Thread: WAL prefetch
There was very interesting presentation at pgconf about pg_prefaulter: http://www.pgcon.org/2018/schedule/events/1204.en.html But it is implemented in GO and using pg_waldump. I tried to do the same but using built-on Postgres WAL traverse functions. I have implemented it as extension for simplicity of integration. In principle it can be started as BG worker. First of all I tried to estimate effect of preloading data. I have implemented prefetch utility with is also attached to this mail. It performs random reads of blocks of some large file and spawns some number of prefetch threads: Just normal read without prefetch: ./prefetch -n 0 SOME_BIG_FILE One prefetch thread which uses pread: ./prefetch SOME_BIG_FILE One prefetch thread which uses posix_fadvise: ./prefetch -f SOME_BIG_FILE 4 prefetch thread which uses posix_fadvise: ./prefetch -f -n 4 SOME_BIG_FILE Based on this experiments (on my desktop), I made the following conclusions: 1. Prefetch at HDD doesn't give any positive effect. 2. Using posix_fadvise allows to speed-up random read speed at SSD up to 2 times. 3. posix_fadvise(WILLNEED) is more efficient than performing normal reads. 4. Calling posix_fadvise in more than one thread has no sense. I have tested wal_prefetch at two powerful servers with 24 cores, 3Tb NVME RAID 10 storage device and 256Gb of RAM connected using InfiniBand. The speed of synchronous replication between two nodes is increased from 56k TPS to 60k TPS (on pgbench with scale 1000). Usage: 1. At master: create extension wal_prefetch 2. At replica: Call pg_wal_prefetch() function: it will not return until you interrupt it. pg_wal_prefetch function will infinitely traverse WAL and prefetch block references in WAL records using posix_fadvise(WILLNEED) system call. It is possible to explicitly specify start LSN for pg_wal_prefetch() function. Otherwise, WAL redo position will be used as start LSN. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On Wed, Jun 13, 2018 at 6:39 PM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > There was very interesting presentation at pgconf about pg_prefaulter: > > http://www.pgcon.org/2018/schedule/events/1204.en.html > > But it is implemented in GO and using pg_waldump. > I tried to do the same but using built-on Postgres WAL traverse functions. > I have implemented it as extension for simplicity of integration. > In principle it can be started as BG worker. > Right or in other words, it could do something like autoprewarm [1] which can allow a more user-friendly interface for this utility if we decides to include it. > First of all I tried to estimate effect of preloading data. > I have implemented prefetch utility with is also attached to this mail. > It performs random reads of blocks of some large file and spawns some number > of prefetch threads: > > Just normal read without prefetch: > ./prefetch -n 0 SOME_BIG_FILE > > One prefetch thread which uses pread: > ./prefetch SOME_BIG_FILE > > One prefetch thread which uses posix_fadvise: > ./prefetch -f SOME_BIG_FILE > > 4 prefetch thread which uses posix_fadvise: > ./prefetch -f -n 4 SOME_BIG_FILE > > Based on this experiments (on my desktop), I made the following conclusions: > > 1. Prefetch at HDD doesn't give any positive effect. > 2. Using posix_fadvise allows to speed-up random read speed at SSD up to 2 > times. > 3. posix_fadvise(WILLNEED) is more efficient than performing normal reads. > 4. Calling posix_fadvise in more than one thread has no sense. > > I have tested wal_prefetch at two powerful servers with 24 cores, 3Tb NVME > RAID 10 storage device and 256Gb of RAM connected using InfiniBand. > The speed of synchronous replication between two nodes is increased from 56k > TPS to 60k TPS (on pgbench with scale 1000). > That's a reasonable improvement. > Usage: > 1. At master: create extension wal_prefetch > 2. At replica: Call pg_wal_prefetch() function: it will not return until you > interrupt it. > I think it is not a very user-friendly interface, but the idea sounds good to me, it can help some other workloads. I think this can help in recovery as well. [1] - https://www.postgresql.org/docs/devel/static/pgprewarm.html -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Thu, Jun 14, 2018 at 1:09 AM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > pg_wal_prefetch function will infinitely traverse WAL and prefetch block > references in WAL records > using posix_fadvise(WILLNEED) system call. Hi Konstantin, Why stop at the page cache... what about shared buffers? -- Thomas Munro http://www.enterprisedb.com
On 14.06.2018 09:52, Thomas Munro wrote: > On Thu, Jun 14, 2018 at 1:09 AM, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: >> pg_wal_prefetch function will infinitely traverse WAL and prefetch block >> references in WAL records >> using posix_fadvise(WILLNEED) system call. > Hi Konstantin, > > Why stop at the page cache... what about shared buffers? > It is good question. I thought a lot about prefetching directly to shared buffers. But the current c'est la vie with Postgres is that allocating too large memory for shared buffers is not recommended. Due to many different reasons: degradation of clock replacement algorithm, "write storm",... If your system has 1Tb of memory, almost none of Postgresql administrators will recommend to use all this 1Tb for shared buffers. Moreover there are recommendations to choose shared buffers size based on size of internal cache of persistent storage device (so that it will be possible to flush changes without doing writes to physical media). So at this system with 1Tb of RAM, size of shared buffers will be most likely set to few hundreds of gigabytes. Also PostgreSQL is not currently supporting dynamic changing of shared buffers size. Without it, the only way of using Postgres in clouds and another multiuser systems where system load is not fully controlled by user is to choose relatively small shared buffer size and rely on OS caching. Yes, access to shared buffer is about two times faster than reading data from file system cache. But it is better, then situation when shared buffers are swapped out and effect of large shared buffers becomes negative. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Wed, Jun 13, 2018 at 11:45 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> I have tested wal_prefetch at two powerful servers with 24 cores, 3Tb NVME >> RAID 10 storage device and 256Gb of RAM connected using InfiniBand. >> The speed of synchronous replication between two nodes is increased from 56k >> TPS to 60k TPS (on pgbench with scale 1000). > > That's a reasonable improvement. Somehow I would have expected more. That's only a 7% speedup. I am also surprised that HDD didn't show any improvement. Since HDD's are bad at random I/O, I would have expected prefetching to help more in that case. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Jun 14, 2018 at 6:14 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Jun 13, 2018 at 11:45 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>> I have tested wal_prefetch at two powerful servers with 24 cores, 3Tb NVME >>> RAID 10 storage device and 256Gb of RAM connected using InfiniBand. >>> The speed of synchronous replication between two nodes is increased from 56k >>> TPS to 60k TPS (on pgbench with scale 1000). >> >> That's a reasonable improvement. > > Somehow I would have expected more. That's only a 7% speedup. > It might be due to the reason that there is already a big overhead of synchronous mode of replication that it didn't show a big speedup. We might want to try recovery (PITR) or maybe async replication to see if we see any better numbers. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 14.06.2018 15:44, Robert Haas wrote: > On Wed, Jun 13, 2018 at 11:45 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>> I have tested wal_prefetch at two powerful servers with 24 cores, 3Tb NVME >>> RAID 10 storage device and 256Gb of RAM connected using InfiniBand. >>> The speed of synchronous replication between two nodes is increased from 56k >>> TPS to 60k TPS (on pgbench with scale 1000). >> That's a reasonable improvement. > Somehow I would have expected more. That's only a 7% speedup. > > I am also surprised that HDD didn't show any improvement. My be pgbench is not the best use case for prefetch. It is updating more or less random pages and if database is large enough and full_page_writes is true (default value) then most pages will be updated only once since last checkpoint and most of updates will be represented in WAL by full page records. And such records do not require reading any data from disk. > Since HDD's > are bad at random I/O, I would have expected prefetching to help more > in that case. > Speed of random HDD access is limited by speed of disk head movement. By running several IO requests in parallel we just increase probability of head movement, so actually parallel access to HDD may even decrease IO speed rather than increase it. In theory, given several concurrent IO requests, driver can execute them in optimal order, trying to minimize head movement. But if there are really access to random pages, then probability that we can win something by such optimization is very small. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Thu, Jun 14, 2018 at 9:23 AM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > Speed of random HDD access is limited by speed of disk head movement. > By running several IO requests in parallel we just increase probability of > head movement, so actually parallel access to HDD may even decrease IO speed > rather than increase it. > In theory, given several concurrent IO requests, driver can execute them in > optimal order, trying to minimize head movement. But if there are really > access to random pages, > then probability that we can win something by such optimization is very > small. You might be right, but I feel like I've heard previous reports of significant speedups from prefetching on HDDs. Perhaps I am mis-remembering. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 14.06.2018 16:25, Robert Haas wrote: > On Thu, Jun 14, 2018 at 9:23 AM, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: >> Speed of random HDD access is limited by speed of disk head movement. >> By running several IO requests in parallel we just increase probability of >> head movement, so actually parallel access to HDD may even decrease IO speed >> rather than increase it. >> In theory, given several concurrent IO requests, driver can execute them in >> optimal order, trying to minimize head movement. But if there are really >> access to random pages, >> then probability that we can win something by such optimization is very >> small. > You might be right, but I feel like I've heard previous reports of > significant speedups from prefetching on HDDs. Perhaps I am > mis-remembering. > It is true for RAIDs of HDD which can really win by issuing parallel IO operations. But there are some many different factors that I will not be surprised by any result:) The last problem I have observed with NVME device at one of the customer's system was huge performance degradation (> 10 times: from 500Mb/sec to 50Mb/sec write speed) after space exhaustion at the device. There is 3Tb NVME RAID device with 1.5Gb database. ext4 was mounted without "discard" option. After incorrect execution of rsync, space was exhausted. Then I removed all data and copied database from master node. Then I observed huge lags in async. replication between master and replica. wal_receiver is saving received data too slowly: write speed is about ~50Mb/sec vs. 0.5Gb at master. All my attempts to use fstrim or ex4defrag didn't help. The problem was solved only after deleting all database files, performing fstrim and copying database once again. After it wal_sender is writing data with normal speed ~0.5Gb and there is no lag between master and replica. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Greetings, * Konstantin Knizhnik (k.knizhnik@postgrespro.ru) wrote: > There was very interesting presentation at pgconf about pg_prefaulter: > > http://www.pgcon.org/2018/schedule/events/1204.en.html I agree and I've chatted a bit w/ Sean further about it. > But it is implemented in GO and using pg_waldump. Yeah, that's not too good if we want it in core. > I tried to do the same but using built-on Postgres WAL traverse functions. > I have implemented it as extension for simplicity of integration. > In principle it can be started as BG worker. I don't think this needs to be, or should be, an extension.. If this is worthwhile (and it certainly appears to be) then we should just do it in core. > First of all I tried to estimate effect of preloading data. > I have implemented prefetch utility with is also attached to this mail. > It performs random reads of blocks of some large file and spawns some number > of prefetch threads: > > Just normal read without prefetch: > ./prefetch -n 0 SOME_BIG_FILE > > One prefetch thread which uses pread: > ./prefetch SOME_BIG_FILE > > One prefetch thread which uses posix_fadvise: > ./prefetch -f SOME_BIG_FILE > > 4 prefetch thread which uses posix_fadvise: > ./prefetch -f -n 4 SOME_BIG_FILE > > Based on this experiments (on my desktop), I made the following conclusions: > > 1. Prefetch at HDD doesn't give any positive effect. > 2. Using posix_fadvise allows to speed-up random read speed at SSD up to 2 > times. > 3. posix_fadvise(WILLNEED) is more efficient than performing normal reads. > 4. Calling posix_fadvise in more than one thread has no sense. Ok. > I have tested wal_prefetch at two powerful servers with 24 cores, 3Tb NVME > RAID 10 storage device and 256Gb of RAM connected using InfiniBand. > The speed of synchronous replication between two nodes is increased from 56k > TPS to 60k TPS (on pgbench with scale 1000). I'm also surprised that it wasn't a larger improvement. Seems like it would make sense to implement in core using posix_fadvise(), perhaps in the wal receiver and in RestoreArchivedFile or nearby.. At least, that's the thinking I had when I was chatting w/ Sean. Thanks! Stephen
Attachment
On Fri, Jun 15, 2018 at 12:16 AM, Stephen Frost <sfrost@snowman.net> wrote: > >> I have tested wal_prefetch at two powerful servers with 24 cores, 3Tb NVME >> RAID 10 storage device and 256Gb of RAM connected using InfiniBand. >> The speed of synchronous replication between two nodes is increased from 56k >> TPS to 60k TPS (on pgbench with scale 1000). > > I'm also surprised that it wasn't a larger improvement. > > Seems like it would make sense to implement in core using > posix_fadvise(), perhaps in the wal receiver and in RestoreArchivedFile > or nearby.. At least, that's the thinking I had when I was chatting w/ > Sean. > Doing in-core certainly has some advantage such as it can easily reuse the existing xlog code rather trying to make a copy as is currently done in the patch, but I think it also depends on whether this is really a win in a number of common cases or is it just a win in some limited cases. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 15.06.2018 07:36, Amit Kapila wrote: > On Fri, Jun 15, 2018 at 12:16 AM, Stephen Frost <sfrost@snowman.net> wrote: >>> I have tested wal_prefetch at two powerful servers with 24 cores, 3Tb NVME >>> RAID 10 storage device and 256Gb of RAM connected using InfiniBand. >>> The speed of synchronous replication between two nodes is increased from 56k >>> TPS to 60k TPS (on pgbench with scale 1000). >> I'm also surprised that it wasn't a larger improvement. >> >> Seems like it would make sense to implement in core using >> posix_fadvise(), perhaps in the wal receiver and in RestoreArchivedFile >> or nearby.. At least, that's the thinking I had when I was chatting w/ >> Sean. >> > Doing in-core certainly has some advantage such as it can easily reuse > the existing xlog code rather trying to make a copy as is currently > done in the patch, but I think it also depends on whether this is > really a win in a number of common cases or is it just a win in some > limited cases. > I am completely agree. It was my mail concern: on which use cases this prefetch will be efficient. If "full_page_writes" is on (and it is safe and default value), then first update of a page since last checkpoint will be written in WAL as full page and applying it will not require reading any data from disk. If this pages is updated multiple times in subsequent transactions, then most likely it will be still present in OS file cache, unless checkpoint interval exceeds OS cache size (amount of free memory in the system). So if this conditions are satisfied then looks like prefetch is not needed. And it seems to be true for most real configurations: checkpoint interval is rarely set larger than hundred of gigabytes and modern servers usually have more RAM. But once this condition is not satisfied and lag is larger than size of OS cache, then prefetch can be not efficient because prefetched pages may be thrown away from OS cache before them are actually accessed by redo process. In this case extra synchronization between prefetch and replay processes is needed so that prefetch is not moving too far away from replayed LSN. It is not a problem to integrate this code in Postgres core and run it in background worker. I do not think that performing prefetch in wal receiver process itself is good idea: it may slow down speed of receiving changes from master. And in this case I really can throw away cut&pasted code. But it is easier to experiment with extension rather than with patch to Postgres core. And I have published this extension to make it possible to perform experiments and check whether it is useful on real workloads. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Fri, Jun 15, 2018 at 1:08 PM, Konstantin Knizhnik
<k.knizhnik@postgrespro.ru> wrote:
>
>
> On 15.06.2018 07:36, Amit Kapila wrote:
>>
>> On Fri, Jun 15, 2018 at 12:16 AM, Stephen Frost <sfrost@snowman.net>
>> wrote:
>>>>
>>>> I have tested wal_prefetch at two powerful servers with 24 cores, 3Tb
>>>> NVME
>>>> RAID 10 storage device and 256Gb of RAM connected using InfiniBand.
