Thread: Making aggregate deserialization (and WAL receive) functions slightly faster
Making aggregate deserialization (and WAL receive) functions slightly faster
From
David Rowley
Date:
While working on 16fd03e95, I noticed that in each aggregate deserialization function, in order to "receive" the bytea value that is the serialized aggregate state, appendBinaryStringInfo is used to append the bytes of the bytea value onto a temporary StringInfoData. Using appendBinaryStringInfo seems a bit wasteful here. We could really just fake up a StringInfoData and point directly to the bytes of the bytea value. The best way I could think of to do this was to invent initStringInfoFromString() which initialises a StringInfoData and has the ->data field point directly at the specified buffer. This will mean that it would be unsafe to do any appendStringInfo* operations on the resulting StringInfoData as enlargeStringInfo would try to repalloc the data buffer, which might not even point to a palloc'd string. I thought it might be fine just to mention that in the comments for the function, but we could probably do a bit better and set maxlen to something like -1 and Assert() we never see -1 in the various append functions. I wasn't sure it was worth it, so didn't do that. I had a look around for other places that might be following the same pattern. I only found range_recv() and XLogWalRcvProcessMsg(). I didn't adjust the range_recv() one as I couldn't see how to do that without casting away a const. I did adjust the XLogWalRcvProcessMsg() one and got rid of a global variable in the process. I've attached the benchmark results I got after testing how the modification changed the performance of string_agg_deserialize(). I was hoping this would have a slightly more impressive performance impact, especially for string_agg() and array_agg() as the aggregate states of those can be large. However, in the test I ran, there's only a very slight performance gain. I may just not have found the best case, however. David
Attachment
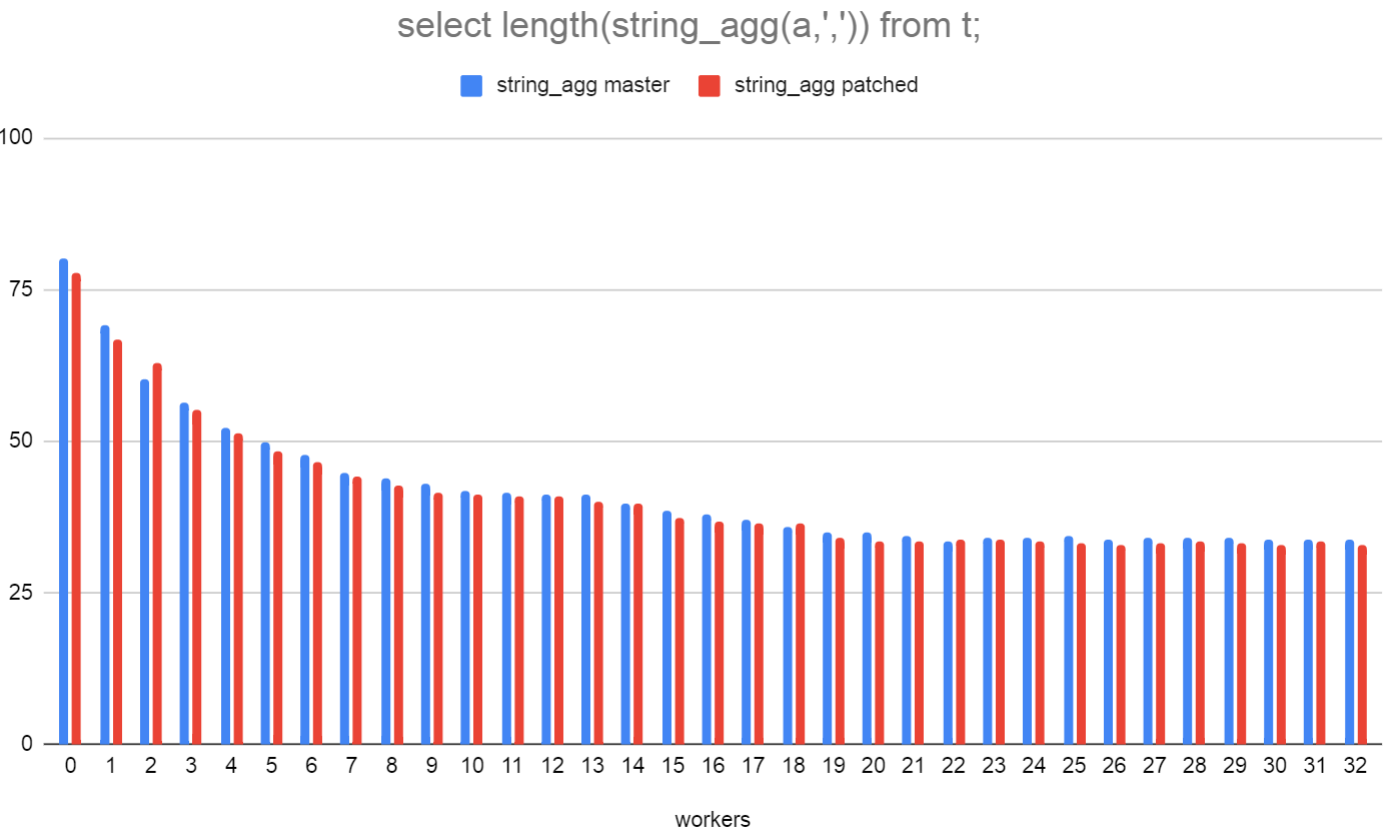{kind=link}
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
Tom Lane
Date:
David Rowley <dgrowleyml@gmail.com> writes:
> While working on 16fd03e95, I noticed that in each aggregate
> deserialization function, in order to "receive" the bytea value that
> is the serialized aggregate state, appendBinaryStringInfo is used to
> append the bytes of the bytea value onto a temporary StringInfoData.
> Using appendBinaryStringInfo seems a bit wasteful here. We could
> really just fake up a StringInfoData and point directly to the bytes
> of the bytea value.
Perhaps, but ...
> The best way I could think of to do this was to invent
> initStringInfoFromString() which initialises a StringInfoData and has
> the ->data field point directly at the specified buffer. This will
> mean that it would be unsafe to do any appendStringInfo* operations on
> the resulting StringInfoData as enlargeStringInfo would try to
> repalloc the data buffer, which might not even point to a palloc'd
> string.
I find this patch horribly dangerous.
It could maybe be okay if we added the capability for StringInfoData
to understand (and enforce) that its "data" buffer is read-only.
