Thread: Built-in connection pooler
Hi hacker,
I am working for some time under built-in connection pooler for Postgres:
https://www.postgresql.org/message-id/flat/a866346d-5582-e8e8-2492-fd32732b0783%40postgrespro.ru#b1c354d5cf937893a75954e1e77f81f5
Unlike existed external pooler, this solution supports session semantic for pooled connections: you can use temporary tables, prepared statements, GUCs,...
But to make it possible I need to store/restore session context.
It is not so difficult, but it requires significant number of changes in Postgres code.
It will be committed in PgProEE-12 version of Postgres Professional version of Postgres,
but I realize that there are few changes to commit it to mainstream version of Postgres.
Dimitri Fontaine proposed to develop much simpler version of pooler which can be community:
So I have implemented solution with traditional proxy approach.
If client changes session context (creates temporary tables, set GUC values, prepare statements,...) then its backend becomes "tainted"
and is not more participate in pooling. It is now dedicated to this backend. But it still receives data through proxy.
Once this client is disconnected, tainted backend is terminated.
Built-in proxy accepts connection on special port (by default 6543).
If you connect to standard port, then normal Postgres backends will be launched and there is no difference with vanilla Postgres .
And if you connect to proxy port, then connection is redirected to one of proxy workers which then perform scheduling of all sessions, assigned to it.
There is currently on migration of sessions between proxies. There are three policies of assigning session to proxy:
random, round-robin and load-balancing.
The main differences with pgbouncer&K are that:
1. It is embedded and requires no extra steps for installation and configurations.
2. It is not single threaded (no bottleneck)
3. It supports all clients (if client needs session semantic, then it will be implicitly given dedicated backend)
Some performance results (pgbench -S -n):
Proxy configuration is the following:
session_pool_size = 4
connection_proxies = 2
postgres=# select * from pg_pooler_state();
pid | n_clients | n_ssl_clients | n_pools | n_backends | n_dedicated_backends | tx_bytes | rx_bytes | n_transactions
------+-----------+---------------+---------+------------+----------------------+----------+----------+----------------
1310 | 1 | 0 | 1 | 4 | 0 | 10324739 | 9834981 | 156388
1311 | 0 | 0 | 1 | 4 | 0 | 10430566 | 9936634 | 158007
(2 rows)
This implementation contains much less changes to Postgres core (it is more like invoking pgbouncer as Postgres worker).
The main things I have added are:
1. Mechanism for sending socket to a process (needed to redirect connection to proxy)
2. Support of edge pooling mode for epoll (needed to multiplex reads and writes)
3. Library libpqconn for establishing libpq connection from core
Proxy version of built-in connection pool is in conn_proxy branch in the following GIT repository:
https://github.com/postgrespro/postgresql.builtin_pool.git
Also I attach patch to the master to this mail.
Will be please to receive your comments.
I am working for some time under built-in connection pooler for Postgres:
https://www.postgresql.org/message-id/flat/a866346d-5582-e8e8-2492-fd32732b0783%40postgrespro.ru#b1c354d5cf937893a75954e1e77f81f5
Unlike existed external pooler, this solution supports session semantic for pooled connections: you can use temporary tables, prepared statements, GUCs,...
But to make it possible I need to store/restore session context.
It is not so difficult, but it requires significant number of changes in Postgres code.
It will be committed in PgProEE-12 version of Postgres Professional version of Postgres,
but I realize that there are few changes to commit it to mainstream version of Postgres.
Dimitri Fontaine proposed to develop much simpler version of pooler which can be community:
Unfortunately, we have not found a way to support SSL connections with socket redirection.The main idea I want to pursue is the following: - only solve the “idle connection” problem, nothing else, making idle connection basically free - implement a layer in between a connection and a session, managing a “client backend” pool - use the ability to give a socket to another process, as you did, so that the pool is not a proxy - allow re-using of a backend for a new session only when it is safe to do so
So I have implemented solution with traditional proxy approach.
If client changes session context (creates temporary tables, set GUC values, prepare statements,...) then its backend becomes "tainted"
and is not more participate in pooling. It is now dedicated to this backend. But it still receives data through proxy.
Once this client is disconnected, tainted backend is terminated.
Built-in proxy accepts connection on special port (by default 6543).
If you connect to standard port, then normal Postgres backends will be launched and there is no difference with vanilla Postgres .
And if you connect to proxy port, then connection is redirected to one of proxy workers which then perform scheduling of all sessions, assigned to it.
There is currently on migration of sessions between proxies. There are three policies of assigning session to proxy:
random, round-robin and load-balancing.
The main differences with pgbouncer&K are that:
1. It is embedded and requires no extra steps for installation and configurations.
2. It is not single threaded (no bottleneck)
3. It supports all clients (if client needs session semantic, then it will be implicitly given dedicated backend)
Some performance results (pgbench -S -n):
| #Connections | Proxy | Proxy/SSL | Direct | Direct/SSL |
| 1 | 13752 | 12396 | 17443 | 15762 |
| 10 | 53415 | 59615 | 68334 | 85885 |
| 1000 | 60152 | 20445 | 60003 | 24047 |
Proxy configuration is the following:
session_pool_size = 4
connection_proxies = 2
postgres=# select * from pg_pooler_state();
pid | n_clients | n_ssl_clients | n_pools | n_backends | n_dedicated_backends | tx_bytes | rx_bytes | n_transactions
------+-----------+---------------+---------+------------+----------------------+----------+----------+----------------
1310 | 1 | 0 | 1 | 4 | 0 | 10324739 | 9834981 | 156388
1311 | 0 | 0 | 1 | 4 | 0 | 10430566 | 9936634 | 158007
(2 rows)
This implementation contains much less changes to Postgres core (it is more like invoking pgbouncer as Postgres worker).
The main things I have added are:
1. Mechanism for sending socket to a process (needed to redirect connection to proxy)
2. Support of edge pooling mode for epoll (needed to multiplex reads and writes)
3. Library libpqconn for establishing libpq connection from core
Proxy version of built-in connection pool is in conn_proxy branch in the following GIT repository:
https://github.com/postgrespro/postgresql.builtin_pool.git
Also I attach patch to the master to this mail.
Will be please to receive your comments.
-- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On Thu, Jan 24, 2019 at 08:14:41PM +0300, Konstantin Knizhnik wrote: > The main differences with pgbouncer&K are that: > > 1. It is embedded and requires no extra steps for installation and > configurations. > 2. It is not single threaded (no bottleneck) > 3. It supports all clients (if client needs session semantic, then it will be > implicitly given dedicated backend) > > > Some performance results (pgbench -S -n): > > ┌────────────────┬────────┬─────────────┬─────────┬─────────────────────────┐ > │ #Connections │ Proxy │ Proxy/SSL │ Direct │ Direct/SSL │ > ├────────────────┼────────┼─────────────┼─────────┼──────────────┤ > │ 1 │ 13752 │ 12396 │ 17443 │ 15762 │ > ├────────────────┼────────┼─────────────┼─────────┼──────────────┤ > │ 10 │ 53415 │ 59615 │ 68334 │ 85885 │ > ├────────────────┼────────┼─────────────┼─────────┼──────────────┤ > │ 1000 │ 60152 │ 20445 │ 60003 │ 24047 │ > └────────────────┴────────┴─────────────┴─────────┴──────────────┘ It is nice it is a smaller patch. Please remind me of the performance advantages of this patch. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + As you are, so once was I. As I am, so you will be. + + Ancient Roman grave inscription +
Hi,
Bruce Momjian <bruce@momjian.us> writes:
> It is nice it is a smaller patch. Please remind me of the performance
> advantages of this patch.
The patch as it stands is mostly helpful in those situations:
- application server(s) start e.g. 2000 connections at start-up and
then use them depending on user traffic
It's then easy to see that if we would only fork as many backends as
we need, while having accepted the 2000 connections without doing
anything about them, we would be in a much better position than when
we fork 2000 unused backends.
- application is partially compatible with pgbouncer transaction
pooling mode
Then in that case, you would need to run with pgbouncer in session
mode. This happens when the application code is using session level
SQL commands/objects, such as prepared statements, temporary tables,
or session-level GUCs settings.
With the attached patch, if the application sessions profiles are
mixed, then you dynamically get the benefits of transaction pooling
mode for those sessions which are not “tainting” the backend, and
session pooling mode for the others.
It means that it's then possible to find the most often used session
and fix that one for immediate benefits, leaving the rest of the
code alone. If it turns out that 80% of your application sessions
are the same code-path and you can make this one “transaction
pooling” compatible, then you most probably are fixing (up to) 80%
of your connection-related problems in production.
- applications that use a very high number of concurrent sessions
In that case, you can either set your connection pooling the same as
max_connection and see no benefits (and hopefully no regressions
either), or set a lower number of backends serving a very high
number of connections, and have sessions waiting their turn at the
“proxy” stage.
This is a kind of naive Admission Control implementation where it's
better to have active clients in the system wait in line consuming
as few resources as possible. Here, in the proxy. It could be done
with pgbouncer already, this patch gives a stop-gap in PostgreSQL
itself for those use-cases.
It would be mostly useful to do that when you have queries that are
benefiting of parallel workers. In that case, controling the number
of active backend forked at any time to serve user queries allows to
have better use of the parallel workers available.
In other cases, it's important to measure and accept the possible
performance cost of running a proxy server between the client connection
and the PostgreSQL backend process. I believe the numbers shown in the
previous email by Konstantin are about showing the kind of impact you
can see when using the patch in a use-case where it's not meant to be
helping much, if at all.
Regards,
--
dim
On Mon, Jan 28, 2019 at 10:33:06PM +0100, Dimitri Fontaine wrote: > In other cases, it's important to measure and accept the possible > performance cost of running a proxy server between the client connection > and the PostgreSQL backend process. I believe the numbers shown in the > previous email by Konstantin are about showing the kind of impact you > can see when using the patch in a use-case where it's not meant to be > helping much, if at all. Have you looked at the possibility of having the proxy worker be spawned as a background worker? I think that we should avoid spawning any new processes on the backend from the ground as we have a lot more infrastructures since 9.3. The patch should actually be bigger, the code is very raw and lacks comments in a lot of areas where the logic is not so obvious, except perhaps to the patch author. -- Michael
Attachment
On 29.01.2019 0:10, Bruce Momjian wrote: > On Thu, Jan 24, 2019 at 08:14:41PM +0300, Konstantin Knizhnik wrote: >> The main differences with pgbouncer&K are that: >> >> 1. It is embedded and requires no extra steps for installation and >> configurations. >> 2. It is not single threaded (no bottleneck) >> 3. It supports all clients (if client needs session semantic, then it will be >> implicitly given dedicated backend) >> >> >> Some performance results (pgbench -S -n): >> >> ┌────────────────┬────────┬─────────────┬─────────┬─────────────────────────┐ >> │ #Connections │ Proxy │ Proxy/SSL │ Direct │ Direct/SSL │ >> ├────────────────┼────────┼─────────────┼─────────┼──────────────┤ >> │ 1 │ 13752 │ 12396 │ 17443 │ 15762 │ >> ├────────────────┼────────┼─────────────┼─────────┼──────────────┤ >> │ 10 │ 53415 │ 59615 │ 68334 │ 85885 │ >> ├────────────────┼────────┼─────────────┼─────────┼──────────────┤ >> │ 1000 │ 60152 │ 20445 │ 60003 │ 24047 │ >> └────────────────┴────────┴─────────────┴─────────┴──────────────┘ > It is nice it is a smaller patch. Please remind me of the performance > advantages of this patch. > The primary purpose of pooler is efficient support of large number of connections and minimizing system resource usage. But as far as Postgres is not scaling well at SMP system with larger number of CPU cores (due to many reasons discussed in hackers) reducing number of concurrently working backends can also significantly increase performance. I have not done such testing yet but I am planing to do it as well as comparison with pgbouncer and Odyssey. But please notice that this proxy approach is by design slower than my previous implementation used in PgPRO-EE (based on socket redirection). At some workloads connections throughout proxy cause up to two times decrease of performance comparing with dedicated backends. There is no such problem with old connection pooler implementation which was always not worser than vanilla. But it doesn't support SSL connections and requires much more changes in Postgres core. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 29.01.2019 8:14, Michael Paquier wrote: > On Mon, Jan 28, 2019 at 10:33:06PM +0100, Dimitri Fontaine wrote: >> In other cases, it's important to measure and accept the possible >> performance cost of running a proxy server between the client connection >> and the PostgreSQL backend process. I believe the numbers shown in the >> previous email by Konstantin are about showing the kind of impact you >> can see when using the patch in a use-case where it's not meant to be >> helping much, if at all. > Have you looked at the possibility of having the proxy worker be > spawned as a background worker? Yes, it was my first attempt. The main reason why I have implemented it in old ways are: 1. I need to know PID of spawned worker. Strange - it is possible to get PID of dynamic bgworker, but no of static one. Certainly it is possible to find a way of passing this PID to postmaster but it complicates start of worker. 2. I need to pass socket to spawner proxy. Once again: it can be implemented also with bgworker but requires more coding (especially taken in account support of Win32 and FORKEXEC mode). > I think that we should avoid spawning > any new processes on the backend from the ground as we have a lot more > infrastructures since 9.3. The patch should actually be bigger, the > code is very raw and lacks comments in a lot of areas where the logic > is not so obvious, except perhaps to the patch author. The main reason for publishing this patch was to receive feedbacks and find places which should be rewritten. I will add more comments but I will be pleased if you point me which places are obscure now and require better explanation. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
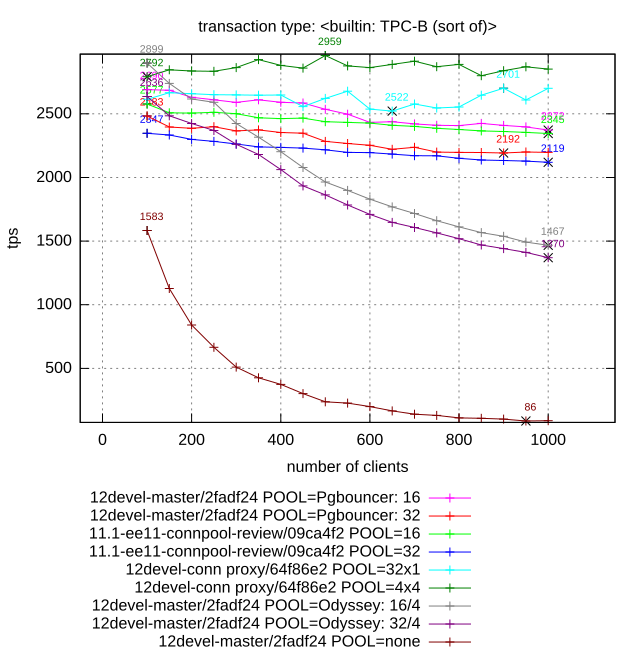
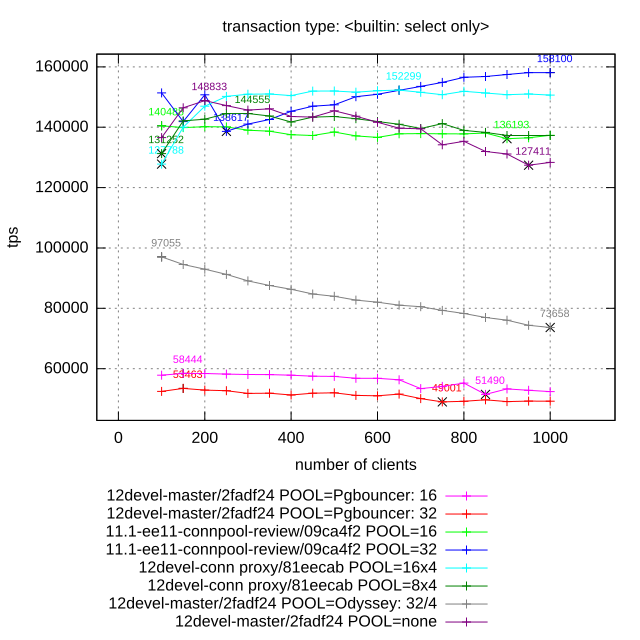
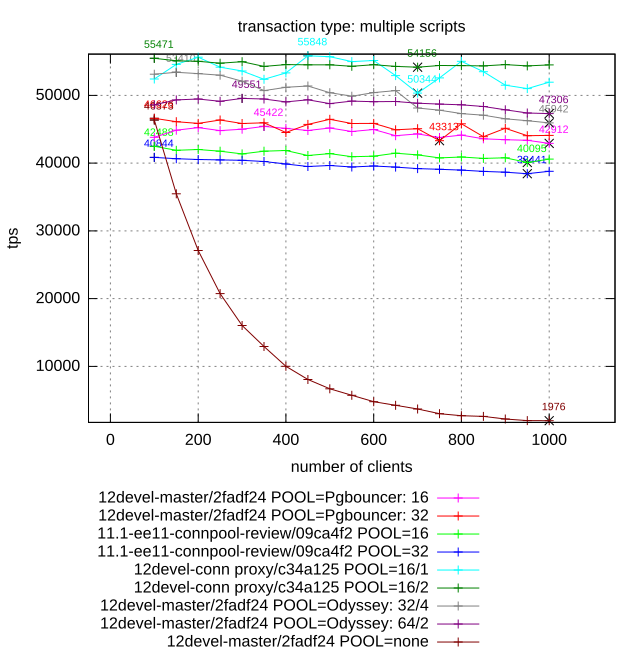
Attached please find results of benchmarking of different connection poolers. Hardware configuration: Intel(R) Xeon(R) CPU X5675 @ 3.07GHz 24 cores (12 physical) 50 GB RAM Tests: pgbench read-write (scale 1): performance is mostly limited by disk throughput pgbench select-only (scale 1): performance is mostly limited by efficient utilization of CPU by all workers pgbench with YCSB-like workload with Zipf distribution: performance is mostly limited by lock contention Participants: 1. pgbouncer (16 and 32 pool size, transaction level pooling) 2. Postgres Pro-EE connection poller: redirection of client connection to poll workers and maintaining of session contexts. 16 and 32 connection pool size (number of worker backend). 3. Built-in proxy connection pooler: implementation proposed in this thread. 16/1 and 16/2 specifies number of worker backends per proxy and number of proxies, total number of backends is multiplication of this values. 4. Yandex Odyssey (32/2 and 64/4 configurations specifies number of backends and Odyssey threads). 5. Vanilla Postgres (marked at diagram as "12devel-master/2fadf24 POOL=none") In all cases except 2) master branch of Postgres is used. Client (pgbench), pooler and postgres are laucnhed at the same host. Communication is though loopback interface (host=localhost). We have tried to find the optimal parameters for each pooler. Three graphics attached to the mail illustrate three different test cases. Few comments about this results: - PgPro EE pooler shows the best results in all cases except tpc-b like. In this case proxy approach is more efficient because more flexible job schedule between workers (in EE sessions are scattered between worker backends at connect time, while proxy chooses least loaded backend for each transaction). - pgbouncer is not able to scale well because of its single-threaded architecture. Certainly it is possible to spawn several instances of pgbouncer and scatter workload between them. But we have not did it. - Vanilla Postgres demonstrates significant degradation of performance for large number of active connections on all workloads except read-only. - Despite to the fact that Odyssey is new player (or may be because of it), Yandex pooler doesn't demonstrate good results. It is the only pooler which also cause degrade of performance with increasing number of connections. May be it is caused by memory leaks, because it memory footprint is also actively increased during test. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
{kind=link}
{kind=link}
{kind=link}
New version of the patch (rebased + bug fixes) is attached to this mail. On 20.03.2019 18:32, Konstantin Knizhnik wrote: > Attached please find results of benchmarking of different connection > poolers. > > Hardware configuration: > Intel(R) Xeon(R) CPU X5675 @ 3.07GHz > 24 cores (12 physical) > 50 GB RAM > > Tests: > pgbench read-write (scale 1): performance is mostly limited by > disk throughput > pgbench select-only (scale 1): performance is mostly limited by > efficient utilization of CPU by all workers > pgbench with YCSB-like workload with Zipf distribution: > performance is mostly limited by lock contention > > Participants: > 1. pgbouncer (16 and 32 pool size, transaction level pooling) > 2. Postgres Pro-EE connection poller: redirection of client > connection to poll workers and maintaining of session contexts. > 16 and 32 connection pool size (number of worker backend). > 3. Built-in proxy connection pooler: implementation proposed in > this thread. > 16/1 and 16/2 specifies number of worker backends per proxy > and number of proxies, total number of backends is multiplication of > this values. > 4. Yandex Odyssey (32/2 and 64/4 configurations specifies number > of backends and Odyssey threads). > 5. Vanilla Postgres (marked at diagram as "12devel-master/2fadf24 > POOL=none") > > In all cases except 2) master branch of Postgres is used. > Client (pgbench), pooler and postgres are laucnhed at the same host. > Communication is though loopback interface (host=localhost). > We have tried to find the optimal parameters for each pooler. > Three graphics attached to the mail illustrate three different test > cases. > > Few comments about this results: > - PgPro EE pooler shows the best results in all cases except tpc-b > like. In this case proxy approach is more efficient because more > flexible job schedule between workers > (in EE sessions are scattered between worker backends at connect > time, while proxy chooses least loaded backend for each transaction). > - pgbouncer is not able to scale well because of its single-threaded > architecture. Certainly it is possible to spawn several instances of > pgbouncer and scatter > workload between them. But we have not did it. > - Vanilla Postgres demonstrates significant degradation of performance > for large number of active connections on all workloads except read-only. > - Despite to the fact that Odyssey is new player (or may be because of > it), Yandex pooler doesn't demonstrate good results. It is the only > pooler which also cause degrade of performance with increasing number > of connections. May be it is caused by memory leaks, because it memory > footprint is also actively increased during test. > -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On Thu, Mar 21, 2019 at 4:33 AM Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > New version of the patch (rebased + bug fixes) is attached to this mail. Hi again Konstantin, Interesting work. No longer applies -- please rebase. -- Thomas Munro https://enterprisedb.com
On 01.07.2019 12:57, Thomas Munro wrote: > On Thu, Mar 21, 2019 at 4:33 AM Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: >> New version of the patch (rebased + bug fixes) is attached to this mail. > Hi again Konstantin, > > Interesting work. No longer applies -- please rebase. > Rebased version of the patch is attached. Also all this version of built-ni proxy can be found in conn_proxy branch of https://github.com/postgrespro/postgresql.builtin_pool.git
Attachment
On Tue, Jul 2, 2019 at 3:11 AM Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > On 01.07.2019 12:57, Thomas Munro wrote: > > Interesting work. No longer applies -- please rebase. > > > Rebased version of the patch is attached. > Also all this version of built-ni proxy can be found in conn_proxy > branch of https://github.com/postgrespro/postgresql.builtin_pool.git Thanks Konstantin. I haven't looked at the code, but I can't help noticing that this CF entry and the autoprepare one are both features that come up again an again on feature request lists I've seen. That's very cool. They also both need architectural-level review. With my Commitfest manager hat on: reviewing other stuff would help with that; if you're looking for something of similar complexity and also the same level of everyone-knows-we-need-to-fix-this-!@#$-we-just-don't-know-exactly-how-yet factor, I hope you get time to provide some more feedback on Takeshi Ideriha's work on shared caches, which doesn't seem a million miles from some of the things you're working on. Could you please fix these compiler warnings so we can see this running check-world on CI? https://ci.appveyor.com/project/postgresql-cfbot/postgresql/build/1.0.46324 https://travis-ci.org/postgresql-cfbot/postgresql/builds/555180678 -- Thomas Munro https://enterprisedb.com
On 08.07.2019 3:37, Thomas Munro wrote: > On Tue, Jul 2, 2019 at 3:11 AM Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: >> On 01.07.2019 12:57, Thomas Munro wrote: >>> Interesting work. No longer applies -- please rebase. >>> >> Rebased version of the patch is attached. >> Also all this version of built-ni proxy can be found in conn_proxy >> branch of https://github.com/postgrespro/postgresql.builtin_pool.git > Thanks Konstantin. I haven't looked at the code, but I can't help > noticing that this CF entry and the autoprepare one are both features > that come up again an again on feature request lists I've seen. > That's very cool. They also both need architectural-level review. > With my Commitfest manager hat on: reviewing other stuff would help > with that; if you're looking for something of similar complexity and > also the same level of > everyone-knows-we-need-to-fix-this-!@#$-we-just-don't-know-exactly-how-yet > factor, I hope you get time to provide some more feedback on Takeshi > Ideriha's work on shared caches, which doesn't seem a million miles > from some of the things you're working on. Thank you, I will look at Takeshi Ideriha's patch. > Could you please fix these compiler warnings so we can see this > running check-world on CI? > > https://ci.appveyor.com/project/postgresql-cfbot/postgresql/build/1.0.46324 > https://travis-ci.org/postgresql-cfbot/postgresql/builds/555180678 > Sorry, I do not have access to Windows host, so can not check Win32 build myself. I have fixed all the reported warnings but can not verify that Win32 build is now ok.
