Thread: Speed up JSON escape processing with SIMD plus other optimisations
Currently the escape_json() function takes a cstring and char-by-char
checks each character in the string up to the NUL and adds the escape
sequence if the character requires it.
Because this function requires a NUL terminated string, we're having
to do a little more work in some places. For example, in
jsonb_put_escaped_value() we call pnstrdup() on the non-NUL-terminated
string to make a NUL-terminated string to pass to escape_json().
To make this faster, we can just have a version of escape_json which
takes a 'len' and stops after doing that many chars rather than
stopping when the NUL char is reached. Now there's no need to
pnstrdup() which saves some palloc()/memcpy() work.
There are also a few places where we do escape_json() with a "text"
typed Datum where we go and convert the text to a NUL-terminated
cstring so we can pass that along to ecape_json(). That's wasteful as
we could just pass the payload of the text Datum directly, and only
allocate memory if the text Datum needs to be de-toasted. That saves
a useless palloc/memcpy/pfree cycle.
Now, to make this more interesting, since we have a version of
escape_json which takes a 'len', we could start looking at more than 1
character at a time. If you look closely add escape_json() all the
special chars apart from " and \ are below the space character.
pg_lfind8() and pg_lfind8_le() allow processing of 16 bytes at a time,
so we only need to search the 16 bytes 3 times to ensure that no
special chars exist within. When that test fails, just go into
byte-at-a-time processing first copying over the portion of the string
that passed the vector test up until that point.
I've attached 2 patches:
0001 does everything I've described aside from SIMD.
0002 does SIMD
I've not personally done too much work in the area of JSON, so I don't
have any canned workloads to throw at this. I did try the following:
create table j1 (very_long_column_name_to_test_json_escape text);
insert into j1 select repeat('x', x) from generate_series(0,1024)x;
vacuum freeze j1;
bench.sql:
select row_to_json(j1)::jsonb from j1;
Master:
$ pgbench -n -f bench.sql -T 10 -M prepared postgres | grep tps
tps = 362.494309 (without initial connection time)
tps = 363.182458 (without initial connection time)
tps = 362.679654 (without initial connection time)
Master + 0001 + 0002
$ pgbench -n -f bench.sql -T 10 -M prepared postgres | grep tps
tps = 426.456885 (without initial connection time)
tps = 430.573046 (without initial connection time)
tps = 431.142917 (without initial connection time)
About 18% faster.
It would be much faster if we could also get rid of the
escape_json_cstring() call in the switch default case of
datum_to_json_internal(). row_to_json() would be heaps faster with
that done. I considered adding a special case for the "text" type
there, but in the end felt that we should just fix that with some
hypothetical other patch that changes how output functions work.
Others may feel it's worthwhile. I certainly could be convinced of it.
I did add a new regression test. I'm not sure I'd want to keep that,
but felt it's worth leaving in there for now.
Other things I considered were if doing 16 bytes at a time is too much
as it puts quite a bit of work into byte-at-a-time processing if just
1 special char exists in a 16-byte chunk. I considered doing SWAR [1]
processing to do the job of vector8_has_le() and vector8_has() byte
maybe with just uint32s. It might be worth doing that. However, I've
not done it yet as it raises the bar for this patch quite a bit. SWAR
vector processing is pretty much write-only code. Imagine trying to
write comments for the code in [2] so that the average person could
understand what's going on!?
I'd be happy to hear from anyone that can throw these patches at a
real-world JSON workload to see if it runs more quickly.
Parking for July CF.
