
2."Setting client side to UTF-8, just like setting server side to UTF-8" in the following mail is not practical for most Chinese IT projects, especially public funding projects. Because GB18030 compatible is a law in Mainland China.
Usually the client side encoding configuration with a GUI is more difficult to be hidden, and most MS Windows users are familiar with GB18030.
MySQL supports GB18030 in server side from V5.7 in 2015. And I am not sure how much this feature contributed to MySQL's more popular in Mainland China.
 | If greenhouse gas emissions continue apace, Greenland and Antarctica’s ice sheets could together contribute more than 15 inches of global sea level rise by 2100 www.nasa.gov |
Parker Han
From: pgsql-general-owner@postgresql.org <pgsql-general-owner@postgresql.org> on behalf of Arjen Nienhuis <a.g.nienhuis@gmail.com>
Sent: Saturday, March 7, 2015 8:18
To: lsliang <lsliang@pconline.com.cn>
Cc: Adrian Klaver <adrian.klaver@aklaver.com>; pgsql-general <pgsql-general@postgresql.org>
Subject: Re: Re: Re: [GENERAL] can postgresql supported utf8mb4 character sets?
Sent: Saturday, March 7, 2015 8:18
To: lsliang <lsliang@pconline.com.cn>
Cc: Adrian Klaver <adrian.klaver@aklaver.com>; pgsql-general <pgsql-general@postgresql.org>
Subject: Re: Re: Re: [GENERAL] can postgresql supported utf8mb4 character sets?
On Fri, Mar 6, 2015 at 3:55 AM, lsliang <lsliang@pconline.com.cn> wrote:
2015-03-06发件人:Adrian Klaver发送时间:2015-03-05 21:31:39收件人:lsliang; pgsql-general抄送:主题:Re: [GENERAL] can postgresql supported utf8mb4 character sets?On 03/05/2015 01:45 AM, lsliang wrote:> can postgresql supported utf8mb4 character set?> today mobile apps support 4-byte character and utf8 can only> support 1-3 bytes characterThe docs would seem to indicate otherwise:> if load string to database which contain a 4-byte character> will failed .Have you actually tried to load strings in to Postgres?If so and it failed what was the method you used and what was the error?> mysql since 5.5.3 support utf8mb4 character sets> I don't find some information about postgresql> thanks--Adrian Klaver>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>thanks for your help .postgresql can support 4-byte charactertest=> select * from utf8mb4_test ;ERROR: character with byte sequence 0xf0 0x9f 0x98 0x84 in encoding "UTF8" has no equivalent in encoding "GB18030"test=> \encoding utf8test=> select * from utf8mb4_test ;content---------😄😄pcauto=>
UTF-8 support works fine. The 3 byte limit was something mysql invented. But it only works if your client encoding is UTF-8. In your example, your terminal is not set to UTF-8.
create table test (glyph text);
insert into test values ('A'), ('馬'), ('𐁀'), ('😄'), ('🇪🇸');
select glyph, convert_to(glyph, 'utf-8'), length(glyph) FROM test;
glyph | convert_to | length
-------+--------------------+--------
A | \x41 | 1
馬 | \xe9a6ac | 1
𐁀 | \xf0908180 | 1
😄 | \xf09f9884 | 1
🇪🇸 | \xf09f87aaf09f87b8 | 2
(5 rows)
What doesn't work is GB18030:
select glyph, convert_to(glyph, 'GB18030'), length(glyph) FROM test;
ERROR: character with byte sequence 0xf0 0x90 0x81 0x80 in encoding "UTF8" has no equivalent in encoding "GB18030"
create table test (glyph text);
insert into test values ('A'), ('馬'), ('𐁀'), ('😄'), ('🇪🇸');
select glyph, convert_to(glyph, 'utf-8'), length(glyph) FROM test;
glyph | convert_to | length
-------+--------------------+--------
A | \x41 | 1
馬 | \xe9a6ac | 1
𐁀 | \xf0908180 | 1
😄 | \xf09f9884 | 1
🇪🇸 | \xf09f87aaf09f87b8 | 2
(5 rows)
What doesn't work is GB18030:
select glyph, convert_to(glyph, 'GB18030'), length(glyph) FROM test;
ERROR: character with byte sequence 0xf0 0x90 0x81 0x80 in encoding "UTF8" has no equivalent in encoding "GB18030"
I think that is a bug.
Gr. Arjen
Re: May "PostgreSQL server side GB18030 character set support" reconsidered?
