Thread: Fast DSM segments
Hello PostgreSQL 14 hackers,
FreeBSD is much faster than Linux (and probably Windows) at parallel
hash joins on the same hardware, primarily because its DSM segments
run in huge pages out of the box. There are various ways to convince
recent-ish Linux to put our DSMs on huge pages (see below for one),
but that's not the only problem I wanted to attack.
The attached highly experimental patch adds a new GUC
dynamic_shared_memory_main_size. If you set it > 0, it creates a
fixed sized shared memory region that supplies memory for "fast" DSM
segments. When there isn't enough free space, dsm_create() falls back
to the traditional approach using eg shm_open(). This allows parallel
queries to run faster, because:
* no more expensive system calls
* no repeated VM allocation (whether explicit posix_fallocate() or first-touch)
* can be in huge pages on Linux and Windows
This makes lots of parallel queries measurably faster, especially
parallel hash join. To demonstrate with a very simple query:
create table t (i int);
insert into t select generate_series(1, 10000000);
select pg_prewarm('t');
set work_mem = '1GB';
select count(*) from t t1 join t t2 using (i);
Here are some quick and dirty results from a Linux 4.19 laptop. The
first column is the new GUC, and the last column is from "perf stat -e
dTLB-load-misses -p <backend>".
size huge_pages time speedup TLB misses
0 off 2.595s 9,131,285
0 on 2.571s 1% 8,951,595
1GB off 2.398s 8% 9,082,803
1GB on 1.898s 37% 169,867
You can get some of this speedup unpatched on a Linux 4.7+ system by
putting "huge=always" in your /etc/fstab options for /dev/shm (= where
shm_open() lives). For comparison, that gives me:
size huge_pages time speedup TLB misses
0 on 2.007s 29% 221,910
That still leave the other 8% on the table, and in fact that 8%
explodes to a much larger number as you throw more cores at the
problem (here I was using defaults, 2 workers). Unfortunately, dsa.c
-- used by parallel hash join to allocate vast amounts of memory
really fast during the build phase -- holds a lock while creating new
segments, as you'll soon discover if you test very large hash join
builds on a 72-way box. I considered allowing concurrent segment
creation, but as far as I could see that would lead to terrible
fragmentation problems, especially in combination with our geometric
growth policy for segment sizes due to limited slots. I think this is
the main factor that causes parallel hash join scalability to fall off
around 8 cores. The present patch should really help with that (more
digging in that area needed; there are other ways to improve that
situation, possibly including something smarter than a stream of of
dsa_allocate(32kB) calls).
A competing idea would have freelists of lingering DSM segments for
reuse. Among other problems, you'd probably have fragmentation
problems due to their differing sizes. Perhaps there could be a
hybrid of these two ideas, putting a region for "fast" DSM segments
inside many OS-supplied segments, though it's obviously much more
complicated.
As for what a reasonable setting would be for this patch, well, erm,
it depends. Obviously that's RAM that the system can't use for other
purposes while you're not running parallel queries, and if it's huge
pages, it can't be swapped out; if it's not huge pages, then it can be
swapped out, and that'd be terrible for performance next time you need
it. So you wouldn't want to set it too large. If you set it too
small, it falls back to the traditional behaviour.
One argument I've heard in favour of creating fresh segments every
time is that NUMA systems configured to prefer local memory allocation
(as opposed to interleaved allocation) probably avoid cross node
traffic. I haven't looked into that topic yet; I suppose one way to
deal with it in this scheme would be to have one such region per node,
and prefer to allocate from the local one.
Attachment
On Thu, Apr 9, 2020 at 1:46 AM Thomas Munro <thomas.munro@gmail.com> wrote: > The attached highly experimental patch adds a new GUC > dynamic_shared_memory_main_size. If you set it > 0, it creates a > fixed sized shared memory region that supplies memory for "fast" DSM > segments. When there isn't enough free space, dsm_create() falls back > to the traditional approach using eg shm_open(). I think this is a reasonable option to have available for people who want to use it. I didn't want to have parallel query be limited to a fixed-size amount of shared memory because I think there are some cases where efficient performance really requires a large chunk of memory, and it seemed impractical to keep the largest amount of memory that any query might need to use permanently allocated, let alone that amount multiplied by the maximum possible number of parallel queries that could be running at the same time. But none of that is any argument against giving people the option to preallocate some memory for parallel query. My guess is that on smaller boxes this won't find a lot of use, but on bigger ones it will be handy. It's hard to imagine setting aside 1GB of memory for this if you only have 8GB total, but if you have 512GB total, it's pretty easy to imagine. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Apr 11, 2020 at 1:55 AM Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Apr 9, 2020 at 1:46 AM Thomas Munro <thomas.munro@gmail.com> wrote: > > The attached highly experimental patch adds a new GUC > > dynamic_shared_memory_main_size. If you set it > 0, it creates a > > fixed sized shared memory region that supplies memory for "fast" DSM > > segments. When there isn't enough free space, dsm_create() falls back > > to the traditional approach using eg shm_open(). > > I think this is a reasonable option to have available for people who > want to use it. I didn't want to have parallel query be limited to a > fixed-size amount of shared memory because I think there are some > cases where efficient performance really requires a large chunk of > memory, and it seemed impractical to keep the largest amount of memory > that any query might need to use permanently allocated, let alone that > amount multiplied by the maximum possible number of parallel queries > that could be running at the same time. But none of that is any > argument against giving people the option to preallocate some memory > for parallel query. That all makes sense. Now I'm wondering if I should use exactly that word in the GUC... dynamic_shared_memory_preallocate?
