Thread: ZFS filesystem - supported ?
Hi, Given an upcoming server upgrade, I'm contemplating moving away from XFS to ZFS (specifically the ZoL flavour via Debian11). BTRFS seems to be falling away (e.g. with Redhat deprecating it etc.), hence my preference for ZFS. However, somewhere in the back of my mind I seem to have a recollection of reading about what could be described as a "strongencouragement" to stick with more traditional options such as ext4 or xfs. A brief search of the docs for "xfs" didn't come up with anything, hence the question here. Thanks ! Laura
On 10/23/21 07:29, Laura Smith wrote: > Hi, > > Given an upcoming server upgrade, I'm contemplating moving away from XFS to ZFS (specifically the ZoL flavour via Debian11). BTRFS seems to be falling away (e.g. with Redhat deprecating it etc.), hence my preference for ZFS. > > However, somewhere in the back of my mind I seem to have a recollection of reading about what could be described as a "strongencouragement" to stick with more traditional options such as ext4 or xfs. > > A brief search of the docs for "xfs" didn't come up with anything, hence the question here. > > Thanks ! > > Laura > > Hi Laura, May I ask why would you like to change file systems? Probably because of the snapshot capability? However, ZFS performance leaves much to be desired. Please see the following article: https://www.phoronix.com/scan.php?page=article&item=ubuntu1910-ext4-zfs&num=1 This is relatively new, from 2019. On the page 3 there are tests with SQLite, Cassandra and RocksDB. Ext4 is much faster in all of them. Finally, there is another article about relational databases and ZFS: https://blog.docbert.org/oracle-on-zfs/ In other words, I would test very thoroughly because your performance is likely to suffer. As for the supported part, that's not a problem. Postgres supports all modern file systems. It uses Posix system calls to manipulate, read and write files. Furthermore, if you need snapshots, disk arrays like NetApp, Hitachi or EMC can always provide that. Regards -- Mladen Gogala Database Consultant Tel: (347) 321-1217 https://dbwhisperer.wordpress.com
On Saturday, October 23rd, 2021 at 14:03, Mladen Gogala <gogala.mladen@gmail.com> wrote: > On 10/23/21 07:29, Laura Smith wrote: > > > Hi, > > > > Given an upcoming server upgrade, I'm contemplating moving away from XFS to ZFS (specifically the ZoL flavour via Debian11). BTRFS seems to be falling away (e.g. with Redhat deprecating it etc.), hence my preference for ZFS. > > > > However, somewhere in the back of my mind I seem to have a recollection of reading about what could be described as a"strong encouragement" to stick with more traditional options such as ext4 or xfs. > > > > A brief search of the docs for "xfs" didn't come up with anything, hence the question here. > > > > Thanks ! > > > > Laura > > Hi Laura, > > May I ask why would you like to change file systems? Probably because of > > the snapshot capability? However, ZFS performance leaves much to be > > desired. Please see the following article: > > https://www.phoronix.com/scan.php?page=article&item=ubuntu1910-ext4-zfs&num=1 > > This is relatively new, from 2019. On the page 3 there are tests with > > SQLite, Cassandra and RocksDB. Ext4 is much faster in all of them. > > Finally, there is another article about relational databases and ZFS: > > https://blog.docbert.org/oracle-on-zfs/ > > In other words, I would test very thoroughly because your performance is > > likely to suffer. As for the supported part, that's not a problem. > > Postgres supports all modern file systems. It uses Posix system calls to > > manipulate, read and write files. Furthermore, if you need snapshots, > > disk arrays like NetApp, Hitachi or EMC can always provide that. > > Regards > > > -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- > > Mladen Gogala > > Database Consultant > > Tel: (347) 321-1217 > > https://dbwhisperer.wordpress.com Hi Mladen, Yes indeed, snapshots is the primary reason, closely followed by zfssend/receive. I'm no stranger to using LVM snapshots with ext4/xfs but it requires a custom shell script to manage the whole process aroundbackups. I feel the whole thing could well be a lot cleaner with zfs. Thank you for the links, I will take a look. Laura
On 10/23/21 09:37, Laura Smith wrote: > Hi Mladen, > > Yes indeed, snapshots is the primary reason, closely followed by zfssend/receive. > > I'm no stranger to using LVM snapshots with ext4/xfs but it requires a custom shell script to manage the whole processaround backups. I feel the whole thing could well be a lot cleaner with zfs. > > Thank you for the links, I will take a look. > > Laura Yes, ZFS is extremely convenient. It's a volume manager and a file system, all rolled into one, with some additiional convenient tools. However, performance is a major concern. If your application is OLTP, ZFS might be a tad too slow for your performance requirements. On the other hand, snapshots can save you a lot of time with backups, especially if you have some commercial backup capable of multiple readers. If your application is OLTP, ZFS might be a tad too slow for your performance requirements. The only way to find out is to test. The ideal tool for testing is pgio: https://kevinclosson.net/2019/09/21/announcing-pgio-the-slob-method-for-postgresql-is-released-under-apache-2-0-and-available-at-github/ For those who do not know, Kevin Closson was the technical architect who has built both Exadata and EMC XTRemIO. He is now the principal engineer of the Amazon RDS. This part is intended only for those who would tell him that "Oracle has it is not good enough" if he ever decided to post here. -- Mladen Gogala Database Consultant Tel: (347) 321-1217 https://dbwhisperer.wordpress.com
On 2021-10-24 06:48, Mladen Gogala wrote:
On 10/23/21 09:37, Laura Smith wrote:Hi Mladen,
Yes indeed, snapshots is the primary reason, closely followed by zfssend/receive.
I'm no stranger to using LVM snapshots with ext4/xfs but it requires a custom shell script to manage the whole process around backups. I feel the whole thing could well be a lot cleaner with zfs.
Thank you for the links, I will take a look.