>>>> The speed of synchronous replication between two nodes is increased from
>>>> 56k
>>>> TPS to 60k TPS (on pgbench with scale 1000).
>>>
>>> I'm also surprised that it wasn't a larger improvement.
>>>
>>> Seems like it would make sense to implement in core using
>>> posix_fadvise(), perhaps in the wal receiver and in RestoreArchivedFile
>>> or nearby.. At least, that's the thinking I had when I was chatting w/
>>> Sean.
>>>
>> Doing in-core certainly has some advantage such as it can easily reuse
>> the existing xlog code rather trying to make a copy as is currently
>> done in the patch, but I think it also depends on whether this is
>> really a win in a number of common cases or is it just a win in some
>> limited cases.
>>
> I am completely agree. It was my mail concern: on which use cases this
> prefetch will be efficient.
> If "full_page_writes" is on (and it is safe and default value), then first
> update of a page since last checkpoint will be written in WAL as full page
> and applying it will not require reading any data from disk.
>
What exactly you mean by above? AFAIU, it needs to read WAL to apply
full page image. See below code:
XLogReadBufferForRedoExtended()
{
..
/* If it has a full-page image and it should be restored, do it. */
if (XLogRecBlockImageApply(record, block_id))
{
Assert(XLogRecHasBlockImage(record, block_id));
*buf = XLogReadBufferExtended(rnode, forknum, blkno,
get_cleanup_lock ? RBM_ZERO_AND_CLEANUP_LOCK : RBM_ZERO_AND_LOCK);
page = BufferGetPage(*buf);
if (!RestoreBlockImage(record, block_id, page))
..
}
--
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
On 15.06.2018 18:03, Amit Kapila wrote:
> On Fri, Jun 15, 2018 at 1:08 PM, Konstantin Knizhnik
> <k.knizhnik@postgrespro.ru> wrote:
>>
>> On 15.06.2018 07:36, Amit Kapila wrote:
>>> On Fri, Jun 15, 2018 at 12:16 AM, Stephen Frost <sfrost@snowman.net>
>>> wrote:
>>>>> I have tested wal_prefetch at two powerful servers with 24 cores, 3Tb
>>>>> NVME
>>>>> RAID 10 storage device and 256Gb of RAM connected using InfiniBand.
>>>>> The speed of synchronous replication between two nodes is increased from
>>>>> 56k
>>>>> TPS to 60k TPS (on pgbench with scale 1000).
>>>> I'm also surprised that it wasn't a larger improvement.
>>>>
>>>> Seems like it would make sense to implement in core using
>>>> posix_fadvise(), perhaps in the wal receiver and in RestoreArchivedFile
>>>> or nearby.. At least, that's the thinking I had when I was chatting w/
>>>> Sean.
>>>>
>>> Doing in-core certainly has some advantage such as it can easily reuse
>>> the existing xlog code rather trying to make a copy as is currently
>>> done in the patch, but I think it also depends on whether this is
>>> really a win in a number of common cases or is it just a win in some
>>> limited cases.
>>>
>> I am completely agree. It was my mail concern: on which use cases this
>> prefetch will be efficient.
>> If "full_page_writes" is on (and it is safe and default value), then first
>> update of a page since last checkpoint will be written in WAL as full page
>> and applying it will not require reading any data from disk.
>>
> What exactly you mean by above? AFAIU, it needs to read WAL to apply
> full page image. See below code:
>
> XLogReadBufferForRedoExtended()
> {
> ..
> /* If it has a full-page image and it should be restored, do it. */
> if (XLogRecBlockImageApply(record, block_id))
> {
> Assert(XLogRecHasBlockImage(record, block_id));
> *buf = XLogReadBufferExtended(rnode, forknum, blkno,
> get_cleanup_lock ? RBM_ZERO_AND_CLEANUP_LOCK : RBM_ZERO_AND_LOCK);
> page = BufferGetPage(*buf);
> if (!RestoreBlockImage(record, block_id, page))
> ..
> }
>
>
Sorry, for my confusing statement.
Definitely we need to read page from WAL.
I mean that in case of "full page write" we do not need to read updated
page from the database.
It can be just overwritten.
pg_prefaulter and my wal_prefetch are not prefetching WAL pages themselves.
There is no sense to do it, because them are just written by
wal_receiver and so should be present in file system cache.
wal_prefetch is prefetching blocks referenced by WAL records. But in
case of "full page writes" such prefetch is not needed and even is harmful.
--
Konstantin Knizhnik
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 2018-06-14 10:13:44 +0300, Konstantin Knizhnik wrote: > > > On 14.06.2018 09:52, Thomas Munro wrote: > > On Thu, Jun 14, 2018 at 1:09 AM, Konstantin Knizhnik > > <k.knizhnik@postgrespro.ru> wrote: > > > pg_wal_prefetch function will infinitely traverse WAL and prefetch block > > > references in WAL records > > > using posix_fadvise(WILLNEED) system call. > > Hi Konstantin, > > > > Why stop at the page cache... what about shared buffers? > > > > It is good question. I thought a lot about prefetching directly to shared > buffers. I think that's definitely how this should work. I'm pretty strongly opposed to a prefetching implementation that doesn't read into s_b. > But the current c'est la vie with Postgres is that allocating too large > memory for shared buffers is not recommended. > Due to many different reasons: degradation of clock replacement algorithm, > "write storm",... I think a lot of that fear is overplayed. And we've fixed a number of issues. We don't really generate write storms in the default config anymore in most scenarios, and if it's an issue you can turn on backend_flush_after. > If your system has 1Tb of memory, almost none of Postgresql administrators > will recommend to use all this 1Tb for shared buffers. I've used 1TB successfully. > Also PostgreSQL is not currently supporting dynamic changing of shared > buffers size. Without it, the only way of using Postgres in clouds and > another multiuser systems where system load is not fully controlled by user > is to choose relatively small shared buffer size and rely on OS caching. That seems largely unrelated to the replay case, because there the data will be read into shared buffers anyway. And it'll be dirtied therein. Greetings, Andres Freund
On Fri, Jun 15, 2018 at 8:45 PM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > On 15.06.2018 18:03, Amit Kapila wrote: > > wal_prefetch is prefetching blocks referenced by WAL records. But in case of > "full page writes" such prefetch is not needed and even is harmful. > Okay, IIUC, the basic idea is to prefetch recently modified data pages, so that they can be referenced. If so, isn't there some overlap with autoprewarm functionality which dumps recently modified blocks and then on recovery, it can prefetch those? -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Fri, Jun 15, 2018 at 11:31 PM, Andres Freund <andres@anarazel.de> wrote: > On 2018-06-14 10:13:44 +0300, Konstantin Knizhnik wrote: >> >> >> On 14.06.2018 09:52, Thomas Munro wrote: >> > On Thu, Jun 14, 2018 at 1:09 AM, Konstantin Knizhnik >> > <k.knizhnik@postgrespro.ru> wrote: >> > > pg_wal_prefetch function will infinitely traverse WAL and prefetch block >> > > references in WAL records >> > > using posix_fadvise(WILLNEED) system call. >> > Hi Konstantin, >> > >> > Why stop at the page cache... what about shared buffers? >> > >> >> It is good question. I thought a lot about prefetching directly to shared >> buffers. > > I think that's definitely how this should work. I'm pretty strongly > opposed to a prefetching implementation that doesn't read into s_b. > We can think of supporting two modes (a) allows to read into shared buffers or (b) allows to read into OS page cache. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 16.06.2018 06:30, Amit Kapila wrote: > On Fri, Jun 15, 2018 at 8:45 PM, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: >> On 15.06.2018 18:03, Amit Kapila wrote: >> >> wal_prefetch is prefetching blocks referenced by WAL records. But in case of >> "full page writes" such prefetch is not needed and even is harmful. >> > Okay, IIUC, the basic idea is to prefetch recently modified data > pages, so that they can be referenced. If so, isn't there some > overlap with autoprewarm functionality which dumps recently modified > blocks and then on recovery, it can prefetch those? > Sorry, I do not see any intersection with autoprewarw functionality: wal prefetch is performed at replica where data was not yet modified: actually the goal of WAL prefetch is to make this update more efficient. WAL prefetch can be also done at standalone server to speed up recovery after crash. But it seems to be much more exotic use case.
On 16.06.2018 06:33, Amit Kapila wrote: > On Fri, Jun 15, 2018 at 11:31 PM, Andres Freund <andres@anarazel.de> wrote: >> On 2018-06-14 10:13:44 +0300, Konstantin Knizhnik wrote: >>> >>> On 14.06.2018 09:52, Thomas Munro wrote: >>>> On Thu, Jun 14, 2018 at 1:09 AM, Konstantin Knizhnik >>>> <k.knizhnik@postgrespro.ru> wrote: >>>>> pg_wal_prefetch function will infinitely traverse WAL and prefetch block >>>>> references in WAL records >>>>> using posix_fadvise(WILLNEED) system call. >>>> Hi Konstantin, >>>> >>>> Why stop at the page cache... what about shared buffers? >>>> >>> It is good question. I thought a lot about prefetching directly to shared >>> buffers. >> I think that's definitely how this should work. I'm pretty strongly >> opposed to a prefetching implementation that doesn't read into s_b. >> > We can think of supporting two modes (a) allows to read into shared > buffers or (b) allows to read into OS page cache. > Unfortunately I afraid that a) requires different approach: unlike posix_fadvise, reading data to shared buffer is blocking operation. If we do it by one worker, then it will read it with the same speed as redo process. So to make prefetch really efficient, in this case we have to spawn multiple workers to perform prefetch in parallel (as pg_prefaulter does). Another my concern against prefetching to shared buffers is that it may flush away from cache pages which are most frequently used by read only queries at hot standby replica.
