Thread: rebased background worker reimplementation prototype
Hi, I've talked a few times about a bgwriter replacement prototype I'd written a few years back. That happened somewhere deep in another thread [1], and thus not easy to fix. Tomas Vondra asked me for a link, but there was some considerable bitrot since. Attached is a rebased and slightly improved version. It's also available at [2][3]. The basic observation is that there's some fairly fundamental issues with the current bgwriter implementation: 1) The pacing logic is complicated, but doesn't work well 2) If most/all buffers have a usagecount, it cannot do anything, because it doesn't participate in the clock-sweep 3) Backends have to re-discover the now clean buffers. The prototype is much simpler - in my opinion of course. It has a ringbuffer of buffers it thinks are clean (which might be reused concurrently though). It fills that ringbuffer by performing clock-sweep, and if necessary cleaning, usagecount=pincount=0 buffers. Backends can then pop buffers from that ringbuffer. Pacing works by bgwriter trying to keep the ringbuffer full, and backends emptying the ringbuffer. If the ringbuffer is less than 1/4 full, backends wake up bgwriter using the existing latch mechanism. The ringbuffer is a pretty simplistic lockless (but just obstruction free, not lock free) implementation, with a lot of unneccessary constraints. I've had to improve the current instrumentation for pgwriter (i.e. pg_stat_bgwriter) considerably - the details in there imo are not even remotely good enough to actually understand the system (nor are the names understandable). That needs to be split into a separate commit, and the half dozen different implementations of the counters need to be unified. Obviously this is very prototype-stage code. But I think it's a good starting point for going forward. To enable it, one currently has to set the bgwriter_legacy = false GUC. Some early benchmarks show that in IO heavy cases there's somewhere between a very mild regression (close to noise), to a pretty considerable improvement. To see a benefit one - fairly obviously - needs a workload that is bigger than shared buffers, because otherwise checkpointer is going to do all writes (and should, it can sort them perfectly!). It's quite possible to saturate what a single bgwriter can write out (as it is before the replacement). I'm inclined to think the next solution for that is asynchronous IO, and write-combining, rather than multiple bgwriters. Here's an example pg_stat_bgwriter from the middle of a pgbench run (after resetting it a short while before): ┌─[ RECORD 1 ]───────────────┬───────────────────────────────┐ │ checkpoints_timed │ 1 │ │ checkpoints_req │ 0 │ │ checkpoint_write_time │ 179491 │ │ checkpoint_sync_time │ 266 │ │ buffers_written_checkpoint │ 172414 │ │ buffers_written_bgwriter │ 475802 │ │ buffers_written_backend │ 7140 │ │ buffers_written_ring │ 0 │ │ buffers_fsync_checkpointer │ 137 │ │ buffers_fsync_bgwriter │ 0 │ │ buffers_fsync_backend │ 0 │ │ buffers_bgwriter_clean │ 832616 │ │ buffers_alloc_preclean │ 1306572 │ │ buffers_alloc_free │ 0 │ │ buffers_alloc_sweep │ 4639 │ │ buffers_alloc_ring │ 767 │ │ buffers_ticks_bgwriter │ 4398290 │ │ buffers_ticks_backend │ 17098 │ │ maxwritten_clean │ 17 │ │ stats_reset │ 2019-06-10 20:17:56.087704-07 │ └────────────────────────────┴───────────────────────────────┘ Note that buffers_written_backend (as buffers_backend before) accounts for file extensions too - which bgwriter can't offload. We should replace that by a non-write (i.e. fallocate) anyway. Greetings, Andres Freund [1] https://postgr.es/m/20160204155458.jrw3crmyscusdqf6%40alap3.anarazel.de [2] https://git.postgresql.org/gitweb/?p=users/andresfreund/postgres.git;a=shortlog;h=refs/heads/bgwriter-rewrite [3] https://github.com/anarazel/postgres/tree/bgwriter-rewrite
Attachment
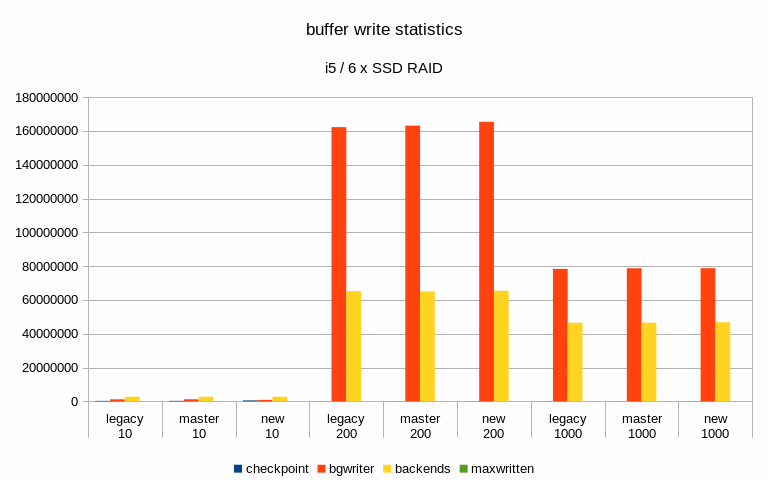
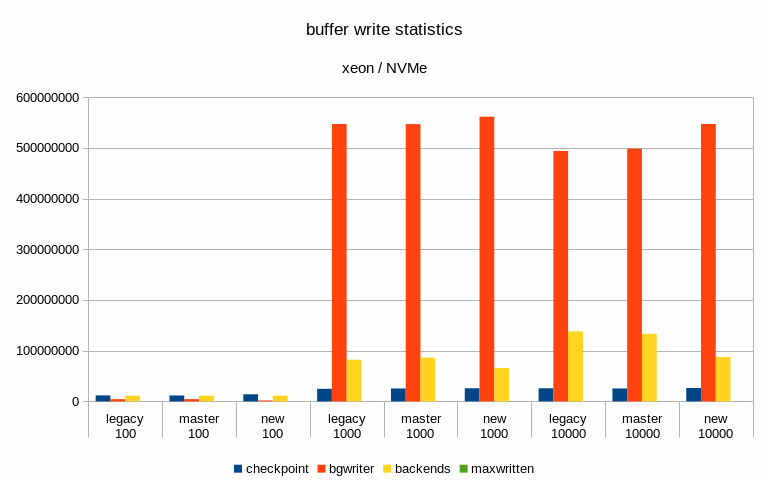
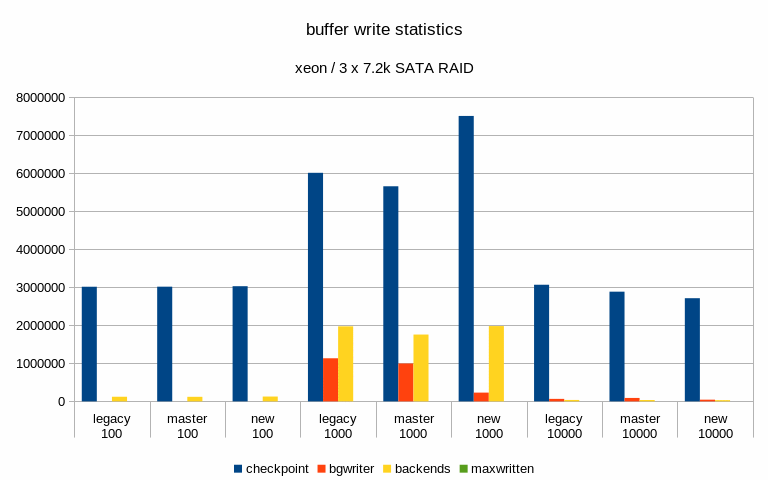
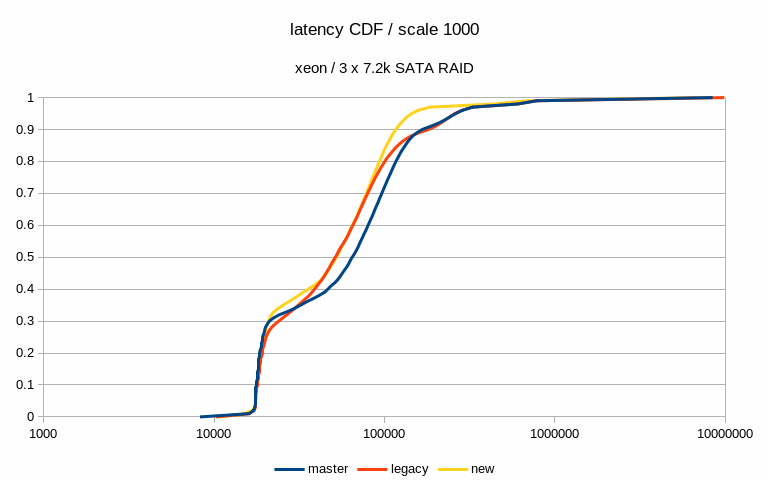
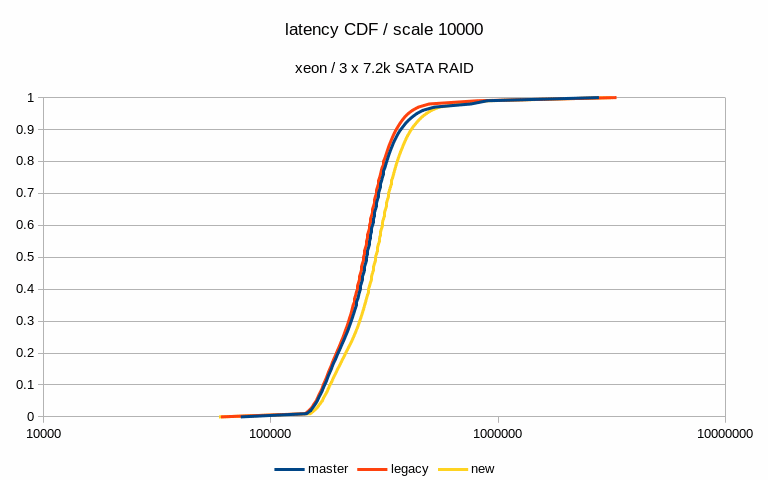
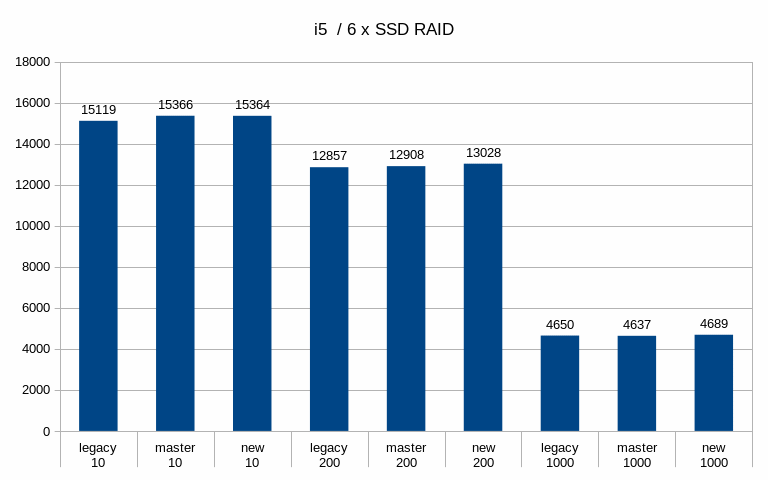
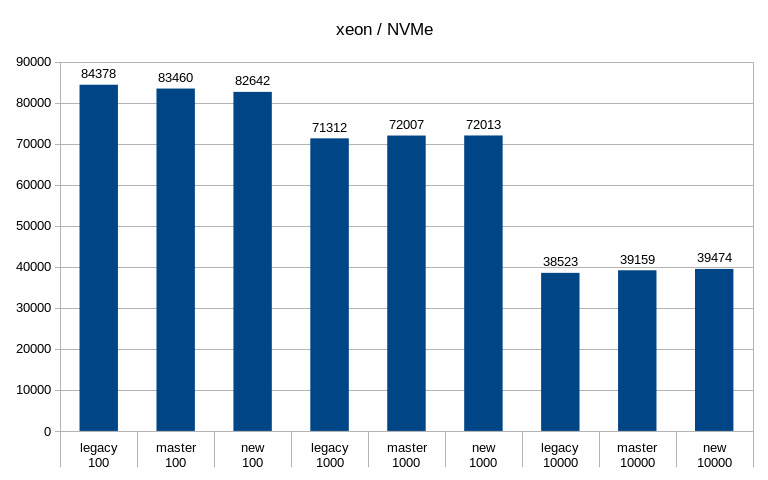
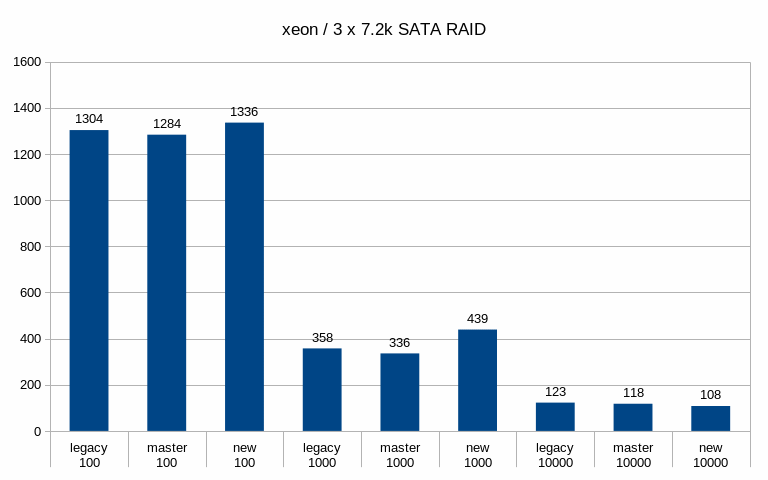
Hi, I've done a bit of benchmarking / testing on this, so let me report some basic results. I haven't done any significant code review, I've simply ran a bunch of pgbench runs on different systems with different scales. System #1 --------- * CPU: Intel i5 * RAM: 8GB * storage: 6 x SATA SSD RAID0 (Intel S3700) * autovacuum_analyze_scale_factor = 0.1 * autovacuum_vacuum_cost_delay = 2 * autovacuum_vacuum_cost_limit = 1000 * autovacuum_vacuum_scale_factor = 0.01 * bgwriter_delay = 100 * bgwriter_lru_maxpages = 10000 * checkpoint_timeout = 30min * max_wal_size = 64GB * shared_buffers = 1GB System #2 --------- * CPU: 2x Xeon E5-2620v5 * RAM: 64GB * storage: 3 x 7.2k SATA RAID0, 1x NVMe * autovacuum_analyze_scale_factor = 0.1 * autovacuum_vacuum_cost_delay = 2 * autovacuum_vacuum_cost_limit = 1000 * autovacuum_vacuum_scale_factor = 0.01 * bgwriter_delay = 100 * bgwriter_lru_maxpages = 10000 * checkpoint_completion_target = 0.9 * checkpoint_timeout = 15min * max_wal_size = 32GB * shared_buffers = 8GB For each config I've done tests with three scales - small (fits into shared buffers), medium (fits into RAM) and large (at least 2x the RAM). Aside from the basic metrics (throughput etc.) I've also sampled data about 5% of transactions, to be able to look at latency stats. The tests were done on master and patched code (both in the 'legacy' and new mode). I haven't done any temporal analysis yet (i.e. I'm only looking at global summaries, not tps