Laura
Yes, ZFS is extremely convenient. It's a volume manager and a file system, all rolled into one, with some additiional convenient tools. However, performance is a major concern. If your application is OLTP, ZFS might be a tad too slow for your performance requirements. On the other hand, snapshots can save you a lot of time with backups, especially if you have some commercial backup capable of multiple readers. If your application is OLTP, ZFS might be a tad too slow for your performance requirements. The only way to find out is to test. The ideal tool for testing is pgio:
https://kevinclosson.net/2019/09/21/announcing-pgio-the-slob-method-for-postgresql-is-released-under-apache-2-0-and-available-at-github/
For those who do not know, Kevin Closson was the technical architect who has built both Exadata and EMC XTRemIO. He is now the principal engineer of the Amazon RDS. This part is intended only for those who would tell him that "Oracle has it is not good enough" if he ever decided to post here.
I don't know where you have your database deployed, but in my case is in AWS EC2 instances. The way I handle backups is at the block storage level, performing EBS snapshots.
Yes, Amazon uses SAN equipment that supports snapshots.
This has proven to work very well for me. I had to restore a few backups already and it always worked. The bad part is that I need to stop the database before performing the Snapshot, for data integrity, so that means that I have a hot-standby server only for these snapshots.Lucas
Actually, you don't need to stop the database. You need to execute pg_start_backup() before taking a snapshot and then pg_stop_backup() when the snapshot is done. You will need to recover the database when you finish the restore but you will not lose any data. I know that pg_begin_backup() and pg_stop_backup() are deprecated but since PostgreSQL doesn't have any API for storage or file system snapshots, that's the only thing that can help you use storage snapshots as backups. To my knowledge,the only database that does have API for storage snapshots is DB2. The API is called "Advanced Copy Services" or ACS. It's documented here:
https://www.ibm.com/docs/en/db2/11.1?topic=recovery-db2-advanced-copy-services-acs
For Postgres, the old begin/stop backup functions should be sufficient.
-- Mladen Gogala Database Consultant Tel: (347) 321-1217 https://dbwhisperer.wordpress.com
‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Saturday, October 23rd, 2021 at 18:48, Mladen Gogala <gogala.mladen@gmail.com> wrote: > On 10/23/21 09:37, Laura Smith wrote: > > > Hi Mladen, > > > > Yes indeed, snapshots is the primary reason, closely followed by zfssend/receive. > > > > I'm no stranger to using LVM snapshots with ext4/xfs but it requires a custom shell script to manage the whole processaround backups. I feel the whole thing could well be a lot cleaner with zfs. > > > > Thank you for the links, I will take a look. > > > > Laura > > Yes, ZFS is extremely convenient. It's a volume manager and a file > > system, all rolled into one, with some additiional convenient tools. > > However, performance is a major concern. If your application is OLTP, > > ZFS might be a tad too slow for your performance requirements. On the > > other hand, snapshots can save you a lot of time with backups, > > especially if you have some commercial backup capable of multiple > > readers. If your application is OLTP, ZFS might be a tad too slow for > > your performance requirements. The only way to find out is to test. The > > ideal tool for testing is pgio: > > https://kevinclosson.net/2019/09/21/announcing-pgio-the-slob-method-for-postgresql-is-released-under-apache-2-0-and-available-at-github/ > > For those who do not know, Kevin Closson was the technical architect who > > has built both Exadata and EMC XTRemIO. He is now the principal engineer > > of the Amazon RDS. This part is intended only for those who would tell > > him that "Oracle has it is not good enough" if he ever decided to post here. > > Thank you Mladen for your very useful food for thought. I think my plan going forward will be to stick to the old XFS+LVM setup and (maybe) when I have some more time on my handsfire up a secondary instance with ZFS and do some experimentation with pgio. Thanks again !
On Sat, 2021-10-23 at 11:29 +0000, Laura Smith wrote: > Given an upcoming server upgrade, I'm contemplating moving away from XFS to ZFS > (specifically the ZoL flavour via Debian 11). > BTRFS seems to be falling away (e.g. with Redhat deprecating it etc.), hence my preference for ZFS. > > However, somewhere in the back of my mind I seem to have a recollection of reading > about what could be described as a "strong encouragement" to stick with more traditional options such as ext4 or xfs. ZFS is probably reliable, so you can use it with PostgreSQL. However, I have seen reports of performance tests that were not favorable for ZFS. So you should test if the performance is good enough for your use case. Yours, Laurenz Albe -- Cybertec | https://www.cybertec-postgresql.com
Greetings, * Mladen Gogala (gogala.mladen@gmail.com) wrote: > On 10/23/21 23:12, Lucas wrote: > >This has proven to work very well for me. I had to restore a few backups > >already and it always worked. The bad part is that I need to stop the > >database before performing the Snapshot, for data integrity, so that means > >that I have a hot-standby server only for these snapshots. > >Lucas > > Actually, you don't need to stop the database. You need to execute > pg_start_backup() before taking a snapshot and then pg_stop_backup() when > the snapshot is done. You will need to recover the database when you finish > the restore but you will not lose any data. I know that pg_begin_backup() > and pg_stop_backup() are deprecated but since PostgreSQL doesn't have any > API for storage or file system snapshots, that's the only thing that can > help you use storage snapshots as backups. To my knowledge,the only database > that does have API for storage snapshots is DB2. The API is called "Advanced > Copy Services" or ACS. It's documented here: > > https://www.ibm.com/docs/en/db2/11.1?topic=recovery-db2-advanced-copy-services-acs > > For Postgres, the old begin/stop backup functions should be sufficient. No, it's not- you must also be sure to archive any WAL that's generated between the pg_start_backup and pg_stop_backup and then to be sure and add into the snapshot the appropriate signal files or recovery.conf, depending on PG version, to indicate that you're restoring from a backup and make sure that the WAL is made available via restore_command. Just doing stat/stop backup is *not* enough and you run the risk of having an invalid backup or corruption when you restore. If the entire system is on a single volume then you could possibly just take a snapshot of it (without any start/stop backup stuff) but it's very risky to do that and then try to do PITR with it because we don't know where consistency is reached in such a case (we *must* play all the way through to the end of the WAL which existed at the time of the snapshot in order to reach consistency). In the end though, really, it's much, much, much better to use a proper backup and archiving tool that's written specifically for PG than to try and roll your own, using snapshots or not. Thanks, Stephen
Attachment
On Sat, 2021-10-23 at 11:29 +0000, Laura Smith wrote:
> Given an upcoming server upgrade, I'm contemplating moving away from XFS to ZFS
> (specifically the ZoL flavour via Debian 11).