On Sat, Jun 16, 2018 at 10:47 AM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > > On 16.06.2018 06:33, Amit Kapila wrote: >> >> On Fri, Jun 15, 2018 at 11:31 PM, Andres Freund <andres@anarazel.de> >> wrote: >>> >>> On 2018-06-14 10:13:44 +0300, Konstantin Knizhnik wrote: >>>> >>>> >>>> On 14.06.2018 09:52, Thomas Munro wrote: >>>>> >>>>> On Thu, Jun 14, 2018 at 1:09 AM, Konstantin Knizhnik >>>>> <k.knizhnik@postgrespro.ru> wrote: >>>>>> >>>>>> pg_wal_prefetch function will infinitely traverse WAL and prefetch >>>>>> block >>>>>> references in WAL records >>>>>> using posix_fadvise(WILLNEED) system call. >>>>> >>>>> Hi Konstantin, >>>>> >>>>> Why stop at the page cache... what about shared buffers? >>>>> >>>> It is good question. I thought a lot about prefetching directly to >>>> shared >>>> buffers. >>> >>> I think that's definitely how this should work. I'm pretty strongly >>> opposed to a prefetching implementation that doesn't read into s_b. >>> >> We can think of supporting two modes (a) allows to read into shared >> buffers or (b) allows to read into OS page cache. >> > Unfortunately I afraid that a) requires different approach: unlike > posix_fadvise, reading data to shared buffer is blocking operation. If we > do it by one worker, then it will read it with the same speed as redo > process. So to make prefetch really efficient, in this case we have to > spawn multiple workers to perform prefetch in parallel (as pg_prefaulter > does). > > Another my concern against prefetching to shared buffers is that it may > flush away from cache pages which are most frequently used by read only > queries at hot standby replica. > Okay, but I am suggesting to make it optional so that it can be enabled when helpful (say when the user has enough shared buffers to hold the data). -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 06/15/2018 08:01 PM, Andres Freund wrote: > On 2018-06-14 10:13:44 +0300, Konstantin Knizhnik wrote: >> >> >> On 14.06.2018 09:52, Thomas Munro wrote: >>> On Thu, Jun 14, 2018 at 1:09 AM, Konstantin Knizhnik >>> <k.knizhnik@postgrespro.ru> wrote: >>>> pg_wal_prefetch function will infinitely traverse WAL and prefetch block >>>> references in WAL records >>>> using posix_fadvise(WILLNEED) system call. >>> Hi Konstantin, >>> >>> Why stop at the page cache... what about shared buffers? >>> >> >> It is good question. I thought a lot about prefetching directly to shared >> buffers. > > I think that's definitely how this should work. I'm pretty strongly > opposed to a prefetching implementation that doesn't read into s_b. > Could you elaborate why prefetching into s_b is so much better (I'm sure it has advantages, but I suppose prefetching into page cache would be much easier to implement). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sat, Jun 16, 2018 at 9:38 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote: > On 06/15/2018 08:01 PM, Andres Freund wrote: >> On 2018-06-14 10:13:44 +0300, Konstantin Knizhnik wrote: >>> On 14.06.2018 09:52, Thomas Munro wrote: >>>> Why stop at the page cache... what about shared buffers? >>> >>> It is good question. I thought a lot about prefetching directly to shared >>> buffers. >> >> I think that's definitely how this should work. I'm pretty strongly >> opposed to a prefetching implementation that doesn't read into s_b. > > Could you elaborate why prefetching into s_b is so much better (I'm sure it has advantages, but I suppose prefetching intopage cache would be much easier to implement). posix_fadvise(POSIX_FADV_WILLNEED) might already get most of the speed-up available here in the short term for this immediate application, but in the long term a shared buffers prefetch system is one of the components we'll need to support direct IO. -- Thomas Munro http://www.enterprisedb.com
On 06/16/2018 12:06 PM, Thomas Munro wrote: > On Sat, Jun 16, 2018 at 9:38 PM, Tomas Vondra > <tomas.vondra@2ndquadrant.com> wrote: >> On 06/15/2018 08:01 PM, Andres Freund wrote: >>> On 2018-06-14 10:13:44 +0300, Konstantin Knizhnik wrote: >>>> On 14.06.2018 09:52, Thomas Munro wrote: >>>>> Why stop at the page cache... what about shared buffers? >>>> >>>> It is good question. I thought a lot about prefetching directly to shared >>>> buffers. >>> >>> I think that's definitely how this should work. I'm pretty strongly >>> opposed to a prefetching implementation that doesn't read into s_b. >> >> Could you elaborate why prefetching into s_b is so much better (I'm sure it has advantages, but I suppose prefetchinginto page cache would be much easier to implement). > > posix_fadvise(POSIX_FADV_WILLNEED) might already get most of the > speed-up available here in the short term for this immediate > application, but in the long term a shared buffers prefetch system is > one of the components we'll need to support direct IO. > Sure. Assuming the switch to direct I/O will happen (it probably will, sooner or later), my question is whether this patch should be required to introduce the prefetching into s_b. Or should we use posix_fadvise for now, get most of the benefit, and leave the prefetch into s_b as an improvement for later? The thing is - we're already doing posix_fadvise prefetching in bitmap heap scans, it would not be putting additional burden on the direct I/O patch (hypothetical, so far). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Greetings, * Tomas Vondra (tomas.vondra@2ndquadrant.com) wrote: > On 06/16/2018 12:06 PM, Thomas Munro wrote: > >On Sat, Jun 16, 2018 at 9:38 PM, Tomas Vondra > ><tomas.vondra@2ndquadrant.com> wrote: > >>On 06/15/2018 08:01 PM, Andres Freund wrote: > >>>On 2018-06-14 10:13:44 +0300, Konstantin Knizhnik wrote: > >>>>On 14.06.2018 09:52, Thomas Munro wrote: > >>>>>Why stop at the page cache... what about shared buffers? > >>>> > >>>>It is good question. I thought a lot about prefetching directly to shared > >>>>buffers. > >>> > >>>I think that's definitely how this should work. I'm pretty strongly > >>>opposed to a prefetching implementation that doesn't read into s_b. > >> > >>Could you elaborate why prefetching into s_b is so much better (I'm sure it has advantages, but I suppose prefetchinginto page cache would be much easier to implement). > > > >posix_fadvise(POSIX_FADV_WILLNEED) might already get most of the > >speed-up available here in the short term for this immediate > >application, but in the long term a shared buffers prefetch system is > >one of the components we'll need to support direct IO. > > > > Sure. Assuming the switch to direct I/O will happen (it probably will, > sooner or later), my question is whether this patch should be required to > introduce the prefetching into s_b. Or should we use posix_fadvise for now, > get most of the benefit, and leave the prefetch into s_b as an improvement > for later? > > The thing is - we're already doing posix_fadvise prefetching in bitmap heap > scans, it would not be putting additional burden on the direct I/O patch > (hypothetical, so far). This was my take on it also. Prefetching is something we've come to accept in other parts of the system and if it's beneficial to add it here then we should certainly do so and it seems like it'd keep the patch nice and simple and small. Thanks! Stephen
Attachment
On 2018-06-16 11:38:59 +0200, Tomas Vondra wrote: > > > On 06/15/2018 08:01 PM, Andres Freund wrote: > > On 2018-06-14 10:13:44 +0300, Konstantin Knizhnik wrote: > > > > > > > > > On 14.06.2018 09:52, Thomas Munro wrote: > > > > On Thu, Jun 14, 2018 at 1:09 AM, Konstantin Knizhnik > > > > <k.knizhnik@postgrespro.ru> wrote: > > > > > pg_wal_prefetch function will infinitely traverse WAL and prefetch block > > > > > references in WAL records > > > > > using posix_fadvise(WILLNEED) system call. > > > > Hi Konstantin, > > > > > > > > Why stop at the page cache... what about shared buffers? > > > > > > > > > > It is good question. I thought a lot about prefetching directly to shared > > > buffers. > > > > I think that's definitely how this should work. I'm pretty strongly > > opposed to a prefetching implementation that doesn't read into s_b. > > > > Could you elaborate why prefetching into s_b is so much better (I'm sure it > has advantages, but I suppose prefetching into page cache would be much > easier to implement). I think there's a number of issues with just issuing prefetch requests via fadvise etc: - it leads to guaranteed double buffering, in a way that's just about guaranteed to *never* be useful. Because we'd only prefetch whenever there's an upcoming write, there's simply no benefit in the page staying in the page cache - we'll write out the whole page back to the OS. - reading from the page cache is far from free - so you add costs to the replay process that it doesn't need to do. - you don't have any sort of completion notification, so you basically just have to guess how far ahead you want to read. If you read a bit too much you suddenly get into synchronous blocking land. - The OS page is actually not particularly scalable to large amounts of data either. Nor are the decisions what to keep cached likley to be particularly useful. - We imo need to add support for direct IO before long, and adding more and more work to reach feature parity strikes meas a bad move. Greetings, Andres Freund
Hi, On 2018-06-13 16:09:45 +0300, Konstantin Knizhnik wrote: > Usage: > 1. At master: create extension wal_prefetch > 2. At replica: Call pg_wal_prefetch() function: it will not return until you > interrupt it. FWIW, I think the proper design would rather be a background worker that does this work. Forcing the user to somehow coordinate starting a permanently running script whenever the database restarts isn't great. There's also some issues around snapshots preventing vacuum (which could be solved, but not nicely). Greetings, Andres Freund
On 06/16/2018 09:02 PM, Andres Freund wrote: > On 2018-06-16 11:38:59 +0200, Tomas Vondra wrote: >> >> >> On 06/15/2018 08:01 PM, Andres Freund wrote: >>> On 2018-06-14 10:13:44 +0300, Konstantin Knizhnik wrote: >>>> >>>> >>>> On 14.06.2018 09:52, Thomas Munro wrote: >>>>> On Thu, Jun 14, 2018 at 1:09 AM, Konstantin Knizhnik >>>>> <k.knizhnik@postgrespro.ru> wrote: >>>>>> pg_wal_prefetch function will infinitely traverse WAL and prefetch block >>>>>> references in WAL records >>>>>> using posix_fadvise(WILLNEED) system call. >>>>> Hi Konstantin, >>>>> >>>>> Why stop at the page cache... what about shared buffers? >>>>> >>>> >>>> It is good question. I thought a lot about prefetching directly to shared >>>> buffers. >>> >>> I think that's definitely how this should work. I'm pretty strongly >>> opposed to a prefetching implementation that doesn't read into s_b. >>> >> >> Could you elaborate why prefetching into s_b is so much better (I'm sure it >> has advantages, but I suppose prefetching into page cache would be much >> easier to implement). > > I think there's a number of issues with just issuing prefetch requests > via fadvise etc: > > - it leads to guaranteed double buffering, in a way that's just about > guaranteed to *never* be useful. Because we'd only prefetch whenever > there's an upcoming write, there's simply no benefit in the page > staying in the page cache - we'll write out the whole page back to the > OS. How does reading directly into shared buffers substantially change the behavior? The only difference is that we end up with the double buffering after performing the write. Which is expected to happen pretty quick after the read request. > - reading from the page cache is far from free - so you add costs to the > replay process that it doesn't need to do. > - you don't have any sort of completion notification, so you basically > just have to guess how far ahead you want to read. If you read a bit > too much you suddenly get into synchronous blocking land. > - The OS page is actually not particularly scalable to large amounts of > data either. Nor are the decisions what to keep cached likley to be > particularly useful. The posix_fadvise approach is not perfect, no doubt about that. But it works pretty well for bitmap heap scans, and it's about 13249x better (rough estimate) than the current solution (no prefetching). > - We imo need to add support for direct IO before long, and adding more > and more work to reach feature parity strikes meas a bad move. > IMHO it's unlikely to happen in PG12, but I might be over-estimating the invasiveness and complexity of the direct I/O change. While this patch seems pretty doable, and the improvements are pretty significant. My point was that I don't think this actually adds a significant amount of work to the direct IO patch, as we already do prefetch for bitmap heap scans. So this needs to be written anyway, and I'd expect those two places to share most of the code. So where's the additional work? I don't think we should reject patches just because it might add a bit of work to some not-yet-written future patch ... (which I however don't think is this case). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, On 2018-06-16 21:34:30 +0200, Tomas Vondra wrote: > > - it leads to guaranteed double buffering, in a way that's just about > > guaranteed to *never* be useful. Because we'd only prefetch whenever > > there's an upcoming write, there's simply no benefit in the page > > staying in the page cache - we'll write out the whole page back to the > > OS. > > How does reading directly into shared buffers substantially change the > behavior? The only difference is that we end up with the double > buffering after performing the write. Which is expected to happen pretty > quick after the read request. Random reads directly as a response to a read() request can be cached differently - and we trivially could force that with another fadvise() - than posix_fadvise(WILLNEED). There's pretty much no other case - so far - where we know as clearly that we won't re-read the page until write as here. > > - you don't have any sort of completion notification, so you basically > > just have to guess how far ahead you want to read. If you read a bit > > too much you suddenly get into synchronous blocking land. > > - The OS page is actually not particularly scalable to large amounts of > > data either. Nor are the decisions what to keep cached likley to be > > particularly useful. > > The posix_fadvise approach is not perfect, no doubt about that. But it > works pretty well for bitmap heap scans, and it's about 13249x better > (rough estimate) than the current solution (no prefetching). Sure, but investing in an architecture we know might not live long also has it's cost. Especially if it's not that complicated to do better. > My point was that I don't think this actually adds a significant amount > of work to the direct IO patch, as we already do prefetch for bitmap > heap scans. So this needs to be written anyway, and I'd expect those two > places to share most of the code. So where's the additional work? I think it's largely entirely separate from what we'd do for bitmap index scans. Greetings, Andres Freund
On 16.06.2018 22:02, Andres Freund wrote: > On 2018-06-16 11:38:59 +0200, Tomas Vondra wrote: >> >> On 06/15/2018 08:01 PM, Andres Freund wrote: >>> On 2018-06-14 10:13:44 +0300, Konstantin Knizhnik wrote: >>>> >>>> On 14.06.2018 09:52, Thomas Munro wrote: >>>>> On Thu, Jun 14, 2018 at 1:09 AM, Konstantin Knizhnik >>>>> <k.knizhnik@postgrespro.ru> wrote: >>>>>> pg_wal_prefetch function will infinitely traverse WAL and prefetch block >>>>>> references in WAL records >>>>>> using posix_fadvise(WILLNEED) system call. >>>>> Hi Konstantin, >>>>> >>>>> Why stop at the page cache... what about shared buffers? >>>>> >>>> It is good question. I thought a lot about prefetching directly to shared >>>> buffers. >>> I think that's definitely how this should work. I'm pretty strongly >>> opposed to a prefetching implementation that doesn't read into s_b. >>> >> Could you elaborate why prefetching into s_b is so much better (I'm sure it >> has advantages, but I suppose prefetching into page cache would be much >> easier to implement). > I think there's a number of issues with just issuing prefetch requests > via fadvise etc: > > - it leads to guaranteed double buffering, in a way that's just about > guaranteed to *never* be useful. Because we'd only prefetch whenever > there's an upcoming write, there's simply no benefit in the page > staying in the page cache - we'll write out the whole page back to the > OS. Sorry, I do not completely understand this. Prefetch is only needed for partial update of a page - in this case we need to first read page from the disk before been able to perform update. So before "we'll write out the whole page back to the OS" we have to read this page. And if page is in OS cached (prefetched) then is can be done much faster. Please notice that at the moment of prefetch there is no double buffering. As far as page is not accessed before, it is not present in shared buffers. And once page is updated, there is really no need to keep it in shared buffers. We can use cyclic buffers (like in case of sequential scan or bulk update) to prevent throwing away useful pages from shared buffers by redo process. So once again there will no double buffering. > - reading from the page cache is far from free - so you add costs to the > replay process that it doesn't need to do. > - you don't have any sort of completion notification, so you basically > just have to guess how far ahead you want to read. If you read a bit > too much you suddenly get into synchronous blocking land. > - The OS page is actually not particularly scalable to large amounts of > data either. Nor are the decisions what to keep cached likley to be > particularly useful. > - We imo need to add support for direct IO before long, and adding more > and more work to reach feature parity strikes meas a bad move. I am not so familiar with current implementation of full page writes mechanism in Postgres. So may be my idea explained below is stupid or already implemented (but I failed to find any traces of this). Prefetch is needed only for WAL records performing partial update. Full page write doesn't require prefetch. Full page write has to be performed when the page is update first time after checkpoint. But what if slightly extend this rule and perform full page write also when distance from previous full page write exceeds some delta (which somehow related with size of OS cache)? In this case even if checkpoint interval is larger than OS cache size, we still can expect that updated pages are present in OS cache. And no WAL prefetch is needed at all!
