Thread: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
Hello,
Attached patch introduces a function pg_column_toast_chunk_id
that returns a chunk ID of a TOASTed value.
Recently, one of our clients needed a way to show which columns
are actually TOASTed because they would like to know how much
updates on the original table affects to its toast table
specifically with regard to auto VACUUM. We could not find a
function for this purpose in the current PostgreSQL, so I would
like propose pg_column_toast_chunk_id.
This function returns a chunk ID of a TOASTed value, or NULL
if the value is not TOASTed. Here is an example;
postgres=# \d val
Table "public.val"
Column | Type | Collation | Nullable | Default
--------+------+-----------+----------+---------
t | text | | |
postgres=# select length(t), pg_column_size(t), pg_column_compression(t), pg_column_toast_chunk_id(t), tableoid from
val;
length | pg_column_size | pg_column_compression | pg_column_toast_chunk_id | tableoid
--------+----------------+-----------------------+--------------------------+----------
3 | 4 | | | 16388
3000 | 46 | pglz | | 16388
32000 | 413 | pglz | | 16388
305 | 309 | | | 16388
64000 | 64000 | | 16393 | 16388
(5 rows)
postgres=# select chunk_id, chunk_seq from pg_toast.pg_toast_16388;
chunk_id | chunk_seq
----------+-----------
16393 | 0
16393 | 1
16393 | 2
(snip)
16393 | 30
16393 | 31
16393 | 32
(33 rows)
This function is also useful to identify a problematic row when
an error like
"ERROR: unexpected chunk number ... (expected ...) for toast value"
occurs.
The patch is a just a concept patch and not including documentation
and tests.
What do you think about this feature?
Regards,
Yugo Nagata
--
Yugo NAGATA <nagata@sraoss.co.jp>
Attachment
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Nikita Malakhov
Date:
Hi!
I like the idea of having a standard function which shows a TOAST value ID
for a row. I've used my own to handle TOAST errors. Just, maybe, more correct
name would be "...value_id", because you actually retrieve valueid field
from the TOAST pointer, and chunk ID consists of valueid + chunk_seq.
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Yugo NAGATA
Date:
Hi Nikita, On Wed, 5 Jul 2023 17:49:20 +0300 Nikita Malakhov <hukutoc@gmail.com> wrote: > Hi! > > I like the idea of having a standard function which shows a TOAST value ID > for a row. I've used my own to handle TOAST errors. Just, maybe, more > correct > name would be "...value_id", because you actually retrieve valueid field > from the TOAST pointer, and chunk ID consists of valueid + chunk_seq. Thank you for your review! Although, the retrieved field is "va_valueid" and it is called "value ID" in the code, I chose the name "..._chunk_id" because I found the description in the documentation as followings: ------------- Every TOAST table has the columns chunk_id (an OID identifying the particular TOASTed value), chunk_seq (a sequence numberfor the chunk within its value), and chunk_data (the actual data of the chunk). A unique index on chunk_id and chunk_seqprovides fast retrieval of the values. A pointer datum representing an out-of-line on-disk TOASTed value thereforeneeds to store the OID of the TOAST table in which to look and the OID of the specific value (its chunk_id) ------------- https://www.postgresql.org/docs/devel/storage-toast.html Here, chunk_id defined separately from chunk_seq. Therefore, I wonder pg_column_toast_chunk_id would be ok. However, I don't insist on this and I would be happy to change it if the other name is more natural for users. Regards, Yugo Nagata > > -- > Regards, > Nikita Malakhov > Postgres Professional > The Russian Postgres Company > https://postgrespro.ru/ -- Yugo NAGATA <nagata@sraoss.co.jp>
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Yugo NAGATA
Date:
On Fri, 7 Jul 2023 17:21:36 +0900 Yugo NAGATA <nagata@sraoss.co.jp> wrote: > Hi Nikita, > > On Wed, 5 Jul 2023 17:49:20 +0300 > Nikita Malakhov <hukutoc@gmail.com> wrote: > > > Hi! > > > > I like the idea of having a standard function which shows a TOAST value ID > > for a row. I've used my own to handle TOAST errors. Just, maybe, more > > correct > > name would be "...value_id", because you actually retrieve valueid field > > from the TOAST pointer, and chunk ID consists of valueid + chunk_seq. > > Thank you for your review! > > Although, the retrieved field is "va_valueid" and it is called "value ID" in the > code, I chose the name "..._chunk_id" because I found the description in the > documentation as followings: > > ------------- > Every TOAST table has the columns chunk_id (an OID identifying the particular TOASTed value), chunk_seq (a sequence numberfor the chunk within its value), and chunk_data (the actual data of the chunk). A unique index on chunk_id and chunk_seqprovides fast retrieval of the values. A pointer datum representing an out-of-line on-disk TOASTed value thereforeneeds to store the OID of the TOAST table in which to look and the OID of the specific value (its chunk_id) > ------------- > https://www.postgresql.org/docs/devel/storage-toast.html > > Here, chunk_id defined separately from chunk_seq. Therefore, I wonder > pg_column_toast_chunk_id would be ok. However, I don't insist on this > and I would be happy to change it if the other name is more natural for users. I attached v2 patch that contains the documentation fix. Regards, Yugo Nagata > > Regards, > Yugo Nagata > > > > > -- > > Regards, > > Nikita Malakhov > > Postgres Professional > > The Russian Postgres Company > > https://postgrespro.ru/ > > > -- > Yugo NAGATA <nagata@sraoss.co.jp> > > -- Yugo NAGATA <nagata@sraoss.co.jp>
Attachment
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Sergei Kornilov
Date:
Hello My +1 to have such a function in core or in some contrib at least (pg_surgery? amcheck?). In the past, more than once I needed to find a damaged tuple knowing only chunk id and toastrelid. This feature would helpa lot. regards, Sergei
minor doc issues.
Returns the chunk id of the TOASTed value, or NULL if the value is not TOASTed.
Should it be "chunk_id"?
you may place it after pg_create_logical_replication_slot entry to
make it look like alphabetical order.
There is no test. maybe we can add following to src/test/regress/sql/misc.sql
create table val(t text);
INSERT into val(t) SELECT string_agg(
chr((ascii('B') + round(random() * 25)) :: integer),'')
FROM generate_series(1,2500);
select pg_column_toast_chunk_id(t) is not null from val;
drop table val;
On Mon, Nov 6, 2023 at 8:00 AM jian he <jian.universality@gmail.com> wrote:
>
> minor doc issues.
> Returns the chunk id of the TOASTed value, or NULL if the value is not TOASTed.
> Should it be "chunk_id"?
>
> you may place it after pg_create_logical_replication_slot entry to
> make it look like alphabetical order.
>
> There is no test. maybe we can add following to src/test/regress/sql/misc.sql
> create table val(t text);
> INSERT into val(t) SELECT string_agg(
> chr((ascii('B') + round(random() * 25)) :: integer),'')
> FROM generate_series(1,2500);
> select pg_column_toast_chunk_id(t) is not null from val;
> drop table val;
Hi
the main C function (pg_column_toast_chunk_id) I didn't change.
I added tests as mentioned above.
tests put it on src/test/regress/sql/misc.sql, i hope that's fine.
I placed pg_column_toast_chunk_id in "Table 9.99. Database Object
Location Functions" (below Table 9.98. Database Object Size
Functions).
Attachment
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Yugo NAGATA
Date:
On Tue, 2 Jan 2024 08:00:00 +0800
jian he <jian.universality@gmail.com> wrote:
> On Mon, Nov 6, 2023 at 8:00 AM jian he <jian.universality@gmail.com> wrote:
> >
> > minor doc issues.
> > Returns the chunk id of the TOASTed value, or NULL if the value is not TOASTed.
> > Should it be "chunk_id"?
Thank you for your suggestion. As you pointed out, it is called "chunk_id"
in the documentation, so I rewrote it and also added a link to the section
where the TOAST table structure is explained.
> > you may place it after pg_create_logical_replication_slot entry to
> > make it look like alphabetical order.
I've been thinking about where we should place the function in the doc,
and I decided place it in the table of Database Object Size Functions
because I think pg_column_toast_chunk_id also would assist understanding
the result of size functions as similar to pg_column_compression; that is,
those function can explain why a large value in size could be stored in
a column.
> > There is no test. maybe we can add following to src/test/regress/sql/misc.sql
> > create table val(t text);
> > INSERT into val(t) SELECT string_agg(
> > chr((ascii('B') + round(random() * 25)) :: integer),'')
> > FROM generate_series(1,2500);
> > select pg_column_toast_chunk_id(t) is not null from val;
> > drop table val;
Thank you for the test proposal. However, if we add a test, I want
to check that the chunk_id returned by the function exists in the
TOAST table, and that it returns NULL if the values is not TOASTed.
