Thread: [PATCH] Use optimized single-datum tuplesort in ExecSort
Hello, While testing the patch "Add proper planner support for ORDER BY / DISTINCT aggregates" [0] I discovered the performance penalty from adding a sort node essentially came from not using the single-datum tuplesort optimization in ExecSort (contrary to the sorting done in ExecAgg). I originally proposed this patch as a companion in the same thread [1], but following James suggestion I'm making a separate thread just for this as the optimization is worthwhile independently of David's patch: it looks like we can expect a 2x speedup on a "select a single ordered column" case. The patch aimed to be as simple as possible: we only turn this optimization on when the tuple being sorted has only one attribute, it is "byval" (so as not to incur copies which would be hard to track in the execution tree) and unbound (again, not having to deal with copying borrowed datum anywhere). The attached patch is originally by me, with some cleanup by Ranier Vilela. I'm sending Ranier's version here. [0]: https://commitfest.postgresql.org/33/3164/ [1]: https://www.postgresql.org/message-id/4480689.ObhdGn8bVM%40aivenronan -- Ronan Dunklau
Attachment
Em ter., 6 de jul. de 2021 às 03:15, Ronan Dunklau <ronan.dunklau@aiven.io> escreveu:
Hello,
While testing the patch "Add proper planner support for ORDER BY / DISTINCT
aggregates" [0] I discovered the performance penalty from adding a sort node
essentially came from not using the single-datum tuplesort optimization in
ExecSort (contrary to the sorting done in ExecAgg).
I originally proposed this patch as a companion in the same thread [1], but
following James suggestion I'm making a separate thread just for this as the
optimization is worthwhile independently of David's patch: it looks like we
can expect a 2x speedup on a "select a single ordered column" case.
The patch aimed to be as simple as possible: we only turn this optimization on
when the tuple being sorted has only one attribute, it is "byval" (so as not
to incur copies which would be hard to track in the execution tree) and
unbound (again, not having to deal with copying borrowed datum anywhere).
The attached patch is originally by me, with some cleanup by Ranier Vilela.
I'm sending Ranier's version here.
Nice Ronan.
But I think there is some confusion here.
The author is not you?
The author is not you?
Just to clarify, at Commitfest, it was supposed to be the other way around.
You as an author and David as a reviewer.
You as an author and David as a reviewer.
I'll put myself as a reviewer too.
regards,
Ranier Vilela
Em ter., 6 de jul. de 2021 às 08:25, Ranier Vilela <ranier.vf@gmail.com> escreveu:
Em ter., 6 de jul. de 2021 às 03:15, Ronan Dunklau <ronan.dunklau@aiven.io> escreveu:Hello,
While testing the patch "Add proper planner support for ORDER BY / DISTINCT
aggregates" [0] I discovered the performance penalty from adding a sort node
essentially came from not using the single-datum tuplesort optimization in
ExecSort (contrary to the sorting done in ExecAgg).
I originally proposed this patch as a companion in the same thread [1], but
following James suggestion I'm making a separate thread just for this as the
optimization is worthwhile independently of David's patch: it looks like we
can expect a 2x speedup on a "select a single ordered column" case.
The patch aimed to be as simple as possible: we only turn this optimization on
when the tuple being sorted has only one attribute, it is "byval" (so as not
to incur copies which would be hard to track in the execution tree) and
unbound (again, not having to deal with copying borrowed datum anywhere).
The attached patch is originally by me, with some cleanup by Ranier Vilela.
I'm sending Ranier's version here.Nice Ronan.But I think there is some confusion here.
The author is not you?Just to clarify, at Commitfest, it was supposed to be the other way around.
You as an author and David as a reviewer.I'll put myself as a reviewer too.
Sorry David, my mistake.
I confused the numbers (id) of Commitfest.
regards,
Ranier Vilela
Adding David since this patch is likely a precondition for [1]. On Tue, Jul 6, 2021 at 2:15 AM Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > > Hello, > > While testing the patch "Add proper planner support for ORDER BY / DISTINCT > aggregates" [0] I discovered the performance penalty from adding a sort node > essentially came from not using the single-datum tuplesort optimization in > ExecSort (contrary to the sorting done in ExecAgg). > > I originally proposed this patch as a companion in the same thread [1], but > following James suggestion I'm making a separate thread just for this as the > optimization is worthwhile independently of David's patch: it looks like we > can expect a 2x speedup on a "select a single ordered column" case. > > The patch aimed to be as simple as possible: we only turn this optimization on > when the tuple being sorted has only one attribute, it is "byval" (so as not > to incur copies which would be hard to track in the execution tree) and > unbound (again, not having to deal with copying borrowed datum anywhere). Thanks again for finding this and working up a patch. I've taken a look, and while I haven't dug into testing it yet, I have a few comments. First, the changes are lacking any explanatory comments. Probably we should follow how nodeAgg does this and add both comments to the ExecSort function header as well as specific comments above the "if" around the new tuplesort_begin_datum explaining the specific conditions that are required for the optimization to be useful and safe. That leads to a question I had: I don't follow why bounded mode (when using byval) needs to be excluded. Comments should be added if there's a good reason (as noted above), but maybe it's a case we can handle safely? A second question: at first glance it's intuitively the case we might not be able to handle byref values. But nodeAgg doesn't seem to have that restriction. What's the difference here? A few small code observations: - In my view the addition of unlikely() in ExecSort is unlikely to be of benefit because it's a single call for the entire node's execution (not in the tuple loop). - It seems clearer to change the "if (!node->is_single_val)" to flip the true/false cases so we don't need the negation. - I assume there are tests that likely already cover this case, but it'd be worth verifying that. Finally, I believe the same optimization likely ought to be added to nodeIncrementalSort. It's less likely the tests there are sufficient for both this and the original case, but we'll see. Thanks, James 1: https://www.postgresql.org/message-id/CAApHDvpHzfo92%3DR4W0%2BxVua3BUYCKMckWAmo-2t_KiXN-wYH%3Dw%40mail.gmail.com
Em ter., 6 de jul. de 2021 às 10:19, James Coleman <jtc331@gmail.com> escreveu:
Adding David since this patch is likely a precondition for [1].
On Tue, Jul 6, 2021 at 2:15 AM Ronan Dunklau <ronan.dunklau@aiven.io> wrote:
>
> Hello,
>
> While testing the patch "Add proper planner support for ORDER BY / DISTINCT
> aggregates" [0] I discovered the performance penalty from adding a sort node
> essentially came from not using the single-datum tuplesort optimization in
> ExecSort (contrary to the sorting done in ExecAgg).
>
> I originally proposed this patch as a companion in the same thread [1], but
> following James suggestion I'm making a separate thread just for this as the
> optimization is worthwhile independently of David's patch: it looks like we
> can expect a 2x speedup on a "select a single ordered column" case.
>
> The patch aimed to be as simple as possible: we only turn this optimization on
> when the tuple being sorted has only one attribute, it is "byval" (so as not
> to incur copies which would be hard to track in the execution tree) and
> unbound (again, not having to deal with copying borrowed datum anywhere).
Thanks again for finding this and working up a patch.
I've taken a look, and while I haven't dug into testing it yet, I have
a few comments.
First, the changes are lacking any explanatory comments. Probably we
should follow how nodeAgg does this and add both comments to the
ExecSort function header as well as specific comments above the "if"
around the new tuplesort_begin_datum explaining the specific
conditions that are required for the optimization to be useful and
safe.
That leads to a question I had: I don't follow why bounded mode (when
using byval) needs to be excluded. Comments should be added if there's
a good reason (as noted above), but maybe it's a case we can handle
safely?
A second question: at first glance it's intuitively the case we might
not be able to handle byref values. But nodeAgg doesn't seem to have
that restriction. What's the difference here?
A few small code observations:
- In my view the addition of unlikely() in ExecSort is unlikely to be
of benefit because it's a single call for the entire node's execution
(not in the tuple loop).
No objection. And I agree that testing is complex and needs to remain as it is.
- It seems clearer to change the "if (!node->is_single_val)" to flip
the true/false cases so we don't need the negation.
I think yes, it can be better.
regards,
Ranier Vilela
On Tue, Jul 6, 2021 at 6:49 PM James Coleman <jtc331@gmail.com> wrote: > > Adding David since this patch is likely a precondition for [1]. > > On Tue, Jul 6, 2021 at 2:15 AM Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > > > > Hello, > > > > While testing the patch "Add proper planner support for ORDER BY / DISTINCT > > aggregates" [0] I discovered the performance penalty from adding a sort node > > essentially came from not using the single-datum tuplesort optimization in > > ExecSort (contrary to the sorting done in ExecAgg). > > > > I originally proposed this patch as a companion in the same thread [1], but > > following James suggestion I'm making a separate thread just for this as the > > optimization is worthwhile independently of David's patch: it looks like we > > can expect a 2x speedup on a "select a single ordered column" case. > > > > The patch aimed to be as simple as possible: we only turn this optimization on > > when the tuple being sorted has only one attribute, it is "byval" (so as not > > to incur copies which would be hard to track in the execution tree) and > > unbound (again, not having to deal with copying borrowed datum anywhere). > > Thanks again for finding this and working up a patch. > > I've taken a look, and while I haven't dug into testing it yet, I have > a few comments. > > First, the changes are lacking any explanatory comments. Probably we > should follow how nodeAgg does this and add both comments to the > ExecSort function header as well as specific comments above the "if" > around the new tuplesort_begin_datum explaining the specific > conditions that are required for the optimization to be useful and > safe. > > That leads to a question I had: I don't follow why bounded mode (when > using byval) needs to be excluded. Comments should be added if there's > a good reason (as noted above), but maybe it's a case we can handle > safely? > > A second question: at first glance it's intuitively the case we might > not be able to handle byref values. But nodeAgg doesn't seem to have > that restriction. What's the difference here? > I think tuplesort_begin_datum, doesn't have any such limitation, it can handle any type of Datum so I think we don't need to consider the only attbyval, we can consider any type of attribute for this optimization. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Thank you for the review, I will address those shortly, but will answer some
questions in the meantime.
> > First, the changes are lacking any explanatory comments. Probably we
> > should follow how nodeAgg does this and add both comments to the
> > ExecSort function header as well as specific comments above the "if"
> > around the new tuplesort_begin_datum explaining the specific
> > conditions that are required for the optimization to be useful and
> > safe.
Done, since I lifted the restrictions following your questions, there isn't
much left to comment. (see below)
> >
> > That leads to a question I had: I don't follow why bounded mode (when
> > using byval) needs to be excluded. Comments should be added if there's
> > a good reason (as noted above), but maybe it's a case we can handle
> > safely?
I had test failures when trying to move the Datum around when performing a
bounded sort, but did not look into it at first.
Now I've looked into it, and the switch to a heapsort when using bounded mode
just unconditionnaly tried to free a tuple that was never there to begin with.
So if the SortTuple does not contain an actual tuple, but only a single datum,
do not do that.
I've updated the patch to fix this and enable the optimization in the case of
bounded sort.