On 16.06.2018 22:23, Andres Freund wrote: > Hi, > > On 2018-06-13 16:09:45 +0300, Konstantin Knizhnik wrote: >> Usage: >> 1. At master: create extension wal_prefetch >> 2. At replica: Call pg_wal_prefetch() function: it will not return until you >> interrupt it. > FWIW, I think the proper design would rather be a background worker that > does this work. Forcing the user to somehow coordinate starting a > permanently running script whenever the database restarts isn't > great. There's also some issues around snapshots preventing vacuum > (which could be solved, but not nicely). As I already wrote, the current my approach with extension and pg_wal_prefetch function called by user can be treated only as prototype implementation which can be used to estimate efficiency of prefetch. But in case of prefetching in shared buffers, one background worker will not be enough. Prefetch can can speedup recovery process if it performs reads in parallel or background. So more than once background worker will be needed for prefetch if we read data to Postgres shared buffers rather then using posix_prefetch to load page in OS cache. > > Greetings, > > Andres Freund
On 2018-06-16 23:25:34 +0300, Konstantin Knizhnik wrote: > > > On 16.06.2018 22:02, Andres Freund wrote: > > On 2018-06-16 11:38:59 +0200, Tomas Vondra wrote: > > > > > > On 06/15/2018 08:01 PM, Andres Freund wrote: > > > > On 2018-06-14 10:13:44 +0300, Konstantin Knizhnik wrote: > > > > > > > > > > On 14.06.2018 09:52, Thomas Munro wrote: > > > > > > On Thu, Jun 14, 2018 at 1:09 AM, Konstantin Knizhnik > > > > > > <k.knizhnik@postgrespro.ru> wrote: > > > > > > > pg_wal_prefetch function will infinitely traverse WAL and prefetch block > > > > > > > references in WAL records > > > > > > > using posix_fadvise(WILLNEED) system call. > > > > > > Hi Konstantin, > > > > > > > > > > > > Why stop at the page cache... what about shared buffers? > > > > > > > > > > > It is good question. I thought a lot about prefetching directly to shared > > > > > buffers. > > > > I think that's definitely how this should work. I'm pretty strongly > > > > opposed to a prefetching implementation that doesn't read into s_b. > > > > > > > Could you elaborate why prefetching into s_b is so much better (I'm sure it > > > has advantages, but I suppose prefetching into page cache would be much > > > easier to implement). > > I think there's a number of issues with just issuing prefetch requests > > via fadvise etc: > > > > - it leads to guaranteed double buffering, in a way that's just about > > guaranteed to *never* be useful. Because we'd only prefetch whenever > > there's an upcoming write, there's simply no benefit in the page > > staying in the page cache - we'll write out the whole page back to the > > OS. > > Sorry, I do not completely understand this. > Prefetch is only needed for partial update of a page - in this case we need > to first read page from the disk Yes. > before been able to perform update. So before "we'll write out the whole > page back to the OS" we have to read this page. > And if page is in OS cached (prefetched) then is can be done much faster. Yes. > Please notice that at the moment of prefetch there is no double > buffering. Sure, but as soon as it's read there is. > As far as page is not accessed before, it is not present in shared buffers. > And once page is updated, there is really no need to keep it in shared > buffers. We can use cyclic buffers (like in case of sequential scan or > bulk update) to prevent throwing away useful pages from shared buffers by > redo process. So once again there will no double buffering. That's a terrible idea. There's a *lot* of spatial locality of further WAL records arriving for the same blocks. > I am not so familiar with current implementation of full page writes > mechanism in Postgres. > So may be my idea explained below is stupid or already implemented (but I > failed to find any traces of this). > Prefetch is needed only for WAL records performing partial update. Full page > write doesn't require prefetch. > Full page write has to be performed when the page is update first time after > checkpoint. > But what if slightly extend this rule and perform full page write also when > distance from previous full page write exceeds some delta > (which somehow related with size of OS cache)? > > In this case even if checkpoint interval is larger than OS cache size, we > still can expect that updated pages are present in OS cache. > And no WAL prefetch is needed at all! We could do so, but I suspect the WAL volume penalty would be prohibitive in many cases. Worthwhile to try though. Greetings, Andres Freund
On 2018-06-16 23:31:49 +0300, Konstantin Knizhnik wrote: > > > On 16.06.2018 22:23, Andres Freund wrote: > > Hi, > > > > On 2018-06-13 16:09:45 +0300, Konstantin Knizhnik wrote: > > > Usage: > > > 1. At master: create extension wal_prefetch > > > 2. At replica: Call pg_wal_prefetch() function: it will not return until you > > > interrupt it. > > FWIW, I think the proper design would rather be a background worker that > > does this work. Forcing the user to somehow coordinate starting a > > permanently running script whenever the database restarts isn't > > great. There's also some issues around snapshots preventing vacuum > > (which could be solved, but not nicely). > > As I already wrote, the current my approach with extension and > pg_wal_prefetch function called by user can be treated only as prototype > implementation which can be used to estimate efficiency of prefetch. But in > case of prefetching in shared buffers, one background worker will not be > enough. Prefetch can can speedup recovery process if it performs reads in > parallel or background. So more than once background worker will be needed > for prefetch if we read data to Postgres shared buffers rather then using > posix_prefetch to load page in OS cache. Sure, we'd need more than one to get the full benefit, but that's not really hard. You'd see benefit even with a single process, because WAL replay often has a lot of other bottlenecks too. But no reason to not have multiple ones. Greetings, Andres Freund
On 17.06.2018 03:00, Andres Freund wrote: > On 2018-06-16 23:25:34 +0300, Konstantin Knizhnik wrote: >> >> On 16.06.2018 22:02, Andres Freund wrote: >>> On 2018-06-16 11:38:59 +0200, Tomas Vondra wrote: >>>> On 06/15/2018 08:01 PM, Andres Freund wrote: >>>>> On 2018-06-14 10:13:44 +0300, Konstantin Knizhnik wrote: >>>>>> On 14.06.2018 09:52, Thomas Munro wrote: >>>>>>> On Thu, Jun 14, 2018 at 1:09 AM, Konstantin Knizhnik >>>>>>> <k.knizhnik@postgrespro.ru> wrote: >>>>>>>> pg_wal_prefetch function will infinitely traverse WAL and prefetch block >>>>>>>> references in WAL records >>>>>>>> using posix_fadvise(WILLNEED) system call. >>>>>>> Hi Konstantin, >>>>>>> >>>>>>> Why stop at the page cache... what about shared buffers? >>>>>>> >>>>>> It is good question. I thought a lot about prefetching directly to shared >>>>>> buffers. >>>>> I think that's definitely how this should work. I'm pretty strongly >>>>> opposed to a prefetching implementation that doesn't read into s_b. >>>>> >>>> Could you elaborate why prefetching into s_b is so much better (I'm sure it >>>> has advantages, but I suppose prefetching into page cache would be much >>>> easier to implement). >>> I think there's a number of issues with just issuing prefetch requests >>> via fadvise etc: >>> >>> - it leads to guaranteed double buffering, in a way that's just about >>> guaranteed to *never* be useful. Because we'd only prefetch whenever >>> there's an upcoming write, there's simply no benefit in the page >>> staying in the page cache - we'll write out the whole page back to the >>> OS. >> Sorry, I do not completely understand this. >> Prefetch is only needed for partial update of a page - in this case we need >> to first read page from the disk > Yes. > > >> before been able to perform update. So before "we'll write out the whole >> page back to the OS" we have to read this page. >> And if page is in OS cached (prefetched) then is can be done much faster. > Yes. > > >> Please notice that at the moment of prefetch there is no double >> buffering. > Sure, but as soon as it's read there is. > > >> As far as page is not accessed before, it is not present in shared buffers. >> And once page is updated, there is really no need to keep it in shared >> buffers. We can use cyclic buffers (like in case of sequential scan or >> bulk update) to prevent throwing away useful pages from shared buffers by >> redo process. So once again there will no double buffering. > That's a terrible idea. There's a *lot* of spatial locality of further > WAL records arriving for the same blocks. In some cases it is true, in some cases - not. In typical OLTP system if record is updated, then there is high probability that it will be accessed soon. So if at such system we perform write requests on master and read-only queries at replicas, keeping updated pages in shared buffers at replica can be very helpful. But if replica is used for running mostly analytic queries while master performs some updates, then it is more useful to keep in replica's cache indexes and most frequently accessed pages, rather than recent updates from the master. So at least it seems to be reasonable to have such parameter and make DBA to choose caching policy at replicas. > > >> I am not so familiar with current implementation of full page writes >> mechanism in Postgres. >> So may be my idea explained below is stupid or already implemented (but I >> failed to find any traces of this). >> Prefetch is needed only for WAL records performing partial update. Full page >> write doesn't require prefetch. >> Full page write has to be performed when the page is update first time after >> checkpoint. >> But what if slightly extend this rule and perform full page write also when >> distance from previous full page write exceeds some delta >> (which somehow related with size of OS cache)? >> >> In this case even if checkpoint interval is larger than OS cache size, we >> still can expect that updated pages are present in OS cache. >> And no WAL prefetch is needed at all! > We could do so, but I suspect the WAL volume penalty would be > prohibitive in many cases. Worthwhile to try though. Well, the typical size of server's memory is now several hundreds of megabytes. Certainly some of this memory is used for shared buffers, backends work memory, ... But still there are hundreds of gigabytes of free memory which can be used by OS for caching. Let's assume that full page write threshold is 100Gb. So one extra 8kb for 100Gb of WAL! Certainly it is estimation only for one page and it is more realistic to expect that we have to force full page writes for most of the updated pages. But still I do not believe that it will cause significant growth of log size. Another question is why do we choose so large checkpoint interval: re than hundred gigabytes. Certainly frequent checkpoints have negative impact on performance. But 100Gb is not "too frequent" in any case...
