Thread: Make tuple deformation faster
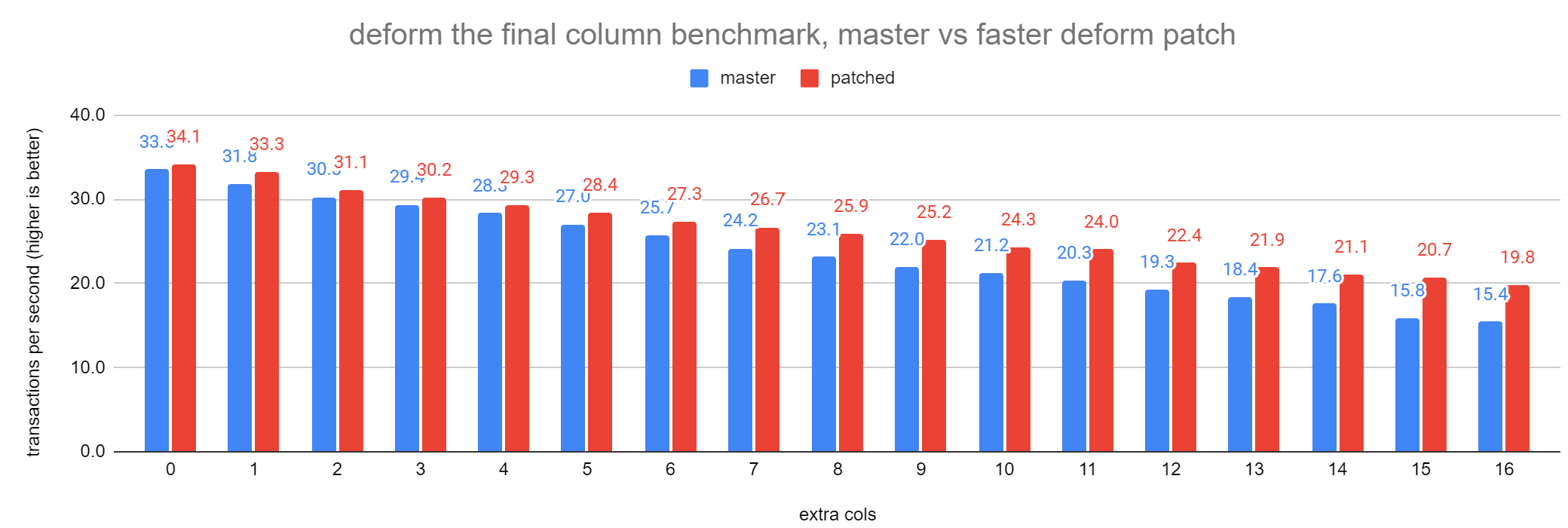
Currently, TupleDescData contains the descriptor's attributes in a variable length array of FormData_pg_attribute allocated within the same allocation as the TupleDescData. According to my IDE, sizeof(FormData_pg_attribute) == 104 bytes. It's that large mainly due to attname being 64 bytes. The TupleDescData.attrs[] array could end up quite large on tables with many columns and that could result in poor CPU cache hit ratios when deforming tuples. Instead, we could make TupleDescData contain an out-of-line pointer to the array of FormData_pg_attribute and have a much more compact inlined array of some other struct that much more densely contains the fields required for tuple deformation. attname and many of the other fields are not required to deform a tuple. I've attached a patch series which does this. 0001: Just fixes up some missing usages of TupleDescAttr(). (mostly missed by me, apparently :-( ) 0002: Adjusts the TupleDescData.attrs array to make it out of line. I wanted to make sure nothing weird happened by doing this before doing the bulk of the other changes to add the new struct. 0003: Adds a very compact 8-byte struct named TupleDescDeformAttr, which can be used for tuple deformation. 8 columns fits on a 64-byte cacheline rather than 13 cachelines. 0004: Adjusts the attalign to change it from char to uint8. See below. The 0004 patch changes the TupleDescDeformAttr.attalign to a uint8 rather than a char containing 'c', 's', 'i' or 'd'. This allows much more simple code in the att_align_nominal() macro. What's in master is quite a complex expression to evaluate every time we deform a column as it much translate: 'c' -> 1, 's' -> 2, 'i' -> 4, 'd' -> 8. If we just store that numeric value in the struct that macro can become a simple TYPEALIGN() so the operation becomes simple bit masking rather than a poorly branch predictable series of compare and jump. The state of this patch series is "proof of concept". I think the current state should be enough to get an idea of the rough amount of code churn this change would cause and also an idea of the expected performance of the change. It certainly isn't in a finished state. I've not put much effort into updating comments or looking at READMEs to see what's now outdated. I also went with trying to patch a bunch of additional boolean columns from pg_attribute so they just take up 1 bit of space in the attflags field in the new struct. I've not tested the performance of expanding this out so these use 1 bool field each. That would make the struct bigger than 8 bytes. Having the struct be a power-of-2 size is also beneficial as it allows fast bit-shifting to be used to get the array element address rather than a more complex (and slower) LEA instruction. I could try making the struct 16 bytes and see if there are any further wins by avoiding the bitwise AND on the TupleDescDeformAttr.attflags field. To test the performance of this, I tried using the attached script which creates a table where the first column is a variable length column and the final column is an int. The query I ran to test the performance inserted 1 million rows into this table and performed a sum() on the final column. The attached graph shows that the query is 30% faster than master with 15 columns between the first and last column. For fewer columns, the speedup is less. This is quite a deform-heavy query so it's not like it speeds up every table with that column arrangement by 30%, but certainly, some queries could see that much gain and even more seems possible. I didn't go to a great deal of trouble to find the most deform-heavy workload. I'll stick this in the July CF. It would be good to get some feedback on the idea and feedback on whether more work on this is worthwhile. As mentioned, the 0001 patch just fixes up the missing usages of the TupleDescAttr() macro. I see no reason not to commit this now. Thanks David
Attachment
{kind=link}
David Rowley <dgrowleyml@gmail.com> writes: > Currently, TupleDescData contains the descriptor's attributes in a > variable length array of FormData_pg_attribute allocated within the > same allocation as the TupleDescData. According to my IDE, > sizeof(FormData_pg_attribute) == 104 bytes. It's that large mainly due > to attname being 64 bytes. The TupleDescData.attrs[] array could end > up quite large on tables with many columns and that could result in > poor CPU cache hit ratios when deforming tuples. ... > > To test the performance of this, I tried using the attached script > which creates a table where the first column is a variable length > column and the final column is an int. The query I ran to test the > performance inserted 1 million rows into this table and performed a > sum() on the final column. The attached graph shows that the query is > 30% faster than master with 15 columns between the first and last > column. Yet another a wonderful optimization! I just want to know how did you find this optimization (CPU cache hit) case and think it worths some time. because before we invest our time to optimize something, it is better know that we can get some measurable improvement after our time is spend. At for this case, 30% is really a huge number even it is a artificial case. Another case is Andrew introduced NullableDatum 5 years ago and said using it in TupleTableSlot could be CPU cache friendly, I can follow that, but how much it can improve in an ideal case, is it possible to forecast it somehow? I ask it here because both cases are optimizing for CPU cache.. -- Best Regards Andy Fan
On Mon, 1 Jul 2024 at 21:17, Andy Fan <zhihuifan1213@163.com> wrote:
> Yet another a wonderful optimization! I just want to know how did you
> find this optimization (CPU cache hit) case and think it worths some
> time. because before we invest our time to optimize something, it is
> better know that we can get some measurable improvement after our time
> is spend. At for this case, 30% is really a huge number even it is a
> artificial case.
>
> Another case is Andrew introduced NullableDatum 5 years ago and said using
> it in TupleTableSlot could be CPU cache friendly, I can follow that, but
> how much it can improve in an ideal case, is it possible to forecast it
> somehow? I ask it here because both cases are optimizing for CPU cache..