> >
> > A second question: at first glance it's intuitively the case we might
> > not be able to handle byref values. But nodeAgg doesn't seem to have
> > that restriction. What's the difference here?
>
> I think tuplesort_begin_datum, doesn't have any such limitation, it
> can handle any type of Datum so I think we don't need to consider the
> only attbyval, we can consider any type of attribute for this
> optimization.
I've restricted the optimization to byval types because of the following
comment in nodeAgg.c:
/*
* Note: if input type is pass-by-ref, the datums returned by the
sort are
* freshly palloc'd in the per-query context, so we must be careful
to
* pfree them when they are no longer needed.
*/
As I was not sure how to handle that, I prefered the safety of not enabling
it. Since you both told me it should be safe, I've lifted that restriction
too.
> A few small code observations:
> - In my view the addition of unlikely() in ExecSort is unlikely to be
> of benefit because it's a single call for the entire node's execution
> (not in the tuple loop).
Done.
> - It seems clearer to change the "if (!node->is_single_val)" to flip
> the true/false cases so we don't need the negation.
Agreed, done.
> - I assume there are tests that likely already cover this case, but
> it'd be worth verifying that.
Yes many test cases cover that, but maybe it would be better to explictly
check for it on some cases: do you think we could add a debug message that can
be checked for ?
> Finally, I believe the same optimization likely ought to be added to
> nodeIncrementalSort. It's less likely the tests there are sufficient
> for both this and the original case, but we'll see.
I will look into it, but isn't incrementalsort used to sort tuples on several
keys, when they are already sorted on the first ? In that case, I doubt we
would ever have a single-valued tuple here, except if there is a projection to
strip the tuple from extraneous attributes.
--
Ronan Dunklau
Attachment
On Tue, Jul 6, 2021 at 11:03 AM Ronan Dunklau <ronan.dunklau@aiven.io> wrote:
>
> Thank you for the review, I will address those shortly, but will answer some
> questions in the meantime.
>
> > > First, the changes are lacking any explanatory comments. Probably we
> > > should follow how nodeAgg does this and add both comments to the
> > > ExecSort function header as well as specific comments above the "if"
> > > around the new tuplesort_begin_datum explaining the specific
> > > conditions that are required for the optimization to be useful and
> > > safe.
>
> Done, since I lifted the restrictions following your questions, there isn't
> much left to comment. (see below)
>
> > >
> > > That leads to a question I had: I don't follow why bounded mode (when
> > > using byval) needs to be excluded. Comments should be added if there's
> > > a good reason (as noted above), but maybe it's a case we can handle
> > > safely?
>
> I had test failures when trying to move the Datum around when performing a
> bounded sort, but did not look into it at first.
>
> Now I've looked into it, and the switch to a heapsort when using bounded mode
> just unconditionnaly tried to free a tuple that was never there to begin with.
> So if the SortTuple does not contain an actual tuple, but only a single datum,
> do not do that.
>
> I've updated the patch to fix this and enable the optimization in the case of
> bounded sort.
Awesome.
> > > A second question: at first glance it's intuitively the case we might
> > > not be able to handle byref values. But nodeAgg doesn't seem to have
> > > that restriction. What's the difference here?
> >
> > I think tuplesort_begin_datum, doesn't have any such limitation, it
> > can handle any type of Datum so I think we don't need to consider the
> > only attbyval, we can consider any type of attribute for this
> > optimization.
>
> I've restricted the optimization to byval types because of the following
> comment in nodeAgg.c:
>
> /*
> * Note: if input type is pass-by-ref, the datums returned by the
> sort are
> * freshly palloc'd in the per-query context, so we must be careful
> to
> * pfree them when they are no longer needed.
> */
>
> As I was not sure how to handle that, I prefered the safety of not enabling
> it. Since you both told me it should be safe, I've lifted that restriction
> too.
To be clear, I don't know for certain it's safe [without extra work],
but even if it involves some extra manual pfree'ing (a la nodeAgg)
it's probably worth it. Maybe someone else will weigh in on whether or
not anything special is required here to ensure we don't leak memory
(I haven't looked in detail yet).
> > A few small code observations:
> > - In my view the addition of unlikely() in ExecSort is unlikely to be
> > of benefit because it's a single call for the entire node's execution
> > (not in the tuple loop).
>
> Done.
>
> > - It seems clearer to change the "if (!node->is_single_val)" to flip
> > the true/false cases so we don't need the negation.
>
> Agreed, done.
Thanks
> > - I assume there are tests that likely already cover this case, but
> > it'd be worth verifying that.
>
> Yes many test cases cover that, but maybe it would be better to explictly
> check for it on some cases: do you think we could add a debug message that can
> be checked for ?
Mostly I think we should verify code coverage and _maybe_ add a
specific test or two that we know execises this path. I don't know
that the debug message needs to be matched in the test (probably more
pain than it's worth), but the debug message ("enabling datum sort
optimizaton" or similar) might be good anyway.
I wonder if we need to change costing of sorts for this case. I don't
like having to do so, but it's a significant change in speed, so
probably should impact what plan gets chosen. Hopefully others will
weigh on this also.
> > Finally, I believe the same optimization likely ought to be added to
> > nodeIncrementalSort. It's less likely the tests there are sufficient
> > for both this and the original case, but we'll see.
>
> I will look into it, but isn't incrementalsort used to sort tuples on several
> keys, when they are already sorted on the first ? In that case, I doubt we
> would ever have a single-valued tuple here, except if there is a projection to
> strip the tuple from extraneous attributes.
Yes and no. When incremental sort has to do a full sort there will
always be at least 2 attributes. But in prefix sort mode (see
prefixsort_state) only non-presorted columns are sorted (i.e., if
given a,b already sorted by a, then only b is sorted). So the
prefixsort_state could use this optimization.
James
Le mardi 6 juillet 2021, 17:37:53 CEST James Coleman a écrit : > Yes and no. When incremental sort has to do a full sort there will > always be at least 2 attributes. But in prefix sort mode (see > prefixsort_state) only non-presorted columns are sorted (i.e., if > given a,b already sorted by a, then only b is sorted). So the > prefixsort_state could use this optimization. The optimization is not when we actually sort on a single key, but when we get a single attribute in / out of the tuplesort. Since sorting always add resjunk entries for the keys being sorted on, I don't think we can ever end up in a situation where the optimization would kick in, since the entries for the already-performed-sort keys will need to be present in the output. Maybe if instead of adding resjunk entries to the whole query's targetlist, sort and incrementalsort nodes were able to do a projection from the input (needed tle + resjunk sorting tle) to a tuple containing only the needed tle on output before actually sorting it, it would be possible, but that would be quite a big design change. In the meantime I fixed some formatting issues, please find attached a new patch. -- Ronan Dunklau
Attachment
On Wed, 7 Jul 2021 at 21:32, Ronan Dunklau <ronan.dunklau@aiven.io> wrote:
> In the meantime I fixed some formatting issues, please find attached a new
> patch.
I started to look at this.
First I wondered how often we might be able to apply this
optimisation, so I ran make check after adding some elog(NOTICE) calls
to output which method is going to be used just before we do the
tuplestore_begin_* calls. It looks like there are 614 instances of
Datum sorts and 4223 of tuple sorts. That's about 14.5% datum sorts.
223 of the 614 are byval types and the other 391 are byref. Not that
the regression tests are a good reflection of the real world, but if
it were then that's quite a good number of cases to be able to
optimise.
As for the patch, just a few things:
1. Can you add the missing braces in this if condition and the else
condition that belongs to it.
+ if (node->is_single_val)
+ for (;;)
+ {
2. I think it would nicer to name the new is_single_val field
"datumSort" instead. To me it seems more clear what it is for.
3. This seems to be a bug fix where byval datum sorts do not properly
handle bounded sorts. I think that maybe that should be fixed and
backpatched. I don't see anything that says Datum sorts can't be
bounded and if there were some restriction on that I'd expect
tuplesort_set_bound() to fail when the Tuplesortstate had been set up
with tuplesort_begin_datum().
static void
free_sort_tuple(Tuplesortstate *state, SortTuple *stup)
{
- FREEMEM(state, GetMemoryChunkSpace(stup->tuple));
- pfree(stup->tuple);
+ /*
+ * If the SortTuple is actually only a single Datum, which was not copied
+ * as it is a byval type, do not try to free it nor account for it in
+ * memory used.
+ */
+ if (stup->tuple)
+ {
+ FREEMEM(state, GetMemoryChunkSpace(stup->tuple));
+ pfree(stup->tuple);
+ }
I can take this to another thread.
That's all I have for now.
David
Le lundi 12 juillet 2021, 15:11:17 CEST David Rowley a écrit :
> On Wed, 7 Jul 2021 at 21:32, Ronan Dunklau <ronan.dunklau@aiven.io> wrote:
> > In the meantime I fixed some formatting issues, please find attached a new
> > patch.
>
> I started to look at this.
Thank you ! I'm attaching a new version of the patch taking your remarks into
account.
>
> First I wondered how often we might be able to apply this
> optimisation, so I ran make check after adding some elog(NOTICE) calls
> to output which method is going to be used just before we do the
> tuplestore_begin_* calls. It looks like there are 614 instances of
> Datum sorts and 4223 of tuple sorts. That's about 14.5% datum sorts.
> 223 of the 614 are byval types and the other 391 are byref. Not that
> the regression tests are a good reflection of the real world, but if
> it were then that's quite a good number of cases to be able to
> optimise.
That's an interesting stat.
>
> As for the patch, just a few things:
>
> 1. Can you add the missing braces in this if condition and the else
> condition that belongs to it.
>
> + if (node->is_single_val)
> + for (;;)
> + {
>
Done.
> 2. I think it would nicer to name the new is_single_val field
> "datumSort" instead. To me it seems more clear what it is for.
Done.
>
> 3. This seems to be a bug fix where byval datum sorts do not properly
> handle bounded sorts. I think that maybe that should be fixed and
> backpatched. I don't see anything that says Datum sorts can't be
> bounded and if there were some restriction on that I'd expect
> tuplesort_set_bound() to fail when the Tuplesortstate had been set up
> with tuplesort_begin_datum().
I've kept this as-is for now, but I will remove it from my patch if it is
deemed worthy of back-patching in your other thread.
