Thread: Linear slow-down while inserting into a table with an ON INSERT trigger ?
Hi,
Probably my google-foo is weak today but I couldn't find any (convincing) explanation for this.
I'm running PostgreSQL 12.6 on 64-bit Linux (CentOS 7, PostgreSQL compiled from sources) and I'm trying to insert 30k rows into a simple table that has an "ON INSERT .. FOR EACH STATEMENT" trigger.
Table "public.parent_table"
Column | Type | Collation | Nullable | Default
-------------+------------------------+-----------+----------+-------------------------------------------- id | bigint | | not null | nextval('parent_table_id_seq'::regclass) name | character varying(64) | | not null |
enabled | boolean | | not null |
description | character varying(255) | | |
deleted | boolean | | not null | false is_default | boolean | | not null | false Indexes: "parent_pkey" PRIMARY KEY, btree (id) "uniq_name" UNIQUE, btree (name) WHERE deleted = false
Referenced by: TABLE "child" CONSTRAINT "child_fkey" FOREIGN KEY (parent_id) REFERENCES parent_table(id) ON DELETE CASCADE
Triggers: parent_changed BEFORE INSERT OR DELETE OR UPDATE OR TRUNCATE ON parent_table FOR EACH STATEMENT EXECUTE FUNCTION parent_table_changed();This is the trigger function
CREATE OR REPLACE FUNCTION parent_table_changed() RETURNS trigger LANGUAGE plpgsql AS $function$ BEGIN UPDATE data_sync SET last_parent_table_change=CURRENT_TIMESTAMP; RETURN NEW; END; $function$
I'm trying to insert 30k rows (inside a single transaction) into the parent table using the following SQL (note that I came across this issue while debugging an application-level performance problem and the SQL I'm using here is similar to what the application is generating):
BEGIN; -- ALTER TABLE public.parent_table DISABLE TRIGGER parent_changed; PREPARE my_insert (varchar(64), boolean, varchar(255), boolean, boolean) AS INSERT INTO public.parent_table (name,enabled,description,deleted,is_default) VALUES($1, $2, $3, $4, $5); EXECUTE my_insert ($$035001$$, true, $$null$$, false, false); EXECUTE my_insert ($$035002$$, true, $$null$$, false, false); ....29998 more lines
This is the execution time I get when running the script while the trigger is enabled:
~/tmp$ time psql -q -Upostgres -h dbhost -f inserts.sql test_db
real 0m8,381s user 0m0,203s sys 0m0,287s
Running the same SQL script with trigger disabled shows a ~4x speed-up:
~/tmp$ time psql -q -Upostgres -h dbhost -f inserts.sql test_db real 0m2,284s user 0m0,171s sys 0m0,261s
Defining the trigger as "BEFORE INSERT" or "AFTER INSERT" made no difference.
I then got curious , put a "/timing" at the start of the SQL script, massaged the psql output a bit and plotted a chart of the statement execution times.
To my surprise, I see a linear increase of the per-INSERT execution times, roughly 4x as well:

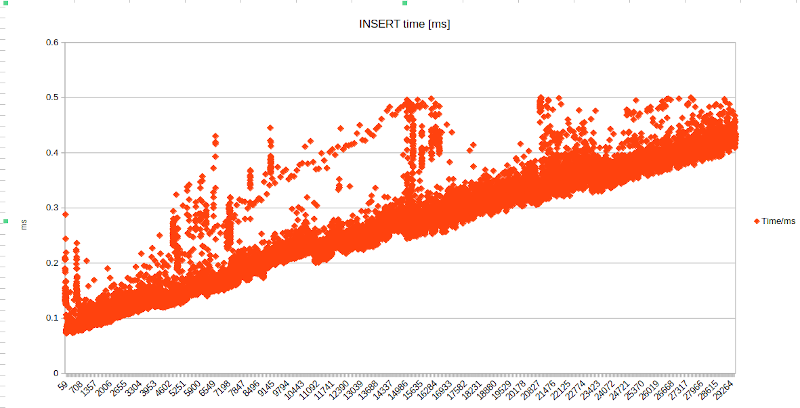
While the execution time per INSERT remains constant when disabling the trigger before inserting the data:
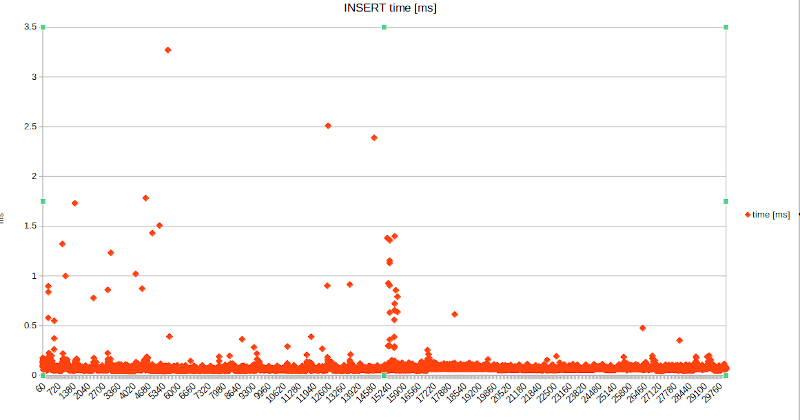
What's causing this slow-down ?
