Thread: Popcount optimization using AVX512
This proposal showcases the speed-up provided to popcount feature when using AVX512 registers. The intent is to share
thepreliminary results with the community and get feedback for adding avx512 support for popcount.
Revisiting the previous discussion/improvements around this feature, I have created a micro-benchmark based on the
pg_popcount()in PostgreSQL's current implementations for x86_64 using the newer AVX512 intrinsics. Playing with this
implementationhas improved performance up to 46% on Intel's Sapphire Rapids platform on AWS. Such gains will benefit
scenariosrelying on popcount.
My setup:
Machine: AWS EC2 m7i - 16vcpu, 64gb RAM
OS : Ubuntu 22.04
GCC: 11.4 and 12.3 with flags "-mavx -mavx512vpopcntdq -mavx512vl -march=native -O2".
1. I copied the pg_popcount() implementation into a new C/C++ project using cmake/make.
a. Software only and
b. SSE 64 bit version
2. I created an implementation using the following AVX512 intrinsics:
a. _mm512_popcnt_epi64()
b. _mm512_reduce_add_epi64()
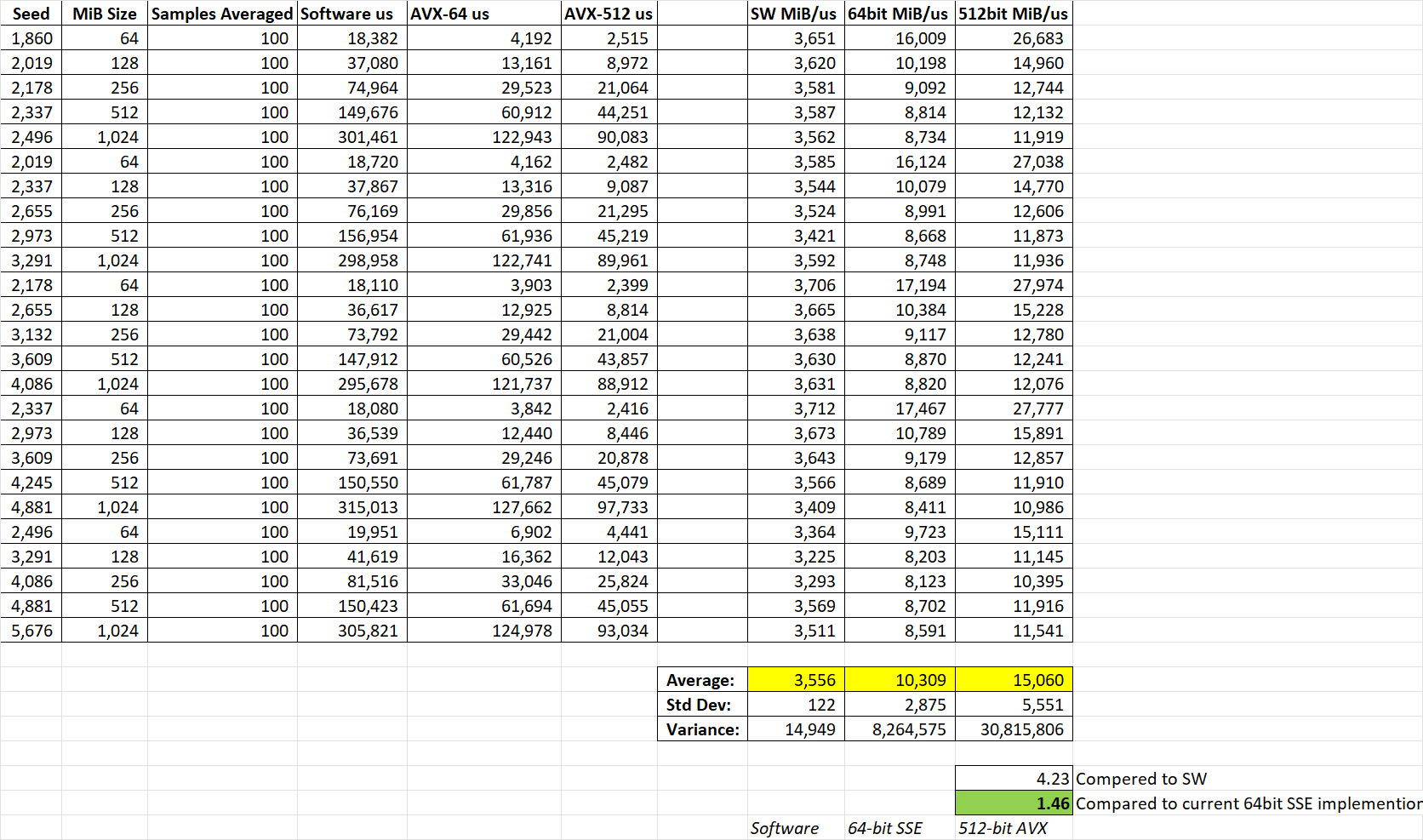
3. I tested random bit streams from 64 MiB to 1024 MiB in length (5 sizes; repeatable with RNG seed [std::mt19937_64])
4. I tested 5 seeds for each input buffer size and averaged 100 runs each (5*5*100=2500 pg_popcount() calls on a single
thread)
5. Data: <See Attached picture.>
The code I wrote uses the 64-bit solution or SW on the memory not aligned to a 512-bit boundary in memory:
///////////////////////////////////////////////////////////////////////
// 512-bit intrisic implementation (AVX512VPOPCNTDQ + AVX512F)
uint64_t popcount_512_impl(const char *bytes, int byteCount) {
#ifdef __AVX__
uint64_t result = 0;
uint64_t remainder = ((uint64_t)bytes) % 64;
result += popcount_64_impl(bytes, remainder);
byteCount -= remainder;
bytes += remainder;
uint64_t vectorCount = byteCount / 64;
remainder = byteCount % 64;
__m512i *vectors = (__m512i *)bytes;
__m512i rv;
while (vectorCount--) {
rv = _mm512_popcnt_epi64(*(vectors++));
result += _mm512_reduce_add_epi64(rv);
}
bytes = (const char *)vectors;
result += popcount_64_impl(bytes, remainder);
return result;
#else
return popcount_64_impl(bytes, byteCount);
#endif
}
There are further optimizations that can be applied here, but for demonstration I added the __AVX__ macro and if not
fallback to the original implementations in PostgreSQL.
The 46% improvement in popcount is worthy of discussion considering the previous popcount 64-bit SSE and SW
implementations.
Thanks,
Paul Amonson
Attachment
{kind=link}
On Thu, 2 Nov 2023 at 15:22, Amonson, Paul D <paul.d.amonson@intel.com> wrote: > > This proposal showcases the speed-up provided to popcount feature when using AVX512 registers. The intent is to share thepreliminary results with the community and get feedback for adding avx512 support for popcount. > > Revisiting the previous discussion/improvements around this feature, I have created a micro-benchmark based on the pg_popcount()in PostgreSQL's current implementations for x86_64 using the newer AVX512 intrinsics. Playing with this implementationhas improved performance up to 46% on Intel's Sapphire Rapids platform on AWS. Such gains will benefit scenariosrelying on popcount. How does this compare to older CPUs, and more mixed workloads? IIRC, the use of AVX512 (which I believe this instruction to be included in) has significant implications for core clock frequency when those instructions are being executed, reducing overall performance if they're not a large part of the workload. > My setup: > > Machine: AWS EC2 m7i - 16vcpu, 64gb RAM > OS : Ubuntu 22.04 > GCC: 11.4 and 12.3 with flags "-mavx -mavx512vpopcntdq -mavx512vl -march=native -O2". > > 1. I copied the pg_popcount() implementation into a new C/C++ project using cmake/make. > a. Software only and > b. SSE 64 bit version > 2. I created an implementation using the following AVX512 intrinsics: > a. _mm512_popcnt_epi64() > b. _mm512_reduce_add_epi64() > 3. I tested random bit streams from 64 MiB to 1024 MiB in length (5 sizes; repeatable with RNG seed [std::mt19937_64]) Apart from the two type functions bytea_bit_count and bit_bit_count (which are not accessed in postgres' own systems, but which could want to cover bytestreams of >BLCKSZ) the only popcount usages I could find were on objects that fit on a page, i.e. <8KiB in size. How does performance compare for bitstreams of such sizes, especially after any CPU clock implications are taken into account? Kind regards, Matthias van de Meent Neon (https://neon.tech)
On Fri, Nov 03, 2023 at 12:16:05PM +0100, Matthias van de Meent wrote: > On Thu, 2 Nov 2023 at 15:22, Amonson, Paul D <paul.d.amonson@intel.com> wrote: >> This proposal showcases the speed-up provided to popcount feature when >> using AVX512 registers. The intent is to share the preliminary results >> with the community and get feedback for adding avx512 support for >> popcount. >> >> Revisiting the previous discussion/improvements around this feature, I >> have created a micro-benchmark based on the pg_popcount() in >> PostgreSQL's current implementations for x86_64 using the newer AVX512 >> intrinsics. Playing with this implementation has improved performance up >> to 46% on Intel's Sapphire Rapids platform on AWS. Such gains will >> benefit scenarios relying on popcount. Nice. I've been testing out AVX2 support in src/include/port/simd.h, and the results look promising there, too. I intend to start a new thread for that (hopefully soon), but one open question I don't have a great answer for yet is how to detect support for newer intrinsics. So far, we've been able to use function pointers (e.g., popcount, crc32c) or deduce support via common predefined compiler macros (e.g., we assume SSE2 is supported if the compiler is targeting 64-bit x86). But the former introduces a performance penalty, and we probably want to inline most of this stuff, anyway. And the latter limits us to stuff that has been around for a decade or two. Like I said, I don't have any proposals yet, but assuming we do want to support newer intrinsics, either open-coded or via auto-vectorization, I suspect we'll need to gather consensus for a new policy/strategy. > Apart from the two type functions bytea_bit_count and bit_bit_count > (which are not accessed in postgres' own systems, but which could want > to cover bytestreams of >BLCKSZ) the only popcount usages I could find > were on objects that fit on a page, i.e. <8KiB in size. How does > performance compare for bitstreams of such sizes, especially after any > CPU clock implications are taken into account? Yeah, the previous optimizations in this area appear to have used ANALYZE as the benchmark, presumably because of visibilitymap_count(). I briefly attempted to measure the difference with and without AVX512 support, but I haven't noticed any difference thus far. One complication for visiblitymap_count() is that the data passed to pg_popcount64() is masked, which requires a couple more intructions when you're using the intrinsics. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Nathan Bossart <nathandbossart@gmail.com> writes:
> Like I said, I don't have any proposals yet, but assuming we do want to
> support newer intrinsics, either open-coded or via auto-vectorization, I
> suspect we'll need to gather consensus for a new policy/strategy.
Yeah. The function-pointer solution kind of sucks, because for the
sort of operation we're considering here, adding a call and return
is probably order-of-100% overhead. Worse, it adds similar overhead
for everyone who doesn't get the benefit of the optimization. (One
of the key things you want to be able to say, when trying to sell
a maybe-it-helps-or-maybe-it-doesnt optimization to the PG community,
is "it doesn't hurt anyone who's not able to benefit".) And you
can't argue that that overhead is negligible either, because if it
is then we're all wasting our time even discussing this. So we need
a better technology, and I fear I have no good ideas about what.
Your comment about vectorization hints at one answer: if you can
amortize the overhead across multiple applications of the operation,
then it doesn't hurt so much. But I'm not sure how often we can
make that answer work.
regards, tom lane
On Mon, Nov 06, 2023 at 09:52:58PM -0500, Tom Lane wrote: > Nathan Bossart <nathandbossart@gmail.com> writes: > > Like I said, I don't have any proposals yet, but assuming we do want to > > support newer intrinsics, either open-coded or via auto-vectorization, I > > suspect we'll need to gather consensus for a new policy/strategy. > > Yeah. The function-pointer solution kind of sucks, because for the > sort of operation we're considering here, adding a call and return > is probably order-of-100% overhead. Worse, it adds similar overhead > for everyone who doesn't get the benefit of the optimization. The glibc/gcc "ifunc" mechanism was designed to solve this problem of choosing a function implementation based on the runtime CPU, without incurring function pointer overhead. I would not attempt to use AVX512 on non-glibc systems, and I would use ifunc to select the desired popcount implementation on glibc: https://gcc.gnu.org/onlinedocs/gcc-4.8.5/gcc/Function-Attributes.html
On Mon, Nov 06, 2023 at 07:15:01PM -0800, Noah Misch wrote: > On Mon, Nov 06, 2023 at 09:52:58PM -0500, Tom Lane wrote: >> Nathan Bossart <nathandbossart@gmail.com> writes: >> > Like I said, I don't have any proposals yet, but assuming we do want to >> > support newer intrinsics, either open-coded or via auto-vectorization, I >> > suspect we'll need to gather consensus for a new policy/strategy. >> >> Yeah. The function-pointer solution kind of sucks, because for the >> sort of operation we're considering here, adding a call and return >> is probably order-of-100% overhead. Worse, it adds similar overhead >> for everyone who doesn't get the benefit of the optimization. > > The glibc/gcc "ifunc" mechanism was designed to solve this problem of choosing > a function implementation based on the runtime CPU, without incurring function > pointer overhead. I would not attempt to use AVX512 on non-glibc systems, and > I would use ifunc to select the desired popcount implementation on glibc: > https://gcc.gnu.org/onlinedocs/gcc-4.8.5/gcc/Function-Attributes.html Thanks, that seems promising for the function pointer cases. I'll plan on trying to convert one of the existing ones to use it. BTW it looks like LLVM has something similar [0]. IIUC this unfortunately wouldn't help for cases where we wanted to keep stuff inlined, such as is_valid_ascii() and the functions in pg_lfind.h, unless we applied it to the calling functions, but that doesn't ѕound particularly maintainable. [0] https://llvm.org/docs/LangRef.html#ifuncs -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Mon, Nov 06, 2023 at 09:59:26PM -0600, Nathan Bossart wrote: > On Mon, Nov 06, 2023 at 07:15:01PM -0800, Noah Misch wrote: > > On Mon, Nov 06, 2023 at 09:52:58PM -0500, Tom Lane wrote: > >> Nathan Bossart <nathandbossart@gmail.com> writes: > >> > Like I said, I don't have any proposals yet, but assuming we do want to > >> > support newer intrinsics, either open-coded or via auto-vectorization, I > >> > suspect we'll need to gather consensus for a new policy/strategy. > >> > >> Yeah. The function-pointer solution kind of sucks, because for the > >> sort of operation we're considering here, adding a call and return > >> is probably order-of-100% overhead. Worse, it adds similar overhead > >> for everyone who doesn't get the benefit of the optimization. > > > > The glibc/gcc "ifunc" mechanism was designed to solve this problem of choosing > > a function implementation based on the runtime CPU, without incurring function > > pointer overhead. I would not attempt to use AVX512 on non-glibc systems, and > > I would use ifunc to select the desired popcount implementation on glibc: > > https://gcc.gnu.org/onlinedocs/gcc-4.8.5/gcc/Function-Attributes.html > > Thanks, that seems promising for the function pointer cases. I'll plan on > trying to convert one of the existing ones to use it. BTW it looks like > LLVM has something similar [0]. > > IIUC this unfortunately wouldn't help for cases where we wanted to keep > stuff inlined, such as is_valid_ascii() and the functions in pg_lfind.h, > unless we applied it to the calling functions, but that doesn't ѕound > particularly maintainable. Agreed, it doesn't solve inline cases. If the gains are big enough, we should move toward packages containing N CPU-specialized copies of the postgres binary, with bin/postgres just exec'ing the right one.
On Mon, Nov 06, 2023 at 09:53:15PM -0800, Noah Misch wrote: > On Mon, Nov 06, 2023 at 09:59:26PM -0600, Nathan Bossart wrote: >> On Mon, Nov 06, 2023 at 07:15:01PM -0800, Noah Misch wrote: >> > The glibc/gcc "ifunc" mechanism was designed to solve this problem of choosing >> > a function implementation based on the runtime CPU, without incurring function >> > pointer overhead. I would not attempt to use AVX512 on non-glibc systems, and >> > I would use ifunc to select the desired popcount implementation on glibc: >> > https://gcc.gnu.org/onlinedocs/gcc-4.8.5/gcc/Function-Attributes.html >> >> Thanks, that seems promising for the function pointer cases. I'll plan on >> trying to convert one of the existing ones to use it. BTW it looks like >> LLVM has something similar [0]. >> >> IIUC this unfortunately wouldn't help for cases where we wanted to keep >> stuff inlined, such as is_valid_ascii() and the functions in pg_lfind.h, >> unless we applied it to the calling functions, but that doesn't ѕound >> particularly maintainable. > > Agreed, it doesn't solve inline cases. If the gains are big enough, we should > move toward packages containing N CPU-specialized copies of the postgres > binary, with bin/postgres just exec'ing the right one. I performed a quick test with ifunc on my x86 machine that ordinarily uses the runtime checks for the CRC32C code, and I actually see a consistent 3.5% regression for pg_waldump -z on 100M 65-byte records. I've attached the patch used for testing. The multiple-copies-of-the-postgres-binary idea seems interesting. That's probably not something that could be enabled by default, but perhaps we could add support for a build option. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
Sorry for the late response here. We spent some time researching and measuring the frequency impact of AVX512 instructionsused here. >How does this compare to older CPUs, and more mixed workloads? IIRC, the use of AVX512 (which I believe this instruction to be included in) has significant implications for core clock frequency when those instructions are being executed, reducing overall performance if they're not a large part of the workload. AVX512 has light and heavy instructions. While the heavy AVX512 instructions have clock frequency implications, the lightinstructions not so much. See [0] for more details. We captured EMON data for the benchmark used in this work, and seethat the instructions are using the licensing level not meant for heavy AVX512 operations. This means the instructionsfor popcount : _mm512_popcnt_epi64(), _mm512_reduce_add_epi64() are not going to have any significant impacton CPU clock frequency. Clock frequency impact aside, we measured the same benchmark for gains on older Intel hardware and observe up to 18% betterperformance on Intel Icelake. On older intel hardware, the popcntdq 512 instruction is not present so it won’t work.If clock frequency is not affected, rest of workload should not be impacted in the case of mixed workloads. >Apart from the two type functions bytea_bit_count and bit_bit_count (which are not accessed in postgres' own systems, but which could want to cover bytestreams of >BLCKSZ) the only popcount usages I could find were on objects that fit on a page, i.e. <8KiB in size. How does performance compare for bitstreams of such sizes, especially after any CPU clock implications are taken into account? Testing this on smaller block sizes < 8KiB shows that AVX512 compared to the current 64bit behavior shows slightly lowerperformance, but with a large variance. We cannot conclude much from it. The testing with ANALYZE benchmark by Nathanalso points to no visible impact as a result of using AVX512. The gains on larger dataset is easily evident, with lessvariance. What are your thoughts if we introduce AVX512 popcount for smaller sizes as an optional feature initially, and then testit more thoroughly over time on this particular use case? Regarding enablement, following the other responses related to function inlining, using ifunc and enabling future intrinsicsupport, it seems a concrete solution would require further discussion. We’re attaching a patch to enable AVX512,which can use AVX512 flags during build. For example: >make -E CFLAGS_AVX512="-mavx -mavx512dq -mavx512vpopcntdq -mavx512vl -march=icelake-server -DAVX512_POPCNT=1" Thoughts or feedback on the approach in the patch? This solution should not impact anyone who doesn’t use the feature i.e.AVX512. Open to additional ideas if this doesn’t seem like the right approach here. [0] https://lemire.me/blog/2018/09/07/avx-512-when-and-how-to-use-these-new-instructions/ -----Original Message----- From: Nathan Bossart <nathandbossart@gmail.com> Sent: Tuesday, November 7, 2023 12:15 PM To: Noah Misch <noah@leadboat.com> Cc: Tom Lane <tgl@sss.pgh.pa.us>; Matthias van de Meent <boekewurm+postgres@gmail.com>; Amonson, Paul D <paul.d.amonson@intel.com>;pgsql-hackers@lists.postgresql.org; Shankaran, Akash <akash.shankaran@intel.com> Subject: Re: Popcount optimization using AVX512 On Mon, Nov 06, 2023 at 09:53:15PM -0800, Noah Misch wrote: > On Mon, Nov 06, 2023 at 09:59:26PM -0600, Nathan Bossart wrote: >> On Mon, Nov 06, 2023 at 07:15:01PM -0800, Noah Misch wrote: >> > The glibc/gcc "ifunc" mechanism was designed to solve this problem >> > of choosing a function implementation based on the runtime CPU, >> > without incurring function pointer overhead. I would not attempt >> > to use AVX512 on non-glibc systems, and I would use ifunc to select the desired popcount implementation on glibc: >> > https://gcc.gnu.org/onlinedocs/gcc-4.8.5/gcc/Function-Attributes.ht >> > ml >> >> Thanks, that seems promising for the function pointer cases. I'll >> plan on trying to convert one of the existing ones to use it. BTW it >> looks like LLVM has something similar [0]. >> >> IIUC this unfortunately wouldn't help for cases where we wanted to >> keep stuff inlined, such as is_valid_ascii() and the functions in >> pg_lfind.h, unless we applied it to the calling functions, but that >> doesn't ѕound particularly maintainable. > > Agreed, it doesn't solve inline cases. If the gains are big enough, > we should move toward packages containing N CPU-specialized copies of > the postgres binary, with bin/postgres just exec'ing the right one. I performed a quick test with ifunc on my x86 machine that ordinarily uses the runtime checks for the CRC32C code, and Iactually see a consistent 3.5% regression for pg_waldump -z on 100M 65-byte records. I've attached the patch used for testing. The multiple-copies-of-the-postgres-binary idea seems interesting. That's probably not something that could be enabled bydefault, but perhaps we could add support for a build option. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
On Wed, Nov 15, 2023 at 08:27:57PM +0000, Shankaran, Akash wrote: > AVX512 has light and heavy instructions. While the heavy AVX512 > instructions have clock frequency implications, the light instructions > not so much. See [0] for more details. We captured EMON data for the > benchmark used in this work, and see that the instructions are using the > licensing level not meant for heavy AVX512 operations. This means the > instructions for popcount : _mm512_popcnt_epi64(), > _mm512_reduce_add_epi64() are not going to have any significant impact on > CPU clock frequency. > > Clock frequency impact aside, we measured the same benchmark for gains on > older Intel hardware and observe up to 18% better performance on Intel > Icelake. On older intel hardware, the popcntdq 512 instruction is not > present so it won’t work. If clock frequency is not affected, rest of > workload should not be impacted in the case of mixed workloads. Thanks for sharing your analysis. > Testing this on smaller block sizes < 8KiB shows that AVX512 compared to > the current 64bit behavior shows slightly lower performance, but with a > large variance. We cannot conclude much from it. The testing with ANALYZE > benchmark by Nathan also points to no visible impact as a result of using > AVX512. The gains on larger dataset is easily evident, with less > variance. > > What are your thoughts if we introduce AVX512 popcount for smaller sizes > as an optional feature initially, and then test it more thoroughly over > time on this particular use case? I don't see any need to rush this. At the very earliest, this feature would go into v17, which doesn't enter feature freeze until April 2024. That seems like enough time to complete any additional testing you'd like to do. However, if you are seeing worse performance with this patch, then it seems unlikely that we'd want to proceed. > Thoughts or feedback on the approach in the patch? This solution should > not impact anyone who doesn’t use the feature i.e. AVX512. Open to > additional ideas if this doesn’t seem like the right approach here. It's true that it wouldn't impact anyone not using the feature, but there's also a decent chance that this code goes virtually untested. As I've stated elsewhere [0], I think we should ensure there's buildfarm coverage for this kind of architecture-specific stuff. [0] https://postgr.es/m/20230726043707.GB3211130%40nathanxps13 -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Sorry for the late response. We did some further testing and research on our end, and ended up modifying the AVX512
basedalgorithm for popcount. We removed a scalar dependency and accumulate the results of popcnt instruction in a zmm
register,only performing the reduce add at the very end, similar to [0].
With the updated patch, we observed significant improvements and handily beat the previous popcount algorithm
performance.No regressions in any scenario are observed:
Platform: Intel Xeon Platinum 8360Y (Icelake) for data sizes 1kb - 64kb.
Microbenchmark: 2x - 3x gains presently vs 19% previously, on the same microbenchmark described initially in this
thread.
PG testing:
SQL bit_count() calls popcount. Using a Postgres benchmark calling "select bit_count(bytea(col1)) from mytable" on a
tablewith ~2M text rows, each row 1-12kb in size, we observe (only comparing with 64bit PG implementation, which is the
fastest):
1. Entire benchmark using AVX512 implementation vs PG 64-bit impl runs 6-13% faster.
2. Reduce time spent on pg_popcount() method in postgres server during the benchmark:
o 64bit (current PG): 29.5%
o AVX512: 3.3%
3. Reduce number of samples processed by popcount:
o 64bit (current PG): 2.4B samples
o AVX512: 285M samples
Compile above patch (on a machine supporting AVX512 vpopcntdq) using: make all CFLAGS_AVX512="-DHAVE__HW_AVX512_POPCNT
-mavx-mavx512vpopcntdq -mavx512f -march=native
Attaching flamegraphs and patch for above observations.
[0] https://github.com/WojciechMula/sse-popcount/blob/master/popcnt-avx512-vpopcnt.cpp
Thanks,
Akash Shankaran
-----Original Message-----
From: Nathan Bossart <nathandbossart@gmail.com>
Sent: Wednesday, November 15, 2023 1:49 PM
To: Shankaran, Akash <akash.shankaran@intel.com>
Cc: Noah Misch <noah@leadboat.com>; Amonson, Paul D <paul.d.amonson@intel.com>; Tom Lane <tgl@sss.pgh.pa.us>; Matthias
vande Meent <boekewurm+postgres@gmail.com>; pgsql-hackers@lists.postgresql.org
Subject: Re: Popcount optimization using AVX512
On Wed, Nov 15, 2023 at 08:27:57PM +0000, Shankaran, Akash wrote:
> AVX512 has light and heavy instructions. While the heavy AVX512
> instructions have clock frequency implications, the light instructions
> not so much. See [0] for more details. We captured EMON data for the
> benchmark used in this work, and see that the instructions are using
> the licensing level not meant for heavy AVX512 operations. This means
> the instructions for popcount : _mm512_popcnt_epi64(),
> _mm512_reduce_add_epi64() are not going to have any significant impact
> on CPU clock frequency.
>
> Clock frequency impact aside, we measured the same benchmark for gains
> on older Intel hardware and observe up to 18% better performance on
> Intel Icelake. On older intel hardware, the popcntdq 512 instruction
> is not present so it won’t work. If clock frequency is not affected,
> rest of workload should not be impacted in the case of mixed workloads.
Thanks for sharing your analysis.
> Testing this on smaller block sizes < 8KiB shows that AVX512 compared
> to the current 64bit behavior shows slightly lower performance, but
> with a large variance. We cannot conclude much from it. The testing
> with ANALYZE benchmark by Nathan also points to no visible impact as a
> result of using AVX512. The gains on larger dataset is easily evident,
> with less variance.
>
> What are your thoughts if we introduce AVX512 popcount for smaller
> sizes as an optional feature initially, and then test it more
> thoroughly over time on this particular use case?
I don't see any need to rush this. At the very earliest, this feature would go into v17, which doesn't enter feature
freezeuntil April 2024.
That seems like enough time to complete any additional testing you'd like to do. However, if you are seeing worse
performancewith this patch, then it seems unlikely that we'd want to proceed.
> Thoughts or feedback on the approach in the patch? This solution
> should not impact anyone who doesn’t use the feature i.e. AVX512. Open
> to additional ideas if this doesn’t seem like the right approach here.
It's true that it wouldn't impact anyone not using the feature, but there's also a decent chance that this code goes
virtuallyuntested. As I've stated elsewhere [0], I think we should ensure there's buildfarm coverage for this kind of
architecture-specificstuff.
[0] https://postgr.es/m/20230726043707.GB3211130%40nathanxps13
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
Attachment
{kind=link}
{kind=link}
On 2024-Jan-25, Shankaran, Akash wrote: > With the updated patch, we observed significant improvements and > handily beat the previous popcount algorithm performance. No > regressions in any scenario are observed: > Platform: Intel Xeon Platinum 8360Y (Icelake) for data sizes 1kb - 64kb. > Microbenchmark: 2x - 3x gains presently vs 19% previously, on the same > microbenchmark described initially in this thread. These are great results. However, it would be much better if the improved code were available for all relevant builds and activated if a CPUID test determines that the relevant instructions are available, instead of requiring a compile-time flag -- which most builds are not going to use, thus wasting the opportunity for running the optimized code. I suppose this would require patching pg_popcount64_choose() to be more specific. Looking at the existing code, I would also consider renaming the "_fast" variants to something like pg_popcount32_asml/ pg_popcount64_asmq so that you can name the new one pg_popcount64_asmdq or such. (Or maybe leave the 32-bit version alone as "fast/slow", since there's no third option for that one -- or do I misread?) I also think this needs to move the CFLAGS-decision-making elsewhere; asking the user to get it right is too much of a burden. Is it workable to simply verify compiler support for the additional flags needed, and if so add them to a new CFLAGS_BITUTILS variable or such? We already have the CFLAGS_CRC model that should be easy to follow. Should be easy enough to mostly copy what's in configure.ac and meson.build, right? Finally, the matter of using ifunc as proposed by Noah seems to be still in the air, with no patches offered for the popcount family. Given that Nathan reports [1] a performance decrease, maybe we should set that thought aside for now and continue to use function pointers. It's worth keeping in mind that popcount is already using function pointers (at least in the case where we try to use POPCNT directly), so patching to select between three options instead of between two wouldn't be a regression. [1] https://postgr.es/m/20231107201441.GA898662@nathanxps13 -- Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/ "Nunca se desea ardientemente lo que solo se desea por razón" (F. Alexandre)
On 2024-Jan-25, Alvaro Herrera wrote: > Finally, the matter of using ifunc as proposed by Noah seems to be still > in the air, with no patches offered for the popcount family. Oh, I just realized that the patch as currently proposed is placing the optimized popcount code in the path that does not require going through a function pointer. So the performance increase is probably coming from both avoiding jumping through the pointer as well as from the improved instruction. This suggests that finding a way to make the ifunc stuff work (with good performance) is critical to this work. -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/ "The ability of users to misuse tools is, of course, legendary" (David Steele) https://postgr.es/m/11b38a96-6ded-4668-b772-40f992132797@pgmasters.net
Hi All,
> However, it would be much better if the improved code were available for
> all relevant builds and activated if a CPUID test determines that the
> relevant instructions are available, instead of requiring a compile-time
> flag -- which most builds are not going to use, thus wasting the
> opportunity for running the optimized code.
