Thread: Multi-Master Logical Replication
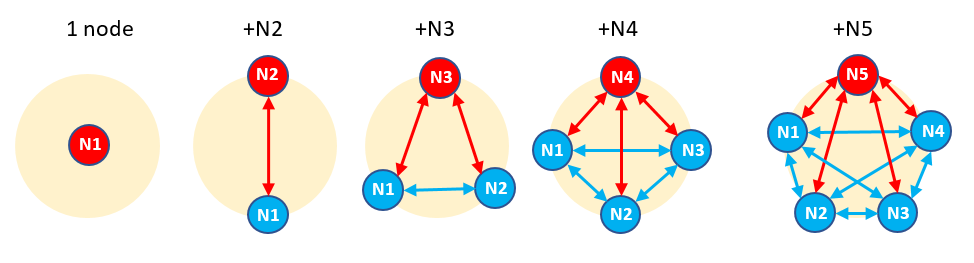
MULTI-MASTER LOGICAL REPLICATION 1.0 BACKGROUND Let’s assume that a user wishes to set up a multi-master environment so that a set of PostgreSQL instances (nodes) use logical replication to share tables with every other node in the set. We define this as a multi-master logical replication (MMLR) node-set. <please refer to the attached node-set diagram> 1.1 ADVANTAGES OF MMLR - Increases write scalability (e.g., all nodes can write arbitrary data). - Allows load balancing - Allows rolling updates of nodes (e.g., logical replication works between different major versions of PostgreSQL). - Improves the availability of the system (e.g., no single point of failure) - Improves performance (e.g., lower latencies for geographically local nodes) 2.0 MMLR AND POSTGRESQL It is already possible to configure a kind of MMLR set in PostgreSQL 15 using PUB/SUB, but it is very restrictive because it can only work when no two nodes operate on the same table. This is because when two nodes try to share the same table then there becomes a circular recursive problem where Node1 replicates data to Node2 which is then replicated back to Node1 and so on. To prevent the circular recursive problem Vignesh is developing a patch [1] that introduces new SUBSCRIPTION options "local_only" (for publishing only data originating at the publisher node) and "copy_data=force". Using this patch, we have created a script [2] demonstrating how to set up all the above multi-node examples. An overview of the necessary steps is given in the next section. 2.1 STEPS – Adding a new node N to an existing node-set step 1. Prerequisites – Apply Vignesh’s patch [1]. All nodes in the set must be visible to each other by a known CONNECTION. All shared tables must already be defined on all nodes. step 2. On node N do CREATE PUBLICATION pub_N FOR ALL TABLES step 3. All other nodes then CREATE SUBSCRIPTION to PUBLICATION pub_N with "local_only=on, copy_data=on" (this will replicate initial data from the node N tables to every other node). step 4. On node N, temporarily ALTER PUBLICATION pub_N to prevent replication of 'truncate', then TRUNCATE all tables of node N, then re-allow replication of 'truncate'. step 5. On node N do CREATE SUBSCRIPTION to the publications of all other nodes in the set 5a. Specify "local_only=on, copy_data=force" for exactly one of the subscriptions (this will make the node N tables now have the same data as the other nodes) 5b. Specify "local_only=on, copy_data=off" for all other subscriptions. step 6. Result - Now changes to any table on any node should be replicated to every other node in the set. Note: Steps 4 and 5 need to be done within the same transaction to avoid loss of data in case of some command failure. (Because we can't perform create subscription in a transaction, we need to create the subscription in a disabled mode first and then enable it in the transaction). 2.2 DIFFICULTIES Notice that it becomes increasingly complex to configure MMLR manually as the number of nodes in the set increases. There are also some difficulties such as - dealing with initial table data - coordinating the timing to avoid concurrent updates - getting the SUBSCRIPTION options for copy_data exactly right. 3.0 PROPOSAL To make the MMLR setup simpler, we propose to create a new API that will hide all the step details and remove the burden on the user to get it right without mistakes. 3.1 MOTIVATION - MMLR (sharing the same tables) is not currently possible - Vignesh's patch [1] makes MMLR possible, but the manual setup is still quite difficult - An MMLR implementation can solve the timing problems (e.g., using Database Locking) 3.2 API Preferably the API would be implemented as new SQL functions in PostgreSQL core, however, implementation using a contrib module or some new SQL syntax may also be possible. SQL functions will be like below: - pg_mmlr_set_create = create a new set, and give it a name - pg_mmlr_node_attach = attach the current node to a specified set - pg_mmlr_node_detach = detach a specified node from a specified set - pg_mmlr_set_delete = delete a specified set For example, internally the pg_mmlr_node_attach API function would execute the equivalent of all the CREATE PUBLICATION, CREATE SUBSCRIPTION, and TRUNCATE steps described above. Notice this proposal has some external API similarities with the BDR extension [3] (which also provides multi-master logical replication), although we plan to implement it entirely using PostgreSQL’s PUB/SUB. 4.0 ACKNOWLEDGEMENTS The following people have contributed to this proposal – Hayato Kuroda, Vignesh C, Peter Smith, Amit Kapila. 5.0 REFERENCES [1] https://www.postgresql.org/message-id/flat/CALDaNm0gwjY_4HFxvvty01BOT01q_fJLKQ3pWP9%3D9orqubhjcQ%40mail.gmail.com [2] https://www.postgresql.org/message-id/CAHut%2BPvY2P%3DUL-X6maMA5QxFKdcdciRRCKDH3j%3D_hO8u2OyRYg%40mail.gmail.com [3] https://www.enterprisedb.com/docs/bdr/latest/ [END] ~~~ One of my colleagues will post more detailed information later. ------ Kind Regards, Peter Smith. Fujitsu Australia
Attachment
{kind=link}
On Thu, 2022-04-28 at 09:49 +1000, Peter Smith wrote: > To prevent the circular recursive problem Vignesh is developing a > patch [1] that introduces new SUBSCRIPTION options "local_only" (for > publishing only data originating at the publisher node) and > "copy_data=force". Using this patch, we have created a script [2] > demonstrating how to set up all the above multi-node examples. An > overview of the necessary steps is given in the next section. I am missing a discussion how replication conflicts are handled to prevent replication from breaking or the databases from drifting apart. Yours, Laurenz Albe
Dear Laurenz, Thank you for your interest in our works! > I am missing a discussion how replication conflicts are handled to > prevent replication from breaking or the databases from drifting apart. Actually we don't have plans for developing the feature that avoids conflict. We think that it should be done as core PUB/SUB feature, and this module will just use that. Best Regards, Hayato Kuroda FUJITSU LIMITED
В Чт, 28/04/2022 в 09:49 +1000, Peter Smith пишет: > 1.1 ADVANTAGES OF MMLR > > - Increases write scalability (e.g., all nodes can write arbitrary data). I've never heard how transactional-aware multimaster increases write scalability. More over, usually even non-transactional multimaster doesn't increase write scalability. At the best it doesn't decrease. That is because all hosts have to write all changes anyway. But side cost increases due to increased network interchange and interlocking (for transaction-aware MM) and increased latency. В Чт, 28/04/2022 в 08:34 +0000, kuroda.hayato@fujitsu.com пишет: > Dear Laurenz, > > Thank you for your interest in our works! > > > I am missing a discussion how replication conflicts are handled to > > prevent replication from breaking > > Actually we don't have plans for developing the feature that avoids conflict. > We think that it should be done as core PUB/SUB feature, and > this module will just use that. If you really want to have some proper isolation levels ( Read Committed? Repeatable Read?) and/or want to have same data on each "master", there is no easy way. If you think it will be "easy", you are already wrong. Our company has MultiMaster which is built on top of logical replication. It is even partially open source ( https://github.com/postgrespro/mmts ) , although some core patches that have to be done for are not up to date. And it is second iteration of MM. First iteration were not "simple" or "easy" already. But even that version had the hidden bug: rare but accumulating data difference between nodes. Attempt to fix this bug led to almost full rewrite of multi-master. (Disclaimer: I had no relation to both MM versions, I just work in the same firm). regards --------- Yura Sokolov
On Thu, Apr 28, 2022 at 4:24 PM Yura Sokolov <y.sokolov@postgrespro.ru> wrote: > > В Чт, 28/04/2022 в 09:49 +1000, Peter Smith пишет: > > > 1.1 ADVANTAGES OF MMLR > > > > - Increases write scalability (e.g., all nodes can write arbitrary data). > > I've never heard how transactional-aware multimaster increases > write scalability. More over, usually even non-transactional > multimaster doesn't increase write scalability. At the best it > doesn't decrease. > > That is because all hosts have to write all changes anyway. But > side cost increases due to increased network interchange and > interlocking (for transaction-aware MM) and increased latency. I agree it won't increase in all cases, but it will be better in a few cases when the user works on different geographical regions operating on independent schemas in asynchronous mode. Since the write node is closer to the geographical zone, the performance will be better in a few cases. > В Чт, 28/04/2022 в 08:34 +0000, kuroda.hayato@fujitsu.com пишет: > > Dear Laurenz, > > > > Thank you for your interest in our works! > > > > > I am missing a discussion how replication conflicts are handled to > > > prevent replication from breaking > > > > Actually we don't have plans for developing the feature that avoids conflict. > > We think that it should be done as core PUB/SUB feature, and > > this module will just use that. > > If you really want to have some proper isolation levels ( > Read Committed? Repeatable Read?) and/or want to have > same data on each "master", there is no easy way. If you > think it will be "easy", you are already wrong. The synchronous_commit and synchronous_standby_names configuration parameters will help in getting the same data across the nodes. Can you give an example for the scenario where it will be difficult? Regards, Vignesh
