Thread: Performance of ByteA: ascii vs binary
I did some benchmarking and in my setup there was major performance difference. I tested a ByteA column. If I used ascii data the tests took 52 seconds. If I used random binary data the test took 250 seconds. binary data is (roughly) five times slower than ascii data? Is this a know fact, or is there something wrong with my benchmark? I used Python and psycopg2. Regards, Thomas Güttler -- Thomas Guettler http://www.thomas-guettler.de/ I am looking for feedback: https://github.com/guettli/programming-guidelines
On 3/18/19 7:33 AM, Thomas Güttler wrote: > I did some benchmarking and in my setup there was major > performance difference. > > I tested a ByteA column. What was the test? > > If I used ascii data the tests took 52 seconds. > If I used random binary data the test took 250 seconds. > > binary data is (roughly) five times slower than ascii data? > > Is this a know fact, or is there something wrong with my benchmark? > > I used Python and psycopg2. > > Regards, > Thomas Güttler > > -- Adrian Klaver adrian.klaver@aklaver.com
Adrian Klaver <adrian.klaver@aklaver.com> writes:
> On 3/18/19 7:33 AM, Thomas Güttler wrote:
>> If I used ascii data the tests took 52 seconds.
>> If I used random binary data the test took 250 seconds.
This doesn't seem terribly surprising in bytea_output = escape
mode. Probably with bytea_output = hex the performance would
be less data-dependent.
regards, tom lane
Am 18.03.19 um 15:49 schrieb Tom Lane: > Adrian Klaver <adrian.klaver@aklaver.com> writes: >> On 3/18/19 7:33 AM, Thomas Güttler wrote: >>> If I used ascii data the tests took 52 seconds. >>> If I used random binary data the test took 250 seconds. > > This doesn't seem terribly surprising in bytea_output = escape > mode. Probably with bytea_output = hex the performance would > be less data-dependent. Thank you for your fast reply. I guess we will use a minio server to store the blobs. -- Thomas Guettler http://www.thomas-guettler.de/ I am looking for feedback: https://github.com/guettli/programming-guidelines
On 3/18/19 7:59 AM, Thomas Güttler wrote: > > > Am 18.03.19 um 15:49 schrieb Tom Lane: >> Adrian Klaver <adrian.klaver@aklaver.com> writes: >>> On 3/18/19 7:33 AM, Thomas Güttler wrote: >>>> If I used ascii data the tests took 52 seconds. >>>> If I used random binary data the test took 250 seconds. >> >> This doesn't seem terribly surprising in bytea_output = escape >> mode. Probably with bytea_output = hex the performance would >> be less data-dependent. > > Thank you for your fast reply. > > I guess we will use a minio server to store the blobs. According to this: http://initd.org/psycopg/docs/usage.html?highlight=bytea#adapt-binary psycopg2 will use 'hex' by default. Have you tried the test outside Python/psycopg2 e.g in psql to see if the performance hit still exists? > > > > -- Adrian Klaver adrian.klaver@aklaver.com
Am 18.03.19 um 17:52 schrieb Adrian Klaver: > On 3/18/19 7:59 AM, Thomas Güttler wrote: >> >> >> Am 18.03.19 um 15:49 schrieb Tom Lane: >>> Adrian Klaver <adrian.klaver@aklaver.com> writes: >>>> On 3/18/19 7:33 AM, Thomas Güttler wrote: >>>>> If I used ascii data the tests took 52 seconds. >>>>> If I used random binary data the test took 250 seconds. >>> >>> This doesn't seem terribly surprising in bytea_output = escape >>> mode. Probably with bytea_output = hex the performance would >>> be less data-dependent. >> >> Thank you for your fast reply. >> >> I guess we will use a minio server to store the blobs. > > According to this: > > http://initd.org/psycopg/docs/usage.html?highlight=bytea#adapt-binary > > psycopg2 will use 'hex' by default. > > Have you tried the test outside Python/psycopg2 e.g in psql to see if the performance hit still exists? No, I did not test it outside Python/psycopg2. Since our code will use Python/psycopg2 I did not run a test outside. The decision was made. Now I am busy learning minio. I use it for the first time. Regards, Thomas Güttler -- Thomas Guettler http://www.thomas-guettler.de/ I am looking for feedback: https://github.com/guettli/programming-guidelines