> BTRFS seems to be falling away (e.g. with Redhat deprecating it etc.), hence my preference for ZFS.
>
> However, somewhere in the back of my mind I seem to have a recollection of reading
> about what could be described as a "strong encouragement" to stick with more traditional options such as ext4 or xfs.
ZFS is probably reliable, so you can use it with PostgreSQL.
However, I have seen reports of performance tests that were not favorable for ZFS.
So you should test if the performance is good enough for your use case.
Yours,
Laurenz Albe
--
Cybertec | https://www.cybertec-postgresql.com
On 10/25/21 13:13, Stephen Frost wrote: > No, it's not- you must also be sure to archive any WAL that's generated > between the pg_start_backup and pg_stop_backup and then to be sure and > add into the snapshot the appropriate signal files or recovery.conf, > depending on PG version, to indicate that you're restoring from a backup > and make sure that the WAL is made available via restore_command. > > Just doing stat/stop backup is*not* enough and you run the risk of > having an invalid backup or corruption when you restore. > > If the entire system is on a single volume then you could possibly just > take a snapshot of it (without any start/stop backup stuff) but it's > very risky to do that and then try to do PITR with it because we don't > know where consistency is reached in such a case (we*must* play all the > way through to the end of the WAL which existed at the time of the > snapshot in order to reach consistency). > > In the end though, really, it's much, much, much better to use a proper > backup and archiving tool that's written specifically for PG than to try > and roll your own, using snapshots or not. > > Thanks, > > Stephen Stephen, thank you for correcting me. You, of course, are right. I have erroneously thought that backup of WAL logs is implied because I always back that up. And yes, that needs to be made clear. Regards -- Mladen Gogala Database Consultant Tel: (347) 321-1217 https://dbwhisperer.wordpress.com
On 10/25/2021 10:13 AM, Stephen Frost wrote: > Greetings, > > * Mladen Gogala (gogala.mladen@gmail.com) wrote: >> On 10/23/21 23:12, Lucas wrote: >>> This has proven to work very well for me. I had to restore a few backups >>> already and it always worked. The bad part is that I need to stop the >>> database before performing the Snapshot, for data integrity, so that means >>> that I have a hot-standby server only for these snapshots. >>> Lucas >> Actually, you don't need to stop the database. You need to execute >> pg_start_backup() before taking a snapshot and then pg_stop_backup() when >> the snapshot is done. You will need to recover the database when you finish >> the restore but you will not lose any data. I know that pg_begin_backup() >> and pg_stop_backup() are deprecated but since PostgreSQL doesn't have any >> API for storage or file system snapshots, that's the only thing that can >> help you use storage snapshots as backups. To my knowledge,the only database >> that does have API for storage snapshots is DB2. The API is called "Advanced >> Copy Services" or ACS. It's documented here: >> >> https://www.ibm.com/docs/en/db2/11.1?topic=recovery-db2-advanced-copy-services-acs >> >> For Postgres, the old begin/stop backup functions should be sufficient. > No, it's not- you must also be sure to archive any WAL that's generated > between the pg_start_backup and pg_stop_backup and then to be sure and > add into the snapshot the appropriate signal files or recovery.conf, > depending on PG version, to indicate that you're restoring from a backup > and make sure that the WAL is made available via restore_command. > > Just doing stat/stop backup is *not* enough and you run the risk of > having an invalid backup or corruption when you restore. > > If the entire system is on a single volume then you could possibly just > take a snapshot of it (without any start/stop backup stuff) but it's > very risky to do that and then try to do PITR with it because we don't > know where consistency is reached in such a case (we *must* play all the > way through to the end of the WAL which existed at the time of the > snapshot in order to reach consistency). > > In the end though, really, it's much, much, much better to use a proper > backup and archiving tool that's written specifically for PG than to try > and roll your own, using snapshots or not. > > Thanks, > > Stephen what about BTRFS since it's the successor of ZFS? -- E-BLOKOS
On 26/10/2021, at 6:13 AM, Stephen Frost <sfrost@snowman.net> wrote: > > Greetings, > > * Mladen Gogala (gogala.mladen@gmail.com) wrote: >> On 10/23/21 23:12, Lucas wrote: >>> This has proven to work very well for me. I had to restore a few backups >>> already and it always worked. The bad part is that I need to stop the >>> database before performing the Snapshot, for data integrity, so that means >>> that I have a hot-standby server only for these snapshots. >>> Lucas >> >> Actually, you don't need to stop the database. You need to execute >> pg_start_backup() before taking a snapshot and then pg_stop_backup() when >> the snapshot is done. You will need to recover the database when you finish >> the restore but you will not lose any data. I know that pg_begin_backup() >> and pg_stop_backup() are deprecated but since PostgreSQL doesn't have any >> API for storage or file system snapshots, that's the only thing that can >> help you use storage snapshots as backups. To my knowledge,the only database >> that does have API for storage snapshots is DB2. The API is called "Advanced >> Copy Services" or ACS. It's documented here: >> >> https://www.ibm.com/docs/en/db2/11.1?topic=recovery-db2-advanced-copy-services-acs >> >> For Postgres, the old begin/stop backup functions should be sufficient. > > No, it's not- you must also be sure to archive any WAL that's generated > between the pg_start_backup and pg_stop_backup and then to be sure and > add into the snapshot the appropriate signal files or recovery.conf, > depending on PG version, to indicate that you're restoring from a backup > and make sure that the WAL is made available via restore_command. > > Just doing stat/stop backup is *not* enough and you run the risk of > having an invalid backup or corruption when you restore. > > If the entire system is on a single volume then you could possibly just > take a snapshot of it (without any start/stop backup stuff) but it's > very risky to do that and then try to do PITR with it because we don't > know where consistency is reached in such a case (we *must* play all the > way through to the end of the WAL which existed at the time of the > snapshot in order to reach consistency). > > In the end though, really, it's much, much, much better to use a proper > backup and archiving tool that's written specifically for PG than to try > and roll your own, using snapshots or not. > > Thanks, > > Stephen When I create a snapshot, the script gets the latest WAL file applied from [1] and adds that information to the SnapshotTags in AWS. I then use that information in the future when restoring the snapshot. The script will read the tagand it will download 50 WAL Files before that and all the WAL files after that required. The WAL files are being backed up to S3. I had to restore the database to a PITR state many times, and it always worked very well. I also create slaves using the snapshot method. So, I don’t mind having to stop/start the Database for the snapshot process,as it’s proven to work fine for the last 5 years. Lucas