David
[1] https://en.wikipedia.org/wiki/SWAR
[2] https://dotat.at/@/2022-06-27-tolower-swar.html
Attachment
On Thu, 23 May 2024 at 13:23, David Rowley <dgrowleyml@gmail.com> wrote: > Master: > $ pgbench -n -f bench.sql -T 10 -M prepared postgres | grep tps > tps = 362.494309 (without initial connection time) > tps = 363.182458 (without initial connection time) > tps = 362.679654 (without initial connection time) > > Master + 0001 + 0002 > $ pgbench -n -f bench.sql -T 10 -M prepared postgres | grep tps > tps = 426.456885 (without initial connection time) > tps = 430.573046 (without initial connection time) > tps = 431.142917 (without initial connection time) > > About 18% faster. > > It would be much faster if we could also get rid of the > escape_json_cstring() call in the switch default case of > datum_to_json_internal(). row_to_json() would be heaps faster with > that done. I considered adding a special case for the "text" type > there, but in the end felt that we should just fix that with some > hypothetical other patch that changes how output functions work. > Others may feel it's worthwhile. I certainly could be convinced of it. Just to turn that into performance numbers, I tried the attached patch. The numbers came out better than I thought. Same test as before: master + 0001 + 0002 + attached hacks: $ pgbench -n -f bench.sql -T 10 -M prepared postgres | grep tps tps = 616.094394 (without initial connection time) tps = 615.928236 (without initial connection time) tps = 614.175494 (without initial connection time) About 70% faster than master. David
Attachment
On 2024-05-22 We 22:15, David Rowley wrote: > On Thu, 23 May 2024 at 13:23, David Rowley <dgrowleyml@gmail.com> wrote: >> Master: >> $ pgbench -n -f bench.sql -T 10 -M prepared postgres | grep tps >> tps = 362.494309 (without initial connection time) >> tps = 363.182458 (without initial connection time) >> tps = 362.679654 (without initial connection time) >> >> Master + 0001 + 0002 >> $ pgbench -n -f bench.sql -T 10 -M prepared postgres | grep tps >> tps = 426.456885 (without initial connection time) >> tps = 430.573046 (without initial connection time) >> tps = 431.142917 (without initial connection time) >> >> About 18% faster. >> >> It would be much faster if we could also get rid of the >> escape_json_cstring() call in the switch default case of >> datum_to_json_internal(). row_to_json() would be heaps faster with >> that done. I considered adding a special case for the "text" type >> there, but in the end felt that we should just fix that with some >> hypothetical other patch that changes how output functions work. >> Others may feel it's worthwhile. I certainly could be convinced of it. > Just to turn that into performance numbers, I tried the attached > patch. The numbers came out better than I thought. > > Same test as before: > > master + 0001 + 0002 + attached hacks: > $ pgbench -n -f bench.sql -T 10 -M prepared postgres | grep tps > tps = 616.094394 (without initial connection time) > tps = 615.928236 (without initial connection time) > tps = 614.175494 (without initial connection time) > > About 70% faster than master. > That's all pretty nice! I'd take the win on this rather than wait for some hypothetical patch that changes how output functions work. cheers andrew -- Andrew Dunstan EDB: https://www.enterprisedb.com
On Fri, 24 May 2024 at 08:34, Andrew Dunstan <andrew@dunslane.net> wrote:
> That's all pretty nice! I'd take the win on this rather than wait for
> some hypothetical patch that changes how output functions work.
On re-think of that, even if we changed the output functions to write
directly to a StringInfo, we wouldn't get the same speedup. All it
would get us is a better ability to know the length of the string the
output function generated by looking at the StringInfoData.len before
and after calling the output function. That *would* allow us to use
the SIMD escaping, but not save the palloc/memcpy cycle for
non-toasted Datums. In other words, if we want this speedup then I
don't see another way other than this special case.
I've attached a rebased patch series which includes the 3rd patch in a
more complete form. This one also adds handling for varchar and
char(n) output functions. Ideally, these would also use textout() to
save from having the ORs in the if condition. The output function code
is the same in each.
Updated benchmarks from the test in [1].
master @ 7c655a04a
$ for i in {1..3}; do pgbench -n -f bench.sql -T 10 -M prepared
postgres | grep tps; done
tps = 366.211426
tps = 359.707014
tps = 362.204383
master + 0001
$ for i in {1..3}; do pgbench -n -f bench.sql -T 10 -M prepared
postgres | grep tps; done
tps = 362.641668
tps = 367.986495
tps = 368.698193 (+1% vs master)
master + 0001 + 0002
$ for i in {1..3}; do pgbench -n -f bench.sql -T 10 -M prepared
postgres | grep tps; done
tps = 430.477314
tps = 425.173469
tps = 431.013275 (+18% vs master)
master + 0001 + 0002 + 0003
$ for i in {1..3}; do pgbench -n -f bench.sql -T 10 -M prepared
postgres | grep tps; done
tps = 606.702305
tps = 625.727031
tps = 617.164822 (+70% vs master)
David
[1] https://postgr.es/m/CAApHDvpLXwMZvbCKcdGfU9XQjGCDm7tFpRdTXuB9PVgpNUYfEQ@mail.gmail.com
Attachment
Hi David,
Thanks for the patch.