Attachment
On Tue, Jul 9, 2019 at 8:30 AM Konstantin Knizhnik
<k.knizhnik@postgrespro.ru> wrote:
>>>> Rebased version of the patch is attached.
Thanks for including nice documentation in the patch, which gives a
good overview of what's going on. I haven't read any code yet, but I
took it for a quick drive to understand the user experience. These
are just some first impressions.
I started my server with -c connection_proxies=1 and tried to connect
to port 6543 and the proxy segfaulted on null ptr accessing
port->gss->enc. I rebuilt without --with-gssapi to get past that.
Using SELECT pg_backend_pid() from many different connections, I could
see that they were often being served by the same process (although
sometimes it created an extra one when there didn't seem to be a good
reason for it to do that). I could see the proxy managing these
connections with SELECT * FROM pg_pooler_state() (I suppose this would
be wrapped in a view with a name like pg_stat_proxies). I could see
that once I did something like SET foo.bar = 42, a backend became
dedicated to my connection and no other connection could use it. As
described. Neat.
Obviously your concept of tainted backends (= backends that can't be
reused by other connections because they contain non-default session
state) is quite simplistic and would help only the very simplest use
cases. Obviously the problems that need to be solved first to do
better than that are quite large. Personally I think we should move
all GUCs into the Session struct, put the Session struct into shared
memory, and then figure out how to put things like prepared plans into
something like Ideriha-san's experimental shared memory context so
that they also can be accessed by any process, and then we'll mostly
be tackling problems that we'll have to tackle for threads too. But I
think you made the right choice to experiment with just reusing the
backends that have no state like that.
On my FreeBSD box (which doesn't have epoll(), so it's latch.c's old
school poll() for now), I see the connection proxy process eating a
lot of CPU and the temperature rising. I see with truss that it's
doing this as fast as it can:
poll({ 13/POLLIN 17/POLLIN|POLLOUT },2,1000) = 1 (0x1)
Ouch. I admit that I had the idea to test on FreeBSD because I
noticed the patch introduces EPOLLET and I figured this might have
been tested only on Linux. FWIW the same happens on a Mac.
That's all I had time for today, but I'm planning to poke this some
more, and get a better understand of how this works at an OS level. I
can see fd passing, IO multiplexing, and other interesting things
happening. I suspect there are many people on this list who have
thoughts about the architecture we should use to allow a smaller
number of PGPROCs and a larger number of connections, with various
different motivations.
> Thank you, I will look at Takeshi Ideriha's patch.
Cool.
> > Could you please fix these compiler warnings so we can see this
> > running check-world on CI?
> >
> > https://ci.appveyor.com/project/postgresql-cfbot/postgresql/build/1.0.46324
> > https://travis-ci.org/postgresql-cfbot/postgresql/builds/555180678
> >
> Sorry, I do not have access to Windows host, so can not check Win32
> build myself.
C:\projects\postgresql\src\include\../interfaces/libpq/libpq-int.h(33):
fatal error C1083: Cannot open include file: 'pthread-win32.h': No
such file or directory (src/backend/postmaster/proxy.c)
[C:\projects\postgresql\postgres.vcxproj]
These relative includes in proxy.c are part of the problem:
#include "../interfaces/libpq/libpq-fe.h"
#include "../interfaces/libpq/libpq-int.h"
I didn't dig into this much but some first reactions:
1. I see that proxy.c uses libpq, and correctly loads it as a dynamic
library just like postgres_fdw. Unfortunately it's part of core, so
it can't use the same technique as postgres_fdw to add the libpq
headers to the include path.
2. libpq-int.h isn't supposed to be included by code outside libpq,
and in this case it fails to find pthead-win32.h which is apparently
expects to find in either the same directory or the include path. I
didn't look into what exactly is going on (I don't have Windows
either) but I think we can say the root problem is that you shouldn't
be including that from backend code.
--
Thomas Munro
https://enterprisedb.com
On 14.07.2019 8:03, Thomas Munro wrote:
> On Tue, Jul 9, 2019 at 8:30 AM Konstantin Knizhnik
> <k.knizhnik@postgrespro.ru> wrote:
>>>>> Rebased version of the patch is attached.
> Thanks for including nice documentation in the patch, which gives a
> good overview of what's going on. I haven't read any code yet, but I
> took it for a quick drive to understand the user experience. These
> are just some first impressions.
>
> I started my server with -c connection_proxies=1 and tried to connect
> to port 6543 and the proxy segfaulted on null ptr accessing
> port->gss->enc. I rebuilt without --with-gssapi to get past that.
First of all a lot of thanks for your review.
Sorry, I failed to reproduce the problem with GSSAPI.
I have configured postgres with --with-openssl --with-gssapi
and then try to connect to the serverwith psql using the following
connection string:
psql "sslmode=require dbname=postgres port=6543 krbsrvname=POSTGRES"
There are no SIGFAULS and port->gss structure is normally initialized.
Can you please explain me more precisely how to reproduce the problem
(how to configure postgres and how to connect to it)?
>
> Using SELECT pg_backend_pid() from many different connections, I could
> see that they were often being served by the same process (although
> sometimes it created an extra one when there didn't seem to be a good
> reason for it to do that). I could see the proxy managing these
> connections with SELECT * FROM pg_pooler_state() (I suppose this would
> be wrapped in a view with a name like pg_stat_proxies). I could see
> that once I did something like SET foo.bar = 42, a backend became
> dedicated to my connection and no other connection could use it. As
> described. Neat.
>
> Obviously your concept of tainted backends (= backends that can't be
> reused by other connections because they contain non-default session
> state) is quite simplistic and would help only the very simplest use
> cases. Obviously the problems that need to be solved first to do
> better than that are quite large. Personally I think we should move
> all GUCs into the Session struct, put the Session struct into shared
> memory, and then figure out how to put things like prepared plans into
> something like Ideriha-san's experimental shared memory context so
> that they also can be accessed by any process, and then we'll mostly
> be tackling problems that we'll have to tackle for threads too. But I
> think you made the right choice to experiment with just reusing the
> backends that have no state like that.
That was not actually my idea: it was proposed by Dimitri Fontaine.
In PgPRO-EE we have another version of builtin connection pooler
which maintains session context and allows to use GUCs, prepared statements
and temporary tables in pooled sessions.
But the main idea of this patch was to make connection pooler less
invasive and
minimize changes in Postgres core. This is why I have implemented proxy.
> On my FreeBSD box (which doesn't have epoll(), so it's latch.c's old
> school poll() for now), I see the connection proxy process eating a
> lot of CPU and the temperature rising. I see with truss that it's
> doing this as fast as it can:
>
> poll({ 13/POLLIN 17/POLLIN|POLLOUT },2,1000) = 1 (0x1)
>
> Ouch. I admit that I had the idea to test on FreeBSD because I
> noticed the patch introduces EPOLLET and I figured this might have
> been tested only on Linux. FWIW the same happens on a Mac.
Yehh.
This is really the problem. In addition to FreeBSD and MacOS, it also
takes place at Win32.
I have to think more how to solve it. We should somehow emulate
"edge-triggered" more for this system.
The source of the problem is that proxy is reading data from one socket
and writing it in another socket.
If write socket is busy, we have to wait until is is available. But at
the same time there can be data available for input,
so poll will return immediately unless we remove read event for this
socket. Not here how to better do it without changing
WaitEvenSet API.
>
> C:\projects\postgresql\src\include\../interfaces/libpq/libpq-int.h(33):
> fatal error C1083: Cannot open include file: 'pthread-win32.h': No
> such file or directory (src/backend/postmaster/proxy.c)
> [C:\projects\postgresql\postgres.vcxproj]
I will investigate the problem with Win32 build once I get image of
Win32 for VirtualBox.
> These relative includes in proxy.c are part of the problem:
>
> #include "../interfaces/libpq/libpq-fe.h"
> #include "../interfaces/libpq/libpq-int.h"
>
> I didn't dig into this much but some first reactions:
I have added
override CPPFLAGS := $(CPPFLAGS) -I$(top_builddir)/src/port
-I$(top_srcdir)/src/port
in Makefile for postmaster in order to fix this problem (as in
interface/libpq/Makefile).
But looks like it is not enough. As I wrote above I will try to solve
this problem once I get access to Win32 environment.
> 1. I see that proxy.c uses libpq, and correctly loads it as a dynamic
> library just like postgres_fdw. Unfortunately it's part of core, so
> it can't use the same technique as postgres_fdw to add the libpq
> headers to the include path.
>
> 2. libpq-int.h isn't supposed to be included by code outside libpq,
> and in this case it fails to find pthead-win32.h which is apparently
> expects to find in either the same directory or the include path. I
> didn't look into what exactly is going on (I don't have Windows
> either) but I think we can say the root problem is that you shouldn't
> be including that from backend code.
>
Looks like proxy.c has to be moved somewhere outside core?
May be make it an extension? But it may be not so easy to implement because
proxy has to be tightly integrated with postmaster.
On Mon, Jul 15, 2019 at 7:56 AM Konstantin Knizhnik
<k.knizhnik@postgrespro.ru> wrote:
> Can you please explain me more precisely how to reproduce the problem
> (how to configure postgres and how to connect to it)?
Maybe it's just that postmaster.c's ConnCreate() always allocates a
struct for port->gss if the feature is enabled, but the equivalent
code in proxy.c's proxy_loop() doesn't?
./configure
--prefix=$HOME/install/postgres \
--enable-cassert \
--enable-debug \
--enable-depend \
--with-gssapi \
--with-icu \
--with-pam \
--with-ldap \
--with-openssl \
--enable-tap-tests \
--with-includes="/opt/local/include" \
--with-libraries="/opt/local/lib" \
CC="ccache cc" CFLAGS="-O0"
~/install/postgres/bin/psql postgres -h localhost -p 6543
2019-07-15 08:37:25.348 NZST [97972] LOG: server process (PID 97974)
was terminated by signal 11: Segmentation fault: 11
(lldb) bt
* thread #1, stop reason = signal SIGSTOP
* frame #0: 0x0000000104163e7e
postgres`secure_read(port=0x00007fda9ef001d0, ptr=0x00000001047ab690,
len=8192) at be-secure.c:164:6
frame #1: 0x000000010417760d postgres`pq_recvbuf at pqcomm.c:969:7
frame #2: 0x00000001041779ed postgres`pq_getbytes(s="??\x04~?,
len=1) at pqcomm.c:1110:8
frame #3: 0x0000000104284147
postgres`ProcessStartupPacket(port=0x00007fda9ef001d0,
secure_done=true) at postmaster.c:2064:6
...
(lldb) f 0
frame #0: 0x0000000104163e7e
postgres`secure_read(port=0x00007fda9ef001d0, ptr=0x00000001047ab690,
len=8192) at be-secure.c:164:6
161 else
162 #endif
163 #ifdef ENABLE_GSS
-> 164 if (port->gss->enc)
165 {
166 n = be_gssapi_read(port, ptr, len);
167 waitfor = WL_SOCKET_READABLE;
(lldb) print port->gss
(pg_gssinfo *) $0 = 0x0000000000000000
> > Obviously your concept of tainted backends (= backends that can't be
> > reused by other connections because they contain non-default session
> > state) is quite simplistic and would help only the very simplest use
> > cases. Obviously the problems that need to be solved first to do
> > better than that are quite large. Personally I think we should move
> > all GUCs into the Session struct, put the Session struct into shared
> > memory, and then figure out how to put things like prepared plans into
> > something like Ideriha-san's experimental shared memory context so
> > that they also can be accessed by any process, and then we'll mostly
> > be tackling problems that we'll have to tackle for threads too. But I
> > think you made the right choice to experiment with just reusing the
> > backends that have no state like that.
>
> That was not actually my idea: it was proposed by Dimitri Fontaine.
> In PgPRO-EE we have another version of builtin connection pooler
> which maintains session context and allows to use GUCs, prepared statements
> and temporary tables in pooled sessions.
Interesting. Do you serialise/deserialise plans and GUCs using
machinery similar to parallel query, and did you changed temporary
tables to use shared buffers? People have suggested that we do that
to allow temporary tables in parallel queries too. FWIW I have also
wondered about per (database, user) pools for reusable parallel
workers.
> But the main idea of this patch was to make connection pooler less
> invasive and
> minimize changes in Postgres core. This is why I have implemented proxy.
How do you do it without a proxy?
One idea I've wondered about that doesn't involve feeding all network
IO through an extra process and extra layer of syscalls like this is
to figure out how to give back your PGPROC slot when idle. If you
don't have one and can't acquire one at the beginning of a
transaction, you wait until one becomes free. When idle and not in a
transaction you give it back to the pool, perhaps after a slight
delay. That may be impossible for some reason or other, I don't know.
If it could be done, it'd deal with the size-of-procarray problem
(since we like to scan it) and provide a kind of 'admission control'
(limiting number of transactions that can run), but wouldn't deal with
the amount-of-backend-memory-wasted-on-per-process-caches problem
(maybe solvable by shared caching).
Ok, time for a little bit more testing. I was curious about the user
experience when there are no free backends.
1. I tested with connection_proxies=1, max_connections=4, and I began
3 transactions. Then I tried to make a 4th connection, and it blocked
while trying to connect and the log shows a 'sorry, too many clients
already' message. Then I committed one of my transactions and the 4th
connection was allowed to proceed.
2. I tried again, this time with 4 already existing connections and
no transactions. I began 3 concurrent transactions, and then when I
tried to begin a 4th transaction the BEGIN command blocked until one
of the other transactions committed.
Some thoughts: Why should case 1 block? Shouldn't I be allowed to
connect, even though I can't begin a transaction without waiting yet?
Why can I run only 3 transactions when I said max_connection=4? Ah,
that's probably because the proxy itself is eating one slot, and
indeed if I set connection_proxies to 2 I can now run only two
concurrent transactions. And yet when there were no transactions
running I could still open 4 connections. Hmm.
The general behaviour of waiting instead of raising an error seems
sensible, and that's how client-side connection pools usually work.
Perhaps some of the people who have wanted admission control were
thinking of doing it at the level of queries rather than whole
transactions though, I don't know. I suppose in extreme cases it's
possible to create invisible deadlocks, if a client is trying to
control more than one transaction concurrently, but that doesn't seem
like a real problem.
> > On my FreeBSD box (which doesn't have epoll(), so it's latch.c's old
> > school poll() for now), I see the connection proxy process eating a
> > lot of CPU and the temperature rising. I see with truss that it's
> > doing this as fast as it can:
> >
> > poll({ 13/POLLIN 17/POLLIN|POLLOUT },2,1000) = 1 (0x1)
> >
> > Ouch. I admit that I had the idea to test on FreeBSD because I
> > noticed the patch introduces EPOLLET and I figured this might have
> > been tested only on Linux. FWIW the same happens on a Mac.
>
> Yehh.
> This is really the problem. In addition to FreeBSD and MacOS, it also
> takes place at Win32.
> I have to think more how to solve it. We should somehow emulate
> "edge-triggered" more for this system.
> The source of the problem is that proxy is reading data from one socket
> and writing it in another socket.
> If write socket is busy, we have to wait until is is available. But at
> the same time there can be data available for input,
> so poll will return immediately unless we remove read event for this
> socket. Not here how to better do it without changing
> WaitEvenSet API.
Can't you do this by removing events you're not interested in right
now, using ModifyWaitEvent() to change between WL_SOCKET_WRITEABLE and
WL_SOCKET_READABLE as appropriate? Perhaps the problem you're worried
about is that this generates extra system calls in the epoll()
implementation? I think that's not a problem for poll(), and could be
fixed for the kqueue() implementation I plan to commit eventually. I
have no clue for Windows.
> Looks like proxy.c has to be moved somewhere outside core?
> May be make it an extension? But it may be not so easy to implement because
> proxy has to be tightly integrated with postmaster.
I'm not sure. Seems like it should be solvable with the code in core.
--
Thomas Munro
https://enterprisedb.com
On 15.07.2019 1:48, Thomas Munro wrote:
> On Mon, Jul 15, 2019 at 7:56 AM Konstantin Knizhnik
> <k.knizhnik@postgrespro.ru> wrote:
>> Can you please explain me more precisely how to reproduce the problem
>> (how to configure postgres and how to connect to it)?
> Maybe it's just that postmaster.c's ConnCreate() always allocates a
> struct for port->gss if the feature is enabled, but the equivalent
> code in proxy.c's proxy_loop() doesn't?
>
> ./configure
> --prefix=$HOME/install/postgres \
> --enable-cassert \
> --enable-debug \
> --enable-depend \
> --with-gssapi \
> --with-icu \
> --with-pam \
> --with-ldap \
> --with-openssl \
> --enable-tap-tests \
> --with-includes="/opt/local/include" \
> --with-libraries="/opt/local/lib" \
> CC="ccache cc" CFLAGS="-O0"
>
> ~/install/postgres/bin/psql postgres -h localhost -p 6543
>
> 2019-07-15 08:37:25.348 NZST [97972] LOG: server process (PID 97974)
> was terminated by signal 11: Segmentation fault: 11
>
> (lldb) bt
> * thread #1, stop reason = signal SIGSTOP
> * frame #0: 0x0000000104163e7e
> postgres`secure_read(port=0x00007fda9ef001d0, ptr=0x00000001047ab690,
> len=8192) at be-secure.c:164:6
> frame #1: 0x000000010417760d postgres`pq_recvbuf at pqcomm.c:969:7
> frame #2: 0x00000001041779ed postgres`pq_getbytes(s="??\x04~?,
> len=1) at pqcomm.c:1110:8
> frame #3: 0x0000000104284147
> postgres`ProcessStartupPacket(port=0x00007fda9ef001d0,
> secure_done=true) at postmaster.c:2064:6
> ...
> (lldb) f 0
> frame #0: 0x0000000104163e7e
> postgres`secure_read(port=0x00007fda9ef001d0, ptr=0x00000001047ab690,
> len=8192) at be-secure.c:164:6
> 161 else
> 162 #endif
> 163 #ifdef ENABLE_GSS
> -> 164 if (port->gss->enc)
> 165 {
> 166 n = be_gssapi_read(port, ptr, len);
> 167 waitfor = WL_SOCKET_READABLE;
> (lldb) print port->gss
> (pg_gssinfo *) $0 = 0x0000000000000000
Thank you, fixed (pushed to
https://github.com/postgrespro/postgresql.builtin_pool.git repository).
I am not sure that GSS authentication works as intended, but at least
psql "sslmode=require dbname=postgres port=6543 krbsrvname=POSTGRES"
is normally connected.
>>> Obviously your concept of tainted backends (= backends that can't be
>>> reused by other connections because they contain non-default session
>>> state) is quite simplistic and would help only the very simplest use
>>> cases. Obviously the problems that need to be solved first to do
>>> better than that are quite large. Personally I think we should move
>>> all GUCs into the Session struct, put the Session struct into shared
>>> memory, and then figure out how to put things like prepared plans into
>>> something like Ideriha-san's experimental shared memory context so
>>> that they also can be accessed by any process, and then we'll mostly
>>> be tackling problems that we'll have to tackle for threads too. But I
>>> think you made the right choice to experiment with just reusing the
>>> backends that have no state like that.
>> That was not actually my idea: it was proposed by Dimitri Fontaine.
>> In PgPRO-EE we have another version of builtin connection pooler
>> which maintains session context and allows to use GUCs, prepared statements
>> and temporary tables in pooled sessions.
> Interesting. Do you serialise/deserialise plans and GUCs using
> machinery similar to parallel query, and did you changed temporary
> tables to use shared buffers? People have suggested that we do that
> to allow temporary tables in parallel queries too. FWIW I have also
> wondered about per (database, user) pools for reusable parallel
> workers.
No. The main difference between PG-Pro (conn_pool) and vanilla
(conn_proxy) version of connection pooler
is that first one bind sessions to pool workers while last one is using
proxy to scatter requests between workers.
So in conn_pool postmaster accepts client connection and the schedule it
(using one of provided scheduling policies, i.e. round robin, random,
load balancing,...) to one of worker backends. Then client socket is
transferred to this backend and client and backend are connected directly.
Session is never rescheduled, i.e. it is bounded to backend. One backend
is serving multiple sessions. Sessions GUCs and some static variables
are saved in session context. Each session has its own temporary
namespace, so temporary tables of different sessions do not interleave.
Direct connection of client and backend allows to eliminate proxy
overhead. But at the same time - binding session to backend it is the
main drawback of this approach. Long living transaction can block all
other sessions scheduled to this backend.
I have though a lot about possibility to reschedule sessions. The main
"show stopper" is actually temporary tables.
Implementation of temporary tables is one of the "bad smelling" places
in Postgres causing multiple problems:
parallel queries, using temporary table at replica, catalog bloating,
connection pooling...
This is why I have tried to implement "global" temporary tables (like in
Oracle).
I am going to publish this patch soon: in this case table definition is
global, but data is local for each session.
Also global temporary tables are accessed through shared pool which
makes it possible to use them in parallel queries.
But it is separate story, not currently related with connection pooling.
Approach with proxy doesn't suffer from this problem.
>> But the main idea of this patch was to make connection pooler less
>> invasive and
>> minimize changes in Postgres core. This is why I have implemented proxy.
> How do you do it without a proxy?
I hope I have explained it above.
Actually this version pf connection pooler is also available at github
https://github.com/postgrespro/postgresql.builtin_pool.git repository
branch conn_pool).
> Ok, time for a little bit more testing. I was curious about the user
> experience when there are no free backends.
>
> 1. I tested with connection_proxies=1, max_connections=4, and I began
> 3 transactions. Then I tried to make a 4th connection, and it blocked
> while trying to connect and the log shows a 'sorry, too many clients
> already' message. Then I committed one of my transactions and the 4th
> connection was allowed to proceed.
>
> 2. I tried again, this time with 4 already existing connections and
> no transactions. I began 3 concurrent transactions, and then when I
> tried to begin a 4th transaction the BEGIN command blocked until one
> of the other transactions committed.
>
> Some thoughts: Why should case 1 block? Shouldn't I be allowed to
> connect, even though I can't begin a transaction without waiting yet?
> Why can I run only 3 transactions when I said max_connection=4? Ah,
> that's probably because the proxy itself is eating one slot, and
> indeed if I set connection_proxies to 2 I can now run only two
> concurrent transactions. And yet when there were no transactions
> running I could still open 4 connections. Hmm.
max_connections is not the right switch to control behavior of
connection pooler.
You should adjust session_pool_size, connection_proxies and max_sessions
parameters.
What happen in 1) case? Default value of session_pool_size is 10. It
means that postgres will spawn up to 10 backens for each database/user
combination. But max_connection limit will exhausted earlier. May be it
is better to prohibit setting session_pool_size larger than max_connection
or automatically adjust it according to max_connections. But it is also
no so easy to enforce, because separate set of pool workers is created for
each database/user combination.
So I agree that observer behavior is confusing, but I do not have good
idea how to improve it.
>
> The general behaviour of waiting instead of raising an error seems
> sensible, and that's how client-side connection pools usually work.
> Perhaps some of the people who have wanted admission control were
> thinking of doing it at the level of queries rather than whole
> transactions though, I don't know. I suppose in extreme cases it's
> possible to create invisible deadlocks, if a client is trying to
> control more than one transaction concurrently, but that doesn't seem
> like a real problem.
>
>>> On my FreeBSD box (which doesn't have epoll(), so it's latch.c's old
>>> school poll() for now), I see the connection proxy process eating a
>>> lot of CPU and the temperature rising. I see with truss that it's
>>> doing this as fast as it can:
>>>
>>> poll({ 13/POLLIN 17/POLLIN|POLLOUT },2,1000) = 1 (0x1)
>>>
>>> Ouch. I admit that I had the idea to test on FreeBSD because I
>>> noticed the patch introduces EPOLLET and I figured this might have
>>> been tested only on Linux. FWIW the same happens on a Mac.
>> Yehh.
>> This is really the problem. In addition to FreeBSD and MacOS, it also
>> takes place at Win32.
>> I have to think more how to solve it. We should somehow emulate
>> "edge-triggered" more for this system.
>> The source of the problem is that proxy is reading data from one socket
>> and writing it in another socket.
>> If write socket is busy, we have to wait until is is available. But at
>> the same time there can be data available for input,
>> so poll will return immediately unless we remove read event for this
>> socket. Not here how to better do it without changing
>> WaitEvenSet API.