From
Tatsuo Ishii
Date:
> Hi, > > May "GB18030 server side support" deserve reconsidering, after about 15 years later than release of GB18030-2005? > It may be the one of most green features for PostgreSQL. Moving GB18030 to server side encoding requires a technical challenge: currently PostgreSQL's SQL parser and perhaps in other parts of backend assume that each byte in a string data is not confused with ASCII byte. Since GB18030's second and fourth byte are in range of 0x40 to 0x7e, backend will be confused. How do you resolve the technical challenge exactly? > 1. In this big data and mobile era, in the country with most population, 50% more disk energy consuming for Chinese characters(UTF-8 usually 3 bytes for a Chinese character, while GB180830 only 2 bytes) is indeed a harm to "Carbon Neutral", along with Polar ice melting. Really? I thought GB18030 uses up to 4 bytes. https://en.wikipedia.org/wiki/GB_18030#Encoding Best regards, -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese:http://www.sraoss.co.jp
Thanks for your comments.
My reply inserted into the following section.
发件人: Tatsuo Ishii <ishii@sraoss.co.jp>
发送时间: 2020年10月5日 8:41
收件人: parker.han@outlook.com <parker.han@outlook.com>
抄送: pgsql-general@postgresql.org <pgsql-general@postgresql.org>
主题: Re: May "PostgreSQL server side GB18030 character set support" reconsidered?
发送时间: 2020年10月5日 8:41
收件人: parker.han@outlook.com <parker.han@outlook.com>
抄送: pgsql-general@postgresql.org <pgsql-general@postgresql.org>
主题: Re: May "PostgreSQL server side GB18030 character set support" reconsidered?
> Hi,
>
> May "GB18030 server side support" deserve reconsidering, after about 15 years later than release of GB18030-2005?
> It may be the one of most green features for PostgreSQL.
Moving GB18030 to server side encoding requires a technical challenge:
currently PostgreSQL's SQL parser and perhaps in other parts of
backend assume that each byte in a string data is not confused with
ASCII byte. Since GB18030's second and fourth byte are in range of
0x40 to 0x7e, backend will be confused. How do you resolve the
technical challenge exactly?
>
> May "GB18030 server side support" deserve reconsidering, after about 15 years later than release of GB18030-2005?
> It may be the one of most green features for PostgreSQL.
Moving GB18030 to server side encoding requires a technical challenge:
currently PostgreSQL's SQL parser and perhaps in other parts of
backend assume that each byte in a string data is not confused with
ASCII byte. Since GB18030's second and fourth byte are in range of
0x40 to 0x7e, backend will be confused. How do you resolve the
technical challenge exactly?
--Parker:
I do not have an exact solution proposal yet.
Maybe an investigation on MySQL's mechanism would be of help.
> 1. In this big data and mobile era, in the country with most population, 50% more disk energy consuming for Chinese characters (UTF-8 usually 3 bytes for a Chinese character, while GB180830 only 2 bytes) is indeed a harm to "Carbon Neutral", along with Polar ice melting.
Really? I thought GB18030 uses up to 4 bytes.
https://en.wikipedia.org/wiki/GB_18030#Encoding
--Parker:
> 1. In this big data and mobile era, in the country with most population, 50% more disk energy consuming for Chinese characters (UTF-8 usually 3 bytes for a Chinese character, while GB180830 only 2 bytes) is indeed a harm to "Carbon Neutral", along with Polar ice melting.
Really? I thought GB18030 uses up to 4 bytes.
https://en.wikipedia.org/wiki/GB_18030#Encoding
--Parker:
More preciously description should be GB18030 use 2 or 4 bytes for Chinese characters.
It's a bit complicated to explain with only words but easy with help of the following graph.
Most frequently used 20902 Chinese characters and 984 symbols in GBK is encoded with 2 bytes, which is a subset of GB18030.
Newly added not so frequently but indeed used characters and symbols in GB18030 use 4 bytes.
