Thread: Parallel CREATE INDEX for GIN indexes
Hi,
In PG17 we shall have parallel CREATE INDEX for BRIN indexes, and back
when working on that I was thinking how difficult would it be to do
something similar to do that for other index types, like GIN. I even had
that on my list of ideas to pitch to potential contributors, as I was
fairly sure it's doable and reasonably isolated / well-defined.
However, I was not aware of any takers, so a couple days ago on a slow
weekend I took a stab at it. And yes, it's doable - attached is a fairly
complete, tested and polished version of the feature, I think. It turned
out to be a bit more complex than I expected, for reasons that I'll get
into when discussing the patches.
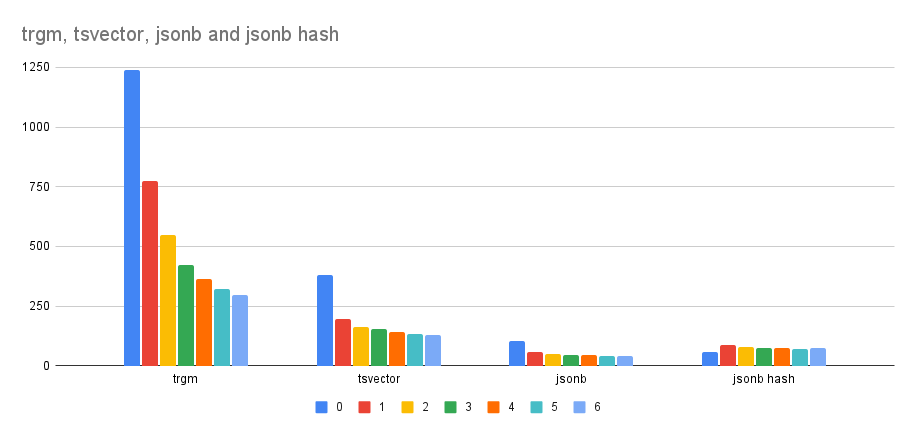
First, let's talk about the benefits - how much faster is that than the
single-process build we have for GIN indexes? I do have a table with the
archive of all our mailing lists - it's ~1.5M messages, table is ~21GB
(raw dump is about 28GB). This does include simple text data (message
body), JSONB (headers) and tsvector (full-text on message body).
If I do CREATE index with different number of workers (0 means serial
build), I get this timings (in seconds):
workers trgm tsvector jsonb jsonb (hash)
-----------------------------------------------------
0 1240 378 104 57
1 773 196 59 85
2 548 163 51 78
3 423 153 45 75
4 362 142 43 75
5 323 134 40 70
6 295 130 39 73
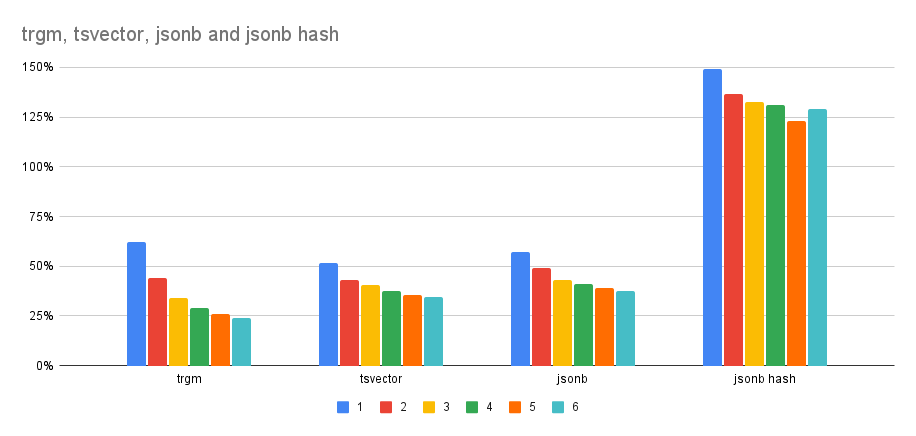
Perhaps an easier to understand result is this table with relative
timing compared to serial build:
workers trgm tsvector jsonb jsonb (hash)
-----------------------------------------------------
1 62% 52% 57% 149%
2 44% 43% 49% 136%
3 34% 40% 43% 132%
4 29% 38% 41% 131%
5 26% 35% 39% 123%
6 24% 34% 38% 129%
This shows the benefits are pretty nice, depending on the opclass. For
most indexes it's maybe ~3-4x faster, which is nice, and I don't think
it's possible to do much better - the actual index inserts can happen
from a single process only, which is the main limit.
For some of the opclasses it can regress (like the jsonb_path_ops). I
don't think that's a major issue. Or more precisely, I'm not surprised
by it. It'd be nice to be able to disable the parallel builds in these
cases somehow, but I haven't thought about that.
I do plan to do some tests with btree_gin, but I don't expect that to
behave significantly differently.
There are small variations in the index size, when built in the serial
way and the parallel way. It's generally within ~5-10%, and I believe
it's due to the serial build adding the TIDs incrementally, while the
build adds them in much larger chunks (possibly even in one chunk with
all the TIDs for the key). I believe the same size variation can happen
if the index gets built in a different way, e.g. by inserting the data
in a different order, etc. I did a number of tests to check if the index
produces the correct results, and I haven't found any issues. So I think
this is OK, and neither a problem nor an advantage of the patch.
Now, let's talk about the code - the series has 7 patches, with 6
non-trivial parts doing changes in focused and easier to understand
pieces (I hope so).
1) v20240502-0001-Allow-parallel-create-for-GIN-indexes.patch
This is the initial feature, adding the "basic" version, implemented as
pretty much 1:1 copy of the BRIN parallel build and minimal changes to
make it work for GIN (mostly about how to store intermediate results).
The basic idea is that the workers do the regular build, but instead of
flushing the data into the index after hitting the memory limit, it gets
written into a shared tuplesort and sorted by the index key. And the
leader then reads this sorted data, accumulates the TID for a given key
and inserts that into the index in one go.
2) v20240502-0002-Use-mergesort-in-the-leader-process.patch
The approach implemented by 0001 works, but there's a little bit of
issue - if there are many distinct keys (e.g. for trigrams that can
happen very easily), the workers will hit the memory limit with only
very short TID lists for most keys. For serial build that means merging
the data into a lot of random places, and in parallel build it means the
leader will have to merge a lot of tiny lists from many sorted rows.
Which can be quite annoying and expensive, because the leader does so
using qsort() in the serial part. It'd be better to ensure most of the
sorting happens in the workers, and the leader can do a mergesort. But
the mergesort must not happen too often - merging many small lists is
not cheaper than a single qsort (especially when the lists overlap).
So this patch changes the workers to process the data in two phases. The
first works as before, but the data is flushed into a local tuplesort.
And then each workers sorts the results it produced, and combines them
into results with much larger TID lists, and those results are written
to the shared tuplesort. So the leader only gets very few lists to
combine for a given key - usually just one list per worker.
3) v20240502-0003-Remove-the-explicit-pg_qsort-in-workers.patch
In 0002 the workers still do an explicit qsort() on the TID list before
writing the data into the shared tuplesort. But we can do better - the
workers can do a merge sort too. To help with this, we add the first TID
to the tuplesort tuple, and sort by that too - it helps the workers to
process the data in an order that allows simple concatenation instead of
the full mergesort.
Note: There's a non-obvious issue due to parallel scans always being
"sync scans", which may lead to very "wide" TID ranges when the scan
wraps around. More about that later.
4) v20240502-0004-Compress-TID-lists-before-writing-tuples-t.patch
The parallel build passes data between processes using temporary files,
which means it may need significant amount of disk space. For BRIN this
was not a major concern, because the summaries tend to be pretty small.
But for GIN that's not the case, and the two-phase processing introduced
by 0002 make it worse, because the worker essentially creates another
copy of the intermediate data. It does not need to copy the key, so
maybe it's not exactly 2x the space requirement, but in the worst case
it's not far from that.
But there's a simple way how to improve this - the TID lists tend to be
very compressible, and GIN already implements a very light-weight TID
compression, so this patch does just that - when building the tuple to
be written into the tuplesort, we just compress the TIDs.
5) v20240502-0005-Collect-and-print-compression-stats.patch
This patch simply collects some statistics about the compression, to
show how much it reduces the amounts of data in the various phases. The
data I've seen so far usually show ~75% compression in the first phase,
and ~30% compression in the second phase.
That is, in the first phase we save ~25% of space, in the second phase
we save ~70% of space. An example of the log messages from this patch,
for one worker (of two) in the trigram phase says:
LOG: _gin_parallel_scan_and_build raw 10158870494 compressed 7519211584
ratio 74.02%
LOG: _gin_process_worker_data raw 4593563782 compressed 1314800758
ratio 28.62%
Put differently, a single-phase version without compression (as in 0001)
would need ~10GB of disk space per worker. With compression, we need
only about ~8.8GB for both phases (or ~7.5GB for the first phase alone).
I do think these numbers look pretty good. The numbers are different for
other opclasses (trigrams are rather extreme in how much space they
need), but the overall behavior is the same.
6) v20240502-0006-Enforce-memory-limit-when-combining-tuples.patch
Until this part, there's no limit on memory used by combining results
for a single index key - it'll simply use as much memory as needed to
combine all the TID lists. Which may not be a huge issue because each
TID is only 6B, and we can accumulate a lot of those in a couple MB. And
a parallel CREATE INDEX usually runs with a fairly significant values of
maintenance_work_mem (in fact it requires it to even allow parallel).
But still, there should be some memory limit.
It however is not as simple as dumping current state into the index,
because the TID lists produced by the workers may overlap, so the tail
of the list may still receive TIDs from some future TID list. And that's
a problem because ginEntryInsert() expects to receive TIDs in order, and
if that's not the case it may fail with "could not split GIN page".
But we already have the first TID for each sort tuple (and we consider
it when sorting the data), and this is useful for deducing how far we
can flush the data, and keep just the minimal part of the TID list that
may change by merging.
So this patch implements that - it introduces the concept of "freezing"
the head of the TID list up to "first TID" from the next tuple, and uses
that to write data into index if needed because of memory limit.
We don't want to do that too often, so it only happens if we hit the
memory limit and there's at least a certain number (1024) of TIDs.
7) v20240502-0007-Detect-wrap-around-in-parallel-callback.patch
There's one more efficiency problem - the parallel scans are required to
be synchronized, i.e. the scan may start half-way through the table, and
then wrap around. Which however means the TID list will have a very wide
range of TID values, essentially the min and max of for the key.
Without 0006 this would cause frequent failures of the index build, with
the error I already mentioned:
ERROR: could not split GIN page; all old items didn't fit
tracking the "safe" TID horizon addresses that. But there's still an
issue with efficiency - having such a wide TID list forces the mergesort
to actually walk the lists, because this wide list overlaps with every
other list produced by the worker. And that's much more expensive than
just simply concatenating them, which is what happens without the wrap
around (because in that case the worker produces non-overlapping lists).
One way to fix this would be to allow parallel scans to not be sync
scans, but that seems fairly tricky and I'm not sure if that can be
done. The BRIN parallel build had a similar issue, and it was just
simpler to deal with this in the build code.
So 0007 does something similar - it tracks if the TID value goes
backward in the callback, and if it does it dumps the state into the
tuplesort before processing the first tuple from the beginning of the
table. Which means we end up with two separate "narrow" TID list, not
one very wide one.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
- gin-parallel-absolute.png
- gin-parallel-relative.png
- v20240502-0001-Allow-parallel-create-for-GIN-indexes.patch
- v20240502-0002-Use-mergesort-in-the-leader-process.patch
- v20240502-0003-Remove-the-explicit-pg_qsort-in-workers.patch
- v20240502-0004-Compress-TID-lists-before-writing-tuples-t.patch
- v20240502-0005-Collect-and-print-compression-stats.patch
- v20240502-0006-Enforce-memory-limit-when-combining-tuples.patch
- v20240502-0007-Detect-wrap-around-in-parallel-callback.patch
{kind=link}
{kind=link}
On Thu, 2 May 2024 at 17:19, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > Hi, > > In PG17 we shall have parallel CREATE INDEX for BRIN indexes, and back > when working on that I was thinking how difficult would it be to do > something similar to do that for other index types, like GIN. I even had > that on my list of ideas to pitch to potential contributors, as I was > fairly sure it's doable and reasonably isolated / well-defined. > > However, I was not aware of any takers, so a couple days ago on a slow > weekend I took a stab at it. And yes, it's doable - attached is a fairly > complete, tested and polished version of the feature, I think. It turned > out to be a bit more complex than I expected, for reasons that I'll get > into when discussing the patches. This is great. I've been thinking about approximately the same issue recently, too, but haven't had time to discuss/implement any of this yet. I think some solutions may even be portable to the btree parallel build: it also has key deduplication (though to a much smaller degree) and could benefit from deduplication during the scan/ssup load phase, rather than only during insertion. > First, let's talk about the benefits - how much faster is that than the > single-process build we have for GIN indexes? I do have a table with the > archive of all our mailing lists - it's ~1.5M messages, table is ~21GB > (raw dump is about 28GB). This does include simple text data (message > body), JSONB (headers) and tsvector (full-text on message body). Sidenote: Did you include the tsvector in the table to reduce time spent during index creation? I would have used an expression in the index definition, rather than a direct column. > If I do CREATE index with different number of workers (0 means serial > build), I get this timings (in seconds): [...] > This shows the benefits are pretty nice, depending on the opclass. For > most indexes it's maybe ~3-4x faster, which is nice, and I don't think > it's possible to do much better - the actual index inserts can happen > from a single process only, which is the main limit. Can we really not insert with multiple processes? It seems to me that GIN could be very suitable for that purpose, with its clear double tree structure distinction that should result in few buffer conflicts if different backends work on known-to-be-very-different keys. We'd probably need multiple read heads on the shared tuplesort, and a way to join the generated top-level subtrees, but I don't think that is impossible. Maybe it's work for later effort though. Have you tested and/or benchmarked this with multi-column GIN indexes? > For some of the opclasses it can regress (like the jsonb_path_ops). I > don't think that's a major issue. Or more precisely, I'm not surprised > by it. It'd be nice to be able to disable the parallel builds in these > cases somehow, but I haven't thought about that. Do you know why it regresses? > I do plan to do some tests with btree_gin, but I don't expect that to > behave significantly differently. > > There are small variations in the index size, when built in the serial > way and the parallel way. It's generally within ~5-10%, and I believe > it's due to the serial build adding the TIDs incrementally, while the > build adds them in much larger chunks (possibly even in one chunk with > all the TIDs for the key). I assume that was '[...] while the [parallel] build adds them [...]', right? > I believe the same size variation can happen > if the index gets built in a different way, e.g. by inserting the data > in a different order, etc. I did a number of tests to check if the index > produces the correct results, and I haven't found any issues. So I think > this is OK, and neither a problem nor an advantage of the patch. > > > Now, let's talk about the code - the series has 7 patches, with 6 > non-trivial parts doing changes in focused and easier to understand > pieces (I hope so). The following comments are generally based on the descriptions; I haven't really looked much at the patches yet except to validate some assumptions. > 1) v20240502-0001-Allow-parallel-create-for-GIN-indexes.patch > > This is the initial feature, adding the "basic" version, implemented as > pretty much 1:1 copy of the BRIN parallel build and minimal changes to > make it work for GIN (mostly about how to store intermediate results). > > The basic idea is that the workers do the regular build, but instead of > flushing the data into the index after hitting the memory limit, it gets > written into a shared tuplesort and sorted by the index key. And the > leader then reads this sorted data, accumulates the TID for a given key > and inserts that into the index in one go. In the code, GIN insertions are still basically single btree insertions, all starting from the top (but with many same-valued tuples at once). Now that we have a tuplesort with the full table's data, couldn't the code be adapted to do more efficient btree loading, such as that seen in the nbtree code, where the rightmost pages are cached and filled sequentially without requiring repeated searches down the tree? I suspect we can gain a lot of time there. I don't need you to do that, but what's your opinion on this? > 2) v20240502-0002-Use-mergesort-in-the-leader-process.patch > > The approach implemented by 0001 works, but there's a little bit of > issue - if there are many distinct keys (e.g. for trigrams that can > happen very easily), the workers will hit the memory limit with only > very short TID lists for most keys. For serial build that means merging > the data into a lot of random places, and in parallel build it means the > leader will have to merge a lot of tiny lists from many sorted rows. > > Which can be quite annoying and expensive, because the leader does so > using qsort() in the serial part. It'd be better to ensure most of the > sorting happens in the workers, and the leader can do a mergesort. But > the mergesort must not happen too often - merging many small lists is > not cheaper than a single qsort (especially when the lists overlap). > > So this patch changes the workers to process the data in two phases. The > first works as before, but the data is flushed into a local tuplesort. > And then each workers sorts the results it produced, and combines them > into results with much larger TID lists, and those results are written > to the shared tuplesort. So the leader only gets very few lists to > combine for a given key - usually just one list per worker. Hmm, I was hoping we could implement the merging inside the tuplesort itself during its own flush phase, as it could save significantly on IO, and could help other users of tuplesort with deduplication, too. > 3) v20240502-0003-Remove-the-explicit-pg_qsort-in-workers.patch > > In 0002 the workers still do an explicit qsort() on the TID list before > writing the data into the shared tuplesort. But we can do better - the > workers can do a merge sort too. To help with this, we add the first TID > to the tuplesort tuple, and sort by that too - it helps the workers to > process the data in an order that allows simple concatenation instead of > the full mergesort. > > Note: There's a non-obvious issue due to parallel scans always being > "sync scans", which may lead to very "wide" TID ranges when the scan > wraps around. More about that later. As this note seems to imply, this seems to have a strong assumption that data received in parallel workers is always in TID order, with one optional wraparound. Non-HEAP TAMs may break with this assumption, so what's the plan on that? > 4) v20240502-0004-Compress-TID-lists-before-writing-tuples-t.patch > > The parallel build passes data between processes using temporary files, > which means it may need significant amount of disk space. For BRIN this > was not a major concern, because the summaries tend to be pretty small. > > But for GIN that's not the case, and the two-phase processing introduced > by 0002 make it worse, because the worker essentially creates another > copy of the intermediate data. It does not need to copy the key, so > maybe it's not exactly 2x the space requirement, but in the worst case > it's not far from that. > > But there's a simple way how to improve this - the TID lists tend to be > very compressible, and GIN already implements a very light-weight TID > compression, so this patch does just that - when building the tuple to > be written into the tuplesort, we just compress the TIDs. See note on 0002: Could we do this in the tuplesort writeback, rather than by moving the data around multiple times? [...] > So 0007 does something similar - it tracks if the TID value goes > backward in the callback, and if it does it dumps the state into the > tuplesort before processing the first tuple from the beginning of the > table. Which means we end up with two separate "narrow" TID list, not > one very wide one. See note above: We may still need a merge phase, just to make sure we handle all TAM parallel scans correctly, even if that merge join phase wouldn't get hit in vanilla PostgreSQL. Kind regards, Matthias van de Meent Neon (https://neon.tech)
On 5/2/24 19:12, Matthias van de Meent wrote: > On Thu, 2 May 2024 at 17:19, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: >> >> Hi, >> >> In PG17 we shall have parallel CREATE INDEX for BRIN indexes, and back >> when working on that I was thinking how difficult would it be to do >> something similar to do that for other index types, like GIN. I even had >> that on my list of ideas to pitch to potential contributors, as I was >> fairly sure it's doable and reasonably isolated / well-defined. >> >> However, I was not aware of any takers, so a couple days ago on a slow >> weekend I took a stab at it. And yes, it's doable - attached is a fairly >> complete, tested and polished version of the feature, I think. It turned >> out to be a bit more complex than I expected, for reasons that I'll get >> into when discussing the patches. > > This is great. I've been thinking about approximately the same issue > recently, too, but haven't had time to discuss/implement any of this > yet. I think some solutions may even be portable to the btree parallel > build: it also has key deduplication (though to a much smaller degree) > and could benefit from deduplication during the scan/ssup load phase, > rather than only during insertion. > Perhaps, although I'm not that familiar with the details of btree builds, and I haven't thought about it when working on this over the past couple days. >> First, let's talk about the benefits - how much faster is that than the >> single-process build we have for GIN indexes? I do have a table with the >> archive of all our mailing lists - it's ~1.5M messages, table is ~21GB >> (raw dump is about 28GB). This does include simple text data (message >> body), JSONB (headers) and tsvector (full-text on message body). > > Sidenote: Did you include the tsvector in the table to reduce time > spent during index creation? I would have used an expression in the > index definition, rather than a direct column. > Yes, it's a materialized column, not computed during index creation. >> If I do CREATE index with different number of workers (0 means serial >> build), I get this timings (in seconds): > > [...] > >> This shows the benefits are pretty nice, depending on the opclass. For >> most indexes it's maybe ~3-4x faster, which is nice, and I don't think >> it's possible to do much better - the actual index inserts can happen >> from a single process only, which is the main limit. > > Can we really not insert with multiple processes? It seems to me that > GIN could be very suitable for that purpose, with its clear double > tree structure distinction that should result in few buffer conflicts > if different backends work on known-to-be-very-different keys. > We'd probably need multiple read heads on the shared tuplesort, and a > way to join the generated top-level subtrees, but I don't think that > is impossible. Maybe it's work for later effort though. > Maybe, but I took it as a restriction and it seemed too difficult to relax (or at least I assume that). > Have you tested and/or benchmarked this with multi-column GIN indexes? > I did test that, and I'm not aware of any bugs/issues. Performance-wise it depends on which opclasses are used by the columns - if you take the speedup for each of them independently, the speedup for the whole index is roughly the average of that. >> For some of the opclasses it can regress (like the jsonb_path_ops). I >> don't think that's a major issue. Or more precisely, I'm not surprised >> by it. It'd be nice to be able to disable the parallel builds in these >> cases somehow, but I haven't thought about that. > > Do you know why it regresses? > No, but one thing that stands out is that the index is much smaller than the other columns/opclasses, and the compression does not save much (only about 5% for both phases). So I assume it's the overhead of writing writing and reading a bunch of GB of data without really gaining much from doing that. >> I do plan to do some tests with btree_gin, but I don't expect that to >> behave significantly differently. >> >> There are small variations in the index size, when built in the serial >> way and the parallel way. It's generally within ~5-10%, and I believe >> it's due to the serial build adding the TIDs incrementally, while the >> build adds them in much larger chunks (possibly even in one chunk with >> all the TIDs for the key). > > I assume that was '[...] while the [parallel] build adds them [...]', right? > Right. The parallel build adds them in larger chunks. >> I believe the same size variation can happen >> if the index gets built in a different way, e.g. by inserting the data >> in a different order, etc. I did a number of tests to check if the index >> produces the correct results, and I haven't found any issues. So I think >> this is OK, and neither a problem nor an advantage of the patch. >> >> >> Now, let's talk about the code - the series has 7 patches, with 6 >> non-trivial parts doing changes in focused and easier to understand >> pieces (I hope so). > > The following comments are generally based on the descriptions; I > haven't really looked much at the patches yet except to validate some > assumptions. > OK >> 1) v20240502-0001-Allow-parallel-create-for-GIN-indexes.patch >> >> This is the initial feature, adding the "basic" version, implemented as >> pretty much 1:1 copy of the BRIN parallel build and minimal changes to >> make it work for GIN (mostly about how to store intermediate results). >> >> The basic idea is that the workers do the regular build, but instead of >> flushing the data into the