Thread: Todo: Teach planner to evaluate multiple windows in the optimal order
Hi,
While looking at one of the todo item in Window function, namely:
Teach planner to evaluate multiple windows in the optimal order Currently windows are always evaluated in the query-specified order.
From threads, relevant points.
Point #1
and Point #2In the above query Oracle 10g performs 2 sorts, DB2 and Sybase perform 3sorts. We also perform 3.
Repro:Teach planner to decide which window to evaluate first based on costs.
Currently the first window in the query is evaluated first, there may be no
index to help sort the first window, but perhaps there are for other windows
in the query. This may allow an index scan instead of a seqscan -> sort.
select pg_catalog.version();
version
----------------------------------------------------------------------------------------------------
PostgreSQL 16devel on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 12.2.0-3ubuntu1) 12.2.0, 64-bit
(1 row)
create table empsalary(depname text, empno int, salary int);
insert into empsalary values (select substr(md5(random()::text), 0, 25), generate_series(1,10), generate_series(10000,12000));
explain SELECT depname, SUM(salary) OVER (ORDER BY salary), SUM(salary) OVER (ORDER BY empno) FROM empsalary ORDER BY salary;
QUERY PLAN
--------------------------------------------------------------------------------------
WindowAgg (cost=289.47..324.48 rows=2001 width=49)
-> Sort (cost=289.47..294.47 rows=2001 width=41)
Sort Key: salary
-> WindowAgg (cost=144.73..179.75 rows=2001 width=41)
-> Sort (cost=144.73..149.73 rows=2001 width=33)
Sort Key: empno
-> Seq Scan on empsalary (cost=0.00..35.01 rows=2001 width=33)
(7 rows)
As it is seen, for case #1, issue looks like resolved and only 2 sorts are performed.
For #2, index col ordering is changed.
create index idx_emp on empsalary (empno);
explain SELECT depname, SUM(salary) OVER (ORDER BY salary), SUM(salary) OVER (ORDER BY empno) FROM empsalary ORDER BY salary;
QUERY PLAN
------------------------------------------------------------------------------------------------
WindowAgg (cost=204.03..239.04 rows=2001 width=49)
-> Sort (cost=204.03..209.03 rows=2001 width=41)
Sort Key: salary
-> WindowAgg (cost=0.28..94.31 rows=2001 width=41)
-> Index Scan using idx_emp on empsalary (cost=0.28..64.29 rows=2001 width=33)
(5 rows)
explain SELECT depname, SUM(salary) OVER (ORDER BY empno), SUM(salary) OVER (ORDER BY salary) FROM empsalary ORDER BY salary;
QUERY PLAN
------------------------------------------------------------------------------------------------
WindowAgg (cost=204.03..239.04 rows=2001 width=49)
-> Sort (cost=204.03..209.03 rows=2001 width=41)
Sort Key: salary
-> WindowAgg (cost=0.28..94.31 rows=2001 width=41)
-> Index Scan using idx_emp on empsalary (cost=0.28..64.29 rows=2001 width=33)
(5 rows)
In both cases, index scan is performed, which means this issue is resolved as well.
Is this todo still relevant?
Further down the threads:
I do think the patch has probably left some low-hanging fruit on the
simpler end of the difficulty spectrum, namely when the window stuff
requires only one ordering that could be done either explicitly or
by an indexscan. That choice should ideally be done with a proper
cost comparison taking any LIMIT into account. I think right now
the LIMIT might not be accounted for, or might be considered even
when it shouldn't be because another sort is needed anyway.
I am not sure if I understand this fully but does it means proposed todo (to use indexes) should be refined to
teach planner to take into account of cost model while deciding to use index or not in window functions? Meaning not always go with index route (modify point #2)?
-- Regards, Ankit Kumar Pandey
On Mon, 26 Dec 2022 at 02:04, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: > Point #1 > > In the above query Oracle 10g performs 2 sorts, DB2 and Sybase perform 3 > sorts. We also perform 3. This shouldn't be too hard to do. See the code in select_active_windows(). You'll likely want to pay attention to the DISTINCT pathkeys if they exist and just use the ORDER BY pathkeys if the query has no DISTINCT clause. DISTINCT is evaluated after Window and before ORDER BY. One idea to implement this would be to adjust the loop in select_active_windows() so that we record any WindowClauses which have the pathkeys contained in the ORDER BY / DISTINCT pathkeys then record those separately and append those onto the end of the actives array after the sort. I do think you'll likely want to put any WindowClauses which have pathkeys which are a true subset or true superset of the ORDER BY / DISTINCT pathkeys last. If they're a superset then we won't need to perform any additional ordering for the DISTINCT / ORDER BY clause. If they're a subset then we might be able to perform an Incremental Sort, which is likely much cheaper than a full sort. The existing code should handle that part. You just need to make select_active_windows() more intelligent. You might also think that we could perform additional optimisations and also adjust the ORDER BY clause of a WindowClause if it contains the pathkeys of the DISTINCT / ORDER BY clause. For example: SELECT *,row_number() over (order by a,b) from tab order by a,b,c; However, if you were to adjust the WindowClauses ORDER BY to become a,b,c then you could produce incorrect results for window functions that change their result based on peer rows. Note the difference in results from: create table ab(a int, b int); insert into ab select x,y from generate_series(1,5) x, generate_Series(1,5)y; select a,b,count(*) over (order by a) from ab order by a,b; select a,b,count(*) over (order by a,b) from ab order by a,b; > and Point #2 > > Teach planner to decide which window to evaluate first based on costs. > Currently the first window in the query is evaluated first, there may be no > index to help sort the first window, but perhaps there are for other windows > in the query. This may allow an index scan instead of a seqscan -> sort. What Tom wrote about that in the first paragraph of [1] still applies. The problem is that if the query contains many joins that to properly find the cheapest way of executing the query we'd have to perform the join search once for each unique sort order of each WindowClause. That's just not practical to do from a performance standpoint. The join search can be very expensive. There may be something that could be done to better determine the most likely candidate for the first WindowClause using some heuristics, but I've no idea what those would be. You should look into point #1 first. Point #2 is significantly more difficult to solve in a way that would be acceptable to the project. David [1] https://www.postgresql.org/message-id/11535.1230501658%40sss.pgh.pa.us
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
On 03/01/23 08:21, David Rowley wrote: > On Mon, 26 Dec 2022 at 02:04, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: >> Point #1 >> >> In the above query Oracle 10g performs 2 sorts, DB2 and Sybase perform 3 >> sorts. We also perform 3. > This shouldn't be too hard to do. See the code in > select_active_windows(). You'll likely want to pay attention to the > DISTINCT pathkeys if they exist and just use the ORDER BY pathkeys if > the query has no DISTINCT clause. DISTINCT is evaluated after Window > and before ORDER BY. > > One idea to implement this would be to adjust the loop in > select_active_windows() so that we record any WindowClauses which have > the pathkeys contained in the ORDER BY / DISTINCT pathkeys then record > those separately and append those onto the end of the actives array > after the sort. > > I do think you'll likely want to put any WindowClauses which have > pathkeys which are a true subset or true superset of the ORDER BY / > DISTINCT pathkeys last. If they're a superset then we won't need to > perform any additional ordering for the DISTINCT / ORDER BY clause. > If they're a subset then we might be able to perform an Incremental > Sort, which is likely much cheaper than a full sort. The existing > code should handle that part. You just need to make > select_active_windows() more intelligent. > > You might also think that we could perform additional optimisations > and also adjust the ORDER BY clause of a WindowClause if it contains > the pathkeys of the DISTINCT / ORDER BY clause. For example: > > SELECT *,row_number() over (order by a,b) from tab order by a,b,c; > > However, if you were to adjust the WindowClauses ORDER BY to become > a,b,c then you could produce incorrect results for window functions > that change their result based on peer rows. > > Note the difference in results from: > > create table ab(a int, b int); > insert into ab select x,y from generate_series(1,5) x, generate_Series(1,5)y; > > select a,b,count(*) over (order by a) from ab order by a,b; > select a,b,count(*) over (order by a,b) from ab order by a,b; > Thanks, let me try this. >> and Point #2 >> >> Teach planner to decide which window to evaluate first based on costs. >> Currently the first window in the query is evaluated first, there may be no >> index to help sort the first window, but perhaps there are for other windows >> in the query. This may allow an index scan instead of a seqscan -> sort. > What Tom wrote about that in the first paragraph of [1] still applies. > The problem is that if the query contains many joins that to properly > find the cheapest way of executing the query we'd have to perform the > join search once for each unique sort order of each WindowClause. > That's just not practical to do from a performance standpoint. The > join search can be very expensive. There may be something that could > be done to better determine the most likely candidate for the first > WindowClause using some heuristics, but I've no idea what those would > be. You should look into point #1 first. Point #2 is significantly > more difficult to solve in a way that would be acceptable to the > project. > Okay, leaving this out for now. -- Regards, Ankit Kumar Pandey
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
Hi,
I do think you'll likely want to put any WindowClauses which have pathkeys which are a true subset or true superset of the ORDER BY / DISTINCT pathkeys last. If they're a superset then we won't need to perform any additional ordering for the DISTINCT / ORDER BY clause. If they're a subset then we might be able to perform an Incremental Sort, which is likely much cheaper than a full sort. The existing code should handle that part. You just need to make select_active_windows() more intelligent.
I think current implementation does exactly this.
#1. If order by clause in the window function is subset of order by in query
create table abcd(a int, b int, c int, d int);
insert into abcd select x,y,z,c from generate_series(1,5) x, generate_Series(1,5)y, generate_Series(1,5) z, generate_Series(1,5) c;
explain analyze select a,row_number() over (order by b),count(*) over (order by a,b) from abcd order by a,b,c;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
-------- Incremental Sort (cost=80.32..114.56 rows=625 width=28) (actual time=1.440..3.311 rows=625 loops=1) Sort Key: a, b, c Presorted Key: a, b Full-sort Groups: 13 Sort Method: quicksort Average Memory: 28kB Peak Memory: 28kB -> WindowAgg (cost=79.24..91.74 rows=625 width=28) (actual time=1.272..2.567 rows=625 loops=1) -> Sort (cost=79.24..80.80 rows=625 width=20) (actual time=1.233..1.296 rows=625 loops=1) Sort Key: a, b Sort Method: quicksort Memory: 64kB -> WindowAgg (cost=39.27..50.21 rows=625 width=20) (actual time=0.304..0.786 rows=625 loops=1) -> Sort (cost=39.27..40.84 rows=625 width=12) (actual time=0.300..0.354 rows=625 loops=1) Sort Key: b Sort Method: quicksort Memory: 54kB -> Seq Scan on abcd (cost=0.00..10.25 rows=625 width=12) (actual time=0.021..0.161 rows=625 l
oops=1) Planning Time: 0.068 ms Execution Time: 3.509 ms
(15 rows)
Here, as window function (row count) has two cols a, b for order by, incremental sort is performed for remaining col in query,
which makes sense.
#2. If order by clause in the Window function is superset of order by in query
explain analyze select a,row_number() over (order by a,b,c),count(*) over (order by a,b) from abcd order by a;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------- WindowAgg (cost=39.27..64.27 rows=625 width=28) (actual time=1.089..3.020 rows=625 loops=1) -> WindowAgg (cost=39.27..53.34 rows=625 width=20) (actual time=1.024..1.635 rows=625 loops=1) -> Sort (cost=39.27..40.84 rows=625 width=12) (actual time=1.019..1.084 rows=625 loops=1) Sort Key: a, b, c Sort Method: quicksort Memory: 54kB -> Seq Scan on abcd (cost=0.00..10.25 rows=625 width=12) (actual time=0.023..0.265 rows=625 loops=1) Planning Time: 0.071 ms Execution Time: 3.156 ms
(8 rows)
No, additional sort is needed to be performed in this case, as you referred.
On 03/01/23 08:21, David Rowley wrote:If they're a superset then we won't need to perform any additional ordering for the DISTINCT / ORDER BY clause.If they're a subset then we might be able to perform an Incremental Sort, which is likely much cheaper than a full sort.
So question is, how current implementation is different from desired one?
-- Regards, Ankit Kumar Pandey
On Wed, 4 Jan 2023 at 03:11, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: > #2. If order by clause in the Window function is superset of order by in query > > explain analyze select a,row_number() over (order by a,b,c),count(*) over (order by a,b) from abcd order by a; > > QUERY PLAN > ---------------------------------------------------------------------------------------------------------------------- > WindowAgg (cost=39.27..64.27 rows=625 width=28) (actual time=1.089..3.020 rows=625 loops=1) > -> WindowAgg (cost=39.27..53.34 rows=625 width=20) (actual time=1.024..1.635 rows=625 loops=1) > -> Sort (cost=39.27..40.84 rows=625 width=12) (actual time=1.019..1.084 rows=625 loops=1) > Sort Key: a, b, c > Sort Method: quicksort Memory: 54kB > -> Seq Scan on abcd (cost=0.00..10.25 rows=625 width=12) (actual time=0.023..0.265 rows=625 loops=1) > Planning Time: 0.071 ms > Execution Time: 3.156 ms > (8 rows) > > No, additional sort is needed to be performed in this case, as you referred. It looks like that works by accident. I see no mention of this either in the comments or in [1]. What seems to be going on is that common_prefix_cmp() is coded in such a way that the WindowClauses end up ordered by the highest tleSortGroupRef first, resulting in the lowest order tleSortGroupRefs being the last WindowAgg to be processed. We do transformSortClause() before transformWindowDefinitions(), this is where the tleSortGroupRef indexes are assigned, so the ORDER BY clause will have a lower tleSortGroupRef than the WindowClauses. If we don't have one already, then we should likely add a regression test that ensures that this remains true. Since it does not seem to be documented in the code anywhere, it seems like something that could easily be overlooked if we were to ever refactor that code. I just tried moving the calls to transformWindowDefinitions() so that they come before transformSortClause() and our regression tests still pass. That's not great. With that change, the following query has an additional sort for the ORDER BY clause which previously wasn't done. explain select a,b,c,row_number() over (order by a) rn1, row_number() over(partition by b) rn2, row_number() over (order by c) from abc order by b; David [1] https://www.postgresql.org/message-id/flat/124A7F69-84CD-435B-BA0E-2695BE21E5C2%40yesql.se
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
It looks like that works by accident. I see no mention of this either in the comments or in [1].
This kind of troubles me because function name select_active_windows doesn't tell me if its only job is
to reorder window clauses for optimizing sort. From code, I don't see it doing anything else either.
If we don't have one already, then we should likely add a regression test that ensures that this remains true. Since it does not seem to be documented in the code anywhere, it seems like something that could easily be overlooked if we were to ever refactor that code.
I don't see any tests in windows specific to sorting operation (and in what order). I will add those.
Also, one thing, consider the following query:
explain analyze select row_number() over (order by a,b),count(*) over (order by a) from abcd order by a,b,c;
In this case, sorting is done on (a,b) followed by incremental sort on c at final stage.
If we do just one sort: a,b,c at first stage then there won't be need to do another sort (incremental one).
Now, I am not sure if which one would be faster: sorting (a,b,c) vs sort(a,b) + incremental sort(c)
because even though datum sort is fast, there can be n number of combos where we won't be doing that.
I might be looking at extreme corner cases though but still wanted to share.
-- Regards, Ankit Kumar Pandey
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
Attaching test cases for this (+ small change in doc). Tested this in one of WIP branch where I had modified select_active_windows and it failed as expected. Please let me know if something can be improved in this. Regards, Ankit Kumar Pandey
Attachment
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
On 05/01/23 07:48, Vik Fearing wrote: > On 1/4/23 13:07, Ankit Kumar Pandey wrote: >> Also, one thing, consider the following query: >> >> explain analyze select row_number() over (order by a,b),count(*) over >> (order by a) from abcd order by a,b,c; >> >> In this case, sorting is done on (a,b) followed by incremental sort >> on c at final stage. >> >> If we do just one sort: a,b,c at first stage then there won't be need >> to do another sort (incremental one). > > > This could give incorrect results. Consider the following query: > > postgres=# select a, b, c, rank() over (order by a, b) > from (values (1, 2, 1), (1, 2, 2), (1, 2, 1)) as abcd (a, b, c) > order by a, b, c; > > a | b | c | rank > ---+---+---+------ > 1 | 2 | 1 | 1 > 1 | 2 | 1 | 1 > 1 | 2 | 2 | 1 > (3 rows) > > > If you change the window's ordering like you suggest, you get this > different result: > > > postgres=# select a, b, c, rank() over (order by a, b, c) > from (values (1, 2, 1), (1, 2, 2), (1, 2, 1)) as abcd (a, b, c) > order by a, b, c; > > a | b | c | rank > ---+---+---+------ > 1 | 2 | 1 | 1 > 1 | 2 | 1 | 1 > 1 | 2 | 2 | 3 > (3 rows) > > We are already doing something like I mentioned. Consider this example: explain SELECT rank() OVER (ORDER BY a), count(*) OVER (ORDER BY a,b) FROM abcd; QUERY PLAN -------------------------------------------------------------------------- WindowAgg (cost=83.80..127.55 rows=1250 width=24) -> WindowAgg (cost=83.80..108.80 rows=1250 width=16) -> Sort (cost=83.80..86.92 rows=1250 width=8) Sort Key: a, b -> Seq Scan on abcd (cost=0.00..19.50 rows=1250 width=8) (5 rows) If it is okay to do extra sort for first window function (rank) here, why would it be any different in case which I mentioned? My suggestion rest on assumption that for a window function, say rank() OVER (ORDER BY a), ordering of columns (other than column 'a') shouldn't matter. -- Regards, Ankit Kumar Pandey
On 1/4/23 13:07, Ankit Kumar Pandey wrote: > Also, one thing, consider the following query: > > explain analyze select row_number() over (order by a,b),count(*) over > (order by a) from abcd order by a,b,c; > > In this case, sorting is done on (a,b) followed by incremental sort on c > at final stage. > > If we do just one sort: a,b,c at first stage then there won't be need to > do another sort (incremental one). This could give incorrect results. Consider the following query: postgres=# select a, b, c, rank() over (order by a, b) from (values (1, 2, 1), (1, 2, 2), (1, 2, 1)) as abcd (a, b, c) order by a, b, c; a | b | c | rank ---+---+---+------ 1 | 2 | 1 | 1 1 | 2 | 1 | 1 1 | 2 | 2 | 1 (3 rows) If you change the window's ordering like you suggest, you get this different result: postgres=# select a, b, c, rank() over (order by a, b, c) from (values (1, 2, 1), (1, 2, 2), (1, 2, 1)) as abcd (a, b, c) order by a, b, c; a | b | c | rank ---+---+---+------ 1 | 2 | 1 | 1 1 | 2 | 1 | 1 1 | 2 | 2 | 3 (3 rows) -- Vik Fearing
On Thu, 5 Jan 2023 at 15:18, Vik Fearing <vik@postgresfriends.org> wrote: > > On 1/4/23 13:07, Ankit Kumar Pandey wrote: > > Also, one thing, consider the following query: > > > > explain analyze select row_number() over (order by a,b),count(*) over > > (order by a) from abcd order by a,b,c; > > > > In this case, sorting is done on (a,b) followed by incremental sort on c > > at final stage. > > > > If we do just one sort: a,b,c at first stage then there won't be need to > > do another sort (incremental one). > > > This could give incorrect results. Yeah, this seems to be what I warned against in [1]. If we wanted to make that work we'd need to do it without adjusting the WindowClause's orderClause so that the peer row checks still worked correctly in nodeWindowAgg.c. Additionally, it's also not that clear to me that sorting by more columns in the sort below the WindowAgg would always be a win over doing the final sort for the ORDER BY. What if the WHERE clause (that could not be pushed down before a join) filtered out the vast majority of the rows before the ORDER BY. It might be cheaper to do the sort then than to sort by the additional columns earlier. David [1] https://www.postgresql.org/message-id/CAApHDvp=r1LnEKCmWCYaruMPL-jP4j_sdc8yeFYwaDT1ac5GsQ@mail.gmail.com
Vik Fearing <vik@postgresfriends.org> writes:
> On 1/4/23 13:07, Ankit Kumar Pandey wrote:
>> Also, one thing, consider the following query:
>> explain analyze select row_number() over (order by a,b),count(*) over
>> (order by a) from abcd order by a,b,c;
>> In this case, sorting is done on (a,b) followed by incremental sort on c
>> at final stage.
>> If we do just one sort: a,b,c at first stage then there won't be need to
>> do another sort (incremental one).
> This could give incorrect results.
Mmmm ... your counterexample doesn't really prove that. Yes,
the "rank()" step must consider only two ORDER BY columns while
deciding which rows are peers, but I don't see why it wouldn't
be okay if the rows happened to already be sorted by "c" within
those peer groups.
I don't recall the implementation details well enough to be sure
how hard it would be to keep that straight.
regards, tom lane
David Rowley <dgrowleyml@gmail.com> writes:
> Additionally, it's also not that clear to me that sorting by more
> columns in the sort below the WindowAgg would always be a win over
> doing the final sort for the ORDER BY. What if the WHERE clause (that
> could not be pushed down before a join) filtered out the vast majority
> of the rows before the ORDER BY. It might be cheaper to do the sort
> then than to sort by the additional columns earlier.