Regards,
--
Ronan Dunklau
Attachment
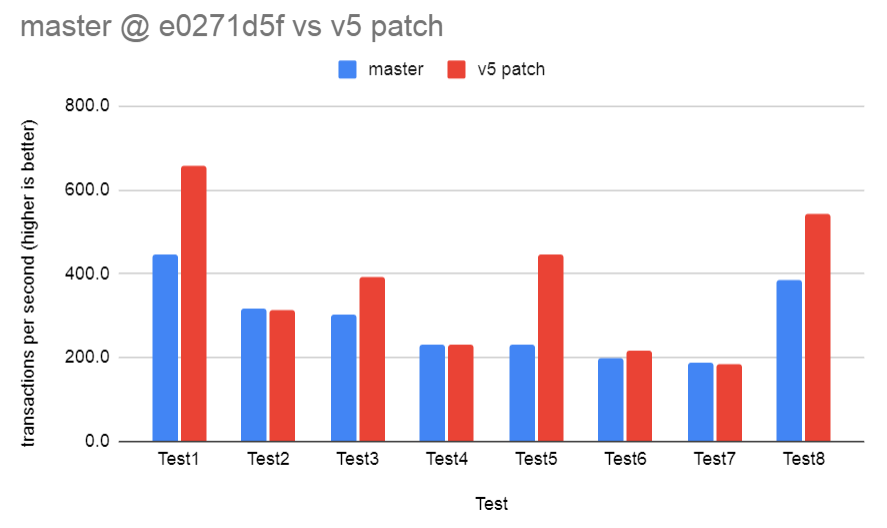
On Tue, 13 Jul 2021 at 01:59, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > > 3. This seems to be a bug fix where byval datum sorts do not properly > > handle bounded sorts. I think that maybe that should be fixed and > > backpatched. I don't see anything that says Datum sorts can't be > > bounded and if there were some restriction on that I'd expect > > tuplesort_set_bound() to fail when the Tuplesortstate had been set up > > with tuplesort_begin_datum(). > > I've kept this as-is for now, but I will remove it from my patch if it is > deemed worthy of back-patching in your other thread. I've now pushed that bug fix so it's fine to remove the change to tuplesort.c now. I also did a round of benchmarking on this patch using the attached script. Anyone wanting to run it will need to run make installcheck first to create the required tables. On an AMD machine, I got the following results. Result in transactions per second. Test master v5 patch compare Test1 446.1 657.3 147.32% Test2 315.8 314.0 99.44% Test3 302.3 392.1 129.67% Test4 232.7 230.7 99.12% Test5 230.0 446.1 194.00% Test6 199.5 217.9 109.23% Test7 188.7 185.3 98.21% Test8 385.4 544.0 141.17% Tests 2, 4, 7 are designed to check if there is any regression from doing the additional run-time checks to see if we're doing datumSort. I measured a very small penalty from this. It's most visible in test7 with a drop of about 1.8%. Each test did OFFSET 1000000 as I didn't want to measure the overhead of outputting tuples. All the other tests show a pretty good gain. Test6 is testing a byref type, so it appears the gains are not just from byval datums. It would be good to see the benchmark script run on a few other machines to get an idea if the gains and losses are consistent. In theory, we likely could get rid of the small regression by having two versions of ExecSort() and setting the correct one during ExecInitSort() by setting the function pointer to the version we want to use in sortstate->ss.ps.ExecProcNode. But maybe the small regression is not worth going to that trouble over. I'm not aware of any other executor nodes that have logic like that so maybe it would be a bad idea to introduce something like that. David
Attachment
{kind=link}
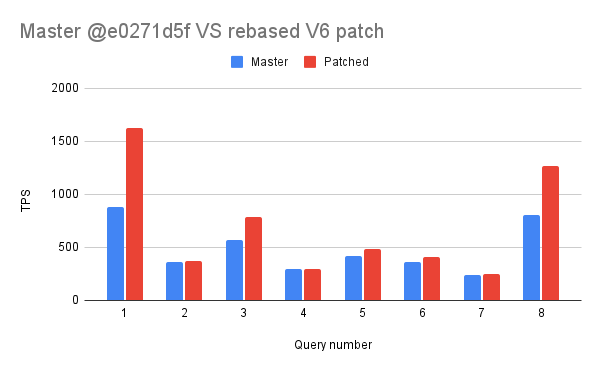
> I've now pushed that bug fix so it's fine to remove the change to > tuplesort.c now. Thanks, I've rebased the patch, please find attached the v6. > > I also did a round of benchmarking on this patch using the attached > script. Anyone wanting to run it will need to run make installcheck > first to create the required tables. I've run your benchmark, keeping the best of three runs each time. This is an intel laptop, so as many things are running on it there is a lot of noise... Both standard and patched run come from a compilation with gcc -O2. No changes have been done to the default settings. Query # Master Patched Variation 1 884 1627 184.05% 2 364 375 103.02% 3 568 783 137.85% 4 296 297 100.34% 5 421 484 114.96% 6 359 408 113.65% 7 237 251 105.91% 8 806 1271 157.69% Since I didn't reproduce your slowdown at all on the first run, I tried to rerun the benchmark several times and for the "dubious cases" (2, 4 and 7), the results are too jittery to conclude one way or another in my case. I don't have access to proper hardware, so not sure if that would be useful in any way to just run the bench for thousands of xacts instead. I would be surprised the check adds that much to the whole execution though. I attach a graph similar to yours for reference. -- Ronan Dunklau
Attachment
{kind=link}
Em ter., 13 de jul. de 2021 às 04:19, Ronan Dunklau <ronan.dunklau@aiven.io> escreveu:
> I've now pushed that bug fix so it's fine to remove the change to
I would be
surprised the check adds that much to the whole execution though.
I think this branch is a misprediction.
In most cases is it not datumSort?
That's why I would like to use unlikely.
IMO all the tests should all be to verify past behavior first.
regards,
Ranier Vilela
On Wed, 14 Jul 2021 at 00:06, Ranier Vilela <ranier.vf@gmail.com> wrote: > > Em ter., 13 de jul. de 2021 às 04:19, Ronan Dunklau <ronan.dunklau@aiven.io> escreveu: >> I would be >> surprised the check adds that much to the whole execution though. > > I think this branch is a misprediction. It could be. I wondered that myself when I saw Ronan's results were better than mine for 2,4 and 7. However, I think Ronan had quite a bit of noise in his results as there's no reason for the speedup in tests 2,4 and 7. > In most cases is it not datumSort? who knows. Maybe someone's workload always requires the datum sort. > That's why I would like to use unlikely. We really only use unlikely() in cases where we want to move code out of line to a cold area because it's really never executed under normal circumstances. We tend to do that for ERROR cases as we don't ever really want to optimise for errors. We also sometimes do it when some function has a branch to initialise something during the first call. The case in question here does not fit for either of those two cases. > IMO all the tests should all be to verify past behavior first. I'm not quire sure what you mean there. David
Em ter., 13 de jul. de 2021 às 09:24, David Rowley <dgrowleyml@gmail.com> escreveu:
On Wed, 14 Jul 2021 at 00:06, Ranier Vilela <ranier.vf@gmail.com> wrote:
>
> Em ter., 13 de jul. de 2021 às 04:19, Ronan Dunklau <ronan.dunklau@aiven.io> escreveu:
>> I would be
>> surprised the check adds that much to the whole execution though.
>
> I think this branch is a misprediction.
It could be. I wondered that myself when I saw Ronan's results were
better than mine for 2,4 and 7. However, I think Ronan had quite a
bit of noise in his results as there's no reason for the speedup in
tests 2,4 and 7.
> In most cases is it not datumSort?
who knows. Maybe someone's workload always requires the datum sort.
> That's why I would like to use unlikely.
We really only use unlikely() in cases where we want to move code out
of line to a cold area because it's really never executed under normal
circumstances. We tend to do that for ERROR cases as we don't ever
really want to optimise for errors. We also sometimes do it when some
function has a branch to initialise something during the first call.
The case in question here does not fit for either of those two cases.
Hum, I understand the usage cases now.
Thanks for the hint.
> IMO all the tests should all be to verify past behavior first.
I'm not quire sure what you mean there.
I'm saying we could help the branch by keeping the same testing logic as before and not reversing it.
Attached is a version to demonstrate this, I don't pretend to be v7.
Attached is a version to demonstrate this, I don't pretend to be v7.
I couldn't find a good phrase to the contrary:
"are we *not* using the single value optimization ?"
I don't have time to take the tests right now.
regards,
Ranier Vilela
Attachment
Em ter., 13 de jul. de 2021 às 09:44, Ranier Vilela <ranier.vf@gmail.com> escreveu:
Em ter., 13 de jul. de 2021 às 09:24, David Rowley <dgrowleyml@gmail.com> escreveu:On Wed, 14 Jul 2021 at 00:06, Ranier Vilela <ranier.vf@gmail.com> wrote:
>
> Em ter., 13 de jul. de 2021 às 04:19, Ronan Dunklau <ronan.dunklau@aiven.io> escreveu:
>> I would be
>> surprised the check adds that much to the whole execution though.
>
> I think this branch is a misprediction.
It could be. I wondered that myself when I saw Ronan's results were
better than mine for 2,4 and 7. However, I think Ronan had quite a
bit of noise in his results as there's no reason for the speedup in
tests 2,4 and 7.
> In most cases is it not datumSort?
who knows. Maybe someone's workload always requires the datum sort.
> That's why I would like to use unlikely.
We really only use unlikely() in cases where we want to move code out
of line to a cold area because it's really never executed under normal
circumstances. We tend to do that for ERROR cases as we don't ever
really want to optimise for errors. We also sometimes do it when some
function has a branch to initialise something during the first call.
The case in question here does not fit for either of those two cases.Hum, I understand the usage cases now.Thanks for the hint.
> IMO all the tests should all be to verify past behavior first.
I'm not quire sure what you mean there.I'm saying we could help the branch by keeping the same testing logic as before and not reversing it.
Attached is a version to demonstrate this, I don't pretend to be v7.I couldn't find a good phrase to the contrary:"are we *not* using the single value optimization ?"I don't have time to take the tests right now.
Finally I had time to benchmark (David's benchsort.sh)
ubuntu 64 bits (20.04) 8gb ram SSD 256GB.
Table with the best results of each.
| HEAD | v6 | v7 | v7b | v6 vs master | v7 vs v6 | v7b vs v6 | |
| Test1 | 288,149636 | 449,018541 | 469,757169 | 550,48505 | 155,83% | 104,62% | 122,60% |
| Test2 | 94,766955 | 95,451406 | 94,556249 | 94,718982 | 100,72% | 99,06% | 99,23% |
| Test3 | 190,521319 | 260,279802 | 259,597067 | 278,115296 | 136,61% | 99,74% | 106,85% |
| Test4 | 78,779344 | 78,253455 | 78,114068 | 77,941482 | 99,33% | 99,82% | 99,60% |
| Test5 | 131,362614 | 142,662223 | 136,436347 | 149,639041 | 108,60% | 95,64% | 104,89% |
| Test6 | 112,884298 | 124,181671 | 115,528328 | 127,58497 | 110,01% | 93,03% | 102,74% |
| Test7 | 69,308587 | 68,643067 | 66,10195 | 69,087544 | 99,04% | 96,30% | 100,65% |
| Test8 | 243,674171 | 364,681142 | 371,928453 | 419,259703 | 149,66% | 101,99% | 114,97% |
v6 slowdown with test4 and test7.
v7b slowdown with test2 and test4, in relation with v7.
If field struct datumSort is not absolutely necessary, I think that v7 will be better.
Attached the patchs and file results.
