Hi,
I've done a bit of benchmarking / testing on this, so let me report some
basic results. I haven't done any significant code review, I've simply
ran a bunch of pgbench runs on different systems with different scales.
System #1
---------
* CPU: Intel i5
* RAM: 8GB
* storage: 6 x SATA SSD RAID0 (Intel S3700)
* autovacuum_analyze_scale_factor = 0.1
* autovacuum_vacuum_cost_delay = 2
* autovacuum_vacuum_cost_limit = 1000
* autovacuum_vacuum_scale_factor = 0.01
* bgwriter_delay = 100
* bgwriter_lru_maxpages = 10000
* checkpoint_timeout = 30min
* max_wal_size = 64GB
* shared_buffers = 1GB
System #2
---------
* CPU: 2x Xeon E5-2620v5
* RAM: 64GB
* storage: 3 x 7.2k SATA RAID0, 1x NVMe
* autovacuum_analyze_scale_factor = 0.1
* autovacuum_vacuum_cost_delay = 2
* autovacuum_vacuum_cost_limit = 1000
* autovacuum_vacuum_scale_factor = 0.01
* bgwriter_delay = 100
* bgwriter_lru_maxpages = 10000
* checkpoint_completion_target = 0.9
* checkpoint_timeout = 15min
* max_wal_size = 32GB
* shared_buffers = 8GB
For each config I've done tests with three scales - small (fits into
shared buffers), medium (fits into RAM) and large (at least 2x the RAM).
Aside from the basic metrics (throughput etc.) I've also sampled data
about 5% of transactions, to be able to look at latency stats.
The tests were done on master and patched code (both in the 'legacy' and
new mode).
I haven't done any temporal analysis yet (i.e. I'm only looking at global
summaries, not tps over time etc).
Attached is a spreadsheet with a summary of the results and a couple of
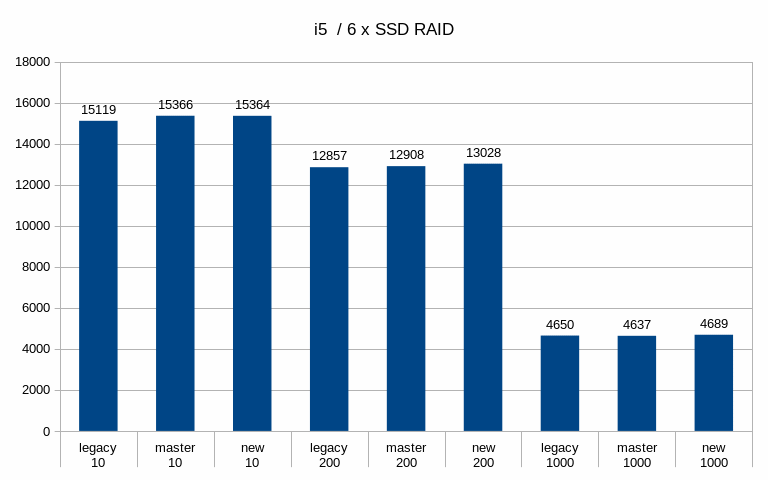
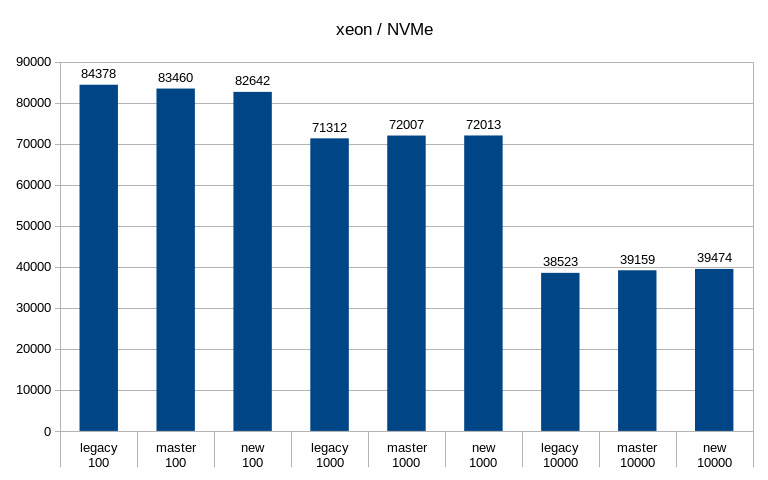
charts. Generally speaking, the patch has minimal impact on throughput,
especially when using SSD/NVMe storage. See the attached "tps" charts.