That's certainly a legitimate question to ask, but I don't quite see
where you figure we'd be sorting more rows? WHERE filtering happens
before window functions, which never eliminate any rows. So it seems
like a sort just before the window functions must sort the same number
of rows as one just after them.
regards, tom lane
On Thu, 5 Jan 2023 at 16:12, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > David Rowley <dgrowleyml@gmail.com> writes: > > Additionally, it's also not that clear to me that sorting by more > > columns in the sort below the WindowAgg would always be a win over > > doing the final sort for the ORDER BY. What if the WHERE clause (that > > could not be pushed down before a join) filtered out the vast majority > > of the rows before the ORDER BY. It might be cheaper to do the sort > > then than to sort by the additional columns earlier. > > That's certainly a legitimate question to ask, but I don't quite see > where you figure we'd be sorting more rows? WHERE filtering happens > before window functions, which never eliminate any rows. So it seems > like a sort just before the window functions must sort the same number > of rows as one just after them. Yeah, I didn't think the WHERE clause thing out carefully enough. I think it's only the WindowClause's runCondition that could possibly filter any rows between the Sort below the WindowAgg and before the ORDER BY is evaluated. David
On Thu, 5 Jan 2023 at 19:14, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: > We are already doing something like I mentioned. > > Consider this example: > > explain SELECT rank() OVER (ORDER BY a), count(*) OVER (ORDER BY a,b) > FROM abcd; > QUERY PLAN > -------------------------------------------------------------------------- > WindowAgg (cost=83.80..127.55 rows=1250 width=24) > -> WindowAgg (cost=83.80..108.80 rows=1250 width=16) > -> Sort (cost=83.80..86.92 rows=1250 width=8) > Sort Key: a, b > -> Seq Scan on abcd (cost=0.00..19.50 rows=1250 width=8) > (5 rows) > > > If it is okay to do extra sort for first window function (rank) here, > why would it be > > any different in case which I mentioned? We *can* reuse Sorts where a more strict or equivalent sort order is available. The question is how do we get the final WindowClause to do something slightly more strict to save having to do anything for the ORDER BY. One way you might think would be to adjust the WindowClause's orderClause to add the additional clauses, but that cannot be done because that would cause are_peers() in nodeWindowAgg.c to not count some rows as peers when they maybe should be given a less strict orderClause in the WindowClause. It might be possible to adjust create_one_window_path() so that when processing the final WindowClause that it looks at the DISTINCT or ORDER BY clause to see if we can sort on a few extra columns to save having to do any further sorting. We just *cannot* make any adjustments to the WindowClause's orderClause. David
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
On 05/01/23 12:53, David Rowley wrote: > > We *can* reuse Sorts where a more strict or equivalent sort order is > available. The question is how do we get the final WindowClause to do > something slightly more strict to save having to do anything for the > ORDER BY. One way you might think would be to adjust the > WindowClause's orderClause to add the additional clauses, but that > cannot be done because that would cause are_peers() in nodeWindowAgg.c > to not count some rows as peers when they maybe should be given a less > strict orderClause in the WindowClause. Okay, now I see issue in my approach. > It might be possible to adjust create_one_window_path() so that when > processing the final WindowClause that it looks at the DISTINCT or > ORDER BY clause to see if we can sort on a few extra columns to save > having to do any further sorting. We just *cannot* make any > adjustments to the WindowClause's orderClause. > This is much better solution. I will check create_one_window_path for the same. -- Regards, Ankit Kumar Pandey
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
Sorry if multiple mails has been sent for this. > On 05/01/23 12:53, David Rowley wrote: >> >> We *can* reuse Sorts where a more strict or equivalent sort order is >> available. The question is how do we get the final WindowClause to do >> something slightly more strict to save having to do anything for the >> ORDER BY. One way you might think would be to adjust the >> WindowClause's orderClause to add the additional clauses, but that >> cannot be done because that would cause are_peers() in nodeWindowAgg.c >> to not count some rows as peers when they maybe should be given a less >> strict orderClause in the WindowClause. I attempted this in attached patch. #1. No op case ------------------------------------------In patched version----------------------------------------------- explain (costs off) SELECT rank() OVER (ORDER BY b), count(*) OVER (ORDER BY a,b,c) FROM abcd order by a; QUERY PLAN ------------------------------------------ WindowAgg -> Sort Sort Key: a, b, c -> WindowAgg -> Sort Sort Key: b -> Seq Scan on abcd (7 rows) explain (costs off) SELECT rank() OVER (ORDER BY b), count(*) OVER (ORDER BY a,b,c) FROM abcd; QUERY PLAN ------------------------------------------ WindowAgg -> Sort Sort Key: b -> WindowAgg -> Sort Sort Key: a, b, c -> Seq Scan on abcd (7 rows) ----------------------------------------------In master-------------------------------------------------------- explain (costs off) SELECT rank() OVER (ORDER BY b), count(*) OVER (ORDER BY a,b,c) FROM abcd order by a; QUERY PLAN ------------------------------------------ WindowAgg -> Sort Sort Key: a, b, c -> WindowAgg -> Sort Sort Key: b -> Seq Scan on abcd (7 rows) explain (costs off) SELECT rank() OVER (ORDER BY b), count(*) OVER (ORDER BY a,b,c) FROM abcd; QUERY PLAN ------------------------------------------ WindowAgg -> Sort Sort Key: b -> WindowAgg -> Sort Sort Key: a, b, c -> Seq Scan on abcd (7 rows) No change between patched version and master. 2. In case where optimization can happen ----------------------------In patched version------------------------------------------------------- explain (costs off) SELECT rank() OVER (ORDER BY b), count(*) OVER (ORDER BY a) FROM abcd order by a,b; QUERY PLAN ------------------------------------------ WindowAgg -> Sort Sort Key: a, b -> WindowAgg -> Sort Sort Key: b -> Seq Scan on abcd (7 rows) explain (costs off) SELECT rank() OVER (ORDER BY a), count(*) OVER (ORDER BY b), count(*) OVER (PARTITION BY a ORDER BY b) FROM abcd order by a,b,c,d; QUERY PLAN ------------------------------------------------ WindowAgg -> WindowAgg -> Sort Sort Key: a, b, c, d -> WindowAgg -> Sort Sort Key: b -> Seq Scan on abcd (8 rows) -------------------------------------------In master-------------------------------------------------------- explain (costs off) SELECT rank() OVER (ORDER BY b), count(*) OVER (ORDER BY a) FROM abcd order by a,b; QUERY PLAN ------------------------------------------------ Incremental Sort Sort Key: a, b Presorted Key: a -> WindowAgg -> Sort Sort Key: a -> WindowAgg -> Sort Sort Key: b -> Seq Scan on abcd (10 rows) explain (costs off) SELECT rank() OVER (ORDER BY a), count(*) OVER (ORDER BY b), count(*) OVER (PARTITION BY a ORDER BY b) FROM abcd order by a,b,c,d; QUERY PLAN ------------------------------------------------------ Incremental Sort Sort Key: a, b, c, d Presorted Key: a, b -> WindowAgg -> WindowAgg -> Sort Sort Key: a, b -> WindowAgg -> Sort Sort Key: b -> Seq Scan on abcd (11 rows) Patched version removes few sorts. Regression tests all passed so it is not breaking anything existing. We don't have any tests for verifying sorting plan in window functions (which would have failed, if present). Please let me know any feedbacks (I have added some my own concerns in the comments) Thanks -- Regards, Ankit Kumar Pandey
Attachment
On Thu, 5 Jan 2023 at 04:11, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: > > Attaching test cases for this (+ small change in doc). > > Tested this in one of WIP branch where I had modified > select_active_windows and it failed > > as expected. > > Please let me know if something can be improved in this. Thanks for writing that. I had a look over the patch and ended up making some adjustments to the tests. Looking back at 728202b63, I think any tests we add here should be kept alongside the tests added by that commit rather than tacked on to the end of the test file. It also makes sense to me just to use the same table as the original tests. I also thought the comment in select_active_windows should be in the sort comparator function instead. I think that's a more likely place to capture the attention of anyone making modifications. I've now pushed the adjusted patch. David
On Sat, 7 Jan 2023 at 02:11, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote:
> > On 05/01/23 12:53, David Rowley wrote:
> >>
> >> We *can* reuse Sorts where a more strict or equivalent sort order is
> >> available. The question is how do we get the final WindowClause to do
> >> something slightly more strict to save having to do anything for the
> >> ORDER BY. One way you might think would be to adjust the
> >> WindowClause's orderClause to add the additional clauses, but that
> >> cannot be done because that would cause are_peers() in nodeWindowAgg.c
> >> to not count some rows as peers when they maybe should be given a less
> >> strict orderClause in the WindowClause.
>
> I attempted this in attached patch.
I had a quick look at this and it's going to need some additional code
to ensure there are no WindowFuncs in the ORDER BY clause. We can't
sort on those before we evaluate them.
Right now you get:
postgres=# explain select *,row_number() over (order by oid) rn1 from
pg_class order by oid,rn1;
ERROR: could not find pathkey item to sort
I also don't think there's any point in adding the additional pathkeys
when the input path is already presorted. Have a look at:
postgres=# set enable_seqscan=0;
SET
postgres=# explain select *,row_number() over (order by oid) rn1 from
pg_class order by oid,relname;
QUERY PLAN
----------------------------------------------------------------------------------------------------
WindowAgg (cost=0.43..85.44 rows=412 width=281)
-> Incremental Sort (cost=0.43..79.26 rows=412 width=273)
Sort Key: oid, relname
Presorted Key: oid
-> Index Scan using pg_class_oid_index on pg_class
(cost=0.27..60.72 rows=412 width=273)
(5 rows)
It would be better to leave this case alone and just do the
incremental sort afterwards.
You also don't seem to be considering the fact that the query might
have a DISTINCT clause. That's evaluated between window functions and
the order by. It would be fairly useless to do a more strict sort when
the sort order is going to be obliterated by a Hash Aggregate. Perhaps
we can just not do this when the query has a DISTINCT clause.
On the other hand, there are also a few reasons why we shouldn't do
this. I mentioned the WindowClause runConditions earlier here.
The patched version produces:
postgres=# explain (analyze, costs off) select * from (select
oid,relname,row_number() over (order by oid) rn1 from pg_class order
by oid,relname) where rn1 < 10;
QUERY PLAN
------------------------------------------------------------------------------
WindowAgg (actual time=0.488..0.497 rows=9 loops=1)
Run Condition: (row_number() OVER (?) < 10)
-> Sort (actual time=0.466..0.468 rows=10 loops=1)
Sort Key: pg_class.oid, pg_class.relname
Sort Method: quicksort Memory: 67kB
-> Seq Scan on pg_class (actual time=0.028..0.170 rows=420 loops=1)
Planning Time: 0.214 ms
Execution Time: 0.581 ms
(8 rows)
Whereas master produces:
postgres=# explain (analyze, costs off) select * from (select
oid,relname,row_number() over (order by oid) rn1 from pg_class order
by oid,relname) where rn1 < 10;
QUERY PLAN
----------------------------------------------------------------------------------------
Incremental Sort (actual time=0.506..0.508 rows=9 loops=1)
Sort Key: pg_class.oid, pg_class.relname
Presorted Key: pg_class.oid
Full-sort Groups: 1 Sort Method: quicksort Average Memory: 26kB
Peak Memory: 26kB
-> WindowAgg (actual time=0.475..0.483 rows=9 loops=1)
Run Condition: (row_number() OVER (?) < 10)
-> Sort (actual time=0.461..0.461 rows=10 loops=1)
Sort Key: pg_class.oid
Sort Method: quicksort Memory: 67kB
-> Seq Scan on pg_class (actual time=0.022..0.178
rows=420 loops=1)
Planning Time: 0.245 ms
Execution Time: 0.594 ms
(12 rows)
(slightly bad example since oid is unique but...)
It's not too clear to me that the patched version is a better plan.
The bottom level sort, which sorts 420 rows has a more complex
comparison to do. Imagine the 2nd column is a long text string. That
would make the sort much more expensive. The top-level sort has far
fewer rows to sort due to the runCondition filtering out anything that
does not match rn1 < 10. The same can be said for a query with a LIMIT
clause.
I think the patch should also be using pathkeys_contained_in() and
Lists of pathkeys rather than concatenating lists of SortGroupClauses
together. That should allow things to work correctly when a given
pathkey has become redundant due to either duplication or a Const in
the Eclass.
Also, since I seem to be only be able to think of these cases properly
by actually trying them, I ended up with the attached patch. I opted
to not do the optimisation when there are runConditions or a LIMIT
clause. Doing it when there are runConditions really should be a
cost-based decision, but we've about no hope of having any idea about
how many rows will match the runCondition. For the LIMIT case, it's
also difficult as it would be hard to get an idea of how many times
the additional sort columns would need their comparison function
called. That's only required in a tie-break when the leading columns
are all equal.
The attached patch has no tests added. It's going to need some of
those. These tests should go directly after the tests added in
a14a58329 and likely use the same table for consistency.
David
Attachment
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
Thanks for looking into this. On 07/01/23 09:58, David Rowley wrote: > On Sat, 7 Jan 2023 at 02:11, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: >>> On 05/01/23 12:53, David Rowley wrote: >>>> We *can* reuse Sorts where a more strict or equivalent sort order is >>>> available. The question is how do we get the final WindowClause to do >>>> something slightly more strict to save having to do anything for the >>>> ORDER BY. One way you might think would be to adjust the >>>> WindowClause's orderClause to add the additional clauses, but that >>>> cannot be done because that would cause are_peers() in nodeWindowAgg.c >>>> to not count some rows as peers when they maybe should be given a less >>>> strict orderClause in the WindowClause. >> I attempted this in attached patch. > I had a quick look at this and it's going to need some additional code > to ensure there are no WindowFuncs in the ORDER BY clause. We can't > sort on those before we evaluate them. Okay I will add this check. > I also don't think there's any point in adding the additional pathkeys > when the input path is already presorted. > > It would be better to leave this case alone and just do the > incremental sort afterwards. So this will be no operation case well. > You also don't seem to be considering the fact that the query might > have a DISTINCT clause. Major reason for this was that I am not exactly aware of what distinct clause means (especially in context of window functions) and how it is different from other sortClauses (partition, order by, group). Comments in parsenodes.h didn't help. > That's evaluated between window functions and > the order by. It would be fairly useless to do a more strict sort when > the sort order is going to be obliterated by a Hash Aggregate. Perhaps > we can just not do this when the query has a DISTINCT clause. > > On the other hand, there are also a few reasons why we shouldn't do > this. I mentioned the WindowClause runConditions earlier here. > > The patched version produces: > > postgres=# explain (analyze, costs off) select * from (select > oid,relname,row_number() over (order by oid) rn1 from pg_class order > by oid,relname) where rn1 < 10; > QUERY PLAN > ------------------------------------------------------------------------------ > WindowAgg (actual time=0.488..0.497 rows=9 loops=1) > Run Condition: (row_number() OVER (?) < 10) > -> Sort (actual time=0.466..0.468 rows=10 loops=1) > Sort Key: pg_class.oid, pg_class.relname > Sort Method: quicksort Memory: 67kB > -> Seq Scan on pg_class (actual time=0.028..0.170 rows=420 loops=1) > Planning Time: 0.214 ms > Execution Time: 0.581 ms > (8 rows) > > Whereas master produces: > > postgres=# explain (analyze, costs off) select * from (select > oid,relname,row_number() over (order by oid) rn1 from pg_class order > by oid,relname) where rn1 < 10; > QUERY PLAN > ---------------------------------------------------------------------------------------- > Incremental Sort (actual time=0.506..0.508 rows=9 loops=1) > Sort Key: pg_class.oid, pg_class.relname > Presorted Key: pg_class.oid > Full-sort Groups: 1 Sort Method: quicksort Average Memory: 26kB > Peak Memory: 26kB > -> WindowAgg (actual time=0.475..0.483 rows=9 loops=1) > Run Condition: (row_number() OVER (?) < 10) > -> Sort (actual time=0.461..0.461 rows=10 loops=1) > Sort Key: pg_class.oid > Sort Method: quicksort Memory: 67kB > -> Seq Scan on pg_class (actual time=0.022..0.178 > rows=420 loops=1) > Planning Time: 0.245 ms > Execution Time: 0.594 ms > (12 rows) > > (slightly bad example since oid is unique but...) > > It's not too clear to me that the patched version is a better plan. > The bottom level sort, which sorts 420 rows has a more complex > comparison to do. Imagine the 2nd column is a long text string. That > would make the sort much more expensive. The top-level sort has far > fewer rows to sort due to the runCondition filtering out anything that > does not match rn1 < 10. The same can be said for a query with a LIMIT > clause. Yes, this is a fair point. Multiple sort is actually beneficial in cases like this, perhaps limits clause and runCondition should be no op too? > I think the patch should also be using pathkeys_contained_in() and > Lists of pathkeys rather than concatenating lists of SortGroupClauses > together. That should allow things to work correctly when a given > pathkey has become redundant due to either duplication or a Const in > the Eclass. Make sense, I actually duplicated that logic from make_pathkeys_for_window. We should make this changes there as well because if we have SELECT rank() OVER (PARTITION BY a ORDER BY a) (weird example but you get the idea), it leads to duplicates in window_sortclauses. > Also, since I seem to be only be able to think of these cases properly > by actually trying them, I ended up with the attached patch. I opted > to not do the optimisation when there are runConditions or a LIMIT > clause. Doing it when there are runConditions really should be a > cost-based decision, but we've about no hope of having any idea about > how many rows will match the runCondition. For the LIMIT case, it's > also difficult as it would be hard to get an idea of how many times > the additional sort columns would need their comparison function > called. That's only required in a tie-break when the leading columns > are all equal. Agree with runConditions part but for limit clause, row reduction happens at the last, so whether we use patched version or master version, none of sorts would benefit/degrade from that, right? > The attached patch has no tests added. It's going to need some of > those. These tests should go directly after the tests added in > a14a58329 and likely use the same table for consistency. > Thanks for the patch. It looks much neater now. I will add cases for this (after a14a58329). I do have a very general question though. Is it okay to add comments in test cases? I don't see it much on existing cases so kind of reluctant to add but it makes intentions much more clear. -- Regards, Ankit Kumar Pandey
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
On 07/01/23 07:59, David Rowley wrote: > On Thu, 5 Jan 2023 at 04:11, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: >> Attaching test cases for this (+ small change in doc). >> >> Tested this in one of WIP branch where I had modified >> select_active_windows and it failed >> >> as expected. >> >> Please let me know if something can be improved in this. > Thanks for writing that. > > I had a look over the patch and ended up making some adjustments to > the tests. Looking back at 728202b63, I think any tests we add here > should be kept alongside the tests added by that commit rather than > tacked on to the end of the test file. It also makes sense to me just > to use the same table as the original tests. I also thought the > comment in select_active_windows should be in the sort comparator > function instead. I think that's a more likely place to capture the > attention of anyone making modifications. Thanks, I will look it through. > I've now pushed the adjusted patch. > I can't seem to find updated patch in the attachment, can you please forward the patch again. Thanks. -- Regards, Ankit Kumar Pandey
Your email client seems to be adding additional vertical space to your emails. I've removed the additional newlines in the quotes. Are you able to fix the client so it does not do that? On Sun, 8 Jan 2023 at 00:10, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: > > On 07/01/23 09:58, David Rowley wrote: > > You also don't seem to be considering the fact that the query might > > have a DISTINCT clause. > > Major reason for this was that I am not exactly aware of what distinct > clause means (especially in > > context of window functions) and how it is different from other > sortClauses (partition, order by, group). I'm talking about the query's DISTINCT clause. i.e SELECT DISTINCT. If you look in the grouping_planner() function, you'll see that create_distinct_paths() is called between create_window_paths() and create_ordered_paths(). > Yes, this is a fair point. Multiple sort is actually beneficial in cases > like this, perhaps limits clause and runCondition should be no op too? I'm not sure what you mean by "no op". Do you mean not apply the optimization? > > I think the patch should also be using pathkeys_contained_in() and > > Lists of pathkeys rather than concatenating lists of SortGroupClauses > > together. That should allow things to work correctly when a given > > pathkey has become redundant due to either duplication or a Const in > > the Eclass. > > Make sense, I actually duplicated that logic from > make_pathkeys_for_window. We should make this changes there as well because > if we have SELECT rank() OVER (PARTITION BY a ORDER BY a) > (weird example but you get the idea), it leads to duplicates in > window_sortclauses. It won't lead to duplicate pathkeys. Look in make_pathkeys_for_sortclauses() and what pathkey_is_redundant() does. Notice that it checks if the pathkey already exists in the list before appending. > Agree with runConditions part but for limit clause, row reduction happens > at the last, so whether we use patched version or master version, > none of sorts would benefit/degrade from that, right? Maybe you're right. Just be aware that a sort done for a query with an ORDER BY LIMIT will perform a top-n sort. top-n sorts only need to store the top-n tuples and that can significantly reduce the memory required for sorting perhaps resulting in the sort fitting in memory rather than spilling out to disk. You might want to test this by having the leading sort column as an INT, and then the 2nd one as a long text column of maybe around two kilobytes. Make all the leading column values the same so that the comparison for the text column is always performed. Make the LIMIT small compared to the total number of rows, that should test the worse case. Check the performance with and without the limitCount != NULL part of the patch that disables the optimization for LIMIT. > Is it okay > to add comments in test cases? I don't see it much on existing cases > so kind of reluctant to add but it makes intentions much more clear. I think tests should always have a comment to state what they're testing. Not many people seem to do that, unfortunately. The problem with not stating what the test is testing is that if, for example, the test is checking that the EXPLAIN output is showing a Sort, what if at some point in the future someone adjusts some costing code and the plan changes to an Index Scan. If there's no comment to state that we're looking for a Sort plan, then the author of the patch that's adjusting the costs might just think it's ok to change the expected plan to an Index Scan. I've seen this problem occur even when the comments *do* exist. There's just about no hope of such a test continuing to do what it's meant to if the comments don't exist. David
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