This makes sense. I addressed the feedback, and am attaching an updated patch. Patch also addresses your feedback of
autconfconfigurations by adding CFLAG support. I tested the runtime check for AVX512 on multiple processors with and
withoutAVX512 and it detected or failed to detect the feature as expected.
> Looking at the existing code, I would also consider renaming
> the "_fast" variants to something like pg_popcount32_asml/
> pg_popcount64_asmq so that you can name the new one pg_popcount64_asmdq
> or such.
I left out the renaming, as it made sense to keep the fast/slow naming for readability.
> Finally, the matter of using ifunc as proposed by Noah seems to be still
> in the air, with no patches offered for the popcount family. Given that
> Nathan reports [1] a performance decrease, maybe we should set that
> thought aside for now and continue to use function pointers.
Since there are improvements without it (results below), I agree with you to continue using function pointers.
I collected data on machines with, and without AVX512 support, using a table with 1M rows and performing SQL
bit_count()on a char column containing (84bytes, 4KiB, 8KiB, 16KiB).
* On non-AVX 512 hardware: no regression or impact at runtime with code built with AVX 512 support in the binary
betweenthe patched and unpatched servers.
* On AVX512 hardware: the max improvement I saw was 17% but was averaged closer to 6.5% on a bare-metal machine.
Thebenefit is lower on smaller cloud VMs on AWS (1 - 3%)
If the patch looks good, please suggest next steps on committing it.
Paul
-----Original Message-----
From: Alvaro Herrera <alvherre@alvh.no-ip.org>
Sent: Thursday, January 25, 2024 1:49 AM
To: Shankaran, Akash <akash.shankaran@intel.com>
Cc: Nathan Bossart <nathandbossart@gmail.com>; Noah Misch <noah@leadboat.com>; Amonson, Paul D
<paul.d.amonson@intel.com>;Tom Lane <tgl@sss.pgh.pa.us>; Matthias van de Meent <boekewurm+postgres@gmail.com>;
pgsql-hackers@lists.postgresql.org
Subject: Re: Popcount optimization using AVX512
On 2024-Jan-25, Shankaran, Akash wrote:
> With the updated patch, we observed significant improvements and
> handily beat the previous popcount algorithm performance. No
> regressions in any scenario are observed:
> Platform: Intel Xeon Platinum 8360Y (Icelake) for data sizes 1kb - 64kb.
> Microbenchmark: 2x - 3x gains presently vs 19% previously, on the same
> microbenchmark described initially in this thread.
These are great results.
However, it would be much better if the improved code were available for all relevant builds and activated if a CPUID
testdetermines that the relevant instructions are available, instead of requiring a compile-time flag -- which most
buildsare not going to use, thus wasting the opportunity for running the optimized code.
I suppose this would require patching pg_popcount64_choose() to be more specific. Looking at the existing code, I
wouldalso consider renaming the "_fast" variants to something like pg_popcount32_asml/ pg_popcount64_asmq so that you
canname the new one pg_popcount64_asmdq or such. (Or maybe leave the 32-bit version alone as "fast/slow", since
there'sno third option for that one -- or do I misread?)
I also think this needs to move the CFLAGS-decision-making elsewhere; asking the user to get it right is too much of a
burden. Is it workable to simply verify compiler support for the additional flags needed, and if so add them to a new
CFLAGS_BITUTILSvariable or such? We already have the CFLAGS_CRC model that should be easy to follow. Should be easy
enoughto mostly copy what's in configure.ac and meson.build, right?
Finally, the matter of using ifunc as proposed by Noah seems to be still in the air, with no patches offered for the
popcountfamily. Given that Nathan reports [1] a performance decrease, maybe we should set that thought aside for now
andcontinue to use function pointers. It's worth keeping in mind that popcount is already using function pointers (at
leastin the case where we try to use POPCNT directly), so patching to select between three options instead of between
twowouldn't be a regression.
[1] https://postgr.es/m/20231107201441.GA898662@nathanxps13
--
Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/
"Nunca se desea ardientemente lo que solo se desea por razón" (F. Alexandre)
Attachment
Hello, This looks quite reasonable. On my machine, I get the compiler test to pass so I get a "yes" in configure; but of course my CPU doesn't support the instructions so I get the slow variant. So here's the patch again with some minor artifacts fixed. I have the following review notes: 1. we use __get_cpuid_count and __cpuidex by relying on macros HAVE__GET_CPUID and HAVE__CPUID respectively; but those macros are (in the current Postgres source) only used and tested for __get_cpuid and __cpuid respectively. So unless there's some reason to be certain that __get_cpuid_count is always present when __get_cpuid is present, and that __cpuidex is present when __cpuid is present, I think we need to add new configure tests and new HAVE_ macros for these. 2. we rely on <immintrin.h> being present with no AC_CHECK_HEADER() test. We currently don't use this header anywhere, so I suppose we need a test for this one as well. (Also, I suppose if we don't have immintrin.h we can skip the rest of it?) 3. We do the __get_cpuid_count/__cpuidex test and we also do a xgetbv test. The comment there claims that this is to check the results for consistency. But ... how would we know that the results are ever inconsistent? As far as I understand, if they were, we would silently become slower. Is this really what we want? I'm confused about this coding. Maybe we do need both tests to succeed? In that case, just reword the comment. I think if both tests are each considered reliable on its own, then we could either choose one of them and stick with it, ignoring the other; or we could use one as primary and then in a USE_ASSERT_CHECKING block verify that the other matches and throw a WARNING if not (but what would that tell us?). Or something like that ... not sure. 4. It needs meson support, which I suppose consists of copying the c-compiler.m4 test into meson.build, mimicking what the tests for CRC instructions do. I started a CI run with this patch applied, https://cirrus-ci.com/build/4912499619790848 but because Meson support is missing, the compile failed immediately: [10:08:48.825] ccache cc -Isrc/port/libpgport_srv.a.p -Isrc/include -I../src/include -Isrc/include/utils -fdiagnostics-color=always-pipe -D_FILE_OFFSET_BITS=64 -Wall -Winvalid-pch -g -fno-strict-aliasing -fwrapv -fexcess-precision=standard-D_GNU_SOURCE -Wmissing-prototypes -Wpointer-arith -Werror=vla -Wendif-labels -Wmissing-format-attribute-Wimplicit-fallthrough=3 -Wcast-function-type -Wshadow=compatible-local -Wformat-security -Wdeclaration-after-statement-Wno-format-truncation -Wno-stringop-truncation -fPIC -pthread -DBUILDING_DLL -MD -MQ src/port/libpgport_srv.a.p/pg_bitutils.c.o-MF src/port/libpgport_srv.a.p/pg_bitutils.c.o.d -o src/port/libpgport_srv.a.p/pg_bitutils.c.o-c ../src/port/pg_bitutils.c [10:08:48.825] ../src/port/pg_bitutils.c: In function ‘pg_popcount512_fast’: [10:08:48.825] ../src/port/pg_bitutils.c:270:11: warning: AVX512F vector return without AVX512F enabled changes the ABI [-Wpsabi] [10:08:48.825] 270 | __m512i accumulator = _mm512_setzero_si512(); [10:08:48.825] | ^~~~~~~~~~~ [10:08:48.825] In file included from /usr/lib/gcc/x86_64-linux-gnu/10/include/immintrin.h:55, [10:08:48.825] from ../src/port/pg_bitutils.c:22: [10:08:48.825] /usr/lib/gcc/x86_64-linux-gnu/10/include/avx512fintrin.h:339:1: error: inlining failed in call to ‘always_inline’‘_mm512_setzero_si512’: target specific option mismatch [10:08:48.825] 339 | _mm512_setzero_si512 (void) [10:08:48.825] | ^~~~~~~~~~~~~~~~~~~~ [10:08:48.825] ../src/port/pg_bitutils.c:270:25: note: called from here [10:08:48.825] 270 | __m512i accumulator = _mm512_setzero_si512(); [10:08:48.825] | ^~~~~~~~~~~~~~~~~~~~~~ Thanks -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/ "Siempre hay que alimentar a los dioses, aunque la tierra esté seca" (Orual)
Attachment
I happened to notice by chance that John Naylor had posted an extension to measure performance of popcount here: https://postgr.es/m/CAFBsxsE7otwnfA36Ly44zZO+b7AEWHRFANxR1h1kxveEV=ghLQ@mail.gmail.com This might be useful as a base for a new one to verify the results of the proposed patch in machines with relevant instruction support. -- Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/ "We're here to devour each other alive" (Hobbes)
Álvaro, All feedback is now completed. I added the additional checks for the new APIs and a separate check for the header to autoconf. About the double check for AVX 512 I added a large comment explaining why both are needed. There are cases where the CPUZMM# registers are not exposed by the OS or hypervisor even if the CPU supports AVX512. The big change is adding all old and new build support to meson. I am new to meson/ninja so please review carefully. Thanks, Paul -----Original Message----- From: Alvaro Herrera <alvherre@alvh.no-ip.org> Sent: Wednesday, February 7, 2024 2:13 AM To: Amonson, Paul D <paul.d.amonson@intel.com> Cc: Shankaran, Akash <akash.shankaran@intel.com>; Nathan Bossart <nathandbossart@gmail.com>; Noah Misch <noah@leadboat.com>;Tom Lane <tgl@sss.pgh.pa.us>; Matthias van de Meent <boekewurm+postgres@gmail.com>; pgsql-hackers@lists.postgresql.org Subject: Re: Popcount optimization using AVX512 Hello, This looks quite reasonable. On my machine, I get the compiler test to pass so I get a "yes" in configure; but of coursemy CPU doesn't support the instructions so I get the slow variant. So here's the patch again with some minor artifactsfixed. I have the following review notes: 1. we use __get_cpuid_count and __cpuidex by relying on macros HAVE__GET_CPUID and HAVE__CPUID respectively; but those macrosare (in the current Postgres source) only used and tested for __get_cpuid and __cpuid respectively. So unless there'ssome reason to be certain that __get_cpuid_count is always present when __get_cpuid is present, and that __cpuidexis present when __cpuid is present, I think we need to add new configure tests and new HAVE_ macros for these. 2. we rely on <immintrin.h> being present with no AC_CHECK_HEADER() test. We currently don't use this header anywhere, soI suppose we need a test for this one as well. (Also, I suppose if we don't have immintrin.h we can skip the rest of it?) 3. We do the __get_cpuid_count/__cpuidex test and we also do a xgetbv test. The comment there claims that this is to checkthe results for consistency. But ... how would we know that the results are ever inconsistent? As far as I understand,if they were, we would silently become slower. Is this really what we want? I'm confused about this coding. Maybe we do need both tests to succeed? In that case, just reword the comment. I think if both tests are each considered reliable on its own, then we could either choose one of them and stick with it,ignoring the other; or we could use one as primary and then in a USE_ASSERT_CHECKING block verify that the other matchesand throw a WARNING if not (but what would that tell us?). Or something like that ... not sure. 4. It needs meson support, which I suppose consists of copying the c-compiler.m4 test into meson.build, mimicking what the tests for CRC instructions do. I started a CI run with this patch applied, https://cirrus-ci.com/build/4912499619790848 but because Meson support is missing, the compile failed immediately: [10:08:48.825] ccache cc -Isrc/port/libpgport_srv.a.p -Isrc/include -I../src/include -Isrc/include/utils -fdiagnostics-color=always-pipe -D_FILE_OFFSET_BITS=64 -Wall -Winvalid-pch -g -fno-strict-aliasing -fwrapv -fexcess-precision=standard-D_GNU_SOURCE -Wmissing-prototypes -Wpointer-arith -Werror=vla -Wendif-labels -Wmissing-format-attribute-Wimplicit-fallthrough=3 -Wcast-function-type -Wshadow=compatible-local -Wformat-security -Wdeclaration-after-statement-Wno-format-truncation -Wno-stringop-truncation -fPIC -pthread -DBUILDING_DLL -MD -MQ src/port/libpgport_srv.a.p/pg_bitutils.c.o-MF src/port/libpgport_srv.a.p/pg_bitutils.c.o.d -o src/port/libpgport_srv.a.p/pg_bitutils.c.o-c ../src/port/pg_bitutils.c [10:08:48.825] ../src/port/pg_bitutils.c: In function‘pg_popcount512_fast’: [10:08:48.825] ../src/port/pg_bitutils.c:270:11: warning: AVX512F vector return without AVX512F enabled changes the ABI [-Wpsabi] [10:08:48.825] 270 | __m512i accumulator = _mm512_setzero_si512(); [10:08:48.825] | ^~~~~~~~~~~ [10:08:48.825] In file included from /usr/lib/gcc/x86_64-linux-gnu/10/include/immintrin.h:55, [10:08:48.825] from ../src/port/pg_bitutils.c:22: [10:08:48.825] /usr/lib/gcc/x86_64-linux-gnu/10/include/avx512fintrin.h:339:1: error: inlining failed in call to ‘always_inline’‘_mm512_setzero_si512’: target specific option mismatch [10:08:48.825] 339 | _mm512_setzero_si512 (void) [10:08:48.825] | ^~~~~~~~~~~~~~~~~~~~ [10:08:48.825] ../src/port/pg_bitutils.c:270:25: note: called from here [10:08:48.825] 270 | __m512i accumulator = _mm512_setzero_si512(); [10:08:48.825] | ^~~~~~~~~~~~~~~~~~~~~~ Thanks -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/ "Siempre hay que alimentar a los dioses, aunque la tierra esté seca" (Orual)
Attachment
Hi, On 2024-01-26 07:42:33 +0100, Alvaro Herrera wrote: > This suggests that finding a way to make the ifunc stuff work (with good > performance) is critical to this work. Ifuncs are effectively implemented as a function call via a pointer, they're not magic, unfortunately. The sole trick they provide is that you don't manually have to use the function pointer. Greetings, Andres
Hi,
On 2024-02-09 17:39:46 +0000, Amonson, Paul D wrote:
> diff --git a/meson.build b/meson.build
> index 8ed51b6aae..1e7a4dc942 100644
> --- a/meson.build
> +++ b/meson.build
> @@ -1773,6 +1773,45 @@ elif cc.links('''
> endif
>
>
> +# XXX: The configure.ac check for __cpuidex() is broken, we don't copy that
> +# here. To prevent problems due to two detection methods working, stop
> +# checking after one.
This seems like a bogus copy-paste.
> +if cc.links('''
> + #include <cpuid.h>
> + int main(int arg, char **argv)
> + {
> + unsigned int exx[4] = {0, 0, 0, 0};
> + __get_cpuid_count(7, 0, &exx[0], &exx[1], &exx[2], &exx[3]);
> + }
> + ''', name: '__get_cpuid_count',
> + args: test_c_args)
> + cdata.set('HAVE__GET_CPUID_COUNT', 1)
> +elif cc.links('''
> + #include <intrin.h>
> + int main(int arg, char **argv)
> + {
> + unsigned int exx[4] = {0, 0, 0, 0};
> + __cpuidex(exx, 7, 0);
> + }
> + ''', name: '__cpuidex',
> + args: test_c_args)
> + cdata.set('HAVE__CPUIDEX', 1)
> +endif
> +
> +
> +# Check for header immintrin.h
> +if cc.links('''
> + #include <immintrin.h>
> + int main(int arg, char **argv)
> + {
> + return 1701;
> + }
> + ''', name: '__immintrin',
> + args: test_c_args)
> + cdata.set('HAVE__IMMINTRIN', 1)
> +endif
Do these all actually have to link? Invoking the linker is slow.
I think you might be able to just use cc.has_header_symbol().
> +###############################################################
> +# AVX 512 POPCNT Intrinsic check
> +###############################################################
> +have_avx512_popcnt = false
> +cflags_avx512_popcnt = []
> +if host_cpu == 'x86_64'
> + prog = '''
> + #include <immintrin.h>
> + #include <stdint.h>
> + void main(void)
> + {
> + __m512i tmp __attribute__((aligned(64)));
> + __m512i input = _mm512_setzero_si512();
> + __m512i output = _mm512_popcnt_epi64(input);
> + uint64_t cnt = 999;
> + _mm512_store_si512(&tmp, output);
> + cnt = _mm512_reduce_add_epi64(tmp);
> + /* return computed value, to prevent the above being optimized away */
> + return cnt == 0;
> + }'''
Does this work with msvc?
> + if cc.links(prog, name: '_mm512_setzero_si512, _mm512_popcnt_epi64, _mm512_store_si512, and
_mm512_reduce_add_epi64with -mavx512vpopcntdq -mavx512f',
That's a very long line in the output, how about using the avx feature name or
something?
> diff --git a/src/port/Makefile b/src/port/Makefile
> index dcc8737e68..6a01a7d89a 100644
> --- a/src/port/Makefile
> +++ b/src/port/Makefile
> @@ -87,6 +87,11 @@ pg_crc32c_sse42.o: CFLAGS+=$(CFLAGS_CRC)
> pg_crc32c_sse42_shlib.o: CFLAGS+=$(CFLAGS_CRC)
> pg_crc32c_sse42_srv.o: CFLAGS+=$(CFLAGS_CRC)
>
> +# Newer Intel processors can use AVX-512 POPCNT Capabilities (01/30/2024)
> +pg_bitutils.o: CFLAGS+=$(CFLAGS_AVX512_POPCNT)
> +pg_bitutils_shlib.o: CFLAGS+=$(CFLAGS_AVX512_POPCNT)
> +pg_bitutils_srv.o:CFLAGS+=$(CFLAGS_AVX512_POPCNT)
> +
> # all versions of pg_crc32c_armv8.o need CFLAGS_CRC
> pg_crc32c_armv8.o: CFLAGS+=$(CFLAGS_CRC)
> pg_crc32c_armv8_shlib.o: CFLAGS+=$(CFLAGS_CRC)
> diff --git a/src/port/meson.build b/src/port/meson.build
> index 69b30ab21b..1c48a3b07e 100644
> --- a/src/port/meson.build
> +++ b/src/port/meson.build
> @@ -184,6 +184,7 @@ foreach name, opts : pgport_variants
> link_with: cflag_libs,
> c_pch: pch_c_h,
> kwargs: opts + {
> + 'c_args': opts.get('c_args', []) + cflags_avx512_popcnt,
> 'dependencies': opts['dependencies'] + [ssl],
> }
> )
This will build all of pgport with the avx flags, which wouldn't be correct, I
think? The compiler might inject automatic uses of avx512 in places, which
would cause problems, no?
While you don't do the same for make, isn't even just using the avx512 for all
of pg_bitutils.c broken for exactly that reson? That's why the existing code
builds the files for various crc variants as their own file.
Greetings,
Andres Freund
On Fri, Feb 09, 2024 at 10:24:32AM -0800, Andres Freund wrote: > On 2024-01-26 07:42:33 +0100, Alvaro Herrera wrote: > > This suggests that finding a way to make the ifunc stuff work (with good > > performance) is critical to this work. > > Ifuncs are effectively implemented as a function call via a pointer, they're > not magic, unfortunately. The sole trick they provide is that you don't > manually have to use the function pointer. The IFUNC creators introduced it so glibc could use arch-specific memcpy with the instruction sequence of a non-pointer, extern function call, not the instruction sequence of a function pointer call. I don't know why the upthread ifunc_test.patch benchmark found ifunc performing worse than function pointers. However, it would be odd if toolchains have replaced the original IFUNC with something equivalent to or slower than function pointers.
Hi,
On 2024-02-09 15:27:57 -0800, Noah Misch wrote:
> On Fri, Feb 09, 2024 at 10:24:32AM -0800, Andres Freund wrote:
> > On 2024-01-26 07:42:33 +0100, Alvaro Herrera wrote:
> > > This suggests that finding a way to make the ifunc stuff work (with good
> > > performance) is critical to this work.
> >
> > Ifuncs are effectively implemented as a function call via a pointer, they're
> > not magic, unfortunately. The sole trick they provide is that you don't
> > manually have to use the function pointer.
>
> The IFUNC creators introduced it so glibc could use arch-specific memcpy with
> the instruction sequence of a non-pointer, extern function call, not the
> instruction sequence of a function pointer call.
My understanding is that the ifunc mechanism just avoid the need for repeated
indirect calls/jumps to implement a single function call, not the use of
indirect function calls at all. Calls into shared libraries, like libc, are
indirected via the GOT / PLT, i.e. an indirect function call/jump. Without
ifuncs, the target of the function call would then have to dispatch to the
resolved function. Ifuncs allow to avoid this repeated dispatch by moving the
dispatch to the dynamic linker stage, modifying the contents of the GOT/PLT to
point to the right function. Thus ifuncs are an optimization when calling a
function in a shared library that's then dispatched depending on the cpu
capabilities.
However, in our case, where the code is in the same binary, function calls
implemented in the main binary directly (possibly via a static library) don't
go through GOT/PLT. In such a case, use of ifuncs turns a normal direct
function call into one going through the GOT/PLT, i.e. makes it indirect. The
same is true for calls within a shared library if either explicit symbol
visibility is used, or -symbolic, -Wl,-Bsymbolic or such is used. Therefore
there's no efficiency gain of ifuncs over a call via function pointer.
This isn't because ifunc is implemented badly or something - the reason for
this is that dynamic relocations aren't typically implemented by patching all
callsites (".text relocations"), which is what you would need to avoid the
need for an indirect call to something that fundamentally cannot be a constant
address at link time. The reason text relocations are disfavored is that
they can make program startup quite slow, that they require allowing
modifications to executable pages which are disliked due to the security
implications, and that they make the code non-shareable, as the in-memory
executable code has to differ from the on-disk code.
I actually think ifuncs within the same binary are a tad *slower* than plain
function pointer calls, unless -fno-plt is used. Without -fno-plt, an ifunc is
called by 1) a direct call into the PLT, 2) loading the target address from
the GOT, 3) making an an indirect jump to that address. Whereas a "plain
indirect function call" is just 1) load target address from variable 2) making
an indirect jump to that address. With -fno-plt the callsites themselves load
the address from the GOT.
Greetings,
Andres Freund
On Fri, Feb 09, 2024 at 08:33:23PM -0800, Andres Freund wrote:
> On 2024-02-09 15:27:57 -0800, Noah Misch wrote:
> > On Fri, Feb 09, 2024 at 10:24:32AM -0800, Andres Freund wrote:
> > > On 2024-01-26 07:42:33 +0100, Alvaro Herrera wrote:
> > > > This suggests that finding a way to make the ifunc stuff work (with good
> > > > performance) is critical to this work.
> > >
> > > Ifuncs are effectively implemented as a function call via a pointer, they're
> > > not magic, unfortunately. The sole trick they provide is that you don't
> > > manually have to use the function pointer.
> >
> > The IFUNC creators introduced it so glibc could use arch-specific memcpy with
> > the instruction sequence of a non-pointer, extern function call, not the
> > instruction sequence of a function pointer call.
>
> My understanding is that the ifunc mechanism just avoid the need for repeated
> indirect calls/jumps to implement a single function call, not the use of
> indirect function calls at all. Calls into shared libraries, like libc, are
> indirected via the GOT / PLT, i.e. an indirect function call/jump. Without
> ifuncs, the target of the function call would then have to dispatch to the
> resolved function. Ifuncs allow to avoid this repeated dispatch by moving the
> dispatch to the dynamic linker stage, modifying the contents of the GOT/PLT to
> point to the right function. Thus ifuncs are an optimization when calling a
> function in a shared library that's then dispatched depending on the cpu
> capabilities.
>
> However, in our case, where the code is in the same binary, function calls
> implemented in the main binary directly (possibly via a static library) don't
> go through GOT/PLT. In such a case, use of ifuncs turns a normal direct
> function call into one going through the GOT/PLT, i.e. makes it indirect. The
> same is true for calls within a shared library if either explicit symbol
> visibility is used, or -symbolic, -Wl,-Bsymbolic or such is used. Therefore
> there's no efficiency gain of ifuncs over a call via function pointer.
>
>
> This isn't because ifunc is implemented badly or something - the reason for
> this is that dynamic relocations aren't typically implemented by patching all
> callsites (".text relocations"), which is what you would need to avoid the
> need for an indirect call to something that fundamentally cannot be a constant
> address at link time. The reason text relocations are disfavored is that
> they can make program startup quite slow, that they require allowing
> modifications to executable pages which are disliked due to the security
> implications, and that they make the code non-shareable, as the in-memory
> executable code has to differ from the on-disk code.
>
>
> I actually think ifuncs within the same binary are a tad *slower* than plain
> function pointer calls, unless -fno-plt is used. Without -fno-plt, an ifunc is
> called by 1) a direct call into the PLT, 2) loading the target address from
> the GOT, 3) making an an indirect jump to that address. Whereas a "plain
> indirect function call" is just 1) load target address from variable 2) making
> an indirect jump to that address. With -fno-plt the callsites themselves load
> the address from the GOT.
That sounds more accurate than what I wrote. Thanks.
My responses with questions,
> > +# XXX: The configure.ac check for __cpuidex() is broken, we don't
> > +copy that # here. To prevent problems due to two detection methods
> > +working, stop # checking after one.
>
> This seems like a bogus copy-paste.
My bad. Will remove the offending comment. :)
> > +# Check for header immintrin.h
> ...
> Do these all actually have to link? Invoking the linker is slow.
> I think you might be able to just use cc.has_header_symbol().
I took this to mean the last of the 3 new blocks. I changed this one to the cc_has_header method. I think I do want the
first2 checking the link as well. If the don't link here they won't link in the actual build.
> Does this work with msvc?
I think it will work but I have no way to validate it. I propose we remove the AVX-512 popcount feature from MSVC
builds.Sound ok?
> That's a very long line in the output, how about using the avx feature name or something?
Agree, will fix.
> This will build all of pgport with the avx flags, which wouldn't be correct, I think? The compiler might inject
automaticuses of avx512 in places, which would cause problems, no?
This will take me some time to learn how to do this in meson. Any pointers here would be helpful.
> While you don't do the same for make, isn't even just using the avx512 for all of pg_bitutils.c broken for exactly
thatreson? That's why the existing code builds the files for various crc variants as their own file.
I don't think its broken, nothing else in pg_bitutils.c will make use of AVX-512, so I am not sure what dividing this
upinto multiple files will yield benefits beyond code readability as they will all be needed during compile time. I
preferto not split if the community agrees to it.
If splitting still makes sense, I propose splitting into 3 files: pg_bitutils.c (entry point +sw popcnt
implementation),pg_popcnt_choose.c (CPUID and xgetbv check) and pg_popcnt_x86_64_accel.c (64/512bit x86
implementations).
I'm not an expert in meson, but splitting might add complexity to meson.build.
Could you elaborate if there are other benefits to the split file approach?
Paul
-----Original Message-----
From: Andres Freund <andres@anarazel.de>
Sent: Friday, February 9, 2024 10:35 AM
To: Amonson, Paul D <paul.d.amonson@intel.com>
Cc: Alvaro Herrera <alvherre@alvh.no-ip.org>; Shankaran, Akash <akash.shankaran@intel.com>; Nathan Bossart
<nathandbossart@gmail.com>;Noah Misch <noah@leadboat.com>; Tom Lane <tgl@sss.pgh.pa.us>; Matthias van de Meent
<boekewurm+postgres@gmail.com>;pgsql-hackers@lists.postgresql.org
Subject: Re: Popcount optimization using AVX512
Hi,
On 2024-02-09 17:39:46 +0000, Amonson, Paul D wrote:
> diff --git a/meson.build b/meson.build index 8ed51b6aae..1e7a4dc942
> 100644
> --- a/meson.build
> +++ b/meson.build
> @@ -1773,6 +1773,45 @@ elif cc.links('''
> endif
>
>
> +# XXX: The configure.ac check for __cpuidex() is broken, we don't
> +copy that # here. To prevent problems due to two detection methods
> +working, stop # checking after one.
This seems like a bogus copy-paste.
> +if cc.links('''
> + #include <cpuid.h>
> + int main(int arg, char **argv)
> + {
> + unsigned int exx[4] = {0, 0, 0, 0};
> + __get_cpuid_count(7, 0, &exx[0], &exx[1], &exx[2], &exx[3]);
> + }
> + ''', name: '__get_cpuid_count',
> + args: test_c_args)
> + cdata.set('HAVE__GET_CPUID_COUNT', 1) elif cc.links('''
> + #include <intrin.h>
> + int main(int arg, char **argv)
> + {
> + unsigned int exx[4] = {0, 0, 0, 0};
> + __cpuidex(exx, 7, 0);
> + }
> + ''', name: '__cpuidex',
> + args: test_c_args)
> + cdata.set('HAVE__CPUIDEX', 1)
> +endif
> +
> +
> +# Check for header immintrin.h
> +if cc.links('''
> + #include <immintrin.h>
> + int main(int arg, char **argv)
> + {
> + return 1701;
> + }
> + ''', name: '__immintrin',
> + args: test_c_args)
> + cdata.set('HAVE__IMMINTRIN', 1)
> +endif
Do these all actually have to link? Invoking the linker is slow.
I think you might be able to just use cc.has_header_symbol().
