Thread: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
Hi All,
Following up on [1] ...
A restrictlist is a list of RestrictInfo nodes, each representing one
clause, applicable to a set of joins. When partitionwise join is used
as a strategy, the restrictlists for child join are obtained by
translating the restrictlists for the parent in
try_partitionwise_join(). That function is called once for every join
order. E.g. when computing join ABC, it will be called for planning
joins AB, BC, AC, (AB)C, A(BC), B(AC). Every time it is called it will
translate the given parent restrictlist. This means that a
RestrictInfo node applicable to given child relations will be
translated as many times as the join orders in which those child
relations appear in different joining relations.
For example, consider a query "select * from A, B, C where A.a = B.a
and B.a = C.a" where A, B and C are partitioned tables. A has
partitions A1, A2, ... An. B has partitions B1, B2, ... Bn and C has
partitions C1, C2, ... Cn. Partitions Ai, Bi and Ci are matching
partitions respectively for all i's. The join ABC is computed as
Append of (A1B1C1, A2B2C2, ... AnBnCn). The clause A.a = B.a is
translated to A1.a = B1.a thrice, when computing A1B1, A1(B1C1) and
B1(A1C1) respectively. Similarly other clauses are translated multiple
times. Some extra translations also happen in
reparameterize_path_by_child().
These translations consume memory which remains allocated till the
statement finishes. A ResrtictInfo should be translated only once per
parent-child pair, thus avoiding consuming extra memory.
There are two patches attached
0001 - to measure memory consumption during planning. This is the same
one as attached to [1].
0002 - WIP patch to avoid repeated translations of RestrictInfo.
The WIP patch avoids repeated translations by tracking the child for
which a RestrictInfo is translated and reusing the same translation
every time it is requested. In order to track the translations,
RestrictInfo gets two new members.
1. parent_rinfo - In a child's RestrictInfo this points to the
RestrictInfo applicable to the topmost parent in partition hierarchy.
This is NULL in the topmost parent's RestrictInfo
2. child_rinfos - In a parent's RestrictInfo, this is a list that
contains all the translated child RestrictInfos. In child
RestrictInfos this is NULL.
Every translated RestrictInfo is stored in the top parent's
RestrictInfo child_rinfos. RestrictInfo::required_relids is used as a
key to search a given translation. I have intercepted
adjust_appendrel_attrs_mutator() to track translations as well as
avoid multiple translations. It first looks for an existing
translation when translating a RestrictInfo and creates a new one only
when one doesn't exist already.
Using this patch the memory consumption for the above query reduces as follows
Number of partitions: 1000
Number of tables | without patch | with patch | % reduction |
being joined | | | |
--------------------------------------------------------------
2 | 40.3 MiB | 37.7 MiB | 6.43% |
3 | 146.8 MiB | 133.0 MiB | 9.42% |
4 | 445.4 MiB | 389.5 MiB | 12.57% |
5 | 1563.2 MiB | 1243.2 MiB | 20.47% |
The number of times a RestrictInfo requires to be translated increases
exponentially with the number of tables joined. Thus we see more
memory saved as the number of tables joined increases. When two tables
are joined there's only a single join planned so no extra translations
happen in try_partitionwise_join(). The memory saved in case of 2
joining tables comes from avoiding extra translations happening during
reparameterization of paths (in reparameterize_path_by_child()).
The attached patch is to show how much memory can be saved if we avoid
extra translation. But I want to discuss the following things about
the approach.
1. The patch uses RestrictInfo::required_relids as the key for
searching child RelOptInfos. I am not sure which of the two viz.
required_relids and clause_relids is a better key. required_relids
seems to be a subset of clause_relids and from the description it
looks like that's the set that decides the applicability of a clause
in a join. But clause_relids is obtained from all the Vars that appear
in the clause, so may be that's the one that matters for the
translations. Can somebody guide me?
2. The patch adds two extra pointers per RestrictInfo. They will
remain unused when partitionwise join is not used. Right now, I do not
see any increase in memory consumed by planner because of those
pointers even in case of unpartitioned tables; maybe they are absorbed
in memory alignment. They may show up as extra memory in the future. I
am wondering whether we can instead save and track translations in
PlannerInfo as a hash table using <rinfo_serial, required_relids (or
whatever is the answer to above question) of parent and child
respectively> as key. That will just add one extra pointer in
PlannerInfo when partitionwise join is not used. Please let me know
your suggestions.
3. I have changed adjust_appendrel_attrs_mutator() to return a
translated RestrictInfo if it already exists. IOW, it won't always
return a deep copy of given RestrictInfo as it does today. This can be
fixed by writing wrappers around adjust_appendrel_attrs() to translate
RestrictInfo specifically. But maybe we don't always need deep copies.
Are there any cases when we need translated deep copies of
RestrictInfo? Those cases will require fixing callers of
adjust_appendrel_attrs() instead of the mutator.
4. IIRC, when partitionwise join was implemented we had discussed
creating child RestrictInfos using a login similar to
build_joinrel_restrictlist(). That might be another way to build
RestrictInfo only once and use it multiple times. But we felt that it
was much harder problem to solve since it's not known which partitions
from joining partitioned tables will match and will be joined till we
enter try_partitionwise_join(), so the required RestrictInfos may not
be available in RelOptInfo::joininfo. Let me know your thoughts on
this.
Comments/suggestions welcome.
references
[1] https://www.postgresql.org/message-id/CAExHW5stmOUobE55pMt83r8UxvfCph+Pvo5dNpdrVCsBgXEzDQ@mail.gmail.com
--
Best Wishes,
Ashutosh Bapat
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
0002 - WIP patch to avoid repeated translations of RestrictInfo.
The WIP patch avoids repeated translations by tracking the child for
which a RestrictInfo is translated and reusing the same translation
every time it is requested. In order to track the translations,
RestrictInfo gets two new members.
1. parent_rinfo - In a child's RestrictInfo this points to the
RestrictInfo applicable to the topmost parent in partition hierarchy.
This is NULL in the topmost parent's RestrictInfo
2. child_rinfos - In a parent's RestrictInfo, this is a list that
contains all the translated child RestrictInfos. In child
RestrictInfos this is NULL.
crash while planning the query below.
regression=# set enable_partitionwise_join to on;
SET
regression=# EXPLAIN (COSTS OFF)
SELECT * FROM prt1 t1, prt2 t2
WHERE t1.a = t2.b AND t1.a < 450 AND t2.b > 250 AND t1.b = 0;
server closed the connection unexpectedly
Thanks
Richard
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Tue, Aug 8, 2023 at 4:08 PM Richard Guo <guofenglinux@gmail.com> wrote: > > > I haven't looked into the details but with 0002 patch I came across a > crash while planning the query below. > > regression=# set enable_partitionwise_join to on; > SET > regression=# EXPLAIN (COSTS OFF) > SELECT * FROM prt1 t1, prt2 t2 > WHERE t1.a = t2.b AND t1.a < 450 AND t2.b > 250 AND t1.b = 0; > server closed the connection unexpectedly Thanks for the report. PFA the patches with this issue fixed. There is another issue seen when running partition_join.sql "ERROR: index key does not match expected index column". I will investigate that issue. Right now I am looking at the 4th point in my first email in this thread. [1]. I am trying to figure whether that approach would work. If that approach doesn't work what's the best to track the translations and also figure out answers to 1, 2, 3 there. Please let me know your opinions if any. -- Best Wishes, Ashutosh Bapat [1] https://www.postgresql.org/message-id/CAExHW5s=bCLMMq8n_bN6iU+Pjau0DS3z_6Dn6iLE69ESmsPMJQ@mail.gmail.com
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Fri, 28 Jul 2023 at 02:06, Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > 0001 - to measure memory consumption during planning. This is the same > one as attached to [1]. I see you're recording the difference in the CurrentMemoryContext of palloc'd memory before and after planning. That won't really alert us to problems if the planner briefly allocates, say 12GBs of memory during, say the join search then quickly pfree's it again. unless it's an oversized chunk, aset.c won't free() any memory until MemoryContextReset(). Chunks just go onto a freelist for reuse later. So at the end of planning, the context may still have that 12GBs malloc'd, yet your new EXPLAIN ANALYZE property might end up just reporting a tiny fraction of that. I wonder if it would be more useful to just have ExplainOneQuery() create a new memory context and switch to that and just report the context's mem_allocated at the end. It's also slightly annoying that these planner-related summary outputs are linked to EXPLAIN ANALYZE. We could be showing them in EXPLAIN without ANALYZE. If we were to change that now, it might be a bit annoying for the regression tests as we'd need to go and add SUMMARY OFF in a load of places... drowley@amd3990x:~/pg_src/src/test/regress/sql$ git grep -i "costs off" | wc -l 1592 hmm, that would cause a bit of churn... :-( David
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Wed, Aug 9, 2023 at 10:12 AM David Rowley <dgrowleyml@gmail.com> wrote: > > On Fri, 28 Jul 2023 at 02:06, Ashutosh Bapat > <ashutosh.bapat.oss@gmail.com> wrote: > > 0001 - to measure memory consumption during planning. This is the same > > one as attached to [1]. > I have started a separate thread to discuss this patch. I am taking this discussion to that thread. -- Best Wishes, Ashutosh Bapat
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
I spent some time on 4th point below but also looked at other points. Here's what I have found so far On Thu, Jul 27, 2023 at 7:35 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > > 1. The patch uses RestrictInfo::required_relids as the key for > searching child RelOptInfos. I am not sure which of the two viz. > required_relids and clause_relids is a better key. required_relids > seems to be a subset of clause_relids and from the description it > looks like that's the set that decides the applicability of a clause > in a join. But clause_relids is obtained from all the Vars that appear > in the clause, so may be that's the one that matters for the > translations. Can somebody guide me? I was wrong that required_relids is subset of clause_relids. The first can contain OJ relids which the other can not. OJ relids do not have any children, so they won't be translated. So clause_relids seems to be a better key. I haven't made a decision yet. > > 2. The patch adds two extra pointers per RestrictInfo. They will > remain unused when partitionwise join is not used. Right now, I do not > see any increase in memory consumed by planner because of those > pointers even in case of unpartitioned tables; maybe they are absorbed > in memory alignment. They may show up as extra memory in the future. I > am wondering whether we can instead save and track translations in > PlannerInfo as a hash table using <rinfo_serial, required_relids (or > whatever is the answer to above question) of parent and child > respectively> as key. That will just add one extra pointer in > PlannerInfo when partitionwise join is not used. Please let me know > your suggestions. I will go ahead with a pointer in PlannerInfo for now. > > 3. I have changed adjust_appendrel_attrs_mutator() to return a > translated RestrictInfo if it already exists. IOW, it won't always > return a deep copy of given RestrictInfo as it does today. This can be > fixed by writing wrappers around adjust_appendrel_attrs() to translate > RestrictInfo specifically. But maybe we don't always need deep copies. > Are there any cases when we need translated deep copies of > RestrictInfo? Those cases will require fixing callers of > adjust_appendrel_attrs() instead of the mutator. I think it's better to handle the tracking logic outside adjust_appendrel_attrs. That will be some code churn but it will be cleaner and won't affect anything other that partitionwise joins. > > 4. IIRC, when partitionwise join was implemented we had discussed > creating child RestrictInfos using a login similar to > build_joinrel_restrictlist(). That might be another way to build > RestrictInfo only once and use it multiple times. But we felt that it > was much harder problem to solve since it's not known which partitions > from joining partitioned tables will match and will be joined till we > enter try_partitionwise_join(), so the required RestrictInfos may not > be available in RelOptInfo::joininfo. Let me know your thoughts on > this. Here's some lengthy description of why I feel translations are better compared to computing restrictlist and joininfo for a child join from joining relation's joininfo Consider a query "select * from p, q, r where p.c1 = q.c1 and q.c1 = r.c1 and p.c2 + q.c2 < r.c2 and p.c3 != q.c3 and q.c3 != r.c3". The query has following clauses 1. p.c1 = q.c1 2. q.c1 = r.c1 3. p.c2 + q.c2 < r.c2 4. p.c3 != q.c3 5. q.c3 != r.c3 The first two clauses are added to EC machinery and do not appear in joininfo. They appear in restrictlist when we construct clauses in restrictlist from ECs. Let's ignore them for now. Assume that each table p, q, r has partitions (p1, p2, ...), (q1, q2, ...) and (r1, r2, ... ) respectively. Each triplet (pi, qi,ri) forms the set of matching partitions from p, q, r respectively for all "i". Consider join, p1q1r1. We will generate relations p1, q1, r1, p1q1, p1r1, q1r1 and p1q1r1 while building the last join. Below is description of how these clauses would look in each of these relations and the list they appear in when computing that join. Please notice the numeric suffixes carefully. p1. joininfo: p1.c2 + q.c2 < r.c2, p1.c3 != q.c3 restrictlist: <> q1 joininfo: p.c2 + q1.c2 < r.c2, p.c3 != q1.c3, q1.c3 != r.c3 restrictlist: <> r1 joininfo: p.c2 + q.c2 < r1.c2, q.c3 != r1.c3 restrictlist: <> p1q1 joininfo: p1.c2 + q1.c2 < r.c2, q1.c3 != r.c3 restrictlist: p1.c3 != q1.c3 q1r1 joininfo: p.c2 + q1.c2 < r1.c2, p.c3 != q1.c3 restrictlist: q1.c3 != r1.c3 p1r1 joininfo: p1.c2 + q.c2 < r1.c2, p1.c3 != q.c3, q.c3 != r1.c3 restrictlist: <> p1q1r1 joininfo: <> restrictlist for (p1q1)r1: p1.c2 + q1.c2 < r1.c2, q1.c3 != r1.c3 restrictlist for (p1r1)q1: p1.c2 + q1.c2 < r1.c2, p1.c3 != q1.c3, q1.c3 != r1.c3 restrictlist for p1(q1r1): p1.c2 + q1.c2 < r1.c2, p1.c3 != q1.c3 If we translate the clauses when building join e.g. translate p1.c3 != q1.c3 when building p1q1 or p1q1r1, it would cause repeated translations. So the translations need to be saved in lower relations when we detect matching partitions and then use these translations. Something I have done in the attached patches. But the problem is the same clause reaches its final translation through different intermediate translations as the join search advances. E.g. the evolution of p.c2 + q.c2 < r.c2 to p1.c2 + q1.c2 < r1.c2 has three different intemediate translations at second level of join. Each of these intermediate translations conflict with each other and none of them can be saved in any of the second level joins as a candidate for the last stage translation. Extending the logic in the patches would make those more complicated. Another possibility is to avoid the same clause being translated multiple times when building the join using RestrictInfo::rinfo_serial. But simply that won't help avoiding repeated translations caused by different join orders. E.g. we won't be able to detect that p.c2 + q.c2 < r.c2 has been translated to p1.c2 + q1.c2 < r1.c2 already when we computed (p1r1)q1 or p1(q1r1) or (p1q1)r1 whichever was computed earlier. For that we need some tracking outside the join relations themselves like I did in my first patch. Coming back to the problem of generating child restrictlist clauses from equivalence classes, I think it's easier with some tweaks to pass child relids down to the minions when dealing with child joins. It seems to be working as is but I haven't tested it thoroughly. Obtaining child clauses from parent clauses by translation and tracking the translations is less complex and may be more efficient too. I will post a patch on those lines soon. -- Best Wishes, Ashutosh Bapat
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
Hi All,
On Fri, Aug 11, 2023 at 6:24 PM Ashutosh Bapat
<ashutosh.bapat.oss@gmail.com> wrote:
>
> Obtaining child clauses from parent clauses by translation and
> tracking the translations is less complex and may be more efficient
> too. I will post a patch on those lines soon.
>
PFA patch set to add infrastructure to track RestrictInfo translations
and reuse them.
PlannerInfo gets a new member "struct HTAB *child_rinfo_hash" which is
a hash table of hash tables keyed by RestrictInfo::rinfo_serial. Each
element in the array is a hash table of RestrictInfos keyed by
RestrictInfo::required_relids as explained in my previous email. When
building child clauses when a. building child join rels or b. when
reparameterizing paths, we first access the first level hash table
using RestrictInfo::rinfo_serial of the parent and search the required
translation by computing the child RestrictInfo::required_relids
obtained by translating RestrictInfo::required_relids of the parent
RestrictInfo. If the translation doesn't exist, we create one and add
to the hash table.
RestrictInfo::required_relids is same for a RestrictInfo and its
commuted RestrictInfo. The order of operands is important for
IndexClauses. Hence we track the commuted RestrictInfo in a new field
RestrictInfo::comm_rinfo. RestrictInfo::is_commuted differentiates
between a RestrictInfo and its commuted version. This is explained as
a comment in the patch. This scheme has a minor benefit of saving
memory when the same RestrictInfo is commuted multiple times.
Hash table of hash table is used instead of an array of hash tables
since a. not every rinfo_serial has a RestrictInfo associated with it
b. not every RestrictInfo has translations, c. I don't think the exact
size of this array is not known till the planning ends since we
continue to create new clauses as we create new RelOptInfos. Of
course, an array can be repalloc'ed and unused slots in the array may
not waste a lot of memory. I am open to change hash table to an array
which may be more efficient.
With these set of patches, the memory consumption stands as below
Number of tables | without patch | with patch | % reduction |
being joined | | | |
--------------------------------------------------------------
2 | 40.8 MiB | 37.4 MiB | 8.46% |
3 | 151.6 MiB | 135.0 MiB | 10.96% |
4 | 464.0 MiB | 403.6 MiB | 12.00% |
5 | 1663.9 MiB | 1329.1 MiB | 20.12% |
The patch set is thus
0001 - patch used to measure memory used during planning
0002 - Patch to free intermediate Relids computed by
adjust_child_relids_multilevel(). I didn't test memory consumption for
multi-level partitioning. But this is clear improvement. In that
function we free the AppendInfos array which as many pointers long as
the number of relids. So it doesn't make sense not to free the Relids
which can be {largest relid}/8 bytes long at least.
0003 - patch to save and reuse commuted RestrictInfo. This patch by
itself shows a small memory saving (3%) in the query below where the
same clause is commuted twice. The query does not contain any
partitioned tables.
create table t2 (a int primary key, b int, c int);
create index t2_a_b on t2(a, b);
select * from t2 where 10 = a
Memory used without patch: 13696 bytes
Memory used with patch: 13264 bytes
0004 - Patch which implements the hash table of hash table described
above and also code to avoid repeated RestrictInfo list translations.
I will add this patchset to next commitfest.
--
Best Wishes,
Ashutosh Bapat
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Thu, Sep 14, 2023 at 4:39 PM Ashutosh Bapat
<ashutosh.bapat.oss@gmail.com> wrote:
>
> The patch set is thus
> 0001 - patch used to measure memory used during planning
>
> 0002 - Patch to free intermediate Relids computed by
> adjust_child_relids_multilevel(). I didn't test memory consumption for
> multi-level partitioning. But this is clear improvement. In that
> function we free the AppendInfos array which as many pointers long as
> the number of relids. So it doesn't make sense not to free the Relids
> which can be {largest relid}/8 bytes long at least.
>
> 0003 - patch to save and reuse commuted RestrictInfo. This patch by
> itself shows a small memory saving (3%) in the query below where the
> same clause is commuted twice. The query does not contain any
> partitioned tables.
> create table t2 (a int primary key, b int, c int);
> create index t2_a_b on t2(a, b);
> select * from t2 where 10 = a
> Memory used without patch: 13696 bytes
> Memory used with patch: 13264 bytes
>
> 0004 - Patch which implements the hash table of hash table described
> above and also code to avoid repeated RestrictInfo list translations.
>
> I will add this patchset to next commitfest.