On 07/01/23 17:28, David Rowley wrote: > Your email client seems to be adding additional vertical space to your > emails. I've removed the additional newlines in the quotes. Are you > able to fix the client so it does not do that? I have adjusted my mail client, hope it is better now? > On Sun, 8 Jan 2023 at 00:10, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: > > > > On 07/01/23 09:58, David Rowley wrote: > > > You also don't seem to be considering the fact that the query might > > > have a DISTINCT clause. > > > > Major reason for this was that I am not exactly aware of what distinct > > clause means (especially in > > > > context of window functions) and how it is different from other > > sortClauses (partition, order by, group). > > I'm talking about the query's DISTINCT clause. i.e SELECT DISTINCT. > If you look in the grouping_planner() function, you'll see that > create_distinct_paths() is called between create_window_paths() and > create_ordered_paths(). Yes just saw this and got what you meant. > > Yes, this is a fair point. Multiple sort is actually beneficial in cases > > like this, perhaps limits clause and runCondition should be no op too? > > I'm not sure what you mean by "no op". Do you mean not apply the optimization? Yes, no op = no optimization. Sorry I didn't mention it before. > > > I think the patch should also be using pathkeys_contained_in() and > > > Lists of pathkeys rather than concatenating lists of SortGroupClauses > > > together. That should allow things to work correctly when a given > > > pathkey has become redundant due to either duplication or a Const in > > > the Eclass. > > > > Make sense, I actually duplicated that logic from > > make_pathkeys_for_window. We should make this changes there as well because > > if we have SELECT rank() OVER (PARTITION BY a ORDER BY a) > > (weird example but you get the idea), it leads to duplicates in > > window_sortclauses. > > It won't lead to duplicate pathkeys. Look in > make_pathkeys_for_sortclauses() and what pathkey_is_redundant() does. > Notice that it checks if the pathkey already exists in the list before > appending. Okay I see this, pathkey_is_redundant is much more smarter as well. Replacing list_concat_copy with list_concat_unique in make_pathkeys_for_window won't be of much benefit. > > Agree with runConditions part but for limit clause, row reduction happens > > at the last, so whether we use patched version or master version, > > none of sorts would benefit/degrade from that, right? > > Maybe you're right. Just be aware that a sort done for a query with an > ORDER BY LIMIT will perform a top-n sort. top-n sorts only need to > store the top-n tuples and that can significantly reduce the memory > required for sorting perhaps resulting in the sort fitting in memory > rather than spilling out to disk. > > You might want to test this by having the leading sort column as an > INT, and then the 2nd one as a long text column of maybe around two > kilobytes. Make all the leading column values the same so that the > comparison for the text column is always performed. Make the LIMIT > small compared to the total number of rows, that should test the worse > case. Check the performance with and without the limitCount != NULL > part of the patch that disables the optimization for LIMIT. I checked this. For limit <<< total number of rows, top-n sort was performed but when I changed limit to higher value (or no limit), quick sort was performed. Top-n sort was twice as fast. Also, tested (first) patch version vs master, top-n sort was twice as fast there as well (outputs mentioned below). Current patch version (with limit excluded for optimizations) explain (analyze ,costs off) select count(*) over (order by id) from tt order by id, name limit 1; QUERY PLAN --------------------------------------------------------------------------------------------------- Limit (actual time=1.718..1.719 rows=1 loops=1) -> Incremental Sort (actual time=1.717..1.717 rows=1 loops=1) Sort Key: id, name Presorted Key: id Full-sort Groups: 1 Sort Method: top-N heapsort Average Memory: 25kB Peak Memory: 25kB -> WindowAgg (actual time=0.028..0.036 rows=6 loops=1) -> Sort (actual time=0.017..0.018 rows=6 loops=1) Sort Key: id Sort Method: quicksort Memory: 25kB -> Seq Scan on tt (actual time=0.011..0.012 rows=6 loops=1) Planning Time: 0.069 ms Execution Time: 1.799 ms Earlier patch(which included limit clause for optimizations) explain (analyze ,costs off) select count(*) over (order by id) from tt order by id, name limit 1; QUERY PLAN ---------------------------------------------------------------------------- Limit (actual time=3.766..3.767 rows=1 loops=1) -> WindowAgg (actual time=3.764..3.765 rows=1 loops=1) -> Sort (actual time=3.749..3.750 rows=6 loops=1) Sort Key: id, name Sort Method: quicksort Memory: 25kB -> Seq Scan on tt (actual time=0.011..0.013 rows=6 loops=1) Planning Time: 0.068 ms Execution Time: 3.881 ms I am just wondering though, why can we not do top-N sort in optimized version if we include limit clause? Is top-N sort is limited to non strict sorting or cases last operation before limit is sort? . > > Is it okay > > to add comments in test cases? I don't see it much on existing cases > > so kind of reluctant to add but it makes intentions much more clear. > > I think tests should always have a comment to state what they're > testing. Not many people seem to do that, unfortunately. The problem > with not stating what the test is testing is that if, for example, the > test is checking that the EXPLAIN output is showing a Sort, what if at > some point in the future someone adjusts some costing code and the > plan changes to an Index Scan. If there's no comment to state that > we're looking for a Sort plan, then the author of the patch that's > adjusting the costs might just think it's ok to change the expected > plan to an Index Scan. I've seen this problem occur even when the > comments *do* exist. There's just about no hope of such a test > continuing to do what it's meant to if the comments don't exist. Thanks for clarifying this out, I will freely add comments if that helps to explain things better. -- Regards, Ankit Kumar Pandey
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
On 07/01/23 09:58, David Rowley wrote: > > The attached patch has no tests added. It's going to need some of > those. While writing test cases, I found that optimization do not happen for case #1 (which is prime candidate for such operation) like EXPLAIN (COSTS OFF) SELECT empno, depname, min(salary) OVER (PARTITION BY depname ORDER BY empno) depminsalary, sum(salary) OVER (PARTITION BY depname) depsalary FROM empsalary ORDER BY depname, empno, enroll_date This happens because mutual exclusiveness of two operands (when number of window functions > 1) viz is_sorted and last activeWindow in the condition: ( !is_sorted && lnext(activeWindows, l) == NULL) For 2nd last window function, is_sorted is false and path keys get added. In next run (for last window function), is_sorted becomes true and whole optimization part is skipped. Note: Major issue that if I remove is_sorted from condition, even though path keys are added, it still do not perform optimization and works same as in master/unoptimized case. Perhaps adding path keys at last window function is not doing trick? Maybe we need to add pathkeys to all window functions which are subset of query's order by irrespective of being last or not? Case #2: For presorted columns, eg CREATE INDEX depname_idx ON empsalary(depname); SET enable_seqscan=0; EXPLAIN (COSTS OFF) SELECT empno, min(salary) OVER (PARTITION BY depname) depminsalary FROM empsalary ORDER BY depname, empno; Is this correct plan: a) QUERY PLAN ------------------------------------------------------- Incremental Sort Sort Key: depname, empno Presorted Key: depname -> WindowAgg -> Index Scan using depname_idx on empsalary (5 rows) or this: b) (Akin to Optimized version) QUERY PLAN ------------------------------------------------------- WindowAgg -> Incremental Sort Sort Key: depname, empno Presorted Key: depname -> Index Scan using depname_idx on empsalary (5 rows) Patched version does (a) because of is_sorted condition. If we remove both is_sorted and lnext(activeWindows, l) == NULL conditions, we get correct results in these two cases. -- Regards, Ankit Kumar Pandey
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
On 07/01/23 21:57, Ankit Kumar Pandey wrote: > On 07/01/23 09:58, David Rowley wrote: > > > > The attached patch has no tests added. It's going to need some of > > those. > > While writing test cases, I found that optimization do not happen for > case #1 > > (which is prime candidate for such operation) like > > EXPLAIN (COSTS OFF) > SELECT empno, > depname, > min(salary) OVER (PARTITION BY depname ORDER BY empno) depminsalary, > sum(salary) OVER (PARTITION BY depname) depsalary > FROM empsalary > ORDER BY depname, empno, enroll_date > > This happens because mutual exclusiveness of two operands (when number > of window functions > 1) viz > > is_sorted and last activeWindow in the condition: > > ( !is_sorted && lnext(activeWindows, l) == NULL) > > For 2nd last window function, is_sorted is false and path keys get added. > > In next run (for last window function), is_sorted becomes true and whole > optimization > > part is skipped. > > Note: Major issue that if I remove is_sorted from condition, even though > > path keys are added, it still do not perform optimization and works same > as in master/unoptimized case. > > Perhaps adding path keys at last window function is not doing trick? > Maybe we need to add pathkeys > > to all window functions which are subset of query's order by > irrespective of being last or not? > > > Case #2: > > For presorted columns, eg > > CREATE INDEX depname_idx ON empsalary(depname); > SET enable_seqscan=0; > EXPLAIN (COSTS OFF) > SELECT empno, > min(salary) OVER (PARTITION BY depname) depminsalary > FROM empsalary > ORDER BY depname, empno; > > Is this correct plan: > > a) > > QUERY PLAN > ------------------------------------------------------- > Incremental Sort > Sort Key: depname, empno > Presorted Key: depname > -> WindowAgg > -> Index Scan using depname_idx on empsalary > (5 rows) > > or this: > > b) (Akin to Optimized version) > > QUERY PLAN > ------------------------------------------------------- > WindowAgg > -> Incremental Sort > Sort Key: depname, empno > Presorted Key: depname > -> Index Scan using depname_idx on empsalary > (5 rows) > > Patched version does (a) because of is_sorted condition. > > If we remove both is_sorted and lnext(activeWindows, l) == NULL conditions, > > we get correct results in these two cases. > > Attached patch with test cases. For case #2, test cases still uses (a) as expected output which I don't think is right and we should revisit. Other than that, only failing case is due to issue mentioned in case #1. Thanks -- Regards, Ankit Kumar Pandey
Attachment
On Sun, 8 Jan 2023 at 01:52, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: > I am just wondering though, why can we not do top-N sort > in optimized version if we include limit clause? Is top-N sort is > limited to non strict sorting or > cases last operation before limit is sort? . Maybe the sort bound can be pushed down. You'd need to adjust ExecSetTupleBound() so that it pushes the bound through WindowAggState. David
(your email client still seems broken) On Sun, 8 Jan 2023 at 05:27, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: > > > While writing test cases, I found that optimization do not happen for > case #1 > > (which is prime candidate for such operation) like > > EXPLAIN (COSTS OFF) > SELECT empno, > depname, > min(salary) OVER (PARTITION BY depname ORDER BY empno) depminsalary, > sum(salary) OVER (PARTITION BY depname) depsalary > FROM empsalary > ORDER BY depname, empno, enroll_date > > This happens because mutual exclusiveness of two operands (when number > of window functions > 1) viz > > is_sorted and last activeWindow in the condition: > > ( !is_sorted && lnext(activeWindows, l) == NULL) > > For 2nd last window function, is_sorted is false and path keys get added. > > In next run (for last window function), is_sorted becomes true and whole > optimization > > part is skipped. > > Note: Major issue that if I remove is_sorted from condition, even though > > path keys are added, it still do not perform optimization and works same > as in master/unoptimized case. > > Perhaps adding path keys at last window function is not doing trick? > Maybe we need to add pathkeys > > to all window functions which are subset of query's order by > irrespective of being last or not? You might need to have another loop before the foreach loop that loops backwards through the WindowClauses and remembers the index of the WindowClause which has pathkeys contained in the query's ORDER BY pathkeys then apply the optimisation from that point in the main foreach loop. Also, if the condition within the foreach loop which checks when we want to apply this optimisation is going to be run > 1 time, then you should probably have boolean variable that's set before the loop which saves if we're going to try to apply the optimisation. That'll save from having to check things like if the query has a LIMIT clause multiple times. > Case #2: > > For presorted columns, eg > > CREATE INDEX depname_idx ON empsalary(depname); > SET enable_seqscan=0; > EXPLAIN (COSTS OFF) > SELECT empno, > min(salary) OVER (PARTITION BY depname) depminsalary > FROM empsalary > ORDER BY depname, empno; > > Is this correct plan: > > a) > > QUERY PLAN > ------------------------------------------------------- > Incremental Sort > Sort Key: depname, empno > Presorted Key: depname > -> WindowAgg > -> Index Scan using depname_idx on empsalary > (5 rows) > > or this: > > b) (Akin to Optimized version) > > QUERY PLAN > ------------------------------------------------------- > WindowAgg > -> Incremental Sort > Sort Key: depname, empno > Presorted Key: depname > -> Index Scan using depname_idx on empsalary > (5 rows) > > Patched version does (a) because of is_sorted condition. a) looks like the best plan to me. What's the point of pushing the sort below the WindowAgg in this case? The point of this optimisation is to reduce the number of sorts not to push them as deep into the plan as possible. We should only be pushing them down when it can reduce the number of sorts. There's no reduction in the number of sorts in the above plan. David
On Sun, 8 Jan 2023 at 05:45, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote:
> Attached patch with test cases.
I can look at this in a bit more detail if you find a way to fix the
case you mentioned earlier. i.e, push the sort down to the deepest
WindowAgg that has pathkeys contained in the query's ORDER BY
pathkeys.
EXPLAIN (COSTS OFF)
SELECT empno,
depname,
min(salary) OVER (PARTITION BY depname ORDER BY empno) depminsalary,
sum(salary) OVER (PARTITION BY depname) depsalary
FROM empsalary
ORDER BY depname, empno, enroll_date;
QUERY PLAN
-----------------------------------------------
Incremental Sort
Sort Key: depname, empno, enroll_date
Presorted Key: depname, empno
-> WindowAgg
-> WindowAgg
-> Sort
Sort Key: depname, empno
-> Seq Scan on empsalary
(8 rows)
You'll also need to pay attention to how the has_runcondition is set.
If you start pushing before looking at all the WindowClauses then you
won't know if some later WindowClause has a runCondition. Adding an
additional backwards foreach loop should allow you to do all the
required prechecks and find the index of the WindowClause which you
should start pushing from.
David
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
On 08/01/23 03:56, David Rowley wrote:
> (your email client still seems broken)
I am looking at this again, will be changing client for here onward.
> You might need to have another loop before the foreach loop that loops
> backwards through the WindowClauses and remembers the index of the
> WindowClause which has pathkeys contained in the query's ORDER BY
> pathkeys then apply the optimisation from that point in the main
> foreach loop. Also, if the condition within the foreach loop which
> checks when we want to apply this optimisation is going to be run > 1
> time, then you should probably have boolean variable that's set
> before the loop which saves if we're going to try to apply the
> optimisation. That'll save from having to check things like if the
> query has a LIMIT clause multiple times.
Thanks, this should do the trick.
> a) looks like the best plan to me. What's the point of pushing the
> sort below the WindowAgg in this case? The point of this optimisation
> is to reduce the number of sorts not to push them as deep into the
> plan as possible. We should only be pushing them down when it can
> reduce the number of sorts. There's no reduction in the number of
> sorts in the above plan.
Yes, you are right, not in this case. I actually mentioned wrong case here,
real problematic case is:
EXPLAIN (COSTS OFF)
SELECT empno,
depname,
min(salary) OVER (PARTITION BY depname ORDER BY empno) depminsalary,
sum(salary) OVER (PARTITION BY depname) depsalary
FROM empsalary
ORDER BY depname, empno, enroll_date;
QUERY PLAN
-------------------------------------------------------------------
Incremental Sort
Sort Key: depname, empno, enroll_date
Presorted Key: depname, empno
-> WindowAgg
-> WindowAgg
-> Incremental Sort
Sort Key: depname, empno
Presorted Key: depname
-> Index Scan using depname_idx on empsalary
(9 rows)
Here, it could have sorted on depname, empno, enroll_date.
Again, as I mentioned before, this is implementation issue. We shouldn't be
skipping optimization if pre-sorted keys are present.
--
Regards,
Ankit Kumar Pandey
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
On 08/01/23 04:06, David Rowley wrote: > On Sun, 8 Jan 2023 at 05:45, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: >> Attached patch with test cases. > I can look at this in a bit more detail if you find a way to fix the > case you mentioned earlier. i.e, push the sort down to the deepest > WindowAgg that has pathkeys contained in the query's ORDER BY > pathkeys. > EXPLAIN (COSTS OFF) > SELECT empno, > depname, > min(salary) OVER (PARTITION BY depname ORDER BY empno) depminsalary, > sum(salary) OVER (PARTITION BY depname) depsalary > FROM empsalary > ORDER BY depname, empno, enroll_date; > QUERY PLAN > ----------------------------------------------- > Incremental Sort > Sort Key: depname, empno, enroll_date > Presorted Key: depname, empno > -> WindowAgg > -> WindowAgg > -> Sort > Sort Key: depname, empno > -> Seq Scan on empsalary > (8 rows) > > You'll also need to pay attention to how the has_runcondition is set. > If you start pushing before looking at all the WindowClauses then you > won't know if some later WindowClause has a runCondition. Yes, this should be the main culprit. > Adding an additional backwards foreach loop should allow you to do all the > required prechecks and find the index of the WindowClause which you > should start pushing from. This should do the trick. Thanks for headup, I will update the patch with suggested changes and required fixes. Regards, Ankit
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
Hi David, Please find attached patch with addressed issues mentioned before. Things resolved: 1. Correct position of window function from where order by push down can happen is determined, this fixes issue mentioned in case #1. > While writing test cases, I found that optimization do not happen for > case #1 > > (which is prime candidate for such operation) like > > EXPLAIN (COSTS OFF) > SELECT empno, > depname, > min(salary) OVER (PARTITION BY depname ORDER BY empno) depminsalary, > sum(salary) OVER (PARTITION BY depname) depsalary > FROM empsalary > ORDER BY depname, empno, enroll_date 2. Point #2 as in above discussions > a) looks like the best plan to me. What's the point of pushing the > sort below the WindowAgg in this case? The point of this optimisation > is to reduce the number of sorts not to push them as deep into the > plan as possible. We should only be pushing them down when it can > reduce the number of sorts. There's no reduction in the number of > sorts in the above plan. Works as mentioned. All test cases (newly added and existing ones) are green. -- Regards, Ankit Kumar Pandey
Attachment
On Sun, 8 Jan 2023 at 23:21, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: > Please find attached patch with addressed issues mentioned before. Here's a quick review: 1. You can use foreach_current_index(l) to obtain the index of the list element. 2. I'd rather see you looping backwards over the list in the first loop. I think it'll be more efficient to loop backwards as you can just break out the loop when you see the pathkeys are not contained in the order by pathkreys. When the optimisation does not apply that means you only need to look at the last item in the list. You could maybe just invent foreach_reverse() for this purpose and put it in pg_list.h. That'll save having to manually code up the loop. 3. I don't think you should call the variable enable_order_by_pushdown. We've a bunch of planner related GUCs that start with enable_. That might cause a bit of confusion. Maybe just try_sort_pushdown. 4. You should widen the scope of orderby_pathkeys and set it within the if (enable_order_by_pushdown) scope. You can reuse this again in the 2nd loop too. Just initialise it to NIL 5. You don't seem to be checking all WindowClauses for a runCondtion. If you do #2 above then you can start that process in the initial reverse loop so that you've checked them all by the time you get around to that WindowClause again in the 2nd loop. 6. The test with "+-- Do not perform additional sort if column is presorted". I don't think "additional" is the correct word here. I think you want to ensure that we don't push down the ORDER BY below the WindowAgg for this case. There is no ability to reduce the sorts here, only move them around, which we agreed we don't want to do for this case. Also, do you want to have a go at coding up the sort bound pushdown too? It'll require removing the limitCount restriction and adjusting ExecSetTupleBound() to recurse through a WindowAggState. I think it's pretty easy. You could try it then play around with it to make sure it works and we get the expected performance. You'll likely want to add a few more rows than the last performance test you did or run the query with pgbench. Running a query once that only takes 1-2ms is likely not a reliable way to test the performance of something. David
On 1/8/23 11:21, Ankit Kumar Pandey wrote: > > Please find attached patch with addressed issues mentioned before. I am curious about this plan: +-- ORDER BY's in multiple Window functions can be combined into one +-- if they are subset of QUERY's ORDER BY +EXPLAIN (COSTS OFF) +SELECT empno, + depname, + min(salary) OVER (PARTITION BY depname ORDER BY empno) depminsalary, + sum(salary) OVER (PARTITION BY depname) depsalary, + count(*) OVER (ORDER BY enroll_date DESC) c +FROM empsalary +ORDER BY depname, empno, enroll_date; + QUERY PLAN +------------------------------------------------------ + WindowAgg + -> WindowAgg + -> Sort + Sort Key: depname, empno, enroll_date + -> WindowAgg + -> Sort + Sort Key: enroll_date DESC + -> Seq Scan on empsalary +(8 rows) + Why aren't min() and sum() calculated on the same WindowAgg run? -- Vik Fearing
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
> On 08/01/23 21:36, Vik Fearing wrote:
> On 1/8/23 11:21, Ankit Kumar Pandey wrote:
>>
>> Please find attached patch with addressed issues mentioned before.
> I am curious about this plan:
> +-- ORDER BY's in multiple Window functions can be combined into one
> +-- if they are subset of QUERY's ORDER BY
> +EXPLAIN (COSTS OFF)
> +SELECT empno,
> + depname,
> + min(salary) OVER (PARTITION BY depname ORDER BY empno) depminsalary,
> + sum(salary) OVER (PARTITION BY depname) depsalary,
> + count(*) OVER (ORDER BY enroll_date DESC) c
> +FROM empsalary
> +ORDER BY depname, empno, enroll_date;
> + QUERY PLAN
> +------------------------------------------------------
> + WindowAgg
> + -> WindowAgg
> + -> Sort
> + Sort Key: depname, empno, enroll_date
> + -> WindowAgg
> + -> Sort
> + Sort Key: enroll_date DESC
> + -> Seq Scan on empsalary
> +(8 rows)
> +
> Why aren't min() and sum() calculated on the same WindowAgg run?
Isn't that exactly what is happening here? First count() with sort on
enroll_date is run and
then min() and sum()?
Only difference between this and plan generated by master(given below)
is a sort in the end.
QUERY PLAN
------------------------------------------------------------
Incremental Sort
Sort Key: depname, empno, enroll_date
Presorted Key: depname, empno
-> WindowAgg
-> WindowAgg
-> Sort
Sort Key: depname, empno
-> WindowAgg
-> Sort
Sort Key: enroll_date DESC
-> Seq Scan on empsalary
Let me know if I am missing anything. Thanks.
--
Regards,
Ankit Kumar Pandey
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
> On 08/01/23 16:33, David Rowley wrote:
> On Sun, 8 Jan 2023 at 23:21, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote:
>> Please find attached patch with addressed issues mentioned before.
>
> Here's a quick review:
>
> 1. You can use foreach_current_index(l) to obtain the index of the list element.
>
> 2. I'd rather see you looping backwards over the list in the first
> loop. I think it'll be more efficient to loop backwards as you can
> just break out the loop when you see the pathkeys are not contained in
> the order by pathkreys. When the optimisation does not apply that
> means you only need to look at the last item in the list. You could
> maybe just invent foreach_reverse() for this purpose and put it in
> pg_list.h. That'll save having to manually code up the loop.
>
> 3. I don't think you should call the variable
> enable_order_by_pushdown. We've a bunch of planner related GUCs that
> start with enable_. That might cause a bit of confusion. Maybe just
> try_sort_pushdown.
>
> 4. You should widen the scope of orderby_pathkeys and set it within
> the if (enable_order_by_pushdown) scope. You can reuse this again in
> the 2nd loop too. Just initialise it to NIL
>
> 5. You don't seem to be checking all WindowClauses for a runCondtion.