index after hitting the memory limit, it gets >> written into a shared tuplesort and sorted by the index key. And the >> leader then reads this sorted data, accumulates the TID for a given key >> and inserts that into the index in one go. > > In the code, GIN insertions are still basically single btree > insertions, all starting from the top (but with many same-valued > tuples at once). Now that we have a tuplesort with the full table's > data, couldn't the code be adapted to do more efficient btree loading, > such as that seen in the nbtree code, where the rightmost pages are > cached and filled sequentially without requiring repeated searches > down the tree? I suspect we can gain a lot of time there. > > I don't need you to do that, but what's your opinion on this? > I have no idea. I started working on this with only very basic idea of how GIN works / is structured, so I simply leveraged the existing callback and massaged it to work in the parallel case too. >> 2) v20240502-0002-Use-mergesort-in-the-leader-process.patch >> >> The approach implemented by 0001 works, but there's a little bit of >> issue - if there are many distinct keys (e.g. for trigrams that can >> happen very easily), the workers will hit the memory limit with only >> very short TID lists for most keys. For serial build that means merging >> the data into a lot of random places, and in parallel build it means the >> leader will have to merge a lot of tiny lists from many sorted rows. >> >> Which can be quite annoying and expensive, because the leader does so >> using qsort() in the serial part. It'd be better to ensure most of the >> sorting happens in the workers, and the leader can do a mergesort. But >> the mergesort must not happen too often - merging many small lists is >> not cheaper than a single qsort (especially when the lists overlap). >> >> So this patch changes the workers to process the data in two phases. The >> first works as before, but the data is flushed into a local tuplesort. >> And then each workers sorts the results it produced, and combines them >> into results with much larger TID lists, and those results are written >> to the shared tuplesort. So the leader only gets very few lists to >> combine for a given key - usually just one list per worker. > > Hmm, I was hoping we could implement the merging inside the tuplesort > itself during its own flush phase, as it could save significantly on > IO, and could help other users of tuplesort with deduplication, too. > Would that happen in the worker or leader process? Because my goal was to do the expensive part in the worker, because that's what helps with the parallelization. >> 3) v20240502-0003-Remove-the-explicit-pg_qsort-in-workers.patch >> >> In 0002 the workers still do an explicit qsort() on the TID list before >> writing the data into the shared tuplesort. But we can do better - the >> workers can do a merge sort too. To help with this, we add the first TID >> to the tuplesort tuple, and sort by that too - it helps the workers to >> process the data in an order that allows simple concatenation instead of >> the full mergesort. >> >> Note: There's a non-obvious issue due to parallel scans always being >> "sync scans", which may lead to very "wide" TID ranges when the scan >> wraps around. More about that later. > > As this note seems to imply, this seems to have a strong assumption > that data received in parallel workers is always in TID order, with > one optional wraparound. Non-HEAP TAMs may break with this assumption, > so what's the plan on that? > Well, that would break the serial build too, right? Anyway, the way this patch works can be extended to deal with that by actually sorting the TIDs when serializing the tuplestore tuple. The consequence of that is the combining will be more expensive, because it'll require a proper mergesort, instead of just appending the lists. >> 4) v20240502-0004-Compress-TID-lists-before-writing-tuples-t.patch >> >> The parallel build passes data between processes using temporary files, >> which means it may need significant amount of disk space. For BRIN this >> was not a major concern, because the summaries tend to be pretty small. >> >> But for GIN that's not the case, and the two-phase processing introduced >> by 0002 make it worse, because the worker essentially creates another >> copy of the intermediate data. It does not need to copy the key, so >> maybe it's not exactly 2x the space requirement, but in the worst case >> it's not far from that. >> >> But there's a simple way how to improve this - the TID lists tend to be >> very compressible, and GIN already implements a very light-weight TID >> compression, so this patch does just that - when building the tuple to >> be written into the tuplesort, we just compress the TIDs. > > See note on 0002: Could we do this in the tuplesort writeback, rather > than by moving the data around multiple times? > No idea, I've never done that ... > [...] >> So 0007 does something similar - it tracks if the TID value goes >> backward in the callback, and if it does it dumps the state into the >> tuplesort before processing the first tuple from the beginning of the >> table. Which means we end up with two separate "narrow" TID list, not >> one very wide one. > > See note above: We may still need a merge phase, just to make sure we > handle all TAM parallel scans correctly, even if that merge join phase > wouldn't get hit in vanilla PostgreSQL. > Well, yeah. But in fact the parallel code already does that, while the existing serial code may fail with the "data don't fit" error. The parallel code will do the mergesort correctly, and only emit TIDs that we know are safe to write to the index (i.e. no future TIDs will go before the "TID horizon"). But the serial build has nothing like that - it will sort the TIDs that fit into the memory limit, but it also relies on not processing data out of order (and disables sync scans to not have wrap around issues). But if the TAM does something funny, this may break. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, Here's a slightly improved version, fixing a couple bugs in handling byval/byref values, causing issues on 32-bit machines (but not only). And also a couple compiler warnings about string formatting. Other than that, no changes. -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- v20240505-0001-Allow-parallel-create-for-GIN-indexes.patch
- v20240505-0002-Use-mergesort-in-the-leader-process.patch
- v20240505-0003-Remove-the-explicit-pg_qsort-in-workers.patch
- v20240505-0004-Compress-TID-lists-before-writing-tuples-t.patch
- v20240505-0005-Collect-and-print-compression-stats.patch
- v20240505-0006-Enforce-memory-limit-when-combining-tuples.patch
- v20240505-0007-Detect-wrap-around-in-parallel-callback.patch
Hello Tomas, >>> 2) v20240502-0002-Use-mergesort-in-the-leader-process.patch >>> >>> The approach implemented by 0001 works, but there's a little bit of >>> issue - if there are many distinct keys (e.g. for trigrams that can >>> happen very easily), the workers will hit the memory limit with only >>> very short TID lists for most keys. For serial build that means merging >>> the data into a lot of random places, and in parallel build it means the >>> leader will have to merge a lot of tiny lists from many sorted rows. >>> >>> Which can be quite annoying and expensive, because the leader does so >>> using qsort() in the serial part. It'd be better to ensure most of the >>> sorting happens in the workers, and the leader can do a mergesort. But >>> the mergesort must not happen too often - merging many small lists is >>> not cheaper than a single qsort (especially when the lists overlap). >>> >>> So this patch changes the workers to process the data in two phases. The >>> first works as before, but the data is flushed into a local tuplesort. >>> And then each workers sorts the results it produced, and combines them >>> into results with much larger TID lists, and those results are written >>> to the shared tuplesort. So the leader only gets very few lists to >>> combine for a given key - usually just one list per worker. >> >> Hmm, I was hoping we could implement the merging inside the tuplesort >> itself during its own flush phase, as it could save significantly on >> IO, and could help other users of tuplesort with deduplication, too. >> > > Would that happen in the worker or leader process? Because my goal was > to do the expensive part in the worker, because that's what helps with > the parallelization. I guess both of you are talking about worker process, if here are something in my mind: *btbuild* also let the WORKER dump the tuples into Sharedsort struct and let the LEADER merge them directly. I think this aim of this design is it is potential to save a mergeruns. In the current patch, worker dump to local tuplesort and mergeruns it and then leader run the merges again. I admit the goal of this patch is reasonable, but I'm feeling we need to adapt this way conditionally somehow. and if we find the way, we can apply it to btbuild as well. -- Best Regards Andy Fan
Tomas Vondra <tomas.vondra@enterprisedb.com> writes: > 3) v20240502-0003-Remove-the-explicit-pg_qsort-in-workers.patch > > In 0002 the workers still do an explicit qsort() on the TID list before > writing the data into the shared tuplesort. But we can do better - the > workers can do a merge sort too. To help with this, we add the first TID > to the tuplesort tuple, and sort by that too - it helps the workers to > process the data in an order that allows simple concatenation instead of > the full mergesort. > > Note: There's a non-obvious issue due to parallel scans always being > "sync scans", which may lead to very "wide" TID ranges when the scan > wraps around. More about that later. This is really amazing. > 7) v20240502-0007-Detect-wrap-around-in-parallel-callback.patch > > There's one more efficiency problem - the parallel scans are required to > be synchronized, i.e. the scan may start half-way through the table, and > then wrap around. Which however means the TID list will have a very wide > range of TID values, essentially the min and max of for the key. > > Without 0006 this would cause frequent failures of the index build, with > the error I already mentioned: > > ERROR: could not split GIN page; all old items didn't fit I have two questions here and both of them are generall gin index questions rather than the patch here. 1. What does the "wrap around" mean in the "the scan may start half-way through the table, and then wrap around". Searching "wrap" in gin/README gets nothing. 2. I can't understand the below error. > ERROR: could not split GIN page; all old items didn't fit When the posting list is too long, we have posting tree strategy. so in which sistuation we could get this ERROR. > issue with efficiency - having such a wide TID list forces the mergesort > to actually walk the lists, because this wide list overlaps with every > other list produced by the worker. If we split the blocks among worker 1-block by 1-block, we will have a serious issue like here. If we can have N-block by N-block, and N-block is somehow fill the work_mem which makes the dedicated temp file, we can make things much better, can we? -- Best Regards Andy Fan
On 5/9/24 12:14, Andy Fan wrote:
>
> Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
>
>> 3) v20240502-0003-Remove-the-explicit-pg_qsort-in-workers.patch
>>
>> In 0002 the workers still do an explicit qsort() on the TID list before
>> writing the data into the shared tuplesort. But we can do better - the
>> workers can do a merge sort too. To help with this, we add the first TID
>> to the tuplesort tuple, and sort by that too - it helps the workers to
>> process the data in an order that allows simple concatenation instead of
>> the full mergesort.
>>
>> Note: There's a non-obvious issue due to parallel scans always being
>> "sync scans", which may lead to very "wide" TID ranges when the scan
>> wraps around. More about that later.
>
> This is really amazing.
>
>> 7) v20240502-0007-Detect-wrap-around-in-parallel-callback.patch
>>
>> There's one more efficiency problem - the parallel scans are required to
>> be synchronized, i.e. the scan may start half-way through the table, and
>> then wrap around. Which however means the TID list will have a very wide
>> range of TID values, essentially the min and max of for the key.
>>
>> Without 0006 this would cause frequent failures of the index build, with
>> the error I already mentioned:
>>
>> ERROR: could not split GIN page; all old items didn't fit
>
> I have two questions here and both of them are generall gin index questions
> rather than the patch here.
>
> 1. What does the "wrap around" mean in the "the scan may start half-way
> through the table, and then wrap around". Searching "wrap" in
> gin/README gets nothing.
>
The "wrap around" is about the scan used to read data from the table
when building the index. A "sync scan" may start e.g. at TID (1000,0)
and read till the end of the table, and then wraps and returns the
remaining part at the beginning of the table for blocks 0-999.
This means the callback would not see a monotonically increasing
sequence of TIDs.
Which is why the serial build disables sync scans, allowing simply
appending values to the sorted list, and even with regular flushes of
data into the index we can simply append data to the posting lists.
> 2. I can't understand the below error.
>
>> ERROR: could not split GIN page; all old items didn't fit
>
> When the posting list is too long, we have posting tree strategy. so in
> which sistuation we could get this ERROR.
>
AFAICS the index build relies on the assumption that we only append data
to the TID list on a leaf page, and when the page gets split, the "old"
part will always fit. Which may not be true, if there was a wrap around
and we're adding low TID values to the list on the leaf page.
FWIW the error in dataBeginPlaceToPageLeaf looks like this:
if (!append || ItemPointerCompare(&maxOldItem, &remaining) >= 0)
elog(ERROR, "could not split GIN page; all old items didn't fit");
It can fail simply because of the !append part.
I'm not sure why dataBeginPlaceToPageLeaf() relies on this assumption,
or with GIN details in general, and I haven't found any explanation. But
AFAIK this is why the serial build disables sync scans.
>> issue with efficiency - having such a wide TID list forces the mergesort
>> to actually walk the lists, because this wide list overlaps with every
>> other list produced by the worker.
>
> If we split the blocks among worker 1-block by 1-block, we will have a
> serious issue like here. If we can have N-block by N-block, and N-block
> is somehow fill the work_mem which makes the dedicated temp file, we
> can make things much better, can we?
>
I don't understand the question. The blocks are distributed to workers
by the parallel table scan, and it certainly does not do that block by
block. But even it it did, that's not a problem for this code.
The problem is that if the scan wraps around, then one of the TID lists
for a given worker will have the min TID and max TID, so it will overlap
with every other TID list for the same key in that worker. And when the
worker does the merging, this list will force a "full" merge sort for
all TID lists (for that key), which is very expensive.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 5/9/24 11:44, Andy Fan wrote: > > Hello Tomas, > >>>> 2) v20240502-0002-Use-mergesort-in-the-leader-process.patch >>>> >>>> The approach implemented by 0001 works, but there's a little bit of >>>> issue - if there are many distinct keys (e.g. for trigrams that can >>>> happen very easily), the workers will hit the memory limit with only >>>> very short TID lists for most keys. For serial build that means merging >>>> the data into a lot of random places, and in parallel build it means the >>>> leader will have to merge a lot of tiny lists from many sorted rows. >>>> >>>> Which can be quite annoying and expensive, because the leader does so >>>> using qsort() in the serial part. It'd be better to ensure most of the >>>> sorting happens in the workers, and the leader can do a mergesort. But >>>> the mergesort must not happen too often - merging many small lists is >>>> not cheaper than a single qsort (especially when the lists overlap). >>>> >>>> So this patch changes the workers to process the data in two phases. The >>>> first works as before, but the data is flushed into a local tuplesort. >>>> And then each workers sorts the results it produced, and combines them >>>> into results with much larger TID lists, and those results are written >>>> to the shared tuplesort. So the leader only gets very few lists to >>>> combine for a given key - usually just one list per worker. >>> >>> Hmm, I was hoping we could implement the merging inside the tuplesort >>> itself during its own flush phase, as it could save significantly on >>> IO, and could help other users of tuplesort with deduplication, too. >>> >> >> Would that happen in the worker or leader process? Because my goal was >> to do the expensive part in the worker, because that's what helps with >> the parallelization. > > I guess both of you are talking about worker process, if here are > something in my mind: > > *btbuild* also let the WORKER dump the tuples into Sharedsort struct > and let the LEADER merge them directly. I think this aim of this design > is it is potential to save a mergeruns. In the current patch, worker dump > to local tuplesort and mergeruns it and then leader run the merges > again. I admit the goal of this patch is reasonable, but I'm feeling we > need to adapt this way conditionally somehow. and if we find the way, we > can apply it to btbuild as well. > I'm a bit confused about what you're proposing here, or how is that related to what this patch is doing and/or to the what Matthias mentioned in his e-mail from last week. Let me explain the relevant part of the patch, and how I understand the improvement suggested by Matthias. The patch does the work in three phases: 1) Worker gets data from table, split that into index items and add those into a "private" tuplesort, and finally sorts that. So a worker may see a key many times, with different TIDs, so the tuplesort may contain many items for the same key, with distinct TID lists: key1: 1, 2, 3, 4 key1: 5, 6, 7 key1: 8, 9, 10 key2: 1, 2, 3 ... 2) Worker reads the sorted data, and combines TIDs for the same key into larger TID lists, depending on work_mem etc. and writes the result into a shared tuplesort. So the worker may write this: key1: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 key2: 1, 2, 3 3) Leader reads this, combines TID lists from all workers (using a higher memory limit, probably), and writes the result into the index. The step (2) is optional - it would work without it. But it helps, as it moves a potentially expensive sort into the workers (and thus the parallel part of the build), and it also makes it cheaper, because in a single worker the lists do not overlap and thus can be simply appended. Which in the leader is not the case, forcing an expensive mergesort. The trouble with (2) is that it "just copies" data from one tuplesort into another, increasing the disk space requirements. In an extreme case, when nothing can be combined, it pretty much doubles the amount of disk space, and makes the build longer. What I think Matthias is suggesting, is that this "TID list merging" could be done directly as part of the tuplesort in step (1). So instead of just moving the "sort tuples" from the appropriate runs, it could also do an optional step of combining the tuples and writing this combined tuple into the tuplesort result (for that worker). Matthias also mentioned this might be useful when building btree indexes with key deduplication. AFAICS this might work, although it probably requires for the "combined" tuple to be smaller than the sum of the combined tuples (in order to fit into the space). But at least in the GIN build in the workers this is likely true, because the TID lists do not overlap (and thus not hurting the compressibility). That being said, I still see this more as an optimization than something required for the patch, and I don't think I'll have time to work on this anytime soon. The patch is not extremely complex, but it's not trivial either. But if someone wants to take a stab at extending tuplesort to allow this, I won't object ... regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 5/2/24 20:22, Tomas Vondra wrote:
>>
>>> For some of the opclasses it can regress (like the jsonb_path_ops). I
>>> don't think that's a major issue. Or more precisely, I'm not surprised
>>> by it. It'd be nice to be able to disable the parallel builds in these
>>> cases somehow, but I haven't thought about that.
>>
>> Do you know why it regresses?
>>
>
> No, but one thing that stands out is that the index is much smaller than
> the other columns/opclasses, and the compression does not save much
> (only about 5% for both phases). So I assume it's the overhead of
> writing writing and reading a bunch of GB of data without really gaining
> much from doing that.
>
I finally got to look into this regression, but I think I must have done
something wrong before because I can't reproduce it. This is the timings
I get now, if I rerun the benchmark:
workers trgm tsvector jsonb jsonb (hash)
-------------------------------------------------------
0 1225 404 104 56
1 772 180 57 60
2 549 143 47 52
3 426 127 43 50
4 364 116 40 48
5 323 111 38 46
6 292 111 37 45
and the speedup, relative to serial build:
workers trgm tsvector jsonb jsonb (hash)
--------------------------------------------------------
1 63% 45% 54% 108%
2 45% 35% 45% 94%
3 35% 31% 41% 89%
4 30% 29% 38% 86%
5 26% 28% 37% 83%
6 24% 28% 35% 81%
So there's a small regression for the jsonb_path_ops opclass, but only
with one worker. After that, it gets a bit faster than serial build.
While not a great speedup, it's far better than the earlier results that
showed maybe 40% regression.
I don't know what I did wrong before - maybe I had a build with an extra
debug info or something like that? No idea why would that affect only
one of the opclasses. But this time I made doubly sure the results are
correct etc.
Anyway, I'm fairly happy with these results. I don't think it's
surprising there are cases where parallel build does not help much.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Thu, 9 May 2024 at 15:13, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > Let me explain the relevant part of the patch, and how I understand the > improvement suggested by Matthias. The patch does the work in three phases: > > > 1) Worker gets data from table, split that into index items and add > those into a "private" tuplesort, and finally sorts that. So a worker > may see a key many times, with different TIDs, so the tuplesort may > contain many items for the same key, with distinct TID lists: > > key1: 1, 2, 3, 4 > key1: 5, 6, 7 > key1: 8, 9, 10 > key2: 1, 2, 3 > ... This step is actually split in several components/phases, too. As opposed to btree, which directly puts each tuple's data into the tuplesort, this GIN approach actually buffers the tuples in memory to generate these TID lists for data keys, and flushes these pairs of Key + TID list into the tuplesort when its own memory limit is exceeded. That means we essentially double the memory used for this data: One GIN deform buffer, and one in-memory sort buffer in the tuplesort. This is fine for now, but feels duplicative, hence my "let's allow tuplesort to merge the key+TID pairs into pairs of key+TID list" comment. > The trouble with (2) is that it "just copies" data from one tuplesort > into another, increasing the disk space requirements. In an extreme > case, when nothing can be combined, it pretty much doubles the amount of > disk space, and makes the build longer. > > What I think Matthias is suggesting, is that this "TID list merging" > could be done directly as part of the tuplesort in step (1). So instead > of just moving the "sort tuples" from the appropriate runs, it could > also do an optional step of combining the tuples and writing this > combined tuple into the tuplesort result (for that worker). Yes, but with a slightly more extensive approach than that even, see above. > Matthias also mentioned this might be useful when building btree indexes > with key deduplication. > > AFAICS this might work, although it probably requires for the "combined" > tuple to be smaller than the sum of the combined tuples (in order to fit > into the space). *must not be larger than the sum; not "must be smaller than the sum" [^0]. For btree tuples with posting lists this is guaranteed to be true: The added size of a btree tuple with a posting list (containing at least 2 values) vs one without is the maxaligned size of 2 TIDs, or 16 bytes (12 on 32-bit systems). The smallest btree tuple with data is also 16 bytes (or 12 bytes on 32-bit systems), so this works out nicely. > But at least in the GIN build in the workers this is > likely true, because the TID lists do not overlap (and thus not hurting > the compressibility). > > That being said, I still see this more as an optimization than something > required for the patch, Agreed. > and I don't think I'll have time to work on this > anytime soon. The patch is not extremely complex, but it's not trivial > either. But if someone wants to take a stab at extending tuplesort to > allow this, I won't object ... Same here: While I do have some ideas on where and how to implement this, I'm not planning on working on that soon. Kind regards, Matthias van de Meent [^0] There's some overhead in the tuplesort serialization too, so there is some leeway there, too.