>
> --
> Best Wishes,
> Ashutosh Bapat
PFA rebased patches. Nothing changes in 0002, 0003 and 0004. 0001 is
the squashed version of the latest patch set at
https://www.postgresql.org/message-id/CAExHW5sCJX7696sF-OnugAiaXS=Ag95=-m1cSrjcmyYj8Pduuw@mail.gmail.com.
--
Best Wishes,
Ashutosh Bapat
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
Hi! Thank you for your work on the subject, I think it's a really useful feature. I've reviewed your patch and I have a few questions.
First of all, have you thought about creating a gun parameter to display memory scheduling information? I agree that this is an important feature, but I think only for debugging.
Secondly, I noticed that for the child_rinfo_hash key you use a counter (int) and can it lead to collisions? Why didn't you generate a hash from childRestrictInfo for this? For example, something like how it is formed here [0].
[0] https://www.postgresql.org/message-id/43ad8a48-b980-410d-a83c-5beebf82a4ed%40postgrespro.ru
-- Regards, Alena Rybakina Postgres Professional
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
Sorry, my first question was not clear, I mean: have you thought about creating a guc parameter to display memory planning information?Hi! Thank you for your work on the subject, I think it's a really useful feature. I've reviewed your patch and I have a few questions.
First of all, have you thought about creating a gun parameter to display memory scheduling information? I agree that this is an important feature, but I think only for debugging.Secondly, I noticed that for the child_rinfo_hash key you use a counter (int) and can it lead to collisions? Why didn't you generate a hash from childRestrictInfo for this? For example, something like how it is formed here [0].
[0] https://www.postgresql.org/message-id/43ad8a48-b980-410d-a83c-5beebf82a4ed%40postgrespro.ru
-- Regards, Alena Rybakina
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Fri, Nov 24, 2023 at 3:56 PM Alena Rybakina <lena.ribackina@yandex.ru> wrote: > > On 24.11.2023 13:20, Alena Rybakina wrote: > > Hi! Thank you for your work on the subject, I think it's a really useful feature. > > I've reviewed your patch and I have a few questions. > > First of all, have you thought about creating a gun parameter to display memory scheduling information? I agree that thisis an important feature, but I think only for debugging. Not a GUC parameter but I have a proposal to use EXPLAIN for the same. [1] > > Secondly, I noticed that for the child_rinfo_hash key you use a counter (int) and can it lead to collisions? Why didn'tyou generate a hash from childRestrictInfo for this? For example, something like how it is formed here [0]. Not usually. But that's the only "key" we have to access a set of sematically same RestrictInfos. Relids is another key to access the exact RestrictInfo. A child RestrictInfo can not be used since there will many child RestrictInfos. Similar parent RestrictInfo can not be used since there will be multiple forms of the same RestrictInfo. [1] https://commitfest.postgresql.org/45/4492/ -- Best Wishes, Ashutosh Bapat
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Tue, 31 Oct 2023 at 10:48, Ashutosh Bapat
<ashutosh.bapat.oss@gmail.com> wrote:
>
> On Thu, Sep 14, 2023 at 4:39 PM Ashutosh Bapat
> <ashutosh.bapat.oss@gmail.com> wrote:
> >
> > The patch set is thus
> > 0001 - patch used to measure memory used during planning
> >
> > 0002 - Patch to free intermediate Relids computed by
> > adjust_child_relids_multilevel(). I didn't test memory consumption for
> > multi-level partitioning. But this is clear improvement. In that
> > function we free the AppendInfos array which as many pointers long as
> > the number of relids. So it doesn't make sense not to free the Relids
> > which can be {largest relid}/8 bytes long at least.
> >
> > 0003 - patch to save and reuse commuted RestrictInfo. This patch by
> > itself shows a small memory saving (3%) in the query below where the
> > same clause is commuted twice. The query does not contain any
> > partitioned tables.
> > create table t2 (a int primary key, b int, c int);
> > create index t2_a_b on t2(a, b);
> > select * from t2 where 10 = a
> > Memory used without patch: 13696 bytes
> > Memory used with patch: 13264 bytes
> >
> > 0004 - Patch which implements the hash table of hash table described
> > above and also code to avoid repeated RestrictInfo list translations.
> >
> > I will add this patchset to next commitfest.
> >
> > --
> > Best Wishes,
> > Ashutosh Bapat
>
> PFA rebased patches. Nothing changes in 0002, 0003 and 0004. 0001 is
> the squashed version of the latest patch set at
> https://www.postgresql.org/message-id/CAExHW5sCJX7696sF-OnugAiaXS=Ag95=-m1cSrjcmyYj8Pduuw@mail.gmail.com.
CFBot shows that the patch does not apply anymore as in [1]:
=== Applying patches on top of PostgreSQL commit ID
7014c9a4bba2d1b67d60687afb5b2091c1d07f73 ===
=== applying patch
./0001-Report-memory-used-for-planning-a-query-in--20231031.patch
...
patching file src/test/regress/expected/explain.out
Hunk #5 FAILED at 290.
Hunk #6 succeeded at 545 (offset 4 lines).
1 out of 6 hunks FAILED -- saving rejects to file
src/test/regress/expected/explain.out.rej
patching file src/tools/pgindent/typedefs.list
Hunk #1 succeeded at 1562 (offset 18 lines).
Please post an updated version for the same.
[1] - http://cfbot.cputube.org/patch_46_4564.log
Regards,
Vignesh
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Sat, Jan 27, 2024 at 8:26 AM vignesh C <vignesh21@gmail.com> wrote:
>
> On Tue, 31 Oct 2023 at 10:48, Ashutosh Bapat
> <ashutosh.bapat.oss@gmail.com> wrote:
> >
> > On Thu, Sep 14, 2023 at 4:39 PM Ashutosh Bapat
> > <ashutosh.bapat.oss@gmail.com> wrote:
> > >
> > > The patch set is thus
> > > 0001 - patch used to measure memory used during planning
> > >
> > > 0002 - Patch to free intermediate Relids computed by
> > > adjust_child_relids_multilevel(). I didn't test memory consumption for
> > > multi-level partitioning. But this is clear improvement. In that
> > > function we free the AppendInfos array which as many pointers long as
> > > the number of relids. So it doesn't make sense not to free the Relids
> > > which can be {largest relid}/8 bytes long at least.
> > >
> > > 0003 - patch to save and reuse commuted RestrictInfo. This patch by
> > > itself shows a small memory saving (3%) in the query below where the
> > > same clause is commuted twice. The query does not contain any
> > > partitioned tables.
> > > create table t2 (a int primary key, b int, c int);
> > > create index t2_a_b on t2(a, b);
> > > select * from t2 where 10 = a
> > > Memory used without patch: 13696 bytes
> > > Memory used with patch: 13264 bytes
> > >
> > > 0004 - Patch which implements the hash table of hash table described
> > > above and also code to avoid repeated RestrictInfo list translations.
> > >
> > > I will add this patchset to next commitfest.
> > >
> > > --
> > > Best Wishes,
> > > Ashutosh Bapat
> >
> > PFA rebased patches. Nothing changes in 0002, 0003 and 0004. 0001 is
> > the squashed version of the latest patch set at
> > https://www.postgresql.org/message-id/CAExHW5sCJX7696sF-OnugAiaXS=Ag95=-m1cSrjcmyYj8Pduuw@mail.gmail.com.
>
> CFBot shows that the patch does not apply anymore as in [1]:
> === Applying patches on top of PostgreSQL commit ID
> 7014c9a4bba2d1b67d60687afb5b2091c1d07f73 ===
> === applying patch
> ./0001-Report-memory-used-for-planning-a-query-in--20231031.patch
> ...
> patching file src/test/regress/expected/explain.out
> Hunk #5 FAILED at 290.
> Hunk #6 succeeded at 545 (offset 4 lines).
> 1 out of 6 hunks FAILED -- saving rejects to file
> src/test/regress/expected/explain.out.rej
> patching file src/tools/pgindent/typedefs.list
> Hunk #1 succeeded at 1562 (offset 18 lines).
>
> Please post an updated version for the same.
>
> [1] - http://cfbot.cputube.org/patch_46_4564.log
>
> Regards,
> Vignesh
Thanks Vignesh for the notification. PFA rebased patches. 0001 in
earlier patch-set is now removed.
--
Best Wishes,
Ashutosh Bapat
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
Hi,
After taking a look at the patch optimizing SpecialJoinInfo allocations,
I decided to take a quick look at this one too. I don't have any
specific comments on the code yet, but it seems quite a bit more complex
than the other patch ... it's introducing a HTAB into the optimizer,
surely that has costs too.
I started by doing the same test as with the other patch, comparing
master to the two patches (applied independently and both). And I got
about this (in MB):
tables master sjinfo rinfo both
-----------------------------------------------
2 37 36 34 33
3 138 129 122 113
4 421 376 363 318
5 1495 1254 1172 931
Unlike the SpecialJoinInfo patch, I haven't seen any reduction in
planning time for this one.
The reduction in allocated memory is nice. I wonder what's allocating
the remaining memory, and we'd have to do to reduce it further.
However, this is a somewhat extreme example - it's joining 5 tables,
each with 1000 partitions, using a partition-wise join. It reduces the
amount of memory, but the planning time is still quite high (and
essentially the same as without the patch). So it's not like it'd make
them significantly more practical ... do we have any other ideas/plans
how to improve that?
AFAIK we don't expect this to improve "regular" cases with modest number
of tables / partitions, etc. But could it make them slower in some case?
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On 19/2/2024 06:05, Tomas Vondra wrote: > However, this is a somewhat extreme example - it's joining 5 tables, > each with 1000 partitions, using a partition-wise join. It reduces the > amount of memory, but the planning time is still quite high (and > essentially the same as without the patch). So it's not like it'd make > them significantly more practical ... do we have any other ideas/plans > how to improve that? The planner principle of cleaning up all allocated structures after the optimization stage simplifies development and code. But, if we want to achieve horizontal scalability on many partitions, we should introduce per-partition memory context and reset it in between. GEQO already has a short-lived memory context, making designing extensions a bit more challenging but nothing too painful. -- regards, Andrei Lepikhov Postgres Professional
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Mon, Feb 19, 2024 at 4:35 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > Hi, > > After taking a look at the patch optimizing SpecialJoinInfo allocations, > I decided to take a quick look at this one too. I don't have any > specific comments on the code yet, but it seems quite a bit more complex > than the other patch ... it's introducing a HTAB into the optimizer, > surely that has costs too. Thanks for looking into this too. > > I started by doing the same test as with the other patch, comparing > master to the two patches (applied independently and both). And I got > about this (in MB): > > tables master sjinfo rinfo both > ----------------------------------------------- > 2 37 36 34 33 > 3 138 129 122 113 > 4 421 376 363 318 > 5 1495 1254 1172 931 > > Unlike the SpecialJoinInfo patch, I haven't seen any reduction in > planning time for this one. Yeah. That agreed with my observation as well. > > The reduction in allocated memory is nice. I wonder what's allocating > the remaining memory, and we'd have to do to reduce it further. Please see reply to SpecialJoinInfo thread. Other that the current patches, we require memory efficient Relids implementation. I have shared some ideas in the slides I shared in the other thread, but haven't spent time experimenting with any ideas there. > > However, this is a somewhat extreme example - it's joining 5 tables, > each with 1000 partitions, using a partition-wise join. It reduces the > amount of memory, but the planning time is still quite high (and > essentially the same as without the patch). So it's not like it'd make > them significantly more practical ... do we have any other ideas/plans > how to improve that? Yuya has been working on reducing planning time [1]. Has some significant improvements in that area based on my experiments. But those patches are complex and still WIP. > > AFAIK we don't expect this to improve "regular" cases with modest number > of tables / partitions, etc. But could it make them slower in some case? > AFAIR, my experiments did not show any degradation in regular cases with modest number of tables/partitions. The variation in planning time was with the usual planning time variations. [1] https://www.postgresql.org/message-id/flat/CAExHW5uVZ3E5RT9cXHaxQ_DEK7tasaMN%3DD6rPHcao5gcXanY5w%40mail.gmail.com#112b3e104e0f9e39eb007abe075aae20 -- Best Wishes, Ashutosh Bapat
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Mon, Feb 19, 2024 at 4:35 AM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
>
> Hi,
>
> After taking a look at the patch optimizing SpecialJoinInfo allocations,
> I decided to take a quick look at this one too. I don't have any
> specific comments on the code yet, but it seems quite a bit more complex
> than the other patch ... it's introducing a HTAB into the optimizer,
> surely that has costs too.
Thanks for looking into this too.
>
> I started by doing the same test as with the other patch, comparing
> master to the two patches (applied independently and both). And I got
> about this (in MB):
>
> tables master sjinfo rinfo both
> -----------------------------------------------
> 2 37 36 34 33
> 3 138 129 122 113
> 4 421 376 363 318
> 5 1495 1254 1172 931
>
> Unlike the SpecialJoinInfo patch, I haven't seen any reduction in
> planning time for this one.
Yeah. That agreed with my observation as well.
>
> The reduction in allocated memory is nice. I wonder what's allocating
> the remaining memory, and we'd have to do to reduce it further.
Please see reply to SpecialJoinInfo thread. Other that the current
patches, we require memory efficient Relids implementation. I have
shared some ideas in the slides I shared in the other thread, but
haven't spent time experimenting with any ideas there.
>
> However, this is a somewhat extreme example - it's joining 5 tables,
> each with 1000 partitions, using a partition-wise join. It reduces the
> amount of memory, but the planning time is still quite high (and
> essentially the same as without the patch). So it's not like it'd make
> them significantly more practical ... do we have any other ideas/plans
> how to improve that?
Yuya has been working on reducing planning time [1]. Has some
significant improvements in that area based on my experiments. But
those patches are complex and still WIP.
>
> AFAIK we don't expect this to improve "regular" cases with modest number
> of tables / partitions, etc. But could it make them slower in some case?
>
AFAIR, my experiments did not show any degradation in regular cases
with modest number of tables/partitions. The variation in planning
time was with the usual planning time variations.
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Mon, Aug 19, 2024 at 6:43 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > > Sorry for the delay in my response. > > On Wed, May 29, 2024 at 9:34 AM Ashutosh Bapat > <ashutosh.bapat.oss@gmail.com> wrote: > > > > Documenting some comments from todays' patch review session > > I forgot to mention back then that both of the suggestions below came > from Tom Lane. > > > 1. Instead of a nested hash table, it might be better to use a flat hash table to save more memory. > > Done. It indeed saves memory without impacting planning time. > > > 2. new comm_rinfo member in RestrictInfo may have problems when copying RestrictInfo or translating it. Instead commutedversions may be tracked outside RestrictInfo > > After commit 767c598954bbf72e0535f667e2e0667765604b2a, > repameterization of parent paths for child relation happen at the time > of creating the plan. This reduces the number of child paths produced > by reparameterization and also reduces the number of RestrictInfos > that get translated during reparameterization. During > reparameterization commuted parent RestrictInfos are required to be > translated to child RestrictInfos. Before the commit, this led to > translating the same commuted parent RestrictInfo multiple times. > After the commit, only one path gets reparameterized for a given > parent and child pair. Hence we do not produce multiple copies of the > same commuted child RestrictInfo. Hence we don't need to keep track of > commuted child RestrictInfos anymore. Removed that portion of code > from the patches. > > I made detailed memory consumption measurements with this patch for > number of partitions changed from 0 (unpartitioned) to 1000 and for 2 > to 5-way joins. They are available in the spreadsheet at [1]. The raw > measurement data is in the first sheet named "pwj_mem_measurements raw > numbers". The averages over multiple runs are in second sheet named > "avg_numbers". Rest of the sheet represent the averages in more > consumable manner. Please note that the averages make sense only for > planning time since the memory consumption remains same with every > run. Also note that EXPLAIN now reports planning memory consumption in > kB. Any changes to memory consumption below 1kB are not reported and > hence not noticed. Here are some observations. > > 1. When partitionwise join is not enabled, no changes to planner's > memory consumption are observed. See sheet named "pwj disabled, > planning memory". > > 2. When partitionwise join is enabled, upto 17% (206MB) memory is > saved by the patch in case of 5-way self-join with 1000 partitions. > This is the maximum memory saving observed. The amount of memory saved > increases with the number of joins and number of partitions. See sheet > with name "pwj enabled, planning memory" > > 3. After commit 767c598954bbf72e0535f667e2e0667765604b2a, we do not > translate a parent RestrictInfo multiple times for the same > parent-child pair in case of a *2-way partitionwise join*. But we > still consume memory in saving the child RestrictInfo in the hash > table. Hence in case of 2-way join we see increased memory consumption > with the patch compared to master. The memory consumption increases by > 13kb, 23kB, 76kB and 146kB for 10, 100, 500, 1000 partitions > respectively. This increase is smaller compared to the overall memory > saving. In order to avoid this memory increase, we will need to avoid > using hash table for 2-way join. We will need to know whether there > will be more than one partitionwise join before translating the > RestrictInfos for the first partitionwise join. This is hard to > achieve in all the cases since the decision to use partitionwise join > happens at the time of creating paths for a given join relation, which > itself is computed on the fly. We may choose some heuristics which > take into account the number of partitioned tables in the query, their > partition schemes, and the quals in the query to decide whether or not > to track the translated child RestrictInfos. But that will make the > code more complex, but more importantly the heuristics may not be able > to keep up if we start using partitionwise join as an optimization > strategy for more cases (e.g. asymmetric partitionwise join [2]). The > attached patch looks like a good tradeoff to me. But other opinions > might vary. Suggestions are welcome. > > 4. There is no noticeable change in the planning time. I ran the same > experiment multiple times. The planning time variations from each > experiment do not show any noticeable pattern suggesting increase or > decrease in the planning time with the patch. > > A note about the code: I have added all the structures and functions > dealing with the RestrictInfo hash table at the end of restrictinfo.c. > I have not come across a C file in PostgreSQL code base where private > structures are defined in the middle the file; usually they are > defined at the beginning of the file. But I have chosen it that way > here since it makes it easy to document the hash table and the > functions at one place at the beginning of this code section. I am > open to suggestions which make the documentation easy while placing > the structures at the beginning of the file. > > [1] https://docs.google.com/spreadsheets/d/1CEjRWZ02vuR8fSwhYaNugewtX8f0kIm5pLoRA95f3s8/edit?usp=sharing > [2] https://www.postgresql.org/message-id/flat/CAOP8fzaVL_2SCJayLL9kj5pCA46PJOXXjuei6-3aFUV45j4LJQ%40mail.gmail.com > Noticed that Tomas's email address has changed. Adding his new email address. -- Best Wishes, Ashutosh Bapat
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
> On Thu, Oct 10, 2024 at 05:36:10PM GMT, Ashutosh Bapat wrote:
>
> 3. With just patch 0001 applied, planning time usually shows
> degradation (column Q and X in planning time sheets) with or without
> PWJ enabled. I first thought that it might be because of the increased
> size of PlannerInfo. We had seen a similar phenomenon when adding a
> new member to WindowAggState [2]. Hence I introduced patch 0002 which
> moves two fields around to not increase the size of structure. But
> that doesn't fix the regression in the planning time (columns R and
> Y). Apart from increasing the PlannerInfo size and may be object file
> size, 0002 does not have any other impact. But the regression seen
> with just that patch is more than what we saw in [2]. More investigate
> is required to decide whether this regression is real or not and if
> real, the root cause. Looking at the numbers, it seems that this
> regression is causing the planning time regression in rest of the
> patches. If we fix regression by 0001, we should not see much
> regression in rest of the patches. I am looking for some guidance in
> investigating this regression.
Hi,
I've tried to reproduce some subset of those results, in case if I would
be able to notice anything useful. Strangely enough, I wasn't able to
get much boost in planning time e.g. with 4 first patches, 100
partitions and 5 joins -- the results you've posted are showing about
16% in that case, where I'm getting only a couple of percents. Probably
I'm doing something differently, but it's turned out to be hard to
reconstruct (based only on this thread) how did you exactly benchmark
the patch -- could you maybe summarize the benchmark in a reproducible
way?
