Thread: Optimising compactify_tuples()
Hi, With [1] applied so that you can get crash recovery to be CPU bound with a pgbench workload, we spend an awful lot of time in qsort(), called from compactify_tuples(). I tried replacing that with a specialised sort, and I got my test crash recovery time from ~55.5s down to ~49.5s quite consistently. I've attached a draft patch. The sort_utils.h thing (which I've proposed before in another context where it didn't turn out to be needed) probably needs better naming, and a few more parameterisations so that it could entirely replace the existing copies of the algorithm rather than adding yet one more. The header also contains some more related algorithms that don't have a user right now; maybe I should remove them. While writing this email, I checked the archives and discovered that a couple of other people have complained about this hot spot before and proposed faster sorts already[2][3], and then there was a wide ranging discussion of various options which ultimately seemed to conclude that we should do what I'm now proposing ... and then it stalled. The present work is independent; I wrote this for some other sorting problem, and then tried it out here when perf told me that it was the next thing to fix to make recovery go faster. So I guess what I'm really providing here is the compelling workload and numbers that were perhaps missing from that earlier thread, but I'm open to other solutions too. [1] https://commitfest.postgresql.org/29/2669/ [2] https://www.postgresql.org/message-id/flat/3c6ff1d3a2ff429ee80d0031e6c69cb7%40postgrespro.ru [3] https://www.postgresql.org/message-id/flat/546B89DE.7030906%40vmware.com
Attachment
On Mon, Aug 17, 2020 at 4:01 AM Thomas Munro <thomas.munro@gmail.com> wrote: > While writing this email, I checked the archives and discovered that a > couple of other people have complained about this hot spot before and > proposed faster sorts already[2][3], and then there was a wide ranging > discussion of various options which ultimately seemed to conclude that > we should do what I'm now proposing ... and then it stalled. I saw compactify_tuples() feature prominently in profiles when testing the deduplication patch. We changed the relevant nbtdedup.c logic to use a temp page rather than incrementally rewriting the authoritative page in shared memory, which sidestepped the problem. I definitely think that we should have something like this, though. It's a relatively easy win. There are plenty of workloads that spend lots of time on pruning. -- Peter Geoghegan
On Tue, Aug 18, 2020 at 6:53 AM Peter Geoghegan <pg@bowt.ie> wrote: > I definitely think that we should have something like this, though. > It's a relatively easy win. There are plenty of workloads that spend > lots of time on pruning. Alright then, here's an attempt to flesh the idea out a bit more, and replace the three other copies of qsort() while I'm at it.
Attachment
On Wed, Aug 19, 2020 at 11:41 PM Thomas Munro <thomas.munro@gmail.com> wrote: > On Tue, Aug 18, 2020 at 6:53 AM Peter Geoghegan <pg@bowt.ie> wrote: > > I definitely think that we should have something like this, though. > > It's a relatively easy win. There are plenty of workloads that spend > > lots of time on pruning. > > Alright then, here's an attempt to flesh the idea out a bit more, and > replace the three other copies of qsort() while I'm at it. I fixed up the copyright messages, and removed some stray bits of build scripting relating to the Perl-generated file. Added to commitfest.
Attachment
On Thu, 20 Aug 2020 at 11:28, Thomas Munro <thomas.munro@gmail.com> wrote:
> I fixed up the copyright messages, and removed some stray bits of
> build scripting relating to the Perl-generated file. Added to
> commitfest.
I'm starting to look at this. So far I've only just done a quick
performance test on it. With the workload I ran, using 0001+0002.
The test replayed ~2.2 GB of WAL. master took 148.581 seconds and
master+0001+0002 took 115.588 seconds. That's about 28% faster. Pretty
nice!
I found running a lower heap fillfactor will cause quite a few more
heap cleanups to occur. Perhaps that's one of the reasons the speedup
I got was more than the 12% you reported.
More details of the test:
Setup:
drowley@amd3990x:~$ cat recoverbench.sh
#!/bin/bash
pg_ctl stop -D pgdata -m smart
pg_ctl start -D pgdata -l pg.log -w
psql -c "drop table if exists t1;" postgres > /dev/null
psql -c "create table t1 (a int primary key, b int not null) with
(fillfactor = 85);" postgres > /dev/null
psql -c "insert into t1 select x,0 from generate_series(1,10000000)
x;" postgres > /dev/null
psql -c "drop table if exists log_wal;" postgres > /dev/null
psql -c "create table log_wal (lsn pg_lsn not null);" postgres > /dev/null
psql -c "insert into log_wal values(pg_current_wal_lsn());" postgres > /dev/null
pgbench -n -f update.sql -t 60000 -c 200 -j 200 -M prepared postgres > /dev/null
psql -c "select 'Used ' ||
pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), lsn)) || ' of
WAL' from log_wal limit 1;" postgres
pg_ctl stop -D pgdata -m immediate -w
echo Starting Postgres...
pg_ctl start -D pgdata -l pg.log
drowley@amd3990x:~$ cat update.sql
\set i random(1,10000000)
update t1 set b = b+1 where a = :i;
Results:
master
Recovery times are indicated in the postgresql log:
2020-09-06 22:38:58.992 NZST [6487] LOG: redo starts at 3/16E4A988
2020-09-06 22:41:27.570 NZST [6487] LOG: invalid record length at
3/F67F8B48: wanted 24, got 0
2020-09-06 22:41:27.573 NZST [6487] LOG: redo done at 3/F67F8B20
recovery duration = 00:02:28.581
drowley@amd3990x:~$ ./recoverbench.sh
waiting for server to shut down.... done
server stopped
waiting for server to start.... done
server started
?column?