On 5/9/24 17:51, Matthias van de Meent wrote: > On Thu, 9 May 2024 at 15:13, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: >> Let me explain the relevant part of the patch, and how I understand the >> improvement suggested by Matthias. The patch does the work in three phases: >> >> >> 1) Worker gets data from table, split that into index items and add >> those into a "private" tuplesort, and finally sorts that. So a worker >> may see a key many times, with different TIDs, so the tuplesort may >> contain many items for the same key, with distinct TID lists: >> >> key1: 1, 2, 3, 4 >> key1: 5, 6, 7 >> key1: 8, 9, 10 >> key2: 1, 2, 3 >> ... > > This step is actually split in several components/phases, too. > As opposed to btree, which directly puts each tuple's data into the > tuplesort, this GIN approach actually buffers the tuples in memory to > generate these TID lists for data keys, and flushes these pairs of Key > + TID list into the tuplesort when its own memory limit is exceeded. > That means we essentially double the memory used for this data: One > GIN deform buffer, and one in-memory sort buffer in the tuplesort. > This is fine for now, but feels duplicative, hence my "let's allow > tuplesort to merge the key+TID pairs into pairs of key+TID list" > comment. > True, although the "GIN deform buffer" (flushed by the callback if using too much memory) likely does most of the merging already. If it only happened in the tuplesort merge, we'd likely have far more tuples and overhead associated with that. So we certainly won't get rid of either of these things. You're right the memory limits are a bit unclear, and need more thought. I certainly have not thought very much about not using more than the specified maintenance_work_mem amount. This includes the planner code determining the number of workers to use - right now it simply does the same thing as for btree/brin, i.e. assumes each workers uses 32MB of memory and checks how many workers fit into maintenance_work_mem. That was a bit bogus even for BRIN, because BRIN sorts only summaries, which is typically tiny - perhaps a couple kB, much less than 32MB. But it's still just one sort, and some opclasses may be much larger (like bloom, for example). So I just went with it. But for GIN it's more complicated, because we have two tuplesorts (not sure if both can use the memory at the same time) and the GIN deform buffer. Which probably means we need to have a per-worker allowance considering all these buffers. >> The trouble with (2) is that it "just copies" data from one tuplesort >> into another, increasing the disk space requirements. In an extreme >> case, when nothing can be combined, it pretty much doubles the amount of >> disk space, and makes the build longer. >> >> What I think Matthias is suggesting, is that this "TID list merging" >> could be done directly as part of the tuplesort in step (1). So instead >> of just moving the "sort tuples" from the appropriate runs, it could >> also do an optional step of combining the tuples and writing this >> combined tuple into the tuplesort result (for that worker). > > Yes, but with a slightly more extensive approach than that even, see above. > >> Matthias also mentioned this might be useful when building btree indexes >> with key deduplication. >> >> AFAICS this might work, although it probably requires for the "combined" >> tuple to be smaller than the sum of the combined tuples (in order to fit >> into the space). > > *must not be larger than the sum; not "must be smaller than the sum" [^0]. Yeah, I wrote that wrong. > For btree tuples with posting lists this is guaranteed to be true: The > added size of a btree tuple with a posting list (containing at least 2 > values) vs one without is the maxaligned size of 2 TIDs, or 16 bytes > (12 on 32-bit systems). The smallest btree tuple with data is also 16 > bytes (or 12 bytes on 32-bit systems), so this works out nicely. > >> But at least in the GIN build in the workers this is >> likely true, because the TID lists do not overlap (and thus not hurting >> the compressibility). >> >> That being said, I still see this more as an optimization than something >> required for the patch, > > Agreed. > OK >> and I don't think I'll have time to work on this >> anytime soon. The patch is not extremely complex, but it's not trivial >> either. But if someone wants to take a stab at extending tuplesort to >> allow this, I won't object ... > > Same here: While I do have some ideas on where and how to implement > this, I'm not planning on working on that soon. > Understood. I don't have a very good intuition on how significant the benefit could be, which is one of the reasons why I have not prioritized this very much. I did a quick experiment, to measure how expensive it is to build the second worker tuplesort - for the pg_trgm index build with 2 workers, it takes ~30seconds. The index build takes ~550s in total, so 30s is ~5%. If we eliminated all of this work we'd save this, but in reality some of it will still be necessary. Perhaps it's more significant for other indexes / slower storage, but it does not seem like a *must have* for v1. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Tomas Vondra <tomas.vondra@enterprisedb.com> writes: >> I guess both of you are talking about worker process, if here are >> something in my mind: >> >> *btbuild* also let the WORKER dump the tuples into Sharedsort struct >> and let the LEADER merge them directly. I think this aim of this design >> is it is potential to save a mergeruns. In the current patch, worker dump >> to local tuplesort and mergeruns it and then leader run the merges >> again. I admit the goal of this patch is reasonable, but I'm feeling we >> need to adapt this way conditionally somehow. and if we find the way, we >> can apply it to btbuild as well. >> > > I'm a bit confused about what you're proposing here, or how is that > related to what this patch is doing and/or to the what Matthias > mentioned in his e-mail from last week. > > Let me explain the relevant part of the patch, and how I understand the > improvement suggested by Matthias. The patch does the work in three phases: What's in my mind is: 1. WORKER-1 Tempfile 1: key1: 1 key3: 2 ... Tempfile 2: key5: 3 key7: 4 ... 2. WORKER-2 Tempfile 1: Key2: 1 Key6: 2 ... Tempfile 2: Key3: 3 Key6: 4 .. In the above example: if we do the the merge in LEADER, only 1 mergerun is needed. reading 4 tempfile 8 tuples in total and write 8 tuples. If we adds another mergerun into WORKER, the result will be: WORKER1: reading 2 tempfile 4 tuples and write 1 tempfile (called X) 4 tuples. WORKER2: reading 2 tempfile 4 tuples and write 1 tempfile (called Y) 4 tuples. LEADER: reading 2 tempfiles (X & Y) including 8 tuples and write it into final tempfile. So the intermedia result X & Y requires some extra effort. so I think the "extra mergerun in worker" is *not always* a win, and my proposal is if we need to distinguish the cases in which one we should add the "extra mergerun in worker" step. > The trouble with (2) is that it "just copies" data from one tuplesort > into another, increasing the disk space requirements. In an extreme > case, when nothing can be combined, it pretty much doubles the amount of > disk space, and makes the build longer. This sounds like the same question as I talk above, However my proposal is to distinguish which cost is bigger between "the cost saving from merging TIDs in WORKERS" and "cost paid because of the extra copy", then we do that only when we are sure we can benefits from it, but I know it is hard and not sure if it is doable. > What I think Matthias is suggesting, is that this "TID list merging" > could be done directly as part of the tuplesort in step (1). So instead > of just moving the "sort tuples" from the appropriate runs, it could > also do an optional step of combining the tuples and writing this > combined tuple into the tuplesort result (for that worker). OK, I get it now. So we talked about lots of merge so far at different stage and for different sets of tuples. 1. "GIN deform buffer" did the TIDs merge for the same key for the tuples in one "deform buffer" batch, as what the current master is doing. 2. "in memory buffer sort" stage, currently there is no TID merge so far and Matthias suggest that. 3. Merge the TIDs for the same keys in LEADER vs in WORKER first + LEADER then. this is what your 0002 commit does now and I raised some concerns as above. > Matthias also mentioned this might be useful when building btree indexes > with key deduplication. > AFAICS this might work, although it probably requires for the "combined" > tuple to be smaller than the sum of the combined tuples (in order to fit > into the space). But at least in the GIN build in the workers this is > likely true, because the TID lists do not overlap (and thus not hurting > the compressibility). > > That being said, I still see this more as an optimization than something > required for the patch, If GIN deform buffer is big enough (like greater than the in memory buffer sort) shall we have any gain because of this, since the scope is the tuples in in-memory-buffer-sort. > and I don't think I'll have time to work on this > anytime soon. The patch is not extremely complex, but it's not trivial > either. But if someone wants to take a stab at extending tuplesort to > allow this, I won't object ... Agree with this. I am more interested with understanding the whole design and the scope to fix in this patch, and then I can do some code review and testing, as for now, I still in the "understanding design and scope" stage. If I'm too slow about this patch, please feel free to commit it any time and I don't expect I can find any valueable improvement and bugs. I probably needs another 1 ~ 2 weeks to study this patch. -- Best Regards Andy Fan
On 5/10/24 07:53, Andy Fan wrote: > > Tomas Vondra <tomas.vondra@enterprisedb.com> writes: > >>> I guess both of you are talking about worker process, if here are >>> something in my mind: >>> >>> *btbuild* also let the WORKER dump the tuples into Sharedsort struct >>> and let the LEADER merge them directly. I think this aim of this design >>> is it is potential to save a mergeruns. In the current patch, worker dump >>> to local tuplesort and mergeruns it and then leader run the merges >>> again. I admit the goal of this patch is reasonable, but I'm feeling we >>> need to adapt this way conditionally somehow. and if we find the way, we >>> can apply it to btbuild as well. >>> >> >> I'm a bit confused about what you're proposing here, or how is that >> related to what this patch is doing and/or to the what Matthias >> mentioned in his e-mail from last week. >> >> Let me explain the relevant part of the patch, and how I understand the >> improvement suggested by Matthias. The patch does the work in three phases: > > What's in my mind is: > > 1. WORKER-1 > > Tempfile 1: > > key1: 1 > key3: 2 > ... > > Tempfile 2: > > key5: 3 > key7: 4 > ... > > 2. WORKER-2 > > Tempfile 1: > > Key2: 1 > Key6: 2 > ... > > Tempfile 2: > Key3: 3 > Key6: 4 > .. > > In the above example: if we do the the merge in LEADER, only 1 mergerun > is needed. reading 4 tempfile 8 tuples in total and write 8 tuples. > > If we adds another mergerun into WORKER, the result will be: > > WORKER1: reading 2 tempfile 4 tuples and write 1 tempfile (called X) 4 > tuples. > WORKER2: reading 2 tempfile 4 tuples and write 1 tempfile (called Y) 4 > tuples. > > LEADER: reading 2 tempfiles (X & Y) including 8 tuples and write it > into final tempfile. > > So the intermedia result X & Y requires some extra effort. so I think > the "extra mergerun in worker" is *not always* a win, and my proposal is > if we need to distinguish the cases in which one we should add the > "extra mergerun in worker" step. > The thing you're forgetting is that the mergesort in the worker is *always* a simple append, because the lists are guaranteed to be non-overlapping, so it's very cheap. The lists from different workers are however very likely to overlap, and hence a "full" mergesort is needed, which is way more expensive. And not only that - without the intermediate merge, there will be very many of those lists the leader would have to merge. If we do the append-only merges in the workers first, we still need to merge them in the leader, of course, but we have few lists to merge (only about one per worker). Of course, this means extra I/O on the intermediate tuplesort, and it's not difficult to imagine cases with no benefit, or perhaps even a regression. For example, if the keys are unique, the in-worker merge step can't really do anything. But that seems quite unlikely IMHO. Also, if this overhead was really significant, we would not see the nice speedups I measured during testing. >> The trouble with (2) is that it "just copies" data from one tuplesort >> into another, increasing the disk space requirements. In an extreme >> case, when nothing can be combined, it pretty much doubles the amount of >> disk space, and makes the build longer. > > This sounds like the same question as I talk above, However my proposal > is to distinguish which cost is bigger between "the cost saving from > merging TIDs in WORKERS" and "cost paid because of the extra copy", > then we do that only when we are sure we can benefits from it, but I > know it is hard and not sure if it is doable. > Yeah. I'm not against picking the right execution strategy during the index build, but it's going to be difficult, because we really don't have the information to make a reliable decision. We can't even use the per-column stats, because it does not say much about the keys extracted by GIN, I think. And we need to do the decision at the very beginning, before we write the first batch of data either to the local or shared tuplesort. But maybe we could wait until we need to flush the first batch of data (in the callback), and make the decision then? In principle, if we only flush once at the end, the intermediate sort is not needed at all (fairy unlikely for large data sets, though). Well, in principle, maybe we could even start writing into the local tuplesort, and then "rethink" after a while and switch to the shared one. We'd still need to copy data we've already written to the local tuplesort, but hopefully that'd be just a fraction compared to doing that for the whole table. >> What I think Matthias is suggesting, is that this "TID list merging" >> could be done directly as part of the tuplesort in step (1). So instead >> of just moving the "sort tuples" from the appropriate runs, it could >> also do an optional step of combining the tuples and writing this >> combined tuple into the tuplesort result (for that worker). > > OK, I get it now. So we talked about lots of merge so far at different > stage and for different sets of tuples. > > 1. "GIN deform buffer" did the TIDs merge for the same key for the tuples > in one "deform buffer" batch, as what the current master is doing. > > 2. "in memory buffer sort" stage, currently there is no TID merge so > far and Matthias suggest that. > > 3. Merge the TIDs for the same keys in LEADER vs in WORKER first + > LEADER then. this is what your 0002 commit does now and I raised some > concerns as above. > OK >> Matthias also mentioned this might be useful when building btree indexes >> with key deduplication. > >> AFAICS this might work, although it probably requires for the "combined" >> tuple to be smaller than the sum of the combined tuples (in order to fit >> into the space). But at least in the GIN build in the workers this is >> likely true, because the TID lists do not overlap (and thus not hurting >> the compressibility). >> >> That being said, I still see this more as an optimization than something >> required for the patch, > > If GIN deform buffer is big enough (like greater than the in memory > buffer sort) shall we have any gain because of this, since the > scope is the tuples in in-memory-buffer-sort. > I don't think this is very likely. The only case when the GIN deform tuple is "big enough" is when we don't need to flush in the callback, but that is going to happen only for "small" tables. And for those we should not really do parallel builds. And even if we do, the overhead would be pretty insignificant. >> and I don't think I'll have time to work on this >> anytime soon. The patch is not extremely complex, but it's not trivial >> either. But if someone wants to take a stab at extending tuplesort to >> allow this, I won't object ... > > Agree with this. I am more interested with understanding the whole > design and the scope to fix in this patch, and then I can do some code > review and testing, as for now, I still in the "understanding design and > scope" stage. If I'm too slow about this patch, please feel free to > commit it any time and I don't expect I can find any valueable > improvement and bugs. I probably needs another 1 ~ 2 weeks to study > this patch. > Sure, happy to discuss and answer questions. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Tomas Vondra <tomas.vondra@enterprisedb.com> writes: >>> 7) v20240502-0007-Detect-wrap-around-in-parallel-callback.patch >>> >>> There's one more efficiency problem - the parallel scans are required to >>> be synchronized, i.e. the scan may start half-way through the table, and >>> then wrap around. Which however means the TID list will have a very wide >>> range of TID values, essentially the min and max of for the key. >> >> I have two questions here and both of them are generall gin index questions >> rather than the patch here. >> >> 1. What does the "wrap around" mean in the "the scan may start half-way >> through the table, and then wrap around". Searching "wrap" in >> gin/README gets nothing. >> > > The "wrap around" is about the scan used to read data from the table > when building the index. A "sync scan" may start e.g. at TID (1000,0) > and read till the end of the table, and then wraps and returns the > remaining part at the beginning of the table for blocks 0-999. > > This means the callback would not see a monotonically increasing > sequence of TIDs. > > Which is why the serial build disables sync scans, allowing simply > appending values to the sorted list, and even with regular flushes of > data into the index we can simply append data to the posting lists. Thanks for the hints, I know the sync strategy comes from syncscan.c now. >>> Without 0006 this would cause frequent failures of the index build, with >>> the error I already mentioned: >>> >>> ERROR: could not split GIN page; all old items didn't fit >> 2. I can't understand the below error. >> >>> ERROR: could not split GIN page; all old items didn't fit > if (!append || ItemPointerCompare(&maxOldItem, &remaining) >= 0) > elog(ERROR, "could not split GIN page; all old items didn't fit"); > > It can fail simply because of the !append part. Got it, Thanks! >> If we split the blocks among worker 1-block by 1-block, we will have a >> serious issue like here. If we can have N-block by N-block, and N-block >> is somehow fill the work_mem which makes the dedicated temp file, we >> can make things much better, can we? > I don't understand the question. The blocks are distributed to workers > by the parallel table scan, and it certainly does not do that block by > block. But even it it did, that's not a problem for this code. OK, I get ParallelBlockTableScanWorkerData.phsw_chunk_size is designed for this. > The problem is that if the scan wraps around, then one of the TID lists > for a given worker will have the min TID and max TID, so it will overlap > with every other TID list for the same key in that worker. And when the > worker does the merging, this list will force a "full" merge sort for > all TID lists (for that key), which is very expensive. OK. Thanks for all the answers, they are pretty instructive! -- Best Regards Andy Fan
On 5/13/24 10:19, Andy Fan wrote: > > Tomas Vondra <tomas.vondra@enterprisedb.com> writes: > >> ... >> >> I don't understand the question. The blocks are distributed to workers >> by the parallel table scan, and it certainly does not do that block by >> block. But even it it did, that's not a problem for this code. > > OK, I get ParallelBlockTableScanWorkerData.phsw_chunk_size is designed > for this. > >> The problem is that if the scan wraps around, then one of the TID lists >> for a given worker will have the min TID and max TID, so it will overlap >> with every other TID list for the same key in that worker. And when the >> worker does the merging, this list will force a "full" merge sort for >> all TID lists (for that key), which is very expensive. > > OK. > > Thanks for all the answers, they are pretty instructive! > Thanks for the questions, it forces me to articulate the arguments more clearly. I guess it'd be good to put some of this into a README or at least a comment at the beginning of gininsert.c or somewhere close. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi Tomas,
I have completed my first round of review, generally it looks good to
me, more testing need to be done in the next days. Here are some tiny
comments from my side, just FYI.
1. Comments about GinBuildState.bs_leader looks not good for me.
/*
* bs_leader is only present when a parallel index build is performed, and
* only in the leader process. (Actually, only the leader process has a
* GinBuildState.)
*/
GinLeader *bs_leader;
In the worker function _gin_parallel_build_main:
initGinState(&buildstate.ginstate, indexRel); is called, and the
following members in workers at least: buildstate.funcCtx,
buildstate.accum and so on. So is the comment "only the leader process
has a GinBuildState" correct?
2. progress argument is not used?
_gin_parallel_scan_and_build(GinBuildState *state,
GinShared *ginshared, Sharedsort *sharedsort,
Relation heap, Relation index,
int sortmem, bool progress)
3. In function tuplesort_begin_index_gin, comments about nKeys takes me
some time to think about why 1 is correct(rather than
IndexRelationGetNumberOfKeyAttributes) and what does the "only the index
key" means.
base->nKeys = 1; /* Only the index key */
finally I think it is because gin index stores each attribute value into
an individual index entry for a multi-column index, so each index entry
has only 1 key. So we can comment it as the following?
"Gin Index stores the value of each attribute into different index entry
for mutli-column index, so each index entry has only 1 key all the
time." This probably makes it easier to understand.
4. GinBuffer: The comment "Similar purpose to BuildAccumulator, but much
simpler." makes me think why do we need a simpler but
similar structure, After some thoughts, they are similar at accumulating
TIDs only. GinBuffer is designed for "same key value" (hence
GinBufferCanAddKey). so IMO, the first comment is good enough and the 2
comments introduce confuses for green hand and is potential to remove
it.
/*
* State used to combine accumulate TIDs from multiple GinTuples for the same
* key value.
*
* XXX Similar purpose to BuildAccumulator, but much simpler.
*/
typedef struct GinBuffer
5. GinBuffer: ginMergeItemPointers always allocate new memory for the
new items and hence we have to pfree old memory each time. However it is
not necessary in some places, for example the new items can be appended
to Buffer->items (and this should be a common case). So could we
pre-allocate some spaces for items and reduce the number of pfree/palloc
and save some TID items copy in the desired case?
6. GinTuple.ItemPointerData first; /* first TID in the array */
is ItemPointerData.ip_blkid good enough for its purpose? If so, we can
save the memory for OffsetNumber for each GinTuple.
Item 5) and 6) needs some coding and testing. If it is OK to do, I'd
like to take it as an exercise in this area. (also including the item
1~4.)
--
Best Regards
Andy Fan
Hi Andy, Thanks for the review. Here's an updated patch series, addressing most of the points you've raised - I've kept them in "fixup" patches for now, should be merged into 0001. More detailed responses below. On 5/28/24 11:29, Andy Fan wrote: > > Hi Tomas, > > I have completed my first round of review, generally it looks good to > me, more testing need to be done in the next days. Here are some tiny > comments from my side, just FYI. > > 1. Comments about GinBuildState.bs_leader looks not good for me. > > /* > * bs_leader is only present when a parallel index build is performed, and > * only in the leader process. (Actually, only the leader process has a > * GinBuildState.) > */ > GinLeader *bs_leader; > > In the worker function _gin_parallel_build_main: > initGinState(&buildstate.ginstate, indexRel); is called, and the > following members in workers at least: buildstate.funcCtx, > buildstate.accum and so on. So is the comment "only the leader process > has a GinBuildState" correct? > Yeah, this is misleading. I don't remember what exactly was my reasoning for this wording, I've removed the comment. > 2. progress argument is not used? > _gin_parallel_scan_and_build(GinBuildState *state, > GinShared *ginshared, Sharedsort *sharedsort, > Relation heap, Relation index, > int sortmem, bool progress) > I've modified the code to use the progress flag, but now that I look at it I'm a bit unsure I understand the purpose of this. I've modeled this after what the btree does, and I see that there are two places calling _bt_parallel_scan_and_sort: 1) _bt_leader_participate_as_worker: progress=true 2) _bt_parallel_build_main: progress=false Isn't that a bit weird? AFAIU the progress will be updated only by the leader, but will that progress be correct? And doesn't that means the if the leader does not participate as a worker, the progress won't be updated? FWIW The parallel BRIN code has the same issue - it's not using the progress flag in _brin_parallel_scan_and_build. > > 3. In function tuplesort_begin_index_gin, comments about nKeys takes me > some time to think about why 1 is correct(rather than > IndexRelationGetNumberOfKeyAttributes) and what does the "only the index > key" means. > > base->nKeys = 1; /* Only the index key */ > > finally I think it is because gin index stores each attribute value into > an individual index entry for a multi-column index, so each index entry > has only 1 key. So we can comment it as the following? > > "Gin Index stores the value of each attribute into different index entry > for mutli-column index, so each index entry has only 1 key all the > time." This probably makes it easier to understand. > OK, I see what you mean. The other tuplesort_begin_ functions nearby have similar comments, but you're right GIN is a bit special in that it "splits" multi-column indexes into individual index entries. I've added a comment (hopefully) clarifying this. > > 4. GinBuffer: The comment "Similar purpose to BuildAccumulator, but much > simpler." makes me think why do we need a simpler but > similar structure, After some thoughts, they are similar at accumulating > TIDs only. GinBuffer is designed for "same key value" (hence > GinBufferCanAddKey). so IMO, the first comment is good enough and the 2 > comments introduce confuses for green hand and is potential to remove > it. > > /* > * State used to combine accumulate TIDs from multiple GinTuples for the same > * key value. > * > * XXX Similar purpose to BuildAccumulator, but much simpler. > */ > typedef struct GinBuffer > I've updated the comment explaining the differences a bit clearer. > > 5. GinBuffer: ginMergeItemPointers always allocate new memory for the > new items and hence we have to pfree old memory each time. However it is > not necessary in some places, for example the new items can be appended > to Buffer->items (and this should be a common case). So could we > pre-allocate some spaces for items and reduce the number of pfree/palloc > and save some TID items copy in the desired case? > Perhaps, but that seems rather independent of this patch. Also, I'm not sure how much would this optimization matter in practice. The merge should happens fairly rarely, when we decide to store the TIDs into the index. And then it's also subject to the caching built into the memory contexts, limiting the malloc costs. We'll still pay for the memcpy, of course. Anyway, it's an optimization that would affect existing callers of ginMergeItemPointers. I don't plan to tweak this in this patch. > 6. GinTuple.ItemPointerData first; /* first TID in the array */ > > is ItemPointerData.ip_blkid good enough for its purpose? If so, we can > save the memory for OffsetNumber for each GinTuple. > > Item 5) and 6) needs some coding and testing. If it is OK to do, I'd > like to take it as an exercise in this area. (also including the item > 1~4.) > It might save 2 bytes in the struct, but that's negligible compared to the memory usage overall (we only keep one GinTuple, but many TIDs and so on), and we allocate the space in power-of-2 pattern anyway (which means the 2B won't matter). Moreover, using just the block number would make it harder to compare the TIDs (now we can just call ItemPointerCompare). regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- v20240619-0001-Allow-parallel-create-for-GIN-indexes.patch
- v20240619-0002-fixup-pass-progress-flag.patch
- v20240619-0003-fixup-remove-inaccurate-comment.patch
- v20240619-0004-fixup-clarify-tuplesort_begin_index_gin.patch
- v20240619-0005-fixup-clarify-GinBuffer-comment.patch
- v20240619-0006-Use-mergesort-in-the-leader-process.patch
- v20240619-0007-Remove-the-explicit-pg_qsort-in-workers.patch
- v20240619-0008-Compress-TID-lists-before-writing-tuples-t.patch
- v20240619-0009-Collect-and-print-compression-stats.patch
- v20240619-0010-Enforce-memory-limit-when-combining-tuples.patch
- v20240619-0011-Detect-wrap-around-in-parallel-callback.patch
Here's a cleaned up patch series, merging the fixup patches into 0001. I've also removed the memset() from ginInsertBAEntry(). This was meant to fix valgrind reports, but I believe this was just a symptom of incorrect handling of byref data types, which was fixed in 2024/05/02 patch version. The other thing I did is cleanup of FIXME and XXX comments. There were a couple stale/obsolete comments, discussing issues that have been already fixed (like the scan wrapping around). A couple things to fix remain, but all of them are minor. And there's also a couple XXX comments, often describing thing that is then done in one of the following patches. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- v20240620-0001-Allow-parallel-create-for-GIN-indexes.patch
- v20240620-0002-Use-mergesort-in-the-leader-process.patch
- v20240620-0003-Remove-the-explicit-pg_qsort-in-workers.patch
- v20240620-0004-Compress-TID-lists-before-writing-tuples-t.patch
- v20240620-0005-Collect-and-print-compression-stats.patch
- v20240620-0006-Enforce-memory-limit-when-combining-tuples.patch
- v20240620-0007-Detect-wrap-around-in-parallel-callback.patch
Here's a bit more cleaned up version, clarifying a lot of comments, removing a bunch of obsolete comments, or comments speculating about possible solutions, that sort of thing. I've also removed couple more XXX comments, etc. The main change however is that the sorting no longer relies on memcmp() to compare the values. I did that because it was enough for the initial WIP patches, and it worked till now - but the comments explained this may not be a good idea if the data type allows the same value to have multiple binary representations, or something like that. I don't have a practical example to show an issue, but I guess if using memcmp() was safe we'd be doing it in a bunch of places already, and AFAIK we're not. And even if it happened to be OK, this is a probably not the place where to start doing it. So I've switched this to use the regular data-type comparisons, with SortSupport etc. There's a bit more cleanup remaining and testing needed, but I'm not aware of any bugs. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- v20240624-0001-Allow-parallel-create-for-GIN-indexes.patch
- v20240624-0002-Use-mergesort-in-the-leader-process.patch
- v20240624-0003-Remove-the-explicit-pg_qsort-in-workers.patch
- v20240624-0004-Compress-TID-lists-before-writing-tuples-t.patch
- v20240624-0005-Collect-and-print-compression-stats.patch
- v20240624-0006-Enforce-memory-limit-when-combining-tuples.patch
- v20240624-0007-Detect-wrap-around-in-parallel-callback.patch
Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
Hi Tomas,
I am in a incompleted review process but I probably doesn't have much
time on this because of my internal tasks. So I just shared what I
did and the non-good-result patch.
What I tried to do is:
1) remove all the "sort" effort for the state->bs_sort_state tuples since
its input comes from state->bs_worker_state which is sorted already.
2). remove *partial* "sort" operations between accum.rbtree to
state->bs_worker_state because the tuple in accum.rbtree is sorted
already.
Both of them can depend on the same API changes.
1.
struct Tuplesortstate
{
..
+ bool input_presorted; /* the tuples are presorted. */
+ new_tapes; // writes the tuples in memory into a new 'run'.
}
and user can set it during tuplesort_begin_xx(, presorte=true);
2. in tuplesort_puttuple, if memory is full but presorted is
true, we can (a) avoid the sort. (b) resuse the existing 'runs'
to reduce the effort of 'mergeruns' unless new_tapes is set to
true. once it switch to a new tapes, the set state->new_tapes to false
and wait 3) to change it to true again.
3. tuplesort_dumptuples(..); // dump the tuples in memory and set
new_tapes=true to tell the *this batch of input is presorted but they
are done, the next batch is just presort in its own batch*.
In the gin-parallel-build case, for the case 1), we can just use
for tuple in bs_worker_sort:
tuplesort_putgintuple(state->bs_sortstate, ..);
tuplesort_dumptuples(..);
At last we can get a). only 1 run in the worker so that the leader can
have merge less runs in mergeruns. b). reduce the sort both in
perform_sort_tuplesort and in sortstate_puttuple_common.
for the case 2). we can have:
for tuple in RBTree.tuples:
tuplesort_puttuples(tuple) ;
// this may cause a dumptuples internally when the memory is full,
// but it is OK.
tuplesort_dumptuples(..);
we can just remove the "sort" into sortstate_puttuple_common but
probably increase the 'runs' in sortstate which will increase the effort
of mergeruns at last.
But the test result is not good, maybe the 'sort' is not a key factor of
this. I do missed the perf step before doing this. or maybe my test data
is too small.
Here is the patch I used for the above activity. and I used the
following sql to test.
CREATE TABLE t(a int[], b numeric[]);
-- generate 1000 * 1000 rows.
insert into t select i, n
from normal_rand_array(1000, 90, 1::int4, 10000::int4) i,
normal_rand_array(1000, 90, '1.00233234'::numeric, '8.239241989134'::numeric) n;
alter table t set (parallel_workers=4);
set debug_parallel_query to on;
set max_parallel_maintenance_workers to 4;
create index on t using gin(a);
create index on t using gin(b);
I found normal_rand_array is handy to use in this case and I
register it into https://commitfest.postgresql.org/48/5061/.