In 0001 patch, I see that there are some escape_json() calls with NUL-terminated strings and gets the length by calling strlen(), like below:
- escape_json(&buf, "timestamp");
+ escape_json(&buf, "timestamp", strlen("timestamp"));
Wouldn't using escape_json_cstring() be better instead? IIUC there isn't much difference between escape_json() and escape_json_cstring(), right? We would avoid strlen() with escape_json_cstring().
Regards,
Melih Mutlu
Microsoft
On 2024-06-11 Tu 08:08, Melih Mutlu wrote:
Hi David,Thanks for the patch.In 0001 patch, I see that there are some escape_json() calls with NUL-terminated strings and gets the length by calling strlen(), like below:- escape_json(&buf, "timestamp");
+ escape_json(&buf, "timestamp", strlen("timestamp"));Wouldn't using escape_json_cstring() be better instead? IIUC there isn't much difference between escape_json() and escape_json_cstring(), right? We would avoid strlen() with escape_json_cstring().
or maybe use sizeof("timestamp") - 1
cheers
andrew
-- Andrew Dunstan EDB: https://www.enterprisedb.com
Thanks for having a look.
On Wed, 12 Jun 2024 at 00:08, Melih Mutlu <m.melihmutlu@gmail.com> wrote:
> In 0001 patch, I see that there are some escape_json() calls with NUL-terminated strings and gets the length by
callingstrlen(), like below:
>
>> - escape_json(&buf, "timestamp");
>> + escape_json(&buf, "timestamp", strlen("timestamp"));
>
> Wouldn't using escape_json_cstring() be better instead? IIUC there isn't much difference between escape_json() and
escape_json_cstring(),right? We would avoid strlen() with escape_json_cstring().
It maybe would be better, but not for this reason. Most compilers will
be able to perform constant folding to transform the
strlen("timestamp") into 9. You can see that's being done by both gcc
and clang in [1].
It might be better to use escape_json_cstring() regardless of that as
the SIMD only kicks in when there are >= 16 chars, so there might be a
few more instructions calling the SIMD version for such a short
string. Probably, if we're worried about performance here we could
just not bother passing the string through the escape function to
search for something we know isn't there and just
appendBinaryStringInfo \""timestamp\":" directly.
I don't really have a preference as to which of these we use. I doubt
the JSON escaping rules would ever change sufficiently that the latter
of these methods would be a bad idea. I just doubt it's worth the
debate as I imagine the performance won't matter that much.
David
[1] https://godbolt.org/z/xqj4rKara
I've attached a rebased set of patches. The previous set no longer applied. David
Attachment
Re: Speed up JSON escape processing with SIMD plus other optimisations
From
Heikki Linnakangas
Date:
On 02/07/2024 07:49, David Rowley wrote: > I've attached a rebased set of patches. The previous set no longer applied. I looked briefly at the first patch. Seems reasonable. One little thing that caught my eye is that in populate_scalar(), you sometimes make a temporary copy of the string to add the null-terminator, but then call escape_json() which doesn't need the null-terminator anymore. See attached patch to avoid that. However, it's not clear to me how to reach that codepath, or if it reachable at all. I tried to add a NOTICE there and ran the regression tests, but got no failures. -- Heikki Linnakangas Neon (https://neon.tech)
Attachment
On Wed, 24 Jul 2024 at 22:55, Heikki Linnakangas <hlinnaka@iki.fi> wrote:
>
> On 02/07/2024 07:49, David Rowley wrote:
> > I've attached a rebased set of patches. The previous set no longer applied.
>
> I looked briefly at the first patch. Seems reasonable.
>
> One little thing that caught my eye is that in populate_scalar(), you
> sometimes make a temporary copy of the string to add the
> null-terminator, but then call escape_json() which doesn't need the
> null-terminator anymore. See attached patch to avoid that. However, it's
> not clear to me how to reach that codepath, or if it reachable at all. I
> tried to add a NOTICE there and ran the regression tests, but got no
> failures.
Thanks for noticing that. It seems like a good simplification
regardless. I've incorporated it.
I made another pass over the 0001 and 0003 patches and after a bit of
renaming, I pushed the result. I ended up keeping escape_json() as-is
and giving the new function the name escape_json_with_len(). The text
version is named ecape_json_text(). I think originally I did it the
other way as thought I'd have been able to adjust more locations than
I did. Having it this way around is slightly less churn.