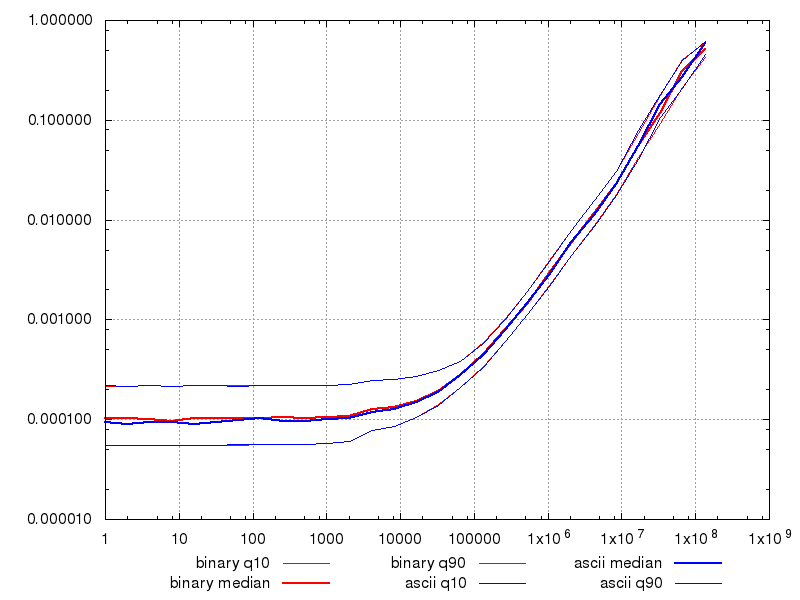
On 2019-03-18 15:33:17 +0100, Thomas Güttler wrote: > I did some benchmarking and in my setup there was major > performance difference. > > I tested a ByteA column. > > If I used ascii data the tests took 52 seconds. > If I used random binary data the test took 250 seconds. > > binary data is (roughly) five times slower than ascii data? > > Is this a know fact, or is there something wrong with my benchmark? > > I used Python and psycopg2. I don't see this here (Debian 9, Python 3,5, psycopg2 2.7.6, PostgreSQL 9.5). I modified my bench-bytea script (https://github.com/hjp/blob-bench) to restrict the byte values to printable ASCII (32 .. 126). There was absolutely no difference, as the attached graph shows. hp -- _ | Peter J. Holzer | we build much bigger, better disasters now |_|_) | | because we have much more sophisticated | | | hjp@hjp.at | management tools. __/ | http://www.hjp.at/ | -- Ross Anderson <https://www.edge.org/>
Attachment
{kind=link}
Am 19.03.19 um 20:37 schrieb Peter J. Holzer: > On 2019-03-18 15:33:17 +0100, Thomas Güttler wrote: >> I did some benchmarking and in my setup there was major >> performance difference. >> >> I tested a ByteA column. >> >> If I used ascii data the tests took 52 seconds. >> If I used random binary data the test took 250 seconds. >> >> binary data is (roughly) five times slower than ascii data? >> >> Is this a know fact, or is there something wrong with my benchmark? >> >> I used Python and psycopg2. > > I don't see this here (Debian 9, Python 3,5, psycopg2 2.7.6, PostgreSQL > 9.5). > > I modified my bench-bytea script (https://github.com/hjp/blob-bench) to > restrict the byte values to printable ASCII (32 .. 126). There was > absolutely no difference, as the attached graph shows. Strange. I saw a big difference. What did you test? I tested inserts. Regards, Thomas Güttler -- Thomas Guettler http://www.thomas-guettler.de/ I am looking for feedback: https://github.com/guettli/programming-guidelines
On 2019-03-20 13:20:57 +0100, Thomas Güttler wrote: > > > Am 19.03.19 um 20:37 schrieb Peter J. Holzer: > > On 2019-03-18 15:33:17 +0100, Thomas Güttler wrote: > > > I did some benchmarking and in my setup there was major > > > performance difference. > > > > > > I tested a ByteA column. > > > > > > If I used ascii data the tests took 52 seconds. > > > If I used random binary data the test took 250 seconds. > > > > > > binary data is (roughly) five times slower than ascii data? > > > > > > Is this a know fact, or is there something wrong with my benchmark? > > > > > > I used Python and psycopg2. > > > > I don't see this here (Debian 9, Python 3,5, psycopg2 2.7.6, PostgreSQL > > 9.5). > > > > I modified my bench-bytea script (https://github.com/hjp/blob-bench) to > > restrict the byte values to printable ASCII (32 .. 126). There was > > absolutely no difference, as the attached graph shows. > > Strange. I saw a big difference. > What did you test? > I tested inserts. The graph with the quantiles was for selects. For inserts I made only a scatterplot and there didn't seem to be any difference either. I'll check the quantiles, too, but I expect to see at most a small difference. A large difference as the one you saw would show up clearly in a scatterplot, too. My test ist in github (see URL above). Do see the same difference with my test on your system? hp -- _ | Peter J. Holzer | we build much bigger, better disasters now |_|_) | | because we have much more sophisticated | | | hjp@hjp.at | management tools. __/ | http://www.hjp.at/ | -- Ross Anderson <https://www.edge.org/>