> If you do #2 above then you can start that process in the initial
> reverse loop so that you've checked them all by the time you get
> around to that WindowClause again in the 2nd loop.
>
> 6. The test with "+-- Do not perform additional sort if column is
> presorted". I don't think "additional" is the correct word here. I
> think you want to ensure that we don't push down the ORDER BY below
> the WindowAgg for this case. There is no ability to reduce the sorts
> here, only move them around, which we agreed we don't want to do for
> this case.
I have addressed all points 1-6 in the attached patch.
I have one doubt regarding runCondition, do we only need to ensure
that window function which has subset sort clause of main query should
not have runCondition or none of the window functions should not contain
runCondition? I have gone with later case but wanted to clarify.
> Also, do you want to have a go at coding up the sort bound pushdown
> too? It'll require removing the limitCount restriction and adjusting
> ExecSetTupleBound() to recurse through a WindowAggState. I think it's
> pretty easy. You could try it then play around with it to make sure it
> works and we get the expected performance.
I tried this in the patch but kept getting `retrieved too many tuples in
a bounded sort`.
Added following code in ExecSetTupleBound which correctly found sortstate
and set bound value.
else if(IsA(child_node, WindowAggState))
{
WindowAggState *winstate = (WindowAggState *) child_node;
if (outerPlanState(winstate))
ExecSetTupleBound(tuples_needed, outerPlanState(winstate));
}
I think problem is that are not using limit clause inside window
function (which
may need to scan all tuples) so passing bound value to
WindowAggState->sortstate
is not working as we might expect. Or maybe I am getting it wrong? I was
trying to
have top-N sort for limit clause if orderby pushdown happens.
> You'll likely want to add a few more rows than the last performance test you did or run the query
> with pgbench. Running a query once that only takes 1-2ms is likely not
> a reliable way to test the performance of something.
I did some profiling.
CREATE TABLE empsalary1 (
depname varchar,
empno bigint,
salary int,
enroll_date date
);
INSERT INTO empsalary1(depname, empno, salary, enroll_date)
SELECT string_agg (substr('abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789', ceil (random() *
62)::integer,1000), '')
AS depname, generate_series(1, 10000000) AS empno, ceil (random()*10000)::integer AS salary
, NOW() + (random() * (interval '90 days')) + '30 days' AS enroll_date;
1) Optimization case
EXPLAIN (ANALYZE)
SELECT empno,
depname,
min(salary) OVER (PARTITION BY depname ORDER BY empno) depminsalary,
sum(salary) OVER (PARTITION BY depname) depsalary,
count(*) OVER (ORDER BY enroll_date DESC) c
FROM empsalary1
ORDER BY depname, empno, enroll_date;
EXPLAIN (ANALYZE)
SELECT empno,
depname,
min(salary) OVER (PARTITION BY depname) depminsalary
FROM empsalary1
ORDER BY depname, empno;
In patched version:
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
-----------------------
WindowAgg (cost=93458.04..93458.08 rows=1 width=61) (actual time=149996.006..156756.995 rows=10000000 loops=1)
-> WindowAgg (cost=93458.04..93458.06 rows=1 width=57) (actual time=108559.126..135892.188 rows=10000000
loops=1)
-> Sort (cost=93458.04..93458.04 rows=1 width=53) (actual time=108554.213..112564.168 rows=10000000
loops=1)
Sort Key: depname, empno, enroll_date
Sort Method: external merge Disk: 645856kB
-> WindowAgg (cost=93458.01..93458.03 rows=1 width=53) (actual time=30386.551..62357.669
rows=10000000lo
ops=1)
-> Sort (cost=93458.01..93458.01 rows=1 width=45) (actual time=23260.104..26313.395
rows=10000000l
oops=1)
Sort Key: enroll_date DESC
Sort Method: external merge Disk: 528448kB
-> Seq Scan on empsalary1 (cost=0.00..93458.00 rows=1 width=45) (actual
time=0.032..4833.603
rows=10000000 loops=1)
Planning Time: 4.693 ms
Execution Time: 158161.281 ms
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
-------------
WindowAgg (cost=1903015.63..2078015.74 rows=10000006 width=39) (actual time=40565.305..46598.984 rows=10000000
loops=1)
-> Sort (cost=1903015.63..1928015.65 rows=10000006 width=39) (actual time=23411.837..27467.962 rows=10000000
loops=1)
Sort Key: depname, empno
Sort Method: external merge Disk: 528448kB
-> Seq Scan on empsalary1 (cost=0.00..193458.06 rows=10000006 width=39) (actual time=5.095..5751.675
rows=10000
000 loops=1)
Planning Time: 0.099 ms
Execution Time: 47415.926 ms
In master:
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
-------------------------------------
Incremental Sort (cost=3992645.36..4792645.79 rows=10000006 width=59) (actual time=147130.132..160985.373
rows=10000000
loops=1)
Sort Key: depname, empno, enroll_date
Presorted Key: depname, empno
Full-sort Groups: 312500 Sort Method: quicksort Average Memory: 28kB Peak Memory: 28kB
-> WindowAgg (cost=3992645.31..4342645.52 rows=10000006 width=59) (actual time=147129.936..154023.147
rows=10000000l
oops=1)
-> WindowAgg (cost=3992645.31..4192645.43 rows=10000006 width=55) (actual time=104665.289..133089.188
rows=1000
0000 loops=1)
-> Sort (cost=3992645.31..4017645.33 rows=10000006 width=51) (actual time=104665.257..108710.282
rows=100
00000 loops=1)
Sort Key: depname, empno
Sort Method: external merge Disk: 645856kB
-> WindowAgg (cost=1971370.63..2146370.74 rows=10000006 width=51) (actual
time=28314.300..59737.949
rows=10000000 loops=1)
-> Sort (cost=1971370.63..1996370.65 rows=10000006 width=43) (actual
time=21190.188..24098.59
6 rows=10000000 loops=1)
Sort Key: enroll_date DESC
Sort Method: external merge Disk: 528448kB
-> Seq Scan on empsalary1 (cost=0.00..193458.06 rows=10000006 width=43) (actual
time=0.
630..5317.862 rows=10000000 loops=1)
Planning Time: 0.982 ms
Execution Time: 163369.242 ms
(16 rows)
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
-------------------
Incremental Sort (cost=3787573.31..3912573.41 rows=10000006 width=39) (actual time=51547.195..53950.034
rows=10000000lo
ops=1)
Sort Key: depname, empno
Presorted Key: depname
Full-sort Groups: 1 Sort Method: quicksort Average Memory: 30kB Peak Memory: 30kB
Pre-sorted Groups: 1 Sort Method: external merge Average Disk: 489328kB Peak Disk: 489328kB
-> WindowAgg (cost=1903015.63..2078015.74 rows=10000006 width=39) (actual time=33413.954..39771.262 rows=10000000
loo
ps=1)
-> Sort (cost=1903015.63..1928015.65 rows=10000006 width=39) (actual time=18991.129..21992.353
rows=10000000lo
ops=1)
Sort Key: depname
Sort Method: external merge Disk: 528456kB
-> Seq Scan on empsalary1 (cost=0.00..193458.06 rows=10000006 width=39) (actual time=1.300..5269.729
rows
=10000000 loops=1)
Planning Time: 4.506 ms
Execution Time: 54768.697 ms
2) No optimization case:
EXPLAIN (ANALYZE)
SELECT empno,
depname,
min(salary) OVER (PARTITION BY depname ORDER BY empno) depminsalary
FROM empsalary1
ORDER BY enroll_date;
Patch:
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
--------------------------------
Sort (cost=3968191.79..3993191.80 rows=10000006 width=43) (actual
time=57863.173..60976.324 rows=10000000 loops=1)
Sort Key: enroll_date
Sort Method: external merge Disk: 528448kB
-> WindowAgg (cost=850613.62..2190279.21 rows=10000006 width=43)
(actual time=7478.966..42502.541 rows=10000000 loops
=1)
-> Gather Merge (cost=850613.62..2015279.11 rows=10000006
width=43) (actual time=7478.935..18037.001 rows=10000
000 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=849613.60..860030.27 rows=4166669
width=43) (actual time=7349.101..9397.713 rows=3333333 lo
ops=3)
Sort Key: depname, empno
Sort Method: external merge Disk: 181544kB
Worker 0: Sort Method: external merge Disk: 169328kB
Worker 1: Sort Method: external merge Disk: 177752kB
-> Parallel Seq Scan on empsalary1
(cost=0.00..135124.69 rows=4166669 width=43) (actual time=0.213.
.2450.635 rows=3333333 loops=3)
Planning Time: 0.100 ms
Execution Time: 63341.783 ms
master:
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
--------------------------------
Sort (cost=3968191.79..3993191.80 rows=10000006 width=43) (actual
time=54097.880..57000.806 rows=10000000 loops=1)
Sort Key: enroll_date
Sort Method: external merge Disk: 528448kB
-> WindowAgg (cost=850613.62..2190279.21 rows=10000006 width=43)
(actual time=7075.245..39200.756 rows=10000000 loops
=1)
-> Gather Merge (cost=850613.62..2015279.11 rows=10000006
width=43) (actual time=7075.217..15988.922 rows=10000
000 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=849613.60..860030.27 rows=4166669
width=43) (actual time=6993.974..8799.701 rows=3333333 lo
ops=3)
Sort Key: depname, empno
Sort Method: external merge Disk: 171904kB
Worker 0: Sort Method: external merge Disk: 178496kB
Worker 1: Sort Method: external merge Disk: 178224kB
-> Parallel Seq Scan on empsalary1
(cost=0.00..135124.69 rows=4166669 width=43) (actual time=0.044.
.2683.598 rows=3333333 loops=3)
Planning Time: 5.718 ms
Execution Time: 59188.469 ms
(15 rows)
Master and patch have same performance as plan is same.
pgbench (this is to find average performance):
create table empsalary2 as select * from empsalary1 limit 1000;
-------------------------------------------------------------------
test.sql
SELECT empno,
depname,
min(salary) OVER (PARTITION BY depname ORDER BY empno) depminsalary,
sum(salary) OVER (PARTITION BY depname) depsalary,
count(*) OVER (ORDER BY enroll_date DESC) c
FROM empsalary2
ORDER BY depname, empno, enroll_date;
SELECT empno,
depname,
min(salary) OVER (PARTITION BY depname) depminsalary
FROM empsalary2
ORDER BY depname, empno;
----------------------------------------------------------------------
/usr/local/pgsql/bin/pgbench -d test -c 10 -j 4 -t 1000 -f test.sql
Patch:
transaction type: test.sql
scaling factor: 1
query mode: simple
number of clients: 10
number of threads: 4
maximum number of tries: 1
number of transactions per client: 1000
number of transactions actually processed: 10000/10000
number of failed transactions: 0 (0.000%)
latency average = 55.262 ms
initial connection time = 8.480 ms
tps = 180.957685 (without initial connection time)
Master:
transaction type: test.sql
scaling factor: 1
query mode: simple
number of clients: 10
number of threads: 4
maximum number of tries: 1
number of transactions per client: 1000
number of transactions actually processed: 10000/10000
number of failed transactions: 0 (0.000%)
latency average = 60.489 ms
initial connection time = 7.069 ms
tps = 165.320205 (without initial connection time)
TPS of patched version is higher than that of master's for same set of
queries.
where optimization is performed.
--
Regards,
Ankit Kumar Pandey
Attachment
On 1/8/23 18:05, Ankit Kumar Pandey wrote: > >> On 08/01/23 21:36, Vik Fearing wrote: > >> On 1/8/23 11:21, Ankit Kumar Pandey wrote: >>> >>> Please find attached patch with addressed issues mentioned before. > > >> I am curious about this plan: > >> +-- ORDER BY's in multiple Window functions can be combined into one >> +-- if they are subset of QUERY's ORDER BY >> +EXPLAIN (COSTS OFF) >> +SELECT empno, >> + depname, >> + min(salary) OVER (PARTITION BY depname ORDER BY empno) >> depminsalary, >> + sum(salary) OVER (PARTITION BY depname) depsalary, >> + count(*) OVER (ORDER BY enroll_date DESC) c >> +FROM empsalary >> +ORDER BY depname, empno, enroll_date; >> + QUERY PLAN >> +------------------------------------------------------ >> + WindowAgg >> + -> WindowAgg >> + -> Sort >> + Sort Key: depname, empno, enroll_date >> + -> WindowAgg >> + -> Sort >> + Sort Key: enroll_date DESC >> + -> Seq Scan on empsalary >> +(8 rows) >> + > > >> Why aren't min() and sum() calculated on the same WindowAgg run? > > Isn't that exactly what is happening here? First count() with sort on > enroll_date is run and > > then min() and sum()? No, there are two passes over the window for those two but I don't see that there needs to be. > Only difference between this and plan generated by master(given below) > is a sort in the end. Then this is probably not this patch's job to fix. -- Vik Fearing
On Mon, 9 Jan 2023 at 05:06, Vik Fearing <vik@postgresfriends.org> wrote: > +EXPLAIN (COSTS OFF) > +SELECT empno, > + depname, > + min(salary) OVER (PARTITION BY depname ORDER BY empno) depminsalary, > + sum(salary) OVER (PARTITION BY depname) depsalary, > + count(*) OVER (ORDER BY enroll_date DESC) c > +FROM empsalary > +ORDER BY depname, empno, enroll_date; > + QUERY PLAN > +------------------------------------------------------ > + WindowAgg > + -> WindowAgg > + -> Sort > + Sort Key: depname, empno, enroll_date > + -> WindowAgg > + -> Sort > + Sort Key: enroll_date DESC > + -> Seq Scan on empsalary > Why aren't min() and sum() calculated on the same WindowAgg run? We'd need to have an ORDER BY per WindowFunc rather than per WindowClause to do that. The problem is when there is no ORDER BY, all rows are peers. Likely there likely are a bunch more optimisations we could do in that area. I think all the builtin window functions (not aggregates being used as window functions) don't care about peer rows, so it may be possible to merge the WindowClauses when the WIndowClause being merged only has window functions that don't care about peer rows. Not for this patch though. David
On Mon, 9 Jan 2023 at 06:17, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote:
> I have addressed all points 1-6 in the attached patch.
A few more things:
1. You're still using the 'i' variable in the foreach loop.
foreach_current_index() will work.
2. I think the "index" variable needs a better name. sort_pushdown_idx maybe.
3. I don't think you need to set "index" on every loop. Why not just
set it to foreach_current_index(l) - 1; break;
4. You're still setting orderby_pathkeys in the foreach loop. That's
already been set above and it won't have changed.
5. I don't think there's any need to check pathkeys_contained_in() in
the foreach loop anymore. With #3 the index will be -1 if the
optimisation cannot apply. You could likely also get rid of
try_sort_pushdown too and just make the condition "if
(sort_pushdown_idx == foreach_current_index(l))". I'm a little unsure
why there's still the is_sorted check there. Shouldn't that always be
false now that you're looping until the pathkeys don't match in the
foreach_reverse loop?
Correct me if I'm wrong as I've not tested, but I think the new code
in the foreach loop can just become:
if (sort_pushdown_idx == foreach_current_index(l))
{
Assert(!is_sorted);
window_pathkeys = orderby_pathkeys;
is_sorted = pathkeys_count_contained_in(window_pathkeys,
path->pathkeys, &presorted_keys);
}
> I have one doubt regarding runCondition, do we only need to ensure
> that window function which has subset sort clause of main query should
> not have runCondition or none of the window functions should not contain
> runCondition? I have gone with later case but wanted to clarify.
Actually, maybe it's ok just to check the top-level WindowClause for
runConditions. It's only that one that'll filter rows. That probably
simplifies the code quite a bit. Lower-level runConditions only serve
to halt the evaluation of WindowFuncs when the runCondition is no
longer met.
>
>
> > Also, do you want to have a go at coding up the sort bound pushdown
> > too? It'll require removing the limitCount restriction and adjusting
> > ExecSetTupleBound() to recurse through a WindowAggState. I think it's
> > pretty easy. You could try it then play around with it to make sure it
> > works and we get the expected performance.
>
> I tried this in the patch but kept getting `retrieved too many tuples in
> a bounded sort`.
>
> Added following code in ExecSetTupleBound which correctly found sortstate
>
> and set bound value.
>
> else if(IsA(child_node, WindowAggState))
>
> {
>
> WindowAggState *winstate = (WindowAggState *) child_node;
>
> if (outerPlanState(winstate))
>
> ExecSetTupleBound(tuples_needed, outerPlanState(winstate));
>
> }
>
> I think problem is that are not using limit clause inside window
> function (which
> may need to scan all tuples) so passing bound value to
> WindowAggState->sortstate
> is not working as we might expect. Or maybe I am getting it wrong? I was
> trying to
> have top-N sort for limit clause if orderby pushdown happens.
hmm, perhaps the Limit would have to be put between the WindowAgg and
Sort for it to work. Maybe that's more complexity than it's worth.
David
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
> On 09/01/23 03:48, David Rowley wrote:
> On Mon, 9 Jan 2023 at 06:17, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote:
>> I have addressed all points 1-6 in the attached patch.
> A few more things:
> 1. You're still using the 'i' variable in the foreach loop.
foreach_current_index() will work.
> 2. I think the "index" variable needs a better name. sort_pushdown_idx maybe.
Done these (1 & 2)
> 3. I don't think you need to set "index" on every loop. Why not just
set it to foreach_current_index(l) - 1; break;
Consider this query
EXPLAIN (COSTS OFF)
SELECT empno,
depname,
min(salary) OVER (PARTITION BY depname ORDER BY empno) depminsalary,
sum(salary) OVER (PARTITION BY depname) depsalary,
count(*) OVER (ORDER BY enroll_date DESC) c
FROM empsalary
ORDER BY depname, empno, enroll_date;
Here, W1 = min(salary) OVER (PARTITION BY depname ORDER BY empno) W2 =
sum(salary) OVER (PARTITION BY depname)
W3 = count(*) OVER (ORDER BY enroll_date DESC)
(1,2,3 are winref).
activeWindows = [W3, W1, W2]
If we iterate from reverse and break at first occurrence, we will
break at W2 and add extra keys there, but what we want it to add
keys at W1 so that it gets spilled to W2 (as existing logic is designed to
carry over sorted cols first to last).
> 4. You're still setting orderby_pathkeys in the foreach loop. That's
already been set above and it won't have changed.
> 5. I don't think there's any need to check pathkeys_contained_in() in
the foreach loop anymore. With #3 the index will be -1 if the
optimisation cannot apply. You could likely also get rid of
try_sort_pushdown too and just make the condition "if
(sort_pushdown_idx == foreach_current_index(l))".
Done this.
Added pathkeys_contained_in as an assert, hope that's okay.
> I'm a little unsure why there's still the is_sorted check there.
Shouldn't that always be false now that you're looping until the pathkeys
don't match in the foreach_reverse loop?
Removing is_sorted causes issue if there is matching pathkey which is
presorted
eg this case
-- Do not perform sort pushdown if column is presorted
CREATE INDEX depname_idx ON empsalary(depname);
SET enable_seqscan=0;
EXPLAIN (COSTS OFF)
SELECT empno,
min(salary) OVER (PARTITION BY depname) depminsalary
FROM empsalary
ORDER BY depname, empno;
We can move this to if (try_sort_pushdown) block but it looks to me bit
ugly.
Nevertheless, it make sense to have it here, sort_pushdown_index should
point to exact
window function which needs to be modified. Having extra check (for
is_sorted) in 2nd foreach loop
adds ambiguity if we don't add it in first check.
foreach_reverse(l, activeWindows)
{
WindowClause *wc = lfirst_node(WindowClause, l);
orderby_pathkeys = make_pathkeys_for_sortclauses(root,root->parse->sortClause,root->processed_tlist);
window_pathkeys = make_pathkeys_for_window(root,wc,root->processed_tlist);
is_sorted = pathkeys_count_contained_in(window_pathkeys,path->pathkeys,&presorted_keys);
has_runcondition |= (wc->runCondition != NIL);
if (!pathkeys_contained_in(window_pathkeys, orderby_pathkeys) || has_runcondition)
break;
if(!is_sorted)
sort_pushdown_idx = foreach_current_index(l);
}
Tests passes on this so logically it is ok.
> Correct me if I'm wrong as I've not tested, but I think the new code
> in the foreach loop can just become:
>
> if (sort_pushdown_idx == foreach_current_index(l))
> {
> Assert(!is_sorted);
> window_pathkeys = orderby_pathkeys;
> is_sorted = pathkeys_count_contained_in(window_pathkeys,
> path->pathkeys, &presorted_keys);
> }
Depending on where we have is_sorted (as mentioned above) it looks a lot
like you mentioned.
Also, we can add Assert(pathkeys_contained_in(window_pathkeys,
orderby_pathkeys))
>> I have one doubt regarding runCondition, do we only need to ensure
>> that window function which has subset sort clause of main query should
>> not have runCondition or none of the window functions should not contain
>> runCondition? I have gone with later case but wanted to clarify.
> Actually, maybe it's ok just to check the top-level WindowClause for
> runConditions. It's only that one that'll filter rows. That probably
> simplifies the code quite a bit. Lower-level runConditions only serve
> to halt the evaluation of WindowFuncs when the runCondition is no
> longer met.
Okay, then this approach makes sense.
> hmm, perhaps the Limit would have to be put between the WindowAgg and
> Sort for it to work. Maybe that's more complexity than it's worth.
Yes, not specific to this change. It is more around allowing top-N sort in
window functions (in general). Once we have it there, then this could be
taken care of.
I have attached patch which fixes 1 & 2 and rearrange is_sorted.
Point #3 needs to be resolved (and perhaps another way to handle is_sorted)
Thanks,
--
Regards,
Ankit Kumar Pandey
Attachment
On Mon, 9 Jan 2023 at 21:34, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote:
>
>
> > On 09/01/23 03:48, David Rowley wrote:
> > 3. I don't think you need to set "index" on every loop. Why not just
> set it to foreach_current_index(l) - 1; break;
>
> Consider this query
>
> EXPLAIN (COSTS OFF)
> SELECT empno,
> depname,
> min(salary) OVER (PARTITION BY depname ORDER BY empno) depminsalary,
> sum(salary) OVER (PARTITION BY depname) depsalary,
> count(*) OVER (ORDER BY enroll_date DESC) c
> FROM empsalary
> ORDER BY depname, empno, enroll_date;
>
>
> Here, W1 = min(salary) OVER (PARTITION BY depname ORDER BY empno) W2 =
> sum(salary) OVER (PARTITION BY depname)
>
> W3 = count(*) OVER (ORDER BY enroll_date DESC)
>
> (1,2,3 are winref).