I did another round of testing on the SIMD patch (attached as v5-0001)
as I wondered if the SIMD loop maybe shouldn't wait too long before
copying the bytes to the destination string. I had wondered if the
JSON string was very large that if we looked ahead too far that by the
time we flush those bytes out to the destination buffer, we'd have
started eviction of L1 cachelines for parts of the buffer that are
still to be flushed. I put this to the test (test 3) and found that
with a 1MB JSON string it is faster to flush every 512 bytes than it
is to only flush after checking the entire 1MB. With a 10kB JSON
string (test 2), the extra code to flush every 512 bytes seems to slow
things down. I'm a bit undecided about whether the flushing is
worthwhile or not. It really depend on the length of JSON strings we'd
like to optimise for. It might be possible to get the best of both but
I think it might require manually implementing portions of
appendBinaryStringInfo(). I'd rather not go there. Does anyone have
any thoughts about that?
Test 2 (10KB) does show a ~261% performance increase but dropped to
~227% flushing every 512 bytes. Test 3 (1MB) increased performance by
~99% without early flushing and increased to ~156% flushing every 512
bytes.
bench.sql: select row_to_json(j1)::jsonb from j1;
## Test 1 (variable JSON strings up to 1KB)
create table j1 (very_long_column_name_to_test_json_escape text);
insert into j1 select repeat('x', x) from generate_series(0,1024)x;
vacuum freeze j1;
master @ 17a5871d:
$ for i in {1..3}; do pgbench -n -f bench.sql -T 10 -M prepared
postgres | grep tps; done
tps = 364.410386 (without initial connection time)
tps = 367.914165 (without initial connection time)
tps = 365.794513 (without initial connection time)
master + v5-0001
$ for i in {1..3}; do pgbench -n -f bench.sql -T 10 -M prepared
postgres | grep tps; done
tps = 683.570613 (without initial connection time)
tps = 685.206578 (without initial connection time)
tps = 679.014056 (without initial connection time)
## Test 2 (10KB JSON strings)
create table j1 (very_long_column_name_to_test_json_escape text);
insert into j1 select repeat('x', 1024*10) from generate_series(0,1024)x;
vacuum freeze j1;
master @ 17a5871d:
$ for i in {1..3}; do pgbench -n -f bench.sql -T 10 -M prepared
postgres | grep tps; done
tps = 23.872630 (without initial connection time)
tps = 26.232014 (without initial connection time)
tps = 26.495739 (without initial connection time)
master + v5-0001
$ for i in {1..3}; do pgbench -n -f bench.sql -T 10 -M prepared
postgres | grep tps; done
tps = 96.813515 (without initial connection time)
tps = 96.023632 (without initial connection time)
tps = 99.630428 (without initial connection time)
master + v5-0001 ESCAPE_JSON_MAX_LOOKHEAD 512
$ for i in {1..3}; do pgbench -n -f bench.sql -T 10 -M prepared
postgres | grep tps; done
tps = 83.597442 (without initial connection time)
tps = 85.045554 (without initial connection time)
tps = 82.105907 (without initial connection time)
## Test 3 (1MB JSON strings)
create table j1 (very_long_column_name_to_test_json_escape text);
insert into j1 select repeat('x', 1024*1024) from generate_series(0,10)x;
vacuum freeze j1;
master @ 17a5871d:
$ for i in {1..3}; do pgbench -n -f bench.sql -T 10 -M prepared
postgres | grep tps; done
tps = 18.885922 (without initial connection time)
tps = 18.829701 (without initial connection time)
tps = 18.889369 (without initial connection time)
master v5-0001
$ for i in {1..3}; do pgbench -n -f bench.sql -T 10 -M prepared
postgres | grep tps; done
tps = 37.464967 (without initial connection time)
tps = 37.536676 (without initial connection time)
tps = 37.561387 (without initial connection time)
master + v5-0001 ESCAPE_JSON_MAX_LOOKHEAD 512
$ for i in {1..3}; do pgbench -n -f bench.sql -T 10 -M prepared
postgres | grep tps; done
tps = 48.296320 (without initial connection time)
tps = 48.118151 (without initial connection time)
tps = 48.507530 (without initial connection time)
David
Attachment
On Sun, 28 Jul 2024 at 00:51, David Rowley <dgrowleyml@gmail.com> wrote:
> I did another round of testing on the SIMD patch (attached as v5-0001)
> as I wondered if the SIMD loop maybe shouldn't wait too long before
> copying the bytes to the destination string. I had wondered if the
> JSON string was very large that if we looked ahead too far that by the
> time we flush those bytes out to the destination buffer, we'd have
> started eviction of L1 cachelines for parts of the buffer that are
> still to be flushed. I put this to the test (test 3) and found that
> with a 1MB JSON string it is faster to flush every 512 bytes than it
> is to only flush after checking the entire 1MB. With a 10kB JSON
> string (test 2), the extra code to flush every 512 bytes seems to slow
> things down.