> Can't you do this by removing events you're not interested in right
> now, using ModifyWaitEvent() to change between WL_SOCKET_WRITEABLE and
> WL_SOCKET_READABLE as appropriate? Perhaps the problem you're worried
> about is that this generates extra system calls in the epoll()
> implementation? I think that's not a problem for poll(), and could be
> fixed for the kqueue() implementation I plan to commit eventually. I
> have no clue for Windows.
Window implementation is similar with poll().
Yes, definitely it can be done by removing read handle from wait even
set after each pending write operation.
But it seems to be very inefficient in case of epoll() implementation
(where changing event set requires separate syscall).
So either we have to add some extra function, i.e. WaitEventEdgeTrigger
which will do nothing for epoll(),
either somehow implement edge triggering inside WaitEvent*
implementation itself (not clear how to do it, since read/write
operations are
not performed through this API).
>> Looks like proxy.c has to be moved somewhere outside core?
>> May be make it an extension? But it may be not so easy to implement because
>> proxy has to be tightly integrated with postmaster.
> I'm not sure. Seems like it should be solvable with the code in core.
>
I also think so. It is now working at Unix and I hope I can also fix
Win32 build.
On 14.07.2019 8:03, Thomas Munro wrote:
>
> On my FreeBSD box (which doesn't have epoll(), so it's latch.c's old
> school poll() for now), I see the connection proxy process eating a
> lot of CPU and the temperature rising. I see with truss that it's
> doing this as fast as it can:
>
> poll({ 13/POLLIN 17/POLLIN|POLLOUT },2,1000) = 1 (0x1)
>
> Ouch. I admit that I had the idea to test on FreeBSD because I
> noticed the patch introduces EPOLLET and I figured this might have
> been tested only on Linux. FWIW the same happens on a Mac.
>
I have committed patch which emulates epoll EPOLLET flag and so should
avoid busy loop with poll().
I will be pleased if you can check it at FreeBSD box.
Attachment
On 15.07.2019 17:04, Konstantin Knizhnik wrote:
>
>
> On 14.07.2019 8:03, Thomas Munro wrote:
>>
>> On my FreeBSD box (which doesn't have epoll(), so it's latch.c's old
>> school poll() for now), I see the connection proxy process eating a
>> lot of CPU and the temperature rising. I see with truss that it's
>> doing this as fast as it can:
>>
>> poll({ 13/POLLIN 17/POLLIN|POLLOUT },2,1000) = 1 (0x1)
>>
>> Ouch. I admit that I had the idea to test on FreeBSD because I
>> noticed the patch introduces EPOLLET and I figured this might have
>> been tested only on Linux. FWIW the same happens on a Mac.
>>
> I have committed patch which emulates epoll EPOLLET flag and so should
> avoid busy loop with poll().
> I will be pleased if you can check it at FreeBSD box.
>
>
Sorry, attached patch was incomplete.
Please try this version of the patch.
Attachment
Hi Konstantin,
Thanks for your work on this. I'll try to do more testing in the next few days, here's what I have so far.
make installcheck-world: passed
The v8 patch [1] applies, though I get indent and whitespace errors:
<stdin>:79: tab in indent."Each proxy launches its own subset of backends. So maximal number of non-tainted backends is "<stdin>:80: tab in indent."session_pool_size*connection_proxies*databases*roles.<stdin>:519: indent with spaces.char buf[CMSG_SPACE(sizeof(sock))];<stdin>:520: indent with spaces.memset(buf, '\0', sizeof(buf));<stdin>:522: indent with spaces./* On Mac OS X, the struct iovec is needed, even if it points to minimal data */warning: squelched 82 whitespace errorswarning: 87 lines add whitespace errors.
In connpool.sgml:
"but it can be changed to standard Postgres 4321"
Should be 5432?
" As far as pooled backends are not terminated on client exist, it will not
be possible to drop database to which them are connected."Active discussion in [2] might change that, it is also in this July commitfest [3].
"Unlike pgbouncer and other external connection poolera"
Should be "poolers"
"So developers of client applications still have a choice
either to avoid using session-specific operations either not to use pooling."That sentence isn't smooth for me to read. Maybe something like:
"Developers of client applications have the choice to either avoid using session-specific operations, or not use built-in pooling."
On Tue, Jul 16, 2019 at 12:20 AM Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote:
On 15.07.2019 17:04, Konstantin Knizhnik wrote:
>
>
> On 14.07.2019 8:03, Thomas Munro wrote:
>>
>> On my FreeBSD box (which doesn't have epoll(), so it's latch.c's old
>> school poll() for now), I see the connection proxy process eating a
>> lot of CPU and the temperature rising. I see with truss that it's
>> doing this as fast as it can:
>>
>> poll({ 13/POLLIN 17/POLLIN|POLLOUT },2,1000) = 1 (0x1)
>>
>> Ouch. I admit that I had the idea to test on FreeBSD because I
>> noticed the patch introduces EPOLLET and I figured this might have
>> been tested only on Linux. FWIW the same happens on a Mac.
>>
> I have committed patch which emulates epoll EPOLLET flag and so should
> avoid busy loop with poll().
> I will be pleased if you can check it at FreeBSD box.
>
>
Sorry, attached patch was incomplete.
Please try this version of the patch.
Hi, Ryan
Thank you for review.
I have fixed all reported issues except one related with "dropdb --force" discussion.
As far as this patch is not yet committed, I can not rely on it yet.
Certainly I can just remove this sentence from documentation, assuming that this patch will be committed soon.
But then some extra efforts will be needed to terminated pooler backends of dropped database.
On 18.07.2019 6:01, Ryan Lambert wrote:
Hi Konstantin,Thanks for your work on this. I'll try to do more testing in the next few days, here's what I have so far.make installcheck-world: passedThe v8 patch [1] applies, though I get indent and whitespace errors:<stdin>:79: tab in indent."Each proxy launches its own subset of backends. So maximal number of non-tainted backends is "<stdin>:80: tab in indent."session_pool_size*connection_proxies*databases*roles.<stdin>:519: indent with spaces.char buf[CMSG_SPACE(sizeof(sock))];<stdin>:520: indent with spaces.memset(buf, '\0', sizeof(buf));<stdin>:522: indent with spaces./* On Mac OS X, the struct iovec is needed, even if it points to minimal data */warning: squelched 82 whitespace errorswarning: 87 lines add whitespace errors.In connpool.sgml:"but it can be changed to standard Postgres 4321"Should be 5432?" As far as pooled backends are not terminated on client exist, it will notbe possible to drop database to which them are connected."Active discussion in [2] might change that, it is also in this July commitfest [3]."Unlike pgbouncer and other external connection poolera"Should be "poolers""So developers of client applications still have a choiceeither to avoid using session-specific operations either not to use pooling."That sentence isn't smooth for me to read. Maybe something like:"Developers of client applications have the choice to either avoid using session-specific operations, or not use built-in pooling."
Thank you for review.
I have fixed all reported issues except one related with "dropdb --force" discussion.
As far as this patch is not yet committed, I can not rely on it yet.
Certainly I can just remove this sentence from documentation, assuming that this patch will be committed soon.
But then some extra efforts will be needed to terminated pooler backends of dropped database.
Attachment
I have fixed all reported issues except one related with "dropdb --force" discussion.
As far as this patch is not yet committed, I can not rely on it yet.
Certainly I can just remove this sentence from documentation, assuming that this patch will be committed soon.
But then some extra efforts will be needed to terminated pooler backends of dropped database.
Great, thanks. Understood about the non-committed item. I did mark that item as ready for committer last night so we will see. I should have time to put the actual functionality of your patch to test later today or tomorrow. Thanks,
Ryan Lambert
Here's what I found tonight in your latest patch (9). The output from git apply is better, fewer whitespace errors, but still getting the following. Ubuntu 18.04 if that helps.
git apply -p1 < builtin_connection_proxy-9.patch
git apply -p1 < builtin_connection_proxy-9.patch
<stdin>:79: tab in indent.
Each proxy launches its own subset of backends.
<stdin>:634: indent with spaces.
union {
<stdin>:635: indent with spaces.
struct sockaddr_in inaddr;
<stdin>:636: indent with spaces.
struct sockaddr addr;
<stdin>:637: indent with spaces.
} a;
warning: squelched 54 whitespace errors
warning: 59 lines add whitespace errors.
A few more minor edits. In config.sgml:
"If the <varname>max_sessions</varname> limit is reached new connection are not accepted."
Should be "connections".
"The default value is 10, so up to 10 backends will server each database,"
"sever" should be "serve" and the sentence should end with a period instead of a comma.
In postmaster.c:
/* The socket number we are listening for poolled connections on */
"poolled" --> "pooled"
"(errmsg("could not create listen socket for locahost")));"
"locahost" -> "localhost".
" * so to support order balancing we should do dome smart work here."
"dome" should be "some"?
Each proxy launches its own subset of backends.
<stdin>:634: indent with spaces.
union {
<stdin>:635: indent with spaces.
struct sockaddr_in inaddr;
<stdin>:636: indent with spaces.
struct sockaddr addr;
<stdin>:637: indent with spaces.
} a;
warning: squelched 54 whitespace errors
warning: 59 lines add whitespace errors.
A few more minor edits. In config.sgml:
"If the <varname>max_sessions</varname> limit is reached new connection are not accepted."
Should be "connections".
"The default value is 10, so up to 10 backends will server each database,"
"sever" should be "serve" and the sentence should end with a period instead of a comma.
In postmaster.c:
/* The socket number we are listening for poolled connections on */
"poolled" --> "pooled"
"(errmsg("could not create listen socket for locahost")));"
"locahost" -> "localhost".
" * so to support order balancing we should do dome smart work here."
"dome" should be "some"?
I don't see any tests covering this new functionality. It seems that this is significant enough functionality to warrant some sort of tests, but I don't know exactly what those would/should be.
Thanks,
Ryan
On 19.07.2019 6:36, Ryan Lambert wrote:
Here's what I found tonight in your latest patch (9). The output from git apply is better, fewer whitespace errors, but still getting the following. Ubuntu 18.04 if that helps.
git apply -p1 < builtin_connection_proxy-9.patch<stdin>:79: tab in indent.
Each proxy launches its own subset of backends.
<stdin>:634: indent with spaces.
union {
<stdin>:635: indent with spaces.
struct sockaddr_in inaddr;
<stdin>:636: indent with spaces.
struct sockaddr addr;
<stdin>:637: indent with spaces.
} a;
warning: squelched 54 whitespace errors
warning: 59 lines add whitespace errors.
A few more minor edits. In config.sgml:
"If the <varname>max_sessions</varname> limit is reached new connection are not accepted."
Should be "connections".
"The default value is 10, so up to 10 backends will server each database,"
"sever" should be "serve" and the sentence should end with a period instead of a comma.
In postmaster.c:
/* The socket number we are listening for poolled connections on */
"poolled" --> "pooled"
"(errmsg("could not create listen socket for locahost")));"
"locahost" -> "localhost".
" * so to support order balancing we should do dome smart work here."
"dome" should be "some"?I don't see any tests covering this new functionality. It seems that this is significant enough functionality to warrant some sort of tests, but I don't know exactly what those would/should be.
Thank you once again for this fixes.
Updated patch is attached.
Concerning testing: I do not think that connection pooler needs some kind of special tests.
The idea of built-in connection pooler is that it should be able to handle all requests normal postgres can do.
I have added to regression tests extra path with enabled connection proxies.
Unfortunately, pg_regress is altering some session variables, so it backend becomes tainted and so
pooling is not actually used (but communication through proxy is tested).
It is also possible to run pg_bench with different number of connections though connection pooler.
Thanks,Ryan
Attachment
Hello Konstantin,
> Concerning testing: I do not think that connection pooler needs some kind of special tests.
> The idea of built-in connection pooler is that it should be able to handle all requests normal postgres can do.
> I have added to regression tests extra path with enabled connection proxies.
> Unfortunately, pg_regress is altering some session variables, so it backend becomes tainted and so
> pooling is not actually used (but communication through proxy is tested).
> Thank you for your work on this patch, I took some good time to really explore the configuration and do some testing with pgbench. This round of testing was done against patch 10 [1] and master branch commit a0555ddab9 from 7/22.
Thank you for explaining, I wasn't sure.
make installcheck-world: tested, passed
Implements feature: tested, passed
Documentation: I need to review again, I saw typos when testing but didn't make note of the details.
Applying the patch [1] has improved from v9, still getting these:
git apply -p1 < builtin_connection_proxy-10.patch
<stdin>:1536: indent with spaces.
/* Has pending clients: serve one of them */
<stdin>:1936: indent with spaces.
/* If we attach new client to the existed backend, then we need to send handshake response to the client */
<stdin>:2208: indent with spaces.
if (port->sock == PGINVALID_SOCKET)
<stdin>:2416: indent with spaces.
FuncCallContext* srf_ctx;
<stdin>:2429: indent with spaces.
ps_ctx = (PoolerStateContext*)palloc(sizeof(PoolerStateContext));
warning: squelched 5 whitespace errors
warning: 10 lines add whitespace errors.
I used a DigitalOcean droplet with 2 CPU and 2 GB RAM and SSD for this testing, Ubuntu 18.04. I chose the smaller server size based on the availability of similar and recent results around connection pooling [2] that used AWS EC2 m4.large instance (2 cores, 8 GB RAM) and pgbouncer. Your prior pgbench tests [3] also focused on larger servers so I wanted to see how this works on smaller hardware.
Considering this from connpool.sgml:
"<varname>connection_proxies</varname> specifies number of connection proxy processes which will be spawned. Default value is zero, so connection pooling is disabled by default."
That hints to me that connection_proxies is the main configuration to start with so that was the only configuration I changed from the default for this feature. I adjusted shared_buffers to 500MB (25% of total) and max_connections to 1000. Only having one proxy gives subpar performance across the board, so did setting this value to 10. My hunch is this value should roughly follow the # of cpus available, but that's just a hunch.
I tested with 25, 75, 150, 300 and 600 connections. Initialized with a scale of 1000 and ran read-only tests. Basic pgbench commands look like the following, I have full commands and results from 18 tests included in the attached MD file. Postgres was restarted between each test.
pgbench -i -s 1000 bench_test
pgbench -p 6543 -c 300 -j 2 -T 600 -P 60 -S bench_test
Tests were all ran from the same server. I intend to do further testing with external connections using SSL.
General observations:
For each value of connection_proxies, the TPS observed at 25 connections held up reliably through 600 connections. For this server using connection_proxies = 2 was the fastest, but setting to 1 or 10 still provided **predictable** throughput. That seems to be a good attribute for this feature.
Also predictable was the latency increase, doubling the connections roughly doubles the latency. This was true with or without connection pooling.
Focusing on disabled connection pooling vs the feature with two proxies, the results are promising, the breakpoint seems to be around 150 connections.
Low connections (25): -15% TPS; +45% latency
Medium connections (300): +21% TPS; +38% latency
High connections (600): Couldn't run without pooling... aka: Win for pooling!
The two attached charts show the TPS and average latency of these two scenarios. This feature does a great job of maintaining a consistent TPS as connection numbers increase. This comes with tradeoffs of lower throughput with < 150 connections, and higher latency across the board.
The increase in latency seems reasonable to me based on the testing I have done so far. Compared to the results from [2] it seems latency is affecting this feature a bit more than it does pgbouncer, yet not unreasonably so given the benefit of having the feature built in and the reduced complexity.
I don't understand yet how max_sessions ties in.
Also, having both session_pool_size and connection_proxies seemed confusing at first. I still haven't figured out exactly how they relate together in the overall operation and their impact on performance. The new view helped, I get the concept of **what** it is doing (connection_proxies = more rows, session_pool_size = n_backends for each row), it's more a lack of understanding the **why** regarding how it will operate.
postgres=# select * from pg_pooler_state();
pid | n_clients | n_ssl_clients | n_pools | n_backends | n_dedicated_backends | tx_bytes | rx_bytes | n_transactions
------+-----------+---------------+---------+------------+----------------------+-----------+-----------+----------------
1682 | 75 | 0 | 1 | 10 | 0 | 366810458 | 353181393 | 5557109
1683 | 75 | 0 | 1 | 10 | 0 | 368464689 | 354778709 | 5582174
(2 rows
I am not sure how I feel about this:
"Non-tainted backends are not terminated even if there are no more connected sessions."
Would it be possible (eventually) to monitor connection rates and free up non-tainted backends after a time? The way I'd like to think of that working would be:
If 50% of backends are unused for more than 1 hour, release 10% of established backends.
The two percentages and time frame would ideally be configurable, but setup in a way that it doesn't let go of connections too quickly, causing unnecessary expense of re-establishing those connections. My thought is if there's one big surge of connections followed by a long period of lower connections, does it make sense to keep those extra backends established?
I'll give the documentation another pass soon. Thanks for all your work on this, I like what I'm seeing so far!
[1] https://www.postgresql.org/message-id/attachment/102732/builtin_connection_proxy-10.patch
[2] http://richyen.com/postgres/2019/06/25/pools_arent_just_for_cars.html
[3] https://www.postgresql.org/message-id/ede4470a-055b-1389-0bbd-840f0594b758%40postgrespro.ru
Thanks,
Ryan Lambert
> Concerning testing: I do not think that connection pooler needs some kind of special tests.
> The idea of built-in connection pooler is that it should be able to handle all requests normal postgres can do.
> I have added to regression tests extra path with enabled connection proxies.
> Unfortunately, pg_regress is altering some session variables, so it backend becomes tainted and so
> pooling is not actually used (but communication through proxy is tested).
> Thank you for your work on this patch, I took some good time to really explore the configuration and do some testing with pgbench. This round of testing was done against patch 10 [1] and master branch commit a0555ddab9 from 7/22.
Thank you for explaining, I wasn't sure.
make installcheck-world: tested, passed
Implements feature: tested, passed
Documentation: I need to review again, I saw typos when testing but didn't make note of the details.
Applying the patch [1] has improved from v9, still getting these:
git apply -p1 < builtin_connection_proxy-10.patch
<stdin>:1536: indent with spaces.
/* Has pending clients: serve one of them */
<stdin>:1936: indent with spaces.
/* If we attach new client to the existed backend, then we need to send handshake response to the client */
<stdin>:2208: indent with spaces.
if (port->sock == PGINVALID_SOCKET)
<stdin>:2416: indent with spaces.
FuncCallContext* srf_ctx;
<stdin>:2429: indent with spaces.
ps_ctx = (PoolerStateContext*)palloc(sizeof(PoolerStateContext));
warning: squelched 5 whitespace errors
warning: 10 lines add whitespace errors.
I used a DigitalOcean droplet with 2 CPU and 2 GB RAM and SSD for this testing, Ubuntu 18.04. I chose the smaller server size based on the availability of similar and recent results around connection pooling [2] that used AWS EC2 m4.large instance (2 cores, 8 GB RAM) and pgbouncer. Your prior pgbench tests [3] also focused on larger servers so I wanted to see how this works on smaller hardware.
Considering this from connpool.sgml:
"<varname>connection_proxies</varname> specifies number of connection proxy processes which will be spawned. Default value is zero, so connection pooling is disabled by default."
That hints to me that connection_proxies is the main configuration to start with so that was the only configuration I changed from the default for this feature. I adjusted shared_buffers to 500MB (25% of total) and max_connections to 1000. Only having one proxy gives subpar performance across the board, so did setting this value to 10. My hunch is this value should roughly follow the # of cpus available, but that's just a hunch.
I tested with 25, 75, 150, 300 and 600 connections. Initialized with a scale of 1000 and ran read-only tests. Basic pgbench commands look like the following, I have full commands and results from 18 tests included in the attached MD file. Postgres was restarted between each test.
pgbench -i -s 1000 bench_test
pgbench -p 6543 -c 300 -j 2 -T 600 -P 60 -S bench_test
Tests were all ran from the same server. I intend to do further testing with external connections using SSL.
General observations:
For each value of connection_proxies, the TPS observed at 25 connections held up reliably through 600 connections. For this server using connection_proxies = 2 was the fastest, but setting to 1 or 10 still provided **predictable** throughput. That seems to be a good attribute for this feature.
Also predictable was the latency increase, doubling the connections roughly doubles the latency. This was true with or without connection pooling.
Focusing on disabled connection pooling vs the feature with two proxies, the results are promising, the breakpoint seems to be around 150 connections.
Low connections (25): -15% TPS; +45% latency
Medium connections (300): +21% TPS; +38% latency
High connections (600): Couldn't run without pooling... aka: Win for pooling!
The two attached charts show the TPS and average latency of these two scenarios. This feature does a great job of maintaining a consistent TPS as connection numbers increase. This comes with tradeoffs of lower throughput with < 150 connections, and higher latency across the board.
The increase in latency seems reasonable to me based on the testing I have done so far. Compared to the results from [2] it seems latency is affecting this feature a bit more than it does pgbouncer, yet not unreasonably so given the benefit of having the feature built in and the reduced complexity.
I don't understand yet how max_sessions ties in.
Also, having both session_pool_size and connection_proxies seemed confusing at first. I still haven't figured out exactly how they relate together in the overall operation and their impact on performance. The new view helped, I get the concept of **what** it is doing (connection_proxies = more rows, session_pool_size = n_backends for each row), it's more a lack of understanding the **why** regarding how it will operate.
postgres=# select * from pg_pooler_state();
pid | n_clients | n_ssl_clients | n_pools | n_backends | n_dedicated_backends | tx_bytes | rx_bytes | n_transactions
------+-----------+---------------+---------+------------+----------------------+-----------+-----------+----------------
1682 | 75 | 0 | 1 | 10 | 0 | 366810458 | 353181393 | 5557109
1683 | 75 | 0 | 1 | 10 | 0 | 368464689 | 354778709 | 5582174
(2 rows
I am not sure how I feel about this:
"Non-tainted backends are not terminated even if there are no more connected sessions."
Would it be possible (eventually) to monitor connection rates and free up non-tainted backends after a time? The way I'd like to think of that working would be:
If 50% of backends are unused for more than 1 hour, release 10% of established backends.
The two percentages and time frame would ideally be configurable, but setup in a way that it doesn't let go of connections too quickly, causing unnecessary expense of re-establishing those connections. My thought is if there's one big surge of connections followed by a long period of lower connections, does it make sense to keep those extra backends established?
I'll give the documentation another pass soon. Thanks for all your work on this, I like what I'm seeing so far!
[1] https://www.postgresql.org/message-id/attachment/102732/builtin_connection_proxy-10.patch
[2] http://richyen.com/postgres/2019/06/25/pools_arent_just_for_cars.html
[3] https://www.postgresql.org/message-id/ede4470a-055b-1389-0bbd-840f0594b758%40postgrespro.ru
Thanks,
Ryan Lambert
On Fri, Jul 19, 2019 at 3:10 PM Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote:
On 19.07.2019 6:36, Ryan Lambert wrote:Here's what I found tonight in your latest patch (9). The output from git apply is better, fewer whitespace errors, but still getting the following. Ubuntu 18.04 if that helps.
git apply -p1 < builtin_connection_proxy-9.patch<stdin>:79: tab in indent.
Each proxy launches its own subset of backends.
<stdin>:634: indent with spaces.
union {
<stdin>:635: indent with spaces.
struct sockaddr_in inaddr;
<stdin>:636: indent with spaces.
struct sockaddr addr;
<stdin>:637: indent with spaces.
} a;
warning: squelched 54 whitespace errors
warning: 59 lines add whitespace errors.
A few more minor edits. In config.sgml:
"If the <varname>max_sessions</varname> limit is reached new connection are not accepted."
Should be "connections".
"The default value is 10, so up to 10 backends will server each database,"
"sever" should be "serve" and the sentence should end with a period instead of a comma.
In postmaster.c:
/* The socket number we are listening for poolled connections on */
"poolled" --> "pooled"
"(errmsg("could not create listen socket for locahost")));"
"locahost" -> "localhost".
" * so to support order balancing we should do dome smart work here."
"dome" should be "some"?I don't see any tests covering this new functionality. It seems that this is significant enough functionality to warrant some sort of tests, but I don't know exactly what those would/should be.
Thank you once again for this fixes.
Updated patch is attached.
Concerning testing: I do not think that connection pooler needs some kind of special tests.
The idea of built-in connection pooler is that it should be able to handle all requests normal postgres can do.
I have added to regression tests extra path with enabled connection proxies.
Unfortunately, pg_regress is altering some session variables, so it backend becomes tainted and so
pooling is not actually used (but communication through proxy is tested).