>
>
> activeWindows = [W3, W1, W2]
>
> If we iterate from reverse and break at first occurrence, we will
> break at W2 and add extra keys there, but what we want it to add
> keys at W1 so that it gets spilled to W2 (as existing logic is designed to
> carry over sorted cols first to last).
We need to keep looping backwards until we find the first WindowClause
which does not contain the pathkeys of the ORDER BY. When we find a
WindowClause that does not contain the pathkeys of the ORDER BY, then
we must set the sort_pushdown_idx to the index of the prior
WindowClause. I couldn't quite understand why the foreach() loop's
condition couldn't just be "if (foreach_current_index(l) ==
sort_pushdown_idx)", but I see that if we don't check if the path is
already correctly sorted that we could end up pushing the sort down
onto the path that's already correctly sorted. We decided we didn't
want to move the sort around if it does not reduce the amount of
sorting.
I had to try this out for myself and I've ended up with the attached
v6 patch. All the tests you added still pass. Although, I didn't
really study the tests yet to see if everything we talked about is
covered.
It turned out the sort_pushdown_idx = foreach_current_index(l) - 1;
break; didn't work as if all the WindowClauses have pathkeys contained
in the order by pathkeys then we don't ever set sort_pushdown_idx. I
adjusted it to do:
if (pathkeys_contained_in(window_pathkeys, orderby_pathkeys))
sort_pushdown_idx = foreach_current_index(l);
else
break;
I also fixed up the outdated comments and changed it so we only set
orderby_pathkeys once instead of once per loop in the
foreach_reverse() loop.
I gave some thought to whether doing foreach_delete_current() is safe
within a foreach_reverse() loop. I didn't try it, but I couldn't see
any reason why not. It is pretty late here and I'd need to test that
to be certain. If it turns out not to be safe then we need to document
that fact in the comments of the foreach_reverse() macro and the
foreach_delete_current() macro.
David
Attachment
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
> On 09/01/23 17:53, David Rowley wrote: > We need to keep looping backwards until we find the first WindowClause > which does not contain the pathkeys of the ORDER BY. I found the cause of confusion, *first* WindowClause means first from forward direction. Since we are looping from backward, I took it first from the last. eg: select count(*) over (order by a), count(*) over (order by a,b), count(*) over (order by a,b,c) from abcd order by a,b,c,d; first window clause is count(*) over (order by a) which we are using for order-by pushdown. This is in sync with implementation as well. > I couldn't quite understand why the foreach() loop's > condition couldn't just be "if (foreach_current_index(l) == > sort_pushdown_idx)", but I see that if we don't check if the path is > already correctly sorted that we could end up pushing the sort down > onto the path that's already correctly sorted. We decided we didn't > want to move the sort around if it does not reduce the amount of > sorting. Yes, this was the reason, the current patch handles this without is_sort now, which is great. > All the tests you added still pass. Although, I didn't > really study the tests yet to see if everything we talked about is > covered. It covers general cases and exceptions. Also, I did few additional tests. Looked good. > It turned out the sort_pushdown_idx = foreach_current_index(l) - 1; > break; didn't work as if all the WindowClauses have pathkeys contained > in the order by pathkeys then we don't ever set sort_pushdown_idx. I > adjusted it to do: > if (pathkeys_contained_in(window_pathkeys, orderby_pathkeys)) > sort_pushdown_idx = foreach_current_index(l); > else > break; Yes, that would have been problematic. I have verified this case and on related note, I have added a test case that ensure order by pushdown shouldn't happen if window function's order by is superset of query's order by. > I also fixed up the outdated comments and changed it so we only set > orderby_pathkeys once instead of once per loop in the > foreach_reverse() loop. Thanks, code look a lot neater now (is_sorted is gone and handled in a better way). > I gave some thought to whether doing foreach_delete_current() is safe > within a foreach_reverse() loop. I didn't try it, but I couldn't see > any reason why not. It is pretty late here and I'd need to test that > to be certain. If it turns out not to be safe then we need to document > that fact in the comments of the foreach_reverse() macro and the > foreach_delete_current() macro. I tested foreach_delete_current inside foreach_reverse loop. It worked fine. I have attached patch with one extra test case (as mentioned above). Rest of the changes are looking fine. Ran pgbench again and optimized version still had a lead (168 tps vs 135 tps) in performance. Do we have any pending items for this patch now? -- Regards, Ankit Kumar Pandey
Attachment
On Tue, 10 Jan 2023 at 06:15, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote:
> Do we have any pending items for this patch now?
I'm just wondering if not trying this when the query has a DISTINCT
clause is a copout. What I wanted to avoid was doing additional
sorting work for WindowAgg just to have it destroyed by Hash
Aggregate. I'm now wondering if adding both the original
slightly-less-sorted path plus the new slightly-more-sorted path then
if distinct decides to Hash Aggregate then it'll still be able to pick
the cheapest input path to do that on. Unfortunately, our sort
costing just does not seem to be advanced enough to know that sorting
by fewer columns might be cheaper, so adding the additional path is
likely just going to result in add_path() ditching the old
slightly-less-sorted path due to the new slightly-more-sorted path
having better pathkeys. So, we'd probably be wasting our time if we
added both paths with the current sort costing code.
# explain analyze select * from pg_Class order by relkind,relname;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Sort (cost=36.01..37.04 rows=412 width=273) (actual
time=0.544..0.567 rows=412 loops=1)
Sort Key: relkind, relname
Sort Method: quicksort Memory: 109kB
-> Seq Scan on pg_class (cost=0.00..18.12 rows=412 width=273)
(actual time=0.014..0.083 rows=412 loops=1)
Planning Time: 0.152 ms
Execution Time: 0.629 ms
(6 rows)
# explain analyze select * from pg_Class order by relkind;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Sort (cost=36.01..37.04 rows=412 width=273) (actual
time=0.194..0.218 rows=412 loops=1)
Sort Key: relkind
Sort Method: quicksort Memory: 109kB
-> Seq Scan on pg_class (cost=0.00..18.12 rows=412 width=273)
(actual time=0.014..0.083 rows=412 loops=1)
Planning Time: 0.143 ms
Execution Time: 0.278 ms
(6 rows)
the total cost is the same for both of these, but the execution time
seems to vary quite a bit.
Maybe we should try and do this for DISTINCT queries if the
distinct_pathkeys match the orderby_pathkeys. That seems a little less
copout-ish. If the ORDER BY is the same as the DISTINCT then it seems
likely that the ORDER BY might opt to use the Unique path for DISTINCT
since it'll already have the correct pathkeys. However, if the ORDER
BY has fewer columns then it might be cheaper to Hash Aggregate and
then sort all over again, especially so when the DISTINCT removes a
large proportion of the rows.
Ideally, our sort costing would just be better, but I think that
raises the bar a little too high to start thinking of making
improvements to that for this patch.
David
David Rowley <dgrowleyml@gmail.com> writes:
> Ideally, our sort costing would just be better, but I think that
> raises the bar a little too high to start thinking of making
> improvements to that for this patch.
It's trickier than it looks, cf f4c7c410e. But if you just want
to add a small correction based on number of columns being sorted
by, that seems within reach. See the comment for cost_sort though.
Also, I suppose for incremental sorts we'd want to consider only
the number of newly-sorted columns, but I'm not sure if that info
is readily at hand either.
regards, tom lane
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
> On 10/01/23 10:53, David Rowley wrote: > On Tue, 10 Jan 2023 at 06:15, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: > > Do we have any pending items for this patch now? > > I'm just wondering if not trying this when the query has a DISTINCT > clause is a copout. What I wanted to avoid was doing additional > sorting work for WindowAgg just to have it destroyed by Hash > Aggregate. I'm now wondering if adding both the original > slightly-less-sorted path plus the new slightly-more-sorted path then > if distinct decides to Hash Aggregate then it'll still be able to pick > the cheapest input path to do that on. Unfortunately, our sort > costing just does not seem to be advanced enough to know that sorting > by fewer columns might be cheaper, so adding the additional path is > likely just going to result in add_path() ditching the old > slightly-less-sorted path due to the new slightly-more-sorted path > having better pathkeys. So, we'd probably be wasting our time if we > added both paths with the current sort costing code. > Maybe we should try and do this for DISTINCT queries if the > distinct_pathkeys match the orderby_pathkeys. That seems a little less > copout-ish. If the ORDER BY is the same as the DISTINCT then it seems > likely that the ORDER BY might opt to use the Unique path for DISTINCT > since it'll already have the correct pathkeys. However, if the ORDER > BY has fewer columns then it might be cheaper to Hash Aggregate and > then sort all over again, especially so when the DISTINCT removes a > large proportion of the rows. > > Ideally, our sort costing would just be better, but I think that > raises the bar a little too high to start thinking of making > improvements to that for this patch. Let me take a stab at this. Depending on complexity, we can take a call to address this in current patch or a follow up. -- Regards, Ankit Kumar Pandey
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
> On 10/01/23 10:53, David Rowley wrote:
> the total cost is the same for both of these, but the execution time
> seems to vary quite a bit.
This is really weird, I tried it different ways (to rule out any issues
due to
caching) and execution time varied in spite of having same cost.
> Maybe we should try and do this for DISTINCT queries if the
> distinct_pathkeys match the orderby_pathkeys. That seems a little less
> copout-ish. If the ORDER BY is the same as the DISTINCT then it seems
> likely that the ORDER BY might opt to use the Unique path for DISTINCT
> since it'll already have the correct pathkeys.
> However, if the ORDER BY has fewer columns then it might be cheaper to Hash Aggregate and
> then sort all over again, especially so when the DISTINCT removes a
> large proportion of the rows.
Isn't order by pathkeys are always fewer than distinct pathkeys?
distinct pathkeys = order by pathkeys + window functions pathkeys
Again, I got your point which that it is okay to pushdown order by clause
if distinct is doing unique sort. But problem is (atleast from what I am
facing),
distinct is not caring about pushed down sortkeys, it goes with hashagg
or unique
with some other logic (mentioned below).
Consider following (with distinct clause restriction removed)
if (parse->distinctClause)
{
List* distinct_pathkeys = make_pathkeys_for_sortclauses(root, parse->distinctClause, root->processed_tlist);
if (!compare_pathkeys(distinct_pathkeys, orderby_pathkeys)==1) // distinct key > order by key
skip = true; // this is used to skip order by pushdown
}
CASE #1:
explain (costs off) select distinct a,b, min(a) over (partition by a), sum (a) over (partition by a) from abcd order by
a,b;
QUERY PLAN
-----------------------------------------------------------
Sort
Sort Key: a, b
-> HashAggregate
Group Key: a, b, min(a) OVER (?), sum(a) OVER (?)
-> WindowAgg
-> Sort
Sort Key: a, b
-> Seq Scan on abcd
(8 rows)
explain (costs off) select distinct a,b,c, min(a) over (partition by a), sum (a) over (partition by a) from abcd order
bya,b,c;
QUERY PLAN
--------------------------------------------------------------
Sort
Sort Key: a, b, c
-> HashAggregate
Group Key: a, b, c, min(a) OVER (?), sum(a) OVER (?)
-> WindowAgg
-> Sort
Sort Key: a, b, c
-> Seq Scan on abcd
(8 rows)
No matter how many columns are pushed down, it does hashagg.
On the other hand:
CASE #2:
EXPLAIN (costs off) SELECT DISTINCT depname, empno, min(salary) OVER (PARTITION BY depname) depminsalary,sum(salary)
OVER(PARTITION BY depname) depsalary
FROM empsalary
ORDER BY depname, empno;
QUERY PLAN
----------------------------------------------------------------------------------
Unique
-> Sort
Sort Key: depname, empno, (min(salary) OVER (?)), (sum(salary) OVER (?))
-> WindowAgg
-> Sort
Sort Key: depname, empno
-> Seq Scan on empsalary
(7 rows)
EXPLAIN (costs off) SELECT DISTINCT depname, empno, enroll_date, min(salary) OVER (PARTITION BY depname)
depminsalary,sum(salary)OVER (PARTITION BY depname) depsalary
FROM empsalary
ORDER BY depname, empno, enroll_date;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Unique
-> Sort
Sort Key: depname, empno, enroll_date, (min(salary) OVER (?)), (sum(salary) OVER (?))
-> WindowAgg
-> Sort
Sort Key: depname, empno, enroll_date
-> Seq Scan on empsalary
(7 rows)
It keeps doing Unique.
In both of the cases, compare_pathkeys(distinct_pathkeys,
orderby_pathkeys) returns 1
Looking bit further, planner is choosing things correctly.
I could see cost of unique being higher in 1st case and lower in 2nd case.
But the point is, if sort for orderby is pushdown, shouldn't there be
some discount on
cost of Unique sort (so that there is more possibility of it being
favorable compared to HashAgg in certain cases)?
Again, cost of Unqiue node is taken as cost of sort node as it is, but
for HashAgg, new cost is being computed. If we do incremental sort here
(for unique node),
as we have pushed down orderby's, unique cost could be reduced and our
optimization could
be made worthwhile (I assume this is what you intended here) in case of
distinct.
Eg:
EXPLAIN SELECT DISTINCT depname, empno, enroll_date, min(salary) OVER (PARTITION BY depname) depminsalary,sum(salary)
OVER(PARTITION BY depname) depsalary
FROM empsalary
ORDER BY depname, empno, enroll_date;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Unique (cost=1.63..1.78 rows=10 width=56)
-> Sort (cost=1.63..1.66 rows=10 width=56)
Sort Key: depname, empno, enroll_date, (min(salary) OVER (?)), (sum(salary) OVER (?))
-> WindowAgg (cost=1.27..1.47 rows=10 width=56)
-> Sort (cost=1.27..1.29 rows=10 width=48)
Sort Key: depname, empno, enroll_date
-> Seq Scan on empsalary (cost=0.00..1.10 rows=10 width=48)
depname, empno, enroll_date are presorted but still strict sorting is
done on all columns.
Additionally,
> the total cost is the same for both of these, but the execution time
> seems to vary quite a bit.
Even if I pushdown one or two path keys, end result is same cost (which
isn't helping).
--
Regards,
Ankit Kumar Pandey
On Wed, 11 Jan 2023 at 08:17, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote:
>
>
> > On 10/01/23 10:53, David Rowley wrote:
>
> > the total cost is the same for both of these, but the execution time
> > seems to vary quite a bit.
>
> This is really weird, I tried it different ways (to rule out any issues
> due to
>
> caching) and execution time varied in spite of having same cost.
>
> > Maybe we should try and do this for DISTINCT queries if the
> > distinct_pathkeys match the orderby_pathkeys. That seems a little less
> > copout-ish. If the ORDER BY is the same as the DISTINCT then it seems
> > likely that the ORDER BY might opt to use the Unique path for DISTINCT
> > since it'll already have the correct pathkeys.
>
> > However, if the ORDER BY has fewer columns then it might be cheaper to Hash Aggregate and
> > then sort all over again, especially so when the DISTINCT removes a
> > large proportion of the rows.
>
> Isn't order by pathkeys are always fewer than distinct pathkeys?
Just thinking about this again, I remembered why I thought DISTINCT
was uninteresting to start with. The problem is that if the query has
WindowFuncs and also has a DISTINCT clause, then the WindowFunc
results *must* be in the DISTINCT clause and, optionally also in the
ORDER BY clause. There's no other place to write WindowFuncs IIRC.
Since we cannot pushdown the sort when the more strict version of the
pathkeys have WindowFuncs, then we must still perform the additional
sort if the planner chooses to do a non-hashed DISTINCT. The aim of
this patch is to reduce the total number of sorts, and I don't think
that's possible in this case as you can't have WindowFuncs in the
ORDER BY when they're not in the DISTINCT clause:
postgres=# select distinct relname from pg_Class order by row_number()
over (order by oid);
ERROR: for SELECT DISTINCT, ORDER BY expressions must appear in select list
LINE 1: select distinct relname from pg_Class order by row_number() ...
Another type of query which is suboptimal still is when there's a
DISTINCT and WindowClause but no ORDER BY. We'll reorder the DISTINCT
clause so that the leading columns of the ORDER BY come first in
transformDistinctClause(), but we've nothing to do the same for
WindowClauses. It can't happen around when transformDistinctClause()
is called as we've yet to decide the WindowClause evaluation order,
so if we were to try to make that better it would maybe have to do in
the upper planner somewhere. It's possible it's too late by that time
to adjust the DISTINCT clause.
Here's an example of it.
# set enable_hashagg=0;
# explain select distinct relname,relkind,count(*) over (partition by
relkind) from pg_Class;
QUERY PLAN
------------------------------------------------------------------------------------
Unique (cost=61.12..65.24 rows=412 width=73)
-> Sort (cost=61.12..62.15 rows=412 width=73)
Sort Key: relname, relkind, (count(*) OVER (?))
-> WindowAgg (cost=36.01..43.22 rows=412 width=73)
-> Sort (cost=36.01..37.04 rows=412 width=65)
Sort Key: relkind
-> Seq Scan on pg_class (cost=0.00..18.12
rows=412 width=65)
(7 rows)
We can simulate the optimisation by swapping the column order in the
targetlist. Note the planner can use Incremental Sort (at least since
3c6fc5820, from about 2 hours ago)
# explain select distinct relkind,relname,count(*) over (partition by
relkind) from pg_Class;
QUERY PLAN
------------------------------------------------------------------------------------
Unique (cost=41.26..65.32 rows=412 width=73)
-> Incremental Sort (cost=41.26..62.23 rows=412 width=73)
Sort Key: relkind, relname, (count(*) OVER (?))
Presorted Key: relkind
-> WindowAgg (cost=36.01..43.22 rows=412 width=73)
-> Sort (cost=36.01..37.04 rows=412 width=65)
Sort Key: relkind
-> Seq Scan on pg_class (cost=0.00..18.12
rows=412 width=65)
(8 rows)
Not sure if we should be trying to improve that in this patch. I just
wanted to identify it as something else that perhaps could be done.
I'm not really all that sure the above query shape makes much sense in
the real world. Would anyone ever want to use DISTINCT on some results
containing WindowFuncs?
David
On Tue, 10 Jan 2023 at 18:36, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > David Rowley <dgrowleyml@gmail.com> writes: > > Ideally, our sort costing would just be better, but I think that > > raises the bar a little too high to start thinking of making > > improvements to that for this patch. > > It's trickier than it looks, cf f4c7c410e. But if you just want > to add a small correction based on number of columns being sorted > by, that seems within reach. See the comment for cost_sort though. > Also, I suppose for incremental sorts we'd want to consider only > the number of newly-sorted columns, but I'm not sure if that info > is readily at hand either. Yeah, I had exactly that in mind when I mentioned about setting the bar higher. It seems like a worthy enough goal to improve the sort costs separately from this work. I'm starting to consider if we might need to revisit cost_sort() anyway. There's been quite a number of performance improvements made to sort in the past few years and I don't recall if anything has been done to check if the sort costs are still realistic. I'm aware that it's a difficult problem as the number of comparisons is highly dependent on the order of the input rows. David
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
> On 11/01/23 06:18, David Rowley wrote:
>
> Not sure if we should be trying to improve that in this patch. I just
> wanted to identify it as something else that perhaps could be done.
This could be within reach but still original problem of having hashagg
removing
any gains from this remains.
eg
set enable_hashagg=0;
explain select distinct relkind, relname, count(*) over (partition by
relkind) from pg_Class;
QUERY PLAN
------------------------------------------------------------------------------------
Unique (cost=41.26..65.32 rows=412 width=73)
-> Incremental Sort (cost=41.26..62.23 rows=412 width=73)
Sort Key: relkind, relname, (count(*) OVER (?))
Presorted Key: relkind
-> WindowAgg (cost=36.01..43.22 rows=412 width=73)
-> Sort (cost=36.01..37.04 rows=412 width=65)
Sort Key: relkind
-> Seq Scan on pg_class (cost=0.00..18.12 rows=412 width=65)
(8 rows)
reset enable_hashagg;
explain select distinct relkind, relname, count(*) over (partition by
relkind) from pg_Class;
QUERY PLAN
------------------------------------------------------------------------------
HashAggregate (cost=46.31..50.43 rows=412 width=73)
Group Key: relkind, relname, count(*) OVER (?)
-> WindowAgg (cost=36.01..43.22 rows=412 width=73)
-> Sort (cost=36.01..37.04 rows=412 width=65)
Sort Key: relkind
-> Seq Scan on pg_class (cost=0.00..18.12 rows=412 width=65)
(6 rows)
HashAgg has better cost than Unique even with incremental sort (tried
with other case
where we have more columns pushed down but still hashAgg wins).
explain select distinct a, b, count(*) over (partition by a order by b) from abcd;
QUERY PLAN
--------------------------------------------------------------------------------------
Unique (cost=345712.12..400370.25 rows=1595 width=16)
-> Incremental Sort (cost=345712.12..395456.14 rows=655214 width=16)
Sort Key: a, b, (count(*) OVER (?))
Presorted Key: a, b
-> WindowAgg (cost=345686.08..358790.36 rows=655214 width=16)
-> Sort (cost=345686.08..347324.11 rows=655214 width=8)
Sort Key: a, b
-> Seq Scan on abcd (cost=0.00..273427.14 rows=655214 width=8)
explain select distinct a, b, count(*) over (partition by a order by b) from abcd;
QUERY PLAN
--------------------------------------------------------------------------------
HashAggregate (cost=363704.46..363720.41 rows=1595 width=16)
Group Key: a, b, count(*) OVER (?)
-> WindowAgg (cost=345686.08..358790.36 rows=655214 width=16)
-> Sort (cost=345686.08..347324.11 rows=655214 width=8)
Sort Key: a, b
-> Seq Scan on abcd (cost=0.00..273427.14 rows=655214 width=8)
(6 rows)
> I'm not really all that sure the above query shape makes much sense in
> the real world. Would anyone ever want to use DISTINCT on some results
> containing WindowFuncs?