I'd been wondering why test 2 (10KB) with v5-0001
ESCAPE_JSON_MAX_LOOKHEAD 512 was not better than v5-0001. It occurred
to me that when using 10KB vs 1MB and flushing the buffer every 512
bytes that enlargeStringInfo() is called more often proportionally to
the length of the string. Doing that causes more repalloc/memcpy work
in stringinfo.c.
We can reduce the repalloc/memcpy work by calling enlargeStringInfo()
once at the beginning of escape_json_with_len(). We already know the
minimum length we're going to append so we might as well do that.
After making that change, doing the 512-byte flushing no longer slows
down test 2.
Here are the results of testing v6-0001. I've added test 4, which
tests a very short string to ensure there are no performance
regressions when we can't do SIMD. Test 2 patched came out 3.74x
faster than master.
## Test 1:
echo "select row_to_json(j1)::jsonb from j1;" > test1.sql
for i in {1..3}; do pgbench -n -f test1.sql -T 10 -M prepared postgres
| grep tps; done
master @ e6a963748:
tps = 339.560611
tps = 344.649009
tps = 343.246659
v6-0001:
tps = 610.734018
tps = 628.297298
tps = 630.028225
v6-0001 ESCAPE_JSON_MAX_LOOKHEAD 512:
tps = 557.562866
tps = 626.476618
tps = 618.665045
## Test 2:
echo "select row_to_json(j2)::jsonb from j2;" > test2.sql
for i in {1..3}; do pgbench -n -f test2.sql -T 10 -M prepared postgres
| grep tps; done
master @ e6a963748:
tps = 25.633934
tps = 18.580632
tps = 25.395866
v6-0001:
tps = 89.325752
tps = 91.277016
tps = 86.289533
v6-0001 ESCAPE_JSON_MAX_LOOKHEAD 512:
tps = 85.194479
tps = 90.054279
tps = 85.483279
## Test 3:
echo "select row_to_json(j3)::jsonb from j3;" > test3.sql
for i in {1..3}; do pgbench -n -f test3.sql -T 10 -M prepared postgres
| grep tps; done
master @ e6a963748:
tps = 18.863420
tps = 18.866374
tps = 18.791395
v6-0001:
tps = 38.990681
tps = 37.893820
tps = 38.057235
v6-0001 ESCAPE_JSON_MAX_LOOKHEAD 512:
tps = 46.076842
tps = 46.400413
tps = 46.165491
## Test 4:
echo "select row_to_json(j4)::jsonb from j4;" > test4.sql
for i in {1..3}; do pgbench -n -f test4.sql -T 10 -M prepared postgres
| grep tps; done
master @ e6a963748:
tps = 1700.888458
tps = 1684.753818
tps = 1690.262772
v6-0001:
tps = 1721.821561
tps = 1699.189207
tps = 1663.618117
v6-0001 ESCAPE_JSON_MAX_LOOKHEAD 512:
tps = 1701.565562
tps = 1706.310398
tps = 1687.585128
I'm pretty happy with this now so I'd like to commit this and move on
to other work. Doing "#define ESCAPE_JSON_MAX_LOOKHEAD 512", seems
like the right thing. If anyone else wants to verify my results or
take a look at the patch, please do so.