> +###############################################################
> +# AVX 512 POPCNT Intrinsic check
> +###############################################################
> +have_avx512_popcnt = false
> +cflags_avx512_popcnt = []
> +if host_cpu == 'x86_64'
> + prog = '''
> + #include <immintrin.h>
> + #include <stdint.h>
> + void main(void)
> + {
> + __m512i tmp __attribute__((aligned(64)));
> + __m512i input = _mm512_setzero_si512();
> + __m512i output = _mm512_popcnt_epi64(input);
> + uint64_t cnt = 999;
> + _mm512_store_si512(&tmp, output);
> + cnt = _mm512_reduce_add_epi64(tmp);
> + /* return computed value, to prevent the above being optimized away */
> + return cnt == 0;
> + }'''
Does this work with msvc?
> + if cc.links(prog, name: '_mm512_setzero_si512,
> + _mm512_popcnt_epi64, _mm512_store_si512, and _mm512_reduce_add_epi64
> + with -mavx512vpopcntdq -mavx512f',
That's a very long line in the output, how about using the avx feature name or something?
> diff --git a/src/port/Makefile b/src/port/Makefile index
> dcc8737e68..6a01a7d89a 100644
> --- a/src/port/Makefile
> +++ b/src/port/Makefile
> @@ -87,6 +87,11 @@ pg_crc32c_sse42.o: CFLAGS+=$(CFLAGS_CRC)
> pg_crc32c_sse42_shlib.o: CFLAGS+=$(CFLAGS_CRC)
> pg_crc32c_sse42_srv.o: CFLAGS+=$(CFLAGS_CRC)
>
> +# Newer Intel processors can use AVX-512 POPCNT Capabilities
> +(01/30/2024)
> +pg_bitutils.o: CFLAGS+=$(CFLAGS_AVX512_POPCNT)
> +pg_bitutils_shlib.o: CFLAGS+=$(CFLAGS_AVX512_POPCNT)
> +pg_bitutils_srv.o:CFLAGS+=$(CFLAGS_AVX512_POPCNT)
> +
> # all versions of pg_crc32c_armv8.o need CFLAGS_CRC
> pg_crc32c_armv8.o: CFLAGS+=$(CFLAGS_CRC)
> pg_crc32c_armv8_shlib.o: CFLAGS+=$(CFLAGS_CRC) diff --git
> a/src/port/meson.build b/src/port/meson.build index
> 69b30ab21b..1c48a3b07e 100644
> --- a/src/port/meson.build
> +++ b/src/port/meson.build
> @@ -184,6 +184,7 @@ foreach name, opts : pgport_variants
> link_with: cflag_libs,
> c_pch: pch_c_h,
> kwargs: opts + {
> + 'c_args': opts.get('c_args', []) + cflags_avx512_popcnt,
> 'dependencies': opts['dependencies'] + [ssl],
> }
> )
This will build all of pgport with the avx flags, which wouldn't be correct, I think? The compiler might inject
automaticuses of avx512 in places, which would cause problems, no?
While you don't do the same for make, isn't even just using the avx512 for all of pg_bitutils.c broken for exactly that
reson?That's why the existing code builds the files for various crc variants as their own file.
Greetings,
Andres Freund
Hi, On 2024-02-12 20:14:06 +0000, Amonson, Paul D wrote: > > > +# Check for header immintrin.h > > ... > > Do these all actually have to link? Invoking the linker is slow. > > I think you might be able to just use cc.has_header_symbol(). > > I took this to mean the last of the 3 new blocks. Yep. > > Does this work with msvc? > > I think it will work but I have no way to validate it. I propose we remove the AVX-512 popcount feature from MSVC builds.Sound ok? CI [1], whould be able to test at least building. Including via cfbot, automatically run for each commitfest entry - you can see prior runs at [2]. They run on Zen 3 epyc instances, so unfortunately runtime won't be tested. If you look at [3], you can see that currently it doesn't seem to be considered supported at configure time: ... [00:23:48.480] Checking if "__get_cpuid" : links: NO [00:23:48.480] Checking if "__cpuid" : links: YES ... [00:23:48.492] Checking if "x86_64: popcntq instruction" compiles: NO ... Unfortunately CI currently is configured to not upload the build logs if the build succeeds, so we don't have enough details to see why. > > This will build all of pgport with the avx flags, which wouldn't be correct, I think? The compiler might inject automaticuses of avx512 in places, which would cause problems, no? > > This will take me some time to learn how to do this in meson. Any pointers > here would be helpful. Should be fairly simple, add it to the replace_funcs_pos and add the relevant cflags to pgport_cflags, similar to how it's done for crc. > > While you don't do the same for make, isn't even just using the avx512 for all of pg_bitutils.c broken for exactly thatreson? That's why the existing code builds the files for various crc variants as their own file. > > I don't think its broken, nothing else in pg_bitutils.c will make use of > AVX-512 You can't really guarantee that compiler auto-vectorization won't decide to do so, no? I wouldn't call it likely, but it's also hard to be sure it won't happen at some point. > If splitting still makes sense, I propose splitting into 3 files: pg_bitutils.c (entry point +sw popcnt implementation),pg_popcnt_choose.c (CPUID and xgetbv check) and pg_popcnt_x86_64_accel.c (64/512bit x86 implementations). > I'm not an expert in meson, but splitting might add complexity to meson.build. > > Could you elaborate if there are other benefits to the split file approach? It won't lead to SIGILLs ;) Greetings, Andres Freund [1] https://github.com/postgres/postgres/blob/master/src/tools/ci/README [2] https://cirrus-ci.com/github/postgresql-cfbot/postgresql/commitfest%2F47%2F4675 [3] https://cirrus-ci.com/task/5645112189911040
On Sat, Feb 10, 2024 at 03:52:38PM -0800, Noah Misch wrote:
> On Fri, Feb 09, 2024 at 08:33:23PM -0800, Andres Freund wrote:
>> My understanding is that the ifunc mechanism just avoid the need for repeated
>> indirect calls/jumps to implement a single function call, not the use of
>> indirect function calls at all. Calls into shared libraries, like libc, are
>> indirected via the GOT / PLT, i.e. an indirect function call/jump. Without
>> ifuncs, the target of the function call would then have to dispatch to the
>> resolved function. Ifuncs allow to avoid this repeated dispatch by moving the
>> dispatch to the dynamic linker stage, modifying the contents of the GOT/PLT to
>> point to the right function. Thus ifuncs are an optimization when calling a
>> function in a shared library that's then dispatched depending on the cpu
>> capabilities.
>>
>> However, in our case, where the code is in the same binary, function calls
>> implemented in the main binary directly (possibly via a static library) don't
>> go through GOT/PLT. In such a case, use of ifuncs turns a normal direct
>> function call into one going through the GOT/PLT, i.e. makes it indirect. The
>> same is true for calls within a shared library if either explicit symbol
>> visibility is used, or -symbolic, -Wl,-Bsymbolic or such is used. Therefore
>> there's no efficiency gain of ifuncs over a call via function pointer.
>>
>>
>> This isn't because ifunc is implemented badly or something - the reason for
>> this is that dynamic relocations aren't typically implemented by patching all
>> callsites (".text relocations"), which is what you would need to avoid the
>> need for an indirect call to something that fundamentally cannot be a constant
>> address at link time. The reason text relocations are disfavored is that
>> they can make program startup quite slow, that they require allowing
>> modifications to executable pages which are disliked due to the security
>> implications, and that they make the code non-shareable, as the in-memory
>> executable code has to differ from the on-disk code.
>>
>>
>> I actually think ifuncs within the same binary are a tad *slower* than plain
>> function pointer calls, unless -fno-plt is used. Without -fno-plt, an ifunc is
>> called by 1) a direct call into the PLT, 2) loading the target address from
>> the GOT, 3) making an an indirect jump to that address. Whereas a "plain
>> indirect function call" is just 1) load target address from variable 2) making
>> an indirect jump to that address. With -fno-plt the callsites themselves load
>> the address from the GOT.
>
> That sounds more accurate than what I wrote. Thanks.
+1, thanks for the detailed explanation, Andres.
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
Hi, I am encountering a problem that I don't think I understand. I cannot get the MSVC build to link in CI. I added 2 files tothe build, but the linker is complaining about the original pg_bitutils.c file is missing (specifically symbol 'pg_popcount').To my knowledge my changes did not change linking for the offending file and I see the compiles for pg_bitutils.cin all 3 libs in the build. All other builds are compiling. Any help on this issue would be greatly appreciated. My fork is at https://github.com/paul-amonson/postgresql/tree/popcnt_patch and the CI build is at https://cirrus-ci.com/task/4927666021728256. Thanks, Paul -----Original Message----- From: Andres Freund <andres@anarazel.de> Sent: Monday, February 12, 2024 12:37 PM To: Amonson, Paul D <paul.d.amonson@intel.com> Cc: Alvaro Herrera <alvherre@alvh.no-ip.org>; Shankaran, Akash <akash.shankaran@intel.com>; Nathan Bossart <nathandbossart@gmail.com>;Noah Misch <noah@leadboat.com>; Tom Lane <tgl@sss.pgh.pa.us>; Matthias van de Meent <boekewurm+postgres@gmail.com>;pgsql-hackers@lists.postgresql.org Subject: Re: Popcount optimization using AVX512 Hi, On 2024-02-12 20:14:06 +0000, Amonson, Paul D wrote: > > > +# Check for header immintrin.h > > ... > > Do these all actually have to link? Invoking the linker is slow. > > I think you might be able to just use cc.has_header_symbol(). > > I took this to mean the last of the 3 new blocks. Yep. > > Does this work with msvc? > > I think it will work but I have no way to validate it. I propose we remove the AVX-512 popcount feature from MSVC builds.Sound ok? CI [1], whould be able to test at least building. Including via cfbot, automatically run for each commitfest entry - youcan see prior runs at [2]. They run on Zen 3 epyc instances, so unfortunately runtime won't be tested. If you look at[3], you can see that currently it doesn't seem to be considered supported at configure time: ... [00:23:48.480] Checking if "__get_cpuid" : links: NO [00:23:48.480] Checking if "__cpuid" : links: YES ... [00:23:48.492] Checking if "x86_64: popcntq instruction" compiles: NO ... Unfortunately CI currently is configured to not upload the build logs if the build succeeds, so we don't have enough detailsto see why. > > This will build all of pgport with the avx flags, which wouldn't be correct, I think? The compiler might inject automaticuses of avx512 in places, which would cause problems, no? > > This will take me some time to learn how to do this in meson. Any > pointers here would be helpful. Should be fairly simple, add it to the replace_funcs_pos and add the relevant cflags to pgport_cflags, similar to how it'sdone for crc. > > While you don't do the same for make, isn't even just using the avx512 for all of pg_bitutils.c broken for exactly thatreson? That's why the existing code builds the files for various crc variants as their own file. > > I don't think its broken, nothing else in pg_bitutils.c will make use > of > AVX-512 You can't really guarantee that compiler auto-vectorization won't decide to do so, no? I wouldn't call it likely, but it'salso hard to be sure it won't happen at some point. > If splitting still makes sense, I propose splitting into 3 files: pg_bitutils.c (entry point +sw popcnt implementation),pg_popcnt_choose.c (CPUID and xgetbv check) and pg_popcnt_x86_64_accel.c (64/512bit x86 implementations). > I'm not an expert in meson, but splitting might add complexity to meson.build. > > Could you elaborate if there are other benefits to the split file approach? It won't lead to SIGILLs ;) Greetings, Andres Freund [1] https://github.com/postgres/postgres/blob/master/src/tools/ci/README [2] https://cirrus-ci.com/github/postgresql-cfbot/postgresql/commitfest%2F47%2F4675 [3] https://cirrus-ci.com/task/5645112189911040
Hello again, This is now a blocking issue. I can find no reason for the failing behavior of the MSVC build. All other languages buildfine in CI including the Mac. Since the master branch builds, I assume I changed something critical to linking, butI can't figure out what that would be. Can someone with Windows/MSVC experience help me? * Code: https://github.com/paul-amonson/postgresql/tree/popcnt_patch * CI build: https://cirrus-ci.com/task/4927666021728256 Thanks, Paul -----Original Message----- From: Amonson, Paul D <paul.d.amonson@intel.com> Sent: Wednesday, February 21, 2024 9:36 AM To: Andres Freund <andres@anarazel.de> Cc: Alvaro Herrera <alvherre@alvh.no-ip.org>; Shankaran, Akash <akash.shankaran@intel.com>; Nathan Bossart <nathandbossart@gmail.com>;Noah Misch <noah@leadboat.com>; Tom Lane <tgl@sss.pgh.pa.us>; Matthias van de Meent <boekewurm+postgres@gmail.com>;pgsql-hackers@lists.postgresql.org Subject: RE: Popcount optimization using AVX512 Hi, I am encountering a problem that I don't think I understand. I cannot get the MSVC build to link in CI. I added 2 files tothe build, but the linker is complaining about the original pg_bitutils.c file is missing (specifically symbol 'pg_popcount').To my knowledge my changes did not change linking for the offending file and I see the compiles for pg_bitutils.cin all 3 libs in the build. All other builds are compiling. Any help on this issue would be greatly appreciated. My fork is at https://github.com/paul-amonson/postgresql/tree/popcnt_patch and the CI build is at https://cirrus-ci.com/task/4927666021728256. Thanks, Paul -----Original Message----- From: Andres Freund <andres@anarazel.de> Sent: Monday, February 12, 2024 12:37 PM To: Amonson, Paul D <paul.d.amonson@intel.com> Cc: Alvaro Herrera <alvherre@alvh.no-ip.org>; Shankaran, Akash <akash.shankaran@intel.com>; Nathan Bossart <nathandbossart@gmail.com>;Noah Misch <noah@leadboat.com>; Tom Lane <tgl@sss.pgh.pa.us>; Matthias van de Meent <boekewurm+postgres@gmail.com>;pgsql-hackers@lists.postgresql.org Subject: Re: Popcount optimization using AVX512 Hi, On 2024-02-12 20:14:06 +0000, Amonson, Paul D wrote: > > > +# Check for header immintrin.h > > ... > > Do these all actually have to link? Invoking the linker is slow. > > I think you might be able to just use cc.has_header_symbol(). > > I took this to mean the last of the 3 new blocks. Yep. > > Does this work with msvc? > > I think it will work but I have no way to validate it. I propose we remove the AVX-512 popcount feature from MSVC builds.Sound ok? CI [1], whould be able to test at least building. Including via cfbot, automatically run for each commitfest entry - youcan see prior runs at [2]. They run on Zen 3 epyc instances, so unfortunately runtime won't be tested. If you look at[3], you can see that currently it doesn't seem to be considered supported at configure time: ... [00:23:48.480] Checking if "__get_cpuid" : links: NO [00:23:48.480] Checking if "__cpuid" : links: YES ... [00:23:48.492] Checking if "x86_64: popcntq instruction" compiles: NO ... Unfortunately CI currently is configured to not upload the build logs if the build succeeds, so we don't have enough detailsto see why. > > This will build all of pgport with the avx flags, which wouldn't be correct, I think? The compiler might inject automaticuses of avx512 in places, which would cause problems, no? > > This will take me some time to learn how to do this in meson. Any > pointers here would be helpful. Should be fairly simple, add it to the replace_funcs_pos and add the relevant cflags to pgport_cflags, similar to how it'sdone for crc. > > While you don't do the same for make, isn't even just using the avx512 for all of pg_bitutils.c broken for exactly thatreson? That's why the existing code builds the files for various crc variants as their own file. > > I don't think its broken, nothing else in pg_bitutils.c will make use > of > AVX-512 You can't really guarantee that compiler auto-vectorization won't decide to do so, no? I wouldn't call it likely, but it'salso hard to be sure it won't happen at some point. > If splitting still makes sense, I propose splitting into 3 files: pg_bitutils.c (entry point +sw popcnt implementation),pg_popcnt_choose.c (CPUID and xgetbv check) and pg_popcnt_x86_64_accel.c (64/512bit x86 implementations). > I'm not an expert in meson, but splitting might add complexity to meson.build. > > Could you elaborate if there are other benefits to the split file approach? It won't lead to SIGILLs ;) Greetings, Andres Freund [1] https://github.com/postgres/postgres/blob/master/src/tools/ci/README [2] https://cirrus-ci.com/github/postgresql-cfbot/postgresql/commitfest%2F47%2F4675 [3] https://cirrus-ci.com/task/5645112189911040
Andres, After consulting some Intel internal experts on MSVC the linking issue as it stood was not resolved. Instead, I created aMSVC ONLY work-around. This adds one extra functional call on the Windows builds (The linker resolves a real function justfine but not a function pointer of the same name). This extra latency does not exist on any of the other platforms. Ialso believe I addressed all issues raised in the previous reviews. The new pg_popcnt_x86_64_accel.c file is now the ONLYfile compiled with the AVX512 compiler flags. I added support for the MSVC compiler flag as well. Both meson and autoconfare updated with the new refactor. I am attaching the new patch. Paul -----Original Message----- From: Amonson, Paul D <paul.d.amonson@intel.com> Sent: Monday, February 26, 2024 9:57 AM To: Amonson, Paul D <paul.d.amonson@intel.com>; Andres Freund <andres@anarazel.de> Cc: Alvaro Herrera <alvherre@alvh.no-ip.org>; Shankaran, Akash <akash.shankaran@intel.com>; Nathan Bossart <nathandbossart@gmail.com>;Noah Misch <noah@leadboat.com>; Tom Lane <tgl@sss.pgh.pa.us>; Matthias van de Meent <boekewurm+postgres@gmail.com>;pgsql-hackers@lists.postgresql.org Subject: RE: Popcount optimization using AVX512 Hello again, This is now a blocking issue. I can find no reason for the failing behavior of the MSVC build. All other languages buildfine in CI including the Mac. Since the master branch builds, I assume I changed something critical to linking, butI can't figure out what that would be. Can someone with Windows/MSVC experience help me? * Code: https://github.com/paul-amonson/postgresql/tree/popcnt_patch * CI build: https://cirrus-ci.com/task/4927666021728256 Thanks, Paul -----Original Message----- From: Amonson, Paul D <paul.d.amonson@intel.com> Sent: Wednesday, February 21, 2024 9:36 AM To: Andres Freund <andres@anarazel.de> Cc: Alvaro Herrera <alvherre@alvh.no-ip.org>; Shankaran, Akash <akash.shankaran@intel.com>; Nathan Bossart <nathandbossart@gmail.com>;Noah Misch <noah@leadboat.com>; Tom Lane <tgl@sss.pgh.pa.us>; Matthias van de Meent <boekewurm+postgres@gmail.com>;pgsql-hackers@lists.postgresql.org Subject: RE: Popcount optimization using AVX512 Hi, I am encountering a problem that I don't think I understand. I cannot get the MSVC build to link in CI. I added 2 files tothe build, but the linker is complaining about the original pg_bitutils.c file is missing (specifically symbol 'pg_popcount').To my knowledge my changes did not change linking for the offending file and I see the compiles for pg_bitutils.cin all 3 libs in the build. All other builds are compiling. Any help on this issue would be greatly appreciated. My fork is at https://github.com/paul-amonson/postgresql/tree/popcnt_patch and the CI build is at https://cirrus-ci.com/task/4927666021728256. Thanks, Paul -----Original Message----- From: Andres Freund <andres@anarazel.de> Sent: Monday, February 12, 2024 12:37 PM To: Amonson, Paul D <paul.d.amonson@intel.com> Cc: Alvaro Herrera <alvherre@alvh.no-ip.org>; Shankaran, Akash <akash.shankaran@intel.com>; Nathan Bossart <nathandbossart@gmail.com>;Noah Misch <noah@leadboat.com>; Tom Lane <tgl@sss.pgh.pa.us>; Matthias van de Meent <boekewurm+postgres@gmail.com>;pgsql-hackers@lists.postgresql.org Subject: Re: Popcount optimization using AVX512 Hi, On 2024-02-12 20:14:06 +0000, Amonson, Paul D wrote: > > > +# Check for header immintrin.h > > ... > > Do these all actually have to link? Invoking the linker is slow. > > I think you might be able to just use cc.has_header_symbol(). > > I took this to mean the last of the 3 new blocks. Yep. > > Does this work with msvc? > > I think it will work but I have no way to validate it. I propose we remove the AVX-512 popcount feature from MSVC builds.Sound ok? CI [1], whould be able to test at least building. Including via cfbot, automatically run for each commitfest entry - youcan see prior runs at [2]. They run on Zen 3 epyc instances, so unfortunately runtime won't be tested. If you look at[3], you can see that currently it doesn't seem to be considered supported at configure time: ... [00:23:48.480] Checking if "__get_cpuid" : links: NO [00:23:48.480] Checking if "__cpuid" : links: YES ... [00:23:48.492] Checking if "x86_64: popcntq instruction" compiles: NO ... Unfortunately CI currently is configured to not upload the build logs if the build succeeds, so we don't have enough detailsto see why. > > This will build all of pgport with the avx flags, which wouldn't be correct, I think? The compiler might inject automaticuses of avx512 in places, which would cause problems, no? > > This will take me some time to learn how to do this in meson. Any > pointers here would be helpful. Should be fairly simple, add it to the replace_funcs_pos and add the relevant cflags to pgport_cflags, similar to how it'sdone for crc. > > While you don't do the same for make, isn't even just using the avx512 for all of pg_bitutils.c broken for exactly thatreson? That's why the existing code builds the files for various crc variants as their own file. > > I don't think its broken, nothing else in pg_bitutils.c will make use > of > AVX-512 You can't really guarantee that compiler auto-vectorization won't decide to do so, no? I wouldn't call it likely, but it'salso hard to be sure it won't happen at some point. > If splitting still makes sense, I propose splitting into 3 files: pg_bitutils.c (entry point +sw popcnt implementation),pg_popcnt_choose.c (CPUID and xgetbv check) and pg_popcnt_x86_64_accel.c (64/512bit x86 implementations). > I'm not an expert in meson, but splitting might add complexity to meson.build. > > Could you elaborate if there are other benefits to the split file approach? It won't lead to SIGILLs ;) Greetings, Andres Freund [1] https://github.com/postgres/postgres/blob/master/src/tools/ci/README [2] https://cirrus-ci.com/github/postgresql-cfbot/postgresql/commitfest%2F47%2F4675 [3] https://cirrus-ci.com/task/5645112189911040
Attachment
Thanks for the new version of the patch. I didn't see a commitfest entry
for this one, and unfortunately I think it's too late to add it for the
March commitfest. I would encourage you to add it to July's commitfest [0]
so that we can get some routine cfbot coverage.
On Tue, Feb 27, 2024 at 08:46:06PM +0000, Amonson, Paul D wrote:
> After consulting some Intel internal experts on MSVC the linking issue as
> it stood was not resolved. Instead, I created a MSVC ONLY work-around.
> This adds one extra functional call on the Windows builds (The linker
> resolves a real function just fine but not a function pointer of the same
> name). This extra latency does not exist on any of the other platforms. I
> also believe I addressed all issues raised in the previous reviews. The
> new pg_popcnt_x86_64_accel.c file is now the ONLY file compiled with the
> AVX512 compiler flags. I added support for the MSVC compiler flag as
> well. Both meson and autoconf are updated with the new refactor.
>
> I am attaching the new patch.
I think this patch might be missing the new files.
-#define LARGE_OFF_T (((off_t) 1 << 62) - 1 + ((off_t) 1 << 62))
+#define LARGE_OFF_T ((((off_t) 1 << 31) << 31) - 1 + (((off_t) 1 << 31) << 31))
IME this means that the autoconf you are using has been patched. A quick
search on the mailing lists seems to indicate that it might be specific to
Debian [1].
-static int pg_popcount32_slow(uint32 word);
-static int pg_popcount64_slow(uint64 word);
+int pg_popcount32_slow(uint32 word);
+int pg_popcount64_slow(uint64 word);
+uint64 pg_popcount_slow(const char *buf, int bytes);
This patch appears to do a lot of refactoring. Would it be possible to
break out the refactoring parts into a prerequisite patch that could be
reviewed and committed independently from the AVX512 stuff?
-#if SIZEOF_VOID_P >= 8
+#if SIZEOF_VOID_P == 8
/* Process in 64-bit chunks if the buffer is aligned. */
- if (buf == (const char *) TYPEALIGN(8, buf))
+ if (buf == (const char *)TYPEALIGN(8, buf))
{
- const uint64 *words = (const uint64 *) buf;
+ const uint64 *words = (const uint64 *)buf;
while (bytes >= 8)
{
@@ -309,9 +213,9 @@ pg_popcount(const char *buf, int bytes)
bytes -= 8;
}
- buf = (const char *) words;
+ buf = (const char *)words;
}
-#else
+#elif SIZEOF_VOID_P == 4
/* Process in 32-bit chunks if the buffer is aligned. */
if (buf == (const char *) TYPEALIGN(4, buf))
{
Most, if not all, of these changes seem extraneous. Do we actually need to
more strictly check SIZEOF_VOID_P?