On Tue, Jun 9, 2020 at 6:03 PM Thomas Munro <thomas.munro@gmail.com> wrote: > That all makes sense. Now I'm wondering if I should use exactly that > word in the GUC... dynamic_shared_memory_preallocate? I tend to prefer verb-object rather than object-verb word ordering, because that's how English normally works, but I realize this is not a unanimous view. It's a little strange because the fact of preallocating it makes it not dynamic any more. I don't know what to do about that. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Jun 11, 2020 at 5:37 AM Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Jun 9, 2020 at 6:03 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > That all makes sense. Now I'm wondering if I should use exactly that > > word in the GUC... dynamic_shared_memory_preallocate? > > I tend to prefer verb-object rather than object-verb word ordering, > because that's how English normally works, but I realize this is not a > unanimous view. It's pretty much just me and Yoda against all the rest of you, so let's try preallocate_dynamic_shared_memory. I guess it could also be min_dynamic_shared_memory to drop the verb. Other ideas welcome. > It's a little strange because the fact of preallocating it makes it > not dynamic any more. I don't know what to do about that. Well, it's not dynamic at the operating system level, but it's still dynamic in the sense that PostgreSQL code can get some and give it back, and there's no change from the point of view of any DSM client code. Admittedly, the shared memory architecture is a bit confusing. We have main shared memory, DSM memory, DSA memory that is inside main shared memory with extra DSMs as required, DSA memory that is inside a DSM and creates extra DSMs as required, and with this patch also DSMs that are inside main shared memory. Not to mention palloc and MemoryContexts and all that. As you probably remember I once managed to give an internal presentation at EDB for one hour of solid talking about all the different kinds of allocators and what they're good for. It was like a Möbius slide deck already. Here's a version that adds some documentation.
Attachment
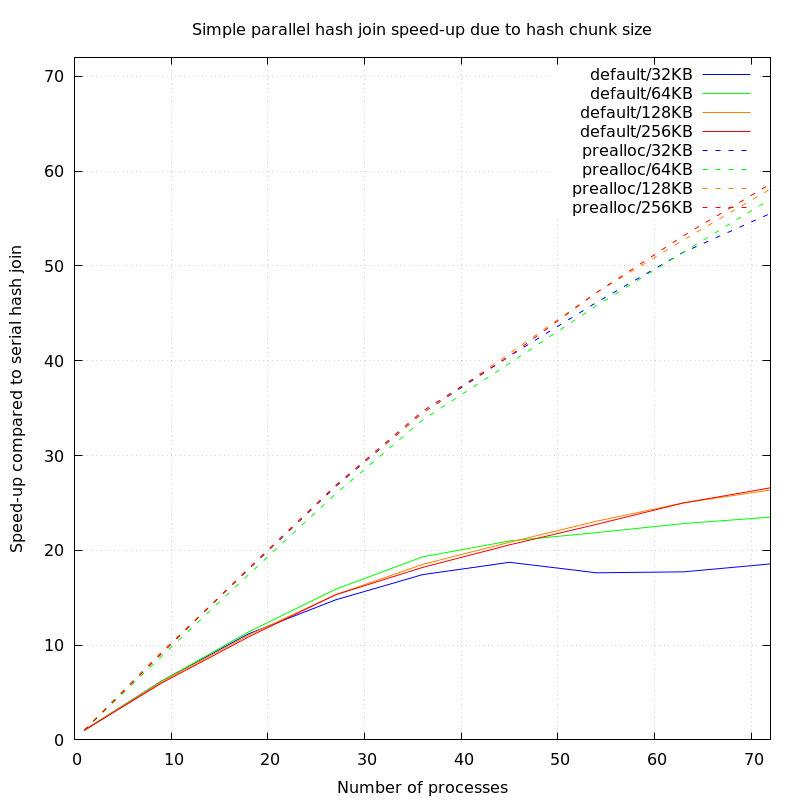
On Thu, Jun 18, 2020 at 6:05 PM Thomas Munro <thomas.munro@gmail.com> wrote: > Here's a version that adds some documentation. I jumped on a dual socket machine with 36 cores/72 threads and 144GB of RAM (Azure F72s_v2) running Linux, configured with 50GB of huge pages available, and I ran a very simple test: select count(*) from t t1 join t t2 using (i), where the table was created with create table t as select generate_series(1, 400000000)::int i, and then prewarmed into 20GB of shared_buffers. I compared the default behaviour to preallocate_dynamic_shared_memory=20GB, with work_mem set sky high so that there would be no batching (you get a hash table of around 16GB), and I set things up so that I could test with a range of worker processes, and computed the speedup compared to a serial hash join. Here's what I got: Processes Default Preallocated 1 627.6s 9 101.3s = 6.1x 68.1s = 9.2x 18 56.1s = 11.1x 34.9s = 17.9x 27 42.5s = 14.7x 23.5s = 26.7x 36 36.0s = 17.4x 18.2s = 34.4x 45 33.5s = 18.7x 15.5s = 40.5x 54 35.6s = 17.6x 13.6s = 46.1x 63 35.4s = 17.7x 12.2s = 51.4x 72 33.8s = 18.5x 11.3s = 55.5x It scaled nearly perfectly up to somewhere just under 36 threads, and then the slope tapered off a bit so that each extra process was supplying somewhere a bit over half of its potential. I can improve the slope after the halfway point a bit by cranking HASH_CHUNK_SIZE up to 128KB (and it doesn't get much better after that): Processes Default Preallocated 1 627.6s 9 102.7s = 6.1x 67.7s = 9.2x 18 56.8s = 11.1x 34.8s = 18.0x 27 41.0s = 15.3x 23.4s = 26.8x 36 33.9s = 18.5x 18.2s = 34.4x 45 30.1s = 20.8x 15.4s = 40.7x 54 27.2s = 23.0x 13.3s = 47.1x 63 25.1s = 25.0x 11.9s = 52.7x 72 23.8s = 26.3x 10.8s = 58.1x I don't claim that this is representative of any particular workload or server configuration, but it's a good way to show that bottleneck, and it's pretty cool to be able to run a query that previously took over 10 minutes in 10 seconds. (I can shave a further 10% off these times with my experimental hash join prefetching patch, but I'll probably write about that separately when I've figured out why it's not doing better than that...).