---------------------
Used 2333 MB of WAL
(1 row)
waiting for server to shut down.... done
server stopped
Starting Postgres...
recovery profile:
28.79% postgres postgres [.] pg_qsort
13.58% postgres postgres [.] itemoffcompare
12.27% postgres postgres [.] PageRepairFragmentation
8.26% postgres libc-2.31.so [.] 0x000000000018e48f
5.90% postgres postgres [.] swapfunc
4.86% postgres postgres [.] hash_search_with_hash_value
2.95% postgres postgres [.] XLogReadBufferExtended
1.83% postgres postgres [.] PinBuffer
1.80% postgres postgres [.] compactify_tuples
1.71% postgres postgres [.] med3
0.99% postgres postgres [.] hash_bytes
0.90% postgres libc-2.31.so [.] 0x000000000018e470
0.89% postgres postgres [.] StartupXLOG
0.84% postgres postgres [.] XLogReadRecord
0.72% postgres postgres [.] LWLockRelease
0.71% postgres postgres [.] PageGetHeapFreeSpace
0.61% postgres libc-2.31.so [.] 0x000000000018e499
0.50% postgres postgres [.] heap_xlog_update
0.50% postgres postgres [.] DecodeXLogRecord
0.50% postgres postgres [.] pg_comp_crc32c_sse42
0.45% postgres postgres [.] LWLockAttemptLock
0.40% postgres postgres [.] ReadBuffer_common
0.40% postgres [kernel.kallsyms] [k] copy_user_generic_string
0.36% postgres libc-2.31.so [.] 0x000000000018e49f
0.33% postgres postgres [.] SlruSelectLRUPage
0.32% postgres postgres [.] PageAddItemExtended
0.31% postgres postgres [.] ReadPageInternal
Patched v2-0001 + v2-0002:
Recovery times are indicated in the postgresql log:
2020-09-06 22:54:25.532 NZST [13252] LOG: redo starts at 3/F67F8C70
2020-09-06 22:56:21.120 NZST [13252] LOG: invalid record length at
4/D633FCD0: wanted 24, got 0
2020-09-06 22:56:21.120 NZST [13252] LOG: redo done at 4/D633FCA8
recovery duration = 00:01:55.588
drowley@amd3990x:~$ ./recoverbench.sh
waiting for server to shut down.... done
server stopped
waiting for server to start.... done
server started
?column?
---------------------
Used 2335 MB of WAL
(1 row)
waiting for server to shut down.... done
server stopped
Starting Postgres...
recovery profile:
32.29% postgres postgres [.] qsort_itemoff
17.73% postgres postgres [.] PageRepairFragmentation
10.98% postgres libc-2.31.so [.] 0x000000000018e48f
5.54% postgres postgres [.] hash_search_with_hash_value
3.60% postgres postgres [.] XLogReadBufferExtended
2.32% postgres postgres [.] compactify_tuples
2.14% postgres postgres [.] PinBuffer
1.39% postgres postgres [.] PageGetHeapFreeSpace
1.38% postgres postgres [.] hash_bytes
1.36% postgres postgres [.] qsort_itemoff_med3
0.94% postgres libc-2.31.so [.] 0x000000000018e499
0.89% postgres postgres [.] XLogReadRecord
0.74% postgres postgres [.] LWLockRelease
0.74% postgres postgres [.] DecodeXLogRecord
0.73% postgres postgres [.] heap_xlog_update
0.66% postgres postgres [.] LWLockAttemptLock
0.65% postgres libc-2.31.so [.] 0x000000000018e470
0.64% postgres postgres [.] pg_comp_crc32c_sse42
0.63% postgres postgres [.] StartupXLOG
0.61% postgres [kernel.kallsyms] [k] copy_user_generic_string
0.60% postgres postgres [.] PageAddItemExtended
0.60% postgres libc-2.31.so [.] 0x000000000018e49f
0.56% postgres libc-2.31.so [.] 0x000000000018e495
0.54% postgres postgres [.] ReadBuffer_common
Settings:
shared_buffers = 10GB
checkpoint_timeout = 1 hour
max_wal_size = 100GB
Hardware:
AMD 3990x
Samsung 970 EVO SSD
64GB DDR4 3600MHz
I'll spend some time looking at the code soon.
David
On Sun, 6 Sep 2020 at 23:37, David Rowley <dgrowleyml@gmail.com> wrote: > The test replayed ~2.2 GB of WAL. master took 148.581 seconds and > master+0001+0002 took 115.588 seconds. That's about 28% faster. Pretty > nice! I was wondering today if we could just get rid of the sort in compactify_tuples() completely. It seems to me that the existing sort is there just so that the memmove() is done in order of tuple at the end of the page first. We seem to be just shunting all the tuples to the end of the page so we need to sort the line items in reverse offset so as not to overwrite memory for other tuples during the copy. I wondered if we could get around that just by having another buffer somewhere and memcpy the tuples into that first then copy the tuples out that buffer back into the page. No need to worry about the order we do that in as there's no chance to overwrite memory belonging to other tuples. Doing that gives me 79.166 seconds in the same recovery test. Or about 46% faster, instead of 22% (I mistakenly wrote 28% yesterday) The top of perf report says: 24.19% postgres postgres [.] PageRepairFragmentation 8.37% postgres postgres [.] hash_search_with_hash_value 7.40% postgres libc-2.31.so [.] 0x000000000018e74b 5.59% postgres libc-2.31.so [.] 0x000000000018e741 5.49% postgres postgres [.] XLogReadBufferExtended 4.05% postgres postgres [.] compactify_tuples 3.27% postgres postgres [.] PinBuffer 2.88% postgres libc-2.31.so [.] 0x000000000018e470 2.02% postgres postgres [.] hash_bytes (I'll need to figure out why libc's debug symbols are not working) I was thinking that there might be a crossover point to where this method becomes faster than the sort method. e.g sorting 1 tuple is pretty cheap, but copying the memory for the entire tuple space might be expensive as that includes the tuples we might be getting rid of. So if we did go down that path we might need some heuristics to decide which method is likely best. Maybe that's based on the number of tuples, I'm not really sure. I've not made any attempt to try to give it a worst-case workload to see if there is a crossover point that's worth worrying about. The attached patch is what I used to test this. It kinda goes and sticks a page-sized variable on the stack, which is not exactly ideal. I think we'd likely want to figure some other way to do that, but I just don't know what that would look like yet. I just put the attached together quickly to test out the idea. (I don't want to derail the sort improvements here. I happen to think those are quite important improvements, so I'll continue to review that patch still. Longer term, we might just end up with something slightly different for compactify_tuples) David
Attachment
On Mon, Sep 7, 2020 at 7:48 PM David Rowley <dgrowleyml@gmail.com> wrote: > I was wondering today if we could just get rid of the sort in > compactify_tuples() completely. It seems to me that the existing sort > is there just so that the memmove() is done in order of tuple at the > end of the page first. We seem to be just shunting all the tuples to > the end of the page so we need to sort the line items in reverse > offset so as not to overwrite memory for other tuples during the copy. > > I wondered if we could get around that just by having another buffer > somewhere and memcpy the tuples into that first then copy the tuples > out that buffer back into the page. No need to worry about the order > we do that in as there's no chance to overwrite memory belonging to > other tuples. > > Doing that gives me 79.166 seconds in the same recovery test. Or about > 46% faster, instead of 22% (I mistakenly wrote 28% yesterday) Wow. One thought is that if we're going to copy everything out and back in again, we might want to consider doing it in a memory-prefetcher-friendly order. Would it be a good idea to rearrange the tuples to match line pointer order, so that the copying work and also later sequential scans are in a forward direction? The copying could also perhaps be done with single memcpy() for ranges of adjacent tuples. Another thought is that it might be possible to identify some easy cases that it can handle with an alternative in-place shifting algorithm without having to go to the copy-out-and-back-in path. For example, when the offset order already matches line pointer order but some dead tuples just need to be squeezed out by shifting ranges of adjacent tuples, and maybe some slightly more complicated cases, but nothing requiring hard work like sorting. > (I don't want to derail the sort improvements here. I happen to think > those are quite important improvements, so I'll continue to review > that patch still. Longer term, we might just end up with something > slightly different for compactify_tuples) Yeah. Perhaps qsort specialisation needs to come back in a new thread with a new use case.
