Thread: Shared Memory: How to use SYSV rather than MMAP ?
Hi,
On AIX, since with MMAP we have only 4K pages though we can have 64K pages with SYSV, we'd like to experiment with SYSV rather than MMAP and measure the impact to the performance.
Looking at file: src/include/storage/dsm_impl.h , it seemed to me that replacing the line:
#define DEFAULT_DYNAMIC_SHARED_MEMORY_TYPE DSM_IMPL_POSIXwas the right thing to do. Plus some changes like:
by the line:
#define DEFAULT_DYNAMIC_SHARED_MEMORY_TYPE DSM_IMPL_SYSV
export LDR_CNTRL=SHMPSIZE=64K
ldedit -btextpsize=64k -bdatapsize=64k -bstackpsize=64k ...../postgres
However, when looking at details by means of procmap tool, it is unclear if that worked or not.
Maybe I was lost by the variables:
HAVE_SHM_OPEN . USE_DSM_POSIX . USE_DSM_SYSV . USE_DSM_MMAP
which are all defined.
So, what should I do in order to use SYSV rather than MMAP for the Shared Memory ?
(PostgreSQL v11.1)
Thanks/Regards,
Tony Reix
tony.reix@atos.net
ATOS / Bull SAS
ATOS Expert
IBM Coop Architect & Technical Leader
On Tue, Nov 20, 2018 at 11:11 PM REIX, Tony <tony.reix@atos.net> wrote: > On AIX, since with MMAP we have only 4K pages though we can have 64K pages with SYSV, we'd like to experiment with SYSVrather than MMAP and measure the impact to the performance. > > Looking at file: src/include/storage/dsm_impl.h , it seemed to me that replacing the line: > > #define DEFAULT_DYNAMIC_SHARED_MEMORY_TYPE DSM_IMPL_POSIX > by the line: > #define DEFAULT_DYNAMIC_SHARED_MEMORY_TYPE DSM_IMPL_SYSV Hi Tony, SHOW dynamic_shared_memory_type to see which one it's actually using, and set it in postgresql.conf to change it. > However, when looking at details by means of procmap tool, it is unclear if that worked or not. These segments are short-lived ones used for parallel query. I haven't used AIX recently but I suspect procmap -X will show them as different types and show the page size, but you'd have to check that while it's actually running a parallel query. For example, a large parallel hash join that runs for a while would do it, and in theory you might be able to see a small performance improvement for larger page sizes due to better TLB cache hit ratios. -- Thomas Munro http://www.enterprisedb.com
On Tue, Nov 20, 2018 at 5:11 AM REIX, Tony <tony.reix@atos.net> wrote: > On AIX, since with MMAP we have only 4K pages though we can have 64K pages with SYSV, we'd like to experiment with SYSVrather than MMAP and measure the impact to the performance. Are you trying to move the main shared memory segment or the dynamic shared memory segments? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi Robert,
We are trying to understand why pgbench on AIX is slower compared to Linux/Power on the same HW/Disks.
So, we have yet no idea about what may be the root cause and what should be changed.
So, changing: dynamic_shared_memory_type = sysv seems to help.
And maybe changing the main shared memory segment could also improve the performance. However, how one can change this?
Tony Reix
tony.reix@atos.net
ATOS / Bull SAS
ATOS Expert
IBM Coop Architect & Technical Leader
Envoyé : mardi 20 novembre 2018 13:53:53
À : REIX, Tony
Cc : pgsql-hackers@postgresql.org; EMPEREUR-MOT, SYLVIE
Objet : Re: Shared Memory: How to use SYSV rather than MMAP ?
> On AIX, since with MMAP we have only 4K pages though we can have 64K pages with SYSV, we'd like to experiment with SYSV rather than MMAP and measure the impact to the performance.
Are you trying to move the main shared memory segment or the dynamic
shared memory segments?
--
Robert Haas
EnterpriseDB: https://emea01.safelinks.protection.outlook.com/?url=http%3A%2F%2Fwww.enterprisedb.com&data=01%7C01%7Ctony.reix%40atos.net%7C09c690fe81b9489e135d08d64ee74b7f%7C33440fc6b7c7412cbb730e70b0198d5a%7C0&sdata=oj%2Fd7djWk16Bb8%2F2I9eiqlWnRBfcFNjYtZCj%2FHd3Qp0%3D&reserved=0
The Enterprise PostgreSQL Company
On Tue, Nov 20, 2018 at 8:36 AM REIX, Tony <tony.reix@atos.net> wrote: > We are trying to understand why pgbench on AIX is slower compared to Linux/Power on the same HW/Disks. > > So, we have yet no idea about what may be the root cause and what should be changed. > > So, changing: dynamic_shared_memory_type = sysv seems to help. > > And maybe changing the main shared memory segment could also improve the performance. However, how one can change this? There's no configuration setting for the main shared memory segment, but removing #define USE_ANONYMOUS_SHMEM from sysv_shmem.c would probably do the trick. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi Robert,
YES ! Reading this file, your suggestion should work ! Thx !
I've rebuilt and run the basic tests. We'll relaunch our tests asap.
Tony Reix
tony.reix@atos.net
ATOS / Bull SAS
ATOS Expert
IBM Coop Architect & Technical Leader
Envoyé : mardi 20 novembre 2018 15:53:11
À : REIX, Tony
Cc : pgsql-hackers@postgresql.org; EMPEREUR-MOT, SYLVIE
Objet : Re: Shared Memory: How to use SYSV rather than MMAP ?
> We are trying to understand why pgbench on AIX is slower compared to Linux/Power on the same HW/Disks.
>
> So, we have yet no idea about what may be the root cause and what should be changed.
>
> So, changing: dynamic_shared_memory_type = sysv seems to help.
>
> And maybe changing the main shared memory segment could also improve the performance. However, how one can change this?
There's no configuration setting for the main shared memory segment,
but removing #define USE_ANONYMOUS_SHMEM from sysv_shmem.c would
probably do the trick.