В Чт, 28/04/2022 в 17:37 +0530, vignesh C пишет: > On Thu, Apr 28, 2022 at 4:24 PM Yura Sokolov <y.sokolov@postgrespro.ru> wrote: > > В Чт, 28/04/2022 в 09:49 +1000, Peter Smith пишет: > > > > > 1.1 ADVANTAGES OF MMLR > > > > > > - Increases write scalability (e.g., all nodes can write arbitrary data). > > > > I've never heard how transactional-aware multimaster increases > > write scalability. More over, usually even non-transactional > > multimaster doesn't increase write scalability. At the best it > > doesn't decrease. > > > > That is because all hosts have to write all changes anyway. But > > side cost increases due to increased network interchange and > > interlocking (for transaction-aware MM) and increased latency. > > I agree it won't increase in all cases, but it will be better in a few > cases when the user works on different geographical regions operating > on independent schemas in asynchronous mode. Since the write node is > closer to the geographical zone, the performance will be better in a > few cases. From EnterpriseDB BDB page [1]: > Adding more master nodes to a BDR Group does not result in > significant write throughput increase when most tables are > replicated because BDR has to replay all the writes on all nodes. > Because BDR writes are in general more effective than writes coming > from Postgres clients via SQL, some performance increase can be > achieved. Read throughput generally scales linearly with the number > of nodes. And I'm sure EnterpriseDB does the best. > > В Чт, 28/04/2022 в 08:34 +0000, kuroda.hayato@fujitsu.com пишет: > > > Dear Laurenz, > > > > > > Thank you for your interest in our works! > > > > > > > I am missing a discussion how replication conflicts are handled to > > > > prevent replication from breaking > > > > > > Actually we don't have plans for developing the feature that avoids conflict. > > > We think that it should be done as core PUB/SUB feature, and > > > this module will just use that. > > > > If you really want to have some proper isolation levels ( > > Read Committed? Repeatable Read?) and/or want to have > > same data on each "master", there is no easy way. If you > > think it will be "easy", you are already wrong. > > The synchronous_commit and synchronous_standby_names configuration > parameters will help in getting the same data across the nodes. Can > you give an example for the scenario where it will be difficult? So, synchronous or asynchronous? Synchronous commit on every master, every alive master or on quorum of masters? And it is not about synchronicity. It is about determinism at conflicts. If you have fully determenistic conflict resolution that works exactly same way on each host, then it is possible to have same data on each host. (But it will not be transactional.)And it seems EDB BDB achieved this. Or if you have fully and correctly implemented one of distributed transactions protocols. [1] https://www.enterprisedb.com/docs/bdr/latest/overview/#characterising-bdr-performance regards ------ Yura Sokolov
On Fri, Apr 29, 2022 at 2:16 PM Yura Sokolov <y.sokolov@postgrespro.ru> wrote: > > В Чт, 28/04/2022 в 17:37 +0530, vignesh C пишет: > > On Thu, Apr 28, 2022 at 4:24 PM Yura Sokolov <y.sokolov@postgrespro.ru> wrote: > > > В Чт, 28/04/2022 в 09:49 +1000, Peter Smith пишет: > > > > > > > 1.1 ADVANTAGES OF MMLR > > > > > > > > - Increases write scalability (e.g., all nodes can write arbitrary data). > > > > > > I've never heard how transactional-aware multimaster increases > > > write scalability. More over, usually even non-transactional > > > multimaster doesn't increase write scalability. At the best it > > > doesn't decrease. > > > > > > That is because all hosts have to write all changes anyway. But > > > side cost increases due to increased network interchange and > > > interlocking (for transaction-aware MM) and increased latency. > > > > I agree it won't increase in all cases, but it will be better in a few > > cases when the user works on different geographical regions operating > > on independent schemas in asynchronous mode. Since the write node is > > closer to the geographical zone, the performance will be better in a > > few cases. > > From EnterpriseDB BDB page [1]: > > > Adding more master nodes to a BDR Group does not result in > > significant write throughput increase when most tables are > > replicated because BDR has to replay all the writes on all nodes. > > Because BDR writes are in general more effective than writes coming > > from Postgres clients via SQL, some performance increase can be > > achieved. Read throughput generally scales linearly with the number > > of nodes. > > And I'm sure EnterpriseDB does the best. > > > > В Чт, 28/04/2022 в 08:34 +0000, kuroda.hayato@fujitsu.com пишет: > > > > Dear Laurenz, > > > > > > > > Thank you for your interest in our works! > > > > > > > > > I am missing a discussion how replication conflicts are handled to > > > > > prevent replication from breaking > > > > > > > > Actually we don't have plans for developing the feature that avoids conflict. > > > > We think that it should be done as core PUB/SUB feature, and > > > > this module will just use that. > > > > > > If you really want to have some proper isolation levels ( > > > Read Committed? Repeatable Read?) and/or want to have > > > same data on each "master", there is no easy way. If you > > > think it will be "easy", you are already wrong. > > > > The synchronous_commit and synchronous_standby_names configuration > > parameters will help in getting the same data across the nodes. Can > > you give an example for the scenario where it will be difficult? > > So, synchronous or asynchronous? > Synchronous commit on every master, every alive master or on quorum > of masters? > > And it is not about synchronicity. It is about determinism at > conflicts. > > If you have fully determenistic conflict resolution that works > exactly same way on each host, then it is possible to have same > data on each host. (But it will not be transactional.)And it seems EDB BDB achieved this. > > Or if you have fully and correctly implemented one of distributed > transactions protocols. > > [1] https://www.enterprisedb.com/docs/bdr/latest/overview/#characterising-bdr-performance > > regards > > ------ > > Yura Sokolov Thanks for your feedback. This MMLR proposal was mostly just to create an interface making it easier to use PostgreSQL core logical replication CREATE PUBLICATION/SUBSCRIPTION for table sharing among a set of nodes. Otherwise, this is difficult for a user to do manually. (e.g. difficulties as mentioned in section 2.2 of the original post [1] - dealing with initial table data, coordinating the timing/locking to avoid concurrent updates, getting the SUBSCRIPTION options for copy_data exactly right etc) At this time we have no provision for HA, nor for transaction consistency awareness, conflict resolutions, node failure detections, DDL replication etc. Some of the features like DDL replication are currently being implemented [2], so when committed it will become available in the core, and can then be integrated into this module. Once the base feature of the current MMLR proposal is done, perhaps it can be extended in subsequent versions. Probably our calling this “Multi-Master” has been misleading/confusing, because that term implies much more to other readers. We really only intended it to mean the ability to set up logical replication across a set of nodes. Of course, we can rename the proposal (and API) to something different if there are better suggestions. ------ [1] https://www.postgresql.org/message-id/CAHut%2BPuwRAoWY9pz%3DEubps3ooQCOBFiYPU9Yi%3DVB-U%2ByORU7OA%40mail.gmail.com [2] https://www.postgresql.org/message-id/flat/45d0d97c-3322-4054-b94f-3c08774bbd90%40www.fastmail.com#db6e810fc93f17b0a5585bac25fb3d4b Kind Regards, Peter Smith. Fujitsu Australia
On Fri, Apr 29, 2022 at 2:35 PM Peter Smith <smithpb2250@gmail.com> wrote: > > On Fri, Apr 29, 2022 at 2:16 PM Yura Sokolov <y.sokolov@postgrespro.ru> wrote: > > > > В Чт, 28/04/2022 в 17:37 +0530, vignesh C пишет: > > > On Thu, Apr 28, 2022 at 4:24 PM Yura Sokolov <y.sokolov@postgrespro.ru> wrote: > > > > В Чт, 28/04/2022 в 09:49 +1000, Peter Smith пишет: > > > > > > > > > 1.1 ADVANTAGES OF MMLR > > > > > > > > > > - Increases write scalability (e.g., all nodes can write arbitrary data). > > > > > > > > I've never heard how transactional-aware multimaster increases > > > > write scalability. More over, usually even non-transactional > > > > multimaster doesn't increase write scalability. At the best it > > > > doesn't decrease. > > > > > > > > That is because all hosts have to write all changes anyway. But > > > > side cost increases due to increased network interchange and > > > > interlocking (for transaction-aware MM) and increased latency. > > > > > > I agree it won't increase in all cases, but it will be better in a few > > > cases when the user works on different geographical regions operating > > > on independent schemas in asynchronous mode. Since the write node is > > > closer to the geographical zone, the performance will be better in a > > > few cases. > > > > From EnterpriseDB BDB page [1]: > > > > > Adding more master nodes to a BDR Group does not result in > > > significant write throughput increase when most tables are > > > replicated because BDR has to replay all the writes on all nodes. > > > Because BDR writes are in general more effective than writes coming > > > from Postgres clients via SQL, some performance increase can be > > > achieved. Read throughput generally scales linearly with the number > > > of nodes. > > > > And I'm sure EnterpriseDB does the best. > > > > > > В Чт, 28/04/2022 в 08:34 +0000, kuroda.hayato@fujitsu.com пишет: > > > > > Dear Laurenz, > > > > > > > > > > Thank you for your interest in our works! > > > > > > > > > > > I am missing a discussion how replication conflicts are handled to > > > > > > prevent replication from breaking > > > > > > > > > > Actually we don't have plans for developing the feature that avoids conflict. > > > > > We think that it should be done as core PUB/SUB feature, and > > > > > this module will just use that. > > > > > > > > If you really want to have some proper isolation levels ( > > > > Read Committed? Repeatable Read?) and/or want to have > > > > same data on each "master", there is no easy way. If you > > > > think it will be "easy", you are already wrong. > > > > > > The synchronous_commit and synchronous_standby_names configuration > > > parameters will help in getting the same data across the nodes. Can > > > you give an example for the scenario where it will be difficult? > > > > So, synchronous or asynchronous? > > Synchronous commit on every master, every alive master or on quorum > > of masters? > > > > And it is not about synchronicity. It is about determinism at > > conflicts. > > > > If you have fully determenistic conflict resolution that works > > exactly same way on each host, then it is possible to have same > > data on each host. (But it will not be transactional.)And it seems EDB BDB achieved this. > > > > Or if you have fully and correctly implemented one of distributed > > transactions protocols. > > > > [1] https://www.enterprisedb.com/docs/bdr/latest/overview/#characterising-bdr-performance > > > > regards > > > > ------ > > > > Yura Sokolov > > Thanks for your feedback. > > This MMLR proposal was mostly just to create an interface making it > easier to use PostgreSQL core logical replication CREATE > PUBLICATION/SUBSCRIPTION for table sharing among a set of nodes. > Otherwise, this is difficult for a user to do manually. (e.g. > difficulties as mentioned in section 2.2 of the original post [1] - > dealing with initial table data, coordinating the timing/locking to > avoid concurrent updates, getting the SUBSCRIPTION options for > copy_data exactly right etc) Different problems and how to solve each scenario is mentioned detailly in [1]. It gets even more complex when there are more nodes associated, let's consider the 3 node case: Adding a new node node3 to the existing node1 and node2 when data is present in existing nodes node1 and node2, the following steps are required: Create a publication in node3: CREATE PUBLICATION pub_node3 for all tables; Create a subscription in node1 to subscribe the changes from node3: CREATE SUBSCRIPTION sub_node1_node3 CONNECTION 'dbname=foo host=node3 user=repuser' PUBLICATION pub_node3 WITH (copy_data = off, local_only = on); Create a subscription in node2 to subscribe the changes from node3: CREATE SUBSCRIPTION sub_node2_node3 CONNECTION 'dbname=foo host=node3 user=repuser' PUBLICATION pub_node3 WITH (copy_data = off, local_only = on); Lock database at node2 and wait till walsender sends WAL to node1(upto current lsn) to avoid any data loss because of node2's WAL not being sent to node1. This lock needs to be held till the setup is complete. Create a subscription in node3 to subscribe the changes from node1, here copy_data is specified as force so that the existing table data is copied during initial sync: CREATE SUBSCRIPTION sub_node3_node1 CONNECTION 'dbname=foo host=node1 user=repuser' PUBLICATION pub_node1 WITH (copy_data = force, local_only = on); Create a subscription in node3 to subscribe the changes from node2: CREATE SUBSCRIPTION sub_node3_node2 CONNECTION 'dbname=foo host=node2 user=repuser' PUBLICATION pub_node2 WITH (copy_data = off, local_only = on); If data is present in node3 few more additional steps are required: a) copying node3 data to node1 b) copying node3 data to node2 c) altering publication not to send truncate operation d) truncate the data in node3 e) altering the publication to include sending of truncate. [1] - https://www.postgresql.org/message-id/CAA4eK1%2Bco2cd8a6okgUD_pcFEHcc7mVc0k_RE2%3D6ahyv3WPRMg%40mail.gmail.com Regards, Vignesh
On Thu, Apr 28, 2022 at 5:20 AM Peter Smith <smithpb2250@gmail.com> wrote: > > MULTI-MASTER LOGICAL REPLICATION > > 1.0 BACKGROUND > > Let’s assume that a user wishes to set up a multi-master environment > so that a set of PostgreSQL instances (nodes) use logical replication > to share tables with every other node in the set. > > We define this as a multi-master logical replication (MMLR) node-set. > > <please refer to the attached node-set diagram> > > 1.1 ADVANTAGES OF MMLR > > - Increases write scalability (e.g., all nodes can write arbitrary data). > - Allows load balancing > - Allows rolling updates of nodes (e.g., logical replication works > between different major versions of PostgreSQL). > - Improves the availability of the system (e.g., no single point of failure) > - Improves performance (e.g., lower latencies for geographically local nodes) > > 2.0 MMLR AND POSTGRESQL > > It is already possible to configure a kind of MMLR set in PostgreSQL > 15 using PUB/SUB, but it is very restrictive because it can only work > when no two nodes operate on the same table. This is because when two > nodes try to share the same table then there becomes a circular > recursive problem where Node1 replicates data to Node2 which is then > replicated back to Node1 and so on. > > To prevent the circular recursive problem Vignesh is developing a > patch [1] that introduces new SUBSCRIPTION options "local_only" (for > publishing only data originating at the publisher node) and > "copy_data=force". Using this patch, we have created a script [2] > demonstrating how to set up all the above multi-node examples. An > overview of the necessary steps is given in the next section. > > 2.1 STEPS – Adding a new node N to an existing node-set > > step 1. Prerequisites – Apply Vignesh’s patch [1]. All nodes in the > set must be visible to each other by a known CONNECTION. All shared > tables must already be defined on all nodes. > > step 2. On node N do CREATE PUBLICATION pub_N FOR ALL TABLES > > step 3. All other nodes then CREATE SUBSCRIPTION to PUBLICATION pub_N > with "local_only=on, copy_data=on" (this will replicate initial data > from the node N tables to every other node). > > step 4. On node N, temporarily ALTER PUBLICATION pub_N to prevent > replication of 'truncate', then TRUNCATE all tables of node N, then > re-allow replication of 'truncate'. > > step 5. On node N do CREATE SUBSCRIPTION to the publications of all > other nodes in the set > 5a. Specify "local_only=on, copy_data=force" for exactly one of the > subscriptions (this will make the node N tables now have the same > data as the other nodes) > 5b. Specify "local_only=on, copy_data=off" for all other subscriptions. > > step 6. Result - Now changes to any table on any node should be > replicated to every other node in the set. > > Note: Steps 4 and 5 need to be done within the same transaction to > avoid loss of data in case of some command failure. (Because we can't > perform create subscription in a transaction, we need to create the > subscription in a disabled mode first and then enable it in the > transaction). > > 2.2 DIFFICULTIES > > Notice that it becomes increasingly complex to configure MMLR manually > as the number of nodes in the set increases. There are also some > difficulties such as > - dealing with initial table data > - coordinating the timing to avoid concurrent updates > - getting the SUBSCRIPTION options for copy_data exactly right. > > 3.0 PROPOSAL > > To make the MMLR setup simpler, we propose to create a new API that > will hide all the step details and remove the burden on the user to > get it right without mistakes. > > 3.1 MOTIVATION > - MMLR (sharing the same tables) is not currently possible > - Vignesh's patch [1] makes MMLR possible, but the manual setup is > still quite difficult > - An MMLR implementation can solve the timing problems (e.g., using > Database Locking) > > 3.2 API > > Preferably the API would be implemented as new SQL functions in > PostgreSQL core, however, implementation using a contrib module or > some new SQL syntax may also be possible. > > SQL functions will be like below: > - pg_mmlr_set_create = create a new set, and give it a name > - pg_mmlr_node_attach = attach the current node to a specified set > - pg_mmlr_node_detach = detach a specified node from a specified set > - pg_mmlr_set_delete = delete a specified set > > For example, internally the pg_mmlr_node_attach API function would > execute the equivalent of all the CREATE PUBLICATION, CREATE > SUBSCRIPTION, and TRUNCATE steps described above. > > Notice this proposal has some external API similarities with the BDR > extension [3] (which also provides multi-master logical replication), > although we plan to implement it entirely using PostgreSQL’s PUB/SUB. > > 4.0 ACKNOWLEDGEMENTS > > The following people have contributed to this proposal – Hayato > Kuroda, Vignesh C, Peter Smith, Amit Kapila. > > 5.0 REFERENCES > > [1] https://www.postgresql.org/message-id/flat/CALDaNm0gwjY_4HFxvvty01BOT01q_fJLKQ3pWP9%3D9orqubhjcQ%40mail.gmail.com > [2] https://www.postgresql.org/message-id/CAHut%2BPvY2P%3DUL-X6maMA5QxFKdcdciRRCKDH3j%3D_hO8u2OyRYg%40mail.gmail.com > [3] https://www.enterprisedb.com/docs/bdr/latest/ > > [END] > > ~~~ > > One of my colleagues will post more detailed information later. MMLR is changed to LRG(Logical replication group) to avoid confusions. The LRG functionality will be implemented as given below: The lrg contrib module provides a set of API to allow setting up bi-directional logical replication among different nodes. The lrg stands for Logical Replication Group. To use this functionality shared_preload_libraries must be set to lrg like: shared_preload_libraries = lrg A new process "lrg launcher" is added which will be launched when the extension is created. This process is responsible for checking if user has created new logical replication group or if the user is attaching a new node to the logical replication group or detach a node or drop a logical replication group and if so, then launches another new “lrg worker” for the corresponding database. The new process "lrg worker" is responsible for handling the core tasks of lrg_create, lrg_node_attach, lrg_node_detach and lrg_drop functionality. The “lrg worker” is required here because there are a lot of steps involved in this process like create publication, create subscription, alter publication, lock table, etc. If there is a failure during any of the process, the worker will be restarted and is responsible to continue the operation from where it left off to completion. The following new tables were added to maintain the logical replication group related information: -- pg_lrg_info table to maintain the logical replication group information. CREATE TABLE lrg.pg_lrg_info ( groupname text PRIMARY KEY, -- name of the logical replication group pubtype text – type of publication(ALL TABLES, SCHEMA, TABLE) currently only “ALL TABLES” is supported ); -- pg_ lrg_nodes table to maintain the node information that are members of the logical replication group. CREATE TABLE lrg.pg_lrg_nodes ( nodeid text PRIMARY KEY, -- node id (actual node_id format is still not finalized) groupname text REFERENCES pg_lrg_info(groupname), -- name of the logical replication group dbid oid NOT NULL, -- db id status text NOT NULL, -- status of the node nodename text, -- node name localconn text NOT NULL, -- local connection string upstreamconn text – upstream connection string to connect to another node already in the logical replication group ); -- pg_ lrg_pub table to maintain the publications that were created for this node. CREATE TABLE lrg.pg_lrg_pub ( groupname text REFERENCES pg_lrg_info(groupname), -- name of the logical replication group pubid oid NOT NULL – oid of the publication ); -- pg_lrg_sub table to maintain the subscriptions that were created for this node. CREATE TABLE lrg.pg_lrg_sub ( groupname text REFERENCES pg_lrg_info(groupname), -- name of the logical replication group subid oid NOT NULL– oid of the subscription ); The following functionality was added to support the various logical replication group functionalities: lrg_create(group_name text, pub_type text, local_connection_string text, node_name text) lrg _node_attach(group_name text, local_connection_string text, upstream_connection_string text, node_name text) lrg_node_detach(group_name text, node_name text) lrg_drop(group_name text) ----------------------------------------------------------------------------------------------------------------------------------- lrg_create – This function creates a logical replication group as specified in group_name. example: postgres=# SELECT lrg.lrg_create('test', 'FOR ALL TABLES', 'user=postgres port=5432', 'testnode1'); This function adds a logical replication group “test” with pubtype as “FOR ALL TABLES” to pg_lrg_info like given below: postgres=# select * from lrg. pg_lrg_info; groupname | pubtype ----------+------------------ test | FOR ALL TABLES (1 row) It adds node information which includes the node id, database id, status, node name, connection string and upstream connection string to pg_lrg_nodes like given below: postgres=# select * from lrg.pg_lrg_nodes ; nodeid | groupname | dbid | status | nodename | localconn | upstreamconn -------------------------------------------------------------+------+--------+-----------+-----------------------------------------+----------------------------------------- 70934590432710321605user=postgres port=5432 | test | 5 | ready | testnode1 | user=postgres port=5432 | (1 row) The “lrg worker” will perform the following: 1) It will lock the pg_lrg_info and pg_lrg_nodes tables. 