On Tue, 8 Sep 2020 at 12:08, Thomas Munro <thomas.munro@gmail.com> wrote: > > One thought is that if we're going to copy everything out and back in > again, we might want to consider doing it in a > memory-prefetcher-friendly order. Would it be a good idea to > rearrange the tuples to match line pointer order, so that the copying > work and also later sequential scans are in a forward direction? That's an interesting idea but wouldn't that require both the copy to the separate buffer *and* a qsort? That's the worst of both implementations. We'd need some other data structure too in order to get the index of the sorted array by reverse lineitem point, which might require an additional array and an additional sort. > The > copying could also perhaps be done with single memcpy() for ranges of > adjacent tuples. I wonder if the additional code required to check for that would be cheaper than the additional function call. If it was then it might be worth trying, but since the tuples can be in any random order then it's perhaps not likely to pay off that often. I'm not really sure how often adjacent line items will also be neighbouring tuples for pages we call compactify_tuples() for. It's certainly going to be common with INSERT only tables, but if we're calling compactify_tuples() then it's not read-only. > Another thought is that it might be possible to > identify some easy cases that it can handle with an alternative > in-place shifting algorithm without having to go to the > copy-out-and-back-in path. For example, when the offset order already > matches line pointer order but some dead tuples just need to be > squeezed out by shifting ranges of adjacent tuples, and maybe some > slightly more complicated cases, but nothing requiring hard work like > sorting. It's likely worth experimenting. The only thing is that the workload I'm using seems to end up with the tuples with line items not in the same order as the tuple offset. So adding a precheck to check the ordering will regress the test I'm doing. We'd need to see if there is any other workload that would keep the tuples more in order then determine how likely that is to occur in the real world. > > (I don't want to derail the sort improvements here. I happen to think > > those are quite important improvements, so I'll continue to review > > that patch still. Longer term, we might just end up with something > > slightly different for compactify_tuples) > > Yeah. Perhaps qsort specialisation needs to come back in a new thread > with a new use case. hmm, yeah, perhaps that's a better way given the subject here is about compactify_tuples() David
On Mon, 7 Sep 2020 at 19:47, David Rowley <dgrowleyml@gmail.com> wrote: > I wondered if we could get around that just by having another buffer > somewhere and memcpy the tuples into that first then copy the tuples > out that buffer back into the page. No need to worry about the order > we do that in as there's no chance to overwrite memory belonging to > other tuples. > > Doing that gives me 79.166 seconds in the same recovery test. Or about > 46% faster, instead of 22% (I mistakenly wrote 28% yesterday) I did some more thinking about this and considered if there's a way to just get rid of the sorting version of compactify_tuples() completely. In the version from yesterday, I fell back on the sort version for when more than half the tuples from the page were being pruned. I'd thought that in this case copying out *all* of the page from pd_upper up to the pd_special (the tuple portion of the page) would maybe be more costly since that would include (needlessly) copying all the pruned tuples too. The sort also becomes cheaper in that case since the number of items to sort is less, hence I thought it was a good idea to keep the old version for some cases. However, I now think we can just fix this by conditionally copying all tuples when in 1 big memcpy when not many tuples have been pruned and when more tuples are pruned we can just do individual memcpys into the separate buffer. I wrote a little .c program to try to figure out of there's some good cut off point to where one method becomes better than the other and I find that generally if we're pruning away about 75% of tuples then doing a memcpy() per non-pruned tuple is faster, otherwise, it seems better just to copy the entire tuple area of the page. See attached compact_test.c I ran this and charted the cut off at (nitems < totaltups / 4) and (nitems < totaltups / 2), and nitems < 16) ./compact_test 32 192 ./compact_test 64 96 ./compact_test 128 48 ./compact_test 256 24 ./compact_test 512 12 The / 4 one gives me the graphs with the smallest step when the method switches. See attached 48_tuples_per_page.png for comparison. I've so far come up with the attached compactify_tuples_dgr_v2.patch.txt. Thomas pointed out to me off-list that using PGAlignedBlock is the general way to allocate a page-sized data on the stack. I'm still classing this patch as PoC grade. I'll need to look a bit harder at the correctness of it all. I did spend quite a bit of time trying to find a case where this is slower than master's version. I can't find a case where there's any noticeable slowdown. Using the same script from [1] I tried a few variations of the t1 table by adding an additional column to pad out the tuple to make it wider. Obviously a wider tuple means fewer tuples on the page so less tuples for master's qsort to sort during compactify_tuples(). I did manage to squeeze a bit more performance out of the test cases. Yesterday I got 79.166 seconds. This version gets me 76.623 seconds. Here are the results of the various tuple widths: narrow width row test: insert into t1 select x,0 from generate_series(1,10000000) x; (32 byte tuples) patched: 76.623 master: 137.593 medium width row test: insert into t1 select x,0,md5(x::text) || md5((x+1)::Text) from generate_series(1,10000000) x; (about 64 byte tuples) patched: 64.411 master: 95.576 wide row test: insert into t1 select x,0,(select string_agg(md5(y::text),'') from generate_Series(x,x+30) y) from generate_series(1,1000000)x; (1024 byte tuples) patched: 88.653 master: 90.077 Changing the test so instead of having 10 million rows in the table and updating a random row 12 million times. I put just 10 rows in the table and updated them 12 million times. This results in compactify_tuples() pruning all but 1 row (since autovac can't keep up with this, each row does end up on a page by itself). I wanted to ensure I didn't regress a workload that master's qsort() version would have done very well at. qsorting 1 element is pretty fast. 10-row narrow test: patched: 10.633 <--- small regression master: 10.366 I could special case this and do a memmove without copying the tuple to another buffer, but I don't think the slowdown is enough to warrant having such a special case. Another thing I tried was to instead of compacting the page in compactify_tuples(), I just get rid of that function and did the compacting in the existing loop in PageRepairFragmentation(). This does require changing the ERROR check to a PANIC since we may have already started shuffling tuples around when we find the corrupted line pointer. However, I was just unable to make this faster than the attached version. I'm still surprised at this as I can completely get rid of the itemidbase array. The best run-time I got with this method out the original test was 86 seconds, so 10 seconds slower than what the attached can do. So I threw that idea away. David [1] https://www.postgresql.org/message-id/CAApHDvoKwqAzhiuxEt8jSquPJKDpH8DNUZDFUSX9P7DXrJdc3Q@mail.gmail.com
Attachment
{kind=link}
On Wed, Sep 9, 2020 at 3:47 AM David Rowley <dgrowleyml@gmail.com> wrote: > On Tue, 8 Sep 2020 at 12:08, Thomas Munro <thomas.munro@gmail.com> wrote: > > One thought is that if we're going to copy everything out and back in > > again, we might want to consider doing it in a > > memory-prefetcher-friendly order. Would it be a good idea to > > rearrange the tuples to match line pointer order, so that the copying > > work and also later sequential scans are in a forward direction? > > That's an interesting idea but wouldn't that require both the copy to > the separate buffer *and* a qsort? That's the worst of both > implementations. We'd need some other data structure too in order to > get the index of the sorted array by reverse lineitem point, which > might require an additional array and an additional sort. Well I may not have had enough coffee yet but I thought you'd just have to spin though the item IDs twice. Once to compute sum(lp_len) so you can compute the new pd_upper, and the second time to copy the tuples from their random locations on the temporary page to new sequential locations, so that afterwards item ID order matches offset order.