--
Robert Haas
EnterpriseDB: https://emea01.safelinks.protection.outlook.com/?url=http%3A%2F%2Fwww.enterprisedb.com&data=01%7C01%7Ctony.reix%40atos.net%7C723ccf057a79436bcf9208d64ef7f48b%7C33440fc6b7c7412cbb730e70b0198d5a%7C0&sdata=ZBRv1Ja1THRJH2symVaZSLjGQ4f9hRP9kw27hFlPdAE%3D&reserved=0
The Enterprise PostgreSQL Company
On Wed, Nov 21, 2018 at 4:37 AM REIX, Tony <tony.reix@atos.net> wrote: > YES ! Reading this file, your suggestion should work ! Thx ! > > I've rebuilt and run the basic tests. We'll relaunch our tests asap. I would be surprised if that makes a difference: anonymous-mmap-then-fork and SysV shm are just two different ways to exchange mappings between processes, but I'd expect the virtual memory object itself to be basically the same, in terms of constraints that might affect page size at least. If you were talking about mmap backed by a file (which is what you get for temporary parallel query segments if you tell it to use dynamic_shared_memory_type = mmap), that might be a different matter, because then the block size of the file system backing it might come into the picture and limit the kernel's options. For example, that is why (with default settings) Parallel Hash can't use large pages on Linux (because Linux's POSIX shm_open() really just opens files on /dev/shm, which has a 4k block size), but can use them on FreeBSD (because its shm_open() isn't bound to page sizes, it can and sometimes decides to use large pages). -- Thomas Munro http://www.enterprisedb.com
Hi, On 2018-11-21 09:00:58 +1300, Thomas Munro wrote: > On Wed, Nov 21, 2018 at 4:37 AM REIX, Tony <tony.reix@atos.net> wrote: > > YES ! Reading this file, your suggestion should work ! Thx ! > > > > I've rebuilt and run the basic tests. We'll relaunch our tests asap. > > I would be surprised if that makes a difference: > anonymous-mmap-then-fork and SysV shm are just two different ways to > exchange mappings between processes, but I'd expect the virtual memory > object itself to be basically the same, in terms of constraints that > might affect page size at least. I don't think that's true on many systems, FWIW. On linux there's certainly different behaviour, and e.g. the way to get hugepages for anon-mmap and SysV shmem aren't the same. [1] strongly suggests that that's not the case on FreeBSD either (with sysv shmem being better). I'd attached a patch to implement a GUC to allow users to choose the shmem implementation back then [2]. [1] http://archives.postgresql.org/message-id/2AE143D2-87D3-4AD1-AC78-CE2258230C05%40FreeBSD.org [2] http://archives.postgresql.org/message-id/20140422121921.GD4449%40awork2.anarazel.de Greetings, Andres Freund
On Wed, Nov 21, 2018 at 9:07 AM Andres Freund <andres@anarazel.de> wrote: > On 2018-11-21 09:00:58 +1300, Thomas Munro wrote: > > On Wed, Nov 21, 2018 at 4:37 AM REIX, Tony <tony.reix@atos.net> wrote: > > > YES ! Reading this file, your suggestion should work ! Thx ! > > > > > > I've rebuilt and run the basic tests. We'll relaunch our tests asap. > > > > I would be surprised if that makes a difference: > > anonymous-mmap-then-fork and SysV shm are just two different ways to > > exchange mappings between processes, but I'd expect the virtual memory > > object itself to be basically the same, in terms of constraints that > > might affect page size at least. > > I don't think that's true on many systems, FWIW. On linux there's > certainly different behaviour, and e.g. the way to get hugepages for > anon-mmap and SysV shmem aren't the same. Right, when asking for them explicitly the API is different (SHM_HUGE flag to shmget(), MAP_HUGETLB flag to mmap()). Actually I was expecting AIX to be more like FreeBSD and Solaris, where you don't do that, the OS just decides what page size to give you, but after some quality time with google I now see that it's more like Linux in the SysV case... there is an explicit flag: https://www.ibm.com/support/knowledgecenter/en/ssw_aix_71/com.ibm.aix.performance/large_pages_shared_mem_segs.htm You also need some special privileges: https://www.ibm.com/support/knowledgecenter/en/ssw_aix_71/com.ibm.aix.performance/large_page_ovw.htm As for the main shared buffers area using anon-mmap, I wonder if it would automagically use large pages if you have the privileges and set the LDR_CNTRL environment variable (or the equivalent XCOFF header for the binary): https://www.ibm.com/support/knowledgecenter/en/ssw_aix_71/com.ibm.aix.performance/set_env_variable_lpages.htm > [1] strongly suggests that > that's not the case on FreeBSD either (with sysv shmem being > better). I'd attached a patch to implement a GUC to allow users to > choose the shmem implementation back then [2]. Surprising. I'd like to know if that's still true. SysV shm is not nice, and if there is anything accidentally better about its performance, I'd love to know what. That report (slightly) predates this work (maybe causally linked), which fixed various VM scale problems hit by PostgreSQL: http://www.kib.kiev.ua/kib/pgsql_perf_v2.0.pdf -- Thomas Munro http://www.enterprisedb.com
Hi Thomas, Andres,
I still have to reread/study in depth the discussion in this thread in order to understand all these information. However, we've already got a very good performance improvement of pgbench on AIX 7.2 / Power9 with that change: + ~38% in best case. See below for the details.
This +38% improvement has been measured by comparison with a PostgreSQL v11.1 code which was built with: XLC -O2 + power9-tuning, plus some changes about inlining for AIX and some fixes dealing with issues with XLC and PostgreSQL #ifdef. Maybe GCC provides better results, we'll know later.
Once we are done with this performance analysis campaign, I'll have to submit patches.
Meanwhile, if anyone has ideas about where the choices made for PostgreSQL on Linux may have an impact to the performance on AIX, I'm very interested!
Regards,
Tony
- Main shared memory segment in sysv_shmem.c
- Dynamic shared memory implementations in src/include/storage/dsm_impl.h :
// #define DEFAULT_DYNAMIC_SHARED_MEMORY_TYPE DSM_IMPL_POSIX
#define DEFAULT_DYNAMIC_SHARED_MEMORY_TYPE DSM_IMPL_SYSV
#endif
- ldedit -btextpsize=64K -bdatapsize=64K -bstackpsize=64K /opt/freeware/bin/postgres_64
- Env variable LDR_CNTRL=SHMPSIZE=64K
Tony Reix
tony.reix@atos.net
ATOS / Bull SAS
ATOS Expert
IBM Coop Architect & Technical Leader
Hi Andres, Thomas,
Here is a patch for enabling SystemV Shared Memory on AIX, for 64K or bigger page size, rather than using MMAP shared memory, which is slower on AIX.
We have tested this code with 64K pages and pgbench, on AIX 7.2 TL2 Power 9, and it provided a maximum of +37% improvement.
We'll test this code with Large Pages (SHM_LGPAGE | SHM_PIN | S_IRUSR | S_IWUSR flags of shmget() ) ASAP.
However, I wanted first to get your comments about this change in order to improve it for acceptance.
Thanks/Regards,
Tony Reix
tony.reix@atos.net
ATOS / Bull SAS
ATOS Expert
IBM Coop Architect & Technical Leader
Envoyé : mercredi 21 novembre 2018 09:45:12
À : Thomas Munro; Andres Freund
Cc : Robert Haas; Pg Hackers; EMPEREUR-MOT, SYLVIE; BERGAMINI, DAMIEN
Objet : RE: Shared Memory: How to use SYSV rather than MMAP ?
Hi Thomas, Andres,
I still have to reread/study in depth the discussion in this thread in order to understand all these information. However, we've already got a very good performance improvement of pgbench on AIX 7.2 / Power9 with that change: + ~38% in best case. See below for the details.
This +38% improvement has been measured by comparison with a PostgreSQL v11.1 code which was built with: XLC -O2 + power9-tuning, plus some changes about inlining for AIX and some fixes dealing with issues with XLC and PostgreSQL #ifdef. Maybe GCC provides better results, we'll know later.
Once we are done with this performance analysis campaign, I'll have to submit patches.
Meanwhile, if anyone has ideas about where the choices made for PostgreSQL on Linux may have an impact to the performance on AIX, I'm very interested!