Thanks,
Tobias
Attachment
Re: Linear slow-down while inserting into a table with an ON INSERT trigger ?
On Fri, Jul 16, 2021 at 11:27:24PM +0200, Tobias Gierke wrote:
> CREATE OR REPLACE FUNCTION parent_table_changed() RETURNS trigger LANGUAGE plpgsql
> AS $function$
> BEGIN
> UPDATE data_sync SET last_parent_table_change=CURRENT_TIMESTAMP;
> RETURN NEW;
> END;
> $function$
>
> I'm trying to insert 30k rows (inside a single transaction) into the parent
The problem is because you're doing 30k updates of data_sync within a txn.
Ideally it starts with 1 tuple in 1 page but every row updated requires
scanning the previous N rows, which haven't been vacuumed (and cannot).
Update is essentially delete+insert, and the table will grow with each update
until the txn ends and it's vacuumed.
pages: 176 removed, 1 remain, 0 skipped due to pins, 0 skipped frozen
tuples: 40000 removed, 1 remain, 0 are dead but not yet removable, oldest xmin: 2027
You could run a single UPDATE rather than 30k triggers.
Or switch to an INSERT on the table, with an index on it, and call
max(last_parent_table_change) from whatever needs to ingest it. And prune the
old entries and vacuum it outside the transaction. Maybe someone else will
have a better suggestion.
--
Justin
Re: Linear slow-down while inserting into a table with an ON INSERT trigger ?
Hi,
Probably my google-foo is weak today but I couldn't find any (convincing) explanation for this.
I'm running PostgreSQL 12.6 on 64-bit Linux (CentOS 7, PostgreSQL compiled from sources) and I'm trying to insert 30k rows into a simple table that has an "ON INSERT .. FOR EACH STATEMENT" trigger.
Table "public.parent_table"Column | Type | Collation | Nullable | Default -------------+------------------------+-----------+----------+-------------------------------------------- id | bigint | | not null | nextval('parent_table_id_seq'::regclass) name | character varying(64) | | not null | enabled | boolean | | not null | description | character varying(255) | | | deleted | boolean | | not null | false is_default | boolean | | not null | falseIndexes: "parent_pkey" PRIMARY KEY, btree (id) "uniq_name" UNIQUE, btree (name) WHERE deleted = falseReferenced by: TABLE "child" CONSTRAINT "child_fkey" FOREIGN KEY (parent_id) REFERENCES parent_table(id) ON DELETE CASCADETriggers: parent_changed BEFORE INSERT OR DELETE OR UPDATE OR TRUNCATE ON parent_table FOR EACH STATEMENT EXECUTE FUNCTION parent_table_changed();This is the trigger functionCREATE OR REPLACE FUNCTION parent_table_changed() RETURNS trigger LANGUAGE plpgsql AS $function$ BEGIN UPDATE data_sync SET last_parent_table_change=CURRENT_TIMESTAMP; RETURN NEW; END; $function$
I'm trying to insert 30k rows (inside a single transaction) into the parent table using the following SQL (note that I came across this issue while debugging an application-level performance problem and the SQL I'm using here is similar to what the application is generating):BEGIN; -- ALTER TABLE public.parent_table DISABLE TRIGGER parent_changed; PREPARE my_insert (varchar(64), boolean, varchar(255), boolean, boolean) AS INSERT INTO public.parent_table (name,enabled,description,deleted,is_default) VALUES($1, $2, $3, $4, $5); EXECUTE my_insert ($$035001$$, true, $$null$$, false, false); EXECUTE my_insert ($$035002$$, true, $$null$$, false, false); ....29998 more lines
This is the execution time I get when running the script while the trigger is enabled:~/tmp$ time psql -q -Upostgres -h dbhost -f inserts.sql test_dbreal 0m8,381s user 0m0,203s sys 0m0,287s
Running the same SQL script with trigger disabled shows a ~4x speed-up:
~/tmp$ time psql -q -Upostgres -h dbhost -f inserts.sql test_db real 0m2,284s user 0m0,171s sys 0m0,261s
Defining the trigger as "BEFORE INSERT" or "AFTER INSERT" made no difference.