From what I understand you were testing againt an empty partitioned table. Here
is what I was doing:
create table t1p (c1 int) partition by list(c1);
select format('create table %I partition of t1p for values in (%s)',
't1p' || i, i) from generate_series(1, 100) i; \gexec
do $x$
declare
i record;
plan float[];
plan_line text;
begin
for i in select * from generate_series(1, 1000) i loop
for plan_line in execute format($y$
explain analyze
select * from t1p t1, t1p t2, t1p t3, t1p t4, t1p t5
where t2.c1 =
t1.c1 and t3.c1 = t2.c1 and t4.c1 = t3.c1 and t5.c1 = t4.c1
$y$) loop
if plan_line like '%Planning Time%' then
plan := array_append(plan, substring(plan_line from '\d+.\d+')::float);
end if;
end loop;
end loop;
-- skip the first record as prewarming
raise warning 'avg: %',
(select avg(v) from unnest(plan[2:]) v);
raise warning 'median: %',
(select percentile_cont(0.5) within group(order by v)
from unnest(plan[2:]) v);
end;
$x$;
As a side note, may I ask to attach benchmark results as files, rather than a
link to a google spreadsheet? It feels nice to have something static to work
with.
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On 2024-Nov-25, Ashutosh Bapat wrote:
> Hmm, I am doing something similar to what you are doing. Here are my
> scripts. setup.sql - creates partitioned table, and functions, tables
> used to run the benchmark benchmark.sh - creates queries with all
> combinations of enable_partitionwise_join, number of partitions, joins
> etc. and runs EXPLAIN on each query recording the results in a table.
I was curious about this still being alive and uncommitted, so I
wondered if Dmitry was on to something about this patch not improving
things. So I tried to rerun Ashutosh's benchmark (of course, on a build
with no C assertions, otherwise the numbers are meaningless). First,
the patches still apply to current master. Turns on that they improve
planning times not insignificantly in the majority of cases (not all).
This is on my laptop and I didn't do anything in particular to keep it
stable, though.
I don't know about this modern googol sheets thing you're talking about,
so I use \crosstabview like my cavemen forefathers did. After running
benchmark.sh (note: it needs "-X" on the psql lines, otherwise it gets
all confused by funny stuff in my .psqlrc) to get the SQL to run, I
obtain a summary table with this psql query:
select code_tag, num_parts, num_joins,
format ('n=%s avg=%s dev=%s', count(planning_time_ms) filter (where pwj),
(avg(planning_time_ms) filter (where pwj))::numeric(6, 2),
(stddev(planning_time_ms) filter (where pwj))::numeric(6,2))
from msmts where code_tag = 'master'
group by code_tag, num_parts, num_joins
order by 1, 2, 3 \crosstabview 2 3 4
Here's the tables I got.
PWJ on, master:
num_parts │ 2 │ 3 │ 4 │ 5
───────────┼───────────────────────────┼────────────────────────────┼─────────────────────────────┼─────────────────────────────
0 │ n=10 avg=0.05 dev=0.00 │ n=10 avg=0.16 dev=0.04 │ n=10 avg=0.38 dev=0.10 │ n=10 avg=0.95
dev=0.14
10 │ n=10 avg=0.41 dev=0.02 │ n=10 avg=1.25 dev=0.09 │ n=10 avg=4.93 dev=0.30 │ n=10 avg=12.12
dev=0.69
100 │ n=10 avg=4.68 dev=0.40 │ n=10 avg=21.34 dev=1.04 │ n=10 avg=65.09 dev=1.91 │ n=10 avg=206.87
dev=3.87
500 │ n=10 avg=55.11 dev=1.43 │ n=10 avg=240.97 dev=7.90 │ n=10 avg=834.72 dev=35.67 │ n=10 avg=2534.78
dev=107.28
1000 │ n=10 avg=242.40 dev=21.09 │ n=10 avg=1085.65 dev=38.11 │ n=10 avg=3161.00 dev=151.04 │ n=10 avg=9634.34
dev=635.57
PWJ on, all patches:
num_parts │ 2 │ 3 │ 4 │ 5
───────────┼──────────────────────────┼───────────────────────────┼─────────────────────────────┼─────────────────────────────
0 │ n=10 avg=0.05 dev=0.00 │ n=10 avg=0.12 dev=0.01 │ n=10 avg=0.34 dev=0.01 │ n=10 avg=0.91
dev=0.02
10 │ n=10 avg=0.37 dev=0.01 │ n=10 avg=1.17 dev=0.07 │ n=10 avg=4.09 dev=0.25 │ n=10 avg=10.31
dev=0.38
100 │ n=10 avg=4.62 dev=0.14 │ n=10 avg=17.17 dev=0.45 │ n=10 avg=54.05 dev=0.98 │ n=10 avg=178.05
dev=2.69
500 │ n=10 avg=61.32 dev=1.91 │ n=10 avg=229.54 dev=15.82 │ n=10 avg=701.33 dev=34.16 │ n=10 avg=2176.00
dev=84.28
1000 │ n=10 avg=195.74 dev=5.73 │ n=10 avg=789.49 dev=16.44 │ n=10 avg=2786.55 dev=254.03 │ n=10 avg=9177.05
dev=467.33
PWJ off, master:
num_parts │ 2 │ 3 │ 4 │ 5
───────────┼──────────────────────────┼───────────────────────────┼────────────────────────────┼─────────────────────────────
0 │ n=10 avg=0.06 dev=0.02 │ n=10 avg=0.16 dev=0.04 │ n=10 avg=0.39 dev=0.07 │ n=10 avg=1.08
dev=0.17
10 │ n=10 avg=0.27 dev=0.03 │ n=10 avg=0.54 dev=0.01 │ n=10 avg=1.05 dev=0.03 │ n=10 avg=2.09
dev=0.07
100 │ n=10 avg=5.17 dev=2.45 │ n=10 avg=8.96 dev=0.14 │ n=10 avg=17.25 dev=0.29 │ n=10 avg=36.11
dev=1.06
500 │ n=10 avg=46.82 dev=1.84 │ n=10 avg=149.06 dev=2.79 │ n=10 avg=396.95 dev=26.15 │ n=10 avg=912.93
dev=31.78
1000 │ n=10 avg=219.86 dev=5.21 │ n=10 avg=697.27 dev=14.96 │ n=10 avg=1925.81 dev=65.78 │ n=10 avg=4857.81
dev=248.71
PWJ off, allpatches:
num_parts │ 2 │ 3 │ 4 │ 5
───────────┼───────────────────────────┼───────────────────────────┼────────────────────────────┼─────────────────────────────
0 │ n=10 avg=0.06 dev=0.01 │ n=10 avg=0.13 dev=0.02 │ n=10 avg=0.34 dev=0.02 │ n=10 avg=0.95
dev=0.06
10 │ n=10 avg=0.25 dev=0.02 │ n=10 avg=0.52 dev=0.01 │ n=10 avg=0.96 dev=0.01 │ n=10 avg=1.86
dev=0.01
100 │ n=10 avg=5.43 dev=2.37 │ n=10 avg=7.30 dev=0.16 │ n=10 avg=12.93 dev=0.35 │ n=10 avg=24.56
dev=0.49
500 │ n=10 avg=50.10 dev=2.35 │ n=10 avg=156.04 dev=11.05 │ n=10 avg=332.48 dev=17.44 │ n=10 avg=711.22
dev=21.44
1000 │ n=10 avg=174.02 dev=15.26 │ n=10 avg=567.23 dev=8.81 │ n=10 avg=1480.75 dev=45.04 │ n=10 avg=3578.19
dev=240.20
So it looks to me like for high number of partitions and joins, this
wins hands down in terms of planning time. For some of the 2/3 joins
and 100/500 partitions, it loses.
As for planner memory, which this was supposed to improve, I don't find
any significant improvement, except for 1000 partitions and 5 joins
(where it goes from 1071991 to 874480 kilobytes); IMO it's not worth
framing this improvement from that point of view, because it doesn't
seem compelling, at least to me.
--
Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/
"Hay dos momentos en la vida de un hombre en los que no debería
especular: cuando puede permitírselo y cuando no puede" (Mark Twain)
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Fri, Jan 31, 2025 at 5:46 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2025-Jan-31, Alvaro Herrera wrote: > > > So I tried to rerun Ashutosh's benchmark (of course, on a build > > with no C assertions, otherwise the numbers are meaningless). First, > > the patches still apply to current master. > > (BTW I just realized that I applied patches 0001-0004, omitting 0005). That's ok. The last patch shows a minor regression wrt 0004. It will be dropped from the patchset anyway. -- Best Wishes, Ashutosh Bapat
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Fri, Jan 31, 2025 at 5:41 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
>
> On 2024-Nov-25, Ashutosh Bapat wrote:
>
> > Hmm, I am doing something similar to what you are doing. Here are my
> > scripts. setup.sql - creates partitioned table, and functions, tables
> > used to run the benchmark benchmark.sh - creates queries with all
> > combinations of enable_partitionwise_join, number of partitions, joins
> > etc. and runs EXPLAIN on each query recording the results in a table.
>
> I was curious about this still being alive and uncommitted, so I
> wondered if Dmitry was on to something about this patch not improving
> things. So I tried to rerun Ashutosh's benchmark (of course, on a build
> with no C assertions, otherwise the numbers are meaningless). First,
> the patches still apply to current master. Turns on that they improve
> planning times not insignificantly in the majority of cases (not all).
> This is on my laptop and I didn't do anything in particular to keep it
> stable, though.
>
> I don't know about this modern googol sheets thing you're talking about,
> so I use \crosstabview like my cavemen forefathers did. After running
> benchmark.sh
Thanks for suggesting \crosstabview. The summary table looks good. But
it doesn't tell the difference (absolute or %), so the reader has to
do the maths themselves. Maybe I could improve the query itself to
report the difference.
> (note: it needs "-X" on the psql lines, otherwise it gets
> all confused by funny stuff in my .psqlrc) to get the SQL to run, I
> obtain a summary table with this psql query:
Will incorporate -X
>
> select code_tag, num_parts, num_joins,
> format ('n=%s avg=%s dev=%s', count(planning_time_ms) filter (where pwj),
> (avg(planning_time_ms) filter (where pwj))::numeric(6, 2),
> (stddev(planning_time_ms) filter (where pwj))::numeric(6,2))
> from msmts where code_tag = 'master'
> group by code_tag, num_parts, num_joins
> order by 1, 2, 3 \crosstabview 2 3 4
>
> Here's the tables I got.
>
> PWJ on, master:
> num_parts │ 2 │ 3 │ 4 │ 5
>
───────────┼───────────────────────────┼────────────────────────────┼─────────────────────────────┼─────────────────────────────
> 0 │ n=10 avg=0.05 dev=0.00 │ n=10 avg=0.16 dev=0.04 │ n=10 avg=0.38 dev=0.10 │ n=10 avg=0.95
dev=0.14
> 10 │ n=10 avg=0.41 dev=0.02 │ n=10 avg=1.25 dev=0.09 │ n=10 avg=4.93 dev=0.30 │ n=10 avg=12.12
dev=0.69
> 100 │ n=10 avg=4.68 dev=0.40 │ n=10 avg=21.34 dev=1.04 │ n=10 avg=65.09 dev=1.91 │ n=10 avg=206.87
dev=3.87
> 500 │ n=10 avg=55.11 dev=1.43 │ n=10 avg=240.97 dev=7.90 │ n=10 avg=834.72 dev=35.67 │ n=10 avg=2534.78
dev=107.28
> 1000 │ n=10 avg=242.40 dev=21.09 │ n=10 avg=1085.65 dev=38.11 │ n=10 avg=3161.00 dev=151.04 │ n=10 avg=9634.34
dev=635.57
>
> PWJ on, all patches:
> num_parts │ 2 │ 3 │ 4 │ 5
>
───────────┼──────────────────────────┼───────────────────────────┼─────────────────────────────┼─────────────────────────────
> 0 │ n=10 avg=0.05 dev=0.00 │ n=10 avg=0.12 dev=0.01 │ n=10 avg=0.34 dev=0.01 │ n=10 avg=0.91
dev=0.02
> 10 │ n=10 avg=0.37 dev=0.01 │ n=10 avg=1.17 dev=0.07 │ n=10 avg=4.09 dev=0.25 │ n=10 avg=10.31
dev=0.38
> 100 │ n=10 avg=4.62 dev=0.14 │ n=10 avg=17.17 dev=0.45 │ n=10 avg=54.05 dev=0.98 │ n=10 avg=178.05
dev=2.69
> 500 │ n=10 avg=61.32 dev=1.91 │ n=10 avg=229.54 dev=15.82 │ n=10 avg=701.33 dev=34.16 │ n=10 avg=2176.00
dev=84.28
> 1000 │ n=10 avg=195.74 dev=5.73 │ n=10 avg=789.49 dev=16.44 │ n=10 avg=2786.55 dev=254.03 │ n=10 avg=9177.05
dev=467.33
>
>
> PWJ off, master:
> num_parts │ 2 │ 3 │ 4 │ 5
>
───────────┼──────────────────────────┼───────────────────────────┼────────────────────────────┼─────────────────────────────
> 0 │ n=10 avg=0.06 dev=0.02 │ n=10 avg=0.16 dev=0.04 │ n=10 avg=0.39 dev=0.07 │ n=10 avg=1.08
dev=0.17
> 10 │ n=10 avg=0.27 dev=0.03 │ n=10 avg=0.54 dev=0.01 │ n=10 avg=1.05 dev=0.03 │ n=10 avg=2.09
dev=0.07
> 100 │ n=10 avg=5.17 dev=2.45 │ n=10 avg=8.96 dev=0.14 │ n=10 avg=17.25 dev=0.29 │ n=10 avg=36.11
dev=1.06
> 500 │ n=10 avg=46.82 dev=1.84 │ n=10 avg=149.06 dev=2.79 │ n=10 avg=396.95 dev=26.15 │ n=10 avg=912.93
dev=31.78
> 1000 │ n=10 avg=219.86 dev=5.21 │ n=10 avg=697.27 dev=14.96 │ n=10 avg=1925.81 dev=65.78 │ n=10 avg=4857.81
dev=248.71
>
>
> PWJ off, allpatches:
> num_parts │ 2 │ 3 │ 4 │ 5
>
───────────┼───────────────────────────┼───────────────────────────┼────────────────────────────┼─────────────────────────────
> 0 │ n=10 avg=0.06 dev=0.01 │ n=10 avg=0.13 dev=0.02 │ n=10 avg=0.34 dev=0.02 │ n=10 avg=0.95
dev=0.06
> 10 │ n=10 avg=0.25 dev=0.02 │ n=10 avg=0.52 dev=0.01 │ n=10 avg=0.96 dev=0.01 │ n=10 avg=1.86
dev=0.01
> 100 │ n=10 avg=5.43 dev=2.37 │ n=10 avg=7.30 dev=0.16 │ n=10 avg=12.93 dev=0.35 │ n=10 avg=24.56
dev=0.49
> 500 │ n=10 avg=50.10 dev=2.35 │ n=10 avg=156.04 dev=11.05 │ n=10 avg=332.48 dev=17.44 │ n=10 avg=711.22
dev=21.44
> 1000 │ n=10 avg=174.02 dev=15.26 │ n=10 avg=567.23 dev=8.81 │ n=10 avg=1480.75 dev=45.04 │ n=10 avg=3578.19
dev=240.20
>
>
> So it looks to me like for high number of partitions and joins, this
> wins hands down in terms of planning time. For some of the 2/3 joins
> and 100/500 partitions, it loses.
>
The combination for which the planning time regresses is not fixed -
it shifts every time I run the benchmark. But I see regression with
one or the other combination. So I haven't been able to decide whether
it's a real regression or not. Planning time for a small number of
joins vary a lot from run to run.
>
> As for planner memory, which this was supposed to improve, I don't find
> any significant improvement, except for 1000 partitions and 5 joins
> (where it goes from 1071991 to 874480 kilobytes); IMO it's not worth
> framing this improvement from that point of view, because it doesn't
> seem compelling, at least to me.
If we are not interested in saving memory, there is a simpler way to
improve planning time by adding a hash table per equivalence class to
store the derived clauses, instead of a linked list, when the number
of derived clauses is higher than a threshold (say 32 same as the
threshold for join_rel_list. Maybe that approach will yield stable
planning time.
--
Best Wishes,
Ashutosh Bapat
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Tue, Feb 4, 2025 at 4:07 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > > If we are not interested in saving memory, there is a simpler way to > improve planning time by adding a hash table per equivalence class to > store the derived clauses, instead of a linked list, when the number > of derived clauses is higher than a threshold (say 32 same as the > threshold for join_rel_list. Maybe that approach will yield stable > planning time. > PFA patchset with conflict, with latest HEAD, resolved. I have dropped 0005 from the previous patchset since it didn't show any significant performance difference. Other than these two things, the patchset is same as the previous one. -- Best Wishes, Ashutosh Bapat
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
> On Mon, Nov 25, 2024 at 11:20:05AM GMT, Ashutosh Bapat wrote: > > I've tried to reproduce some subset of those results, in case if I would > > be able to notice anything useful. Strangely enough, I wasn't able to > > get much boost in planning time e.g. with 4 first patches, 100 > > partitions and 5 joins -- the results you've posted are showing about > > 16% in that case, where I'm getting only a couple of percents. Probably > > I'm doing something differently, but it's turned out to be hard to > > reconstruct (based only on this thread) how did you exactly benchmark > > the patch -- could you maybe summarize the benchmark in a reproducible > > way? > > Hmm, I am doing something similar to what you are doing. Here are my scripts. > setup.sql - creates partitioned table, and functions, tables used to > run the benchmark > benchmark.sh - creates queries with all combinations of > enable_partitionwise_join, number of partitions, joins etc. and runs > EXPLAIN on each query recording the results in a table. > run_bm_on_commits.sh - runs setup.sql once, then runs benchmark.sh on > each commit (using git rebase) and finally outputs the average numbers > to be fed to the "aggregate numbers" sheet. Just FYI, I've finally found time to figure out why do I get slightly different results. It turns out I was running tests against a partitioned table without a primary key, which obviously affects planner, making planning time shorter and reducing the delta between the patched version and the main branch. But of course a partitioned table without a pk makes little sense, so I guess those results are not very relevant. I've done another round with pk, and got results similar to yours.
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
Hi,
On Thu, Feb 20, 2025 at 5:28 PM Ashutosh Bapat
<ashutosh.bapat.oss@gmail.com> wrote:
>
> On Tue, Feb 4, 2025 at 4:07 PM Ashutosh Bapat
> <ashutosh.bapat.oss@gmail.com> wrote:
> >
> > If we are not interested in saving memory, there is a simpler way to
> > improve planning time by adding a hash table per equivalence class to
> > store the derived clauses, instead of a linked list, when the number
> > of derived clauses is higher than a threshold (say 32 same as the
> > threshold for join_rel_list. Maybe that approach will yield stable
> > planning time.
> >
I implemented the above idea in attached patches. I also added the
following query, inspired from Alvaro's query, to summarise the
results.
with master_avgs as
(select code_tag, num_parts, num_joins, pwj, avg(planning_time_ms)
avg_pt, stddev(planning_time_ms) stddev_pt
from msmts where code_tag = 'master'
group by code_tag, num_parts, num_joins, pwj),
patched_avgs as
(select code_tag, num_parts, num_joins, pwj, avg(planning_time_ms)
avg_pt, stddev(planning_time_ms) stddev_pt
from msmts where code_tag = 'patched'
group by code_tag, num_parts, num_joins, pwj)
select num_parts,
num_joins,
format('s=%s%% md=%s%% pd=%s%%',
((m.avg_pt - p.avg_pt)/m.avg_pt * 100)::numeric(6, 2),
(m.stddev_pt/m.avg_pt * 100)::numeric(6, 2),
(p.stddev_pt/p.avg_pt * 100)::numeric(6, 2))
from master_avgs m join patched_avgs p using (num_parts, num_joins,
pwj) where not pwj order by 1, 2, 3;
\crosstabview 1 2 3
not pwj in the last line should be changed to pwj to get results with
enable_partitionwise_join = true.