This could still have been good to have if there were no negative impact
and some benefit in few cases but as mentioned before, if hashagg removes
any sort (which happened due to push down), all gains will be lost
and we will be probably worse off than before.
--
Regards,
Ankit Kumar Pandey
On Wed, 11 Jan 2023 at 19:21, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote:
> HashAgg has better cost than Unique even with incremental sort (tried
> with other case
>
> where we have more columns pushed down but still hashAgg wins).
I don't think you can claim that one so easily. The two should have
quite different scaling characteristics which will be more evident
with a larger number of input rows. Also, Hash Aggregate makes use of
work_mem * hash_mem_multiplier, whereas sort uses work_mem. Consider
a hash_mem_multiplier less than 1.0.
> > I'm not really all that sure the above query shape makes much sense in
> > the real world. Would anyone ever want to use DISTINCT on some results
> > containing WindowFuncs?
>
> This could still have been good to have if there were no negative impact
>
> and some benefit in few cases but as mentioned before, if hashagg removes
>
> any sort (which happened due to push down), all gains will be lost
>
> and we will be probably worse off than before.
We could consider adjusting the create_distinct_paths() so that it
uses some newly invented and less strict pathkey comparison where the
order of the pathkeys does not matter. It would just care if the
pathkeys were present and return a list of pathkeys not contained so
that an incremental sort could be done only on the returned list and a
Unique on an empty returned list. Something like that might be able
to apply in more cases, for example:
select distinct b,a from ab where a < 10;
the distinct pathkeys would be b,a but if there's an index on (a),
then we might have a path with pathkeys containing "a".
You can see when we manually swap the order of the DISTINCT clause
that we get a more optimal plan (even if they're not costed quite as
accurately as we might have liked)
create table ab(a int, b int);
create index on ab(a);
set enable_hashagg=0;
set enable_seqscan=0;
insert into ab select x,y from generate_series(1,100)x, generate_Series(1,100)y;
analyze ab;
# explain select distinct b,a from ab where a < 10;
QUERY PLAN
----------------------------------------------------------------------------------
Unique (cost=72.20..78.95 rows=611 width=8)
-> Sort (cost=72.20..74.45 rows=900 width=8)
Sort Key: b, a
-> Index Scan using ab_a_idx on ab (cost=0.29..28.04
rows=900 width=8)
Index Cond: (a < 10)
(5 rows)
# explain select distinct a,b from ab where a < 10; -- manually swap
DISTINCT column order.
QUERY PLAN
----------------------------------------------------------------------------------
Unique (cost=0.71..60.05 rows=611 width=8)
-> Incremental Sort (cost=0.71..55.55 rows=900 width=8)
Sort Key: a, b
Presorted Key: a
-> Index Scan using ab_a_idx on ab (cost=0.29..28.04
rows=900 width=8)
Index Cond: (a < 10)
(6 rows)
We might also want to also consider if Pathkey.pk_strategy and
pk_nulls_first need to be compared too. That makes the check a bit
more expensive as Pathkeys are canonical and if those fields vary then
we need to perform more than just a comparison by the memory address
of the pathkey. This very much seems like a separate effort than the
WindowClause sort reduction work. I think it gives us everything we've
talked about extra we might want out of reducing WindowClause sorts
and more.
David
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
> On 13/01/23 07:48, David Rowley wrote: > I don't think you can claim that one so easily. The two should have > quite different scaling characteristics which will be more evident > with a larger number of input rows. Also, Hash Aggregate makes use of > work_mem * hash_mem_multiplier, whereas sort uses work_mem. Consider > a hash_mem_multiplier less than 1.0. In this case, it would make sense to do push down. I will do testing around large data to see it myself. > We could consider adjusting the create_distinct_paths() so that it > uses some newly invented and less strict pathkey comparison where the > order of the pathkeys does not matter. It would just care if the > pathkeys were present and return a list of pathkeys not contained so > that an incremental sort could be done only on the returned list and a > Unique on an empty returned list. Something like that might be able > to apply in more cases, for example: > select distinct b,a from ab where a < 10; > the distinct pathkeys would be b,a but if there's an index on (a), > then we might have a path with pathkeys containing "a". This would be a very good improvement. > even if they're not costed quite as > accurately as we might have liked This is very exciting piece actually. Once current set of optimizations gets ahead, I will be giving this a shot. We need to look at cost models for sorting. > We might also want to also consider if Pathkey.pk_strategy and > pk_nulls_first need to be compared too. That makes the check a bit > more expensive as Pathkeys are canonical and if those fields vary then > we need to perform more than just a comparison by the memory address > of the pathkey. > This very much seems like a separate effort than the > WindowClause sort reduction work. I think it gives us everything we've > talked about extra we might want out of reducing WindowClause sorts > and more. I will work on this as separate patch (against HEAD). It makes much more sense to look this as distinct sort related optimizations (which window sort optimization can take benefit). We may take a call to combine them or apply in series. For unit of work perspective, I would prefer later. Anyways, the forthcoming patch will contain the following: 1. Modify create_distinct_paths with newly invented and less strict pathkey comparison where the order of the pathkeys does not matter. 2. Handle Pathkey.pk_strategy and pk_nulls comparison. 3. Test cases Thanks Regards, Ankit Kumar Pandey
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
> On 13/01/23 07:48, David Rowley wrote:
> It would just care if the
> pathkeys were present and return a list of pathkeys not contained so
> that an incremental sort could be done only on the returned list and a
> Unique on an empty returned list.
In create_final_distinct_paths, presorted keys are determined from
input_rel->pathlist & needed_pathkeys. Problem with input_rel->pathlist
is that, for index node, useful_pathkeys is stored in
input_rel->pathlist but this useful_pathkeys
is determined from truncate_useless_pathkeys(index_pathkeys) which
removes index_keys if ordering is different.
Hence, input_rel->pathlist returns null for select distinct b,a from ab
where a < 10; even if index is created on a.
In order to tackle this, I have added index_pathkeys in indexpath node
itself.
Although I started this patch from master, I merged changes to window sort
optimizations.
In patched version:
set enable_hashagg=0;
set enable_seqscan=0;
explain select distinct relname,relkind,count(*) over (partition by
relkind) from pg_Class;
QUERY PLAN
-------------------------------------------------------------------------------------------------------
Unique (cost=10000000039.49..10000000063.73 rows=415 width=73)
-> Incremental Sort (cost=10000000039.49..10000000060.62 rows=415 width=73)
Sort Key: relkind, relname, (count(*) OVER (?))
Presorted Key: relkind
-> WindowAgg (cost=10000000034.20..10000000041.46 rows=415 width=73)
-> Sort (cost=10000000034.20..10000000035.23 rows=415 width=65)
Sort Key: relkind
-> Seq Scan on pg_class (cost=10000000000.00..10000000016.15 rows=415 width=65)
(8 rows)
explain select distinct b,a from ab where a < 10;
QUERY PLAN
----------------------------------------------------------------------------------
Unique (cost=0.71..60.05 rows=611 width=8)
-> Incremental Sort (cost=0.71..55.55 rows=900 width=8)
Sort Key: a, b
Presorted Key: a
-> Index Scan using ab_a_idx on ab (cost=0.29..28.04 rows=900 width=8)
Index Cond: (a < 10)
(6 rows)
explain select distinct b,a, count(*) over (partition by a) from abcd order by a,b;
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Unique (cost=10000021174.63..10000038095.75 rows=60 width=16)
-> Incremental Sort (cost=10000021174.63..10000036745.75 rows=180000 width=16)
Sort Key: a, b, (count(*) OVER (?))
Presorted Key: a, b
-> WindowAgg (cost=10000020948.87..10000024098.87 rows=180000 width=16)
-> Sort (cost=10000020948.87..10000021398.87 rows=180000 width=8)
Sort Key: a, b
-> Seq Scan on abcd (cost=10000000000.00..10000002773.00 rows=180000 width=8)
(8 rows)
explain select distinct a, b, count(*) over (partition by a,b,c) from abcd;
QUERY PLAN
------------------------------------------------------------------------------------------------------
Unique (cost=10000021580.47..10000036629.31 rows=60 width=20)
-> Incremental Sort (cost=10000021580.47..10000035279.31 rows=180000 width=20)
Sort Key: a, b, c, (count(*) OVER (?))
Presorted Key: a, b, c
-> WindowAgg (cost=10000021561.37..10000025611.37 rows=180000 width=20)
-> Sort (cost=10000021561.37..10000022011.37 rows=180000 width=12)
Sort Key: a, b, c
-> Seq Scan on abcd (cost=10000000000.00..10000002773.00 rows=180000 width=12)
(8 rows)
explain select distinct a, b, count(*) over (partition by b,a, c) from abcd;
QUERY PLAN
---------------------------------------------------------------------------------------------------
Unique (cost=2041.88..36764.90 rows=60 width=20)
-> Incremental Sort (cost=2041.88..35414.90 rows=180000 width=20)
Sort Key: b, a, c, (count(*) OVER (?))
Presorted Key: b, a, c
-> WindowAgg (cost=1989.94..25746.96 rows=180000 width=20)
-> Incremental Sort (cost=1989.94..22146.96 rows=180000 width=12)
Sort Key: b, a, c
Presorted Key: b
-> Index Scan using b_idx on abcd (cost=0.29..7174.62 rows=180000 width=12)
(9 rows)
In master:
explain select distinct relname,relkind,count(*) over (partition by
relkind) from pg_Class;
QUERY PLAN
-------------------------------------------------------------------------------------------------------
Unique (cost=10000000059.50..10000000063.65 rows=415 width=73)
-> Sort (cost=10000000059.50..10000000060.54 rows=415 width=73)
Sort Key: relname, relkind, (count(*) OVER (?))
-> WindowAgg (cost=10000000034.20..10000000041.46 rows=415 width=73)
-> Sort (cost=10000000034.20..10000000035.23 rows=415 width=65)
Sort Key: relkind
-> Seq Scan on pg_class (cost=10000000000.00..10000000016.15 rows=415 width=65)
(7 rows)
explain select distinct b,a from ab where a < 10;
QUERY PLAN
----------------------------------------------------------------------------------
Unique (cost=72.20..78.95 rows=611 width=8)
-> Sort (cost=72.20..74.45 rows=900 width=8)
Sort Key: b, a
-> Index Scan using ab_a_idx on ab (cost=0.29..28.04 rows=900 width=8)
Index Cond: (a < 10)
(5 rows)
explain select distinct b,a, count(*) over (partition by a) from abcd order by a,b;
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Unique (cost=10000023704.77..10000041084.40 rows=60 width=16)
-> Incremental Sort (cost=10000023704.77..10000039734.40 rows=180000 width=16)
Sort Key: a, b, (count(*) OVER (?))
Presorted Key: a
-> WindowAgg (cost=10000020948.87..10000024098.87 rows=180000 width=16)
-> Sort (cost=10000020948.87..10000021398.87 rows=180000 width=8)
Sort Key: a
-> Seq Scan on abcd (cost=10000000000.00..10000002773.00 rows=180000 width=8)
(8 rows)
explain select distinct a, b, count(*) over (partition by b,a, c) from abcd;
QUERY PLAN
---------------------------------------------------------------------------------------------------
Unique (cost=45151.33..46951.33 rows=60 width=20)
-> Sort (cost=45151.33..45601.33 rows=180000 width=20)
Sort Key: a, b, (count(*) OVER (?))
-> WindowAgg (cost=1989.94..25746.96 rows=180000 width=20)
-> Incremental Sort (cost=1989.94..22146.96 rows=180000 width=12)
Sort Key: b, a, c
Presorted Key: b
-> Index Scan using b_idx on abcd (cost=0.29..7174.62 rows=180000 width=12)
(8 rows)
Note: Composite keys are also handled.
create index xy_idx on xyz(x,y);
explain select distinct x,z,y from xyz;
QUERY PLAN
----------------------------------------------------------------------------------
Unique (cost=0.86..55.97 rows=60 width=12)
-> Incremental Sort (cost=0.86..51.47 rows=600 width=12)
Sort Key: x, y, z
Presorted Key: x, y
-> Index Scan using xy_idx on xyz (cost=0.15..32.80 rows=600 width=12)
(5 rows)
There are some cases where different kind of scan happens
explain select distinct x,y from xyz where y < 10;
QUERY PLAN
-----------------------------------------------------------------------------------
Unique (cost=47.59..51.64 rows=60 width=8)
-> Sort (cost=47.59..48.94 rows=540 width=8)
Sort Key: x, y
-> Bitmap Heap Scan on xyz (cost=12.34..23.09 rows=540 width=8)
Recheck Cond: (y < 10)
-> Bitmap Index Scan on y_idx (cost=0.00..12.20
rows=540 width=0)
Index Cond: (y < 10)
(7 rows)
As code only checks from IndexPath (at the moment), other scan paths are
not covered.
Is it okay to cover these in same way as I did for IndexPath? (with no
limitation on this behaviour on certain path types?)
Also, I am assuming distinct pathkeys can be changed without any issues.
As changes are limited to modification in distinct path only,
I don't see this affecting other nodes. Test cases are green,
with a couple of failures in window functions (one which I had added)
and one very weird:
EXPLAIN (COSTS OFF)
SELECT DISTINCT
empno,
enroll_date,
depname,
sum(salary) OVER (PARTITION BY depname order by empno) depsalary,
min(salary) OVER (PARTITION BY depname order by enroll_date) depminsalary
FROM empsalary
ORDER BY depname, empno;
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Incremental Sort
Sort Key: depname, empno
Presorted Key: depname
-> Unique
-> Incremental Sort
Sort Key: depname, enroll_date, empno, (sum(salary) OVER (?)), (min(salary) OVER (?))
Presorted Key: depname
-> WindowAgg
-> Incremental Sort
Sort Key: depname, empno
Presorted Key: depname
-> WindowAgg
-> Sort
Sort Key: depname, enroll_date
-> Seq Scan on empsalary
(15 rows)
In above query plan, unique used to come after Incremental sort in the
master.
Pending:
1. Consider if Pathkey.pk_strategy and pk_nulls_first need to be
compared too, this is pending
as I have to look these up and understand them.
2. Test cases (failures and new cases)
3. Improve comments
Patch v8 attached.
Please let me know any review comments, will address these in followup patch
with pending items.
Thanks,
Ankit
Attachment
On Mon, 16 Jan 2023 at 06:52, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: > Hence, input_rel->pathlist returns null for select distinct b,a from ab > where a < 10; even if index is created on a. > > In order to tackle this, I have added index_pathkeys in indexpath node > itself. I don't think we should touch this. It could significantly increase the number of indexes that we consider when generating paths on base relations and therefore *significantly* increase the number of paths we consider during the join search. What I had in mind was just making better use of existing paths to see if we can find a cheaper way to perform the DISTINCT. That'll only possibly increase the number of paths for the distinct upper relation which really only increases the number of paths which are considered in create_ordered_paths(). That's unlikely to cause much of a slowdown in the planner. > Although I started this patch from master, I merged changes to window sort > optimizations. I'm seeing these two things as separate patches. I don't think there's any need to add further complexity to the patch that tries to reduce the number of sorts for WindowAggs. I think you'd better start a new thread for this. > Also, I am assuming distinct pathkeys can be changed without any issues. > As changes are limited to modification in distinct path only, As far as I see it, you shouldn't be touching the distinct_pathkeys. Those are set in such a way as to minimise the likelihood of an additional sort for the ORDER BY. If you've fiddled with that, then I imagine this is why the plan below has an additional Incremental Sort that didn't exist before. I've not looked at your patch, but all I imagine you need to do for it is to invent a function in pathkeys.c which is along the lines of what pathkeys_count_contained_in() does, but returns a List of pathkeys which are in keys1 but not in keys2 and NIL if keys2 has a pathkey that does not exist as a pathkey in keys1. In create_final_distinct_paths(), you can then perform an incremental sort on any input_path which has a non-empty return list and in create_incremental_sort_path(), you'll pass presorted_keys as the number of pathkeys in the path, and the required pathkeys the input_path->pathkeys + the pathkeys returned from the new function. As an optimization, you might want to consider that the distinct_pathkeys list might be long and that the new function, if you code the lookup as a nested loop, might be slow. You might want to consider hashing the distinct_pathkeys once in create_final_distinct_paths(), then for each input_path, perform a series of hash lookups to see which of the input_path->pathkeys are in the hash table. That might require adding two functions to pathkeys.c, one to build the hash table and then another to probe it and return the remaining pathkeys list. I'd go and make sure it all works as we expect before going to the trouble of trying to optimize this. A simple nested loop lookup will allow us to review that this works as we expect. > EXPLAIN (COSTS OFF) > SELECT DISTINCT > empno, > enroll_date, > depname, > sum(salary) OVER (PARTITION BY depname order by empno) depsalary, > min(salary) OVER (PARTITION BY depname order by enroll_date) depminsalary > FROM empsalary > ORDER BY depname, empno; > QUERY PLAN > ----------------------------------------------------------------------------------------------------- > Incremental Sort > Sort Key: depname, empno > Presorted Key: depname > -> Unique > -> Incremental Sort > Sort Key: depname, enroll_date, empno, (sum(salary) OVER (?)), (min(salary) OVER (?)) > Presorted Key: depname > -> WindowAgg > -> Incremental Sort > Sort Key: depname, empno > Presorted Key: depname > -> WindowAgg > -> Sort > Sort Key: depname, enroll_date > -> Seq Scan on empsalary > (15 rows) David
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
> On 16/01/23 09:48, David Rowley wrote: > I don't think we should touch this. It could significantly increase > the number of indexes that we consider when generating paths on base > relations and therefore *significantly* increase the number of paths > we consider during the join search. What I had in mind was just > making better use of existing paths to see if we can find a cheaper > way to perform the DISTINCT. That'll only possibly increase the > number of paths for the distinct upper relation which really only > increases the number of paths which are considered in > create_ordered_paths(). That's unlikely to cause much of a slowdown in > the planner. Okay, I see the issue. Makes sense > I'm seeing these two things as separate patches. I don't think there's > any need to add further complexity to the patch that tries to reduce > the number of sorts for WindowAggs. I think you'd better start a new > thread for this. Will be starting new thread for this and separate patch. > As far as I see it, you shouldn't be touching the distinct_pathkeys. > Those are set in such a way as to minimise the likelihood of an > additional sort for the ORDER BY. If you've fiddled with that, then I > imagine this is why the plan below has an additional Incremental Sort > that didn't exist before. > I've not looked at your patch, but all I imagine you need to do for it > is to invent a function in pathkeys.c which is along the lines of what > pathkeys_count_contained_in() does, but returns a List of pathkeys > which are in keys1 but not in keys2 and NIL if keys2 has a pathkey > that does not exist as a pathkey in keys1. In > create_final_distinct_paths(), you can then perform an incremental > sort on any input_path which has a non-empty return list and in > create_incremental_sort_path(), you'll pass presorted_keys as the > number of pathkeys in the path, and the required pathkeys the > input_path->pathkeys + the pathkeys returned from the new function. Okay, this should be straightforward. Let me try this. > As an optimization, you might want to consider that the > distinct_pathkeys list might be long and that the new function, if you > code the lookup as a nested loop, might be slow. You might want to > consider hashing the distinct_pathkeys once in > create_final_distinct_paths(), then for each input_path, perform a > series of hash lookups to see which of the input_path->pathkeys are in > the hash table. That might require adding two functions to pathkeys.c, > one to build the hash table and then another to probe it and return > the remaining pathkeys list. I'd go and make sure it all works as we > expect before going to the trouble of trying to optimize this. A > simple nested loop lookup will allow us to review that this works as > we expect. Okay make sense, will start with nested loop while it is in review and then optimal version once it is all good to go. Thanks, Ankit
On Tue, 10 Jan 2023 at 06:15, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: > > > > On 09/01/23 17:53, David Rowley wrote: > > I gave some thought to whether doing foreach_delete_current() is safe > > within a foreach_reverse() loop. I didn't try it, but I couldn't see > > any reason why not. It is pretty late here and I'd need to test that > > to be certain. If it turns out not to be safe then we need to document > > that fact in the comments of the foreach_reverse() macro and the > > foreach_delete_current() macro. > > I tested foreach_delete_current inside foreach_reverse loop. > > It worked fine. I also thought I'd better test that foreach_delete_current() works with foreach_reverse(). I can confirm that it *does not* work correctly. I guess maybe you only tested the fact that it deleted the current item and not that the subsequent loop correctly went to the item directly before the deleted item. There's a problem with that. We skip an item. Instead of fixing that, I think it's likely better just to loop backwards manually with a for() loop, so I've adjusted the patch to work that way. It's quite likely that the additional code in foreach() and what was in foreach_reverse() is slower than looping manually due to the additional work those macros do to set the cell to NULL when we run out of cells to loop over. > I have attached patch with one extra test case (as mentioned above). > Rest of the changes are looking fine. I made another pass over the v7 patch and fixed a bug that was disabling the optimization when the deepest WindowAgg had a runCondition. This should have been using llast_node instead of linitial_node. The top-level WindowAgg is the last in the list. I also made a pass over the tests and added a test case for the runCondition check to make sure we disable the optimization when the top-level WindowAgg has one of those. I wasn't sure what your test comments case numbers were meant to represent. They were not aligned with the code comments that document when the optimisation is disabled, they started out aligned, but seemed to go off the rails at #3. I've now made them follow the comments in create_one_window_path() and made it more clear what we expect the test outcome to be in each case. I've attached the v9 patch. I feel like this patch is quite self-contained and I'm quite happy with it now. If there are no objections soon, I'm planning on pushing it. David
Attachment
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
> On 18/01/23 15:12, David Rowley wrote:
> I also thought I'd better test that foreach_delete_current() works
> with foreach_reverse(). I can confirm that it *does not* work
> correctly. I guess maybe you only tested the fact that it deleted the
> current item and not that the subsequent loop correctly went to the
> item directly before the deleted item. There's a problem with that. We
> skip an item.