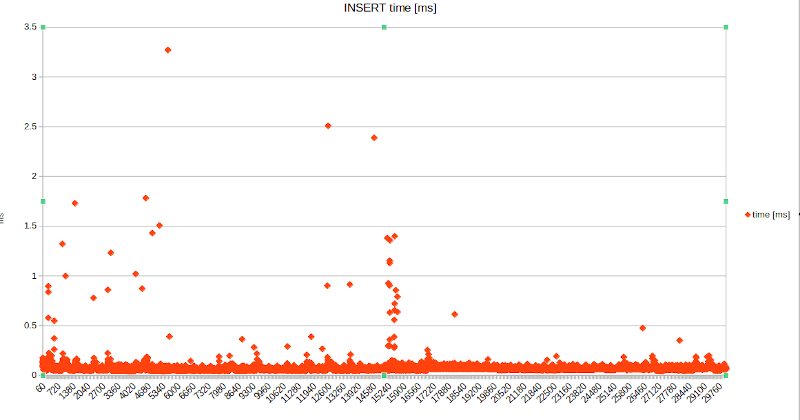
I then got curious , put a "/timing" at the start of the SQL script, massaged the psql output a bit and plotted a chart of the statement execution times.
To my surprise, I see a linear increase of the per-INSERT execution times, roughly 4x as well:
While the execution time per INSERT remains constant when disabling the trigger before inserting the data:
What's causing this slow-down ?
Thanks,
Tobias
Attachment
Re: Linear slow-down while inserting into a table with an ON INSERT trigger ?
On Sat, 17 Jul 2021 at 16:40, Justin Pryzby <pryzby@telsasoft.com> wrote: > You could run a single UPDATE rather than 30k triggers. > Or switch to an INSERT on the table, with an index on it, and call > max(last_parent_table_change) from whatever needs to ingest it. And prune the > old entries and vacuum it outside the transaction. Maybe someone else will > have a better suggestion. Maybe just change the UPDATE statement to: UPDATE data_sync SET last_parent_table_change=CURRENT_TIMESTAMP WHERE last_parent_table_change <> CURRENT_TIMESTAMP; That should reduce the number of actual updates to 1 per transaction. David
David Rowley <dgrowleyml@gmail.com> writes: > On Sat, 17 Jul 2021 at 16:40, Justin Pryzby <pryzby@telsasoft.com> wrote: >> You could run a single UPDATE rather than 30k triggers. >> Or switch to an INSERT on the table, with an index on it, and call >> max(last_parent_table_change) from whatever needs to ingest it. And prune the >> old entries and vacuum it outside the transaction. Maybe someone else will >> have a better suggestion. > Maybe just change the UPDATE statement to: > UPDATE data_sync SET last_parent_table_change=CURRENT_TIMESTAMP WHERE > last_parent_table_change <> CURRENT_TIMESTAMP; > That should reduce the number of actual updates to 1 per transaction. Or, if it's impractical to make the application do that for itself, this could be a job for suppress_redundant_updates_trigger(). https://www.postgresql.org/docs/current/functions-trigger.html regards, tom lane
Hi,
Probably my google-foo is weak today but I couldn't find any (convincing) explanation for this.
I'm running PostgreSQL 12.6 on 64-bit Linux (CentOS 7, PostgreSQL compiled from sources) and I'm trying to insert 30k rows into a simple table that has an "ON INSERT .. FOR EACH STATEMENT" trigger.