over time etc). Attached is a spreadsheet with a summary of the results and a couple of charts. Generally speaking, the patch has minimal impact on throughput, especially when using SSD/NVMe storage. See the attached "tps" charts. When running on the 7.2k SATA RAID, the throughput improves with the medium scale - from ~340tps to ~439tps, which is a pretty significant jump. But on the large scale this disappears (in fact, it seems to be a bit lower than master/legacy cases). Of course, all this is just from a single run (although 4h, so noise should even out). I've also computed latency CDF (from the 5% sample) - I've attached this for the two interesting cases mentioned in the previous paragraph. This shows that with the medium scale the latencies move down (with the patch, both in the legacy and "new" modes), while on large scale the "new" mode moves a bit to the right to higher values). And finally, I've looked at buffer stats, i.e. number of buffers written in various ways (checkpoing, bgwriter, backends) etc. Interestingly enough, these numbers did not change very much - especially on the flash storage. Maybe that's expected, though. The one case where it did change is the "medium" scale on SATA storage, where the throughput improved with the patch. But the change is kinda strange, because the number of buffers evicted by the bgwriter decreased (and instead it got evicted by the checkpointer). Which might explain the higher throughput, because checkpointer is probably more efficient. results -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hi, On 2019-07-12 15:47:02 +0200, Tomas Vondra wrote: > I've done a bit of benchmarking / testing on this, so let me report some > basic results. I haven't done any significant code review, I've simply > ran a bunch of pgbench runs on different systems with different scales. Thanks! > System #1 > --------- > * CPU: Intel i5 > * RAM: 8GB > * storage: 6 x SATA SSD RAID0 (Intel S3700) > * autovacuum_analyze_scale_factor = 0.1 > * autovacuum_vacuum_cost_delay = 2 > * autovacuum_vacuum_cost_limit = 1000 > * autovacuum_vacuum_scale_factor = 0.01 > * bgwriter_delay = 100 > * bgwriter_lru_maxpages = 10000 > * checkpoint_timeout = 30min > * max_wal_size = 64GB > * shared_buffers = 1GB What's the controller situation here? Can the full SATA3 bandwidth on all of those drives be employed concurrently? > System #2 > --------- > * CPU: 2x Xeon E5-2620v5 > * RAM: 64GB > * storage: 3 x 7.2k SATA RAID0, 1x NVMe > * autovacuum_analyze_scale_factor = 0.1 > * autovacuum_vacuum_cost_delay = 2 > * autovacuum_vacuum_cost_limit = 1000 > * autovacuum_vacuum_scale_factor = 0.01 > * bgwriter_delay = 100 > * bgwriter_lru_maxpages = 10000 > * checkpoint_completion_target = 0.9 > * checkpoint_timeout = 15min > * max_wal_size = 32GB > * shared_buffers = 8GB What type of NVMe