For the purpose, I wrote a test using a dynamic SQL since the table
name of the TOAST table have to be generated from the main table's OID.
> Hi
> the main C function (pg_column_toast_chunk_id) I didn't change.
> I added tests as mentioned above.
> tests put it on src/test/regress/sql/misc.sql, i hope that's fine.
> I placed pg_column_toast_chunk_id in "Table 9.99. Database Object
> Location Functions" (below Table 9.98. Database Object Size
> Functions).
I could not find any change in your patch from my previous patch.
Maybe, you attached wrong file. I attached a patch updated based
on your review, including the documentation fixes and a test.
What do you think about this it?
Regards,
Yugo Nagata
--
Yugo NAGATA <nagata@sraoss.co.jp>
Attachment
On Fri, Jan 26, 2024 at 8:42 AM Yugo NAGATA <nagata@sraoss.co.jp> wrote:
>
> On Tue, 2 Jan 2024 08:00:00 +0800
> jian he <jian.universality@gmail.com> wrote:
>
> > On Mon, Nov 6, 2023 at 8:00 AM jian he <jian.universality@gmail.com> wrote:
> > >
> > > minor doc issues.
> > > Returns the chunk id of the TOASTed value, or NULL if the value is not TOASTed.
> > > Should it be "chunk_id"?
>
> Thank you for your suggestion. As you pointed out, it is called "chunk_id"
> in the documentation, so I rewrote it and also added a link to the section
> where the TOAST table structure is explained.
>
> > > you may place it after pg_create_logical_replication_slot entry to
> > > make it look like alphabetical order.
>
> I've been thinking about where we should place the function in the doc,
> and I decided place it in the table of Database Object Size Functions
> because I think pg_column_toast_chunk_id also would assist understanding
> the result of size functions as similar to pg_column_compression; that is,
> those function can explain why a large value in size could be stored in
> a column.
diff --git a/doc/src/sgml/func.sgml b/doc/src/sgml/func.sgml
index 210c7c0b02..2d82331323 100644
--- a/doc/src/sgml/func.sgml
+++ b/doc/src/sgml/func.sgml
@@ -28078,6 +28078,23 @@ postgres=# SELECT '0/0'::pg_lsn +
pd.segment_number * ps.setting::int + :offset
</para></entry>
</row>
+ <row>
+ <entry role="func_table_entry"><para role="func_signature">
+ <indexterm>
+ <primary>pg_column_toast_chunk_id</primary>
+ </indexterm>
+ <function>pg_column_toast_chunk_id</function> ( <type>"any"</type> )
+ <returnvalue>oid</returnvalue>
+ </para>
+ <para>
+ Shows the <structfield>chunk_id</structfield> of an on-disk
+ <acronym>TOAST</acronym>ed value. Returns <literal>NULL</literal>
+ if the value is un-<acronym>TOAST</acronym>ed or not on-disk.
+ See <xref linkend="storage-toast-ondisk"/> for details about
+ <acronym>TOAST</acronym>.
+ </para></entry>
+ </row>
v3 patch will place it on `Table 9.97. Replication Management Functions`
I agree with you. it should be placed after pg_column_compression. but
apply your patch, it will be at
> > > There is no test. maybe we can add following to src/test/regress/sql/misc.sql
> > > create table val(t text);
> > > INSERT into val(t) SELECT string_agg(
> > > chr((ascii('B') + round(random() * 25)) :: integer),'')
> > > FROM generate_series(1,2500);
> > > select pg_column_toast_chunk_id(t) is not null from val;
> > > drop table val;
>
> Thank you for the test proposal. However, if we add a test, I want
> to check that the chunk_id returned by the function exists in the
> TOAST table, and that it returns NULL if the values is not TOASTed.
> For the purpose, I wrote a test using a dynamic SQL since the table
> name of the TOAST table have to be generated from the main table's OID.
>
> > Hi
> > the main C function (pg_column_toast_chunk_id) I didn't change.
> > I added tests as mentioned above.
> > tests put it on src/test/regress/sql/misc.sql, i hope that's fine.
> > I placed pg_column_toast_chunk_id in "Table 9.99. Database Object
> > Location Functions" (below Table 9.98. Database Object Size
> > Functions).
>
> I could not find any change in your patch from my previous patch.
> Maybe, you attached wrong file. I attached a patch updated based
> on your review, including the documentation fixes and a test.