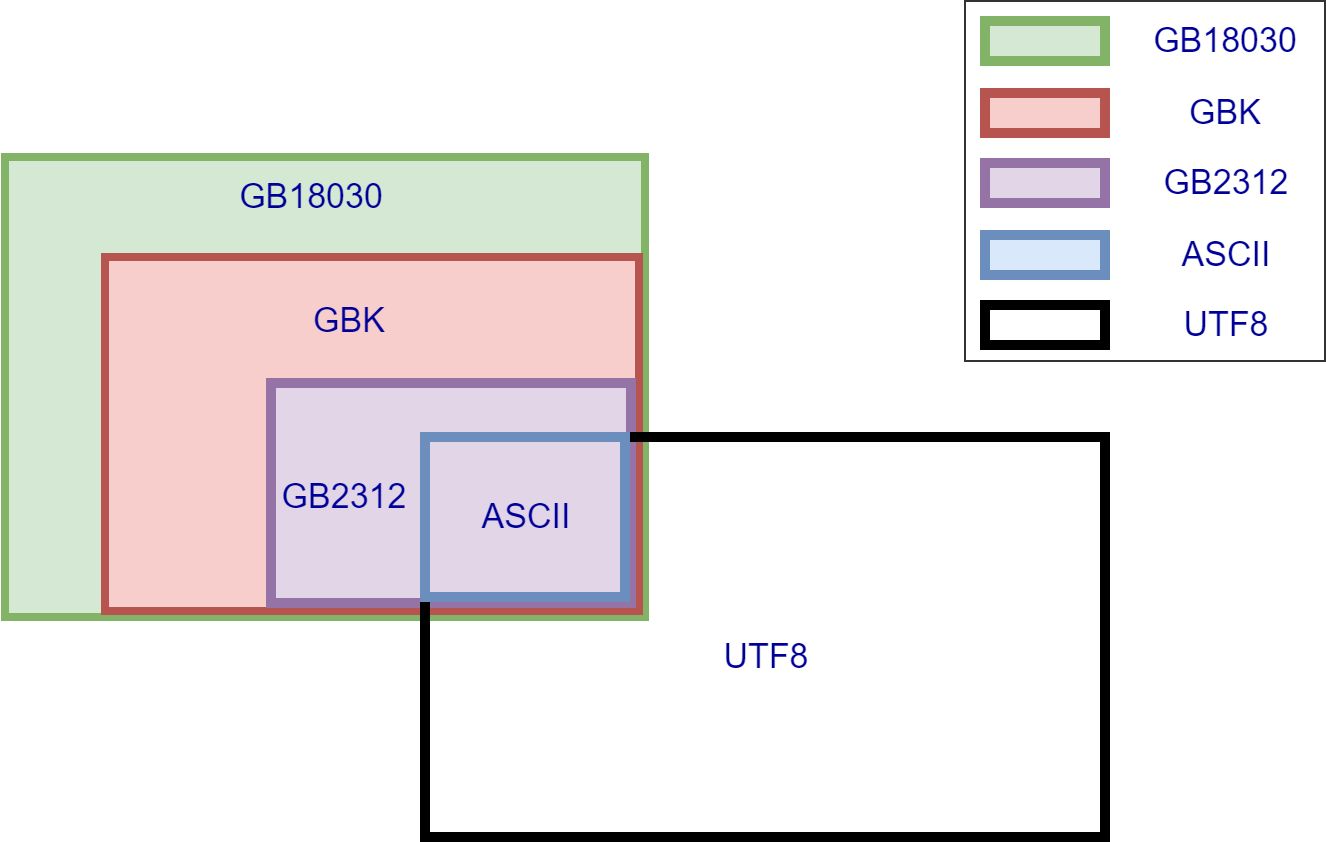
Best regards,
--
Tatsuo Ishii
SRA OSS, Inc. Japan
English: http://www.sraoss.co.jp/index_en.php
Japanese:http://www.sraoss.co.jp
Attachment
Re: 回复: May "PostgreSQL server side GB18030 character set support" reconsidered?
From
Tatsuo Ishii
Date:
>> 1. In this big data and mobile era, in the country with most population, 50% more disk energy consuming for Chinese characters(UTF-8 usually 3 bytes for a Chinese character, while GB180830 only 2 bytes) is indeed a harm to "Carbon Neutral", along with Polar ice melting. > > Really? I thought GB18030 uses up to 4 bytes. > https://en.wikipedia.org/wiki/GB_18030#Encoding > > --Parker: > More preciously description should be GB18030 use 2 or 4 bytes for Chinese characters. > It's a bit complicated to explain with only words but easy with help of the following graph. > > Most frequently used 20902 Chinese characters and 984 symbols in GBK is encoded with 2 bytes, which is a subset of GB18030. It does not sound fair argument unless you are going to implement only GBK compatible part of GB18030. Best regards, -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese:http://www.sraoss.co.jp
Re: 回复: May "PostgreSQL server side GB18030 character set support" reconsidered?