Hmm, not really sure why did I miss that. I tried this again (added
following in postgres.c above
PortalStart)
List* l = NIL;
l = lappend(l, 1);
l = lappend(l, 2);
l = lappend(l, 3);
l = lappend(l, 4);
ListCell *lc;
foreach_reverse(lc, l)
{
if (foreach_current_index(lc) == 2) // delete 3
{
foreach_delete_current(l, lc);
}
}
foreach(lc, l)
{
int i = (int) lfirst(lc);
ereport(LOG,(errmsg("%d", i)));
}
Got result:
2023-01-18 20:23:28.115 IST [51007] LOG: 1
2023-01-18 20:23:28.115 IST [51007] STATEMENT: select pg_backend_pid();
2023-01-18 20:23:28.115 IST [51007] LOG: 2
2023-01-18 20:23:28.115 IST [51007] STATEMENT: select pg_backend_pid();
2023-01-18 20:23:28.115 IST [51007] LOG: 4
2023-01-18 20:23:28.115 IST [51007] STATEMENT: select pg_backend_pid();
I had expected list_delete_cell to take care of rest.
> Instead of fixing that, I think it's likely better just to loop
> backwards manually with a for() loop, so I've adjusted the patch to
> work that way. It's quite likely that the additional code in
> foreach() and what was in foreach_reverse() is slower than looping
> manually due to the additional work those macros do to set the cell to
> NULL when we run out of cells to loop over.
Okay, current version looks fine as well.
> I made another pass over the v7 patch and fixed a bug that was
> disabling the optimization when the deepest WindowAgg had a
> runCondition. This should have been using llast_node instead of
> linitial_node. The top-level WindowAgg is the last in the list.
> I also made a pass over the tests and added a test case for the
> runCondition check to make sure we disable the optimization when the
> top-level WindowAgg has one of those.
> I wasn't sure what your test comments case numbers were meant to represent.
> They were not aligned with the code comments that document when the optimisation is
> disabled, they started out aligned, but seemed to go off the rails at
> #3. I've now made them follow the comments in create_one_window_path()
> and made it more clear what we expect the test outcome to be in each
> case.
Those were just numbering for exceptional cases, making them in sync
with comments
wasn't really on my mind, but now they looks better.
> I've attached the v9 patch. I feel like this patch is quite
> self-contained and I'm quite happy with it now. If there are no
> objections soon, I'm planning on pushing it.
Patch is already rebased with latest master, tests are all green.
Tried some basic profiling and it looked good.
I also tried a bit unrealistic case.
create table abcdefgh(a int, b int, c int, d int, e int, f int, g int, h int);
insert into abcdefgh select a,b,c,d,e,f,g,h from
generate_series(1,7) a,
generate_series(1,7) b,
generate_series(1,7) c,
generate_series(1,7) d,
generate_series(1,7) e,
generate_series(1,7) f,
generate_series(1,7) g,
generate_series(1,7) h;
explain analyze select count(*) over (order by a),
row_number() over (partition by a order by b) from abcdefgh order by a,b,c,d,e,f,g,h;
In patch version
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
---------------
WindowAgg (cost=1023241.14..1225007.67 rows=5764758 width=48) (actual
time=64957.894..81950.352 rows=5764801 loops=1)
-> WindowAgg (cost=1023241.14..1138536.30 rows=5764758 width=40)
(actual time=37959.055..60391.799 rows=5764801 loops
=1)
-> Sort (cost=1023241.14..1037653.03 rows=5764758 width=32)
(actual time=37959.045..52968.791 rows=5764801 loop
s=1)
Sort Key: a, b, c, d, e, f, g, h
Sort Method: external merge Disk: 237016kB
-> Seq Scan on abcdefgh (cost=0.00..100036.58
rows=5764758 width=32) (actual time=0.857..1341.107 rows=57
64801 loops=1)
Planning Time: 0.168 ms
Execution Time: 82748.789 ms
(8 rows)
In Master
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
---------------------
Incremental Sort (cost=1040889.72..1960081.97 rows=5764758 width=48)
(actual time=23461.815..69654.700 rows=5764801 loop
s=1)
Sort Key: a, b, c, d, e, f, g, h
Presorted Key: a, b
Full-sort Groups: 49 Sort Method: quicksort Average Memory: 30kB
Peak Memory: 30kB
Pre-sorted Groups: 49 Sort Method: external merge Average Disk:
6688kB Peak Disk: 6688kB
-> WindowAgg (cost=1023241.14..1225007.67 rows=5764758 width=48)
(actual time=22729.171..40189.407 rows=5764801 loops
=1)
-> WindowAgg (cost=1023241.14..1138536.30 rows=5764758
width=40) (actual time=8726.562..18268.663 rows=5764801
loops=1)
-> Sort (cost=1023241.14..1037653.03 rows=5764758
width=32) (actual time=8726.551..11291.494 rows=5764801
loops=1)
Sort Key: a, b
Sort Method: external merge Disk: 237016kB
-> Seq Scan on abcdefgh (cost=0.00..100036.58
rows=5764758 width=32) (actual time=0.029..1600.042 r
ows=5764801 loops=1)
Planning Time: 2.742 ms
Execution Time: 71172.586 ms
(13 rows)
Patch version is approx 11 sec slower.
Patch version sort took around 15 sec, whereas master sort took ~2 + 46
= around 48 sec
BUT somehow master version is faster as Window function took 10 sec less
time.
Maybe I am interpreting it wrong but still wanted to bring this to notice.
Thanks,
Ankit
On Thu, 19 Jan 2023 at 06:27, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote:
> Hmm, not really sure why did I miss that. I tried this again (added
> following in postgres.c above
>
> PortalStart)
>
> List* l = NIL;
> l = lappend(l, 1);
> l = lappend(l, 2);
> l = lappend(l, 3);
> l = lappend(l, 4);
>
> ListCell *lc;
> foreach_reverse(lc, l)
> {
> if (foreach_current_index(lc) == 2) // delete 3
> {
> foreach_delete_current(l, lc);
> }
> }
The problem is that the next item looked at is 1 and the value 2 is skipped.
> I also tried a bit unrealistic case.
>
> create table abcdefgh(a int, b int, c int, d int, e int, f int, g int, h int);
>
> insert into abcdefgh select a,b,c,d,e,f,g,h from
> generate_series(1,7) a,
> generate_series(1,7) b,
> generate_series(1,7) c,
> generate_series(1,7) d,
> generate_series(1,7) e,
> generate_series(1,7) f,
> generate_series(1,7) g,
> generate_series(1,7) h;
>
> explain analyze select count(*) over (order by a),
> row_number() over (partition by a order by b) from abcdefgh order by a,b,c,d,e,f,g,h;
>
> In patch version
> Execution Time: 82748.789 ms
> In Master
> Execution Time: 71172.586 ms
> Patch version sort took around 15 sec, whereas master sort took ~2 + 46
> = around 48 sec
> Maybe I am interpreting it wrong but still wanted to bring this to notice.
I think you are misinterpreting the results, but the main point
remains - it's slower. The explain analyze timing shows the time
between outputting the first row and the last row. For sort, there's a
lot of work that needs to be done before you output the first row.
I looked into this a bit further and using the same table as you, and
the attached set of hacks that adjust the ORDER BY path generation to
split a Sort into a Sort and Incremental Sort when the number of
pathkeys to sort by is > 2.
work_mem = '1GB' in all cases below:
I turned off the timing in EXPLAIN so that wasn't a factor in the
results. Generally having more nodes means more timing requests and
that's got > 0 overhead.
explain (analyze,timing off) select * from abcdefgh order by a,b,c,d,e,f,g,h;
7^8 rows
Master: Execution Time: 7444.479 ms
master + sort_hacks.diff: Execution Time: 5147.937 ms
So I'm also seeing Incremental Sort - > Sort faster than a single Sort
for 7^8 rows.
With 5^8 rows:
master: Execution Time: 299.949 ms
master + sort_hacks: Execution Time: 239.447 ms
and 4^8 rows:
master: Execution Time: 62.596 ms
master + sort_hacks: Execution Time: 67.900 ms
So at 4^8 sort_hacks becomes slower. I suspect this might be to do
with having to perform more swaps in the array elements that we're
sorting by with the full sort. When work_mem is large this array no
longer fits in CPU cache and I suspect those swaps become more costly
when there are more cache lines having to be fetched from RAM.
I think we really should fix tuplesort.c so that it batches sorts into
about L3 CPU cache-sized chunks in RAM rather than trying to sort much
larger arrays.
I'm just unsure if we should write this off as the expected behaviour
of Sort and continue with the patch or delay the whole thing until we
make some improvements to sort. I think more benchmarking is required
so we can figure out if this is a corner case or a common case. On the
other hand, we already sort WindowClauses with the most strict sort
order first which results in a full Sort and no additional sort for
subsequent WindowClauses that can make use of that sort order. It
would be bizarre to reverse the final few lines of common_prefix_cmp
so that we sort the least strict order first so we end up injecting
Incremental Sorts into the plan to make it faster!
David
Attachment
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
> On 19/01/23 08:58, David Rowley wrote: > The problem is that the next item looked at is 1 and the value 2 is skipped. Okay, I see the issue. > I think you are misinterpreting the results, but the main point > remains - it's slower. The explain analyze timing shows the time > between outputting the first row and the last row. For sort, there's a > lot of work that needs to be done before you output the first row. Okay got it. > I looked into this a bit further and using the same table as you, and > the attached set of hacks that adjust the ORDER BY path generation to > split a Sort into a Sort and Incremental Sort when the number of > pathkeys to sort by is > 2. Okay, so this is issue with strict sort itself. I will play around with current patch but it should be fine for current work and would account for issue in strict sort. > I suspect this might be to do with having to perform more swaps in the > array elements that we'resorting by with the full sort. When work_mem is > large this array no longer fits in CPU cache and I suspect those swaps become > more costly when there are more cache lines having to be fetched from RAM. Looks like possible reason. > I think we really should fix tuplesort.c so that it batches sorts into > about L3 CPU cache-sized chunks in RAM rather than trying to sort much > larger arrays. I assume same thing we are doing for incremental sort and that's why it perform better here? Or is it due to shorter tuple width and thus being able to fit into memory easily? > On the > other hand, we already sort WindowClauses with the most strict sort > order first which results in a full Sort and no additional sort for > subsequent WindowClauses that can make use of that sort order. It > would be bizarre to reverse the final few lines of common_prefix_cmp > so that we sort the least strict order first so we end up injecting > Incremental Sorts into the plan to make it faster! I would see this as beneficial when tuple size is too huge for strict sort. Basically cost(sort(a,b,c,d,e)) > cost(sort(a)+sort(b)+sort(c)+ sort(d,e)) Don't know if cost based decision is realistic or not in current state of things. > I think more benchmarking is required > so we can figure out if this is a corner case or a common case I will do few more benchmarks. I assume all scaling issue with strict sort to remain as it is but no further issue due to this change itself comes up. > I'm just unsure if we should write this off as the expected behaviour > of Sort and continue with the patch or delay the whole thing until we > make some improvements to sort. Unless we found more issues, we might be good with the former but you can make better call on this. As much as I would love my first patch to get merged, I would want it to be right. Thanks, Ankit
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
> I think more benchmarking is required
> so we can figure out if this is a corner case or a common case
I did some more benchmarks:
#1. AIM: Pushdown column whose size is very high
create table test(a int, b int, c text);
insert into test select a,b,c from generate_series(1,1000)a, generate_series(1,1000)b, repeat(md5(random()::text),
999)c;
explain (analyze, costs off) select count(*) over (order by a), row_number() over (order by a, b) from test order by
a,b,c;
QUERY PLAN
----------------------------------------------------------------------------------------------------------
Incremental Sort (actual time=1161.605..6577.141 rows=1000000 loops=1)
Sort Key: a, b, c
Presorted Key: a, b
Full-sort Groups: 31250 Sort Method: quicksort Average Memory: 39kB Peak Memory: 39kB
-> WindowAgg (actual time=1158.896..5819.460 rows=1000000 loops=1)
-> WindowAgg (actual time=1154.614..3391.537 rows=1000000 loops=1)
-> Gather Merge (actual time=1154.602..2404.125 rows=1000000 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (actual time=1118.326..1295.743 rows=333333 loops=3)
Sort Key: a, b
Sort Method: external merge Disk: 145648kB
Worker 0: Sort Method: external merge Disk: 140608kB
Worker 1: Sort Method: external merge Disk: 132792kB
-> Parallel Seq Scan on test (actual time=0.018..169.319 rows=333333 loops=3)
Planning Time: 0.091 ms
Execution Time: 6816.616 ms
(17 rows)
Planner choose faster path correctly (which was not path which had pushed down column).
#2. AIM: Check strict vs incremental sorts wrt to large size data
Patch version is faster as for external merge sort, disk IO is main bottleneck and if we sort an extra column,
it doesn't have major impact. This is when work mem is very small.
For larger work_mem, difference between patched version and master is minimal and
they both provide somewhat comparable performance.
Tried permutation of few cases which we have already covered but I did not see anything alarming in those.
> I'm just unsure if we should write this off as the expected behaviour
> of Sort and continue with the patch or delay the whole thing until we
> make some improvements to sort.
I am not seeing other cases where patch version is consistently slower.
Thanks,
Ankit
On Wed, 25 Jan 2023 at 06:32, Ankit Kumar Pandey <itsankitkp@gmail.com> wrote: > I am not seeing other cases where patch version is consistently slower. I just put together a benchmark script to try to help paint a picture of under what circumstances reducing the number of sorts slows down performance. The benchmark I used creates a table with 2 int4 columns, "a" and "b". I have a single WindowClause that sorts on "a" and then ORDER BY a,b. In each test, I change the number of distinct values in "a" starting with 1 distinct value then in each subsequent test I multiply that number by 10 each time all the way up to 1 million. The idea here is to control how often the sort that's performing a sort by both columns must call the tiebreak function. I did 3 subtests for each number of distinct rows in "a". 1) Unsorted case where the rows are put into the tuples store in an order that's not presorted, 2) tuplestore rows are already sorted leading to hitting our qsort fast path. 3) random order. You can see from the results that the patched version is not looking particularly great. I did a 1 million row test and a 10 million row test. work_mem was 4GB for each, so the sorts never went to disk. Overall, the 1 million row test on master took 11.411 seconds and the patched version took 11.282 seconds, so there was a *small* gain overall there. With the 10 million row test, overall, master took 121.063 seconds, whereas patched took 130.727 seconds. So quite a large performance regression there. I'm unsure if 69749243 might be partially to blame here as it favours single-key sorts. If you look at qsort_tuple_signed_compare(), you'll see that the tiebreak function will be called only when it's needed and there are > 1 sort keys. The comparetup function will re-compare the first key all over again. If I get some more time I'll run the tests again with the sort specialisation code disabled to see if the situation is the same or not. Another way to test that would be to have a table with 3 columns and always sort by at least 2. I've attached the benchmark script that I used and also a copy of the patch with a GUC added solely to allow easier benchmarking of patched vs unpatched. I think we need to park this patch until we can figure out what can be done to stop these regressions. We might want to look at 1) Expanding on what 69749243 did and considering if we want sort specialisations that are specifically for 1 column and another set for multi-columns. The multi-column ones don't need to re-compare key[0] again. 2) Sorting in smaller batches that better fit into CPU cache. Both of these ideas would require a large amount of testing and discussion. For #1 we're considering other specialisations, for example NOT NULL, and we don't want to explode the number of specialisations we have to compile into the binary. David
Attachment
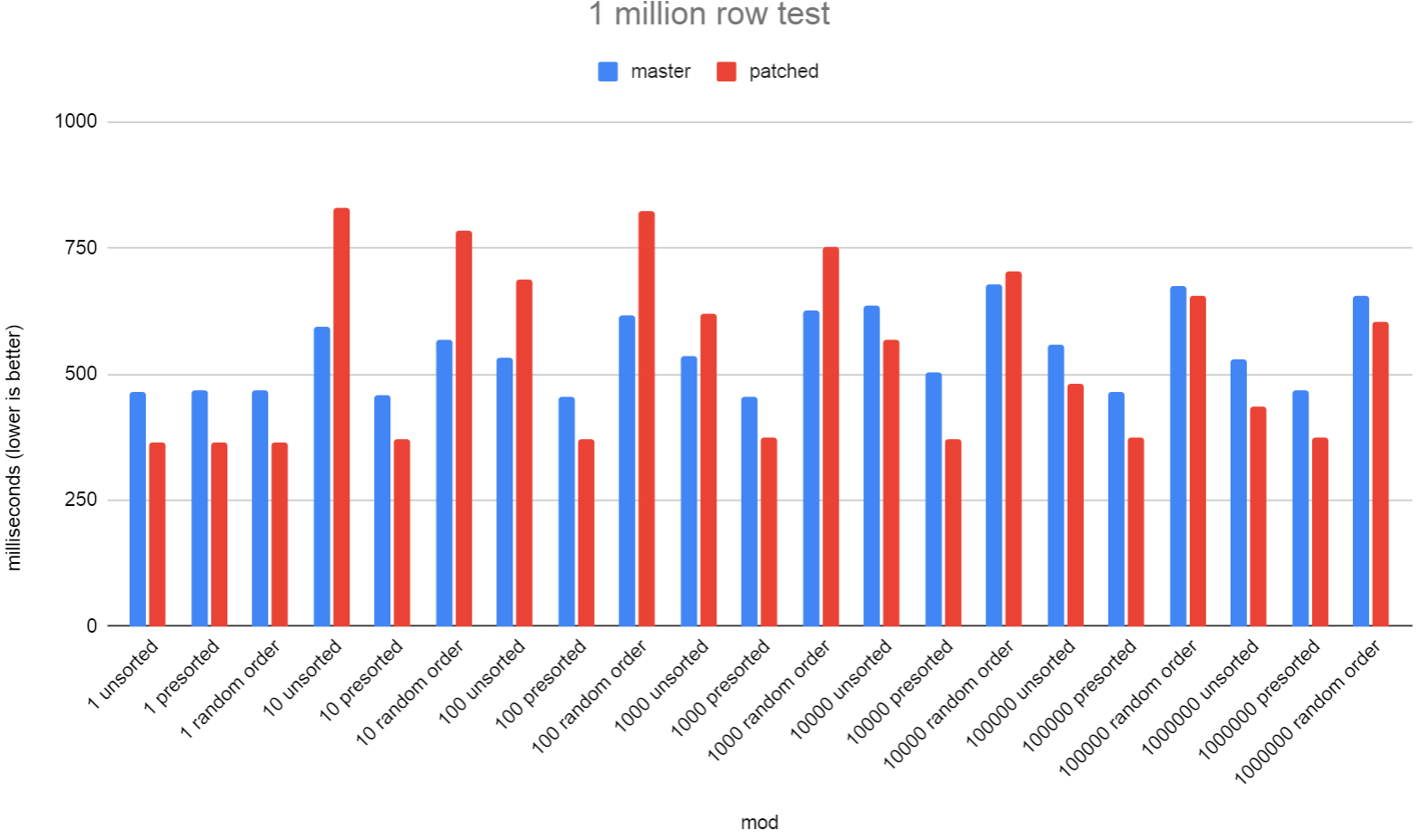{kind=link}
{kind=link}
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
> On 26/01/23 07:40, David Rowley wrote: > You can see from the results that the patched version is not looking > particularly great. I did a 1 million row test and a 10 million row > test. work_mem was 4GB for each, so the sorts never went to disk. Yes, its lackluster gains are very limited (pretty much when data gets pushed to disk). > I'm unsure if 69749243 might be partially to blame here as it favours > single-key sorts. If you look at qsort_tuple_signed_compare(), you'll > see that the tiebreak function will be called only when it's needed > and there are > 1 sort keys. The comparetup function will re-compare > the first key all over again. If I get some more time I'll run the > tests again with the sort specialisation code disabled to see if the > situation is the same or not. > Another way to test that would be to have a table with 3 columns and > always sort by at least 2. I will need to go through this. > I've attached the benchmark script that I used and also a copy of the > patch with a GUC added solely to allow easier benchmarking of patched > vs unpatched. This is much relief, will be easier to repro and create more cases. Thanks. > I think we need to park this patch until we can figure out what can be > done to stop these regressions. Makes sense. > We might want to look at 1) Expanding > on what 69749243 did and considering if we want sort specialisations > that are specifically for 1 column and another set for multi-columns. > The multi-column ones don't need to re-compare key[0] again. 2) > Sorting in smaller batches that better fit into CPU cache. Both of > these ideas would require a large amount of testing and discussion. > For #1 we're considering other specialisations, for example NOT NULL, > and we don't want to explode the number of specialisations we have to > compile into the binary. Yes, 1 & 2 needs to be addressed before going ahead with this patch. Do we any have ongoing thread with #1 and #2? Also, we have seen an issue with cost ( 1 sort vs 2 sorts, both having same cost) https://www.postgresql.org/message-id/CAApHDvo2y9S2AO-BPYo7gMPYD0XE2Lo-KFLnqX80fcftqBCcyw@mail.gmail.com This needs to be investigated too (although might not be related but need to check at least) I will do some study around things mentioned here and will setup new threads (if they don't exists) based on discussions we had here . Thanks, Ankit
On Sat, Jan 28, 2023 at 3:21 PM Ankit Kumar Pandey <itsankitkp@gmail.com> wrote:
>
> > On 26/01/23 07:40, David Rowley wrote:
> > on what 69749243 did and considering if we want sort specialisations
> > that are specifically for 1 column and another set for multi-columns.
> > The multi-column ones don't need to re-compare key[0] again. 2)
> > Sorting in smaller batches that better fit into CPU cache. Both of
> > these ideas would require a large amount of testing and discussion.
> > For #1 we're considering other specialisations, for example NOT NULL,
> > and we don't want to explode the number of specialisations we have to
> > compile into the binary.
>
> Yes, 1 & 2 needs to be addressed before going ahead with this patch.
> Do we any have ongoing thread with #1 and #2?