With the attached patches, I observe following results
With PWJ disabled
num_parts | 2 | 3
| 4 | 5
-----------+-------------------------------+------------------------------+----------------------------+-----------------------------
0 | s=-4.44% md=17.91% pd=23.05% | s=-0.83% md=11.10%
pd=19.58% | s=0.87% md=4.04% pd=7.91% | s=-35.24% md=7.63% pd=9.69%
10 | s=30.13% md=118.18% pd=37.44% | s=-3.49% md=0.58%
pd=0.49% | s=-0.83% md=0.29% pd=0.35% | s=-0.24% md=0.35% pd=0.32%
100 | s=1.94% md=13.19% pd=4.08% | s=-0.27% md=0.18%
pd=0.44% | s=7.04% md=3.05% pd=3.11% | s=12.75% md=1.69% pd=0.81%
500 | s=4.39% md=1.71% pd=1.33% | s=10.17% md=1.28%
pd=1.90% | s=23.04% md=0.24% pd=0.58% | s=30.87% md=0.30% pd=1.11%
1000 | s=4.27% md=1.21% pd=1.97% | s=13.97% md=0.44%
pd=0.79% | s=24.05% md=0.63% pd=1.02% | s=30.77% md=0.77% pd=0.17%
Each cell is a triple (s, md, pd) where s is improvement in planning
time using the patches in % as compared to the master (higher the
better), md = standard deviation as % of the average planning time on
master, pd = is standard deviation as % of the average planning time
with patches.
With PWJ enabled
num_parts | 2 | 3
| 4 | 5
-----------+------------------------------+------------------------------+-----------------------------+------------------------------
0 | s=-94.25% md=6.98% pd=56.03% | s=44.10% md=141.13%
pd=9.32% | s=42.71% md=46.00% pd=6.55% | s=-26.12% md=6.72% pd=15.20%
10 | s=-25.89% md=4.29% pd=63.75% | s=-1.34% md=3.15% pd=3.26%
| s=0.31% md=4.13% pd=4.34% | s=-1.34% md=3.10% pd=6.73%
100 | s=-2.83% md=0.94% pd=1.31% | s=-2.17% md=4.57% pd=4.41%
| s=0.98% md=1.59% pd=1.81% | s=1.87% md=1.10% pd=0.79%
500 | s=1.57% md=3.01% pd=1.70% | s=6.99% md=1.58% pd=1.68%
| s=11.11% md=0.24% pd=0.62% | s=11.65% md=0.18% pd=0.90%
1000 | s=3.59% md=0.98% pd=1.78% | s=10.83% md=0.88% pd=0.46%
| s=15.62% md=0.46% pd=0.13% | s=16.38% md=0.63% pd=0.29%
Same numbers measured for previous set of patches [1], which improves
both memory consumption as well as planning time.
With PWJ disabled
num_parts | 2 | 3
| 4 | 5
-----------+-------------------------------+------------------------------+------------------------------+--------------------------------
0 | s=4.68% md=18.17% pd=22.09% | s=-2.54% md=12.00%
pd=13.81% | s=-2.02% md=3.84% pd=4.43% | s=-69.14% md=11.06%
pd=126.87%
10 | s=-24.85% md=20.42% pd=35.69% | s=-4.31% md=0.73%
pd=1.53% | s=-14.97% md=0.32% pd=31.90% | s=-0.57% md=0.79% pd=0.50%
100 | s=0.27% md=4.69% pd=1.55% | s=4.16% md=0.29% pd=0.18%
| s=11.76% md=0.85% pd=0.49% | s=15.76% md=1.64% pd=2.32%
500 | s=0.54% md=1.88% pd=1.81% | s=9.36% md=1.17% pd=0.87%
| s=21.45% md=0.74% pd=0.88% | s=30.47% md=0.17% pd=1.17%
1000 | s=3.22% md=1.36% pd=0.99% | s=14.74% md=0.86%
pd=0.44% | s=24.50% md=0.36% pd=0.31% | s=27.97% md=0.27% pd=0.25%
With PWJ enabled
num_parts | 2 | 3
| 4 | 5
-----------+-----------------------------+----------------------------+----------------------------+-----------------------------
0 | s=11.07% md=19.28% pd=8.70% | s=-1.18% md=5.88% pd=4.31%
| s=-2.25% md=8.42% pd=3.77% | s=25.07% md=11.48% pd=3.87%
10 | s=-9.07% md=2.65% pd=14.58% | s=0.55% md=3.10% pd=3.41%
| s=3.89% md=3.94% pd=3.79% | s=7.25% md=2.87% pd=3.03%
100 | s=-4.53% md=0.49% pd=8.53% | s=2.24% md=4.24% pd=3.96%
| s=6.70% md=1.30% pd=2.08% | s=9.09% md=1.39% pd=1.50%
500 | s=-1.65% md=1.59% pd=1.44% | s=6.31% md=0.89% pd=1.11%
| s=12.72% md=0.20% pd=0.29% | s=15.02% md=0.28% pd=0.83%
1000 | s=1.53% md=1.01% pd=1.66% | s=11.80% md=0.66% pd=0.71%
| s=16.23% md=0.58% pd=0.18% | s=17.16% md=0.67% pd=0.68%
There are a few things to notice
1. There is not much difference in the planning time improvement by
both the patchsets. But the patchset attached to [1] improves memory
consumption as well. So it looks more attractive.
2. The performance regressions usually coincide with higher standard
deviation. This indicates that both the performance gains or losses
seen at lower numbers of partitions and joins are not real and
possibly ignored. I have run the script multiple times but some or
other combination of lower number of partitions and lower number of
joins shows higher deviation and thus unstable results. I have not be
able to find a way where all the combinations show a stable result.
I think the first patch in the attached set is worth committing, just
to tighten things up.
[1] https://www.postgresql.org/message-id/CAExHW5t6NpGaif6ZO_P+L1cPZk27+Ye2LxfqRVXf0OiSsW9WSg@mail.gmail.com
--
Best Wishes,
Ashutosh Bapat
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
Hi Ashutosh,
On Tue, Feb 25, 2025 at 8:04 PM Ashutosh Bapat
<ashutosh.bapat.oss@gmail.com> wrote:
> On Thu, Feb 20, 2025 at 5:28 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote:
> > On Tue, Feb 4, 2025 at 4:07 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote:
> > > If we are not interested in saving memory, there is a simpler way to
> > > improve planning time by adding a hash table per equivalence class to
> > > store the derived clauses, instead of a linked list, when the number
> > > of derived clauses is higher than a threshold (say 32 same as the
> > > threshold for join_rel_list. Maybe that approach will yield stable
> > > planning time.
>
> I implemented the above idea in attached patches. I also added the
> following query, inspired from Alvaro's query, to summarise the
> results.
> with master_avgs as
> (select code_tag, num_parts, num_joins, pwj, avg(planning_time_ms)
> avg_pt, stddev(planning_time_ms) stddev_pt
> from msmts where code_tag = 'master'
> group by code_tag, num_parts, num_joins, pwj),
> patched_avgs as
> (select code_tag, num_parts, num_joins, pwj, avg(planning_time_ms)
> avg_pt, stddev(planning_time_ms) stddev_pt
> from msmts where code_tag = 'patched'
> group by code_tag, num_parts, num_joins, pwj)
> select num_parts,
> num_joins,
> format('s=%s%% md=%s%% pd=%s%%',
> ((m.avg_pt - p.avg_pt)/m.avg_pt * 100)::numeric(6, 2),
> (m.stddev_pt/m.avg_pt * 100)::numeric(6, 2),
> (p.stddev_pt/p.avg_pt * 100)::numeric(6, 2))
> from master_avgs m join patched_avgs p using (num_parts, num_joins,
> pwj) where not pwj order by 1, 2, 3;
> \crosstabview 1 2 3
>
> not pwj in the last line should be changed to pwj to get results with
> enable_partitionwise_join = true.
>
> With the attached patches, I observe following results
>
> With PWJ disabled
> num_parts | 2 | 3
> | 4 | 5
>
-----------+-------------------------------+------------------------------+----------------------------+-----------------------------
> 0 | s=-4.44% md=17.91% pd=23.05% | s=-0.83% md=11.10%
> pd=19.58% | s=0.87% md=4.04% pd=7.91% | s=-35.24% md=7.63% pd=9.69%
> 10 | s=30.13% md=118.18% pd=37.44% | s=-3.49% md=0.58%
> pd=0.49% | s=-0.83% md=0.29% pd=0.35% | s=-0.24% md=0.35% pd=0.32%
> 100 | s=1.94% md=13.19% pd=4.08% | s=-0.27% md=0.18%
> pd=0.44% | s=7.04% md=3.05% pd=3.11% | s=12.75% md=1.69% pd=0.81%
> 500 | s=4.39% md=1.71% pd=1.33% | s=10.17% md=1.28%
> pd=1.90% | s=23.04% md=0.24% pd=0.58% | s=30.87% md=0.30% pd=1.11%
> 1000 | s=4.27% md=1.21% pd=1.97% | s=13.97% md=0.44%
> pd=0.79% | s=24.05% md=0.63% pd=1.02% | s=30.77% md=0.77% pd=0.17%
>
>
> Each cell is a triple (s, md, pd) where s is improvement in planning
> time using the patches in % as compared to the master (higher the
> better), md = standard deviation as % of the average planning time on
> master, pd = is standard deviation as % of the average planning time
> with patches.
>
> With PWJ enabled
> num_parts | 2 | 3
> | 4 | 5
>
-----------+------------------------------+------------------------------+-----------------------------+------------------------------
> 0 | s=-94.25% md=6.98% pd=56.03% | s=44.10% md=141.13%
> pd=9.32% | s=42.71% md=46.00% pd=6.55% | s=-26.12% md=6.72% pd=15.20%
> 10 | s=-25.89% md=4.29% pd=63.75% | s=-1.34% md=3.15% pd=3.26%
> | s=0.31% md=4.13% pd=4.34% | s=-1.34% md=3.10% pd=6.73%
> 100 | s=-2.83% md=0.94% pd=1.31% | s=-2.17% md=4.57% pd=4.41%
> | s=0.98% md=1.59% pd=1.81% | s=1.87% md=1.10% pd=0.79%
> 500 | s=1.57% md=3.01% pd=1.70% | s=6.99% md=1.58% pd=1.68%
> | s=11.11% md=0.24% pd=0.62% | s=11.65% md=0.18% pd=0.90%
> 1000 | s=3.59% md=0.98% pd=1.78% | s=10.83% md=0.88% pd=0.46%
> | s=15.62% md=0.46% pd=0.13% | s=16.38% md=0.63% pd=0.29%
>
> Same numbers measured for previous set of patches [1], which improves
> both memory consumption as well as planning time.
>
> With PWJ disabled
> num_parts | 2 | 3
> | 4 | 5
>
-----------+-------------------------------+------------------------------+------------------------------+--------------------------------
> 0 | s=4.68% md=18.17% pd=22.09% | s=-2.54% md=12.00%
> pd=13.81% | s=-2.02% md=3.84% pd=4.43% | s=-69.14% md=11.06%
> pd=126.87%
> 10 | s=-24.85% md=20.42% pd=35.69% | s=-4.31% md=0.73%
> pd=1.53% | s=-14.97% md=0.32% pd=31.90% | s=-0.57% md=0.79% pd=0.50%
> 100 | s=0.27% md=4.69% pd=1.55% | s=4.16% md=0.29% pd=0.18%
> | s=11.76% md=0.85% pd=0.49% | s=15.76% md=1.64% pd=2.32%
> 500 | s=0.54% md=1.88% pd=1.81% | s=9.36% md=1.17% pd=0.87%
> | s=21.45% md=0.74% pd=0.88% | s=30.47% md=0.17% pd=1.17%
> 1000 | s=3.22% md=1.36% pd=0.99% | s=14.74% md=0.86%
> pd=0.44% | s=24.50% md=0.36% pd=0.31% | s=27.97% md=0.27% pd=0.25%
>
> With PWJ enabled
> num_parts | 2 | 3
> | 4 | 5
>
-----------+-----------------------------+----------------------------+----------------------------+-----------------------------
> 0 | s=11.07% md=19.28% pd=8.70% | s=-1.18% md=5.88% pd=4.31%
> | s=-2.25% md=8.42% pd=3.77% | s=25.07% md=11.48% pd=3.87%
> 10 | s=-9.07% md=2.65% pd=14.58% | s=0.55% md=3.10% pd=3.41%
> | s=3.89% md=3.94% pd=3.79% | s=7.25% md=2.87% pd=3.03%
> 100 | s=-4.53% md=0.49% pd=8.53% | s=2.24% md=4.24% pd=3.96%
> | s=6.70% md=1.30% pd=2.08% | s=9.09% md=1.39% pd=1.50%
> 500 | s=-1.65% md=1.59% pd=1.44% | s=6.31% md=0.89% pd=1.11%
> | s=12.72% md=0.20% pd=0.29% | s=15.02% md=0.28% pd=0.83%
> 1000 | s=1.53% md=1.01% pd=1.66% | s=11.80% md=0.66% pd=0.71%
> | s=16.23% md=0.58% pd=0.18% | s=17.16% md=0.67% pd=0.68%
>
> There are a few things to notice
> 1. There is not much difference in the planning time improvement by
> both the patchsets. But the patchset attached to [1] improves memory
> consumption as well. So it looks more attractive.
> 2. The performance regressions usually coincide with higher standard
> deviation. This indicates that both the performance gains or losses
> seen at lower numbers of partitions and joins are not real and
> possibly ignored. I have run the script multiple times but some or
> other combination of lower number of partitions and lower number of
> joins shows higher deviation and thus unstable results. I have not be
> able to find a way where all the combinations show a stable result.
Thanks for the patch and the extensive benchmarking.
Would you please also share a simple, self-contained example that I
can use to reproduce and verify the performance improvements? It’s
helpful to first see the patch in action with a representative query,
and then refer to the more extensive benchmark results you've already
shared as needed. I'm also having a hard time telling from the scripts
which query was used to produce the numbers in the report.
Btw, in the commit message, you mention:
===
When there are thousands of partitions in a partitioned table, there
can be thousands of derived clauses in the list making it inefficient
for a lookup.
===
I haven’t found a description of how that many clauses end up in the
ec->ec_derived list. IIUC, it's create_join_clause() where the child
clauses get added, and it would be helpful to mention that, since that
also appears to be the hotspot your patch is addressing.
> I think the first patch in the attached set is worth committing, just
> to tighten things up.
I agree and am happy to commit it if there are no objections.
--
Thanks, Amit Langote
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Fri, Mar 14, 2025 at 5:36 PM Amit Langote <amitlangote09@gmail.com> wrote: > > Thanks for the patch and the extensive benchmarking. > > Would you please also share a simple, self-contained example that I > can use to reproduce and verify the performance improvements? It’s > helpful to first see the patch in action with a representative query, > and then refer to the more extensive benchmark results you've already > shared as needed. I'm also having a hard time telling from the scripts > which query was used to produce the numbers in the report. > Here are steps 1. Run setup.sql attached in [1]. It will add a few helper functions and create required tables (partitioned and non-partitioned ones). 2. The sheet named "rae data" attached to [1] has queries whose performance is measured. They use the tables created by setup.sql. You may further use the same scripts to run benchmarks. > Btw, in the commit message, you mention: > > === > When there are thousands of partitions in a partitioned table, there > can be thousands of derived clauses in the list making it inefficient > for a lookup. > === > > I haven’t found a description of how that many clauses end up in the > ec->ec_derived list. IIUC, it's create_join_clause() where the child > clauses get added, and it would be helpful to mention that, since that > also appears to be the hotspot your patch is addressing. you are right. create_join_clause() adds the derived clauses for partitions. Please note that the optimization, being modelled after join rel list, is applicable to partitioned, non-partititoned cases as well as with or without partitionwise join. > > > I think the first patch in the attached set is worth committing, just > > to tighten things up. > > I agree and am happy to commit it if there are no objections. Thanks. [1] https://www.postgresql.org/message-id/CAExHW5vnwgTgfsCiNM7E4TnkxD1b_ZHPafNe1f041u=o131PYg@mail.gmail.com -- Best Wishes, Ashutosh Bapat
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Mon, Mar 17, 2025 at 5:47 PM Ashutosh Bapat
<ashutosh.bapat.oss@gmail.com> wrote:
> On Fri, Mar 14, 2025 at 5:36 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > Thanks for the patch and the extensive benchmarking.
> >
> > Would you please also share a simple, self-contained example that I
> > can use to reproduce and verify the performance improvements? It’s
> > helpful to first see the patch in action with a representative query,
> > and then refer to the more extensive benchmark results you've already
> > shared as needed. I'm also having a hard time telling from the scripts
> > which query was used to produce the numbers in the report.
> >
>
> Here are steps
> 1. Run setup.sql attached in [1]. It will add a few helper functions
> and create required tables (partitioned and non-partitioned ones).
> 2. The sheet named "rae data" attached to [1] has queries whose
> performance is measured. They use the tables created by setup.sql.
>
> You may further use the same scripts to run benchmarks.
Thanks for pointing me to that.
I ran a couple of benchmarks of my own as follows.
cat benchmark_amit.sh
for p in 0 16 32 64 128 256 512 1024; do
echo -ne "$p\t";
pgbench -i --partitions=$p > /dev/null 2>&1
pgbench -n -T 30 -f /tmp/query.sql | grep latency | awk '{print $4}';
done
For a 3-way join:
cat /tmp/query.sql
select * from pgbench_accounts t1, pgbench_accounts t2,
pgbench_accounts t3 where t2.aid = t1.aid AND t3.aid = t2.aid;
nparts master patched %change
0 35.508 36.066 1.571
16 66.79 67.704 1.368
32 67.774 68.179 0.598
64 51.023 50.471 -1.082
128 56.4 55.759 -1.137
256 70.134 68.401 -2.471
512 120.621 113.552 -5.861
1024 405.339 312.726 -22.848
For a 6-way jon
cat /tmp/query.sql
select * from pgbench_accounts t1, pgbench_accounts t2,
pgbench_accounts t3, pgbench_accounts t4, pgbench_accounts t5,
pgbench_accounts t6 where t2.aid = t1.aid AND t3.aid = t2.aid and
t4.aid = t3.aid and t5.aid = t4.aid and t6.aid = t5.aid;
nparts master patched %change
0 66.144 64.932 -1.832
16 100.874 100.491 -0.380
32 104.645 104.536 -0.104
64 114.415 109.193 -4.564
128 145.422 130.458 -10.290
256 273.761 209.919 -23.320
512 1359.896 616.295 -54.681
1024 7183.765 2857.086 -60.229
-60% means 60% reduction in latency due to the patch.
As others have already found, performance improvements become
substantial as both partition count and join depth increase. The patch
seems to have minimal impact at low partition counts and low join
complexity -- base cases (e.g., 0–32 partitions, 3-way joins) are
essentially unchanged, which is good to see.
I haven’t measured memory increase from the patch, but let me know if
that has already been evaluated and shown not to be a showstopper.
I also noticed using perf that create_join_clause() is a hotspot when
running without the patch, especially at high partition counts (> 500)
and the more join relations.
Let me know if my methodology seems off or if the results look reasonable.