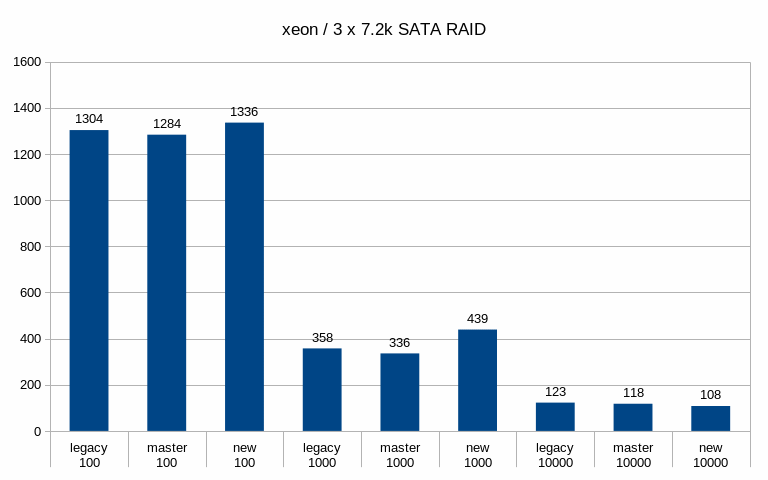
When running on the 7.2k SATA RAID, the throughput improves with the
medium scale - from ~340tps to ~439tps, which is a pretty significant
jump. But on the large scale this disappears (in fact, it seems to be a
bit lower than master/legacy cases). Of course, all this is just from a
single run (although 4h, so noise should even out).
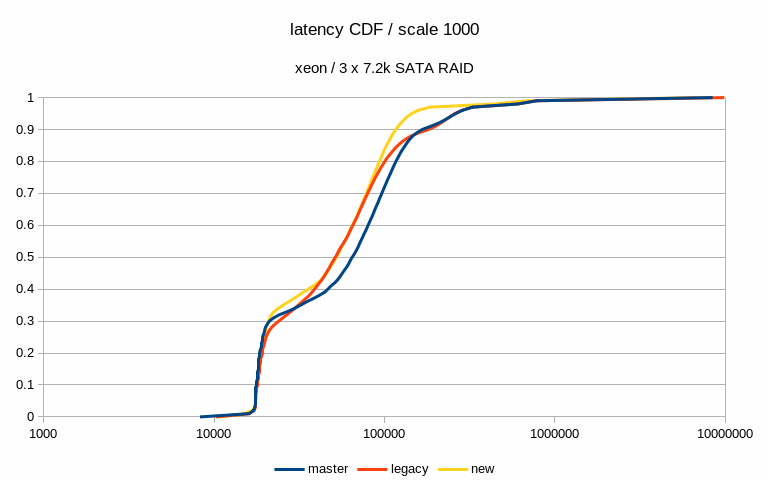
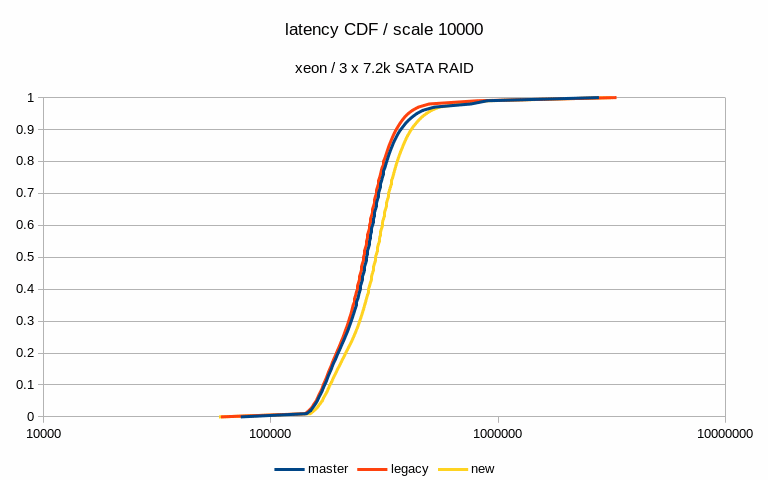
I've also computed latency CDF (from the 5% sample) - I've attached this
for the two interesting cases mentioned in the previous paragraph. This
shows that with the medium scale the latencies move down (with the patch,
both in the legacy and "new" modes), while on large scale the "new" mode
moves a bit to the right to higher values).