2) It will create the publication in the current node. 3) It will change the (pg_lrg_nodes) status from init to createpublication. 4) It will unlock the pg_lrg_info and pg_lrg_nodes tables 5) It will change the (pg_lrg_nodes) status from createpublication to ready. ----------------------------------------------------------------------------------------------------------------------------------- lrg_node_attach – Attach the specified node to the specified logical replication group. example: postgres=# SELECT lrg.lrg_node_attach('test', 'user=postgres port=9999', 'user=postgres port=5432', 'testnode2') This function adds logical replication group “test” with pubtype as “FOR ALL TABLES” to pg_lrg_info in the new node like given below: postgres=# select * from pg_lrg_info; groupname | pubtype ----------+------------------ test | FOR ALL TABLES (1 row) This is the same group name that was added during lrg_create in the create node. Now this information will be available in the new node too. This information will help the user to attach to any of the nodes present in the logical replication group. It adds node information which includes the node id, database id, status, node name, connection string and upstream connection string of the current node and the other nodes that are part of the logical replication group to pg_lrg_nodes like given below: postgres=# select * from lrg.pg_lrg_nodes ; nodeid | groupname | dbid | status | nodename | localconn | upstreamconn -------------------------------------------------------------+------+--------+-----------+-----------------------------------------+----------------------------------------- 70937999584732760095user=vignesh dbname=postgres port=9999 | test | 5 | ready | testnode2 | user=vignesh dbname=postgres port=9999 | user=vignesh dbname=postgres port=5432 70937999523629205245user=vignesh dbname=postgres port=5432 | test | 5 | ready | testnode1 | user=vignesh dbname=postgres port=5432 | (2 rows) It will use the upstream connection to connect to the upstream node and get the nodes that are part of the logical replication group. Note: The nodeid used here is for illustrative purpose, actual nodeid format is still not finalized. For this API the “lrg worker” will perform the following: 1) It will lock the pg_lrg_info and pg_lrg_nodes tables. 2) It will connect to the upstream node specified and get the list of other nodes present in the logical replication group. 3) It will connect to the remaining nodes and lock the database so that no new operations are performed. 4) It will wait in the upstream node till it reaches the latest lsn of the remaining nodes, this is somewhat similar to wait_for_catchup function in tap tests. 5) It will change the status (pg_lrg_nodes) from init to waitforlsncatchup. 6) It will create the publication in the current node. 7) It will change the status (pg_lrg_nodes) from waitforlsncatchup to createpublication. 8) It will create a subscription in all the remaining nodes to get the data from new node. 9) It will change the status (pg_lrg_nodes) from createpublication to createsubscription. 10) It will alter the publication not to replicate truncate operation. 11) It will truncate the table. 12) It will alter the publication to include sending the truncate operation. 13) It will create a subscription in the current node to subscribe the data with copy_data force. 14) It will create a subscription in the remaining nodes to subscribe the data with copy_data off. 15) It will unlock the database in all the remaining nodes. 16) It will unlock the pg_lrg_info and pg_lrg_nodes tables. 17) It will change the status (pg_lrg_nodes) from createsubscription to ready. The status will be useful to display the progress of the operation to the user and help in failure handling to continue the operation from the state it had failed. ----------------------------------------------------------------------------------------------------------------------------------- lrg_node_detach – detach a node from the logical replication group. example: postgres=# SELECT lrg.lrg_node_detach('test', 'testnode'); For this API the “lrg worker” will perform the following: 1) It will lock the pg_lrg_info and pg_lrg_nodes tables. 2) It will get the list of other nodes present in the logical replication group. 3) It will connect to the remaining nodes and lock the database so that no new operations are performed. 4) It will drop the subscription in all the nodes corresponding to this node of the cluster. 5) It will drop the publication in the current node. 6) It will remove all the data associated with this logical replication group from pg_lrg_* tables. 7) It will unlock the pg_lrg_info and pg_lrg_nodes tables. ----------------------------------------------------------------------------------------------------------------------------------- lrg_drop - drop a group from logical replication groups. example: postgres=# SELECT lrg.lrg_drop('test'); This function removes the group specified from the logical replication groups. This function must be executed at the member of a given logical replication group. For this API the “lrg worker” will perform the following: 1) It will lock the pg_lrg_info and pg_lrg_nodes tables.. 2) DROP PUBLICATION of this node that was created for this logical replication group. 3) Remove all data from the logical replication group system table associated with the logical replication group. 4) It will unlock the pg_lrg_info and pg_lrg_nodes tables. If there are no objections the API can be implemented as SQL functions in PostgreSQL core and the new tables can be created as system tables. Thoughts? Regards, Vignesh
On Fri, Apr 29, 2022 at 07:05:11PM +1000, Peter Smith wrote:
> This MMLR proposal was mostly just to create an interface making it
> easier to use PostgreSQL core logical replication CREATE
> PUBLICATION/SUBSCRIPTION for table sharing among a set of nodes.
> Otherwise, this is difficult for a user to do manually. (e.g.
> difficulties as mentioned in section 2.2 of the original post [1] -
> dealing with initial table data, coordinating the timing/locking to
> avoid concurrent updates, getting the SUBSCRIPTION options for
> copy_data exactly right etc)
>
> At this time we have no provision for HA, nor for transaction
> consistency awareness, conflict resolutions, node failure detections,
> DDL replication etc. Some of the features like DDL replication are
> currently being implemented [2], so when committed it will become
> available in the core, and can then be integrated into this module.
Uh, without these features, what workload would this help with? I think
you made the mistake of jumping too far into implementation without
explaining the problem you are trying to solve. The TODO list has this
ordering:
https://wiki.postgresql.org/wiki/Todo
Desirability -> Design -> Implement -> Test -> Review -> Commit
--
Bruce Momjian <bruce@momjian.us> https://momjian.us
EDB https://enterprisedb.com
Indecision is a decision. Inaction is an action. Mark Batterson
On Sat, May 14, 2022 at 12:33 AM Bruce Momjian <bruce@momjian.us> wrote: > > Uh, without these features, what workload would this help with? > To allow replication among multiple nodes when some of the nodes may have pre-existing data. This work plans to provide simple APIs to achieve that. Now, let me try to explain the difficulties users can face with the existing interface. It is simple to set up replication among various nodes when they don't have any pre-existing data but even in that case if the user operates on the same table at multiple nodes, the replication will lead to an infinite loop and won't proceed. The example in email [1] demonstrates that and the patch in that thread attempts to solve it. I have mentioned that problem because this work will need that patch. Now, let's take a simple case where two nodes have the same table which has some pre-existing data: Node-1: Table t1 (c1 int) has data 1, 2, 3, 4 Node-2: Table t1 (c1 int) has data 5, 6, 7, 8 If we have to set up replication among the above two nodes using existing interfaces, it could be very tricky. Say user performs operations like below: Node-1 #Publication for t1 Create Publication pub1 For Table t1; Node-2 #Publication for t1, Create Publication pub1_2 For Table t1; Node-1: Create Subscription sub1 Connection '<node-2 details>' Publication pub1_2; Node-2: Create Subscription sub1_2 Connection '<node-1 details>' Publication pub1; After this the data will be something like this: Node-1: 1, 2, 3, 4, 5, 6, 7, 8 Node-2: 1, 2, 3, 4, 5, 6, 7, 8, 5, 6, 7, 8 So, you can see that data on Node-2 (5, 6, 7, 8) is duplicated. In case, table t1 has a unique key, it will lead to a unique key violation and replication won't proceed. Here, I have assumed that we already have functionality for the patch in email [1], otherwise, replication will be an infinite loop replicating the above data again and again. Now one way to achieve this could be that we can ask users to stop all operations on both nodes before starting replication between those and take data dumps of tables from each node they want to replicate and restore them to other nodes. Then use the above commands to set up replication and allow to start operations on those nodes. The other possibility for users could be as below. Assume, we have already created publications as in the above example, and then: Node-2: Create Subscription sub1_2 Connection '<node-1 details>' Publication pub1; #Wait for the initial sync of table t1 to finish. Users can ensure that by checking 'srsubstate' in pg_subscription_rel. Node-1: Begin; # Disallow truncates to be published and then truncate the table Alter Publication pub1 Set (publish = 'insert, update, delete'); Truncate t1; Create Subscription sub1 Connection '<node-2 details>' Publication pub1_2; Alter Publication pub1 Set (publish = 'insert, update, delete, truncate'); Commit; This will become more complicated when more than two nodes are involved, see the example provided for the three nodes case [2]. Can you think of some other simpler way to achieve the same? If not, I don't think the current way is ideal and even users won't prefer that. I am not telling that the APIs proposed in this thread is the only or best way to achieve the desired purpose but I think we should do something to allow users to easily set up replication among multiple nodes. [1] - https://www.postgresql.org/message-id/CALDaNm0gwjY_4HFxvvty01BOT01q_fJLKQ3pWP9%3D9orqubhjcQ%40mail.gmail.com [2] - https://www.postgresql.org/message-id/CALDaNm3aD3nZ0HWXA8V435AGMvORyR5-mq2FzqQdKQ8CPomB5Q%40mail.gmail.com -- With Regards, Amit Kapila.