On 10/25/21 15:43, E-BLOKOS wrote: > what about BTRFS since it's the successor of ZFS? BTRFS is NOT the successor to ZFS. It never was. It was completely new file system developed by Oracle Corp. For some reason, Oracle seems to have lost interest in it. Red Hat has deprecated and, in all likelihood, BTRFS will go the way of Solaris and SPARC chips: ride into the glorious history of the computer science. However, BTRFS has never been widely used, not even among Fedora users like me. BTRFS was suffering from problems with corruption and performance. This is probably not the place to discuss the inner workings of snapshots, but it is worth knowing that snapshots drastically increase the IO rate on the file system - for every snapshot. That's where the slowness comes from. -- Mladen Gogala Database Consultant Tel: (347) 321-1217 https://dbwhisperer.wordpress.com
On 10/25/21 1:40 PM, Mladen Gogala wrote: > This is probably not the place > to discuss the inner workings of snapshots, but it is worth knowing that > snapshots drastically increase the IO rate on the file system - for > every snapshot. That's where the slowness comes from. I have recent anecdotal experience of this. I experiment with using Btrfs for a 32 TB backup system that has five 8 TB spinning disks. There's an average of 8 MBps of writes scattered around the disks, which isn't super high, obviously. The results were vaguely acceptable until I created a snapshot of it, at which point it became completely unusable. Even having one snapshot present caused hundreds of btrfs-related kernel threads to thrash in the "D" state almost constantly, and it never stopped doing that even when left for many hours. I then experimented with adding a bcache layer on top of Btrfs to see if it would help. I added a 2 TB SSD using bcache, partitioned as 1900 GB read cache and 100 GB write cache. It made very little difference and was still unusable as soon as a snapshot was taken. I did play with the various btrfs and bcache tuning knobs quite a bit and couldn't improve it. Since that test was a failure, I then decided to try the same setup with OpenZFS on a lark, with the same set of disks in a "raidz" array, with the 2 TB SSD as an l2arc read cache (no write cache). It easily handles the same load, even with 72 hourly snapshots present, with the default settings. I'm actually quite impressed with it. I'm sure that the RAID, snapshots and copy-on-write reduce the maximum performance considerably, compared to ext4. But on the other hand, it did provide the performance I expected to be possible given the setup. Btrfs *definitely* didn't; I was surprised at how badly it performed. -- Robert L Mathews, Tiger Technologies, http://www.tigertech.net/
On 10/25/21 1:40 PM, Mladen Gogala wrote:
> This is probably not the place
> to discuss the inner workings of snapshots, but it is worth knowing that
> snapshots drastically increase the IO rate on the file system - for
> every snapshot. That's where the slowness comes from.
I have recent anecdotal experience of this. I experiment with using
Btrfs for a 32 TB backup system that has five 8 TB spinning disks.
There's an average of 8 MBps of writes scattered around the disks, which
isn't super high, obviously.
The results were vaguely acceptable until I created a snapshot of it, at
which point it became completely unusable. Even having one snapshot
present caused hundreds of btrfs-related kernel threads to thrash in the
"D" state almost constantly, and it never stopped doing that even when
left for many hours.
I then experimented with adding a bcache layer on top of Btrfs to see if
it would help. I added a 2 TB SSD using bcache, partitioned as 1900 GB
read cache and 100 GB write cache. It made very little difference and
was still unusable as soon as a snapshot was taken.
I did play with the various btrfs and bcache tuning knobs quite a bit
and couldn't improve it.
Since that test was a failure, I then decided to try the same setup with
OpenZFS on a lark, with the same set of disks in a "raidz" array, with
the 2 TB SSD as an l2arc read cache (no write cache). It easily handles
the same load, even with 72 hourly snapshots present, with the default
settings. I'm actually quite impressed with it.
I'm sure that the RAID, snapshots and copy-on-write reduce the maximum
performance considerably, compared to ext4. But on the other hand, it
did provide the performance I expected to be possible given the setup.
Btrfs *definitely* didn't; I was surprised at how badly it performed.
--
Robert L Mathews, Tiger Technologies, http://www.tigertech.net/
In my opinion, ext4 will solve any and all problems without a very deep understanding of file system architecture. In short, i would stick with ext4 unless you have a good reason not to. Maybe there is one. I have done this a long time and never thought twice about which file system should support my servers.On Mon, Oct 25, 2021, 6:01 PM Robert L Mathews <lists@tigertech.com> wrote:On 10/25/21 1:40 PM, Mladen Gogala wrote:
> This is probably not the place
> to discuss the inner workings of snapshots, but it is worth knowing that
> snapshots drastically increase the IO rate on the file system - for
> every snapshot. That's where the slowness comes from.
I have recent anecdotal experience of this. I experiment with using
Btrfs for a 32 TB backup system that has five 8 TB spinning disks.
There's an average of 8 MBps of writes scattered around the disks, which
isn't super high, obviously.
The results were vaguely acceptable until I created a snapshot of it, at
which point it became completely unusable. Even having one snapshot
present caused hundreds of btrfs-related kernel threads to thrash in the
"D" state almost constantly, and it never stopped doing that even when
left for many hours.
I then experimented with adding a bcache layer on top of Btrfs to see if
it would help. I added a 2 TB SSD using bcache, partitioned as 1900 GB
read cache and 100 GB write cache. It made very little difference and
was still unusable as soon as a snapshot was taken.