On Wed, 9 Sep 2020 at 05:38, Thomas Munro <thomas.munro@gmail.com> wrote: > > On Wed, Sep 9, 2020 at 3:47 AM David Rowley <dgrowleyml@gmail.com> wrote: > > On Tue, 8 Sep 2020 at 12:08, Thomas Munro <thomas.munro@gmail.com> wrote: > > > One thought is that if we're going to copy everything out and back in > > > again, we might want to consider doing it in a > > > memory-prefetcher-friendly order. Would it be a good idea to > > > rearrange the tuples to match line pointer order, so that the copying > > > work and also later sequential scans are in a forward direction? > > > > That's an interesting idea but wouldn't that require both the copy to > > the separate buffer *and* a qsort? That's the worst of both > > implementations. We'd need some other data structure too in order to > > get the index of the sorted array by reverse lineitem point, which > > might require an additional array and an additional sort. > > Well I may not have had enough coffee yet but I thought you'd just > have to spin though the item IDs twice. Once to compute sum(lp_len) > so you can compute the new pd_upper, and the second time to copy the > tuples from their random locations on the temporary page to new > sequential locations, so that afterwards item ID order matches offset > order. I think you were adequately caffeinated. You're right that this is fairly simple to do, but it looks even more simple than looping twice of the array. I think it's just a matter of looping over the itemidbase backwards and putting the higher itemid tuples at the end of the page. I've done it this way in the attached patch. I also added a presorted path which falls back on doing memmoves without the temp buffer when the itemidbase array indicates that higher lineitems all have higher offsets. I'm doing the presort check in the calling function since that loops over the lineitems already. We can just memmove the tuples in reverse order without overwriting any yet to be moved tuples when these are in order. Also, I added code to collapse the memcpy and memmoves for adjacent tuples so that we perform the minimal number of calls to those functions. Once we've previously compacted a page it seems that the code is able to reduce the number of calls significantly. I added some logging and reviewed at after a run of the benchmark and saw that for about 192 tuples we're mostly just doing 3-4 memcpys in the non-presorted path and just 2 memmoves, for the presorted code path. I also found that in my test the presorted path was only taken 12.39% of the time. Trying with 120 million UPDATEs instead of 12 million in the test ended up reducing this to just 10.89%. It seems that it'll just be 1 or 2 tuples spoiling it since new tuples will still be added earlier in the page after we free up space to add more. I also experimented seeing what would happen if I also tried to collapse the memcpys for copying to the temp buffer. The performance got a little worse from doing that. So I left that code #ifdef'd out With the attached v3, performance is better. The test now runs recovery 65.6 seconds, vs master's 148.5 seconds. So about 2.2x faster. We should probably consider what else can be done to try to write pages with tuples for earlier lineitems earlier in the page. VACUUM FULLs and friends will switch back to the opposite order when rewriting the heap. Also fixed my missing libc debug symbols: 24.90% postgres postgres [.] PageRepairFragmentation 15.26% postgres libc-2.31.so [.] __memmove_avx_unaligned_erms 9.61% postgres postgres [.] hash_search_with_hash_value 8.03% postgres postgres [.] compactify_tuples 6.25% postgres postgres [.] XLogReadBufferExtended 3.74% postgres postgres [.] PinBuffer 2.25% postgres postgres [.] hash_bytes 1.79% postgres postgres [.] heap_xlog_update 1.47% postgres postgres [.] LWLockRelease 1.44% postgres postgres [.] XLogReadRecord 1.33% postgres postgres [.] PageGetHeapFreeSpace 1.16% postgres postgres [.] DecodeXLogRecord 1.13% postgres postgres [.] pg_comp_crc32c_sse42 1.12% postgres postgres [.] LWLockAttemptLock 1.09% postgres postgres [.] StartupXLOG 0.90% postgres postgres [.] ReadBuffer_common 0.84% postgres postgres [.] SlruSelectLRUPage 0.74% postgres libc-2.31.so [.] __memcmp_avx2_movbe 0.68% postgres [kernel.kallsyms] [k] copy_user_generic_string 0.66% postgres postgres [.] PageAddItemExtended 0.66% postgres postgres [.] PageIndexTupleOverwrite 0.62% postgres postgres [.] smgropen 0.60% postgres postgres [.] ReadPageInternal 0.57% postgres postgres [.] GetPrivateRefCountEntry 0.52% postgres postgres [.] heap_redo 0.51% postgres postgres [.] AdvanceNextFullTransactionIdPastXid David
Attachment
On Thu, Sep 10, 2020 at 2:34 AM David Rowley <dgrowleyml@gmail.com> wrote: > I think you were adequately caffeinated. You're right that this is > fairly simple to do, but it looks even more simple than looping twice > of the array. I think it's just a matter of looping over the > itemidbase backwards and putting the higher itemid tuples at the end > of the page. I've done it this way in the attached patch. Yeah, I was wondering how to make as much of the algorithm work in a memory-forwards direction as possible (even the item pointer access), but it was just a hunch. Once you have the adjacent-tuple merging thing so you're down to just a couple of big memcpy calls, it's probably moot anyway. > I also added a presorted path which falls back on doing memmoves > without the temp buffer when the itemidbase array indicates that > higher lineitems all have higher offsets. I'm doing the presort check > in the calling function since that loops over the lineitems already. > We can just memmove the tuples in reverse order without overwriting > any yet to be moved tuples when these are in order. Great. I wonder if we could also identify a range at the high end that is already correctly sorted and maximally compacted so it doesn't even need to be copied out. + * Do