From
Tom Lane
Date:
Han Parker <parker.han@outlook.com> writes:
> ·¢¼þÈË: Tatsuo Ishii <ishii@sraoss.co.jp>
>> Moving GB18030 to server side encoding requires a technical challenge:
>> currently PostgreSQL's SQL parser and perhaps in other parts of
>> backend assume that each byte in a string data is not confused with
>> ASCII byte. Since GB18030's second and fourth byte are in range of
>> 0x40 to 0x7e, backend will be confused. How do you resolve the
>> technical challenge exactly?
> I do not have an exact solution proposal yet.
> Maybe an investigation on MySQL's mechanism would be of help.
TBH, even if you came up with a complete patch, we'd probably
reject it as unmaintainable and a security hazard. The problem
is that code may scan a string looking for certain ASCII characters
such as backslash (\), which up to now it's always been able to do
byte-by-byte without fear that non-ASCII characters could confuse it.
To support GB18030 (or other encodings with the same issue, such as
SJIS), every such loop would have to be modified to advance character
by character, thus roughly "p += pg_mblen(p)" instead of "p++".
Anyplace that neglected to do that would have a bug --- one that
could only be exposed by careful testing using GB18030 encoding.
What's more, such bugs could easily be security problems.
Mis-detecting a backslash, for example, could lead to wrong decisions
about where string literals end, allowing SQL-injection exploits.
> Most frequently used 20902 Chinese characters and 984 symbols in GBK is encoded with 2 bytes, which is a subset of
GB18030.
> Newly added not so frequently but indeed used characters and symbols in GB18030 use 4 bytes.
Any efficiency argument has to consider processing costs not just
storage costs. As I showed above, catering for GB18030 would make
certain loops substantially slower, so that you might pay in CPU
cycles what you saved on disk space. It doesn't help any that the
extra processing costs would be paid by every Postgres user on the
planet, whether they used GB18030 or not.
In short, I think this is very unlikely to happen.
regards, tom lane
Re: 回复: May "PostgreSQL server side GB18030 character set support" reconsidered?
From
Tatsuo Ishii
Date:
> TBH, even if you came up with a complete patch, we'd probably > reject it as unmaintainable and a security hazard. The problem > is that code may scan a string looking for certain ASCII characters > such as backslash (\), which up to now it's always been able to do > byte-by-byte without fear that non-ASCII characters could confuse it. > To support GB18030 (or other encodings with the same issue, such as > SJIS), every such loop would have to be modified to advance character > by character, thus roughly "p += pg_mblen(p)" instead of "p++". > Anyplace that neglected to do that would have a bug --- one that > could only be exposed by careful testing using GB18030 encoding. > What's more, such bugs could easily be security problems. > Mis-detecting a backslash, for example, could lead to wrong decisions > about where string literals end, allowing SQL-injection exploits. One of ideas to avoid the concern could be "shifting" GB18030 code points into "ASCII safe" code range with some calculations so that backend can handle them without worrying about the concern above. This way, we could avoid a table lookup overhead which is necessary in conversion between GB18030 and UTF8 and so on. However I don't come up with such a mathematical conversion method for now. Best regards, -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese:http://www.sraoss.co.jp
Re: 回复: May "PostgreSQL server side GB18030 character set support" reconsidered?
From
Tom Lane
Date:
Tatsuo Ishii <ishii@sraoss.co.jp> writes:
> One of ideas to avoid the concern could be "shifting" GB18030 code
> points into "ASCII safe" code range with some calculations so that
> backend can handle them without worrying about the concern above. This
> way, we could avoid a table lookup overhead which is necessary in
> conversion between GB18030 and UTF8 and so on.
Hmm ... interesting idea, basically invent our own modified version
of GB18030 (or SJIS?) for backend-internal storage. But I'm not
sure how to make it work without enlarging the string, which'd defeat
the OP's argument. It looks to me like the second-byte code space is
already pretty full in both encodings.
regards, tom lane
回复: 回复: May "PostgreSQL server side GB18030 character set support" reconsidered?
From
Han Parker
Date:
Thanks for your reply.
Regards,
Parker Han
发件人: Tom Lane <tgl@sss.pgh.pa.us>
发送时间: 2020年10月5日 14:30
收件人: Han Parker <parker.han@outlook.com>
抄送: Tatsuo Ishii <ishii@sraoss.co.jp>; pgsql-general@postgresql.org <pgsql-general@postgresql.org>
主题: Re: 回复: May "PostgreSQL server side GB18030 character set support" reconsidered?