Attachment
"Peter J. Holzer" <hjp-pgsql@hjp.at> writes:
> On 2019-03-20 13:20:57 +0100, Thomas Güttler wrote:
>> Strange. I saw a big difference.
>> What did you test?
>> I tested inserts.
> The graph with the quantiles was for selects.
Hmm, so there are two different code paths being considered here
-- the OP is apparently talking about the speed of bytea_in,
while the rest of us have been thinking about bytea_out.
The question about whether the text representation is hex or
"escape" style still applies, though.
regards, tom lane
On 3/21/19 6:49 AM, Tom Lane wrote: > "Peter J. Holzer" <hjp-pgsql@hjp.at> writes: >> On 2019-03-20 13:20:57 +0100, Thomas Güttler wrote: >>> Strange. I saw a big difference. >>> What did you test? >>> I tested inserts. > >> The graph with the quantiles was for selects. > > Hmm, so there are two different code paths being considered here > -- the OP is apparently talking about the speed of bytea_in, > while the rest of us have been thinking about bytea_out. > > The question about whether the text representation is hex or > "escape" style still applies, though. Yes, it would be nice to see the test code. > > regards, tom lane > > -- Adrian Klaver adrian.klaver@aklaver.com
Thank you for asking several times for a benchmark. I wrote it now and it is visible: inserting random bytes into bytea is much slower, if you use the psycopg2 defaults. Here is the chart: https://github.com/guettli/misc/blob/master/bench-bytea-inserts-postrgres.png And here is the script which creates the chart: https://github.com/guettli/misc/blob/master/bench-bytea-inserts-postrgres.py Please let me know if there is something wrong or could get improved. Regards, Thomas Güttler Am 18.03.19 um 15:33 schrieb Thomas Güttler: > I did some benchmarking and in my setup there was major > performance difference. > > I tested a ByteA column. > > If I used ascii data the tests took 52 seconds. > If I used random binary data the test took 250 seconds. > > binary data is (roughly) five times slower than ascii data? > > Is this a know fact, or is there something wrong with my benchmark? > > I used Python and psycopg2. > > Regards, > Thomas Güttler > > -- Thomas Guettler http://www.thomas-guettler.de/ I am looking for feedback: https://github.com/guettli/programming-guidelines
{kind=link}
Thomas: On Fri, Mar 22, 2019 at 11:22 AM Thomas Güttler <guettliml@thomas-guettler.de> wrote: > Thank you for asking several times for a benchmark. > I wrote it now and it is visible: inserting random bytes into bytea is much slower, > if you use the psycopg2 defaults. > Here is the chart: > https://github.com/guettli/misc/blob/master/bench-bytea-inserts-postrgres.png > And here is the script which creates the chart: > https://github.com/guettli/misc/blob/master/bench-bytea-inserts-postrgres.py I'm not too sure, but I read ( in the code ) you are measuring a nearly not compressible urandom data againtst a highly compressible ( 'x'*i ) data, are you sure the difference is not due to data being compressed and generating much less disk usage in toast-tables/wal? Francisco Olarte.