Besides the above stuff, I didn't find anything wrong in the currrent
patch, and the above stuff can be categoried into "furture improvement"
even it is worthy to.
--
Best Regards
Andy Fan
Attachment
On 7/2/24 02:07, Andy Fan wrote:
> Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
>
> Hi Tomas,
>
> I am in a incompleted review process but I probably doesn't have much
> time on this because of my internal tasks. So I just shared what I
> did and the non-good-result patch.
>
> What I tried to do is:
> 1) remove all the "sort" effort for the state->bs_sort_state tuples since
> its input comes from state->bs_worker_state which is sorted already.
>
> 2). remove *partial* "sort" operations between accum.rbtree to
> state->bs_worker_state because the tuple in accum.rbtree is sorted
> already.
>
> Both of them can depend on the same API changes.
>
> 1.
> struct Tuplesortstate
> {
> ..
> + bool input_presorted; /* the tuples are presorted. */
> + new_tapes; // writes the tuples in memory into a new 'run'.
> }
>
> and user can set it during tuplesort_begin_xx(, presorte=true);
>
>
> 2. in tuplesort_puttuple, if memory is full but presorted is
> true, we can (a) avoid the sort. (b) resuse the existing 'runs'
> to reduce the effort of 'mergeruns' unless new_tapes is set to
> true. once it switch to a new tapes, the set state->new_tapes to false
> and wait 3) to change it to true again.
>
> 3. tuplesort_dumptuples(..); // dump the tuples in memory and set
> new_tapes=true to tell the *this batch of input is presorted but they
> are done, the next batch is just presort in its own batch*.
>
> In the gin-parallel-build case, for the case 1), we can just use
>
> for tuple in bs_worker_sort:
> tuplesort_putgintuple(state->bs_sortstate, ..);
> tuplesort_dumptuples(..);
>
> At last we can get a). only 1 run in the worker so that the leader can
> have merge less runs in mergeruns. b). reduce the sort both in
> perform_sort_tuplesort and in sortstate_puttuple_common.
>
> for the case 2). we can have:
>
> for tuple in RBTree.tuples:
> tuplesort_puttuples(tuple) ;
> // this may cause a dumptuples internally when the memory is full,
> // but it is OK.
> tuplesort_dumptuples(..);
>
> we can just remove the "sort" into sortstate_puttuple_common but
> probably increase the 'runs' in sortstate which will increase the effort
> of mergeruns at last.
>
> But the test result is not good, maybe the 'sort' is not a key factor of
> this. I do missed the perf step before doing this. or maybe my test data
> is too small.
>
If I understand the idea correctly, you're saying that we write the data
from BuildAccumulator already sorted, so if we do that only once, it's
already sorted and we don't actually need the in-worker tuplesort.
I think that's a good idea in principle, but maybe the simplest way to
handle this is by remembering if we already flushed any data, and if we
do that for the first time at the very end of the scan, we can write
stuff directly to the shared tuplesort. That seems much simpler than
doing this inside the tuplesort code.
Or did I get the idea wrong?
FWIW I'm not sure how much this will help in practice. We only really
want to do parallel index build for fairly large tables, which makes it
less likely the data will fit into the buffer (and if we flush during
the scan, that disables the optimization).
> Here is the patch I used for the above activity. and I used the
> following sql to test.
>
> CREATE TABLE t(a int[], b numeric[]);
>
> -- generate 1000 * 1000 rows.
> insert into t select i, n
> from normal_rand_array(1000, 90, 1::int4, 10000::int4) i,
> normal_rand_array(1000, 90, '1.00233234'::numeric, '8.239241989134'::numeric) n;
>
> alter table t set (parallel_workers=4);
> set debug_parallel_query to on;
I don't think this forces parallel index builds - this GUC only affects
queries that go through the regular planner, but index build does not do
that, it just scans the table directly.
So maybe your testing did not actually do any parallel index builds?
That might explain why you didn't see any improvements.
Maybe try this to "force" parallel index builds:
set min_parallel_table_scan = '64kB';
set maintenance_work_mem = '256MB';
> set max_parallel_maintenance_workers to 4;
>
> create index on t using gin(a);
> create index on t using gin(b);
>
> I found normal_rand_array is handy to use in this case and I
> register it into https://commitfest.postgresql.org/48/5061/.
>
> Besides the above stuff, I didn't find anything wrong in the currrent
> patch, and the above stuff can be categoried into "furture improvement"
> even it is worthy to.
>
Thanks for the review!
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Mon, 24 Jun 2024 at 02:58, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > Here's a bit more cleaned up version, clarifying a lot of comments, > removing a bunch of obsolete comments, or comments speculating about > possible solutions, that sort of thing. I've also removed couple more > XXX comments, etc. > > The main change however is that the sorting no longer relies on memcmp() > to compare the values. I did that because it was enough for the initial > WIP patches, and it worked till now - but the comments explained this > may not be a good idea if the data type allows the same value to have > multiple binary representations, or something like that. > > I don't have a practical example to show an issue, but I guess if using > memcmp() was safe we'd be doing it in a bunch of places already, and > AFAIK we're not. And even if it happened to be OK, this is a probably > not the place where to start doing it. I think one such example would be the values '5.00'::jsonb and '5'::jsonb when indexed using GIN's jsonb_ops, though I'm not sure if they're treated as having the same value inside the opclass' ordering. > So I've switched this to use the regular data-type comparisons, with > SortSupport etc. There's a bit more cleanup remaining and testing > needed, but I'm not aware of any bugs. A review of patch 0001: --- > src/backend/access/gin/gininsert.c | 1449 +++++++++++++++++++- The nbtree code has `nbtsort.c` for its sort- and (parallel) build state handling, which is exclusively used during index creation. As the changes here seem to be largely related to bulk insertion, how much effort would it be to split the bulk insertion code path into a separate file? I noticed that new fields in GinBuildState do get to have a bs_*-prefix, but none of the other added or previous fields of the modified structs in gininsert.c have such prefixes. Could this be unified? > +/* Magic numbers for parallel state sharing */ > +#define PARALLEL_KEY_GIN_SHARED UINT64CONST(0xB000000000000001) > ... These overlap with BRIN's keys; can we make them unique while we're at it? > + * mutex protects all fields before heapdesc. I can't find the field that this `heapdesc` might refer to. > +_gin_begin_parallel(GinBuildState *buildstate, Relation heap, Relation index, > ... > + if (!isconcurrent) > + snapshot = SnapshotAny; > + else > + snapshot = RegisterSnapshot(GetTransactionSnapshot()); grumble: I know this is required from the index with the current APIs, but I'm kind of annoyed that each index AM has to construct the table scan and snapshot in their own code. I mean, this shouldn't be meaningfully different across AMs, so every AM implementing this same code makes me feel like we've got the wrong abstraction. I'm not asking you to change this, but it's one more case where I'm annoyed by the state of the system, but not quite enough yet to change it. --- > +++ b/src/backend/utils/sort/tuplesortvariants.c I was thinking some more about merging tuples inside the tuplesort. I realized that this could be implemented by allowing buffering of tuple writes in writetup. This would require adding a flush operation at the end of mergeonerun to store the final unflushed tuple on the tape, but that shouldn't be too expensive. This buffering, when implemented through e.g. a GinBuffer in TuplesortPublic->arg, could allow us to merge the TID lists of same-valued GIN tuples while they're getting stored and re-sorted, thus reducing the temporary space usage of the tuplesort by some amount with limited overhead for other non-deduplicating tuplesorts. I've not yet spent the time to get this to work though, but I'm fairly sure it'd use less temporary space than the current approach with the 2 tuplesorts, and could have lower overall CPU overhead as well because the number of sortable items gets reduced much earlier in the process. --- > +++ b/src/include/access/gin_tuple.h > + typedef struct GinTuple I think this needs some more care: currently, each GinTuple is at least 36 bytes in size on 64-bit systems. By using int instead of Size (no normal indexable tuple can be larger than MaxAllocSize), and packing the fields better we can shave off 10 bytes; or 12 bytes if GinTuple.keylen is further adjusted to (u)int16: a key needs to fit on a page, so we can probably safely assume that the key size fits in (u)int16. Kind regards, Matthias van de Meent Neon (https://neon.tech)
On Wed, 3 Jul 2024 at 20:36, Matthias van de Meent
<boekewurm+postgres@gmail.com> wrote:
>
> On Mon, 24 Jun 2024 at 02:58, Tomas Vondra
> <tomas.vondra@enterprisedb.com> wrote:
> > So I've switched this to use the regular data-type comparisons, with
> > SortSupport etc. There's a bit more cleanup remaining and testing
> > needed, but I'm not aware of any bugs.
I've hit assertion failures in my testing of the combined patches, in
AssertCheckItemPointers: it assumes it's never called when the buffer
is empty and uninitialized, but that's wrong: we don't initialize the
items array until the first tuple, which will cause the assertion to
fire. By updating the first 2 assertions of AssertCheckItemPointers, I
could get it working.
> ---
> > +++ b/src/backend/utils/sort/tuplesortvariants.c
>
> I was thinking some more about merging tuples inside the tuplesort. I
> realized that this could be implemented by allowing buffering of tuple
> writes in writetup. This would require adding a flush operation at the
> end of mergeonerun to store the final unflushed tuple on the tape, but
> that shouldn't be too expensive. This buffering, when implemented
> through e.g. a GinBuffer in TuplesortPublic->arg, could allow us to
> merge the TID lists of same-valued GIN tuples while they're getting
> stored and re-sorted, thus reducing the temporary space usage of the
> tuplesort by some amount with limited overhead for other
> non-deduplicating tuplesorts.
>
> I've not yet spent the time to get this to work though, but I'm fairly
> sure it'd use less temporary space than the current approach with the
> 2 tuplesorts, and could have lower overall CPU overhead as well
> because the number of sortable items gets reduced much earlier in the
> process.
I've now spent some time on this. Attached the original patchset, plus
2 incremental patches, the first of which implement the above design
(patch no. 8).
Local tests show it's significantly faster: for the below test case
I've seen reindex time reduced from 777455ms to 626217ms, or ~20%
improvement.
After applying the 'reduce the size of GinTuple' patch, index creation
time is down to 551514ms, or about 29% faster total. This all was
tested with a fresh stock postgres configuration.
"""
CREATE UNLOGGED TABLE testdata
AS SELECT sha256(i::text::bytea)::text
FROM generate_series(1, 15000000) i;
CREATE INDEX ON testdata USING gin (sha256 gin_trgm_ops);
"""
Kind regards,
Matthias van de Meent
Neon (https://neon.tech)
Attachment
- v20240705-0003-Remove-the-explicit-pg_qsort-in-workers.patch
- v20240705-0004-Compress-TID-lists-before-writing-tuples-t.patch
- v20240705-0005-Collect-and-print-compression-stats.patch
- v20240705-0002-Use-mergesort-in-the-leader-process.patch
- v20240705-0001-Allow-parallel-create-for-GIN-indexes.patch
- v20240705-0006-Enforce-memory-limit-when-combining-tuples.patch
- v20240705-0009-Reduce-the-size-of-GinTuple-by-12-bytes.patch
- v20240705-0007-Detect-wrap-around-in-parallel-callback.patch
- v20240705-0008-Use-a-single-GIN-tuplesort.patch
On 7/3/24 20:36, Matthias van de Meent wrote: > On Mon, 24 Jun 2024 at 02:58, Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> >> Here's a bit more cleaned up version, clarifying a lot of comments, >> removing a bunch of obsolete comments, or comments speculating about >> possible solutions, that sort of thing. I've also removed couple more >> XXX comments, etc. >> >> The main change however is that the sorting no longer relies on memcmp() >> to compare the values. I did that because it was enough for the initial >> WIP patches, and it worked till now - but the comments explained this >> may not be a good idea if the data type allows the same value to have >> multiple binary representations, or something like that. >> >> I don't have a practical example to show an issue, but I guess if using >> memcmp() was safe we'd be doing it in a bunch of places already, and >> AFAIK we're not. And even if it happened to be OK, this is a probably >> not the place where to start doing it. > > I think one such example would be the values '5.00'::jsonb and > '5'::jsonb when indexed using GIN's jsonb_ops, though I'm not sure if > they're treated as having the same value inside the opclass' ordering. > Yeah, possibly. But doing the comparison the "proper" way seems to be working pretty well, so I don't plan to investigate this further. >> So I've switched this to use the regular data-type comparisons, with >> SortSupport etc. There's a bit more cleanup remaining and testing >> needed, but I'm not aware of any bugs. > > A review of patch 0001: > > --- > >> src/backend/access/gin/gininsert.c | 1449 +++++++++++++++++++- > > The nbtree code has `nbtsort.c` for its sort- and (parallel) build > state handling, which is exclusively used during index creation. As > the changes here seem to be largely related to bulk insertion, how > much effort would it be to split the bulk insertion code path into a > separate file? > Hmmm. I haven't tried doing that, but I guess it's doable. I assume we'd want to do the move first, because it involves pre-existing code, and then do the patch on top of that. But what would be the benefit of doing that? I'm not sure doing it just to make it look more like btree code is really worth it. Do you expect the result to be clearer? > I noticed that new fields in GinBuildState do get to have a > bs_*-prefix, but none of the other added or previous fields of the > modified structs in gininsert.c have such prefixes. Could this be > unified? > Yeah, these are inconsistencies from copying the infrastructure code to make the parallel builds work, etc. >> +/* Magic numbers for parallel state sharing */ >> +#define PARALLEL_KEY_GIN_SHARED UINT64CONST(0xB000000000000001) >> ... > > These overlap with BRIN's keys; can we make them unique while we're at it? > We could, and I recall we had a similar discussion in the parallel BRIN thread, right?. But I'm somewhat unsure why would we actually want/need these keys to be unique. Surely, we don't need to mix those keys in the single shm segment, right? So it seems more like an aesthetic thing. Or is there some policy to have unique values for these keys? >> + * mutex protects all fields before heapdesc. > > I can't find the field that this `heapdesc` might refer to. > Yeah, likely a leftover from copying a bunch of code and then removing it without updating the comment. Will fix. >> +_gin_begin_parallel(GinBuildState *buildstate, Relation heap, Relation index, >> ... >> + if (!isconcurrent) >> + snapshot = SnapshotAny; >> + else >> + snapshot = RegisterSnapshot(GetTransactionSnapshot()); > > grumble: I know this is required from the index with the current APIs, > but I'm kind of annoyed that each index AM has to construct the table > scan and snapshot in their own code. I mean, this shouldn't be > meaningfully different across AMs, so every AM implementing this same > code makes me feel like we've got the wrong abstraction. > > I'm not asking you to change this, but it's one more case where I'm > annoyed by the state of the system, but not quite enough yet to change > it. > Yeah, it's not great, but not something I intend to rework. > --- >> +++ b/src/backend/utils/sort/tuplesortvariants.c > > I was thinking some more about merging tuples inside the tuplesort. I > realized that this could be implemented by allowing buffering of tuple > writes in writetup. This would require adding a flush operation at the > end of mergeonerun to store the final unflushed tuple on the tape, but > that shouldn't be too expensive. This buffering, when implemented > through e.g. a GinBuffer in TuplesortPublic->arg, could allow us to > merge the TID lists of same-valued GIN tuples while they're getting > stored and re-sorted, thus reducing the temporary space usage of the > tuplesort by some amount with limited overhead for other > non-deduplicating tuplesorts. > > I've not yet spent the time to get this to work though, but I'm fairly > sure it'd use less temporary space than the current approach with the > 2 tuplesorts, and could have lower overall CPU overhead as well > because the number of sortable items gets reduced much earlier in the > process. > Will respond to your later message about this. > --- > >> +++ b/src/include/access/gin_tuple.h >> + typedef struct GinTuple > > I think this needs some more care: currently, each GinTuple is at > least 36 bytes in size on 64-bit systems. By using int instead of Size > (no normal indexable tuple can be larger than MaxAllocSize), and > packing the fields better we can shave off 10 bytes; or 12 bytes if > GinTuple.keylen is further adjusted to (u)int16: a key needs to fit on > a page, so we can probably safely assume that the key size fits in > (u)int16. > Yeah, I guess using int64 is a bit excessive - you're right about that. I'm not sure this is necessarily about "indexable tuples" (GinTuple is not indexed, it's more an intermediate representation). But if we can make it smaller, that probably can't hurt. I don't have a great intuition on how beneficial this might be. For cases with many TIDs per index key, it probably won't matter much. But if there's many keys (so that GinTuples store only very few TIDs), it might make a difference. I'll try to measure the impact on the same "realistic" cases I used for the earlier steps. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 7/5/24 21:45, Matthias van de Meent wrote: > On Wed, 3 Jul 2024 at 20:36, Matthias van de Meent > <boekewurm+postgres@gmail.com> wrote: >> >> On Mon, 24 Jun 2024 at 02:58, Tomas Vondra >> <tomas.vondra@enterprisedb.com> wrote: >>> So I've switched this to use the regular data-type comparisons, with >>> SortSupport etc. There's a bit more cleanup remaining and testing >>> needed, but I'm not aware of any bugs. > > I've hit assertion failures in my testing of the combined patches, in > AssertCheckItemPointers: it assumes it's never called when the buffer > is empty and uninitialized, but that's wrong: we don't initialize the > items array until the first tuple, which will cause the assertion to > fire. By updating the first 2 assertions of AssertCheckItemPointers, I > could get it working. > Yeah, sorry. I think I broke this assert while doing the recent cleanups. The assert used to be called only when doing a sort, and then it certainly can't be empty. But then I moved it to be called from the generic GinTuple assert function, and that broke this assumption. >> --- >>> +++ b/src/backend/utils/sort/tuplesortvariants.c >> >> I was thinking some more about merging tuples inside the tuplesort. I >> realized that this could be implemented by allowing buffering of tuple >> writes in writetup. This would require adding a flush operation at the >> end of mergeonerun to store the final unflushed tuple on the tape, but >> that shouldn't be too expensive. This buffering, when implemented >> through e.g. a GinBuffer in TuplesortPublic->arg, could allow us to >> merge the TID lists of same-valued GIN tuples while they're getting >> stored and re-sorted, thus reducing the temporary space usage of the >> tuplesort by some amount with limited overhead for other >> non-deduplicating tuplesorts. >> >> I've not yet spent the time to get this to work though, but I'm fairly >> sure it'd use less temporary space than the current approach with the >> 2 tuplesorts, and could have lower overall CPU overhead as well >> because the number of sortable items gets reduced much earlier in the >> process. > > I've now spent some time on this. Attached the original patchset, plus > 2 incremental patches, the first of which implement the above design > (patch no. 8). > > Local tests show it's significantly faster: for the below test case > I've seen reindex time reduced from 777455ms to 626217ms, or ~20% > improvement. > > After applying the 'reduce the size of GinTuple' patch, index creation > time is down to 551514ms, or about 29% faster total. This all was > tested with a fresh stock postgres configuration. > > """ > CREATE UNLOGGED TABLE testdata > AS SELECT sha256(i::text::bytea)::text > FROM generate_series(1, 15000000) i; > CREATE INDEX ON testdata USING gin (sha256 gin_trgm_ops); > """ > Those results look really promising. I certainly would not have expected such improvements - 20-30% speedup on top of the already parallel run seems great. I'll do a bit more testing to see how much this helps for the "more realistic" data sets. I can't say I 100% understand how the new stuff in tuplesortvariants.c works, but that's mostly because my knowledge of tuplesort internals is fairly limited (and I managed to survive without that until now). What makes me a bit unsure/uneasy is that this seems to "inject" custom code fairly deep into the tuplesort logic. I'm not quite sure if this is a good idea ... regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sun, 7 Jul 2024, 18:11 Tomas Vondra, <tomas.vondra@enterprisedb.com> wrote: > > On 7/3/24 20:36, Matthias van de Meent wrote: >> On Mon, 24 Jun 2024 at 02:58, Tomas Vondra >> <tomas.vondra@enterprisedb.com> wrote: >>> So I've switched this to use the regular data-type comparisons, with >>> SortSupport etc. There's a bit more cleanup remaining and testing >>> needed, but I'm not aware of any bugs. >> >> A review of patch 0001: >> >> --- >> >>> src/backend/access/gin/gininsert.c | 1449 +++++++++++++++++++- >> >> The nbtree code has `nbtsort.c` for its sort- and (parallel) build >> state handling, which is exclusively used during index creation. As >> the changes here seem to be largely related to bulk insertion, how >> much effort would it be to split the bulk insertion code path into a >> separate file? >> > > Hmmm. I haven't tried doing that, but I guess it's doable. I assume we'd > want to do the move first, because it involves pre-existing code, and > then do the patch on top of that. > > But what would be the benefit of doing that? I'm not sure doing it just > to make it look more like btree code is really worth it. Do you expect > the result to be clearer? It was mostly a consideration of file size and separation of concerns. The sorted build path is quite different from the unsorted build, after all. >> I noticed that new fields in GinBuildState do get to have a >> bs_*-prefix, but none of the other added or previous fields of the >> modified structs in gininsert.c have such prefixes. Could this be >> unified? >> > > Yeah, these are inconsistencies from copying the infrastructure code to > make the parallel builds work, etc. > >>> +/* Magic numbers for parallel state sharing */ >>> +#define PARALLEL_KEY_GIN_SHARED UINT64CONST(0xB000000000000001) >>> ... >> >> These overlap with BRIN's keys; can we make them unique while we're at it? >> > > We could, and I recall we had a similar discussion in the parallel BRIN > thread, right?. But I'm somewhat unsure why would we actually want/need > these keys to be unique. Surely, we don't need to mix those keys in the > single shm segment, right? So it seems more like an aesthetic thing. Or > is there some policy to have unique values for these keys? Uniqueness would be mostly useful for debugging shared memory issues, but indeed, in a correctly working system we wouldn't have to worry about parallel state key type confusion. >> --- >> >>> +++ b/src/include/access/gin_tuple.h >>> + typedef struct GinTuple >> >> I think this needs some more care: currently, each GinTuple is at >> least 36 bytes in size on 64-bit systems. By using int instead of Size >> (no normal indexable tuple can be larger than MaxAllocSize), and >> packing the fields better we can shave off 10 bytes; or 12 bytes if >> GinTuple.keylen is further adjusted to (u)int16: a key needs to fit on >> a page, so we can probably safely assume that the key size fits in >> (u)int16. > > Yeah, I guess using int64 is a bit excessive - you're right about that. > I'm not sure this is necessarily about "indexable tuples" (GinTuple is > not indexed, it's more an intermediate representation). Yes, but even if the GinTuple itself isn't stored on disk in the index, a GinTuple's key *is* part of the the primary GIN btree's keys somewhere down the line, and thus must fit on a page somewhere. That's what I was referring to. > But if we can make it smaller, that probably can't hurt. > > I don't have a great intuition on how beneficial this might be. For > cases with many TIDs per index key, it probably won't matter much. But > if there's many keys (so that GinTuples store only very few TIDs), it > might make a difference. This will indeed matter most when small TID lists are common. I suspect it's not uncommon to find us such a in situation when users have a low maintenance_work_mem (and thus don't have much space to buffer and combine index tuples before they're flushed), or when the generated index keys can't be store in the available memory (such as in my example; it didn't tune m_w_m at all, and the table I tested had ~15GB of data). > I'll try to measure the impact on the same "realistic" cases I used for > the earlier steps. That would be greatly appreciated, thanks! Kind regards, Matthias van de Meent Neon (https://neon.tech)