发送时间: 2020年10月5日 14:30
收件人: Han Parker <parker.han@outlook.com>
抄送: Tatsuo Ishii <ishii@sraoss.co.jp>; pgsql-general@postgresql.org <pgsql-general@postgresql.org>
主题: Re: 回复: May "PostgreSQL server side GB18030 character set support" reconsidered?
Han Parker <parker.han@outlook.com> writes:
> ·¢¼þÈË: Tatsuo Ishii <ishii@sraoss.co.jp>
>> Moving GB18030 to server side encoding requires a technical challenge:
>> currently PostgreSQL's SQL parser and perhaps in other parts of
>> backend assume that each byte in a string data is not confused with
>> ASCII byte. Since GB18030's second and fourth byte are in range of
>> 0x40 to 0x7e, backend will be confused. How do you resolve the
>> technical challenge exactly?
> I do not have an exact solution proposal yet.
> Maybe an investigation on MySQL's mechanism would be of help.
TBH, even if you came up with a complete patch, we'd probably
reject it as unmaintainable and a security hazard. The problem
is that code may scan a string looking for certain ASCII characters
such as backslash (\), which up to now it's always been able to do
byte-by-byte without fear that non-ASCII characters could confuse it.
To support GB18030 (or other encodings with the same issue, such as
SJIS), every such loop would have to be modified to advance character
by character, thus roughly "p += pg_mblen(p)" instead of "p++".
Anyplace that neglected to do that would have a bug --- one that
could only be exposed by careful testing using GB18030 encoding.
What's more, such bugs could easily be security problems.
Mis-detecting a backslash, for example, could lead to wrong decisions
about where string literals end, allowing SQL-injection exploits.
> ·¢¼þÈË: Tatsuo Ishii <ishii@sraoss.co.jp>
>> Moving GB18030 to server side encoding requires a technical challenge:
>> currently PostgreSQL's SQL parser and perhaps in other parts of
>> backend assume that each byte in a string data is not confused with
>> ASCII byte. Since GB18030's second and fourth byte are in range of
>> 0x40 to 0x7e, backend will be confused. How do you resolve the
>> technical challenge exactly?
> I do not have an exact solution proposal yet.
> Maybe an investigation on MySQL's mechanism would be of help.
TBH, even if you came up with a complete patch, we'd probably
reject it as unmaintainable and a security hazard. The problem
is that code may scan a string looking for certain ASCII characters
such as backslash (\), which up to now it's always been able to do
byte-by-byte without fear that non-ASCII characters could confuse it.
To support GB18030 (or other encodings with the same issue, such as
SJIS), every such loop would have to be modified to advance character
by character, thus roughly "p += pg_mblen(p)" instead of "p++".
Anyplace that neglected to do that would have a bug --- one that
could only be exposed by careful testing using GB18030 encoding.
What's more, such bugs could easily be security problems.
Mis-detecting a backslash, for example, could lead to wrong decisions
about where string literals end, allowing SQL-injection exploits.
--From Parker:
Agree that it may not a cheap feature.
1. pg_mblen() etc. would involve long term costs as well as short term refactoring cost.
2. '0x5c' (backslash) appears in the low bytes of a multiply-bytes-character, increases exposure of SQL-injection risk.
--
> Most frequently used 20902 Chinese characters and 984 symbols in GBK is encoded with 2 bytes, which is a subset of GB18030.
> Newly added not so frequently but indeed used characters and symbols in GB18030 use 4 bytes.
Any efficiency argument has to consider processing costs not just
storage costs. As I showed above, catering for GB18030 would make
certain loops substantially slower, so that you might pay in CPU
cycles what you saved on disk space. It doesn't help any that the
extra processing costs would be paid by every Postgres user on the
planet, whether they used GB18030 or not.
--From Parker:
It depends on use scenarios, so leaving this decision making to application developers with a GUC may be an option.
OLTP may pay more processing cost than storage saving, while OLAP may pay less processing cost than storage saving.
---
In short, I think this is very unlikely to happen.
regards, tom lane
Re: 回复: May "PostgreSQL server side GB18030 character set support" reconsidered?