David
Attachment
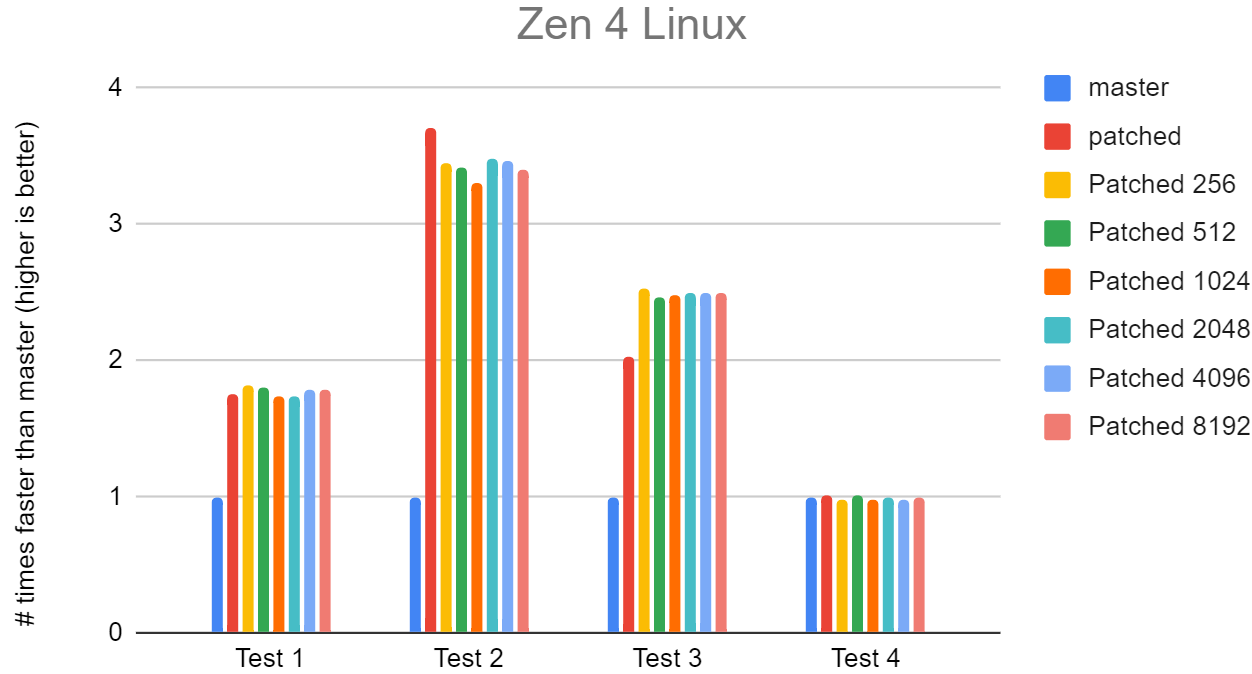
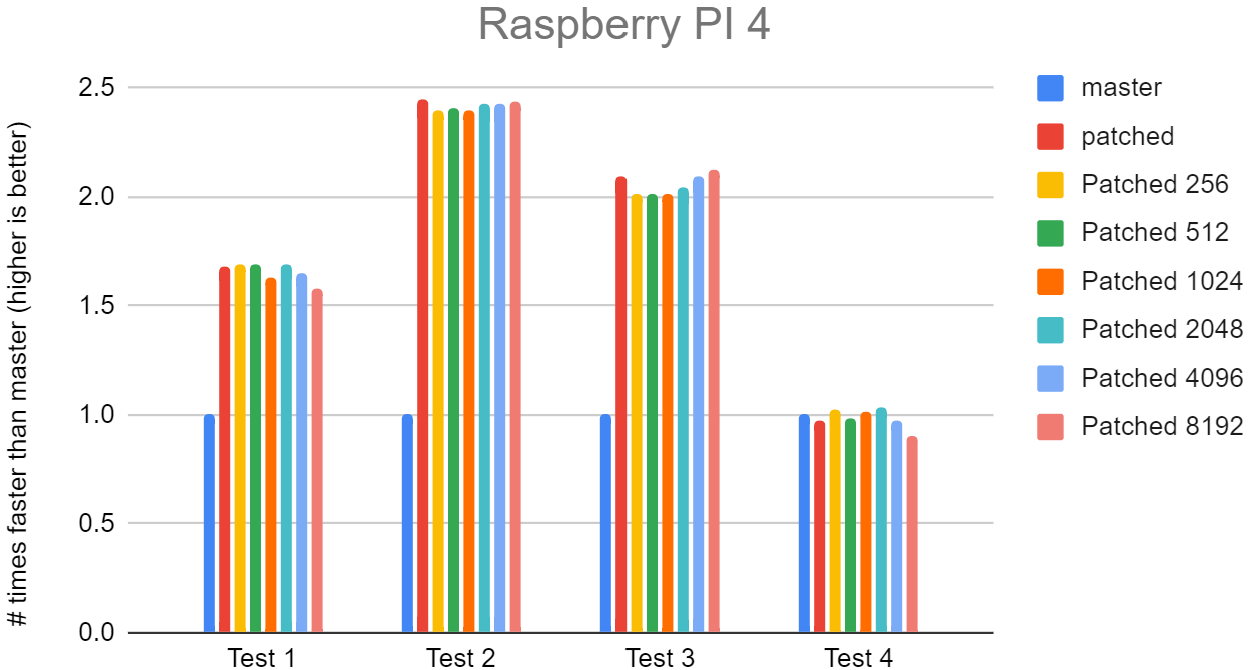
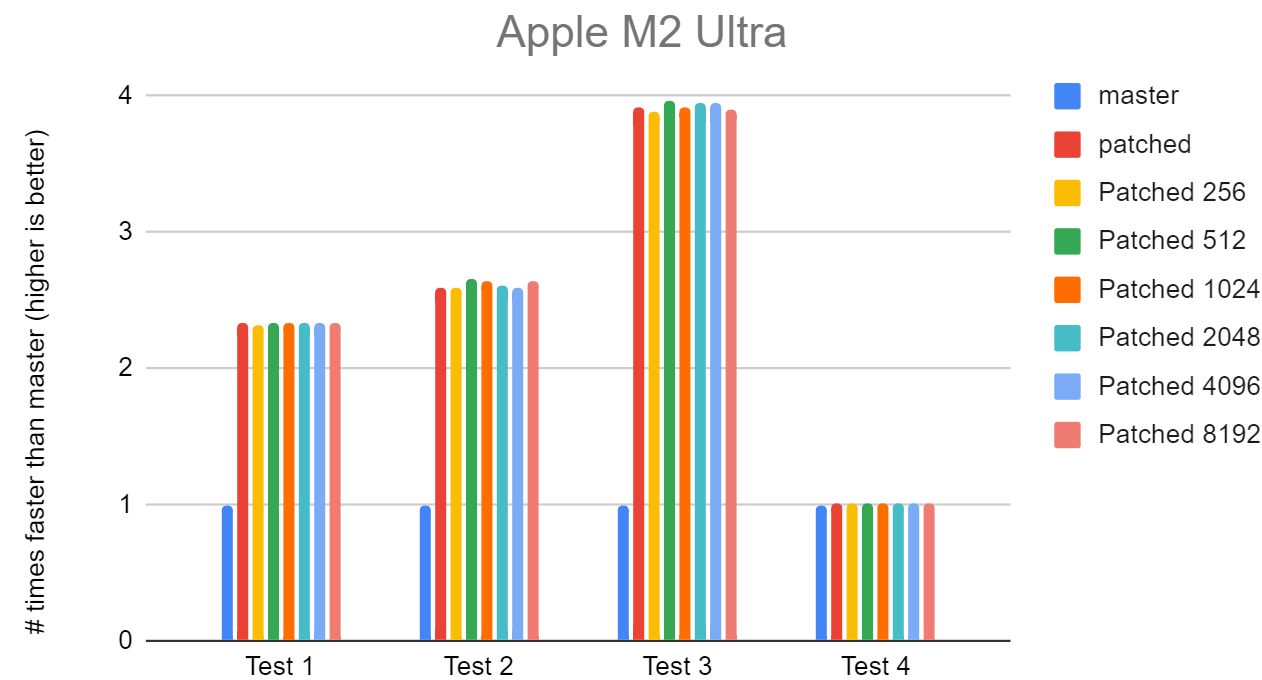
On Thu, 1 Aug 2024 at 16:15, David Rowley <dgrowleyml@gmail.com> wrote: > I'm pretty happy with this now so I'd like to commit this and move on > to other work. Doing "#define ESCAPE_JSON_MAX_LOOKHEAD 512", seems > like the right thing. If anyone else wants to verify my results or > take a look at the patch, please do so. I did some more testing on this on a few different machines; apple M2 Ultra, AMD 7945HX and with a Raspberry Pi 4. I've attached the results as graphs with the master time normalised to 1. I tried out quite a few different values for flushing the buffer, 256 bytes in powers of 2 up to 8192 bytes. It seems like each machine has its own preference to what this should be set to, but no machine seems to be too picky about the exact value. They're all small enough values to fit in L1d cache on each of the CPUs. Test 4 shouldn't