[0] https://commitfest.postgresql.org/48/
[1] https://postgr.es/m/20230211020042.uthdgj72kp3xlqam%40awork3.anarazel.de
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
Hi, First, apologies on the patch. Find re-attached updated version. Now I have some questions.... #1 > -#define LARGE_OFF_T (((off_t) 1 << 62) - 1 + ((off_t) 1 << 62)) > +#define LARGE_OFF_T ((((off_t) 1 << 31) << 31) - 1 + (((off_t) 1 << 31) > +<< 31)) > > IME this means that the autoconf you are using has been patched. A quick search on the mailing lists seems to indicatethat it might be specific to Debian [1]. I am not sure what the ask is here? I made changes to the configure.ac and ran autoconf2.69 to get builds to succeed. Doyou have a separate feedback here? #2 As for the refactoring, this was done to satisfy previous review feedback about applying the AVX512 CFLAGS to the entirepg_bitutils.c file. Mainly to avoid segfault due to the AVX512 flags. If its ok, I would prefer to make a single commitas the change is pretty small and straight forward. #3 I am not sure I understand the comment about the SIZE_VOID_P checks. Aren't they necessary to choose which functions to callbased on 32 or 64 bit architectures? #4 Would this change qualify for Workflow A as described in [0] and can be picked up by a committer, given it has been reviewedby multiple committers so far? The scope of the change is pretty contained as well. [0] https://wiki.postgresql.org/wiki/Submitting_a_Patch Thanks, Paul -----Original Message----- From: Nathan Bossart <nathandbossart@gmail.com> Sent: Friday, March 1, 2024 1:45 PM To: Amonson, Paul D <paul.d.amonson@intel.com> Cc: Andres Freund <andres@anarazel.de>; Alvaro Herrera <alvherre@alvh.no-ip.org>; Shankaran, Akash <akash.shankaran@intel.com>;Noah Misch <noah@leadboat.com>; Tom Lane <tgl@sss.pgh.pa.us>; Matthias van de Meent <boekewurm+postgres@gmail.com>;pgsql-hackers@lists.postgresql.org Subject: Re: Popcount optimization using AVX512 Thanks for the new version of the patch. I didn't see a commitfest entry for this one, and unfortunately I think it's toolate to add it for the March commitfest. I would encourage you to add it to July's commitfest [0] so that we can getsome routine cfbot coverage. On Tue, Feb 27, 2024 at 08:46:06PM +0000, Amonson, Paul D wrote: > After consulting some Intel internal experts on MSVC the linking issue > as it stood was not resolved. Instead, I created a MSVC ONLY work-around. > This adds one extra functional call on the Windows builds (The linker > resolves a real function just fine but not a function pointer of the > same name). This extra latency does not exist on any of the other > platforms. I also believe I addressed all issues raised in the > previous reviews. The new pg_popcnt_x86_64_accel.c file is now the > ONLY file compiled with the > AVX512 compiler flags. I added support for the MSVC compiler flag as > well. Both meson and autoconf are updated with the new refactor. > > I am attaching the new patch. I think this patch might be missing the new files. -#define LARGE_OFF_T (((off_t) 1 << 62) - 1 + ((off_t) 1 << 62)) +#define LARGE_OFF_T ((((off_t) 1 << 31) << 31) - 1 + (((off_t) 1 << 31) +<< 31)) IME this means that the autoconf you are using has been patched. A quick search on the mailing lists seems to indicate thatit might be specific to Debian [1]. -static int pg_popcount32_slow(uint32 word); -static int pg_popcount64_slow(uint64 word); +int pg_popcount32_slow(uint32 word); +int pg_popcount64_slow(uint64 word); +uint64 pg_popcount_slow(const char *buf, int bytes); This patch appears to do a lot of refactoring. Would it be possible to break out the refactoring parts into a prerequisitepatch that could be reviewed and committed independently from the AVX512 stuff? -#if SIZEOF_VOID_P >= 8 +#if SIZEOF_VOID_P == 8 /* Process in 64-bit chunks if the buffer is aligned. */ - if (buf == (const char *) TYPEALIGN(8, buf)) + if (buf == (const char *)TYPEALIGN(8, buf)) { - const uint64 *words = (const uint64 *) buf; + const uint64 *words = (const uint64 *)buf; while (bytes >= 8) { @@ -309,9 +213,9 @@ pg_popcount(const char *buf, int bytes) bytes -= 8; } - buf = (const char *) words; + buf = (const char *)words; } -#else +#elif SIZEOF_VOID_P == 4 /* Process in 32-bit chunks if the buffer is aligned. */ if (buf == (const char *) TYPEALIGN(4, buf)) { Most, if not all, of these changes seem extraneous. Do we actually need to more strictly check SIZEOF_VOID_P? [0] https://commitfest.postgresql.org/48/ [1] https://postgr.es/m/20230211020042.uthdgj72kp3xlqam%40awork3.anarazel.de -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
(Please don't top-post on the Postgres lists.) On Mon, Mar 04, 2024 at 09:39:36PM +0000, Amonson, Paul D wrote: > First, apologies on the patch. Find re-attached updated version. Thanks for the new version of the patch. >> -#define LARGE_OFF_T (((off_t) 1 << 62) - 1 + ((off_t) 1 << 62)) >> +#define LARGE_OFF_T ((((off_t) 1 << 31) << 31) - 1 + (((off_t) 1 << 31) >> +<< 31)) >> >> IME this means that the autoconf you are using has been patched. A >> quick search on the mailing lists seems to indicate that it might be >> specific to Debian [1]. > > I am not sure what the ask is here? I made changes to the configure.ac > and ran autoconf2.69 to get builds to succeed. Do you have a separate > feedback here? These LARGE_OFF_T changes are unrelated to the patch at hand and should be removed. This likely means that you are using a patched autoconf that is making these extra changes. > As for the refactoring, this was done to satisfy previous review feedback > about applying the AVX512 CFLAGS to the entire pg_bitutils.c file. Mainly > to avoid segfault due to the AVX512 flags. If its ok, I would prefer to > make a single commit as the change is pretty small and straight forward. Okay. The only reason I suggest this is to ease review. For example, if there is some required refactoring that doesn't involve any functionality changes, it can be advantageous to get that part reviewed and committed first so that reviewers can better focus on the code for the new feature. But, of course, that isn't necessary and/or isn't possible in all cases. > I am not sure I understand the comment about the SIZE_VOID_P checks. > Aren't they necessary to choose which functions to call based on 32 or 64 > bit architectures? Yes. My comment was that the patch appeared to make unnecessary changes to this code. Perhaps I am misunderstanding something here. > Would this change qualify for Workflow A as described in [0] and can be > picked up by a committer, given it has been reviewed by multiple > committers so far? The scope of the change is pretty contained as well. I think so. I would still encourage you to create an entry for this so that it is automatically tested via cfbot [0]. [0] http://commitfest.cputube.org/ -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Hi, I am not sure what "top-post" means but I am not doing anything different but using "reply to all" in Outlook. Please enlightenme. 😊 This is the new patch with the hand edit to remove the offending lines from the patch file. I did a basic test to make thepatch would apply and build. It succeeded. Thanks, Paul -----Original Message----- From: Nathan Bossart <nathandbossart@gmail.com> Sent: Monday, March 4, 2024 2:21 PM To: Amonson, Paul D <paul.d.amonson@intel.com> Cc: Andres Freund <andres@anarazel.de>; Alvaro Herrera <alvherre@alvh.no-ip.org>; Shankaran, Akash <akash.shankaran@intel.com>;Noah Misch <noah@leadboat.com>; Tom Lane <tgl@sss.pgh.pa.us>; Matthias van de Meent <boekewurm+postgres@gmail.com>;pgsql-hackers@lists.postgresql.org Subject: Re: Popcount optimization using AVX512 (Please don't top-post on the Postgres lists.) On Mon, Mar 04, 2024 at 09:39:36PM +0000, Amonson, Paul D wrote: > First, apologies on the patch. Find re-attached updated version. Thanks for the new version of the patch. >> -#define LARGE_OFF_T (((off_t) 1 << 62) - 1 + ((off_t) 1 << 62)) >> +#define LARGE_OFF_T ((((off_t) 1 << 31) << 31) - 1 + (((off_t) 1 << >> +31) << 31)) >> >> IME this means that the autoconf you are using has been patched. A >> quick search on the mailing lists seems to indicate that it might be >> specific to Debian [1]. > > I am not sure what the ask is here? I made changes to the > configure.ac and ran autoconf2.69 to get builds to succeed. Do you > have a separate feedback here? These LARGE_OFF_T changes are unrelated to the patch at hand and should be removed. This likely means that you are usinga patched autoconf that is making these extra changes. > As for the refactoring, this was done to satisfy previous review > feedback about applying the AVX512 CFLAGS to the entire pg_bitutils.c > file. Mainly to avoid segfault due to the AVX512 flags. If its ok, I > would prefer to make a single commit as the change is pretty small and straight forward. Okay. The only reason I suggest this is to ease review. For example, if there is some required refactoring that doesn'tinvolve any functionality changes, it can be advantageous to get that part reviewed and committed first so that reviewerscan better focus on the code for the new feature. But, of course, that isn't necessary and/or isn't possible in all cases. > I am not sure I understand the comment about the SIZE_VOID_P checks. > Aren't they necessary to choose which functions to call based on 32 or > 64 bit architectures? Yes. My comment was that the patch appeared to make unnecessary changes to this code. Perhaps I am misunderstanding somethinghere. > Would this change qualify for Workflow A as described in [0] and can > be picked up by a committer, given it has been reviewed by multiple > committers so far? The scope of the change is pretty contained as well. I think so. I would still encourage you to create an entry for this so that it is automatically tested via cfbot [0]. [0] http://commitfest.cputube.org/ -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
On Tue, Mar 05, 2024 at 04:31:15PM +0000, Amonson, Paul D wrote:
> I am not sure what "top-post" means but I am not doing anything different
> but using "reply to all" in Outlook. Please enlighten me. 😊
The following link provides some more information:
https://wiki.postgresql.org/wiki/Mailing_Lists#Email_etiquette_mechanics
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
-----Original Message----- >From: Nathan Bossart <nathandbossart@gmail.com> >Sent: Tuesday, March 5, 2024 8:38 AM >To: Amonson, Paul D <paul.d.amonson@intel.com> >Cc: Andres Freund <andres@anarazel.de>; Alvaro Herrera <alvherre@alvh.no-ip.org>; Shankaran, Akash <akash.shankaran@intel.com>;Noah Misch <noah@leadboat.com>; Tom Lane <tgl@sss.pgh.pa.us>; Matthias van de Meent <boekewurm+postgres@gmail.com>;>pgsql-hackers@lists.postgresql.org >Subject: Re: Popcount optimization using AVX512 > >On Tue, Mar 05, 2024 at 04:31:15PM +0000, Amonson, Paul D wrote: >> I am not sure what "top-post" means but I am not doing anything >> different but using "reply to all" in Outlook. Please enlighten me. 😊 > >The following link provides some more information: > > https://wiki.postgresql.org/wiki/Mailing_Lists#Email_etiquette_mechanics > >-- >Nathan Bossart >Amazon Web Services: https://aws.amazon.com Ahhhh.....Ok... guess it's time to thank Microsoft then. ;) Noted I will try to do the "reduced" bottom-posting. I mightslip up occasionally because it's an Intel habit. Is there a way to make Outlook do the leading ">" in a reply for theprevious message? BTW: Created the commit-fest submission. Paul
On Tue, Mar 5, 2024 at 04:52:23PM +0000, Amonson, Paul D wrote: > -----Original Message----- > >From: Nathan Bossart <nathandbossart@gmail.com> > >Sent: Tuesday, March 5, 2024 8:38 AM > >To: Amonson, Paul D <paul.d.amonson@intel.com> > >Cc: Andres Freund <andres@anarazel.de>; Alvaro Herrera <alvherre@alvh.no-ip.org>; Shankaran, Akash <akash.shankaran@intel.com>;Noah Misch <noah@leadboat.com>; Tom Lane <tgl@sss.pgh.pa.us>; Matthias van de Meent <boekewurm+postgres@gmail.com>;>pgsql-hackers@lists.postgresql.org > >Subject: Re: Popcount optimization using AVX512 > > > >On Tue, Mar 05, 2024 at 04:31:15PM +0000, Amonson, Paul D wrote: > >> I am not sure what "top-post" means but I am not doing anything > >> different but using "reply to all" in Outlook. Please enlighten me. 😊 > > > >The following link provides some more information: > > > > https://wiki.postgresql.org/wiki/Mailing_Lists#Email_etiquette_mechanics > > > >-- > >Nathan Bossart > >Amazon Web Services: https://aws.amazon.com > > Ahhhh.....Ok... guess it's time to thank Microsoft then. ;) Noted I will try to do the "reduced" bottom-posting. I mightslip up occasionally because it's an Intel habit. Is there a way to make Outlook do the leading ">" in a reply for theprevious message? Here is a blog post about how complex email posting can be: https://momjian.us/main/blogs/pgblog/2023.html#September_8_2023 -- Bruce Momjian <bruce@momjian.us> https://momjian.us EDB https://enterprisedb.com Only you can decide what is important to you.
On Tue, Mar 05, 2024 at 04:52:23PM +0000, Amonson, Paul D wrote: > Noted I will try to do the "reduced" bottom-posting. I might slip up > occasionally because it's an Intel habit. No worries. > Is there a way to make Outlook do the leading ">" in a reply for the > previous message? I do not know, sorry. I personally use mutt for the lists. > BTW: Created the commit-fest submission. Thanks. I intend to provide a more detailed review shortly, as I am aiming to get this one committed for v17. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On 2024-Mar-04, Amonson, Paul D wrote: > > -#define LARGE_OFF_T (((off_t) 1 << 62) - 1 + ((off_t) 1 << 62)) > > +#define LARGE_OFF_T ((((off_t) 1 << 31) << 31) - 1 + (((off_t) 1 << 31) > > +<< 31)) > > > > IME this means that the autoconf you are using has been patched. A > > quick search on the mailing lists seems to indicate that it might be > > specific to Debian [1]. > > I am not sure what the ask is here? I made changes to the > configure.ac and ran autoconf2.69 to get builds to succeed. Do you > have a separate feedback here? So what happens here is that autoconf-2.69 as shipped by Debian contains some patches on top of the one released by GNU. We use the latter, so if you run Debian's, then the generated configure script will contain the differences coming from Debian's version. Really, I don't think this is very important as a review point, because if the configure.ac file is changed in the patch, it's best for the committer to run autoconf on their own, using a pristine GNU autoconf; the configure file in the submitted patch is not relevant, only configure.ac matters. What committers do (or should do) is keep an install of autoconf-2.69 straight from GNU. -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/
On Thu, Mar 07, 2024 at 06:53:12PM +0100, Alvaro Herrera wrote: > Really, I don't think this is very important as a review point, because > if the configure.ac file is changed in the patch, it's best for the > committer to run autoconf on their own, using a pristine GNU autoconf; > the configure file in the submitted patch is not relevant, only > configure.ac matters. Agreed. I didn't intend for this to be a major review point, and I apologize for the extra noise. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
As promised...
> +# Check for Intel AVX512 intrinsics to do POPCNT calculations.
> +#
> +PGAC_AVX512_POPCNT_INTRINSICS([])
> +if test x"$pgac_avx512_popcnt_intrinsics" != x"yes"; then
> + PGAC_AVX512_POPCNT_INTRINSICS([-mavx512vpopcntdq -mavx512f])
> +fi
> +AC_SUBST(CFLAGS_AVX512_POPCNT)
I'm curious why we need both -mavx512vpopcntdq and -mavx512f. On my
machine, -mavx512vpopcntdq alone is enough to pass this test, so if there
are other instructions required that need -mavx512f, then we might need to
expand the test.
> 13 files changed, 657 insertions(+), 119 deletions(-)
I still think it's worth breaking this change into at least 2 patches. In
particular, I think there's an opportunity to do the refactoring into
pg_popcnt_choose.c and pg_popcnt_x86_64_accel.c prior to adding the AVX512
stuff. These changes are likely straightforward, and getting them out of
the way early would make it easier to focus on the more interesting
changes. IMHO there are a lot of moving parts in this patch.
> +#undef HAVE__GET_CPUID_COUNT
> +
> +/* Define to 1 if you have immintrin. */
> +#undef HAVE__IMMINTRIN
Is this missing HAVE__CPUIDEX?
> uint64
> -pg_popcount(const char *buf, int bytes)
> +pg_popcount_slow(const char *buf, int bytes)
> {
> uint64 popcnt = 0;
>
> -#if SIZEOF_VOID_P >= 8
> +#if SIZEOF_VOID_P == 8
> /* Process in 64-bit chunks if the buffer is aligned. */
> if (buf == (const char *) TYPEALIGN(8, buf))
> {
> @@ -311,7 +224,7 @@ pg_popcount(const char *buf, int bytes)
>
> buf = (const char *) words;
> }
> -#else
> +#elif SIZEOF_VOID_P == 4
> /* Process in 32-bit chunks if the buffer is aligned. */
> if (buf == (const char *) TYPEALIGN(4, buf))
> {
Apologies for harping on this, but I'm still not seeing the need for these
SIZEOF_VOID_P changes. While it's unlikely that this makes any practical
difference, I see no reason to more strictly check SIZEOF_VOID_P here.
> + /* Process any remaining bytes */
> + while (bytes--)
> + popcnt += pg_number_of_ones[(unsigned char) *buf++];
> + return popcnt;
> +#else
> + return pg_popcount_slow(buf, bytes);
> +#endif /* USE_AVX512_CODE */
nitpick: Could we call pg_popcount_slow() in a common section for these
"remaining bytes?"
> +#if defined(_MSC_VER)
> + pg_popcount_indirect = pg_popcount512_fast;
> +#else
> + pg_popcount = pg_popcount512_fast;
> +#endif
These _MSC_VER sections are interesting. I'm assuming this is the
workaround for the MSVC linking issue you mentioned above. I haven't
looked too closely, but I wonder if the CRC32C code (see
src/include/port/pg_crc32c.h) is doing something different to avoid this
issue.
Upthread, Alvaro suggested a benchmark [0] that might be useful. I scanned
through this thread and didn't see any recent benchmark results for the
latest form of the patch. I think it's worth verifying that we are still
seeing the expected improvements.
[0] https://postgr.es/m/202402071953.5c4z7t6kl7ts%40alvherre.pgsql
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
> -----Original Message-----
> From: Nathan Bossart <nathandbossart@gmail.com>
> Sent: Thursday, March 7, 2024 1:36 PM
> Subject: Re: Popcount optimization using AVX512
I will be splitting the request into 2 patches. I am attaching the first patch (refactoring only) and I updated the
commitfestentry to match this patch. I have a question however:
Do I need to wait for the refactor patch to be merged before I post the AVX portion of this feature in this thread?
> > + PGAC_AVX512_POPCNT_INTRINSICS([-mavx512vpopcntdq -mavx512f])
>
> I'm curious why we need both -mavx512vpopcntdq and -mavx512f. On my
> machine, -mavx512vpopcntdq alone is enough to pass this test, so if there are
> other instructions required that need -mavx512f, then we might need to
> expand the test.
First, nice catch on the required flags to build! When I changed my algorithm, dependence on the -mavx512f flag was no
longerneeded, In the second patch (AVX specific) I will fix this.
> I still think it's worth breaking this change into at least 2 patches. In particular,
> I think there's an opportunity to do the refactoring into pg_popcnt_choose.c
> and pg_popcnt_x86_64_accel.c prior to adding the AVX512 stuff. These
> changes are likely straightforward, and getting them out of the way early
> would make it easier to focus on the more interesting changes. IMHO there
> are a lot of moving parts in this patch.
As stated above I am doing this in 2 patches. :)
> > +#undef HAVE__GET_CPUID_COUNT
> > +
> > +/* Define to 1 if you have immintrin. */ #undef HAVE__IMMINTRIN
>
> Is this missing HAVE__CPUIDEX?
Yes I missed it, I will include in the second patch (AVX specific) of the 2 patches.
> > uint64
> > -pg_popcount(const char *buf, int bytes)
> > +pg_popcount_slow(const char *buf, int bytes)
> > {
> > uint64 popcnt = 0;
> >
> > -#if SIZEOF_VOID_P >= 8
> > +#if SIZEOF_VOID_P == 8
> > /* Process in 64-bit chunks if the buffer is aligned. */
> > if (buf == (const char *) TYPEALIGN(8, buf))
> > {
> > @@ -311,7 +224,7 @@ pg_popcount(const char *buf, int bytes)
> >
> > buf = (const char *) words;
> > }
> > -#else
> > +#elif SIZEOF_VOID_P == 4
> > /* Process in 32-bit chunks if the buffer is aligned. */
> > if (buf == (const char *) TYPEALIGN(4, buf))
> > {
>
> Apologies for harping on this, but I'm still not seeing the need for these
> SIZEOF_VOID_P changes. While it's unlikely that this makes any practical
> difference, I see no reason to more strictly check SIZEOF_VOID_P here.
I got rid of the second occurrence as I agree it is not needed but unless you see something I don't how to know which
functionto call between a 32-bit and 64-bit architecture? Maybe I am missing something obvious? What exactly do you
suggesthere? I am happy to always call either pg_popcount32() or pg_popcount64() with the understanding that it may not
beoptimal, but I do need to know which to use.
> > + /* Process any remaining bytes */
> > + while (bytes--)
> > + popcnt += pg_number_of_ones[(unsigned char) *buf++];
> > + return popcnt;
> > +#else
> > + return pg_popcount_slow(buf, bytes);
> > +#endif /* USE_AVX512_CODE */
>
> nitpick: Could we call pg_popcount_slow() in a common section for these
> "remaining bytes?"
Agreed, will fix in the second patch as well.
> > +#if defined(_MSC_VER)
> > + pg_popcount_indirect = pg_popcount512_fast; #else
> > + pg_popcount = pg_popcount512_fast; #endif
> These _MSC_VER sections are interesting. I'm assuming this is the
> workaround for the MSVC linking issue you mentioned above. I haven't
> looked too closely, but I wonder if the CRC32C code (see
> src/include/port/pg_crc32c.h) is doing something different to avoid this issue.
Using the latest master branch, I see what the needed changes are, I will implement using PGDLLIMPORT macro in the
secondpatch.
> Upthread, Alvaro suggested a benchmark [0] that might be useful. I scanned
> through this thread and didn't see any recent benchmark results for the latest
> form of the patch. I think it's worth verifying that we are still seeing the
> expected improvements.
I will get new benchmarks using the same process I used before (from Akash) so I get apples to apples. These are
pendingcompletion of the second patch which is still in progress.
Just a reminder, I asked questions above about 1) multi-part dependent patches and, 2) What specifically to do about
theSIZE_VOID_P checks. :)
Thanks,
Paul
Attachment
On Mon, Mar 11, 2024 at 09:59:53PM +0000, Amonson, Paul D wrote: > I will be splitting the request into 2 patches. I am attaching the first > patch (refactoring only) and I updated the commitfest entry to match this > patch. I have a question however: > Do I need to wait for the refactor patch to be merged before I post the > AVX portion of this feature in this thread? Thanks. There's no need to wait to post the AVX portion. I recommend using "git format-patch" to construct the patch set for the lists. >> Apologies for harping on this, but I'm still not seeing the need for these >> SIZEOF_VOID_P changes. While it's unlikely that this makes any practical >> difference, I see no reason to more strictly check SIZEOF_VOID_P here. > > I got rid of the second occurrence as I agree it is not needed but unless > you see something I don't how to know which function to call between a > 32-bit and 64-bit architecture? Maybe I am missing something obvious? > What exactly do you suggest here? I am happy to always call either > pg_popcount32() or pg_popcount64() with the understanding that it may not > be optimal, but I do need to know which to use. I'm recommending that we don't change any of the code in the pg_popcount() function (which is renamed to pg_popcount_slow() in your v6 patch). If pointers are 8 or more bytes, we'll try to process the buffer in 64-bit chunks. Else, we'll try to process it in 32-bit chunks. Any remaining bytes will be processed one-by-one. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
A couple of thoughts on v7-0001: +extern int pg_popcount32_slow(uint32 word); +extern int pg_popcount64_slow(uint64 word); +/* In pg_popcnt_*_accel source file. */ +extern int pg_popcount32_fast(uint32 word); +extern int pg_popcount64_fast(uint64 word); Can these prototypes be moved to a header file (maybe pg_bitutils.h)? It looks like these are defined twice in the patch, and while I'm not positive that it's against project policy to declare extern function prototypes in .c files, it appears to be pretty rare. + 'pg_popcnt_choose.c', + 'pg_popcnt_x86_64_accel.c', I think we want these to be architecture-specific, i.e., only built for x86_64 if the compiler knows how to use the relevant instructions. There is a good chance that we'll want to add similar support for other systems. The CRC32C files are probably a good reference point for how to do this. +#ifdef TRY_POPCNT_FAST IIUC this macro can be set if either 1) the popcntq test in the autoconf/meson scripts passes or 2) we're building with MSVC on x86_64. I wonder if it would be better to move the MSVC/x86_64 check to the autoconf/meson scripts so that we could avoid surrounding large portions of the popcount code with this macro. This might even be a necessary step towards building these files in an architecture-specific fashion. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
> -----Original Message----- > From: Nathan Bossart <nathandbossart@gmail.com> > Sent: Wednesday, March 13, 2024 9:39 AM > To: Amonson, Paul D <paul.d.amonson@intel.com> > +extern int pg_popcount32_slow(uint32 word); extern int > +pg_popcount64_slow(uint64 word); > > +/* In pg_popcnt_*_accel source file. */ extern int > +pg_popcount32_fast(uint32 word); extern int pg_popcount64_fast(uint64 > +word); > > Can these prototypes be moved to a header file (maybe pg_bitutils.h)? It > looks like these are defined twice in the patch, and while I'm not positive that > it's against project policy to declare extern function prototypes in .c files, it > appears to be pretty rare. Originally, I intentionally did not put these in the header file as I want them to be private, but they are not defined inthis .c file hence extern. Now I realize the "extern" part is not needed to accomplish my goal. Will fix by removing the"extern" keyword. > + 'pg_popcnt_choose.c', > + 'pg_popcnt_x86_64_accel.c', > > I think we want these to be architecture-specific, i.e., only built for > x86_64 if the compiler knows how to use the relevant instructions. There is a > good chance that we'll want to add similar support for other systems. > The CRC32C files are probably a good reference point for how to do this. I will look at this for the 'pg_popcnt_x86_64_accel.c' file but the 'pg_popcnt_choose.c' file is intended to be for any platformthat may need accelerators including a possible future ARM accelerator. > +#ifdef TRY_POPCNT_FAST > > IIUC this macro can be set if either 1) the popcntq test in the autoconf/meson > scripts passes or 2) we're building with MSVC on x86_64. I wonder if it would > be better to move the MSVC/x86_64 check to the autoconf/meson scripts so > that we could avoid surrounding large portions of the popcount code with this > macro. This might even be a necessary step towards building these files in an > architecture-specific fashion. I see the point here; however, this will take some time to get right especially since I don't have a Windows box to do compileson. Should I attempt to do this in this patch? Thanks, Paul
On Wed, Mar 13, 2024 at 05:52:14PM +0000, Amonson, Paul D wrote: >> I think we want these to be architecture-specific, i.e., only built for >> x86_64 if the compiler knows how to use the relevant instructions. There is a >> good chance that we'll want to add similar support for other systems. >> The CRC32C files are probably a good reference point for how to do this. > > I will look at this for the 'pg_popcnt_x86_64_accel.c' file but the > 'pg_popcnt_choose.c' file is intended to be for any platform that may > need accelerators including a possible future ARM accelerator. I worry that using the same file for *_choose.c for all architectures would become rather #ifdef heavy. Since we are already separating out this code into new files, IMO we might as well try to avoid too many #ifdefs, too. But this is admittedly less important right now because there's almost no chance of any new architecture support here for v17. >> +#ifdef TRY_POPCNT_FAST >> >> IIUC this macro can be set if either 1) the popcntq test in the autoconf/meson >> scripts passes or 2) we're building with MSVC on x86_64. I wonder if it would >> be better to move the MSVC/x86_64 check to the autoconf/meson scripts so >> that we could avoid surrounding large portions of the popcount code with this >> macro. This might even be a necessary step towards building these files in an >> architecture-specific fashion. > > I see the point here; however, this will take some time to get right > especially since I don't have a Windows box to do compiles on. Should I > attempt to do this in this patch? This might also be less important given the absence of any imminent new architecture support in this area. I'm okay with it, given we are just maintaining the status quo. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
> -----Original Message----- > From: Nathan Bossart <nathandbossart@gmail.com> > Sent: Monday, March 11, 2024 6:35 PM > To: Amonson, Paul D <paul.d.amonson@intel.com> > Thanks. There's no need to wait to post the AVX portion. I recommend using > "git format-patch" to construct the patch set for the lists. After exploring git format-patch command I think I understand what you need. Attached. > > What exactly do you suggest here? I am happy to always call either > > pg_popcount32() or pg_popcount64() with the understanding that it may > > not be optimal, but I do need to know which to use. > > I'm recommending that we don't change any of the code in the pg_popcount() > function (which is renamed to pg_popcount_slow() in your v6 patch). If > pointers are 8 or more bytes, we'll try to process the buffer in 64-bit chunks. > Else, we'll try to process it in 32-bit chunks. Any remaining bytes will be > processed one-by-one. Ok, we are on the same page now. :) It is already fixed that way in the refactor patch #1. As for new performance numbers: I just ran a full suite like I did earlier in the process. My latest results an equivalentto a pgbench scale factor 10 DB with the target column having varying column widths and appropriate random dataare 1.2% improvement with a 2.2% Margin of Error at a 98% confidence level. Still seeing improvement and no regressions. As stated in the previous separate chain I updated the code removing the extra "extern" keywords. Thanks, Paul
Attachment
On Thu, Mar 14, 2024 at 07:50:46PM +0000, Amonson, Paul D wrote:
> As for new performance numbers: I just ran a full suite like I did
> earlier in the process. My latest results an equivalent to a pgbench
> scale factor 10 DB with the target column having varying column widths
> and appropriate random data are 1.2% improvement with a 2.2% Margin of
> Error at a 98% confidence level. Still seeing improvement and no
> regressions.
Which test suite did you run? Those numbers seem potentially
indistinguishable from noise, which probably isn't great for such a large
patch set.
I ran John Naylor's test_popcount module [0] with the following command on
an i7-1195G7:
time psql postgres -c 'select drive_popcount(10000000, 1024)'
Without your patches, this seems to take somewhere around 8.8 seconds.
With your patches, it takes 0.6 seconds. (I re-compiled and re-ran the
tests a couple of times because I had a difficult time believing the amount
of improvement.)
[0] https://postgr.es/m/CAFBsxsE7otwnfA36Ly44zZO%2Bb7AEWHRFANxR1h1kxveEV%3DghLQ%40mail.gmail.com
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
> -----Original Message-----
> From: Nathan Bossart <nathandbossart@gmail.com>
> Sent: Friday, March 15, 2024 8:06 AM
> To: Amonson, Paul D <paul.d.amonson@intel.com>
> Cc: Andres Freund <andres@anarazel.de>; Alvaro Herrera <alvherre@alvh.no-
> ip.org>; Shankaran, Akash <akash.shankaran@intel.com>; Noah Misch
> <noah@leadboat.com>; Tom Lane <tgl@sss.pgh.pa.us>; Matthias van de
> Meent <boekewurm+postgres@gmail.com>; pgsql-
> hackers@lists.postgresql.org
> Subject: Re: Popcount optimization using AVX512
>
> Which test suite did you run? Those numbers seem potentially
> indistinguishable from noise, which probably isn't great for such a large patch
> set.
I ran...
psql -c "select bitcount(column) from table;"
...in a loop with "column" widths of 84, 4096, 8192, and 16384 containing random data. There DB has 1 million rows. In
theloop before calling the select I have code to clear all system caches. If I omit the code to clear system caches the
marginof error remains the same but the improvement percent changes from 1.2% to 14.6% (much less I/O when cached data
isavailable).
> I ran John Naylor's test_popcount module [0] with the following command on
> an i7-1195G7:
>
> time psql postgres -c 'select drive_popcount(10000000, 1024)'
>
> Without your patches, this seems to take somewhere around 8.8 seconds.
> With your patches, it takes 0.6 seconds. (I re-compiled and re-ran the tests a
> couple of times because I had a difficult time believing the amount of
> improvement.)
When I tested the code outside postgres in a micro benchmark I got 200-300% improvements. Your results are interesting,
asit implies more than 300% improvement. Let me do some research on the benchmark you referenced. However, in all cases
itseems that there is no regression so should we move forward on merging while I run some more local tests?