Attachment
Em ter., 13 de jul. de 2021 às 14:42, Ranier Vilela <ranier.vf@gmail.com> escreveu:
Em ter., 13 de jul. de 2021 às 09:44, Ranier Vilela <ranier.vf@gmail.com> escreveu:Em ter., 13 de jul. de 2021 às 09:24, David Rowley <dgrowleyml@gmail.com> escreveu:On Wed, 14 Jul 2021 at 00:06, Ranier Vilela <ranier.vf@gmail.com> wrote:
>
> Em ter., 13 de jul. de 2021 às 04:19, Ronan Dunklau <ronan.dunklau@aiven.io> escreveu:
>> I would be
>> surprised the check adds that much to the whole execution though.
>
> I think this branch is a misprediction.
It could be. I wondered that myself when I saw Ronan's results were
better than mine for 2,4 and 7. However, I think Ronan had quite a
bit of noise in his results as there's no reason for the speedup in
tests 2,4 and 7.
> In most cases is it not datumSort?
who knows. Maybe someone's workload always requires the datum sort.
> That's why I would like to use unlikely.
We really only use unlikely() in cases where we want to move code out
of line to a cold area because it's really never executed under normal
circumstances. We tend to do that for ERROR cases as we don't ever
really want to optimise for errors. We also sometimes do it when some
function has a branch to initialise something during the first call.
The case in question here does not fit for either of those two cases.Hum, I understand the usage cases now.Thanks for the hint.
> IMO all the tests should all be to verify past behavior first.
I'm not quire sure what you mean there.I'm saying we could help the branch by keeping the same testing logic as before and not reversing it.
Attached is a version to demonstrate this, I don't pretend to be v7.I couldn't find a good phrase to the contrary:"are we *not* using the single value optimization ?"I don't have time to take the tests right now.Finally I had time to benchmark (David's benchsort.sh)ubuntu 64 bits (20.04) 8gb ram SSD 256GB.Table with the best results of each.
HEAD v6 v7 v7b v6 vs master v7 vs v6 v7b vs v6 Test1 288,149636 449,018541 469,757169 550,48505 155,83% 104,62% 122,60% Test2 94,766955 95,451406 94,556249 94,718982 100,72% 99,06% 99,23% Test3 190,521319 260,279802 259,597067 278,115296 136,61% 99,74% 106,85% Test4 78,779344 78,253455 78,114068 77,941482 99,33% 99,82% 99,60% Test5 131,362614 142,662223 136,436347 149,639041 108,60% 95,64% 104,89% Test6 112,884298 124,181671 115,528328 127,58497 110,01% 93,03% 102,74% Test7 69,308587 68,643067 66,10195 69,087544 99,04% 96,30% 100,65% Test8 243,674171 364,681142 371,928453 419,259703 149,66% 101,99% 114,97% I have no idea why v7 failed with test6?v6 slowdown with test4 and test7.v7b slowdown with test2 and test4, in relation with v7.
v7b slowdown with test2 and test4, in relation with *v6*.
If field struct datumSort is not absolutely necessary, I think that v7 will be better.
*v7b* will be better.
Sorry for the noise.
regards,
Ranier Vilela
On Tue, 13 Jul 2021 at 15:15, David Rowley <dgrowleyml@gmail.com> wrote: > In theory, we likely could get rid of the small regression by having > two versions of ExecSort() and setting the correct one during > ExecInitSort() by setting the function pointer to the version we want > to use in sortstate->ss.ps.ExecProcNode. Just to see how it would perform, I tried what I mentioned above. I've included what I ended up with in the attached POC patch. I got the following results on my AMD hardware. Test master v8 patch comparison Test1 448.0 671.7 149.9% Test2 316.4 317.5 100.3% Test3 299.5 381.6 127.4% Test4 219.7 229.5 104.5% Test5 226.3 254.6 112.5% Test6 197.9 217.9 110.1% Test7 179.2 185.3 103.4% Test8 389.2 544.8 140.0% This time I saw no regression on tests 2, 4 and 7. I looked to see if there was anywhere else in the executor that conditionally uses a different exec function in this way and found nothing, so I'm not too sure if it's a good idea to start doing this. It would be good to get a 2nd opinion about this idea. Also, more benchmark results with v6 and v8 would be good too. David
Attachment
Em qua., 14 de jul. de 2021 às 07:14, David Rowley <dgrowleyml@gmail.com> escreveu:
On Tue, 13 Jul 2021 at 15:15, David Rowley <dgrowleyml@gmail.com> wrote:
> In theory, we likely could get rid of the small regression by having
> two versions of ExecSort() and setting the correct one during
> ExecInitSort() by setting the function pointer to the version we want
> to use in sortstate->ss.ps.ExecProcNode.
Just to see how it would perform, I tried what I mentioned above. I've
included what I ended up with in the attached POC patch.
I got the following results on my AMD hardware.
Test master v8 patch comparison
Test1 448.0 671.7 149.9%
Test2 316.4 317.5 100.3%
Test3 299.5 381.6 127.4%
Test4 219.7 229.5 104.5%
Test5 226.3 254.6 112.5%
Test6 197.9 217.9 110.1%
Test7 179.2 185.3 103.4%
Test8 389.2 544.8 140.0%
I'm a little surprised by your results.
Test1 and Test8 look pretty good to me.
What is compiler and environment?
I repeated (3 times) the benchmark with v8 here,
and the results were not good.
| HEAD | v6 | v7b | v8 | v6 vs head | v8 vs v6 | v8 vs v7b | |
| Test1 | 288,149636 | 449,018541 | 550,48505 | 468,168165 | 155,83% | 104,26% | 85,05% |
| Test2 | 94,766955 | 95,451406 | 94,718982 | 94,800275 | 100,72% | 99,32% | 100,09% |
| Test3 | 190,521319 | 260,279802 | 278,115296 | 262,538383 | 136,61% | 100,87% | 94,40% |
| Test4 | 78,779344 | 78,253455 | 77,941482 | 78,471546 | 99,33% | 100,28% | 100,68% |
| Test5 | 131,362614 | 142,662223 | 149,639041 | 144,849303 | 108,60% | 101,53% | 96,80% |
| Test6 | 112,884298 | 124,181671 | 127,58497 | 124,29376 | 110,01% | 100,09% | 97,42% |
| Test7 | 69,308587 | 68,643067 | 69,087544 | 69,437312 | 99,04% | 101,16% | 100,51% |
| Test8 | 243,674171 | 364,681142 | 419,259703 | 369,239176 | 149,66% | 101,25% | 88,07% |
This time I saw no regression on tests 2, 4 and 7.
I looked to see if there was anywhere else in the executor that
conditionally uses a different exec function in this way and found
nothing, so I'm not too sure if it's a good idea to start doing this.
Specialized functions can be a way to optimize. The compilers themselves do it.
But the ExecSortTuple and ExecSortDatum are much more similar,
which can cause maintenance problems.
I don't think in this case it would be a good idea.
It would be good to get a 2nd opinion about this idea. Also, more
benchmark results with v6 and v8 would be good too.
Yeah, another different machine.
I would like to see other results with v7b.
Attached the file with all results from v8.
regards,
Ranier Vilela
Attachment
On Wed, Jul 14, 2021 at 6:14 AM David Rowley <dgrowleyml@gmail.com> wrote:
> It would be good to get a 2nd opinion about this idea. Also, more
> benchmark results with v6 and v8 would be good too.
I tested this on an older Xeon, gcc 8.4 (here median of each test, full results attached):
> benchmark results with v6 and v8 would be good too.
I tested this on an older Xeon, gcc 8.4 (here median of each test, full results attached):
test HEAD v6 v8
Test1 588 1007 998
Test2 198 202 197
Test3 374 516 512
Test4 172 165 166
Test5 255 279 283
Test6 227 251 251
Test7 145 147 146
Test8 474 783 770
Test1 588 1007 998
Test2 198 202 197
Test3 374 516 512
Test4 172 165 166
Test5 255 279 283
Test6 227 251 251
Test7 145 147 146
Test8 474 783 770
Test4 could be a regression, but 2 and 7 look fine here.
Attachment
On Thu, 15 Jul 2021 at 05:55, Ranier Vilela <ranier.vf@gmail.com> wrote: > I repeated (3 times) the benchmark with v8 here, > and the results were not good. Do you have any good theories on why the additional branching that's done in v7b vs v8 might cause it to run faster? David
Em qua., 14 de jul. de 2021 às 20:43, David Rowley <dgrowleyml@gmail.com> escreveu:
On Thu, 15 Jul 2021 at 05:55, Ranier Vilela <ranier.vf@gmail.com> wrote:
> I repeated (3 times) the benchmark with v8 here,
> and the results were not good.
Do you have any good theories on why the additional branching that's
done in v7b vs v8 might cause it to run faster?
Branch Predictions works with *more* probable path,
otherwise a penalty occurs and the cpu must revert the results.
In this case it seems to me that most of the time, tuplesort is the path.
So as it is tested if it is *datumSort* and the *prediction* fails,
So as it is tested if it is *datumSort* and the *prediction* fails,
the cpu has more work to reverse the wrong path.
To help the branch, test a more probable case first, anywhere.
if, switch, etc.
Another gain is the local variable tupleSort, which is obviously faster than node.
regards,
Ranier Vilela
On Thu, 15 Jul 2021 at 12:10, Ranier Vilela <ranier.vf@gmail.com> wrote: > > Em qua., 14 de jul. de 2021 às 20:43, David Rowley <dgrowleyml@gmail.com> escreveu: >> >> On Thu, 15 Jul 2021 at 05:55, Ranier Vilela <ranier.vf@gmail.com> wrote: >> > I repeated (3 times) the benchmark with v8 here, >> > and the results were not good. >> >> Do you have any good theories on why the additional branching that's >> done in v7b vs v8 might cause it to run faster? > > > Branch Predictions works with *more* probable path, > otherwise a penalty occurs and the cpu must revert the results. But, in v8 there is no additional branch, so no branch to mispredict. I don't really see how your explanation fits. It seems much more likely to me that the results were just noisy. It would be good to see if you can recreate them consistently. David
Em qua., 14 de jul. de 2021 às 21:21, David Rowley <dgrowleyml@gmail.com> escreveu:
On Thu, 15 Jul 2021 at 12:10, Ranier Vilela <ranier.vf@gmail.com> wrote:
>
> Em qua., 14 de jul. de 2021 às 20:43, David Rowley <dgrowleyml@gmail.com> escreveu:
>>
>> On Thu, 15 Jul 2021 at 05:55, Ranier Vilela <ranier.vf@gmail.com> wrote:
>> > I repeated (3 times) the benchmark with v8 here,
>> > and the results were not good.
>>
>> Do you have any good theories on why the additional branching that's
>> done in v7b vs v8 might cause it to run faster?
>
>
> Branch Predictions works with *more* probable path,
> otherwise a penalty occurs and the cpu must revert the results.
But, in v8 there is no additional branch, so no branch to mispredict.
I don't really see how your explanation fits.
In v8 the branch occurs at :
+ if (ExecGetResultType(outerPlanState(sortstate))->natts == 1)
datumSort is tested first.
Cpu time is a more expensive resource.
Always is executed two branches, if it is right path, win,
otherwise occurs a penalty time.
It seems much more likely to me that the results were just noisy. It
would be good to see if you can recreate them consistently.