Attachment
{kind=link}
Hi, On 2020-06-19 17:42:41 +1200, Thomas Munro wrote: > On Thu, Jun 18, 2020 at 6:05 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > Here's a version that adds some documentation. > > I jumped on a dual socket machine with 36 cores/72 threads and 144GB > of RAM (Azure F72s_v2) running Linux, configured with 50GB of huge > pages available, and I ran a very simple test: select count(*) from t > t1 join t t2 using (i), where the table was created with create table > t as select generate_series(1, 400000000)::int i, and then prewarmed > into 20GB of shared_buffers. I assume all the data fits into 20GB? Which kernel version is this? How much of the benefit comes from huge pages being used, how much from avoiding the dsm overhead, and how much from the page table being shared for that mapping? Do you have a rough idea? Greetings, Andres Freund
On Sat, Jun 20, 2020 at 7:17 AM Andres Freund <andres@anarazel.de> wrote: > On 2020-06-19 17:42:41 +1200, Thomas Munro wrote: > > On Thu, Jun 18, 2020 at 6:05 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > > Here's a version that adds some documentation. > > > > I jumped on a dual socket machine with 36 cores/72 threads and 144GB > > of RAM (Azure F72s_v2) running Linux, configured with 50GB of huge > > pages available, and I ran a very simple test: select count(*) from t > > t1 join t t2 using (i), where the table was created with create table > > t as select generate_series(1, 400000000)::int i, and then prewarmed > > into 20GB of shared_buffers. > > I assume all the data fits into 20GB? Yep. > Which kernel version is this? Tested on 4.19 (Debian stable/10). > How much of the benefit comes from huge pages being used, how much from > avoiding the dsm overhead, and how much from the page table being shared > for that mapping? Do you have a rough idea? Without huge pages, the 36 process version of the test mentioned above shows around a 1.1x speedup, which is in line with the numbers from my first message (which was from a much smaller computer). The rest of the speedup (2x) is due to huge pages. Further speedups are available by increasing the hash chunk size, and probably doing NUMA-aware allocation, in later work. Here's a new version, using the name min_dynamic_shared_memory, which sounds better to me. Any objections? I also fixed the GUC's maximum setting so that it's sure to fit in size_t.
Attachment
On Mon, Jul 27, 2020 at 2:45 PM Thomas Munro <thomas.munro@gmail.com> wrote:
> Here's a new version, using the name min_dynamic_shared_memory, which
> sounds better to me. Any objections? I also fixed the GUC's maximum
> setting so that it's sure to fit in size_t.
I pushed it like that. Happy to rename the GUC if someone has a better idea.
I don't really love the way dsm_create()'s code flows, but I didn't
see another way to do this within the existing constraints. I think
it'd be nice to rewrite this thing to get rid of the random
number-based handles that are directly convertible to key_t/pathname,
and instead use something holding {slot number, generation number}.
Then you could improve that code flow and get rid of several cases of
linear array scans under an exclusive lock. The underlying
key_t/pathname would live in the slot. You'd need a new way to find
the control segment itself after a restart, where
dsm_cleanup_using_control_segment() cleans up after the previous
incarnation, but I think that just requires putting the key_t/pathname
directly in PGShmemHeader, instead of a new {slot number, generation
number} style handle. Or maybe a separate mapped file opened by well
known pathname, or something like that.