I did play with the various btrfs and bcache tuning knobs quite a bit
and couldn't improve it.
Since that test was a failure, I then decided to try the same setup with
OpenZFS on a lark, with the same set of disks in a "raidz" array, with
the 2 TB SSD as an l2arc read cache (no write cache). It easily handles
the same load, even with 72 hourly snapshots present, with the default
settings. I'm actually quite impressed with it.
I'm sure that the RAID, snapshots and copy-on-write reduce the maximum
performance considerably, compared to ext4. But on the other hand, it
did provide the performance I expected to be possible given the setup.
Btrfs *definitely* didn't; I was surprised at how badly it performed.
--
Robert L Mathews, Tiger Technologies, http://www.tigertech.net/
Sent with ProtonMail Secure Email. ‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ On Tuesday, October 26th, 2021 at 01:18, Benedict Holland <benedict.m.holland@gmail.com> wrote: > In my opinion, ext4 will solve any and all problems without a very deep understanding of file system architecture. In short,i would stick with ext4 unless you have a good reason not to. Maybe there is one. I have done this a long time andnever thought twice about which file system should support my servers. > Curious, when it comes to "traditional" filesystems, why ext4 and not xfs ? AFAIK the legacy issues associated with xfs arelong gone ?
On 10/26/2021 2:35 AM, Laura Smith wrote: > Sent with ProtonMail Secure Email. > > ‐‐‐‐‐‐‐ Original Message ‐‐‐‐‐‐‐ > > On Tuesday, October 26th, 2021 at 01:18, Benedict Holland <benedict.m.holland@gmail.com> wrote: > >> In my opinion, ext4 will solve any and all problems without a very deep understanding of file system architecture. Inshort, i would stick with ext4 unless you have a good reason not to. Maybe there is one. I have done this a long time andnever thought twice about which file system should support my servers. >> > > Curious, when it comes to "traditional" filesystems, why ext4 and not xfs ? AFAIK the legacy issues associated with xfsare long gone ? > > > XFS is indeed for me the most stable and performant for postgresql today. EXT4 was good too, but less performant. -- E-BLOKOS
On Mon, Oct 25, 2021 at 07:53:02PM +0200, Chris Travers wrote: > On the whole ZFS on spinning disks is going to have some performance... rough > corners..... And it is a lot harder to reason about a lot of things including > capacity and performance when you are doing copy on write on both the db and FS > level, and have compression in the picture. And there are other areas of > complexity, such as how you handle partial page writes. > > On the whole I think for small dbs it might perform well enough. On large or > high velocity dbs I think you will have more problems than expected. > > Having worked with PostgreSQL on ZFS I wouldn't generally recommend it as a > general tool. I know ZFS has a lot of features/options, and some of those can cause corruption, so if you modify ZFS options, you need to be sure they don't affect Postgres reliability. -- Bruce Momjian <bruce@momjian.us> https://momjian.us EDB https://enterprisedb.com If only the physical world exists, free will is an illusion.
On 27/10/2021, at 8:35 AM, Stephen Frost <sfrost@snowman.net> wrote:Greetings,
* Lucas (root@sud0.nz) wrote:On 26/10/2021, at 6:13 AM, Stephen Frost <sfrost@snowman.net> wrote:* Mladen Gogala (gogala.mladen@gmail.com) wrote:On 10/23/21 23:12, Lucas wrote:This has proven to work very well for me. I had to restore a few backups
already and it always worked. The bad part is that I need to stop the
database before performing the Snapshot, for data integrity, so that means
that I have a hot-standby server only for these snapshots.
Lucas
Actually, you don't need to stop the database. You need to execute
pg_start_backup() before taking a snapshot and then pg_stop_backup() when
the snapshot is done. You will need to recover the database when you finish
the restore but you will not lose any data. I know that pg_begin_backup()
and pg_stop_backup() are deprecated but since PostgreSQL doesn't have any
API for storage or file system snapshots, that's the only thing that can
help you use storage snapshots as backups. To my knowledge,the only database
that does have API for storage snapshots is DB2. The API is called "Advanced
Copy Services" or ACS. It's documented here:
https://www.ibm.com/docs/en/db2/11.1?topic=recovery-db2-advanced-copy-services-acs
For Postgres, the old begin/stop backup functions should be sufficient.
No, it's not- you must also be sure to archive any WAL that's generated
between the pg_start_backup and pg_stop_backup and then to be sure and
add into the snapshot the appropriate signal files or recovery.conf,
depending on PG version, to indicate that you're restoring from a backup
and make sure that the WAL is made available via restore_command.
Just doing stat/stop backup is *not* enough and you run the risk of
having an invalid backup or corruption when you restore.
If the entire system is on a single volume then you could possibly just
take a snapshot of it (without any start/stop backup stuff) but it's
very risky to do that and then try to do PITR with it because we don't
know where consistency is reached in such a case (we *must* play all the
way through to the end of the WAL which existed at the time of the
snapshot in order to reach consistency).
In the end though, really, it's much, much, much better to use a proper
backup and archiving tool that's written specifically for PG than to try
and roll your own, using snapshots or not.
When I create a snapshot, the script gets the latest WAL file applied from [1] and adds that information to the Snapshot Tags in AWS. I then use that information in the future when restoring the snapshot. The script will read the tag and it will download 50 WAL Files before that and all the WAL files after that required.
The WAL files are being backed up to S3.
I had to restore the database to a PITR state many times, and it always worked very well.
I also create slaves using the snapshot method. So, I don’t mind having to stop/start the Database for the snapshot process, as it’s proven to work fine for the last 5 years.
I have to say that the process used here isn't terribly clear to me (you
cleanly shut down the database ... and also copy the WAL files?), so I
don't really want to comment on if it's actually correct or not because
I can't say one way or the other if it is or isn't.
I do want to again stress that I don't recommend writing your own tools
for doing backup/restore/PITR and I would caution people against people
trying to use this approach you've suggested. Also, being able to tell
when such a process *doesn't* work is non-trivial (look at how long it
took us to discover the issues around fsync..), so saying that it seems
to have worked for a long time for you isn't really enough to make me
feel comfortable with it.