I do.
Can you please share results with v7b?
regards,
Ranier Vilela
On Thu, 15 Jul 2021 at 12:30, Ranier Vilela <ranier.vf@gmail.com> wrote: > > Em qua., 14 de jul. de 2021 às 21:21, David Rowley <dgrowleyml@gmail.com> escreveu: >> But, in v8 there is no additional branch, so no branch to mispredict. >> I don't really see how your explanation fits. > > In v8 the branch occurs at : > + if (ExecGetResultType(outerPlanState(sortstate))->natts == 1) You do know that branch is in a function that's only executed once during executor initialization, right? David
Em qua., 14 de jul. de 2021 às 22:22, David Rowley <dgrowleyml@gmail.com> escreveu:
On Thu, 15 Jul 2021 at 12:30, Ranier Vilela <ranier.vf@gmail.com> wrote:
>
> Em qua., 14 de jul. de 2021 às 21:21, David Rowley <dgrowleyml@gmail.com> escreveu:
>> But, in v8 there is no additional branch, so no branch to mispredict.
>> I don't really see how your explanation fits.
>
> In v8 the branch occurs at :
> + if (ExecGetResultType(outerPlanState(sortstate))->natts == 1)
You do know that branch is in a function that's only executed once
during executor initialization, right?
The branch prediction should work better.
I have no idea why it works worse.
I redid all tests:
notebook 8GB RAM 256GB SSD
ubuntu 64 bits (20.04)
clang-12
powerhigh (charger on)
none configuration (all defaults)
| HEAD | v6 | v7b | v8 | v6 vs head | v7b vs v6 | v8 vs v7b | |
| Test1 | 576,868013 | 940,947236 | 1090,253859 | 1016,0443 | 163,11% | 115,87% | 93,19% |
| Test2 | 184,748363 | 177,6254 | 177,346229 | 178,230258 | 96,14% | 99,84% | 100,50% |
| Test3 | 410,030055 | 541,889704 | 605,843924 | 534,946166 | 132,16% | 111,80% | 88,30% |
| Test4 | 153,331752 | 147,98418 | 148,010894 | 147,771155 | 96,51% | 100,02% | 99,84% |
| Test5 | 268,97555 | 301,979647 | 316,928492 | 300,94932 | 112,27% | 104,95% | 94,96% |
| Test6 | 234,910125 | 259,71483 | 269,851427 | 260,567637 | 110,56% | 103,90% | 96,56% |
| Test7 | 142,704153 | 136,09163 | 136,802695 | 136,935709 | 95,37% | 100,52% | 100,10% |
| Test8 | 498,634855 | 763,482151 | 867,350046 | 804,833884 | 153,11% | 113,60% | 92,79% |
The values are high here, because now, the tests are made with full power of cpu to all patchs!
I think that more testing is needed with v7b and v8.
Anyway, two functions (ExecSortTuple and ExecSortDatum) are almost equal, maybe not a good idea.
file results attached.
regards,
Ranier Vilela
Attachment
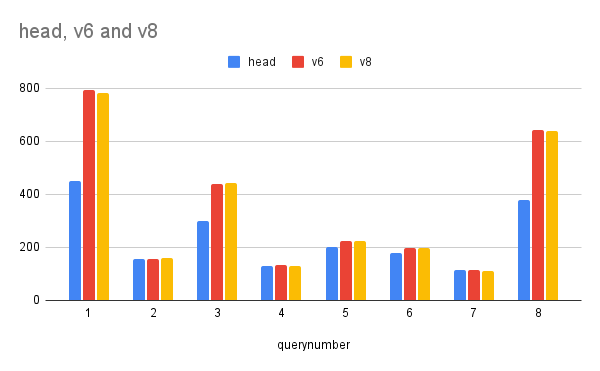
Le jeudi 15 juillet 2021, 01:30:26 CEST John Naylor a écrit : > On Wed, Jul 14, 2021 at 6:14 AM David Rowley <dgrowleyml@gmail.com> wrote: > > It would be good to get a 2nd opinion about this idea. Also, more > > benchmark results with v6 and v8 would be good too. > Hello, Thank you for trying this approach in v8 David ! I've decided to test on more "stable" hardware, an EC-2 medium instance, compiling with Debian's gcc 8.3. That's still not ideal but a lot better than a laptop. To gather more meaningful results, I ran every pgbench for 30s instead of the 10 in the initial script provided by David. I ran the full script once for HEAD, v6, v8, then a second time for HEAD, v6, v8 to try to eliminate noise that could happen for 90 consecutive seconds, and took for each of those the median of the 6 runs. It's much less noisy than my previous runs but still not as as stable as I'd like to. The results are attached in graph form, as well as the raw data if someone wants it. As a conclusion, I don't think it's worth it to introduce a separate execprocnode function for that case. It is likely the minor difference still observed can be explained to noise, as they fluctuate if you compare the min, max, average or median values from the results. Best regards, -- Ronan Dunklau
Attachment
{kind=link}
Em qui., 15 de jul. de 2021 às 07:18, Ronan Dunklau <ronan.dunklau@aiven.io> escreveu:
Le jeudi 15 juillet 2021, 01:30:26 CEST John Naylor a écrit :
> On Wed, Jul 14, 2021 at 6:14 AM David Rowley <dgrowleyml@gmail.com> wrote:
> > It would be good to get a 2nd opinion about this idea. Also, more
> > benchmark results with v6 and v8 would be good too.
>
Hello,
Thank you for trying this approach in v8 David !
I've decided to test on more "stable" hardware, an EC-2 medium instance,
compiling with Debian's gcc 8.3. That's still not ideal but a lot better than
a laptop.
To gather more meaningful results, I ran every pgbench for 30s instead of the
10 in the initial script provided by David. I ran the full script once for
HEAD, v6, v8, then a second time for HEAD, v6, v8 to try to eliminate noise
that could happen for 90 consecutive seconds, and took for each of those the
median of the 6 runs. It's much less noisy than my previous runs but still
not as as stable as I'd like to.
The results are attached in graph form, as well as the raw data if someone
wants it.
As a conclusion, I don't think it's worth it to introduce a separate
execprocnode function for that case. It is likely the minor difference still
observed can be explained to noise, as they fluctuate if you compare the min,
max, average or median values from the results.
Is there a special reason to not share v7b tests and results?
IMHO he is much more branch friendly.
regards,
Ranier Vilela
Le jeudi 15 juillet 2021, 14:09:26 CEST Ranier Vilela a écrit : > Is there a special reason to not share v7b tests and results? > The v7b patch is wrong, as it loses the type of tuplesort being used and as such always tries to fetch results using tuplesort_gettupleslot after the first tuple is fetched. -- Ronan Dunklau
Em qui., 15 de jul. de 2021 às 09:27, Ronan Dunklau <ronan.dunklau@aiven.io> escreveu:
Le jeudi 15 juillet 2021, 14:09:26 CEST Ranier Vilela a écrit :
> Is there a special reason to not share v7b tests and results?
>
The v7b patch is wrong, as it loses the type of tuplesort being used
I don't see 'node->datumSort' being anywhere else yet.
and as
such always tries to fetch results using tuplesort_gettupleslot after the first
tuple is fetched.
Is that why it is faster than v6?
regards,
Ranier Vilela
On Wed, Jul 14, 2021 at 9:22 PM David Rowley <dgrowleyml@gmail.com> wrote: > > On Thu, 15 Jul 2021 at 12:30, Ranier Vilela <ranier.vf@gmail.com> wrote: > > > > Em qua., 14 de jul. de 2021 às 21:21, David Rowley <dgrowleyml@gmail.com> escreveu: > >> But, in v8 there is no additional branch, so no branch to mispredict. > >> I don't really see how your explanation fits. > > > > In v8 the branch occurs at : > > + if (ExecGetResultType(outerPlanState(sortstate))->natts == 1) > > You do know that branch is in a function that's only executed once > during executor initialization, right? This is why I have a hard time believing there's a "real" change here and not the result of either noise or something not really controllable like executable layout changing. James
On Fri, 16 Jul 2021 at 01:44, James Coleman <jtc331@gmail.com> wrote: > > On Wed, Jul 14, 2021 at 9:22 PM David Rowley <dgrowleyml@gmail.com> wrote: > > > > On Thu, 15 Jul 2021 at 12:30, Ranier Vilela <ranier.vf@gmail.com> wrote: > > > > > > Em qua., 14 de jul. de 2021 às 21:21, David Rowley <dgrowleyml@gmail.com> escreveu: > > >> But, in v8 there is no additional branch, so no branch to mispredict. > > >> I don't really see how your explanation fits. > > > > > > In v8 the branch occurs at : > > > + if (ExecGetResultType(outerPlanState(sortstate))->natts == 1) > > > > You do know that branch is in a function that's only executed once > > during executor initialization, right? > > This is why I have a hard time believing there's a "real" change here > and not the result of either noise or something not really > controllable like executable layout changing. Yeah, I think we likely are at the level where layout changes in the compiled code are going to make things hard to measure. I just want to make sure we're not going to end up with some regression that's actual and not random depending on layout changes of unrelated code. I think a branch that's taken consistently *should* be predicted correctly each time. Anyway, I think all the comparisons with v7b can safely be ignored. As Ronan pointed out, v7b has some issues due to it not recording the sort method in the executor state that leads to it forgetting which method it used once we start pulling tuples from it. The reproductions of that are it calling tuplesort_gettupleslot() from the 2nd tuple onwards regardless of if we've done a datum or tuple sort. Ronan's latest results plus John's make me think there's no need to separate out the node function as I did in v8. However, I do think v6 could learn a little from v8. I think I'd rather see the sort method determined in ExecInitSort() rather than ExecSort(). I think minimising those few extra instructions in ExecSort() might help the L1 instruction cache. David
Em qua., 14 de jul. de 2021 às 22:22, David Rowley <dgrowleyml@gmail.com> escreveu:
On Thu, 15 Jul 2021 at 12:30, Ranier Vilela <ranier.vf@gmail.com> wrote:
>
> Em qua., 14 de jul. de 2021 às 21:21, David Rowley <dgrowleyml@gmail.com> escreveu:
>> But, in v8 there is no additional branch, so no branch to mispredict.
>> I don't really see how your explanation fits.
>
> In v8 the branch occurs at :
> + if (ExecGetResultType(outerPlanState(sortstate))->natts == 1)
You do know that branch is in a function that's only executed once
during executor initialization, right?
There's a real difference between v8 and v6, if I understood correctly.
v6 the branches is per tuple:
+ if (tupDesc->natts == 1)
v8 the branches is per state:
+ if (ExecGetResultType(outerPlanState(sortstate))->natts == 1)I think that a big different way to solve the problem.
Or am I getting it wrong?
If the sortstate number of attributes is equal to 1, is it worth the same for each tuple?