On Sun, 7 Jul 2024, 18:26 Tomas Vondra, <tomas.vondra@enterprisedb.com> wrote: > > On 7/5/24 21:45, Matthias van de Meent wrote: >> On Wed, 3 Jul 2024 at 20:36, Matthias van de Meent >> <boekewurm+postgres@gmail.com> wrote: >>> >>> On Mon, 24 Jun 2024 at 02:58, Tomas Vondra >>> <tomas.vondra@enterprisedb.com> wrote: >>>> So I've switched this to use the regular data-type comparisons, with >>>> SortSupport etc. There's a bit more cleanup remaining and testing >>>> needed, but I'm not aware of any bugs. >>> --- >>>> +++ b/src/backend/utils/sort/tuplesortvariants.c >>> >>> I was thinking some more about merging tuples inside the tuplesort. I >>> realized that this could be implemented by allowing buffering of tuple >>> writes in writetup. This would require adding a flush operation at the >>> end of mergeonerun to store the final unflushed tuple on the tape, but >>> that shouldn't be too expensive. This buffering, when implemented >>> through e.g. a GinBuffer in TuplesortPublic->arg, could allow us to >>> merge the TID lists of same-valued GIN tuples while they're getting >>> stored and re-sorted, thus reducing the temporary space usage of the >>> tuplesort by some amount with limited overhead for other >>> non-deduplicating tuplesorts. >>> >>> I've not yet spent the time to get this to work though, but I'm fairly >>> sure it'd use less temporary space than the current approach with the >>> 2 tuplesorts, and could have lower overall CPU overhead as well >>> because the number of sortable items gets reduced much earlier in the >>> process. >> >> I've now spent some time on this. Attached the original patchset, plus >> 2 incremental patches, the first of which implement the above design >> (patch no. 8). >> >> Local tests show it's significantly faster: for the below test case >> I've seen reindex time reduced from 777455ms to 626217ms, or ~20% >> improvement. >> >> After applying the 'reduce the size of GinTuple' patch, index creation >> time is down to 551514ms, or about 29% faster total. This all was >> tested with a fresh stock postgres configuration. >> >> """ >> CREATE UNLOGGED TABLE testdata >> AS SELECT sha256(i::text::bytea)::text >> FROM generate_series(1, 15000000) i; >> CREATE INDEX ON testdata USING gin (sha256 gin_trgm_ops); >> """ >> > > Those results look really promising. I certainly would not have expected > such improvements - 20-30% speedup on top of the already parallel run > seems great. I'll do a bit more testing to see how much this helps for > the "more realistic" data sets. > > I can't say I 100% understand how the new stuff in tuplesortvariants.c > works, but that's mostly because my knowledge of tuplesort internals is > fairly limited (and I managed to survive without that until now). > > What makes me a bit unsure/uneasy is that this seems to "inject" custom > code fairly deep into the tuplesort logic. I'm not quite sure if this is > a good idea ... I thought it was still fairly high-level: it adds (what seems to me) a natural extension to the pre-existing "write a tuple to the tape" API, allowing the Tuplesort (TS) implementation to further optimize its ordered tape writes through buffering (and combining) of tuple writes. While it does remove the current 1:1 relation of TS tape writes to tape reads for the GIN case, there is AFAIK no code in TS that relies on that 1:1 relation. As to the GIN TS code itself; yes it's more complicated, mainly because it uses several optimizations to reduce unnecessary allocations and (de)serializations of GinTuples, and I'm aware of even more such optimizations that can be added at some point. As an example: I suspect the use of GinBuffer in writetup_index_gin to be a significant resource drain in my patch because it lacks "freezing" in the tuplesort buffer. When no duplicate key values are encountered, the code is nearly optimal (except for a full tuple copy to get the data into the GinBuffer's memory context), but if more than one GinTuple has the same key in the merge phase we deserialize both tuple's posting lists and merge the two. I suspect that merge to be more expensive than operating on the compressed posting lists of the GinTuples themselves, so that's something I think could be improved. I suspect/guess it could save another 10% in select cases, and will definitely reduce the memory footprint of the buffer. Another thing that can be optimized is the current approach of inserting data into the index: I think it's kind of wasteful to decompress and later re-compress the posting lists once we start storing the tuples on disk. Kind regards, Matthias van de Meent
On 7/8/24 11:45, Matthias van de Meent wrote: > On Sun, 7 Jul 2024, 18:26 Tomas Vondra, <tomas.vondra@enterprisedb.com> wrote: >> >> On 7/5/24 21:45, Matthias van de Meent wrote: >>> On Wed, 3 Jul 2024 at 20:36, Matthias van de Meent >>> <boekewurm+postgres@gmail.com> wrote: >>>> >>>> On Mon, 24 Jun 2024 at 02:58, Tomas Vondra >>>> <tomas.vondra@enterprisedb.com> wrote: >>>>> So I've switched this to use the regular data-type comparisons, with >>>>> SortSupport etc. There's a bit more cleanup remaining and testing >>>>> needed, but I'm not aware of any bugs. >>>> --- >>>>> +++ b/src/backend/utils/sort/tuplesortvariants.c >>>> >>>> I was thinking some more about merging tuples inside the tuplesort. I >>>> realized that this could be implemented by allowing buffering of tuple >>>> writes in writetup. This would require adding a flush operation at the >>>> end of mergeonerun to store the final unflushed tuple on the tape, but >>>> that shouldn't be too expensive. This buffering, when implemented >>>> through e.g. a GinBuffer in TuplesortPublic->arg, could allow us to >>>> merge the TID lists of same-valued GIN tuples while they're getting >>>> stored and re-sorted, thus reducing the temporary space usage of the >>>> tuplesort by some amount with limited overhead for other >>>> non-deduplicating tuplesorts. >>>> >>>> I've not yet spent the time to get this to work though, but I'm fairly >>>> sure it'd use less temporary space than the current approach with the >>>> 2 tuplesorts, and could have lower overall CPU overhead as well >>>> because the number of sortable items gets reduced much earlier in the >>>> process. >>> >>> I've now spent some time on this. Attached the original patchset, plus >>> 2 incremental patches, the first of which implement the above design >>> (patch no. 8). >>> >>> Local tests show it's significantly faster: for the below test case >>> I've seen reindex time reduced from 777455ms to 626217ms, or ~20% >>> improvement. >>> >>> After applying the 'reduce the size of GinTuple' patch, index creation >>> time is down to 551514ms, or about 29% faster total. This all was >>> tested with a fresh stock postgres configuration. >>> >>> """ >>> CREATE UNLOGGED TABLE testdata >>> AS SELECT sha256(i::text::bytea)::text >>> FROM generate_series(1, 15000000) i; >>> CREATE INDEX ON testdata USING gin (sha256 gin_trgm_ops); >>> """ >>> >> >> Those results look really promising. I certainly would not have expected >> such improvements - 20-30% speedup on top of the already parallel run >> seems great. I'll do a bit more testing to see how much this helps for >> the "more realistic" data sets. >> >> I can't say I 100% understand how the new stuff in tuplesortvariants.c >> works, but that's mostly because my knowledge of tuplesort internals is >> fairly limited (and I managed to survive without that until now). >> >> What makes me a bit unsure/uneasy is that this seems to "inject" custom >> code fairly deep into the tuplesort logic. I'm not quite sure if this is >> a good idea ... > > I thought it was still fairly high-level: it adds (what seems to me) a > natural extension to the pre-existing "write a tuple to the tape" API, > allowing the Tuplesort (TS) implementation to further optimize its > ordered tape writes through buffering (and combining) of tuple writes. > While it does remove the current 1:1 relation of TS tape writes to > tape reads for the GIN case, there is AFAIK no code in TS that relies > on that 1:1 relation. > > As to the GIN TS code itself; yes it's more complicated, mainly > because it uses several optimizations to reduce unnecessary > allocations and (de)serializations of GinTuples, and I'm aware of even > more such optimizations that can be added at some point. > > As an example: I suspect the use of GinBuffer in writetup_index_gin to > be a significant resource drain in my patch because it lacks > "freezing" in the tuplesort buffer. When no duplicate key values are > encountered, the code is nearly optimal (except for a full tuple copy > to get the data into the GinBuffer's memory context), but if more than > one GinTuple has the same key in the merge phase we deserialize both > tuple's posting lists and merge the two. I suspect that merge to be > more expensive than operating on the compressed posting lists of the > GinTuples themselves, so that's something I think could be improved. I > suspect/guess it could save another 10% in select cases, and will > definitely reduce the memory footprint of the buffer. > Another thing that can be optimized is the current approach of > inserting data into the index: I think it's kind of wasteful to > decompress and later re-compress the posting lists once we start > storing the tuples on disk. > I need to experiment with this a bit more, to better understand the behavior and pros/cons. But one thing that's not clear to me is why would this be better than simply increasing the amount of memory for the initial BuildAccumulator buffer ... Wouldn't that have pretty much the same effect? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, 8 Jul 2024, 13:38 Tomas Vondra, <tomas.vondra@enterprisedb.com> wrote: > > On 7/8/24 11:45, Matthias van de Meent wrote: > > As to the GIN TS code itself; yes it's more complicated, mainly > > because it uses several optimizations to reduce unnecessary > > allocations and (de)serializations of GinTuples, and I'm aware of even > > more such optimizations that can be added at some point. > > > > As an example: I suspect the use of GinBuffer in writetup_index_gin to > > be a significant resource drain in my patch because it lacks > > "freezing" in the tuplesort buffer. When no duplicate key values are > > encountered, the code is nearly optimal (except for a full tuple copy > > to get the data into the GinBuffer's memory context), but if more than > > one GinTuple has the same key in the merge phase we deserialize both > > tuple's posting lists and merge the two. I suspect that merge to be > > more expensive than operating on the compressed posting lists of the > > GinTuples themselves, so that's something I think could be improved. I > > suspect/guess it could save another 10% in select cases, and will > > definitely reduce the memory footprint of the buffer. > > Another thing that can be optimized is the current approach of > > inserting data into the index: I think it's kind of wasteful to > > decompress and later re-compress the posting lists once we start > > storing the tuples on disk. > > > > I need to experiment with this a bit more, to better understand the > behavior and pros/cons. But one thing that's not clear to me is why > would this be better than simply increasing the amount of memory for the > initial BuildAccumulator buffer ... > > Wouldn't that have pretty much the same effect? I don't think so: The BuildAccumulator buffer will probably never be guaranteed to have space for all index entries, though it does use memory more efficiently than Tuplesort. Therefore, it will likely have to flush keys multiple times into sorted runs, with likely duplicate keys existing in the tuplesort. My patch 0008 targets the reduction of IO and CPU once BuildAccumulator has exceeded its memory limits. It reduces the IO and computational requirement of Tuplesort's sorted-run merging by merging the tuples in those sorted runs in that merge process, reducing the number of tuples, bytes stored, and number of compares required in later operations. It enables some BuildAccumulator-like behaviour inside the tuplesort, without needing to assign huge amounts of memory to the BuildAccumulator by allowing efficient spilling to disk of the incomplete index data. And, during merging, it can work with O(n_merge_tapes * tupsz) of memory, rather than O(n_distinct_keys * tupsz). This doesn't make BuildAccumulator totally useless, but it does reduce the relative impact of assigning more memory. One significant difference between the modified Tuplesort and BuildAccumulator is that the modified Tuplesort only merges the entries once they're getting written, i.e. flushed from the in-memory structure; while BuildAccumulator merges entries as they're being added to the in-memory structure. Note that this difference causes BuildAccumulator to use memory more efficiently during in-memory workloads (it doesn't duplicate keys in memory), but as BuildAccumulator doesn't have spilling it doesn't handle full indexes' worth of data (it does duplciate keys on disk). I hope this clarifies things a bit. I'd be thrilled if we'd be able to put BuildAccumulator-like behaviour into the in-memory portion of Tuplesort, but that'd require a significantly deeper understanding of the Tuplesort internals than what I currently have, especially in the area of its memory management. Kind regards Matthias van de Meent Neon (https://neon.tech)
Andy Fan <zhihuifan1213@163.com> writes:
I just realize all my replies is replied to sender only recently,
probably because I upgraded the email cient and the short-cut changed
sliently, resent the lastest one only....
>>> Suppose RBTree's output is:
>>>
>>> batch-1 at RBTree:
>>> 1 [tid1, tid8, tid100]
>>> 2 [tid1, tid9, tid800]
>>> ...
>>> 78 [tid23, tid99, tid800]
>>>
>>> batch-2 at RBTree
>>> 1 [tid1001, tid1203, tid1991]
>>> ...
>>> ...
>>> 97 [tid1023, tid1099, tid1800]
>>>
>>> Since all the tuples in each batch (1, 2, .. 78) are sorted already, we
>>> can just flush them into tuplesort as a 'run' *without any sorts*,
>>> however within this way, it is possible to produce more 'runs' than what
>>> you did in your patch.
>>>
>>
>> Oh! Now I think I understand what you were proposing - you're saying
>> that when dumping the RBTree to the tuplesort, we could tell the
>> tuplesort this batch of tuples is already sorted, and tuplesort might
>> skip some of the work when doing the sort later.
>>
>> I guess that's true, and maybe it'd be useful elsewhere, I still think
>> this could be left as a future improvement. Allowing it seems far from
>> trivial, and it's not quite clear if it'd be a win (it might interfere
>> with the existing sort code in unexpected ways).
>
> Yes, and I agree that can be done later and I'm thinking Matthias's
> proposal is more promising now.
>
>>> new way: the No. of batch depends on size of RBTree's batch size.
>>> existing way: the No. of batch depends on size of work_mem in tuplesort.
>>> Usually the new way would cause more no. of runs which is harmful for
>>> mergeruns. so I can't say it is an improve of not and not include it in
>>> my previous patch.
>>>
>>> however case 1 sounds a good canidiates for this method.
>>>
>>> Tuples from state->bs_worker_state after the perform_sort and ctid
>>> merge:
>>>
>>> 1 [tid1, tid8, tid100, tid1001, tid1203, tid1991]
>>> 2 [tid1, tid9, tid800]
>>> 78 [tid23, tid99, tid800]
>>> 97 [tid1023, tid1099, tid1800]
>>>
>>> then when we move tuples to bs_sort_state, a). we don't need to sort at
>>> all. b). we can merge all of them into 1 run which is good for mergerun
>>> on leader as well. That's the thing I did in the previous patch.
>>>
>>
>> I'm sorry, I don't understand what you're proposing. Could you maybe
>> elaborate in more detail?
>
> After we called "tuplesort_performsort(state->bs_worker_sort);" in
> _gin_process_worker_data, all the tuples in bs_worker_sort are sorted
> already, and in the same function _gin_process_worker_data, we have
> code:
>
> while ((tup = tuplesort_getgintuple(worker_sort, &tuplen, true)) != NULL)
> {
>
> ....(1)
>
> tuplesort_putgintuple(state->bs_sortstate, ntup, ntuplen);
>
> }
>
> and later we called 'tuplesort_performsort(state->bs_sortstate);'. Even
> we have some CTID merges activity in '....(1)', the tuples are still
> ordered, so the sort (in both tuplesort_putgintuple and
> 'tuplesort_performsort) are not necessary, what's more, in the each of
> 'flush-memory-to-disk' in tuplesort, it create a 'sorted-run', and in
> this case, acutally we only need 1 run only since all the input tuples
> in the worker is sorted. The reduction of 'sort-runs' in worker will be
> helpful to leader's final mergeruns. the 'sorted-run' benefit doesn't
> exist for the case-1 (RBTree -> worker_state).
>
> If Matthias's proposal is adopted, my optimization will not be useful
> anymore and Matthias's porposal looks like a more natural and effecient
> way.
--
Best Regards
Andy Fan
Hi, I got to do the detailed benchmarking on the latest version of the patch series, so here's the results. My goal was to better understand the impact of each patch individually - especially the two parts introduced by Matthias, but not only - so I ran the test on a build with each fo the 0001-0009 patches. This is the same test I did at the very beginning, but the basic details are that I have a 22GB table with archives of our mailing lists (1.6M messages, roughly), and I build a couple different GIN indexes on that: create index trgm on messages using gin (msg_body gin_trgm_ops); create index tsvector on messages using gin (msg_body_tsvector); create index jsonb on messages using gin (msg_headers); create index jsonb_hash on messages using gin (msg_headers jsonb_path_ops); The indexes are 700MB-3GB, so not huge, but also not tiny. I did the test with a varying number of parallel workers for each patch, measuring the execution time and a couple more metrics (using pg_stat_statements). See the attached scripts for details, and also conf/results from the two machines I use for these tests. Attached is also a PDF with a summary of the tests - there are four sections with results in total, two for each machine with different work_mem values (more on this later). For each configuration, there are tables/charts for three metrics: - total CREATE INDEX duration - relative CREATE INDEX duration (relative to serial build) - amount of temporary files written Hopefully it's easy to understand/interpret, but feel free to ask. There's also CSVs with raw results, in case you choose to do your own analysis (there's more metrics than presented here). While doing these tests, I realized there's a bug in how the patches handle collations - it simply grabbed the value for the indexed column, but if that's missing (e.g. for tsvector), it fell over. Instead the patch needs to use the default collation, so that's fixed in 0001. The other thing I realized while working on this is that it's probably wrong to tie parallel callback to work_mem - both conceptually, but also for performance reasons. I did the first run with the default work_mem (4MB), and that showed some serious regressions with the 0002 patch (where it took ~3.5x longer than serial build). It seemed to be due to a lot of merges of small TID lists, so I tried re-running the tests with work_mem=32MB, and the regression pretty much disappeared. Also, with 4MB there were almost no benefits of parallelism on the smaller indexes (jsonb and jsonb_hash) - that's probably not unexpected, but 32MB did improve that a little bit (still not great, though). In practice this would not be a huge issue, because the later patches make the regression go away - so unless we commit only the first couple patches, the users would not be affected by this. But it's annoying, and more importantly it's a bit bogus to use work_mem here - why should that be appropriate? It was more a temporary hack because I didn't have a better idea, and the comment in ginBuildCallbackParallel() questions this too, after all. My plan is to derive this from maintenance_work_mem, or rather the fraction we "allocate" for each worker. The planner logic caps the number of workers to maintenance_work_mem / 32MB, which means each worker has >=32MB of maintenance_work_mem at it's disposal. The worker needs to do the BuildAccumulator thing, and also the tuplesort. So it seems reasonable to use 1/2 of the budget (>=16MB) for each of those. Which seems good enough, IMHO. It's significantly more than 4MB, and the 32MB I used for the second round was rather arbitrary. So for further discussion, let's focus on results in the two sections for 32MB ... And let's talk about the improvement by Matthias, namely: * 0008 Use a single GIN tuplesort * 0009 Reduce the size of GinTuple by 12 bytes I haven't really seen any impact on duration - it seems more or less within noise. Maybe it would be different on machines with less RAM, but on my two systems it didn't really make a difference. It did significantly reduce the amount of temporary data written, by ~40% or so. This is pretty nicely visible on the "trgm" case, which generates the most temp files of the four indexes. An example from the i5/32MB section looks like this: label 0000 0001 0002 0003 0004 0005 0006 0007 0008 0009 0010 ------------------------------------------------------------------------ trgm / 3 0 2635 3690 3715 1177 1177 1179 1179 696 682 1016 So we start with patches producing 2.6GB - 3.7GB of temp files. Then the compression of TID lists cuts that down to ~1.2GB, and the 0008 patch cuts that to just 700MB. That's pretty nice, even if it doesn't speed things up. The 0009 (GinTuple reduction) improves that a little bit, but the difference is smaller. I'm still a bit unsure about the tuplesort changes, but producing less temporary files seems like a good thing. Now, what's the 0010 patch about? For some indexes (e.g. trgm), the parallel builds help a lot, because they produce a lot of temporary data and the parallel sort is a substantial part of the work. But for other indexes (especially the "smaller" indexes on jsonb headers), it's not that great. For example for "jsonb", having 3 workers shaves off only ~25% of the time, not 75%. Clearly, this happens because a lot of time is spent outside the sort, actually inserting data into the index. So I was wondering if we might parallelize that too, and how much time would it save - 0010 is an experimental patch doing that. It splits the processing into 3 phases: 1. workers feeding data into tuplesort 2. leader finishes sort and "repartitions" the data 3. workers inserting their partition into index The patch is far from perfect (more a PoC) - it implements these phases by introducing a barrier to coordinate the processes. Workers feed the data into the tuplesort as now, but instead of terminating they wait on a barrier. The leader reads data from the tuplesort, and partitions them evenly into the a SharedFileSet with one file per worker. And then wakes up the workers through the barrier again, and they do the inserts. This does help a little bit, reducing the duration by ~15-25%. I wonder if this might be improved by partitioning the data differently - not by shuffling everything from the tuplesort into fileset (it increases the amount of temporary data in the charts). And also by by distributing the data differently - right now it's a bit of a round robin, because it wasn't clear we know how many entries are there. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
- gin-parallel-builds.pdf
- i5.tgz
- xeon.tgz
- v20240712-0001-Allow-parallel-create-for-GIN-indexes.patch
- v20240712-0002-Use-mergesort-in-the-leader-process.patch
- v20240712-0003-Remove-the-explicit-pg_qsort-in-workers.patch
- v20240712-0004-Compress-TID-lists-before-writing-tuples-t.patch
- v20240712-0005-Collect-and-print-compression-stats.patch
- v20240712-0006-Enforce-memory-limit-when-combining-tuples.patch
- v20240712-0007-Detect-wrap-around-in-parallel-callback.patch
- v20240712-0008-Use-a-single-GIN-tuplesort.patch
- v20240712-0009-Reduce-the-size-of-GinTuple-by-12-bytes.patch
- v20240712-0010-WIP-parallel-inserts-into-GIN-index.patch
On Tue, 9 Jul 2024 at 03:18, Andy Fan <zhihuifan1213@163.com> wrote: >> and later we called 'tuplesort_performsort(state->bs_sortstate);'. Even >> we have some CTID merges activity in '....(1)', the tuples are still >> ordered, so the sort (in both tuplesort_putgintuple and >> 'tuplesort_performsort) are not necessary, what's more, in the each of >> 'flush-memory-to-disk' in tuplesort, it create a 'sorted-run', and in >> this case, acutally we only need 1 run only since all the input tuples >> in the worker is sorted. The reduction of 'sort-runs' in worker will be >> helpful to leader's final mergeruns. the 'sorted-run' benefit doesn't >> exist for the case-1 (RBTree -> worker_state). >> >> If Matthias's proposal is adopted, my optimization will not be useful >> anymore and Matthias's porposal looks like a more natural and effecient >> way. I think they might be complementary. I don't think it's reasonable to expect GIN's BuildAccumulator to buffer all the index tuples at the same time (as I mentioned upthread: we are or should be limited by work memory), but the BuildAccumulator will do a much better job at combining tuples than the in-memory sort + merge-write done by Tuplesort (because BA will use (much?) less memory for the same number of stored values). So, the idea of making BuildAccumulator responsible for providing the initial sorted runs does resonate with me, and can also be worth pursuing. I think it would indeed save time otherwise spent comparing if tuples can be merged before they're first spilled to disk, when we already have knowledge about which tuples are a sorted run. Afterwards, only the phases where we merge sorted runs from disk would require my buffered write approach that merges Gin tuples. Kind regards, Matthias van de Meent Neon (https://neon.tech)
Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
> Hi,
>
> I got to do the detailed benchmarking on the latest version of the patch
> series, so here's the results. My goal was to better understand the
> impact of each patch individually - especially the two parts introduced
> by Matthias, but not only - so I ran the test on a build with each fo
> the 0001-0009 patches.
>
> This is the same test I did at the very beginning, but the basic details
> are that I have a 22GB table with archives of our mailing lists (1.6M
> messages, roughly), and I build a couple different GIN indexes on
> that:
..
>
Very impresive testing!
> And let's talk about the improvement by Matthias, namely:
>
> * 0008 Use a single GIN tuplesort
> * 0009 Reduce the size of GinTuple by 12 bytes
>
> I haven't really seen any impact on duration - it seems more or less
> within noise. Maybe it would be different on machines with less RAM, but
> on my two systems it didn't really make a difference.
>
> It did significantly reduce the amount of temporary data written, by
> ~40% or so. This is pretty nicely visible on the "trgm" case, which
> generates the most temp files of the four indexes. An example from the
> i5/32MB section looks like this:
>
> label 0000 0001 0002 0003 0004 0005 0006 0007 0008 0009 0010
> ------------------------------------------------------------------------
> trgm / 3 0 2635 3690 3715 1177 1177 1179 1179 696 682
> 1016
After seeing the above data, I want to know where the time is spent and
why the ~40% IO doesn't make a measurable duration improvement. then I
did the following test.
create table gin_t (a int[]);
insert into gin_t select * from rand_array(30000000, 0, 100, 0, 50); [1]
select pg_prewarm('gin_t');
postgres=# create index on gin_t using gin(a);
INFO: pid: 145078, stage 1 took 44476 ms
INFO: pid: 145177, stage 1 took 44474 ms
INFO: pid: 145078, stage 2 took 2662 ms
INFO: pid: 145177, stage 2 took 2611 ms
INFO: pid: 145177, stage 3 took 240 ms
INFO: pid: 145078, stage 3 took 239 ms
CREATE INDEX
Time: 79472.135 ms (01:19.472)
Then we can see stage 1 take 56% execution time. stage 2 + stage 3 take
3% execution time. and the leader's work takes the rest 41% execution
time. I think that's why we didn't see much performance improvement of
0008 since it improves the "stage 2 and stage 3".
==== Here is my definition for stage 1/2/3.
stage 1:
reltuples = table_index_build_scan(heap, index, indexInfo, true, progress,
ginBuildCallbackParallel, state, scan);
/* write remaining accumulated entries */
ginFlushBuildState(state, index);
stage 2:
_gin_process_worker_data(state, state->bs_worker_sort)
stage 3:
tuplesort_performsort(state->bs_sortstate);
But 0008 still does many good stuff:
1. Reduce the IO usage, this would be more useful on some heavily IO
workload.
2. Simplify the building logic by removing one stage.
3. Add the 'buffer-writetup' to tuplesort.c, I don't have other user
case for now, but it looks like a reasonable design.
I think the current blocker is if it is safe to hack the tuplesort.c.
With my current knowledge, It looks good to me, but it would be better
open a dedicated thread to discuss this specially, the review would not
take a long time if a people who is experienced on this area would take
a look.