It is also possible to run pg_bench with different number of connections though connection pooler.Thanks,Ryan
Attachment
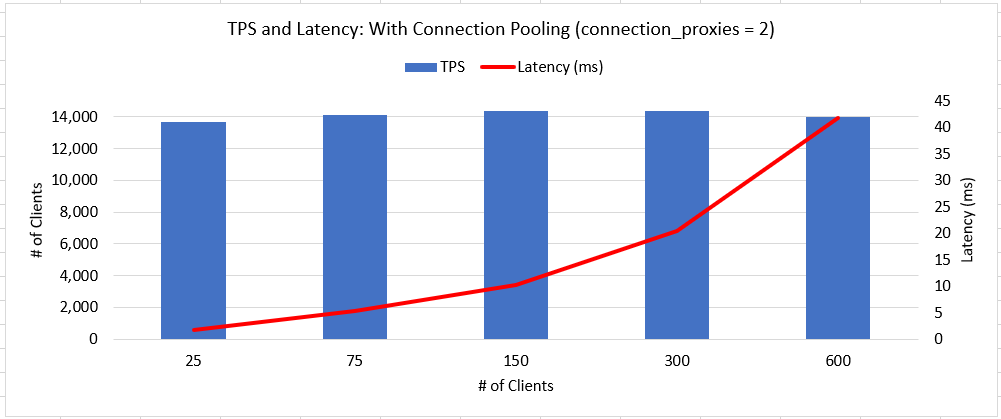{kind=link}
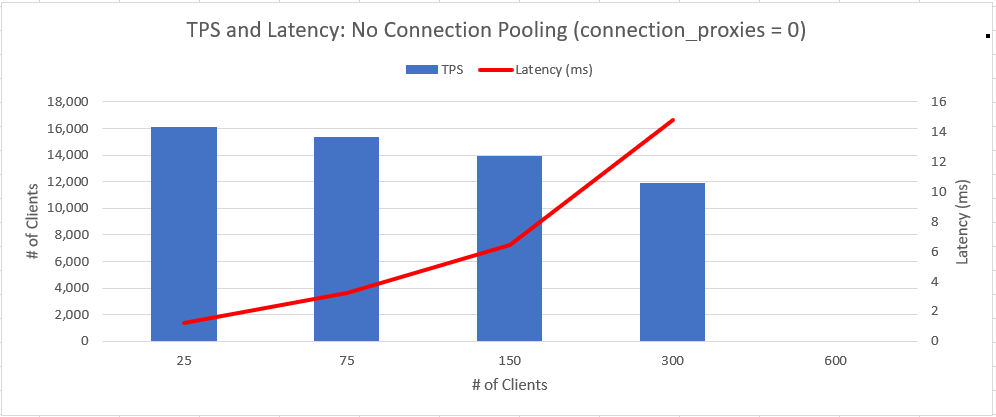{kind=link}
Hello Ryan, Thank you very much for review and benchmarking. My answers are inside. On 25.07.2019 0:58, Ryan Lambert wrote: > > Applying the patch [1] has improved from v9, still getting these: > Fixed. > used a DigitalOcean droplet with 2 CPU and 2 GB RAM and SSD for this > testing, Ubuntu 18.04. I chose the smaller server size based on the > availability of similar and recent results around connection pooling > [2] that used AWS EC2 m4.large instance (2 cores, 8 GB RAM) and > pgbouncer. Your prior pgbench tests [3] also focused on larger > servers so I wanted to see how this works on smaller hardware. > > Considering this from connpool.sgml: > "<varname>connection_proxies</varname> specifies number of connection > proxy processes which will be spawned. Default value is zero, so > connection pooling is disabled by default." > > That hints to me that connection_proxies is the main configuration to > start with so that was the only configuration I changed from the > default for this feature. I adjusted shared_buffers to 500MB (25% of > total) and max_connections to 1000. Only having one proxy gives > subpar performance across the board, so did setting this value to 10. > My hunch is this value should roughly follow the # of cpus available, > but that's just a hunch. > I do not think that number of proxies should depend on number of CPUs. Proxy process is not performing any computations, it is just redirecting data from client to backend and visa versa. Certainly starting form some number of connections is becomes bottleneck. The same is true for pgbouncer: you need to start several pgbouncer instances to be able to utilize all resources and provide best performance at computer with large number of cores. The optimal value greatly depends on number on workload, it is difficult to suggest some formula which allows to calculate optimal number of proxies for each configuration. > I don't understand yet how max_sessions ties in. > Also, having both session_pool_size and connection_proxies seemed > confusing at first. I still haven't figured out exactly how they > relate together in the overall operation and their impact on performance. "max_sessions" is mostly technical parameter. To listen client connections I need to initialize WaitEvent set specdify maximal number of events. It should not somehow affect performance. So just specifying large enough value should work in most cases. But I do not want to hardcode some constants and that it why I add GUC variable. "connections_proxies" is used mostly to toggle connection pooling. Using more than 1 proxy is be needed only for huge workloads (hundreds connections). And "session_pool_size" is core parameter which determine efficiency of pooling. The main trouble with it now, is that it is per database/user combination. Each such combination will have its own connection pool. Choosing optimal value of pooler backends is non-trivial task. It certainly depends on number of available CPU cores. But if backends and mostly disk-bounded, then optimal number of pooler worker can be large than number of cores. Presence of several pools make this choice even more complicated. > The new view helped, I get the concept of **what** it is doing > (connection_proxies = more rows, session_pool_size = n_backends for > each row), it's more a lack of understanding the **why** regarding how > it will operate. > > > postgres=# select * from pg_pooler_state(); > pid | n_clients | n_ssl_clients | n_pools | n_backends | > n_dedicated_backends | tx_bytes | rx_bytes | n_transactions > ------+-----------+---------------+---------+------------+----------------------+-----------+-----------+---------------- > 1682 | 75 | 0 | 1 | 10 | > 0 | 366810458 | 353181393 | 5557109 > 1683 | 75 | 0 | 1 | 10 | > 0 | 368464689 | 354778709 | 5582174 > (2 rows > > > > I am not sure how I feel about this: > "Non-tainted backends are not terminated even if there are no more > connected sessions." PgPRO EE version of connection pooler has "idle_pool_worker_timeout" parameter which allows to terminate idle workers. It is possible to implement it also for vanilla version of pooler. But primary intention of this patch was to minimize changes in Postgres core > > Would it be possible (eventually) to monitor connection rates and free > up non-tainted backends after a time? The way I'd like to think of > that working would be: > > If 50% of backends are unused for more than 1 hour, release 10% of > established backends. > > The two percentages and time frame would ideally be configurable, but > setup in a way that it doesn't let go of connections too quickly, > causing unnecessary expense of re-establishing those connections. My > thought is if there's one big surge of connections followed by a long > period of lower connections, does it make sense to keep those extra > backends established? > I think that idle timeout is enough but more complicated logic can also be implemented. > > I'll give the documentation another pass soon. Thanks for all your > work on this, I like what I'm seeing so far! > Thank you very much. I attached new version of the patch with fixed indentation problems and Win32 specific fixes. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
> I attached new version of the patch with fixed indentation problems and
> Win32 specific fixes.
Great, this latest patch applies cleanly to master. installcheck world still passes.
> "connections_proxies" is used mostly to toggle connection pooling.
> Using more than 1 proxy is be needed only for huge workloads (hundreds
> connections).
> Using more than 1 proxy is be needed only for huge workloads (hundreds
> connections).
My testing showed using only one proxy performing very poorly vs not using the pooler, even at 300 connections, with -3% TPS. At lower numbers of connections it was much worse than other configurations I tried. I just shared my full pgbench results [1], the "No Pool" and "# Proxies 2" data is what I used to generate the charts I previously shared. The 1 proxy and 10 proxy data I had referred to but hadn't shared the results, sorry about that.
> And "session_pool_size" is core parameter which determine efficiency of
> pooling.> The main trouble with it now, is that it is per database/user
> combination. Each such combination will have its own connection pool.
> Choosing optimal value of pooler backends is non-trivial task. It
> certainly depends on number of available CPU cores.
> But if backends and mostly disk-bounded, then optimal number of pooler
> worker can be large than number of cores.
I will do more testing around this variable next. It seems that increasing session_pool_size for connection_proxies = 1 might help and leaving it at its default was my problem.
> PgPRO EE version of connection pooler has "idle_pool_worker_timeout"
> parameter which allows to terminate idle workers.+1
> It is possible to implement it also for vanilla version of pooler. But
> primary intention of this patch was to minimize changes in Postgres core
Understood.
I attached a patch to apply after your latest patch [2] with my suggested changes to the docs. I tried to make things read smoother without altering your meaning. I don't think the connection pooler chapter fits in The SQL Language section, it seems more like Server Admin functionality so I moved it to follow the chapter on HA, load balancing and replication. That made more sense to me looking at the overall ToC of the docs.
Thanks,
Ryan
Attachment
Thank you.I attached a patch to apply after your latest patch [2] with my suggested changes to the docs. I tried to make things read smoother without altering your meaning. I don't think the connection pooler chapter fits in The SQL Language section, it seems more like Server Admin functionality so I moved it to follow the chapter on HA, load balancing and replication. That made more sense to me looking at the overall ToC of the docs.
I have committed your documentation changes in my Git repository and attach new patch with your corrections.
-- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
Hi Konstantin,
I've started reviewing this patch and experimenting with it, so let me
share some initial thoughts.
1) not handling session state (yet)
I understand handling session state would mean additional complexity, so
I'm OK with not having it in v1. That being said, I think this is the
primary issue with connection pooling on PostgreSQL - configuring and
running a separate pool is not free, of course, but when people complain
to us it's when they can't actually use a connection pool because of
this limitation.
So what are your plans regarding this feature? I think you mentioned
you already have the code in another product. Do you plan to submit it
in the pg13 cycle, or what's the plan? I'm willing to put some effort
into reviewing and testing that.
FWIW it'd be nice to expose it as some sort of interface, so that other
connection pools can leverage it too. There are use cases that don't
work with a built-in connection pool (say, PAUSE/RESUME in pgbouncer
allows restarting the database) so projects like pgbouncer or odyssey
are unlikely to disappear anytime soon.
I also wonder if we could make it more permissive even in v1, without
implementing dump/restore of session state.
Consider for example patterns like this:
BEGIN;
SET LOCAL enable_nestloop = off;
...
COMMIT;
or
PREPARE x(int) AS SELECT ...;
EXECUTE x(1);
EXECUTE x(2);
...
EXECUTE x(100000);
DEALLOCATE x;
or perhaps even
CREATE FUNCTION f() AS $$ ... $$
LANGUAGE sql
SET enable_nestloop = off;
In all those cases (and I'm sure there are other similar examples) the
connection pool considers the session 'tainted' it marks it as tainted
and we never reset that. So even when an application tries to play nice,
it can't use pooling.
Would it be possible to maybe track this with more detail (number of
prepared statements, ignore SET LOCAL, ...)? That should allow us to do
pooling even without full support for restoring session state.
2) configuration
I think we need to rethink how the pool is configured. The options
available at the moment are more a consequence of the implementation and
are rather cumbersome to use in some cases.
For example, we have session_pool_size, which is (essentially) the
number of backends kept in the pool. Which seems fine at first, because
it seems like you might say
max_connections = 100
session_pool_size = 50
to say the connection pool will only ever use 50 connections, leaving
the rest for "direct" connection. But that does not work at all, because
the number of backends the pool can open is
session_pool_size * connection_proxies * databases * roles
which pretty much means there's no limit, because while we can specify
the number of proxies, the number of databases and roles is arbitrary.
And there's no way to restrict which dbs/roles can use the pool.
So you can happily do this
max_connections = 100
connection_proxies = 4
session_pool_size = 10
pgbench -c 24 -U user1 test1
pgbench -c 24 -U user2 test2
pgbench -c 24 -U user3 test3
pgbench -c 24 -U user4 test4
at which point it's pretty much game over, because each proxy has 4
pools, each with ~6 backends, 96 backends in total. And because
non-tainted connections are never closed, no other users/dbs can use the
pool (will just wait indefinitely).
To allow practical configurations, I think we need to be able to define:
* which users/dbs can use the connection pool
* minimum/maximum pool size per user, per db and per user/db
* maximum number of backend connections
We need to be able to close connections when needed (when not assigned,
and we need the connection for someone else).
Plus those limits need to be global, not "per proxy" - it's just strange
that increasing connection_proxies bumps up the effective pool size.
I don't know what's the best way to specify this configuration - whether
to store it in a separate file, in some system catalog, or what.
3) monitoring
I think we need much better monitoring capabilities. At this point we
have a single system catalog (well, a SRF) giving us proxy-level
summary. But I think we need much more detailed overview - probably
something like pgbouncer has - listing of client/backend sessions, with
various details.
Of course, that's difficult to do when those lists are stored in private
memory of each proxy process - I think we need to move this to shared
memory, which would also help to address some of the issues I mentioned
in the previous section (particularly that the limits need to be global,
not per proxy).
4) restart_pooler_on_reload
I find it quite strange that restart_pooler_on_reload binds restart of
the connection pool to reload of the configuration file. That seems like
a rather surprising behavior, and I don't see why would you ever want
that? Currently it seems like the only way to force the proxies to close
the connections (the docs mention DROP DATABASE), but why shouldn't we
have separate functions to do that? In particular, why would you want to
close connections for all databases and not just for the one you're
trying to drop?
5) session_schedule
It's nice we support different strategies to assign connections to
worker processes, but how do you tune it? How do you pick the right
option for your workload? We either need to provide metrics to allow
informed decision, or just not provide the option.
And "load average" may be a bit misleading term (as used in the section
about load-balancing option). It kinda suggests we're measuring how busy
the different proxies were recently (that's what load average in Unix
does) - by counting active processes, CPU usage or whatever. But AFAICS
that's not what's happening at all - it just counts the connections,
with SSL connections counted as more expensive.
6) issues during testin
While testing, I've seen a couple of issues. Firstly, after specifying a
db that does not exist:
psql -h localhost -p 6543 xyz
just hangs and waits forever. In the server log I see this:
2019-07-25 23:16:50.229 CEST [31296] FATAL: database "xyz" does not exist
2019-07-25 23:16:50.258 CEST [31251] WARNING: could not setup local connect to server
2019-07-25 23:16:50.258 CEST [31251] DETAIL: FATAL: database "xyz" does not exist
But the client somehow does not get the message and waits.
Secondly, when trying this
pgbench -p 5432 -U x -i -s 1 test
pgbench -p 6543 -U x -c 24 -C -T 10 test
it very quickly locks up, with plenty of non-granted locks in pg_locks,
but I don't see any interventions by deadlock detector so I presume
the issue is somewhere else. I don't see any such issues whe running
without the connection pool or without the -C option:
pgbench -p 5432 -U x -c 24 -C -T 10 test
pgbench -p 6543 -U x -c 24 -T 10 test
This is with default postgresql.conf, except for
connection_proxies = 4
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Responses inline. I just picked up this thread so please bear with me.
On Fri, 26 Jul 2019 at 16:24, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
Hi Konstantin,
I've started reviewing this patch and experimenting with it, so let me
share some initial thoughts.
1) not handling session state (yet)
I understand handling session state would mean additional complexity, so
I'm OK with not having it in v1. That being said, I think this is the
primary issue with connection pooling on PostgreSQL - configuring and
running a separate pool is not free, of course, but when people complain
to us it's when they can't actually use a connection pool because of
this limitation.
So what are your plans regarding this feature? I think you mentioned
you already have the code in another product. Do you plan to submit it
in the pg13 cycle, or what's the plan? I'm willing to put some effort
into reviewing and testing that.
I too would like to see the plan of how to make this feature complete.
My concern here is that for the pgjdbc client at least *every* connection does some set parameter so I see from what I can tell from scanning this thread pooling would not be used at all.I suspect the .net driver does the same thing.
FWIW it'd be nice to expose it as some sort of interface, so that other
connection pools can leverage it too. There are use cases that don't
work with a built-in connection pool (say, PAUSE/RESUME in pgbouncer
allows restarting the database) so projects like pgbouncer or odyssey
are unlikely to disappear anytime soon.
Agreed, and as for other projects. I see their value in having the pool on a separate host as being a strength. I certainly don't see them going anywhere soon. Either way having a unified pooling API would be a useful goal.
I also wonder if we could make it more permissive even in v1, without
implementing dump/restore of session state.
Consider for example patterns like this:
BEGIN;
SET LOCAL enable_nestloop = off;
...
COMMIT;
or
PREPARE x(int) AS SELECT ...;
EXECUTE x(1);
EXECUTE x(2);
...
EXECUTE x(100000);
DEALLOCATE x;
Again pgjdbc does use server prepared statements so I'm assuming this would not work for clients using pgjdbc or .net
Additionally we have setSchema, which is really set search_path, again incompatible.
Regards,
Dave
On Tue, Jul 16, 2019 at 2:04 AM Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > I have committed patch which emulates epoll EPOLLET flag and so should > avoid busy loop with poll(). > I will be pleased if you can check it at FreeBSD box. I tried your v12 patch and it gets stuck in a busy loop during make check. You can see it on Linux with ./configure ... CFLAGS="-DWAIT_USE_POLL". -- Thomas Munro https://enterprisedb.com
On 26.07.2019 23:24, Tomas Vondra wrote: > Hi Konstantin, > > I've started reviewing this patch and experimenting with it, so let me > share some initial thoughts. > > > 1) not handling session state (yet) > > I understand handling session state would mean additional complexity, so > I'm OK with not having it in v1. That being said, I think this is the > primary issue with connection pooling on PostgreSQL - configuring and > running a separate pool is not free, of course, but when people complain > to us it's when they can't actually use a connection pool because of > this limitation. > > So what are your plans regarding this feature? I think you mentioned > you already have the code in another product. Do you plan to submit it > in the pg13 cycle, or what's the plan? I'm willing to put some effort > into reviewing and testing that. I completely agree with you. My original motivation of implementation of built-in connection pooler was to be able to preserve session semantic (prepared statements, GUCs, temporary tables) for pooled connections. Almost all production system have to use some kind of pooling. But in case of using pgbouncer&Co we are loosing possibility to use prepared statements which can cause up to two time performance penalty (in simple OLTP queries). So I have implemented such version of connection pooler of PgPro EE. It require many changes in Postgres core so I realized that there are no chances to commit in community (taken in account that may other my patches like autoprepare and libpq compression are postponed for very long time, although them are much smaller and less invasive). Then Dimitri Fontaine proposed me to implement much simple version of pooler based on traditional proxy approach. This patch is result of our conversation with Dimitri. You are asking me about my plans... I think that it will be better to try first to polish this version of the patch and commit it and only after it add more sophisticated features like saving/restoring session state. > > FWIW it'd be nice to expose it as some sort of interface, so that other > connection pools can leverage it too. There are use cases that don't > work with a built-in connection pool (say, PAUSE/RESUME in pgbouncer > allows restarting the database) so projects like pgbouncer or odyssey > are unlikely to disappear anytime soon. Obviously built-in connection pooler will never completely substitute external poolers like pgbouncer, which provide more flexibility, i.e. make it possible to install pooler at separate host or at client side. > > I also wonder if we could make it more permissive even in v1, without > implementing dump/restore of session state. > > Consider for example patterns like this: > > BEGIN; > SET LOCAL enable_nestloop = off; > ... > COMMIT; > > or > > PREPARE x(int) AS SELECT ...; > EXECUTE x(1); > EXECUTE x(2); > ... > EXECUTE x(100000); > DEALLOCATE x; > > or perhaps even > > CREATE FUNCTION f() AS $$ ... $$ > LANGUAGE sql > SET enable_nestloop = off; > > In all those cases (and I'm sure there are other similar examples) the > connection pool considers the session 'tainted' it marks it as tainted > and we never reset that. So even when an application tries to play nice, > it can't use pooling. > > Would it be possible to maybe track this with more detail (number of > prepared statements, ignore SET LOCAL, ...)? That should allow us to do > pooling even without full support for restoring session state. Sorry, I do not completely understand your idea (how to implement this features without maintaining session state). To implement prepared statements we need to store them in session context or at least add some session specific prefix to prepare statement name. Temporary tables also require per-session temporary table space. With GUCs situation is even more complicated - actually most of the time in my PgPro-EE pooler version I have spent in the fight with GUCs (default values, reloading configuration, memory alllocation/deallocation,...). But the "show stopper" are temporary tables: if them are accessed through internal (non-shared buffer), then you can not reschedule session to some other backend. This is why I have now patch with implementation of global temporary tables (a-la Oracle) which has global metadata and are accessed though shared buffers (which also allows to use them in parallel queries). > 2) configuration > > I think we need to rethink how the pool is configured. The options > available at the moment are more a consequence of the implementation and > are rather cumbersome to use in some cases. > > For example, we have session_pool_size, which is (essentially) the > number of backends kept in the pool. Which seems fine at first, because > it seems like you might say > > max_connections = 100 > session_pool_size = 50 > > to say the connection pool will only ever use 50 connections, leaving > the rest for "direct" connection. But that does not work at all, because > the number of backends the pool can open is > > session_pool_size * connection_proxies * databases * roles > > which pretty much means there's no limit, because while we can specify > the number of proxies, the number of databases and roles is arbitrary. > And there's no way to restrict which dbs/roles can use the pool. > > So you can happily do this > > max_connections = 100 > connection_proxies = 4 > session_pool_size = 10 > > pgbench -c 24 -U user1 test1 > pgbench -c 24 -U user2 test2 > pgbench -c 24 -U user3 test3 > pgbench -c 24 -U user4 test4 > > at which point it's pretty much game over, because each proxy has 4 > pools, each with ~6 backends, 96 backends in total. And because > non-tainted connections are never closed, no other users/dbs can use the > pool (will just wait indefinitely). > > To allow practical configurations, I think we need to be able to define: > > * which users/dbs can use the connection pool > * minimum/maximum pool size per user, per db and per user/db > * maximum number of backend connections > > We need to be able to close connections when needed (when not assigned, > and we need the connection for someone else). > > Plus those limits need to be global, not "per proxy" - it's just strange > that increasing connection_proxies bumps up the effective pool size. > > I don't know what's the best way to specify this configuration - whether > to store it in a separate file, in some system catalog, or what. > Well, I agree with you, that maintaining separate connection pool for each database/role pain may be confusing. My assumption was that in many configurations application are accessing the same (or few databases) with one (or very small) number of users. If you have hundreds of databases or users (each connection to the database under its OS name), then connection pooler will not work in any case, doesn't matter how you will configure it. It is true also for pgbouncer and any other pooler. If Postgres backend is able to work only with on database, then you will have to start at least such number of backends as number of databases you have. Situation with users is more obscure - it may be possible to implement multiuser access to the same backend (as it can be done now using "set role"). So I am not sure that if we implement sophisticated configurator which allows to specify in some configuration file for each database/role pair maximal/optimal number of workers, then it completely eliminate the problem with multiple session pools. Particularly, assume that we have 3 databases and want to server them with 10 workers. Now we receive 10 requests to database A. We start 10 backends which server this queries. The we receive 10 requests to database B. What should we do then. Terminate all this 10 backends and start new 10 instead of them? Or should we start 3 workers for database A, 3 workers for database B and 4 workers for database C. In this case of most of requests are to database A, we will not be able to utilize all system resources. Certainly we can specify in configuration file that database A needs 6 workers and B/C - two workers. But it will work only in case if we statically know workload... So I have though a lot about it, but failed to find some good and flexible solution. Looks like if you wan to efficiently do connection pooler, you should restrict number of database and roles. > > 3) monitoring > > I think we need much better monitoring capabilities. At this point we > have a single system catalog (well, a SRF) giving us proxy-level > summary. But I think we need much more detailed overview - probably > something like pgbouncer has - listing of client/backend sessions, with > various details. > > Of course, that's difficult to do when those lists are stored in private > memory of each proxy process - I think we need to move this to shared > memory, which would also help to address some of the issues I mentioned > in the previous section (particularly that the limits need to be global, > not per proxy). > > I also agree that more monitoring facilities are needed. Just want to get better understanding what kind of information we need to monitor. As far as pooler is done at transaction level, all non-active session are in idle state and state of active sessions can be inspected using pg_stat_activity. > 4) restart_pooler_on_reload > > I find it quite strange that restart_pooler_on_reload binds restart of > the connection pool to reload of the configuration file. That seems like > a rather surprising behavior, and I don't see why would you ever want > that? Currently it seems like the only way to force the proxies to close > the connections (the docs mention DROP DATABASE), but why shouldn't we > have separate functions to do that? In particular, why would you want to > close connections for all databases and not just for the one you're > trying to drop? Reload configuration is already broadcasted to all backends. In case of using some other approach for controlling pool worker, it will be necessary to implement own notification mechanism. Certainly it is doable. But as I already wrote, the primary idea was to minimize this patch and make it as less invasive as possible. > > > 5) session_schedule > > It's nice we support different strategies to assign connections to > worker processes, but how do you tune it? How do you pick the right > option for your workload? We either need to provide metrics to allow > informed decision, or just not provide the option. > The honest answer for this question is "I don't know". I have just implemented few different policies and assume that people will test them on their workloads and tell me which one will be most efficient. Then it will be possible to give some recommendations how to choose policies. Also current criteria for "load-balancing" may be too dubious. May be formula should include some other metrics rather than just number of connected clients. > And "load average" may be a bit misleading term (as used in the section > about load-balancing option). It kinda suggests we're measuring how busy > the different proxies were recently (that's what load average in Unix > does) - by counting active processes, CPU usage or whatever. But AFAICS > that's not what's happening at all - it just counts the connections, > with SSL connections counted as more expensive. > > Generally I agree. Current criteria for "load-balancing" may be too dubious. May be formula should include some other metrics rather than just number of connected clients. But I failed to find such metrices. CPU usage? But proxy themselve are using CPU only for redirecting traffic. Assume that one proxy is serving 10 clients performing OLAP queries and another one 100 clients performing OLTP queries. Certainly OLTP queries are used to be executed much faster. But it is hard to estimate amount of transferred data for both proxies. Generally OLTP queries are used to access few records, while OLAP access much more data. But OLAP queries usually performs some aggregation, so final result may be also small... Looks like we need to measure not only load of proxy itself but also load of proxies connected to this proxy. But it requires much more efforts. > 6) issues during testin > > While testing, I've seen a couple of issues. Firstly, after specifying a > db that does not exist: > > psql -h localhost -p 6543 xyz > > just hangs and waits forever. In the server log I see this: > > 2019-07-25 23:16:50.229 CEST [31296] FATAL: database "xyz" does not > exist > 2019-07-25 23:16:50.258 CEST [31251] WARNING: could not setup local > connect to server > 2019-07-25 23:16:50.258 CEST [31251] DETAIL: FATAL: database "xyz" > does not exist > > But the client somehow does not get the message and waits. > Fixed. > Secondly, when trying this > pgbench -p 5432 -U x -i -s 1 test > pgbench -p 6543 -U x -c 24 -C -T 10 test > > it very quickly locks up, with plenty of non-granted locks in pg_locks, > but I don't see any interventions by deadlock detector so I presume > the issue is somewhere else. I don't see any such issues whe running > without the connection pool or without the -C option: > > pgbench -p 5432 -U x -c 24 -C -T 10 test > pgbench -p 6543 -U x -c 24 -T 10 test > > This is with default postgresql.conf, except for > > connection_proxies = 4 > I need more time to investigate this problem. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 27.07.2019 14:49, Thomas Munro wrote: > On Tue, Jul 16, 2019 at 2:04 AM Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: >> I have committed patch which emulates epoll EPOLLET flag and so should >> avoid busy loop with poll(). >> I will be pleased if you can check it at FreeBSD box. > I tried your v12 patch and it gets stuck in a busy loop during make > check. You can see it on Linux with ./configure ... > CFLAGS="-DWAIT_USE_POLL". > > > -- > Thomas Munro > https://enterprisedb.com New version of the patch is attached which fixes poll() and Win32 implementations of WaitEventSet. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On Mon, Jul 29, 2019 at 07:14:27PM +0300, Konstantin Knizhnik wrote: > > >On 26.07.2019 23:24, Tomas Vondra wrote: >>Hi Konstantin, >> >>I've started reviewing this patch and experimenting with it, so let me >>share some initial thoughts. >> >> >>1) not handling session state (yet) >> >>I understand handling session state would mean additional complexity, so >>I'm OK with not having it in v1. That being said, I think this is the >>primary issue with connection pooling on PostgreSQL - configuring and >>running a separate pool is not free, of course, but when people complain >>to us it's when they can't actually use a connection pool because of >>this limitation. >> >>So what are your plans regarding this feature? I think you mentioned >>you already have the code in another product. Do you plan to submit it >>in the pg13 cycle, or what's the plan? I'm willing to put some effort >>into reviewing and testing that. > >I completely agree with you. My original motivation of implementation >of built-in connection pooler >was to be able to preserve session semantic (prepared statements, >GUCs, temporary tables) for pooled connections. >Almost all production system have to use some kind of pooling. But in >case of using pgbouncer&Co we are loosing possibility >to use prepared statements which can cause up to two time performance >penalty (in simple OLTP queries). >So I have implemented such version of connection pooler of PgPro EE. >It require many changes in Postgres core so I realized that there are >no chances to commit in community >(taken in account that may other my patches like autoprepare and libpq >compression are postponed for very long time, although >them are much smaller and less invasive). > >Then Dimitri Fontaine proposed me to implement much simple version of >pooler based on traditional proxy approach. >This patch is result of our conversation with Dimitri. >You are asking me about my plans... I think that it will be better to >try first to polish this version of the patch and commit it and only >after it add more sophisticated features >like saving/restoring session state. > Well, I understand the history of this patch, and I have no problem with getting a v1 of a connection pool without this feature. After all, that's the idea of incremental development. But that only works when v1 allows adding that feature in v2, and I can't quite judge that. Which is why I've asked you about your plans, because you clearly have more insight thanks to writing the pooler for PgPro EE. > > >> >>FWIW it'd be nice to expose it as some sort of interface, so that other >>connection pools can leverage it too. There are use cases that don't >>work with a built-in connection pool (say, PAUSE/RESUME in pgbouncer >>allows restarting the database) so projects like pgbouncer or odyssey >>are unlikely to disappear anytime soon. > >Obviously built-in connection pooler will never completely substitute >external poolers like pgbouncer, which provide more flexibility, i.e. >make it possible to install pooler at separate host or at client side. > Sure. But that wasn't really my point - I was suggesting to expose this hypothetical feature (managing session state) as some sort of API usable from other connection pools. >> >>I also wonder if we could make it more permissive even in v1, without >>implementing dump/restore of session state. >> >>Consider for example patterns like this: >> >> BEGIN; >> SET LOCAL enable_nestloop = off; >> ... >> COMMIT; >> >>or >> >> PREPARE x(int) AS SELECT ...; >> EXECUTE x(1); >> EXECUTE x(2); >> ... >> EXECUTE x(100000); >> DEALLOCATE x; >> >>or perhaps even >> >> CREATE FUNCTION f() AS $$ ... $$ >> LANGUAGE sql >> SET enable_nestloop = off; >> >>In all those cases (and I'm sure there are other similar examples) the >>connection pool considers the session 'tainted' it marks it as tainted >>and we never reset that. So even when an application tries to play nice, >>it can't use pooling. >> >>Would it be possible to maybe track this with more detail (number of >>prepared statements, ignore SET LOCAL, ...)? That should allow us to do >>pooling even without full support for restoring session state. > >Sorry, I do not completely understand your idea (how to implement this >features without maintaining session state). My idea (sorry if it wasn't too clear) was that we might handle some cases more gracefully. For example, if we only switch between transactions, we don't quite care about 'SET LOCAL' (but the current patch does set the tainted flag). The same thing applies to GUCs set for a function. For prepared statements, we might count the number of statements we prepared and deallocated, and treat it as 'not tained' when there are no statements. Maybe there's some risk I can't think of. The same thing applies to temporary tables - if you create and drop a temporary table, is there a reason to still treat the session as tained? >To implement prepared statements we need to store them in session >context or at least add some session specific prefix to prepare >statement name. >Temporary tables also require per-session temporary table space. With >GUCs situation is even more complicated - actually most of the time in >my PgPro-EE pooler version >I have spent in the fight with GUCs (default values, reloading >configuration, memory alllocation/deallocation,...). >But the "show stopper" are temporary tables: if them are accessed >through internal (non-shared buffer), then you can not reschedule >session to some other backend. >This is why I have now patch with implementation of global temporary >tables (a-la Oracle) which has global metadata and are accessed though >shared buffers (which also allows to use them >in parallel queries). > Yeah, temporary tables are messy. Global temporary tables would be nice, not just because of this, but also because of catalog bloat. > > >>2) configuration >> >>I think we need to rethink how the pool is configured. The options >>available at the moment are more a consequence of the implementation and >>are rather cumbersome to use in some cases. >> >>For example, we have session_pool_size, which is (essentially) the >>number of backends kept in the pool. Which seems fine at first, because >>it seems like you might say >> >> max_connections = 100 >> session_pool_size = 50 >> >>to say the connection pool will only ever use 50 connections, leaving >>the rest for "direct" connection. But that does not work at all, because >>the number of backends the pool can open is >> >> session_pool_size * connection_proxies * databases * roles >> >>which pretty much means there's no limit, because while we can specify >>the number of proxies, the number of databases and roles is arbitrary. >>And there's no way to restrict which dbs/roles can use the pool. >> >>So you can happily do this >> >> max_connections = 100 >> connection_proxies = 4 >> session_pool_size = 10 >> >> pgbench -c 24 -U user1 test1 >> pgbench -c 24 -U user2 test2 >> pgbench -c 24 -U user3 test3 >> pgbench -c 24 -U user4 test4 >> >>at which point it's pretty much game over, because each proxy has 4 >>pools, each with ~6 backends, 96 backends in total. And because >>non-tainted connections are never closed, no other users/dbs can use the >>pool (will just wait indefinitely). >> >>To allow practical configurations, I think we need to be able to define: >> >>* which users/dbs can use the connection pool >>* minimum/maximum pool size per user, per db and per user/db >>* maximum number of backend connections >> >>We need to be able to close connections when needed (when not assigned, >>and we need the connection for someone else). >> >>Plus those limits need to be global, not "per proxy" - it's just strange >>that increasing connection_proxies bumps up the effective pool size. >> >>I don't know what's the best way to specify this configuration - whether >>to store it in a separate file, in some system catalog, or what. >> >Well, I agree with you, that maintaining separate connection pool for >each database/role pain may be confusing. Anything can be confusing ... >My assumption was that in many configurations application are >accessing the same (or few databases) with one (or very small) number >of users. >If you have hundreds of databases or users (each connection to the >database under its OS name), then >connection pooler will not work in any case, doesn't matter how you >will configure it. It is true also for pgbouncer and any other pooler. Sure, but I don't expect connection pool to work in such cases. But I do expect to be able to configure which users can use the connection pool at all, and maybe assign them different pool sizes. >If Postgres backend is able to work only with on database, then you >will have to start at least such number of backends as number of >databases you have. >Situation with users is more obscure - it may be possible to implement >multiuser access to the same backend (as it can be done now using "set >role"). > I don't think I've said we need anything like that. The way I'd expect it to work that when we run out of backend connections, we terminate some existing ones (and then fork new backends). >So I am not sure that if we implement sophisticated configurator which >allows to specify in some configuration file for each database/role >pair maximal/optimal number >of workers, then it completely eliminate the problem with multiple >session pools. > Why would we need to invent any sophisticated configurator? Why couldn't we use some version of what pgbouncer already does, or maybe integrate it somehow into pg_hba.conf? >Particularly, assume that we have 3 databases and want to server them >with 10 workers. >Now we receive 10 requests to database A. We start 10 backends which >server this queries. >The we receive 10 requests to database B. What should we do then. >Terminate all this 10 backends and start new 10 >instead of them? Or should we start 3 workers for database A, 3 >workers for database B and 4 workers for database C. >In this case of most of requests are to database A, we will not be >able to utilize all system resources. >Certainly we can specify in configuration file that database A needs 6 >workers and B/C - two workers. >But it will work only in case if we statically know workload... > My concern is not as much performance as inability to access the database at all. There's no reasonable way to "guarantee" some number of connections to a given database. Which is what pgbouncer does (through min_pool_size). Yes, it requires knowledge of the workload, and I don't think that's an issue. >So I have though a lot about it, but failed to find some good and >flexible solution. >Looks like if you wan to efficiently do connection pooler, you should >restrict number of >database and roles. I agree we should not over-complicate this, but I still find the current configuration insufficient. > >> >>3) monitoring >> >>I think we need much better monitoring capabilities. At this point we >>have a single system catalog (well, a SRF) giving us proxy-level >>summary. But I think we need much more detailed overview - probably >>something like pgbouncer has - listing of client/backend sessions, with >>various details. >> >>Of course, that's difficult to do when those lists are stored in private >>memory of each proxy process - I think we need to move this to shared >>memory, which would also help to address some of the issues I mentioned >>in the previous section (particularly that the limits need to be global, >>not per proxy). >> >> >I also agree that more monitoring facilities are needed. >Just want to get better understanding what kind of information we need >to monitor. >As far as pooler is done at transaction level, all non-active session >are in idle state >and state of active sessions can be inspected using pg_stat_activity. > Except when sessions are tainted, for example. And when the transactions are long-running, it's still useful to list the connections. I'd suggest looking at the stats available in pgbouncer, most of that actually comes from practice (monitoring metrics, etc.) > >>4) restart_pooler_on_reload >> >>I find it quite strange that restart_pooler_on_reload binds restart of >>the connection pool to reload of the configuration file. That seems like >>a rather surprising behavior, and I don't see why would you ever want >>that? Currently it seems like the only way to force the proxies to close >>the connections (the docs mention DROP DATABASE), but why shouldn't we >>have separate functions to do that? In particular, why would you want to >>close connections for all databases and not just for the one you're >>trying to drop? > >Reload configuration is already broadcasted to all backends. >In case of using some other approach for controlling pool worker, >it will be necessary to implement own notification mechanism. >Certainly it is doable. But as I already wrote, the primary idea was >to minimize >this patch and make it as less invasive as possible. > OK >> >> >>5) session_schedule >> >>It's nice we support different strategies to assign connections to >>worker processes, but how do you tune it? How do you pick the right >>option for your workload? We either need to provide metrics to allow >>informed decision, or just not provide the option. >> >The honest answer for this question is "I don't know". >I have just implemented few different policies and assume that people >will test them on their workloads and >tell me which one will be most efficient. Then it will be possible to >give some recommendations how to >choose policies. > >Also current criteria for "load-balancing" may be too dubious. >May be formula should include some other metrics rather than just >number of connected clients. > OK > >>And "load average" may be a bit misleading term (as used in the section >>about load-balancing option). It kinda suggests we're measuring how busy >>the different proxies were recently (that's what load average in Unix >>does) - by counting active processes, CPU usage or whatever. But AFAICS >>that's not what's happening at all - it just counts the connections, >>with SSL connections counted as more expensive. >> >> >Generally I agree. Current criteria for "load-balancing" may be too dubious. >May be formula should include some other metrics rather than just >number of connected clients. >But I failed to find such metrices. CPU usage? But proxy themselve are >using CPU only for redirecting traffic. >Assume that one proxy is serving 10 clients performing OLAP queries >and another one 100 clients performing OLTP queries. >Certainly OLTP queries are used to be executed much faster. But it is >hard to estimate amount of transferred data for both proxies. >Generally OLTP queries are used to access few records, while OLAP >access much more data. But OLAP queries usually performs some >aggregation, >so final result may be also small... > >Looks like we need to measure not only load of proxy itself but also >load of proxies connected to this proxy. >But it requires much more efforts. > I think "smart" load-balancing is fairly difficult to get right. I'd just cut it from initial patch, keeping just the simple strategies (random, round-robin). > >>6) issues during testin >> >>While testing, I've seen a couple of issues. Firstly, after specifying a >>db that does not exist: >> >> psql -h localhost -p 6543 xyz >> >>just hangs and waits forever. In the server log I see this: >> >> 2019-07-25 23:16:50.229 CEST [31296] FATAL: database "xyz" does >>not exist >> 2019-07-25 23:16:50.258 CEST [31251] WARNING: could not setup >>local connect to server >> 2019-07-25 23:16:50.258 CEST [31251] DETAIL: FATAL: database >>"xyz" does not exist >> >>But the client somehow does not get the message and waits. >> > >Fixed. > >>Secondly, when trying this >> pgbench -p 5432 -U x -i -s 1 test >> pgbench -p 6543 -U x -c 24 -C -T 10 test >> >>it very quickly locks up, with plenty of non-granted locks in pg_locks, >>but I don't see any interventions by deadlock detector so I presume >>the issue is somewhere else. I don't see any such issues whe running >>without the connection pool or without the -C option: >> >> pgbench -p 5432 -U x -c 24 -C -T 10 test >> pgbench -p 6543 -U x -c 24 -T 10 test >> >>This is with default postgresql.conf, except for >> >> connection_proxies = 4 >> >I need more time to investigate this problem. > OK regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 30.07.2019 4:02, Tomas Vondra wrote: > > My idea (sorry if it wasn't too clear) was that we might handle some > cases more gracefully. > > For example, if we only switch between transactions, we don't quite care > about 'SET LOCAL' (but the current patch does set the tainted flag). The > same thing applies to GUCs set for a function. > For prepared statements, we might count the number of statements we > prepared and deallocated, and treat it as 'not tained' when there are no > statements. Maybe there's some risk I can't think of. > > The same thing applies to temporary tables - if you create and drop a > temporary table, is there a reason to still treat the session as tained? > > I already handling temporary tables with transaction scope (created using "create temp table ... on commit drop" command) - backend is not marked as tainted in this case. Thank you for your notice about "set local" command - attached patch is also handling such GUCs. >> To implement prepared statements we need to store them in session >> context or at least add some session specific prefix to prepare >> statement name. >> Temporary tables also require per-session temporary table space. With >> GUCs situation is even more complicated - actually most of the time >> in my PgPro-EE pooler version >> I have spent in the fight with GUCs (default values, reloading >> configuration, memory alllocation/deallocation,...). >> But the "show stopper" are temporary tables: if them are accessed >> through internal (non-shared buffer), then you can not reschedule >> session to some other backend. >> This is why I have now patch with implementation of global temporary >> tables (a-la Oracle) which has global metadata and are accessed >> though shared buffers (which also allows to use them >> in parallel queries). >> > > Yeah, temporary tables are messy. Global temporary tables would be nice, > not just because of this, but also because of catalog bloat. > Global temp tables solves two problems: 1. catalog bloating 2. parallel query execution. Them are not solving problem with using temporary tables at replica. May be this problem can be solved by implementing special table access method for temporary tables. But I am still no sure how useful will be such implementation of special table access method for temporary tables. Obviously it requires much more efforts (need to reimplement a lot of heapam stuff). But it will allow to eliminate MVCC overhead for temporary tuple and may be also reduce space by reducing size of tuple header. > >> If Postgres backend is able to work only with on database, then you >> will have to start at least such number of backends as number of >> databases you have. >> Situation with users is more obscure - it may be possible to >> implement multiuser access to the same backend (as it can be done now >> using "set role"). >> > > I don't think I've said we need anything like that. The way I'd expect > it to work that when we run out of backend connections, we terminate > some existing ones (and then fork new backends). I afraid that it may eliminate most of positive effect of session pooling if we will terminate and launch new backends without any attempt to bind backends to database and reuse them. > >> So I am not sure that if we implement sophisticated configurator >> which allows to specify in some configuration file for each >> database/role pair maximal/optimal number >> of workers, then it completely eliminate the problem with multiple >> session pools. >> > > Why would we need to invent any sophisticated configurator? Why couldn't > we use some version of what pgbouncer already does, or maybe integrate > it somehow into pg_hba.conf? I didn't think about such possibility. But I suspect many problems with reusing pgbouncer code and moving it to Postgres core. > I also agree that more monitoring facilities are needed. >> Just want to get better understanding what kind of information we >> need to monitor. >> As far as pooler is done at transaction level, all non-active session >> are in idle state >> and state of active sessions can be inspected using pg_stat_activity. >> > > Except when sessions are tainted, for example. And when the transactions > are long-running, it's still useful to list the connections. > Tainted backends are very similar with normal postgres backends. The only difference is that them are still connected with client though proxy. What I wanted to say is that pg_stat_activity will show you information about all active transactions even in case of connection polling. You will no get information about pended sessions, waiting for idle backends. But such session do not have any state (transaction is not started yet). So there is no much useful information we can show about them except just number of such pended sessions. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On 26.07.2019 23:24, Tomas Vondra wrote: > Secondly, when trying this > pgbench -p 5432 -U x -i -s 1 test > pgbench -p 6543 -U x -c 24 -C -T 10 test > > it very quickly locks up, with plenty of non-granted locks in pg_locks, > but I don't see any interventions by deadlock detector so I presume > the issue is somewhere else. I don't see any such issues whe running > without the connection pool or without the -C option: > > pgbench -p 5432 -U x -c 24 -C -T 10 test > pgbench -p 6543 -U x -c 24 -T 10 test > > This is with default postgresql.conf, except for > > connection_proxies = 4 > After some investigation I tend to think that it is problem of pgbench. It synchronously establishes new connection: #0 0x00007f022edb7730 in __poll_nocancel () at ../sysdeps/unix/syscall-template.S:84 #1 0x00007f022f7ceb77 in pqSocketPoll (sock=4, forRead=1, forWrite=0, end_time=-1) at fe-misc.c:1164 #2 0x00007f022f7cea32 in pqSocketCheck (conn=0x1273bf0, forRead=1, forWrite=0, end_time=-1) at fe-misc.c:1106 #3 0x00007f022f7ce8f2 in pqWaitTimed (forRead=1, forWrite=0, conn=0x1273bf0, finish_time=-1) at fe-misc.c:1038 #4 0x00007f022f7c0cdb in connectDBComplete (conn=0x1273bf0) at fe-connect.c:2029 #5 0x00007f022f7be71f in PQconnectdbParams (keywords=0x7ffc1add5640, values=0x7ffc1add5680, expand_dbname=1) at fe-connect.c:619 #6 0x0000000000403a4e in doConnect () at pgbench.c:1185 #7 0x0000000000407715 in advanceConnectionState (thread=0x1268570, st=0x1261778, agg=0x7ffc1add5880) at pgbench.c:2919 #8 0x000000000040f1b1 in threadRun (arg=0x1268570) at pgbench.c:6121 #9 0x000000000040e59d in main (argc=10, argv=0x7ffc1add5f98) at pgbench.c:5848 I.e. is starts normal transaction in one connection (few select/update/insert statement which are part of pgbench standard transaction) and at the same time tries to establish new connection. As far as built-in connection pooler performs transaction level scheduling, first session is grabbing backend until end of transaction. So until this transaction is completed backend will not be able to process some other transaction or accept new connection. But pgbench is completing this transaction because it is blocked in waiting response for new connection. The problem can be easily reproduced with just two connections if connection_proxies=1 and session_pool_size=1: pgbench -p 6543 -n -c 2 -C -T 10 postgres <hanged> knizhnik@knizhnik:~/postgrespro.ee11$ ps aux | fgrep postgres knizhnik 14425 0.0 0.1 172220 17540 ? Ss 09:48 0:00 /home/knizhnik/postgresql.builtin_pool/dist/bin/postgres -D pgsql.proxy knizhnik 14427 0.0 0.0 183440 5052 ? Ss 09:48 0:00 postgres: connection proxy knizhnik 14428 0.0 0.0 172328 4580 ? Ss 09:48 0:00 postgres: checkpointer knizhnik 14429 0.0 0.0 172220 4892 ? Ss 09:48 0:00 postgres: background writer knizhnik 14430 0.0 0.0 172220 7692 ? Ss 09:48 0:00 postgres: walwriter knizhnik 14431 0.0 0.0 172760 5640 ? Ss 09:48 0:00 postgres: autovacuum launcher knizhnik 14432 0.0 0.0 26772 2292 ? Ss 09:48 0:00 postgres: stats collector knizhnik 14433 0.0 0.0 172764 5884 ? Ss 09:48 0:00 postgres: logical replication launcher knizhnik 14434 0.0 0.0 22740 3084 pts/21 S+ 09:48 0:00 pgbench -p 6543 -n -c 2 -C -T 10 postgres knizhnik 14435 0.0 0.0 173828 13400 ? Ss 09:48 0:00 postgres: knizhnik postgres [local] idle in transaction knizhnik 21927 0.0 0.0 11280 936 pts/19 S+ 11:58 0:00 grep -F --color=auto postgres But if you run each connection in separate thread, then this test is normally completed: nizhnik@knizhnik:~/postgresql.builtin_pool$ pgbench -p 6543 -n -j 2 -c 2 -C -T 10 postgres transaction type: <builtin: TPC-B (sort of)> scaling factor: 1 query mode: simple number of clients: 2 number of threads: 2 duration: 10 s number of transactions actually processed: 9036 latency average = 2.214 ms tps = 903.466234 (including connections establishing) tps = 1809.317395 (excluding connections establishing) -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Tue, Jul 30, 2019 at 01:01:48PM +0300, Konstantin Knizhnik wrote: > > >On 30.07.2019 4:02, Tomas Vondra wrote: >> >>My idea (sorry if it wasn't too clear) was that we might handle some >>cases more gracefully. >> >>For example, if we only switch between transactions, we don't quite care >>about 'SET LOCAL' (but the current patch does set the tainted flag). The >>same thing applies to GUCs set for a function. >>For prepared statements, we might count the number of statements we >>prepared and deallocated, and treat it as 'not tained' when there are no >>statements. Maybe there's some risk I can't think of. >> >>The same thing applies to temporary tables - if you create and drop a >>temporary table, is there a reason to still treat the session as tained? >> >> > >I already handling temporary tables with transaction scope (created >using "create temp table ... on commit drop" command) - backend is not >marked as tainted in this case. >Thank you for your notice about "set local" command - attached patch >is also handling such GUCs. > Thanks. > >>>To implement prepared statements we need to store them in session >>>context or at least add some session specific prefix to prepare >>>statement name. >>>Temporary tables also require per-session temporary table space. >>>With GUCs situation is even more complicated - actually most of >>>the time in my PgPro-EE pooler version >>>I have spent in the fight with GUCs (default values, reloading >>>configuration, memory alllocation/deallocation,...). >>>But the "show stopper" are temporary tables: if them are accessed >>>through internal (non-shared buffer), then you can not reschedule >>>session to some other backend. >>>This is why I have now patch with implementation of global >>>temporary tables (a-la Oracle) which has global metadata and are >>>accessed though shared buffers (which also allows to use them >>>in parallel queries). >>> >> >>Yeah, temporary tables are messy. Global temporary tables would be nice, >>not just because of this, but also because of catalog bloat. >> > >Global temp tables solves two problems: >1. catalog bloating >2. parallel query execution. > >Them are not solving problem with using temporary tables at replica. >May be this problem can be solved by implementing special table access >method for temporary tables. >But I am still no sure how useful will be such implementation of >special table access method for temporary tables. >Obviously it requires much more efforts (need to reimplement a lot of >heapam stuff). >But it will allow to eliminate MVCC overhead for temporary tuple and >may be also reduce space by reducing size of tuple header. > Sure. Temporary tables are a hard issue (another place where they cause trouble are 2PC transactions, IIRC), so I think it's perfectly sensible to accept the limitation, handle cases that we can handle and see if we can improve the remaining cases later. > > >> >>>If Postgres backend is able to work only with on database, then >>>you will have to start at least such number of backends as number >>>of databases you have. >>>Situation with users is more obscure - it may be possible to >>>implement multiuser access to the same backend (as it can be done >>>now using "set role"). >>> Yes, that's a direct consequence of the PostgreSQL process model. >> >>I don't think I've said we need anything like that. The way I'd expect >>it to work that when we run out of backend connections, we terminate >>some existing ones (and then fork new backends). > >I afraid that it may eliminate most of positive effect of session >pooling if we will terminate and launch new backends without any >attempt to bind backends to database and reuse them. > I'm not sure I understand. Surely we'd still reuse connections as much as possible - we'd still keep the per-db/user connection pools, but after running out of backend connections we'd pick a victim in one of the pools, close it and open a new connection. We'd need some logic for picking the 'victim' but that does not seem particularly hard - idle connections first, then connections from "oversized" pools (this is one of the reasons why pgbouncer has min_connection_pool). >> >>>So I am not sure that if we implement sophisticated configurator >>>which allows to specify in some configuration file for each >>>database/role pair maximal/optimal number >>>of workers, then it completely eliminate the problem with multiple >>>session pools. >>> >> >>Why would we need to invent any sophisticated configurator? Why couldn't >>we use some version of what pgbouncer already does, or maybe integrate >>it somehow into pg_hba.conf? > >I didn't think about such possibility. >But I suspect many problems with reusing pgbouncer code and moving it >to Postgres core. > To be clear - I wasn't suggesting to copy any code from pgbouncer. It's far too different (style, ...) compared to core. I'm suggesting to adopt roughly the same configuration approach, i.e. what parameters are allowed for each pool, global limits, etc. I don't know whether we should have a separate configuration file, make it part of pg_hba.conf somehow, or store the configuration in a system catalog. But I'm pretty sure we don't need a "sophisticated configurator". >>I also agree that more monitoring facilities are needed. >>>Just want to get better understanding what kind of information we >>>need to monitor. >>>As far as pooler is done at transaction level, all non-active >>>session are in idle state >>>and state of active sessions can be inspected using pg_stat_activity. >>> >> >>Except when sessions are tainted, for example. And when the transactions >>are long-running, it's still useful to list the connections. >> >Tainted backends are very similar with normal postgres backends. >The only difference is that them are still connected with client >though proxy. >What I wanted to say is that pg_stat_activity will show you >information about all active transactions >even in case of connection polling. You will no get information about >pended sessions, waiting for >idle backends. But such session do not have any state (transaction is >not started yet). So there is no much useful information >we can show about them except just number of such pended sessions. > I suggest you take a look at metrics used for pgbouncer monitoring. Even when you have pending connection, you can still get useful data about that (e.g. average wait time to get a backend, maximum wait time, ...). Furthermore, how will you know from pg_stat_activity whether a connection is coming through a connection pool or not? Or that it's (not) tainted? Or how many backends are used by all connection pools combined? Because those are questions people will be asking when investigating issues, and so on. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 26.07.2019 19:20, Ryan Lambert wrote:
> PgPRO EE version of connection pooler has "idle_pool_worker_timeout"> parameter which allows to terminate idle workers.+1
I have implemented idle_pool_worker_timeout.