the tuple compactification. Collapse memmove calls for adjacent + * tuples. s/memmove/memcpy/ > With the attached v3, performance is better. The test now runs > recovery 65.6 seconds, vs master's 148.5 seconds. So about 2.2x > faster. On my machine I'm seeing 57s, down from 86s on unpatched master, for the simple pgbench workload from https://github.com/macdice/redo-bench/. That's not quite what you're reporting but it still blows the doors off the faster sorting patch, which does it in 74s. > We should probably consider what else can be done to try to write > pages with tuples for earlier lineitems earlier in the page. VACUUM > FULLs and friends will switch back to the opposite order when > rewriting the heap. Yeah, and also bulk inserts/COPY. Ultimately if we flipped our page format on its head that'd come for free, but that'd be a bigger project with more ramifications. So one question is whether we want to do the order-reversing as part of this patch, or wait for a more joined-up project to make lots of code paths collude on making scan order match memory order (corellation = 1). Most or all of the gain from your patch would presumably still apply if did the exact opposite and forced offset order to match reverse-item ID order (correlation = -1), which also happens to be the initial state when you insert tuples today; you'd still tend towards a state that allows nice big memmov/memcpy calls during page compaction. IIUC currently we start with correlation -1 and then tend towards correlation = 0 after many random updates because we can't change the order, so it gets scrambled over time. I'm not sure what I think about that. PS You might as well post future patches with .patch endings so that the cfbot tests them; it seems pretty clear now that a patch to optimise sorting (as useful as it may be for future work) can't beat a patch to skip it completely. I took the liberty of switching the author and review names in the commitfest entry to reflect this.
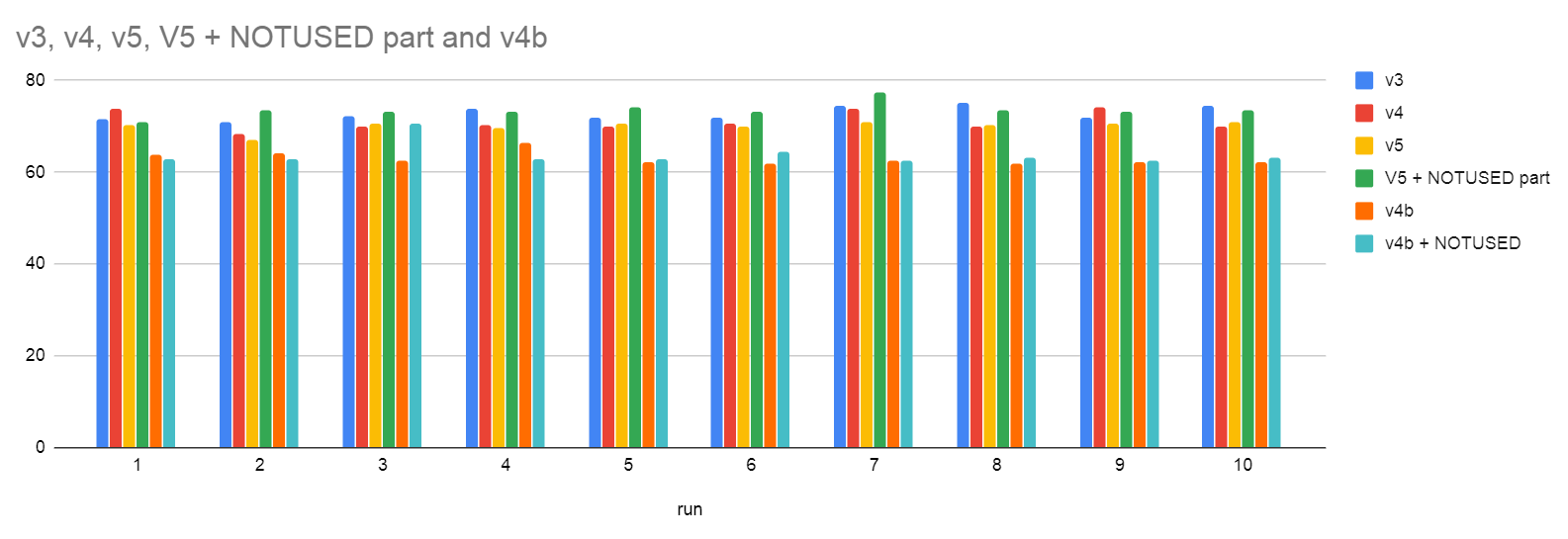
On Thu, 10 Sep 2020 at 10:40, Thomas Munro <thomas.munro@gmail.com> wrote: > > I wonder if we could also identify a range at the high end that is > already correctly sorted and maximally compacted so it doesn't even > need to be copied out. I've experimented quite a bit with this patch today. I think I've tested every idea you've mentioned here, so there's quite a lot of information to share. I did write code to skip the copy to the separate buffer for tuples that are already in the correct place and with a version of the patch which keeps tuples in their traditional insert order (later lineitem's tuple located earlier in the page) I see a generally a very large number of tuples being skipped with this method. See attached v4b_skipped_tuples.png. The vertical axis is the number of compactify_tuple() calls during the benchmark where we were able to skip that number of tuples. The average skipped tuples overall calls during recovery was 81 tuples, so we get to skip about half the tuples in the page doing this on this benchmark. > > With the attached v3, performance is better. The test now runs > > recovery 65.6 seconds, vs master's 148.5 seconds. So about 2.2x > > faster. > > On my machine I'm seeing 57s, down from 86s on unpatched master, for > the simple pgbench workload from > https://github.com/macdice/redo-bench/. That's not quite what you're > reporting but it still blows the doors off the faster sorting patch, > which does it in 74s. Thanks for running the numbers on that. I might be seeing a bit more gain as I dropped the fillfactor down to 85. That seems to cause more calls to compactify_tuples(). > So one question is whether we want to do the order-reversing as part > of this patch, or wait for a more joined-up project to make lots of > code paths collude on making scan order match memory order > (corellation = 1). Most or all of the gain from your patch would > presumably still apply if did the exact opposite and forced offset > order to match reverse-item ID order (correlation = -1), which also > happens to be the initial state when you insert tuples today; you'd > still tend towards a state that allows nice big memmov/memcpy calls > during page compaction. IIUC currently we start with correlation -1 > and then tend towards correlation = 0 after many random updates > because we can't change the order, so it gets scrambled over time. > I'm not sure what I think about that. So I did lots of benchmarking with both methods and my conclusion is that I think we should stick to the traditional INSERT order with this patch. But we should come back and revisit that more generally one day. The main reason that I'm put off flipping the tuple order is that it significantly reduces the number of times we hit the preordered case. We go to all the trouble of reversing the order only to have it broken again when we add 1 more tuple to the page. If we keep this the traditional way, then it's much more likely that we'll maintain that pre-order and hit the more optimal memmove code path. To put that into numbers, using my benchmark, I see 13.25% of calls to compactify_tuples() when the tuple order is reversed (i.e earlier lineitems earlier in the page). However, if I keep the lineitems in their proper order where earlier lineitems are at the end of the page then I hit the preordered case 60.37% of the time. Hitting the presorted case really that much more often is really speeding things up even further. I've attached some benchmark results as benchmark_table.txt, and benchmark_chart.png. The v4 patch implements your copy skipping idea for the prefix of tuples which are already in the correct location. v4b is that patch but changed to keep the tuples in the traditional order. v5 was me experimenting further by adding a precalculated end of tuple Offset to save having to calculate it each time by adding itemoff and alignedlen together. It's