> Now, what's the 0010 patch about?
>
> For some indexes (e.g. trgm), the parallel builds help a lot, because
> they produce a lot of temporary data and the parallel sort is a
> substantial part of the work. But for other indexes (especially the
> "smaller" indexes on jsonb headers), it's not that great. For example
> for "jsonb", having 3 workers shaves off only ~25% of the time, not 75%.
>
> Clearly, this happens because a lot of time is spent outside the sort,
> actually inserting data into the index.
You can always foucs on the most important part which inpires me a lot,
even with my simple testing, the "inserting data into index" stage take
40% time.
> So I was wondering if we might
> parallelize that too, and how much time would it save - 0010 is an
> experimental patch doing that. It splits the processing into 3 phases:
>
> 1. workers feeding data into tuplesort
> 2. leader finishes sort and "repartitions" the data
> 3. workers inserting their partition into index
>
> The patch is far from perfect (more a PoC) ..
>
> This does help a little bit, reducing the duration by ~15-25%. I wonder
> if this might be improved by partitioning the data differently - not by
> shuffling everything from the tuplesort into fileset (it increases the
> amount of temporary data in the charts). And also by by distributing the
> data differently - right now it's a bit of a round robin, because it
> wasn't clear we know how many entries are there.
Due to the complexity of the existing code, I would like to foucs on
existing patch first. So I vote for this optimization as a dedeciated
patch.
>>> and later we called 'tuplesort_performsort(state->bs_sortstate);'. Even
>>> we have some CTID merges activity in '....(1)', the tuples are still
>>> ordered, so the sort (in both tuplesort_putgintuple and
>>> 'tuplesort_performsort) are not necessary,
>>> ..
>>> If Matthias's proposal is adopted, my optimization will not be useful
>>> anymore and Matthias's porposal looks like a more natural and effecient
>>> way.
>
> I think they might be complementary. I don't think it's reasonable to
> expect GIN's BuildAccumulator to buffer all the index tuples at the
> same time (as I mentioned upthread: we are or should be limited by
> work memory), but the BuildAccumulator will do a much better job at
> combining tuples than the in-memory sort + merge-write done by
> Tuplesort (because BA will use (much?) less memory for the same number
> of stored values).
Thank you Matthias for valuing my point! and thanks for highlighting the
benefit that BuildAccumulator can do a better job for sorting in memory
(I think it is mainly because BuildAccumulator can do run-time merge
when accept more tuples). but I still not willing to go further at this
direction. Reasons are: a). It probably can't make a big difference at
the final result. b). The best implementation of this idea would be
allowing the user of tuplesort.c to insert the pre-sort tuples into tape
directly rather than inserting them into tuplesort's memory and dump
them into tape without a sort. However I can't define a clean API for
the former case. c). create-index is a maintenance work, improving it by
30% would be good, but if we just improve it by <3, it looks not very
charming in practice.
So my option is if we can have agreement on 0008, then we can final
review/test on the existing code (including 0009), and leave further
improvement as a dedicated patch.
What do you think?
[1] https://www.postgresql.org/message-id/87le0iqrsu.fsf%40163.com
--
Best Regards
Andy Fan
On 8/27/24 12:14, Andy Fan wrote:
> Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
>
>> Hi,
>>
>> I got to do the detailed benchmarking on the latest version of the patch
>> series, so here's the results. My goal was to better understand the
>> impact of each patch individually - especially the two parts introduced
>> by Matthias, but not only - so I ran the test on a build with each fo
>> the 0001-0009 patches.
>>
>> This is the same test I did at the very beginning, but the basic details
>> are that I have a 22GB table with archives of our mailing lists (1.6M
>> messages, roughly), and I build a couple different GIN indexes on
>> that:
> ..
>>
>
> Very impresive testing!
>
>> And let's talk about the improvement by Matthias, namely:
>>
>> * 0008 Use a single GIN tuplesort
>> * 0009 Reduce the size of GinTuple by 12 bytes
>>
>> I haven't really seen any impact on duration - it seems more or less
>> within noise. Maybe it would be different on machines with less RAM, but
>> on my two systems it didn't really make a difference.
>>
>> It did significantly reduce the amount of temporary data written, by
>> ~40% or so. This is pretty nicely visible on the "trgm" case, which
>> generates the most temp files of the four indexes. An example from the
>> i5/32MB section looks like this:
>>
>> label 0000 0001 0002 0003 0004 0005 0006 0007 0008 0009 0010
>> ------------------------------------------------------------------------
>> trgm / 3 0 2635 3690 3715 1177 1177 1179 1179 696 682
>> 1016
>
> After seeing the above data, I want to know where the time is spent and
> why the ~40% IO doesn't make a measurable duration improvement. then I
> did the following test.
>
> create table gin_t (a int[]);
> insert into gin_t select * from rand_array(30000000, 0, 100, 0, 50); [1]
> select pg_prewarm('gin_t');
>
> postgres=# create index on gin_t using gin(a);
> INFO: pid: 145078, stage 1 took 44476 ms
> INFO: pid: 145177, stage 1 took 44474 ms
> INFO: pid: 145078, stage 2 took 2662 ms
> INFO: pid: 145177, stage 2 took 2611 ms
> INFO: pid: 145177, stage 3 took 240 ms
> INFO: pid: 145078, stage 3 took 239 ms
>
> CREATE INDEX
> Time: 79472.135 ms (01:19.472)
>
> Then we can see stage 1 take 56% execution time. stage 2 + stage 3 take
> 3% execution time. and the leader's work takes the rest 41% execution
> time. I think that's why we didn't see much performance improvement of
> 0008 since it improves the "stage 2 and stage 3".
>
Yes, that makes sense. It's so small fraction of the computation that it
can't translate to a meaningful speed.
> ==== Here is my definition for stage 1/2/3.
> stage 1:
> reltuples = table_index_build_scan(heap, index, indexInfo, true, progress,
> ginBuildCallbackParallel, state, scan);
>
> /* write remaining accumulated entries */
> ginFlushBuildState(state, index);
>
> stage 2:
> _gin_process_worker_data(state, state->bs_worker_sort)
>
> stage 3:
> tuplesort_performsort(state->bs_sortstate);
>
>
> But 0008 still does many good stuff:
> 1. Reduce the IO usage, this would be more useful on some heavily IO
> workload.
> 2. Simplify the building logic by removing one stage.
> 3. Add the 'buffer-writetup' to tuplesort.c, I don't have other user
> case for now, but it looks like a reasonable design.
>
> I think the current blocker is if it is safe to hack the tuplesort.c.
> With my current knowledge, It looks good to me, but it would be better
> open a dedicated thread to discuss this specially, the review would not
> take a long time if a people who is experienced on this area would take
> a look.
>
I agree. I expressed the same impression earlier in this thread, IIRC.
>> Now, what's the 0010 patch about?
>>
>> For some indexes (e.g. trgm), the parallel builds help a lot, because
>> they produce a lot of temporary data and the parallel sort is a
>> substantial part of the work. But for other indexes (especially the
>> "smaller" indexes on jsonb headers), it's not that great. For example
>> for "jsonb", having 3 workers shaves off only ~25% of the time, not 75%.
>>
>> Clearly, this happens because a lot of time is spent outside the sort,
>> actually inserting data into the index.
>
> You can always foucs on the most important part which inpires me a lot,
> even with my simple testing, the "inserting data into index" stage take
> 40% time.
>>> So I was wondering if we might
>> parallelize that too, and how much time would it save - 0010 is an
>> experimental patch doing that. It splits the processing into 3 phases:
>>
>> 1. workers feeding data into tuplesort
>> 2. leader finishes sort and "repartitions" the data
>> 3. workers inserting their partition into index
>>
>> The patch is far from perfect (more a PoC) ..
>>
>> This does help a little bit, reducing the duration by ~15-25%. I wonder
>> if this might be improved by partitioning the data differently - not by
>> shuffling everything from the tuplesort into fileset (it increases the
>> amount of temporary data in the charts). And also by by distributing the
>> data differently - right now it's a bit of a round robin, because it
>> wasn't clear we know how many entries are there.
>
> Due to the complexity of the existing code, I would like to foucs on
> existing patch first. So I vote for this optimization as a dedeciated
> patch.
>
I agree. Even if we decide to do these parallel inserts, it relies on
doing the parallel sort first. So it makes sense to leave that for
later, as an additional improvement.
>>>> and later we called 'tuplesort_performsort(state->bs_sortstate);'. Even
>>>> we have some CTID merges activity in '....(1)', the tuples are still
>>>> ordered, so the sort (in both tuplesort_putgintuple and
>>>> 'tuplesort_performsort) are not necessary,
>>>> ..
>>>> If Matthias's proposal is adopted, my optimization will not be useful
>>>> anymore and Matthias's porposal looks like a more natural and effecient
>>>> way.
>>
>> I think they might be complementary. I don't think it's reasonable to
>> expect GIN's BuildAccumulator to buffer all the index tuples at the
>> same time (as I mentioned upthread: we are or should be limited by
>> work memory), but the BuildAccumulator will do a much better job at
>> combining tuples than the in-memory sort + merge-write done by
>> Tuplesort (because BA will use (much?) less memory for the same number
>> of stored values).
>
> Thank you Matthias for valuing my point! and thanks for highlighting the
> benefit that BuildAccumulator can do a better job for sorting in memory
> (I think it is mainly because BuildAccumulator can do run-time merge
> when accept more tuples). but I still not willing to go further at this
> direction. Reasons are: a). It probably can't make a big difference at
> the final result. b). The best implementation of this idea would be
> allowing the user of tuplesort.c to insert the pre-sort tuples into tape
> directly rather than inserting them into tuplesort's memory and dump
> them into tape without a sort. However I can't define a clean API for
> the former case. c). create-index is a maintenance work, improving it by
> 30% would be good, but if we just improve it by <3, it looks not very
> charming in practice.
>
> So my option is if we can have agreement on 0008, then we can final
> review/test on the existing code (including 0009), and leave further
> improvement as a dedicated patch.
>
> What do you think?
>
Yeah. I think we have agreement on 0001-0007. I'm a bit torn about 0008,
I have not expected changing tuplesort like this when I started working
on the patch, but I can't deny it's a massive speedup for some cases
(where the patch doesn't help otherwise). But then in other cases it
doesn't help at all, and 0010 helps. I wonder if maybe there's a good
way to "flip" between those two approaches, by some heuristics.
regards
--
Tomas Vondra
On Tue, 27 Aug 2024 at 12:15, Andy Fan <zhihuifan1213@163.com> wrote: > > Tomas Vondra <tomas.vondra@enterprisedb.com> writes: > > And let's talk about the improvement by Matthias, namely: > > > > * 0008 Use a single GIN tuplesort > > * 0009 Reduce the size of GinTuple by 12 bytes > > > > I haven't really seen any impact on duration - it seems more or less > > within noise. Maybe it would be different on machines with less RAM, but > > on my two systems it didn't really make a difference. > > > > It did significantly reduce the amount of temporary data written, by > > ~40% or so. This is pretty nicely visible on the "trgm" case, which > > generates the most temp files of the four indexes. An example from the > > i5/32MB section looks like this: > > > > label 0000 0001 0002 0003 0004 0005 0006 0007 0008 0009 0010 > > ------------------------------------------------------------------------ > > trgm / 3 0 2635 3690 3715 1177 1177 1179 1179 696 682 > > 1016 > > After seeing the above data, I want to know where the time is spent and > why the ~40% IO doesn't make a measurable duration improvement. then I > did the following test. [...] > ==== Here is my definition for stage 1/2/3. > stage 1: > reltuples = table_index_build_scan(heap, index, indexInfo, true, progress, > ginBuildCallbackParallel, state, scan); > > /* write remaining accumulated entries */ > ginFlushBuildState(state, index); > > stage 2: > _gin_process_worker_data(state, state->bs_worker_sort) > > stage 3: > tuplesort_performsort(state->bs_sortstate); Note that tuplesort does most of its sort and IO work while receiving tuples, which in this case would be during table_index_build_scan. tuplesort_performsort usually only needs to flush the last elements of a sort that it still has in memory, which is thus generally a cheap operation bound by maintenance work memory, and definitely not representative of the total cost of sorting data. In certain rare cases it may take a longer time as it may have to merge sorted runs, but those cases are quite rare in my experience. > But 0008 still does many good stuff: > 1. Reduce the IO usage, this would be more useful on some heavily IO > workload. > 2. Simplify the building logic by removing one stage. > 3. Add the 'buffer-writetup' to tuplesort.c, I don't have other user > case for now, but it looks like a reasonable design. I'd imagine nbtree would like to use this too, for applying some deduplication in the sort stage. The IO benefits are quite likely to be worth it; a minimum space saving of 25% on duplicated key values in tuple sorts sounds real great. And it doesn't even have to merge all duplicates: even if you only merge 10 tuples at a time, the space saving on those duplicates would be at least 47% on 64-bit systems. > I think the current blocker is if it is safe to hack the tuplesort.c. > With my current knowledge, It looks good to me, but it would be better > open a dedicated thread to discuss this specially, the review would not > take a long time if a people who is experienced on this area would take > a look. I could adapt the patch for nbtree use, to see if anyone's willing to review that? > > Now, what's the 0010 patch about? > > > > For some indexes (e.g. trgm), the parallel builds help a lot, because > > they produce a lot of temporary data and the parallel sort is a > > substantial part of the work. But for other indexes (especially the > > "smaller" indexes on jsonb headers), it's not that great. For example > > for "jsonb", having 3 workers shaves off only ~25% of the time, not 75%. > > > > Clearly, this happens because a lot of time is spent outside the sort, > > actually inserting data into the index. > > You can always foucs on the most important part which inpires me a lot, > even with my simple testing, the "inserting data into index" stage take > 40% time. nbtree does sorted insertions into the tree, constructing leaf pages one at a time and adding separator keys in the page above when the leaf page was filled, thus removing the need to descend the btree. I imagine we can save some performance by mirroring that in GIN too, with as additional bonus that we'd be free to start logging completed pages before we're done with the full index, reducing max WAL throughput in GIN index creation. > > I think they might be complementary. I don't think it's reasonable to > > expect GIN's BuildAccumulator to buffer all the index tuples at the > > same time (as I mentioned upthread: we are or should be limited by > > work memory), but the BuildAccumulator will do a much better job at > > combining tuples than the in-memory sort + merge-write done by > > Tuplesort (because BA will use (much?) less memory for the same number > > of stored values). > > Thank you Matthias for valuing my point! and thanks for highlighting the > benefit that BuildAccumulator can do a better job for sorting in memory > (I think it is mainly because BuildAccumulator can do run-time merge > when accept more tuples). but I still not willing to go further at this > direction. Reasons are: a). It probably can't make a big difference at > the final result. b). The best implementation of this idea would be > allowing the user of tuplesort.c to insert the pre-sort tuples into tape > directly rather than inserting them into tuplesort's memory and dump > them into tape without a sort. You'd still need to keep track of sorted runs on those tapes, which is what tuplesort.c does for us. > However I can't define a clean API for > the former case. I imagine a pair of tuplesort_beginsortedrun(); tuplesort_endsortedrun() -functions to help this, but I'm not 100% sure if we'd want to expose Tuplesort to non-PG sorting algorithms, as it would be one easy way to create incorrect results if the sort used in tuplesort isn't exactly equivalent to the sort used by the provider of the tuples. > c). create-index is a maintenance work, improving it by > 30% would be good, but if we just improve it by <3, it looks not very > charming in practice. I think improving 3% on reindex operations can be well worth the effort. Also, do note that the current patch does (still) not correctly handle [maintenance_]work_mem: Every backend's BuildAccumulator uses up to work_mem of memory here, while the launched tuplesorts use an additional maintenance_work_mem of memory, for a total of (workers + 1) * work_mem + m_w_m of memory usage. The available memory should instead be allocated between tuplesort and BuildAccumulator, but can probably mostly be allocated to just BuildAccumulator if we can dump the data into the tuplesort directly, as it'd reduce the overall number of operations and memory allocations for the tuplesort. I think that once we correctly account for memory allocations (and an improved write path) we'll be able to see a meaningfully larger performance improvement. > So my option is if we can have agreement on 0008, then we can final > review/test on the existing code (including 0009), and leave further > improvement as a dedicated patch. As mentioned above, I think I could update the patch for a btree implementation that also has immediate benefits, if so desired? Kind regards, Matthias van de Meent Neon (https://neon.tech)
Matthias van de Meent <boekewurm+postgres@gmail.com> writes: > tuplesort_performsort usually only needs to flush the last elements of > ... In certain rare > cases it may take a longer time as it may have to merge sorted runs, > but those cases are quite rare in my experience. OK, I am expecting such cases are not rare, Suppose we have hundreds of GB heap tuple, and have the 64MB or 1GB maintenance_work_mem setup, it probably hit this sistuation. I'm not mean at which experience is the fact, but I am just to highlights the gap in our minds. and thanks for sharing this, I can pay more attention in this direction in my future work. To be clearer, my setup hit the 'mergeruns' case. > >> But 0008 still does many good stuff: >> 1. Reduce the IO usage, this would be more useful on some heavily IO >> workload. >> 2. Simplify the building logic by removing one stage. >> 3. Add the 'buffer-writetup' to tuplesort.c, I don't have other user >> case for now, but it looks like a reasonable design. > > I'd imagine nbtree would like to use this too, for applying some > deduplication in the sort stage. The current ntbtree do the deduplication during insert into the nbtree IIUC, in your new strategy, we can move it the "sort" stage, which looks good to me [to confirm my understanding]. > The IO benefits are quite likely to > be worth it; a minimum space saving of 25% on duplicated key values in > tuple sorts sounds real great. Just be clearer on the knowledge, the IO benefits can be only gained when the tuplesort's memory can't hold all the tuples, and in such case, tuplesort_performsort would run the 'mergeruns', or else we can't get any benefit? > >> I think the current blocker is if it is safe to hack the tuplesort.c. >> With my current knowledge, It looks good to me, but it would be better >> open a dedicated thread to discuss this specially, the review would not >> take a long time if a people who is experienced on this area would take >> a look. > > I could adapt the patch for nbtree use, to see if anyone's willing to > review that? I'm interested with it and can do some review & testing. But the keypoint would be we need some authorities are willing to review it, to make it happen to a bigger extent, a dedicated thread would be helpful. >> > Now, what's the 0010 patch about? >> > >> > For some indexes (e.g. trgm), the parallel builds help a lot, because >> > they produce a lot of temporary data and the parallel sort is a >> > substantial part of the work. But for other indexes (especially the >> > "smaller" indexes on jsonb headers), it's not that great. For example >> > for "jsonb", having 3 workers shaves off only ~25% of the time, not 75%. >> > >> > Clearly, this happens because a lot of time is spent outside the sort, >> > actually inserting data into the index. >> >> You can always foucs on the most important part which inpires me a lot, >> even with my simple testing, the "inserting data into index" stage take >> 40% time. > > nbtree does sorted insertions into the tree, constructing leaf pages > one at a time and adding separator keys in the page above when the > leaf page was filled, thus removing the need to descend the btree. I > imagine we can save some performance by mirroring that in GIN too, > with as additional bonus that we'd be free to start logging completed > pages before we're done with the full index, reducing max WAL > throughput in GIN index creation. I agree this is a promising direction as well. >> > I think they might be complementary. I don't think it's reasonable to >> > expect GIN's BuildAccumulator to buffer all the index tuples at the >> > same time (as I mentioned upthread: we are or should be limited by >> > work memory), but the BuildAccumulator will do a much better job at >> > combining tuples than the in-memory sort + merge-write done by >> > Tuplesort (because BA will use (much?) less memory for the same number >> > of stored values). >> >> Thank you Matthias for valuing my point! and thanks for highlighting the >> benefit that BuildAccumulator can do a better job for sorting in memory >> (I think it is mainly because BuildAccumulator can do run-time merge >> when accept more tuples). but I still not willing to go further at this >> direction. Reasons are: a). It probably can't make a big difference at >> the final result. b). The best implementation of this idea would be >> allowing the user of tuplesort.c to insert the pre-sort tuples into tape >> directly rather than inserting them into tuplesort's memory and dump >> them into tape without a sort. > > You'd still need to keep track of sorted runs on those tapes, which is what > tuplesort.c does for us. > >> However I can't define a clean API for >> the former case. > > I imagine a pair of tuplesort_beginsortedrun(); > tuplesort_endsortedrun() -functions to help this. This APIs do are better than the ones in my mind:) during the range between tuplesort_beginsortedrun and tuplesort_endsortedrun(), we can bypass the tuplessort's memory. > but I'm not 100% > sure if we'd want to expose Tuplesort to non-PG sorting algorithms, as > it would be one easy way to create incorrect results if the sort used > in tuplesort isn't exactly equivalent to the sort used by the provider > of the tuples. OK. > >> c). create-index is a maintenance work, improving it by >> 30% would be good, but if we just improve it by <3, it looks not very >> charming in practice. > > I think improving 3% on reindex operations can be well worth the effort. > Also, do note that the current patch does (still) not correctly handle > [maintenance_]work_mem: Every backend's BuildAccumulator uses up to > work_mem of memory here, while the launched tuplesorts use an > additional maintenance_work_mem of memory, for a total of (workers + > 1) * work_mem + m_w_m of memory usage. The available memory should > instead be allocated between tuplesort and BuildAccumulator, but can > probably mostly be allocated to just BuildAccumulator if we can dump > the data into the tuplesort directly, as it'd reduce the overall > number of operations and memory allocations for the tuplesort. I think > that once we correctly account for memory allocations (and an improved > write path) we'll be able to see a meaningfully larger performance > improvement. Personally I am more fans of your "buffer writetup" idea, but not the same interests with the tuplesort_beginsortedrun / tuplesort_endsortedrun. I said the '3%' is for the later one and I guess you understand it as the former one. > >> So my option is if we can have agreement on 0008, then we can final >> review/test on the existing code (including 0009), and leave further >> improvement as a dedicated patch. > > As mentioned above, I think I could update the patch for a btree > implementation that also has immediate benefits, if so desired? If you are saying about the buffered-writetup in tuplesort, then I think it is great, and in a dedicated thread for better exposure. -- Best Regards Andy Fan
On Wed, 28 Aug 2024 at 02:38, Andy Fan <zhihuifan1213@163.com> wrote: > > Matthias van de Meent <boekewurm+postgres@gmail.com> writes: > > tuplesort_performsort usually only needs to flush the last elements of > > ... In certain rare > > cases it may take a longer time as it may have to merge sorted runs, > > but those cases are quite rare in my experience. > > OK, I am expecting such cases are not rare, Suppose we have hundreds of > GB heap tuple, and have the 64MB or 1GB maintenance_work_mem setup, it > probably hit this sistuation. I'm not mean at which experience is the > fact, but I am just to highlights the gap in our minds. and thanks for > sharing this, I can pay more attention in this direction in my future > work. To be clearer, my setup hit the 'mergeruns' case. Huh, I've never noticed the performsort phase of btree index creation (as seen in pg_stat_progress_create_index) take much time if any, especially when compared to the tuple loading phase, so I assumed it didn't happen often. Hmm, maybe I've just been quite lucky. > > > >> But 0008 still does many good stuff: > >> 1. Reduce the IO usage, this would be more useful on some heavily IO > >> workload. > >> 2. Simplify the building logic by removing one stage. > >> 3. Add the 'buffer-writetup' to tuplesort.c, I don't have other user > >> case for now, but it looks like a reasonable design. > > > > I'd imagine nbtree would like to use this too, for applying some > > deduplication in the sort stage. > > The current ntbtree do the deduplication during insert into the nbtree > IIUC, in your new strategy, we can move it the "sort" stage, which looks > good to me [to confirm my understanding]. Correct: We can do at least some deduplication in the sort stage. Not all, because tuples need to fit on pages and we don't want to make the tuples so large that we'd cause unnecessary splits while loading the tree, but merging runs of 10-30 tuples should reduce IO requirements by some margin for indexes where deduplication is important. > > The IO benefits are quite likely to > > be worth it; a minimum space saving of 25% on duplicated key values in > > tuple sorts sounds real great. > > Just be clearer on the knowledge, the IO benefits can be only gained > when the tuplesort's memory can't hold all the tuples, and in such case, > tuplesort_performsort would run the 'mergeruns', or else we can't get > any benefit? It'd be when the tuplesort's memory can't hold all tuples, but mergeruns isn't strictly required here, as dumptuples() would already allow some tuple merging. > >> I think the current blocker is if it is safe to hack the tuplesort.c. > >> With my current knowledge, It looks good to me, but it would be better > >> open a dedicated thread to discuss this specially, the review would not > >> take a long time if a people who is experienced on this area would take > >> a look. > > > > I could adapt the patch for nbtree use, to see if anyone's willing to > > review that? > > I'm interested with it and can do some review & testing. But the > keypoint would be we need some authorities are willing to review it, to > make it happen to a bigger extent, a dedicated thread would be helpful. Then I'll split it off into a new thread sometime later this week. > > nbtree does sorted insertions into the tree, constructing leaf pages > > one at a time and adding separator keys in the page above when the > > leaf page was filled, thus removing the need to descend the btree. I > > imagine we can save some performance by mirroring that in GIN too, > > with as additional bonus that we'd be free to start logging completed > > pages before we're done with the full index, reducing max WAL > > throughput in GIN index creation. > > I agree this is a promising direction as well. It'd be valuable to see if the current patch's "parallel sorted" insertion is faster even than the current GIN insertion path even if we use only the primary process, as it could be competative. Btree-like bulk tree loading might even be meaningfully faster than GIN's current index creation process. However, as I mentioned significantly upthread, I don't expect that change to happen in this patch series. > > I imagine a pair of tuplesort_beginsortedrun(); > > tuplesort_endsortedrun() -functions to help this. > > This APIs do are better than the ones in my mind:) during the range > between tuplesort_beginsortedrun and tuplesort_endsortedrun(), we can > bypass the tuplessort's memory. Exactly, we'd have the user call tuplesort_beginsortedrun(); then iteratively insert its sorted tuples using the usual tuplesort_putYYY() api, and then call _endsortedrun() when the sorted run is complete. It does need some work in tuplesort state handling and internals, but I think that's quite achievable. Kind regards, Matthias van de Meent
Tomas Vondra <tomas@vondra.me> writes:
Hi Tomas,
> Yeah. I think we have agreement on 0001-0007.