Regards,
Tony
- Main shared memory segment in sysv_shmem.c
- Dynamic shared memory implementations in src/include/storage/dsm_impl.h :
// #define DEFAULT_DYNAMIC_SHARED_MEMORY_TYPE DSM_IMPL_POSIX
#define DEFAULT_DYNAMIC_SHARED_MEMORY_TYPE DSM_IMPL_SYSV
#endif
- ldedit -btextpsize=64K -bdatapsize=64K -bstackpsize=64K /opt/freeware/bin/postgres_64
- Env variable LDR_CNTRL=SHMPSIZE=64K
Tony Reix
tony.reix@atos.net
ATOS / Bull SAS
ATOS Expert
IBM Coop Architect & Technical Leader
Attachment
On Sat, Nov 24, 2018 at 4:54 AM REIX, Tony <tony.reix@atos.net> wrote: > Here is a patch for enabling SystemV Shared Memory on AIX, for 64K or bigger page size, rather than using MMAP shared memory,which is slower on AIX. > We have tested this code with 64K pages and pgbench, on AIX 7.2 TL2 Power 9, and it provided a maximum of +37% improvement. You also mentioned changing from XLC to GCC. Did you test the various changes in isolation? XLC->GCC, mmap->shmget, with/without SHM_LGPAGE. 37% is a bigger performance change than I expected from large pages, since reports from other architectures are single-digit percentage increases with pgbench -S. If just changing to GCC gives you a big speed-up, it could of course just be different/better code generation (though that'd be a bit sad for XLC), but I also wonder if the different atomics support in our tree could be implicated. > We'll test this code with Large Pages (SHM_LGPAGE | SHM_PIN | S_IRUSR | S_IWUSR flags of shmget() ) ASAP. > > > However, I wanted first to get your comments about this change in order to improve it for acceptance. I think we should respect the huge_pages GUC, as we do on Linux and Windows (since there are downsides to using large pages, maybe not everyone would want that). It could even be useful to allow different page sizes to be requested by GUC (I see that DB2 has an option to use 16GB pages -- yikes). It also seems like a good idea to have a shared_memory_type GUC as Andres proposed (see his link), instead of using a compile time option. I guess it was made a compile time option because nobody could imagine wanting to go back to SysV shm! (I'm still kinda surprised that MAP_ANONYMOUS memory can't be coaxed into large pages by environment variables or loader controls, since apparently other things like data segments etc apparently can, though I can't find any text that says that's the case and I have no AIX system). -- Thomas Munro http://www.enterprisedb.com
Hi Thomas,
About reliability, I've compiled/tested with GCC/XLCC on 2 machines in order to check that my patches are OK (no impact to PostgreSQL tests, OK both with GCC & XLC).
We do not have yet performance comparison between GCC & XLC since, though we experimented with both, we moved from v11beta1 to beta4 to 11.0 and now with 11.1 . We'll do asap.
About performance, we have deeply compared MMAP (4KB) vs SysV (64KB) Shared Memory, for dynamic and main shared memory segments, with the SAME exact HW + SW environment, using XLC -O2 + tune=pwr9.
We have not yet experimented with Large Pages (16MB), however the flags added to the 3rd parameter of shmget() are said to have no impact to performance unless Large Pages are really used.
Same with Huge Pages (16GB). We'll study this later.
So, the +37% (maximum value seen. +29% in average) improvement is the result of the single change: MMAP 4K to SysV 64K.
(this improvement is due to 2 things: mmap on AIX has perf drawbacks vs Sys V ShMem, and 64K vs 4K).
That's for 64bit only, on AIX 7.2 only. About 32bit, we do not have done measures.
We'll have to discuss in more depth your last paragraph how to handle this not only for AIX in PostgreSQL code.
Regards,
Tony Reix
tony.reix@atos.net
ATOS / Bull SAS
ATOS Expert
IBM Coop Architect & Technical Leader
Envoyé : vendredi 23 novembre 2018 22:07:23
À : REIX, Tony
Cc : Andres Freund; Robert Haas; Pg Hackers; EMPEREUR-MOT, SYLVIE; BERGAMINI, DAMIEN
Objet : Re: Shared Memory: How to use SYSV rather than MMAP ?
> Here is a patch for enabling SystemV Shared Memory on AIX, for 64K or bigger page size, rather than using MMAP shared memory, which is slower on AIX.
> We have tested this code with 64K pages and pgbench, on AIX 7.2 TL2 Power 9, and it provided a maximum of +37% improvement.
You also mentioned changing from XLC to GCC. Did you test the various
changes in isolation? XLC->GCC, mmap->shmget, with/without
SHM_LGPAGE. 37% is a bigger performance change than I expected from
large pages, since reports from other architectures are single-digit
percentage increases with pgbench -S.
If just changing to GCC gives you a big speed-up, it could of course
just be different/better code generation (though that'd be a bit sad
for XLC), but I also wonder if the different atomics support in our
tree could be implicated.
> We'll test this code with Large Pages (SHM_LGPAGE | SHM_PIN | S_IRUSR | S_IWUSR flags of shmget() ) ASAP.
>
>
> However, I wanted first to get your comments about this change in order to improve it for acceptance.
I think we should respect the huge_pages GUC, as we do on Linux and
Windows (since there are downsides to using large pages, maybe not
everyone would want that). It could even be useful to allow different
page sizes to be requested by GUC (I see that DB2 has an option to use
16GB pages -- yikes). It also seems like a good idea to have a
shared_memory_type GUC as Andres proposed (see his link), instead of
using a compile time option. I guess it was made a compile time
option because nobody could imagine wanting to go back to SysV shm!
(I'm still kinda surprised that MAP_ANONYMOUS memory can't be coaxed
into large pages by environment variables or loader controls, since
apparently other things like data segments etc apparently can, though
I can't find any text that says that's the case and I have no AIX
system).
--
Thomas Munro
https://emea01.safelinks.protection.outlook.com/?url=http%3A%2F%2Fwww.enterprisedb.com&data=01%7C01%7Ctony.reix%40atos.net%7C1e06667e1d304905267c08d65187c41e%7C33440fc6b7c7412cbb730e70b0198d5a%7C0&sdata=%2Feor3O4UXCcXlLrJWXQS8HWpfa77b86HCYQ3Ot24Vzk%3D&reserved=0
Hi Thomas,
You said:
Windows (since there are downsides to using large pages, maybe not
everyone would want that). It could even be useful to allow different
page sizes to be requested by GUC (I see that DB2 has an option to use
16GB pages -- yikes). It also seems like a good idea to have a
shared_memory_type GUC as Andres proposed (see his link), instead of
using a compile time option. I guess it was made a compile time
option because nobody could imagine wanting to go back to SysV shm!
(I'm still kinda surprised that MAP_ANONYMOUS memory can't be coaxed
into large pages by environment variables or loader controls, since
apparently other things like data segments etc apparently can, though
I can't find any text that says that's the case and I have no AIX
system).
I guess that you are talking about CPP & C variables:
HUGE_PAGES_ON
HUGE_PAGES_TRY)
For now, these variables for Huge Pages are used only for MMAP.
About SysV shared memory, as far as I know, shmget() options for AIX and Linux are different.
Moreover, AIX also provides Large Pages (16MB).
About Andres proposal, I've read his link. However, the patch he proposed: is no more available (Attachment not found).
I confirm that I got the SysV Shared Memory by means of a "compile time option".
About "still kinda surprised that MAP_ANONYMOUS memory can't be coaxed
into large pages by environment variables or loader controls" I confirm that,
on AIX, only 4K pages are available for mmap().
I do agree that options in the postgresql.conf file would be the best solution,
since the code for SysV shared memory and MMAP shared memory seems always present.
Regards,
Tony
Hi Thomas,
Here is the patch we are using now on AIX for enabling SysV shm for AIX, which improves greatly the performance on AIX.
It is compile time.
It seems to me that you'd like this to become a shared_memory_type GUC. Correct? However, I do not know how to do.
Even as-is, this patch would greatly improve the performance of PostgreSQL v11.1 in the field on AIX machines. So, we'd like this change to be available for AIX asap.
What are the next steps to get this patch accepted? or What are your suggestions for improving it?
Thanks/Regards
Tony Reix
tony.reix@atos.net
ATOS / Bull SAS
ATOS Expert
IBM Coop Architect & Technical Leader
Envoyé : lundi 26 novembre 2018 18:00:15
À : Thomas Munro
Cc : Andres Freund; Robert Haas; Pg Hackers; EMPEREUR-MOT, SYLVIE; BERGAMINI, DAMIEN
Objet : RE: Shared Memory: How to use SYSV rather than MMAP ?
Hi Thomas,
You said:
Windows (since there are downsides to using large pages, maybe not
everyone would want that). It could even be useful to allow different
page sizes to be requested by GUC (I see that DB2 has an option to use
16GB pages -- yikes). It also seems like a good idea to have a
shared_memory_type GUC as Andres proposed (see his link), instead of
using a compile time option. I guess it was made a compile time
option because nobody could imagine wanting to go back to SysV shm!