disk is this? I'm mostly wondering whether it's fast enough that there's no conceivable way that IO scheduling is going to make a meaningful difference, given other bottlenecks in postgres. In some preliminary benchmark runs I've seen fairly significant gains on SATA and SAS SSDs, as well as spinning rust, but I've not yet benchmarked on a decent NVMe SSD. > For each config I've done tests with three scales - small (fits into > shared buffers), medium (fits into RAM) and large (at least 2x the RAM). > Aside from the basic metrics (throughput etc.) I've also sampled data > about 5% of transactions, to be able to look at latency stats. > > The tests were done on master and patched code (both in the 'legacy' and > new mode). > I haven't done any temporal analysis yet (i.e. I'm only looking at global > summaries, not tps over time etc). FWIW, I'm working on a tool that generates correlated graphs of OS, PG, pgbench stats. Especially being able to correlate the kernel's 'Writeback' stats (grep Writeback: /proc/meminfo) and latency is very valuable. Sampling wait events over time also is worthwhile. > When running on the 7.2k SATA RAID, the throughput improves with the > medium scale - from ~340tps to ~439tps, which is a pretty significant > jump. But on the large scale this disappears (in fact, it seems to be a > bit lower than master/legacy cases). Of course, all this is just from a > single run (although 4h, so noise should even out). Any chance there's an order-of-test factor here? In my tests I found two related issues very important: 1) the first few tests are slower, because WAL segments don't yet exist. 2) Some poor bugger of a later test will get hit with anti-wraparound vacuums, even if otherwise not necessary. The fact that the master and "legacy" numbers differ significantly e.g. in the "xeon sata scale 1000" latency CDF does make me wonder whether there's an effect like that. While there might be some small performance difference due to different stats message sizes, and a few additional branches, I don't see how it could be that noticable. > I've also computed latency CDF (from the 5% sample) - I've attached this > for the two interesting cases mentioned in the previous paragraph. This > shows that with the medium scale the latencies move down (with the patch, > both in the legacy and "new" modes), while on large scale the "new" mode > moves a bit to the right to higher values). Hm. I can't yet explain that. > And finally, I've looked at buffer stats, i.e. number of buffers written > in various ways (checkpoing, bgwriter, backends) etc. Interestingly > enough, these numbers did not change very much - especially on the flash > storage. Maybe that's expected, though. Some of that is expected, e.g. because file extensions count as backend writes, and are going to be roughly correlate