Table "public.parent_table"Column | Type | Collation | Nullable | Default -------------+------------------------+-----------+----------+-------------------------------------------- id | bigint | | not null | nextval('parent_table_id_seq'::regclass) name | character varying(64) | | not null | enabled | boolean | | not null | description | character varying(255) | | | deleted | boolean | | not null | false is_default | boolean | | not null | falseIndexes: "parent_pkey" PRIMARY KEY, btree (id) "uniq_name" UNIQUE, btree (name) WHERE deleted = falseReferenced by: TABLE "child" CONSTRAINT "child_fkey" FOREIGN KEY (parent_id) REFERENCES parent_table(id) ON DELETE CASCADETriggers: parent_changed BEFORE INSERT OR DELETE OR UPDATE OR TRUNCATE ON parent_table FOR EACH STATEMENT EXECUTE FUNCTION parent_table_changed();This is the trigger functionCREATE OR REPLACE FUNCTION parent_table_changed() RETURNS trigger LANGUAGE plpgsql AS $function$ BEGIN UPDATE data_sync SET last_parent_table_change=CURRENT_TIMESTAMP; RETURN NEW; END; $function$
I'm trying to insert 30k rows (inside a single transaction) into the parent table using the following SQL (note that I came across this issue while debugging an application-level performance problem and the SQL I'm using here is similar to what the application is generating):BEGIN; -- ALTER TABLE public.parent_table DISABLE TRIGGER parent_changed; PREPARE my_insert (varchar(64), boolean, varchar(255), boolean, boolean) AS INSERT INTO public.parent_table (name,enabled,description,deleted,is_default) VALUES($1, $2, $3, $4, $5); EXECUTE my_insert ($$035001$$, true, $$null$$, false, false); EXECUTE my_insert ($$035002$$, true, $$null$$, false, false); ....29998 more lines
This is the execution time I get when running the script while the trigger is enabled:~/tmp$ time psql -q -Upostgres -h dbhost -f inserts.sql test_dbreal 0m8,381s user 0m0,203s sys 0m0,287s
Running the same SQL script with trigger disabled shows a ~4x speed-up:
~/tmp$ time psql -q -Upostgres -h dbhost -f inserts.sql test_db real 0m2,284s user 0m0,171s sys 0m0,261s
Defining the trigger as "BEFORE INSERT" or "AFTER INSERT" made no difference.
I then got curious , put a "/timing" at the start of the SQL script, massaged the psql output a bit and plotted a chart of the statement execution times.
To my surprise, I see a linear increase of the per-INSERT execution times, roughly 4x as well:
While the execution time per INSERT remains constant when disabling the trigger before inserting the data:
What's causing this slow-down ?
Thanks,
Tobias


Attachment
Re: Linear slow-down while inserting into a table with an ON INSERT trigger ?
How much does the function-ed UPDATE statement take?
INSERTs into the parent table are taking ~0.1 ms/INSERT at the beginning of the transaction and this increases to ~0.43 ms after 30k INSERTs. Without the trigger, INSERTs into the parent table consistently take around 0.05ms.
Regards,
Tobias
Regards,Ninad ShahOn Sat, 17 Jul 2021 at 02:57, Tobias Gierke <tobias.gierke@code-sourcery.de> wrote:Hi,
Probably my google-foo is weak today but I couldn't find any (convincing) explanation for this.
I'm running PostgreSQL 12.6 on 64-bit Linux (CentOS 7, PostgreSQL compiled from sources) and I'm trying to insert 30k rows into a simple table that has an "ON INSERT .. FOR EACH STATEMENT" trigger.
Table "public.parent_table"Column | Type | Collation | Nullable | Default -------------+------------------------+-----------+----------+-------------------------------------------- id | bigint | | not null | nextval('parent_table_id_seq'::regclass) name | character varying(64) | | not null | enabled | boolean | | not null | description | character varying(255) | | | deleted | boolean | | not null | false is_default | boolean | | not null | falseIndexes: "parent_pkey" PRIMARY KEY, btree (id) "uniq_name" UNIQUE, btree (name) WHERE deleted = falseReferenced by: TABLE "child" CONSTRAINT "child_fkey" FOREIGN KEY (parent_id) REFERENCES parent_table(id) ON DELETE CASCADETriggers: parent_changed BEFORE INSERT OR DELETE OR UPDATE OR TRUNCATE ON parent_table FOR EACH STATEMENT EXECUTE FUNCTION parent_table_changed();This is the trigger functionCREATE OR REPLACE FUNCTION parent_table_changed() RETURNS trigger LANGUAGE plpgsql AS $function$ BEGIN UPDATE data_sync SET last_parent_table_change=CURRENT_TIMESTAMP; RETURN NEW; END; $function$
I'm trying to insert 30k rows (inside a single transaction) into the parent table using the following SQL (note that I came across this issue while debugging an application-level performance problem and the SQL I'm using here is similar to what the application is generating):BEGIN; -- ALTER TABLE public.parent_table DISABLE TRIGGER parent_changed; PREPARE my_insert (varchar(64), boolean, varchar(255), boolean, boolean) AS INSERT INTO public.parent_table (name,enabled,description,deleted,is_default) VALUES($1, $2, $3, $4, $5); EXECUTE my_insert ($$035001$$, true, $$null$$, false, false); EXECUTE my_insert ($$035002$$, true, $$null$$, false, false); ....29998 more lines
This is the execution time I get when running the script while the trigger is enabled:~/tmp$ time psql -q -Upostgres -h dbhost -f inserts.sql test_dbreal 0m8,381s user 0m0,203s sys 0m0,287s
Running the same SQL script with trigger disabled shows a ~4x speed-up:
~/tmp$ time psql -q -Upostgres -h dbhost -f inserts.sql test_db real 0m2,284s user 0m0,171s sys 0m0,261s
Defining the trigger as "BEFORE INSERT" or "AFTER INSERT" made no difference.