However, that'd add overhead to every existing use-case.
> I've attached the benchmark results I got after testing how the
> modification changed the performance of string_agg_deserialize().
> I was hoping this would have a slightly more impressive performance
> impact, especially for string_agg() and array_agg() as the aggregate
> states of those can be large. However, in the test I ran, there's
> only a very slight performance gain. I may just not have found the
> best case, however.
I do not think we should even consider this without solid evidence
for *major* performance improvements. As it stands, it's a
quintessential example of a loaded foot-gun, and it seems clear
that making it safe enough to use would add more overhead than
it saves.
regards, tom lane
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
David Rowley
Date:
On Sun, 12 Feb 2023 at 19:39, Tom Lane <tgl@sss.pgh.pa.us> wrote: > I find this patch horribly dangerous. I see LogicalRepApplyLoop() does something similar with a StringInfoData. Maybe it's just scarier having an external function in stringinfo.c which does this as having it increases the chances of someone using it for the wrong thing. > It could maybe be okay if we added the capability for StringInfoData > to understand (and enforce) that its "data" buffer is read-only. > However, that'd add overhead to every existing use-case. I'm not very excited by that. I considered just setting maxlen = -1 in the new function and adding Asserts to check for that in each of the appendStringInfo* functions. However, since the performance gains are not so great, I'll probably just drop the whole thing given there's resistance. David
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
David Rowley
Date:
On Sun, 12 Feb 2023 at 23:43, David Rowley <dgrowleyml@gmail.com> wrote: > > On Sun, 12 Feb 2023 at 19:39, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > It could maybe be okay if we added the capability for StringInfoData > > to understand (and enforce) that its "data" buffer is read-only. > > However, that'd add overhead to every existing use-case. > > I'm not very excited by that. I considered just setting maxlen = -1 > in the new function and adding Asserts to check for that in each of > the appendStringInfo* functions. However, since the performance gains > are not so great, I'll probably just drop the whole thing given > there's resistance. I know I said I'd drop this, but I was reminded of it again today. I ended up adjusting the patch so that it no longer adds a helper function to stringinfo.c and instead just manually assigns the StringInfo.data field to point to the bytea's buffer. This follows what's done in some existing places such as LogicalParallelApplyLoop(), ReadArrayBinary() and record_recv() to name a few. I ran a fresh set of benchmarks on today's master with and without the patch applied. I used the same benchmark as I did in [1]. The average performance increase from between 0 and 12 workers is about 6.6%. This seems worthwhile to me. Any objections? David [1] https://postgr.es/m/CAApHDvr%3De-YOigriSHHm324a40HPqcUhSp6pWWgjz5WwegR%3DcQ%40mail.gmail.com
Attachment
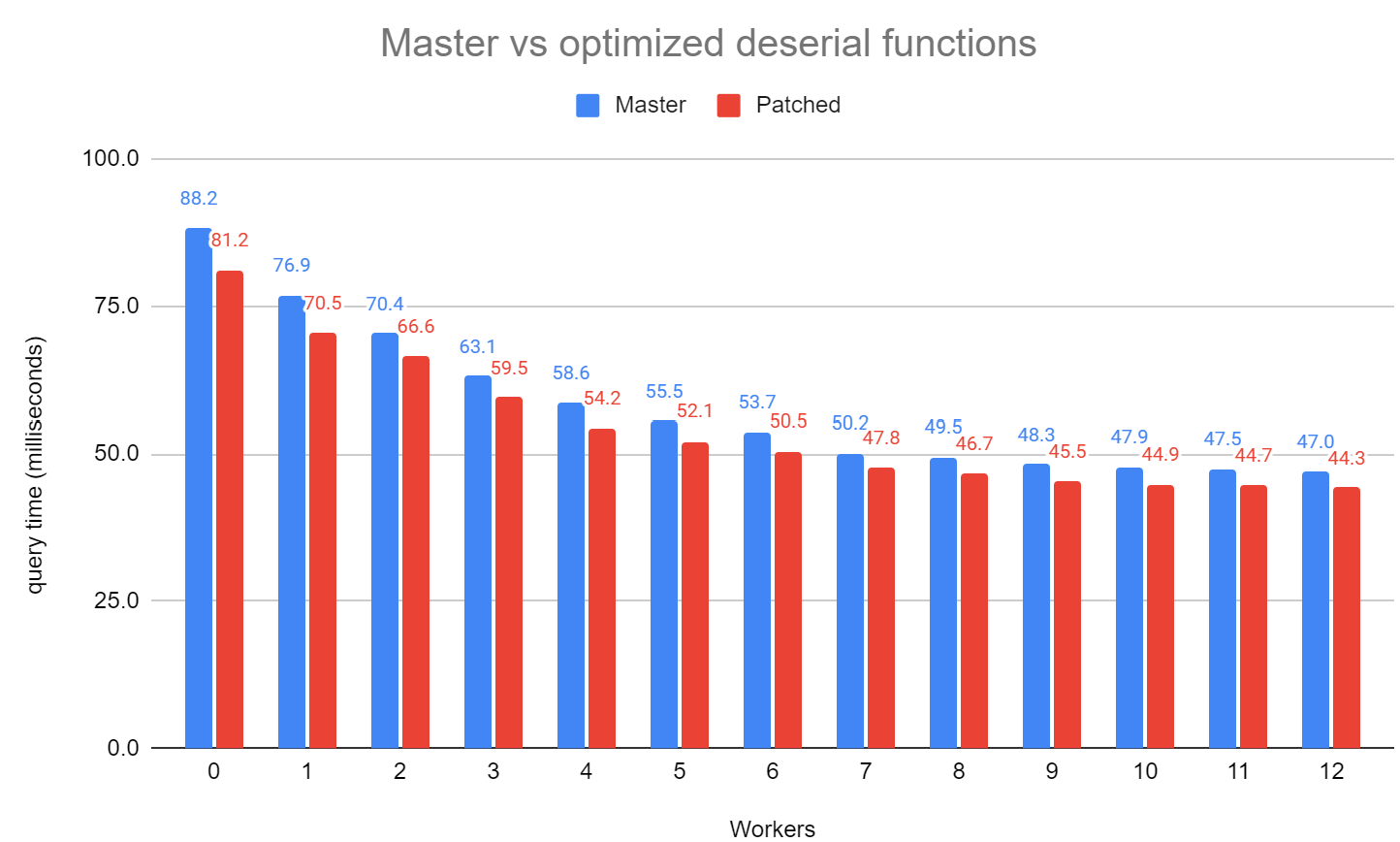{kind=link}
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
Michael Paquier
Date:
On Tue, Oct 03, 2023 at 06:02:10PM +1300, David Rowley wrote: > I know I said I'd drop this, but I was reminded of it again today. I > ended up adjusting the patch so that it no longer adds a helper > function to stringinfo.c and instead just manually assigns the > StringInfo.data field to point to the bytea's buffer. This follows > what's done in some existing places such as > LogicalParallelApplyLoop(), ReadArrayBinary() and record_recv() to > name a few. > > I ran a fresh set of benchmarks on today's master with and without the > patch applied. I used the same benchmark as I did in [1]. The average > performance increase from between 0 and 12 workers is about 6.6%. > > This seems worthwhile to me. Any objections? Interesting. + buf.len = VARSIZE_ANY_EXHDR(sstate); + buf.maxlen = 0; + buf.cursor = 0; Perhaps it would be worth hiding that in a macro defined in stringinfo.h? -- Michael
Attachment
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
David Rowley
Date:
Thanks for taking a look at this. On Wed, 4 Oct 2023 at 16:57, Michael Paquier <michael@paquier.xyz> wrote: > + buf.len = VARSIZE_ANY_EXHDR(sstate); > + buf.maxlen = 0; > + buf.cursor = 0; > > Perhaps it would be worth hiding that in a macro defined in > stringinfo.h? The original patch had a new function in stringinfo.c which allowed a StringInfoData to be initialised from an existing string with some given length. Tom wasn't a fan of that because there wasn't any protection against someone trying to use the given StringInfoData and then calling appendStringInfo to append another string. That can't be done in this case as we can't repalloc the VARDATA_ANY(state) pointer due to it not pointing directly to a palloc'd chunk. Tom's complaint seemed to be about having a reusable function which could be abused, so I modified the patch to remove the reusable code. I think your macro idea in stringinfo.h would put the patch in the same position as it was initially. It would be possible to do something like have maxlen == -1 mean that the StringInfoData.data field isn't being managed internally in stringinfo.c and then have all the appendStringInfo functions check for that, but I really don't want to add overhead to everything that uses appendStringInfo just for this. David