Have a look at:
perf stat --pid=<backend pid>
On my AMD Zen4 machine running the 16 extra column test from the
script in my last email, I see:
$ echo master && perf stat --pid=389510 sleep 10
master
Performance counter stats for process id '389510':
9990.65 msec task-clock:u # 0.999 CPUs utilized
0 context-switches:u # 0.000 /sec
0 cpu-migrations:u # 0.000 /sec
0 page-faults:u # 0.000 /sec
49407204156 cycles:u # 4.945 GHz
18529494 stalled-cycles-frontend:u # 0.04% frontend
cycles idle
8505168 stalled-cycles-backend:u # 0.02% backend cycles idle
165442142326 instructions:u # 3.35 insn per cycle
# 0.00 stalled
cycles per insn
39409877343 branches:u # 3.945 G/sec
146350275 branch-misses:u # 0.37% of all branches
10.001012132 seconds time elapsed
$ echo patched && perf stat --pid=380216 sleep 10
patched
Performance counter stats for process id '380216':
9989.14 msec task-clock:u # 0.998 CPUs utilized
0 context-switches:u # 0.000 /sec
0 cpu-migrations:u # 0.000 /sec
0 page-faults:u # 0.000 /sec
49781280456 cycles:u # 4.984 GHz
22922276 stalled-cycles-frontend:u # 0.05% frontend
cycles idle
24259785 stalled-cycles-backend:u # 0.05% backend cycles idle
213688149862 instructions:u # 4.29 insn per cycle
# 0.00 stalled
cycles per insn
44147675129 branches:u # 4.420 G/sec
14282567 branch-misses:u # 0.03% of all branches
10.005034271 seconds time elapsed
You can see the branch predictor has done a *much* better job in the
patched code vs master with about 10x fewer misses. This should have
helped contribute to the "insn per cycle" increase. 4.29 is quite
good for postgres. I often see that around 0.5. According to [1]
(relating to Zen4), "We get a ridiculous 12 NOPs per cycle out of the
micro-op cache". I'm unsure how micro-ops translate to "insn per
cycle" that's shown in perf stat. I thought 4-5 was about the maximum
pipeline size from today's era of CPUs. Maybe someone else can explain
better than I can. In more simple terms, generally, the higher the
"insn per cycle", the better. Also, the lower all of the idle and
branch miss percentages are that's generally also better. However,
you'll notice that the patched version has more front and backend
stalls. I assume this is due to performing more instructions per cycle
from improved branch prediction causing memory and instruction stalls
to occur more frequently, effectively (I think) it's just hitting the
next bottleneck(s) - memory and instruction decoding. At least, modern
CPUs should be able to out-pace RAM in many workloads, so perhaps it's
not that surprising that "backend cycles idle" has gone up due to such
a large increase in instructions per cycle due to improved branch
prediction.
It would be nice to see this tested on some modern Intel CPU. A 13th
series or 14th series, for example, or even any intel from the past 5
years would be better than nothing.
David
[1] https://chipsandcheese.com/2022/11/05/amds-zen-4-part-1-frontend-and-execution-engine/
On Mon, 1 Jul 2024 at 10:56, David Rowley <dgrowleyml@gmail.com> wrote: > > Currently, TupleDescData contains the descriptor's attributes in a > variable length array of FormData_pg_attribute allocated within the > same allocation as the TupleDescData. According to my IDE, > sizeof(FormData_pg_attribute) == 104 bytes. It's that large mainly due > to attname being 64 bytes. The TupleDescData.attrs[] array could end > up quite large on tables with many columns and that could result in > poor CPU cache hit ratios when deforming tuples. > > Instead, we could make TupleDescData contain an out-of-line pointer to > the array of FormData_pg_attribute and have a much more compact > inlined array of some other struct that much more densely contains the > fields required for tuple deformation. attname and many of the other > fields are not required to deform a tuple. +1 > I've attached a patch series which does this. > > 0001: Just fixes up some missing usages of TupleDescAttr(). (mostly > missed by me, apparently :-( ) > 0002: Adjusts the TupleDescData.attrs array to make it out of line. I > wanted to make sure nothing weird happened by doing this before doing > the bulk of the other changes to add the new struct. > 0003: Adds a very compact 8-byte struct named TupleDescDeformAttr, > which can be used for tuple deformation. 8 columns fits on a 64-byte > cacheline rather than 13 cachelines. Cool, that's similar to, but even better than, my patch from 2021 over at [0]. One thing I'm slightly concerned about is that this allocates another 8 bytes for each attribute in the tuple descriptor. While that's not a lot when compared with the ->attrs array, it's still quite a lot when we might not care at all about this data; e.g. in temporary tuple descriptors during execution, in intermediate planner nodes. Did you test for performance gains (or losses) with an out-of-line TupleDescDeformAttr array? One benefit from this would be that we could reuse the deform array for suffix truncated TupleDescs, reuse of which currently would require temporarily updating TupleDesc->natts with a smaller value; but with out-of-line ->attrs and ->deform_attrs, we could reuse these arrays between TupleDescs if one is shorter than the other, but has otherwise fully matching attributes. I know that btree split code would benefit from this, as it wouldn't have to construct a full new TupleDesc when it creates a suffix-truncated tuple during page splits. > 0004: Adjusts the attalign to change it from char to uint8. See below. > > The 0004 patch changes the TupleDescDeformAttr.attalign to a uint8 > rather than a char containing 'c', 's', 'i' or 'd'. This allows much > more simple code in the att_align_nominal() macro. What's in master is > quite a complex expression to evaluate every time we deform a column > as it much translate: 'c' -> 1, 's' -> 2, 'i' -> 4, 'd' -> 8. If we > just store that numeric value in the struct that macro can become a > simple TYPEALIGN() so the operation becomes simple bit masking rather > than a poorly branch predictable series of compare and jump. +1, that's something I'd missed in my patches, and is probably the largest contributor to the speedup. > I'll stick this in the July CF. It would be good to get some feedback > on the idea and feedback on whether more work on this is worthwhile. Do you plan to remove the ->attcacheoff catalog field from the FormData_pg_attribute, now that (with your patch) it isn't used anymore as a placeholder field for fast (de)forming of tuples? Kind regards, Matthias van de Meent [0] https://www.postgresql.org/message-id/CAEze2Wh8-metSryZX_Ubj-uv6kb%2B2YnzHAejmEdubjhmGusBAg%40mail.gmail.com
On Mon, 1 Jul 2024 at 22:07, Matthias van de Meent
<boekewurm+postgres@gmail.com> wrote:
> Cool, that's similar to, but even better than, my patch from 2021 over at [0].
I'll have a read of that. Thanks for pointing it out.
> One thing I'm slightly concerned about is that this allocates another
> 8 bytes for each attribute in the tuple descriptor. While that's not a
> lot when compared with the ->attrs array, it's still quite a lot when
> we might not care at all about this data; e.g. in temporary tuple
> descriptors during execution, in intermediate planner nodes.
I've not done it in the patch, but one way to get some of that back is
to ditch pg_attribute.attcacheoff. There's no need for it after this
patch. That's only 4 out of 8 bytes, however. I think in most cases
due to FormData_pg_attribute being so huge, the aset.c power-of-2
roundup behaviour will be unlikely to cross a power-of-2 boundary.
The following demonstrates which column counts that actually makes a
difference with:
select c as n_cols,old_bytes, new_bytes from (select c,24+104*c as
old_bytes, 32+100*c+8*c as new_bytes from generate_series(1,1024) c)
where position('1' in old_bytes::bit(32)::text) != position('1' in
new_bytes::bit(32)::text);
That returns just 46 column counts out of 1024 where we cross a power
of 2 boundaries with the patched code that we didn't cross in master.
Of course, larger pallocs will result in a malloc() directly, so
perhaps that's not a good measure. At least for smaller column counts
it should be mainly the same amount of memory used. There are only 6
rows in there for column counts below 100. I think if we were worried
about memory there are likely 100 other things we could do to reclaim
some. It would only take some shuffling of fields in RelationData. I
count 50 bytes of holes in that struct out of the 488 bytes. There are
probably a few that could be moved without upsetting the
struct-field-order-lords too much.
> Did you test for performance gains (or losses) with an out-of-line
> TupleDescDeformAttr array? One benefit from this would be that we
> could reuse the deform array for suffix truncated TupleDescs, reuse of
> which currently would require temporarily updating TupleDesc->natts
> with a smaller value; but with out-of-line ->attrs and ->deform_attrs,
> we could reuse these arrays between TupleDescs if one is shorter than
> the other, but has otherwise fully matching attributes. I know that
> btree split code would benefit from this, as it wouldn't have to
> construct a full new TupleDesc when it creates a suffix-truncated
> tuple during page splits.
No, but it sounds easy to test as patch 0002 moves that out of line
and does nothing else.
> > 0004: Adjusts the attalign to change it from char to uint8. See below.
> >
> > The 0004 patch changes the TupleDescDeformAttr.attalign to a uint8
> > rather than a char containing 'c', 's', 'i' or 'd'. This allows much
> > more simple code in the att_align_nominal() macro. What's in master is
> > quite a complex expression to evaluate every time we deform a column
> > as it much translate: 'c' -> 1, 's' -> 2, 'i' -> 4, 'd' -> 8. If we
> > just store that numeric value in the struct that macro can become a
> > simple TYPEALIGN() so the operation becomes simple bit masking rather
> > than a poorly branch predictable series of compare and jump.
>
> +1, that's something I'd missed in my patches, and is probably the
> largest contributor to the speedup.
I think so too and I did consider if we should try and do that to
pg_attribute, renaming the column to attalignby. I started but didn't
finish a patch for that.
> > I'll stick this in the July CF. It would be good to get some feedback
> > on the idea and feedback on whether more work on this is worthwhile.
>
> Do you plan to remove the ->attcacheoff catalog field from the
> FormData_pg_attribute, now that (with your patch) it isn't used
> anymore as a placeholder field for fast (de)forming of tuples?
Yes, I plan to do that once I get more confidence I'm on to a winner here.
Thanks for having a look at this.