not an improvement, so but I just wanted to mention that I tried it. If you look the benchmark results, you'll see that v4b is the winner. The v4b + NOTUSED is me changing the #ifdef NOTUSED part so that we use the smarter code to populate the backup buffer. Remember that I got 60.37% of calls hitting the preordered case in v4b, so less than 40% had to do the backup buffer. So the slowness of that code is more prominent when you compare v5 to v5 NOTUSED since the benchmark is hitting the non-preordered code 86.75% of the time with that version. > PS You might as well post future patches with .patch endings so that > the cfbot tests them; it seems pretty clear now that a patch to > optimise sorting (as useful as it may be for future work) can't beat a > patch to skip it completely. I took the liberty of switching the > author and review names in the commitfest entry to reflect this. Thank you. I've attached v4b (b is for backwards since the traditional backwards tuple order is maintained). v4b seems to be able to run my benchmark in 63 seconds. I did 10 runs today of yesterday's v3 patch and got an average of 72.8 seconds, so quite a big improvement from yesterday. The profile indicates there's now bigger fish to fry: 25.25% postgres postgres [.] PageRepairFragmentation 13.57% postgres libc-2.31.so [.] __memmove_avx_unaligned_erms 10.87% postgres postgres [.] hash_search_with_hash_value 7.07% postgres postgres [.] XLogReadBufferExtended 5.57% postgres postgres [.] compactify_tuples 4.06% postgres postgres [.] PinBuffer 2.78% postgres postgres [.] heap_xlog_update 2.42% postgres postgres [.] hash_bytes 1.65% postgres postgres [.] XLogReadRecord 1.55% postgres postgres [.] LWLockRelease 1.42% postgres postgres [.] SlruSelectLRUPage 1.38% postgres postgres [.] PageGetHeapFreeSpace 1.20% postgres postgres [.] DecodeXLogRecord 1.16% postgres postgres [.] pg_comp_crc32c_sse42 1.15% postgres postgres [.] StartupXLOG 1.14% postgres postgres [.] LWLockAttemptLock 0.90% postgres postgres [.] ReadBuffer_common 0.81% postgres libc-2.31.so [.] __memcmp_avx2_movbe 0.71% postgres postgres [.] smgropen 0.65% postgres postgres [.] PageAddItemExtended 0.60% postgres postgres [.] PageIndexTupleOverwrite 0.57% postgres postgres [.] ReadPageInternal 0.54% postgres postgres [.] UnpinBuffer.constprop.0 0.53% postgres postgres [.] AdvanceNextFullTransactionIdPastXid I'll still class v4b as POC grade. I've not thought too hard about comments or done a huge amount of testing on it. We'd better decide on all the exact logic first. I've also attached another tiny patch that I think is pretty useful separate from this. It basically changes: LOG: redo done at 0/D518FFD0 into: LOG: redo done at 0/D518FFD0 system usage: CPU: user: 58.93 s, system: 0.74 s, elapsed: 62.31 s (I was getting sick of having to calculate the time spent from the log timestamps.) David
Attachment
{kind=link}
{kind=link}
On Fri, 11 Sep 2020 at 01:45, David Rowley <dgrowleyml@gmail.com> wrote: > I've attached v4b (b is for backwards since the traditional backwards > tuple order is maintained). v4b seems to be able to run my benchmark > in 63 seconds. I did 10 runs today of yesterday's v3 patch and got an > average of 72.8 seconds, so quite a big improvement from yesterday. After reading the patch back again I realised there are a few more things that can be done to make it a bit faster. 1. When doing the backup buffer, use code to skip over tuples that don't need to be moved at the end of the page and only memcpy() tuples earlier than that. 2. The position that's determined in #1 can be used to start the memcpy() loop at the first tuple that needs to be moved. 3. In the memmove() code for the preorder check, we can do a similar skip of the tuples at the end of the page that don't need to be moved. I also ditched the #ifdef'd out code as I'm pretty sure #1 and #2 are a much better way of doing the backup buffer given how many tuples are likely to be skipped due to maintaining the traditional tuple order. That gets my benchmark down to 60.8 seconds, so 2.2 seconds better than v4b. I've attached v6b and an updated chart showing the results of the 10 runs I did of it. David
Attachment
{kind=link}
On Fri, Sep 11, 2020 at 1:45 AM David Rowley <dgrowleyml@gmail.com> wrote: > On Thu, 10 Sep 2020 at 10:40, Thomas Munro <thomas.munro@gmail.com> wrote: > > I wonder if we could also identify a range at the high end that is > > already correctly sorted and maximally compacted so it doesn't even > > need to be copied out. > > I've experimented quite a bit with this patch today. I think I've > tested every idea you've mentioned here, so there's quite a lot of > information to share. > > I did write code to skip the copy to the separate buffer for tuples > that are already in the correct place and with a version of the patch > which keeps tuples in their traditional insert order (later lineitem's > tuple located earlier in the page) I see a generally a very large > number of tuples being skipped with this method. See attached > v4b_skipped_tuples.png. The vertical axis is the number of > compactify_tuple() calls during the benchmark where we were able to > skip that number of tuples. The average skipped tuples overall calls > during recovery was 81 tuples, so we get to skip about half the tuples > in the page doing this on this benchmark. Excellent. > > So one question is whether we want to do the order-reversing as part > > of this patch, or wait for a more joined-up project to make lots of > > code paths collude on making scan order match memory order > > (corellation = 1). Most or all of the gain from your patch would > > presumably still apply if did the exact opposite and forced offset > > order to match reverse-item ID order (correlation = -1), which also > > happens to be the initial state when you insert tuples today; you'd > > still tend towards a state that allows nice big