Can you explain this, please?
regards,
Ranier Vilela
Em qui., 15 de jul. de 2021 às 11:19, David Rowley <dgrowleyml@gmail.com> escreveu:
On Fri, 16 Jul 2021 at 01:44, James Coleman <jtc331@gmail.com> wrote:
>
> On Wed, Jul 14, 2021 at 9:22 PM David Rowley <dgrowleyml@gmail.com> wrote:
> >
> > On Thu, 15 Jul 2021 at 12:30, Ranier Vilela <ranier.vf@gmail.com> wrote:
> > >
> > > Em qua., 14 de jul. de 2021 às 21:21, David Rowley <dgrowleyml@gmail.com> escreveu:
> > >> But, in v8 there is no additional branch, so no branch to mispredict.
> > >> I don't really see how your explanation fits.
> > >
> > > In v8 the branch occurs at :
> > > + if (ExecGetResultType(outerPlanState(sortstate))->natts == 1)
> >
> > You do know that branch is in a function that's only executed once
> > during executor initialization, right?
>
> This is why I have a hard time believing there's a "real" change here
> and not the result of either noise or something not really
> controllable like executable layout changing.
Yeah, I think we likely are at the level where layout changes in the
compiled code are going to make things hard to measure. I just want
to make sure we're not going to end up with some regression that's
actual and not random depending on layout changes of unrelated code.
I think a branch that's taken consistently *should* be predicted
correctly each time.
Anyway, I think all the comparisons with v7b can safely be ignored. As
Ronan pointed out, v7b has some issues due to it not recording the
sort method in the executor state that leads to it forgetting which
method it used once we start pulling tuples from it. The reproductions
of that are it calling tuplesort_gettupleslot() from the 2nd tuple
onwards regardless of if we've done a datum or tuple sort.
Sorry for insisting on this.
Assuming v7b is doing it the wrong way, which I still don't think it is.
Why is it still faster than v6 and v8?
Why is it still faster than v6 and v8?
regards,
Ranier Vilela
Le jeudi 15 juillet 2021, 16:19:23 CEST David Rowley a écrit :> > Ronan's latest results plus John's make me think there's no need to > separate out the node function as I did in v8. However, I do think v6 > could learn a little from v8. I think I'd rather see the sort method > determined in ExecInitSort() rather than ExecSort(). I think > minimising those few extra instructions in ExecSort() might help the > L1 instruction cache. > I'm not sure I understand what you expect from moving that to ExecInitSort ? Maybe we should also implement the tuplesort_state initialization in ExecInitSort ? (not the actual feeding and sorting of course). Please find attached a v9 just moving the flag setting to ExecInitSort, and my apologies if I misunderstood your point. -- Ronan Dunklau
Attachment
On Thu, Jul 15, 2021 at 10:19 AM David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Fri, 16 Jul 2021 at 01:44, James Coleman <jtc331@gmail.com> wrote:
> >
> > On Wed, Jul 14, 2021 at 9:22 PM David Rowley <dgrowleyml@gmail.com> wrote:
> > >
> > > On Thu, 15 Jul 2021 at 12:30, Ranier Vilela <ranier.vf@gmail.com> wrote:
> > > >
> > > > Em qua., 14 de jul. de 2021 às 21:21, David Rowley <dgrowleyml@gmail.com> escreveu:
> > > >> But, in v8 there is no additional branch, so no branch to mispredict.
> > > >> I don't really see how your explanation fits.
> > > >
> > > > In v8 the branch occurs at :
> > > > + if (ExecGetResultType(outerPlanState(sortstate))->natts == 1)
> > >
> > > You do know that branch is in a function that's only executed once
> > > during executor initialization, right?
> >
> > This is why I have a hard time believing there's a "real" change here
> > and not the result of either noise or something not really
> > controllable like executable layout changing.
>
> Yeah, I think we likely are at the level where layout changes in the
> compiled code are going to make things hard to measure. I just want
> to make sure we're not going to end up with some regression that's
> actual and not random depending on layout changes of unrelated code.
> I think a branch that's taken consistently *should* be predicted
> correctly each time.
>
> Anyway, I think all the comparisons with v7b can safely be ignored. As
> Ronan pointed out, v7b has some issues due to it not recording the
> sort method in the executor state that leads to it forgetting which
> method it used once we start pulling tuples from it. The reproductions
> of that are it calling tuplesort_gettupleslot() from the 2nd tuple
> onwards regardless of if we've done a datum or tuple sort.
>
> Ronan's latest results plus John's make me think there's no need to
> separate out the node function as I did in v8. However, I do think v6
> could learn a little from v8. I think I'd rather see the sort method
> determined in ExecInitSort() rather than ExecSort(). I think
> minimising those few extra instructions in ExecSort() might help the
> L1 instruction cache.
I ran master/v6/v8 tests for 90s each with David's test script on an
AWS c5n.metal instance (so should be immune to noise neighbor issues).
Here are comparative results:
Test1 Test2 Test3 Test4 Test5 Test6 Test7 Test8
v6 68.66% 0.05% 32.21% -0.83% 12.58% 10.42% -1.48% 50.98%
v8 69.78% -0.44% 32.45% -1.11% 12.01% 10.58% -1.40% 49.30%
So I see a consistent change in the data, but I don't really see a
good explanation for it not being noise. Can't prove that yet though.
James
On Fri, 16 Jul 2021 at 02:53, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > > Le jeudi 15 juillet 2021, 16:19:23 CEST David Rowley a écrit :> > > Ronan's latest results plus John's make me think there's no need to > > separate out the node function as I did in v8. However, I do think v6 > > could learn a little from v8. I think I'd rather see the sort method > > determined in ExecInitSort() rather than ExecSort(). I think > > minimising those few extra instructions in ExecSort() might help the > > L1 instruction cache. > > > > I'm not sure I understand what you expect from moving that to ExecInitSort ? The motivation was to reduce the extra code that's being added to ExecSort. I checked the assembly of ExecSort on v6 and v9 and v6 was 544 lines of assembly and v9 is 534 lines. > Maybe we should also implement the tuplesort_state initialization in > ExecInitSort ? (not the actual feeding and sorting of course). I don't think that would be a good idea. Setting the datumSort does not require any new memory to be allocated. That's not the case for the tuplesort_begin routines. The difference here is that we can delay the memory allocation until we pull the first tuple and if we don't pull any tuples from the outer node then there are no needless allocations. > Please find attached a v9 just moving the flag setting to ExecInitSort, and my > apologies if I misunderstood your point. That's exactly what I meant. Thanks David
On Fri, 16 Jul 2021 at 02:53, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > Please find attached a v9 just moving the flag setting to ExecInitSort, and my > apologies if I misunderstood your point. I took this and adjusted a few things and ended up with the attached patch. The changes are fairly minor. I made the bracing consistent between both tuplesort_begin calls. I rewrote the comment at the top of ExecSort() to make it more clear about each method used. I also adjusted the comment down at the end of ExecSort that was mentioning something about tuplesort_gettupleslot returning NULL. Your patch didn't touch this, but to me, the comment just looked wrong both before and after the changes. tuplesort_gettupleslot returns false and sets the slot to empty when it runs out of tuples. Anyway, I wrote something there that I think improves that. I feel like this patch is commit-worthy now. However, I'll leave it for a few days, maybe until after the weekend as there's been a fair bit of interest and I imagine someone will have comments to make. David
Attachment
Em sex., 16 de jul. de 2021 às 00:45, David Rowley <dgrowleyml@gmail.com> escreveu:
On Fri, 16 Jul 2021 at 02:53, Ronan Dunklau <ronan.dunklau@aiven.io> wrote:
> Please find attached a v9 just moving the flag setting to ExecInitSort, and my
> apologies if I misunderstood your point.
I took this and adjusted a few things and ended up with the attached patch.
The changes are fairly minor. I made the bracing consistent between
both tuplesort_begin calls. I rewrote the comment at the top of
ExecSort() to make it more clear about each method used.
With relation to the braces, it's still not clear to me which style to follow.
I gave Ronan directions about it.
And I think maybe, it's still not clear when to use it or not.
I gave Ronan directions about it.
And I think maybe, it's still not clear when to use it or not.
I also adjusted the comment down at the end of ExecSort that was
mentioning something about tuplesort_gettupleslot returning NULL.
Your patch didn't touch this, but to me, the comment just looked wrong
both before and after the changes. tuplesort_gettupleslot returns
false and sets the slot to empty when it runs out of tuples. Anyway,
I wrote something there that I think improves that.
Can help a little here, but, seems good to me.
I feel like this patch is commit-worthy now. However, I'll leave it
for a few days, maybe until after the weekend as there's been a fair
bit of interest and I imagine someone will have comments to make.
A little lack of time.
But I finally can understand v7b.
Really struct field is necessary and he fails with the next tuple, ok.
The only conclusion I can come to is that he is faster because he fails to sort correctly.
It's no use being faster and getting wrong results.
It's no use being faster and getting wrong results.
So, +1 from me to commit v10.
Thanks for working together.
Ranier Vilela
On Thu, Jul 15, 2021 at 11:45 PM David Rowley <dgrowleyml@gmail.com> wrote: > > On Fri, 16 Jul 2021 at 02:53, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > > Please find attached a v9 just moving the flag setting to ExecInitSort, and my > > apologies if I misunderstood your point. > > I took this and adjusted a few things and ended up with the attached patch. > > The changes are fairly minor. I made the bracing consistent between > both tuplesort_begin calls. I rewrote the comment at the top of > ExecSort() to make it more clear about each method used. > > I also adjusted the comment down at the end of ExecSort that was > mentioning something about tuplesort_gettupleslot returning NULL. > Your patch didn't touch this, but to me, the comment just looked wrong > both before and after the changes. tuplesort_gettupleslot returns > false and sets the slot to empty when it runs out of tuples. Anyway, > I wrote something there that I think improves that. > > I feel like this patch is commit-worthy now. However, I'll leave it > for a few days, maybe until after the weekend as there's been a fair > bit of interest and I imagine someone will have comments to make. The only remaining question I have is whether or not costing needs to change, given the very significant speedup for datum sort. James
On Sat, 17 Jul 2021 at 01:14, James Coleman <jtc331@gmail.com> wrote:
> The only remaining question I have is whether or not costing needs to
> change, given the very significant speedup for datum sort.
I'm looking at cost_tuplesort and the only thing that I think might
make sense would be to adjust how the input_bytes value is calculated.
For now, that's done with the following function that's used in quite
a number of places.
static double
relation_byte_size(double tuples, int width)
{
return tuples * (MAXALIGN(width) + MAXALIGN(SizeofHeapTupleHeader));
}
It seems, at least in the case of Sort, that using SizeofHeapTupleHead
is just always wrong as it should be SizeofMinimalTupleHeader. I know
that's also the case for Memoize too. I've not checked the other
locations.
The only thing I can really see that we might do would be not add the
MAXALIGN(SizeofHeapTupleHeader) when there's just a single column.
We'd need to pass down the number of attributes from
create_sort_path() so we'd know when and when not to add that. I'm not
saying that we should do this. I'm just saying that I don't really see
what else we might do.