David
On Mon, 1 Jul 2024 at 12:49, David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Mon, 1 Jul 2024 at 22:07, Matthias van de Meent
> <boekewurm+postgres@gmail.com> wrote:
> > One thing I'm slightly concerned about is that this allocates another
> > 8 bytes for each attribute in the tuple descriptor. While that's not a
> > lot when compared with the ->attrs array, it's still quite a lot when
> > we might not care at all about this data; e.g. in temporary tuple
> > descriptors during execution, in intermediate planner nodes.
>
> I've not done it in the patch, but one way to get some of that back is
> to ditch pg_attribute.attcacheoff. There's no need for it after this
> patch. That's only 4 out of 8 bytes, however.
FormData_pg_attribute as a C struct has 4-byte alignment; AFAIK it
doesn't have any fields that require 8-byte alignment? Only on 64-bit
systems we align the tuples on pages with 8-byte alignment, but
in-memory arrays of the struct wouldn't have to deal with that, AFAIK.
> I think in most cases
> due to FormData_pg_attribute being so huge, the aset.c power-of-2
> roundup behaviour will be unlikely to cross a power-of-2 boundary.
ASet isn't the only allocator, but default enough for this to make sense, yes.
> The following demonstrates which column counts that actually makes a
> difference with:
>
> select c as n_cols,old_bytes, new_bytes from (select c,24+104*c as
> old_bytes, 32+100*c+8*c as new_bytes from generate_series(1,1024) c)
> where position('1' in old_bytes::bit(32)::text) != position('1' in
> new_bytes::bit(32)::text);
>
> That returns just 46 column counts out of 1024 where we cross a power
> of 2 boundaries with the patched code that we didn't cross in master.
> Of course, larger pallocs will result in a malloc() directly, so
> perhaps that's not a good measure. At least for smaller column counts
> it should be mainly the same amount of memory used. There are only 6
> rows in there for column counts below 100. I think if we were worried
> about memory there are likely 100 other things we could do to reclaim
> some. It would only take some shuffling of fields in RelationData. I
> count 50 bytes of holes in that struct out of the 488 bytes. There are
> probably a few that could be moved without upsetting the
> struct-field-order-lords too much.
I'd love for RelationData to be split into IndexRelation,
TableRelation, ForeignTableRelation, etc., as there's a lot of wastage
caused by exclusive fields, too.
> > > 0004: Adjusts the attalign to change it from char to uint8. See below.
> > >
> > > The 0004 patch changes the TupleDescDeformAttr.attalign to a uint8
> > > rather than a char containing 'c', 's', 'i' or 'd'. This allows much
> > > more simple code in the att_align_nominal() macro. What's in master is
> > > quite a complex expression to evaluate every time we deform a column
> > > as it much translate: 'c' -> 1, 's' -> 2, 'i' -> 4, 'd' -> 8. If we
> > > just store that numeric value in the struct that macro can become a
> > > simple TYPEALIGN() so the operation becomes simple bit masking rather
> > > than a poorly branch predictable series of compare and jump.
> >
> > +1, that's something I'd missed in my patches, and is probably the
> > largest contributor to the speedup.
>
> I think so too and I did consider if we should try and do that to
> pg_attribute, renaming the column to attalignby. I started but didn't
> finish a patch for that.
I'm not sure we have a pg_type entry that that supports numeric
attalign values without increasing the size of the field, as the one
single-byte integer-like type (char) is always used as a printable
character, and implied to always be printable through its usage in
e.g. nodeToString infrastructure.
I'd love to have a better option, but we don't seem to have one yet.
Kind regards,
Matthias van de Meent
Neon (https://neon.tech)
On Mon, 1 Jul 2024 at 23:42, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > > On Mon, 1 Jul 2024 at 12:49, David Rowley <dgrowleyml@gmail.com> wrote: > > > > On Mon, 1 Jul 2024 at 22:07, Matthias van de Meent > > <boekewurm+postgres@gmail.com> wrote: > > > One thing I'm slightly concerned about is that this allocates another > > > 8 bytes for each attribute in the tuple descriptor. While that's not a > > > lot when compared with the ->attrs array, it's still quite a lot when > > > we might not care at all about this data; e.g. in temporary tuple > > > descriptors during execution, in intermediate planner nodes. > > > > I've not done it in the patch, but one way to get some of that back is > > to ditch pg_attribute.attcacheoff. There's no need for it after this > > patch. That's only 4 out of 8 bytes, however. > > FormData_pg_attribute as a C struct has 4-byte alignment; AFAIK it > doesn't have any fields that require 8-byte alignment? Only on 64-bit > systems we align the tuples on pages with 8-byte alignment, but > in-memory arrays of the struct wouldn't have to deal with that, AFAIK. Yeah, 4-byte alignment. "out of 8 bytes" I was talking about is sizeof(TupleDescDeformAttr), which I believe is the same "another 8 bytes" you had mentioned. What I meant was that deleting attcacheoff only reduces FormData_pg_attribute by 4 bytes per column and adding TupleDescDeformAttr adds 8 per column, so we still use 4 more bytes per column with the patch. I really doubt the 4 bytes extra memory is a big concern here. It would be more concerning for patch that wanted to do something like change NAMEDATALEN to 128, but I think the main concern with that would be even slower tuple deforming. Additional memory would also be concerning, but I doubt that's more important than the issue of making all queries slower due to slower tuple deformation, which is what such a patch would result in. > > I think in most cases > > due to FormData_pg_attribute being so huge, the aset.c power-of-2 > > roundup behaviour will be unlikely to cross a power-of-2 boundary. > > ASet isn't the only allocator, but default enough for this to make sense, yes. It's the only allocator we use for allocating TupleDescs, so other types and their behaviour are not relevant here. > I'm not sure we have a pg_type entry that that supports numeric > attalign values without increasing the size of the field, as the one > single-byte integer-like type (char) is always used as a printable > character, and implied to always be printable through its usage in > e.g. nodeToString infrastructure. > > I'd love to have a better option, but we don't seem to have one yet. yeah, select typname from pg_Type where typalign = 'c' and typlen=1; has just bool and char. I'm happy to keep going with this version of the patch unless someone points out some good reason that we should go with the alternative instead. David
David Rowley <dgrowleyml@gmail.com> writes: > You can see the branch predictor has done a *much* better job in the > patched code vs master with about 10x fewer misses. This should have > helped contribute to the "insn per cycle" increase. 4.29 is quite > good for postgres. I often see that around 0.5. According to [1] > (relating to Zen4), "We get a ridiculous 12 NOPs per cycle out of the > micro-op cache". I'm unsure how micro-ops translate to "insn per > cycle" that's shown in perf stat. I thought 4-5 was about the maximum > pipeline size from today's era of CPUs. Maybe someone else can explain > better than I can. In more simple terms, generally, the higher the > "insn per cycle", the better. Also, the lower all of the idle and > branch miss percentages are that's generally also better. However, > you'll notice that the patched version has more front and backend > stalls. I assume this is due to performing more instructions per cycle > from improved branch prediction causing memory and instruction stalls > to occur more frequently, effectively (I think) it's just hitting the > next bottleneck(s) - memory and instruction decoding. At least, modern > CPUs should be able to out-pace RAM in many workloads, so perhaps it's > not that surprising that "backend cycles idle" has gone up due to such > a large increase in instructions per cycle due to improved branch > prediction. Thanks for the answer, just another area desvers to exploring. > It would be nice to see this tested on some modern Intel CPU. A 13th > series or 14th series, for example, or even any intel from the past 5 > years would be better than nothing. I have two kind of CPUs. a). Intel Xeon Processor (Icelake) for my ECS b). Intel(R) Core(TM) i5-8259U CPU @ 2.30GHz at Mac. My ECS reports "<not supported> branch-misses", probabaly because it runs in virtualization software , and Mac doesn't support perf yet :( -- Best Regards Andy Fan
On Tue, 2 Jul 2024 at 02:23, David Rowley <dgrowleyml@gmail.com> wrote: > > On Mon, 1 Jul 2024 at 23:42, Matthias van de Meent > <boekewurm+postgres@gmail.com> wrote: > > > > On Mon, 1 Jul 2024 at 12:49, David Rowley <dgrowleyml@gmail.com> wrote: > > > > > > On Mon, 1 Jul 2024 at 22:07, Matthias van de Meent > > > <boekewurm+postgres@gmail.com> wrote: > > > > One thing I'm slightly concerned about is that this allocates another > > > > 8 bytes for each attribute in the tuple descriptor. While that's not a > > > > lot when compared with the ->attrs array, it's still quite a lot when > > > > we might not care at all about this data; e.g. in temporary tuple > > > > descriptors during execution, in intermediate planner nodes. > > > > > > I've not done it in the patch, but one way to get some of that back is > > > to ditch pg_attribute.attcacheoff. There's no need for it after this > > > patch. That's only 4 out of 8 bytes, however. > > > > FormData_pg_attribute as a C struct has 4-byte alignment; AFAIK it > > doesn't have any fields that require 8-byte alignment? Only on 64-bit > > systems we align the tuples on pages with 8-byte alignment, but > > in-memory arrays of the struct wouldn't have to deal with that, AFAIK. > > Yeah, 4-byte alignment. "out of 8 bytes" I was talking about is > sizeof(TupleDescDeformAttr), which I believe is the same "another 8 > bytes" you had mentioned. What I meant was that deleting attcacheoff > only reduces FormData_pg_attribute by 4 bytes per column and adding > TupleDescDeformAttr adds 8 per column, so we still use 4 more bytes > per column with the patch. I see I was confused, thank you for clarifying. As I said, the concerns were only small; 4 more bytes only in memory shouldn't matter much in the grand scheme of things. > I'm happy to keep going with this version of the patch +1, go for it. Kind regards, Matthias van de Meent Neon (https://neon.tech)
On Mon, Jul 1, 2024 at 5:07 PM David Rowley <dgrowleyml@gmail.com> wrote: > cycles idle > 8505168 stalled-cycles-backend:u # 0.02% backend cycles idle > 165442142326 instructions:u # 3.35 insn per cycle > # 0.00 stalled > cycles per insn > 39409877343 branches:u # 3.945 G/sec > 146350275 branch-misses:u # 0.37% of all branches > patched > cycles idle > 24259785 stalled-cycles-backend:u # 0.05% backend cycles idle > 213688149862 instructions:u # 4.29 insn per cycle > # 0.00 stalled > cycles per insn > 44147675129 branches:u # 4.420 G/sec > 14282567 branch-misses:u # 0.03% of all branches > You can see the branch predictor has done a *much* better job in the > patched code vs master with about 10x fewer misses. This should have Nice! > helped contribute to the "insn per cycle" increase. 4.29 is quite > good for postgres. I often see that around 0.5. According to [1] > (relating to Zen4), "We get a ridiculous 12 NOPs per cycle out of the > micro-op cache". I'm unsure how micro-ops translate to "insn per > cycle" that's shown in perf stat. I thought 4-5 was about the maximum > pipeline size from today's era of CPUs. "ins per cycle" is micro-ops retired (i.e. excludes those executed speculatively on a mispredicted branch). That article mentions that 6 micro-ops per cycle can enter the backend from the frontend, but that can happen only with internally cached ops, since only 4 instructions per cycle can be decoded. In specific cases, CPUs can fuse multiple front-end instructions into a single macro-op, which I think means a pair of micro-ops that can "travel together" as one. The authors concluded further down that "Zen 4’s reorder buffer is also special, because each entry can hold up to 4 NOPs. Pairs of NOPs are likely fused by the decoders, and pairs of fused NOPs are fused again at the rename stage."