Yes, the design of 0001-0007 looks good to me and because of the
existing compexitity, I want to foucs on this part for now. I am doing
code review from yesterday, and now my work is done. Just some small
questions:
1. In GinBufferStoreTuple,
/*
* Check if the last TID in the current list is frozen. This is the case
* when merging non-overlapping lists, e.g. in each parallel worker.
*/
if ((buffer->nitems > 0) &&
(ItemPointerCompare(&buffer->items[buffer->nitems - 1], &tup->first) == 0))
buffer->nfrozen = buffer->nitems;
should we do (ItemPointerCompare(&buffer->items[buffer->nitems - 1],
&tup->first) "<=" 0), rather than "=="?
2. Given the "non-overlap" case should be the major case
GinBufferStoreTuple , does it deserve a fastpath for it before calling
ginMergeItemPointers since ginMergeItemPointers have a unconditionally
memory allocation directly, and later we pfree it?
new = ginMergeItemPointers(&buffer->items[buffer->nfrozen], /* first unfronzen */
(buffer->nitems - buffer->nfrozen), /* num of unfrozen */
items, tup->nitems, &nnew);
3. The following comment in index_build is out-of-date now :)
/*
* Determine worker process details for parallel CREATE INDEX. Currently,
* only btree has support for parallel builds.
*
4. Comments - Buffer is not empty and it's storing "a different key"
looks wrong to me. the key may be same and we just need to flush them
because of memory usage. There is the same issue in both
_gin_process_worker_data and _gin_parallel_merge.
if (GinBufferShouldTrim(buffer, tup))
{
Assert(buffer->nfrozen > 0);
state->buildStats.nTrims++;
/*
* Buffer is not empty and it's storing a different key - flush
* the data into the insert, and start a new entry for current
* GinTuple.
*/
AssertCheckItemPointers(buffer, true);
I also run valgrind testing with some testcase, no memory issue is
found.
> I'm a bit torn about 0008, I have not expected changing tuplesort like
> this when I started working
> on the patch, but I can't deny it's a massive speedup for some cases
> (where the patch doesn't help otherwise). But then in other cases it
> doesn't help at all, and 0010 helps.
Yes, I'd like to see these improvements both 0008 and 0010 as a
dedicated improvement.
--
Best Regards
Andy Fan
On Tue, 8 Oct 2024 at 17:06, Tomas Vondra <tomas@vondra.me> wrote:
>
> On 10/8/24 04:03, Michael Paquier wrote:
> >
> > _gin_parallel_build_main() is introduced in 0001. Please make sure to
> > pass down a query ID.
>
> Thanks for the ping. Here's an updated patch doing that, and also fixing
> a couple whitespace issues. No other changes, but I plan to get back to
> this patch soon - before the next CF.
>
>
> regards
>
> --
> Tomas Vondra
Hi! I was looking through this series of patches because thread of
GIN&GIST amcheck patch references it.
I have spotted this in gininsert.c:
1)
>/*
>* Store shared tuplesort-private state, for which we reserved space.
>* Then, initialize opaque state using tuplesort routine.
>*/
>sharedsort = (Sharedsort *) shm_toc_allocate(pcxt->toc, estsort);
>tuplesort_initialize_shared(sharedsort, scantuplesortstates,>
pcxt->seg);
>/*
>* Store shared tuplesort-private state, for which we reserved space.
>* Then, initialize opaque state using tuplesort routine.
>*/
Is it necessary to duplicate the entire comment?
And, while we are here, isn't it " initialize the opaque state "?
2) typo :
* the TID array, and returning false if it's too large (more thant work_mem,
3) in _gin_build_tuple:
....
else if (typlen == -2)
keylen = strlen(DatumGetPointer(key)) + 1;
else
elog(ERROR, "invalid typlen");
Maybe `elog(ERROR, "invalid typLen: %d", typLen); ` as in `datumGetSize`?
4) in _gin_compare_tuples:
> if ((a->category == GIN_CAT_NORM_KEY) &&
(b->category == GIN_CAT_NORM_KEY))
maybe just a->category == GIN_CAT_NORM_KEY? a->category is already
equal to b->category because of previous if statements.
5) In _gin_partition_sorted_data:
>char fname[128];
>sprintf(fname, "worker-%d", i);
Other places use MAXPGPATH in similar cases.
Also, code `sprintf(fname, "worker-%d",...);` duplicates. This might
be error-prone. Should we have a macro/inline function for this?
I will take another look later, maybe reporting real problems, not nit-picks.
--
Best regards,
Kirill Reshke
On Sat, 4 Jan 2025 at 17:58, Tomas Vondra <tomas@vondra.me> wrote: > > On 11/24/24 19:04, Kirill Reshke wrote: > > On Tue, 8 Oct 2024 at 17:06, Tomas Vondra <tomas@vondra.me> wrote: > >> > >> On 10/8/24 04:03, Michael Paquier wrote: > >>> > >>> _gin_parallel_build_main() is introduced in 0001. Please make sure to > >>> pass down a query ID. > >> > >> Thanks for the ping. Here's an updated patch doing that, and also fixing > >> a couple whitespace issues. No other changes, but I plan to get back to > >> this patch soon - before the next CF. > >> > >> > >> regards > >> > >> -- > >> Tomas Vondra > > > > Hi! I was looking through this series of patches because thread of > > GIN&GIST amcheck patch references it. > > > > I have spotted this in gininsert.c: > > 1) > >> /* > >> * Store shared tuplesort-private state, for which we reserved space. > >> * Then, initialize opaque state using tuplesort routine. > >> */ > >> sharedsort = (Sharedsort *) shm_toc_allocate(pcxt->toc, estsort); > >> tuplesort_initialize_shared(sharedsort, scantuplesortstates,> > > pcxt->seg); > >> /* > >> * Store shared tuplesort-private state, for which we reserved space. > >> * Then, initialize opaque state using tuplesort routine. > >> */ > > > > Is it necessary to duplicate the entire comment? > > > > Yes, that's a copy-paste mistake. Removed the second comment. > > > And, while we are here, isn't it " initialize the opaque state "? > > > > Not sure, this is copy pasted as-is from nbtree code. > > > 2) typo : > > * the TID array, and returning false if it's too large (more thant work_mem, > > > > Fixed. > > > 3) in _gin_build_tuple: > > > > .... > > else if (typlen == -2) > > keylen = strlen(DatumGetPointer(key)) + 1; > > else > > elog(ERROR, "invalid typlen"); > > > > > > Maybe `elog(ERROR, "invalid typLen: %d", typLen); ` as in `datumGetSize`? > > > > Makes sense, I reworded it a little bit. But it's however supposed to be > a can't happen condition. > > > 4) in _gin_compare_tuples: > > > >> if ((a->category == GIN_CAT_NORM_KEY) && > > (b->category == GIN_CAT_NORM_KEY)) > > > > maybe just a->category == GIN_CAT_NORM_KEY? a->category is already > > equal to b->category because of previous if statements. > > > > True. I've simplified the condition. > > > 5) In _gin_partition_sorted_data: > > > >> char fname[128]; > >> sprintf(fname, "worker-%d", i); > > > > Other places use MAXPGPATH in similar cases. > > > > OK, fixed the two places that format worker-%d. > > > Also, code `sprintf(fname, "worker-%d",...);` duplicates. This might > > be error-prone. Should we have a macro/inline function for this? > > > > Maybe. I think using a constant might be a good idea, but anything more > complicated is not worth it. There's only two places using it, not very > far apart. > > > I will take another look later, maybe reporting real problems, not nit-picks. > > > > Thanks. Attached is a rebased patch series fixing those issues, and one > issue I found in an AssertCheckGinBuffer, which was calling the other > assert (AssertCheckItemPointers) even for empty buffers. I think this > part might need some more work, so that it's clear what the various > asserts assume (or rather to allow just calling AssertCheckGinBuffer > everywhere, with some flags). Thanks for the rebase. > 0001 In gininsert.c, I think I'd prefer GinBuildShared over GinShared. While current GIN infrastructure doesn't do parallel index scans (and I can't think of an easy way to parallelize it) I think this it's better to make clear that this isn't related to index scan. > + * mutex protects all fields before heapdesc. This comment is still inaccurate. > + /* FIXME likely duplicate with indtuples */ I think this doesn't have to be duplicate, as we can distinguish between number of heap tuples and the number of GIN (key, TID) pairs loaded. This distinction doesn't really exist anywhere else, though, so to expose this to users we may need changes in pg_stat_progress_create_index. While I haven't checked if that distinction is being made in the code, I think it would be a useful distinction to have. > GinBufferInit This seems to depend on the btree operator classes to get sortsupport functions, bypassing the GIN compare support function (support function 1) and adding a dependency on the btree opclasses for indexable types. This can cause "bad" ordering, or failure to build the index when the parallel path is chosen and no default btree opclass is defined for the type. I think it'd be better if we allowed users to specify which sortsupport function to use, or at least use the correct compare function when it's defined on the attribute's operator class. > include/access/gin_tuple.h > + OffsetNumber attrnum; /* attnum of index key */ I think this would best be AttrNumber-typed? Looks like I didn't notice or fix that in 0009. > My plan is to eventually commit the first couple patches, possibly up > 0007 or even 0009. Sounds good. I'll see if I have some time to do some cleanup on my patches (0008 and 0009), as they need some better polish on the comments and commit messages. Kind regards, Matthias van de Meent Neon (https://neon.tech)
On Tue, 7 Jan 2025 at 12:59, Tomas Vondra <tomas@vondra.me> wrote: > > On 1/6/25 20:13, Matthias van de Meent wrote: >> ... >>> >>> Thanks. Attached is a rebased patch series fixing those issues, and one >>> issue I found in an AssertCheckGinBuffer, which was calling the other >>> assert (AssertCheckItemPointers) even for empty buffers. I think this >>> part might need some more work, so that it's clear what the various >>> asserts assume (or rather to allow just calling AssertCheckGinBuffer >>> everywhere, with some flags). >> >> Thanks for the rebase. >> >>> 0001 >>> + * mutex protects all fields before heapdesc. >> >> This comment is still inaccurate. >> > > Hmm, yeah. But this comment originates from btree, so maybe it's wrong > there (and in BRIN too)? I believe it refers to the descriptors stored > after the struct, i.e. it means "all fields after the mutex". Yeah, I think that's just the comment that needs updating. >>> + /* FIXME likely duplicate with indtuples */ >> >> I think this doesn't have to be duplicate, as we can distinguish >> between number of heap tuples and the number of GIN (key, TID) pairs >> loaded. This distinction doesn't really exist anywhere else, though, >> so to expose this to users we may need changes in >> pg_stat_progress_create_index. >> >> While I haven't checked if that distinction is being made in the code, >> I think it would be a useful distinction to have. >> > > I haven't done anything about this, but I'm not sure adding the number > of GIN tuples to pg_stat_progress_create_index would be very useful. We > don't know the total number of entries, so it can't show the progress. For btree scans, we update the number of to-be-inserted tuples together with the number of blocks scanned. Can we do something similar with GIN? Can we track data for pg_stat_progress_create_index? >>> GinBufferInit >> >> This seems to depend on the btree operator classes to get sortsupport >> functions, bypassing the GIN compare support function (support >> function 1) and adding a dependency on the btree opclasses for >> indexable types. This can cause "bad" ordering, or failure to build >> the index when the parallel path is chosen and no default btree >> opclass is defined for the type. I think it'd be better if we allowed >> users to specify which sortsupport function to use, or at least use >> the correct compare function when it's defined on the attribute's >> operator class. >> > > Good point! I fixed this by copying the logic from initGinState. > >>> include/access/gin_tuple.h >>> + OffsetNumber attrnum; /* attnum of index key */ >> >> I think this would best be AttrNumber-typed? Looks like I didn't >> notice or fix that in 0009. >> > > You're probably right, but I see the GIN code uses OffsetNumber for > attrnum in a number of places. I wonder why is that. I don't think it > can be harmful, because we can't have GIN on system columns, right? Indeed, indexes on system columns are not supported, which includes GIN indexes. >>> I need to figure out how to squash the patches - I don't want to >>> squash this into a single much-harder-to-understand commit, but maybe it >>> has too many parts. I think the following would be good: Commits: 1.) 0001 (parallel create) + 0009 (reduce the size of ...) + 0002 (mergesort) + 0003 (remove explicit pg_qsort) + 0007 (detect wrap-around) 2.) 0004 (compress) + 0006 (enforce memory limit) 3.) 0008 (single tuplesort) Note that 0009 is a drop-in improvement, so I don't think order makes much of a difference there. IIUC, 0005 was only for development insights, and not proposed to get committed. If that was wrong, I'd squash it into the second commit, together with 0004/0006. I'll try to provide a more polished version of 0008 soon, with improved comments/commit message, however that'll depend on me not getting distracted with $job items first; it's taken quite some time recently. Kind regards, Matthias van de Meent
On 2/12/25 15:59, Matthias van de Meent wrote: > On Tue, 7 Jan 2025 at 12:59, Tomas Vondra <tomas@vondra.me> wrote: >> >> On 1/6/25 20:13, Matthias van de Meent wrote: >>> ... >>>> >>>> Thanks. Attached is a rebased patch series fixing those issues, and one >>>> issue I found in an AssertCheckGinBuffer, which was calling the other >>>> assert (AssertCheckItemPointers) even for empty buffers. I think this >>>> part might need some more work, so that it's clear what the various >>>> asserts assume (or rather to allow just calling AssertCheckGinBuffer >>>> everywhere, with some flags). >>> >>> Thanks for the rebase. >>> >>>> 0001 >>>> + * mutex protects all fields before heapdesc. >>> >>> This comment is still inaccurate. >>> >> >> Hmm, yeah. But this comment originates from btree, so maybe it's wrong >> there (and in BRIN too)? I believe it refers to the descriptors stored >> after the struct, i.e. it means "all fields after the mutex". > > Yeah, I think that's just the comment that needs updating. > >>>> + /* FIXME likely duplicate with indtuples */ >>> >>> I think this doesn't have to be duplicate, as we can distinguish >>> between number of heap tuples and the number of GIN (key, TID) pairs >>> loaded. This distinction doesn't really exist anywhere else, though, >>> so to expose this to users we may need changes in >>> pg_stat_progress_create_index. >>> >>> While I haven't checked if that distinction is being made in the code, >>> I think it would be a useful distinction to have. >>> >> >> I haven't done anything about this, but I'm not sure adding the number >> of GIN tuples to pg_stat_progress_create_index would be very useful. We >> don't know the total number of entries, so it can't show the progress. > > For btree scans, we update the number of to-be-inserted tuples > together with the number of blocks scanned. Can we do something > similar with GIN? > > Can we track data for pg_stat_progress_create_index? > >>>> GinBufferInit >>> >>> This seems to depend on the btree operator classes to get sortsupport >>> functions, bypassing the GIN compare support function (support >>> function 1) and adding a dependency on the btree opclasses for >>> indexable types. This can cause "bad" ordering, or failure to build >>> the index when the parallel path is chosen and no default btree >>> opclass is defined for the type. I think it'd be better if we allowed >>> users to specify which sortsupport function to use, or at least use >>> the correct compare function when it's defined on the attribute's >>> operator class. >>> >> >> Good point! I fixed this by copying the logic from initGinState. >> >>>> include/access/gin_tuple.h >>>> + OffsetNumber attrnum; /* attnum of index key */ >>> >>> I think this would best be AttrNumber-typed? Looks like I didn't >>> notice or fix that in 0009. >>> >> >> You're probably right, but I see the GIN code uses OffsetNumber for >> attrnum in a number of places. I wonder why is that. I don't think it >> can be harmful, because we can't have GIN on system columns, right? > > Indeed, indexes on system columns are not supported, which includes GIN indexes. > >>>> I need to figure out how to squash the patches - I don't want to >>>> squash this into a single much-harder-to-understand commit, but maybe it >>>> has too many parts. > > I think the following would be good: > > Commits: > 1.) 0001 (parallel create) + 0009 (reduce the size of ...) + 0002 > (mergesort) + 0003 (remove explicit pg_qsort) + 0007 (detect > wrap-around) > 2.) 0004 (compress) + 0006 (enforce memory limit) > 3.) 0008 (single tuplesort) > Thanks. It's been so long since I looked at the patches that I don't quite recall all the details - it's almost as if it was authored by someone else ;-) But your proposal makes sense. I was torn between committing this in smaller "increments" and squashing it like this. The smaller steps are easier to follow and debug. But that mattered during the development, and evaluation of those changes. It's not that useful for commit, because the parts will get pushed over a relatively short time period anyway. > Note that 0009 is a drop-in improvement, so I don't think order makes > much of a difference there. > True. > IIUC, 0005 was only for development insights, and not proposed to get > committed. If that was wrong, I'd squash it into the second commit, > together with 0004/0006. > Nope, it was for development only. I'll however consider keeping 0004 and 0006 separate, because those seem like pretty separate changes. I don't see much point in not committing them in (1) and then squashing them together into a single commit. > I'll try to provide a more polished version of 0008 soon, with > improved comments/commit message, however that'll depend on me not > getting distracted with $job items first; it's taken quite some time > recently. > Cool, thanks! regards -- Tomas Vondra
On 2/12/25 15:59, Matthias van de Meent wrote: > On Tue, 7 Jan 2025 at 12:59, Tomas Vondra <tomas@vondra.me> wrote: >> >> ... >> >> I haven't done anything about this, but I'm not sure adding the number >> of GIN tuples to pg_stat_progress_create_index would be very useful. We >> don't know the total number of entries, so it can't show the progress. > > For btree scans, we update the number of to-be-inserted tuples > together with the number of blocks scanned. Can we do something > similar with GIN? > I've been thinking about this, but I'm not quite sure how should that work. The problem is in btree we have a 1:1 mapping to heap tuples, but in GIN that's not quite that simple. Not only do we generate multiple GIN entries for each heap row, but we also combine / merge those tuples in various levels. But I think it might look like this: 1) Each worker counts the number of GinTuples written to the shared tuplesort, after the in-worker merge phase (i.e. it'd not be the number of GIN entries generated in ginBuildCallbackParallel). 2) The leader then counts the number of entries it loaded from the tuplesort, before merging/writing them into the index. I think this would work as a measure of progress, even though it does not really match the number of index tuples. One thing I'm not not sure about is how would this work with the "single tuplesort" patch? That patch moves the merging to the tuplesort code, and there doesn't seem to be a nice way to pass the number of merged outside. > Can we track data for pg_stat_progress_create_index? > Which data? I think progress for the CREATE INDEX would be nice, ofc. regards -- Tomas Vondra
On Sun, 16 Feb 2025 at 04:47, Tomas Vondra <tomas@vondra.me> wrote: > > Hi, > > Attached is a cleaned up version of the patch series, squashed into > fewer patches as discussed. I also went through all the comments, and > removed/updated some obsolete ones. I also updated the commit messages, > it'd be nice if someone could read through those, to make sure it's > clear enough. > > While cleaning the comments, I realized there's a couple remaining XXX > and FIXME comments, with some valid open questions. > > 1) There are two places that explicitly zero memory, suggesting it's > because of padding causing issues in valgrind (in tuplesort). I need to > check if that's still true, but I wonder what do the other tuplesort > variants write stuff without tripping valgrind. Maybe the GinTuple is > too unique. > 2) ginBuildCallbackParallel says this about memory limits: > > * XXX It might seem this should set the memory limit to 32MB, same as > * what plan_create_index_workers() uses to calculate the number of > * parallel workers, but that's the limit for tuplesort. So it seems > * better to keep using work_mem here. > * > * XXX But maybe we should calculate this as a per-worker fraction of > * maintenance_work_mem. It's weird to use work_mem here, in a clearly > * maintenance command. > > The function uses work_mem to limit the amount of memory used by each > worker, which seems a bit strange - it's a maintenance operation, so it > would be more appropriate to use maintenance_work_mem I guess. > > I see the btree code also uses work_mem in some cases when building the > index, although that uses it to size the tuplesort. And here we have > both the tuplesorts (sized just like in nbtree code), but also the > buffer used to accumulate entries. I think that's a bug in btree code. > I wonder if maybe the right solution would be to use half the allowance > for tuplesort and half for the buffer. In the workers the allowance is > > maintenance_work_mem / ginleader->nparticipanttuplesorts > > while in the leader it's maintenance_work_mem. Opinions? Why is the allowance in the leader not affected by memory usage of parallel workers? Shouldn't that also be m_w_m / nparticipants? IIRC, in nbtree, the leader will use (n_planned_part - n_launched_part) * (m_w_m / n_planned_part), which in practice is 1 * (m_w_m / n_planned_part). > 3) There's a XXX comment suggesting to use a separate memory context for > the GinBuffer, but I decided it doesn't seem really necessary. We're not > running any complex function or anything like that in this code, so I > don't see a huge benefit of a separate context. > > I know the patch reworking this to use a single tuplesort actually adds > the memory context, maybe it's helpful for that patch. But for now I > don't see the point. I think I added that for the reduced cost of memory cleanup using mctx resets vs repeated pfree(), when we're in the tuplesort merge phase. > 4) The patch saving 12B in the GinTuple also added this comment: > > * XXX: Update description with new architecture > > but I'm a bit unsure what exactly is meant but "architecture" or what > should I add a description for. I worked on both 'smaller GinTuple' and the 'single tuplesort' patch in one go, without any intermediate commits to delineate work on either patch, and picked the changes for 'smaller GinTuple' from that large pile of changes. That XXX was supposed to go into the second patch, and was there to signal me to update the overarching architecture documentation for Parallel GIN index builds (which I subsequently forgot to do with the 'single tuplesort' patch). So, it's not relevant to the 12B patch, but could be relevant to what is now patch 0004. Kind regards, Matthias van de Meent
Hi,
After stress-testing all the patches (which yielded no issues except for
the barrier hang in 0005, which is not for commit yet), I proceeded to
do some basic perf testing.
I simply built a bunch of GIN indexes on a database with current mailing
list archives. The database is ~23GB, and the indexes were these:
CREATE INDEX headers_jsonb_path_idx
ON messages USING gin (msg_headers jsonb_path_ops);
CREATE INDEX headers_jsonb_idx
ON messages USING gin (msg_headers);
CREATE INDEX subject_trgm_idx
ON messages USING gin (msg_subject gin_trgm_ops);
CREATE INDEX body_tsvector_idx
ON messages USING gin (msg_body_tsvector);
CREATE INDEX subject_tsvector_idx
ON messages USING gin (msg_subject_tsvector);
So the indexes are on different data types, columns of different size,
etc. I did this on my two machines:
1) xeon - 44 cores, but old (~2016)
2) ryzen - 12 cores, brand new CPU (2024)
And I ran the CREATE INDEX with a range of worker counts (0, 1, 4, ...).
The count was set using ALTER TABLE, which just sets that without the
additional plan_create_index_workers() heuristics. There was always
enough workers to satisfy this.
The m_w_m was set to 1GB for all runs, which should leave "enough"
memory for to 32 workers (plan_create_index_workers leaves at least 32MB
per worker).
The results are in the attached PDF tables. I think the results are
mostly as expected ...
timing
------
For the "timing" charts, there are two colored sections. The first shows
"comparison to 0 workers" (i.e. serial build), and then "comparison to
ideal speedup" (essentially time/(N+1), where N is the number of
workers). In both cases green=good, red=bad.
The "patch" is the number of patch in the patch series, without the "0"
prefix. Patch "0" means "master" without patches.