memmov/memcpy calls > > during page compaction. IIUC currently we start with correlation -1 > > and then tend towards correlation = 0 after many random updates > > because we can't change the order, so it gets scrambled over time. > > I'm not sure what I think about that. > > So I did lots of benchmarking with both methods and my conclusion is > that I think we should stick to the traditional INSERT order with this > patch. But we should come back and revisit that more generally one > day. The main reason that I'm put off flipping the tuple order is that > it significantly reduces the number of times we hit the preordered > case. We go to all the trouble of reversing the order only to have it > broken again when we add 1 more tuple to the page. If we keep this > the traditional way, then it's much more likely that we'll maintain > that pre-order and hit the more optimal memmove code path. Right, that makes sense. Thanks for looking into it! > I've also attached another tiny patch that I think is pretty useful > separate from this. It basically changes: > > LOG: redo done at 0/D518FFD0 > > into: > > LOG: redo done at 0/D518FFD0 system usage: CPU: user: 58.93 s, > system: 0.74 s, elapsed: 62.31 s +1
On Fri, Sep 11, 2020 at 3:53 AM David Rowley <dgrowleyml@gmail.com> wrote: > That gets my benchmark down to 60.8 seconds, so 2.2 seconds better than v4b. . o O ( I wonder if there are opportunities to squeeze some more out of this with __builtin_prefetch... ) > I've attached v6b and an updated chart showing the results of the 10 > runs I did of it. One failure seen like this while running check word (cfbot): #2 0x000000000091f93f in ExceptionalCondition (conditionName=conditionName@entry=0x987284 "nitems > 0", errorType=errorType@entry=0x97531d "FailedAssertion", fileName=fileName@entry=0xa9df0d "bufpage.c", lineNumber=lineNumber@entry=442) at assert.c:67
On Fri, 11 Sep 2020 at 17:48, Thomas Munro <thomas.munro@gmail.com> wrote: > > On Fri, Sep 11, 2020 at 3:53 AM David Rowley <dgrowleyml@gmail.com> wrote: > > That gets my benchmark down to 60.8 seconds, so 2.2 seconds better than v4b. > > . o O ( I wonder if there are opportunities to squeeze some more out > of this with __builtin_prefetch... ) I'd be tempted to go down that route if we had macros already defined for that, but it looks like we don't. > > I've attached v6b and an updated chart showing the results of the 10 > > runs I did of it. > > One failure seen like this while running check word (cfbot): > > #2 0x000000000091f93f in ExceptionalCondition > (conditionName=conditionName@entry=0x987284 "nitems > 0", > errorType=errorType@entry=0x97531d "FailedAssertion", > fileName=fileName@entry=0xa9df0d "bufpage.c", > lineNumber=lineNumber@entry=442) at assert.c:67 Thanks. I neglected to check the other call site properly checked for nitems > 0. Looks like PageIndexMultiDelete() relied on compacify_tuples() to set pd_upper to pd_special when nitems == 0. That's not what PageRepairFragmentation() did, so I've now aligned the two so they work the same way. I've attached patches in git format-patch format. I'm proposing to commit these in about 48 hours time unless there's some sort of objection before then. Thanks for reviewing this. David
Attachment
David Rowley wrote:
> I've attached patches in git format-patch format. I'm proposing to commit these in about 48 hours time unless there's
somesort of objection before then.
Hi David, no objections at all, I've just got reaffirming results here, as per [1] (SLRU thread but combined results
withqsort testing) I've repeated crash-recovery tests here again:
TEST0a: check-world passes
TEST0b: brief check: DB after recovery returns correct data which was present only into the WAL stream - SELECT sum(c)
fromsometable
TEST1: workload profile test as per standard TPC-B [2], with majority of records in WAL stream being Heap/HOT_UPDATE on
samesystem with NVMe as described there.
results of master (62e221e1c01e3985d2b8e4b68c364f8486c327ab) @ 15/09/2020 as baseline:
15.487, 1.013
15.789, 1.033
15.942, 1.118
profile looks most of the similar:
17.14% postgres libc-2.17.so [.] __memmove_ssse3_back
---__memmove_ssse3_back
compactify_tuples
PageRepairFragmentation
heap2_redo
StartupXLOG
8.16% postgres postgres [.] hash_search_with_hash_value
---hash_search_with_hash_value
|--4.49%--BufTableLookup
[..]
--3.67%--smgropen
master with 2 patches by David (v8-0001-Optimize-compactify_tuples-function.patch +
v8-0002-Report-resource-usage-at-the-end-of-recovery.patch):
14.236, 1.02
14.431, 1.083
14.256, 1.02
so 9-10% faster in this simple verification check. If I had pgbench running the result would be probably better.
Profileis similar:
13.88% postgres libc-2.17.so [.] __memmove_ssse3_back
---__memmove_ssse3_back
--13.47%--compactify_tuples
10.61% postgres postgres [.] hash_search_with_hash_value
---hash_search_with_hash_value
|--5.31%--smgropen
[..]
--5.31%--BufTableLookup
TEST2: update-only test, just as you performed in [3] to trigger the hotspot, with table fillfactor=85 and update.sql
(100%updates, ~40% Heap/HOT_UPDATE [N], ~40-50% [record sizes]) with slightly different amount of data.
results of master as baseline:
233.377, 0.727
233.233, 0.72
234.085, 0.729
with profile:
24.49% postgres postgres [.] pg_qsort
17.01% postgres postgres [.] PageRepairFragmentation
12.93% postgres postgres [.] itemoffcompare
(sometimes I saw also a ~13% swapfunc)
results of master with above 2 patches, 2.3x speedup:
101.6, 0.709
101.837, 0.71
102.243, 0.712
with profile (so yup the qsort is gone, hurray!):
32.65% postgres postgres [.] PageRepairFragmentation
---PageRepairFragmentation
heap2_redo
StartupXLOG
10.88% postgres postgres [.] compactify_tuples
---compactify_tuples
8.84% postgres postgres [.] hash_search_with_hash_value
BTW: this message "redo done at 0/9749FF70 system usage: CPU: user: 13.46 s, system: 0.78 s, elapsed: 14.25 s" is
pricelessaddition :)
-J.