On Tue, 16 Jul 2024 at 00:13, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > > On Tue, 2 Jul 2024 at 02:23, David Rowley <dgrowleyml@gmail.com> wrote: > > I'm happy to keep going with this version of the patch > > +1, go for it. I've attached an updated patch series which are a bit more polished than the last set. I've attempted to document the distinction between FormData_pg_attribute and the abbreviated struct and tried to give an indication of which one should be used. Apart from that, changes include: * I pushed the v1-0001 patch, so that's removed from the patch series. * Rename TupleDescDeformAttr struct. It's now called CompactAttribute. * Rename TupleDescDeformAttr() macro. It's now called TupleDescCompactAttr() * Other macro renaming. e.g. ATT_IS_PACKABLE_FAST to COMPACT_ATTR_IS_PACKABLE * In 0003, renamed CompactAttribute.attalign to attalignby to make it easier to understand the distinction between the align char and the number of bytes. * Added 0004 patch to remove pg_attribute.attcacheoff. There are a few more things that could be done to optimise a few more things. For example, a bunch of places still use att_align_nominal(). With a bit more work, these could use att_nominal_alignby(). I'm not yet sure of the cleanest way to do this. Adding alignby to the typecache might be one way, or maybe just a function that converts the attalign to the number of bytes. This would be useful in all places where att_align_nominal() is used in loops, as converting the char to the number of bytes would only be done once rather than once per loop. I feel like this patch series is probably big enough for now, so I'd like to opt for those improvements to take place as follow-on work. I'll put this up for the CF bot to run with for a bit as the patch has needed a rebase since I pushed the v1-0001 patch. David
Attachment
Hi,
A few weeks ago David and I discussed this patch. We were curious *why* the
flags approach was slower. It turns out that, at least on my machine, this is
just a compiler optimization issue. Putting a pg_compiler_barrier() just
after:
> for (; attnum < natts; attnum++)
> {
> - Form_pg_attribute thisatt = TupleDescAttr(tupleDesc, attnum);
> + CompactAttribute *thisatt = TupleDescCompactAttr(tupleDesc, attnum);
addressed the issue. The problem basically is that instead of computing the
address of thisatt once, gcc for some reason instead uses complex addressing
lea instructions, which are slower on some machines.
Not sure what a good way to deal with that is. I haven't tried, but it could
be that just advancing thisatt using++ would do the trick?
I think this generally looks quite good and the performance wins are quite
nice! I'm a bit concerned about the impact on various extensions - I haven't
looked, but I wouldn't be surprised if this requires a bunch of of changes.
Perhaps we could reduce that a bit?
Could it make sense to use bitfields instead of flag values, to reduce the
impact?
> From 35a6cdc2056decc31d67ad552826b573d2b66073 Mon Sep 17 00:00:00 2001
> From: David Rowley <dgrowley@gmail.com>
> Date: Tue, 28 May 2024 20:10:50 +1200
> Subject: [PATCH v3 2/5] Introduce CompactAttribute array in TupleDesc
>
> This array stores a subset of the fields of FormData_pg_attribute,
> primarily the ones for deforming tuples, but since we have additional
> space, pack a few additional boolean columns in the attflags field.
>
> Many areas of the code can get away with only accessing the
> CompactAttribute array, which because the details of each attribute is
> stored much more densely than FormData_pg_attribute, many operations can
> be performed accessing fewer cachelines which can improve performance.
>
> This also makes pg_attribute.attcacheoff redundant. A follow-on commit
> will remove it.
Yay.
> diff --git a/src/include/access/tupdesc.h b/src/include/access/tupdesc.h
> index 2c435cdcb2..478ebbe1f4 100644
> --- a/src/include/access/tupdesc.h
> +++ b/src/include/access/tupdesc.h
> @@ -45,6 +45,46 @@ typedef struct TupleConstr
> bool has_generated_stored;
> } TupleConstr;
>
> +/*
> + * CompactAttribute
> + * Cut-down version of FormData_pg_attribute for faster access for tasks
> + * such as tuple deformation.
> + */
> +typedef struct CompactAttribute
> +{
> + int32 attcacheoff; /* fixed offset into tuple, if known, or -1 */
For a short while I thought we could never have a large offset here, due to
toast, but that's only when tuples come from a table...
> + int16 attlen; /* attr len in bytes or -1 = varlen, -2 =
> + * cstring */
It's hard to imagine fixed-dith types longer than 256 bits long making sense,
but even if we wanted to change that, it'd not be sensible to change that in
this patch...
> +#ifdef USE_ASSERT_CHECKING
> +
> +/*
> + * Accessor for the i'th CompactAttribute of tupdesc. In Assert enabled
> + * builds we verify that the CompactAttribute is populated correctly.
> + * This helps find bugs in places such as ALTER TABLE where code makes changes
> + * to the FormData_pg_attribute but forgets to call populate_compact_attribute
> + */
> +static inline CompactAttribute *
> +TupleDescCompactAttr(TupleDesc tupdesc, int i)
> +{
> + CompactAttribute snapshot;
> + CompactAttribute *cattr = &tupdesc->compact_attrs[i];
> +
> + /*
> + * Take a snapshot of how the CompactAttribute is now before calling
> + * populate_compact_attribute to make it up-to-date with the
> + * FormData_pg_attribute.
> + */
> + memcpy(&snapshot, cattr, sizeof(CompactAttribute));
> +
> + populate_compact_attribute(tupdesc, i);
> +
> + /* reset attcacheoff back to what it was */
> + cattr->attcacheoff = snapshot.attcacheoff;
> +
> + /* Ensure the snapshot matches the freshly populated CompactAttribute */
> + Assert(memcmp(&snapshot, cattr, sizeof(CompactAttribute)) == 0);
> +
> + return cattr;
> +}
> +
> +#else
> +/* Accessor for the i'th CompactAttribute of tupdesc */
> +#define TupleDescCompactAttr(tupdesc, i) (&(tupdesc)->compact_attrs[(i)])
> +#endif
Personally I'd have the ifdef inside the static inline function, rather than
changing between a static inline and a macro depending on
USE_ASSERT_CHECKING..
> #ifndef FRONTEND
> /*
> - * Given a Form_pg_attribute and a pointer into a tuple's data area,
> + * Given a CompactAttribute pointer and a pointer into a tuple's data area,
> * return the correct value or pointer.
> *
> * We return a Datum value in all cases. If the attribute has "byval" false,
> @@ -43,7 +43,7 @@ att_isnull(int ATT, const bits8 *BITS)
> *
> * Note that T must already be properly aligned for this to work correctly.