> What do you think about this it?
>
sorry, I had attached the wrong file.
but your v3 also has no tests, documentation didn't fix.
maybe you also attached the wrong file too?
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Yugo NAGATA
Date:
On Tue, 30 Jan 2024 12:12:31 +0800
jian he <jian.universality@gmail.com> wrote:
> On Fri, Jan 26, 2024 at 8:42 AM Yugo NAGATA <nagata@sraoss.co.jp> wrote:
> >
> > On Tue, 2 Jan 2024 08:00:00 +0800
> > jian he <jian.universality@gmail.com> wrote:
> >
> > > On Mon, Nov 6, 2023 at 8:00 AM jian he <jian.universality@gmail.com> wrote:
> > > >
> > > > minor doc issues.
> > > > Returns the chunk id of the TOASTed value, or NULL if the value is not TOASTed.
> > > > Should it be "chunk_id"?
> >
> > Thank you for your suggestion. As you pointed out, it is called "chunk_id"
> > in the documentation, so I rewrote it and also added a link to the section
> > where the TOAST table structure is explained.
> >
> > > > you may place it after pg_create_logical_replication_slot entry to
> > > > make it look like alphabetical order.
> >
> > I've been thinking about where we should place the function in the doc,
> > and I decided place it in the table of Database Object Size Functions
> > because I think pg_column_toast_chunk_id also would assist understanding
> > the result of size functions as similar to pg_column_compression; that is,
> > those function can explain why a large value in size could be stored in
> > a column.
>
> diff --git a/doc/src/sgml/func.sgml b/doc/src/sgml/func.sgml
> index 210c7c0b02..2d82331323 100644
> --- a/doc/src/sgml/func.sgml
> +++ b/doc/src/sgml/func.sgml
> @@ -28078,6 +28078,23 @@ postgres=# SELECT '0/0'::pg_lsn +
> pd.segment_number * ps.setting::int + :offset
> </para></entry>
> </row>
>
> + <row>
> + <entry role="func_table_entry"><para role="func_signature">
> + <indexterm>
> + <primary>pg_column_toast_chunk_id</primary>
> + </indexterm>
> + <function>pg_column_toast_chunk_id</function> ( <type>"any"</type> )
> + <returnvalue>oid</returnvalue>
> + </para>
> + <para>
> + Shows the <structfield>chunk_id</structfield> of an on-disk
> + <acronym>TOAST</acronym>ed value. Returns <literal>NULL</literal>
> + if the value is un-<acronym>TOAST</acronym>ed or not on-disk.
> + See <xref linkend="storage-toast-ondisk"/> for details about
> + <acronym>TOAST</acronym>.
> + </para></entry>
> + </row>
>
> v3 patch will place it on `Table 9.97. Replication Management Functions`
> I agree with you. it should be placed after pg_column_compression. but
> apply your patch, it will be at
>
>
> > > > There is no test. maybe we can add following to src/test/regress/sql/misc.sql
> > > > create table val(t text);
> > > > INSERT into val(t) SELECT string_agg(
> > > > chr((ascii('B') + round(random() * 25)) :: integer),'')
> > > > FROM generate_series(1,2500);
> > > > select pg_column_toast_chunk_id(t) is not null from val;
> > > > drop table val;
> >
> > Thank you for the test proposal. However, if we add a test, I want
> > to check that the chunk_id returned by the function exists in the
> > TOAST table, and that it returns NULL if the values is not TOASTed.
> > For the purpose, I wrote a test using a dynamic SQL since the table
> > name of the TOAST table have to be generated from the main table's OID.
> >
> > > Hi
> > > the main C function (pg_column_toast_chunk_id) I didn't change.
> > > I added tests as mentioned above.
> > > tests put it on src/test/regress/sql/misc.sql, i hope that's fine.
> > > I placed pg_column_toast_chunk_id in "Table 9.99. Database Object
> > > Location Functions" (below Table 9.98. Database Object Size
> > > Functions).
> >
> > I could not find any change in your patch from my previous patch.
> > Maybe, you attached wrong file. I attached a patch updated based
> > on your review, including the documentation fixes and a test.
> > What do you think about this it?
> >
>
> sorry, I had attached the wrong file.
> but your v3 also has no tests, documentation didn't fix.
> maybe you also attached the wrong file too?
>
Sorry, I also attached a wrong file.
Attached is the correct one.