Thanks,
Paul
> -----Original Message----- > From: Amonson, Paul D <paul.d.amonson@intel.com> > Sent: Friday, March 15, 2024 8:31 AM > To: Nathan Bossart <nathandbossart@gmail.com> ... > When I tested the code outside postgres in a micro benchmark I got 200- > 300% improvements. Your results are interesting, as it implies more than > 300% improvement. Let me do some research on the benchmark you > referenced. However, in all cases it seems that there is no regression so should > we move forward on merging while I run some more local tests? When running quick test with small buffers (1 to 32K) I see up to about a 740% improvement. This was using my stand-alonemicro benchmark outside of PG. My original 200-300% numbers were averaged including sizes up to 512MB which seemsto not run as well on large buffers. I will try the referenced micro benchmark on Monday. None of my benchmark testingused the command line "time" command. For Postgres is set "\timing" before the run and for the stand-alone benchmarkis took timestamps in the code. In all cases I used -O2 for optimization. Thanks, Paul
On Sat, 16 Mar 2024 at 04:06, Nathan Bossart <nathandbossart@gmail.com> wrote: > I ran John Naylor's test_popcount module [0] with the following command on > an i7-1195G7: > > time psql postgres -c 'select drive_popcount(10000000, 1024)' > > Without your patches, this seems to take somewhere around 8.8 seconds. > With your patches, it takes 0.6 seconds. (I re-compiled and re-ran the > tests a couple of times because I had a difficult time believing the amount > of improvement.) > > [0] https://postgr.es/m/CAFBsxsE7otwnfA36Ly44zZO%2Bb7AEWHRFANxR1h1kxveEV%3DghLQ%40mail.gmail.com I think most of that will come from getting rid of the indirect function that currently exists in pg_popcount(). Using the attached quick hack, the performance using John's test module goes from: -- master postgres=# select drive_popcount(10000000, 1024); Time: 9832.845 ms (00:09.833) Time: 9844.460 ms (00:09.844) Time: 9858.608 ms (00:09.859) -- with attached hacky and untested patch postgres=# select drive_popcount(10000000, 1024); Time: 2539.029 ms (00:02.539) Time: 2598.223 ms (00:02.598) Time: 2611.435 ms (00:02.611) --- and with the avx512 patch on an AMD 7945HX CPU: postgres=# select drive_popcount(10000000, 1024); Time: 564.982 ms Time: 556.540 ms Time: 554.032 ms The following comment seems like it could do with some improvements. * Use AVX-512 Intrinsics for supported Intel CPUs or fall back the the software * loop in pg_bunutils.c and use the best 32 or 64 bit fast methods. If no fast * methods are used this will fall back to __builtin_* or pure software. There's nothing much specific to Intel here. AMD Zen4 has AVX512. Plus "pg_bunutils.c" should be "pg_bitutils.c" and "the the" How about just: * Use AVX-512 Intrinsics on supported CPUs. Fall back the software loop in * pg_popcount_slow() when AVX-512 is unavailable. Maybe it's worth exploring something along the lines of the attached before doing the AVX512 stuff. It seems like a pretty good speed-up and will apply for CPUs without AVX512 support. David
Attachment
On Mon, Mar 18, 2024 at 09:56:32AM +1300, David Rowley wrote: > Maybe it's worth exploring something along the lines of the attached > before doing the AVX512 stuff. It seems like a pretty good speed-up > and will apply for CPUs without AVX512 support. +1 -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Won't I still need the runtime checks? If I compile with a compiler supporting the HW "feature" but run on HW without thatfeature, I will want to avoid faults due to illegal operations. Won't that also affect performance? Paul > -----Original Message----- > From: Nathan Bossart <nathandbossart@gmail.com> > Sent: Monday, March 18, 2024 8:29 AM > To: David Rowley <dgrowleyml@gmail.com> > Cc: Amonson, Paul D <paul.d.amonson@intel.com>; Andres Freund > <andres@anarazel.de>; Alvaro Herrera <alvherre@alvh.no-ip.org>; Shankaran, > Akash <akash.shankaran@intel.com>; Noah Misch <noah@leadboat.com>; > Tom Lane <tgl@sss.pgh.pa.us>; Matthias van de Meent > <boekewurm+postgres@gmail.com>; pgsql-hackers@lists.postgresql.org > Subject: Re: Popcount optimization using AVX512 > > On Mon, Mar 18, 2024 at 09:56:32AM +1300, David Rowley wrote: > > Maybe it's worth exploring something along the lines of the attached > > before doing the AVX512 stuff. It seems like a pretty good speed-up > > and will apply for CPUs without AVX512 support. > > +1 > > -- > Nathan Bossart > Amazon Web Services: https://aws.amazon.com
On Mon, Mar 18, 2024 at 04:07:40PM +0000, Amonson, Paul D wrote: > Won't I still need the runtime checks? If I compile with a compiler > supporting the HW "feature" but run on HW without that feature, I will > want to avoid faults due to illegal operations. Won't that also affect > performance? I don't think David was suggesting that we need to remove the runtime checks for AVX512. IIUC he was pointing out that most of the performance gain is from removing the function call overhead, which your v8-0002 patch already does for the proposed AVX512 code. We can apply a similar optimization for systems without AVX512 by inlining the code for pg_popcount64() and pg_popcount32(). -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
> -----Original Message----- > From: Nathan Bossart <nathandbossart@gmail.com> > Sent: Monday, March 18, 2024 9:20 AM > ... > I don't think David was suggesting that we need to remove the runtime checks > for AVX512. IIUC he was pointing out that most of the performance gain is > from removing the function call overhead, which your v8-0002 patch already > does for the proposed AVX512 code. We can apply a similar optimization for > systems without AVX512 by inlining the code for > pg_popcount64() and pg_popcount32(). Ok, got you. Question: I applied the patch for the drive_popcount* functions and rebuilt. The resultant server complains that the functionis missing. What is the trick to make this work? Another Question: Is there a reason "time psql" is used over the Postgres "\timing" command? Thanks, Paul
On Mon, Mar 18, 2024 at 11:20:18AM -0500, Nathan Bossart wrote: > I don't think David was suggesting that we need to remove the runtime > checks for AVX512. IIUC he was pointing out that most of the performance > gain is from removing the function call overhead, which your v8-0002 patch > already does for the proposed AVX512 code. We can apply a similar > optimization for systems without AVX512 by inlining the code for > pg_popcount64() and pg_popcount32(). Here is a more fleshed-out version of what I believe David is proposing. On my machine, the gains aren't quite as impressive (~8.8s to ~5.2s for the test_popcount benchmark). I assume this is because this patch turns pg_popcount() into a function pointer, which is what the AVX512 patches do, too. I left out the 32-bit section from pg_popcount_fast(), but I'll admit that I'm not yet 100% sure that we can assume we're on a 64-bit system there. IMHO this work is arguably a prerequisite for the AVX512 work, as turning pg_popcount() into a function pointer will likely regress performance for folks on systems without AVX512 otherwise. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
On Mon, Mar 18, 2024 at 05:28:32PM +0000, Amonson, Paul D wrote: > Question: I applied the patch for the drive_popcount* functions and > rebuilt. The resultant server complains that the function is missing. > What is the trick to make this work? You probably need to install the test_popcount extension and run "CREATE EXTENION test_popcount;". > Another Question: Is there a reason "time psql" is used over the Postgres > "\timing" command? I don't think there's any strong reason. I've used both. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Mon, Mar 18, 2024 at 12:30:04PM -0500, Nathan Bossart wrote: > Here is a more fleshed-out version of what I believe David is proposing. > On my machine, the gains aren't quite as impressive (~8.8s to ~5.2s for the > test_popcount benchmark). I assume this is because this patch turns > pg_popcount() into a function pointer, which is what the AVX512 patches do, > too. I left out the 32-bit section from pg_popcount_fast(), but I'll admit > that I'm not yet 100% sure that we can assume we're on a 64-bit system > there. > > IMHO this work is arguably a prerequisite for the AVX512 work, as turning > pg_popcount() into a function pointer will likely regress performance for > folks on systems without AVX512 otherwise. Apologies for the noise. I noticed that we could (and probably should) inline the pg_popcount32/64 calls in the "slow" version, too. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
On Tue, 19 Mar 2024 at 06:30, Nathan Bossart <nathandbossart@gmail.com> wrote: > Here is a more fleshed-out version of what I believe David is proposing. > On my machine, the gains aren't quite as impressive (~8.8s to ~5.2s for the > test_popcount benchmark). I assume this is because this patch turns > pg_popcount() into a function pointer, which is what the AVX512 patches do, > too. I left out the 32-bit section from pg_popcount_fast(), but I'll admit > that I'm not yet 100% sure that we can assume we're on a 64-bit system > there. I looked at your latest patch and tried out the performance on a Zen4 running windows and a Zen2 running on Linux. As follows: AMD 3990x: master: postgres=# select drive_popcount(10000000, 1024); Time: 11904.078 ms (00:11.904) Time: 11907.176 ms (00:11.907) Time: 11927.983 ms (00:11.928) patched: postgres=# select drive_popcount(10000000, 1024); Time: 3641.271 ms (00:03.641) Time: 3610.934 ms (00:03.611) Time: 3663.423 ms (00:03.663) AMD 7945HX Windows master: postgres=# select drive_popcount(10000000, 1024); Time: 9832.845 ms (00:09.833) Time: 9844.460 ms (00:09.844) Time: 9858.608 ms (00:09.859) patched: postgres=# select drive_popcount(10000000, 1024); Time: 3427.942 ms (00:03.428) Time: 3364.262 ms (00:03.364) Time: 3413.407 ms (00:03.413) The only thing I'd question in the patch is in pg_popcount_fast(). It looks like you've opted to not do the 32-bit processing on 32-bit machines. I think that's likely still worth coding in a similar way to how pg_popcount_slow() works. i.e. use "#if SIZEOF_VOID_P >= 8". Probably one day we'll remove that code, but it seems strange to have pg_popcount_slow() do it and not pg_popcount_fast(). > IMHO this work is arguably a prerequisite for the AVX512 work, as turning > pg_popcount() into a function pointer will likely regress performance for > folks on systems without AVX512 otherwise. I think so too. David
On Tue, Mar 19, 2024 at 10:02:18AM +1300, David Rowley wrote: > I looked at your latest patch and tried out the performance on a Zen4 > running windows and a Zen2 running on Linux. As follows: Thanks for taking a look. > The only thing I'd question in the patch is in pg_popcount_fast(). It > looks like you've opted to not do the 32-bit processing on 32-bit > machines. I think that's likely still worth coding in a similar way to > how pg_popcount_slow() works. i.e. use "#if SIZEOF_VOID_P >= 8". > Probably one day we'll remove that code, but it seems strange to have > pg_popcount_slow() do it and not pg_popcount_fast(). The only reason I left it out was because I couldn't convince myself that it wasn't dead code, given we assume that popcntq is available in pg_popcount64_fast() today. But I don't see any harm in adding that just in case. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
> -----Original Message----- > From: Nathan Bossart <nathandbossart@gmail.com> > Sent: Monday, March 18, 2024 2:08 PM > To: David Rowley <dgrowleyml@gmail.com> > Cc: Amonson, Paul D <paul.d.amonson@intel.com>; Andres Freund >... > > The only reason I left it out was because I couldn't convince myself that it > wasn't dead code, given we assume that popcntq is available in > pg_popcount64_fast() today. But I don't see any harm in adding that just in > case. I am not sure how to read this. Does this mean that for popcount32_fast and popcount64_fast I can assume that the x86(_64)instructions exists and stop doing the runtime checks for instruction availability? Thanks, Paul
On Mon, Mar 18, 2024 at 09:22:43PM +0000, Amonson, Paul D wrote: >> The only reason I left it out was because I couldn't convince myself that it >> wasn't dead code, given we assume that popcntq is available in >> pg_popcount64_fast() today. But I don't see any harm in adding that just in >> case. > > I am not sure how to read this. Does this mean that for popcount32_fast > and popcount64_fast I can assume that the x86(_64) instructions exists > and stop doing the runtime checks for instruction availability? I think my question boils down to "if pg_popcount_available() returns true, can I safely assume I'm on a 64-bit machine?" -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Tue, 19 Mar 2024 at 10:08, Nathan Bossart <nathandbossart@gmail.com> wrote: > > On Tue, Mar 19, 2024 at 10:02:18AM +1300, David Rowley wrote: > > The only thing I'd question in the patch is in pg_popcount_fast(). It > > looks like you've opted to not do the 32-bit processing on 32-bit > > machines. I think that's likely still worth coding in a similar way to > > how pg_popcount_slow() works. i.e. use "#if SIZEOF_VOID_P >= 8". > > Probably one day we'll remove that code, but it seems strange to have > > pg_popcount_slow() do it and not pg_popcount_fast(). > > The only reason I left it out was because I couldn't convince myself that > it wasn't dead code, given we assume that popcntq is available in > pg_popcount64_fast() today. But I don't see any harm in adding that just > in case. It's probably more of a case of using native instructions rather than ones that might be implemented only via microcode. For the record, I don't know if that would be the case for popcntq on x86 32-bit and I don't have the hardware to test it. It just seems less risky just to do it. David
On Tue, Mar 19, 2024 at 10:27:58AM +1300, David Rowley wrote: > On Tue, 19 Mar 2024 at 10:08, Nathan Bossart <nathandbossart@gmail.com> wrote: >> On Tue, Mar 19, 2024 at 10:02:18AM +1300, David Rowley wrote: >> > The only thing I'd question in the patch is in pg_popcount_fast(). It >> > looks like you've opted to not do the 32-bit processing on 32-bit >> > machines. I think that's likely still worth coding in a similar way to >> > how pg_popcount_slow() works. i.e. use "#if SIZEOF_VOID_P >= 8". >> > Probably one day we'll remove that code, but it seems strange to have >> > pg_popcount_slow() do it and not pg_popcount_fast(). >> >> The only reason I left it out was because I couldn't convince myself that >> it wasn't dead code, given we assume that popcntq is available in >> pg_popcount64_fast() today. But I don't see any harm in adding that just >> in case. > > It's probably more of a case of using native instructions rather than > ones that might be implemented only via microcode. For the record, I > don't know if that would be the case for popcntq on x86 32-bit and I > don't have the hardware to test it. It just seems less risky just to > do it. Agreed. Will send an updated patch shortly. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Mon, Mar 18, 2024 at 04:29:19PM -0500, Nathan Bossart wrote: > Agreed. Will send an updated patch shortly. As promised... -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
On Tue, 19 Mar 2024 at 11:08, Nathan Bossart <nathandbossart@gmail.com> wrote: > > On Mon, Mar 18, 2024 at 04:29:19PM -0500, Nathan Bossart wrote: > > Agreed. Will send an updated patch shortly. > > As promised... Looks good. David
On Tue, Mar 19, 2024 at 12:30:50PM +1300, David Rowley wrote: > Looks good. Committed. Thanks for the suggestion and for reviewing! Paul, I suspect your patches will need to be rebased after commit cc4826d. Would you mind doing so? -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
> -----Original Message----- > From: Nathan Bossart <nathandbossart@gmail.com> > > Committed. Thanks for the suggestion and for reviewing! > > Paul, I suspect your patches will need to be rebased after commit cc4826d. > Would you mind doing so? Changed in this patch set. * Rebased. * Direct *slow* calls via macros as shown in example patch. * Changed the choose filename to be platform specific as suggested. * Falls back to intermediate "Fast" methods if AVX512 is not available at runtime. * inline used where is makes sense, remember using "extern" negates "inline". * Fixed comment issues pointed out in review. I tested building with and without TRY_POPCOUNT_FAST, for both configure and meson build systems, and ran in CI. Thanks, Paul
Attachment
On Wed, 20 Mar 2024 at 11:56, Amonson, Paul D <paul.d.amonson@intel.com> wrote: > Changed in this patch set. Thanks for rebasing. I don't think there's any need to mention Intel in each of the following comments: +# Check for Intel AVX512 intrinsics to do POPCNT calculations. +# Newer Intel processors can use AVX-512 POPCNT Capabilities (01/30/2024) AMD's Zen4 also has AVX512, so it's misleading to indicate it's an Intel only instruction. Also, writing the date isn't necessary as we have "git blame" David
> -----Original Message----- > From: David Rowley <dgrowleyml@gmail.com> > Sent: Tuesday, March 19, 2024 9:26 PM > To: Amonson, Paul D <paul.d.amonson@intel.com> > > AMD's Zen4 also has AVX512, so it's misleading to indicate it's an Intel only > instruction. Also, writing the date isn't necessary as we have "git blame" Fixed. Thanks, Paul
Attachment
On Wed, 20 Mar 2024 at 11:56, Amonson, Paul D <paul.d.amonson@intel.com> wrote: > Changed in this patch set. > > * Rebased. > * Direct *slow* calls via macros as shown in example patch. > * Changed the choose filename to be platform specific as suggested. > * Falls back to intermediate "Fast" methods if AVX512 is not available at runtime. > * inline used where is makes sense, remember using "extern" negates "inline". I'm not sure about this "extern negates inline" comment. It seems to me the compiler is perfectly free to inline a static function into an external function and it's free to inline the static function elsewhere within the same .c file. The final sentence of the following comment that the 0001 patch removes explains this: /* * When the POPCNT instruction is not available, there's no point in using * function pointers to vary the implementation between the fast and slow * method. We instead just make these actual external functions when * TRY_POPCNT_FAST is not defined. The compiler should be able to inline * the slow versions here. */ Also, have a look at [1]. You'll see f_slow() wasn't even compiled and the code was just inlined into f(). I just added the __attribute__((noinline)) so that usage() wouldn't just perform constant folding and just return 6. I think, unless you have evidence that some common compiler isn't inlining the static into the extern then we shouldn't add the macros. It adds quite a bit of churn to the patch and will break out of core code as you no longer have functions named pg_popcount32(), pg_popcount64() and pg_popcount(). David [1] https://godbolt.org/z/6joExb79d
> -----Original Message----- > From: David Rowley <dgrowleyml@gmail.com> > Sent: Wednesday, March 20, 2024 5:28 PM > To: Amonson, Paul D <paul.d.amonson@intel.com> > Cc: Nathan Bossart <nathandbossart@gmail.com>; Andres Freund > > I'm not sure about this "extern negates inline" comment. It seems to me the > compiler is perfectly free to inline a static function into an external function > and it's free to inline the static function elsewhere within the same .c file. > > The final sentence of the following comment that the 0001 patch removes > explains this: > > /* > * When the POPCNT instruction is not available, there's no point in using > * function pointers to vary the implementation between the fast and slow > * method. We instead just make these actual external functions when > * TRY_POPCNT_FAST is not defined. The compiler should be able to inline > * the slow versions here. > */ > > Also, have a look at [1]. You'll see f_slow() wasn't even compiled and the code > was just inlined into f(). I just added the > __attribute__((noinline)) so that usage() wouldn't just perform constant > folding and just return 6. > > I think, unless you have evidence that some common compiler isn't inlining the > static into the extern then we shouldn't add the macros. > It adds quite a bit of churn to the patch and will break out of core code as you > no longer have functions named pg_popcount32(), > pg_popcount64() and pg_popcount(). This may be a simple misunderstanding extern != static. If I use the "extern" keyword then a symbol *will* be generated andinline will be ignored. This is NOT true of "static inline", where the compiler will try to inline the method. :) In this patch set: * I removed the macro implementation. * Made everything that could possibly be inlined marked with the "static inline" keyword. * Conditionally made the *_slow() functions "static inline" when TRY_POPCONT_FAST is not set. * Found and fixed some whitespace errors in the AVX code implementation. Thanks, Paul
Attachment
> -----Original Message----- > From: Amonson, Paul D <paul.d.amonson@intel.com> > Sent: Thursday, March 21, 2024 12:18 PM > To: David Rowley <dgrowleyml@gmail.com> > Cc: Nathan Bossart <nathandbossart@gmail.com>; Andres Freund I am re-posting the patches as CI for Mac failed (CI error not code/test error). The patches are the same as last time. Thanks, Paul
Attachment
"Amonson, Paul D" <paul.d.amonson@intel.com> writes:
> I am re-posting the patches as CI for Mac failed (CI error not code/test error). The patches are the same as last
time.
Just for a note --- the cfbot will re-test existing patches every
so often without needing a bump. The current cycle period seems to
be about two days.
regards, tom lane
> -----Original Message----- > From: Tom Lane <tgl@sss.pgh.pa.us> > Sent: Monday, March 25, 2024 8:12 AM > To: Amonson, Paul D <paul.d.amonson@intel.com> > Cc: David Rowley <dgrowleyml@gmail.com>; Nathan Bossart > Subject: Re: Popcount optimization using AVX512 >... > Just for a note --- the cfbot will re-test existing patches every so often without > needing a bump. The current cycle period seems to be about two days. > > regards, tom lane Good to know! Maybe this is why I thought it originally passed CI and suddenly this morning there is a failure. I noticedat least 2 other patch runs also failed in the same way. Thanks, Paul
On 3/25/24 11:12, Tom Lane wrote: > "Amonson, Paul D" <paul.d.amonson@intel.com> writes: >> I am re-posting the patches as CI for Mac failed (CI error not code/test error). The patches are the same as last time. > > Just for a note --- the cfbot will re-test existing patches every > so often without needing a bump. The current cycle period seems to > be about two days. Just an FYI -- there seems to be an issue with all three of the macos cfbot runners (mine included). I spent time over the weekend working with Thomas Munro (added to CC list) trying different fixes to no avail. Help from macos CI wizards would be gratefully accepted... -- Joe Conway PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
> -----Original Message----- > From: Amonson, Paul D <paul.d.amonson@intel.com> > Sent: Monday, March 25, 2024 8:20 AM > To: Tom Lane <tgl@sss.pgh.pa.us> > Cc: David Rowley <dgrowleyml@gmail.com>; Nathan Bossart > <nathandbossart@gmail.com>; Andres Freund <andres@anarazel.de>; Alvaro > Herrera <alvherre@alvh.no-ip.org>; Shankaran, Akash > <akash.shankaran@intel.com>; Noah Misch <noah@leadboat.com>; Matthias > van de Meent <boekewurm+postgres@gmail.com>; pgsql- > hackers@lists.postgresql.org > Subject: RE: Popcount optimization using AVX512 > Ok, CI turned green after my re-post of the patches. Can this please get merged? Thanks, Paul
On Mon, Mar 25, 2024 at 06:42:36PM +0000, Amonson, Paul D wrote: > Ok, CI turned green after my re-post of the patches. Can this please get > merged? Thanks for the new patches. I intend to take another look soon. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Mon, Mar 25, 2024 at 03:05:51PM -0500, Nathan Bossart wrote: > On Mon, Mar 25, 2024 at 06:42:36PM +0000, Amonson, Paul D wrote: >> Ok, CI turned green after my re-post of the patches. Can this please get >> merged? > > Thanks for the new patches. I intend to take another look soon. Thanks for your patience. I spent most of my afternoon looking into the latest patch set, but I needed to do a CHECKPOINT and take a break. I am in the middle of doing some rather heavy editorialization, but the core of your changes will remain the same (and so I still intend to give you authorship credit). I've attached what I have so far, which is still missing the configuration checks and the changes to make sure the extra compiler flags make it to the right places. Unless something pops up while I work on the remainder of this patch, I think we'll end up going with a simpler approach. I originally set out to make this look like the CRC32C stuff (e.g., a file per implementation), but that seemed primarily useful if we can choose which files need to be compiled at configure-time. However, the TRY_POPCNT_FAST macro is defined at compile-time (AFAICT for good reason [0]), so we end up having to compile all the files in many cases anyway, and we continue to need to surround lots of code with "#ifdef TRY_POPCNT_FAST" or similar. So, my current thinking is that we should only move the AVX512 stuff to its own file for the purposes of compiling it with special flags when possible. (I realize that I'm essentially recanting much of my previous feedback, which I apologize for.) [0] https://postgr.es/m/CAApHDvrONNcYxGV6C0O3ZmaL0BvXBWY%2BrBOCBuYcQVUOURwhkA%40mail.gmail.com -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
> -----Original Message----- > From: Nathan Bossart <nathandbossart@gmail.com> > Sent: Wednesday, March 27, 2024 3:00 PM > To: Amonson, Paul D <paul.d.amonson@intel.com> > > ... (I realize that I'm essentially > recanting much of my previous feedback, which I apologize for.) It happens. LOL As long as the algorithm for AVX-512 is not altered I am confident that your new refactor will be fine. :) Thanks, Paul
Here is a v14 of the patch that I think is beginning to approach something committable. Besides general review and testing, there are two things that I'd like to bring up: * The latest patch set from Paul Amonson appeared to support MSVC in the meson build, but not the autoconf one. I don't have much expertise here, so the v14 patch doesn't have any autoconf/meson support for MSVC, which I thought might be okay for now. IIUC we assume that 64-bit/MSVC builds can always compile the x86_64 popcount code, but I don't know whether that's safe for AVX512. * I think we need to verify there isn't a huge performance regression for smaller arrays. IIUC those will still require an AVX512 instruction or two as well as a function call, which might add some noticeable overhead. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
On Thu, Mar 28, 2024 at 04:38:54PM -0500, Nathan Bossart wrote:
> Here is a v14 of the patch that I think is beginning to approach something
> committable. Besides general review and testing, there are two things that
> I'd like to bring up:
>
> * The latest patch set from Paul Amonson appeared to support MSVC in the
> meson build, but not the autoconf one. I don't have much expertise here,
> so the v14 patch doesn't have any autoconf/meson support for MSVC, which
> I thought might be okay for now. IIUC we assume that 64-bit/MSVC builds
> can always compile the x86_64 popcount code, but I don't know whether
> that's safe for AVX512.
>
> * I think we need to verify there isn't a huge performance regression for
> smaller arrays. IIUC those will still require an AVX512 instruction or
> two as well as a function call, which might add some noticeable overhead.
I forgot to mention that I also want to understand whether we can actually
assume availability of XGETBV when CPUID says we support AVX512:
> + /*
> + * We also need to check that the OS has enabled support for the ZMM
> + * registers.
> + */
> +#ifdef _MSC_VER
> + return (_xgetbv(0) & 0xe0) != 0;
> +#else
> + uint64 xcr = 0;
> + uint32 high;
> + uint32 low;
> +
> +__asm__ __volatile__(" xgetbv\n":"=a"(low), "=d"(high):"c"(xcr));
> + return (low & 0xe0) != 0;
> +#endif
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
> -----Original Message----- > From: Nathan Bossart <nathandbossart@gmail.com> > Sent: Thursday, March 28, 2024 2:39 PM > To: Amonson, Paul D <paul.d.amonson@intel.com> > > * The latest patch set from Paul Amonson appeared to support MSVC in the > meson build, but not the autoconf one. I don't have much expertise here, > so the v14 patch doesn't have any autoconf/meson support for MSVC, which > I thought might be okay for now. IIUC we assume that 64-bit/MSVC builds > can always compile the x86_64 popcount code, but I don't know whether > that's safe for AVX512. I also do not know how to integrate MSVC+Autoconf, the CI uses MSVC+Meson+Ninja so I stuck with that. > * I think we need to verify there isn't a huge performance regression for > smaller arrays. IIUC those will still require an AVX512 instruction or > two as well as a function call, which might add some noticeable overhead. Not considering your changes, I had already tested small buffers. At less than 512 bytes there was no measurable regression(there was one extra condition check) and for 512+ bytes it moved from no regression to some gains between 512and 4096 bytes. Assuming you introduced no extra function calls, it should be the same. > I forgot to mention that I also want to understand whether we can actually assume availability of XGETBV when CPUID sayswe support AVX512: You cannot assume as there are edge cases where AVX-512 was found on system one during compile but it's not actually availablein a kernel on a second system at runtime despite the CPU actually having the hardware feature. I will review the new patch to see if there are anything that jumps out at me. Thanks, Paul
On 2024-Mar-28, Amonson, Paul D wrote: > > -----Original Message----- > > From: Nathan Bossart <nathandbossart@gmail.com> > > Sent: Thursday, March 28, 2024 2:39 PM > > To: Amonson, Paul D <paul.d.amonson@intel.com> > > > > * The latest patch set from Paul Amonson appeared to support MSVC in the > > meson build, but not the autoconf one. I don't have much expertise here, > > so the v14 patch doesn't have any autoconf/meson support for MSVC, which > > I thought might be okay for now. IIUC we assume that 64-bit/MSVC builds > > can always compile the x86_64 popcount code, but I don't know whether > > that's safe for AVX512. > > I also do not know how to integrate MSVC+Autoconf, the CI uses > MSVC+Meson+Ninja so I stuck with that. We don't do MSVC via autoconf/Make. We used to have a special build framework for MSVC which parsed Makefiles to produce "solution" files, but it was removed as soon as Meson was mature enough to build. See commit 1301c80b2167. If it builds with Meson, you're good. -- Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/ "[PostgreSQL] is a great group; in my opinion it is THE best open source development communities in existence anywhere." (Lamar Owen)
> -----Original Message----- > From: Amonson, Paul D <paul.d.amonson@intel.com> > Sent: Thursday, March 28, 2024 3:03 PM > To: Nathan Bossart <nathandbossart@gmail.com> > ... > I will review the new patch to see if there are anything that jumps out at me. I see in the meson.build you added the new file twice? @@ -7,6 +7,7 @@ pgport_sources = [ 'noblock.c', 'path.c', 'pg_bitutils.c', + 'pg_popcount_avx512.c', 'pg_strong_random.c', 'pgcheckdir.c', 'pgmkdirp.c', @@ -84,6 +85,7 @@ replace_funcs_pos = [ ['pg_crc32c_sse42', 'USE_SSE42_CRC32C_WITH_RUNTIME_CHECK', 'crc'], ['pg_crc32c_sse42_choose', 'USE_SSE42_CRC32C_WITH_RUNTIME_CHECK'], ['pg_crc32c_sb8', 'USE_SSE42_CRC32C_WITH_RUNTIME_CHECK'], + ['pg_popcount_avx512', 'USE_AVX512_POPCNT_WITH_RUNTIME_CHECK', 'avx512_popcnt'], I was putting the file with special flags ONLY in the second section and all seemed to work. :) Everything else seems good to me. Thanks, Paul
On Thu, Mar 28, 2024 at 10:03:04PM +0000, Amonson, Paul D wrote: >> * I think we need to verify there isn't a huge performance regression for >> smaller arrays. IIUC those will still require an AVX512 instruction or >> two as well as a function call, which might add some noticeable overhead. > > Not considering your changes, I had already tested small buffers. At less > than 512 bytes there was no measurable regression (there was one extra > condition check) and for 512+ bytes it moved from no regression to some > gains between 512 and 4096 bytes. Assuming you introduced no extra > function calls, it should be the same. Cool. I think we should run the benchmarks again to be safe, though. >> I forgot to mention that I also want to understand whether we can >> actually assume availability of XGETBV when CPUID says we support >> AVX512: > > You cannot assume as there are edge cases where AVX-512 was found on > system one during compile but it's not actually available in a kernel on > a second system at runtime despite the CPU actually having the hardware > feature. Yeah, I understand that much, but I want to know how portable the XGETBV instruction is. Unless I can assume that all x86_64 systems and compilers support that instruction, we might need an additional configure check and/or CPUID check. It looks like MSVC has had support for the _xgetbv intrinsic for quite a while, but I'm still researching the other cases. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Thu, Mar 28, 2024 at 11:10:33PM +0100, Alvaro Herrera wrote: > We don't do MSVC via autoconf/Make. We used to have a special build > framework for MSVC which parsed Makefiles to produce "solution" files, > but it was removed as soon as Meson was mature enough to build. See > commit 1301c80b2167. If it builds with Meson, you're good. The latest cfbot build for this seems to indicate that at least newer MSVC knows AVX512 intrinsics without any special compiler flags [0], so maybe what I had in v14 is good enough. A previous version of the patch set [1] had the following lines: + if host_system == 'windows' + test_flags = ['/arch:AVX512'] + endif I'm not sure if this is needed for older MSVC or something else. IIRC I couldn't find any other examples of this sort of thing in the meson scripts, either. Paul, do you recall why you added this? [0] https://cirrus-ci.com/task/5787206636273664?logs=configure#L159 [1] https://postgr.es/m/attachment/158206/v12-0002-Feature-Added-AVX-512-acceleration-to-the-pg_popcoun.patch -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Thu, Mar 28, 2024 at 10:29:47PM +0000, Amonson, Paul D wrote:
> I see in the meson.build you added the new file twice?