> */
> -#define fetchatt(A,T) fetch_att(T, (A)->attbyval, (A)->attlen)
> +#define fetchatt(A, T) fetch_att(T, CompactAttrByVal(A), (A)->attlen)
Stuff like this seems like it might catch some extensions unaware. I think it
might make sense to change macros like this to be a static inline, so that you
get proper type mismatch errors, rather than errors about invalid casts or
nonexistant fields.
> From c75d072b8bc43ba4f9b7fbe2f99b65edc7421a15 Mon Sep 17 00:00:00 2001
> From: David Rowley <dgrowley@gmail.com>
> Date: Wed, 29 May 2024 12:19:03 +1200
> Subject: [PATCH v3 3/5] Optimize alignment calculations in tuple form/deform
>
> This converts CompactAttribute.attalign from a char which is directly
> derived from pg_attribute.attalign into a uint8 which specifies the
> number of bytes to align the column by. Also, rename the field to
> attalignby to make the distinction more clear in code.
>
> This removes the complexity of checking each char value and transforming
> that into the appropriate alignment call. This can just be a simple
> TYPEALIGN passing in the number of bytes.
I like this a lot.
> diff --git a/contrib/amcheck/verify_heapam.c b/contrib/amcheck/verify_heapam.c
> index 08772de39f..b66eb178b9 100644
> --- a/contrib/amcheck/verify_heapam.c
> +++ b/contrib/amcheck/verify_heapam.c
> @@ -1592,7 +1592,7 @@ check_tuple_attribute(HeapCheckContext *ctx)
> /* Skip non-varlena values, but update offset first */
> if (thisatt->attlen != -1)
> {
> - ctx->offset = att_align_nominal(ctx->offset, thisatt->attalign);
> + ctx->offset = att_nominal_alignby(ctx->offset, thisatt->attalignby);
> ctx->offset = att_addlength_pointer(ctx->offset, thisatt->attlen,
> tp + ctx->offset);
> if (ctx->tuphdr->t_hoff + ctx->offset > ctx->lp_len)
A bit confused about the change in naming policy here...
> From d1ec19a46a480b0c75f9df468b2765ad4e51dce2 Mon Sep 17 00:00:00 2001
> From: David Rowley <dgrowley@gmail.com>
> Date: Tue, 3 Sep 2024 14:05:30 +1200
> Subject: [PATCH v3 5/5] Try a larger CompactAttribute struct without flags
>
> Benchmarks have shown that making the CompactAttribute struct larger and
> getting rid of the flags to reduce the bitwise-ANDing requirements makes
> things go faster.
I think we have some way of not needing this. I don't like my compiler barrier
hack, but I'm sure we can hold the hands of the compiler sufficiently to
generate useful code.
But this made me wonder:
> ---
> src/backend/access/common/tupdesc.c | 21 ++++++----------
> src/include/access/tupdesc.h | 39 ++++++++++-------------------
> 2 files changed, 20 insertions(+), 40 deletions(-)
>
> diff --git a/src/backend/access/common/tupdesc.c b/src/backend/access/common/tupdesc.c
> index 74f22cffb9..95c92e6585 100644
> --- a/src/backend/access/common/tupdesc.c
> +++ b/src/backend/access/common/tupdesc.c
> @@ -67,20 +67,13 @@ populate_compact_attribute(TupleDesc tupdesc, int i)
> dst->attcacheoff = -1;
> dst->attlen = src->attlen;
>
> - dst->attflags = 0;
> -
> - if (src->attbyval)
> - dst->attflags |= COMPACT_ATTR_FLAG_BYVAL;
> - if (src->attstorage != TYPSTORAGE_PLAIN)
> - dst->attflags |= COMPACT_ATTR_FLAG_IS_PACKABLE;
> - if (src->atthasmissing)
> - dst->attflags |= COMPACT_ATTR_FLAG_HAS_MISSING;
> - if (src->attisdropped)
> - dst->attflags |= COMPACT_ATTR_FLAG_IS_DROPPED;
> - if (src->attgenerated)
> - dst->attflags |= COMPACT_ATTR_FLAG_IS_GENERATED;
> - if (src->attnotnull)
> - dst->attflags |= COMPACT_ATTR_FLAG_IS_NOTNULL;
> +
> + dst->attbyval = src->attbyval;
> + dst->attispackable = (src->attstorage != TYPSTORAGE_PLAIN);
> + dst->atthasmissing = src->atthasmissing;
> + dst->attisdropped = src->attisdropped;
> + dst->attgenerated = src->attgenerated;
> + dst->attnotnull = src->attnotnull;
It'd sure be nice if we could condense some of these fields in pg_attribute
too. It obviously shouldn't be a requirement for this patch, don't get me
wrong!
Production systems have often very large pg_attribute tables, which makes this
a fairly worthwhile optimization target.
I wonder if we could teach the bootstrap and deform logic about bool:1 or such
and have it generate the right code for that.
Greetings,
Andres Freund
On Mon, 2 Dec 2024 at 23:24, David Rowley <dgrowleyml@gmail.com> wrote: > I spent all day today reviewing and fixing up a few missing comments > for the v5 patch series. I'm quite happy with these now. If nobody > else wants to look or test, I plan on pushing these tomorrow (Tuesday > UTC+13). If anyone wants me to delay so they can look, they better let > me know soon. After making some last-minute cosmetic adjustments, I've just pushed the 0001 patch. I planning on pushing up to 0004 over the next 8 hours, pending feedback from the buildfarm. David
Hi, On 2024-12-05 01:42:36 +1300, David Rowley wrote: > On Tue, 3 Dec 2024 at 16:54, David Rowley <dgrowleyml@gmail.com> wrote: > > After making some last-minute cosmetic adjustments, I've just pushed > > the 0001 patch. > > So that commit broke all of the debug_parallel_query = regress > buildfarm animals. Seems we need a query in the regression tests that trigger the issue even without debug_parallel_query = regress. > In the attached v7-0001 patch, I've now got rid of the > TupleDescData->attrs field. Figuring out the base address of the > FormData_pg_attribute array is now done by the TupleDescAttr() inline > function (this used to be a macro). Possibly stupid idea: Could we instead store the attributes *before* the main TupleDescData, with increasing "distance" for increased attnos? That way we wouldn't need to calculate any variable offsets. Of course the price would be to have some slightly more complicated invocation of pfree(), but that's comparatively rare. > Because that function is called often in a tight loop, I wanted to ensure > compilers wouldn't calculate the base address of the array on each iteration > of the loop. Looking at [1], it seems gcc and clang are smart about this > and calculate the base address before the loop and add > sizeof(FormData_pg_attribute) to the register that's being used for the > element pointer. > > Changing this then caused some other issues... The GIST code was doing > the following to get a TupleDesc without the INCLUDE columns of the > index: > > giststate->nonLeafTupdesc = CreateTupleDescCopyConstr(index->rd_att); > giststate->nonLeafTupdesc->natts = > IndexRelationGetNumberOfKeyAttributes(index); That is somewhat ugly... > Since I'm calculating the base address of the FormData_pg_attribute > array in TupleDesc by looking at natts, when this code changes natts > on the fly, that means calls to TupleDescAttr end up looking in the > wrong place for the required FormData_pg_attribute element. It's possible out-of-core code is doing that too, could we detect this in assert enabled builds? > To fix this I invented CreateTupleDescTruncatedCopy() and used it in all the > places that were fiddling with the natts field. Makes sense. > v7-0002 is not for commit. That's me cheekily exploiting the CFBot's CI > testing machines to run in debug_parallel_query = regress mode. I think it might actually make sense to enable debug_parallel_query = regress in one of the CI tasks... Perhaps FreeBSD? That's reasonably fast right now (and a *LOT* cheaper to run than macos). Greetings, Andres Freund
On Thu, 5 Dec 2024 at 03:51, Andres Freund <andres@anarazel.de> wrote: > Possibly stupid idea: Could we instead store the attributes *before* the main > TupleDescData, with increasing "distance" for increased attnos? That way we > wouldn't need to calculate any variable offsets. Of course the price would be > to have some slightly more complicated invocation of pfree(), but that's > comparatively rare. Are you thinking this to make the address calculation cheaper? or so that the hacky code that truncates the TupleDesc would work without crashing still? If it's for the latter then the pfree() would be tricky to make work still as natts would need to be consulted to find the address to pfree. > On 2024-12-05 01:42:36 +1300, David Rowley wrote: > > Since I'm calculating the base address of the FormData_pg_attribute > > array in TupleDesc by looking at natts, when this code changes natts > > on the fly, that means calls to TupleDescAttr end up looking in the > > wrong place for the required FormData_pg_attribute element. > > It's possible out-of-core code is doing that too, could we detect this in > assert enabled builds? The assert in TupleDescCompactAttr() which verifies the CompactAttribute matches the FormData_pg_attribute did highlight these issues. It's just it wasn't that obvious what the cause of the issue was from that failing assert. I expect there would be some breaking of extensions by removing the attrs array anyway. 65b71dec2d fixed up some cases where TupleDescAttr() wasn't being used, so anything out there that's doing something similar to what that commit fixed would fail to compile. One way to ensure we purposefully break any code manually adjusting natts would be to rename that field. That would mean having to adjust all the loops over each attribute in core. There are quite a few: $ git grep -E "^\s+for.*->natts;" | wc -l 147 David