Hi hackers, I created a small PoC. Please see the attached patches. REQUIREMENT Before patching them, patches in [1] must also be applied. DIFFERENCES FROM PREVIOUS DESCRIPTIONS * LRG is now implemented as SQL functions, not as a contrib module. * New tables are added as system catalogs. Therefore, added tables have oid column. * The node_id is the strcat of system identifier and dbid. HOW TO USE In the document patch, a subsection 'Example' was added for understanding LRG. In short, we can do 1. lrg_create on one node 2. lrg_node_attach on another node Also attached is a test script that constructs a three-nodes system. LIMITATIONS This feature is under development, so there are many limitations for use case. * The function for detaching a node from a group is not implemented. * The function for removing a group is not implemented. * LRG does not lock system catalogs and databases. Concurrent operations may cause inconsistent state. * LRG does not wait until the upstream node reaches the latest lsn of the remaining nodes. * LRG does not support initial data sync. That is, it can work well only when all nodes do not have initial data. [1]: https://commitfest.postgresql.org/38/3610/ Best Regards, Hayato Kuroda FUJITSU LIMITED
Attachment
Hi hackers, [1] has changed the name of the parameter, so I rebased the patch. Furthermore I implemented the first version of lrg_node_detach and lrg_drop functions, and some code comments are fixed. 0001 and 0002 were copied from the [1], they were attached for the cfbot. Please see 0003 and 0004 for LRG related codes. Best Regards, Hayato Kuroda FUJITSU LIMITED
Attachment
Sorry, I forgot to attach the test script. For cfbot I attached again all files. Sorry for the noise. Best Regards, Hayato Kuroda FUJITSU LIMITED
Attachment
On Sat, May 14, 2022 at 12:20:05PM +0530, Amit Kapila wrote: > On Sat, May 14, 2022 at 12:33 AM Bruce Momjian <bruce@momjian.us> wrote: > > > > Uh, without these features, what workload would this help with? > > > > To allow replication among multiple nodes when some of the nodes may > have pre-existing data. This work plans to provide simple APIs to > achieve that. Now, let me try to explain the difficulties users can > face with the existing interface. It is simple to set up replication > among various nodes when they don't have any pre-existing data but > even in that case if the user operates on the same table at multiple > nodes, the replication will lead to an infinite loop and won't > proceed. The example in email [1] demonstrates that and the patch in > that thread attempts to solve it. I have mentioned that problem > because this work will need that patch. ... > This will become more complicated when more than two nodes are > involved, see the example provided for the three nodes case [2]. Can > you think of some other simpler way to achieve the same? If not, I > don't think the current way is ideal and even users won't prefer that. > I am not telling that the APIs proposed in this thread is the only or > best way to achieve the desired purpose but I think we should do > something to allow users to easily set up replication among multiple > nodes. You still have not answered my question above. "Without these features, what workload would this help with?" You have only explained how the patch would fix one of the many larger problems. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EDB https://enterprisedb.com Indecision is a decision. Inaction is an action. Mark Batterson
On Tue, May 24, 2022 at 5:57 PM Bruce Momjian <bruce@momjian.us> wrote: > > On Sat, May 14, 2022 at 12:20:05PM +0530, Amit Kapila wrote: > > On Sat, May 14, 2022 at 12:33 AM Bruce Momjian <bruce@momjian.us> wrote: > > > > > > Uh, without these features, what workload would this help with? > > > > > > > To allow replication among multiple nodes when some of the nodes may > > have pre-existing data. This work plans to provide simple APIs to > > achieve that. Now, let me try to explain the difficulties users can > > face with the existing interface. It is simple to set up replication > > among various nodes when they don't have any pre-existing data but > > even in that case if the user operates on the same table at multiple > > nodes, the replication will lead to an infinite loop and won't > > proceed. The example in email [1] demonstrates that and the patch in > > that thread attempts to solve it. I have mentioned that problem > > because this work will need that patch. > ... > > This will become more complicated when more than two nodes are > > involved, see the example provided for the three nodes case [2]. Can > > you think of some other simpler way to achieve the same? If not, I > > don't think the current way is ideal and even users won't prefer that. > > I am not telling that the APIs proposed in this thread is the only or > > best way to achieve the desired purpose but I think we should do > > something to allow users to easily set up replication among multiple > > nodes. > > You still have not answered my question above. "Without these features, > what workload would this help with?" You have only explained how the > patch would fix one of the many larger problems. > It helps with setting up logical replication among two or more nodes (data flows both ways) which is important for use cases where applications are data-aware. For such apps, it will be beneficial to always send and retrieve data to local nodes in a geographically distributed database. Now, for such apps, to get 100% consistent data among nodes, one needs to enable synchronous_mode (aka set synchronous_standby_names) but if that hurts performance and the data is for analytical purposes then one can use it in asynchronous mode. Now, for such cases, if the local node goes down, the other master node can be immediately available to use, sure it may slow down the operations for some time till the local node come-up. For such apps, later it will be also easier to perform online upgrades. Without this, if the user tries to achieve the same via physical replication by having two local nodes, it can take quite long before the standby can be promoted to master and local reads/writes will be much costlier. -- With Regards, Amit Kapila.
On Wed, May 25, 2022 at 4:43 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, May 24, 2022 at 5:57 PM Bruce Momjian <bruce@momjian.us> wrote: > > > > On Sat, May 14, 2022 at 12:20:05PM +0530, Amit Kapila wrote: > > > On Sat, May 14, 2022 at 12:33 AM Bruce Momjian <bruce@momjian.us> wrote: > > > > > > > > Uh, without these features, what workload would this help with? > > > > > > > > > > To allow replication among multiple nodes when some of the nodes may > > > have pre-existing data. This work plans to provide simple APIs to > > > achieve that. Now, let me try to explain the difficulties users can > > > face with the existing interface. It is simple to set up replication > > > among various nodes when they don't have any pre-existing data but > > > even in that case if the user operates on the same table at multiple > > > nodes, the replication will lead to an infinite loop and won't > > > proceed. The example in email [1] demonstrates that and the patch in > > > that thread attempts to solve it. I have mentioned that problem > > > because this work will need that patch. > > ... > > > This will become more complicated when more than two nodes are > > > involved, see the example provided for the three nodes case [2]. Can > > > you think of some other simpler way to achieve the same? If not, I > > > don't think the current way is ideal and even users won't prefer that. > > > I am not telling that the APIs proposed in this thread is the only or > > > best way to achieve the desired purpose but I think we should do > > > something to allow users to easily set up replication among multiple > > > nodes. > > > > You still have not answered my question above. "Without these features, > > what workload would this help with?" You have only explained how the > > patch would fix one of the many larger problems. > > > > It helps with setting up logical replication among two or more nodes > (data flows both ways) which is important for use cases where > applications are data-aware. For such apps, it will be beneficial to > always send and retrieve data to local nodes in a geographically > distributed database. Now, for such apps, to get 100% consistent data > among nodes, one needs to enable synchronous_mode (aka set > synchronous_standby_names) but if that hurts performance and the data > is for analytical purposes then one can use it in asynchronous mode. > Now, for such cases, if the local node goes down, the other master > node can be immediately available to use, sure it may slow down the > operations for some time till the local node come-up. For such apps, > later it will be also easier to perform online upgrades. > > Without this, if the user tries to achieve the same via physical > replication by having two local nodes, it can take quite long before > the standby can be promoted to master and local reads/writes will be > much costlier. > As mentioned above, the LRG idea might be a useful addition to logical replication for configuring certain types of "data-aware" applications. LRG for data-aware apps (e.g. sensor data) ------------------------------------------ Consider an example where there are multiple weather stations for a country. Each weather station is associated with a PostgreSQL node and inserts the local sensor data (e.g wind/rain/sunshine etc) once a minute to some local table. The row data is identified by some station ID. - Perhaps there are many nodes. - Loss of a single row of replicated sensor data if some node goes down is not a major problem for this sort of application. - Benefits of processing data locally can be realised. - Using LRG simplifies the setup/sharing of the data across all group nodes via a common table. ~~ LRG makes setup easier ---------------------- Although it is possible already (using Vignesh's "infinite recursion" WIP patch [1]) to set up this kind of environment using logical replication, as the number of nodes grows it becomes more and more difficult to do it. For each new node, there needs to be N-1 x CREATE SUBSCRIPTION for the other group nodes, meaning the connection details for every other node also must be known up-front for the script. OTOH, the LRG API can simplify all this, removing the user's burden and risk of mistakes. Also, LRG only needs to know how to reach just 1 other node in the group (the implementation will discover all the other node connection details internally). ~~ LRG can handle initial table data -------------------------------- If the joining node (e.g. a new weather station) already has some initial local sensor data then sharing that initial data manually with all the other nodes requires some tricky steps. LRG can hide all this complexity behind the API, so it is not a user problem anymore. ------ [1] https://www.postgresql.org/message-id/flat/CALDaNm0gwjY_4HFxvvty01BOT01q_fJLKQ3pWP9%3D9orqubhjcQ%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
On Wed, May 25, 2022 at 12:13:17PM +0530, Amit Kapila wrote: > > You still have not answered my question above. "Without these features, > > what workload would this help with?" You have only explained how the > > patch would fix one of the many larger problems. > > > > It helps with setting up logical replication among two or more nodes > (data flows both ways) which is important for use cases where > applications are data-aware. For such apps, it will be beneficial to That does make sense, thanks. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EDB https://enterprisedb.com Indecision is a decision. Inaction is an action. Mark Batterson
Dear hackers, I added documentation more and tap-tests about LRG. Same as previous e-mail, 0001 and 0002 are copied from [1]. Following lists are the TODO of patches, they will be solved one by one. ## Functional * implement a new state "waitforlsncatchup", that waits until the upstream node receives the latest lsn of the remaining nodes, * implement an over-node locking mechanism * implement operations that shares initial data * implement mechanisms to avoid concurrent API execution Note that tap-test must be also added if above are added. ## Implemental * consider failure-handing while executing APIs * add error codes for LRG * move elog() to ereport() for native language support * define pg_lrg_nodes that has NULL-able attribute as proper style [1]: https://commitfest.postgresql.org/38/3610/ Best Regards, Hayato Kuroda FUJITSU LIMITED
Attachment
On Wed, May 25, 2022 at 10:32:50PM -0400, Bruce Momjian wrote: > On Wed, May 25, 2022 at 12:13:17PM +0530, Amit Kapila wrote: > > > You still have not answered my question above. "Without these features, > > > what workload would this help with?" You have only explained how the > > > patch would fix one of the many larger problems. > > > > > > > It helps with setting up logical replication among two or more nodes > > (data flows both ways) which is important for use cases where > > applications are data-aware. For such apps, it will be beneficial to > > That does make sense, thanks. Uh, thinking some more, why would anyone set things up this way --- having part of a table being primary on one server and a different part of the table be a subscriber. Seems it would be simpler and safer to create two child tables and have one be primary on only one server. Users can access both tables using the parent. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EDB https://enterprisedb.com Indecision is a decision. Inaction is an action. Mark Batterson
On Tue, May 31, 2022 at 7:36 PM Bruce Momjian <bruce@momjian.us> wrote: > > On Wed, May 25, 2022 at 10:32:50PM -0400, Bruce Momjian wrote: > > On Wed, May 25, 2022 at 12:13:17PM +0530, Amit Kapila wrote: > > > > > > It helps with setting up logical replication among two or more nodes > > > (data flows both ways) which is important for use cases where > > > applications are data-aware. For such apps, it will be beneficial to > > > > That does make sense, thanks. > > Uh, thinking some more, why would anyone set things up this way --- > having part of a table being primary on one server and a different part > of the table be a subscriber. Seems it would be simpler and safer to > create two child tables and have one be primary on only one server. > Users can access both tables using the parent. > Yes, users can choose to do that way but still, to keep the nodes in sync and continuity of operations, it will be very difficult to manage the operations without the LRG APIs. Let us consider a simple two-node example where on each node there is Table T that has partitions P1 and P2. As far as I can understand, one needs to have the below kind of set-up to allow local operations on geographically distributed nodes. Node-1: node1 writes to P1 node1 publishes P1 node2 subscribes to P1 of node1 Node-2: node2 writes to P2 node2 publishes P2 node1 subscribes to P2 on node2 In this setup, we need to publish individual partitions, otherwise, we will face the loop problem where the data sent by node-1 to node-2 via logical replication will again come back to it causing problems like constraints violations, duplicate data, etc. There could be other ways to do this set up with current logical replication commands (for ex. publishing via root table) but that would require ways to avoid loops and could have other challenges. Now, in such a setup/scheme, consider a scenario (scenario-1), where node-2 went off (either it crashes, went out of network, just died, etc.) and comes up after some time. Now, one can either make the node-2 available by fixing the problem it has or can promote standby in that location (if any) to become master, both might require some time. In the meantime to continue the operations (which provides a seamless experience to users), users will be connected to node-1 to perform the required write operations. Now, to achieve this without LRG APIs, it will be quite complex for users to keep the data in sync. One needs to perform various steps to get the partition P2 data that went to node-1 till the time node-2 was not available. On node-1, it has to publish P2 changes for the time node-2 becomes available with the help of Create/Drop Publication APIs. And when node-2 comes back, it has to create a subscription for the above publication pub-2 to get that data, ensure both the nodes and in sync, and then allow operations on node-2. Not only this, but if there are more nodes in this set-up (say-10), it has to change (drop/create) subscriptions corresponding to partition P2 on all other nodes as each individual node is the owner of some partition. Another possibility is that the entire data center where node-2 was present was gone due to some unfortunate incident in which case they need to set up a new data center and hence a new node. Now, in such a case, the user needs to do all the steps mentioned in the previous scenario and additionally, it needs to ensure that it set up the node to sync all the existing data (of all partitions) before this node again starts receiving write changes for partition P2. I think all this should be relatively simpler with LRG APIs wherein for the second scenario user ideally just needs to use the lrg_attach* API and in the first scenario, it should automatically sync the missing data once the node-2 comes back. Now, the other important point that we should also consider for these LRG APIs is the ease of setup even in the normal case where we are just adding a new node as mentioned by Peter Smith in his email [1] (LRG makes setup easier). e.g. even if there are many nodes we only need a single lrg_attach by the joining node instead of needing N-1 subscriptions on all the existing nodes. [1] - https://www.postgresql.org/message-id/CAHut%2BPsvvfTWWwE8vkgUg4q%2BQLyoCyNE7NU%3DmEiYHcMcXciXdg%40mail.gmail.com -- With Regards, Amit Kapila.