--
Thanks, Amit Langote
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
Hi Amit,
On Tue, Mar 18, 2025 at 4:02 PM Amit Langote <amitlangote09@gmail.com> wrote:
>
> I ran a couple of benchmarks of my own as follows.
>
> cat benchmark_amit.sh
> for p in 0 16 32 64 128 256 512 1024; do
> echo -ne "$p\t";
> pgbench -i --partitions=$p > /dev/null 2>&1
> pgbench -n -T 30 -f /tmp/query.sql | grep latency | awk '{print $4}';
> done
>
> For a 3-way join:
> cat /tmp/query.sql
> select * from pgbench_accounts t1, pgbench_accounts t2,
> pgbench_accounts t3 where t2.aid = t1.aid AND t3.aid = t2.aid;
>
> nparts master patched %change
> 0 35.508 36.066 1.571
> 16 66.79 67.704 1.368
> 32 67.774 68.179 0.598
> 64 51.023 50.471 -1.082
> 128 56.4 55.759 -1.137
> 256 70.134 68.401 -2.471
> 512 120.621 113.552 -5.861
> 1024 405.339 312.726 -22.848
>
> For a 6-way jon
> cat /tmp/query.sql
> select * from pgbench_accounts t1, pgbench_accounts t2,
> pgbench_accounts t3, pgbench_accounts t4, pgbench_accounts t5,
> pgbench_accounts t6 where t2.aid = t1.aid AND t3.aid = t2.aid and
> t4.aid = t3.aid and t5.aid = t4.aid and t6.aid = t5.aid;
>
> nparts master patched %change
> 0 66.144 64.932 -1.832
> 16 100.874 100.491 -0.380
> 32 104.645 104.536 -0.104
> 64 114.415 109.193 -4.564
> 128 145.422 130.458 -10.290
> 256 273.761 209.919 -23.320
> 512 1359.896 616.295 -54.681
> 1024 7183.765 2857.086 -60.229
>
> -60% means 60% reduction in latency due to the patch.
>
> As others have already found, performance improvements become
> substantial as both partition count and join depth increase. The patch
> seems to have minimal impact at low partition counts and low join
> complexity -- base cases (e.g., 0–32 partitions, 3-way joins) are
> essentially unchanged, which is good to see.
I assume these are with enable_partitionwise_join = off since it's not
enabled in the query.
With lower number of partitions and joins the execution time will be
substantial compared to planning time hence the changes in execution
time will affect the changes in latency. So I agree that the
difference in numbers for lower number of partitions and joins is
noise. That agrees with my results posted a few emails before.
At a higher number of partitions and joins, the planning time
dominates the latency. Hence any variation in the planning time
dominates a variation in the latency. Thus the improvements seen here
are due to improvements in the planning time. Again that agrees with
my results in the previous email.
>
> I haven’t measured memory increase from the patch, but let me know if
> that has already been evaluated and shown not to be a showstopper.
There's a slight increase in memory consumption because of the hash
table but it's very minimal.
Here are memory numbers in kb (presented in the same format as before)
with pwj disabled
num_parts | 2 | 3 |
4 | 5
-----------+--------------------------+--------------------------+---------------------------+-----------------------------
0 | s=0 md=15 pd=15 | s=0 md=21 pd=21 | s=0
md=27 pd=27 | s=0 md=33 pd=33
10 | s=0 md=218 pd=218 | s=-20 md=455 pd=475 |
s=-20 md=868 pd=888 | s=-20 md=1697 pd=1717
100 | s=-20 md=1824 pd=1844 | s=-80 md=3718 pd=3798 |
s=-160 md=6400 pd=6560 | s=-320 md=10233 pd=10553
500 | s=-160 md=9395 pd=9555 | s=-320 md=20216 pd=20536 |
s=-640 md=35735 pd=36375 | s=-1280 md=60808 pd=62088
1000 | s=-320 md=19862 pd=20182 | s=-640 md=45739 pd=46379 |
s=-1280 md=84210 pd=85490 | s=-2561 md=149740 pd=152301
each column is s=difference in memory consumed, md = memory consumed
without patch, pd = memory consumed with patch. -ve difference shows
increase in memory consumption.
with pwj enabled
num_parts | 2 | 3 |
4 | 5
-----------+--------------------------+----------------------------+-----------------------------+-------------------------------
0 | s=0 md=15 pd=15 | s=0 md=21 pd=21 |
s=0 md=27 pd=27 | s=0 md=33 pd=33
10 | s=0 md=365 pd=365 | s=-20 md=1198 pd=1218 |
s=-20 md=3571 pd=3591 | s=-20 md=10426 pd=10446
100 | s=-21 md=3337 pd=3358 | s=-80 md=11237 pd=11317 |
s=-160 md=33845 pd=34005 | s=-320 md=99502 pd=99822
500 | s=-160 md=17206 pd=17366 | s=-320 md=60096 pd=60416 |
s=-640 md=183306 pd=183946 | s=-1280 md=556705 pd=557985
1000 | s=-320 md=36119 pd=36439 | s=-640 md=131457 pd=132097 |
s=-1280 md=404809 pd=406089 | s=-2561 md=1263664 pd=1266225
%wise this is 3-4% maximum.
>
> I also noticed using perf that create_join_clause() is a hotspot when
> running without the patch, especially at high partition counts (> 500)
> and the more join relations.
That's an interesting observation. Any hotspot in planning would show
up as hotspot in total execution time. So expected.
>
> Let me know if my methodology seems off or if the results look reasonable.
Thanks for benchmarking using a different method. The results agree
with my results.
--
Best Wishes,
Ashutosh Bapat
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Tue, Mar 18, 2025 at 8:48 PM Ashutosh Bapat
<ashutosh.bapat.oss@gmail.com> wrote:
> On Tue, Mar 18, 2025 at 4:02 PM Amit Langote <amitlangote09@gmail.com> wrote:
> >
> > I ran a couple of benchmarks of my own as follows.
> >
> > cat benchmark_amit.sh
> > for p in 0 16 32 64 128 256 512 1024; do
> > echo -ne "$p\t";
> > pgbench -i --partitions=$p > /dev/null 2>&1
> > pgbench -n -T 30 -f /tmp/query.sql | grep latency | awk '{print $4}';
> > done
> >
> > For a 3-way join:
> > cat /tmp/query.sql
> > select * from pgbench_accounts t1, pgbench_accounts t2,
> > pgbench_accounts t3 where t2.aid = t1.aid AND t3.aid = t2.aid;
> >
> > nparts master patched %change
> > 0 35.508 36.066 1.571
> > 16 66.79 67.704 1.368
> > 32 67.774 68.179 0.598
> > 64 51.023 50.471 -1.082
> > 128 56.4 55.759 -1.137
> > 256 70.134 68.401 -2.471
> > 512 120.621 113.552 -5.861
> > 1024 405.339 312.726 -22.848
> >
> > For a 6-way jon
> > cat /tmp/query.sql
> > select * from pgbench_accounts t1, pgbench_accounts t2,
> > pgbench_accounts t3, pgbench_accounts t4, pgbench_accounts t5,
> > pgbench_accounts t6 where t2.aid = t1.aid AND t3.aid = t2.aid and
> > t4.aid = t3.aid and t5.aid = t4.aid and t6.aid = t5.aid;
> >
> > nparts master patched %change
> > 0 66.144 64.932 -1.832
> > 16 100.874 100.491 -0.380
> > 32 104.645 104.536 -0.104
> > 64 114.415 109.193 -4.564
> > 128 145.422 130.458 -10.290
> > 256 273.761 209.919 -23.320
> > 512 1359.896 616.295 -54.681
> > 1024 7183.765 2857.086 -60.229
> >
> > -60% means 60% reduction in latency due to the patch.
> >
> > As others have already found, performance improvements become
> > substantial as both partition count and join depth increase. The patch
> > seems to have minimal impact at low partition counts and low join
> > complexity -- base cases (e.g., 0–32 partitions, 3-way joins) are
> > essentially unchanged, which is good to see.
>
> I assume these are with enable_partitionwise_join = off since it's not
> enabled in the query.
Yes, those were with pwj=off. FTR, numbers I get with pwj=on.
3-way:
nparts master patched %change
0 38.407 34.675 -9.717
16 69.357 64.312 -7.274
32 70.027 67.079 -4.210
64 73.807 70.725 -4.176
128 83.875 81.945 -2.301
256 102.858 106.19 3.239
512 181.95 180.891 -0.582
1024 464.503 440.355 -5.199
6-way:
nparts master patched %change
0 64.411 67.175 4.291
16 203.344 209.75 3.150
32 296.952 300.966 1.352
64 445.536 449.917 0.983
128 805.103 781.892 -2.883
256 1695.746 1574.346 -7.159
512 4743.16 4010.196 -15.453
1024 16772.454 12284.706 -26.757
So a bit less impressive than the improvements for pwj=off. Also,
patch seems to make things worse for low partition counts (0-16) for
6-way joins, which I am not quite sure is within the noise range.
Have you noticed that too and, if yes, do you know what might be
causing it?
> > I haven’t measured memory increase from the patch, but let me know if
> > that has already been evaluated and shown not to be a showstopper.
>
> There's a slight increase in memory consumption because of the hash
> table but it's very minimal.
>
> Here are memory numbers in kb (presented in the same format as before)
> with pwj disabled
> num_parts | 2 | 3 |
> 4 | 5
>
-----------+--------------------------+--------------------------+---------------------------+-----------------------------
> 0 | s=0 md=15 pd=15 | s=0 md=21 pd=21 | s=0
> md=27 pd=27 | s=0 md=33 pd=33
> 10 | s=0 md=218 pd=218 | s=-20 md=455 pd=475 |
> s=-20 md=868 pd=888 | s=-20 md=1697 pd=1717
> 100 | s=-20 md=1824 pd=1844 | s=-80 md=3718 pd=3798 |
> s=-160 md=6400 pd=6560 | s=-320 md=10233 pd=10553
> 500 | s=-160 md=9395 pd=9555 | s=-320 md=20216 pd=20536 |
> s=-640 md=35735 pd=36375 | s=-1280 md=60808 pd=62088
> 1000 | s=-320 md=19862 pd=20182 | s=-640 md=45739 pd=46379 |
> s=-1280 md=84210 pd=85490 | s=-2561 md=149740 pd=152301
>
> each column is s=difference in memory consumed, md = memory consumed
> without patch, pd = memory consumed with patch. -ve difference shows
> increase in memory consumption.
>
> with pwj enabled
> num_parts | 2 | 3 |
> 4 | 5
>
-----------+--------------------------+----------------------------+-----------------------------+-------------------------------
> 0 | s=0 md=15 pd=15 | s=0 md=21 pd=21 |
> s=0 md=27 pd=27 | s=0 md=33 pd=33
> 10 | s=0 md=365 pd=365 | s=-20 md=1198 pd=1218 |
> s=-20 md=3571 pd=3591 | s=-20 md=10426 pd=10446
> 100 | s=-21 md=3337 pd=3358 | s=-80 md=11237 pd=11317 |
> s=-160 md=33845 pd=34005 | s=-320 md=99502 pd=99822
> 500 | s=-160 md=17206 pd=17366 | s=-320 md=60096 pd=60416 |
> s=-640 md=183306 pd=183946 | s=-1280 md=556705 pd=557985
> 1000 | s=-320 md=36119 pd=36439 | s=-640 md=131457 pd=132097 |
> s=-1280 md=404809 pd=406089 | s=-2561 md=1263664 pd=1266225
>
> %wise this is 3-4% maximum.
Ok, thanks for those. Looks within acceptable range to me.
--
Thanks, Amit Langote
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Wed, Mar 19, 2025 at 8:22 AM Amit Langote <amitlangote09@gmail.com> wrote:
>
> On Tue, Mar 18, 2025 at 8:48 PM Ashutosh Bapat
> <ashutosh.bapat.oss@gmail.com> wrote:
> > On Tue, Mar 18, 2025 at 4:02 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > >
> > > I ran a couple of benchmarks of my own as follows.
> > >
> > > cat benchmark_amit.sh
> > > for p in 0 16 32 64 128 256 512 1024; do
> > > echo -ne "$p\t";
> > > pgbench -i --partitions=$p > /dev/null 2>&1
> > > pgbench -n -T 30 -f /tmp/query.sql | grep latency | awk '{print $4}';
> > > done
> > >
> > > For a 3-way join:
> > > cat /tmp/query.sql
> > > select * from pgbench_accounts t1, pgbench_accounts t2,
> > > pgbench_accounts t3 where t2.aid = t1.aid AND t3.aid = t2.aid;
> > >
> > > nparts master patched %change
> > > 0 35.508 36.066 1.571
> > > 16 66.79 67.704 1.368
> > > 32 67.774 68.179 0.598
> > > 64 51.023 50.471 -1.082
> > > 128 56.4 55.759 -1.137
> > > 256 70.134 68.401 -2.471
> > > 512 120.621 113.552 -5.861
> > > 1024 405.339 312.726 -22.848
> > >
> > > For a 6-way jon
> > > cat /tmp/query.sql
> > > select * from pgbench_accounts t1, pgbench_accounts t2,
> > > pgbench_accounts t3, pgbench_accounts t4, pgbench_accounts t5,
> > > pgbench_accounts t6 where t2.aid = t1.aid AND t3.aid = t2.aid and
> > > t4.aid = t3.aid and t5.aid = t4.aid and t6.aid = t5.aid;
> > >
> > > nparts master patched %change
> > > 0 66.144 64.932 -1.832
> > > 16 100.874 100.491 -0.380
> > > 32 104.645 104.536 -0.104
> > > 64 114.415 109.193 -4.564
> > > 128 145.422 130.458 -10.290
> > > 256 273.761 209.919 -23.320
> > > 512 1359.896 616.295 -54.681
> > > 1024 7183.765 2857.086 -60.229
> > >
> > > -60% means 60% reduction in latency due to the patch.
> > >
> > > As others have already found, performance improvements become
> > > substantial as both partition count and join depth increase. The patch
> > > seems to have minimal impact at low partition counts and low join
> > > complexity -- base cases (e.g., 0–32 partitions, 3-way joins) are
> > > essentially unchanged, which is good to see.
> >
> > I assume these are with enable_partitionwise_join = off since it's not
> > enabled in the query.
>
> Yes, those were with pwj=off. FTR, numbers I get with pwj=on.
>
> 3-way:
>
> nparts master patched %change
> 0 38.407 34.675 -9.717
> 16 69.357 64.312 -7.274
> 32 70.027 67.079 -4.210
> 64 73.807 70.725 -4.176
> 128 83.875 81.945 -2.301
> 256 102.858 106.19 3.239
> 512 181.95 180.891 -0.582
> 1024 464.503 440.355 -5.199
>
> 6-way:
>
> nparts master patched %change
> 0 64.411 67.175 4.291
> 16 203.344 209.75 3.150
> 32 296.952 300.966 1.352
> 64 445.536 449.917 0.983
> 128 805.103 781.892 -2.883
> 256 1695.746 1574.346 -7.159
> 512 4743.16 4010.196 -15.453
> 1024 16772.454 12284.706 -26.757
>
> So a bit less impressive than the improvements for pwj=off. Also,
> patch seems to make things worse for low partition counts (0-16) for
> 6-way joins, which I am not quite sure is within the noise range.
> Have you noticed that too and, if yes, do you know what might be
> causing it?
I have observed similar things with lower numbers of partitions. In my
observation, such results have coincided with relatively large
variance. With 0 partitions there is no difference in the code
behaviour irrespective of pwj ON or Off. Hence we don't expect any
variation in the numbers you posted yesterday and today when nparts =
0. But there it is. I have always observed that much variation in
planning time for one combination or the other.
With 6 -way join there will be 6 * 5 - 5 derived clauses in one
equivalence class, That's close to 32, which is the threshold to start
using a hash table. So some slight perturbation is expected around
that threshold. But given that it's lower than 32, that shouldn't
apply here.
--
Best Wishes,
Ashutosh Bapat
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Wed, Mar 19, 2025 at 3:31 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > On Wed, Mar 19, 2025 at 8:22 AM Amit Langote <amitlangote09@gmail.com> wrote: > > Yes, those were with pwj=off. FTR, numbers I get with pwj=on. > > > > 3-way: > > > > nparts master patched %change > > 0 38.407 34.675 -9.717 > > 16 69.357 64.312 -7.274 > > 32 70.027 67.079 -4.210 > > 64 73.807 70.725 -4.176 > > 128 83.875 81.945 -2.301 > > 256 102.858 106.19 3.239 > > 512 181.95 180.891 -0.582 > > 1024 464.503 440.355 -5.199 > > > > 6-way: > > > > nparts master patched %change > > 0 64.411 67.175 4.291 > > 16 203.344 209.75 3.150 > > 32 296.952 300.966 1.352 > > 64 445.536 449.917 0.983 > > 128 805.103 781.892 -2.883 > > 256 1695.746 1574.346 -7.159 > > 512 4743.16 4010.196 -15.453 > > 1024 16772.454 12284.706 -26.757 > > > > So a bit less impressive than the improvements for pwj=off. Also, > > patch seems to make things worse for low partition counts (0-16) for > > 6-way joins, which I am not quite sure is within the noise range. > > Have you noticed that too and, if yes, do you know what might be > > causing it? > > I have observed similar things with lower numbers of partitions. In my > observation, such results have coincided with relatively large > variance. With 0 partitions there is no difference in the code > behaviour irrespective of pwj ON or Off. Hence we don't expect any > variation in the numbers you posted yesterday and today when nparts = > 0. But there it is. I have always observed that much variation in > planning time for one combination or the other. > > With 6 -way join there will be 6 * 5 - 5 derived clauses in one > equivalence class, That's close to 32, which is the threshold to start > using a hash table. So some slight perturbation is expected around > that threshold. But given that it's lower than 32, that shouldn't > apply here. Ok, thanks for that analysis. I don't think there's anything about the patch that makes it particularly less suitable for pwj=on. I read patch 0002 in detail last week and wrote a follow-up patch (0003), mostly for cosmetic improvements, which I plan to squash into 0002. I’ve also revised the commit messages for 0001 and 0002. Let me know if that looks reasonable or if I’ve missed any credits. -- Thanks, Amit Langote
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Mon, Mar 24, 2025 at 7:23 PM Amit Langote <amitlangote09@gmail.com> wrote: > > Ok, thanks for that analysis. I don't think there's anything about > the patch that makes it particularly less suitable for pwj=on. > I agree. > I read patch 0002 in detail last week and wrote a follow-up patch > (0003), mostly for cosmetic improvements, which I plan to squash into > 0002. For some reason v2-0003 didn't apply cleanly on my local branch. Possibly v2-0002 is a modified version of my 0002. In order to not disturb your patchset, I have attached my edits as a diff. If you find those useful, apply them to 0003 and then squash it into 0002. Here are some more cosmetic comments on 0003. A bit of discussion might be needed. Hence did not edit myself. -/* Hash table entry in ec_derives_hash. */ +/* Hash table entry used in ec_derives_hash. */ I think we don't need "used" here entry in hash table is good enough. But I am ok even if it stays that way. - add_derived_clauses(ec1, ec2->ec_derives_list); + /* Updates ec1's ec_derives_list and ec_derives_hash if present. */ + ec_add_derived_clauses(ec1, ec2->ec_derives_list); Suggestion in the attached diff. ec1->ec_relids = bms_join(ec1->ec_relids, ec2->ec_relids); ec1->ec_has_const |= ec2->ec_has_const; /* can't need to set has_volatile */ @@ -396,7 +400,7 @@ process_equivalence(PlannerInfo *root, /* just to avoid debugging confusion w/ dangling pointers: */ ec2->ec_members = NIL; ec2->ec_sources = NIL; - clear_ec_derived_clauses(ec2); + ec_clear_derived_clauses(ec2); I pondered about this naming convention when naming the functions. But it seems it's not used everywhere in this file OR I am not able to see the underlying naming rule if any. So I used a mixed naming. Let's keep your names though. I think they are better. @@ -1403,6 +1403,17 @@ typedef struct JoinDomain * entry: consider SELECT random() AS a, random() AS b ... ORDER BY b,a. * So we record the SortGroupRef of the originating sort clause. * + * Derived equality clauses between EC members are stored in ec_derives_list. "clauses between EC members" doesn't read correctly - "clauses equating EC members" seems better. We actually don't need to mention "between EC members" at all - it's not relevant to the "size of the list" which is the subject of this paragraph. What do you think? + * For small queries, this list is scanned directly during lookup. For larger + * queries -- e.g., with many partitions or joins -- a hash table + * (ec_derives_hash) is built for faster lookup. Both structures contain the + * same RestrictInfos and are maintained in parallel. If only the list exists, there is nothing to maintain in parallel. The sentence seems to indicate that both the hash table and the list are always present (and maintained in parallel). How about dropping "Both ... parallel" and modifying the previous sentence as " ... faster lookup when the list grows beyond a threshold" or something similar. The next sentence anyway mentions that both the structures are maintained. + We retain the list even + * when the hash is used to simplify serialization (e.g., in + * _outEquivalenceClass()) and support EquivalenceClass merging. Thanks for the review. -- Best Wishes, Ashutosh Bapat
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Tue, Mar 25, 2025 at 3:17 PM Ashutosh Bapat
<ashutosh.bapat.oss@gmail.com> wrote:
> On Mon, Mar 24, 2025 at 7:23 PM Amit Langote <amitlangote09@gmail.com> wrote:
> >
> > Ok, thanks for that analysis. I don't think there's anything about
> > the patch that makes it particularly less suitable for pwj=on.