On Wed, 4 Dec 2024 at 23:52, David Rowley <dgrowleyml@gmail.com> wrote: > > On Thu, 5 Dec 2024 at 03:51, Andres Freund <andres@anarazel.de> wrote: > > Possibly stupid idea: Could we instead store the attributes *before* the main > > TupleDescData, with increasing "distance" for increased attnos? That way we > > wouldn't need to calculate any variable offsets. Of course the price would be > > to have some slightly more complicated invocation of pfree(), but that's > > comparatively rare. > > Are you thinking this to make the address calculation cheaper? or so > that the hacky code that truncates the TupleDesc would work without > crashing still? > > If it's for the latter then the pfree() would be tricky to make work > still as natts would need to be consulted to find the address to > pfree. It's certainly tricky (I'd say quite a hack, even), but you could put a MCTX_ALIGNED_REDIRECT_ID -type memory chunk ahead of the main TupleDescData, and put any other data you want ahead of that redirect chunk (so you'd have the normal palloc() MemoryChunk header (at allocptr - sizeof(MemoryChunk), followed by variable data, followed by the redirect MemoryChunk, followed by the to-be-returned TupleDesc's data). This ALIGNED_REDIRECT MemoryChunk will safely forward calls to pfree on the TupleDesc pointer to the base pointer of the palloc()-ed area, which then is forwarded to the actual memory context. That said, I don't think it'd be safe to use with repalloc, as that would likely truncate the artificial hole in the memory chunk, probably requiring restoration work by the callee on the prefixed arrays. That may be a limitation we can live with, but I haven't checked to see if there are any usages of repalloc() on TupleDesc. Kind regards, Matthias van de Meent Neon (https://neon.tech)
Hi, On 2024-12-05 11:52:01 +1300, David Rowley wrote: > On Thu, 5 Dec 2024 at 03:51, Andres Freund <andres@anarazel.de> wrote: > > Possibly stupid idea: Could we instead store the attributes *before* the main > > TupleDescData, with increasing "distance" for increased attnos? That way we > > wouldn't need to calculate any variable offsets. Of course the price would be > > to have some slightly more complicated invocation of pfree(), but that's > > comparatively rare. > > Are you thinking this to make the address calculation cheaper? or so > that the hacky code that truncates the TupleDesc would work without > crashing still? Primarily to make the address calculation cheaper. > If it's for the latter then the pfree() would be tricky to make work > still as natts would need to be consulted to find the address to > pfree. But is that really a problem? Freeing a tupledesc needs to go through FreeTupleDesc() (unless a shared one, but that's just one additional place), and the TupleDesc could just store a pointer/offset to its start. > > On 2024-12-05 01:42:36 +1300, David Rowley wrote: > > > Since I'm calculating the base address of the FormData_pg_attribute > > > array in TupleDesc by looking at natts, when this code changes natts > > > on the fly, that means calls to TupleDescAttr end up looking in the > > > wrong place for the required FormData_pg_attribute element. > > > > It's possible out-of-core code is doing that too, could we detect this in > > assert enabled builds? > > The assert in TupleDescCompactAttr() which verifies the > CompactAttribute matches the FormData_pg_attribute did highlight these > issues. Cool. > One way to ensure we purposefully break any code manually adjusting > natts would be to rename that field. That would mean having to adjust > all the loops over each attribute in core. There are quite a few: > > $ git grep -E "^\s+for.*->natts;" | wc -l > 147 That doesn't seem worth it... Greetings, Andres Freund
On Thu, 5 Dec 2024 at 13:09, Andres Freund <andres@anarazel.de> wrote: > On 2024-12-05 11:52:01 +1300, David Rowley wrote: > > On Thu, 5 Dec 2024 at 03:51, Andres Freund <andres@anarazel.de> wrote: > > > Possibly stupid idea: Could we instead store the attributes *before* the main > > > TupleDescData, with increasing "distance" for increased attnos? That way we > > > wouldn't need to calculate any variable offsets. Of course the price would be > > > to have some slightly more complicated invocation of pfree(), but that's > > > comparatively rare. > > > > Are you thinking this to make the address calculation cheaper? or so > > that the hacky code that truncates the TupleDesc would work without > > crashing still? > > Primarily to make the address calculation cheaper. I mostly got that working, but there were quite several adjustments needed to fix various things. For example, there are a few places that are pfreeing a TupleDesc without going through FreeTupleDesc(); namely index_truncate_tuple() and InsertOneTuple(). There was also a bit more complexity around the TupleDescs stored in DSA memory as the base address of those is the start of the FormData_pg_attribute array, so some offsetting is needed to get the TupleDesc address. None of those changes are complex themselves, but it was quite painful to find all those places and I started to worry that there might end up being a bit more fallout from that method and I basically chickened out. I agree the address calculation is cheaper, but accessing FormData_pg_attribute isn't as performance-critical anymore as CompactAttribute is doing the performance-critical work now. I've now pushed the 0001 patch and the 0002 patch as one commit. I'm going to give the buildfarm a bit of time then push the commit to remove pg_attribute.attcacheoff. I'm planning on letting that settle overnight then if all is well push the attalignby changes. David
Hello David,
20.12.2024 12:31, David Rowley wrote:
20.12.2024 12:31, David Rowley wrote:
The attcacheoff removal is now pushed. I've attached the two remaining patches.
Please look at the following query, which triggers (sometimes not on a
first run) an assert added with 5983a4cff:
regression=# SELECT COUNT(*) FROM
(SELECT (aclexplode(proacl)).* FROM pg_proc) a,
(SELECT oid FROM pg_proc UNION ALL SELECT oid FROM pg_proc) b;
count
--------
520366
(1 row)
regression=# SELECT COUNT(*) FROM
(SELECT (aclexplode(proacl)).* FROM pg_proc) a,
(SELECT oid FROM pg_proc UNION ALL SELECT oid FROM pg_proc) b;
WARNING: terminating connection because of crash of another server process
...
TRAP: failed Assert("memcmp(&snapshot, cattr, sizeof(CompactAttribute)) == 0"), File: "../../../../src/include/access/tupdesc.h", Line: 191, PID: 1302048
ExceptionalCondition at assert.c:52:13
TupleDescCompactAttr at tupdesc.h:195:1
nocachegetattr at heaptuple.c:668:8
fastgetattr at htup_details.h:768:11
heap_getattr at htup_details.h:804:11
ExecEvalFieldSelect at execExprInterp.c:3623:17
ExecInterpExpr at execExprInterp.c:1542:4
MemoryContextSwitchTo at palloc.h:128:23
(inlined by) ExecEvalExprSwitchContext at executor.h:370:2
ExecProject at executor.h:409:18
ExecResult at nodeResult.c:139:1
ExecProcNode at executor.h:273:1
SubqueryNext at nodeSubqueryscan.c:61:1
ExecScanFetch at execScan.c:131:10
ExecScan at execScan.c:197:10
ExecSubqueryScan at nodeSubqueryscan.c:90:1
ExecProcNode at executor.h:273:1
ExecMaterial at nodeMaterial.c:134:15
ExecProcNode at executor.h:273:1
ExecNestLoop at nodeNestloop.c:160:29
ExecProcNode at executor.h:273:1
fetch_input_tuple at nodeAgg.c:561:10
agg_retrieve_direct at nodeAgg.c:2459:18
...
LaunchMissingBackgroundProcesses at postmaster.c:3220:1
(I've discovered this with SQLsmith.)
Best regards,
Alexander
On Tue, 24 Dec 2024 at 02:00, Alexander Lakhin <exclusion@gmail.com> wrote:
> regression=# SELECT COUNT(*) FROM
> (SELECT (aclexplode(proacl)).* FROM pg_proc) a,
> (SELECT oid FROM pg_proc UNION ALL SELECT oid FROM pg_proc) b;
> WARNING: terminating connection because of crash of another server process
> ...
> TRAP: failed Assert("memcmp(&snapshot, cattr, sizeof(CompactAttribute)) == 0"), File:
"../../../../src/include/access/tupdesc.h",Line: 191, PID: 1302048
Thanks. Looking now.
David
On Tue, 24 Dec 2024 at 11:19, David Rowley <dgrowleyml@gmail.com> wrote: > The attached adjusts that Assert code so that a fresh CompactAttribute > is populated instead of modifying the TupleDesc's one. I'm not sure > if populate_compact_attribute_internal() is exactly the nicest way to > do this. I'll think a bit harder about that. Assume the attached is > POC grade. I've now pushed a fix for this using the same method but with the code factored around a little differently. I didn't want to expose the populate_compact_attribute_internal() function externally, so I invented verify_compact_attribute() to call from TupleDescCompactAttr(). Thanks for the report. David
On Thu, 2024-10-10 at 02:59 +1300, David Rowley wrote:
> > A few weeks ago David and I discussed this patch. We were curious
> > *why* the
> > flags approach was slower.