Thanks,
Stephen
On 10/26/21 05:35, Laura Smith wrote: > Curious, when it comes to "traditional" filesystems, why ext4 and not xfs ? AFAIK the legacy issues associated with xfsare long gone ? XFS is not being very actively developed any more. Ext4 is being actively developed and it has some features to help with SSD space allocation. Phoronix has some very useful benchmarks: https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.14-File-Systems Ext4 is much better than XFS with SQLite tests and almost equal with MariaDB test. PostgreSQL is a relational database (let's forget the object part for now) and the IO patterns will be similar to SQLite and MariaDB. That benchmark is brand new, done on the kernel 5.14. Of course, the only guarantee is doing your own benchmark, with your own application. -- Mladen Gogala Database Consultant Tel: (347) 321-1217 https://dbwhisperer.wordpress.com
On 10/26/2021 4:42 PM, Mladen Gogala wrote: > > On 10/26/21 05:35, Laura Smith wrote: >> Curious, when it comes to "traditional" filesystems, why ext4 and not >> xfs ? AFAIK the legacy issues associated with xfs are long gone ? > > XFS is not being very actively developed any more. Ext4 is being > actively developed and it has some features to help with SSD space > allocation. Phoronix has some very useful benchmarks: > > https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.14-File-Systems > > > Ext4 is much better than XFS with SQLite tests and almost equal with > MariaDB test. PostgreSQL is a relational database (let's forget the > object part for now) and the IO patterns will be similar to SQLite and > MariaDB. That benchmark is brand new, done on the kernel 5.14. Of > course, the only guarantee is doing your own benchmark, with your own > application. > RedHat and Oracle are mostly maintaining XFS updates, and I didn't see anything saying it's not mainained actively, especially when they offering many solutions with XFS as default -- E-BLOKOS
On 10/26/21 20:12, E-BLOKOS wrote: > RedHat and Oracle are mostly maintaining XFS updates, and I didn't see > anything saying it's not mainained actively, > especially when they offering many solutions with XFS as default Oh, they are maintaining it, all right, but they're not developing it. XFS is still the file system for rotational disks with plates, reading heads, tracks and sectors, the type we were taught about in school. Allocation policy for SSD devices is completely different as are physical characteristics. Ext4 is being adjusted to ever more popular NVME devices. XFS is not. In the long run, my money is on Ext4 or its successors. Here is another useful benchmark: https://www.percona.com/blog/2012/03/15/ext4-vs-xfs-on-ssd/ This one is a bit old, but it shows clear advantage for Ext4 in async mode. I maybe wrong. Neither of the two file systems has gained any new features since 2012. The future may lay in F2FS ("Flash Friendly File System") which is very new but has a ton of optimizations for SSD devices. Personally, I usually use XFS for my databases but I am testing Ext4 with Oracle 21c on Fedora. So far, I don't have any results to report. The difference is imperceptible. I am primarily an Oracle DBA and I am testing with Oracle. That doesn't necessarily have to be pertinent for Postgres. -- Mladen Gogala Database Consultant Tel: (347) 321-1217 https://dbwhisperer.wordpress.com
> Ext4 is much better than XFS with SQLite tests and almost equal with
> MariaDB test. PostgreSQL is a relational database (let's forget the
> object part for now) and the IO patterns will be similar to SQLite and
> MariaDB.
there is a link from the Phoronix page to the full OpenBenchmarking.org result file
On 10/26/21 05:35, Laura Smith wrote:
> Curious, when it comes to "traditional" filesystems, why ext4 and not xfs ? AFAIK the legacy issues associated with xfs are long gone ?
XFS is not being very actively developed any more. Ext4 is being
actively developed and it has some features to help with SSD space
allocation. Phoronix has some very useful benchmarks:
https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.14-File-Systems
Ext4 is much better than XFS with SQLite tests and almost equal with
MariaDB test. PostgreSQL is a relational database (let's forget the
object part for now) and the IO patterns will be similar to SQLite and
MariaDB. That benchmark is brand new, done on the kernel 5.14. Of
course, the only guarantee is doing your own benchmark, with your own
application.
--
Mladen Gogala
Database Consultant
Tel: (347) 321-1217
https://dbwhisperer.wordpress.com
> Phoronix has some very useful benchmarks:> https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.14-File-Systems
> Ext4 is much better than XFS with SQLite tests and almost equal with
> MariaDB test. PostgreSQL is a relational database (let's forget the
> object part for now) and the IO patterns will be similar to SQLite and
> MariaDB.
there is a link from the Phoronix page to the full OpenBenchmarking.org result fileand multiple PostgreSQL 13 pgbench results included: https://openbenchmarking.org/result/2108260-PTS-SSDS978300&sor&ppt=D&oss=postgres( XFS, F2FS, EXT4, BTRFS )Regards,Imre
Wow! That is really interesting. Here is the gist of it:
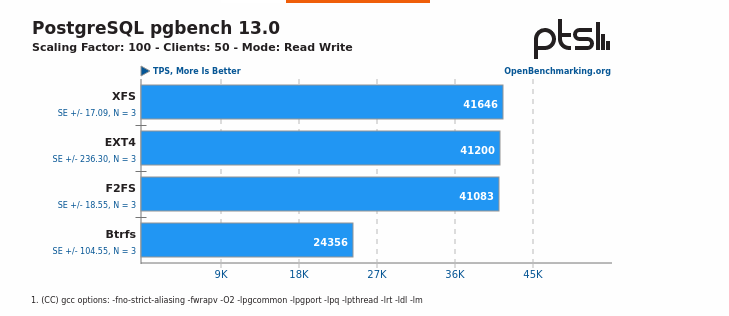
XFS is the clear winner. It also answers the question about BTRFS. Thanks Imre!
-- Mladen Gogala Database Consultant Tel: (347) 321-1217 https://dbwhisperer.wordpress.com
Attachment
On 10/26/21 20:50, Imre Samu wrote:> Phoronix has some very useful benchmarks:> https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.14-File-Systems
> Ext4 is much better than XFS with SQLite tests and almost equal with
> MariaDB test. PostgreSQL is a relational database (let's forget the
> object part for now) and the IO patterns will be similar to SQLite and
> MariaDB.