I then got curious , put a "/timing" at the start of the SQL script, massaged the psql output a bit and plotted a chart of the statement execution times.
To my surprise, I see a linear increase of the per-INSERT execution times, roughly 4x as well:
While the execution time per INSERT remains constant when disabling the trigger before inserting the data:
What's causing this slow-down ?
Thanks,
Tobias


Attachment
Re: Linear slow-down while inserting into a table with an ON INSERT trigger ?
Great idea ! This brought the time per INSERT into the parent table down to a consistent ~0.065ms again (compared to 0.05ms when completely removing the trigger, so penalty for the trigger is roughly ~20%). > On Sat, 17 Jul 2021 at 16:40, Justin Pryzby <pryzby@telsasoft.com> wrote: >> You could run a single UPDATE rather than 30k triggers. >> Or switch to an INSERT on the table, with an index on it, and call >> max(last_parent_table_change) from whatever needs to ingest it. And prune the >> old entries and vacuum it outside the transaction. Maybe someone else will >> have a better suggestion. > Maybe just change the UPDATE statement to: > > UPDATE data_sync SET last_parent_table_change=CURRENT_TIMESTAMP WHERE > last_parent_table_change <> CURRENT_TIMESTAMP; > > That should reduce the number of actual updates to 1 per transaction. > > David
Re: Linear slow-down while inserting into a table with an ON INSERT trigger ?
Thank you for the detailed explanation ! Just one more question: I've did an experiment and reduced the fillfactor on the table updated by the trigger to 50%, hoping the HOT feature would kick in and each subsequent INSERT would clean up the "HOT chain" of the previous INSERT ... but execution times did not change at all compared to 100% fillfactor, why is this ? Does the HOT feature only work if a different backend accesses the table concurrently ? Thanks, Tobias > On Fri, Jul 16, 2021 at 11:27:24PM +0200, Tobias Gierke wrote: >> CREATE OR REPLACE FUNCTION parent_table_changed() RETURNS trigger LANGUAGE plpgsql >> AS $function$ >> BEGIN >> UPDATE data_sync SET last_parent_table_change=CURRENT_TIMESTAMP; >> RETURN NEW; >> END; >> $function$ >> >> I'm trying to insert 30k rows (inside a single transaction) into the parent > The problem is because you're doing 30k updates of data_sync within a txn. > Ideally it starts with 1 tuple in 1 page but every row updated requires > scanning the previous N rows, which haven't been vacuumed (and cannot). > Update is essentially delete+insert, and the table will grow with each update > until the txn ends and it's vacuumed. > > pages: 176 removed, 1 remain, 0 skipped due to pins, 0 skipped frozen > tuples: 40000 removed, 1 remain, 0 are dead but not yet removable, oldest xmin: 2027 > > You could run a single UPDATE rather than 30k triggers. > Or switch to an INSERT on the table, with an index on it, and call > max(last_parent_table_change) from whatever needs to ingest it. And prune the > old entries and vacuum it outside the transaction. Maybe someone else will > have a better suggestion. >
Re: Linear slow-down while inserting into a table with an ON INSERT trigger ?
On Sun, 2021-07-18 at 09:36 +0200, Tobias Gierke wrote: > Thank you for the detailed explanation ! Just one more question: I've > did an experiment and reduced the fillfactor on the table updated by the > trigger to 50%, hoping the HOT feature would kick in and each > subsequent INSERT would clean up the "HOT chain" of the previous INSERT > ... but execution times did not change at all compared to 100% > fillfactor, why is this ? Does the HOT feature only work if a different > backend accesses the table concurrently ? No, but until the transaction is done, the tuples cannot be removed, no matter if they are HOT or not. Yours, Laurenz Albe -- Cybertec | https://www.cybertec-postgresql.com