with throughput, and not much else. But they're more similar than I'd actually expect. I do see a pretty big difference in the number of bgwriter written backends in the "new" case for scale 10000, on the nvme? For the SATA SSD case, I wonder if the throughput bottleneck is WAL writes. I see much more noticable differences if I enable wal_compression or disable full_page_writes, because otherwise the bulk of the volume is WAL data. But even in that case, I see a latency stddev reduction with the new bgwriter around checkpoints. > The one case where it did change is the "medium" scale on SATA storage, > where the throughput improved with the patch. But the change is kinda > strange, because the number of buffers evicted by the bgwriter decreased > (and instead it got evicted by the checkpointer). Which might explain the > higher throughput, because checkpointer is probably more efficient. Well, one problem with the current bgwriter implementation is that the victim selection isn't good. Because it doesn't perform clock sweep, and doesn't clean buffers with a usagecount, it'll often run until it finds a dirty buffer that's pretty far ahead of the clock hand, and clean those. But with a random test like pgbench it's somewhat likely that those buffers will get re-dirtied before backends actually get to reusing them (that's a problem with the new implementation too, the window just is smaller). But I'm far from sure that that's the cause here. Greetings, Andres Freund
On Tue, Jul 16, 2019 at 10:53:46AM -0700, Andres Freund wrote: >Hi, > >On 2019-07-12 15:47:02 +0200, Tomas Vondra wrote: >> I've done a bit of benchmarking / testing on this, so let me report some >> basic results. I haven't done any significant code review, I've simply >> ran a bunch of pgbench runs on different systems with different scales. > >Thanks! > > >> System #1 >> --------- >> * CPU: Intel i5 >> * RAM: 8GB >> * storage: 6 x SATA SSD RAID0 (Intel S3700) >> * autovacuum_analyze_scale_factor = 0.1 >> * autovacuum_vacuum_cost_delay = 2 >> * autovacuum_vacuum_cost_limit = 1000 >> * autovacuum_vacuum_scale_factor = 0.01 >> * bgwriter_delay = 100 >> * bgwriter_lru_maxpages = 10000 >> * checkpoint_timeout = 30min >> * max_wal_size = 64GB >> * shared_buffers = 1GB > >What's the controller situation here? Can the full SATA3 bandwidth on >all of those drives be employed concurrently? > There's just an on-board SATA controller, so it might be a bottleneck. A single drive can do ~440 MB/s reads sequentially, and the whole RAID0 array (Linux sw raid) does ~1.6GB/s, so not exactly 6x that. But I don't think we're generating that many writes during the test. > >> System #2 >> --------- >> * CPU: 2x Xeon E5-2620v5 >> * RAM: 64GB >> * storage: 3 x 7.2k SATA RAID0, 1x NVMe >> * autovacuum_analyze_scale_factor = 0.1 >> * autovacuum_vacuum_cost_delay = 2 >> * autovacuum_vacuum_cost_limit = 1000 >> * autovacuum_vacuum_scale_factor = 0.01 >> * bgwriter_delay = 100 >> * bgwriter_lru_maxpages = 10000 >> * checkpoint_completion_target = 0.9 >> * checkpoint_timeout = 15min >> * max_wal_size = 32GB >> * shared_buffers = 8GB > >What type of NVMe disk is this? I'm mostly wondering whether it's fast >enough that there's no conceivable way that IO scheduling is going to >make a meaningful difference, given other bottlenecks in postgres. > >In some preliminary benchmark runs I've seen fairly significant gains on >SATA and SAS SSDs, as well as spinning rust, but I've not yet >benchmarked on a decent NVMe SSD. > Intel Optane 900P 280MB (model SSDPED1D280GA) [1]. [1] https://ssd.userbenchmark.com/SpeedTest/315555/INTEL-SSDPED1D280GA I think one of the main improvements in this generation of drives is good performance with low queue depth. See for example [2]. [2] https://www.anandtech.com/show/12136/the-intel-optane-ssd-900p-480gb-review/5 Not sure if that plays role here, but I've seen this to afffect prefetch and similar things. > >> For each config I've done tests with three scales - small (fits into >> shared buffers), medium (fits into RAM) and large (at least 2x the RAM). >> Aside from the basic metrics (throughput etc.) I've also sampled data >> about 5% of transactions, to be able to look at latency stats. >> >> The tests were done on master and patched code (both in the 'legacy' and >> new mode). > > > >> I haven't done any temporal analysis yet (i.e. I'm only looking at global >> summaries, not tps over time etc). > >FWIW, I'm working on a tool that generates correlated graphs of OS, PG, >pgbench stats. Especially being able to correlate the kernel's >'Writeback' stats (grep Writeback: /proc/meminfo) and latency is very >valuable. Sampling wait events over time also is worthwhile. > Good to know, although I don't think it's difficult to fetch the data from sar and plot it. I might even already have ugly bash scripts doing that, somewhere. > >> When running on the 7.2k SATA RAID, the throughput improves with the >> medium scale - from ~340tps to ~439tps, which is a pretty significant >> jump. But on the large scale this disappears (in fact, it seems to be a >> bit lower than master/legacy cases). Of course, all this is just from a >> single run (although 4h, so noise should even out). > >Any chance there's an order-of-test factor here? In my tests I found two >related issues very important: 1) the first few tests are slower, >because WAL segments don't yet exist. 