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
Michael Paquier
Date:
On Wed, Oct 04, 2023 at 07:47:11PM +1300, David Rowley wrote: > The original patch had a new function in stringinfo.c which allowed a > StringInfoData to be initialised from an existing string with some > given length. Tom wasn't a fan of that because there wasn't any > protection against someone trying to use the given StringInfoData and > then calling appendStringInfo to append another string. That can't be > done in this case as we can't repalloc the VARDATA_ANY(state) pointer > due to it not pointing directly to a palloc'd chunk. Tom's complaint > seemed to be about having a reusable function which could be abused, > so I modified the patch to remove the reusable code. I think your > macro idea in stringinfo.h would put the patch in the same position as > it was initially. Ahem, well. Based on this argument my own argument does not hold much. Perhaps I'd still use a macro at the top of array_userfuncs.c and numeric.c, to avoid repeating the same pattern respectively two and four times, documenting once on top of both macros that this is a fake StringInfo because of the reasons documented in these code paths. -- Michael
Attachment
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
David Rowley
Date:
On Thu, 5 Oct 2023 at 18:23, Michael Paquier <michael@paquier.xyz> wrote: > > On Wed, Oct 04, 2023 at 07:47:11PM +1300, David Rowley wrote: > > The original patch had a new function in stringinfo.c which allowed a > > StringInfoData to be initialised from an existing string with some > > given length. Tom wasn't a fan of that because there wasn't any > > protection against someone trying to use the given StringInfoData and > > then calling appendStringInfo to append another string. That can't be > > done in this case as we can't repalloc the VARDATA_ANY(state) pointer > > due to it not pointing directly to a palloc'd chunk. Tom's complaint > > seemed to be about having a reusable function which could be abused, > > so I modified the patch to remove the reusable code. I think your > > macro idea in stringinfo.h would put the patch in the same position as > > it was initially. > > Ahem, well. Based on this argument my own argument does not hold > much. Perhaps I'd still use a macro at the top of array_userfuncs.c > and numeric.c, to avoid repeating the same pattern respectively two > and four times, documenting once on top of both macros that this is a > fake StringInfo because of the reasons documented in these code paths. I looked at the patch again and I just couldn't bring myself to change it to that. If it were a macro going into stringinfo.h then I'd agree with having a macro or inline function as it would allow the reader to conceptualise what's happening after learning what the function does. Having multiple macros defined in various C files means that much harder as there are more macros to learn. Since we're only talking 4 lines of code, I think I'd rather reduce the number of hops the reader must do to find out what's going on and just leave the patch as is. I considered if it might be better to reduce the 4 lines down to 3 by chaining the assignments like: buf.maxlen = buf.cursor = 0; but I think I might instead change it so that maxlen gets set to -1 to follow what's done in LogicalParallelApplyLoop() and LogicalRepApplyLoop(). In the absence of having a function/macro in stringinfo.h, it might make grepping for this type of thing easier. If anyone else has a good argument for having multiple macros for this purpose then I could reconsider. David
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
David Rowley
Date:
On Thu, 5 Oct 2023 at 21:24, David Rowley <dgrowleyml@gmail.com> wrote: > > On Thu, 5 Oct 2023 at 18:23, Michael Paquier <michael@paquier.xyz> wrote: > > Ahem, well. Based on this argument my own argument does not hold > > much. Perhaps I'd still use a macro at the top of array_userfuncs.c > > and numeric.c, to avoid repeating the same pattern respectively two > > and four times, documenting once on top of both macros that this is a > > fake StringInfo because of the reasons documented in these code paths. > > I looked at the patch again and I just couldn't bring myself to change > it to that. If it were a macro going into stringinfo.h then I'd agree > with having a macro or inline function as it would allow the reader to > conceptualise what's happening after learning what the function does. I've pushed this patch. I didn't go with the macros in the end. I just felt it wasn't an improvement and none of the existing code which does the same thing bothers with a macro. I got the idea you were not particularly for the macro given that you used the word "Perhaps". Anyway, thank you for having a look at this. David
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
Tom Lane
Date:
David Rowley <dgrowleyml@gmail.com> writes:
> On Thu, 5 Oct 2023 at 21:24, David Rowley <dgrowleyml@gmail.com> wrote:
>> I looked at the patch again and I just couldn't bring myself to change
>> it to that. If it were a macro going into stringinfo.h then I'd agree
>> with having a macro or inline function as it would allow the reader to
>> conceptualise what's happening after learning what the function does.