...
> > Could it make sense to use bitfields instead of flag values, to
> > reduce the
> > impact?
>
> Yeah. That's a good idea.
I happened to run into the code and was surprised to see a strongly-
worded comment about the size of CompactAttribute, but then also see
independent booleans rather than flags or bitfields.
Did the discussion end here, or was there some kind of conclusion? Is
it worth adding a comment about why we use independent booleans, even
if we don't have a complete answer?
Regards,
Jeff Davis
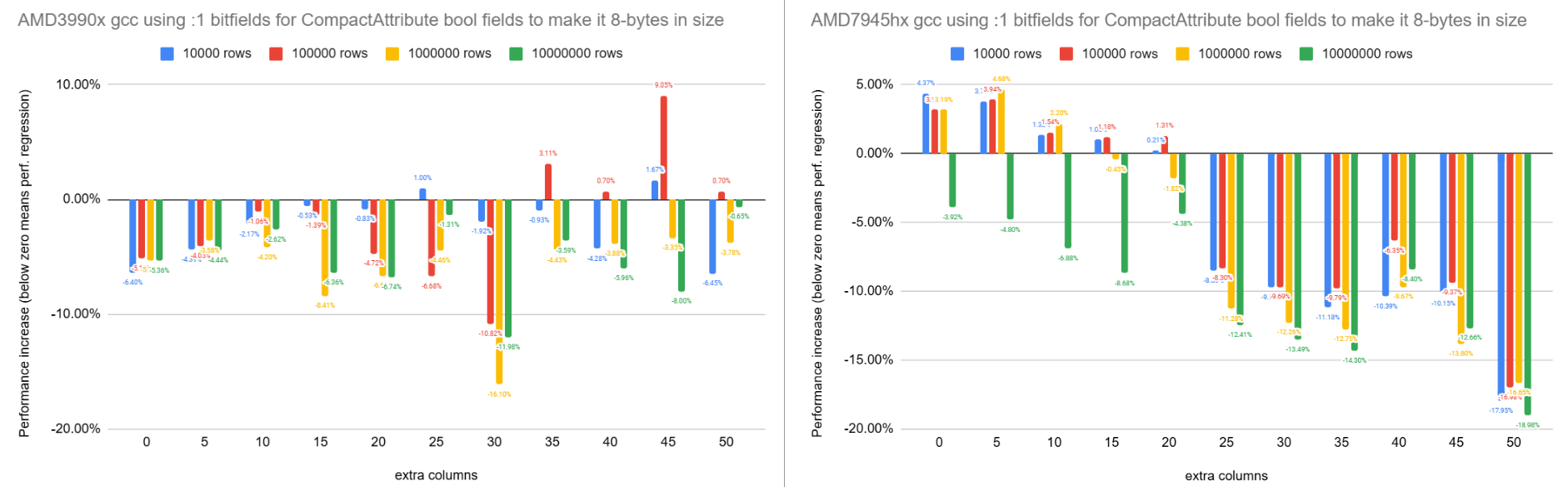
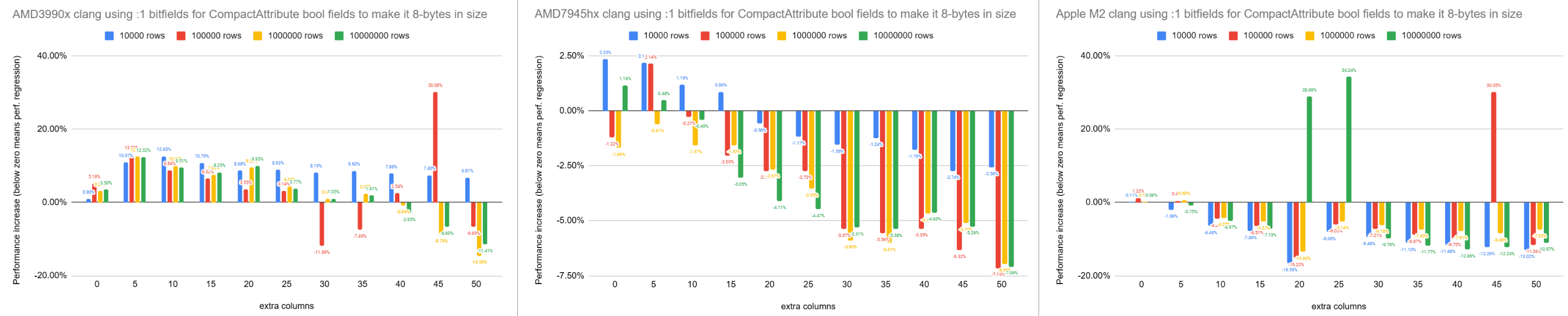
On Wed, 5 Mar 2025 at 08:48, Jeff Davis <pgsql@j-davis.com> wrote: > I happened to run into the code and was surprised to see a strongly- > worded comment about the size of CompactAttribute, but then also see > independent booleans rather than flags or bitfields. > > Did the discussion end here, or was there some kind of conclusion? Is > it worth adding a comment about why we use independent booleans, even > if we don't have a complete answer? I must have either forgotten to try that, or I tried it and wrote it off and forgot to document it. Anyway, I've now benchmarked using bitfields on the same 3 machines that I used last time. There are certainly some cases where it's faster with the bitfields, but it's mainly slower. I've attached the results. The 3990x with clang looks good, but the rest are mostly slower. David
Attachment
{kind=link}
{kind=link}
On Thu, 2025-03-06 at 01:07 +1300, David Rowley wrote:
> I've attached the results. The 3990x with clang looks good, but the
> rest are mostly slower.
I am still curious why.
If it's due to compiler misoptimization, is that kind of thing often
misoptimized, or is there something we're doing in particular?
Even if we don't have answers, it might be worth adding a brief comment
that we empirically determined that booleans are faster than bitfields
or flags. In the future, maybe compilers mostly get this right, and we
want to change to bitfields.
Regards,
Jeff Davis
On Wed, Mar 5, 2025 at 10:40 AM Jeff Davis <pgsql@j-davis.com> wrote: > > On Thu, 2025-03-06 at 01:07 +1300, David Rowley wrote: > > I've attached the results. The 3990x with clang looks good, but the > > rest are mostly slower. > > I am still curious why. > > If it's due to compiler misoptimization, is that kind of thing often > misoptimized, or is there something we're doing in particular? > > Even if we don't have answers, it might be worth adding a brief comment > that we empirically determined that booleans are faster than bitfields > or flags. In the future, maybe compilers mostly get this right, and we > want to change to bitfields. I haven't run this sort of experiment in years, and CPUs continue to improve -- but with a Boolean, the CPU can read from or write to that Boolean directly, one instruction. A Boolean tends to be a byte, and memory is byte-addressable. For a bitfield, however, the CPU has to read from or write to the byte that contains the bit, but then it also has to mask out the *other* bits in that bitfield. This is a data dependency, so it stalls the CPU pipeline. So Booleans tend to be faster than bitfields, because they avoid a pipeline stall. James Hunter
On Wed, 2025-03-05 at 11:33 -0800, James Hunter wrote:
> For a bitfield, however, the CPU has to read from or write to the
> byte
> that contains the bit, but then it also has to mask out the *other*
> bits in that bitfield. This is a data dependency, so it stalls the
> CPU
> pipeline.
Here the bits aren't changing, so we're only talking about mask-and-
test, right? My intuition is that wouldn't cause much of a problem.