change much as there's no SIMD going on in that test. You might notice a bit of noise from all machines for test 4, apart from the M2. You can assume a similar level of noise for tests 1 to 3 on each of the machines. The Raspberry Pi does seem to prefer not flushing the buffer until the end (listed as "patched" in the graphs). I suspect that's because that CPU does better with less code. I've not taken these results quite as seriously since it's likely a platform that we wouldn't want to prefer when it comes to tuning optimisations. I was mostly interested in not seeing regressions. I think, if nobody else thinks differently, I'll rename ESCAPE_JSON_MAX_LOOKHEAD to ESCAPE_JSON_FLUSH_AFTER and set it to 512. The exact value does not seem to matter too much and 512 seems fine. It's better for the M2 than the 7945HX, but not by much. I've also attached the script I ran to get these results and also the full results. David
Attachment
{kind=link}
{kind=link}
{kind=link}
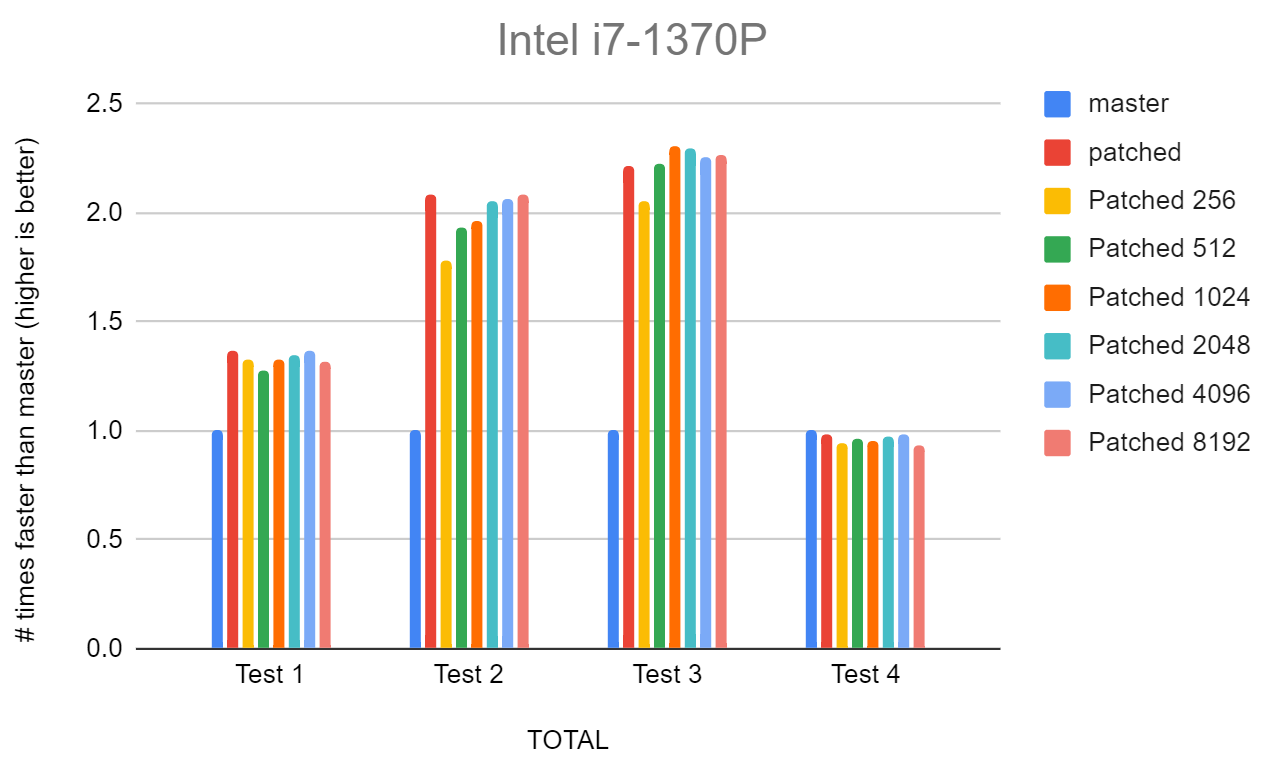
On Sun, 4 Aug 2024 at 02:11, David Rowley <dgrowleyml@gmail.com> wrote: > I did some more testing on this on a few different machines; apple M2 > Ultra, AMD 7945HX and with a Raspberry Pi 4. I did some more testing on this patch today as I wanted to see what Intel CPUs thought about it. The only modern Intel CPU I have is a 13th-generation laptop CPU. It's an i7-1370P. It's in a laptop with solid-state cooling. At least, I've never heard a fan running on it. Watching the clock speed during the test had it jumping around wildly, so I assume it was thermally throttling. I've attached the results here anyway. They're very noisy. I also did a test where I removed all the escaping logic and had the code copy the source string to the destination without checking for chars to escape. I wanted to see how much was left performance-wise. There was only a further 10% increase. I tidied up the patch a bit more and pushed it. Thanks for the reviews. David
{kind=link}