On Sat, Jun 16, 2018 at 3:41 PM, Andres Freund <andres@anarazel.de> wrote: >> The posix_fadvise approach is not perfect, no doubt about that. But it >> works pretty well for bitmap heap scans, and it's about 13249x better >> (rough estimate) than the current solution (no prefetching). > > Sure, but investing in an architecture we know might not live long also > has it's cost. Especially if it's not that complicated to do better. My guesses are: - Using OS prefetching is a very small patch. - Prefetching into shared buffers is a much bigger patch. - It'll be five years before we have direct I/O. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2018-06-18 16:44:09 -0400, Robert Haas wrote: > On Sat, Jun 16, 2018 at 3:41 PM, Andres Freund <andres@anarazel.de> wrote: > >> The posix_fadvise approach is not perfect, no doubt about that. But it > >> works pretty well for bitmap heap scans, and it's about 13249x better > >> (rough estimate) than the current solution (no prefetching). > > > > Sure, but investing in an architecture we know might not live long also > > has it's cost. Especially if it's not that complicated to do better. > > My guesses are: > > - Using OS prefetching is a very small patch. > - Prefetching into shared buffers is a much bigger patch. Why? The majority of the work is standing up a bgworker that does prefetching (i.e. reads WAL, figures out reads not in s_b, does prefetch). Allowing a configurable number + some synchronization between them isn't that much more work. > - It'll be five years before we have direct I/O. I think we'll have lost a significant market share by then if that's the case. Deservedly so. Greetings, Andres Freund
On 18.06.2018 23:47, Andres Freund wrote: > On 2018-06-18 16:44:09 -0400, Robert Haas wrote: >> On Sat, Jun 16, 2018 at 3:41 PM, Andres Freund <andres@anarazel.de> wrote: >>>> The posix_fadvise approach is not perfect, no doubt about that. But it >>>> works pretty well for bitmap heap scans, and it's about 13249x better >>>> (rough estimate) than the current solution (no prefetching). >>> Sure, but investing in an architecture we know might not live long also >>> has it's cost. Especially if it's not that complicated to do better. >> My guesses are: >> >> - Using OS prefetching is a very small patch. >> - Prefetching into shared buffers is a much bigger patch. > Why? The majority of the work is standing up a bgworker that does > prefetching (i.e. reads WAL, figures out reads not in s_b, does > prefetch). Allowing a configurable number + some synchronization between > them isn't that much more work. I do not think that prefetching in shared buffers requires much more efforts and make patch more envasive... It even somehow simplify it, because there is no to maintain own cache of prefetched pages... But it will definitely have much more impact on Postgres performance: contention for buffer locks, throwing away pages accessed by read-only queries,... Also there are two points which makes prefetching into shared buffers more complex: 1. Need to spawn multiple workers to make prefetch in parallel and somehow distribute work between them. 2. Synchronize work of recovery process with prefetch to prevent prefetch to go too far and doing useless job. The same problem exists for prefetch in OS cache, but here risk of false prefetch is less critical. > > >> - It'll be five years before we have direct I/O. > I think we'll have lost a significant market share by then if that's the > case. Deservedly so. I have implemented some number of DBMS engines (GigaBASE, GOODS, FastDB, ...) and have supported direct IO (as option) in most of them. But at most workloads I have not get any significant improvement in performance. Certainly, it may be some problem with my implementations... and Linux kernel is significantly changed since this time. But there is one "axiom" which complicates usage of direct IO: only OS knows at each moment of time how much free memory it has. So only OS can efficiently schedule memory so that all system RAM is used. It is very hard if ever possible to do it at application level. As a result you will have to be very conservative in choosing size of shared buffers to fit in RAM and avoid swapping. It may be possible if you have complete control on the server and there is just one Postgres instance running at this server. But now there is a trend towards visualization and clouds and such assumption is not true in most cases. So double buffering (or even triple if take in account on-device internal caches) is definitely an issue. But direct IO seems to be not a silver bullet for solving it... Concerning WAL perfetch I still have a serious doubt if it is needed at all: if checkpoint interval is less than size of free memory at the system, then redo process should not read much. And if checkpoint interval is much larger than OS cache (are there cases when it is really needed?) then quite small patch (as it seems to me now) forcing full page write when distance between page LSN and current WAL insertion point exceeds some threshold should eliminate random reads also in this case. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 06/19/2018 11:08 AM, Konstantin Knizhnik wrote: > > > On 18.06.2018 23:47, Andres Freund wrote: >> On 2018-06-18 16:44:09 -0400, Robert Haas wrote: >>> On Sat, Jun 16, 2018 at 3:41 PM, Andres Freund <andres@anarazel.de> >>> wrote: >>>>> The posix_fadvise approach is not perfect, no doubt about that. But it >>>>> works pretty well for bitmap heap scans, and it's about 13249x better >>>>> (rough estimate) than the current solution (no prefetching). >>>> Sure, but investing in an architecture we know might not live long also >>>> has it's cost. Especially if it's not that complicated to do better. >>> My guesses are: >>> >>> - Using OS prefetching is a very small patch. >>> - Prefetching into shared buffers is a much bigger patch. >> Why? The majority of the work is standing up a bgworker that does >> prefetching (i.e. reads WAL, figures out reads not in s_b, does >> prefetch). Allowing a configurable number + some synchronization between >> them isn't that much more work. > > I do not think that prefetching in shared buffers requires much more > efforts and make patch more envasive... > It even somehow simplify it, because there is no to maintain own cache > of prefetched pages... > But it will definitely have much more impact on Postgres performance: > contention for buffer locks, throwing away pages accessed by read-only > queries,... > > Also there are two points which makes prefetching into shared buffers > more complex: > 1. Need to spawn multiple workers to make prefetch in parallel and > somehow distribute work between them. > 2. Synchronize work of recovery process with prefetch to prevent > prefetch to go too far and doing useless job. > The same problem exists for prefetch in OS cache, but here risk of false > prefetch is less critical. > I think the main challenge here is that all buffer reads are currently synchronous (correct me if I'm wrong), while the posix_fadvise() allows a to prefetch the buffers asynchronously. I don't think simply spawning a couple of bgworkers to prefetch buffers is going to be equal to async prefetch, unless we support some sort of async I/O. Maybe something has changed recently, but every time I looked for good portable async I/O API/library I got burned. Now, maybe a couple of bgworkers prefetching buffers synchronously would be good enough for WAL refetching - after all, we only need to prefetch data fast enough for the recovery not to wait. But I doubt it's going to be good enough for bitmap heap scans, for example. We need a prefetch that allows filling the I/O queues with hundreds of requests, and I don't think sync prefetch from a handful of bgworkers can achieve that. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 19.06.2018 14:03, Tomas Vondra wrote: > > > On 06/19/2018 11:08 AM, Konstantin Knizhnik wrote: >> >> >> On 18.06.2018 23:47, Andres Freund wrote: >>> On 2018-06-18 16:44:09 -0400, Robert Haas wrote: >>>> On Sat, Jun 16, 2018 at 3:41 PM, Andres Freund <andres@anarazel.de> >>>> wrote: >>>>>> The posix_fadvise approach is not perfect, no doubt about that. >>>>>> But it >>>>>> works pretty well for bitmap heap scans, and it's about 13249x >>>>>> better >>>>>> (rough estimate) than the current solution (no prefetching). >>>>> Sure, but investing in an architecture we know might not live long >>>>> also >>>>> has it's cost. Especially if it's not that complicated to do better. >>>> My guesses are: >>>> >>>> - Using OS prefetching is a very small patch. >>>> - Prefetching into shared buffers is a much bigger patch. >>> Why? The majority of the work is standing up a bgworker that does >>> prefetching (i.e. reads WAL, figures out reads not in s_b, does >>> prefetch). Allowing a configurable number + some synchronization >>> between >>> them isn't that much more work. >> >> I do not think that prefetching in shared buffers requires much more >> efforts and make patch more envasive... >> It even somehow simplify it, because there is no to maintain own >> cache of prefetched pages... >> But it will definitely have much more impact on Postgres performance: >> contention for buffer locks, throwing away pages accessed by >> read-only queries,... >> >> Also there are two points which makes prefetching into shared buffers >> more complex: >> 1. Need to spawn multiple workers to make prefetch in parallel and >> somehow distribute work between them. >> 2. Synchronize work of recovery process with prefetch to prevent >> prefetch to go too far and doing useless job. >> The same problem exists for prefetch in OS cache, but here risk of >> false prefetch is less critical. >> > > I think the main challenge here is that all buffer reads are currently > synchronous (correct me if I'm wrong), while the posix_fadvise() > allows a to prefetch the buffers asynchronously. Yes, this is why we have to spawn several concurrent background workers to perfrom prefetch. > > I don't think simply spawning a couple of bgworkers to prefetch > buffers is going to be equal to async prefetch, unless we support some > sort of async I/O. Maybe something has changed recently, but every > time I looked for good portable async I/O API/library I got burned. > > Now, maybe a couple of bgworkers prefetching buffers synchronously > would be good enough for WAL refetching - after all, we only need to > prefetch data fast enough for the recovery not to wait. But I doubt > it's going to be good enough for bitmap heap scans, for example. > > We need a prefetch that allows filling the I/O queues with hundreds of > requests, and I don't think sync prefetch from a handful of bgworkers > can achieve that. > > regards > -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 06/19/2018 02:33 PM, Konstantin Knizhnik wrote: > > On 19.06.2018 14:03, Tomas Vondra wrote: >> >> On 06/19/2018 11:08 AM, Konstantin Knizhnik wrote: >>> >>> ... >>> >>> Also there are two points which makes prefetching into shared buffers >>> more complex: >>> 1. Need to spawn multiple workers to make prefetch in parallel and >>> somehow distribute work between them. >>> 2. Synchronize work of recovery process with prefetch to prevent >>> prefetch to go too far and doing useless job. >>> The same problem exists for prefetch in OS cache, but here risk of >>> false prefetch is less critical. >>> >> >> I think the main challenge here is that all buffer reads are currently >> synchronous (correct me if I'm wrong), while the posix_fadvise() >> allows a to prefetch the buffers asynchronously. > > Yes, this is why we have to spawn several concurrent background workers > to perfrom prefetch. Right. My point is that while spawning bgworkers probably helps, I don't expect it to be enough to fill the I/O queues on modern storage systems. Even if you start say 16 prefetch bgworkers, that's not going to be enough for large arrays or SSDs. Those typically need way more than 16 requests in the queue. Consider for example [1] from 2014 where Merlin reported how S3500 (Intel SATA SSD) behaves with different effective_io_concurrency values: [1] https://www.postgresql.org/message-id/CAHyXU0yiVvfQAnR9cyH=HWh1WbLRsioe=mzRJTHwtr=2azsTdQ@mail.gmail.com Clearly, you need to prefetch 32/64 blocks or so. Consider you may have multiple such devices in a single RAID array, and that this device is from 2014 (and newer flash devices likely need even deeper queues). ISTM a small number of bgworkers is not going to be sufficient. It might be enough for WAL prefetching (where we may easily run into the redo-is-single-threaded bottleneck), but it's hardly a solution for bitmap heap scans, for example. We'll need to invent something else for that. OTOH my guess is that whatever solution we'll end up implementing for bitmap heap scans, it will be applicable for WAL prefetching too. Which is why I'm suggesting simply using posix_fadvise is not going to make the direct I/O patch significantly more complicated. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Jun 19, 2018 at 4:04 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
Right. My point is that while spawning bgworkers probably helps, I don't
expect it to be enough to fill the I/O queues on modern storage systems.
Even if you start say 16 prefetch bgworkers, that's not going to be
enough for large arrays or SSDs. Those typically need way more than 16
requests in the queue.
Consider for example [1] from 2014 where Merlin reported how S3500
(Intel SATA SSD) behaves with different effective_io_concurrency values:
[1]
https://www.postgresql.org/message-id/CAHyXU0yiVvfQAnR9cyH=HWh1WbLRsioe=mzRJTHwtr=2azsTdQ@mail.gmail.com
Clearly, you need to prefetch 32/64 blocks or so. Consider you may have
multiple such devices in a single RAID array, and that this device is
from 2014 (and newer flash devices likely need even deeper queues).'
For reference, a typical datacenter SSD needs a queue depth of 128 to saturate a single device. [1] Multiply that appropriately for RAID arrays.
Regards,
Ants Aasma
Ants Aasma
On 19.06.2018 16:57, Ants Aasma wrote:
On Tue, Jun 19, 2018 at 4:04 PM Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:Right. My point is that while spawning bgworkers probably helps, I don't
expect it to be enough to fill the I/O queues on modern storage systems.
Even if you start say 16 prefetch bgworkers, that's not going to be
enough for large arrays or SSDs. Those typically need way more than 16
requests in the queue.
Consider for example [1] from 2014 where Merlin reported how S3500
(Intel SATA SSD) behaves with different effective_io_concurrency values:
[1]
https://www.postgresql.org/message-id/CAHyXU0yiVvfQAnR9cyH=HWh1WbLRsioe=mzRJTHwtr=2azsTdQ@mail.gmail.com
Clearly, you need to prefetch 32/64 blocks or so. Consider you may have
multiple such devices in a single RAID array, and that this device is
from 2014 (and newer flash devices likely need even deeper queues).'For reference, a typical datacenter SSD needs a queue depth of 128 to saturate a single device. [1] Multiply that appropriately for RAID arrays.So
How it is related with results for S3500 where this is almost now performance improvement for effective_io_concurrency >8?
Starting 128 or more workers for performing prefetch is definitely not acceptable...
-- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 06/19/2018 04:50 PM, Konstantin Knizhnik wrote: > > > On 19.06.2018 16:57, Ants Aasma wrote: >> On Tue, Jun 19, 2018 at 4:04 PM Tomas Vondra >> <tomas.vondra@2ndquadrant.com <mailto:tomas.vondra@2ndquadrant.com>> >> wrote: >> >> Right. My point is that while spawning bgworkers probably helps, I >> don't >> expect it to be enough to fill the I/O queues on modern storage >> systems. >> Even if you start say 16 prefetch bgworkers, that's not going to be >> enough for large arrays or SSDs. Those typically need way more >> than 16 >> requests in the queue. >> >> Consider for example [1] from 2014 where Merlin reported how S3500 >> (Intel SATA SSD) behaves with different effective_io_concurrency >> values: >> >> [1] >> https://www.postgresql.org/message-id/CAHyXU0yiVvfQAnR9cyH=HWh1WbLRsioe=mzRJTHwtr=2azsTdQ@mail.gmail.com >> >> Clearly, you need to prefetch 32/64 blocks or so. Consider you may >> have >> multiple such devices in a single RAID array, and that this device is >> from 2014 (and newer flash devices likely need even deeper queues).' >> >> >> For reference, a typical datacenter SSD needs a queue depth of 128 to >> saturate a single device. [1] Multiply that appropriately for RAID >> arrays.So > > How it is related with results for S3500 where this is almost now > performance improvement for effective_io_concurrency >8? > Starting 128 or more workers for performing prefetch is definitely not > acceptable... > I'm not sure what you mean by "almost now performance improvement", but I guess you meant "almost no performance improvement" instead? If that's the case, it's not quite true - increasing the queue depth above 8 further improved the throughput by about ~10-20% (both by duration and peak throughput measured by iotop). But more importantly, this is just a single device - you typically have multiple of them in a larger arrays, to get better capacity, performance and/or reliability. So if you have 16 such drives, and you want to send at least 8 requests to each, suddenly you need at least 128 requests. And as pointed out before, S3500 is about 5-years old device (it was introduced in Q2/2013). On newer devices the difference is usually way more significant / the required queue depth is much higher. Obviously, this is a somewhat simplified view, ignoring various details (e.g. that there may be multiple concurrent queries, each sending I/O requests - what matters is the combined number of requests, of course). But I don't think this makes a huge difference. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2018-06-19 12:08:27 +0300, Konstantin Knizhnik wrote: > I do not think that prefetching in shared buffers requires much more efforts > and make patch more envasive... > It even somehow simplify it, because there is no to maintain own cache of > prefetched pages... > But it will definitely have much more impact on Postgres performance: > contention for buffer locks, throwing away pages accessed by read-only > queries,... These arguments seem bogus to me. Otherwise the startup process is going to do that work. > Also there are two points which makes prefetching into shared buffers more > complex: > 1. Need to spawn multiple workers to make prefetch in parallel and somehow > distribute work between them. I'm not even convinced that's true. It doesn't seem insane to have a queue of, say, 128 requests that are done with posix_fadvise WILLNEED, where the oldest requests is read into shared buffers by the prefetcher. And then discarded from the page cache with WONTNEED. I think we're going to want a queue that's sorted in the prefetch process anyway, because there's a high likelihood that we'll otherwise issue prfetch requets for the same pages over and over again. That gets rid of most of the disadvantages: We have backpressure (because the read into shared buffers will block if not yet ready), we'll prevent double buffering, we'll prevent the startup process from doing the victim buffer search. > Concerning WAL perfetch I still have a serious doubt if it is needed at all: > if checkpoint interval is less than size of free memory at the system, then > redo process should not read much. I'm confused. Didn't you propose this? FWIW, there's a significant number of installations where people have observed this problem in practice. > And if checkpoint interval is much larger than OS cache (are there cases > when it is really needed?) Yes, there are. Percentage of FPWs can cause serious problems, as do repeated writouts by the checkpointer. > then quite small patch (as it seems to me now) forcing full page write > when distance between page LSN and current WAL insertion point exceeds > some threshold should eliminate random reads also in this case. I'm pretty sure that that'll hurt a significant number of installations, that set the timeout high, just so they can avoid FPWs. Greetings, Andres Freund
On 19.06.2018 18:50, Andres Freund wrote: > On 2018-06-19 12:08:27 +0300, Konstantin Knizhnik wrote: >> I do not think that prefetching in shared buffers requires much more efforts >> and make patch more envasive... >> It even somehow simplify it, because there is no to maintain own cache of >> prefetched pages... >> But it will definitely have much more impact on Postgres performance: >> contention for buffer locks, throwing away pages accessed by read-only >> queries,... > These arguments seem bogus to me. Otherwise the startup process is going > to do that work. There is just one process replaying WAL. Certainly it has some impact on hot standby query execution. But if there will be several prefetch workers (128???) then this impact will be dramatically increased. > >> Also there are two points which makes prefetching into shared buffers more >> complex: >> 1. Need to spawn multiple workers to make prefetch in parallel and somehow >> distribute work between them. > I'm not even convinced that's true. It doesn't seem insane to have a > queue of, say, 128 requests that are done with posix_fadvise WILLNEED, > where the oldest requests is read into shared buffers by the > prefetcher. And then discarded from the page cache with WONTNEED. I > think we're going to want a queue that's sorted in the prefetch process > anyway, because there's a high likelihood that we'll otherwise issue > prfetch requets for the same pages over and over again. > > That gets rid of most of the disadvantages: We have backpressure > (because the read into shared buffers will block if not yet ready), > we'll prevent double buffering, we'll prevent the startup process from > doing the victim buffer search. > > >> Concerning WAL perfetch I still have a serious doubt if it is needed at all: >> if checkpoint interval is less than size of free memory at the system, then >> redo process should not read much. > I'm confused. Didn't you propose this? FWIW, there's a significant > number of installations where people have observed this problem in > practice. Well, originally it was proposed by Sean - the author of pg-prefaulter. I just ported it from GO to C using standard PostgreSQL WAL iterator. Then I performed some measurements and didn't find some dramatic improvement in performance (in case of synchronous replication) or reducing replication lag for asynchronous replication neither at my desktop (SSD, 16Gb RAM, local replication within same computer, pgbench scale 1000), neither at pair of two powerful servers connected by InfiniBand and 3Tb NVME (pgbench with scale 100000). Also I noticed that read rate at replica is almost zero. What does it mean: 1. I am doing something wrong. 2. posix_prefetch is not so efficient. 3. pgbench is not right workload to demonstrate effect of prefetch. 4. Hardware which I am using is not typical. So it make me think when such prefetch may be needed... And it caused new questions: I wonder how frequently checkpoint interval is much larger than OS cache? If we enforce full pages writes (let's say each after each 1Gb), how it affect wal size and performance? Looks like it is difficult to answer the second question without implementing some prototype. May be I will try to do it. >> And if checkpoint interval is much larger than OS cache (are there cases >> when it is really needed?) > Yes, there are. Percentage of FPWs can cause serious problems, as do > repeated writouts by the checkpointer. One more consideration: data is written to the disk as blocks in any case. If you updated just few bytes on a page, then still the whole page has to be written in database file. So avoiding full page writes allows to reduce WAL size and amount of data written to the WAL, but not amount of data written to the database itself. It means that if we completely eliminate FPW and transactions are updating random pages, then disk traffic is reduced less than two times... > > >> then quite small patch (as it seems to me now) forcing full page write >> when distance between page LSN and current WAL insertion point exceeds >> some threshold should eliminate random reads also in this case. > I'm pretty sure that that'll hurt a significant number of installations, > that set the timeout high, just so they can avoid FPWs. May be, but I am not so sure. This is why I will try to investigate it more. > Greetings, > > Andres Freund -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 06/19/2018 05:50 PM, Andres Freund wrote: > On 2018-06-19 12:08:27 +0300, Konstantin Knizhnik wrote: >> I do not think that prefetching in shared buffers requires much more efforts >> and make patch more envasive... >> It even somehow simplify it, because there is no to maintain own cache of >> prefetched pages... > >> But it will definitely have much more impact on Postgres performance: >> contention for buffer locks, throwing away pages accessed by read-only >> queries,... > > These arguments seem bogus to me. Otherwise the startup process is going > to do that work. > > >> Also there are two points which makes prefetching into shared buffers more >> complex: >> 1. Need to spawn multiple workers to make prefetch in parallel and somehow >> distribute work between them. > > I'm not even convinced that's true. It doesn't seem insane to have a > queue of, say, 128 requests that are done with posix_fadvise WILLNEED, > where the oldest requests is read into shared buffers by the > prefetcher. And then discarded from the page cache with WONTNEED. I > think we're going to want a queue that's sorted in the prefetch process > anyway, because there's a high likelihood that we'll otherwise issue > prfetch requets for the same pages over and over again. > > That gets rid of most of the disadvantages: We have backpressure > (because the read into shared buffers will block if not yet ready), > we'll prevent double buffering, we'll prevent the startup process from > doing the victim buffer search. > I'm confused. I thought you wanted to prefetch directly to shared buffers, so that it also works with direct I/O in the future. But now you suggest to use posix_fadvise() to work around the synchronous buffer read limitation. I don't follow ... regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2018-06-19 19:34:22 +0300, Konstantin Knizhnik wrote: > On 19.06.2018 18:50, Andres Freund wrote: > > On 2018-06-19 12:08:27 +0300, Konstantin Knizhnik wrote: > > > I do not think that prefetching in shared buffers requires much more efforts > > > and make patch more envasive... > > > It even somehow simplify it, because there is no to maintain own cache of > > > prefetched pages... > > > But it will definitely have much more impact on Postgres performance: > > > contention for buffer locks, throwing away pages accessed by read-only > > > queries,... > > These arguments seem bogus to me. Otherwise the startup process is going > > to do that work. > > There is just one process replaying WAL. Certainly it has some impact on hot > standby query execution. > But if there will be several prefetch workers (128???) then this impact will > be dramatically increased. Hence me suggesting how you can do that with one process (re locking). I still entirely fail to see how "throwing away pages accessed by read-only queries" is meaningful here - the startup process is going to read the data anyway, and we *do not* want to use a ringbuffer as that'd make the situation dramatically worse. > Well, originally it was proposed by Sean - the author of pg-prefaulter. I > just ported it from GO to C using standard PostgreSQL WAL iterator. > Then I performed some measurements and didn't find some dramatic improvement > in performance (in case of synchronous replication) or reducing replication > lag for asynchronous replication neither at my desktop (SSD, 16Gb RAM, local > replication within same computer, pgbench scale 1000), neither at pair of > two powerful servers connected by > InfiniBand and 3Tb NVME (pgbench with scale 100000). > Also I noticed that read rate at replica is almost zero. > What does it mean: > 1. I am doing something wrong. > 2. posix_prefetch is not so efficient. > 3. pgbench is not right workload to demonstrate effect of prefetch. > 4. Hardware which I am using is not typical. I think it's probably largely a mix of 3 and 4. pgbench with random distribution probably indeed is a bad testcase, because either everything is in cache or just about every write ends up as a full page write because of the scale. You might want to try a) turn of full page writes b) use a less random distribution. > So it make me think when such prefetch may be needed... And it caused new > questions: > I wonder how frequently checkpoint interval is much larger than OS > cache? Extremely common. > If we enforce full pages writes (let's say each after each 1Gb), how it > affect wal size and performance? Extremely badly. If you look at stats of production servers (using pg_waldump) you can see that large percentage of the total WAL volume is FPWs, that FPWs are a storage / bandwidth / write issue, and that higher FPW rates after a checkpoint correlate strongly negatively with performance. Greetings, Andres Freund