On Fri, Mar 22, 2019 at 01:40:28PM +0100, Francisco Olarte wrote: > Thomas: > > On Fri, Mar 22, 2019 at 11:22 AM Thomas Güttler > <guettliml@thomas-guettler.de> wrote: > > Thank you for asking several times for a benchmark. > > I wrote it now and it is visible: inserting random bytes into bytea is much slower, > > if you use the psycopg2 defaults. > > Here is the chart: > > https://github.com/guettli/misc/blob/master/bench-bytea-inserts-postrgres.png > > And here is the script which creates the chart: > > https://github.com/guettli/misc/blob/master/bench-bytea-inserts-postrgres.py > > I'm not too sure, but I read ( in the code ) you are measuring a > nearly not compressible urandom data againtst a highly compressible ( > 'x'*i ) data, > are you sure the difference is not due to data being compressed and > generating much less disk usage in toast-tables/wal? > > Francisco Olarte. > +1 Regards, Ken
Am 22.03.19 um 13:40 schrieb Francisco Olarte: > Thomas: > > On Fri, Mar 22, 2019 at 11:22 AM Thomas Güttler > <guettliml@thomas-guettler.de> wrote: >> Thank you for asking several times for a benchmark. >> I wrote it now and it is visible: inserting random bytes into bytea is much slower, >> if you use the psycopg2 defaults. >> Here is the chart: >> https://github.com/guettli/misc/blob/master/bench-bytea-inserts-postrgres.png >> And here is the script which creates the chart: >> https://github.com/guettli/misc/blob/master/bench-bytea-inserts-postrgres.py > > I'm not too sure, but I read ( in the code ) you are measuring a > nearly not compressible urandom data againtst a highly compressible ( > 'x'*i ) data, > are you sure the difference is not due to data being compressed and > generating much less disk usage in toast-tables/wal? +1 for this case toast-tables/wal is a detail of the implementation. This tests does not care about the "why it takes longer". It just generates a performance chart. Yes, it does exactly what you say: it compares nearly not compressible urandom data against a highly compressible data. In my case, will get nearly random data (binary PDF, JPG, ...). And that's why I wanted to benchmark it. Regards, Thomas -- Thomas Guettler http://www.thomas-guettler.de/ I am looking for feedback: https://github.com/guettli/programming-guidelines
On 3/22/19 6:04 AM, Thomas Güttler wrote: > > > Am 22.03.19 um 13:40 schrieb Francisco Olarte: >> Thomas: >> >> On Fri, Mar 22, 2019 at 11:22 AM Thomas Güttler >> <guettliml@thomas-guettler.de> wrote: >>> Thank you for asking several times for a benchmark. >>> I wrote it now and it is visible: inserting random bytes into bytea >>> is much slower, >>> if you use the psycopg2 defaults. >>> Here is the chart: >>> >>> https://github.com/guettli/misc/blob/master/bench-bytea-inserts-postrgres.png >>> >>> And here is the script which creates the chart: >>> >>> https://github.com/guettli/misc/blob/master/bench-bytea-inserts-postrgres.py >>> >> >> I'm not too sure, but I read ( in the code ) you are measuring a >> nearly not compressible urandom data againtst a highly compressible ( >> 'x'*i ) data, >> are you sure the difference is not due to data being compressed and >> generating much less disk usage in toast-tables/wal? > > +1 > > for this case toast-tables/wal is a detail of the implementation. > This tests does not care about the "why it takes longer". It just generates > a performance chart. TOAST is tunable, might want to take a look at: https://www.postgresql.org/docs/11/storage-toast.html > > Yes, it does exactly what you say: it compares > nearly not compressible urandom data against a highly compressible data. > > In my case, will get nearly random data (binary PDF, JPG, ...). And > that's why > I wanted to benchmark it. > > Regards, > Thomas > > -- Adrian Klaver adrian.klaver@aklaver.com