On Wed, Jun 1, 2022 at 10:27:27AM +0530, Amit Kapila wrote: > On Tue, May 31, 2022 at 7:36 PM Bruce Momjian <bruce@momjian.us> wrote: > > Uh, thinking some more, why would anyone set things up this way --- > > having part of a table being primary on one server and a different part > > of the table be a subscriber. Seems it would be simpler and safer to > > create two child tables and have one be primary on only one server. > > Users can access both tables using the parent. > > Yes, users can choose to do that way but still, to keep the nodes in > sync and continuity of operations, it will be very difficult to manage > the operations without the LRG APIs. Let us consider a simple two-node > example where on each node there is Table T that has partitions P1 and > P2. As far as I can understand, one needs to have the below kind of > set-up to allow local operations on geographically distributed nodes. > > Node-1: > node1 writes to P1 > node1 publishes P1 > node2 subscribes to P1 of node1 > > Node-2: > node2 writes to P2 > node2 publishes P2 > node1 subscribes to P2 on node2 Yes, that is how you would set it up. > In this setup, we need to publish individual partitions, otherwise, we > will face the loop problem where the data sent by node-1 to node-2 via > logical replication will again come back to it causing problems like > constraints violations, duplicate data, etc. There could be other ways > to do this set up with current logical replication commands (for ex. > publishing via root table) but that would require ways to avoid loops > and could have other challenges. Right, individual paritions. > Now, in such a setup/scheme, consider a scenario (scenario-1), where > node-2 went off (either it crashes, went out of network, just died, > etc.) and comes up after some time. Now, one can either make the > node-2 available by fixing the problem it has or can promote standby > in that location (if any) to become master, both might require some > time. In the meantime to continue the operations (which provides a > seamless experience to users), users will be connected to node-1 to > perform the required write operations. Now, to achieve this without > LRG APIs, it will be quite complex for users to keep the data in sync. > One needs to perform various steps to get the partition P2 data that > went to node-1 till the time node-2 was not available. On node-1, it > has to publish P2 changes for the time node-2 becomes available with > the help of Create/Drop Publication APIs. And when node-2 comes back, > it has to create a subscription for the above publication pub-2 to get > that data, ensure both the nodes and in sync, and then allow > operations on node-2. Well, you are going to need to modify the app so it knows it can write to both partitions on failover anyway. I just don't see how adding this complexity is wise. My big point is that you should not be showing up with a patch but rather have these discussions to get agreement that this is the direction the community wants to go. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EDB https://enterprisedb.com Indecision is a decision. Inaction is an action. Mark Batterson
On Wed, Jun 1, 2022 at 7:33 PM Bruce Momjian <bruce@momjian.us> wrote: > > On Wed, Jun 1, 2022 at 10:27:27AM +0530, Amit Kapila wrote: > > On Tue, May 31, 2022 at 7:36 PM Bruce Momjian <bruce@momjian.us> wrote: > > > Uh, thinking some more, why would anyone set things up this way --- > > > having part of a table being primary on one server and a different part > > > of the table be a subscriber. Seems it would be simpler and safer to > > > create two child tables and have one be primary on only one server. > > > Users can access both tables using the parent. > > > > Yes, users can choose to do that way but still, to keep the nodes in > > sync and continuity of operations, it will be very difficult to manage > > the operations without the LRG APIs. Let us consider a simple two-node > > example where on each node there is Table T that has partitions P1 and > > P2. As far as I can understand, one needs to have the below kind of > > set-up to allow local operations on geographically distributed nodes. > > > > Node-1: > > node1 writes to P1 > > node1 publishes P1 > > node2 subscribes to P1 of node1 > > > > Node-2: > > node2 writes to P2 > > node2 publishes P2 > > node1 subscribes to P2 on node2 > > Yes, that is how you would set it up. > > > In this setup, we need to publish individual partitions, otherwise, we > > will face the loop problem where the data sent by node-1 to node-2 via > > logical replication will again come back to it causing problems like > > constraints violations, duplicate data, etc. There could be other ways > > to do this set up with current logical replication commands (for ex. > > publishing via root table) but that would require ways to avoid loops > > and could have other challenges. > > Right, individual paritions. > > > Now, in such a setup/scheme, consider a scenario (scenario-1), where > > node-2 went off (either it crashes, went out of network, just died, > > etc.) and comes up after some time. Now, one can either make the > > node-2 available by fixing the problem it has or can promote standby > > in that location (if any) to become master, both might require some > > time. In the meantime to continue the operations (which provides a > > seamless experience to users), users will be connected to node-1 to > > perform the required write operations. Now, to achieve this without > > LRG APIs, it will be quite complex for users to keep the data in sync. > > One needs to perform various steps to get the partition P2 data that > > went to node-1 till the time node-2 was not available. On node-1, it > > has to publish P2 changes for the time node-2 becomes available with > > the help of Create/Drop Publication APIs. And when node-2 comes back, > > it has to create a subscription for the above publication pub-2 to get > > that data, ensure both the nodes and in sync, and then allow > > operations on node-2. > > Well, you are going to need to modify the app so it knows it can write > to both partitions on failover anyway. > I am not sure if this point is clear to me. From what I can understand there are two possibilities for the app in this case and both seem to be problematic. (a) The app can be taught to write to the P2 partition in node-1 till the time node-2 is not available. If so, how will we get the partition P2 data that went to node-1 till the time node-2 was unavailable? If we don't get the data to node-2 then the operations on node-2 (once it comes back) can return incorrect results. Also, we need to ensure all the data for P2 that went to node-1 should be replicated to all other nodes in the system and for that also we need to create new subscriptions pointing to node-1. It is easier to think of doing this for physical replication where after failover the old master node can start following the new node and the app just need to be taught to write to the new master node. I can't see how we can achieve that by current logical replication APIs (apart from doing the complex steps shared by me). One of the purposes of these new LRG APIs is to ensure that users don't need to follow those complex steps after failover. (b) The other possibility is that the app is responsible to ensure that the same data is written on both node-1 and node-2 for the time one of those is not available. For that app needs to store the data at someplace for the time one of the nodes is unavailable and then write it once the other node becomes available? Also, it won't be practical when there are more partitions (say 10 or more) as all the partitions data needs to be present on each node. I think it is the responsibility of the database to keep the data in sync among nodes when one or more of the nodes are not available. -- With Regards, Amit Kapila.