Regards,
Jeff Davis
On Wed, Mar 5, 2025 at 12:16 PM Jeff Davis <pgsql@j-davis.com> wrote: > > On Wed, 2025-03-05 at 11:33 -0800, James Hunter wrote: > > For a bitfield, however, the CPU has to read from or write to the > > byte > > that contains the bit, but then it also has to mask out the *other* > > bits in that bitfield. This is a data dependency, so it stalls the > > CPU > > pipeline. > > Here the bits aren't changing, so we're only talking about mask-and- > test, right? My intuition is that wouldn't cause much of a problem. Right, so that's just +1 pipeline stall (load, mask, and test; vs. just load and test). But you can imagine microbenchmarks / situations where that extra "mask" matters (like some of the benchmarks David ran). "Mask + test" has to wait for the mask to complete, before it can perform the test; so it's slower than two independent instructions would be. But -- cost vs. benefit, a Boolean is typically 1 byte; a cache line is typically 64 bytes, with maybe CPU prefetch making it behave like 128 bytes. So replacing 6 bytes of Booleans with 6 bits saves us < 10% of a cache line -- it's "only" an 8-to-1 compression ratio -- which might or might not be worth it, as David's benchmarks show... James Hunter
Hi, On 2025-03-05 12:15:57 -0800, Jeff Davis wrote: > On Wed, 2025-03-05 at 11:33 -0800, James Hunter wrote: > > For a bitfield, however, the CPU has to read from or write to the > > byte > > that contains the bit, but then it also has to mask out the *other* > > bits in that bitfield. This is a data dependency, so it stalls the > > CPU > > pipeline. > > Here the bits aren't changing, so we're only talking about mask-and- > test, right? My intuition is that wouldn't cause much of a problem. FWIW, I am fairly certain that I looked at this at an earlier state of the patch, and at least for me the issue wasn't that it was inherently slower to use the bitmask, but that it was hard to convince the compiler not generate worse code. IIRC the compiler generated more complicated address gathering instructions which are slower on some older microarchitectures, but this is a vague memory. Greetings, Andres
On Thu, 6 Mar 2025 at 10:17, Andres Freund <andres@anarazel.de> wrote: > FWIW, I am fairly certain that I looked at this at an earlier state of the > patch, and at least for me the issue wasn't that it was inherently slower to > use the bitmask, but that it was hard to convince the compiler not generate > worse code. > > IIRC the compiler generated more complicated address gathering instructions > which are slower on some older microarchitectures, but this is a vague memory. I've been reading GCC's assembly output with -fverbose-asm. I find it quite hard to follow as the changes between the 16-byte and 8-byte CompactAttribute versions are vast (see attached). A few interesting things jump out. e.g, in master: # execTuples.c:1080: thisatt->attcacheoff = *offp; .loc 1 1080 26 is_stmt 0 view .LVU1468 movl %ebp, (%rax) # off, MEM[(int *)_22] whereas with the 8-byte version, I see: # execTuples.c:1080: thisatt->attcacheoff = *offp; .loc 1 1080 26 is_stmt 0 view .LVU1484 movl %ebp, 24(%rax) # off, MEM[(int *)_358 + 24B] You can see the MOVL in the 8-byte version should amount to an additional micro op to add 24 to RAX before the dereference. One interesting thing to note about having CompactAttribute in its 8-byte form is that the compiler is tempted into sharing a register with the tts_values array before Datum is also 8-bytes. Note the difference in [1] between the two left compiler outputs and the right-hand one. You can see RCX is dedicated for addressing CompactAttribute in the right window, but RAX is used for both arrays in the left two. I don't 100% know for sure that's the reason for the slowness with the full version but it does seem from the fragment I posted just above that RAX does need 24 bytes added in the 8 bytes version but not in the 16 byte version, so RAX is certainly not dedicated and ready pointing to attcacheoff at that point. Jeff, I'm not sure if I understand this well enough to write a meaningful comment to explain why we don't use bitflags. With my current knowledge level on this, it's a bit hand-wavy at best. Are you content with this, or do you want to see something written into the header comment for CompactAttribute in the code? David [1] https://godbolt.org/z/7hWvqdW6E
Attachment
Hello David,
24.12.2024 03:57, David Rowley wrote:
24.12.2024 03:57, David Rowley wrote:
On Tue, 24 Dec 2024 at 11:19, David Rowley <dgrowleyml@gmail.com> wrote:The attached adjusts that Assert code so that a fresh CompactAttribute is populated instead of modifying the TupleDesc's one. I'm not sure if populate_compact_attribute_internal() is exactly the nicest way to do this. I'll think a bit harder about that. Assume the attached is POC grade.I've now pushed a fix for this using the same method but with the code factored around a little differently. I didn't want to expose the populate_compact_attribute_internal() function externally, so I invented verify_compact_attribute() to call from TupleDescCompactAttr().
I stumbled upon that assertion failure again. It's not reproduced easily,
but maybe you can forgive me the following modification:
--- a/src/backend/access/common/tupdesc.c
+++ b/src/backend/access/common/tupdesc.c
@@ -159,8 +159,11 @@ verify_compact_attribute(TupleDesc tupdesc, int attnum)
tmp.attcacheoff = cattr->attcacheoff;
tmp.attnullability = cattr->attnullability;
+for (int i = 0; i < 1000; i++)
+{
/* Check the freshly populated CompactAttribute matches the TupleDesc's */
Assert(memcmp(&tmp, cattr, sizeof(CompactAttribute)) == 0);
+}
#endif
}
which helps for this script:
for i in {1..50}; do
echo "ITERATION $i"
for c in {1..20}; do
echo "
set parallel_setup_cost = 1;
set min_parallel_table_scan_size = '1kB';
select * from information_schema.role_udt_grants limit 50;
" | psql > psql-$c.log &
done
wait
grep 'was terminated by signal' server.log && break;
done
to fail for me as below:
...
ITERATION 34
WARNING: terminating connection because of crash of another server process
DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
HINT: In a moment you should be able to reconnect to the database and repeat your command.
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to server was lost
2025-06-07 13:01:39.326 EEST [537106] LOG: background worker "parallel worker" (PID 539473) was terminated by signal 6: Aborted
Core was generated by `postgres: parallel worker for PID 539434 '.
Program terminated with signal SIGABRT, Aborted.
(gdb) bt
#0 __pthread_kill_implementation (no_tid=0, signo=6, threadid=<optimized out>) at ./nptl/pthread_kill.c:44
#1 __pthread_kill_internal (signo=6, threadid=<optimized out>) at ./nptl/pthread_kill.c:78
#2 __GI___pthread_kill (threadid=<optimized out>, signo=signo@entry=6) at ./nptl/pthread_kill.c:89
#3 0x00007de05ec4526e in __GI_raise (sig=sig@entry=6) at ../sysdeps/posix/raise.c:26
#4 0x00007de05ec288ff in __GI_abort () at ./stdlib/abort.c:79
#5 0x00005dd0a1788377 in ExceptionalCondition (conditionName=0x5dd0a1822ee8 "memcmp(&tmp, cattr, sizeof(CompactAttribute)) == 0",
fileName=0x5dd0a1822ed9 "tupdesc.c", lineNumber=165) at assert.c:66
#6 0x00005dd0a0f85bfd in verify_compact_attribute (tupdesc=0x7de05ef01000, attnum=1) at tupdesc.c:165
#7 0x00005dd0a0f72a25 in TupleDescCompactAttr (tupdesc=0x7de05ef01000, i=1) at ../../../../src/include/access/tupdesc.h:182
#8 0x00005dd0a0f73da6 in nocachegetattr (tup=0x7ffc737cc550, attnum=1, tupleDesc=0x7de05ef01000) at heaptuple.c:581
#9 0x00005dd0a12719c9 in fastgetattr (tup=0x7ffc737cc550, attnum=2, tupleDesc=0x7de05ef01000, isnull=0x5dd0a7b919d5)
at ../../../src/include/access/htup_details.h:880
#10 0x00005dd0a1271a74 in heap_getattr (tup=0x7ffc737cc550, attnum=2, tupleDesc=0x7de05ef01000, isnull=0x5dd0a7b919d5)
at ../../../src/include/access/htup_details.h:916
#11 0x00005dd0a127a50d in ExecEvalFieldSelect (state=0x5dd0a7b919d0, op=0x5dd0a7b93258, econtext=0x5dd0a7b86648) at execExprInterp.c:3837
#12 0x00005dd0a12759ce in ExecInterpExpr (state=0x5dd0a7b919d0, econtext=0x5dd0a7b86648, isnull=0x0) at execExprInterp.c:1698
#13 0x00005dd0a127702f in ExecInterpExprStillValid (state=0x5dd0a7b919d0, econtext=0x5dd0a7b86648, isNull=0x0) at execExprInterp.c:2299
#14 0x00005dd0a12db079 in ExecEvalExprNoReturn (state=0x5dd0a7b919d0, econtext=0x5dd0a7b86648) at ../../../src/include/executor/executor.h:417
#15 0x00005dd0a12db137 in ExecEvalExprNoReturnSwitchContext (state=0x5dd0a7b919d0, econtext=0x5dd0a7b86648) at ../../../src/include/executor/executor.h:458
#16 0x00005dd0a12db198 in ExecProject (projInfo=0x5dd0a7b919c8) at ../../../src/include/executor/executor.h:490
#17 0x00005dd0a12db3bb in ExecResult (pstate=0x5dd0a7b86538) at nodeResult.c:135
#18 0x00005dd0a1290e47 in ExecProcNodeFirst (node=0x5dd0a7b86538) at execProcnode.c:469
#19 0x00005dd0a12e2823 in ExecProcNode (node=0x5dd0a7b86538) at ../../../src/include/executor/executor.h:313
#20 0x00005dd0a12e2848 in SubqueryNext (node=0x5dd0a7b86318) at nodeSubqueryscan.c:53
#21 0x00005dd0a1295a36 in ExecScanFetch (node=0x5dd0a7b86318, epqstate=0x0, accessMtd=0x5dd0a12e2825 <SubqueryNext>,
...
(gdb) f 6
#6 0x00005dd0a0f85bfd in verify_compact_attribute (tupdesc=0x7de05ef01000, attnum=1) at tupdesc.c:165
165 Assert(memcmp(&tmp, cattr, sizeof(CompactAttribute)) == 0);
(gdb) p i
$1 = 484
(I've compiled postgres with -O0.)
Could you look at this once again, please?
Best regards,
Alexander