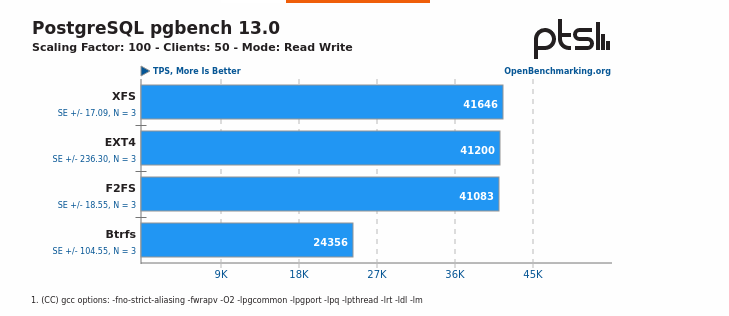
there is a link from the Phoronix page to the full OpenBenchmarking.org result fileand multiple PostgreSQL 13 pgbench results included: https://openbenchmarking.org/result/2108260-PTS-SSDS978300&sor&ppt=D&oss=postgres( XFS, F2FS, EXT4, BTRFS )Regards,ImreWow! That is really interesting. Here is the gist of it:
XFS is the clear winner. It also answers the question about BTRFS. Thanks Imre!
-- Mladen Gogala Database Consultant Tel: (347) 321-1217 https://dbwhisperer.wordpress.com
Attachment
On 10/26/21 20:50, Imre Samu wrote:> Phoronix has some very useful benchmarks:> https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.14-File-Systems
> Ext4 is much better than XFS with SQLite tests and almost equal with
> MariaDB test. PostgreSQL is a relational database (let's forget the
> object part for now) and the IO patterns will be similar to SQLite and
> MariaDB.
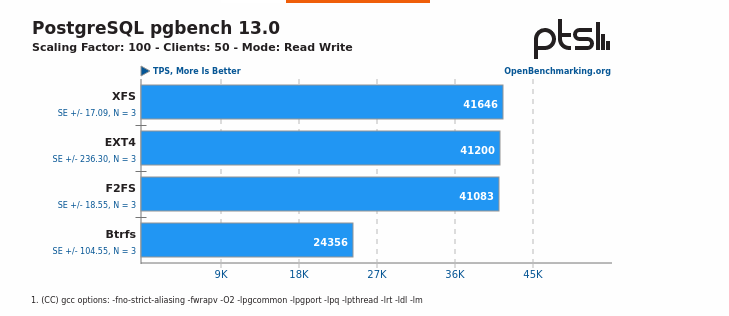
there is a link from the Phoronix page to the full OpenBenchmarking.org result fileand multiple PostgreSQL 13 pgbench results included: https://openbenchmarking.org/result/2108260-PTS-SSDS978300&sor&ppt=D&oss=postgres( XFS, F2FS, EXT4, BTRFS )Regards,ImreWow! That is really interesting. Here is the gist of it:
XFS is the clear winner. It also answers the question about BTRFS. Thanks Imre!
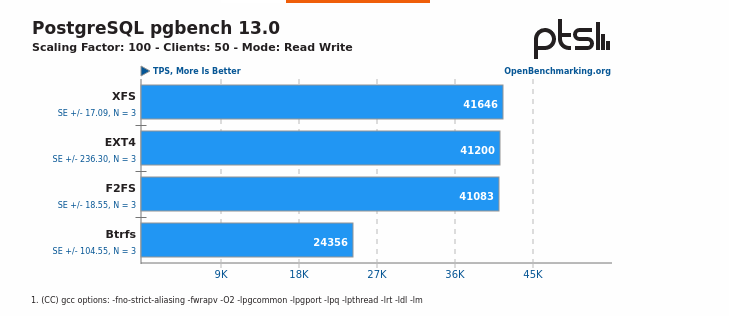{kind=link}
{kind=link}
XFS is 1.08% faster than ext4. That's very close to being statistical noise.
Angular momentum makes the world go 'round.
Attachment
On 11/1/21 12:00 PM, Stephen Frost wrote: [snip] > Having the database offline for 10 minutes is a luxury that many don't > have; I'm a bit surprised that it's not an issue here, but if it isn't, > then that's great. Exactly. Shutting down the database is easy... shutting down the "application" can be tricky, multi-step, and involve lots of pointing and clicking. -- Angular momentum makes the world go 'round.
On 2/11/2021, at 6:00 AM, Stephen Frost <sfrost@snowman.net> wrote:Greetings,
* Lucas (root@sud0.nz) wrote:On 27/10/2021, at 8:35 AM, Stephen Frost <sfrost@snowman.net> wrote:
I do want to again stress that I don't recommend writing your own tools
for doing backup/restore/PITR and I would caution people against people
trying to use this approach you've suggested. Also, being able to tell
when such a process *doesn't* work is non-trivial (look at how long it
took us to discover the issues around fsync..), so saying that it seems
to have worked for a long time for you isn't really enough to make me
feel comfortable with it.
I think it is worth mentioning that we’re using PG 9.2, so I don’t benefit from features like logical replication to help with backups and such.
(Yes, I know it’s old and that I should upgrade ASAP. We’re working on it)
You'll certainly want to upgrade, of course. That said, logical
replication isn't for backups, so not sure how that's relevant here.
The snapshots are done this way:
1. Grab the latest applied WAL File for further references, stores that in a variable in Bash
2. Stop the Postgres process
How is PostgreSQL stopped here..?
3. Check it is stopped
4. Start the Block level EBS Snapshot process
5. Applied tags to the snapshot, such as the WAL file from Step #1
6. Wait for snapshot to complete, querying the AWS API for that
7. Start PG
8. Check it is started
9. Check it is replicating from master
This doesn't explain how the snapshot is restored. That's a huge part
of making sure that any process is implemented properly.
The entire process takes around 10 minutes to complete.