>
> @@ -7,6 +7,7 @@ pgport_sources = [
> 'noblock.c',
> 'path.c',
> 'pg_bitutils.c',
> + 'pg_popcount_avx512.c',
> 'pg_strong_random.c',
> 'pgcheckdir.c',
> 'pgmkdirp.c',
> @@ -84,6 +85,7 @@ replace_funcs_pos = [
> ['pg_crc32c_sse42', 'USE_SSE42_CRC32C_WITH_RUNTIME_CHECK', 'crc'],
> ['pg_crc32c_sse42_choose', 'USE_SSE42_CRC32C_WITH_RUNTIME_CHECK'],
> ['pg_crc32c_sb8', 'USE_SSE42_CRC32C_WITH_RUNTIME_CHECK'],
> + ['pg_popcount_avx512', 'USE_AVX512_POPCNT_WITH_RUNTIME_CHECK', 'avx512_popcnt'],
>
> I was putting the file with special flags ONLY in the second section and all seemed to work. :)
Ah, yes, I think that's a mistake, and without looking closely, might
explain the MSVC warnings [0]:
[22:05:47.444] pg_popcount_avx512.c.obj : warning LNK4006: pg_popcount_avx512_available already defined in
pg_popcount_a...
It might be nice if we conditionally built pg_popcount_avx512.o in autoconf
builds, too, but AFAICT we still need to wrap most of that code with
macros, so I'm not sure it's worth the trouble. I'll take another look at
this...
[0] http://commitfest.cputube.org/highlights/all.html#4883
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
Attachment
> -----Original Message----- > > Cool. I think we should run the benchmarks again to be safe, though. Ok, sure go ahead. :) > >> I forgot to mention that I also want to understand whether we can > >> actually assume availability of XGETBV when CPUID says we support > >> AVX512: > > > > You cannot assume as there are edge cases where AVX-512 was found on > > system one during compile but it's not actually available in a kernel > > on a second system at runtime despite the CPU actually having the > > hardware feature. > > Yeah, I understand that much, but I want to know how portable the XGETBV > instruction is. Unless I can assume that all x86_64 systems and compilers > support that instruction, we might need an additional configure check and/or > CPUID check. It looks like MSVC has had support for the _xgetbv intrinsic for > quite a while, but I'm still researching the other cases. I see google web references to the xgetbv instruction as far back as 2009 for Intel 64 bit HW and 2010 for AMD 64bit HW,maybe you could test for _xgetbv() MSVC built-in. How far back do you need to go? Thanks, Paul
On Fri, Mar 29, 2024 at 04:06:17PM +0000, Amonson, Paul D wrote: >> Yeah, I understand that much, but I want to know how portable the XGETBV >> instruction is. Unless I can assume that all x86_64 systems and compilers >> support that instruction, we might need an additional configure check and/or >> CPUID check. It looks like MSVC has had support for the _xgetbv intrinsic for >> quite a while, but I'm still researching the other cases. > > I see google web references to the xgetbv instruction as far back as 2009 > for Intel 64 bit HW and 2010 for AMD 64bit HW, maybe you could test for > _xgetbv() MSVC built-in. How far back do you need to go? Hm. It seems unlikely that a compiler would understand AVX512 intrinsics and not XGETBV then. I guess the other question is whether CPUID indicating AVX512 is enabled implies the availability of XGETBV on the CPU. If that's not safe, we might need to add another CPUID test. It would probably be easy enough to add a couple of tests for this, but if we don't have reason to believe there's any practical case to do so, I don't know why we would. I'm curious what others think about this. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Fri, Mar 29, 2024 at 10:59:40AM -0500, Nathan Bossart wrote: > It might be nice if we conditionally built pg_popcount_avx512.o in autoconf > builds, too, but AFAICT we still need to wrap most of that code with > macros, so I'm not sure it's worth the trouble. I'll take another look at > this... If we assumed that TRY_POPCNT_FAST would be set and either HAVE__GET_CPUID_COUNT or HAVE__CPUIDEX would be set whenever USE_AVX512_POPCNT_WITH_RUNTIME_CHECK is set, we could probably remove the surrounding macros and just compile pg_popcount_avx512.c conditionally based on USE_AVX512_POPCNT_WITH_RUNTIME_CHECK. However, the surrounding code seems to be pretty cautious about these assumptions (e.g., the CPUID macros are checked before setting TRY_POPCNT_FAST), so this would stray from the nearby precedent a bit. A counterexample is the CRC32C code. AFAICT we assume the presence of CPUID in that code (and #error otherwise). I imagine its probably safe to assume the compiler understands CPUID if it understands AVX512 intrinsics, but that is still mostly a guess. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Nathan Bossart <nathandbossart@gmail.com> writes:
>> I see google web references to the xgetbv instruction as far back as 2009
>> for Intel 64 bit HW and 2010 for AMD 64bit HW, maybe you could test for
>> _xgetbv() MSVC built-in. How far back do you need to go?
> Hm. It seems unlikely that a compiler would understand AVX512 intrinsics
> and not XGETBV then. I guess the other question is whether CPUID
> indicating AVX512 is enabled implies the availability of XGETBV on the CPU.
> If that's not safe, we might need to add another CPUID test.
Some quick googling says that (1) XGETBV predates AVX and (2) if you
are worried about old CPUs, you should check CPUID to verify whether
XGETBV exists before trying to use it. I did not look for the
bit-level details on how to do that.
regards, tom lane
> From: Nathan Bossart <nathandbossart@gmail.com> > Sent: Friday, March 29, 2024 9:17 AM > To: Amonson, Paul D <paul.d.amonson@intel.com> > On Fri, Mar 29, 2024 at 04:06:17PM +0000, Amonson, Paul D wrote: >> Yeah, I understand that much, but I want to know how portable the >> XGETBV instruction is. Unless I can assume that all x86_64 systems >> and compilers support that instruction, we might need an additional >> configure check and/or CPUID check. It looks like MSVC has had >> support for the _xgetbv intrinsic for quite a while, but I'm still researching the other cases. > > I see google web references to the xgetbv instruction as far back as > 2009 for Intel 64 bit HW and 2010 for AMD 64bit HW, maybe you could > test for > _xgetbv() MSVC built-in. How far back do you need to go? > Hm. It seems unlikely that a compiler would understand AVX512 intrinsics and not XGETBV then. I guess the other questionis whether CPUID indicating AVX512 is enabled implies the availability of XGETBV on the CPU. > If that's not safe, we might need to add another CPUID test. > It would probably be easy enough to add a couple of tests for this, but if we don't have reason to believe there's anypractical case to do so, I don't know why we would. I'm curious what others think about this. This seems unlikely. Machines supporting XGETBV would support AVX512 intrinsics. Xgetbv instruction seems to be part of xsavefeature set as per intel developer manual [2]. XGETBV/XSAVE came first, and seems to be available in all x86 systemsavailable since 2011, since Intel SandyBridge architecture and AMD the Opteron Gen4 [0]. AVX512 first came into a product in 2016 [1] [0]: https://kb.vmware.com/s/article/1005764 [1]: https://en.wikipedia.org/wiki/AVX-512 [2]: https://cdrdv2-public.intel.com/774475/252046-sdm-change-document.pdf - Akash Shankaran
On Fri, Mar 29, 2024 at 12:30:14PM -0400, Tom Lane wrote: > Nathan Bossart <nathandbossart@gmail.com> writes: >>> I see google web references to the xgetbv instruction as far back as 2009 >>> for Intel 64 bit HW and 2010 for AMD 64bit HW, maybe you could test for >>> _xgetbv() MSVC built-in. How far back do you need to go? > >> Hm. It seems unlikely that a compiler would understand AVX512 intrinsics >> and not XGETBV then. I guess the other question is whether CPUID >> indicating AVX512 is enabled implies the availability of XGETBV on the CPU. >> If that's not safe, we might need to add another CPUID test. > > Some quick googling says that (1) XGETBV predates AVX and (2) if you > are worried about old CPUs, you should check CPUID to verify whether > XGETBV exists before trying to use it. I did not look for the > bit-level details on how to do that. That extra CPUID check should translate to exactly one additional line of code, so I think I'm inclined to just add it. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
> On Thu, Mar 28, 2024 at 11:10:33PM +0100, Alvaro Herrera wrote: > > We don't do MSVC via autoconf/Make. We used to have a special build > > framework for MSVC which parsed Makefiles to produce "solution" files, > > but it was removed as soon as Meson was mature enough to build. See > > commit 1301c80b2167. If it builds with Meson, you're good. > > The latest cfbot build for this seems to indicate that at least newer MSVC > knows AVX512 intrinsics without any special compiler flags [0], so maybe > what I had in v14 is good enough. A previous version of the patch set [1] had > the following lines: > > + if host_system == 'windows' > + test_flags = ['/arch:AVX512'] > + endif > > I'm not sure if this is needed for older MSVC or something else. IIRC I couldn't > find any other examples of this sort of thing in the meson scripts, either. Paul, > do you recall why you added this? I asked internal folks here in-the-know and they suggested I add it. I personally am not a Windows guy. If it works withoutit and you are comfortable not including the lines, I am fine with it. Thanks, Paul
> A counterexample is the CRC32C code. AFAICT we assume the presence of > CPUID in that code (and #error otherwise). I imagine its probably safe to > assume the compiler understands CPUID if it understands AVX512 intrinsics, > but that is still mostly a guess. If AVX-512 intrinsics are available, then yes you will have CPUID. CPUID is much older in the hardware/software timelinethan AVX-512. Thanks, Paul
Okay, here is a slightly different approach that I've dubbed the "maximum assumption" approach. In short, I wanted to see how much we could simplify the patch by making all possibly-reasonable assumptions about the compiler and CPU. These include: * If the compiler understands AVX512 intrinsics, we assume that it also knows about the required CPUID and XGETBV intrinsics, and we assume that the conditions for TRY_POPCNT_FAST are true. * If this is x86_64, CPUID will be supported by the CPU. * If CPUID indicates AVX512 POPCNT support, the CPU also supports XGETBV. Do any of these assumptions seem unreasonable or unlikely to be true for all practical purposes? I don't mind adding back some or all of the configure/runtime checks if they seem necessary. I guess the real test will be the buildfarm... Another big change in this version is that I've moved pg_popcount_avx512_available() to its own file so that we only compile pg_popcount_avx512() with the special compiler flags. This is just an oversight in previous versions. Finally, I've modified the build scripts so that the AVX512 popcount stuff is conditionally built based on the configure checks for both autoconf/meson. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
On Fri, Mar 29, 2024 at 02:13:12PM -0500, Nathan Bossart wrote:
> * If the compiler understands AVX512 intrinsics, we assume that it also
> knows about the required CPUID and XGETBV intrinsics, and we assume that
> the conditions for TRY_POPCNT_FAST are true.
Bleh, cfbot's 32-bit build is unhappy with this [0]. It looks like it's
trying to build the AVX512 stuff, but TRY_POPCNT_FAST isn't set.
[19:39:11.306] ../src/port/pg_popcount_avx512.c:39:18: warning: implicit declaration of function ‘pg_popcount_fast’;
didyou mean ‘pg_popcount’? [-Wimplicit-function-declaration]
[19:39:11.306] 39 | return popcnt + pg_popcount_fast(buf, bytes);
[19:39:11.306] | ^~~~~~~~~~~~~~~~
[19:39:11.306] | pg_popcount
There's also a complaint about the inline assembly:
[19:39:11.443] ../src/port/pg_popcount_avx512_choose.c:55:1: error: inconsistent operand constraints in an ‘asm’
[19:39:11.443] 55 | __asm__ __volatile__(" xgetbv\n":"=a"(low), "=d"(high):"c"(xcr));
[19:39:11.443] | ^~~~~~~
I'm looking into this...
> +#if defined(HAVE__GET_CPUID)
> + __get_cpuid_count(7, 0, &exx[0], &exx[1], &exx[2], &exx[3]);
> +#elif defined(HAVE__CPUID)
> + __cpuidex(exx, 7, 0);
Is there any reason we can't use __get_cpuid() and __cpuid() here, given
the sub-leaf is 0?
[0] https://cirrus-ci.com/task/5475113447981056
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
On Fri, Mar 29, 2024 at 03:08:28PM -0500, Nathan Bossart wrote: >> +#if defined(HAVE__GET_CPUID) >> + __get_cpuid_count(7, 0, &exx[0], &exx[1], &exx[2], &exx[3]); >> +#elif defined(HAVE__CPUID) >> + __cpuidex(exx, 7, 0); > > Is there any reason we can't use __get_cpuid() and __cpuid() here, given > the sub-leaf is 0? The answer to this seems to be "no." After additional research, __get_cpuid_count/__cpuidex seem new enough that we probably want configure checks for them, so I'll add those back in the next version of the patch. Apologies for the stream of consciousness today... -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Here's a v17 of the patch. This one has configure checks for everything (i.e., CPUID, XGETBV, and the AVX512 intrinsics) as well as the relevant runtime checks (i.e., we call CPUID to check for XGETBV and AVX512 POPCNT availability, and we call XGETBV to ensure the ZMM registers are enabled). I restricted the AVX512 configure checks to x86_64 since we know we won't have TRY_POPCNT_FAST on 32-bit, and we rely on pg_popcount_fast() as our fallback implementation in the AVX512 version. Finally, I removed the inline assembly in favor of using the _xgetbv() intrinsic on all systems. It looks like that's available on gcc, clang, and msvc, although it sometimes requires -mxsave, so that's applied to pg_popcount_avx512_choose.o as needed. I doubt this will lead to SIGILLs, but it's admittedly a little shaky. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
I used John Naylor's test_popcount module [0] to put together the attached graphs (note that the "small arrays" one is semi-logarithmic). For both graphs, the X-axis is the number of 64-bit words in the array, and Y-axis is the amount of time in milliseconds to run pg_popcount() on it 100,000 times (along with a bit of overhead). This test didn't show any regressions with a relatively small number of bytes, and it showed the expected improvements with many bytes. There isn't a ton of use of pg_popcount() in Postgres, but I do see a few places that call it with enough bytes for the AVX512 optimization to take effect. There may be more callers in the future, though, and it seems generally useful to have some of the foundational work for using AVX512 instructions in place. My current plan is to add some new tests for pg_popcount() with many bytes, and then I'll give it a few more days for any additional feedback before committing. [0] https://postgr.es/m/CAFBsxsE7otwnfA36Ly44zZO+b7AEWHRFANxR1h1kxveEV=ghLQ@mail.gmail.com -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
{kind=link}
{kind=link}
On Sat, Mar 30, 2024 at 03:03:29PM -0500, Nathan Bossart wrote: > My current plan is to add some new tests for > pg_popcount() with many bytes, and then I'll give it a few more days for > any additional feedback before committing. Here is a v18 with a couple of new tests. Otherwise, it is the same as v17. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
On 2024-Mar-31, Nathan Bossart wrote:
> +uint64
> +pg_popcount_avx512(const char *buf, int bytes)
> +{
> + uint64 popcnt;
> + __m512i accum = _mm512_setzero_si512();
> +
> + for (; bytes >= sizeof(__m512i); bytes -= sizeof(__m512i))
> + {
> + const __m512i val = _mm512_loadu_si512((const __m512i *) buf);
> + const __m512i cnt = _mm512_popcnt_epi64(val);
> +
> + accum = _mm512_add_epi64(accum, cnt);
> + buf += sizeof(__m512i);
> + }
> +
> + popcnt = _mm512_reduce_add_epi64(accum);
> + return popcnt + pg_popcount_fast(buf, bytes);
> +}
Hmm, doesn't this arrangement cause an extra function call to
pg_popcount_fast to be used here? Given the level of micro-optimization
being used by this code, I would have thought that you'd have tried to
avoid that. (At least, maybe avoid the call if bytes is 0, no?)
--
Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/
"El Maquinismo fue proscrito so pena de cosquilleo hasta la muerte"
(Ijon Tichy en Viajes, Stanislaw Lem)
On Mon, Apr 01, 2024 at 01:06:12PM +0200, Alvaro Herrera wrote:
> On 2024-Mar-31, Nathan Bossart wrote:
>> + popcnt = _mm512_reduce_add_epi64(accum);
>> + return popcnt + pg_popcount_fast(buf, bytes);
>
> Hmm, doesn't this arrangement cause an extra function call to
> pg_popcount_fast to be used here? Given the level of micro-optimization
> being used by this code, I would have thought that you'd have tried to
> avoid that. (At least, maybe avoid the call if bytes is 0, no?)
Yes, it does. I did another benchmark on very small arrays and can see the
overhead. This is the time in milliseconds to run pg_popcount() on an
array 1 billion times:
size (bytes) HEAD AVX512-POPCNT
1 1707.685 3480.424
2 1926.694 4606.182
4 3210.412 5284.506
8 1920.703 3640.968
16 2936.91 4045.586
32 3627.956 5538.418
64 5347.213 3748.212
I suspect that anything below 64 bytes will see this regression, as that is
the earliest point where there are enough bytes for ZMM registers.
We could avoid the call if there are no remaining bytes, but the numbers
for the smallest arrays probably wouldn't improve much, and that might
actually add some overhead due to branching. The other option to avoid
this overhead is to put most of pg_bitutils.c into its header file so that
we can inline the call.
Reviewing the current callers of pg_popcount(), IIUC the only ones that are
passing very small arrays are the bit_count() implementations and a call in
the syslogger for a single byte. I don't know how much to worry about the
overhead for bit_count() since there's presumably a bunch of other
overhead, and the syslogger one could probably be fixed via an inline
function that pulled the value from pg_number_of_ones (which would probably
be an improvement over the status quo, anyway). But this is all to save a
couple of nanoseconds...
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
On Mon, 1 Apr 2024 at 18:53, Nathan Bossart <nathandbossart@gmail.com> wrote: > > On Mon, Apr 01, 2024 at 01:06:12PM +0200, Alvaro Herrera wrote: > > On 2024-Mar-31, Nathan Bossart wrote: > >> + popcnt = _mm512_reduce_add_epi64(accum); > >> + return popcnt + pg_popcount_fast(buf, bytes); > > > > Hmm, doesn't this arrangement cause an extra function call to > > pg_popcount_fast to be used here? Given the level of micro-optimization > > being used by this code, I would have thought that you'd have tried to > > avoid that. (At least, maybe avoid the call if bytes is 0, no?) > > Yes, it does. I did another benchmark on very small arrays and can see the > overhead. This is the time in milliseconds to run pg_popcount() on an > array 1 billion times: > > size (bytes) HEAD AVX512-POPCNT > 1 1707.685 3480.424 > 2 1926.694 4606.182 > 4 3210.412 5284.506 > 8 1920.703 3640.968 > 16 2936.91 4045.586 > 32 3627.956 5538.418 > 64 5347.213 3748.212 > > I suspect that anything below 64 bytes will see this regression, as that is > the earliest point where there are enough bytes for ZMM registers. What about using the masking capabilities of AVX-512 to handle the tail in the same code path? Masked out portions of a load instruction will not generate an exception. To allow byte level granularity masking, -mavx512bw is needed. Based on wikipedia this will only disable this fast path on Knights Mill (Xeon Phi), in all other cases VPOPCNTQ implies availability of BW. Attached is an example of what I mean. I did not have a machine to test it with, but the code generated looks sane. I added the clang pragma because it insisted on unrolling otherwise and based on how the instruction dependencies look that is probably not too helpful even for large cases (needs to be tested). The configure check and compile flags of course need to be amended for BW. Regards, Ants Aasma
Attachment
On Tue, Apr 02, 2024 at 12:11:59AM +0300, Ants Aasma wrote: > What about using the masking capabilities of AVX-512 to handle the > tail in the same code path? Masked out portions of a load instruction > will not generate an exception. To allow byte level granularity > masking, -mavx512bw is needed. Based on wikipedia this will only > disable this fast path on Knights Mill (Xeon Phi), in all other cases > VPOPCNTQ implies availability of BW. Sounds promising. IMHO we should really be sure that these kinds of loads won't generate segfaults and the like due to the masked-out portions. I searched around a little bit but haven't found anything that seemed definitive. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Tue, 2 Apr 2024 at 00:31, Nathan Bossart <nathandbossart@gmail.com> wrote: > > On Tue, Apr 02, 2024 at 12:11:59AM +0300, Ants Aasma wrote: > > What about using the masking capabilities of AVX-512 to handle the > > tail in the same code path? Masked out portions of a load instruction > > will not generate an exception. To allow byte level granularity > > masking, -mavx512bw is needed. Based on wikipedia this will only > > disable this fast path on Knights Mill (Xeon Phi), in all other cases > > VPOPCNTQ implies availability of BW. > > Sounds promising. IMHO we should really be sure that these kinds of loads > won't generate segfaults and the like due to the masked-out portions. I > searched around a little bit but haven't found anything that seemed > definitive. Interestingly the Intel software developer manual is not exactly crystal clear on how memory faults with masks work, but volume 2A chapter 2.8 [1] does specify that MOVDQU8 is of exception class E4.nb that supports memory fault suppression on page fault. Regards, Ants Aasma [1] https://cdrdv2-public.intel.com/819712/253666-sdm-vol-2a.pdf
Here is a v19 of the patch set. I moved out the refactoring of the function pointer selection code to 0001. I think this is a good change independent of $SUBJECT, and I plan to commit this soon. In 0002, I changed the syslogger.c usage of pg_popcount() to use pg_number_of_ones instead. This is standard practice elsewhere where the popcount functions are unlikely to win. I'll probably commit this one soon, too, as it's even more trivial than 0001. 0003 is the AVX512 POPCNT patch. Besides refactoring out 0001, there are no changes from v18. 0004 is an early proof-of-concept for using AVX512 for the visibility map code. The code is missing comments, and I haven't performed any benchmarking yet, but I figured I'd post it because it demonstrates how it's possible to build upon 0003 in other areas. AFAICT the main open question is the function call overhead in 0003 that Alvaro brought up earlier. After 0002 is committed, I believe the only in-tree caller of pg_popcount() with very few bytes is bit_count(), and I'm not sure it's worth expending too much energy to make sure there are absolutely no regressions there. However, I'm happy to do so if folks feel that it is necessary, and I'd be grateful for thoughts on how to proceed on this one. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
On Tue, Apr 02, 2024 at 01:09:57AM +0300, Ants Aasma wrote: > On Tue, 2 Apr 2024 at 00:31, Nathan Bossart <nathandbossart@gmail.com> wrote: >> On Tue, Apr 02, 2024 at 12:11:59AM +0300, Ants Aasma wrote: >> > What about using the masking capabilities of AVX-512 to handle the >> > tail in the same code path? Masked out portions of a load instruction >> > will not generate an exception. To allow byte level granularity >> > masking, -mavx512bw is needed. Based on wikipedia this will only >> > disable this fast path on Knights Mill (Xeon Phi), in all other cases >> > VPOPCNTQ implies availability of BW. >> >> Sounds promising. IMHO we should really be sure that these kinds of loads >> won't generate segfaults and the like due to the masked-out portions. I >> searched around a little bit but haven't found anything that seemed >> definitive. > > Interestingly the Intel software developer manual is not exactly > crystal clear on how memory faults with masks work, but volume 2A > chapter 2.8 [1] does specify that MOVDQU8 is of exception class E4.nb > that supports memory fault suppression on page fault. Perhaps Paul or Akash could chime in here... -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Mon, Apr 01, 2024 at 05:11:17PM -0500, Nathan Bossart wrote:
> Here is a v19 of the patch set. I moved out the refactoring of the
> function pointer selection code to 0001. I think this is a good change
> independent of $SUBJECT, and I plan to commit this soon. In 0002, I
> changed the syslogger.c usage of pg_popcount() to use pg_number_of_ones
> instead. This is standard practice elsewhere where the popcount functions
> are unlikely to win. I'll probably commit this one soon, too, as it's even
> more trivial than 0001.
>
> 0003 is the AVX512 POPCNT patch. Besides refactoring out 0001, there are
> no changes from v18. 0004 is an early proof-of-concept for using AVX512
> for the visibility map code. The code is missing comments, and I haven't
> performed any benchmarking yet, but I figured I'd post it because it
> demonstrates how it's possible to build upon 0003 in other areas.
I've committed the first two patches, and I've attached a rebased version
of the latter two.
> AFAICT the main open question is the function call overhead in 0003 that
> Alvaro brought up earlier. After 0002 is committed, I believe the only
> in-tree caller of pg_popcount() with very few bytes is bit_count(), and I'm
> not sure it's worth expending too much energy to make sure there are
> absolutely no regressions there. However, I'm happy to do so if folks feel
> that it is necessary, and I'd be grateful for thoughts on how to proceed on
> this one.
Another idea I had is to turn pg_popcount() into a macro that just uses the
pg_number_of_ones array when called for few bytes:
static inline uint64
pg_popcount_inline(const char *buf, int bytes)
{
uint64 popcnt = 0;
while (bytes--)
popcnt += pg_number_of_ones[(unsigned char) *buf++];
return popcnt;
}
#define pg_popcount(buf, bytes) \
((bytes < 64) ? \
pg_popcount_inline(buf, bytes) : \
pg_popcount_optimized(buf, bytes))
But again, I'm not sure this is really worth it for the current use-cases.
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
Attachment
On 2024-Apr-02, Nathan Bossart wrote:
> Another idea I had is to turn pg_popcount() into a macro that just uses the
> pg_number_of_ones array when called for few bytes:
>
> static inline uint64
> pg_popcount_inline(const char *buf, int bytes)
> {
> uint64 popcnt = 0;
>
> while (bytes--)
> popcnt += pg_number_of_ones[(unsigned char) *buf++];
>
> return popcnt;
> }
>
> #define pg_popcount(buf, bytes) \
> ((bytes < 64) ? \
> pg_popcount_inline(buf, bytes) : \
> pg_popcount_optimized(buf, bytes))
>
> But again, I'm not sure this is really worth it for the current use-cases.
Eh, that seems simple enough, and then you can forget about that case.
--
Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/
"No hay hombre que no aspire a la plenitud, es decir,
la suma de experiencias de que un hombre es capaz"
Alvaro Herrera <alvherre@alvh.no-ip.org> writes:
> On 2024-Apr-02, Nathan Bossart wrote:
>> Another idea I had is to turn pg_popcount() into a macro that just uses the
>> pg_number_of_ones array when called for few bytes:
>>
>> static inline uint64
>> pg_popcount_inline(const char *buf, int bytes)
>> {
>> uint64 popcnt = 0;
>>
>> while (bytes--)
>> popcnt += pg_number_of_ones[(unsigned char) *buf++];
>>
>> return popcnt;
>> }
>>
>> #define pg_popcount(buf, bytes) \
>> ((bytes < 64) ? \
>> pg_popcount_inline(buf, bytes) : \
>> pg_popcount_optimized(buf, bytes))
>>
>> But again, I'm not sure this is really worth it for the current use-cases.
> Eh, that seems simple enough, and then you can forget about that case.
I don't like the double evaluation of the macro argument. Seems like
you could get the same results more safely with
static inline uint64
pg_popcount(const char *buf, int bytes)
{
if (bytes < 64)
{
uint64 popcnt = 0;
while (bytes--)
popcnt += pg_number_of_ones[(unsigned char) *buf++];
return popcnt;
}
return pg_popcount_optimized(buf, bytes);
}
regards, tom lane
On Tue, Apr 02, 2024 at 01:43:48PM -0400, Tom Lane wrote:
> Alvaro Herrera <alvherre@alvh.no-ip.org> writes:
>> On 2024-Apr-02, Nathan Bossart wrote:
>>> Another idea I had is to turn pg_popcount() into a macro that just uses the
>>> pg_number_of_ones array when called for few bytes:
>>>
>>> static inline uint64
>>> pg_popcount_inline(const char *buf, int bytes)
>>> {
>>> uint64 popcnt = 0;
>>>
>>> while (bytes--)
>>> popcnt += pg_number_of_ones[(unsigned char) *buf++];
>>>
>>> return popcnt;
>>> }
>>>
>>> #define pg_popcount(buf, bytes) \
>>> ((bytes < 64) ? \
>>> pg_popcount_inline(buf, bytes) : \
>>> pg_popcount_optimized(buf, bytes))
>>>
>>> But again, I'm not sure this is really worth it for the current use-cases.
>
>> Eh, that seems simple enough, and then you can forget about that case.
>
> I don't like the double evaluation of the macro argument. Seems like
> you could get the same results more safely with
>
> static inline uint64
> pg_popcount(const char *buf, int bytes)
> {
> if (bytes < 64)
> {
> uint64 popcnt = 0;
>
> while (bytes--)
> popcnt += pg_number_of_ones[(unsigned char) *buf++];
>
> return popcnt;
> }
> return pg_popcount_optimized(buf, bytes);
> }
Yeah, I like that better. I'll do some testing to see what the threshold
really should be before posting an actual patch.