On Thu, Jun 2, 2022 at 12:03 AM Bruce Momjian <bruce@momjian.us> wrote: > > On Wed, Jun 1, 2022 at 10:27:27AM +0530, Amit Kapila wrote: ... > My big point is that you should not be showing up with a patch but > rather have these discussions to get agreement that this is the > direction the community wants to go. The purpose of posting the POC patch was certainly not to present a fait accompli design/implementation. We wanted to solicit some community feedback about the desirability of the feature, but because LRG is complicated to describe we felt that having a basic functional POC might help to better understand the proposal. Also, we thought the ability to experiment with the proposed API could help people to decide whether LRG is something worth pursuing or not. ------ Kind Regards, Peter Smith. Fujitsu Australia
On Thu, Jun 2, 2022 at 05:12:49PM +1000, Peter Smith wrote: > On Thu, Jun 2, 2022 at 12:03 AM Bruce Momjian <bruce@momjian.us> wrote: > > > > On Wed, Jun 1, 2022 at 10:27:27AM +0530, Amit Kapila wrote: > ... > > > My big point is that you should not be showing up with a patch but > > rather have these discussions to get agreement that this is the > > direction the community wants to go. > > The purpose of posting the POC patch was certainly not to present a > fait accompli design/implementation. > > We wanted to solicit some community feedback about the desirability of > the feature, but because LRG is complicated to describe we felt that > having a basic functional POC might help to better understand the > proposal. Also, we thought the ability to experiment with the proposed > API could help people to decide whether LRG is something worth > pursuing or not. I don't think the POC is helping, and I am not sure we really want to support this style of architecture due to its complexity vs other options. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EDB https://enterprisedb.com Indecision is a decision. Inaction is an action. Mark Batterson
On Fri, Jun 3, 2022 at 7:12 AM Bruce Momjian <bruce@momjian.us> wrote: > > On Thu, Jun 2, 2022 at 05:12:49PM +1000, Peter Smith wrote: > > On Thu, Jun 2, 2022 at 12:03 AM Bruce Momjian <bruce@momjian.us> wrote: > > > > > > On Wed, Jun 1, 2022 at 10:27:27AM +0530, Amit Kapila wrote: > > ... > > > > > My big point is that you should not be showing up with a patch but > > > rather have these discussions to get agreement that this is the > > > direction the community wants to go. > > > > The purpose of posting the POC patch was certainly not to present a > > fait accompli design/implementation. > > > > We wanted to solicit some community feedback about the desirability of > > the feature, but because LRG is complicated to describe we felt that > > having a basic functional POC might help to better understand the > > proposal. Also, we thought the ability to experiment with the proposed > > API could help people to decide whether LRG is something worth > > pursuing or not. > > I don't think the POC is helping, and I am not sure we really want to > support this style of architecture due to its complexity vs other > options. > None of the other options discussed on this thread appears to be better or can serve the intent. What other options do you have in mind and how are they simpler than this? As far as I can understand this provides a simple way to set up n-way replication among nodes. I see that other databases provide similar ways to set up n-way replication. See [1] and in particular [2][3][4] provides a way to set up n-way replication via APIs. Yet, another way is via configuration as seems to be provided by MySQL [5] (Group Replication Settings). Most of the advantages have already been shared but let me summarize again the benefits it brings (a) more localized database access for geographically distributed databases, (b) ensuring continuous availability in case of the primary site becomes unavailable due to a system or network outage, any natural disaster on the site, (c) environments that require a fluid replication infrastructure, where the number of servers has to grow or shrink dynamically and with as few side-effects as possible. For instance, database services for the cloud, and (d) load balancing. Some of these can probably be served in other ways but not everything. I see your point about POC not helping here and it can also sometimes discourage OP if we decide not to do this feature or do it in an entirely different way. But OTOH, I don't see it stopping us from discussing the desirability or design of this feature. [1] - https://docs.oracle.com/cd/E18283_01/server.112/e10707/rarrcatpac.htm [2] - https://docs.oracle.com/cd/E18283_01/server.112/e10707/rarrcatpac.htm#i96251 [3] - https://docs.oracle.com/cd/E18283_01/server.112/e10707/rarrcatpac.htm#i94500 [4] - https://docs.oracle.com/cd/E18283_01/server.112/e10707/rarrcatpac.htm#i97185 [5] - https://dev.mysql.com/doc/refman/8.0/en/group-replication-configuring-instances.html -- With Regards, Amit Kapila.
Dear hackers, I found another use-case for LRG. It might be helpful for migration. LRG for migration ------------------------------------------ LRG may be helpful for machine migration, OS upgrade, or PostgreSQL itself upgrade. Assumes that users want to migrate database to other environment, e.g., PG16 on RHEL7 to PG18 on RHEL8. Users must copy all data into new server and catchup all changes. In this case streaming replication cannot be used because it requires same OS and same PostgreSQL major version. Moreover, it is desirable to be able to return to the original environment at any time in case of application or other environmental deficiencies. Operation steps with LRG ------------------------------------------ LRG is appropriate for the situation. Following lines are the workflow that users must do: 1. Copy the table definition to the newer node(PG18), via pg_dump/pg_restore 2. Execute lrg_create() in the older node(PG16) 3. Execute lrg_node_attach() in PG18 === data will be shared here=== 4. Change the connection of the user application to PG18 5. Check whether ERROR is raised or not. If some ERRORs are raised, users can change back the connection to PG16. 6. Remove the created node group if application works well. These operations may reduce system downtime due to incompatibilities associated with version upgrades. Best Regards, Hayato Kuroda FUJITSU LIMITED
On Thu, Apr 28, 2022 at 5:20 AM Peter Smith <smithpb2250@gmail.com> wrote: > > MULTI-MASTER LOGICAL REPLICATION > > 1.0 BACKGROUND > > Let’s assume that a user wishes to set up a multi-master environment > so that a set of PostgreSQL instances (nodes) use logical replication > to share tables with every other node in the set. > > We define this as a multi-master logical replication (MMLR) node-set. > > <please refer to the attached node-set diagram> > > 1.1 ADVANTAGES OF MMLR > > - Increases write scalability (e.g., all nodes can write arbitrary data). > - Allows load balancing > - Allows rolling updates of nodes (e.g., logical replication works > between different major versions of PostgreSQL). > - Improves the availability of the system (e.g., no single point of failure) > - Improves performance (e.g., lower latencies for geographically local nodes) Thanks for working on this proposal. I have a few high-level thoughts, please bear with me if I repeat any of them: 1. Are you proposing to use logical replication subscribers to be in sync quorum? In other words, in an N-masters node, M (M >= N)-node configuration, will each master be part of the sync quorum in the other master? 2. Is there any mention of reducing the latencies that logical replication will have generally (initial table sync and after-caught-up decoding and replication latencies)? 3. What if "some" postgres provider assures an SLA of very few seconds for failovers in typical HA set up with primary and multiple sync and async standbys? In this context, where does the multi-master architecture sit in the broad range of postgres use-cases? 4. Can the design proposed here be implemented as an extension instead of a core postgres solution? 5. Why should one use logical replication for multi master replication? If logical replication is used, isn't it going to be something like logically decode and replicate every WAL record from one master to all other masters? Instead, can't it be achieved via streaming/physical replication? Regards, Bharath Rupireddy.
On Thu, Jun 9, 2022 at 6:04 PM Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> wrote: > > On Thu, Apr 28, 2022 at 5:20 AM Peter Smith <smithpb2250@gmail.com> wrote: > > > > MULTI-MASTER LOGICAL REPLICATION > > > > 1.0 BACKGROUND > > > > Let’s assume that a user wishes to set up a multi-master environment > > so that a set of PostgreSQL instances (nodes) use logical replication > > to share tables with every other node in the set. > > > > We define this as a multi-master logical replication (MMLR) node-set. > > > > <please refer to the attached node-set diagram> > > > > 1.1 ADVANTAGES OF MMLR > > > > - Increases write scalability (e.g., all nodes can write arbitrary data). > > - Allows load balancing > > - Allows rolling updates of nodes (e.g., logical replication works > > between different major versions of PostgreSQL). > > - Improves the availability of the system (e.g., no single point of failure) > > - Improves performance (e.g., lower latencies for geographically local nodes) > > Thanks for working on this proposal. I have a few high-level thoughts, > please bear with me if I repeat any of them: > > 1. Are you proposing to use logical replication subscribers to be in > sync quorum? In other words, in an N-masters node, M (M >= N)-node > configuration, will each master be part of the sync quorum in the > other master? > What exactly do you mean by sync quorum here? If you mean to say that each master node will be allowed to wait till the commit happens on all other nodes similar to how our current synchronous_commit and synchronous_standby_names work, then yes, it could be achieved. I think the patch currently doesn't support this but it could be extended to support the same. Basically, one can be allowed to set up async and sync nodes in combination depending on its use case. > 2. Is there any mention of reducing the latencies that logical > replication will have generally (initial table sync and > after-caught-up decoding and replication latencies)? > No, this won't change under the hood replication mechanism. > 3. What if "some" postgres provider assures an SLA of very few seconds > for failovers in typical HA set up with primary and multiple sync and > async standbys? In this context, where does the multi-master > architecture sit in the broad range of postgres use-cases? > I think this is one of the primary use cases of the n-way logical replication solution where in there shouldn't be any noticeable wait time when one or more of the nodes goes down. All nodes have the capability to allow writes so the app just needs to connect to another node. I feel some analysis is required to find out and state exactly how the users can achieve this but seems doable. The other use cases are discussed in this thread and are summarized in emails [1][2]. > 4. Can the design proposed here be implemented as an extension instead > of a core postgres solution? > Yes, I think it could be. I think this proposal introduces some system tables, so need to analyze what to do about that. BTW, do you see any advantages to doing so? > 5. Why should one use logical replication for multi master > replication? If logical replication is used, isn't it going to be > something like logically decode and replicate every WAL record from > one master to all other masters? Instead, can't it be achieved via > streaming/physical replication? > The failover/downtime will be much lesser in a solution based on logical replication because all nodes are master nodes and users will be allowed to write on other nodes instead of waiting for the physical standby to become writeable. Then it will allow more localized database access for geographically distributed databases, see the email for further details on this [3]. Also, the benefiting scenarios are the same as all usual Logical Replication quoted benefits - e.g version independence, getting selective/required data, etc. [1] - https://www.postgresql.org/message-id/CAA4eK1%2BZP9c6q1BQWSQC__w09WQ-qGt22dTmajDmTxR_CAUyJQ%40mail.gmail.com [2] - https://www.postgresql.org/message-id/TYAPR01MB58660FCFEC7633E15106C94BF5A29%40TYAPR01MB5866.jpnprd01.prod.outlook.com [3] - https://www.postgresql.org/message-id/CAA4eK1%2BDRHCNLongM0stsVBY01S-s%3DEa_yjBFnv_Uz3m3Hky-w%40mail.gmail.com -- With Regards, Amit Kapila.
On Fri, Jun 10, 2022 at 9:54 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Thu, Jun 9, 2022 at 6:04 PM Bharath Rupireddy
> <bharath.rupireddyforpostgres@gmail.com> wrote:
> >
> > On Thu, Apr 28, 2022 at 5:20 AM Peter Smith <smithpb2250@gmail.com> wrote:
> > >
> > > MULTI-MASTER LOGICAL REPLICATION
> > >
> > > 1.0 BACKGROUND
> > >
> > > Let’s assume that a user wishes to set up a multi-master environment
> > > so that a set of PostgreSQL instances (nodes) use logical replication
> > > to share tables with every other node in the set.
> > >
> > > We define this as a multi-master logical replication (MMLR) node-set.
> > >
> > > <please refer to the attached node-set diagram>
> > >
> > > 1.1 ADVANTAGES OF MMLR
> > >
> > > - Increases write scalability (e.g., all nodes can write arbitrary data).
> > > - Allows load balancing
> > > - Allows rolling updates of nodes (e.g., logical replication works
> > > between different major versions of PostgreSQL).
> > > - Improves the availability of the system (e.g., no single point of failure)
> > > - Improves performance (e.g., lower latencies for geographically local nodes)
> >
> > Thanks for working on this proposal. I have a few high-level thoughts,
> > please bear with me if I repeat any of them:
> >
> > 1. Are you proposing to use logical replication subscribers to be in
> > sync quorum? In other words, in an N-masters node, M (M >= N)-node
> > configuration, will each master be part of the sync quorum in the
> > other master?