How much the parallelism helps depends on the column. For some columns
(body_trgm, subject_trgm, subject_tsvector) it helps a lot, for others
it's less beneficial. But in all cases it helps, cutting the duration
(at least) in half.
On both machines the performance stops improving at ~4 workers. I guess
that's expected, and AFAICS we wouldn't really try to use more workers
for these index builds anyway.
One thing I don't quite understand is that on the ryzen machine, this
also seems to speed up patch "0" (i.e. master with no parallel builds).
At first I thought it's just random run-to-run noise, but looking at
those results it doesn't seem to be the case. E.g. for body_trgm_idx it
changes from ~686 seconds to ~634 seconds. For the other columns it's
less significant, but still pretty consistent.
On the xeon machine this doesn't happen at all.
I don't have a great explanation for this, because the patch does not
modify serial builds at all. The only idea I have is change in binary
layout between builds, but that's just "I don't know" in disguise.
temporary files
---------------
The other set of charts "temporary MB" shows amount of temporary files
produced with each of the patches. It's not showing "patch 0" (aka
master) because serial builds don't use temp files at all. The % values
are relative to "patch 1".
The 0002 patch is the compression, and that helps a lot (but depends on
the column). 0003 is just about enforcing memory limit, it does not
affect the temporary files at all.
Then 0004 "single tuplesort" does help a lot too, sometimes cutting the
amount in half. Which makes sense, because we suddenly don't need to
shuffle data between two tuplesorts.
But the results of 0005 are a bit bizarre - it mostly undoes the 0004
benefits, for some reason. I wonder why.
Anyway, I'm mostly happy about how this performs for 0001-0003, which
are the parts I plan to push in the coming days.
regards
--
Tomas Vondra
Attachment
Hi, here's a rebased version of the patch series. I realized I made a silly merge mistake in the 0004 patch during the last rebase, so cfbot was not happy. So here's a fixed version. This also squashes the memory size adjustments (0002 patch in the last patch), into 0001. regards -- Tomas Vondra
Attachment
One more patch version / rebase. I've been planning to get 0001 committed, but I realized there's one more loose end - progress reporting. I could have committed it without it, I guess, but Matthias actually mentioned this a couple days ago so I took a stab at it. The build goes through these 5 build stages (on top of "INITIALIZE"): PROGRESS_GIN_PHASE_INDEXBUILD_TABLESCAN PROGRESS_GIN_PHASE_PERFORMSORT_1 PROGRESS_GIN_PHASE_MERGE_1 PROGRESS_GIN_PHASE_PERFORMSORT_2 PROGRESS_GIN_PHASE_MERGE_2 The phases up to PROGRESS_GIN_PHASE_MERGE_1 happen in workers, i.e. it ends with workers feeding the sorted/merged data into the shared tuplesort. The last two phases are in the leader, which merges the data and actually inserts it into the GIN index. The "parallel" part has the blocks_done/blocks_total showing progress, per the parallel scan. The "leader" phases use tuples_done/tuples_total, where "tuple" is the GIN tuple produced by workers (each worker reports the number of "tuples" it writes into the shared tuplesort, the leader then tracks how many it processed). I think this works pretty nicely. I'm not entirely sure we need all the phases, maybe it'd be fine to have the sort+merge as a single phase? Or maybe there should be one extra "sort" phase? Workers do two sorts, first on their "private" tuplesort, then on the "shared" one. What annoys me a little bit is that we only see those stages if the leader participates as a worker. With parallel_leader_participation=off none of this is visible anyway (we still see the blocks from the scan). regards -- Tomas Vondra
Attachment
- v20250225-0001-Allow-parallel-CREATE-INDEX-for-GIN-indexe.patch
- v20250225-0002-cleanup.patch
- v20250225-0003-progress.patch
- v20250225-0004-Compress-TID-lists-when-writing-GIN-tuples.patch
- v20250225-0005-Enforce-memory-limit-during-parallel-GIN-b.patch
- v20250225-0006-Use-a-single-GIN-tuplesort.patch
- v20250225-0007-WIP-parallel-inserts-into-GIN-index.patch
While working on the progress reporting, I've been looking into the
performance results, particularly why the parallelism doesn't help much
for some indexes - e.g. the index on the headers JSONB column.
CREATE INDEX headers_jsonb_idx
ON messages USING gin (msg_headers);
In this case the parallelism helps only a little bit - serial build
takes ~47 seconds, parallel builds with 1 worker (so 2 with leader)
takes ~40 seconds. Not great.
There are two reasons for this. First, the "keys" (JSONB values) are
mostly unique, with only 1 or 2 TIDs per key, which means the workers
can't really do much merging. But shifting the merges to workers is the
main benefit of parallel builds - if the merge happens in the leader
anyway, this explains the lack of speedup.
The other reason is that with JSON keys the comparisons are rather
expensive, and we're comparing a lot of keys. It occurred to me we can
work around this by comparing hashes first, and comparing the full keys
only when the hashes match. And indeed, this helps a lot (there's a very
rough PoC patch attached) - I'm seeing ~20% speedup from this, so the
parallel build runs in ~30 seconds now. Still not quite serial speedup,
but better than before.
But I think this optimization is mostly orthogonal to parallel builds,
i.e. we could do the same thing for serial builds (while accumulating
data in memory, we could do these comparisons). But it needs to be
careful about still writing the data out in the "natural" order, not
ordered by hash. The hash randomizes the pattern, making it much less
efficient for bulk inserts (it trashes the buffers, etc.). The PoC patch
for parallel builds addresses this by ignoring the hash during the final
tuplesort, the serial builds would need to do something similar.
My conclusion is this can be left as a future improvement, independent
of the parallel builds.
regards
--
Tomas Vondra
Attachment
I've pushed the first part of the series (0001 + the cleanup and progress patch). That leaves the two smaller improvement parts (compression + memory limit enforcement) - I intend to push those sometime this week, if possible. Here's a rebased version of the whole patch series, including the two WIP parts that are unlikely to make it into PG18 at this point. regards -- Tomas Vondra
Attachment
I pushed the two smaller parts today. Here's the remaining two parts, to keep cfbot happy. I don't expect to get these into PG18, though. regards -- Tomas Vondra
Attachment
On Tue, 4 Mar 2025 at 20:50, Tomas Vondra <tomas@vondra.me> wrote: > > I pushed the two smaller parts today. > > Here's the remaining two parts, to keep cfbot happy. I don't expect to > get these into PG18, though. As promised on- and off-list, here's the 0001 patch, polished, split, and further adapted for performance. As seen before, it reduces tempspace requirements by up to 50%. I've not tested this against HEAD for performance. It has been split into: 0001: Some API cleanup/changes that creaped into the patch. This removes manual length-passing from the gin tuplesort APIs, instead relying on GinTuple's tuplen field. It's not critical for anything, and could be ignored if so desired. 0002: Tuplesort changes to allow TupleSort users to buffer and merge tuples during the sort operations. The patch was pulled directly from [0] (which was derived from earlier work in this thread), is fairly easy to understand, and has no other moving parts. 0003: Deduplication in tuplesort's flush-to-disk actions, utilizing API introduced with 0002. This improves temporary disk usage by deduplicating data even further, for when there's a lot of duplicated data but the data has enough distinct values to not fit in the available memory. 0004: Use a single tuplesort. This removes the worker-local tuplesort in favor of only storing data in the global one. This mainly reduces the code size and complexity of parallel GIN builds; we already were using that global sort for various tasks. Open questions and open items for this: - I did not yet update the pg_stat_progress systems, nor docs. - Maybe 0003 needs further splitting up, one for the optimizations in GinBuffer, one for the tuplesort buffering. - Maybe we need to trim the buffer in gin's tuplesort flush? - Maybe we should grow the GinBuffer->items array superlinearly rather than to the exact size requirement of the merge operation. Apart from the complexities in 0003, I think the changes are fairly straightforward. I did not include the 0002 of the earlier patch, as it was WIP and its feature explicitly conflicts with my 0004. Kind regards, Matthias van de Meent Neon (https://neon.tech) [0] https://www.postgresql.org/message-id/CAEze2WhRFzd=nvh9YevwiLjrS1j1fP85vjNCXAab=iybZ2rNKw@mail.gmail.com
Attachment
Tomas Vondra <tomas@vondra.me> writes:
> I pushed the two smaller parts today.
Coverity is a little unhappy about this business in
_gin_begin_parallel:
bool leaderparticipates = true;
...
#ifdef DISABLE_LEADER_PARTICIPATION
leaderparticipates = false;
#endif
...
scantuplesortstates = leaderparticipates ? request + 1 : request;
It says
>>> CID 1644203: Possible Control flow issues (DEADCODE)
>>> Execution cannot reach the expression "request" inside this statement: "scantuplesortstates = (lead...".
924 scantuplesortstates = leaderparticipates ? request + 1 : request;
If this were just temporary code I'd let it pass, but I see nothing
replacing this logic in the follow-up patches, so I think we ought
to do something to shut it up.
It's not complaining about the later bits like
if (leaderparticipates)
ginleader->nparticipanttuplesorts++;
(perhaps because there's no dead code there?) So one idea is
scantuplesortstates = request;
if (leaderparticipates)
scantuplesortstates++;
which would look more like the other code anyway.
regards, tom lane
On 3/9/25 17:38, Tom Lane wrote: > Tomas Vondra <tomas@vondra.me> writes: >> I pushed the two smaller parts today. > > Coverity is a little unhappy about this business in > _gin_begin_parallel: > > bool leaderparticipates = true; > ... > #ifdef DISABLE_LEADER_PARTICIPATION > leaderparticipates = false; > #endif > ... > scantuplesortstates = leaderparticipates ? request + 1 : request; > > It says > >>>> CID 1644203: Possible Control flow issues (DEADCODE) >>>> Execution cannot reach the expression "request" inside this statement: "scantuplesortstates = (lead...". > 924 scantuplesortstates = leaderparticipates ? request + 1 : request; > > If this were just temporary code I'd let it pass, but I see nothing > replacing this logic in the follow-up patches, so I think we ought > to do something to shut it up. > > It's not complaining about the later bits like > > if (leaderparticipates) > ginleader->nparticipanttuplesorts++; > > (perhaps because there's no dead code there?) So one idea is > > scantuplesortstates = request; > if (leaderparticipates) > scantuplesortstates++; > > which would look more like the other code anyway. > I don't mind doing it differently, but this code is just a copy from _bt_begin_parallel. So how come coverity does not complain about that? Or is that whitelisted? thanks -- Tomas Vondra
Tomas Vondra <tomas@vondra.me> writes:
> On 3/9/25 17:38, Tom Lane wrote:
>> Coverity is a little unhappy about this business in
>> _gin_begin_parallel:
> I don't mind doing it differently, but this code is just a copy from
> _bt_begin_parallel. So how come coverity does not complain about that?
> Or is that whitelisted?
Ah. Most likely somebody dismissed it years ago. Given that
precedent, I'm content to dismiss this one too.
regards, tom lane
On Sun, Mar 9, 2025 at 6:23 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Ah. Most likely somebody dismissed it years ago. Given that > precedent, I'm content to dismiss this one too. It is dead code, unless somebody decides to #define DISABLE_LEADER_PARTICIPATION to debug a problem. -- Peter Geoghegan
Hi Matthias, On Fri, Mar 7, 2025 at 4:08 AM Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > > On Tue, 4 Mar 2025 at 20:50, Tomas Vondra <tomas@vondra.me> wrote: > > > > I pushed the two smaller parts today. > > > > Here's the remaining two parts, to keep cfbot happy. I don't expect to > > get these into PG18, though. > > As promised on- and off-list, here's the 0001 patch, polished, split, > and further adapted for performance. > > As seen before, it reduces tempspace requirements by up to 50%. I've > not tested this against HEAD for performance. > > It has been split into: > > 0001: Some API cleanup/changes that creaped into the patch. This > removes manual length-passing from the gin tuplesort APIs, instead > relying on GinTuple's tuplen field. It's not critical for anything, > and could be ignored if so desired. > > 0002: Tuplesort changes to allow TupleSort users to buffer and merge > tuples during the sort operations. > The patch was pulled directly from [0] (which was derived from earlier > work in this thread), is fairly easy to understand, and has no other > moving parts. > > 0003: Deduplication in tuplesort's flush-to-disk actions, utilizing > API introduced with 0002. > This improves temporary disk usage by deduplicating data even further, > for when there's a lot of duplicated data but the data has enough > distinct values to not fit in the available memory. > > 0004: Use a single tuplesort. This removes the worker-local tuplesort > in favor of only storing data in the global one. > > This mainly reduces the code size and complexity of parallel GIN > builds; we already were using that global sort for various tasks. > > Open questions and open items for this: > - I did not yet update the pg_stat_progress systems, nor docs. > - Maybe 0003 needs further splitting up, one for the optimizations in > GinBuffer, one for the tuplesort buffering. Yes, please. That would simplify the detailed review. > - Maybe we need to trim the buffer in gin's tuplesort flush? I didn't get it. Could you please elaborate more on this? > - Maybe we should grow the GinBuffer->items array superlinearly rather > than to the exact size requirement of the merge operation. +1 for this > Apart from the complexities in 0003, I think the changes are fairly > straightforward. Yes, 0001, 0002 and 0004 are pretty straightforward. Regarding 0003, having separate deformed tuple in GinBuffer and cached tuples looks a bit cumbersome. Could we simplify this? I understand that we need to decompress items array lazily. But could we leave just items-related fields in GinBuffer, but have the rest always in GinBuffer.cached? So, if GinBuffer.items != NULL then we have items decompressed already, otherwise have to decompress them when needed. ------ Regards, Alexander Korotkov Supabase
Hi, On 2025-03-04 20:50:43 +0100, Tomas Vondra wrote: > I pushed the two smaller parts today. > > Here's the remaining two parts, to keep cfbot happy. I don't expect to > get these into PG18, though. If that's the case, could we either close the CF entry, or move it to the next fest? Greetings, Andres Freund
On 4/2/25 18:43, Andres Freund wrote: > Hi, > > On 2025-03-04 20:50:43 +0100, Tomas Vondra wrote: >> I pushed the two smaller parts today. >> >> Here's the remaining two parts, to keep cfbot happy. I don't expect to >> get these into PG18, though. > > If that's the case, could we either close the CF entry, or move it to the next > fest? Possibly. Let me check if I can get some of the patches posted by Mattias after I wrote that. If not, I'll move it to the next CF. thanks -- Tomas Vondra
On Thu, 3 Apr 2025 at 01:19, Tomas Vondra <tomas@vondra.me> wrote: > > On 4/2/25 18:43, Andres Freund wrote: > > Hi, > > > > On 2025-03-04 20:50:43 +0100, Tomas Vondra wrote: > >> I pushed the two smaller parts today. > >> > >> Here's the remaining two parts, to keep cfbot happy. I don't expect to > >> get these into PG18, though. > > > > If that's the case, could we either close the CF entry, or move it to the next > > fest? > > Possibly. Let me check if I can get some of the patches posted by > Mattias after I wrote that. If not, I'll move it to the next CF. Looks like no more patches will get into v18 so i moved the CF -- Best regards, Kirill Reshke
Hello, As part of testing this change I believe I found a scenario where the parallel build seems to trigger OOMs for larger indexes. Specifically, the calls for ginEntryInsert seem to leak memory into TopTransactionContext and OOM/crash the outer process. For serial build, the calls for ginEntryInsert tend to happen in a temporary memory context that gets reset at the end of the ginBuildCallback. For inserts, the call has a custom memory context and gets reset at the end of the insert. For parallel build, during the merge phase, the MemoryContext isn't swapped - and so this happens on the TopTransactionContext, and ends up growing (especially for larger indexes). I believe at the very least these should happen inside the tmpCtx found in the GinBuildState and reset periodically. In the attached patch, I've tried to do this, and I'm able to build the index without OOMing, and only consuming maintenance_work_mem through the merge process. Would appreciate your thoughts on this (and whether there's other approaches to resolve this too). Thanks, Vinod On Thu, 17 Apr 2025 at 13:58, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > > > On 7/3/24 20:36, Matthias van de Meent wrote: > > On Mon, 24 Jun 2024 at 02:58, Tomas Vondra > > <tomas.vondra@enterprisedb.com> wrote: > >> > >> Here's a bit more cleaned up version, clarifying a lot of comments, > >> removing a bunch of obsolete comments, or comments speculating about > >> possible solutions, that sort of thing. I've also removed couple more > >> XXX comments, etc. > >> > >> The main change however is that the sorting no longer relies on memcmp() > >> to compare the values. I did that because it was enough for the initial > >> WIP patches, and it worked till now - but the comments explained this > >> may not be a good idea if the data type allows the same value to have > >> multiple binary representations, or something like that. > >> > >> I don't have a practical example to show an issue, but I guess if using > >> memcmp() was safe we'd be doing it in a bunch of places already, and > >> AFAIK we're not. And even if it happened to be OK, this is a probably > >> not the place where to start doing it. > > > > I think one such example would be the values '5.00'::jsonb and > > '5'::jsonb when indexed using GIN's jsonb_ops, though I'm not sure if > > they're treated as having the same value inside the opclass' ordering. > > > > Yeah, possibly. But doing the comparison the "proper" way seems to be > working pretty well, so I don't plan to investigate this further. > > >> So I've switched this to use the regular data-type comparisons, with > >> SortSupport etc. There's a bit more cleanup remaining and testing > >> needed, but I'm not aware of any bugs. > > > > A review of patch 0001: > > > > --- > > > >> src/backend/access/gin/gininsert.c | 1449 +++++++++++++++++++- > > > > The nbtree code has `nbtsort.c` for its sort- and (parallel) build > > state handling, which is exclusively used during index creation. As > > the changes here seem to be largely related to bulk insertion, how > > much effort would it be to split the bulk insertion code path into a > > separate file? > > > > Hmmm. I haven't tried doing that, but I guess it's doable. I assume we'd > want to do the move first, because it involves pre-existing code, and > then do the patch on top of that. > > But what would be the benefit of doing that? I'm not sure doing it just > to make it look more like btree code is really worth it. Do you expect > the result to be clearer? > > > I noticed that new fields in GinBuildState do get to have a > > bs_*-prefix, but none of the other added or previous fields of the > > modified structs in gininsert.c have such prefixes. Could this be > > unified? > > > > Yeah, these are inconsistencies from copying the infrastructure code to > make the parallel builds work, etc. > > >> +/* Magic numbers for parallel state sharing */ > >> +#define PARALLEL_KEY_GIN_SHARED UINT64CONST(0xB000000000000001) > >> ... > > > > These overlap with BRIN's keys; can we make them unique while we're at it? > > > > We could, and I recall we had a similar discussion in the parallel BRIN > thread, right?. But I'm somewhat unsure why would we actually want/need > these keys to be unique. Surely, we don't need to mix those keys in the > single shm segment, right? So it seems more like an aesthetic thing. Or > is there some policy to have unique values for these keys? > > >> + * mutex protects all fields before heapdesc. > > > > I can't find the field that this `heapdesc` might refer to. > > > > Yeah, likely a leftover from copying a bunch of code and then removing > it without updating the comment. Will fix. > > >> +_gin_begin_parallel(GinBuildState *buildstate, Relation heap, Relation index, > >> ... > >> + if (!isconcurrent) > >> + snapshot = SnapshotAny; > >> + else > >> + snapshot = RegisterSnapshot(GetTransactionSnapshot()); > > > > grumble: I know this is required from the index with the current APIs, > > but I'm kind of annoyed that each index AM has to construct the table > > scan and snapshot in their own code. I mean, this shouldn't be > > meaningfully different across AMs, so every AM implementing this same > > code makes me feel like we've got the wrong abstraction. > > > > I'm not asking you to change this, but it's one more case where I'm > > annoyed by the state of the system, but not quite enough yet to change > > it. > > > > Yeah, it's not great, but not something I intend to rework. > > > --- > >> +++ b/src/backend/utils/sort/tuplesortvariants.c > > > > I was thinking some more about merging tuples inside the tuplesort. I > > realized that this could be implemented by allowing buffering of tuple > > writes in writetup. This would require adding a flush operation at the > > end of mergeonerun to store the final unflushed tuple on the tape, but > > that shouldn't be too expensive. This buffering, when implemented > > through e.g. a GinBuffer in TuplesortPublic->arg, could allow us to > > merge the TID lists of same-valued GIN tuples while they're getting > > stored and re-sorted, thus reducing the temporary space usage of the > > tuplesort by some amount with limited overhead for other > > non-deduplicating tuplesorts. > > > > I've not yet spent the time to get this to work though, but I'm fairly > > sure it'd use less temporary space than the current approach with the > > 2 tuplesorts, and could have lower overall CPU overhead as well > > because the number of sortable items gets reduced much earlier in the > > process. > > > > Will respond to your later message about this. > > > --- > > > >> +++ b/src/include/access/gin_tuple.h > >> + typedef struct GinTuple > > > > I think this needs some more care: currently, each GinTuple is at > > least 36 bytes in size on 64-bit systems. By using int instead of Size > > (no normal indexable tuple can be larger than MaxAllocSize), and > > packing the fields better we can shave off 10 bytes; or 12 bytes if > > GinTuple.keylen is further adjusted to (u)int16: a key needs to fit on > > a page, so we can probably safely assume that the key size fits in > > (u)int16. > > > > Yeah, I guess using int64 is a bit excessive - you're right about that. > I'm not sure this is necessarily about "indexable tuples" (GinTuple is > not indexed, it's more an intermediate representation). But if we can > make it smaller, that probably can't hurt. > > I don't have a great intuition on how beneficial this might be. For > cases with many TIDs per index key, it probably won't matter much. But > if there's many keys (so that GinTuples store only very few TIDs), it > might make a difference. > > I'll try to measure the impact on the same "realistic" cases I used for > the earlier steps. > > regards > > -- > Tomas Vondra > EnterpriseDB: http://www.enterprisedb.com > The Enterprise PostgreSQL Company > > > >
Attachment
On 4/18/25 03:03, Vinod Sridharan wrote: > Hello, > As part of testing this change I believe I found a scenario where the > parallel build seems to trigger OOMs for larger indexes. Specifically, > the calls for ginEntryInsert seem to leak memory into > TopTransactionContext and OOM/crash the outer process. > For serial build, the calls for ginEntryInsert tend to happen in a > temporary memory context that gets reset at the end of the > ginBuildCallback. > For inserts, the call has a custom memory context and gets reset at > the end of the insert. > For parallel build, during the merge phase, the MemoryContext isn't > swapped - and so this happens on the TopTransactionContext, and ends > up growing (especially for larger indexes). > > I believe at the very least these should happen inside the tmpCtx > found in the GinBuildState and reset periodically. > > In the attached patch, I've tried to do this, and I'm able to build > the index without OOMing, and only consuming maintenance_work_mem > through the merge process. > > Would appreciate your thoughts on this (and whether there's other approaches to > resolve this too). > Thanks for the report. I didn't have time to look at this in detail yet, but the fix looks roughly correct. I've added this to the list of open items for PG18. regards -- Tomas Vondra
On 4/18/25 03:03, Vinod Sridharan wrote: > Hello, > As part of testing this change I believe I found a scenario where the > parallel build seems to trigger OOMs for larger indexes. Specifically, > the calls for ginEntryInsert seem to leak memory into > TopTransactionContext and OOM/crash the outer process. > For serial build, the calls for ginEntryInsert tend to happen in a > temporary memory context that gets reset at the end of the > ginBuildCallback. > For inserts, the call has a custom memory context and gets reset at > the end of the insert. > For parallel build, during the merge phase, the MemoryContext isn't > swapped - and so this happens on the TopTransactionContext, and ends > up growing (especially for larger indexes). > Yes, that's true. The ginBuildCallbackParallel() already releases memory after flushing the in-memory state, but I missed _gin_parallel_merge() needs to be careful about memory usage too. I haven't been able to trigger OOM (or even particularly bad) memory usage, but I suppose it might be an issue with custom GIN opclasses with much wider keys. > I believe at the very least these should happen inside the tmpCtx > found in the GinBuildState and reset periodically. > > In the attached patch, I've tried to do this, and I'm able to build > the index without OOMing, and only consuming maintenance_work_mem > through the merge process. > > Would appreciate your thoughts on this (and whether there's other approaches to > resolve this too). > The patch seems fine to me - I repeated the tests with mailing list archives, with MemoryContextStats() in _gin_parallel_merge, and it reliably minimizes the memory usage. So that's fine. I was also worried if this might have performance impact, but it actually seems to make it a little bit faster. I'll get this pushed. thanks -- Tomas Vondra
On 4/30/25 14:39, Tomas Vondra wrote: > > On 4/18/25 03:03, Vinod Sridharan wrote: >> ... >> > > The patch seems fine to me - I repeated the tests with mailing list > archives, with MemoryContextStats() in _gin_parallel_merge, and it > reliably minimizes the memory usage. So that's fine. > > I was also worried if this might have performance impact, but it > actually seems to make it a little bit faster. > > I'll get this pushed. > And pushed, so it'll be in beta1. Thanks! -- Tomas Vondra