(I'm still kinda surprised that MAP_ANONYMOUS memory can't be coaxed
into large pages by environment variables or loader controls, since
apparently other things like data segments etc apparently can, though
I can't find any text that says that's the case and I have no AIX
system).
I guess that you are talking about CPP & C variables:
HUGE_PAGES_ON
HUGE_PAGES_TRY)
For now, these variables for Huge Pages are used only for MMAP.
About SysV shared memory, as far as I know, shmget() options for AIX and Linux are different.
Moreover, AIX also provides Large Pages (16MB).
About Andres proposal, I've read his link. However, the patch he proposed: is no more available (Attachment not found).
I confirm that I got the SysV Shared Memory by means of a "compile time option".
About "still kinda surprised that MAP_ANONYMOUS memory can't be coaxed
into large pages by environment variables or loader controls" I confirm that,
on AIX, only 4K pages are available for mmap().
I do agree that options in the postgresql.conf file would be the best solution,
since the code for SysV shared memory and MMAP shared memory seems always present.
Regards,
Tony
Attachment
On Wed, Dec 19, 2018 at 4:17 AM REIX, Tony <tony.reix@atos.net> wrote: > Here is the patch we are using now on AIX for enabling SysV shm for AIX, which improves greatly the performance on AIX. > > It is compile time. > > It seems to me that you'd like this to become a shared_memory_type GUC. Correct? However, I do not know how to do. > > > Even as-is, this patch would greatly improve the performance of PostgreSQL v11.1 in the field on AIX machines. So, we'dlike this change to be available for AIX asap. > > > What are the next steps to get this patch accepted? or What are your suggestions for improving it? Hi Tony, Since it's not fixing a bug, we wouldn't back-patch that into existing releases. But I agree that we should do something like this for PostgreSQL 12, and I think we should make it user configurable. Here is a quick rebase of Andres's shared_memory_type patch for master, so that you can put shared_memory_type=sysv in postgresql.conf to get the old pre-9.3 behaviour (this may also be useful for other operating systems). Here also is a "blind" patch that makes it respect huge_pages=try/on on AIX (or at least, I think it does; I don't have an AIX to try it, it almost certainly needs some adjustments). Thoughts? -- Thomas Munro http://www.enterprisedb.com
Attachment
Thomas Munro <thomas.munro@enterprisedb.com> writes:
> Since it's not fixing a bug, we wouldn't back-patch that into existing
> releases. But I agree that we should do something like this for
> PostgreSQL 12, and I think we should make it user configurable.
I'm -1 on making this user configurable via a GUC; that adds documentation
and compatibility burdens that we don't need, for something of no value
to 99.99% of users. The fact that the default would need to be
platform-dependent just makes that tradeoff even worse. I think the other
0.01% who need to change the default (and are bright enough to be doing
the right thing for the right reasons) could certainly handle something
like a pg_config_manual.h control symbol --- see USE_PPC_LWARX_MUTEX_HINT
for a precedent that I think applies well here. So I'd favor just doing
it that way.
regards, tom lane
On Wed, Dec 26, 2018 at 11:43 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Thomas Munro <thomas.munro@enterprisedb.com> writes: > > Since it's not fixing a bug, we wouldn't back-patch that into existing > > releases. But I agree that we should do something like this for > > PostgreSQL 12, and I think we should make it user configurable. > > I'm -1 on making this user configurable via a GUC; that adds documentation > and compatibility burdens that we don't need, for something of no value > to 99.99% of users. The fact that the default would need to be > platform-dependent just makes that tradeoff even worse. I think the other > 0.01% who need to change the default (and are bright enough to be doing > the right thing for the right reasons) could certainly handle something > like a pg_config_manual.h control symbol --- see USE_PPC_LWARX_MUTEX_HINT > for a precedent that I think applies well here. So I'd favor just doing > it that way. I disagree. I think there is a growing body of evidence that b0fc0df9364d2d2d17c0162cf3b8b59f6cb09f67 killed performance on many types of non-Linux systems. This is the first report I recall about AIX, but there have been previous complaints about some BSD variants. When I was working on developing that commit, I went and tried to find out all of the different ways of getting some shared memory from various operating systems and compared them. Anonymous shared memory allocated via mmap() was the hands-down winner in almost every respect: supported on many systems, no annoying operating system limits, automatic deallocation when the last process exits. It had the disadvantage that it didn't have an equivalent of nattch, which meant that we had to keep a small System V segment around just for that purpose, but otherwise it looked really good. However, I only considered the situation from a functional point of view. I never considered the possibility that the method used to obtain shared memory from the operating system would affect the performance of that shared memory. To my surprise, however, it does, and on multiple operating systems from various parts of the UNIX family tree. If I'd known that at the time, that commit probably would not have gone into the tree in the form that it did. I suspect that there would have been a loud clamor for configurability, and I think I would have agreed. You may be right that this is of no value to a high percentage our users, but I think that's only because a high percentage of our users run Linux or Windows, which happen not to be affected. I'm rather proud, though, of PostgreSQL's long history of trying to be cross-platform. Even if operating systems like AIX or BSD are a small percentage of the overall user base, I think it's totally fair to add a GUC which likely be helpful to a large percentage of those people, and I think the GUC proposed here likely falls into that category. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On December 26, 2018 6:48:31 PM GMT+01:00, Robert Haas <robertmhaas@gmail.com> wrote: >I disagree. I think there is a growing body of evidence that >b0fc0df9364d2d2d17c0162cf3b8b59f6cb09f67 killed performance on many >types of non-Linux systems. This is the first report I recall about >AIX, but there have been previous complaints about some BSD variants. Exactly. I think we should have added this a few years ago. Andres -- Sent from my Android device with K-9 Mail. Please excuse my brevity.
Robert Haas <robertmhaas@gmail.com> writes:
> On Wed, Dec 26, 2018 at 11:43 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> I'm -1 on making this user configurable via a GUC; that adds documentation
>> and compatibility burdens that we don't need, for something of no value
>> to 99.99% of users.
> ...
> You may be right that this is of no value to a high percentage our
> users, but I think that's only because a high percentage of our users
> run Linux or Windows, which happen not to be affected. I'm rather
> proud, though, of PostgreSQL's long history of trying to be
> cross-platform. Even if operating systems like AIX or BSD are a small
> percentage of the overall user base, I think it's totally fair to add
> a GUC which likely be helpful to a large percentage of those people,
> and I think the GUC proposed here likely falls into that category.
You misread what I said. I don't say that we shouldn't fix this;
what I'm saying is we should not do so via a user-configurable knob.
We should be able to auto-configure this and just handle it internally.
I have zero faith in the idea that users would set the knob correctly.