> >
>
> I agree.
>
> > I read patch 0002 in detail last week and wrote a follow-up patch
> > (0003), mostly for cosmetic improvements, which I plan to squash into
> > 0002.
>
> For some reason v2-0003 didn't apply cleanly on my local branch.
> Possibly v2-0002 is a modified version of my 0002.
Ah, right -- I probably tweaked your 0002 a bit before splitting out
my changes into a separate patch.
> In order to not
> disturb your patchset, I have attached my edits as a diff. If you find
> those useful, apply them to 0003 and then squash it into 0002.
>
> Here are some more cosmetic comments on 0003. A bit of discussion
> might be needed. Hence did not edit myself.
>
> -/* Hash table entry in ec_derives_hash. */
> +/* Hash table entry used in ec_derives_hash. */
>
> I think we don't need "used" here entry in hash table is good enough. But I am
> ok even if it stays that way.
Ok, let's drop "used".
> - add_derived_clauses(ec1, ec2->ec_derives_list);
> + /* Updates ec1's ec_derives_list and ec_derives_hash if present. */
> + ec_add_derived_clauses(ec1, ec2->ec_derives_list);
>
> Suggestion in the attached diff.
Makes sense, though I added it after a small wording tweak to avoid
implying that the hash tables are merged in some special way. So now
it reads:
- /* Updates ec1's ec_derives_list and ec_derives_hash if present. */
+ /*
+ * Appends ec2's derived clauses to ec1->ec_derives_list and adds
+ * them to ec1->ec_derives_hash if present.
+ */
> @@ -396,7 +400,7 @@ process_equivalence(PlannerInfo *root,
> /* just to avoid debugging confusion w/ dangling pointers: */
> ec2->ec_members = NIL;
> ec2->ec_sources = NIL;
> - clear_ec_derived_clauses(ec2);
> + ec_clear_derived_clauses(ec2);
>
> I pondered about this naming convention when naming the functions. But
> it seems it's not used everywhere in this file OR I am not able to see
> the underlying naming rule if any. So I used a mixed naming. Let's
> keep your names though. I think they are better.
Got it -- I went with the ec_ prefix mainly to make the new additions
self-consistent, since the file doesn’t seem to follow a strict naming
pattern. Glad the names work for you. While at it, I also applied the
same naming convention to two new functions I hadn’t touched earlier
for some reason.
> @@ -1403,6 +1403,17 @@ typedef struct JoinDomain
> * entry: consider SELECT random() AS a, random() AS b ... ORDER BY b,a.
> * So we record the SortGroupRef of the originating sort clause.
> *
> + * Derived equality clauses between EC members are stored in ec_derives_list.
>
> "clauses between EC members" doesn't read correctly - "clauses
> equating EC members" seems better. We actually don't need to mention
> "between EC members" at all - it's not relevant to the "size of the
> list" which is the subject of this paragraph. What do you think?
OK, I agree -- we don't need to mention EC members here. I've updated
the comment to keep the focus on the list itself
> + * For small queries, this list is scanned directly during lookup. For larger
> + * queries -- e.g., with many partitions or joins -- a hash table
> + * (ec_derives_hash) is built for faster lookup. Both structures contain the
> + * same RestrictInfos and are maintained in parallel.
>
> If only the list exists, there is nothing to maintain in parallel. The
> sentence seems to indicate that both the hash table and the list are
> always present (and maintained in parallel). How about dropping "Both
> ... parallel" and modifying the previous sentence as " ... faster
> lookup when the list grows beyond a threshold" or something similar.
> The next sentence anyway mentions that both the structures are
> maintained.
Agree here too. Here's the revised comment addressing these two points:
+ * Derived equality clauses are stored in ec_derives_list. For small queries,
+ * this list is scanned directly during lookup. For larger queries -- e.g.,
+ * with many partitions or joins -- a hash table (ec_derives_hash) is built
+ * when the list grows beyond a threshold, for faster lookup. When present,
+ * the hash table contains the same RestrictInfos and is maintained alongside
+ * the list. We retain the list even when the hash is used to simplify
+ * serialization (e.g., in _outEquivalenceClass()) and support
+ * EquivalenceClass merging.
I've merged my delta + your suggested changes as discussed above into 0002.
Btw, about ec_clear_derived_clauses():
@@ -749,7 +749,7 @@ remove_rel_from_eclass(EquivalenceClass *ec,
SpecialJoinInfo *sjinfo,
* drop them. (At this point, any such clauses would be base restriction
* clauses, which we'd not need anymore anyway.)
*/
- ec->ec_derives = NIL;
+ ec_clear_derived_clauses(ec);
}
/*
@@ -1544,8 +1544,7 @@ update_eclasses(EquivalenceClass *ec, int from, int to)
list_free(ec->ec_members);
ec->ec_members = new_members;
- list_free(ec->ec_derives);
- ec->ec_derives = NULL;
+ ec_clear_derived_clauses(ec);
We're losing that list_free() in the second hunk, aren't we?
There's also this comment:
+ * XXX: When thousands of partitions are involved, the list can become
+ * sizable. It might be worth freeing it explicitly in such cases.
So maybe ec_clear_derived_clauses() should take a free_list parameter,
to preserve the original behavior? What do you think?
--
Thanks, Amit Langote
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Tue, Mar 25, 2025 at 12:58 PM Amit Langote <amitlangote09@gmail.com> wrote: > > - /* Updates ec1's ec_derives_list and ec_derives_hash if present. */ > + /* > + * Appends ec2's derived clauses to ec1->ec_derives_list and adds > + * them to ec1->ec_derives_hash if present. > + */ WFM. > > > @@ -396,7 +400,7 @@ process_equivalence(PlannerInfo *root, > > /* just to avoid debugging confusion w/ dangling pointers: */ > > ec2->ec_members = NIL; > > ec2->ec_sources = NIL; > > - clear_ec_derived_clauses(ec2); > > + ec_clear_derived_clauses(ec2); > > > > I pondered about this naming convention when naming the functions. But > > it seems it's not used everywhere in this file OR I am not able to see > > the underlying naming rule if any. So I used a mixed naming. Let's > > keep your names though. I think they are better. > > Got it -- I went with the ec_ prefix mainly to make the new additions > self-consistent, since the file doesn’t seem to follow a strict naming > pattern. Glad the names work for you. While at it, I also applied the > same naming convention to two new functions I hadn’t touched earlier > for some reason. WFM. > > + * Derived equality clauses are stored in ec_derives_list. For small queries, > + * this list is scanned directly during lookup. For larger queries -- e.g., > + * with many partitions or joins -- a hash table (ec_derives_hash) is built > + * when the list grows beyond a threshold, for faster lookup. When present, > + * the hash table contains the same RestrictInfos and is maintained alongside > + * the list. We retain the list even when the hash is used to simplify > + * serialization (e.g., in _outEquivalenceClass()) and support > + * EquivalenceClass merging. > > I've merged my delta + your suggested changes as discussed above into 0002. > LGTM. > Btw, about ec_clear_derived_clauses(): > > @@ -749,7 +749,7 @@ remove_rel_from_eclass(EquivalenceClass *ec, > SpecialJoinInfo *sjinfo, > * drop them. (At this point, any such clauses would be base restriction > * clauses, which we'd not need anymore anyway.) > */ > - ec->ec_derives = NIL; > + ec_clear_derived_clauses(ec); > } > > /* > @@ -1544,8 +1544,7 @@ update_eclasses(EquivalenceClass *ec, int from, int to) > list_free(ec->ec_members); > ec->ec_members = new_members; > > - list_free(ec->ec_derives); > - ec->ec_derives = NULL; > + ec_clear_derived_clauses(ec); > > We're losing that list_free() in the second hunk, aren't we? > > There's also this comment: > > + * XXX: When thousands of partitions are involved, the list can become > + * sizable. It might be worth freeing it explicitly in such cases. > > So maybe ec_clear_derived_clauses() should take a free_list parameter, > to preserve the original behavior? What do you think? Well spotted. How about just calling list_free() in ec_clear_derived_clauses() to simplify things. I mean list_free() might spend some cycles under remove_rel_from_eclass() and process_equivalence() freeing the array but that should be ok. Just setting it to NIL by itself looks fine. If we bundle it in a function with a flag, we will need to explain why/when to free list and when to not. That's unnecessary complexity I feel. In other places where the structures have potential to grow in size, we have resorted to freeing them rather than just forgetting them. For example, we free appinfos in try_partitionwise_join() or child_relids. The list shouldn't be referenced anywhere else, so it should be safe to free it. Note that I thought list_concat() used by process_equivalence() would reuse the memory allocated to ec2->ec_derives_list but it doesn't. I verified that by setting the threshold to 0, thus forcing the hash table always and running a regression suite. It runs without any segfaults. I don't see any change in time required to run regression. PFA patchset 0001, 0002 are same as your patchset except some of my edits to the commit message. Please feel free to accept or reject the edits. 0003 adds list_free() to ec_clear_derived_clauses() -- Best Wishes, Ashutosh Bapat
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Tue, Mar 25, 2025 at 6:36 PM Ashutosh Bapat
<ashutosh.bapat.oss@gmail.com> wrote:
> On Tue, Mar 25, 2025 at 12:58 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > Btw, about ec_clear_derived_clauses():
> >
> > @@ -749,7 +749,7 @@ remove_rel_from_eclass(EquivalenceClass *ec,
> > SpecialJoinInfo *sjinfo,
> > * drop them. (At this point, any such clauses would be base restriction
> > * clauses, which we'd not need anymore anyway.)
> > */
> > - ec->ec_derives = NIL;
> > + ec_clear_derived_clauses(ec);
> > }
> >
> > /*
> > @@ -1544,8 +1544,7 @@ update_eclasses(EquivalenceClass *ec, int from, int to)
> > list_free(ec->ec_members);
> > ec->ec_members = new_members;
> >
> > - list_free(ec->ec_derives);
> > - ec->ec_derives = NULL;
> > + ec_clear_derived_clauses(ec);
> >
> > We're losing that list_free() in the second hunk, aren't we?
> >
> > There's also this comment:
> >
> > + * XXX: When thousands of partitions are involved, the list can become
> > + * sizable. It might be worth freeing it explicitly in such cases.
> >
> > So maybe ec_clear_derived_clauses() should take a free_list parameter,
> > to preserve the original behavior? What do you think?
>
> Well spotted. How about just calling list_free() in
> ec_clear_derived_clauses() to simplify things. I mean list_free()
> might spend some cycles under remove_rel_from_eclass() and
> process_equivalence() freeing the array but that should be ok. Just
> setting it to NIL by itself looks fine. If we bundle it in a function
> with a flag, we will need to explain why/when to free list and when to
> not. That's unnecessary complexity I feel. In other places where the
> structures have potential to grow in size, we have resorted to freeing
> them rather than just forgetting them. For example, we free appinfos
> in try_partitionwise_join() or child_relids.
>
> The list shouldn't be referenced anywhere else, so it should be safe
> to free it. Note that I thought list_concat() used by
> process_equivalence() would reuse the memory allocated to
> ec2->ec_derives_list but it doesn't. I verified that by setting the
> threshold to 0, thus forcing the hash table always and running a
> regression suite. It runs without any segfaults. I don't see any
> change in time required to run regression.
>
> PFA patchset
> 0001, 0002 are same as your patchset except some of my edits to the
> commit message. Please feel free to accept or reject the edits.
Thanks, I've noted your suggestions.
> 0003 adds list_free() to ec_clear_derived_clauses()
Thanks, I've merged it into 0002, with this blurb in its commit
message to describe it:
The new ec_clear_derived_clauses() always frees ec_derives_list, even
though some of the original code paths that cleared the old ec_derives
field did not. This ensures consistent cleanup and avoids leaking
memory when the list grows large.
I needed to do this though ;)
- ec->ec_derives_list = NIL;
list_free(ec->ec_derives_list);
+ ec->ec_derives_list = NIL;
--
Thanks, Amit Langote
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Tue, Mar 25, 2025 at 5:20 PM Amit Langote <amitlangote09@gmail.com> wrote: > > On Tue, Mar 25, 2025 at 6:36 PM Ashutosh Bapat > <ashutosh.bapat.oss@gmail.com> wrote: > > On Tue, Mar 25, 2025 at 12:58 PM Amit Langote <amitlangote09@gmail.com> wrote: > > > Btw, about ec_clear_derived_clauses(): > > > > > > @@ -749,7 +749,7 @@ remove_rel_from_eclass(EquivalenceClass *ec, > > > SpecialJoinInfo *sjinfo, > > > * drop them. (At this point, any such clauses would be base restriction > > > * clauses, which we'd not need anymore anyway.) > > > */ > > > - ec->ec_derives = NIL; > > > + ec_clear_derived_clauses(ec); > > > } > > > > > > /* > > > @@ -1544,8 +1544,7 @@ update_eclasses(EquivalenceClass *ec, int from, int to) > > > list_free(ec->ec_members); > > > ec->ec_members = new_members; > > > > > > - list_free(ec->ec_derives); > > > - ec->ec_derives = NULL; > > > + ec_clear_derived_clauses(ec); > > > > > > We're losing that list_free() in the second hunk, aren't we? > > > > > > There's also this comment: > > > > > > + * XXX: When thousands of partitions are involved, the list can become > > > + * sizable. It might be worth freeing it explicitly in such cases. > > > > > > So maybe ec_clear_derived_clauses() should take a free_list parameter, > > > to preserve the original behavior? What do you think? > > > > Well spotted. How about just calling list_free() in > > ec_clear_derived_clauses() to simplify things. I mean list_free() > > might spend some cycles under remove_rel_from_eclass() and > > process_equivalence() freeing the array but that should be ok. Just > > setting it to NIL by itself looks fine. If we bundle it in a function > > with a flag, we will need to explain why/when to free list and when to > > not. That's unnecessary complexity I feel. In other places where the > > structures have potential to grow in size, we have resorted to freeing > > them rather than just forgetting them. For example, we free appinfos > > in try_partitionwise_join() or child_relids. > > > > The list shouldn't be referenced anywhere else, so it should be safe > > to free it. Note that I thought list_concat() used by > > process_equivalence() would reuse the memory allocated to > > ec2->ec_derives_list but it doesn't. I verified that by setting the > > threshold to 0, thus forcing the hash table always and running a > > regression suite. It runs without any segfaults. I don't see any > > change in time required to run regression. > > > > PFA patchset > > 0001, 0002 are same as your patchset except some of my edits to the > > commit message. Please feel free to accept or reject the edits. > > Thanks, I've noted your suggestions. > > > 0003 adds list_free() to ec_clear_derived_clauses() > > Thanks, I've merged it into 0002, with this blurb in its commit > message to describe it: > > The new ec_clear_derived_clauses() always frees ec_derives_list, even > though some of the original code paths that cleared the old ec_derives > field did not. This ensures consistent cleanup and avoids leaking > memory when the list grows large. > > I needed to do this though ;) > > - ec->ec_derives_list = NIL; > list_free(ec->ec_derives_list); > + ec->ec_derives_list = NIL; Silly me. I reran regression by setting the threshold to 0 and still didn't get segmentation fault or an increase in regression run time. So the change is safe. -- Best Wishes, Ashutosh Bapat
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
In earlier benchmark runs we saw that some combinations of lower number of joins and lower number of partitions showed planning time higher with patch compared to without patch. Those coincided with higher deviation in measurement. In an offline chat David Rowley suggested taking an average of many runs for those cases. Here are results with a lesser number of partitions, where average is taken over thousands of runs. Planning time of a query was sampled as many times as the number of runs that fit in 30s and then averages were calculated. This exercise was repeated twice.
Each cell is a triple (s, md, pd) where s is improvement in planning
time using the patches in % as compared to the master (higher the
better), md = standard deviation as % of the average planning time on
master, pd = is standard deviation as % of the average planning time
with patches.