> I've pushed this patch. I didn't go with the macros in the end. I
> just felt it wasn't an improvement and none of the existing code which
> does the same thing bothers with a macro. I got the idea you were not
> particularly for the macro given that you used the word "Perhaps".
Sorry for not having paid more attention to this thread ... but
I'm pretty desperately unhappy with the patch as-pushed. I agree
with the criticism that this is a very repetitive coding pattern
that could have used a macro. But my real problem with this:
+ buf.data = VARDATA_ANY(sstate);
+ buf.len = VARSIZE_ANY_EXHDR(sstate);
+ buf.maxlen = 0;
+ buf.cursor = 0;
is that it totally breaks the StringInfo API without even
attempting to fix the API specs that it falsifies,
particularly this in stringinfo.h:
* maxlen is the allocated size in bytes of 'data', i.e. the maximum
* string size (including the terminating '\0' char) that we can
* currently store in 'data' without having to reallocate
* more space. We must always have maxlen > len.
I could see inventing a notion of a "read-only StringInfo"
to legitimize what you've done here, but you didn't bother
to try. I do not like this one bit. This is a fairly
fundamental API and we shouldn't be so cavalier about
breaking it.
regards, tom lane
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
David Rowley
Date:
On Mon, 9 Oct 2023 at 17:37, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Sorry for not having paid more attention to this thread ... but > I'm pretty desperately unhappy with the patch as-pushed. I agree > with the criticism that this is a very repetitive coding pattern > that could have used a macro. But my real problem with this: > > + buf.data = VARDATA_ANY(sstate); > + buf.len = VARSIZE_ANY_EXHDR(sstate); > + buf.maxlen = 0; > + buf.cursor = 0; > > is that it totally breaks the StringInfo API without even > attempting to fix the API specs that it falsifies, > particularly this in stringinfo.h: > > * maxlen is the allocated size in bytes of 'data', i.e. the maximum > * string size (including the terminating '\0' char) that we can > * currently store in 'data' without having to reallocate > * more space. We must always have maxlen > len. > > I could see inventing a notion of a "read-only StringInfo" > to legitimize what you've done here, but you didn't bother > to try. I do not like this one bit. This is a fairly > fundamental API and we shouldn't be so cavalier about > breaking it. You originally called the centralised logic a "loaded foot-gun" [1], but now you're complaining about a lack of loaded foot-gun and want a macro? Which part did I misunderstand? Enlighten me, please. Here are some more thoughts on how we could improve this: 1. Adjust the definition of StringInfoData.maxlen to define that -1 means the StringInfoData's buffer is externally managed. 2. Adjust enlargeStringInfo() to add a check for maxlen = -1 and have it palloc, say, pg_next_pow2(str->len * 2) bytes and memcpy the existing (externally managed string) into the newly palloc'd buffer. 3. Add a new function along the lines of what I originally proposed to allow init of a StringInfoData using an existing allocated string which sets maxlen = -1. 4. Update all the existing places, including the ones I just committed (plus the ones you committed in ba1e066e4) to make use of the function added in #3. Better ideas? David [1] https://postgr.es/m/770055.1676183953@sss.pgh.pa.us
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
David Rowley
Date:
On Mon, 9 Oct 2023 at 21:17, David Rowley <dgrowleyml@gmail.com> wrote:
> Here are some more thoughts on how we could improve this:
>
> 1. Adjust the definition of StringInfoData.maxlen to define that -1
> means the StringInfoData's buffer is externally managed.
> 2. Adjust enlargeStringInfo() to add a check for maxlen = -1 and have
> it palloc, say, pg_next_pow2(str->len * 2) bytes and memcpy the
> existing (externally managed string) into the newly palloc'd buffer.
> 3. Add a new function along the lines of what I originally proposed to
> allow init of a StringInfoData using an existing allocated string
> which sets maxlen = -1.
> 4. Update all the existing places, including the ones I just committed
> (plus the ones you committed in ba1e066e4) to make use of the function
> added in #3.
I just spent the past few hours playing around with the attached WIP
patch to try to clean up the various places where we manually build
StringInfoDatas around the tree.
While working on this, I added an Assert in the new
initStringInfoFromStringWithLen function to ensure that data[len] ==
'\0' per the "There is guaranteed to be a terminating '\0' at
data[len]" comment in stringinfo.h. It looks like we have some
existing breakers of this rule.
If you apply the attached patch to 608fd198de~1 and ignore the
rejected hunks from the deserial functions, you'll see an Assert
failure during 023_twophase_stream.pl
023_twophase_stream_subscriber.log indicates:
TRAP: failed Assert("data[len] == '\0'"), File:
"../../../../src/include/lib/stringinfo.h", Line: 97, PID: 1073141
postgres: subscriber: logical replication parallel apply worker for
subscription 16396 (ExceptionalCondition+0x70)[0x56160451e9d0]
postgres: subscriber: logical replication parallel apply worker for
subscription 16396 (ParallelApplyWorkerMain+0x53c)[0x5616043618cc]
postgres: subscriber: logical replication parallel apply worker for
subscription 16396 (StartBackgroundWorker+0x20b)[0x56160434452b]
So it seems like we have some existing issues with
LogicalParallelApplyLoop(). The code there does not properly NUL
terminate the StringInfoData.data field. There are some examples in
exec_bind_message() of how that could be fixed. I've CC'd Amit to let
him know about this.
I'll also need to revert 608fd198 as this also highlights that setting
the StringInfoData.data to point to a bytea Datum can't be done either
as those aren't NUL terminated strings.
If people think it's worthwhile having something like the attached to
try to eliminate our need to manually build StringInfoDatas then I can
spend more time on it once LogicalParallelApplyLoop() is fixed.
David
Attachment
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
Tom Lane
Date:
David Rowley <dgrowleyml@gmail.com> writes:
> On Mon, 9 Oct 2023 at 21:17, David Rowley <dgrowleyml@gmail.com> wrote:
>> Here are some more thoughts on how we could improve this:
>>
>> 1. Adjust the definition of StringInfoData.maxlen to define that -1
>> means the StringInfoData's buffer is externally managed.