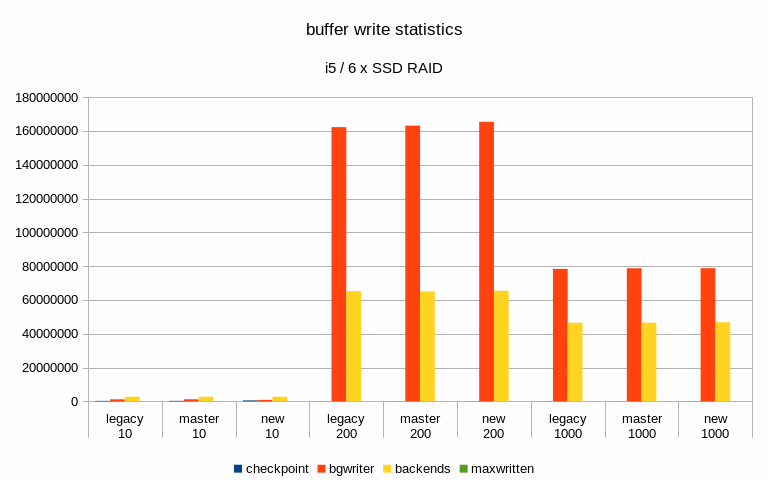
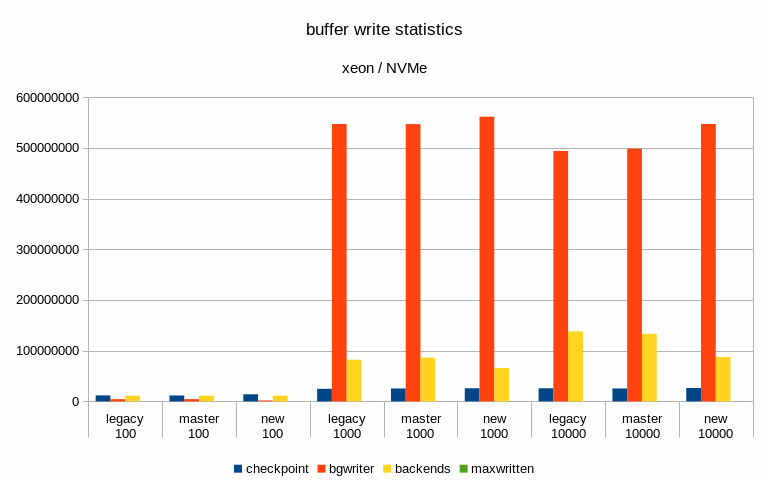
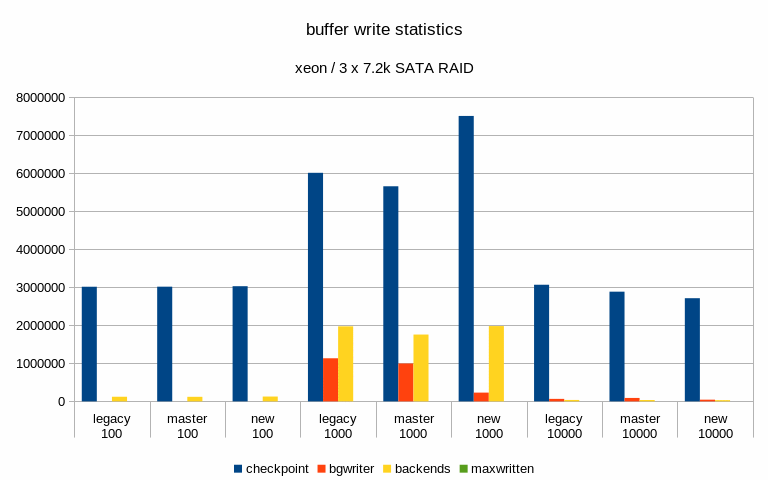
And finally, I've looked at buffer stats, i.e. number of buffers written
in various ways (checkpoing, bgwriter, backends) etc. Interestingly
enough, these numbers did not change very much - especially on the flash
storage. Maybe that's expected, though.
The one case where it did change is the "medium" scale on SATA storage,
where the throughput improved with the patch. But the change is kinda
strange, because the number of buffers evicted by the bgwriter decreased
(and instead it got evicted by the checkpointer). Which might explain the
higher throughput, because checkpointer is probably more efficient.
results
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}