regards, tom lane
On Thu, Dec 27, 2018 at 6:48 AM Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Dec 26, 2018 at 11:43 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Thomas Munro <thomas.munro@enterprisedb.com> writes: > > > Since it's not fixing a bug, we wouldn't back-patch that into existing > > > releases. But I agree that we should do something like this for > > > PostgreSQL 12, and I think we should make it user configurable. > > > > I'm -1 on making this user configurable via a GUC; that adds documentation > > and compatibility burdens that we don't need, for something of no value > > to 99.99% of users. The fact that the default would need to be > > platform-dependent just makes that tradeoff even worse. I think the other > > 0.01% who need to change the default (and are bright enough to be doing > > the right thing for the right reasons) could certainly handle something > > like a pg_config_manual.h control symbol --- see USE_PPC_LWARX_MUTEX_HINT > > for a precedent that I think applies well here. So I'd favor just doing > > it that way. > > I disagree. I think there is a growing body of evidence that > b0fc0df9364d2d2d17c0162cf3b8b59f6cb09f67 killed performance on many > types of non-Linux systems. This is the first report I recall about > AIX, but there have been previous complaints about some BSD variants. FTR, I think the main FreeBSD complaint in a nutshell was: 1. There are/were some lock contention problems on internal VM objects and page tracking structures (pv entries copied for every process sharing a VM object). 2. SysV shmem offers a workaround in the form of sysctl kern.ipc.shm_use_phys which effectively pins all SysV shared memory (so it shows up in procstat -v as "ph" rather than "sw", ie it's not swappable). "Unmanaged pages never require finding all the instances of their mappings, so the associated data structure used to find all mappings (Described in Section 6.13) need not be allocated" (from 6.10 in the D&I of FreeBSD book). 3. Shared anonymous mmap has no way to ask for that. That wasn't all, though; see the PDF I mentioned up-thread. I'm hoping to learn more about this subject, hence my interest in reviving that patch. So far I can't reproduce the effect here, probably due to lack of cores and probably also various changes that have been made (but not the main ones described in that report, apparently). -- Thomas Munro http://www.enterprisedb.com
On Wed, Dec 26, 2018 at 1:57 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > You misread what I said. I don't say that we shouldn't fix this; > what I'm saying is we should not do so via a user-configurable knob. > We should be able to auto-configure this and just handle it internally. > I have zero faith in the idea that users would set the knob correctly. I don't see how you can auto-configure a performance vs. usability trade-off. Remember, the original reason why we switched away from doing a large System V shared memory allocation is that such allocations tend to fail due to OS limits. People who have those limits set high enough will presumably prefer System V shared memory allocation, while those who do not will prefer anonymous shared memory over failure to start. I guess we could try System V and fall back to anonymous shared memory, but I think that's masterminding. It risks masking a performance problem that the user would like to notice and fix. Also, I doubt whether this is the only reason to have a GUC for this. For instance, I seem to recall that there was some discussion of it possibly being useful to let developers switch back to the all-System-V approach for reasons that I don't recall at the moment, and it even seems possible that somebody might want to use POSIX shared memory so that they can open up the file that gets created and inspect the contents using arbitrary tools. I definitely agree that an average user probably won't have any idea how to configure settings like this, so we will want to think carefully about what the platform defaults should be, but I also think that a GUC-less solution is depriving those users who ARE smart enough to set the GUC the opportunity to choose the value that works best for them. Way back in high school somebody gave me a copy of the Camel book, and it said something along the lines of: A good programming language makes simple things simple and difficult things possible. I thought then, and still think now, that that's a very wise statement, and I think it also applies to tools other than programming languages, like, say, databases. Refusing to add a GUC is just deciding that we don't trust our users with power tools, and that's not a philosophy with which I can agree. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Dec 27, 2018 at 8:59 AM Thomas Munro
<thomas.munro@enterprisedb.com> wrote:
> ... So far I can't reproduce the effect here, probably due to
> lack of cores and probably also various changes that have been made
> (but not the main ones described in that report, apparently).
I decided to blow today's coffee money on a couple of hours on a 40
CPU m4.x10large at the Amazon arcade, running "FreeBSD
12.0-RELEASE-amd64-f5af2713-6d84-41f0-95ea-2eaee78f2af4-ami-03b0f822e17669866.4
(ami-0ec55ef66da2c9765)" on a 20GB SSD with UFS. Some time when there
isn't a commitfest looming I'll try to do some proper testing, but in
a quick and dirty smoke test (-s 600, -S -T 60, shared_buffers=6GB,
for a range of client counts), mmap and sysv were the same, but there
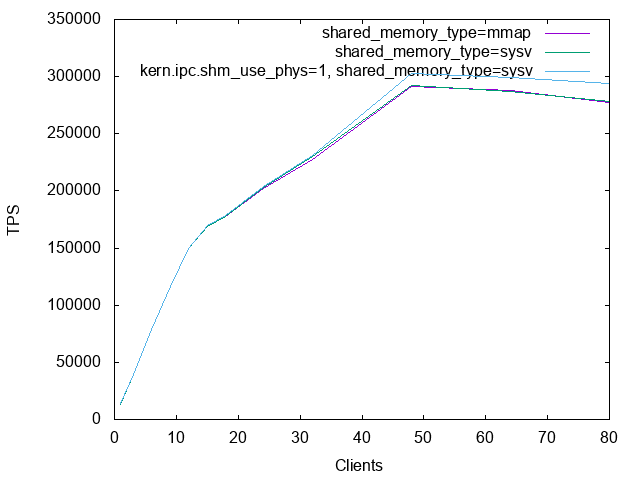
did seem to be a measurable speed-up available at high client counts
with kern.ipc.shm_use_phys=1 and thus for sysv only, for people
prepared to set 3 sysctls and this proposed new GUC. Maybe the effect
would be greater with bigger shared_buffers or smaller pages (this
test ran on super pages)? More work required to figure that out.
Graph attached.
clients mmap sysv sysv+ph
======= ======= ======= =======
1 13341 13277 13600
3 39262 39431 39504
6 78456 78702 78717
9 116281 116356 116349
12 149433 149284 149361
15 169096 169224 169903
18 177632 177774 178177
24 202376 202574 203843
32 227606 229967 231142
48 291641 292431 302510
64 287625 287118 298857
80 277412 278449 293781
--
Thomas Munro
http://www.enterprisedb.com
Attachment
{kind=link}
On Thu, Dec 27, 2018 at 7:25 AM Andres Freund <andres@anarazel.de> wrote: > On December 26, 2018 6:48:31 PM GMT+01:00, Robert Haas <robertmhaas@gmail.com> wrote: > >I disagree. I think there is a growing body of evidence that > >b0fc0df9364d2d2d17c0162cf3b8b59f6cb09f67 killed performance on many > >types of non-Linux systems. This is the first report I recall about > >AIX, but there have been previous complaints about some BSD variants. > > Exactly. I think we should have added this a few years ago. I added a commitfest entry for this. The 0001 patch (shared_memory_type GUC, code written by Andres, with a first swing at documentation by me) seems close to committable, but as Tom pointed out, there is a documentation burden here, and I'm planning to go through and make sure that other relevant sections explain the situation clearly. I don't propose to change the default on any platform. It's a shame that it's still advantageous to use clunky sysv facilities on some systems, but so long as that is the case, it's good to be able to reach that; it's also good to have a reasonable default that doesn't require any sysctl changes, so I think this is a good thing to have as a GUC and mmap should be the default. For the 0002 patch (essentially what Tony asked for, except made to respect the huge_pages GUC by me, untested), I hope Tony or another AIX user will be able to help get this into the right shape. The main idea there is that the default setting huge_pages=try should use large pages if the OS is configured to support that, but otherwise fall back to regular pages (just as we do on Linux and Windows). -- Thomas Munro http://www.enterprisedb.com
On 27/12/2018 00:53, Thomas Munro wrote: > mmap and sysv were the same, but there > did seem to be a measurable speed-up available at high client counts > with kern.ipc.shm_use_phys=1 and thus for sysv only, for people > prepared to set 3 sysctls and this proposed new GUC. Maybe the effect > would be greater with bigger shared_buffers or smaller pages (this > test ran on super pages)? More work required to figure that out. Could you get a similar effect for mmap by using mlock() to prevent the pages from being swapped? -- Peter Eisentraut http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi Thomas,
I'm back from vacations.
Thanks for the 2 patches!
I've seen also the discussion around this subject. Very interesting. Should I wait for a decision been taken? or should I study and experiment your patches before?
I'm now in the process of studying with gprof what Postgres does on AIX compared to Linux/Power, in order to understand where time goes.
Regards,
Tony Reix
tony.reix@atos.net
ATOS / Bull SAS
ATOS Expert
IBM Coop Architect & Technical Leader
Envoyé : mercredi 26 décembre 2018 00:28:54
À : REIX, Tony
Cc : Andres Freund; Robert Haas; Pg Hackers; EMPEREUR-MOT, SYLVIE
Objet : Re: Shared Memory: How to use SYSV rather than MMAP ?