I can imagine another patch might just want to do a complete overhaul
of all locations that use relation_byte_size(). There are various
things that function just does not account for. e.g, the fact that we
allocate chunks in powers of 2 and that there's a chunk header added
on. Of course, "width" is just an estimate, so maybe trying to
calculate something too precisely wouldn't be too wise. However,
there's a bit of a chicken and the egg problem there as there'd be
little incentive to improve "width" unless we started making more
accurate use of the value.
Anyway, none of the above take into account that the Datum sort is
just a little faster, The only thing that exists in the existing cost
modal that we could use to adjust the cost of an in memory sort is the
comparison_cost. The problem there is that the comparison is exactly
the same in both Datum and Tuple sorts. The only thing that really
changes between Datum and Tuple sort is the fact that we don't make a
MinimalTuple when doing a Datum sort. The cost modal, unfortunately,
does not account for that. That kinda makes me think that we should
do nothing as if we start to account for making MemoryTuples then
we'll just penalise Tuple sorts and that might cause someone to be
upset.
David
Le samedi 17 juillet 2021, 10:36:09 CEST David Rowley a écrit :
> On Sat, 17 Jul 2021 at 01:14, James Coleman <jtc331@gmail.com> wrote:
> > The only remaining question I have is whether or not costing needs to
> > change, given the very significant speedup for datum sort.
>
> I'm looking at cost_tuplesort and the only thing that I think might
> make sense would be to adjust how the input_bytes value is calculated.
> For now, that's done with the following function that's used in quite
> a number of places.
>
> static double
> relation_byte_size(double tuples, int width)
> {
> return tuples * (MAXALIGN(width) + MAXALIGN(SizeofHeapTupleHeader));
> }
>
> It seems, at least in the case of Sort, that using SizeofHeapTupleHead
> is just always wrong as it should be SizeofMinimalTupleHeader. I know
> that's also the case for Memoize too. I've not checked the other
> locations.
>
> The only thing I can really see that we might do would be not add the
> MAXALIGN(SizeofHeapTupleHeader) when there's just a single column.
> We'd need to pass down the number of attributes from
> create_sort_path() so we'd know when and when not to add that. I'm not
> saying that we should do this. I'm just saying that I don't really see
> what else we might do.
>
> I can imagine another patch might just want to do a complete overhaul
> of all locations that use relation_byte_size(). There are various
> things that function just does not account for. e.g, the fact that we
> allocate chunks in powers of 2 and that there's a chunk header added
> on. Of course, "width" is just an estimate, so maybe trying to
> calculate something too precisely wouldn't be too wise. However,
> there's a bit of a chicken and the egg problem there as there'd be
> little incentive to improve "width" unless we started making more
> accurate use of the value.
>
> Anyway, none of the above take into account that the Datum sort is
> just a little faster, The only thing that exists in the existing cost
> modal that we could use to adjust the cost of an in memory sort is the
> comparison_cost. The problem there is that the comparison is exactly
> the same in both Datum and Tuple sorts. The only thing that really
> changes between Datum and Tuple sort is the fact that we don't make a
> MinimalTuple when doing a Datum sort. The cost modal, unfortunately,
> does not account for that. That kinda makes me think that we should
> do nothing as if we start to account for making MemoryTuples then
> we'll just penalise Tuple sorts and that might cause someone to be
> upset.
>
Thank you for taking the time to perform that analysis. I agree with you and
tt looks to me that if we were to start accounting for it, we would have to
make the change almost transparent for tuple sorts so that it stays roughly
the same, which is impossible since we don't apply the comparison cost to all
tuples but only to the number of tuples we actually expect to compare.
On the other hand, if we don't change the sorting cost and it just ends up
being faster in some cases I doubt anyone would complain.
--
Ronan Dunklau
On Sat, Jul 17, 2021 at 4:36 AM David Rowley <dgrowleyml@gmail.com> wrote:
>
> On Sat, 17 Jul 2021 at 01:14, James Coleman <jtc331@gmail.com> wrote:
> > The only remaining question I have is whether or not costing needs to
> > change, given the very significant speedup for datum sort.
>
> I'm looking at cost_tuplesort and the only thing that I think might
> make sense would be to adjust how the input_bytes value is calculated.
> For now, that's done with the following function that's used in quite
> a number of places.
>
> static double
> relation_byte_size(double tuples, int width)
> {
> return tuples * (MAXALIGN(width) + MAXALIGN(SizeofHeapTupleHeader));
> }
>
> It seems, at least in the case of Sort, that using SizeofHeapTupleHead
> is just always wrong as it should be SizeofMinimalTupleHeader. I know
> that's also the case for Memoize too. I've not checked the other
> locations.
>
> The only thing I can really see that we might do would be not add the
> MAXALIGN(SizeofHeapTupleHeader) when there's just a single column.
> We'd need to pass down the number of attributes from
> create_sort_path() so we'd know when and when not to add that. I'm not
> saying that we should do this. I'm just saying that I don't really see
> what else we might do.
>
> I can imagine another patch might just want to do a complete overhaul
> of all locations that use relation_byte_size(). There are various
> things that function just does not account for. e.g, the fact that we
> allocate chunks in powers of 2 and that there's a chunk header added
> on. Of course, "width" is just an estimate, so maybe trying to
> calculate something too precisely wouldn't be too wise. However,
> there's a bit of a chicken and the egg problem there as there'd be
> little incentive to improve "width" unless we started making more
> accurate use of the value.
>
> Anyway, none of the above take into account that the Datum sort is
> just a little faster, The only thing that exists in the existing cost
> modal that we could use to adjust the cost of an in memory sort is the
> comparison_cost. The problem there is that the comparison is exactly
> the same in both Datum and Tuple sorts. The only thing that really
> changes between Datum and Tuple sort is the fact that we don't make a
> MinimalTuple when doing a Datum sort. The cost modal, unfortunately,
> does not account for that. That kinda makes me think that we should
> do nothing as if we start to account for making MemoryTuples then
> we'll just penalise Tuple sorts and that might cause someone to be
> upset.
To be clear up front: I'm in favor of the patch, and I don't want to
put unnecessary stumbling blocks up for it getting committed. So if we
decide to proceed as is, that's fine with me.
But I'm not sure that the "cost model, unfortunately, does not account
for that" is entirely accurate. The end of cost_tuplesort contains a
cost "per extracted tuple". It does, however, note that it doesn't
charge cpu_tuple_cost, which maybe is what you'd want to fully
incorporate this into the model. But given this run_cost isn't about
accounting for comparison cost (that's been done earlier) which is the
part that'd be the same between tuple and datum sort, it seems to me
that we could lower the cpu_operator_cost here by something like 10%
if it's byref and 30% if it's byval?
James
On Tue, 20 Jul 2021 at 01:10, James Coleman <jtc331@gmail.com> wrote:
> To be clear up front: I'm in favor of the patch, and I don't want to
> put unnecessary stumbling blocks up for it getting committed. So if we
> decide to proceed as is, that's fine with me.
Thanks for making that clear.
> But I'm not sure that the "cost model, unfortunately, does not account
> for that" is entirely accurate. The end of cost_tuplesort contains a
> cost "per extracted tuple". It does, however, note that it doesn't
> charge cpu_tuple_cost, which maybe is what you'd want to fully
> incorporate this into the model. But given this run_cost isn't about
> accounting for comparison cost (that's been done earlier) which is the
> part that'd be the same between tuple and datum sort, it seems to me
> that we could lower the cpu_operator_cost here by something like 10%
> if it's byref and 30% if it's byval?
I failed to notice that last part that adds the additional cpu_operator_cost.
The default cpu_operator_cost is 0.0025, so with the 10k tuple
benchmark, that adds an additional charge of 25 to the total cost.
If we take test 1 from my results on v5 as an example:
> Test1 446.1 657.3 147.32%
Looking at explain for that query:
regression=# explain select two from tenk1 order by two offset 1000000;
QUERY PLAN
----------------------------------------------------------------------
Limit (cost=1133.95..1133.95 rows=1 width=4)
-> Sort (cost=1108.97..1133.95 rows=9995 width=4)
Sort Key: two
-> Seq Scan on tenk1 (cost=0.00..444.95 rows=9995 width=4)
(4 rows)
If we want the costs to reflect reality again here then we'd have
reduce 1133.95 by something like 147.32% (the performance difference).
That would bring the cost down to 769.72, which is way more than we
have to play with than the 25 that the cpu_operator_cost * tuples
gives us.
If we reduced the 25 by 30% in this case, we'd get 17.5 and the total
cost would become 1126.45. That's not great considering the actual
performance indicates that 769.72 would be a better number.
If we look at John's result for test 1: He saw 588 tps on master and
998 on v8. 1133.95 / 998.0 * 588.0 = 668.09, so we'd need even more
to get close to reality on that machine.
My thoughts are that the small surcharge added at the end of
cost_tuplesort() is just not enough for us to play with. I think to
get us closer to fixing this correctly would require a redesign of the
tuplesort costing entirely. I think that would be about an order of
magnitude more effort than this patch was, so I really feel like I
don't want to do this.
I kinda feel that since the comparison_cost is always just 2.0 *
cpu_operator_cost regardless of the number of columns in the sort,
then if we add too many new smarts to try and properly adjust for this
new optimization, unless we do a completly new cost modal for this,
then we might as well be putting lipstick on a pig.
It sounds like James mostly just mentioned the sorting just to ensure
it was properly considered and does not really feel strongly that it
needs to be adjusted. Does anyone else feel that we should be
adjusting it?
David
Em ter., 20 de jul. de 2021 às 05:35, David Rowley <dgrowleyml@gmail.com> escreveu:
On Tue, 20 Jul 2021 at 01:10, James Coleman <jtc331@gmail.com> wrote:
> To be clear up front: I'm in favor of the patch, and I don't want to
> put unnecessary stumbling blocks up for it getting committed. So if we
> decide to proceed as is, that's fine with me.
Thanks for making that clear.
> But I'm not sure that the "cost model, unfortunately, does not account
> for that" is entirely accurate. The end of cost_tuplesort contains a
> cost "per extracted tuple". It does, however, note that it doesn't
> charge cpu_tuple_cost, which maybe is what you'd want to fully
> incorporate this into the model. But given this run_cost isn't about
> accounting for comparison cost (that's been done earlier) which is the
> part that'd be the same between tuple and datum sort, it seems to me
> that we could lower the cpu_operator_cost here by something like 10%
> if it's byref and 30% if it's byval?
I failed to notice that last part that adds the additional cpu_operator_cost.
The default cpu_operator_cost is 0.0025, so with the 10k tuple
benchmark, that adds an additional charge of 25 to the total cost.
If we take test 1 from my results on v5 as an example:
> Test1 446.1 657.3 147.32%
Looking at explain for that query:
regression=# explain select two from tenk1 order by two offset 1000000;
QUERY PLAN
----------------------------------------------------------------------
Limit (cost=1133.95..1133.95 rows=1 width=4)
-> Sort (cost=1108.97..1133.95 rows=9995 width=4)
Sort Key: two
-> Seq Scan on tenk1 (cost=0.00..444.95 rows=9995 width=4)
(4 rows)
If we want the costs to reflect reality again here then we'd have
reduce 1133.95 by something like 147.32% (the performance difference).