> >
>
> What exactly do you mean by sync quorum here? If you mean to say that
> each master node will be allowed to wait till the commit happens on
> all other nodes similar to how our current synchronous_commit and
> synchronous_standby_names work, then yes, it could be achieved. I
> think the patch currently doesn't support this but it could be
> extended to support the same. Basically, one can be allowed to set up
> async and sync nodes in combination depending on its use case.
Yes, I meant each master node will be in synchronous_commit with
others. In this setup, do you see any problems such as deadlocks if
write-txns on the same table occur on all the masters at a time?
If the master nodes are not in synchronous_commit i.e. connected in
asynchronous mode, don't we have data synchronous problems because of
logical decoding and replication latencies? Say, I do a bulk-insert to
a table foo on master 1, Imagine there's a latency with which the
inserted rows get replicated to master 2 and meanwhile I do update on
the same table foo on master 2 based on the rows inserted in master 1
- master 2 doesn't have all the inserted rows on master 1 - how does
the solution proposed here address this problem?
> > 3. What if "some" postgres provider assures an SLA of very few seconds
> > for failovers in typical HA set up with primary and multiple sync and
> > async standbys? In this context, where does the multi-master
> > architecture sit in the broad range of postgres use-cases?
> >
>
> I think this is one of the primary use cases of the n-way logical
> replication solution where in there shouldn't be any noticeable wait
> time when one or more of the nodes goes down. All nodes have the
> capability to allow writes so the app just needs to connect to another
> node. I feel some analysis is required to find out and state exactly
> how the users can achieve this but seems doable. The other use cases
> are discussed in this thread and are summarized in emails [1][2].
IIUC, the main goals of this feature are - zero failover times and
less write latencies, right? How is it going to solve the data
synchronization problem (stated above) with the master nodes connected
to each other in asynchronous mode?
> > 4. Can the design proposed here be implemented as an extension instead
> > of a core postgres solution?
> >
>
> Yes, I think it could be. I think this proposal introduces some system
> tables, so need to analyze what to do about that. BTW, do you see any
> advantages to doing so?
IMO, yes, doing it the extension way has many advantages - it doesn't
have to touch the core part of postgres, usability will be good -
whoever requires this solution will use and we can avoid code chunks
within the core such as if (feature_enabled) { do foo} else { do bar}
sorts. Since this feature is based on core postgres logical
replication infrastructure, I think it's worth implementing it as an
extension first, maybe the extension as a PoC?
> > 5. Why should one use logical replication for multi master
> > replication? If logical replication is used, isn't it going to be
> > something like logically decode and replicate every WAL record from
> > one master to all other masters? Instead, can't it be achieved via
> > streaming/physical replication?
> >
>
> The failover/downtime will be much lesser in a solution based on
> logical replication because all nodes are master nodes and users will
> be allowed to write on other nodes instead of waiting for the physical
> standby to become writeable.
I don't think that's a correct statement unless the design proposed
here addresses the data synchronization problem (stated above) with
the master nodes connected to each other in asynchronous mode.
> Then it will allow more localized
> database access for geographically distributed databases, see the
> email for further details on this [3]. Also, the benefiting scenarios
> are the same as all usual Logical Replication quoted benefits - e.g
> version independence, getting selective/required data, etc.
>
> [1] - https://www.postgresql.org/message-id/CAA4eK1%2BZP9c6q1BQWSQC__w09WQ-qGt22dTmajDmTxR_CAUyJQ%40mail.gmail.com
> [2] -
https://www.postgresql.org/message-id/TYAPR01MB58660FCFEC7633E15106C94BF5A29%40TYAPR01MB5866.jpnprd01.prod.outlook.com
> [3] - https://www.postgresql.org/message-id/CAA4eK1%2BDRHCNLongM0stsVBY01S-s%3DEa_yjBFnv_Uz3m3Hky-w%40mail.gmail.com
IMHO, geographically distributed databases are "different sorts in
themselves" and have different ways and means to address data
synchronization, latencies, replication, failovers, conflict
resolutions etc. (I'm no expert there, others may have better
thoughts).
Having said that, it will be great to know if there are any notable or
mentionable customer typical scenarios or use-cases for multi master
solutions within postgres.
Regards,
Bharath Rupireddy.
On Fri, Jun 10, 2022 at 12:40 PM Bharath Rupireddy
<bharath.rupireddyforpostgres@gmail.com> wrote:
>
> On Fri, Jun 10, 2022 at 9:54 AM Amit Kapila <amit.kapila16@gmail.com> wrote:
> > >
> > > 1. Are you proposing to use logical replication subscribers to be in
> > > sync quorum? In other words, in an N-masters node, M (M >= N)-node
> > > configuration, will each master be part of the sync quorum in the
> > > other master?
> > >
> >
> > What exactly do you mean by sync quorum here? If you mean to say that
> > each master node will be allowed to wait till the commit happens on
> > all other nodes similar to how our current synchronous_commit and
> > synchronous_standby_names work, then yes, it could be achieved. I
> > think the patch currently doesn't support this but it could be
> > extended to support the same. Basically, one can be allowed to set up
> > async and sync nodes in combination depending on its use case.
>
> Yes, I meant each master node will be in synchronous_commit with
> others. In this setup, do you see any problems such as deadlocks if
> write-txns on the same table occur on all the masters at a time?
>
I have not tried but I don't see in theory why this should happen
unless someone tries to update a similar set of rows in conflicting
order similar to how it can happen in a single node. If so, it will
error out and one of the conflicting transactions needs to be retried.
IOW, I think the behavior should be the same as on a single node. Do
you have any particular examples in mind?
> If the master nodes are not in synchronous_commit i.e. connected in
> asynchronous mode, don't we have data synchronous problems because of
> logical decoding and replication latencies? Say, I do a bulk-insert to
> a table foo on master 1, Imagine there's a latency with which the
> inserted rows get replicated to master 2 and meanwhile I do update on
> the same table foo on master 2 based on the rows inserted in master 1
> - master 2 doesn't have all the inserted rows on master 1 - how does
> the solution proposed here address this problem?
>
I don't think that is possible even in theory and none of the other
n-way replication solutions I have read seems to be claiming to have
something like that. It is quite possible that I am missing something
here but why do we want to have such a requirement from asynchronous
replication? I think in such cases even for load balancing we can
distribute reads where eventually consistent data is acceptable and
writes on separate tables/partitions can be distributed.
I haven't responded to some of your other points as they are
associated with the above theory.
>
> > > 4. Can the design proposed here be implemented as an extension instead
> > > of a core postgres solution?
> > >
> >
> > Yes, I think it could be. I think this proposal introduces some system
> > tables, so need to analyze what to do about that. BTW, do you see any
> > advantages to doing so?
>
> IMO, yes, doing it the extension way has many advantages - it doesn't
> have to touch the core part of postgres, usability will be good -
> whoever requires this solution will use and we can avoid code chunks
> within the core such as if (feature_enabled) { do foo} else { do bar}
> sorts. Since this feature is based on core postgres logical
> replication infrastructure, I think it's worth implementing it as an
> extension first, maybe the extension as a PoC?
>
I don't know if it requires the kind of code you are thinking but I
agree that it is worth considering implementing it as an extension.
--
With Regards,
Amit Kapila.
Hi, In addition to the use cases mentioned above, some users want to use n-way replication of partial database. The following is the typical use case. * There are several data centers. (ex. Japan and India) * The database in each data center has its unique data. (ex. the database in Japan has the data related to Japan) * There are some common data. (ex. the shipment data from Japan to India should be stored on both database) * To replicate common data, users want to use n-way replication. The current POC patch seems to support only n-way replication of entire database, but I think we should support n-way replication of partial database to achieve above use case. > I don't know if it requires the kind of code you are thinking but I > agree that it is worth considering implementing it as an extension. I think the other advantage to implement as an extension is that users could install the extension to older Postgres. As mentioned in previous email, the one use case of n-way replication is migration from older Postgres to newer Postgres. If we implement as an extension, users could use n-way replication for migration from PG10 to PG16. Regards, Ryohei Takahashi
Dear Takahashi-san, Thanks for giving feedbacks! > > I don't know if it requires the kind of code you are thinking but I > > agree that it is worth considering implementing it as an extension. > > I think the other advantage to implement as an extension is that users could > install the extension to older Postgres. > > As mentioned in previous email, the one use case of n-way replication is migration > from older Postgres to newer Postgres. > > If we implement as an extension, users could use n-way replication for migration > from PG10 to PG16. > I think even if LRG is implemented as contrib modules or any extensions, it will deeply depend on the subscription option "origin" proposed in [1]. So LRG cannot be used for older version, only PG16 or later. [1]: https://www.postgresql.org/message-id/CALDaNm3Pt1CpEb3y9pE7ff91gZVpNXr91y4ZtWiw6h+GAyG4Gg@mail.gmail.com Best Regards, Hayato Kuroda FUJITSU LIMITED
Hi Kuroda san, > I think even if LRG is implemented as contrib modules or any extensions, > it will deeply depend on the subscription option "origin" proposed in [1]. > So LRG cannot be used for older version, only PG16 or later. Sorry, I misunderstood. I understand now. Regards, Ryohei Takahashi
Hi hackers, While analyzing about failure handling in the N-way logical replication, I found that in previous PoC detaching API cannot detach a node which has failed. I though lack of the feature was not suitable for testing purpose, so I would like to post a new version. Also this patch was adjusted to new version of the infinite recursive patch[1]. 0001-0004 were copied from the thread. Note that LRG has been still implemented as the core feature. We have not yet compared advantages for implementing as contrib modules. [1]: https://www.postgresql.org/message-id/CALDaNm0PYba4dJPO9YAnQmuCFHgLEfOBFwbfidB1-pOS3pBCXA@mail.gmail.com Best Regards, Hayato Kuroda FUJITSU LIMITED
Attachment
- v4-0005-PoC-implement-LRG.patch
- v4-0006-Document-Logical-Replication-Group.patch
- v4-0007-Tests-for-Logical-Replication-Group.patch
- v25-0001-Add-a-missing-test-to-verify-only-local-paramete.patch
- v25-0002-Skip-replication-of-non-local-data.patch
- v25-0003-Check-and-throw-an-error-if-publication-tables-w.patch
- v25-0004-Document-bidirectional-logical-replication-steps.patch