>> 2. Adjust enlargeStringInfo() to add a check for maxlen = -1 and have
>> it palloc, say, pg_next_pow2(str->len * 2) bytes and memcpy the
>> existing (externally managed string) into the newly palloc'd buffer.
>> 3. Add a new function along the lines of what I originally proposed to
>> allow init of a StringInfoData using an existing allocated string
>> which sets maxlen = -1.
>> 4. Update all the existing places, including the ones I just committed
>> (plus the ones you committed in ba1e066e4) to make use of the function
>> added in #3.
Hm. I'd be inclined to use maxlen == 0 as the indicator of a read-only
buffer, just because that would not create a problem if we ever want
to change it to an unsigned type. Other than that, I agree with the
idea of using a special maxlen value to indicate that the buffer is
read-only and not owned by the StringInfo. We need to nail down the
exact semantics though.
> While working on this, I added an Assert in the new
> initStringInfoFromStringWithLen function to ensure that data[len] ==
> '\0' per the "There is guaranteed to be a terminating '\0' at
> data[len]" comment in stringinfo.h. It looks like we have some
> existing breakers of this rule.
Ugh. The point that 608fd198d also broke the terminating-nul
convention was something that occurred to me after sending
my previous message. That's something we can't readily accommodate
within the concept of a read-only buffer, but I think we can't
give it up without risking a lot of obscure bugs.
> I'll also need to revert 608fd198 as this also highlights that setting
> the StringInfoData.data to point to a bytea Datum can't be done either
> as those aren't NUL terminated strings.
Yeah. I would revert that as a separate commit and then think about
how we want to proceed, but I generally agree that there could be
value in the idea of a setup function that accepts a caller-supplied
buffer.
regards, tom lane
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
David Rowley
Date:
On Tue, 10 Oct 2023 at 06:38, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Hm. I'd be inclined to use maxlen == 0 as the indicator of a read-only > buffer, just because that would not create a problem if we ever want > to change it to an unsigned type. Other than that, I agree with the > idea of using a special maxlen value to indicate that the buffer is > read-only and not owned by the StringInfo. We need to nail down the > exact semantics though. I've attached a slightly more worked on patch that makes maxlen == 0 mean read-only. Unsure if a macro is worthwhile there or not. The patch still fails during 023_twophase_stream.pl for the reasons mentioned upthread. Getting rid of the Assert in initStringInfoFromStringWithLen() allows it to pass. One thought I had about this is that the memory context behaviour might catch someone out at some point. Right now if you do initStringInfo() the memory context of the "data" field will be CurrentMemoryContext, but if someone does initStringInfoFromStringWithLen() and then changes to some other memory context before doing an appendStringInfo on that string, then we'll allocate "data" in whatever that memory context is. Maybe that's ok if we document it. Fixing it would mean adding a MemoryContext field to StringInfoData which would be set to CurrentMemoryContext during initStringInfo() and initStringInfoFromStringWithLen(). I'm not fully happy with the extra code added in enlargeStringInfo(). It's a little repetitive. Fixing it up would mean having to have a boolean variable to mark if the string was readonly so at the end we'd know to repalloc or palloc/memcpy. For now, I just marked that code as unlikely() since there's no place in the code base that uses it. David
Attachment
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
vignesh C
Date:
On Mon, 9 Oct 2023 at 16:20, David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Mon, 9 Oct 2023 at 21:17, David Rowley <dgrowleyml@gmail.com> wrote:
> > Here are some more thoughts on how we could improve this:
> >
> > 1. Adjust the definition of StringInfoData.maxlen to define that -1
> > means the StringInfoData's buffer is externally managed.
> > 2. Adjust enlargeStringInfo() to add a check for maxlen = -1 and have
> > it palloc, say, pg_next_pow2(str->len * 2) bytes and memcpy the
> > existing (externally managed string) into the newly palloc'd buffer.
> > 3. Add a new function along the lines of what I originally proposed to
> > allow init of a StringInfoData using an existing allocated string
> > which sets maxlen = -1.
> > 4. Update all the existing places, including the ones I just committed
> > (plus the ones you committed in ba1e066e4) to make use of the function
> > added in #3.
>
> I just spent the past few hours playing around with the attached WIP
> patch to try to clean up the various places where we manually build
> StringInfoDatas around the tree.
>
> While working on this, I added an Assert in the new
> initStringInfoFromStringWithLen function to ensure that data[len] ==
> '\0' per the "There is guaranteed to be a terminating '\0' at
> data[len]" comment in stringinfo.h. It looks like we have some
> existing breakers of this rule.
>
> If you apply the attached patch to 608fd198de~1 and ignore the
> rejected hunks from the deserial functions, you'll see an Assert
> failure during 023_twophase_stream.pl
>
> 023_twophase_stream_subscriber.log indicates:
> TRAP: failed Assert("data[len] == '\0'"), File:
> "../../../../src/include/lib/stringinfo.h", Line: 97, PID: 1073141
> postgres: subscriber: logical replication parallel apply worker for
> subscription 16396 (ExceptionalCondition+0x70)[0x56160451e9d0]
> postgres: subscriber: logical replication parallel apply worker for
> subscription 16396 (ParallelApplyWorkerMain+0x53c)[0x5616043618cc]
> postgres: subscriber: logical replication parallel apply worker for
> subscription 16396 (StartBackgroundWorker+0x20b)[0x56160434452b]
>
> So it seems like we have some existing issues with
> LogicalParallelApplyLoop(). The code there does not properly NUL
> terminate the StringInfoData.data field. There are some examples in
> exec_bind_message() of how that could be fixed. I've CC'd Amit to let
> him know about this.
Thanks for reporting this issue, I was able to reproduce this issue
with the steps provided. I will analyze further and start a new thread
to provide the details of the same.
Regards,
Vignesh
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
Tom Lane
Date:
David Rowley <dgrowleyml@gmail.com> writes:
> I've attached a slightly more worked on patch that makes maxlen == 0
> mean read-only. Unsure if a macro is worthwhile there or not.
A few thoughts:
* initStringInfoFromStringWithLen() is kind of a mouthful.
How about "initStringInfoWithBuf", or something like that?
* logicalrep_read_tuple is doing something different from these
other callers: it's creating a *fully valid* StringInfo that
could be enlarged via repalloc. (Whether anything downstream
depends on that, I dunno.) Is it worth having two new init
functions, one that has that spec and initializes maxlen
appropriately, and the other that sets maxlen to 0?