Regards,
Yugo Nagata
--
Yugo NAGATA <nagata@sraoss.co.jp>
Attachment
On Tue, Jan 30, 2024 at 12:35 PM Yugo NAGATA <nagata@sraoss.co.jp> wrote: > > > Sorry, I also attached a wrong file. > Attached is the correct one. I think you attached the wrong file again. also please name it as v4.
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Yugo NAGATA
Date:
On Tue, 30 Jan 2024 13:47:45 +0800 jian he <jian.universality@gmail.com> wrote: > On Tue, Jan 30, 2024 at 12:35 PM Yugo NAGATA <nagata@sraoss.co.jp> wrote: > > > > > > Sorry, I also attached a wrong file. > > Attached is the correct one. > I think you attached the wrong file again. also please name it as v4. Opps..sorry, again. I attached the correct one, v4. Regards, Yugo Nagata -- Yugo NAGATA <nagata@sraoss.co.jp>
Attachment
On Tue, Jan 30, 2024 at 1:56 PM Yugo NAGATA <nagata@sraoss.co.jp> wrote:
>
> I attached the correct one, v4.
>
+-- Test pg_column_toast_chunk_id:
+-- Check if the returned chunk_id exists in the TOAST table
+CREATE TABLE test_chunk_id (v1 text, v2 text);
+INSERT INTO test_chunk_id VALUES (
+ repeat('0123456789', 10), -- v1: small enough not to be TOASTed
+ repeat('0123456789', 100000)); -- v2: large enough to be TOASTed
select pg_size_pretty(100000::bigint);
return 98kb.
I think this is just too much, maybe I didn't consider the
implications of compression.
Anyway, I refactored the tests, making the toast value size be small.
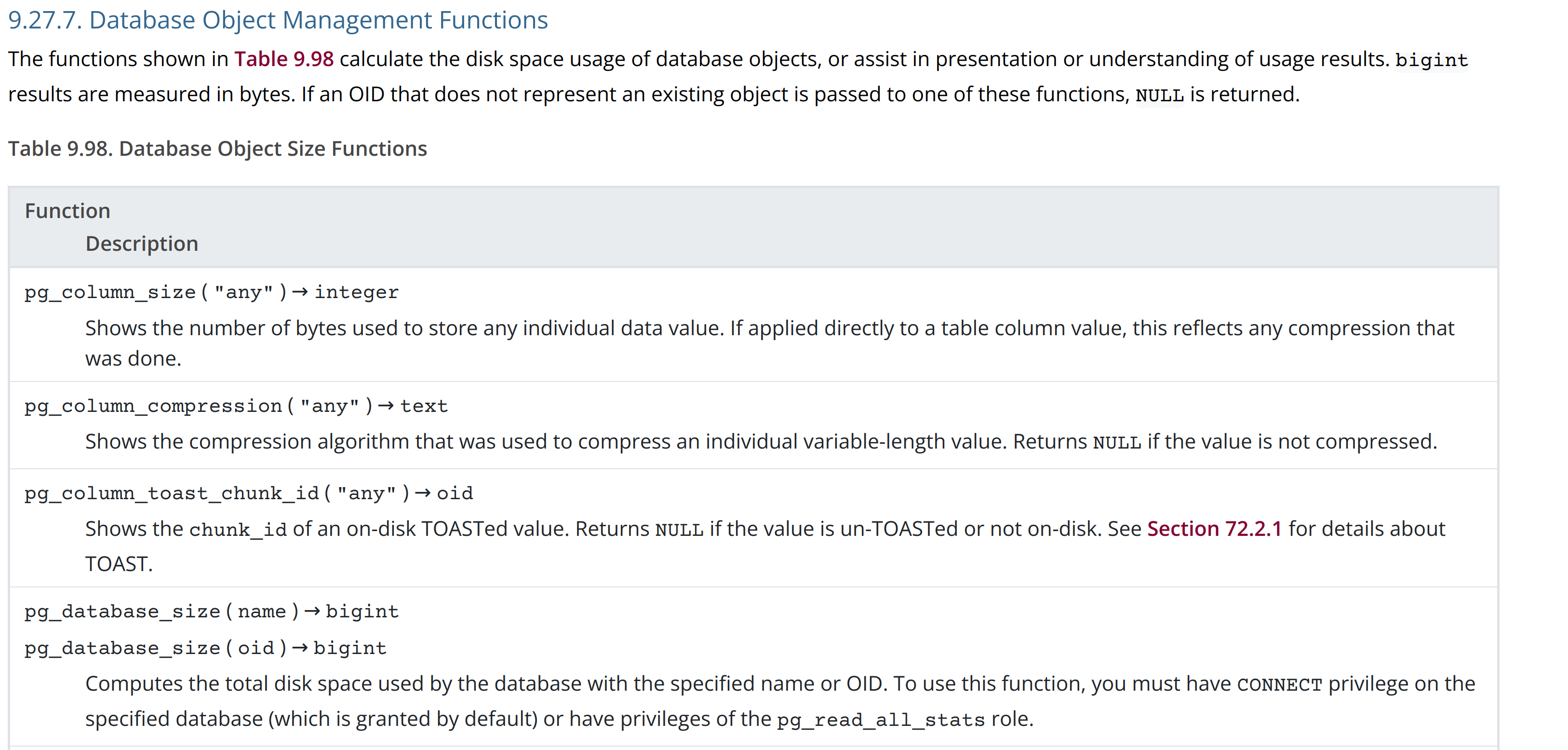
I aslo refactor the doc.