2) Some poor bugger of a later >test will get hit with anti-wraparound vacuums, even if otherwise not >necessary. > Not sure - I'll check, but I find it unlikely. I need to repeat the tests to have multiple runs. >The fact that the master and "legacy" numbers differ significantly >e.g. in the "xeon sata scale 1000" latency CDF does make me wonder >whether there's an effect like that. While there might be some small >performance difference due to different stats message sizes, and a few >additional branches, I don't see how it could be that noticable. > That's about the one case where things like anti-wraparound are pretty much impossible, because the SATA storage is so slow ... > >> I've also computed latency CDF (from the 5% sample) - I've attached this >> for the two interesting cases mentioned in the previous paragraph. This >> shows that with the medium scale the latencies move down (with the patch, >> both in the legacy and "new" modes), while on large scale the "new" mode >> moves a bit to the right to higher values). > >Hm. I can't yet explain that. > > >> And finally, I've looked at buffer stats, i.e. number of buffers written >> in various ways (checkpoing, bgwriter, backends) etc. Interestingly >> enough, these numbers did not change very much - especially on the flash >> storage. Maybe that's expected, though. > >Some of that is expected, e.g. because file extensions count as backend >writes, and are going to be roughly correlate with throughput, and not >much else. But they're more similar than I'd actually expect. > >I do see a pretty big difference in the number of bgwriter written >backends in the "new" case for scale 10000, on the nvme? > Right. >For the SATA SSD case, I wonder if the throughput bottleneck is WAL >writes. I see much more noticable differences if I enable >wal_compression or disable full_page_writes, because otherwise the bulk >of the volume is WAL data. But even in that case, I see a latency >stddev reduction with the new bgwriter around checkpoints. > I may try that during the next round of tests. > >> The one case where it did change is the "medium" scale on SATA storage, >> where the throughput improved with the patch. But the change is kinda >> strange, because the number of buffers evicted by the bgwriter decreased >> (and instead it got evicted by the checkpointer). Which might explain the >> higher throughput, because checkpointer is probably more efficient. > >Well, one problem with the current bgwriter implementation is that the >victim selection isn't good. Because it doesn't perform clock sweep, and >doesn't clean buffers with a usagecount, it'll often run until it finds >a dirty buffer that's pretty far ahead of the clock hand, and clean >those. But with a random test like pgbench it's somewhat likely that >those buffers will get re-dirtied before backends actually get to >reusing them (that's a problem with the new implementation too, the >window just is smaller). But I'm far from sure that that's the cause here. > OK. Time for more tests, I guess. -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services