Hi, On 2018-06-19 18:41:24 +0200, Tomas Vondra wrote: > I'm confused. I thought you wanted to prefetch directly to shared buffers, > so that it also works with direct I/O in the future. But now you suggest to > use posix_fadvise() to work around the synchronous buffer read limitation. I > don't follow ... Well, I have multiple goals. For one I think using prefetching without any sort of backpressure and mechanism to see which have completed will result in hard to monitor and random performance. For another I'm concerned with wasting a significant amount of memory for the OS cache of all the read data that's guaranteed to never be needed (as we'll *always* write to the relevant page shortly down the road). For those reasons alone I think prefetching just into the OS cache is a bad idea, and should be rejected. I also would want something that's more compatible with DIO. But people pushed back on that, so... As long as we build something that looks like a request queue (which my proposal does), it's also something that can later with some reduced effort be ported onto asynchronous io. Greetings, Andres Freund
On 06/19/2018 06:34 PM, Konstantin Knizhnik wrote: > > > On 19.06.2018 18:50, Andres Freund wrote: >> On 2018-06-19 12:08:27 +0300, Konstantin Knizhnik wrote: >>> I do not think that prefetching in shared buffers requires much more >>> efforts >>> and make patch more envasive... >>> It even somehow simplify it, because there is no to maintain own >>> cache of >>> prefetched pages... >>> But it will definitely have much more impact on Postgres performance: >>> contention for buffer locks, throwing away pages accessed by read-only >>> queries,... >> These arguments seem bogus to me. Otherwise the startup process is going >> to do that work. > > There is just one process replaying WAL. Certainly it has some impact on > hot standby query execution. > But if there will be several prefetch workers (128???) then this impact > will be dramatically increased. > The goal of prefetching is better saturation of the storage. Which means less bandwidth remaining for other processes (that have to compete for the same storage). I don't think "startup process is going to do that work" is entirely true - it'd do that work, but likely over longer period of time. But I don't think this is an issue - I'd expect having some GUC defining how many records to prefetch (just like effective_io_concurrency). >>> Concerning WAL perfetch I still have a serious doubt if it is needed >>> at all: >>> if checkpoint interval is less than size of free memory at the >>> system, then >>> redo process should not read much. >> I'm confused. Didn't you propose this? FWIW, there's a significant >> number of installations where people have observed this problem in >> practice. > > Well, originally it was proposed by Sean - the author of pg-prefaulter. > I just ported it from GO to C using standard PostgreSQL WAL iterator. > Then I performed some measurements and didn't find some dramatic > improvement in performance (in case of synchronous replication) or > reducing replication lag for asynchronous replication neither at my > desktop (SSD, 16Gb RAM, local replication within same computer, pgbench > scale 1000), neither at pair of two powerful servers connected by > InfiniBand and 3Tb NVME (pgbench with scale 100000). > Also I noticed that read rate at replica is almost zero. > What does it mean: > 1. I am doing something wrong. > 2. posix_prefetch is not so efficient. > 3. pgbench is not right workload to demonstrate effect of prefetch. > 4. Hardware which I am using is not typical. > pgbench is a perfectly sufficient workload to demonstrate the issue, all you need to do is use sufficiently large scale factor (say 2*RAM) and large number of clients to generate writes on the primary (to actually saturate the storage). Then the redo on replica won't be able to keep up, because the redo only fetches one page at a time. > So it make me think when such prefetch may be needed... And it caused > new questions: > I wonder how frequently checkpoint interval is much larger than OS cache? Pretty often. Furthermore, replicas may also run queries (often large ones), pushing pages related to redo from RAM. > If we enforce full pages writes (let's say each after each 1Gb), how it > affect wal size and performance? > It would improve redo performance, of course, exactly because the page would not need to be loaded from disk. But the amount of WAL can increase tremendously, causing issues for network bandwidth (particularly between different data centers). > Looks like it is difficult to answer the second question without > implementing some prototype. > May be I will try to do it. Perhaps you should prepare some examples of workloads demonstrating the issue, before trying implementing a solution. >>> And if checkpoint interval is much larger than OS cache (are there cases >>> when it is really needed?) >> Yes, there are. Percentage of FPWs can cause serious problems, as do >> repeated writouts by the checkpointer. > > One more consideration: data is written to the disk as blocks in any > case. If you updated just few bytes on a page, then still the whole page > has to be written in database file. > So avoiding full page writes allows to reduce WAL size and amount of > data written to the WAL, but not amount of data written to the database > itself. > It means that if we completely eliminate FPW and transactions are > updating random pages, then disk traffic is reduced less than two times... > I don't follow. What do you mean by "less than two times"? Surely the difference can be anything between 0 and infinity, depending on how often you write a single page. The other problem with just doing FPI all the time is backups. To do physical backups / WAL archival, you need to store all the WAL segments. If the amount of WAL increases 10x you're going to be unhappy. >> >> >>> then quite small patch (as it seems to me now) forcing full page write >>> when distance between page LSN and current WAL insertion point exceeds >>> some threshold should eliminate random reads also in this case. >> I'm pretty sure that that'll hurt a significant number of installations, >> that set the timeout high, just so they can avoid FPWs. > May be, but I am not so sure. This is why I will try to investigate it > more. > I'd say checkpoints already do act as such timeout (not only, but people are setting it high to get rid of FPIs). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
I continue my experiments with WAL prefetch. I have embedded prefetch in Postgres: now walprefetcher is started together with startup process and is able to help it to speedup recovery. The patch is attached. Unfortunately result is negative (at least at my desktop: SSD, 16Gb RAM). Recovery with prefetch is 3 times slower than without it. What I am doing: Configuration: max_wal_size=min_wal_size=10Gb, shared)buffers = 1Gb Database: pgbench -i -s 1000 Test: pgbench -c 10 -M prepared -N -T 100 -P 1 pkill postgres echo 3 > /proc/sys/vm/drop_caches time pg_ctl -t 1000 -D pgsql -l logfile start Without prefetch it is 19 seconds (recovered about 4Gb of WAL), with prefetch it is about one minute. About 400k blocks are prefetched. CPU usage is small (<20%), both processes as in "Ds" state. vmstat without prefetch shows the following output: procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 2 2667964 11465832 7892 2515588 0 0 344272 2 6129 22290 8 4 84 5 0 3 1 2667960 10013900 9516 3963056 6 0 355606 8772 7412 25228 12 6 74 8 0 1 0 2667960 8526228 11036 5440192 0 0 366910 242 6123 19476 8 5 83 3 0 1 1 2667960 7824816 11060 6141920 0 0 166860 171638 9581 24746 4 4 79 13 0 0 4 2667960 7822824 11072 6143788 0 0 264 376836 19292 49973 1 3 69 27 0 1 0 2667960 7033140 11220 6932400 0 0 188810 168070 14610 41390 5 4 72 19 0 1 1 2667960 5739616 11384 8226148 0 0 254492 57884 6733 19263 8 5 84 4 0 0 3 2667960 5024380 11400 8941532 0 0 8 398198 18164 45782 2 5 70 23 0 0 0 2667960 5020152 11428 8946000 0 0 168 69128 3918 10370 2 1 91 6 0 with prefetch: procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 2 2651816 12340648 11148 1564420 0 0 178980 96 4411 14237 5 2 90 3 0 2 0 2651816 11771612 11712 2132180 0 0 169572 0 6388 18244 5 3 72 20 0 2 0 2651816 11199248 12008 2701960 0 0 168966 162 6677 18816 5 3 72 20 0 1 3 2651816 10660512 12028 3241604 0 0 162666 16 7065 21668 6 5 69 20 0 0 2 2651816 10247180 12052 3653888 0 0 131564 18112 7376 22023 6 3 69 23 0 0 2 2651816 9850424 12096 4064980 0 0 133158 238 6398 17557 4 2 71 22 0 2 0 2651816 9456616 12108 4459456 0 0 134702 44 6219 16665 3 2 73 22 0 0 2 2651816 9161336 12160 4753868 0 0 111168 74408 8038 20440 3 3 69 25 0 3 0 2651816 8810336 12172 5106068 0 0 134694 0 6251 16978 4 2 73 22 0 0 2 2651816 8451924 12192 5463692 0 0 137546 80 6264 16930 3 2 73 22 0 1 1 2651816 8108000 12596 5805856 0 0 135212 10 6218 16827 4 2 72 22 0 1 3 2651816 7793992 12612 6120376 0 0 135072 0 6233 16736 3 2 73 22 0 0 2 2651816 7507644 12632 6406512 0 0 134830 90 6267 16910 3 2 73 22 0 0 2 2651816 7246696 12776 6667804 0 0 122656 51820 7419 19384 3 3 71 23 0 1 2 2651816 6990080 12784 6924352 0 0 121248 55284 7527 19794 3 3 71 23 0 0 3 2651816 6913648 12804 7000376 0 0 36078 295140 14852 37925 2 3 67 29 0 0 2 2651816 6873112 12804 7040852 0 0 19180 291330 16167 41711 1 3 68 28 0 5 1 2651816 6641848 12812 7271736 0 0 107696 68 5760 15301 3 2 73 22 0 3 1 2651816 6426356 12820 7490636 0 0 103412 0 5942 15994 3 2 72 22 0 0 2 2651816 6195288 12824 7720720 0 0 104446 0 5605 14757 3 2 73 22 0 0 2 2651816 5946876 12980 7970912 0 0 113340 74 5980 15678 3 2 71 24 0 1 2 2651816 5655768 12984 8262880 0 0 137290 0 6235 16412 3 2 73 21 0 2 0 2651816 5359548 13120 8557072 0 0 137608 86 6309 16658 3 2 73 21 0 2 0 2651816 5068268 13124 8849136 0 0 137386 0 6225 16589 3 2 73 21 0 2 0 2651816 4816812 13124 9100600 0 0 120116 53284 7273 18776 3 2 72 23 0 0 2 2651816 4563152 13132 9353232 0 0 117972 54352 7423 19375 3 2 73 22 0 1 2 2651816 4367108 13144 9549712 0 0 51994 239498 10846 25987 3 5 73 19 0 0 0 2651816 4366356 13164 9549892 0 0 168 294196 14981 39432 1 3 79 17 0 So as you can see, read speed with prefetch is smaller: < 130Mb/sec, while without prefetch up to 366Mb/sec. My hypothesis is that prefetch flushes dirty pages from cache and as a result, more data has to be written and backends are more frequently blocked in write. In any case - very upsetting result. Any comments are welcome. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On 06/21/2018 04:01 PM, Konstantin Knizhnik wrote:
> I continue my experiments with WAL prefetch.
> I have embedded prefetch in Postgres: now walprefetcher is started
> together with startup process and is able to help it to speedup recovery.
> The patch is attached.
>
> Unfortunately result is negative (at least at my desktop: SSD, 16Gb
