Thread: Logical replication stuck in catchup state
Hi All,
We have a setup in which there are several master nodes replicating to a single slave/backup node. We are using Postgres 11.4.
Recently, one of the nodes seems to be stuck and stopped replicating.
I did some basic troubleshooting and couldn't find the root cause for that.
On one hand:
- the replication slot does seem to be active according to pg_replication_slots (Sorry no screenshot)
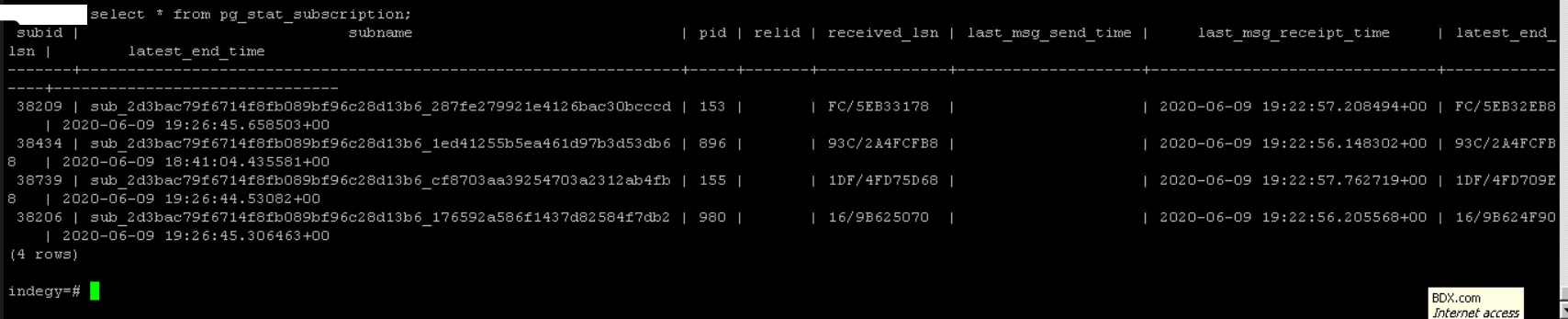
- on slave node it seems that last_msg_receipt_time is updating on pg_stat_subscription
On the other hand:
- on the slave node: received_lsn keeps pointing on the same wal segment (pg_stat_subscription)
- redo_lsn - restart_lsn shows ~20GB lag
According to logs on the master it seems that the sender hits a timeout, when trying to increase the wal_sender_timeout even to 0 (no timeout) - it doesn't have any effect. On the other hand, the last_msg_receipt_time is updated. How is that possible?
Screenshots attached. The stuck subscription/replication slot is the one ending with "53db6". On images with more than one row - it's the second one.
Any suggestions on what may be the root cause or how to continue debugging?
Appreciate your help.
Thank you,
Dan.
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I don't know if it would be relevant to this problem, but you are missing almost 1 full year of bug fixes. 11.4 was released on 20 June last year. Upgrading minor versions asap is recommended.
I do see this in the release notes from 11.8 last month (https://www.postgresql.org/docs/release/11.8/)-
Ensure that a replication slot's io_in_progress_lock is released in failure code paths (Pavan Deolasee)
--This could result in a walsender later becoming stuck waiting for the lock.
--This could result in a walsender later becoming stuck waiting for the lock.
On 2020-06-09 23:30, Dan shmidt wrote: > We have a setup in which there are several master nodes replicating to a > single slave/backup node. We are using Postgres 11.4. > Recently, one of the nodes seems to be stuck and stopped replicating. > I did some basic troubleshooting and couldn't find the root cause for that. Have you checked the server logs? Maybe it has trouble applying a change, for example due to a unique constraint or something like that. -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Thank you very much for your replies.
Regarding the server logs, I didn't find anything but healthy log when the server start which says that it is going to recover from the same point in WAL which was last sent.
Regarding bugfixes, I will try to update ASAP - but wouldn't a restart of the server release the lock? Is there a way to release the lock manually?
Any other suggestion on how to recover from this state without upgrading?
Is there a way to restart the replication from scratch?
Sent from Outlook
From: Dan shmidt
Sent: Wednesday, June 10, 2020 12:30 AM
To: pgsql-general@postgresql.org <pgsql-general@postgresql.org>
Subject: Logical replication stuck in catchup state
Sent: Wednesday, June 10, 2020 12:30 AM
To: pgsql-general@postgresql.org <pgsql-general@postgresql.org>
Subject: Logical replication stuck in catchup state
Hi All,
We have a setup in which there are several master nodes replicating to a single slave/backup node. We are using Postgres 11.4.
Recently, one of the nodes seems to be stuck and stopped replicating.
I did some basic troubleshooting and couldn't find the root cause for that.
On one hand:
- the replication slot does seem to be active according to pg_replication_slots (Sorry no screenshot)
- on slave node it seems that last_msg_receipt_time is updating on pg_stat_subscription
On the other hand:
- on the slave node: received_lsn keeps pointing on the same wal segment (pg_stat_subscription)
- redo_lsn - restart_lsn shows ~20GB lag
According to logs on the master it seems that the sender hits a timeout, when trying to increase the wal_sender_timeout even to 0 (no timeout) - it doesn't have any effect. On the other hand, the last_msg_receipt_time is updated. How is that possible?
Screenshots attached. The stuck subscription/replication slot is the one ending with "53db6". On images with more than one row - it's the second one.
Any suggestions on what may be the root cause or how to continue debugging?
Appreciate your help.
Thank you,
Dan.