> Here is the patch we are using now on AIX for enabling SysV shm for AIX, which improves greatly the performance on AIX.
>
> It is compile time.
>
> It seems to me that you'd like this to become a shared_memory_type GUC. Correct? However, I do not know how to do.
>
>
> Even as-is, this patch would greatly improve the performance of PostgreSQL v11.1 in the field on AIX machines. So, we'd like this change to be available for AIX asap.
>
>
> What are the next steps to get this patch accepted? or What are your suggestions for improving it?
Hi Tony,
Since it's not fixing a bug, we wouldn't back-patch that into existing
releases. But I agree that we should do something like this for
PostgreSQL 12, and I think we should make it user configurable.
Here is a quick rebase of Andres's shared_memory_type patch for
master, so that you can put shared_memory_type=sysv in postgresql.conf
to get the old pre-9.3 behaviour (this may also be useful for other
operating systems). Here also is a "blind" patch that makes it
respect huge_pages=try/on on AIX (or at least, I think it does; I
don't have an AIX to try it, it almost certainly needs some
adjustments). Thoughts?
--
Thomas Munro
https://emea01.safelinks.protection.outlook.com/?url=http%3A%2F%2Fwww.enterprisedb.com&data=02%7C01%7Ctony.reix%40atos.net%7C554c8fd9266d4fc3674808d66ac0d8cc%7C33440fc6b7c7412cbb730e70b0198d5a%7C0%7C0%7C636813773841365546&sdata=lpXwVIYe5lE2P6lC1fhgqcxsuQG6sVdb5FZ9k3d590U%3D&reserved=0
ATOS WARNING !
This message contains attachments that could potentially harm your computer.
Please make sure you open ONLY attachments from senders you know, trust and is in an e-mail that you are expecting.
AVERTISSEMENT ATOS !
Ce message contient des pièces jointes qui peuvent potentiellement endommager votre ordinateur.
Merci de vous assurer que vous ouvrez uniquement les pièces jointes provenant d’emails que vous attendez et dont vous connaissez les expéditeurs et leur faites confiance.
AVISO DE ATOS !
Este mensaje contiene datos adjuntos que pudiera ser que dañaran su ordenador.
Asegúrese de abrir SOLO datos adjuntos enviados desde remitentes de confianza y que procedan de un correo esperado.
ATOS WARNUNG !
Diese E-Mail enthält Anlagen, welche möglicherweise ihren Computer beschädigen könnten.
Bitte beachten Sie, daß Sie NUR Anlagen öffnen, von einem Absender den Sie kennen, vertrauen und vom dem Sie vor allem auch E-Mails mit Anlagen erwarten.
Bonjour Tony, On Sat, Jan 5, 2019 at 3:35 AM REIX, Tony <tony.reix@atos.net> wrote: > Thanks for the 2 patches! > > I've seen also the discussion around this subject. Very interesting. Should I wait for a decision been taken? or shouldI study and experiment your patches before? I am planning to commit the 0001 patch shortly, unless there are objections. I attach a new version, which improves the documentation a bit (cross-referencing the new GUC and the section on sysctl settings). That will give us shared_memory_type = sysv. Can you please try out the 0002 patch on AIX and see if it works, and if not, tell us how to fix it? :-) The desired behaviour is: 1. If huge_pages = off, it doesn't use them. 2. ff huge_pages = try, it tries to use them, but if it can't (perhaps because the Unix user doesn't have CAP_BYPASS_RAC_VMM capability), it should fall back to non-huge page. 3. If huge_pages = on, it tries to use them, but if it can't it fails to start up. There may also be a case for supporting different page sizes explicitly (huge_pages = 16GB?), but that could be done later. -- Thomas Munro http://www.enterprisedb.com
Attachment
Hi Thomas,
Thanks for the patch !
I've started to work with it. It is now compiling.
Hummmm I have an issue here:
# gmake
/opt/freeware/bin/xmllint --path . --noout --valid postgres.sgml
/opt/freeware/bin/xsltproc --path . --stringparam pg.version '11.1' stylesheet.xsl postgres.sgml
Makefile:135: recipe for target 'html-stamp' failed
gmake: *** [html-stamp] Segmentation fault (core dumped)
That reaches an issue in /opt/freeware/bin/xsltproc , on AIX.
I never had this I think.
That seems to have nothing to do with your patch, however. Investigating.
I'm trying to work-around this.
I'll let you know.
About testing it, I guess that I'll have to add:
huge_pages = on
in the postgresql.conf file. Correct ?
Thanks !
Tony Reix
tony.reix@atos.net
ATOS / Bull SAS
ATOS Expert
IBM Coop Architect & Technical Leader
Envoyé : vendredi 1 février 2019 14:49:01
À : REIX, Tony
Cc : Andres Freund; Robert Haas; Pg Hackers; EMPEREUR-MOT, SYLVIE
Objet : Re: Shared Memory: How to use SYSV rather than MMAP ?
On Sat, Jan 5, 2019 at 3:35 AM REIX, Tony <tony.reix@atos.net> wrote:
> Thanks for the 2 patches!
>
> I've seen also the discussion around this subject. Very interesting. Should I wait for a decision been taken? or should I study and experiment your patches before?
I am planning to commit the 0001 patch shortly, unless there are
objections. I attach a new version, which improves the documentation
a bit (cross-referencing the new GUC and the section on sysctl
settings). That will give us shared_memory_type = sysv.
Can you please try out the 0002 patch on AIX and see if it works, and
if not, tell us how to fix it? :-) The desired behaviour is:
1. If huge_pages = off, it doesn't use them.
2. ff huge_pages = try, it tries to use them, but if it can't
(perhaps because the Unix user doesn't have CAP_BYPASS_RAC_VMM
capability), it should fall back to non-huge page.
3. If huge_pages = on, it tries to use them, but if it can't it fails
to start up.
There may also be a case for supporting different page sizes
explicitly (huge_pages = 16GB?), but that could be done later.
--
Thomas Munro
https://emea01.safelinks.protection.outlook.com/?url=http%3A%2F%2Fwww.enterprisedb.com&data=02%7C01%7Ctony.reix%40atos.net%7C1c903b29b1f04b1f7ae208d6884c2a9a%7C33440fc6b7c7412cbb730e70b0198d5a%7C0%7C0%7C636846258044522047&sdata=GsmfQPlv5hvfesT7gZpthSY5hDc7j5Lp4HsPy6VP9k8%3D&reserved=0
ATOS WARNING !
This message contains attachments that could potentially harm your computer.
Please make sure you open ONLY attachments from senders you know, trust and is in an e-mail that you are expecting.
AVERTISSEMENT ATOS !
Ce message contient des pièces jointes qui peuvent potentiellement endommager votre ordinateur.
Merci de vous assurer que vous ouvrez uniquement les pièces jointes provenant d’emails que vous attendez et dont vous connaissez les expéditeurs et leur faites confiance.
AVISO DE ATOS !
Este mensaje contiene datos adjuntos que pudiera ser que dañaran su ordenador.
Asegúrese de abrir SOLO datos adjuntos enviados desde remitentes de confianza y que procedan de un correo esperado.
ATOS WARNUNG !
Diese E-Mail enthält Anlagen, welche möglicherweise ihren Computer beschädigen könnten.
Bitte beachten Sie, daß Sie NUR Anlagen öffnen, von einem Absender den Sie kennen, vertrauen und vom dem Sie vor allem auch E-Mails mit Anlagen erwarten.