Also I added _idle_clients and n_idle_backends fields to proxy statistic returned by pg_pooler_state() function.
-- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On 02.08.2019 12:57, DEV_OPS wrote: > Hello Konstantin > > > would you please re-base this patch? I'm going to test it, and back port > into PG10 stable and PG9 stable > > > thank you very much > > Thank you. Rebased patch is attached. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
Hi Konstantin,
Ryan Lambert
I did some testing with the latest patch [1] on a small local VM with 1 CPU and 2GB RAM with the intention of exploring pg_pooler_state().
Configuration:
idle_pool_worker_timeout = 0 (default)
connection_proxies = 2
max_sessions = 10 (default)
max_connections = 1000
Initialized pgbench w/ scale 10 for the small server.
Running pgbench w/out connection pooler with 300 connections:
pgbench -p 5432 -c 300 -j 1 -T 60 -P 15 -S bench_test
starting vacuum...end.
progress: 15.0 s, 1343.3 tps, lat 123.097 ms stddev 380.780
progress: 30.0 s, 1086.7 tps, lat 155.586 ms stddev 376.963
progress: 45.1 s, 1103.8 tps, lat 156.644 ms stddev 347.058
progress: 60.6 s, 652.6 tps, lat 271.060 ms stddev 575.295
transaction type: <builtin: select only>
scaling factor: 10
query mode: simple
number of clients: 300
number of threads: 1
duration: 60 s
number of transactions actually processed: 63387
latency average = 171.079 ms
latency stddev = 439.735 ms
tps = 1000.918781 (including connections establishing)
tps = 1000.993926 (excluding connections establishing)
It crashes when I attempt to run with the connection pooler, 300 connections:
pgbench -p 6543 -c 300 -j 1 -T 60 -P 15 -S bench_test
starting vacuum...end.
connection to database "bench_test" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
In the logs I get:
WARNING: PROXY: Failed to add new client - too much sessions: 18 clients, 1 backends. Try to increase 'max_sessions' configuration parameter.
The logs report 1 backend even though max_sessions is the default of 10. Why is there only 1 backend reported? Is that error message getting the right value?
Minor grammar fix, the logs on this warning should say "too many sessions" instead of "too much sessions."
Reducing pgbench to only 30 connections keeps it from completely crashing but it still does not run successfully.
pgbench -p 6543 -c 30 -j 1 -T 60 -P 15 -S bench_test
starting vacuum...end.
client 9 aborted in command 1 (SQL) of script 0; perhaps the backend died while processing
client 11 aborted in command 1 (SQL) of script 0; perhaps the backend died while processing
client 13 aborted in command 1 (SQL) of script 0; perhaps the backend died while processing
...
...
progress: 15.0 s, 5734.5 tps, lat 1.191 ms stddev 10.041
progress: 30.0 s, 7789.6 tps, lat 0.830 ms stddev 6.251
progress: 45.0 s, 8211.3 tps, lat 0.810 ms stddev 5.970
progress: 60.0 s, 8466.5 tps, lat 0.789 ms stddev 6.151
transaction type: <builtin: select only>
scaling factor: 10
query mode: simple
number of clients: 30
number of threads: 1
duration: 60 s
number of transactions actually processed: 453042
latency average = 0.884 ms
latency stddev = 7.182 ms
tps = 7549.373416 (including connections establishing)
tps = 7549.402629 (excluding connections establishing)
Run was aborted; the above results are incomplete.
Logs for that run show (truncated):
2019-08-07 00:19:37.707 UTC [22152] WARNING: PROXY: Failed to add new client - too much sessions: 18 clients, 1 backends. Try to increase 'max_sessions' configuration parameter.
2019-08-07 00:31:10.467 UTC [22151] WARNING: PROXY: Failed to add new client - too much sessions: 15 clients, 4 backends. Try to increase 'max_sessions' configuration parameter.
2019-08-07 00:31:10.468 UTC [22152] WARNING: PROXY: Failed to add new client - too much sessions: 15 clients, 4 backends. Try to increase 'max_sessions' configuration parameter.
...
...
Here it is reporting fewer clients with more backends. Still, only 4 backends reported with 15 clients doesn't seem right. Looking at the results from pg_pooler_state() at the same time (below) showed 5 and 7 backends for the two different proxies, so why are the logs only reporting 4 backends when pg_pooler_state() reports 12 total?
Why is n_idle_clients negative? In this case it showed -21 and -17. Each proxy reported 7 clients, with max_sessions = 10, having those n_idle_client results doesn't make sense to me.
postgres=# SELECT * FROM pg_pooler_state();
pid | n_clients | n_ssl_clients | n_pools | n_backends | n_dedicated_backends | n_idle_backends | n_idle_clients | tx_bytes | rx_bytes | n_transactions
-------+-----------+---------------+---------+------------+----------------------+-----------------+----------------+----------+----------+---------------
-
25737 | 7 | 0 | 1 | 5 | 0 | 0 | -21 | 4099541 | 3896792 | 61959
25738 | 7 | 0 | 1 | 7 | 0 | 2 | -17 | 4530587 | 4307474 | 68490
(2 rows)
I get errors running pgbench down to only 20 connections with this configuration. I tried adjusting connection_proxies = 1 and it handles even fewer connections. Setting connection_proxies = 4 allows it to handle 20 connections without error, but by 40 connections it starts having issues.
While I don't have expectations of this working great (or even decent) on a tiny server, I don't expect it to crash in a case where the standard connections work. Also, the logs and the function both show that the total backends is less than the total available and the two don't seem to agree on the details.
I think it would help to have details about the pg_pooler_state function added to the docs, maybe in this section [2]?
I'll take some time later this week to examine pg_pooler_state further on a more appropriately sized server.
Configuration:
idle_pool_worker_timeout = 0 (default)
connection_proxies = 2
max_sessions = 10 (default)
max_connections = 1000
Initialized pgbench w/ scale 10 for the small server.
Running pgbench w/out connection pooler with 300 connections:
pgbench -p 5432 -c 300 -j 1 -T 60 -P 15 -S bench_test
starting vacuum...end.
progress: 15.0 s, 1343.3 tps, lat 123.097 ms stddev 380.780
progress: 30.0 s, 1086.7 tps, lat 155.586 ms stddev 376.963
progress: 45.1 s, 1103.8 tps, lat 156.644 ms stddev 347.058
progress: 60.6 s, 652.6 tps, lat 271.060 ms stddev 575.295
transaction type: <builtin: select only>
scaling factor: 10
query mode: simple
number of clients: 300
number of threads: 1
duration: 60 s
number of transactions actually processed: 63387
latency average = 171.079 ms
latency stddev = 439.735 ms
tps = 1000.918781 (including connections establishing)
tps = 1000.993926 (excluding connections establishing)
It crashes when I attempt to run with the connection pooler, 300 connections:
pgbench -p 6543 -c 300 -j 1 -T 60 -P 15 -S bench_test
starting vacuum...end.
connection to database "bench_test" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
In the logs I get:
WARNING: PROXY: Failed to add new client - too much sessions: 18 clients, 1 backends. Try to increase 'max_sessions' configuration parameter.
The logs report 1 backend even though max_sessions is the default of 10. Why is there only 1 backend reported? Is that error message getting the right value?
Minor grammar fix, the logs on this warning should say "too many sessions" instead of "too much sessions."
Reducing pgbench to only 30 connections keeps it from completely crashing but it still does not run successfully.
pgbench -p 6543 -c 30 -j 1 -T 60 -P 15 -S bench_test
starting vacuum...end.
client 9 aborted in command 1 (SQL) of script 0; perhaps the backend died while processing
client 11 aborted in command 1 (SQL) of script 0; perhaps the backend died while processing
client 13 aborted in command 1 (SQL) of script 0; perhaps the backend died while processing
...
...
progress: 15.0 s, 5734.5 tps, lat 1.191 ms stddev 10.041
progress: 30.0 s, 7789.6 tps, lat 0.830 ms stddev 6.251
progress: 45.0 s, 8211.3 tps, lat 0.810 ms stddev 5.970
progress: 60.0 s, 8466.5 tps, lat 0.789 ms stddev 6.151
transaction type: <builtin: select only>
scaling factor: 10
query mode: simple
number of clients: 30
number of threads: 1
duration: 60 s
number of transactions actually processed: 453042
latency average = 0.884 ms
latency stddev = 7.182 ms
tps = 7549.373416 (including connections establishing)
tps = 7549.402629 (excluding connections establishing)
Run was aborted; the above results are incomplete.
Logs for that run show (truncated):
2019-08-07 00:19:37.707 UTC [22152] WARNING: PROXY: Failed to add new client - too much sessions: 18 clients, 1 backends. Try to increase 'max_sessions' configuration parameter.
2019-08-07 00:31:10.467 UTC [22151] WARNING: PROXY: Failed to add new client - too much sessions: 15 clients, 4 backends. Try to increase 'max_sessions' configuration parameter.
2019-08-07 00:31:10.468 UTC [22152] WARNING: PROXY: Failed to add new client - too much sessions: 15 clients, 4 backends. Try to increase 'max_sessions' configuration parameter.
...
...
Here it is reporting fewer clients with more backends. Still, only 4 backends reported with 15 clients doesn't seem right. Looking at the results from pg_pooler_state() at the same time (below) showed 5 and 7 backends for the two different proxies, so why are the logs only reporting 4 backends when pg_pooler_state() reports 12 total?
Why is n_idle_clients negative? In this case it showed -21 and -17. Each proxy reported 7 clients, with max_sessions = 10, having those n_idle_client results doesn't make sense to me.
postgres=# SELECT * FROM pg_pooler_state();
pid | n_clients | n_ssl_clients | n_pools | n_backends | n_dedicated_backends | n_idle_backends | n_idle_clients | tx_bytes | rx_bytes | n_transactions
-------+-----------+---------------+---------+------------+----------------------+-----------------+----------------+----------+----------+---------------
-
25737 | 7 | 0 | 1 | 5 | 0 | 0 | -21 | 4099541 | 3896792 | 61959
25738 | 7 | 0 | 1 | 7 | 0 | 2 | -17 | 4530587 | 4307474 | 68490
(2 rows)
I get errors running pgbench down to only 20 connections with this configuration. I tried adjusting connection_proxies = 1 and it handles even fewer connections. Setting connection_proxies = 4 allows it to handle 20 connections without error, but by 40 connections it starts having issues.
While I don't have expectations of this working great (or even decent) on a tiny server, I don't expect it to crash in a case where the standard connections work. Also, the logs and the function both show that the total backends is less than the total available and the two don't seem to agree on the details.
I think it would help to have details about the pg_pooler_state function added to the docs, maybe in this section [2]?
I'll take some time later this week to examine pg_pooler_state further on a more appropriately sized server.
Thanks,
[1] https://www.postgresql.org/message-id/attachment/103046/builtin_connection_proxy-16.patch
[2] https://www.postgresql.org/docs/current/functions-info.html
[1] https://www.postgresql.org/message-id/attachment/103046/builtin_connection_proxy-16.patch
[2] https://www.postgresql.org/docs/current/functions-info.html
Ryan Lambert
Hi, Konstantin I test the patch-16 on postgresql master branch, and I find the temporary table cannot removed when we re-connect to it. Here is my test: japin@ww-it:~/WwIT/postgresql/Debug/connpool$ initdb The files belonging to this database system will be owned by user "japin". This user must also own the server process. The database cluster will be initialized with locale "en_US.UTF-8". The default database encoding has accordingly been set to "UTF8". The default text search configuration will be set to "english". Data page checksums are disabled. creating directory /home/japin/WwIT/postgresql/Debug/connpool/DATA ... ok creating subdirectories ... ok selecting dynamic shared memory implementation ... posix selecting default max_connections ... 100 selecting default shared_buffers ... 128MB selecting default time zone ... Asia/Shanghai creating configuration files ... ok running bootstrap script ... ok performing post-bootstrap initialization ... ok syncing data to disk ... ok initdb: warning: enabling "trust" authentication for local connections You can change this by editing pg_hba.conf or using the option -A, or --auth-local and --auth-host, the next time you run initdb. Success. You can now start the database server using: pg_ctl -D /home/japin/WwIT/postgresql/Debug/connpool/DATA -l logfile start japin@ww-it:~/WwIT/postgresql/Debug/connpool$ pg_ctl -l /tmp/log start waiting for server to start.... done server started japin@ww-it:~/WwIT/postgresql/Debug/connpool$ psql postgres psql (13devel) Type "help" for help. postgres=# ALTER SYSTEM SET connection_proxies TO 1; ALTER SYSTEM postgres=# ALTER SYSTEM SET session_pool_size TO 1; ALTER SYSTEM postgres=# \q japin@ww-it:~/WwIT/postgresql/Debug/connpool$ pg_ctl -l /tmp/log restart waiting for server to shut down.... done server stopped waiting for server to start.... done server started japin@ww-it:~/WwIT/postgresql/Debug/connpool$ psql -p 6543 postgres psql (13devel) Type "help" for help. postgres=# CREATE TEMP TABLE test(id int, info text); CREATE TABLE postgres=# INSERT INTO test SELECT id, md5(id::text) FROM generate_series(1, 10) id; INSERT 0 10 postgres=# select * from pg_pooler_state(); pid | n_clients | n_ssl_clients | n_pools | n_backends | n_dedicated_backends | n_idle_backends | n_idle_clients | tx_bytes | rx_bytes | n_transactions ------+-----------+---------------+---------+------------+----------------------+-----------------+----------------+----------+----------+---------------- 3885 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1154 | 2880 | 6 (1 row) postgres=# \q japin@ww-it:~/WwIT/postgresql/Debug/connpool$ psql -p 6543 postgres psql (13devel) Type "help" for help. postgres=# \d List of relations Schema | Name | Type | Owner -----------+------+-------+------- pg_temp_3 | test | table | japin (1 row) postgres=# select * from pg_pooler_state(); pid | n_clients | n_ssl_clients | n_pools | n_backends | n_dedicated_backends | n_idle_backends | n_idle_clients | tx_bytes | rx_bytes | n_transactions ------+-----------+---------------+---------+------------+----------------------+-----------------+----------------+----------+----------+---------------- 3885 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 2088 | 3621 | 8 (1 row) postgres=# select * from test ; id | info ----+---------------------------------- 1 | c4ca4238a0b923820dcc509a6f75849b 2 | c81e728d9d4c2f636f067f89cc14862c 3 | eccbc87e4b5ce2fe28308fd9f2a7baf3 4 | a87ff679a2f3e71d9181a67b7542122c 5 | e4da3b7fbbce2345d7772b0674a318d5 6 | 1679091c5a880faf6fb5e6087eb1b2dc 7 | 8f14e45fceea167a5a36dedd4bea2543 8 | c9f0f895fb98ab9159f51fd0297e236d 9 | 45c48cce2e2d7fbdea1afc51c7c6ad26 10 | d3d9446802a44259755d38e6d163e820 (10 rows) I inspect the code, and find the following code in DefineRelation function: if (stmt->relation->relpersistence != RELPERSISTENCE_TEMP && stmt->oncommit != ONCOMMIT_DROP) MyProc->is_tainted = true; For temporary table, MyProc->is_tainted might be true, I changed it as following: if (stmt->relation->relpersistence == RELPERSISTENCE_TEMP || stmt->oncommit == ONCOMMIT_DROP) MyProc->is_tainted = true; For temporary table, it works. I not sure the changes is right. On 8/2/19 7:05 PM, Konstantin Knizhnik wrote: > > > On 02.08.2019 12:57, DEV_OPS wrote: >> Hello Konstantin >> >> >> would you please re-base this patch? I'm going to test it, and back port >> into PG10 stable and PG9 stable >> >> >> thank you very much >> >> > > Thank you. > Rebased patch is attached. > >
Hi, Li Thank you very much for reporting the problem. On 07.08.2019 7:21, Li Japin wrote: > I inspect the code, and find the following code in DefineRelation function: > > if (stmt->relation->relpersistence != RELPERSISTENCE_TEMP > && stmt->oncommit != ONCOMMIT_DROP) > MyProc->is_tainted = true; > > For temporary table, MyProc->is_tainted might be true, I changed it as > following: > > if (stmt->relation->relpersistence == RELPERSISTENCE_TEMP > || stmt->oncommit == ONCOMMIT_DROP) > MyProc->is_tainted = true; > > For temporary table, it works. I not sure the changes is right. Sorry, it is really a bug. My intention was to mark backend as tainted if it is creating temporary table without ON COMMIT DROP clause (in the last case temporary table will be local to transaction and so cause no problems with pooler). Th right condition is: if (stmt->relation->relpersistence == RELPERSISTENCE_TEMP && stmt->oncommit != ONCOMMIT_DROP) MyProc->is_tainted = true; -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Hi Ryan, On 07.08.2019 6:18, Ryan Lambert wrote: > Hi Konstantin, > > I did some testing with the latest patch [1] on a small local VM with > 1 CPU and 2GB RAM with the intention of exploring pg_pooler_state(). > > Configuration: > > idle_pool_worker_timeout = 0 (default) > connection_proxies = 2 > max_sessions = 10 (default) > max_connections = 1000 > > Initialized pgbench w/ scale 10 for the small server. > > Running pgbench w/out connection pooler with 300 connections: > > pgbench -p 5432 -c 300 -j 1 -T 60 -P 15 -S bench_test > starting vacuum...end. > progress: 15.0 s, 1343.3 tps, lat 123.097 ms stddev 380.780 > progress: 30.0 s, 1086.7 tps, lat 155.586 ms stddev 376.963 > progress: 45.1 s, 1103.8 tps, lat 156.644 ms stddev 347.058 > progress: 60.6 s, 652.6 tps, lat 271.060 ms stddev 575.295 > transaction type: <builtin: select only> > scaling factor: 10 > query mode: simple > number of clients: 300 > number of threads: 1 > duration: 60 s > number of transactions actually processed: 63387 > latency average = 171.079 ms > latency stddev = 439.735 ms > tps = 1000.918781 (including connections establishing) > tps = 1000.993926 (excluding connections establishing) > > > It crashes when I attempt to run with the connection pooler, 300 > connections: > > pgbench -p 6543 -c 300 -j 1 -T 60 -P 15 -S bench_test > starting vacuum...end. > connection to database "bench_test" failed: > server closed the connection unexpectedly > This probably means the server terminated abnormally > before or while processing the request. > > In the logs I get: > > WARNING: PROXY: Failed to add new client - too much sessions: 18 > clients, 1 backends. Try to increase 'max_sessions' configuration > parameter. > > The logs report 1 backend even though max_sessions is the default of > 10. Why is there only 1 backend reported? Is that error message > getting the right value? > > Minor grammar fix, the logs on this warning should say "too many > sessions" instead of "too much sessions." > > Reducing pgbench to only 30 connections keeps it from completely > crashing but it still does not run successfully. > > pgbench -p 6543 -c 30 -j 1 -T 60 -P 15 -S bench_test > starting vacuum...end. > client 9 aborted in command 1 (SQL) of script 0; perhaps the backend > died while processing > client 11 aborted in command 1 (SQL) of script 0; perhaps the backend > died while processing > client 13 aborted in command 1 (SQL) of script 0; perhaps the backend > died while processing > ... > ... > progress: 15.0 s, 5734.5 tps, lat 1.191 ms stddev 10.041 > progress: 30.0 s, 7789.6 tps, lat 0.830 ms stddev 6.251 > progress: 45.0 s, 8211.3 tps, lat 0.810 ms stddev 5.970 > progress: 60.0 s, 8466.5 tps, lat 0.789 ms stddev 6.151 > transaction type: <builtin: select only> > scaling factor: 10 > query mode: simple > number of clients: 30 > number of threads: 1 > duration: 60 s > number of transactions actually processed: 453042 > latency average = 0.884 ms > latency stddev = 7.182 ms > tps = 7549.373416 (including connections establishing) > tps = 7549.402629 (excluding connections establishing) > Run was aborted; the above results are incomplete. > > Logs for that run show (truncated): > > > 2019-08-07 00:19:37.707 UTC [22152] WARNING: PROXY: Failed to add new > client - too much sessions: 18 clients, 1 backends. Try to increase > 'max_sessions' configuration parameter. > 2019-08-07 00:31:10.467 UTC [22151] WARNING: PROXY: Failed to add new > client - too much sessions: 15 clients, 4 backends. Try to increase > 'max_sessions' configuration parameter. > 2019-08-07 00:31:10.468 UTC [22152] WARNING: PROXY: Failed to add new > client - too much sessions: 15 clients, 4 backends. Try to increase > 'max_sessions' configuration parameter. > ... > ... > > > Here it is reporting fewer clients with more backends. Still, only 4 > backends reported with 15 clients doesn't seem right. Looking at the > results from pg_pooler_state() at the same time (below) showed 5 and 7 > backends for the two different proxies, so why are the logs only > reporting 4 backends when pg_pooler_state() reports 12 total? > > Why is n_idle_clients negative? In this case it showed -21 and -17. > Each proxy reported 7 clients, with max_sessions = 10, having those > n_idle_client results doesn't make sense to me. > > > postgres=# SELECT * FROM pg_pooler_state(); > pid | n_clients | n_ssl_clients | n_pools | n_backends | > n_dedicated_backends | n_idle_backends | n_idle_clients | tx_bytes | > rx_bytes | n_transactions > > -------+-----------+---------------+---------+------------+----------------------+-----------------+----------------+----------+----------+--------------- > - > 25737 | 7 | 0 | 1 | 5 | > 0 | 0 | -21 | 4099541 | 3896792 | > 61959 > 25738 | 7 | 0 | 1 | 7 | > 0 | 2 | -17 | 4530587 | 4307474 | > 68490 > (2 rows) > > > I get errors running pgbench down to only 20 connections with this > configuration. I tried adjusting connection_proxies = 1 and it handles > even fewer connections. Setting connection_proxies = 4 allows it to > handle 20 connections without error, but by 40 connections it starts > having issues. > > While I don't have expectations of this working great (or even decent) > on a tiny server, I don't expect it to crash in a case where the > standard connections work. Also, the logs and the function both show > that the total backends is less than the total available and the two > don't seem to agree on the details. > > I think it would help to have details about the pg_pooler_state > function added to the docs, maybe in this section [2]? > > I'll take some time later this week to examine pg_pooler_state further > on a more appropriately sized server. > > Thanks, > > > [1] > https://www.postgresql.org/message-id/attachment/103046/builtin_connection_proxy-16.patch > [2] https://www.postgresql.org/docs/current/functions-info.html > > Ryan Lambert > Sorry, looks like there is misunderstanding with meaning of max_sessions parameters. First of all default value of this parameter is 1000, not 10. Looks like you have explicitly specify value 10 and it cause this problems. So "max_sessions" parameter specifies how much sessions can be handled by one backend. Certainly it makes sense only if pooler is switched on (number of proxies is not zero). If pooler is switched off, than backend is handling exactly one session/ There is no much sense in limiting number of sessions server by one backend, because the main goal of connection pooler is to handle arbitrary number of client connections with limited number of backends. The only reason for presence of this parameter is that WaitEventSet requires to specify maximal number of events. And proxy needs to multiplex connected backends and clients. So it create WaitEventSet with size max_sessions*2 (mutiplied by two because it has to listen both for clients and backends). So the value of this parameter should be large enough. Default value is 1000, but there should be no problem to set it to 10000 or even 1000000 (hoping that IS will support it). But observer behavior ("server closed the connection unexpectedly" and hegative number of idle clients) is certainly not correct. I attached to this mail patch which is fixing both problems: correctly reports error to the client and calculates number of idle clients). New version also available in my GIT repoistory: https://github.com/postgrespro/postgresql.builtin_pool.git branch conn_proxy. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
First of all default value of this parameter is 1000, not 10.