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
On Tue, 2 Apr 2024 at 00:31, Nathan Bossart <nathandbossart@gmail.com> wrote: > On Tue, Apr 02, 2024 at 12:11:59AM +0300, Ants Aasma wrote: > > What about using the masking capabilities of AVX-512 to handle the > > tail in the same code path? Masked out portions of a load instruction > > will not generate an exception. To allow byte level granularity > > masking, -mavx512bw is needed. Based on wikipedia this will only > > disable this fast path on Knights Mill (Xeon Phi), in all other cases > > VPOPCNTQ implies availability of BW. > > Sounds promising. IMHO we should really be sure that these kinds of loads > won't generate segfaults and the like due to the masked-out portions. I > searched around a little bit but haven't found anything that seemed > definitive. After sleeping on the problem, I think we can avoid this question altogether while making the code faster by using aligned accesses. Loads that straddle cache line boundaries run internally as 2 load operations. Gut feel says that there are enough out-of-order resources available to make it not matter in most cases. But even so, not doing the extra work is surely better. Attached is another approach that does aligned accesses, and thereby avoids going outside bounds. Would be interesting to see how well that fares in the small use case. Anything that fits into one aligned cache line should be constant speed, and there is only one branch, but the mask setup and folding the separate popcounts together should add up to about 20-ish cycles of overhead. Regards, Ants Aasma
Attachment
On Tue, Apr 02, 2024 at 01:40:21PM -0500, Nathan Bossart wrote:
> On Tue, Apr 02, 2024 at 01:43:48PM -0400, Tom Lane wrote:
>> I don't like the double evaluation of the macro argument. Seems like
>> you could get the same results more safely with
>>
>> static inline uint64
>> pg_popcount(const char *buf, int bytes)
>> {
>> if (bytes < 64)
>> {
>> uint64 popcnt = 0;
>>
>> while (bytes--)
>> popcnt += pg_number_of_ones[(unsigned char) *buf++];
>>
>> return popcnt;
>> }
>> return pg_popcount_optimized(buf, bytes);
>> }
>
> Yeah, I like that better. I'll do some testing to see what the threshold
> really should be before posting an actual patch.
My testing shows that inlining wins with fewer than 8 bytes for the current
"fast" implementation. The "fast" implementation wins with fewer than 64
bytes compared to the AVX-512 implementation. These results are pretty
intuitive because those are the points at which the optimizations kick in.
In v21, 0001 is just the above inlining idea, which seems worth doing
independent of $SUBJECT. 0002 and 0003 are the AVX-512 patches, which I've
modified similarly to 0001, i.e., I've inlined the "fast" version in the
function pointer to avoid the function call overhead when there are fewer
than 64 bytes. All of this overhead juggling should result in choosing the
optimal popcount implementation depending on how many bytes there are to
process, roughly speaking.
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
Attachment
On Tue, Apr 02, 2024 at 05:01:32PM -0500, Nathan Bossart wrote: > In v21, 0001 is just the above inlining idea, which seems worth doing > independent of $SUBJECT. 0002 and 0003 are the AVX-512 patches, which I've > modified similarly to 0001, i.e., I've inlined the "fast" version in the > function pointer to avoid the function call overhead when there are fewer > than 64 bytes. All of this overhead juggling should result in choosing the > optimal popcount implementation depending on how many bytes there are to > process, roughly speaking. Sorry for the noise. I noticed a couple of silly mistakes immediately after sending v21. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
On Tue, Apr 02, 2024 at 05:20:20PM -0500, Nathan Bossart wrote: > Sorry for the noise. I noticed a couple of silly mistakes immediately > after sending v21. Sigh... I missed a line while rebasing these patches, which seems to have grossly offended cfbot. Apologies again for the noise. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
I committed v23-0001. Here is a rebased version of the remaining patches. I intend to test the masking idea from Ants next. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
On Wed, Apr 03, 2024 at 12:41:27PM -0500, Nathan Bossart wrote: > I committed v23-0001. Here is a rebased version of the remaining patches. > I intend to test the masking idea from Ants next. 0002 was missing a cast that is needed for the 32-bit builds. I've fixed that in v25. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
On Tue, Apr 02, 2024 at 11:30:39PM +0300, Ants Aasma wrote:
> On Tue, 2 Apr 2024 at 00:31, Nathan Bossart <nathandbossart@gmail.com> wrote:
>> On Tue, Apr 02, 2024 at 12:11:59AM +0300, Ants Aasma wrote:
>> > What about using the masking capabilities of AVX-512 to handle the
>> > tail in the same code path? Masked out portions of a load instruction
>> > will not generate an exception. To allow byte level granularity
>> > masking, -mavx512bw is needed. Based on wikipedia this will only
>> > disable this fast path on Knights Mill (Xeon Phi), in all other cases
>> > VPOPCNTQ implies availability of BW.
>>
>> Sounds promising. IMHO we should really be sure that these kinds of loads
>> won't generate segfaults and the like due to the masked-out portions. I
>> searched around a little bit but haven't found anything that seemed
>> definitive.
>
> After sleeping on the problem, I think we can avoid this question
> altogether while making the code faster by using aligned accesses.
> Loads that straddle cache line boundaries run internally as 2 load
> operations. Gut feel says that there are enough out-of-order resources
> available to make it not matter in most cases. But even so, not doing
> the extra work is surely better. Attached is another approach that
> does aligned accesses, and thereby avoids going outside bounds.
>
> Would be interesting to see how well that fares in the small use case.
> Anything that fits into one aligned cache line should be constant
> speed, and there is only one branch, but the mask setup and folding
> the separate popcounts together should add up to about 20-ish cycles
> of overhead.
I tested your patch in comparison to v25 and saw the following:
bytes v25 v25+ants
2 1108.205 1033.132
4 1311.227 1289.373
8 1927.954 2360.113
16 2281.091 2365.408
32 3856.992 2390.688
64 3648.72 3242.498
128 4108.549 3607.148
256 4910.076 4496.852
For 2 bytes and 4 bytes, the inlining should take effect, so any difference
there is likely just noise. At 8 bytes, we are calling the function
pointer, and there is a small regression with the masking approach.
However, by 16 bytes, the masking approach is on par with v25, and it wins
for all larger buffers, although the gains seem to taper off a bit.
If we can verify this approach won't cause segfaults and can stomach the
regression between 8 and 16 bytes, I'd happily pivot to this approach so
that we can avoid the function call dance that I have in v25.
Thoughts?
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
On Thu, 4 Apr 2024 at 11:50, Nathan Bossart <nathandbossart@gmail.com> wrote: > If we can verify this approach won't cause segfaults and can stomach the > regression between 8 and 16 bytes, I'd happily pivot to this approach so > that we can avoid the function call dance that I have in v25. > > Thoughts? If we're worried about regressions with some narrow range of byte values, wouldn't it make more sense to compare that to cc4826dd5~1 at the latest rather than to some version that's already probably faster than PG16? David
On Thu, 4 Apr 2024 at 01:50, Nathan Bossart <nathandbossart@gmail.com> wrote: > If we can verify this approach won't cause segfaults and can stomach the > regression between 8 and 16 bytes, I'd happily pivot to this approach so > that we can avoid the function call dance that I have in v25. The approach I posted does not rely on masking performing page fault suppression. All loads are 64 byte aligned and always contain at least one byte of the buffer and therefore are guaranteed to be within a valid page. I personally don't mind it being slower for the very small cases, because when performance on those sizes really matters it makes much more sense to shoot for an inlined version instead. Speaking of which, what does bumping up the inlined version threshold to 16 do with and without AVX-512 available? Linearly extrapolating the 2 and 4 byte numbers it might just come ahead in both cases, making the choice easy. Regards, Ants Aasma
On Thu, Apr 04, 2024 at 04:28:58PM +1300, David Rowley wrote:
> On Thu, 4 Apr 2024 at 11:50, Nathan Bossart <nathandbossart@gmail.com> wrote:
>> If we can verify this approach won't cause segfaults and can stomach the
>> regression between 8 and 16 bytes, I'd happily pivot to this approach so
>> that we can avoid the function call dance that I have in v25.
>
> If we're worried about regressions with some narrow range of byte
> values, wouldn't it make more sense to compare that to cc4826dd5~1 at
> the latest rather than to some version that's already probably faster
> than PG16?
Good point. When compared with REL_16_STABLE, Ants's idea still wins:
bytes v25 v25+ants REL_16_STABLE
2 1108.205 1033.132 2039.342
4 1311.227 1289.373 3207.217
8 1927.954 2360.113 3200.238
16 2281.091 2365.408 4457.769
32 3856.992 2390.688 6206.689
64 3648.72 3242.498 9619.403
128 4108.549 3607.148 17912.081
256 4910.076 4496.852 33591.385
As before, with 2 and 4 bytes, HEAD is using the inlined approach, but
REL_16_STABLE is doing a function call. For 8 bytes, REL_16_STABLE is
doing a function call as well as a call to a function pointer. At 16
bytes, it's doing a function call and two calls to a function pointer.
With Ant's approach, both 8 and 16 bytes require a single call to a
function pointer, and of course we are using the AVX-512 implementation for
both.
I think this is sufficient to justify switching approaches.
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
On Thu, Apr 04, 2024 at 04:02:53PM +0300, Ants Aasma wrote: > Speaking of which, what does bumping up the inlined version threshold > to 16 do with and without AVX-512 available? Linearly extrapolating > the 2 and 4 byte numbers it might just come ahead in both cases, > making the choice easy. IIRC the inlined version starts losing pretty quickly after 8 bytes. As I noted in my previous message, I think we have enough data to switch to your approach already, so I think it's a moot point. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Here is an updated patch set. IMHO this is in decent shape and is approaching committable. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
On Fri, 5 Apr 2024 at 07:15, Nathan Bossart <nathandbossart@gmail.com> wrote:
> Here is an updated patch set. IMHO this is in decent shape and is
> approaching committable.
I checked the code generation on various gcc and clang versions. It
looks mostly fine starting from versions where avx512 is supported,
gcc-7.1 and clang-5.
The main issue I saw was that clang was able to peel off the first
iteration of the loop and then eliminate the mask assignment and
replace masked load with a memory operand for vpopcnt. I was not able
to convince gcc to do that regardless of optimization options.
Generated code for the inner loop:
clang:
<L2>:
50: add rdx, 64
54: cmp rdx, rdi
57: jae <L1>
59: vpopcntq zmm1, zmmword ptr [rdx]
5f: vpaddq zmm0, zmm1, zmm0
65: jmp <L2>
gcc:
<L1>:
38: kmovq k1, rdx
3d: vmovdqu8 zmm0 {k1} {z}, zmmword ptr [rax]
43: add rax, 64
47: mov rdx, -1
4e: vpopcntq zmm0, zmm0
54: vpaddq zmm0, zmm0, zmm1
5a: vmovdqa64 zmm1, zmm0
60: cmp rax, rsi
63: jb <L1>
I'm not sure how much that matters in practice. Attached is a patch to
do this manually giving essentially the same result in gcc. As most
distro packages are built using gcc I think it would make sense to
have the extra code if it gives a noticeable benefit for large cases.
The visibility map patch has the same issue, otherwise looks good.
Regards,
Ants Aasma
Attachment
On Fri, Apr 05, 2024 at 10:33:27AM +0300, Ants Aasma wrote:
> The main issue I saw was that clang was able to peel off the first
> iteration of the loop and then eliminate the mask assignment and
> replace masked load with a memory operand for vpopcnt. I was not able
> to convince gcc to do that regardless of optimization options.
> Generated code for the inner loop:
>
> clang:
> <L2>:
> 50: add rdx, 64
> 54: cmp rdx, rdi
> 57: jae <L1>
> 59: vpopcntq zmm1, zmmword ptr [rdx]
> 5f: vpaddq zmm0, zmm1, zmm0
> 65: jmp <L2>
>
> gcc:
> <L1>:
> 38: kmovq k1, rdx
> 3d: vmovdqu8 zmm0 {k1} {z}, zmmword ptr [rax]
> 43: add rax, 64
> 47: mov rdx, -1
> 4e: vpopcntq zmm0, zmm0
> 54: vpaddq zmm0, zmm0, zmm1
> 5a: vmovdqa64 zmm1, zmm0
> 60: cmp rax, rsi
> 63: jb <L1>
>
> I'm not sure how much that matters in practice. Attached is a patch to
> do this manually giving essentially the same result in gcc. As most
> distro packages are built using gcc I think it would make sense to
> have the extra code if it gives a noticeable benefit for large cases.
Yeah, I did see this, but I also wasn't sure if it was worth further
complicating the code. I can test with and without your fix and see if it
makes any difference in the benchmarks.
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
On Fri, Apr 05, 2024 at 07:58:44AM -0500, Nathan Bossart wrote:
> On Fri, Apr 05, 2024 at 10:33:27AM +0300, Ants Aasma wrote:
>> The main issue I saw was that clang was able to peel off the first
>> iteration of the loop and then eliminate the mask assignment and
>> replace masked load with a memory operand for vpopcnt. I was not able
>> to convince gcc to do that regardless of optimization options.
>> Generated code for the inner loop:
>>
>> clang:
>> <L2>:
>> 50: add rdx, 64
>> 54: cmp rdx, rdi
>> 57: jae <L1>
>> 59: vpopcntq zmm1, zmmword ptr [rdx]
>> 5f: vpaddq zmm0, zmm1, zmm0
>> 65: jmp <L2>
>>
>> gcc:
>> <L1>:
>> 38: kmovq k1, rdx
>> 3d: vmovdqu8 zmm0 {k1} {z}, zmmword ptr [rax]
>> 43: add rax, 64
>> 47: mov rdx, -1
>> 4e: vpopcntq zmm0, zmm0
>> 54: vpaddq zmm0, zmm0, zmm1
>> 5a: vmovdqa64 zmm1, zmm0
>> 60: cmp rax, rsi
>> 63: jb <L1>
>>
>> I'm not sure how much that matters in practice. Attached is a patch to
>> do this manually giving essentially the same result in gcc. As most
>> distro packages are built using gcc I think it would make sense to
>> have the extra code if it gives a noticeable benefit for large cases.
>
> Yeah, I did see this, but I also wasn't sure if it was worth further
> complicating the code. I can test with and without your fix and see if it
> makes any difference in the benchmarks.
This seems to provide a small performance boost, so I've incorporated it
into v27.
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
Attachment
On Sat, 6 Apr 2024 at 04:38, Nathan Bossart <nathandbossart@gmail.com> wrote: > This seems to provide a small performance boost, so I've incorporated it > into v27. Won't Valgrind complain about this? +pg_popcount_avx512(const char *buf, int bytes) + buf = (const char *) TYPEALIGN_DOWN(sizeof(__m512i), buf); + val = _mm512_maskz_loadu_epi8(mask, (const __m512i *) buf); David
On Sat, Apr 06, 2024 at 12:08:14PM +1300, David Rowley wrote: > Won't Valgrind complain about this? > > +pg_popcount_avx512(const char *buf, int bytes) > > + buf = (const char *) TYPEALIGN_DOWN(sizeof(__m512i), buf); > > + val = _mm512_maskz_loadu_epi8(mask, (const __m512i *) buf); I haven't been able to generate any complaints, at least with some simple tests. But I see your point. If this did cause such complaints, ISTM we'd just want to add it to the suppression file. Otherwise, I think we'd have to go back to the non-maskz approach (which I really wanted to avoid because of the weird function overhead juggling) or find another way to do a partial load into an __m512i. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Sat, 6 Apr 2024 at 14:17, Nathan Bossart <nathandbossart@gmail.com> wrote:
>
> On Sat, Apr 06, 2024 at 12:08:14PM +1300, David Rowley wrote:
> > Won't Valgrind complain about this?
> >
> > +pg_popcount_avx512(const char *buf, int bytes)
> >
> > + buf = (const char *) TYPEALIGN_DOWN(sizeof(__m512i), buf);
> >
> > + val = _mm512_maskz_loadu_epi8(mask, (const __m512i *) buf);
>
> I haven't been able to generate any complaints, at least with some simple
> tests. But I see your point. If this did cause such complaints, ISTM we'd
> just want to add it to the suppression file. Otherwise, I think we'd have
> to go back to the non-maskz approach (which I really wanted to avoid
> because of the weird function overhead juggling) or find another way to do
> a partial load into an __m512i.
[1] seems to think it's ok. If this is true then the following
shouldn't segfault:
The following seems to run without any issue and if I change the mask
to 1 it crashes, as you'd expect.
#include <immintrin.h>
#include <stdio.h>
int main(void)
{
__m512i val;
val = _mm512_maskz_loadu_epi8((__mmask64) 0, NULL);
printf("%llu\n", _mm512_reduce_add_epi64(val));
return 0;
}
gcc avx512.c -o avx512 -O0 -mavx512f -march=native
David
[1]
https://stackoverflow.com/questions/54497141/when-using-a-mask-register-with-avx-512-load-and-stores-is-a-fault-raised-for-i
On Sat, Apr 06, 2024 at 02:51:39PM +1300, David Rowley wrote: > On Sat, 6 Apr 2024 at 14:17, Nathan Bossart <nathandbossart@gmail.com> wrote: >> On Sat, Apr 06, 2024 at 12:08:14PM +1300, David Rowley wrote: >> > Won't Valgrind complain about this? >> > >> > +pg_popcount_avx512(const char *buf, int bytes) >> > >> > + buf = (const char *) TYPEALIGN_DOWN(sizeof(__m512i), buf); >> > >> > + val = _mm512_maskz_loadu_epi8(mask, (const __m512i *) buf); >> >> I haven't been able to generate any complaints, at least with some simple >> tests. But I see your point. If this did cause such complaints, ISTM we'd >> just want to add it to the suppression file. Otherwise, I think we'd have >> to go back to the non-maskz approach (which I really wanted to avoid >> because of the weird function overhead juggling) or find another way to do >> a partial load into an __m512i. > > [1] seems to think it's ok. If this is true then the following > shouldn't segfault: > > The following seems to run without any issue and if I change the mask > to 1 it crashes, as you'd expect. Cool. Here is what I have staged for commit, which I intend to do shortly. At some point, I'd like to revisit converting TRY_POPCNT_FAST to a configure-time check and maybe even moving the "fast" and "slow" implementations to their own files, but since that's mostly for code neatness and we are rapidly approaching the v17 deadline, I'm content to leave that for v18. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
On Sat, Apr 06, 2024 at 02:41:01PM -0500, Nathan Bossart wrote: > Here is what I have staged for commit, which I intend to do shortly. Committed. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Nathan Bossart <nathandbossart@gmail.com> writes:
> Here is what I have staged for commit, which I intend to do shortly.
Today's Coverity run produced this warning, which seemingly was
triggered by one of these commits, but I can't make much sense
of it:
*** CID 1596255: Uninitialized variables (UNINIT)
/usr/lib/gcc/x86_64-linux-gnu/10/include/avxintrin.h: 1218 in _mm256_undefined_si256()
1214 extern __inline __m256i __attribute__((__gnu_inline__, __always_inline__, __artificial__))
1215 _mm256_undefined_si256 (void)
1216 {
1217 __m256i __Y = __Y;
>>> CID 1596255: Uninitialized variables (UNINIT)
>>> Using uninitialized value "__Y".
1218 return __Y;
1219 }
I see the same code in my local copy of avxintrin.h,
and I quite agree that it looks like either an undefined
value or something that properly ought to be an error.
If we are calling this, why (and from where)?
Anyway, we can certainly just dismiss this warning if it
doesn't correspond to any real problem in our code.
But I thought I'd raise the question.
regards, tom lane
On Sun, Apr 07, 2024 at 08:42:12PM -0400, Tom Lane wrote:
> Today's Coverity run produced this warning, which seemingly was
> triggered by one of these commits, but I can't make much sense
> of it:
>
> *** CID 1596255: Uninitialized variables (UNINIT)
> /usr/lib/gcc/x86_64-linux-gnu/10/include/avxintrin.h: 1218 in _mm256_undefined_si256()
> 1214 extern __inline __m256i __attribute__((__gnu_inline__, __always_inline__, __artificial__))
> 1215 _mm256_undefined_si256 (void)
> 1216 {
> 1217 __m256i __Y = __Y;
>>>> CID 1596255: Uninitialized variables (UNINIT)
>>>> Using uninitialized value "__Y".
> 1218 return __Y;
> 1219 }
>
> I see the same code in my local copy of avxintrin.h,
> and I quite agree that it looks like either an undefined
> value or something that properly ought to be an error.
> If we are calling this, why (and from where)?
Nothing in these commits uses this, or even uses the 256-bit registers.
avxintrin.h is included by immintrin.h, which is probably why this is
showing up. I believe you're supposed to use immintrin.h for the
intrinsics used in these commits, so I don't immediately see a great way to
avoid this. The Intel documentation for _mm256_undefined_si256() [0]
indicates that it is intended to return "undefined elements," so it seems
like the use of an uninitialized variable might be intentional.
> Anyway, we can certainly just dismiss this warning if it
> doesn't correspond to any real problem in our code.
> But I thought I'd raise the question.
That's probably the right thing to do, unless there's some action we can
take to suppress this warning.
[0]
https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html#text=_mm256_undefined_si256&ig_expand=6943
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
On Sun, Apr 07, 2024 at 08:23:32PM -0500, Nathan Bossart wrote: > The Intel documentation for _mm256_undefined_si256() [0] > indicates that it is intended to return "undefined elements," so it seems > like the use of an uninitialized variable might be intentional. See also https://gcc.gnu.org/git/gitweb.cgi?p=gcc.git;h=72af61b122. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Nathan Bossart <nathandbossart@gmail.com> writes: > On Sun, Apr 07, 2024 at 08:23:32PM -0500, Nathan Bossart wrote: >> The Intel documentation for _mm256_undefined_si256() [0] >> indicates that it is intended to return "undefined elements," so it seems >> like the use of an uninitialized variable might be intentional. > See also https://gcc.gnu.org/git/gitweb.cgi?p=gcc.git;h=72af61b122. Ah, interesting. That hasn't propagated to stable distros yet, evidently (and even when it does, I wonder how soon Coverity will understand it). Anyway, that does establish that it's gcc's problem not ours. Thanks for digging! regards, tom lane
It was brought to my attention [0] that we probably should be checking for the OSXSAVE bit instead of the XSAVE bit when determining whether there's support for the XGETBV instruction. IIUC that should indicate that both the OS and the processor have XGETBV support (not just the processor). I've attached a one-line patch to fix this. [0] https://github.com/pgvector/pgvector/pull/519#issuecomment-2062804463 -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
> It was brought to my attention [0] that we probably should be checking for the OSXSAVE bit instead of the XSAVE bit whendetermining whether there's support for the XGETBV instruction. IIUC that should indicate that both the OS and the processorhave XGETBV support (not just the processor). > I've attached a one-line patch to fix this. > [0] https://github.com/pgvector/pgvector/pull/519#issuecomment-2062804463 Good find. I confirmed after speaking with an intel expert, and from the intel AVX-512 manual [0] section 14.3, which recommendsto check bit27. From the manual: "Prior to using Intel AVX, the application must identify that the operating system supports the XGETBV instruction, the YMM register state, in addition to processor's support for YMM state management using XSAVE/XRSTOR and AVX instructions. The following simplified sequence accomplishes both and is strongly recommended. 1) Detect CPUID.1:ECX.OSXSAVE[bit 27] = 1 (XGETBV enabled for application use1). 2) Issue XGETBV and verify that XCR0[2:1] = '11b' (XMM state and YMM state are enabled by OS). 3) detect CPUID.1:ECX.AVX[bit 28] = 1 (AVX instructions supported). (Step 3 can be done in any order relative to 1 and 2.)" It also seems that step 1 and step 2 need to be done prior to the CPUID OSXSAVE check in the popcount code. [0]: https://cdrdv2.intel.com/v1/dl/getContent/671200 - Akash Shankaran
On Thu, Apr 18, 2024 at 06:12:22PM +0000, Shankaran, Akash wrote: > Good find. I confirmed after speaking with an intel expert, and from the intel AVX-512 manual [0] section 14.3, which recommendsto check bit27. From the manual: > > "Prior to using Intel AVX, the application must identify that the operating system supports the XGETBV instruction, > the YMM register state, in addition to processor's support for YMM state management using XSAVE/XRSTOR and > AVX instructions. The following simplified sequence accomplishes both and is strongly recommended. > 1) Detect CPUID.1:ECX.OSXSAVE[bit 27] = 1 (XGETBV enabled for application use1). > 2) Issue XGETBV and verify that XCR0[2:1] = '11b' (XMM state and YMM state are enabled by OS). > 3) detect CPUID.1:ECX.AVX[bit 28] = 1 (AVX instructions supported). > (Step 3 can be done in any order relative to 1 and 2.)" Thanks for confirming. IIUC my patch should be sufficient, then. > It also seems that step 1 and step 2 need to be done prior to the CPUID OSXSAVE check in the popcount code. This seems to contradict the note about doing step 3 at any point, and given step 1 is the OSXSAVE check, I'm not following what this means, anyway. I'm also wondering if we need to check that (_xgetbv(0) & 0xe6) == 0xe6 instead of just (_xgetbv(0) & 0xe0) != 0, as the status of the lower half of some of the ZMM registers is stored in the SSE and AVX state [0]. I don't know how likely it is that 0xe0 would succeed but 0xe6 wouldn't, but we might as well make it correct. [0] https://en.wikipedia.org/wiki/Control_register#cite_ref-23 -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Thu, Apr 18, 2024 at 08:24:03PM +0000, Devulapalli, Raghuveer wrote:
>> This seems to contradict the note about doing step 3 at any point, and
>> given step 1 is the OSXSAVE check, I'm not following what this means,
>> anyway.
>
> It is recommended that you run the xgetbv code before you check for cpu
> features avx512-popcnt and avx512-bw. The way it is written now is the
> opposite order. I would also recommend splitting the cpuid feature check
> for avx512popcnt/avx512bw and xgetbv section into separate functions to
> make them modular. Something like:
>
> static inline
> int check_os_avx512_support(void)
> {
> // (1) run cpuid leaf 1 to check for xgetbv instruction support:
> unsigned int exx[4] = {0, 0, 0, 0};
> __get_cpuid(1, &exx[0], &exx[1], &exx[2], &exx[3]);
> if ((exx[2] & (1 << 27)) == 0) /* xsave */
> return false;
>
> /* Does XGETBV say the ZMM/YMM/XMM registers are enabled? */
> return (_xgetbv(0) & 0xe0) == 0xe0;
> }
>
>> I'm also wondering if we need to check that (_xgetbv(0) & 0xe6) == 0xe6
>> instead of just (_xgetbv(0) & 0xe0) != 0, as the status of the lower
>> half of some of the ZMM registers is stored in the SSE and AVX state
>> [0]. I don't know how likely it is that 0xe0 would succeed but 0xe6
>> wouldn't, but we might as well make it correct.
>
> This is correct. It needs to check all the 3 bits (XMM/YMM and ZMM). The
> way it is written is now is in-correct.
Thanks for the feedback. I've attached an updated patch.
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
Attachment
> Thanks for the feedback. I've attached an updated patch. (1) Shouldn't it be: return (_xgetbv(0) & 0xe6) == 0xe6; ? Otherwise zmm_regs_available() will return false. (2) Nitpick: avx512_popcnt_available and avx512_bw_available() run the same cpuid leaf. You could combine them into one toavoid running cpuid twice. My apologies, I should have mentioned this before.
On Thu, Apr 18, 2024 at 09:29:55PM +0000, Devulapalli, Raghuveer wrote: > (1) Shouldn't it be: return (_xgetbv(0) & 0xe6) == 0xe6; ? Otherwise > zmm_regs_available() will return false.. Yes, that's a mistake. I fixed that in v3. > (2) Nitpick: avx512_popcnt_available and avx512_bw_available() run the > same cpuid leaf. You could combine them into one to avoid running cpuid > twice. My apologies, I should have mentioned this before.. Good call. The byte-and-word instructions were a late addition to the patch, so I missed this originally. On that note, is it necessary to also check for avx512f? At the moment, we are assuming that's supported if the other AVX-512 instructions are available. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
> On that note, is it necessary to also check for avx512f? At the moment, we are assuming that's supported if the otherAVX-512 instructions are available. No, it's not needed. There are no CPU's with avx512bw/avx512popcnt without avx512f. Unfortunately though, avx512popcnt doesnot mean avx512bw (I think the deprecated Xeon Phi processors falls in this category) which is why we need both.
On Thu, Apr 18, 2024 at 10:11:08PM +0000, Devulapalli, Raghuveer wrote: >> On that note, is it necessary to also check for avx512f? At the moment, >> we are assuming that's supported if the other AVX-512 instructions are >> available. > > No, it's not needed. There are no CPU's with avx512bw/avx512popcnt > without avx512f. Unfortunately though, avx512popcnt does not mean > avx512bw (I think the deprecated Xeon Phi processors falls in this > category) which is why we need both. Makes sense, thanks. I'm planning to commit this fix sometime early next week. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
On Thu, Apr 18, 2024 at 05:13:58PM -0500, Nathan Bossart wrote: > Makes sense, thanks. I'm planning to commit this fix sometime early next > week. Committed. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Hi,
On 2024-04-23 11:02:07 -0500, Nathan Bossart wrote:
> On Thu, Apr 18, 2024 at 05:13:58PM -0500, Nathan Bossart wrote:
> > Makes sense, thanks. I'm planning to commit this fix sometime early next
> > week.
>
> Committed.
I've noticed that the configure probes for this are quite slow - pretty much
the slowest step in a meson setup (and autoconf is similar). While looking
into this, I also noticed that afaict the tests don't do the right thing for
msvc.
...
[6.825] Checking if "__sync_val_compare_and_swap(int64)" : links: YES
[6.883] Checking if " __atomic_compare_exchange_n(int32)" : links: YES
[6.940] Checking if " __atomic_compare_exchange_n(int64)" : links: YES
[7.481] Checking if "XSAVE intrinsics without -mxsave" : links: NO
[8.097] Checking if "XSAVE intrinsics with -mxsave" : links: YES
[8.641] Checking if "AVX-512 popcount without -mavx512vpopcntdq -mavx512bw" : links: NO
[9.183] Checking if "AVX-512 popcount with -mavx512vpopcntdq -mavx512bw" : links: YES
[9.242] Checking if "_mm_crc32_u8 and _mm_crc32_u32 without -msse4.2" : links: NO
[9.333] Checking if "_mm_crc32_u8 and _mm_crc32_u32 with -msse4.2" : links: YES
[9.367] Checking if "x86_64: popcntq instruction" compiles: YES
[9.382] Has header "atomic.h" : NO
...