* I think that this bit in the new enlargeStringInfo code path
is wrong:
+ newlen = pg_nextpower2_32(str->len) * 2;
+ while (needed > newlen)
+ newlen = 2 * newlen;
In the admittedly-unlikely case that str->len is more than half a GB
to start with, pg_nextpower2_32() will round up to 1GB and then the *2
overflows. I think you should make this just
+ newlen = pg_nextpower2_32(str->len);
+ while (needed > newlen)
+ newlen = 2 * newlen;
It's fairly likely that this path will never be taken at all,
so trying to shave a cycle or two seems unnecessary.
> One thought I had about this is that the memory context behaviour
> might catch someone out at some point. Right now if you do
> initStringInfo() the memory context of the "data" field will be
> CurrentMemoryContext, but if someone does
> initStringInfoFromStringWithLen() and then changes to some other
> memory context before doing an appendStringInfo on that string, then
> we'll allocate "data" in whatever that memory context is. Maybe that's
> ok if we document it. Fixing it would mean adding a MemoryContext
> field to StringInfoData which would be set to CurrentMemoryContext
> during initStringInfo() and initStringInfoFromStringWithLen().
I think documenting it is sufficient. I don't really foresee use-cases
where the string would get enlarged, anyway.
On the whole, I wonder about the value of allowing such a StringInfo to be
enlarged at all. If we are defining the case as being a "read only"
buffer, under what circumstances would it be useful to enlarge it?
I'm tempted to suggest that we should just Assert(maxlen > 0) in
enlargeStringInfo, and anywhere else in stringinfo.c that modifies
the buffer. That also removes the concern about which context the
enlargement would happen in.
I'm not really happy with what you did documentation-wise in
stringinfo.h. I suggest more like
* StringInfoData holds information about an extensible string.
* data is the current buffer for the string (allocated with palloc).
* len is the current string length. There is guaranteed to be
* a terminating '\0' at data[len], although this is not very
* useful when the string holds binary data rather than text.
* maxlen is the allocated size in bytes of 'data', i.e. the maximum
* string size (including the terminating '\0' char) that we can
* currently store in 'data' without having to reallocate
-* more space. We must always have maxlen > len, except
+* in the read-only case described below.
* cursor is initialized to zero by makeStringInfo or initStringInfo,
* but is not otherwise touched by the stringinfo.c routines.
* Some routines use it to scan through a StringInfo.
+*
+* As a special case, a StringInfoData can be initialized with a read-only
+* string buffer. In this case "data" does not necessarily point at a
+* palloc'd chunk, and management of the buffer storage is the caller's
+* responsibility. maxlen is set to zero to indicate that this is the case.
Also, the following comment block asserting that there are "two ways"
to initialize a StringInfo needs work, and I guess so does the above-
cited comment about the cursor field.
regards, tom lane
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
David Rowley
Date:
On Wed, 11 Oct 2023 at 08:52, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > David Rowley <dgrowleyml@gmail.com> writes: > > I've attached a slightly more worked on patch that makes maxlen == 0 > > mean read-only. Unsure if a macro is worthwhile there or not. > > A few thoughts: Thank you for the review. I spent more time on this and did end up with 2 new init functions as you mentioned. One for strictly read-only (initReadOnlyStringInfo), which cannot be appended to, and as you mentioned, another (initStringInfoFromString) which can accept a palloc'd buffer which becomes managed by the stringinfo code. I know these names aren't exactly as you mentioned. I'm open to adjusting still. This means I got rid of the read-only conversion code in enlargeStringInfo(). I didn't do anything to try to handle buffer enlargement more efficiently in enlargeStringInfo() for the case where initStringInfoFromString sets maxlen to some non-power-of-2. The doubling code seems like it'll work ok without power-of-2 values, it'll just end up calling repalloc() with non-power-of-2 values. I did also wonder if resetStringInfo() would have any business touching the existing buffer in a read-only StringInfo and came to the conclusion that it wouldn't be very read-only if we allowed resetStringInfo() to do its thing on it. I added an Assert to fail if resetStringInfo() receives a read-only StringInfo. Also, since it's still being discussed, I left out the adjustment to LogicalParallelApplyLoop(). That also allows the tests to pass without the failing Assert that was checking for the NUL terminator. David
Attachment
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
Tom Lane
Date:
David Rowley <dgrowleyml@gmail.com> writes:
> I spent more time on this and did end up with 2 new init functions as
> you mentioned. One for strictly read-only (initReadOnlyStringInfo),
> which cannot be appended to, and as you mentioned, another
> (initStringInfoFromString) which can accept a palloc'd buffer which
> becomes managed by the stringinfo code. I know these names aren't
> exactly as you mentioned. I'm open to adjusting still.
This v3 looks pretty decent, although I noted one significant error
and a few minor issues:
* in initStringInfoFromString, str->maxlen must be set to len+1 not len
* comment in exec_bind_message doesn't look like pgindent will like it
* same in record_recv, plus it has a misspelling "Initalize"
* in stringinfo.c, inclusion of pg_bitutils.h seems no longer needed
I guess the next question is whether we want to stop here or
try to relax the requirement about NUL-termination. I'd be inclined
to call that a separate issue deserving a separate commit, so maybe
we should go ahead and commit this much anyway.
regards, tom lane
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
David Rowley
Date:
On Mon, 16 Oct 2023 at 05:56, Tom Lane <tgl@sss.pgh.pa.us> wrote: > * in initStringInfoFromString, str->maxlen must be set to len+1 not len > > * comment in exec_bind_message doesn't look like pgindent will like it > > * same in record_recv, plus it has a misspelling "Initalize" > > * in stringinfo.c, inclusion of pg_bitutils.h seems no longer needed Thank you for looking again. I've addressed all of these in the attached. > I guess the next question is whether we want to stop here or > try to relax the requirement about NUL-termination. I'd be inclined > to call that a separate issue deserving a separate commit, so maybe > we should go ahead and commit this much anyway. I am keen to see this relaxed. I agree that a separate effort is best. David
Attachment
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
David Rowley
Date:
On Tue, 17 Oct 2023 at 20:39, David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Mon, 16 Oct 2023 at 05:56, Tom Lane <tgl@sss.pgh.pa.us> wrote:
> > I guess the next question is whether we want to stop here or
> > try to relax the requirement about NUL-termination. I'd be inclined
> > to call that a separate issue deserving a separate commit, so maybe
> > we should go ahead and commit this much anyway.
>
> I am keen to see this relaxed. I agree that a separate effort is best.