I recently brought up this older thread (mostly about #1), partly because of the issues discovered above, and partly because I hope to make progress on it before feature freeze (likely early April):
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
> On 28/01/23 14:31, John Naylor wrote: > I recently brought up this older thread (mostly about #1), partly because of the issues discovered above, and partly because I hope to make progress on it before feature freeze (likely early April): > https://www.postgresql.org/message-id/CAApHDvqXcmzAZDsj8iQs84%2Bdrzo0PgYub_QYzT6Zdj6p4A3A5A%40mail.gmail.com <https://www.postgresql.org/message-id/CAApHDvqXcmzAZDsj8iQs84%2Bdrzo0PgYub_QYzT6Zdj6p4A3A5A%40mail.gmail.com> Thanks John for letting me know. I will keep eye on above thread and will focus on rest of issues. Regards, Ankit
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
> On 26/01/23 07:40, David Rowley wrote: > I just put together a benchmark script to try to help paint a picture > of under what circumstances reducing the number of sorts slows down > performance. work_mem was 4GB for each, so the sorts never went to disk. I tried same test suit albeit work_mem = 1 MB to check how sort behaves with frequent disk IO. For 1 million row test, patch version shows some promise but performance degrades in 10 million row test. There is also an anomalies in middle range for 100/1000 random value. I have also added results of benchmark with sorting fix enabled and table with 3 columns and sorting done on > 2 columns. I don't see much improvement vs master here. Again, these results are for work_mem = 1 MB. > Sorting in smaller batches that better fit into CPU cache. More reading yielded that we are looking for cache-oblivious sorting algorithm. One the papers[1] mentions that in quick sort, whenever we reach size which can fit in cache, instead of partitioning it further, we can do insertion sort there itself. > Memory-tuned quicksort uses insertion sort to sort small subsets while they are in > the cache, instead of partitioning further. This increases the instruction count, > but reduces the cache misses If this looks step in right direction, I can give it a try and do more reading and experimentation. [1] http://www.ittc.ku.edu/~jsv/Papers/WAC01.sorting_using_registers.pdf Thanks, Ankit
Attachment
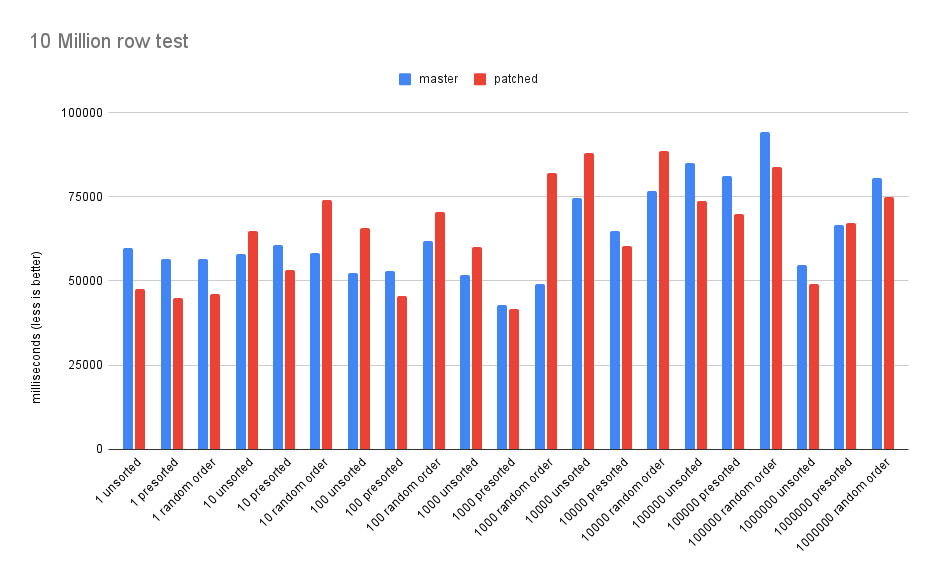{kind=link}
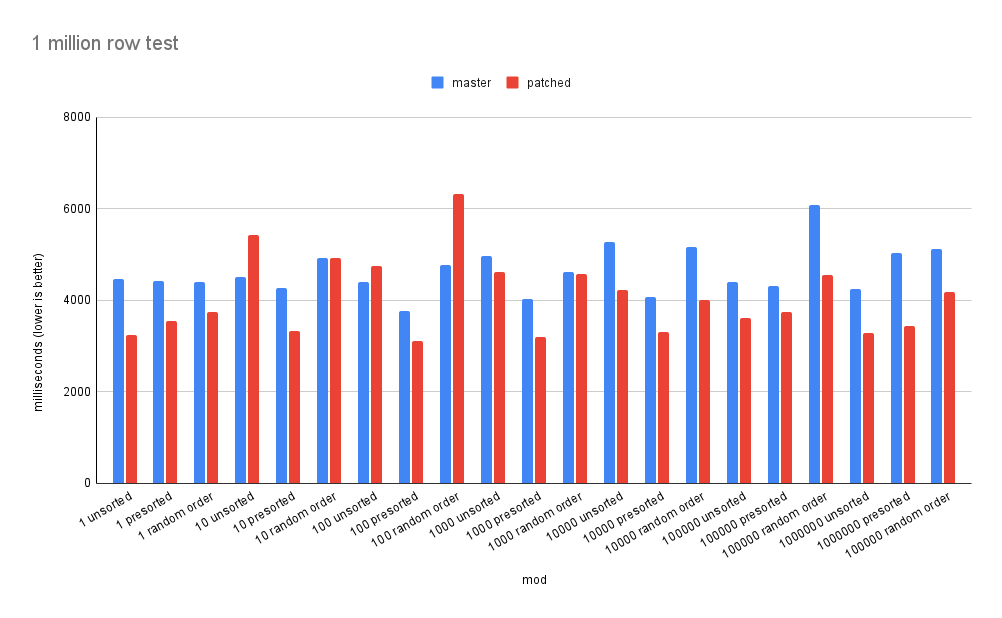{kind=link}
.png){kind=link}
.png){kind=link}
On Sun, Jan 29, 2023 at 7:05 PM Ankit Kumar Pandey <itsankitkp@gmail.com> wrote:
>
>
> > On 26/01/23 07:40, David Rowley wrote:
>
> More reading yielded that we are looking for cache-oblivious
> sorting algorithm.
> One the papers[1] mentions that in quick sort, whenever we reach size which can fit in cache,
> instead of partitioning it further, we can do insertion sort there itself.
> > Memory-tuned quicksort uses insertion sort to sort small subsets while they are in
> > the cache, instead of partitioning further. This increases the instruction count,
> > but reduces the cache misses
>
> If this looks step in right direction, I can give it a try and do more reading and experimentation.
I'm not close enough to this thread to guess at the right direction (although I hope related work will help), but I have a couple general remarks:
Re: Todo: Teach planner to evaluate multiple windows in the optimal order
> On 30/01/23 11:01, John Naylor wrote: > Since David referred to L3 size as the starting point of a possible configuration parameter, that's actually cache-conscious. Okay, makes sense. I am correcting error on my part. > I'm not close enough to this thread to guess at the right direction (although I hope related work will help), but I have a couple general remarks: > 1. In my experience, academic papers like to test sorting with register-sized numbers or strings. Our sorttuples are bigger, have complex comparators, and can fall back to fields in the full tuple. > 2. That paper is over 20 years old. If it demonstrated something genuinely useful, some of those concepts would likely be implemented in the real-world somewhere. Looking for evidence of that might be a good exercise. > 3. 20 year-old results may not carry over to modern hardware. > 4. Open source software is more widespread in the academic world now than 20 years ago, so papers with code (maybe even the author's github) are much more useful to us in my view. > 5. It's actually not terribly hard to make sorting faster for some specific cases -- the hard part is keeping other inputs of interest from regressing. > 6. The bigger the change, the bigger the risk of regressing somewhere. Thanks John, these inputs are actually what I was looking for. I will do more research based on these inputs and build up my understanding. Regards, Ankit
On Thu, Jan 26, 2023 at 9:11 AM David Rowley <dgrowleyml@gmail.com> wrote:
>
> I'm unsure if 69749243 might be partially to blame here as it favours
> single-key sorts. If you look at qsort_tuple_signed_compare(), you'll
> see that the tiebreak function will be called only when it's needed
> and there are > 1 sort keys. The comparetup function will re-compare
> the first key all over again. If I get some more time I'll run the
> tests again with the sort specialisation code disabled to see if the
> situation is the same or not.
> patch with a GUC added solely to allow easier benchmarking of patched
> vs unpatched.
I've attached a cleaned up v2 (*) of a patch to avoid rechecking the first column if a specialized comparator already did so, and the results of the "bench_windowsort" benchmark. Here, master vs. patch refers to skipping the first column recheck, and on/off is the dev guc from David's last patch.
* v1 was here, but I thought it best to keep everything in the same thread, and that thread is nominally about a different kind of specialization:
Attachment
On Tue, 14 Feb 2023 at 17:21, John Naylor <john.naylor@enterprisedb.com> wrote:
> Not rechecking seems to eliminate the regression in 4 cases, and reduce it in the other 2 cases. For those 2 cases
(10e6rows, random, mod 10 and 100), it might be worthwhile to "zoom in" with more measurements, but haven't done that
yet.
Thanks for writing up this patch and for running those tests again.
I'm surprised to see there's a decent about of truth in the surplus
recheck of the first column in tiebreaks (mostly) causing the
regression. I really would have suspected CPU caching effects to be a
bigger factor. From looking at your numbers, it looks like it's just
the mod=100 test in random and unsorted. fallback-on looks faster than
master-off for random mod=10.
I didn't do a detailed review of the sort patch, but I did wonder
about the use of the name "fallback" in the new functions. The
comment in the following snippet from qsort_tuple_unsigned_compare()
makes me think "tiebreak" is a better name.
/*
* No need to waste effort calling the tiebreak function when there are no
* other keys to sort on.
*/
if (state->base.onlyKey != NULL)
return 0;
return state->base.comparetup_fallback(a, b, state);
I think if we fixed this duplicate recompare thing then I'd be much
more inclined to push the windowagg sort reduction stuff.
I also wonder if the weirdness I reported in [1] would also disappear
with your patch. There's a patch on that thread that hacks up the
planner to split multi-column sorts into Sort -> Incremental Sort
rather than just a single sort.
David
[1] https://www.postgresql.org/message-id/CAApHDvpAO5H_L84kn9gCJ_hihOavtmDjimKYyftjWtF69BJ=8Q@mail.gmail.com
On Tue, Feb 14, 2023 at 5:46 PM David Rowley <dgrowleyml@gmail.com> wrote:
>
> I didn't do a detailed review of the sort patch, but I did wonder
> about the use of the name "fallback" in the new functions. The
> comment in the following snippet from qsort_tuple_unsigned_compare()
> makes me think "tiebreak" is a better name.
I agree "tiebreak" is better.
> I also wonder if the weirdness I reported in [1] would also disappear
> with your patch. There's a patch on that thread that hacks up the
> planner to split multi-column sorts into Sort -> Incremental Sort
> rather than just a single sort.
I tried that test (attached in script form) with and without the tiebreaker patch and got some improvement:
5 ^ 8: latency average = 783.830 ms
6 ^ 8: latency average = 3990.351 ms
7 ^ 8: latency average = 15793.629 ms
Skip rechecking first key:
5 ^ 8: latency average = 732.327 ms
6 ^ 8: latency average = 3709.882 ms
7 ^ 8: latency average = 14570.651 ms
I gather that planner hack was just a demonstration, so I didn't test it, but if that was a move toward something larger I can run additional tests.
work_mem = '4GB';
Attachment
On Wed, 15 Feb 2023 at 17:23, John Naylor <john.naylor@enterprisedb.com> wrote: > HEAD: > > 4 ^ 8: latency average = 113.976 ms > 5 ^ 8: latency average = 783.830 ms > 6 ^ 8: latency average = 3990.351 ms > 7 ^ 8: latency average = 15793.629 ms > > Skip rechecking first key: > > 4 ^ 8: latency average = 107.028 ms > 5 ^ 8: latency average = 732.327 ms > 6 ^ 8: latency average = 3709.882 ms > 7 ^ 8: latency average = 14570.651 ms Thanks for testing that. It's good to see improvements in each of them. > I gather that planner hack was just a demonstration, so I didn't test it, but if that was a move toward something largerI can run additional tests. Yeah, just a hack. My intention with it was just to prove we had a problem because sometimes Sort -> Incremental Sort was faster than Sort. Ideally, with your change, we'd see that it's always faster to do the full sort in one go. It would be good to see your patch with and without the planner hack patch to ensure sort is now always faster than sort -> incremental sort. David
I wrote:
> it might be worthwhile to "zoom in" with more measurements, but haven't done that yet.
I've attached the script and image for 1 million / random / varying the mod by quarter-log intervals. Unfortunately I didn't get as good results as yesterday. Immediately going from mod 1 to mod 2, sort pushdown regresses sharply and stays regressed up until 10000. The tiebreaker patch helps but never removes the regression.
Attachment
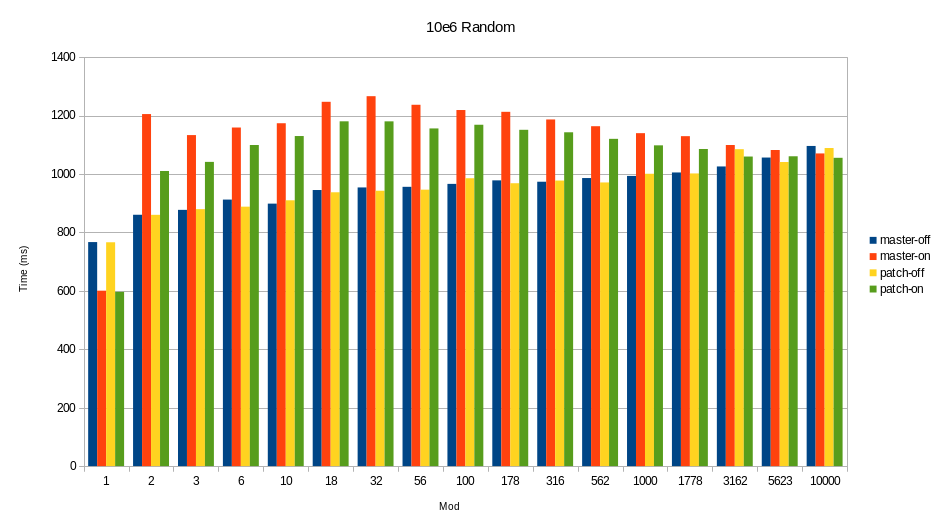{kind=link}
On Wed, Feb 15, 2023 at 3:02 PM David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Wed, 15 Feb 2023 at 17:23, John Naylor <john.naylor@enterprisedb.com> wrote:
> > HEAD:
> >
> > 4 ^ 8: latency average = 113.976 ms
> > 5 ^ 8: latency average = 783.830 ms
> > 6 ^ 8: latency average = 3990.351 ms
> > 7 ^ 8: latency average = 15793.629 ms
> >
> > Skip rechecking first key:
> >
> > 4 ^ 8: latency average = 107.028 ms
> > 5 ^ 8: latency average = 732.327 ms
> > 6 ^ 8: latency average = 3709.882 ms
> > 7 ^ 8: latency average = 14570.651 ms
> Yeah, just a hack. My intention with it was just to prove we had a
> problem because sometimes Sort -> Incremental Sort was faster than
> Sort. Ideally, with your change, we'd see that it's always faster to
> do the full sort in one go. It would be good to see your patch with
> and without the planner hack patch to ensure sort is now always faster
> than sort -> incremental sort.
Okay, here's a rerun including the sort hack, and it looks like incremental sort is only ahead with the smallest set, otherwise same or maybe slightly slower:
4 ^ 8: latency average = 113.461 ms
5 ^ 8: latency average = 786.080 ms
6 ^ 8: latency average = 3948.388 ms
7 ^ 8: latency average = 15733.348 ms
tiebreaker:
4 ^ 8: latency average = 106.556 ms
5 ^ 8: latency average = 734.834 ms
6 ^ 8: latency average = 3640.507 ms
7 ^ 8: latency average = 14470.199 ms
tiebreaker + incr sort hack:
4 ^ 8: latency average = 93.998 ms
5 ^ 8: latency average = 740.120 ms
6 ^ 8: latency average = 3715.942 ms
7 ^ 8: latency average = 14749.323 ms
And as far as this:
Attached is a script and image for fixing the input at random / mod32 and varying work_mem. There is not a whole lot of variation here: pushdown regresses and the tiebreaker patch only helped marginally. I'm still not sure why the results from yesterday looked better than today.
--
John Naylor
EDB: http://www.enterprisedb.com
Attachment
{kind=link}
On Thu, 16 Feb 2023 at 00:45, John Naylor <john.naylor@enterprisedb.com> wrote:
> Okay, here's a rerun including the sort hack, and it looks like incremental sort is only ahead with the smallest set,
otherwisesame or maybe slightly slower:
>
> HEAD:
>
> 4 ^ 8: latency average = 113.461 ms
> 5 ^ 8: latency average = 786.080 ms
> 6 ^ 8: latency average = 3948.388 ms
> 7 ^ 8: latency average = 15733.348 ms
>
> tiebreaker:
>
> 4 ^ 8: latency average = 106.556 ms
> 5 ^ 8: latency average = 734.834 ms
> 6 ^ 8: latency average = 3640.507 ms
> 7 ^ 8: latency average = 14470.199 ms
>
> tiebreaker + incr sort hack:
>
> 4 ^ 8: latency average = 93.998 ms
> 5 ^ 8: latency average = 740.120 ms
> 6 ^ 8: latency average = 3715.942 ms
> 7 ^ 8: latency average = 14749.323 ms
Sad news :( the sort hacks are still quite a bit faster for 4 ^ 8.
I was fooling around with the attached (very quickly and crudely put
together) patch just there. The idea is to sort during
tuplesort_puttuple_common() when the memory consumption goes over some
approximation of L3 cache size in the hope we still have cache lines
for the tuples in question still. The code is not ideal there as we
track availMem rather than the used mem, so maybe I need to do that
better as we could cross some boundary without actually having done
very much, plus we USEMEM for other reasons too.
I found that the patch didn't really help:
create table t (a int not null, b int not null);
insert into t select (x*random())::int % 100,(x*random())::int % 100
from generate_Series(1,10000000)x;
vacuum freeze t;
select pg_prewarm('t');
show work_mem;
work_mem
----------
4GB
explain (analyze, timing off) select * from t order by a,b;
master:
Execution Time: 5620.704 ms
Execution Time: 5506.705 ms
patched:
Execution Time: 6801.421 ms
Execution Time: 6762.130 ms
I suspect it's slower because the final sort must sort the entire
array still without knowledge that portions of it are pre-sorted. It
would be very interesting to improve this and do some additional work
and keep track of the "memtupsortedto" index by pushing them onto a
List each time we cross the availMem boundary, then do then qsort just
the final portion of the array in tuplesort_performsort() before doing
a k-way merge on each segment rather than qsorting the entire thing
again. I suspect this would be faster when work_mem exceeds L3 by some
large amount.
David
Attachment
> I suspect it's slower because the final sort must sort the entire
> array still without knowledge that portions of it are pre-sorted. It
> would be very interesting to improve this and do some additional work
> and keep track of the "memtupsortedto" index by pushing them onto a
> List each time we cross the availMem boundary, then do then qsort just
> the final portion of the array in tuplesort_performsort() before doing
> a k-way merge on each segment rather than qsorting the entire thing
> again. I suspect this would be faster when work_mem exceeds L3 by some
> large amount.
Sounds like a reasonable thing to try.
It seems like in-memory merge could still use abbreviation, unlike external merge.
--
John Naylor
EDB: http://www.enterprisedb.com
On Wed, Feb 15, 2023 at 11:23 AM John Naylor <john.naylor@enterprisedb.com> wrote:
>
>
> On Tue, Feb 14, 2023 at 5:46 PM David Rowley <dgrowleyml@gmail.com> wrote:
> >
> > I didn't do a detailed review of the sort patch, but I did wonder
> > about the use of the name "fallback" in the new functions. The
> > comment in the following snippet from qsort_tuple_unsigned_compare()
> > makes me think "tiebreak" is a better name.
>
> I agree "tiebreak" is better.
Here is v3 with that change. I still need to make sure the tests cover all cases, so I'll do that as time permits. Also creating CF entry.
--
John Naylor
EDB: http://www.enterprisedb.com
Attachment
On Fri, 30 Jun 2023 at 18:45, John Naylor <john.naylor@enterprisedb.com> wrote: > Here is v3 with that change. I still need to make sure the tests cover all cases, so I'll do that as time permits. Alsocreating CF entry. Thanks for picking this back up again for the v17 cycle. I've reread the entire thread to remind myself where we got to. I looked over your patch and don't see anything to report aside from the unfinished/undecided part around the tiebreak function for tuplesort_begin_index_hash(). I also ran the benchmark script [1] with the patch from [2] and calculated the speedup with [2] with and without your v3 patch. I've attached two graphs with the benchmark results. Any value >100% indicates that performing the sort for the ORDER BY at the same time as the WindowAgg improves performance, whereas anything < 100% indicates a regression. The bars in blue show the results without your v3 patch and the red bars show the results with your v3 patch. Looking at the remaining regressions it does not really feel like we've found the culprit for the regressions. Certainly, v3 helps, but I just don't think it's to the level we'd need to make the window sort changes a good idea. I'm not sure exactly how best to proceed here. I think the tiebreak stuff is worth doing regardless, so maybe that can just go in to eliminate that as a factor and we or I can continue to see what else is to blame. David [1] https://www.postgresql.org/message-id/attachment/143109/bench_windowsort.sh.txt [2] https://www.postgresql.org/message-id/attachment/143112/orderby_windowclause_pushdown_testing_only.patch.txt
Attachment
{kind=link}
{kind=link}
On Mon, Jul 3, 2023 at 5:15 PM David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Fri, 30 Jun 2023 at 18:45, John Naylor <john.naylor@enterprisedb.com> wrote:
> the unfinished/undecided part around the tiebreak function for
> tuplesort_begin_index_hash().
I went ahead and added a degenerate function, just for consistency -- might also head off possible alarms from code analysis tools.
> I also ran the benchmark script [1] with the patch from [2] and
> calculated the speedup with [2] with and without your v3 patch. I've
> attached two graphs with the benchmark results. Any value >100%
> indicates that performing the sort for the ORDER BY at the same time
> as the WindowAgg improves performance, whereas anything < 100%
> indicates a regression. The bars in blue show the results without
> your v3 patch and the red bars show the results with your v3 patch.
> Looking at the remaining regressions it does not really feel like
> we've found the culprit for the regressions. Certainly, v3 helps, but
> I just don't think it's to the level we'd need to make the window sort
> changes a good idea.
>
> I'm not sure exactly how best to proceed here. I think the tiebreak
> stuff is worth doing regardless, so maybe that can just go in to
> eliminate that as a factor and we or I can continue to see what else
> is to blame.
Thanks for testing again. Sounds good, I removed a now-invalidated comment, pgindent'd, and pushed.