Hi All,
We have a setup in which there are several master nodes replicating to a single slave/backup node. We are using Postgres 11.4.
Recently, one of the nodes seems to be stuck and stopped replicating.
I did some basic troubleshooting and couldn't find the root cause for that.
On one hand:
- the replication slot does seem to be active according to pg_replication_slots (Sorry no screenshot)
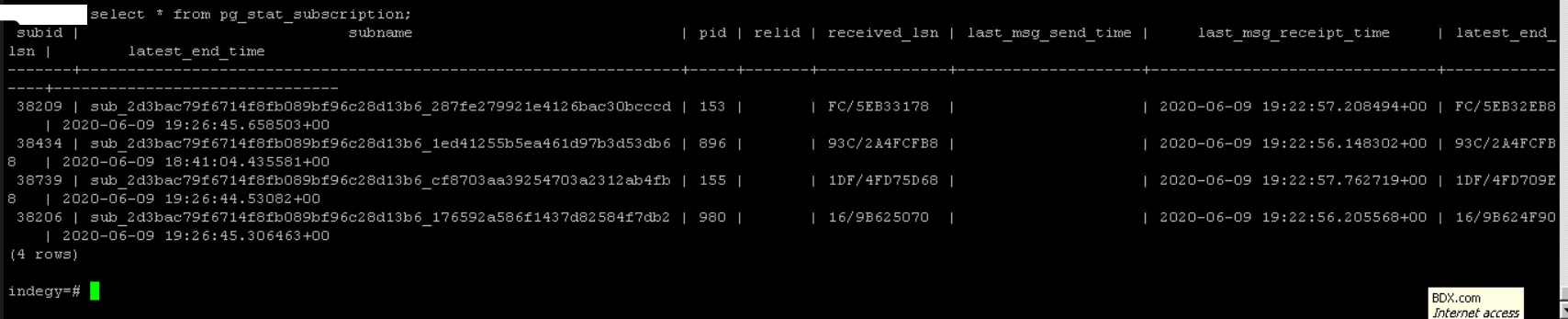
- on slave node it seems that last_msg_receipt_time is updating on pg_stat_subscription
On the other hand:
- on the slave node: received_lsn keeps pointing on the same wal segment (pg_stat_subscription)
- redo_lsn - restart_lsn shows ~20GB lag
According to logs on the master it seems that the sender hits a timeout, when trying to increase the wal_sender_timeout even to 0 (no timeout) - it doesn't have any effect. On the other hand, the last_msg_receipt_time is updated. How is that possible?
Screenshots attached. The stuck subscription/replication slot is the one ending with "53db6". On images with more than one row - it's the second one.
Any suggestions on what may be the root cause or how to continue debugging?
Appreciate your help.
Thank you,
Dan.
{kind=link}
{kind=link}
{kind=link}
{kind=link}