I looked at the latest posted patch again today with thoughts about
pushing it but there's something I'm a bit unhappy with that makes me
think we should maybe do the NUL-termination relaxation in the same
commit.
The problem is in LogicalRepApplyLoop() the current patch adjusts the
manual building of the StringInfoData to make use of
initReadOnlyStringInfo() instead. The problem I have with that is that
the string that's given to initReadOnlyStringInfo() comes from
walrcv_receive() and on looking at the API spec for walrcv_receive_fn
I see:
/*
* walrcv_receive_fn
*
* Receive a message available from the WAL stream. 'buffer' is a pointer
* to a buffer holding the message received. Returns the length of the data,
* 0 if no data is available yet ('wait_fd' is a socket descriptor which can
* be waited on before a retry), and -1 if the cluster ended the COPY.
*/
i.e, no mention that the buffer will be NUL terminated upon return.
Looking at pqGetCopyData3(), is see the buffer does get NUL
terminated, but without the API spec mentioning this I'm not feeling
good about going ahead with wrapping that up in
initReadOnlyStringInfo() which Asserts the buffer will be NUL
terminated.
I've attached a patch which builds on the previous patch and relaxes
the rule that the StringInfo must be NUL-terminated. The rule is
only relaxed for StringInfos that are initialized with
initReadOnlyStringInfo. On working on this I went over the locations
where we've added code to add a '\0' char to the buffer. If you look
at, for example, record_recv() and array_agg_deserialize() in master,
we modify the StringInfo's data to set a \0 at the end of the string.
I've removed that code as I *believe* this isn't required for the
type's receive function.
There's also an existing confusing comment in logicalrep_read_tuple()
which seems to think we're just setting the NUL terminator to conform
to StringInfo's practises. This is misleading as the NUL is required
for LOGICALREP_COLUMN_TEXT mode as we use the type's input function
instead of the receive function. You don't have to look very hard to
find an input function that needs a NUL terminator.
I'm a bit less confident that the type's receive function will never
need to be NUL terminated. cstring_recv() came to mind as one I should
look at, but on looking I see it's not required as it just reads the
remaining bytes from the input StringInfo. Is it safe to assume this?
or could there be some UDF receive function which requires this?
David
Attachment
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
Tom Lane
Date:
David Rowley <dgrowleyml@gmail.com> writes:
> I've attached a patch which builds on the previous patch and relaxes
> the rule that the StringInfo must be NUL-terminated. The rule is
> only relaxed for StringInfos that are initialized with
> initReadOnlyStringInfo.
Yeah, that's probably a reasonable way to frame it.
> There's also an existing confusing comment in logicalrep_read_tuple()
> which seems to think we're just setting the NUL terminator to conform
> to StringInfo's practises. This is misleading as the NUL is required
> for LOGICALREP_COLUMN_TEXT mode as we use the type's input function
> instead of the receive function. You don't have to look very hard to
> find an input function that needs a NUL terminator.
Right, input functions are likely to expect this.
> I'm a bit less confident that the type's receive function will never
> need to be NUL terminated. cstring_recv() came to mind as one I should
> look at, but on looking I see it's not required as it just reads the
> remaining bytes from the input StringInfo. Is it safe to assume this?
I think that we can make that assumption starting with v17.
Back-patching it would be hazardous perhaps; but if there's some
function out there that depends on NUL termination, testing should
expose it before too long. Wouldn't hurt to mention this explicitly
as a possible incompatibility in the commit message.
Looking over the v5 patch, I have some nits:
* In logicalrep_read_tuple,
s/input function require that/input functions require that/
(or fix the grammatical disagreement some other way)
* In exec_bind_message, you removed the comment pointing out that
we are scribbling directly on the message buffer, even though
we still are. This patch does nothing to make that any safer,
so I object to removing the comment.
* In stringinfo.h, I'd suggest adding text more or less like this
within or at the end of the "As a special case, ..." para in
the first large comment block:
* Also, it is caller's option whether a read-only string buffer has
* a terminating '\0' or not. This depends on the intended usage.
That's partially redundant with some other comments, but this para
is defining the API for read-only buffers, so I think it would
be good to include it here.
regards, tom lane
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
David Rowley
Date:
On Thu, 26 Oct 2023 at 08:43, Tom Lane <tgl@sss.pgh.pa.us> wrote: > I think that we can make that assumption starting with v17. > Back-patching it would be hazardous perhaps; but if there's some > function out there that depends on NUL termination, testing should > expose it before too long. Wouldn't hurt to mention this explicitly > as a possible incompatibility in the commit message. > > Looking over the v5 patch, I have some nits: Thanks for looking at this again. I fixed up each of those and pushed the result, mentioning the incompatibility in the commit message. Now that that's done, I've attached a patch which makes use of the new initReadOnlyStringInfo initializer function for the original case mentioned when I opened this thread. I don't think there are any remaining objections to this, but I'll let it sit for a bit to see. David
Attachment
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
David Rowley
Date:
On Thu, 26 Oct 2023 at 17:00, David Rowley <dgrowleyml@gmail.com> wrote: > Thanks for looking at this again. I fixed up each of those and pushed > the result, mentioning the incompatibility in the commit message. > > Now that that's done, I've attached a patch which makes use of the new > initReadOnlyStringInfo initializer function for the original case > mentioned when I opened this thread. I don't think there are any > remaining objections to this, but I'll let it sit for a bit to see. I've just pushed the deserial function optimisation patch. I was just looking at a few other places where we might want to make use of initReadOnlyStringInfo. * parallel.c in HandleParallelMessages(): Drilling into HandleParallelMessage(), I see the PqMsg_BackendKeyData case just reads a fixed number of bytes. In some of the other "switch" cases, I see calls pq_getmsgrawstring() either directly or indirectly. I see the counterpart to pq_getmsgrawstring() is pq_sendstring() which always appends the NUL char to the StringInfo, so I don't think not NUL terminating the received bytes is a problem as cstrings seem to be sent with the NUL terminator. This case just seems to handle ERROR/NOTICE messages coming from parallel workers. Not tuples themselves. It may not be that interesting a case to speed up. * applyparallelworker.c in HandleParallelApplyMessages(): Drilling into HandleParallelApplyMessage(), I don't see anything there that needs the input StringInfo to be NUL terminated. * worker.c in apply_spooled_messages(): Drilling into apply_dispatch() and going through each of the cases, I see logicalrep_read_tuple() pallocs a new buffer and ensures it's always NUL terminated which will be required in LOGICALREP_COLUMN_TEXT mode. (There seems to be further optimisation opportunities there where we could not do the palloc when in LOGICALREP_COLUMN_BINARY mode and just point value's buffer directly to the correct portion of the input StringInfo's buffer). * walreceiver.c in XLogWalRcvProcessMsg(): Nothing there seems to require the incoming_message StringInfo to have a NUL terminator. I imagine this one is the most worthwhile to do out of the 4. I've not tested to see if there are any performance improvements. Does anyone see any reason why we can't do the attached? David