Oops, my bad! Sorry about that, I'm not sure how I got that in my head last night but I see how that would make it act strange now. I'll adjust my notes before re-testing. :)
Thanks,
Ryan Lambert
On Wed, Aug 7, 2019 at 4:57 AM Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote:
Hi Ryan,
On 07.08.2019 6:18, Ryan Lambert wrote:
> Hi Konstantin,
>
> I did some testing with the latest patch [1] on a small local VM with
> 1 CPU and 2GB RAM with the intention of exploring pg_pooler_state().
>
> Configuration:
>
> idle_pool_worker_timeout = 0 (default)
> connection_proxies = 2
> max_sessions = 10 (default)
> max_connections = 1000
>
> Initialized pgbench w/ scale 10 for the small server.
>
> Running pgbench w/out connection pooler with 300 connections:
>
> pgbench -p 5432 -c 300 -j 1 -T 60 -P 15 -S bench_test
> starting vacuum...end.
> progress: 15.0 s, 1343.3 tps, lat 123.097 ms stddev 380.780
> progress: 30.0 s, 1086.7 tps, lat 155.586 ms stddev 376.963
> progress: 45.1 s, 1103.8 tps, lat 156.644 ms stddev 347.058
> progress: 60.6 s, 652.6 tps, lat 271.060 ms stddev 575.295
> transaction type: <builtin: select only>
> scaling factor: 10
> query mode: simple
> number of clients: 300
> number of threads: 1
> duration: 60 s
> number of transactions actually processed: 63387
> latency average = 171.079 ms
> latency stddev = 439.735 ms
> tps = 1000.918781 (including connections establishing)
> tps = 1000.993926 (excluding connections establishing)
>
>
> It crashes when I attempt to run with the connection pooler, 300
> connections:
>
> pgbench -p 6543 -c 300 -j 1 -T 60 -P 15 -S bench_test
> starting vacuum...end.
> connection to database "bench_test" failed:
> server closed the connection unexpectedly
> This probably means the server terminated abnormally
> before or while processing the request.
>
> In the logs I get:
>
> WARNING: PROXY: Failed to add new client - too much sessions: 18
> clients, 1 backends. Try to increase 'max_sessions' configuration
> parameter.
>
> The logs report 1 backend even though max_sessions is the default of
> 10. Why is there only 1 backend reported? Is that error message
> getting the right value?
>
> Minor grammar fix, the logs on this warning should say "too many
> sessions" instead of "too much sessions."
>
> Reducing pgbench to only 30 connections keeps it from completely
> crashing but it still does not run successfully.
>
> pgbench -p 6543 -c 30 -j 1 -T 60 -P 15 -S bench_test
> starting vacuum...end.
> client 9 aborted in command 1 (SQL) of script 0; perhaps the backend
> died while processing
> client 11 aborted in command 1 (SQL) of script 0; perhaps the backend
> died while processing
> client 13 aborted in command 1 (SQL) of script 0; perhaps the backend
> died while processing
> ...
> ...
> progress: 15.0 s, 5734.5 tps, lat 1.191 ms stddev 10.041
> progress: 30.0 s, 7789.6 tps, lat 0.830 ms stddev 6.251
> progress: 45.0 s, 8211.3 tps, lat 0.810 ms stddev 5.970
> progress: 60.0 s, 8466.5 tps, lat 0.789 ms stddev 6.151
> transaction type: <builtin: select only>
> scaling factor: 10
> query mode: simple
> number of clients: 30
> number of threads: 1
> duration: 60 s
> number of transactions actually processed: 453042
> latency average = 0.884 ms
> latency stddev = 7.182 ms
> tps = 7549.373416 (including connections establishing)
> tps = 7549.402629 (excluding connections establishing)
> Run was aborted; the above results are incomplete.
>
> Logs for that run show (truncated):
>
>
> 2019-08-07 00:19:37.707 UTC [22152] WARNING: PROXY: Failed to add new
> client - too much sessions: 18 clients, 1 backends. Try to increase
> 'max_sessions' configuration parameter.
> 2019-08-07 00:31:10.467 UTC [22151] WARNING: PROXY: Failed to add new
> client - too much sessions: 15 clients, 4 backends. Try to increase
> 'max_sessions' configuration parameter.
> 2019-08-07 00:31:10.468 UTC [22152] WARNING: PROXY: Failed to add new
> client - too much sessions: 15 clients, 4 backends. Try to increase
> 'max_sessions' configuration parameter.
> ...
> ...
>
>
> Here it is reporting fewer clients with more backends. Still, only 4
> backends reported with 15 clients doesn't seem right. Looking at the
> results from pg_pooler_state() at the same time (below) showed 5 and 7
> backends for the two different proxies, so why are the logs only
> reporting 4 backends when pg_pooler_state() reports 12 total?
>
> Why is n_idle_clients negative? In this case it showed -21 and -17.
> Each proxy reported 7 clients, with max_sessions = 10, having those
> n_idle_client results doesn't make sense to me.
>
>
> postgres=# SELECT * FROM pg_pooler_state();
> pid | n_clients | n_ssl_clients | n_pools | n_backends |
> n_dedicated_backends | n_idle_backends | n_idle_clients | tx_bytes |
> rx_bytes | n_transactions
>
> -------+-----------+---------------+---------+------------+----------------------+-----------------+----------------+----------+----------+---------------
> -
> 25737 | 7 | 0 | 1 | 5 |
> 0 | 0 | -21 | 4099541 | 3896792 |
> 61959
> 25738 | 7 | 0 | 1 | 7 |
> 0 | 2 | -17 | 4530587 | 4307474 |
> 68490
> (2 rows)
>
>
> I get errors running pgbench down to only 20 connections with this
> configuration. I tried adjusting connection_proxies = 1 and it handles
> even fewer connections. Setting connection_proxies = 4 allows it to
> handle 20 connections without error, but by 40 connections it starts
> having issues.
>
> While I don't have expectations of this working great (or even decent)
> on a tiny server, I don't expect it to crash in a case where the
> standard connections work. Also, the logs and the function both show
> that the total backends is less than the total available and the two
> don't seem to agree on the details.
>
> I think it would help to have details about the pg_pooler_state
> function added to the docs, maybe in this section [2]?
>
> I'll take some time later this week to examine pg_pooler_state further
> on a more appropriately sized server.
>
> Thanks,
>
>
> [1]
> https://www.postgresql.org/message-id/attachment/103046/builtin_connection_proxy-16.patch
> [2] https://www.postgresql.org/docs/current/functions-info.html
>
> Ryan Lambert
>
Sorry, looks like there is misunderstanding with meaning of max_sessions
parameters.
First of all default value of this parameter is 1000, not 10.
Looks like you have explicitly specify value 10 and it cause this problems.
So "max_sessions" parameter specifies how much sessions can be handled
by one backend.
Certainly it makes sense only if pooler is switched on (number of
proxies is not zero).
If pooler is switched off, than backend is handling exactly one session/
There is no much sense in limiting number of sessions server by one
backend, because the main goal of connection pooler is to handle arbitrary
number of client connections with limited number of backends.
The only reason for presence of this parameter is that WaitEventSet
requires to specify maximal number of events.
And proxy needs to multiplex connected backends and clients. So it
create WaitEventSet with size max_sessions*2 (mutiplied by two because
it has to listen both for clients and backends).
So the value of this parameter should be large enough. Default value is
1000, but there should be no problem to set it to 10000 or even 1000000
(hoping that IS will support it).
But observer behavior ("server closed the connection unexpectedly" and
hegative number of idle clients) is certainly not correct.
I attached to this mail patch which is fixing both problems: correctly
reports error to the client and calculates number of idle clients).
New version also available in my GIT repoistory:
https://github.com/postgrespro/postgresql.builtin_pool.git
branch conn_proxy.
--
Konstantin Knizhnik
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
I attached to this mail patch which is fixing both problems: correctly
reports error to the client and calculates number of idle clients).
Yes, this works much better with max_sessions=1000. Now it's handling the 300 connections on the small server. n_idle_clients now looks accurate with the rest of the stats here.
postgres=# SELECT n_clients, n_backends, n_idle_backends, n_idle_clients FROM pg_pooler_state();
n_clients | n_backends | n_idle_backends | n_idle_clients
-----------+------------+-----------------+----------------
150 | 10 | 9 | 149
150 | 10 | 6 | 146
n_clients | n_backends | n_idle_backends | n_idle_clients
-----------+------------+-----------------+----------------
150 | 10 | 9 | 149
150 | 10 | 6 | 146
Ryan Lambert
Updated version of the patch is attached. I rewrote edge-triggered mode emulation and have tested it at MacOS/X. So right now three major platforms: Linux, MaxOS and Windows are covered. In theory it should work on most of other Unix dialects. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On 30.07.2019 16:12, Tomas Vondra wrote: > On Tue, Jul 30, 2019 at 01:01:48PM +0300, Konstantin Knizhnik wrote: >> >> >> On 30.07.2019 4:02, Tomas Vondra wrote: >>> >>> My idea (sorry if it wasn't too clear) was that we might handle some >>> cases more gracefully. >>> >>> For example, if we only switch between transactions, we don't quite >>> care >>> about 'SET LOCAL' (but the current patch does set the tainted flag). >>> The >>> same thing applies to GUCs set for a function. >>> For prepared statements, we might count the number of statements we >>> prepared and deallocated, and treat it as 'not tained' when there >>> are no >>> statements. Maybe there's some risk I can't think of. >>> >>> The same thing applies to temporary tables - if you create and drop a >>> temporary table, is there a reason to still treat the session as >>> tained? >>> >>> >> I have implemented one more trick reducing number of tainted backends: now it is possible to use session variables in pooled backends. How it works? Proxy determines "SET var=" statements and converts them to "SET LOCAL var=". Also all such assignments are concatenated and stored in session context at proxy. Then proxy injects this statement inside each transaction block or prepend to standalone statements. This mechanism works only for GUCs set outside transaction. By default it is switched off. To enable it you should switch on "proxying_gucs" parameter. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On Thu, 15 Aug 2019 at 06:01, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > I have implemented one more trick reducing number of tainted backends: > now it is possible to use session variables in pooled backends. > > How it works? > Proxy determines "SET var=" statements and converts them to "SET LOCAL > var=". > Also all such assignments are concatenated and stored in session context > at proxy. > Then proxy injects this statement inside each transaction block or > prepend to standalone statements. > > This mechanism works only for GUCs set outside transaction. > By default it is switched off. To enable it you should switch on > "proxying_gucs" parameter. > > there is definitively something odd here. i applied the patch and changed these parameters connection_proxies = '3' session_pool_size = '33' port = '5433' proxy_port = '5432' after this i run "make installcheck", the idea is to prove if an application going through proxy will behave sanely. As far as i understood in case the backend needs session mode it will taint the backend otherwise it will act as transaction mode. Sadly i got a lot of FAILED tests, i'm attaching the diffs on regression with installcheck and installcheck-parallel. btw, after make installcheck-parallel i wanted to do a new test but wasn't able to drop regression database because there is still a subscription, so i tried to drop it and got a core file (i was connected trough the pool_worker), i'm attaching the backtrace of the crash too. -- Jaime Casanova www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On 06.09.2019 1:01, Jaime Casanova wrote:
> On Thu, 15 Aug 2019 at 06:01, Konstantin Knizhnik
> <k.knizhnik@postgrespro.ru> wrote:
>> I have implemented one more trick reducing number of tainted backends:
>> now it is possible to use session variables in pooled backends.
>>
>> How it works?
>> Proxy determines "SET var=" statements and converts them to "SET LOCAL
>> var=".
>> Also all such assignments are concatenated and stored in session context
>> at proxy.
>> Then proxy injects this statement inside each transaction block or
>> prepend to standalone statements.
>>
>> This mechanism works only for GUCs set outside transaction.
>> By default it is switched off. To enable it you should switch on
>> "proxying_gucs" parameter.
>>
>>
> there is definitively something odd here. i applied the patch and
> changed these parameters
>
> connection_proxies = '3'
> session_pool_size = '33'
> port = '5433'
> proxy_port = '5432'
>
> after this i run "make installcheck", the idea is to prove if an
> application going through proxy will behave sanely. As far as i
> understood in case the backend needs session mode it will taint the
> backend otherwise it will act as transaction mode.
>
> Sadly i got a lot of FAILED tests, i'm attaching the diffs on
> regression with installcheck and installcheck-parallel.
> btw, after make installcheck-parallel i wanted to do a new test but
> wasn't able to drop regression database because there is still a
> subscription, so i tried to drop it and got a core file (i was
> connected trough the pool_worker), i'm attaching the backtrace of the
> crash too.
>
Thank you very much for testing connection pooler.
The problem with "make installcheck" is caused by GUCs passed by
pg_regress inside startup packet:
putenv("PGTZ=PST8PDT");
putenv("PGDATESTYLE=Postgres, MDY");
Them are not currently handled by builtin proxy.
Just because I didn't find some acceptable solution for it.
With newly added proxying_gucs options it is possible, this problem is
solved, but it leads to other problem:
some Postgres statements are not transactional and can not be used
inside block.
As far as proxying_gucs appends gucs setting to the statement (and so
implicitly forms transaction block),
such statement cause errors. I added check to avoid prepending GUCs
settings to non-transactional statements.
But this check seems to be not so trivial. At least I failed to make it
work: it doesn;t correctly handle specifying default namespace.
"make installcheck" can be passed if you add the folowing three settings
to configuration file:
datestyle='Postgres, MDY'
timezone='PST8PDT'
intervalstyle='postgres_verbose'
Sorry, I failed to reproduce the crash.
So if you will be able to find out some scenario for reproduce it, I
will be very pleased to receive it.
I attached to this main new version of the patch. It includes
multitenancy support.
Before separate proxy instance is created for each <dbname,role> pair.
Postgres backend is not able to work with more than one database.
But it is possible to change current user (role) inside one connection.
If "multitenent_proxy" options is switched on, then separate proxy will
be create only for each database and current user is explicitly
specified for each transaction/standalone
statement using "set command" clause.
To support this mode you need to grant permissions to all roles to
switch between each other.
So basically multitenancy support uses the same mechanism as GUCs proxying.
I will continue work on improving GUCs proxying mechanism, so that it
can pass regression tests.