[1] -
https://www.postgresql.org/message-id/flat/VI1PR0701MB696023DA7815207237196DC8F6570%40VI1PR0701MB6960.eurprd07.prod.outlook.com#188ad4e772615999ec427486d1066948
[2] - pgbench -i -s 100, pgbench -c8 -j8 -T 240, ~1.6GB DB with 2.3GB after crash in pg_wal to be replayed
[3] - https://www.postgresql.org/message-id/CAApHDvoKwqAzhiuxEt8jSquPJKDpH8DNUZDFUSX9P7DXrJdc3Q%40mail.gmail.com , in
mycase: pgbench -c 16 -j 16 -T 240 -f update.sql , ~1GB DB with 4.3GB after crash in pg_wal to be replayed
On Wed, 16 Sep 2020 at 02:10, Jakub Wartak <Jakub.Wartak@tomtom.com> wrote: > BTW: this message "redo done at 0/9749FF70 system usage: CPU: user: 13.46 s, system: 0.78 s, elapsed: 14.25 s" is pricelessaddition :) Thanks a lot for the detailed benchmark results and profiles. That was useful. I've pushed both patches now. I did a bit of a sweep of the comments on the 0001 patch before pushing it. I also did some further performance tests of something other than recovery. I can also report a good performance improvement in VACUUM. Something around the ~25% reduction mark psql -c "drop table if exists t1;" postgres > /dev/null psql -c "create table t1 (a int primary key, b int not null) with (autovacuum_enabled = false, fillfactor = 85);" postgres > /dev/null psql -c "insert into t1 select x,0 from generate_series(1,10000000) x;" postgres > /dev/null psql -c "drop table if exists log_wal;" postgres > /dev/null psql -c "create table log_wal (lsn pg_lsn not null);" postgres > /dev/null psql -c "insert into log_wal values(pg_current_wal_lsn());" postgres > /dev/null pgbench -n -f update.sql -t 60000 -c 200 -j 200 -M prepared postgres psql -c "select 'Used ' || pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), lsn)) || ' of WAL' from log_wal limit 1;" postgres psql postgres \timing on VACUUM t1; Fillfactor = 85 patched: Time: 2917.515 ms (00:02.918) Time: 2944.564 ms (00:02.945) Time: 3004.136 ms (00:03.004) master: Time: 4050.355 ms (00:04.050) Time: 4104.999 ms (00:04.105) Time: 4158.285 ms (00:04.158) Fillfactor = 100 Patched: Time: 4245.676 ms (00:04.246) Time: 4251.485 ms (00:04.251) Time: 4247.802 ms (00:04.248) Master: Time: 5459.433 ms (00:05.459) Time: 5917.356 ms (00:05.917) Time: 5430.986 ms (00:05.431) David
On Wed, Sep 16, 2020 at 1:30 PM David Rowley <dgrowleyml@gmail.com> wrote: > Thanks a lot for the detailed benchmark results and profiles. That was > useful. I've pushed both patches now. I did a bit of a sweep of the > comments on the 0001 patch before pushing it. > > I also did some further performance tests of something other than > recovery. I can also report a good performance improvement in VACUUM. > Something around the ~25% reduction mark Wonderful results. It must be rare for a such a localised patch to have such a large effect on such common workloads.
On Tue, Sep 15, 2020 at 7:01 PM Thomas Munro <thomas.munro@gmail.com> wrote: > On Wed, Sep 16, 2020 at 1:30 PM David Rowley <dgrowleyml@gmail.com> wrote: > > I also did some further performance tests of something other than > > recovery. I can also report a good performance improvement in VACUUM. > > Something around the ~25% reduction mark > > Wonderful results. It must be rare for a such a localised patch to > have such a large effect on such common workloads. Yes, that's terrific. -- Peter Geoghegan
On Thu, 10 Sep 2020 at 14:45, David Rowley <dgrowleyml@gmail.com> wrote: > I've also attached another tiny patch that I think is pretty useful > separate from this. It basically changes: > > LOG: redo done at 0/D518FFD0 > > into: > > LOG: redo done at 0/D518FFD0 system usage: CPU: user: 58.93 s, > system: 0.74 s, elapsed: 62.31 s > > (I was getting sick of having to calculate the time spent from the log > timestamps.) I really like this patch, thanks for proposing it. Should pg_rusage_init(&ru0); be at the start of the REDO loop, since you only use it if we take that path? -- Simon Riggs http://www.2ndQuadrant.com/ Mission Critical Databases
On Wed, Sep 16, 2020 at 2:54 PM Simon Riggs <simon@2ndquadrant.com> wrote: > I really like this patch, thanks for proposing it. I'm pleased to be able to say that I agree completely with this comment from Simon. :-) -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2020-09-16 14:01:21 +1200, Thomas Munro wrote: > On Wed, Sep 16, 2020 at 1:30 PM David Rowley <dgrowleyml@gmail.com> wrote: > > Thanks a lot for the detailed benchmark results and profiles. That was > > useful. I've pushed both patches now. I did a bit of a sweep of the > > comments on the 0001 patch before pushing it. > > > > I also did some further performance tests of something other than > > recovery. I can also report a good performance improvement in VACUUM. > > Something around the ~25% reduction mark > > Wonderful results. It must be rare for a such a localised patch to > have such a large effect on such common workloads. Indeed!
Hi Simon, On Thu, 17 Sep 2020 at 06:54, Simon Riggs <simon@2ndquadrant.com> wrote: > Should pg_rusage_init(&ru0); > be at the start of the REDO loop, since you only use it if we take that path? Thanks for commenting. I may be misunderstanding your words, but as far as I see it the pg_rusage_init() is only called if we're going to go into recovery. The pg_rusage_init() and pg_rusage_show() seem to be in the same scope, so I can't quite see how we could do the pg_rusage_init() without the pg_rusage_show(). Oh wait, there's the possibility that if recoveryTargetAction == RECOVERY_TARGET_ACTION_SHUTDOWN that we'll exit before we report end of recovery. I'm pretty sure I'm misunderstanding you though. If it's easier to explain, please just post a small patch with what you mean. David