Exercise 1
num_parts | 2 | 3 | 4 | 5
-----------+----------------------------+----------------------------+----------------------------+----------------------------
0 | s=-0.96% md=7.63% pd=9.43% | s=-0.68% md=5.94% pd=5.65% | s=-0.29% md=5.15% pd=5.67% | s=0.19% md=6.25% pd=5.21%
16 | s=-3.07% md=6.57% pd=3.56% | s=-1.52% md=1.29% pd=1.21% | s=-0.58% md=1.78% pd=1.47% | s=0.41% md=1.84% pd=1.51%
32 | s=-1.40% md=2.58% pd=2.77% | s=-0.23% md=3.21% pd=1.16% | s=2.86% md=1.83% pd=1.78% | s=4.16% md=1.23% pd=1.62%
64 | s=-0.09% md=2.10% pd=2.11% | s=0.22% md=1.75% pd=4.23% | s=5.86% md=1.87% pd=1.38% | s=10.86% md=1.06% pd=0.84%
128 | s=-1.15% md=2.79% pd=2.48% | s=3.45% md=1.67% pd=2.08% | s=9.63% md=0.88% pd=1.98% | s=17.33% md=1.46% pd=1.59%
256 | s=-2.88% md=2.79% pd=2.53% | s=5.87% md=0.79% pd=1.80% | s=13.63% md=1.07% pd=1.58% | s=23.57% md=0.78% pd=0.69%
planning time improvement with PWJ=on
num_parts | 2 | 3 | 4 | 5
-----------+----------------------------+----------------------------+----------------------------+----------------------------
0 | s=-0.35% md=7.98% pd=7.32% | s=-0.84% md=6.40% pd=6.36% | s=-0.18% md=5.68% pd=5.62% | s=-1.13% md=4.64% pd=6.16%
16 | s=-1.61% md=2.62% pd=2.26% | s=-0.42% md=1.27% pd=1.18% | s=-0.27% md=2.17% pd=2.23% | s=-0.86% md=1.46% pd=1.44%
32 | s=-1.73% md=6.91% pd=6.56% | s=0.64% md=2.75% pd=2.12% | s=1.03% md=2.23% pd=1.44% | s=0.80% md=2.63% pd=1.71%
64 | s=-1.12% md=4.13% pd=4.25% | s=1.81% md=5.22% pd=2.20% | s=0.99% md=2.14% pd=2.20% | s=1.64% md=1.24% pd=1.57%
128 | s=-0.94% md=2.68% pd=3.27% | s=-2.82% md=4.00% pd=4.73% | s=2.43% md=2.28% pd=2.11% | s=5.96% md=2.01% pd=1.23%
256 | s=0.31% md=3.21% pd=2.58% | s=3.74% md=3.48% pd=1.89% | s=4.18% md=1.36% pd=1.36% | s=5.49% md=0.52% pd=1.24%
Exercise 2
planning time improvement with PWJ=off
num_parts | 2 | 3 | 4 | 5
-----------+-----------------------------+----------------------------+----------------------------+----------------------------
0 | s=1.26% md=16.39% pd=16.52% | s=-0.68% md=4.66% pd=5.15% | s=-1.62% md=4.38% pd=4.21% | s=-0.25% md=4.10% pd=4.29%
16 | s=-4.40% md=8.67% pd=7.18% | s=-1.08% md=1.44% pd=1.83% | s=1.12% md=0.75% pd=1.50% | s=0.14% md=0.56% pd=0.46%
32 | s=-1.17% md=5.86% pd=5.86% | s=-0.39% md=1.22% pd=0.75% | s=3.33% md=0.40% pd=0.84% | s=5.89% md=0.35% pd=0.65%
64 | s=0.41% md=4.36% pd=4.77% | s=0.93% md=0.29% pd=0.30% | s=3.38% md=0.51% pd=0.28% | s=9.63% md=0.19% pd=1.08%
128 | s=-0.50% md=3.40% pd=3.06% | s=1.54% md=0.31% pd=0.58% | s=12.47% md=0.36% pd=0.62% | s=19.30% md=0.18% pd=0.24%
256 | s=-3.42% md=2.93% pd=2.80% | s=2.94% md=0.29% pd=0.36% | s=12.50% md=0.22% pd=0.27% | s=23.14% md=0.30% pd=0.55%
planning time improvement with PWJ=on
num_parts | 2 | 3 | 4 | 5
-----------+----------------------------+----------------------------+----------------------------+----------------------------
0 | s=1.47% md=6.05% pd=6.20% | s=-0.72% md=5.14% pd=5.09% | s=0.53% md=4.17% pd=4.39% | s=-0.13% md=4.03% pd=3.58%
16 | s=-0.94% md=3.91% pd=3.51% | s=-1.46% md=2.24% pd=2.47% | s=1.12% md=0.67% pd=1.50% | s=-0.64% md=0.76% pd=0.70%
32 | s=-0.50% md=6.46% pd=6.11% | s=1.73% md=2.78% pd=1.30% | s=3.47% md=0.77% pd=0.53% | s=3.13% md=0.59% pd=0.31%
64 | s=-1.19% md=3.52% pd=4.08% | s=-0.47% md=1.49% pd=0.48% | s=-1.04% md=0.67% pd=0.61% | s=5.87% md=2.50% pd=0.54%
128 | s=-1.67% md=2.22% pd=2.45% | s=1.54% md=1.16% pd=1.21% | s=4.26% md=0.43% pd=1.24% | s=4.31% md=0.82% pd=0.51%
256 | s=-2.10% md=1.66% pd=2.85% | s=0.96% md=1.04% pd=0.46% | s=3.18% md=0.55% pd=0.53% | s=7.41% md=1.08% pd=0.30%
The averages are now more stable than the previous exercise. Some regressions seen with the first exercise are not seen with the other and some improvements seens with the first exercise are not seen with the second and vice versa. The regressions present in both the exercises will not be seen, if I repeat the exercise a few more times. So I think those regressions or improvements seen with lower number of joins and lower number of partitions aren't real and they are mostly within noise level. However, the improvements seen with higher numbers of joins and partitions are always there irrespective of the number of times I repeat the exercise. Please note that we have only tried partitions upto 256. Previous measurements have seen stable improvements in case of higher number of partitions.
--
Best Wishes,
Ashutosh Bapat
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
Hi, On Wed, Mar 26, 2025 at 4:59 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > > > The averages are now more stable than the previous exercise. Some regressions seen with the first exercise are not seenwith the other and some improvements seens with the first exercise are not seen with the second and vice versa. The regressionspresent in both the exercises will not be seen, if I repeat the exercise a few more times. So I think those regressionsor improvements seen with lower number of joins and lower number of partitions aren't real and they are mostlywithin noise level. However, the improvements seen with higher numbers of joins and partitions are always there irrespectiveof the number of times I repeat the exercise. Please note that we have only tried partitions upto 256. Previousmeasurements have seen stable improvements in case of higher number of partitions. > Further, I experimented with hash table size. Attached images have four graphs for planning time and planner's memory consumption measured for a 3-way join for initial has table sizes of 64, 128 and 256 respectively. 1. Planning time vs number of partitions with PWJ enabled 2. planning time vs number of partitions with PWJ disabled 3. Memory consumed vs number of partitions with PWJ enabled 4. Memory consumed vs number of partitions with PWJ disabled Also find attached the spreadsheet containing the measurements and also the charts. In the graphs, one can observe that the lines corresponding to all three hash table sizes are inseparable. That leads to a conclusion that the planning time or memory consumption doesn't change with hash table size. As a result I am keeping the initial hash table size = 256L, same as the previously attached patches. -- Best Wishes, Ashutosh Bapat
Attachment
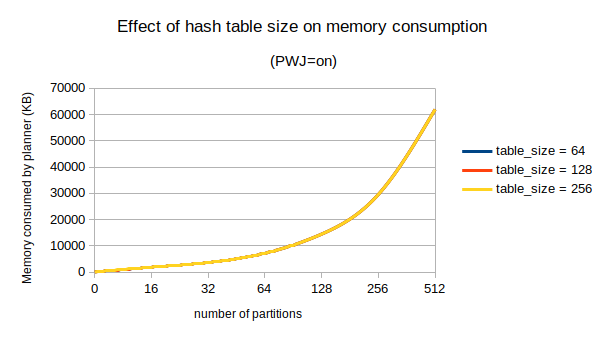{kind=link}
{kind=link}
{kind=link}
{kind=link}
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Thu, 27 Mar 2025 at 23:27, Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > Further, I experimented with hash table size. Attached images have > four graphs for planning time and planner's memory consumption > measured for a 3-way join for initial has table sizes of 64, 128 and > 256 respectively. I put together a benchmarking script so I could learn the performance of this patch. See attached. It does not seem that surprising that you're not seeing much difference in memory consumption. I believe your test case has a single EquivalenceClass. The hashtable bucket size is 40 bytes on my machine, so going between 256*40 and 64*40 isn't much memory. My off-list mention of using 64 buckets as the initial size was because you're switching to the hashing method at 32 items. If you made the table 32, then it's guaranteed to need to be enlarged, so that's not good. If you make it 64, then the worst-case fillfactor is 50% rather than 12.5% with 256 elements. Performing lookups on an appropriately sized hash table is going to perform better than lookups on a sparse table. The reason for this is that hash table probes rarely ever have a predictable memory access pattern, and the larger the bucket array is, the more chance of having a backend stall while fetching cache lines from some higher cache level or RAM. So, IMO, using 256, you're leaving performance on the table and paying in RAM for the privilege. You might not be too concerned about the memory because you've done the tests, but testing with one EC and calling it good seems naive to me. I recall one query that Tom posted when I was working on the EC index stuff for 3373c7155 that had over 1000 EquivalenceClasses. I don't know how many of those would have had > 32 ec_derives entries, but check [1] if you want to see. I experimented by applying your v4 along with 0001-0003 of Yuya's v35 patchset from [2]. See the attached bz2 for my results run on an AMD Zen2 machine. The CREATE TABLE statement is in the attached script. If I run: select testname,parts,avg(joins),sum(plan_time) as plan_time,avg(mem_used) mem_used,avg(mem_alloc) mem_alloc from bench_results where testname not ilike '%pwj%' and testname ilike '%yuya%' group by 1,2 order by parts,testname; There are no results > 32 parts where 256 elements are faster than 64. 64 averages about 1% faster. That could be noise, but slightly less memory seems quite attractive to me when there's some evidence that also comes with better performance. Just to explain the names of the tests in the results: v4_yuya_v35-0001-0003_list_free = Your v4 patch with Yuya's 0001-0003 with the fix for the pfree on the list. v4_64buckets_yuya_v35-0001-0003_list_free is the same but with 64 bucket ec_derives_hash table. For the test, the names should be fairly self-explanatory. If the name has "pwj" in it, then I had partitionwise-joins enabled, if not, I had it disabled. master is 5d5f41581. David [1] https://www.postgresql.org/message-id/6970.1545327857%40sss.pgh.pa.us [2] https://postgr.es/m/CAJ2pMkZ2soD_99UTGkvg4_fX=PAvd7oDNYUMOksqbEMzpdeJAA@mail.gmail.com
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
Hi David, On Fri, Mar 28, 2025 at 8:32 AM David Rowley <dgrowleyml@gmail.com> wrote: > > Performing lookups on an appropriately sized hash table is going to > perform better than lookups on a sparse table. The reason for this is > that hash table probes rarely ever have a predictable memory access > pattern, and the larger the bucket array is, the more chance of having > a backend stall while fetching cache lines from some higher cache > level or RAM. So, IMO, using 256, you're leaving performance on the > table and paying in RAM for the privilege. I don't know much about cache lines but searching for cachelines shows that they are 64 or 128 bytes long. The hash entry here is 40 bytes long, so at most 1 or 3 entries would fit in a cache line. My understanding could be wrong but it seems that we will incur a cache line fault almost for every entry that we fetch even if we fetch the entries in a tight loop. If we are performing other operations in-between like what will happen with the patch, the cache lines are going to fault anyway. So it seems the size of the hash table or its sparseness wouldn't affect timing much. Please correct me if I am wrong. > > You might not be too concerned about the memory because you've done > the tests, but testing with one EC and calling it good seems naive to > me. I recall one query that Tom posted when I was working on the EC > index stuff for 3373c7155 that had over 1000 EquivalenceClasses. I > don't know how many of those would have had > 32 ec_derives entries, > but check [1] if you want to see. Comparing root->join_rel_hash with EC->ec_derives_hash in the context of initial hash table size is a thinko on my part. It's less likely that there will be 1000 subqueries (requiring 1000 PlannerInfos) each with more than 32 join rels than a query with 1000 equivalence classes in one PlannerInfo with more than 32 ec_derives. So if using a small initial hash table doesn't impact performance negatively, why not save some memory. Thinking more about it, we know the size of ec_derives_list when creating the hash table and we are using simplehash which uses its own fillfactor and its own logic to expand the hash table, I think we should just use the length of ec_derives_list as the initial size. What do you think? -- Best Wishes, Ashutosh Bapat
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Fri, Mar 28, 2025 at 12:01 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > > Comparing root->join_rel_hash with EC->ec_derives_hash in the context > of initial hash table size is a thinko on my part. It's less likely > that there will be 1000 subqueries (requiring 1000 PlannerInfos) each > with more than 32 join rels than a query with 1000 equivalence classes > in one PlannerInfo with more than 32 ec_derives. So if using a small > initial hash table doesn't impact performance negatively, why not save > some memory. Thinking more about it, we know the size of > ec_derives_list when creating the hash table and we are using > simplehash which uses its own fillfactor and its own logic to expand > the hash table, I think we should just use the length of > ec_derives_list as the initial size. What do you think? > PFA patches. 0001 and 0002 are the same as the previous set. 0003 changes the initial hash table size to the length of ec_derives. -- Best Wishes, Ashutosh Bapat
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On 2025-Mar-28, David Rowley wrote: > I experimented by applying your v4 along with 0001-0003 of Yuya's v35 > patchset from [2]. See the attached bz2 for my results run on an AMD > Zen2 machine. The CREATE TABLE statement is in the attached script. Eyeballing these results, unless I am misreading them, the patch brings zero benefit. With PWJ off, there's no plan time improvement and no memory consumption improvement either; only with Watari-san's patch there's an improvement in plan time (and with Watari's patch, I see negligible difference between the case with 64 buckets and the other case, which I assume has 256 buckets). But the "master" vs. "v4_patch" cases seem to be essentially identical. With PWJ on, the situation is the same. master_pwj looks pretty much the same as v4_pwj. -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Fri, Mar 28, 2025 at 10:46 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2025-Mar-28, David Rowley wrote: > > > I experimented by applying your v4 along with 0001-0003 of Yuya's v35 > > patchset from [2]. See the attached bz2 for my results run on an AMD > > Zen2 machine. The CREATE TABLE statement is in the attached script. > > Eyeballing these results, unless I am misreading them, the patch brings > zero benefit. > > With PWJ off, there's no plan time improvement and no memory consumption > improvement either; only with Watari-san's patch there's an improvement > in plan time (and with Watari's patch, I see negligible difference > between the case with 64 buckets and the other case, which I assume has > 256 buckets). But the "master" vs. "v4_patch" cases seem to be > essentially identical. > > With PWJ on, the situation is the same. master_pwj looks pretty much > the same as v4_pwj. My patch optimizes create_join_clause() which is invoked when planning index scans. David's script does not create any indexes - implicit or explicit. My script for example has the partition key as primary key. So this is not surprising. If the script is modified to create the partitioned table with the primary key, it gives similar results as mine. That also explains why he doesn't see any changes in memory consumption. EC members are created irrespective of whether there are indexes or not and Yuya's first three patches are related to ec_members handling. So those show some improvement with David's script. -- Best Wishes, Ashutosh Bapat
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Sat, 29 Mar 2025 at 05:46, Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > PFA patches. 0001 and 0002 are the same as the previous set. 0003 > changes the initial hash table size to the length of ec_derives. I'm just not following the logic in making it the length of the ec_derives List. If you have 32 buckets and try to insert 32 elements, you're guaranteed to need a resize after inserting 28 elements. See the grow_threshold logic SH_UPDATE_PARAMETERS(). The point of making it 64 was to ensure the table is never unnecessarily sparse and to also ensure we make it at least big enough for the minimum number of ec_derives that we're about to insert. Looking more closely at the patch's ec_add_clause_to_derives_hash() function, I see you're actually making two hash table entries for each RestrictInfo, so without any em_is_const members, you'll insert 64 entries into the hash table with a ec_derives list of 32, in which case 64 buckets isn't enough and the table will end up growing to 128 elements. I think you'd be better off coming up with some logic like putting the lowest pointer value'd EM first in the key and ensure that all lookups do that too by wrapping the lookups in some helper function. That'll half the number of hash table entries at the cost of some very cheap comparisons. David
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Mon, Mar 31, 2025 at 8:27 AM David Rowley <dgrowleyml@gmail.com> wrote: > > On Sat, 29 Mar 2025 at 05:46, Ashutosh Bapat > <ashutosh.bapat.oss@gmail.com> wrote: > > PFA patches. 0001 and 0002 are the same as the previous set. 0003 > > changes the initial hash table size to the length of ec_derives. > > I'm just not following the logic in making it the length of the > ec_derives List. If you have 32 buckets and try to insert 32 elements, > you're guaranteed to need a resize after inserting 28 elements. See > the grow_threshold logic SH_UPDATE_PARAMETERS(). The point of making > it 64 was to ensure the table is never unnecessarily sparse and to > also ensure we make it at least big enough for the minimum number of > ec_derives that we're about to insert. If I am reading SH_CREATE correctly, it will initially set the size to 32/.9 = 36 and in SH_UPDATE_PARAMETERS will set grow_threshold to 36 * .9 = 32. So it will leave some room even after inserting the initial elements. But looking at SH_INSERT_HASH_INTERNAL(), it will soon expand the table even if there's space. We certainly need a size much more than 32. 32 is an arbitrary/empirical threshold to create a hash table. Using that threshold as initial hash table size means the table size would be arbitrary too. Using twice the length of ec_derives_list seems more reasonable since the length will decide the initial number of entries. > > Looking more closely at the patch's ec_add_clause_to_derives_hash() > function, I see you're actually making two hash table entries for each > RestrictInfo, so without any em_is_const members, you'll insert 64 > entries into the hash table with a ec_derives list of 32, in which > case 64 buckets isn't enough and the table will end up growing to 128 > elements. > Yes, that's right. > I think you'd be better off coming up with some logic like putting the > lowest pointer value'd EM first in the key and ensure that all lookups > do that too by wrapping the lookups in some helper function. That'll > half the number of hash table entries at the cost of some very cheap > comparisons. That's a good suggestion. I searched for C standard documentation which specifies that the pointer comparison, especially inequality, is stable and safe to use. But I didn't find any. While according to the C standard, the result of comparison between pointers within the same array or a struct is specified, that between pointers from two different objects is unspecified. The existing code relies on the EM pointers being stable and also relies on equality between them to be stable. It has withstood the test of time and a variety of compilers. Hence I think it should be safe to rely on pointer comparisons being stable. But since I didn't find any documentation which confirms it, I have left those changes as a separate patch. Some internet sources discussing pointer comparison can be found at [1], [2] (which mentions the C standard but doesn't provide a link). PFA the next patchset 0001, 0002 are same as in the previous set 0003 changes the initial hash table size to length(ec->ec_derives_list) * 4 to accomodate for commuted entries. 0004 uses canonical keys per your suggestion and also reduces the initial hash table size to length(ec->ec_derives_list) * 2. When the number of initial elements to be added to the hash table is known, I see users of simplehash.h using that as an estimate rather than the nearest power of two. Hence following the logic here. [1] https://stackoverflow.com/questions/59516346/how-does-pointer-comparison-work-in-c-is-it-ok-to-compare-pointers-that-dont-p [2] https://www.gnu.org/software/c-intro-and-ref/manual/html_node/Pointer-Comparison.html -- Best Wishes, Ashutosh Bapat
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Mon, Mar 31, 2025 at 7:00 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > On Mon, Mar 31, 2025 at 8:27 AM David Rowley <dgrowleyml@gmail.com> wrote: > > > > On Sat, 29 Mar 2025 at 05:46, Ashutosh Bapat > > <ashutosh.bapat.oss@gmail.com> wrote: > > > PFA patches. 0001 and 0002 are the same as the previous set. 0003 > > > changes the initial hash table size to the length of ec_derives. > > > > I'm just not following the logic in making it the length of the > > ec_derives List. If you have 32 buckets and try to insert 32 elements, > > you're guaranteed to need a resize after inserting 28 elements. See > > the grow_threshold logic SH_UPDATE_PARAMETERS(). The point of making > > it 64 was to ensure the table is never unnecessarily sparse and to > > also ensure we make it at least big enough for the minimum number of > > ec_derives that we're about to insert. > > If I am reading SH_CREATE correctly, it will initially set the size to > 32/.9 = 36 and in SH_UPDATE_PARAMETERS will set grow_threshold to 36 * > .9 = 32. So it will leave some room even after inserting the initial > elements. But looking at SH_INSERT_HASH_INTERNAL(), it will soon > expand the table even if there's space. We certainly need a size much > more than 32. 32 is an arbitrary/empirical threshold to create a hash > table. Using that threshold as initial hash table size means the table > size would be arbitrary too. Using twice the length of > ec_derives_list seems more reasonable since the length will decide the > initial number of entries. I think David’s suggestion to use 64 as the fixed initial size is simpler and more predictable. Since list_length * 2 will always be >= 64 anyway, unless we expect clause counts to grow significantly right after the threshold, the fixed size avoids the need to reason about sizing heuristics and keeps the logic clearer. It also lines up well with David’s point -- 64 strikes a good balance for both memory usage and CPU efficiency. Unless there’s a strong reason to favor dynamic sizing, I’d prefer to stick with the fixed 64. > > I think you'd be better off coming up with some logic like putting the > > lowest pointer value'd EM first in the key and ensure that all lookups > > do that too by wrapping the lookups in some helper function. That'll > > half the number of hash table entries at the cost of some very cheap > > comparisons. > > That's a good suggestion. I searched for C standard documentation > which specifies that the pointer comparison, especially inequality, is > stable and safe to use. But I didn't find any. While according to the > C standard, the result > of comparison between pointers within the same array or a struct is > specified, that between pointers from two different objects is > unspecified. The existing code relies on the EM pointers being stable > and also relies on equality between > them to be stable. It has withstood the test of time and a variety of > compilers. Hence I think it should be safe to rely on pointer > comparisons being stable. But since I didn't find any documentation > which confirms it, I have left those changes as a separate patch. Some > internet sources discussing pointer comparison can be found at [1], > [2] (which mentions the C standard but doesn't provide a link). > > PFA the next patchset > > 0001, 0002 are same as in the previous set > 0003 changes the initial hash table size to > length(ec->ec_derives_list) * 4 to accomodate for commuted entries. > 0004 uses canonical keys per your suggestion and also reduces the > initial hash table size to length(ec->ec_derives_list) * 2. Thanks for the new patches. As David suggested off-list, it seems better to have a static inline function for the key canonicalization logic than to duplicate it in the insert and lookup paths, as done in your 0004. Also, using macros for the ec_derives_hash threshold and initial size seems cleaner than hardcoding the values. I’ve combined your 0003 and 0004 into the attached 0003, which: * Adds the canonicalization logic via fill_ec_derives_key(). * Replaces literal values for threshold and initial size with macros, defined near the key and entry types. * Updates code comments to reflect the new design. I wasn’t sure why you removed this comment: - * We do not attempt a second lookup with EMs swapped when using the hash - * table; such clauses are inserted under both orderings at the time of - * insertion. We still avoid the second lookup, but the reason has changed -- we now canonicalize keys during both insertion and lookup, which makes the second probe unnecessary. So I rewrote it as: + * We do not attempt a second lookup with EMs swapped, because the key is + * canonicalized during both insertion and lookup. 0003’s commit message includes a blurb I plan to paste into the main patch’s message (with minor tweaks) when we squash the patches. -- Thanks, Amit Langote
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Tue, Apr 1, 2025 at 1:32 PM Amit Langote <amitlangote09@gmail.com> wrote:
>
> I think David’s suggestion to use 64 as the fixed initial size is
> simpler and more predictable. Since list_length * 2 will always be >=
> 64 anyway, unless we expect clause counts to grow significantly right
> after the threshold, the fixed size avoids the need to reason about
> sizing heuristics and keeps the logic clearer.