--
Konstantin Knizhnik
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Attachment
On 06.09.2019 19:41, Konstantin Knizhnik wrote: > > > On 06.09.2019 1:01, Jaime Casanova wrote: >> >> Sadly i got a lot of FAILED tests, i'm attaching the diffs on >> regression with installcheck and installcheck-parallel. >> btw, after make installcheck-parallel i wanted to do a new test but >> wasn't able to drop regression database because there is still a >> subscription, so i tried to drop it and got a core file (i was >> connected trough the pool_worker), i'm attaching the backtrace of the >> crash too. >> > > Sorry, I failed to reproduce the crash. > So if you will be able to find out some scenario for reproduce it, I > will be very pleased to receive it. I was able to reproduce the crash. Patch is attached. Also I added proxyign of RESET command. Unfortunately it is still not enough to pass regression tests with "proxying_gucs=on". Mostly because error messages doesn't match after prepending "set local" commands. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On 09.09.2019 18:12, Konstantin Knizhnik wrote: > > > On 06.09.2019 19:41, Konstantin Knizhnik wrote: >> >> >> On 06.09.2019 1:01, Jaime Casanova wrote: >>> >>> Sadly i got a lot of FAILED tests, i'm attaching the diffs on >>> regression with installcheck and installcheck-parallel. >>> btw, after make installcheck-parallel i wanted to do a new test but >>> wasn't able to drop regression database because there is still a >>> subscription, so i tried to drop it and got a core file (i was >>> connected trough the pool_worker), i'm attaching the backtrace of the >>> crash too. >>> >> >> Sorry, I failed to reproduce the crash. >> So if you will be able to find out some scenario for reproduce it, I >> will be very pleased to receive it. > > I was able to reproduce the crash. > Patch is attached. Also I added proxyign of RESET command. > Unfortunately it is still not enough to pass regression tests with > "proxying_gucs=on". > Mostly because error messages doesn't match after prepending "set > local" commands. > > I have implemented passing startup options to pooler backend. Now "make installcheck" is passed without manual setting datestyle/timezone/intervalstyle in postgresql.conf. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
Travis complains that the SGML docs are broken. Please fix. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 25.09.2019 23:14, Alvaro Herrera wrote: > Travis complains that the SGML docs are broken. Please fix. > Sorry. Patch with fixed SGML formating error is attached. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
New version of builtin connection pooler fixing handling messages of extended protocol. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
Hi. >From: Konstantin Knizhnik [mailto:k.knizhnik@postgrespro.ru] > >New version of builtin connection pooler fixing handling messages of extended >protocol. > Here are things I've noticed. 1. Is adding guc to postgresql.conf.sample useful for users? 2. When proxy_port is a bit large (perhaps more than 2^15), connection failed though regular "port" is fine with number more than 2^15. $ bin/psql -p 32768 2019-11-12 16:11:25.460 JST [5617] LOG: Message size 84 2019-11-12 16:11:25.461 JST [5617] WARNING: could not setup local connect to server 2019-11-12 16:11:25.461 JST [5617] DETAIL: invalid port number: "-22768" 2019-11-12 16:11:25.461 JST [5617] LOG: Handshake response will be sent to the client later when backed is assigned psql: error: could not connect to server: invalid port number: "-22768" 3. When porxy_port is 6543 and connection_proxies is 2, running "make installcheck" twice without restarting server failed. This is because of remaining backend. ============== dropping database "regression" ============== ERROR: database "regression" is being accessed by other users DETAIL: There is 1 other session using the database. command failed: "/usr/local/pgsql-connection-proxy-performance/bin/psql" -X -c "DROP DATABASE IF EXISTS \"regression\"" "postgres" 4. When running "make installcheck-world" with various connection-proxies, it results in a different number of errors. With connection_proxies = 2, the test never ends. With connection_proxies = 20, 23 tests failed. More connection_proxies, the number of failed tests decreased. Regards, Takeshi Ideriha
Hi On 12.11.2019 10:50, ideriha.takeshi@fujitsu.com wrote: > Hi. > >> From: Konstantin Knizhnik [mailto:k.knizhnik@postgrespro.ru] >> >> New version of builtin connection pooler fixing handling messages of extended >> protocol. >> > Here are things I've noticed. > > 1. Is adding guc to postgresql.conf.sample useful for users? Good catch: I will add it. > > 2. When proxy_port is a bit large (perhaps more than 2^15), connection failed > though regular "port" is fine with number more than 2^15. > > $ bin/psql -p 32768 > 2019-11-12 16:11:25.460 JST [5617] LOG: Message size 84 > 2019-11-12 16:11:25.461 JST [5617] WARNING: could not setup local connect to server > 2019-11-12 16:11:25.461 JST [5617] DETAIL: invalid port number: "-22768" > 2019-11-12 16:11:25.461 JST [5617] LOG: Handshake response will be sent to the client later when backed is assigned > psql: error: could not connect to server: invalid port number: "-22768" Hmmm, ProxyPortNumber is used exactly in the same way as PostPortNumber. I was able to connect to the specified port: knizhnik@knizhnik:~/dtm-data$ psql postgres -p 42768 psql (13devel) Type "help" for help. postgres=# \q knizhnik@knizhnik:~/dtm-data$ psql postgres -h 127.0.0.1 -p 42768 psql (13devel) Type "help" for help. postgres=# \q > 3. When porxy_port is 6543 and connection_proxies is 2, running "make installcheck" twice without restarting server failed. > This is because of remaining backend. > > ============== dropping database "regression" ============== > ERROR: database "regression" is being accessed by other users > DETAIL: There is 1 other session using the database. > command failed: "/usr/local/pgsql-connection-proxy-performance/bin/psql" -X -c "DROP DATABASE IF EXISTS \"regression\"""postgres" Yes, this is known limitation. Frankly speaking I do not consider it as a problem: it is not possible to drop database while there are active sessions accessing it. And definitely proxy has such sessions. You can specify idle_pool_worker_timeout to shutdown pooler workers after some idle time. In this case, if you make large enough pause between test iterations, then workers will be terminated and it will be possible to drop database. > 4. When running "make installcheck-world" with various connection-proxies, it results in a different number of errors. > With connection_proxies = 2, the test never ends. With connection_proxies = 20, 23 tests failed. > More connection_proxies, the number of failed tests decreased. Please notice, that each proxy maintains its own connection pool. Default number of pooled backends is 10 (session_pool_size). If you specify too large number of proxies then number of spawned backends = session_pool_size * connection_proxies can be too large (for the specified number of max_connections). Please notice the difference between number of proxies and number of pooler backends. Usually one proxy process is enough to serve all workers. Only in case of MPP systems with large number of cores and especially with SSL connections, proxy can become a bottleneck. In this case you can configure several proxies. But having more than 1-4 proxies seems to be bad idea. But in case of check-world the problem is not related with number of proxies. It takes place even with connection_proxies = 1 There was one bug with handling clients terminated inside transaction. It is fixed in the attached patch. But there is still problem with passing isolation tests under connection proxy: them are using pg_isolation_test_session_is_blocked function which checks if backends with specified PIDs are blocked. But as far as in case of using connection proxy session is no more bounded to the particular backend, this check may not work as expected and test is blocked. I do not know how it can be fixed and not sure if it has to be fixed at all. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
Hi >From: Konstantin Knizhnik [mailto:k.knizhnik@postgrespro.ru] >>> From: Konstantin Knizhnik [mailto:k.knizhnik@postgrespro.ru] >>> >>> New version of builtin connection pooler fixing handling messages of >>> extended protocol. >>> >> 2. When proxy_port is a bit large (perhaps more than 2^15), connection >> failed though regular "port" is fine with number more than 2^15. >> >> $ bin/psql -p 32768 >> 2019-11-12 16:11:25.460 JST [5617] LOG: Message size 84 >> 2019-11-12 16:11:25.461 JST [5617] WARNING: could not setup local >> connect to server >> 2019-11-12 16:11:25.461 JST [5617] DETAIL: invalid port number: "-22768" >> 2019-11-12 16:11:25.461 JST [5617] LOG: Handshake response will be >> sent to the client later when backed is assigned >> psql: error: could not connect to server: invalid port number: "-22768" >Hmmm, ProxyPortNumber is used exactly in the same way as PostPortNumber. >I was able to connect to the specified port: > > >knizhnik@knizhnik:~/dtm-data$ psql postgres -p 42768 psql (13devel) Type "help" for >help. > >postgres=# \q >knizhnik@knizhnik:~/dtm-data$ psql postgres -h 127.0.0.1 -p 42768 psql (13devel) >Type "help" for help. > >postgres=# \q For now I replay for the above. Oh sorry, I was wrong about the condition. The error occurred under following condition. - port = 32768 - proxy_port = 6543 - $ psql postgres -p 6543 $ bin/pg_ctl start -D data waiting for server to start.... LOG: starting PostgreSQL 13devel on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-28), 64-bit LOG: listening on IPv6 address "::1", port 6543 LOG: listening on IPv4 address "127.0.0.1", port 6543 LOG: listening on IPv6 address "::1", port 32768 LOG: listening on IPv4 address "127.0.0.1", port 32768 LOG: listening on Unix socket "/tmp/.s.PGSQL.6543" LOG: listening on Unix socket "/tmp/.s.PGSQL.32768" LOG: Start proxy process 25374 LOG: Start proxy process 25375 LOG: database system was shut down at 2019-11-12 16:49:20 JST LOG: database system is ready to accept connections server started [postgres@vm-7kfq-coreban connection-pooling]$ psql -p 6543 LOG: Message size 84 WARNING: could not setup local connect to server DETAIL: invalid port number: "-32768" LOG: Handshake response will be sent to the client later when backed is assigned psql: error: could not connect to server: invalid port number: "-32768" By the way, the patch has some small conflicts against master. Regards, Takeshi Ideriha
> For now I replay for the above. Oh sorry, I was wrong about the condition. > The error occurred under following condition. > - port = 32768 > - proxy_port = 6543 > - $ psql postgres -p 6543 > > $ bin/pg_ctl start -D data > waiting for server to start.... > LOG: starting PostgreSQL 13devel on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-28), 64-bit > LOG: listening on IPv6 address "::1", port 6543 > LOG: listening on IPv4 address "127.0.0.1", port 6543 > LOG: listening on IPv6 address "::1", port 32768 > LOG: listening on IPv4 address "127.0.0.1", port 32768 > LOG: listening on Unix socket "/tmp/.s.PGSQL.6543" > LOG: listening on Unix socket "/tmp/.s.PGSQL.32768" > LOG: Start proxy process 25374 > LOG: Start proxy process 25375 > LOG: database system was shut down at 2019-11-12 16:49:20 JST > LOG: database system is ready to accept connections > > server started > [postgres@vm-7kfq-coreban connection-pooling]$ psql -p 6543 > LOG: Message size 84 > WARNING: could not setup local connect to server > DETAIL: invalid port number: "-32768" > LOG: Handshake response will be sent to the client later when backed is assigned > psql: error: could not connect to server: invalid port number: "-32768" > > By the way, the patch has some small conflicts against master. Thank you very much for reporting the problem. It was caused by using pg_itoa for string representation of port (I could not imagine that unlike standard itoa it accepts int16 parameter instead of int). Attached please find rebased patch with this bug fixed. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
Hi Konstantin, On 11/14/19 2:06 AM, Konstantin Knizhnik wrote: > Attached please find rebased patch with this bug fixed. This patch no longer applies: http://cfbot.cputube.org/patch_27_2067.log CF entry has been updated to Waiting on Author. Regards, -- -David david@pgmasters.net
Hi David, On 24.03.2020 16:26, David Steele wrote: > Hi Konstantin, > > On 11/14/19 2:06 AM, Konstantin Knizhnik wrote: >> Attached please find rebased patch with this bug fixed. > > This patch no longer applies: http://cfbot.cputube.org/patch_27_2067.log > > CF entry has been updated to Waiting on Author. > Rebased version of the patch is attached. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
> On 24 Mar 2020, at 17:24, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > Rebased version of the patch is attached. And this patch also fails to apply now, can you please submit a new version? Marking the entry as Waiting on Author in the meantime. cheers ./daniel
On 01.07.2020 12:30, Daniel Gustafsson wrote: >> On 24 Mar 2020, at 17:24, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: >> Rebased version of the patch is attached. > And this patch also fails to apply now, can you please submit a new version? > Marking the entry as Waiting on Author in the meantime. > > cheers ./daniel Rebased version of the patch is attached.
Attachment
> On 2 Jul 2020, at 13:33, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote:
> On 01.07.2020 12:30, Daniel Gustafsson wrote:
>>> On 24 Mar 2020, at 17:24, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote:
>>> Rebased version of the patch is attached.
>> And this patch also fails to apply now, can you please submit a new version?
>> Marking the entry as Waiting on Author in the meantime.
>>
>> cheers ./daniel
> Rebased version of the patch is attached.
Both Travis and Appveyor fails to compile this version:
proxy.c: In function ‘client_connect’:
proxy.c:302:6: error: too few arguments to function ‘ParseStartupPacket’
if (ParseStartupPacket(chan->client_port, chan->proxy->parse_ctx, startup_packet+4, startup_packet_size-4, false) !=
STATUS_OK)/* skip packet size */
^
In file included from proxy.c:8:0:
../../../src/include/postmaster/postmaster.h:71:12: note: declared here
extern int ParseStartupPacket(struct Port* port, MemoryContext memctx, void* pkg_body, int pkg_size, bool ssl_done,
boolgss_done);
^
<builtin>: recipe for target 'proxy.o' failed
make[3]: *** [proxy.o] Error 1
cheers ./daniel
On 02.07.2020 17:44, Daniel Gustafsson wrote: >> On 2 Jul 2020, at 13:33, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: >> On 01.07.2020 12:30, Daniel Gustafsson wrote: >>>> On 24 Mar 2020, at 17:24, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: >>>> Rebased version of the patch is attached. >>> And this patch also fails to apply now, can you please submit a new version? >>> Marking the entry as Waiting on Author in the meantime. >>> >>> cheers ./daniel >> Rebased version of the patch is attached. > Both Travis and Appveyor fails to compile this version: > > proxy.c: In function ‘client_connect’: > proxy.c:302:6: error: too few arguments to function ‘ParseStartupPacket’ > if (ParseStartupPacket(chan->client_port, chan->proxy->parse_ctx, startup_packet+4, startup_packet_size-4, false) !=STATUS_OK) /* skip packet size */ > ^ > In file included from proxy.c:8:0: > ../../../src/include/postmaster/postmaster.h:71:12: note: declared here > extern int ParseStartupPacket(struct Port* port, MemoryContext memctx, void* pkg_body, int pkg_size, bool ssl_done,bool gss_done); > ^ > <builtin>: recipe for target 'proxy.o' failed > make[3]: *** [proxy.o] Error 1 > > cheers ./daniel Sorry, correct patch is attached.
Attachment
On Wed, 7 Aug 2019 at 02:49, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > Hi, Li > > Thank you very much for reporting the problem. > > On 07.08.2019 7:21, Li Japin wrote: > > I inspect the code, and find the following code in DefineRelation function: > > > > if (stmt->relation->relpersistence != RELPERSISTENCE_TEMP > > && stmt->oncommit != ONCOMMIT_DROP) > > MyProc->is_tainted = true; > > > > For temporary table, MyProc->is_tainted might be true, I changed it as > > following: > > > > if (stmt->relation->relpersistence == RELPERSISTENCE_TEMP > > || stmt->oncommit == ONCOMMIT_DROP) > > MyProc->is_tainted = true; > > > > For temporary table, it works. I not sure the changes is right. > Sorry, it is really a bug. > My intention was to mark backend as tainted if it is creating temporary > table without ON COMMIT DROP clause (in the last case temporary table > will be local to transaction and so cause no problems with pooler). > Th right condition is: > > if (stmt->relation->relpersistence == RELPERSISTENCE_TEMP > && stmt->oncommit != ONCOMMIT_DROP) > MyProc->is_tainted = true; > > You should also allow cursors without the WITH HOLD option or there is something i'm missing? a few questions about tainted backends: - why the use of check_primary_key() and check_foreign_key() in contrib/spi/refint.c make the backend tainted? - the comment in src/backend/commands/sequence.c needs some fixes, it seems just quickly typed some usability problem: - i compiled this on a debian machine with "--enable-debug --enable-cassert --with-pgport=54313", so nothing fancy - then make, make install, and initdb: so far so good configuration: listen_addresses = '*' connection_proxies = 20 and i got this: """ jcasanov@DangerBox:/opt/var/pgdg/14dev$ /opt/var/pgdg/14dev/bin/psql -h 127.0.0.1 -p 6543 postgres psql: error: could not connect to server: no se pudo conectar con el servidor: No existe el fichero o el directorio ¿Está el servidor en ejecución localmente y aceptando conexiones en el socket de dominio Unix «/var/run/postgresql/.s.PGSQL.54313»? """ but connect at the postgres port works well """ jcasanov@DangerBox:/opt/var/pgdg/14dev$ /opt/var/pgdg/14dev/bin/psql -h 127.0.0.1 -p 54313 postgres psql (14devel) Type "help" for help. postgres=# \q jcasanov@DangerBox:/opt/var/pgdg/14dev$ /opt/var/pgdg/14dev/bin/psql -p 54313 postgres psql (14devel) Type "help" for help. postgres=# """ PS: unix_socket_directories is setted at /tmp and because i'm not doing this with postgres user i can use /var/run/postgresql -- Jaime Casanova www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Thank your for your help. On 05.07.2020 07:17, Jaime Casanova wrote: > You should also allow cursors without the WITH HOLD option or there is > something i'm missing? Yes, good point. > a few questions about tainted backends: > - why the use of check_primary_key() and check_foreign_key() in > contrib/spi/refint.c make the backend tainted? I think this is because without it contrib test is not passed with connection pooler. This extension uses static variables which are assumed to be session specific but in case f connection pooler are shared by all backends. > - the comment in src/backend/commands/sequence.c needs some fixes, it > seems just quickly typed Sorry, done. > > some usability problem: > - i compiled this on a debian machine with "--enable-debug > --enable-cassert --with-pgport=54313", so nothing fancy > - then make, make install, and initdb: so far so good > > configuration: > listen_addresses = '*' > connection_proxies = 20 > > and i got this: > > """ > jcasanov@DangerBox:/opt/var/pgdg/14dev$ /opt/var/pgdg/14dev/bin/psql > -h 127.0.0.1 -p 6543 postgres > psql: error: could not connect to server: no se pudo conectar con el > servidor: No existe el fichero o el directorio > ¿Está el servidor en ejecución localmente y aceptando > conexiones en el socket de dominio Unix «/var/run/postgresql/.s.PGSQL.54313»? > """ > > but connect at the postgres port works well > """ > jcasanov@DangerBox:/opt/var/pgdg/14dev$ /opt/var/pgdg/14dev/bin/psql > -h 127.0.0.1 -p 54313 postgres > psql (14devel) > Type "help" for help. > > postgres=# \q > jcasanov@DangerBox:/opt/var/pgdg/14dev$ /opt/var/pgdg/14dev/bin/psql > -p 54313 postgres > psql (14devel) > Type "help" for help. > > postgres=# > """ > > PS: unix_socket_directories is setted at /tmp and because i'm not > doing this with postgres user i can use /var/run/postgresql > Looks like for some reasons your Postgres was not configured to accept TCP connection. It accepts only local connections through Unix sockets. But pooler is not listening unix sockets because there is absolutely no sense in pooling local connections. I have done the same steps as you and have no problem to access pooler: knizhnik@xps:~/postgresql.vanilla$ psql postgres -h 127.0.0.1 -p 6543 psql (14devel) Type "help" for help. postgres=# \q Please notice that if I specify some unexisted port, then I get error message which is different with yours: knizhnik@xps:~/postgresql.vanilla$ psql postgres -h 127.0.0.1 -p 65433 psql: error: could not connect to server: could not connect to server: Connection refused Is the server running on host "127.0.0.1" and accepting TCP/IP connections on port 65433? So Postgres is not mentioning unix socket path in this case. It makes me think that your server is not accepting TCP connections at all (despite to listen_addresses = '*' )
Change a constraint's index - ALTER TABLE ... ALTER CONSTRAINT ... USING INDEX ...
From
Anna Akenteva
Date:
Hello, hackers! I'd like to propose a feature for changing a constraint's index. The provided patch allows to do it for EXCLUDE, UNIQUE, PRIMARY KEY and FOREIGN KEY constraints. Feature description: ALTER TABLE ... ALTER CONSTRAINT ... USING INDEX ... Replace a constraint's index with another sufficiently similar index. Use cases: - Removing index bloat [1] (now also achieved by REINDEX CONCURRENTLY) - Swapping a normal index for an index with INCLUDED columns, or vice versa Example of use: CREATE TABLE target_tbl ( id integer PRIMARY KEY, info text ); CREATE TABLE referencing_tbl ( id_ref integer REFERENCES target_tbl (id) ); -- Swapping primary key's index for an equivalent index, -- but with INCLUDE-d attributes. CREATE UNIQUE INDEX new_idx ON target_tbl (id) INCLUDE (info); ALTER TABLE target_tbl ALTER CONSTRAINT target_tbl_pkey USING INDEX new_idx; ALTER TABLE referencing_tbl ALTER CONSTRAINT referencing_tbl_id_ref_fkey USING INDEX new_idx; DROP INDEX target_tbl_pkey; I'd like to hear your feedback on this feature. Also, some questions: 1) If the index supporting a UNIQUE or PRIMARY KEY constraint is changed, should foreign keys also automatically switch to the new index? Or should the user switch it manually, by using ALTER CONSTRAINT USING INDEX on the foreign key? 2) Whose name should change to fit the other - constraint's or index's? [1] https://www.postgresql.org/message-id/flat/CABwTF4UxTg%2BkERo1Nd4dt%2BH2miJoLPcASMFecS1-XHijABOpPg%40mail.gmail.com
Attachment
On Thu, Jul 02, 2020 at 06:38:02PM +0300, Konstantin Knizhnik wrote: > Sorry, correct patch is attached. This needs again a rebase, and has been waiting on author for 6 weeks now, so I am switching it to RwF. -- Michael
Attachment
On 17.09.2020 8:07, Michael Paquier wrote: > On Thu, Jul 02, 2020 at 06:38:02PM +0300, Konstantin Knizhnik wrote: >> Sorry, correct patch is attached. > This needs again a rebase, and has been waiting on author for 6 weeks > now, so I am switching it to RwF. > -- > Michael Attached is rebased version of the patch. I wonder what is the correct policy of handling patch status? This patch was marked as WfA 2020-07-01 because it was not applied any more. 2020-07-02 I have sent rebased version of the patch. Since this time there was not unanswered questions. So I actually didn't consider that some extra activity from my side is need. I have not noticed that patch is not applied any more. And now it is marked as returned with feedback. So my questions are: 1. Should I myself change status from WfA to some other? 2. Is there some way to receive notifications that patch is not applied any more? I can resubmit this patch to the next commitfest if it is still interesting for community. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
> On 17 Sep 2020, at 10:40, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote:
> 1. Should I myself change status from WfA to some other?
Yes, when you've addressed any issues raised and posted a new version it's very
helpful to the CFM and the community if you update the status.
> 2. Is there some way to receive notifications that patch is not applied any more?
Not at the moment, but periodically checking the CFBot page for your patches is
a good habit:
http://cfbot.cputube.org/konstantin-knizhnik.html
cheers ./daniel
People asked me to resubmit built-in connection pooler patch to commitfest. Rebased version of connection pooler is attached.
Attachment
Hi,
+ With <literal>load-balancing</literal> policy postmaster choose proxy with lowest load average.
+ Load average of proxy is estimated by number of clients connection assigned to this proxy with extra weight for SSL connections.
+ Load average of proxy is estimated by number of clients connection assigned to this proxy with extra weight for SSL connections.
I think 'load-balanced' may be better than 'load-balancing'.
postmaster choose proxy -> postmaster chooses proxy
+ Load average of proxy is estimated by number of clients connection assigned to this proxy with extra weight for SSL connections.
I wonder if there would be a mixture of connections with and without SSL.
+ Terminate an idle connection pool worker after the specified number of milliseconds.
Should the time unit be seconds ? It seems a worker would exist for at least a second.
+ * Portions Copyright (c) 1996-2018, PostgreSQL Global Development Group
It would be better to update the year in the header.
+ * Use then for launching pooler worker backends and report error
Not sure I understand the above sentence. Did you mean 'them' instead of 'then' ?
Cheers
On Sun, Mar 21, 2021 at 11:32 AM Konstantin Knizhnik <knizhnik@garret.ru> wrote:
People asked me to resubmit built-in connection pooler patch to commitfest.
Rebased version of connection pooler is attached.
Hi, Thank you for review! On 21.03.2021 23:59, Zhihong Yu wrote: > Hi, > > + With <literal>load-balancing</literal> policy postmaster > choose proxy with lowest load average. > + Load average of proxy is estimated by number of clients > connection assigned to this proxy with extra weight for SSL connections. > > I think 'load-balanced' may be better than 'load-balancing'. Sorry, I am not a native speaker. But it seems to me (based on the articles I have read), then "load-balancing" is more widely used term: https://en.wikipedia.org/wiki/Load_balancing_(computing) > postmaster choose proxy -> postmaster chooses proxy Fixed. > > + Load average of proxy is estimated by number of clients > connection assigned to this proxy with extra weight for SSL connections. > > I wonder if there would be a mixture of connections with and without SSL. Why not? And what is wrong with it? > > + Terminate an idle connection pool worker after the specified > number of milliseconds. > > Should the time unit be seconds ? It seems a worker would exist for at > least a second. > Most of other similar timeouts: statement timeout, session timeout... are specified in milliseconds. > + * Portions Copyright (c) 1996-2018, PostgreSQL Global Development Group > > It would be better to update the year in the header. Fixed. > > + * Use then for launching pooler worker backends and report error > > Not sure I understand the above sentence. Did you mean 'them' instead > of 'then' ? Sorry, it is really mistyping. "them" should be used. Fixed.
Konstantin Knizhnik <knizhnik@garret.ru> wrote:
> People asked me to resubmit built-in connection pooler patch to commitfest.
> Rebased version of connection pooler is attached.
I've reviewd the patch but haven't read the entire thread thoroughly. I hope
that I don't duplicate many comments posted earlier by others.
(Please note that the patch does not apply to the current master, I had to
reset the head of my repository to the appropriate commit.)
Documentation / user interface
------------------------------
* session_pool_size (config.sgml)
I wonder if
"The default value is 10, so up to 10 backends will serve each database,"
should rather be
"The default value is 10, so up to 10 backends will serve each database/user combination."
However, when I read the code, I think that each proxy counts the size of the
pool separately, so the total number of backends used for particular
database/user combination seems to be
session_pool_size * connection_proxies
Since the feature uses shared memory statistics anyway, shouldn't it only
count the total number of backends per database/user? It would need some
locking, but the actual pools (hash tables) could still be local to the proxy
processes.
* connection_proxies
(I've noticed that Ryan Lambert questioned this variable upthread.)
I think this variable makes the configuration less straightforward from the
user perspective. Cannot the server launch additional proxies dynamically, as
needed, e.g. based on the shared memory statistics that the patch introduces?
I see that postmaster would have to send the sockets in a different way. How
about adding a "proxy launcher" process that would take care of the scheduling
and launching new proxies?
* multitenant_proxy
I thought the purpose of this setting is to reduce the number of backends
needed, but could not find evidence in the code. In particular,
client_attach() always retrieves the backend from the appropriate pool, and
backend_reschedule() does so as well. Thus the role of both client and backend
should always match. What piece of information do I miss?
* typo (2 occurrences in config.sgml)
"stanalone" -> "standalone"
Design / coding
---------------
* proxy.c:backend_start() does not change the value of the "host" parameter to
the socket directory, so I assume the proxy connects to the backend via TCP
protocol. I think the unix socket should be preferred for this connection if
the platform has it, however:
* is libpq necessary for the proxy to connect to backend at all? Maybe
postgres.c:ReadCommand() can be adjusted so that the backend can communicate
with the proxy just via the plain socket.
I don't like the idea of server components communicating via libpq (do we
need anything else of the libpq connection than the socket?) as such, but
especially these includes in proxy.c look weird:
#include "../interfaces/libpq/libpq-fe.h"
#include "../interfaces/libpq/libpq-int.h"
* How does the proxy recognize connections to the walsender? I haven't tested
that, but it's obvious that these connections should not be proxied.
* ConnectionProxyState is in shared memory, so access to its fields should be
synchronized.
* StartConnectionProxies() is only called from PostmasterMain(), so I'm not
sure the proxies get restarted after crash. Perhaps PostmasterStateMachine()
needs to call it too after calling StartupDataBase().
* Why do you need the Channel.magic integer field? Wouldn't a boolean field
"active" be sufficient?
** In proxy_loop(), I've noticed tests (chan->magic == ACTIVE_CHANNEL_MAGIC)
tests inside the branch
else if (chan->magic == ACTIVE_CHANNEL_MAGIC)
Since neither channel_write() nor channel_read() seem to change the
value, I think those tests are not necessary.
* Comment lines are often too long.
* pgindent should be applied to the patch at some point.
I can spend more time reviewing the patch during the next CF.
--
Antonin Houska
Web: https://www.cybertec-postgresql.com
On Mar 22, 2021, at 4:59 AM, Zhihong Yu <zyu@yugabyte.com> wrote:Hi,+ With <literal>load-balancing</literal> policy postmaster choose proxy with lowest load average.
+ Load average of proxy is estimated by number of clients connection assigned to this proxy with extra weight for SSL connections.I think 'load-balanced' may be better than 'load-balancing'.postmaster choose proxy -> postmaster chooses proxy+ Load average of proxy is estimated by number of clients connection assigned to this proxy with extra weight for SSL connections.I wonder if there would be a mixture of connections with and without SSL.+ Terminate an idle connection pool worker after the specified number of milliseconds.Should the time unit be seconds ? It seems a worker would exist for at least a second.+ * Portions Copyright (c) 1996-2018, PostgreSQL Global Development GroupIt would be better to update the year in the header.+ * Use then for launching pooler worker backends and report errorNot sure I understand the above sentence. Did you mean 'them' instead of 'then' ?CheersOn Sun, Mar 21, 2021 at 11:32 AM Konstantin Knizhnik <knizhnik@garret.ru> wrote:People asked me to resubmit built-in connection pooler patch to commitfest.
Rebased version of connection pooler is attached.
Does the PostgreSQL core do not interested in the built-in connection pool? If so, could
somebody tell me why we do not need it? If not, how can we do for this to make it in core?
Thanks in advance!
[Sorry if you already receive this email, since I typo an invalid pgsql list email address in previous email.]
--
Best regards
Japin Li