pg_column_toast_chunk_id entry will be right after pg_column_compression entry.
You can check the screenshot.
Attachment
{kind=link}
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Yugo NAGATA
Date:
On Tue, 30 Jan 2024 14:57:20 +0800
jian he <jian.universality@gmail.com> wrote:
> On Tue, Jan 30, 2024 at 1:56 PM Yugo NAGATA <nagata@sraoss.co.jp> wrote:
> >
> > I attached the correct one, v4.
> >
>
> +-- Test pg_column_toast_chunk_id:
> +-- Check if the returned chunk_id exists in the TOAST table
> +CREATE TABLE test_chunk_id (v1 text, v2 text);
> +INSERT INTO test_chunk_id VALUES (
> + repeat('0123456789', 10), -- v1: small enough not to be TOASTed
> + repeat('0123456789', 100000)); -- v2: large enough to be TOASTed
>
> select pg_size_pretty(100000::bigint);
> return 98kb.
>
> I think this is just too much, maybe I didn't consider the
> implications of compression.
> Anyway, I refactored the tests, making the toast value size be small.
Actually the data is compressed and the size is much smaller,
but I agree with you it is better not to generate large data unnecessarily.
I rewrote the test to disallow compression in the toast data using
"ALTER TABLE ... SET STORAGE EXTERNAL". In this case, any text larger
than 2k will be TOASTed on disk without compression, and it makes the
test simple, not required to use string_agg.
>
> I aslo refactor the doc.
> pg_column_toast_chunk_id entry will be right after pg_column_compression entry.
> You can check the screenshot.
I found the document order was not changed between my patch and yours.
In both, pg_column_toast_chunk_id entry is right after
pg_column_compression.
Here is a updated patch, v6.
Regards,
Yugo Nagata
--
Yugo NAGATA <nagata@sraoss.co.jp>
Attachment
On Thu, Feb 1, 2024 at 12:45 PM Yugo NAGATA <nagata@sraoss.co.jp> wrote: > > Here is a updated patch, v6. v6 patch looks good.
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Yugo NAGATA
Date:
On Thu, 1 Feb 2024 17:59:56 +0800 jian he <jian.universality@gmail.com> wrote: > On Thu, Feb 1, 2024 at 12:45 PM Yugo NAGATA <nagata@sraoss.co.jp> wrote: > > > > Here is a updated patch, v6. > > v6 patch looks good. Thank you for your review and updating the status to RwC! Regards, Yugo Nagata -- Yugo NAGATA <nagata@sraoss.co.jp>
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Nathan Bossart
Date:
On Mon, Feb 05, 2024 at 04:28:23PM +0900, Yugo NAGATA wrote: > On Thu, 1 Feb 2024 17:59:56 +0800 > jian he <jian.universality@gmail.com> wrote: >> v6 patch looks good. > > Thank you for your review and updating the status to RwC! I think this one needs a (pretty trivial) rebase. I spent a few minutes testing it out and looking at the code, and it seems generally reasonable to me. Do you think it's worth adding something like a pg_column_toast_num_chunks() function that returns the number of chunks for the TOASTed value, too? -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Yugo NAGATA
Date:
On Thu, 7 Mar 2024 16:56:17 -0600 Nathan Bossart <nathandbossart@gmail.com> wrote: > On Mon, Feb 05, 2024 at 04:28:23PM +0900, Yugo NAGATA wrote: > > On Thu, 1 Feb 2024 17:59:56 +0800 > > jian he <jian.universality@gmail.com> wrote: > >> v6 patch looks good. > > > > Thank you for your review and updating the status to RwC! > > I think this one needs a (pretty trivial) rebase. I spent a few minutes > testing it out and looking at the code, and it seems generally reasonable Thank you for your review. I've attached a rebased patch. > to me. Do you think it's worth adding something like a > pg_column_toast_num_chunks() function that returns the number of chunks for > the TOASTed value, too? If we want to know the number of chunks of a specified chunk_id, we can get this by the following query. postgres=# SELECT id, (SELECT count(*) FROM pg_toast.pg_toast_16384 WHERE chunk_id = id) FROM (SELECT pg_column_toast_chunk_id(v) AS id FROM t); id | count -------+------- 16389 | 3 16390 | 287 (2 rows) However, if there are needs for getting such information in a simpler way, it might be worth making a new function. Regards, Yugo Nagata > -- > Nathan Bossart > Amazon Web Services: https://aws.amazon.com -- Yugo NAGATA <nagata@sraoss.co.jp>
Attachment
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Nathan Bossart
Date:
On Fri, Mar 08, 2024 at 03:31:55PM +0900, Yugo NAGATA wrote:
> On Thu, 7 Mar 2024 16:56:17 -0600
> Nathan Bossart <nathandbossart@gmail.com> wrote:
>> to me. Do you think it's worth adding something like a
>> pg_column_toast_num_chunks() function that returns the number of chunks for
>> the TOASTed value, too?
>
> If we want to know the number of chunks of a specified chunk_id,
> we can get this by the following query.
>
> postgres=# SELECT id, (SELECT count(*) FROM pg_toast.pg_toast_16384 WHERE chunk_id = id)
> FROM (SELECT pg_column_toast_chunk_id(v) AS id FROM t);
Good point. Overall, I think this patch is in decent shape, so I'll aim to
commit it sometime next week.
> +{ oid => '8393', descr => 'chunk ID of on-disk TOASTed value',
> + proname => 'pg_column_toast_chunk_id', provolatile => 's', prorettype => 'oid',
> + proargtypes => 'any', prosrc => 'pg_column_toast_chunk_id' },
Note to self: this change requires a catversion bump.
> +INSERT INTO test_chunk_id(v1,v2)
> + VALUES (repeat('x', 1), repeat('x', 2048));
Is this guaranteed to be TOASTed for all possible page sizes?
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Yugo NAGATA
Date:
On Fri, 8 Mar 2024 16:17:58 -0600
Nathan Bossart <nathandbossart@gmail.com> wrote:
> On Fri, Mar 08, 2024 at 03:31:55PM +0900, Yugo NAGATA wrote:
> > On Thu, 7 Mar 2024 16:56:17 -0600
> > Nathan Bossart <nathandbossart@gmail.com> wrote:
> >> to me. Do you think it's worth adding something like a
> >> pg_column_toast_num_chunks() function that returns the number of chunks for
> >> the TOASTed value, too?
> >
> > If we want to know the number of chunks of a specified chunk_id,
> > we can get this by the following query.
> >
> > postgres=# SELECT id, (SELECT count(*) FROM pg_toast.pg_toast_16384 WHERE chunk_id = id)
> > FROM (SELECT pg_column_toast_chunk_id(v) AS id FROM t);
>
> Good point. Overall, I think this patch is in decent shape, so I'll aim to
> commit it sometime next week.
Thank you.
>
> > +{ oid => '8393', descr => 'chunk ID of on-disk TOASTed value',
> > + proname => 'pg_column_toast_chunk_id', provolatile => 's', prorettype => 'oid',
> > + proargtypes => 'any', prosrc => 'pg_column_toast_chunk_id' },
>
> Note to self: this change requires a catversion bump.
>
> > +INSERT INTO test_chunk_id(v1,v2)
> > + VALUES (repeat('x', 1), repeat('x', 2048));
>
> Is this guaranteed to be TOASTed for all possible page sizes?
Should we use block_size?
SHOW block_size \gset
INSERT INTO test_chunk_id(v1,v2)
VALUES (repeat('x', 1), repeat('x', (:block_size / 4)));
I think this will work in various page sizes.
I've attached a patch in which the test is updated.