From
Tatsuo Ishii
Date:
> Hmm ... interesting idea, basically invent our own modified version > of GB18030 (or SJIS?) for backend-internal storage. But I'm not > sure how to make it work without enlarging the string, which'd defeat > the OP's argument. It looks to me like the second-byte code space is > already pretty full in both encodings. But as he already admitted, actually GB18030 is 4 byte encoding, rather than 2 bytes. So maybe we could find a way to map original GB18030 to ASCII-safe GB18030 using 4 bytes. As for SJIS, no big demand for the encoding in Japan these days. So I think we can leave it as it is. Best regards, -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese:http://www.sraoss.co.jp
Re: 回复: May "PostgreSQL server side GB18030 character set support" reconsidered?
From
Tatsuo Ishii
Date:
> But as he already admitted, actually GB18030 is 4 byte encoding, rather > than 2 bytes. So maybe we could find a way to map original GB18030 to > ASCII-safe GB18030 using 4 bytes. Here is an idea (in-byte represents GB18030, out-byte represents internal server encoding): if (in-byte1 is 0x00-80) /* ASCII */ out-byte1 = in-byte1 else if (in-byte1 is 0x81-0xfe && in-byte2 is 0x40-0x7f) /* 2 bytes GB18030 */ out-byte1 = in-byte1 out-byte2 = 0x80 out-byte3 = in-byte2 + 0x80 (should be 0xc0-0xc9) out-byte4 = 0x80 else if (in-byte1 is 0x81-0xfe && in-byte2 is 0x80-0xfe) /* 2 bytes GB18030 */ out-byte1 = in-byte1 out-byte2 = 0x80 out-byte3 = 0x80 out-byte4 = in-byte2 (should be 0x80-0xfe) else if (in-byte1 is 0x81-0xfe && in-byte2 is 0x30-0x39) /* 4 bytes GB18030 */ out-byte1 = in-byte1 out-byte2 = in-byte2 + 0x80 (should be 0xb0-0xb9) out-byte3 = in-byte3 out-byte4 = in-byte4 + 0x80 (should be 0xb0-0xb9) Best regards, -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese:http://www.sraoss.co.jp
回复: 回复: May "PostgreSQL server side GB18030 character set support" reconsidered?
From
Han Parker
Date:
发件人: Tatsuo Ishii <ishii@sraoss.co.jp>
发送时间: 2020年10月6日 2:15
收件人: tgl@sss.pgh.pa.us <tgl@sss.pgh.pa.us>
抄送: parker.han@outlook.com <parker.han@outlook.com>; pgsql-general@postgresql.org <pgsql-general@postgresql.org>
主题: Re: 回复: May "PostgreSQL server side GB18030 character set support" reconsidered?
发送时间: 2020年10月6日 2:15
收件人: tgl@sss.pgh.pa.us <tgl@sss.pgh.pa.us>
抄送: parker.han@outlook.com <parker.han@outlook.com>; pgsql-general@postgresql.org <pgsql-general@postgresql.org>
主题: Re: 回复: May "PostgreSQL server side GB18030 character set support" reconsidered?
> Hmm ... interesting idea, basically invent our own modified version
> of GB18030 (or SJIS?) for backend-internal storage. But I'm not
> sure how to make it work without enlarging the string, which'd defeat
> the OP's argument. It looks to me like the second-byte code space is
> already pretty full in both encodings.
>But as he already admitted, actually GB18030 is 4 byte encoding, rather
> of GB18030 (or SJIS?) for backend-internal storage. But I'm not
> sure how to make it work without enlarging the string, which'd defeat
> the OP's argument. It looks to me like the second-byte code space is
> already pretty full in both encodings.
>But as he already admitted, actually GB18030 is 4 byte encoding, rather
>than 2 bytes. So maybe we could find a way to map original GB18030 to
>ASCII-safe GB18030 using 4 bytes.>
>As for SJIS, no big demand for the encoding in Japan these days. So I
>think we can leave it as it is.>
>Best regards,
>--
>Tatsuo Ishii
>SRA OSS, Inc. Japan
>English: http://www.sraoss.co.jp/index_en.php
>Japanese:http://www.sraoss.co.jpSo the key lies in a ASCII-safe GB18030 simple mapping algorithm (Maybe named with abbreviation "GB18030as" of GB18030_ascii_safe?), which not break "ASCII-safe" while save lots of storage (The ANSI-safe GB2312 contains most frequently used 6763 characters).
In fact, it was GBK designed by Microsoft broke "ASCII-safe" in about 1995 with the popular of Win95. Later GB18030 inherited it because it had to compatible with GBK.
Thanks.
I will try to find whether any opinions regarding "a ASCII-safe GB18030 simple mapping algorithm" exist in GB18030 standard maintainers community.