>
> It also lines up well with David’s point -- 64 strikes a good balance
> for both memory usage and CPU efficiency. Unless there’s a strong
> reason to favor dynamic sizing, I’d prefer to stick with the fixed 64.
Consider following table and query (based on a similar table in
join.sql, which exercises find_derived_clause_for_ec_member() code
path.
#create table fkest (x integer, x10 integer, x10b integer, x100
integer, unique(x, x10, x100), foreign key (x, x10b, x100) references
fkest(x, x10, x100));
#select 'select * from fkest f1 join ' || string_agg(format('fkest f%s
on (f1.x = f%s.x and f1.x10 = f%s.x10b and f1.x100 = f%s.x100)', i, i,
i , i), ' join ') || ' where f1.x100 = 2' query from
generate_series(2, 100) i; \gset
#explain (summary) :query;
This is a 100-way self-join between foreign key and referenced key and
one of the foreign keys being set to a constant. This exercises the
case of derived clauses with constant EM.
When planning this query, all the 100 derived clauses containing the
constant EM are created first and then they are searched one by one
for every EM. Thus when the hash table is created in
find_derived_clause_for_ec_member()->ec_search_derived_clause_for_ems(),
the length of ec_derives_list is already 100, so the hash table will
be expanded while it's being filled up the first time, if we use
constant 64 as initial hash table size. This can be avoided if we use
list_length() * 2. The pattern for create_join_clause() however is
search then insert - so it will always create the hash table with
initial size 64 right when the list length is 32. Both these cases are
served well if we base the initial hash table size as a multiple of
list_length(ec_derives_list).
For the record, without the patch this query takes about 5800ms on
average for planning on my laptop. With the patch the planning time
reduces to about 5400ms - 6-7% of improvement if my approximate math
is correct.
>
> As David suggested off-list, it seems better to have a static inline
> function for the key canonicalization logic than to duplicate it in
> the insert and lookup paths, as done in your 0004.
Static inline function to fill the key in canonical form is a good
idea. Thanks for the patch.
>
> * Replaces literal values for threshold and initial size with macros,
> defined near the key and entry types.
I don't see this in your attached patches. Am I missing something?
It's still using list_length() for initial hash table size. But with
my explanation above, I believe we will keep it that way.
>
> I wasn’t sure why you removed this comment:
>
> - * We do not attempt a second lookup with EMs swapped when using the hash
> - * table; such clauses are inserted under both orderings at the time of
> - * insertion.
When I read it, I didn't understand why we mentioned a second lookup,
so I dropped it. But now I see that the comment is in the context of
two comparisons being done when using list. I have rephrased the
comment a bit to make this comparison clear.
>
> 0003’s commit message includes a blurb I plan to paste into the main
> patch’s message (with minor tweaks) when we squash the patches.
Slight correction in the first sentence of that blurb message.
Derived clauses are now stored in the ec_derives_hash using canonicalized
keys: the EquivalenceMember with lower memory address is always placed
in em1, and ...
+/*
+ * fill_ec_derives_key
+ * Compute a canonical key for ec_derives_hash lookup or insertion.
+ *
+ * Derived clauses are looked up using a pair of EquivalenceMembers and a
+ * parent EquivalenceClass. To avoid storing or searching for both EM
orderings,
+ * we canonicalize the key:
+ *
+ * - For clauses involving two non-constant EMs, we order the EMs by address
+ * and place the lower one first.
+ * - For clauses involving a constant EM, the caller must pass the non-constant
+ * EM as leftem; we then set em1 = NULL and em2 = leftem.
+ */
+static inline void
+fill_ec_derives_key(ECDerivesKey *key,
+ EquivalenceMember *leftem,
+ EquivalenceMember *rightem,
+ EquivalenceClass *parent_ec)
+{
+ Assert(leftem); /* Always required for lookup or insertion */
+
+ /*
+ * Clauses with a constant EM are always stored and looked up using only
+ * the non-constant EM, with the other key slot set to NULL.
+ */
This comment seems to overlap with what's already there in the
prologue. However "Clauses with a constant EM are always stored and
looked up using the non-constant EM" is non-overlapping part. This
part is also repeated in ec_add_clause_to_derives_hash(), which I
think is a better place for this comment. Changed in the attached
patch.
*/
Assert(!rinfo->left_em->em_is_const);
+ /*
+ * Clauses containing a constant are never considered redundant, so
+ * parent_ec is not set.
+ */
+ Assert(!rinfo->parent_ec || !rinfo->right_em->em_is_const);
These two Assertions are applicable to all the derived clauses but are
added to a function which deals with only hash table. If an EC doesn't
have enough derived clauses to create a hash table these assertions
won't be checked. The reason they are here is because we are using
these properties to create canonical hash table key. Should we move
them to ec_add_derived_clause() for better coverage?
I have also removed some comments repeated in the function prologue
and function body.
0001, 0002 and 0003 are the same as your set. 0004 contains my changes
in a separate patch so that it's easy to review those.
--
Best Wishes,
Ashutosh Bapat
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Wed, Apr 2, 2025 at 1:58 AM Ashutosh Bapat
<ashutosh.bapat.oss@gmail.com> wrote:
> On Tue, Apr 1, 2025 at 1:32 PM Amit Langote <amitlangote09@gmail.com> wrote:
> >
> > I think David’s suggestion to use 64 as the fixed initial size is
> > simpler and more predictable. Since list_length * 2 will always be >=
> > 64 anyway, unless we expect clause counts to grow significantly right
> > after the threshold, the fixed size avoids the need to reason about
> > sizing heuristics and keeps the logic clearer.
> >
> > It also lines up well with David’s point -- 64 strikes a good balance
> > for both memory usage and CPU efficiency. Unless there’s a strong
> > reason to favor dynamic sizing, I’d prefer to stick with the fixed 64.
>
> Consider following table and query (based on a similar table in
> join.sql, which exercises find_derived_clause_for_ec_member() code
> path.
> #create table fkest (x integer, x10 integer, x10b integer, x100
> integer, unique(x, x10, x100), foreign key (x, x10b, x100) references
> fkest(x, x10, x100));
> #select 'select * from fkest f1 join ' || string_agg(format('fkest f%s
> on (f1.x = f%s.x and f1.x10 = f%s.x10b and f1.x100 = f%s.x100)', i, i,
> i , i), ' join ') || ' where f1.x100 = 2' query from
> generate_series(2, 100) i; \gset
> #explain (summary) :query;
>
> This is a 100-way self-join between foreign key and referenced key and
> one of the foreign keys being set to a constant. This exercises the
> case of derived clauses with constant EM.
>
> When planning this query, all the 100 derived clauses containing the
> constant EM are created first and then they are searched one by one
> for every EM. Thus when the hash table is created in
> find_derived_clause_for_ec_member()->ec_search_derived_clause_for_ems(),
> the length of ec_derives_list is already 100, so the hash table will
> be expanded while it's being filled up the first time, if we use
> constant 64 as initial hash table size. This can be avoided if we use
> list_length() * 2. The pattern for create_join_clause() however is
> search then insert - so it will always create the hash table with
> initial size 64 right when the list length is 32. Both these cases are
> served well if we base the initial hash table size as a multiple of
> list_length(ec_derives_list).
>
> For the record, without the patch this query takes about 5800ms on
> average for planning on my laptop. With the patch the planning time
> reduces to about 5400ms - 6-7% of improvement if my approximate math
> is correct.
Yeah, I figured the constant EM case might end up adding a bunch of
derived clauses before the hash table is built, but this example
really helps illustrate that, thanks.
It does seem like a special case --
generate_base_implied_equalities_const() dumps in a whole bunch of
clauses up front, unlike the usual search-then-insert pattern in
create_join_clause().
After our chat with David, I think using list_length(ec_derives_list)
to size the hash table is reasonable. Given how simplehash rounds up
-- dividing by the fillfactor and rounding to the next power of two --
we still end up with 64 buckets around the threshold. So the dynamic
sizing behaves pretty predictably and doesn't seem like a bad choice
after all.
> > * Replaces literal values for threshold and initial size with macros,
> > defined near the key and entry types.
>
> I don't see this in your attached patches. Am I missing something?
> It's still using list_length() for initial hash table size. But with
> my explanation above, I believe we will keep it that way.
Oops, looks like I created those (v6) patches before adding those macro changes.
> > I wasn’t sure why you removed this comment:
> >
> > - * We do not attempt a second lookup with EMs swapped when using the hash
> > - * table; such clauses are inserted under both orderings at the time of
> > - * insertion.
>
> When I read it, I didn't understand why we mentioned a second lookup,
> so I dropped it. But now I see that the comment is in the context of
> two comparisons being done when using list. I have rephrased the
> comment a bit to make this comparison clear.
Looks good.
> > 0003’s commit message includes a blurb I plan to paste into the main
> > patch’s message (with minor tweaks) when we squash the patches.
>
> Slight correction in the first sentence of that blurb message.
>
> Derived clauses are now stored in the ec_derives_hash using canonicalized
> keys: the EquivalenceMember with lower memory address is always placed
> in em1, and ...
Looks good.
> +/*
> + * fill_ec_derives_key
> + * Compute a canonical key for ec_derives_hash lookup or insertion.
> + *
> + * Derived clauses are looked up using a pair of EquivalenceMembers and a
> + * parent EquivalenceClass. To avoid storing or searching for both EM
> orderings,
> + * we canonicalize the key:
> + *
> + * - For clauses involving two non-constant EMs, we order the EMs by address
> + * and place the lower one first.
> + * - For clauses involving a constant EM, the caller must pass the non-constant
> + * EM as leftem; we then set em1 = NULL and em2 = leftem.
> + */
> +static inline void
> +fill_ec_derives_key(ECDerivesKey *key,
> + EquivalenceMember *leftem,
> + EquivalenceMember *rightem,
> + EquivalenceClass *parent_ec)
> +{
> + Assert(leftem); /* Always required for lookup or insertion */
> +
> + /*
> + * Clauses with a constant EM are always stored and looked up using only
> + * the non-constant EM, with the other key slot set to NULL.
> + */
>
> This comment seems to overlap with what's already there in the
> prologue. However "Clauses with a constant EM are always stored and
> looked up using the non-constant EM" is non-overlapping part. This
> part is also repeated in ec_add_clause_to_derives_hash(), which I
> think is a better place for this comment. Changed in the attached
> patch.
Ok, those comment changes look good overall.
> */
> Assert(!rinfo->left_em->em_is_const);
> + /*
> + * Clauses containing a constant are never considered redundant, so
> + * parent_ec is not set.
> + */
> + Assert(!rinfo->parent_ec || !rinfo->right_em->em_is_const);
>
> These two Assertions are applicable to all the derived clauses but are
> added to a function which deals with only hash table. If an EC doesn't
> have enough derived clauses to create a hash table these assertions
> won't be checked. The reason they are here is because we are using
> these properties to create canonical hash table key. Should we move
> them to ec_add_derived_clause() for better coverage?
Yes, good idea.
> I have also removed some comments repeated in the function prologue
> and function body.
>
> 0001, 0002 and 0003 are the same as your set. 0004 contains my changes
> in a separate patch so that it's easy to review those.
Here's v7 in which I have merged 0003 and 0004 into 0002.
You'll see that threshold now uses a macro and
list_length(ec->ec_derives_list) is passed as initial size.
I'm feeling good about this version, but let me know if you have any
further thoughts / comments.
--
Thanks, Amit Langote
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Wed, Apr 2, 2025 at 1:00 PM Amit Langote <amitlangote09@gmail.com> wrote: > > I'm feeling good about this version, but let me know if you have any > further thoughts / comments. Thanks for incorporating the changes and fixing initial hash table size. + #define EC_DERIVES_HASH_THRESHOLD 32 Given that the constant is being used only at a single place, we don't need a macro. But I am not against the macro. PFA patch set with some minor edits in 0003. Also I have edited commit message of 0001 and 0002. In the commit messages of 0002, 1. mentioning that the lookup happens only for join clause generation is not accurate, since we lookup EM = constant clauses as well which are not join clauses. 2. In the second paragraph em1 and em2 are mentioned without mentioning what are they. I have rephrased it so as to avoid mentioning names of structure member. -- Best Wishes, Ashutosh Bapat
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Wed, Apr 2, 2025 at 9:52 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > On Wed, Apr 2, 2025 at 1:00 PM Amit Langote <amitlangote09@gmail.com> wrote: > > I'm feeling good about this version, but let me know if you have any > > further thoughts / comments. > > Thanks for incorporating the changes and fixing initial hash table size. > > + #define EC_DERIVES_HASH_THRESHOLD 32 > > Given that the constant is being used only at a single place, we don't > need a macro. But I am not against the macro. Yeah, let's keep it, because it documents well. > PFA patch set with some minor edits in 0003. Also I have edited commit > message of 0001 and 0002. > > In the commit messages of 0002, > 1. mentioning that the lookup happens only for join clause generation > is not accurate, since we lookup EM = constant clauses as well which > are not join clauses. > 2. In the second paragraph em1 and em2 are mentioned without > mentioning what are they. I have rephrased it so as to avoid > mentioning names of structure member. Incorporated, thanks. I'll plan to commit these tomorrow barring objections. -- Thanks, Amit Langote
Attachment
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Thu, Apr 3, 2025 at 12:28 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Wed, Apr 2, 2025 at 9:52 PM Ashutosh Bapat > <ashutosh.bapat.oss@gmail.com> wrote: > > On Wed, Apr 2, 2025 at 1:00 PM Amit Langote <amitlangote09@gmail.com> wrote: > > > I'm feeling good about this version, but let me know if you have any > > > further thoughts / comments. > > > > Thanks for incorporating the changes and fixing initial hash table size. > > > > + #define EC_DERIVES_HASH_THRESHOLD 32 > > > > Given that the constant is being used only at a single place, we don't > > need a macro. But I am not against the macro. > > Yeah, let's keep it, because it documents well. > > > PFA patch set with some minor edits in 0003. Also I have edited commit > > message of 0001 and 0002. > > > > In the commit messages of 0002, > > 1. mentioning that the lookup happens only for join clause generation > > is not accurate, since we lookup EM = constant clauses as well which > > are not join clauses. > > 2. In the second paragraph em1 and em2 are mentioned without > > mentioning what are they. I have rephrased it so as to avoid > > mentioning names of structure member. > > Incorporated, thanks. > > I'll plan to commit these tomorrow barring objections. I’ve now marked this as committed after pushing the patches earlier today. I realize the CF entry was originally about the project to reduce memory usage during partitionwise join planning, but we ended up committing something else. I suppose we can create a new entry if and when we pick that original work back up. -- Thanks, Amit Langote
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Fri, Apr 4, 2025 at 2:04 PM Amit Langote <amitlangote09@gmail.com> wrote: > > On Thu, Apr 3, 2025 at 12:28 PM Amit Langote <amitlangote09@gmail.com> wrote: > > On Wed, Apr 2, 2025 at 9:52 PM Ashutosh Bapat > > <ashutosh.bapat.oss@gmail.com> wrote: > > > On Wed, Apr 2, 2025 at 1:00 PM Amit Langote <amitlangote09@gmail.com> wrote: > > > > I'm feeling good about this version, but let me know if you have any > > > > further thoughts / comments. > > > > > > Thanks for incorporating the changes and fixing initial hash table size. > > > > > > + #define EC_DERIVES_HASH_THRESHOLD 32 > > > > > > Given that the constant is being used only at a single place, we don't > > > need a macro. But I am not against the macro. > > > > Yeah, let's keep it, because it documents well. > > > > > PFA patch set with some minor edits in 0003. Also I have edited commit > > > message of 0001 and 0002. > > > > > > In the commit messages of 0002, > > > 1. mentioning that the lookup happens only for join clause generation > > > is not accurate, since we lookup EM = constant clauses as well which > > > are not join clauses. > > > 2. In the second paragraph em1 and em2 are mentioned without > > > mentioning what are they. I have rephrased it so as to avoid > > > mentioning names of structure member. > > > > Incorporated, thanks. > > > > I'll plan to commit these tomorrow barring objections. > > I’ve now marked this as committed after pushing the patches earlier today. Thanks a lot. > > I realize the CF entry was originally about the project to reduce > memory usage during partitionwise join planning, but we ended up > committing something else. I suppose we can create a new entry if and > when we pick that original work back up. Will create a new CF entry just to keep the patch floated. -- Best Wishes, Ashutosh Bapat
Re: Reducing memory consumed by RestrictInfo list translations in partitionwise join planning
On Fri, Apr 4, 2025 at 5:48 PM Ashutosh Bapat <ashutosh.bapat.oss@gmail.com> wrote: > On Fri, Apr 4, 2025 at 2:04 PM Amit Langote <amitlangote09@gmail.com> wrote: > > I’ve now marked this as committed after pushing the patches earlier today. > > Thanks a lot. Thank you too for working on it. > > I realize the CF entry was originally about the project to reduce > > memory usage during partitionwise join planning, but we ended up > > committing something else. I suppose we can create a new entry if and > > when we pick that original work back up. > > Will create a new CF entry just to keep the patch floated. Sounds good. Saving memory where we can does seem worthwhile, as long as the approach stays simple. If there’s any doubt on that front, maybe it’s worth spending a bit more time to see if things can be simplified. -- Thanks, Amit Langote