(the times here are a bit exaggerated, enabling them in meson also turns on
python profiling, which makes everything a bit slower)
Looks like this is largely the fault of including immintrin.h:
echo -e '#include <immintrin.h>\nint main(){return _xgetbv(0) & 0xe0;}'|time gcc -mxsave -xc - -o /dev/null
0.45user 0.04system 0:00.50elapsed 99%CPU (0avgtext+0avgdata 94184maxresident)k
echo -e '#include <immintrin.h>\n'|time gcc -c -mxsave -xc - -o /dev/null
0.43user 0.03system 0:00.46elapsed 99%CPU (0avgtext+0avgdata 86004maxresident)k
Do we really need to link the generated programs? If we instead were able to
just rely on the preprocessor, it'd be vastly faster.
The __sync* and __atomic* checks actually need to link, as the compiler ends
up generating calls to unimplemented functions if the compilation target
doesn't support some operation natively - but I don't think that's true for
the xsave/avx512 stuff
Afaict we could just check for predefined preprocessor macros:
echo|time gcc -c -mxsave -mavx512vpopcntdq -mavx512bw -xc -dM -E - -o -|grep -E
'__XSAVE__|__AVX512BW__|__AVX512VPOPCNTDQ__'
#define __AVX512BW__ 1
#define __AVX512VPOPCNTDQ__ 1
#define __XSAVE__ 1
0.00user 0.00system 0:00.00elapsed 100%CPU (0avgtext+0avgdata 13292maxresident)k
echo|time gcc -c -march=nehalem -xc -dM -E - -o -|grep -E '__XSAVE__|__AVX512BW__|__AVX512VPOPCNTDQ__'
0.00user 0.00system 0:00.00elapsed 100%CPU (0avgtext+0avgdata 10972maxresident)k
Now, a reasonable counter-argument would be that only some of these macros are
defined for msvc ([1]). However, as it turns out, the test is broken
today, as msvc doesn't error out when using an intrinsic that's not
"available" by the target architecture, it seems to assume that the caller did
a cpuid check ahead of time.
Check out [2], it shows the various predefined macros for gcc, clang and msvc.
ISTM that the msvc checks for xsave/avx512 being broken should be an open
item?
Greetings,
Andres
[1] https://learn.microsoft.com/en-us/cpp/preprocessor/predefined-macros?view=msvc-170
[2] https://godbolt.org/z/c8Kj8r3PK
On Tue, Jul 30, 2024 at 02:07:01PM -0700, Andres Freund wrote:
> I've noticed that the configure probes for this are quite slow - pretty much
> the slowest step in a meson setup (and autoconf is similar). While looking
> into this, I also noticed that afaict the tests don't do the right thing for
> msvc.
>
> ...
> [6.825] Checking if "__sync_val_compare_and_swap(int64)" : links: YES
> [6.883] Checking if " __atomic_compare_exchange_n(int32)" : links: YES
> [6.940] Checking if " __atomic_compare_exchange_n(int64)" : links: YES
> [7.481] Checking if "XSAVE intrinsics without -mxsave" : links: NO
> [8.097] Checking if "XSAVE intrinsics with -mxsave" : links: YES
> [8.641] Checking if "AVX-512 popcount without -mavx512vpopcntdq -mavx512bw" : links: NO
> [9.183] Checking if "AVX-512 popcount with -mavx512vpopcntdq -mavx512bw" : links: YES
> [9.242] Checking if "_mm_crc32_u8 and _mm_crc32_u32 without -msse4.2" : links: NO
> [9.333] Checking if "_mm_crc32_u8 and _mm_crc32_u32 with -msse4.2" : links: YES
> [9.367] Checking if "x86_64: popcntq instruction" compiles: YES
> [9.382] Has header "atomic.h" : NO
> ...
>
> (the times here are a bit exaggerated, enabling them in meson also turns on
> python profiling, which makes everything a bit slower)
>
>
> Looks like this is largely the fault of including immintrin.h:
>
> echo -e '#include <immintrin.h>\nint main(){return _xgetbv(0) & 0xe0;}'|time gcc -mxsave -xc - -o /dev/null
> 0.45user 0.04system 0:00.50elapsed 99%CPU (0avgtext+0avgdata 94184maxresident)k
>
> echo -e '#include <immintrin.h>\n'|time gcc -c -mxsave -xc - -o /dev/null
> 0.43user 0.03system 0:00.46elapsed 99%CPU (0avgtext+0avgdata 86004maxresident)k
Interesting. Thanks for bringing this to my attention.
> Do we really need to link the generated programs? If we instead were able to
> just rely on the preprocessor, it'd be vastly faster.
>
> The __sync* and __atomic* checks actually need to link, as the compiler ends
> up generating calls to unimplemented functions if the compilation target
> doesn't support some operation natively - but I don't think that's true for
> the xsave/avx512 stuff
>
> Afaict we could just check for predefined preprocessor macros:
>
> echo|time gcc -c -mxsave -mavx512vpopcntdq -mavx512bw -xc -dM -E - -o -|grep -E
'__XSAVE__|__AVX512BW__|__AVX512VPOPCNTDQ__'
> #define __AVX512BW__ 1
> #define __AVX512VPOPCNTDQ__ 1
> #define __XSAVE__ 1
> 0.00user 0.00system 0:00.00elapsed 100%CPU (0avgtext+0avgdata 13292maxresident)k
>
> echo|time gcc -c -march=nehalem -xc -dM -E - -o -|grep -E '__XSAVE__|__AVX512BW__|__AVX512VPOPCNTDQ__'
> 0.00user 0.00system 0:00.00elapsed 100%CPU (0avgtext+0avgdata 10972maxresident)k
Seems promising. I can't think of a reason that wouldn't work.
> Now, a reasonable counter-argument would be that only some of these macros are
> defined for msvc ([1]). However, as it turns out, the test is broken
> today, as msvc doesn't error out when using an intrinsic that's not
> "available" by the target architecture, it seems to assume that the caller did
> a cpuid check ahead of time.
>
>
> Check out [2], it shows the various predefined macros for gcc, clang and msvc.
>
>
> ISTM that the msvc checks for xsave/avx512 being broken should be an open
> item?
I'm not following this one. At the moment, we always do a runtime check
for the AVX-512 stuff, so in the worst case we'd check CPUID at startup and
set the function pointers appropriately, right? We could, of course, still
fix it, though.
--
nathan
On Tue, Jul 30, 2024 at 04:32:07PM -0500, Nathan Bossart wrote: > On Tue, Jul 30, 2024 at 02:07:01PM -0700, Andres Freund wrote: >> Afaict we could just check for predefined preprocessor macros: >> >> echo|time gcc -c -mxsave -mavx512vpopcntdq -mavx512bw -xc -dM -E - -o -|grep -E '__XSAVE__|__AVX512BW__|__AVX512VPOPCNTDQ__' >> #define __AVX512BW__ 1 >> #define __AVX512VPOPCNTDQ__ 1 >> #define __XSAVE__ 1 >> 0.00user 0.00system 0:00.00elapsed 100%CPU (0avgtext+0avgdata 13292maxresident)k >> >> echo|time gcc -c -march=nehalem -xc -dM -E - -o -|grep -E '__XSAVE__|__AVX512BW__|__AVX512VPOPCNTDQ__' >> 0.00user 0.00system 0:00.00elapsed 100%CPU (0avgtext+0avgdata 10972maxresident)k > > Seems promising. I can't think of a reason that wouldn't work. > >> Now, a reasonable counter-argument would be that only some of these macros are >> defined for msvc ([1]). However, as it turns out, the test is broken >> today, as msvc doesn't error out when using an intrinsic that's not >> "available" by the target architecture, it seems to assume that the caller did >> a cpuid check ahead of time. Hm. Upon further inspection, I see that MSVC appears to be missing __XSAVE__ and __AVX512VPOPCNTDQ__, which is unfortunate. Still, I think the worst case scenario is that the CPUID check fails and we don't use AVX-512 instructions. AFAICT we aren't adding new function pointers in any builds that don't already have them, just compiling some extra unused code. -- nathan
Hi, On 2024-07-30 16:32:07 -0500, Nathan Bossart wrote: > On Tue, Jul 30, 2024 at 02:07:01PM -0700, Andres Freund wrote: > > Now, a reasonable counter-argument would be that only some of these macros are > > defined for msvc ([1]). However, as it turns out, the test is broken > > today, as msvc doesn't error out when using an intrinsic that's not > > "available" by the target architecture, it seems to assume that the caller did > > a cpuid check ahead of time. > > > > > > Check out [2], it shows the various predefined macros for gcc, clang and msvc. > > > > > > ISTM that the msvc checks for xsave/avx512 being broken should be an open > > item? > > I'm not following this one. At the moment, we always do a runtime check > for the AVX-512 stuff, so in the worst case we'd check CPUID at startup and > set the function pointers appropriately, right? We could, of course, still > fix it, though. Ah, I somehow thought we'd avoid the runtime check in case we determine at compile time we don't need any extra flags to enable the AVX512 stuff (similar to how we deal with crc32). But it looks like that's not the case - which seems pretty odd to me: This turns something that can be a single instruction into an indirect function call, even if we could know that it's guaranteed to be available for the compilation target, due to -march=.... It's one thing for the avx512 path to have that overhead, but it's particularly absurd for pg_popcount32/pg_popcount64, where a) The function call overhead is a larger proportion of the cost. b) the instruction is almost universally available, including in the architecture baseline x86-64-v2, which several distros are using as the x86-64 baseline. Why are we actually checking for xsave? We're not using xsave itself and I couldn't find a comment in 792752af4eb5 explaining what we're using it as a proxy for? Is that just to know if _xgetbv() exists? Is it actually possible that xsave isn't available when avx512 is? Greetings, Andres Freund
On Wed, Jul 31, 2024 at 12:50 PM Andres Freund <andres@anarazel.de> wrote: > It's one thing for the avx512 path to have that overhead, but it's > particularly absurd for pg_popcount32/pg_popcount64, where > > a) The function call overhead is a larger proportion of the cost. > b) the instruction is almost universally available, including in the > architecture baseline x86-64-v2, which several distros are using as the > x86-64 baseline. FWIW, another recent thread about that: https://www.postgresql.org/message-id/flat/CA%2BhUKGKS64zJezV9y9mPcB-J0i%2BfLGiv3FAdwSH_3SCaVdrjyQ%40mail.gmail.com
On Tue, Jul 30, 2024 at 05:49:59PM -0700, Andres Freund wrote: > Ah, I somehow thought we'd avoid the runtime check in case we determine at > compile time we don't need any extra flags to enable the AVX512 stuff (similar > to how we deal with crc32). But it looks like that's not the case - which > seems pretty odd to me: > > This turns something that can be a single instruction into an indirect > function call, even if we could know that it's guaranteed to be available for > the compilation target, due to -march=.... > > It's one thing for the avx512 path to have that overhead, but it's > particularly absurd for pg_popcount32/pg_popcount64, where > > a) The function call overhead is a larger proportion of the cost. > b) the instruction is almost universally available, including in the > architecture baseline x86-64-v2, which several distros are using as the > x86-64 baseline. Yeah, pg_popcount32/64 have been doing this since v12 (02a6a54). Until v17 (cc4826d), pg_popcount() repeatedly calls these function pointers, too. I think it'd be awesome if we could start requiring some of these "almost universally available" instructions, but AFAICT that brings its own complexity [0]. > Why are we actually checking for xsave? We're not using xsave itself and I > couldn't find a comment in 792752af4eb5 explaining what we're using it as a > proxy for? Is that just to know if _xgetbv() exists? Is it actually possible > that xsave isn't available when avx512 is? Yes, it's to verify we have XGETBV, which IIUC requires support from both the processor and the OS (see 598e011 and upthread discussion). AFAIK the way we are detecting AVX-512 support is quite literally by-the-book unless I've gotten something wrong. [0] https://postgr.es/m/ZmpG2ZzT30Q75BZO%40nathan -- nathan
Hi, On 2024-07-30 20:20:34 -0500, Nathan Bossart wrote: > On Tue, Jul 30, 2024 at 05:49:59PM -0700, Andres Freund wrote: > > Ah, I somehow thought we'd avoid the runtime check in case we determine at > > compile time we don't need any extra flags to enable the AVX512 stuff (similar > > to how we deal with crc32). But it looks like that's not the case - which > > seems pretty odd to me: > > > > This turns something that can be a single instruction into an indirect > > function call, even if we could know that it's guaranteed to be available for > > the compilation target, due to -march=.... > > > > It's one thing for the avx512 path to have that overhead, but it's > > particularly absurd for pg_popcount32/pg_popcount64, where > > > > a) The function call overhead is a larger proportion of the cost. > > b) the instruction is almost universally available, including in the > > architecture baseline x86-64-v2, which several distros are using as the > > x86-64 baseline. > > Yeah, pg_popcount32/64 have been doing this since v12 (02a6a54). Until v17 > (cc4826d), pg_popcount() repeatedly calls these function pointers, too. I > think it'd be awesome if we could start requiring some of these "almost > universally available" instructions, but AFAICT that brings its own > complexity [0]. I'll respond there... > > Why are we actually checking for xsave? We're not using xsave itself and I > > couldn't find a comment in 792752af4eb5 explaining what we're using it as a > > proxy for? Is that just to know if _xgetbv() exists? Is it actually possible > > that xsave isn't available when avx512 is? > > Yes, it's to verify we have XGETBV, which IIUC requires support from both > the processor and the OS (see 598e011 and upthread discussion). AFAIK the > way we are detecting AVX-512 support is quite literally by-the-book unless > I've gotten something wrong. I'm basically wondering whether we need to check for compiler (not OS support) support for xsave if we also check for -mavx512vpopcntdq -mavx512bw support. Afaict the latter implies support for xsave. andres@alap6:~$ echo|gcc -c - -march=x86-64 -xc -dM -E - -o -|grep '__XSAVE__' andres@alap6:~$ echo|gcc -c - -march=x86-64 -mavx512vpopcntdq -mavx512bw -xc -dM -E - -o -|grep '__XSAVE__' #define __XSAVE__ 1 #define __XSAVE__ 1 Greetings, Andres Freund
On Tue, Jul 30, 2024 at 06:46:51PM -0700, Andres Freund wrote: > On 2024-07-30 20:20:34 -0500, Nathan Bossart wrote: >> On Tue, Jul 30, 2024 at 05:49:59PM -0700, Andres Freund wrote: >> > Why are we actually checking for xsave? We're not using xsave itself and I >> > couldn't find a comment in 792752af4eb5 explaining what we're using it as a >> > proxy for? Is that just to know if _xgetbv() exists? Is it actually possible >> > that xsave isn't available when avx512 is? >> >> Yes, it's to verify we have XGETBV, which IIUC requires support from both >> the processor and the OS (see 598e011 and upthread discussion). AFAIK the >> way we are detecting AVX-512 support is quite literally by-the-book unless >> I've gotten something wrong. > > I'm basically wondering whether we need to check for compiler (not OS support) > support for xsave if we also check for -mavx512vpopcntdq -mavx512bw > support. Afaict the latter implies support for xsave. The main purpose of the XSAVE compiler check is to determine whether we need to add -mxsave in order to use _xgetbv() [0]. If that wasn't a factor, we could probably skip it. Earlier versions of the patch used inline assembly in the non-MSVC path to call XGETBV, which I was trying to avoid. [0] https://postgr.es/m/20240330032209.GA2018686%40nathanxps13 -- nathan
Hi,
On 2024-07-30 21:01:31 -0500, Nathan Bossart wrote:
> On Tue, Jul 30, 2024 at 06:46:51PM -0700, Andres Freund wrote:
> > On 2024-07-30 20:20:34 -0500, Nathan Bossart wrote:
> >> On Tue, Jul 30, 2024 at 05:49:59PM -0700, Andres Freund wrote:
> >> > Why are we actually checking for xsave? We're not using xsave itself and I
> >> > couldn't find a comment in 792752af4eb5 explaining what we're using it as a
> >> > proxy for? Is that just to know if _xgetbv() exists? Is it actually possible
> >> > that xsave isn't available when avx512 is?
> >>
> >> Yes, it's to verify we have XGETBV, which IIUC requires support from both
> >> the processor and the OS (see 598e011 and upthread discussion). AFAIK the
> >> way we are detecting AVX-512 support is quite literally by-the-book unless
> >> I've gotten something wrong.
> >
> > I'm basically wondering whether we need to check for compiler (not OS support)
> > support for xsave if we also check for -mavx512vpopcntdq -mavx512bw
> > support. Afaict the latter implies support for xsave.
>
> The main purpose of the XSAVE compiler check is to determine whether we
> need to add -mxsave in order to use _xgetbv() [0]. If that wasn't a
> factor, we could probably skip it. Earlier versions of the patch used
> inline assembly in the non-MSVC path to call XGETBV, which I was trying to
> avoid.
My point is that _xgetbv() is made available by -mavx512vpopcntdq -mavx512bw
alone, without needing -mxsave:
echo -e '#include <immintrin.h>\nint main() { return _xgetbv(0) & 0xe0; }'|time gcc -march=x86-64 -c -xc - -o
/dev/null
-> fails
echo -e '#include <immintrin.h>\nint main() { return _xgetbv(0) & 0xe0;}'|time gcc -march=x86-64 -mavx512vpopcntdq
-mavx512bw-c -xc - -o /dev/null
-> succeeds
Greetings,
Andres Freund
On Tue, Jul 30, 2024 at 07:43:08PM -0700, Andres Freund wrote: > On 2024-07-30 21:01:31 -0500, Nathan Bossart wrote: >> The main purpose of the XSAVE compiler check is to determine whether we >> need to add -mxsave in order to use _xgetbv() [0]. If that wasn't a >> factor, we could probably skip it. Earlier versions of the patch used >> inline assembly in the non-MSVC path to call XGETBV, which I was trying to >> avoid. > > My point is that _xgetbv() is made available by -mavx512vpopcntdq -mavx512bw > alone, without needing -mxsave: Oh, I see. I'll work on a patch to remove that compiler check, then... -- nathan
On Tue, Jul 30, 2024 at 10:01:50PM -0500, Nathan Bossart wrote: > On Tue, Jul 30, 2024 at 07:43:08PM -0700, Andres Freund wrote: >> My point is that _xgetbv() is made available by -mavx512vpopcntdq -mavx512bw >> alone, without needing -mxsave: > > Oh, I see. I'll work on a patch to remove that compiler check, then... As I started on this, I remembered why I needed it. The file pg_popcount_avx512_choose.c is compiled without the AVX-512 flags in order to avoid inadvertently issuing any AVX-512 instructions before determining we have support. If that's not a concern, we could still probably remove the XSAVE check. -- nathan
Hi, On 2024-07-30 22:12:18 -0500, Nathan Bossart wrote: > On Tue, Jul 30, 2024 at 10:01:50PM -0500, Nathan Bossart wrote: > > On Tue, Jul 30, 2024 at 07:43:08PM -0700, Andres Freund wrote: > >> My point is that _xgetbv() is made available by -mavx512vpopcntdq -mavx512bw > >> alone, without needing -mxsave: > > > > Oh, I see. I'll work on a patch to remove that compiler check, then... > > As I started on this, I remembered why I needed it. The file > pg_popcount_avx512_choose.c is compiled without the AVX-512 flags in order > to avoid inadvertently issuing any AVX-512 instructions before determining > we have support. If that's not a concern, we could still probably remove > the XSAVE check. I think it's a valid concern - but isn't that theoretically also an issue with xsave itself? I guess practically the compiler won't do that, because there's no practical reason to emit any instructions enabled by -mxsave (in contrast to e.g. -mavx, which does trigger gcc to emit different instructions even for basic math). I think this is one of the few instances where msvc has the right approach - if I use intrinsics to emit a specific instruction, the intrinsic should do so, regardless of whether the compiler is allowed to do so on its own. I think enabling options like these on a per-translation-unit basis isn't really a scalable approach. To actually be safe there could only be a single function in each TU and that function could only be called after a cpuid check performed in a separate TU. That a) ends up pretty unreadable b) requires functions to be implemented in .c files, which we really don't want for some of this. I think we'd be better off enabling architectural features on a per-function basis, roughly like this: https://godbolt.org/z/a4q9Gc6Ez For posterity, in the unlikely case anybody reads this after godbolt shuts down: I'm thinking we'd have an attribute like this: /* * GCC like compilers don't support intrinsics without those intrinsics explicitly * having been enabled. We can't just add these options more widely, as that allows the * compiler to emit such instructions more widely, even if we gate reaching the code using * intrinsics. So we just enable the relevant support for individual functions. * * In contrast to this, msvc allows use of intrinsics independent of what the compiler * otherwise is allowed to emit. */ #ifdef __GNUC__ #define pg_enable_target(foo) __attribute__ ((__target__ (foo))) #else #define pg_enable_target(foo) #endif and then use that selectively for some functions: /* FIXME: Should be gated by configure check of -mavx512vpopcntdq -mavx512bw support */ pg_enable_target("avx512vpopcntdq,avx512bw") uint64_t pg_popcount_avx512(const char *buf, int bytes) ... Greetings, Andres Freund
On Wed, Jul 31, 2024 at 01:52:54PM -0700, Andres Freund wrote:
> On 2024-07-30 22:12:18 -0500, Nathan Bossart wrote:
>> As I started on this, I remembered why I needed it. The file
>> pg_popcount_avx512_choose.c is compiled without the AVX-512 flags in order
>> to avoid inadvertently issuing any AVX-512 instructions before determining
>> we have support. If that's not a concern, we could still probably remove
>> the XSAVE check.
>
> I think it's a valid concern - but isn't that theoretically also an issue with
> xsave itself? I guess practically the compiler won't do that, because there's
> no practical reason to emit any instructions enabled by -mxsave (in contrast
> to e.g. -mavx, which does trigger gcc to emit different instructions even for
> basic math).
Yeah, this crossed my mind. It's certainly not the sturdiest of
assumptions...
> I think enabling options like these on a per-translation-unit basis isn't
> really a scalable approach. To actually be safe there could only be a single
> function in each TU and that function could only be called after a cpuid check
> performed in a separate TU. That a) ends up pretty unreadable b) requires
> functions to be implemented in .c files, which we really don't want for some
> of this.
Agreed.
> I think we'd be better off enabling architectural features on a per-function
> basis, roughly like this:
>
> [...]
>
> /* FIXME: Should be gated by configure check of -mavx512vpopcntdq -mavx512bw support */
> pg_enable_target("avx512vpopcntdq,avx512bw")
> uint64_t
> pg_popcount_avx512(const char *buf, int bytes)
> ...
I remember wondering why the CRC-32C code wasn't already doing something
like this (old compiler versions? non-gcc-like compilers?), and I'm not
sure I ever discovered the reason, so out of an abundance of caution I used
the same approach for AVX-512. If we can convince ourselves that
__attribute__((target("..."))) is standard enough at this point, +1 for
moving to that.
--
nathan
On Wed, Jul 31, 2024 at 04:43:02PM -0500, Nathan Bossart wrote:
> On Wed, Jul 31, 2024 at 01:52:54PM -0700, Andres Freund wrote:
>> I think we'd be better off enabling architectural features on a per-function
>> basis, roughly like this:
>>
>> [...]
>>
>> /* FIXME: Should be gated by configure check of -mavx512vpopcntdq -mavx512bw support */
>> pg_enable_target("avx512vpopcntdq,avx512bw")
>> uint64_t
>> pg_popcount_avx512(const char *buf, int bytes)
>> ...
>
> I remember wondering why the CRC-32C code wasn't already doing something
> like this (old compiler versions? non-gcc-like compilers?), and I'm not
> sure I ever discovered the reason, so out of an abundance of caution I used
> the same approach for AVX-512. If we can convince ourselves that
> __attribute__((target("..."))) is standard enough at this point, +1 for
> moving to that.
I looked into this some more, and found the following:
* We added SSE 4.2 CRC support in April 2015 (commit 3dc2d62). gcc support
for __attribute__((target("sse4.2"))) was added in 4.9.0 (April 2014).
clang support was added in 3.8 (March 2016).
* We added ARMv8 CRC support in April 2018 (commit f044d71). gcc support
for __attribute__((target("+crc"))) was added in 6.3 (December 2016). I
didn't find precisely when clang support was added, but until 16.0.0
(March 2023), including arm_acle.h requires the -march flag [0], and you
had to use "crc" (plus sign omitted) as the target [1].
* We added AVX-512 support in April 2024 (commit 792752a). gcc support for
__attribute__((target("avx512vpopcntdq,avx512bw"))) was added in 7.1 (May
2017). clang support was added in 5.0.0 (September 2017). However, the
"xsave" target was not supported until 9.1 for gcc (May 2019) and 9.0.0
for clang (September 2019), and we need that for our AVX-512 code, too.
So, at least for the CRC code, __attribute__((target("..."))) was probably
not widely available enough yet when it was first added. Unfortunately,
the ARMv8 CRC target support (without -march) is still pretty new, but it
might be possible to switch the others to a per-function approach in v18.
[0] https://github.com/llvm/llvm-project/commit/30b67c6
[1] https://releases.llvm.org/16.0.0/tools/clang/docs/ReleaseNotes.html#arm-and-aarch64-support
--
nathan
The following review has been posted through the commitfest application: make installcheck-world: tested, failed Implements feature: tested, failed Spec compliant: tested, failed Documentation: tested, failed Changes LGTM. Makes the Makefile look clean. Built and ran tests with `make check` with gcc-13 on a ICX and gcc-11 on SKX.I built on top of this patch and converted SSE4.2 and AVX-512 CRC32C to use function attributes too. The new status of this patch is: Ready for Committer
BTW, I just realized function attributes for xsave and avx512 don't work on MSVC (see https://developercommunity.visualstudio.com/t/support-function-target-attribute-and-mutiversioning/10130630).Not sure ifyou care about it. Its an easy fix (see https://gcc.godbolt.org/z/Pebdj3vMx).
On Wed, Oct 30, 2024 at 08:53:10PM +0000, Raghuveer Devulapalli wrote: > BTW, I just realized function attributes for xsave and avx512 don't work > on MSVC (see > https://developercommunity.visualstudio.com/t/support-function-target-attribute-and-mutiversioning/10130630). > Not sure if you care about it. Its an easy fix (see > https://gcc.godbolt.org/z/Pebdj3vMx). Oh, good catch. IIUC we only need to check for #ifndef _MSC_VER in the configure programs for meson. pg_attribute_target will be empty on MSVC, and I believe we only support meson builds there. -- nathan
> Oh, good catch. IIUC we only need to check for #ifndef _MSC_VER in the > configure programs for meson. pg_attribute_target will be empty on MSVC, and I > believe we only support meson builds there. Right. __has_attribute (target) produces a compiler warning on MSVC: https://gcc.godbolt.org/z/EfWGxbvj3. Might need to guardthat with #if defined(__has_attribute) to get rid of it. > > -- > nathan
> Here is an updated patch with this change. LGTM. Raghuveer
On Thu, Oct 31, 2024 at 07:58:06PM +0000, Devulapalli, Raghuveer wrote: > LGTM. Thanks. Barring additional feedback, I plan to commit this soon. -- nathan
Hi, On 2024-11-06 20:26:47 -0600, Nathan Bossart wrote: > From d0fb7e0e375f7b76d4df90910c21e9448dd3b380 Mon Sep 17 00:00:00 2001 > From: Nathan Bossart <nathan@postgresql.org> > Date: Wed, 16 Oct 2024 15:57:55 -0500 > Subject: [PATCH v3 1/1] use __attribute__((target(...))) for AVX-512 stuff One thing that'd I'd like to see this being used is to elide the indirection when the current target platform *already* supports the necessary intrinsics. Adding a bunch of indirection for short & common operations is decidedly not great. It doesn't have to be part of the same commit, but it seems like it's worth doing as part of the same series, as I think it'll lead to rather different looking configure checks. > diff --git a/src/include/c.h b/src/include/c.h > index 55dec71a6d..6f5ca25542 100644 > --- a/src/include/c.h > +++ b/src/include/c.h > @@ -174,6 +174,16 @@ > #define pg_attribute_nonnull(...) > #endif > > +/* > + * pg_attribute_target allows specifying different target options that the > + * function should be compiled with (e.g., for using special CPU instructions). > + */ > +#if __has_attribute (target) > +#define pg_attribute_target(...) __attribute__((target(__VA_ARGS__))) > +#else > +#define pg_attribute_target(...) > +#endif Think it'd be good to mention that there still needs to be configure check to verify that specific target attribute is understood by the compiler. Greetings, Andres Freund
On Thu, Nov 07, 2024 at 11:12:37AM -0500, Andres Freund wrote: > One thing that'd I'd like to see this being used is to elide the indirection > when the current target platform *already* supports the necessary > intrinsics. Adding a bunch of indirection for short & common operations is > decidedly not great. It doesn't have to be part of the same commit, but it > seems like it's worth doing as part of the same series, as I think it'll lead > to rather different looking configure checks. The main hurdle, at least for AVX-512, is that we still need to check (at runtime) whether the OS supports XGETBV and whether the ZMM registers are fully enabled. We might be able to skip those checks in limited cases (e.g., you are building on the target machine and can perhaps just check it once at build time), but that probably won't help packagers. >> +/* >> + * pg_attribute_target allows specifying different target options that the >> + * function should be compiled with (e.g., for using special CPU instructions). >> + */ >> +#if __has_attribute (target) >> +#define pg_attribute_target(...) __attribute__((target(__VA_ARGS__))) >> +#else >> +#define pg_attribute_target(...) >> +#endif > > Think it'd be good to mention that there still needs to be configure check to > verify that specific target attribute is understood by the compiler. Will do. -- nathan
Committed. -- nathan
> Of course, as soon as I committed this, I noticed that it's broken. It seems that > compilers are rather picky about how multiple target options are specified. Just curious, which compiler complained? Raghuveer
On Thu, Nov 07, 2024 at 08:38:21PM +0000, Devulapalli, Raghuveer wrote: > >> Of course, as soon as I committed this, I noticed that it's broken. It seems that >> compilers are rather picky about how multiple target options are specified. > > Just curious, which compiler complained? Clang. -- nathan