Having the database offline for 10 minutes is a luxury that many don't
have; I'm a bit surprised that it's not an issue here, but if it isn't,
then that's great.
As noted down-thread though, if you stop PostgreSQL cleanly in step #2
(that is, either 'fast' or 'smart' shutdown modes are used) then you
don't need to do anything else, a 'shutdown' checkpoint will have been
written into the WAL that is included in the snapshot and everything
should be good. Note that this presumes that the snapshot above
includes the entire PG data directory, all tablespaces, and the WAL. If
that's not the case then more discussion would be needed.I copy the WAL files to S3 in case I ever need to restore an old snapshot (we keep snapshots for 30 days), which won’t have the WAL files in the volume itself. Also for safety reasons, after reading this <https://about.gitlab.com/blog/2017/02/10/postmortem-of-database-outage-of-january-31/> article many many times.
If the database has been cleanly shut down and the pg_wal (pg_xlog)
directory of the running database is included in that snapshot then you
don't need any other WAL in order to be able to restore an individual
snapshot. If you want to be able to perform PITR
(Point-In-Time-Recovery, which you can play forward through the WAL to
any point in time that you want to restore to without having to pick one
of the snapshots) then you would want to archive *all* of your WAL using
archive_command and a tool like pgbackrest.We’re working on a migration to PG 14 so, please, feel free to suggest another best way to achieve this, but it would be better in a new thread I reckon.
It isn't terribly clear what you're actually looking for in terms of
capability and so it's kind of hard to suggest something to "achieve
this". Having snapshots taken while the database is down and then
talking about copying WAL files to s3 to restore those snapshots doesn't
strike me as making much sense though and I'd worry about other
misunderstandings around how PG writes data and how WAL is handled and
how to properly perform PG backups (online and offline) and restores.
I'm afraid that this is a quite complicated area and reading blog posts
about database outage postmortems (or even our own documentation,
frankly) is rarely enough to be able to become an expert in writing
tools for that purpose.
Thanks,
Stephen
- / = for the root volume
- /pgsql = for the PG Data directory (i.e. /pgsql/9.2/main)
- 2TB EBS gp3 volume with 8000 IOPS and 440 MB/s of throughput
- /data = for WAL files and PostgreSQL Logs
- The /pgsql/9.2/main/pg_xlog folder is located in /data/wal_files - There is a symlink.
- PG is writing logs to /data/postgresql/logs - instead of /var/log/postgres
- On the 5th slave, we take note of the last applied WAL File
- We stop PG with systemctl stop postgresql
- We create the snapshot using awscli
- We add custom tags to the snapshot, such as the WAL file from Step 1
- We wait until the snapshot is completed, querying the AWS api
- Once the snapshot is completed, we start postgres with systemctl start postgresql
- Our script checks if PG is actually started, by running some queries. Otherwise we get pinged on Slack and PagerDuty.
- We modify our CloudFormation templates with some relevant information, like for example: Stack name, EC2 Instance name, EC2 instance type, etc.
- We launch the new CloudFormation stack - it will search for the latest snapshot using tags, and then it will remember the WAL file tag for later
- CFN creates the new stack, there is a lot involved here, but basically it will:
- Searches the latest snapshot created by the slave
- Create the instance and its volumes
- Gets the WAL file Snapshot tag, searches it in S3 and downloads 50 WAL files prior and all after
- Once all WAL files have been downloaded, it will modify the recovery.conf with relevant information
- Starts PG
- At this point, we have a new PG slave applying WAL Files to catch-up with master and it will essentially stream replicate from Master automatically, once the recovery of WAL files have been completed.
- Then, we have a script that will notify us when the server is ready. The server will automatically register with our Zabbix server and New Relic, for monitoring.
On 2/11/2021, at 10:58 AM, Stephen Frost <sfrost@snowman.net> wrote:
Well, at least one alternative to performing these snapshots would be to
use a tool like pg_basebackup or pgbackrest to perform the backups
instead. At least with pgbackrest you can run a backup which pushes the
data directly to s3 for storage (rather than having to use EBS volumes
and snapshots..) and it can back up the stats and such from the primary, and
then use a replica to grab the rest to avoid putting load on the
primary's I/O. All of this without any of the PG systems involved
having to be shut down, and it can handle doing the restores and writing
the recovery.conf or creating the appropriate signal files for you,
depending on the version of PG that you're running on (in other words,
pgbackrest handles those version differences for you).
Thanks,
Stephen
On 11/1/21 17:58, Stephen Frost wrote: > Well, at least one alternative to performing these snapshots would be to > use a tool like pg_basebackup or pgbackrest to perform the backups > instead. File system based backups are much slower than snapshots. The feasibility of file based utility like pg_basebackup depends on the size of the database and the quality of the infrastructure. However, if opting for snapshot based solutions, I would advise something like Pure or NetApp which use special hardware to accelerate the process and have tools to backup snapshots, like SnapVault (NetApp). Also, when using file level utilities, I would go full commercial. Commercial backup utilities are usually optimized for speed, support deduplication and maintain backup catalog, which can come handy if there are regulatory requirements about preserving your backups (HIPPA, SOX) -- Mladen Gogala Database Consultant Tel: (347) 321-1217 https://dbwhisperer.wordpress.com
On 11/1/21 17:58, Stephen Frost wrote:
> Well, at least one alternative to performing these snapshots would be to
> use a tool like pg_basebackup or pgbackrest to perform the backups
> instead.
File system based backups are much slower than snapshots. The
feasibility of file based utility like pg_basebackup depends on the size
of the database and the quality of the infrastructure. However, if
opting for snapshot based solutions, I would advise something like Pure
or NetApp which use special hardware to accelerate the process and have
tools to backup snapshots, like SnapVault (NetApp).
Also, when using file level utilities, I would go full commercial.
Commercial backup utilities are usually optimized for speed, support
deduplication and maintain backup catalog, which can come handy if there
are regulatory requirements about preserving your backups (HIPPA, SOX)
--
Mladen Gogala
Database Consultant
Tel: (347) 321-1217
https://dbwhisperer.wordpress.com