Regards,
Yugo Nagata
>
> --
> Nathan Bossart
> Amazon Web Services: https://aws.amazon.com
--
Yugo NAGATA <nagata@sraoss.co.jp>
Attachment
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Nathan Bossart
Date:
On Sat, Mar 09, 2024 at 11:57:18AM +0900, Yugo NAGATA wrote:
> On Fri, 8 Mar 2024 16:17:58 -0600
> Nathan Bossart <nathandbossart@gmail.com> wrote:
>> Is this guaranteed to be TOASTed for all possible page sizes?
>
> Should we use block_size?
>
> SHOW block_size \gset
> INSERT INTO test_chunk_id(v1,v2)
> VALUES (repeat('x', 1), repeat('x', (:block_size / 4)));
>
> I think this will work in various page sizes.
WFM
> +SHOW block_size; \gset
> + block_size
> +------------
> + 8192
> +(1 row)
I think we need to remove the ';' so that the output of the query is not
saved in the ".out" file. With that change, this test passes when Postgres
is built with --with-blocksize=32. However, many other unrelated tests
begin failing, so I guess this fix isn't tremendously important.
--
Nathan Bossart
Amazon Web Services: https://aws.amazon.com
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Yugo NAGATA
Date:
On Sat, 9 Mar 2024 08:50:28 -0600
Nathan Bossart <nathandbossart@gmail.com> wrote:
> On Sat, Mar 09, 2024 at 11:57:18AM +0900, Yugo NAGATA wrote:
> > On Fri, 8 Mar 2024 16:17:58 -0600
> > Nathan Bossart <nathandbossart@gmail.com> wrote:
> >> Is this guaranteed to be TOASTed for all possible page sizes?
> >
> > Should we use block_size?
> >
> > SHOW block_size \gset
> > INSERT INTO test_chunk_id(v1,v2)
> > VALUES (repeat('x', 1), repeat('x', (:block_size / 4)));
> >
> > I think this will work in various page sizes.
>
> WFM
>
> > +SHOW block_size; \gset
> > + block_size
> > +------------
> > + 8192
> > +(1 row)
>
> I think we need to remove the ';' so that the output of the query is not
> saved in the ".out" file. With that change, this test passes when Postgres
> is built with --with-blocksize=32. However, many other unrelated tests
> begin failing, so I guess this fix isn't tremendously important.
I rewrote the patch to use current_setting('block_size') instead of SHOW
and \gset as other tests do. Although some tests are failing with block_size=32,
I wonder it is a bit better to use "block_size" instead of the constant
to make the test more general to some extent.
Regards,
Yugo Nagata
>
> --
> Nathan Bossart
> Amazon Web Services: https://aws.amazon.com
--
Yugo NAGATA <nagata@sraoss.co.jp>
Attachment
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Nathan Bossart
Date:
I did some light editing to prepare this for commit. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Attachment
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Yugo NAGATA
Date:
On Tue, 12 Mar 2024 22:07:17 -0500 Nathan Bossart <nathandbossart@gmail.com> wrote: > I did some light editing to prepare this for commit. Thank you. I confirmed the test you improved and I am fine with that. Regards, Yugo Nagata > > -- > Nathan Bossart > Amazon Web Services: https://aws.amazon.com -- Yugo NAGATA <nagata@sraoss.co.jp>
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Nathan Bossart
Date:
On Wed, Mar 13, 2024 at 01:09:18PM +0700, Yugo NAGATA wrote: > On Tue, 12 Mar 2024 22:07:17 -0500 > Nathan Bossart <nathandbossart@gmail.com> wrote: >> I did some light editing to prepare this for commit. > > Thank you. I confirmed the test you improved and I am fine with that. Committed. -- Nathan Bossart Amazon Web Services: https://aws.amazon.com
Re: pg_column_toast_chunk_id: a function to get a chunk ID of a TOASTed value
From
Yugo NAGATA
Date:
On Thu, 14 Mar 2024 11:10:42 -0500 Nathan Bossart <nathandbossart@gmail.com> wrote: > On Wed, Mar 13, 2024 at 01:09:18PM +0700, Yugo NAGATA wrote: > > On Tue, 12 Mar 2024 22:07:17 -0500 > > Nathan Bossart <nathandbossart@gmail.com> wrote: > >> I did some light editing to prepare this for commit. > > > > Thank you. I confirmed the test you improved and I am fine with that. > > Committed. Thank you! > > -- > Nathan Bossart > Amazon Web Services: https://aws.amazon.com -- Yugo NAGATA <nagata@sraoss.co.jp>