Attachment
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
Amit Kapila
Date:
On Fri, Oct 27, 2023 at 3:23 AM David Rowley <dgrowleyml@gmail.com> wrote: > > On Thu, 26 Oct 2023 at 17:00, David Rowley <dgrowleyml@gmail.com> wrote: > > Thanks for looking at this again. I fixed up each of those and pushed > > the result, mentioning the incompatibility in the commit message. > > > > Now that that's done, I've attached a patch which makes use of the new > > initReadOnlyStringInfo initializer function for the original case > > mentioned when I opened this thread. I don't think there are any > > remaining objections to this, but I'll let it sit for a bit to see. > > I've just pushed the deserial function optimisation patch. > > I was just looking at a few other places where we might want to make > use of initReadOnlyStringInfo. > > * parallel.c in HandleParallelMessages(): > > Drilling into HandleParallelMessage(), I see the PqMsg_BackendKeyData > case just reads a fixed number of bytes. In some of the other > "switch" cases, I see calls pq_getmsgrawstring() either directly or > indirectly. I see the counterpart to pq_getmsgrawstring() is > pq_sendstring() which always appends the NUL char to the StringInfo, > so I don't think not NUL terminating the received bytes is a problem > as cstrings seem to be sent with the NUL terminator. > > This case just seems to handle ERROR/NOTICE messages coming from > parallel workers. Not tuples themselves. It may not be that > interesting a case to speed up. > > * applyparallelworker.c in HandleParallelApplyMessages(): > > Drilling into HandleParallelApplyMessage(), I don't see anything there > that needs the input StringInfo to be NUL terminated. > Both the above calls are used to handle ERROR/NOTICE messages from parallel workers as you have also noticed. The comment atop initReadOnlyStringInfo() clearly states that it is used in the performance-critical path. So, is it worth changing these places? In the future, this may pose the risk of this API being used inconsistently. -- With Regards, Amit Kapila.
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
David Rowley
Date:
On Mon, 30 Oct 2023 at 23:48, Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Fri, Oct 27, 2023 at 3:23 AM David Rowley <dgrowleyml@gmail.com> wrote: > > * parallel.c in HandleParallelMessages(): > > * applyparallelworker.c in HandleParallelApplyMessages(): > > Both the above calls are used to handle ERROR/NOTICE messages from > parallel workers as you have also noticed. The comment atop > initReadOnlyStringInfo() clearly states that it is used in the > performance-critical path. So, is it worth changing these places? In > the future, this may pose the risk of this API being used > inconsistently. I'm ok to leave those ones out. But just a note on the performance side, if we go around needlessly doing palloc/memcpy then we'll be flushing possibly useful cachelines out and cause slowdowns elsewhere. That's a pretty hard thing to quantify, but something to keep in mind. David
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
Amit Kapila
Date:
On Tue, Oct 31, 2023 at 2:25 AM David Rowley <dgrowleyml@gmail.com> wrote: > > On Mon, 30 Oct 2023 at 23:48, Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Fri, Oct 27, 2023 at 3:23 AM David Rowley <dgrowleyml@gmail.com> wrote: > > > * parallel.c in HandleParallelMessages(): > > > * applyparallelworker.c in HandleParallelApplyMessages(): > > > > Both the above calls are used to handle ERROR/NOTICE messages from > > parallel workers as you have also noticed. The comment atop > > initReadOnlyStringInfo() clearly states that it is used in the > > performance-critical path. So, is it worth changing these places? In > > the future, this may pose the risk of this API being used > > inconsistently. > > I'm ok to leave those ones out. > The other two look good to me. -- With Regards, Amit Kapila.
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
David Rowley
Date:
On Thu, 2 Nov 2023 at 22:42, Amit Kapila <amit.kapila16@gmail.com> wrote: > The other two look good to me. Thanks for looking. I spent some time trying to see if the performance changes much with either of these cases. For the XLogWalRcvProcessMsg() I was unable to measure any difference even when replaying inserts into a table with a single int4 column and no indexes. I think that change is worthwhile regardless as it allows us to get rid of a global variable. I was tempted to shorten the name of that variable a bit since it's now local, but didn't as it causes a bit more churn. For the apply_spooled_messages() change, I tried logical decoding but quickly saw apply_spooled_messages() isn't the normal case. I didn't quite find a test case that caused the changes to be serialized to a file, but I do see that the number of bytes can be large so thought that it's worthwhile saving the memcpy for that case. I pushed those two changes. David
Re: Making aggregate deserialization (and WAL receive) functions slightly faster
From
Amit Kapila
Date:
On Tue, Nov 7, 2023 at 3:56 AM David Rowley <dgrowleyml@gmail.com> wrote: > > On Thu, 2 Nov 2023 at 22:42, Amit Kapila <amit.kapila16@gmail.com> wrote: > > The other two look good to me. > > Thanks for looking. > > I spent some time trying to see if the performance changes much with > either of these cases. For the XLogWalRcvProcessMsg() I was unable to > measure any difference even when replaying inserts into a table with a > single int4 column and no indexes. I think that change is worthwhile > regardless as it allows us to get rid of a global variable. I was > tempted to shorten the name of that variable a bit since it's now > local, but didn't as it causes a bit more churn. > > For the apply_spooled_messages() change, I tried logical decoding but > quickly saw apply_spooled_messages() isn't the normal case. I didn't > quite find a test case that caused the changes to be serialized to a > file, but I do see that the number of bytes can be large so thought > that it's worthwhile saving the memcpy for that case. > Yeah, and another reason is that the usage of StringInfo becomes consistent with LogicalRepApplyLoop(). One can always configure the lower value of logical_decoding_work_mem or use debug_logical_replication_streaming for a smaller number of changes to follow that code path. But I am not sure how much practically it will help because we are anyway reading file to apply the changes. -- With Regards, Amit Kapila.