That would bring the cost down to 769.72, which is way more than we
have to play with than the 25 that the cpu_operator_cost * tuples
gives us.
If we reduced the 25 by 30% in this case, we'd get 17.5 and the total
cost would become 1126.45. That's not great considering the actual
performance indicates that 769.72 would be a better number.
If we look at John's result for test 1: He saw 588 tps on master and
998 on v8. 1133.95 / 998.0 * 588.0 = 668.09, so we'd need even more
to get close to reality on that machine.
My thoughts are that the small surcharge added at the end of
cost_tuplesort() is just not enough for us to play with. I think to
get us closer to fixing this correctly would require a redesign of the
tuplesort costing entirely. I think that would be about an order of
magnitude more effort than this patch was, so I really feel like I
don't want to do this.
I understand that redesign would require a lot of work,
but why not do it step by step?
I kinda feel that since the comparison_cost is always just 2.0 *
cpu_operator_cost regardless of the number of columns in the sort,
then if we add too many new smarts to try and properly adjust for this
new optimization, unless we do a completly new cost modal for this,
then we might as well be putting lipstick on a pig.
I think one first step is naming this 2.0?
Does this magic number don't have a good name?
It sounds like James mostly just mentioned the sorting just to ensure
it was properly considered and does not really feel strongly that it
needs to be adjusted. Does anyone else feel that we should be
adjusting it?
I took a look at cost_tuplesort and I think that some small adjustments could be made as part of the improvement process.
It is attached.
It is attached.
1. long is a very problematic type; better int64?
2. 1024 can be int, not long?
3. 2 changed all to 2.0 (double)?
4. If disk-based is not needed, IMO can we avoid calling relation_byte_size?
Finally, to at least document (add comments) those conclusions,
would be nice, wouldn't it?
regards,
Ranier Vilela
Attachment
On Fri, 16 Jul 2021 at 15:44, David Rowley <dgrowleyml@gmail.com> wrote: > > On Fri, 16 Jul 2021 at 02:53, Ronan Dunklau <ronan.dunklau@aiven.io> wrote: > > Please find attached a v9 just moving the flag setting to ExecInitSort, and my > > apologies if I misunderstood your point. > > I took this and adjusted a few things and ended up with the attached patch. Attaching the same v10 patch again so the CF bot picks up the correct patch again. David
Attachment
On Tue, 20 Jul 2021 at 23:28, Ranier Vilela <ranier.vf@gmail.com> wrote: > I took a look at cost_tuplesort and I think that some small adjustments could be made as part of the improvement process. > It is attached. > 1. long is a very problematic type; better int64? > 2. 1024 can be int, not long? > 3. 2 changed all to 2.0 (double)? > 4. If disk-based is not needed, IMO can we avoid calling relation_byte_size? > > Finally, to at least document (add comments) those conclusions, > would be nice, wouldn't it? I don't think there's anything useful here. If you think otherwise, please take it to another thread. Also, I'd recommend at least compiling any patches you send to -hackers in the future. Going by the CF bot, this one does not. You might also want to read up on type promotion rules in C. Your sort_mem calculation change does not do what you think it does. Class it as homework to figure out what's wrong with it. No need to report your findings here. Just thought it would be useful for you to learn those things. David
On Tue, Jul 20, 2021 at 4:35 AM David Rowley <dgrowleyml@gmail.com> wrote: > > On Tue, 20 Jul 2021 at 01:10, James Coleman <jtc331@gmail.com> wrote: > > To be clear up front: I'm in favor of the patch, and I don't want to > > put unnecessary stumbling blocks up for it getting committed. So if we > > decide to proceed as is, that's fine with me. > > Thanks for making that clear. > > > But I'm not sure that the "cost model, unfortunately, does not account > > for that" is entirely accurate. The end of cost_tuplesort contains a > > cost "per extracted tuple". It does, however, note that it doesn't > > charge cpu_tuple_cost, which maybe is what you'd want to fully > > incorporate this into the model. But given this run_cost isn't about > > accounting for comparison cost (that's been done earlier) which is the > > part that'd be the same between tuple and datum sort, it seems to me > > that we could lower the cpu_operator_cost here by something like 10% > > if it's byref and 30% if it's byval? > > I failed to notice that last part that adds the additional cpu_operator_cost. > > The default cpu_operator_cost is 0.0025, so with the 10k tuple > benchmark, that adds an additional charge of 25 to the total cost. > > If we take test 1 from my results on v5 as an example: > > > Test1 446.1 657.3 147.32% > > Looking at explain for that query: > > regression=# explain select two from tenk1 order by two offset 1000000; > QUERY PLAN > ---------------------------------------------------------------------- > Limit (cost=1133.95..1133.95 rows=1 width=4) > -> Sort (cost=1108.97..1133.95 rows=9995 width=4) > Sort Key: two > -> Seq Scan on tenk1 (cost=0.00..444.95 rows=9995 width=4) > (4 rows) > > If we want the costs to reflect reality again here then we'd have > reduce 1133.95 by something like 147.32% (the performance difference). > That would bring the cost down to 769.72, which is way more than we > have to play with than the 25 that the cpu_operator_cost * tuples > gives us. > > If we reduced the 25 by 30% in this case, we'd get 17.5 and the total > cost would become 1126.45. That's not great considering the actual > performance indicates that 769.72 would be a better number. > > If we look at John's result for test 1: He saw 588 tps on master and > 998 on v8. 1133.95 / 998.0 * 588.0 = 668.09, so we'd need even more > to get close to reality on that machine. > > My thoughts are that the small surcharge added at the end of > cost_tuplesort() is just not enough for us to play with. I think to > get us closer to fixing this correctly would require a redesign of the > tuplesort costing entirely. I think that would be about an order of > magnitude more effort than this patch was, so I really feel like I > don't want to do this. > > I kinda feel that since the comparison_cost is always just 2.0 * > cpu_operator_cost regardless of the number of columns in the sort, > then if we add too many new smarts to try and properly adjust for this > new optimization, unless we do a completly new cost modal for this, > then we might as well be putting lipstick on a pig. > > It sounds like James mostly just mentioned the sorting just to ensure > it was properly considered and does not really feel strongly that it > needs to be adjusted. Does anyone else feel that we should be > adjusting it? Thanks for doing the math measuring how much we could impact things. I'm +lots on getting this committed as is. Thanks all for your work on the improvement! James
On Wed, 21 Jul 2021 at 13:39, James Coleman <jtc331@gmail.com> wrote: > Thanks for doing the math measuring how much we could impact things. > > I'm +lots on getting this committed as is. Ok good. I plan on taking a final look at the v10 patch tomorrow morning NZ time (about 12 hours from now) and if all is well, I'll push it. If anyone feels differently, please let me know before then. David
From: David Rowley <dgrowleyml@gmail.com>
> On Wed, 21 Jul 2021 at 13:39, James Coleman <jtc331@gmail.com> wrote:
> > Thanks for doing the math measuring how much we could impact things.
> >
> > I'm +lots on getting this committed as is.
>
> Ok good. I plan on taking a final look at the v10 patch tomorrow morning NZ
> time (about 12 hours from now) and if all is well, I'll push it.
>
> If anyone feels differently, please let me know before then.
Hi,
I noticed a minor thing about the v10 patch.
-
- for (;;)
+ if (node->datumSort)
{
- slot = ExecProcNode(outerNode);
-
- if (TupIsNull(slot))
- break;
-
- tuplesort_puttupleslot(tuplesortstate, slot);
+ for (;;)
+ {
+ slot = ExecProcNode(outerNode);
+
+ if (TupIsNull(slot))
+ break;
+ slot_getsomeattrs(slot, 1);
+ tuplesort_putdatum(tuplesortstate,
+ slot->tts_values[0],
+ slot->tts_isnull[0]);
+ }
+ }
+ else
+ {
+ for (;;)
+ {
+ slot = ExecProcNode(outerNode);
+
+ if (TupIsNull(slot))
+ break;
+ tuplesort_puttupleslot(tuplesortstate, slot);
+ }
The above seems can be shorter like the following ?
for (;;)
{
slot = ExecProcNode(outerNode);
if (TupIsNull(slot))
break;
if (node->datumSort)
{
slot_getsomeattrs(slot, 1);
tuplesort_putdatum(tuplesortstate,
slot->tts_values[0],
slot->tts_isnull[0]);
}
else
tuplesort_puttupleslot(tuplesortstate, slot);
}
Best regards,
houzj
On Thu, 22 Jul 2021 at 12:27, houzj.fnst@fujitsu.com
<houzj.fnst@fujitsu.com> wrote:
> The above seems can be shorter like the following ?
>
> for (;;)
> {
> slot = ExecProcNode(outerNode);
> if (TupIsNull(slot))
> break;
> if (node->datumSort)
> {
> slot_getsomeattrs(slot, 1);
> tuplesort_putdatum(tuplesortstate,
> slot->tts_values[0],
> slot->tts_isnull[0]);
> }
> else
> tuplesort_puttupleslot(tuplesortstate, slot);
> }
I don't think that's a good change. It puts the branch inside the
loop the pulls all tuples from the subplan. Given the loop is likely
to be very hot combined with the fact that it's so simple, I'd much
rather have two separate loops to keep the extra branch outside the
loop. It's true the branch predictor is likely to get the prediction
correct on each iteration, but unless the compiler rewrites this into
two loops then the comparison and jump must be done per loop.
David
On July 22, 2021 8:38 AM David Rowley <dgrowleyml@gmail.com>
> On Thu, 22 Jul 2021 at 12:27, houzj.fnst@fujitsu.com <houzj.fnst@fujitsu.com>
> wrote:
> > The above seems can be shorter like the following ?
> >
> > for (;;)
> > {
> > slot = ExecProcNode(outerNode);
> > if (TupIsNull(slot))
> > break;
> > if (node->datumSort)
> > {
> > slot_getsomeattrs(slot, 1);
> > tuplesort_putdatum(tuplesortstate,
> > slot->tts_values[0],
> > slot->tts_isnull[0]);
> > }
> > else
> > tuplesort_puttupleslot(tuplesortstate, slot); }
>
> I don't think that's a good change. It puts the branch inside the loop the pulls
> all tuples from the subplan. Given the loop is likely to be very hot combined
> with the fact that it's so simple, I'd much rather have two separate loops to
> keep the extra branch outside the loop. It's true the branch predictor is likely
> to get the prediction correct on each iteration, but unless the compiler
> rewrites this into two loops then the comparison and jump must be done per
> loop.
Ah, you are right, I missed that. Thanks for the explanation.
Best regards,
houzj
On Wed, 21 Jul 2021 at 22:09, David Rowley <dgrowleyml@gmail.com> wrote: > > On Wed, 21 Jul 2021 at 13:39, James Coleman <jtc331@gmail.com> wrote: > > Thanks for doing the math measuring how much we could impact things. > > > > I'm +lots on getting this committed as is. > > Ok good. I plan on taking a final look at the v10 patch tomorrow > morning NZ time (about 12 hours from now) and if all is well, I'll > push it. Pushed. David