On Sat, Feb 2, 2019 at 2:23 AM REIX, Tony <tony.reix@atos.net> wrote: > Hummmm I have an issue here: > > # cd /home2/freeware/src/packages/BUILD/postgresql-11.1/64bit/doc/src/sgml > # gmake > /opt/freeware/bin/xmllint --path . --noout --valid postgres.sgml > /opt/freeware/bin/xsltproc --path . --stringparam pg.version '11.1' stylesheet.xsl postgres.sgml > Makefile:135: recipe for target 'html-stamp' failed > gmake: *** [html-stamp] Segmentation fault (core dumped) > > That reaches an issue in /opt/freeware/bin/xsltproc , on AIX. > I never had this I think. Strange. By the way, the patches are for master (12-to-be), but I guess they'll work fine on 11.x too. > About testing it, I guess that I'll have to add: > > huge_pages = on > > in the postgresql.conf file. Correct ? Correct. -- Thomas Munro http://www.enterprisedb.com
On Sat, Feb 2, 2019 at 12:49 AM Thomas Munro <thomas.munro@enterprisedb.com> wrote: > I am planning to commit the 0001 patch shortly, unless there are > objections. I attach a new version, which improves the documentation > a bit (cross-referencing the new GUC and the section on sysctl > settings). That will give us shared_memory_type = sysv. Committed 0001. I also tweaked the notes for both FreeBSD and NetBSD where we mention kern.ipc.shm_use_phys to clarify that this refers only to System V shared memory (before this commit, those notes were arguably a bit misleading). I noticed in passing that the comments about jails and System V shared memory are out of date (the key namespace situation changed in FreeBSD 11), but I'll look into that another day. I've moved the CF entry to the next Commitfest, since we still have to fix up and commit the 0002 patch for AIX. -- Thomas Munro http://www.enterprisedb.com
On Sun, Feb 3, 2019 at 10:56 PM Thomas Munro <thomas.munro@enterprisedb.com> wrote: > Committed 0001. > I've moved the CF entry to the next Commitfest, since we still have to > fix up and commit the 0002 patch for AIX. For the record, one problem with the shared_memory_type=sysv patch as committed is that if you set huge_pages=on on Linux, it is allowed but ignored. I think we should respect it by passing SHM_HUGETLB to shmget(), which, although not especially interesting as a feature (given that there is no good reason for Linux users to prefer System V shared memory anyway), it has the advantage that the code path would be nearly identical to the proposed AIX huge page support (just a different flag name), which is useful for development and testing (by those of us with no AIX access). Then the AIX support will be a very tiny patch on top of that, which Tony can verify. -- Thomas Munro http://www.enterprisedb.com
Hi Thomas,
Thanks for your help,
Here are my experiments on the AIX 7.2 machine.
That sounds good !
About "huge", we have plans for AIX. But it is not urgent. Let's go with this patch.
Regards,
Tony
Buffers for SharedMemory PSIZ has been extended by:
ldedit -btextpsize=64k -bdatapsize=64k -bstackpsize=64k /opt/freeware/bin/postgres_64
1) shm: mmap / huge: try
$PGDATA/postgresql.conf :
shared_memory_type = mmap
huge_pages = try
-[ RECORD 1 ]------+-----
shared_memory_type | mmap
-[ RECORD 1 ]--------------+-----
dynamic_shared_memory_type | mmap
-[ RECORD 1 ]---
huge_pages | try
Procmap :
a00000000000000 a00000008dca000 145192K rw- sm SMMAP 8ce86c
+ grep MAIN /tmp/PG.procmap
100000000 10090c883 9266K r-x m MAINTEXT 8a62ea postgres_64
1100009ea 1100f7500 986K rw- m MAINDATA 836822 postgres_64
+ grep SHM /tmp/PG.procmap
a00010000000000 a00010000010000 64K rw- m SHM 81b5e1 shmid:138413056
2) shm: mmap / huge: on
$PGDATA/postgresql.conf :
shared_memory_type = mmap
huge_pages = on
$ pg_ctl start :
FATAL: huge pages not supported on this platform
3) shm: mmap / huge: try
$PGDATA/postgresql.conf :
shared_memory_type = mmap
huge_pages = try
$ pg_ctl start : OK - No message
4) shm: sysv / huge: off
shared_memory_type = sysv
huge_pages = off
-[ RECORD 1 ]------+-----
shared_memory_type | sysv
-[ RECORD 1 ]--------------+-----
dynamic_shared_memory_type | sysv
-[ RECORD 1 ]---
huge_pages | off
Procmap :
+ grep MAIN /tmp/PG.procmap
100000000 10090c883 9266K r-x m MAINTEXT 886229 postgres_64
1100009ea 1100f7500 986K rw- m MAINDATA 8ee2ce postgres_64
+ grep SHM /tmp/PG.procmap
a00000000000000 a00000008dd0000 145216K rw- m SHM 8745c7 shmid:139461632
a00000010000000 a00000010010000 64K rw- m SHM 80b380 shmid:685769729
$ pg_ctl start : OK - No message
5) shm: sysv / huge: on
FATAL: huge pages not supported on this platform
6) shm: sysv / huge: try
PID=` ps -edf | grep /opt/freeware/bin/postgres | grep " 1" | awk '{print $2}'`
procmap -nfX > /tmp/PG.procmap $PID
grep SMMAP /tmp/PG.procmap
grep MAIN /tmp/PG.procmap
grep SHM /tmp/PG.procmap
SHOW shared_memory_type;
SHOW dynamic_shared_memory_type;
SHOW huge_pages;
Tony Reix
tony.reix@atos.net
ATOS / Bull SAS
ATOS Expert
IBM Coop Architect & Technical Leader
Envoyé : jeudi 7 février 2019 03:30
À : REIX, Tony
Cc : EMPEREUR-MOT, SYLVIE
Objet : Re: Shared Memory: How to use SYSV rather than MMAP ?
> I've been able to build/install/test the version 11.1 with your patch, on AIX 7.2 .
>
>
> I've changed the postgresql.conf file we use for our benchmark, and I've checked that, when starting postgres, it reads this file.
>
> However, I'm not sure that it takes into account the values that I have set. Or maybe the "postgres --describe-config" command does not do what I am expecting (print the value of all the parameters set in the postgresql.conf file)?
SHOW shared_memory_type;
SHOW dynamic_shared_memory_type;
Maybe you can also see a difference in the output of "procmap" for a
backend process? I am not sure about that.