Thomas: On Fri, Mar 22, 2019 at 2:03 PM Thomas Güttler <guettliml@thomas-guettler.de> wrote: > > I'm not too sure, but I read ( in the code ) you are measuring a > > nearly not compressible urandom data againtst a highly compressible ( ... > for this case toast-tables/wal is a detail of the implementation. > This tests does not care about the "why it takes longer". It just generates > a performance chart. > Yes, it does exactly what you say: it compares > nearly not compressible urandom data against a highly compressible data. > In my case, will get nearly random data (binary PDF, JPG, ...). And that's why > I wanted to benchmark it. Well, if all you wanted is to benchmark, a performance chart, you know it. I assumed you wanted to know more, like where the bottleneck is and how to try to avoid it. My fault. I was specifically confused because, IIRC, you said ascii data took much longer than binary, which is a completely different test ( you can test ascii vs binary by generating chunks of random numbers in say, the 0 to 127 and sending that data once as is and once more shifting left by one every byte. That should test ascii-binary differences, but if you test random vs uniform I think the problem is in the randomness, you could just test sending '\x92'*i, or something similar, but if you are just interested in the benchmark, you have it done. Just one thing, a single graph with two labels "ascii" and "random" is misleading, as constant/random is orthogonal with ascii/binary, but as I said, my fault, all the text about psycopg and other stuff led me to think you wanted some kind of diagnosis and improvements. Regards.
On 2019-03-22 13:40:28 +0100, Francisco Olarte wrote: > On Fri, Mar 22, 2019 at 11:22 AM Thomas Güttler > <guettliml@thomas-guettler.de> wrote: > > Thank you for asking several times for a benchmark. > > I wrote it now and it is visible: inserting random bytes into bytea > > is much slower, if you use the psycopg2 defaults. > > Here is the chart: > > https://github.com/guettli/misc/blob/master/bench-bytea-inserts-postrgres.png > > And here is the script which creates the chart: > > https://github.com/guettli/misc/blob/master/bench-bytea-inserts-postrgres.py > > I'm not too sure, but I read ( in the code ) you are measuring a > nearly not compressible urandom data againtst a highly compressible ( > 'x'*i ) data, Yes, that seems to be the main difference. My "ascii" test creates random data in the range [32, 126], which is not very compressible, and I didn't see much of a difference to the full range (10th percentile and median were the same, 90th percentile was noticeably better). If I create "random" data in the range [120, 120], I also get a large speedup (about 3.5 times). Interestingly the difference vanishes for large (> 10 MB) blobs. > are you sure the difference is not due to data being compressed and > generating much less disk usage in toast-tables/wal? Yes, I think that's it: He is basically measuring how fast his CPU can compress a stream of constant bytes. Not very meaningful. Another difference I noticed between our benchmarks is that I used a plain bytes object while he used a psycopg2.Binary object. Those might be serialized differently, but since the speed difference is adequately explained by the (lack of) randomness, I am not going to investigate this. hp -- _ | Peter J. Holzer | we build much bigger, better disasters now |_|_) | | because we have much more sophisticated | | | hjp@hjp.at | management tools. __/ | http://www.hjp.at/ | -- Ross Anderson <https://www.edge.org/>
Attachment
Just theoretically assumption. PostgreSQL sometimes may optimise internal format of data and can sometimes zip data. ASCIIdata can be zipped better, then binary random data. Also PostgreSQL sometimes take decision to keep a column in an externalfile, if the column is still too big after zip. I don’t know what exactly happens in your case, but here can be areason. > 18 марта 2019 г., в 17:33, Thomas Güttler <guettliml@thomas-guettler.de> написал(а): > > I did some benchmarking and in my setup there was major > performance difference. > > I tested a ByteA column. > > If I used ascii data the tests took 52 seconds. > If I used random binary data the test took 250 seconds. > > binary data is (roughly) five times slower than ascii data? > > Is this a know fact, or is there something wrong with my benchmark? > > I used Python and psycopg2. > > Regards, > Thomas Güttler > > > -- > Thomas Guettler http://www.thomas-guettler.de/ > I am looking for feedback: https://github.com/guettli/programming-guidelines >