--
Thomas Munro
https://emea01.safelinks.protection.outlook.com/?url=http%3A%2F%2Fwww.enterprisedb.com&data=02%7C01%7Ctony.reix%40atos.net%7C1f0898d2c4fe4073023908d68ca45bcc%7C33440fc6b7c7412cbb730e70b0198d5a%7C0%7C0%7C636851034874173812&sdata=Jre8GiJFU%2FobP3K6xsYrV9dOg2nS7%2F7y9J81fDqTwJg%3D&reserved=0
On 2019-Feb-03, Thomas Munro wrote: > On Sat, Feb 2, 2019 at 12:49 AM Thomas Munro > <thomas.munro@enterprisedb.com> wrote: > > I am planning to commit the 0001 patch shortly, unless there are > > objections. I attach a new version, which improves the documentation > > a bit (cross-referencing the new GUC and the section on sysctl > > settings). That will give us shared_memory_type = sysv. > > Committed 0001. So can you please rebase what remains? -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Wed, Sep 4, 2019 at 10:30 AM Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > On 2019-Feb-03, Thomas Munro wrote: > > On Sat, Feb 2, 2019 at 12:49 AM Thomas Munro > > <thomas.munro@enterprisedb.com> wrote: > > > I am planning to commit the 0001 patch shortly, unless there are > > > objections. I attach a new version, which improves the documentation > > > a bit (cross-referencing the new GUC and the section on sysctl > > > settings). That will give us shared_memory_type = sysv. > > > > Committed 0001. > > So can you please rebase what remains? Here's a quick rebase. It needs testing, review and (probably) adjustment from AIX users. I'm not going to be able to do anything with it on my own due to lack of access, though I'm happy to help get this committed eventually. If we don't get any traction in this CF, I'll withdraw this submission for now. For consistency, I think we should eventually also do the same thing for Linux when using sysv (it's pretty similar, it just uses different flag names; it may also be necessary to query the page size and round up the requested size, on one or both of those OSes; I'm not sure). -- Thomas Munro https://enterprisedb.com
Attachment
On 2019-Sep-10, Thomas Munro wrote: > Here's a quick rebase. It needs testing, review and (probably) > adjustment from AIX users. I'm not going to be able to do anything > with it on my own due to lack of access, though I'm happy to help get > this committed eventually. If we don't get any traction in this CF, > I'll withdraw this submission for now. For consistency, I think we > should eventually also do the same thing for Linux when using sysv > (it's pretty similar, it just uses different flag names; it may also > be necessary to query the page size and round up the requested size, > on one or both of those OSes; I'm not sure). Tony, Sylvie, any chance for some testing on this patch? It seems that without that, this patch is going to waste. If I don't hear from anyone on September 30, I'm going to close this as Returned with Feedback. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Envoyé : jeudi 26 septembre 2019 21:22
À : Thomas Munro <thomas.munro@gmail.com>
Cc : REIX, Tony <tony.reix@atos.net>; Andres Freund <andres@anarazel.de>; Robert Haas <robertmhaas@gmail.com>; Pg Hackers <pgsql-hackers@postgresql.org>; EMPEREUR-MOT, SYLVIE <sylvie.empereur-mot@atos.net>
Objet : Re: Shared Memory: How to use SYSV rather than MMAP ?
> Here's a quick rebase. It needs testing, review and (probably)
> adjustment from AIX users. I'm not going to be able to do anything
> with it on my own due to lack of access, though I'm happy to help get
> this committed eventually. If we don't get any traction in this CF,
> I'll withdraw this submission for now. For consistency, I think we
> should eventually also do the same thing for Linux when using sysv
> (it's pretty similar, it just uses different flag names; it may also
> be necessary to query the page size and round up the requested size,
> on one or both of those OSes; I'm not sure).
Tony, Sylvie, any chance for some testing on this patch? It seems that
without that, this patch is going to waste.
If I don't hear from anyone on September 30, I'm going to close this as
Returned with Feedback.
--
Álvaro Herrera https://eur01.safelinks.protection.outlook.com/?url=https%3A%2F%2Fwww.2ndQuadrant.com%2F&data=02%7C01%7Ctony.reix%40atos.net%7C9f484c05852d40cda8cb08d742b6ea15%7C33440fc6b7c7412cbb730e70b0198d5a%7C0%7C0%7C637051225687793704&sdata=bFOxofqr6Rbig8A2pPaz7ZhuGr5GOtJPntuCEQnEdww%3D&reserved=0
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi Tony, On 2019-Sep-27, REIX, Tony wrote: > Hello Thomas, Alvaro, > > Sorry for the late answer, I missed your message of September 10. (I'm working on several different projects in parallel.) > Let me talk with Sylvie ASAP and see when I will be able to test it, probably next week, Tuesday. Is that OK for you? Sure -- I'm inclined to push this patch in state Needs Review to the November commitfest in this case. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Envoyé : vendredi 27 septembre 2019 14:39
À : REIX, Tony <tony.reix@atos.net>
Cc : Thomas Munro <thomas.munro@gmail.com>; Andres Freund <andres@anarazel.de>; Robert Haas <robertmhaas@gmail.com>; Pg Hackers <pgsql-hackers@postgresql.org>; EMPEREUR-MOT, SYLVIE <sylvie.empereur-mot@atos.net>
Objet : Re: Shared Memory: How to use SYSV rather than MMAP ?
On 2019-Sep-27, REIX, Tony wrote:
> Hello Thomas, Alvaro,
>
> Sorry for the late answer, I missed your message of September 10. (I'm working on several different projects in parallel.)
> Let me talk with Sylvie ASAP and see when I will be able to test it, probably next week, Tuesday. Is that OK for you?
Sure -- I'm inclined to push this patch in state Needs Review to the
November commitfest in this case.
--
Álvaro Herrera https://eur01.safelinks.protection.outlook.com/?url=https%3A%2F%2Fwww.2ndQuadrant.com%2F&data=02%7C01%7Ctony.reix%40atos.net%7C1a83e1b688064d2068c808d7434f8ac5%7C33440fc6b7c7412cbb730e70b0198d5a%7C0%7C0%7C637051881216955303&sdata=YwnDQn4%2Finz3eT7clMl7fKK6WEKHtTebqcPbNy4N8ms%3D&reserved=0
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Envoyé : mardi 10 septembre 2019 00:57
À : Alvaro Herrera <alvherre@2ndquadrant.com>
Cc : REIX, Tony <tony.reix@atos.net>; Andres Freund <andres@anarazel.de>; Robert Haas <robertmhaas@gmail.com>; Pg Hackers <pgsql-hackers@postgresql.org>; EMPEREUR-MOT, SYLVIE <sylvie.empereur-mot@atos.net>
Objet : Re: Shared Memory: How to use SYSV rather than MMAP ?
> On 2019-Feb-03, Thomas Munro wrote:
> > On Sat, Feb 2, 2019 at 12:49 AM Thomas Munro
> > <thomas.munro@enterprisedb.com> wrote:
> > > I am planning to commit the 0001 patch shortly, unless there are
> > > objections. I attach a new version, which improves the documentation
> > > a bit (cross-referencing the new GUC and the section on sysctl
> > > settings). That will give us shared_memory_type = sysv.
> >
> > Committed 0001.
>
> So can you please rebase what remains?
Here's a quick rebase. It needs testing, review and (probably)
adjustment from AIX users. I'm not going to be able to do anything
with it on my own due to lack of access, though I'm happy to help get
this committed eventually. If we don't get any traction in this CF,
I'll withdraw this submission for now. For consistency, I think we
should eventually also do the same thing for Linux when using sysv
(it's pretty similar, it just uses different flag names; it may also
be necessary to query the page size and round up the requested size,
on one or both of those OSes; I'm not sure).
--
Thomas Munro
https://eur01.safelinks.protection.outlook.com/?url=https%3A%2F%2Fenterprisedb.com&data=02%7C01%7Ctony.reix%40atos.net%7C1d6794406e304ea3813b08d7357931e2%7C33440fc6b7c7412cbb730e70b0198d5a%7C0%7C0%7C637036666949593490&sdata=8D7VDNLLLs1Aj9XZ8o%2B3YveH6iDQcM3E67AiE66v4f8%3D&reserved=0
ATOS WARNING !
This message contains attachments that could potentially harm your computer.
Please make sure you open ONLY attachments from senders you know, trust and is in an e-mail that you are expecting.
AVERTISSEMENT ATOS !
Ce message contient des pièces jointes qui peuvent potentiellement endommager votre ordinateur.
Merci de vous assurer que vous ouvrez uniquement les pièces jointes provenant d’emails que vous attendez et dont vous connaissez les expéditeurs et leur faites confiance.
AVISO DE ATOS !
Este mensaje contiene datos adjuntos que pudiera ser que dañaran su ordenador.
Asegúrese de abrir SOLO datos adjuntos enviados desde remitentes de confianza y que procedan de un correo esperado.
ATOS WARNUNG !
Diese E-Mail enthält Anlagen, welche möglicherweise ihren Computer beschädigen könnten.
Bitte beachten Sie, daß Sie NUR Anlagen öffnen, von einem Absender den Sie kennen, vertrauen und vom dem Sie vor allem auch E-Mails mit Anlagen erwarten.