> RAM). Recovery with prefetch is 3 times slower than without it.
> What I am doing:
>
> Configuration:
> max_wal_size=min_wal_size=10Gb,
> shared)buffers = 1Gb
> Database:
> pgbench -i -s 1000
> Test:
> pgbench -c 10 -M prepared -N -T 100 -P 1
> pkill postgres
> echo 3 > /proc/sys/vm/drop_caches
> time pg_ctl -t 1000 -D pgsql -l logfile start
>
> Without prefetch it is 19 seconds (recovered about 4Gb of WAL), with
> prefetch it is about one minute. About 400k blocks are prefetched.
> CPU usage is small (<20%), both processes as in "Ds" state.
>
Based on a quick test, my guess is that the patch is broken in several
ways. Firstly, with the patch attached (and wal_prefetch_enabled=on,
which I think is needed to enable the prefetch) I can't even restart the
server, because pg_ctl restart just hangs (the walprefetcher process
gets stuck in WaitForWAL, IIRC).
I have added an elog(LOG,...) to walprefetcher.c, right before the
FilePrefetch call, and (a) I don't see any actual prefetch calls during
recovery but (b) I do see the prefetch happening during the pgbench.
That seems a bit ... wrong?
Furthermore, you've added an extra
signal_child(BgWriterPID, SIGHUP);
to SIGHUP_handler, which seems like a bug too. I don't have time to
investigate/debug this further.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 21.06.2018 19:57, Tomas Vondra wrote: > > > On 06/21/2018 04:01 PM, Konstantin Knizhnik wrote: >> I continue my experiments with WAL prefetch. >> I have embedded prefetch in Postgres: now walprefetcher is started >> together with startup process and is able to help it to speedup >> recovery. >> The patch is attached. >> >> Unfortunately result is negative (at least at my desktop: SSD, 16Gb >> RAM). Recovery with prefetch is 3 times slower than without it. >> What I am doing: >> >> Configuration: >> max_wal_size=min_wal_size=10Gb, >> shared)buffers = 1Gb >> Database: >> pgbench -i -s 1000 >> Test: >> pgbench -c 10 -M prepared -N -T 100 -P 1 >> pkill postgres >> echo 3 > /proc/sys/vm/drop_caches >> time pg_ctl -t 1000 -D pgsql -l logfile start >> >> Without prefetch it is 19 seconds (recovered about 4Gb of WAL), with >> prefetch it is about one minute. About 400k blocks are prefetched. >> CPU usage is small (<20%), both processes as in "Ds" state. >> > > Based on a quick test, my guess is that the patch is broken in several > ways. Firstly, with the patch attached (and wal_prefetch_enabled=on, > which I think is needed to enable the prefetch) I can't even restart > the server, because pg_ctl restart just hangs (the walprefetcher > process gets stuck in WaitForWAL, IIRC). > > I have added an elog(LOG,...) to walprefetcher.c, right before the > FilePrefetch call, and (a) I don't see any actual prefetch calls > during recovery but (b) I do see the prefetch happening during the > pgbench. That seems a bit ... wrong? > > Furthermore, you've added an extra > > signal_child(BgWriterPID, SIGHUP); > > to SIGHUP_handler, which seems like a bug too. I don't have time to > investigate/debug this further. > > regards Sorry, updated version of the patch is attached. Please also notice that you can check number of prefetched pages using pg_stat_activity() - it is reported for walprefetcher process. Concerning the fact that you have no see prefetches at recovery time: please check that min_wal_size and max_wal_size are large enough and pgbench (or whatever else) committed large enough changes so that recovery will take some time. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On 22.06.2018 11:35, Konstantin Knizhnik wrote: > > > On 21.06.2018 19:57, Tomas Vondra wrote: >> >> >> On 06/21/2018 04:01 PM, Konstantin Knizhnik wrote: >>> I continue my experiments with WAL prefetch. >>> I have embedded prefetch in Postgres: now walprefetcher is started >>> together with startup process and is able to help it to speedup >>> recovery. >>> The patch is attached. >>> >>> Unfortunately result is negative (at least at my desktop: SSD, 16Gb >>> RAM). Recovery with prefetch is 3 times slower than without it. >>> What I am doing: >>> >>> Configuration: >>> max_wal_size=min_wal_size=10Gb, >>> shared)buffers = 1Gb >>> Database: >>> pgbench -i -s 1000 >>> Test: >>> pgbench -c 10 -M prepared -N -T 100 -P 1 >>> pkill postgres >>> echo 3 > /proc/sys/vm/drop_caches >>> time pg_ctl -t 1000 -D pgsql -l logfile start >>> >>> Without prefetch it is 19 seconds (recovered about 4Gb of WAL), with >>> prefetch it is about one minute. About 400k blocks are prefetched. >>> CPU usage is small (<20%), both processes as in "Ds" state. >>> >> >> Based on a quick test, my guess is that the patch is broken in >> several ways. Firstly, with the patch attached (and >> wal_prefetch_enabled=on, which I think is needed to enable the >> prefetch) I can't even restart the server, because pg_ctl restart >> just hangs (the walprefetcher process gets stuck in WaitForWAL, IIRC). >> >> I have added an elog(LOG,...) to walprefetcher.c, right before the >> FilePrefetch call, and (a) I don't see any actual prefetch calls >> during recovery but (b) I do see the prefetch happening during the >> pgbench. That seems a bit ... wrong? >> >> Furthermore, you've added an extra >> >> signal_child(BgWriterPID, SIGHUP); >> >> to SIGHUP_handler, which seems like a bug too. I don't have time to >> investigate/debug this further. >> >> regards > > Sorry, updated version of the patch is attached. > Please also notice that you can check number of prefetched pages using > pg_stat_activity() - it is reported for walprefetcher process. > Concerning the fact that you have no see prefetches at recovery time: > please check that min_wal_size and max_wal_size are large enough and > pgbench (or whatever else) > committed large enough changes so that recovery will take some time. > > I have improved my WAL prefetch patch. The main reason of slowdown recovery speed with enabled prefetch was that it doesn't take in account initialized pages (XLOG_HEAP_INIT_PAGE) and doesn't remember (cache) full page writes. The main differences of new version of the patch: 1. Use effective_cache_size as size of cache of prefetched blocks 2. Do not prefetch blocks sent in shared buffers 3. Do not prefetch blocks for RM_HEAP_ID with XLOG_HEAP_INIT_PAGE bit set 4. Remember new/fpw pages in prefetch cache, to avoid prefetch them for subsequent WAL records. 5. Add min/max prefetch lead parameters to make it possible to synchronize speed of prefetch with speed of replay. 6. Increase size of open file cache to avoid redundant open/close operations. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On 06/27/2018 11:44 AM, Konstantin Knizhnik wrote: > > ... > > I have improved my WAL prefetch patch. The main reason of slowdown > recovery speed with enabled prefetch was that it doesn't take in account > initialized pages (XLOG_HEAP_INIT_PAGE) > and doesn't remember (cache) full page writes. > The main differences of new version of the patch: > > 1. Use effective_cache_size as size of cache of prefetched blocks > 2. Do not prefetch blocks sent in shared buffers > 3. Do not prefetch blocks for RM_HEAP_ID with XLOG_HEAP_INIT_PAGE bit set > 4. Remember new/fpw pages in prefetch cache, to avoid prefetch them for > subsequent WAL records. > 5. Add min/max prefetch lead parameters to make it possible to > synchronize speed of prefetch with speed of replay. > 6. Increase size of open file cache to avoid redundant open/close > operations. > Thanks. I plan to look at it and do some testing, but I won't have time until the end of next week (probably). regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, I've done a bit of testing on the current patch, mostly to see how much the prefetching can help (if at all). While the patch is still in early WIP stages (at least that's my assessment, YMMV), the improvement are already quite significant. I've also planned to compare it to the pg_prefaulter [1] which kinda started this all, but I've been unable to get it working with my very limited knowledge of golang. I've fixed the simple stuff (references to renamed PostgreSQL functions etc.) but then it does not do anything :-( I wonder if it's working on FreeBSD only, or something like that ... So this compares only master with and without WAL prefetching. Instead of killing the server and measuring local recovery (which is what Konstantin did before), I've decided to use replication. That is, setup a replica, run pgbench on the master and see how much apply lag we end up with over time. I find this much easier to reproduce, monitor over time, do longer runs, ... master ------ * 32 cores (2x E5-2620v4) * 32GB of RAM * Intel Optane SSD 280GB * shared_buffers=4GB * max_wal_size=128GB * checkpoint_timeout=30min replica ------- * 4 cores (i5-2500k) * 8GB RAM * 6x Intel S3700 SSD (RAID0) * shared_buffers=512MB * effective_cache_size=256MB I've also decided to use pgbench scale 1000 (~16GB) which fits into RAM on the master but not the replica. This may seem like a bit strange choice, but I think it's not entirely crazy, for a couple of reasons: * It's not entirely uncommon to have replicas with different hardware condiguration. For HA it's a bad idea, but there are valid use cases. * Even with the same hardware config, you may have very different workload on the replica, accessing very different subset of the data. Consider master doing OLTP on small active set, while replica runs BI queries on almost all data, pushing everything else from RAM. * It amplifies the effect of prefetching, which is nice for testing. * I don't have two machines with exactly the same config anyway ;-) The pgbench test is then executed on master like this: pgbench -c 32 -j 8 -T 3600 -l --aggregate-interval=1 test The replica is unlikely to keep up with the master, so the question is how much apply lag we end up with at the end. Without prefetching, it's ~70GB of WAL. With prefetching, it's only about 30GB. Considering the 1-hour test generates about 90GB of WAL, this means the replay speed grew from 20GB/h to almost 60GB/h. That's rather measurable improvement ;-) The attached replication-lag.png chart, showing how the lag grows over time. The "bumps" after ~30 minutes coincide with a checkpoint, triggering FPIs for a short while. The record-size.png and fpi-size.png come from pg_waldump and show what part of WAL consists of regular records and FPIs. Note: I've done two runs with each configuration, so there are four data series on all charts. With prefetching the lag drops down a bit after a while (by about the same amount of WAL), while without prefetch it does not. My explanation is that the replay is so slow it does not get to the FPIs until after the test - so it happens, but we don't see it here. Now, how does this look on system metrics? Without prefetching we see low CPU usage, because the process is waiting for I/O. And the I/O is under-utilized, because we only issue one request at a time (which means short I/O queues, low utilization of individual devices in the RAID). In this case I see that without prefetching, the replay process uses about 20% of a CPU. With prefetching increases this to ~60%, which is nice. At the storage level, the utilization for each device in the RAID0 array is ~20%, and with prefetching enabled this jumps up to ~40%. If you look at IOPS instead, that jumps from ~2000 to ~6500, so about 3x. How is this possible when the utilization grew only ~2x? We're generating longer I/O queues (20 requests instead of 3), and the devices can optimize it quite a bit. I think there's a room for additional improvement. We probably can't get the CPU usage to 100%, but 60% is still quite low. The storage can certainly handle more requests, the devices are doing something only about 40% of the time. But overall it looks quite nice, and I think it's worth to keep working on it. BTW to make this work, I had to tweak NUM_AUXILIARY_PROCS (increase it from 4 to 5), otherwise InitAuxiliaryProcess() fails because there's not room for additional process. I assume it works with local recovery, but once you need to start walreceiver it fails. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
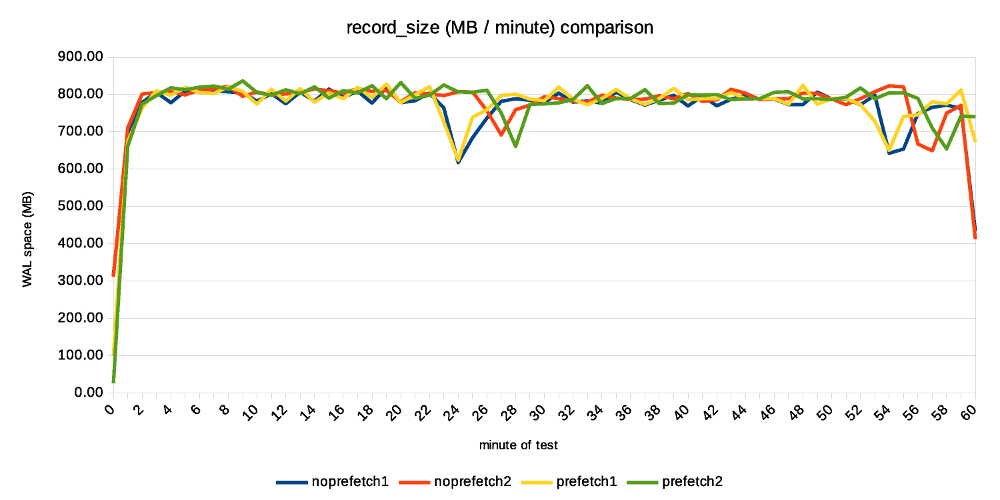{kind=link}
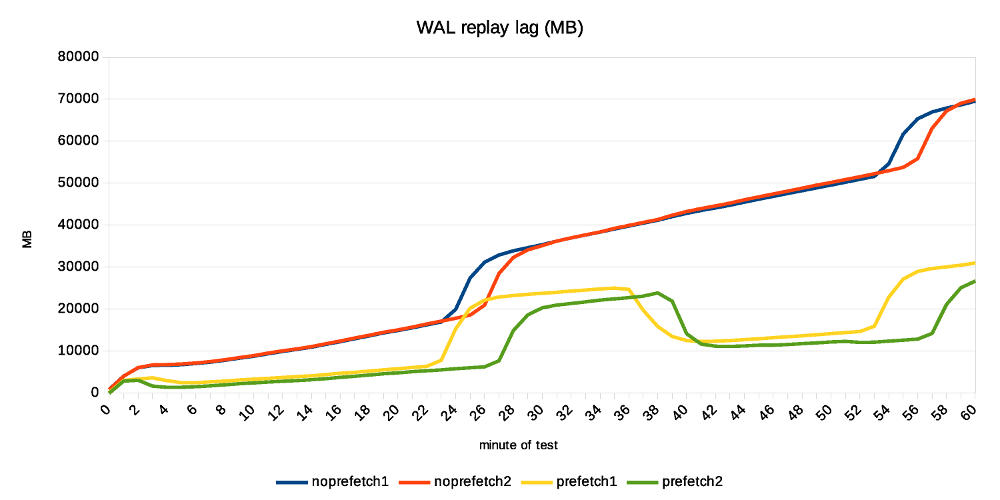{kind=link}
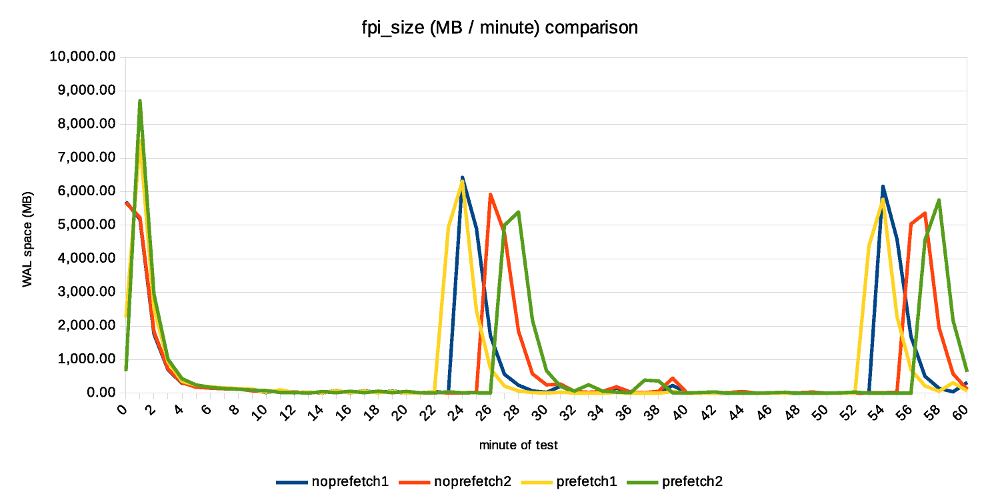{kind=link}
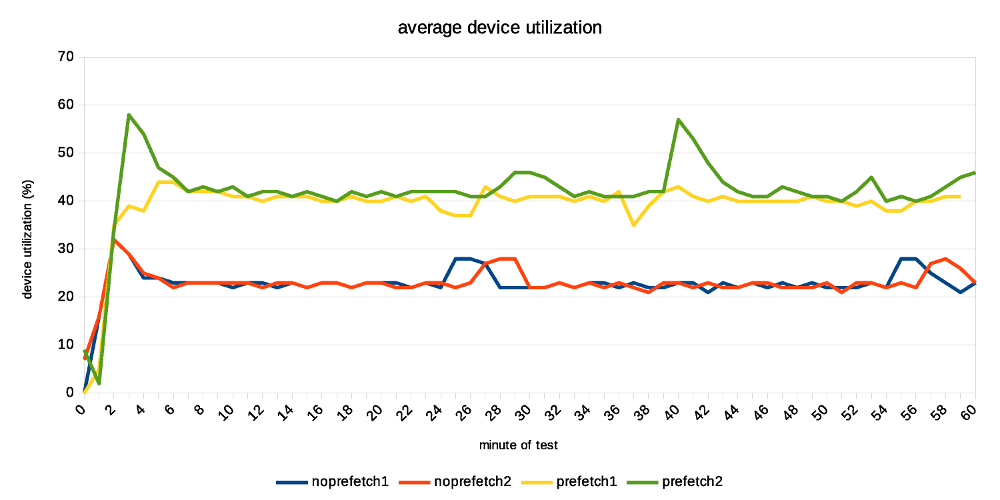{kind=link}
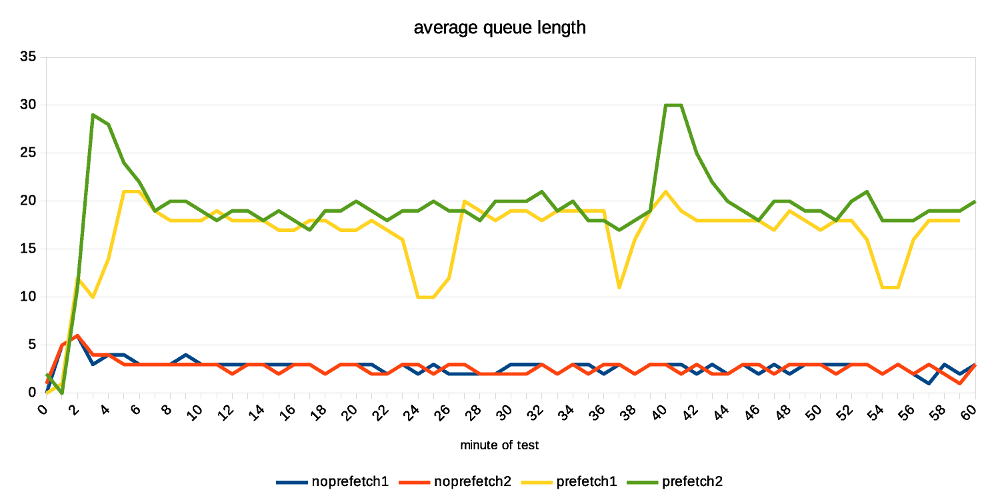{kind=link}
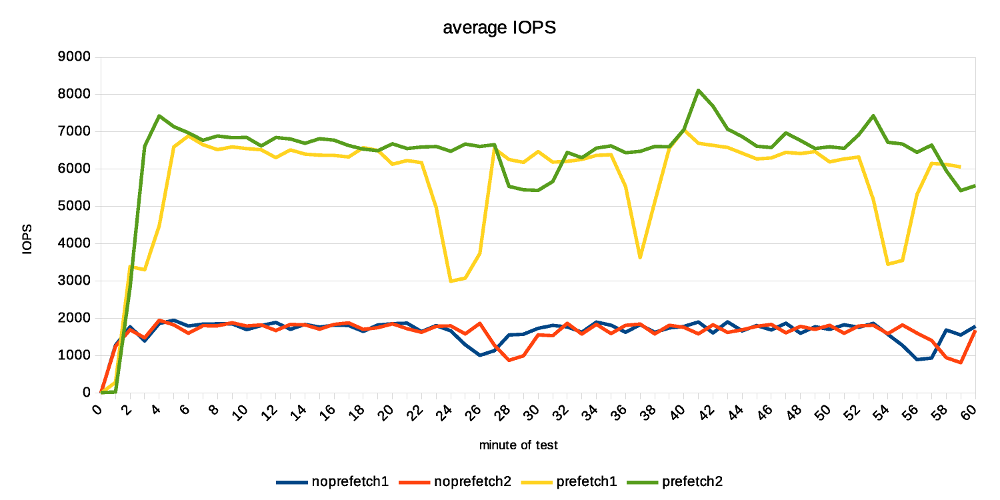{kind=link}
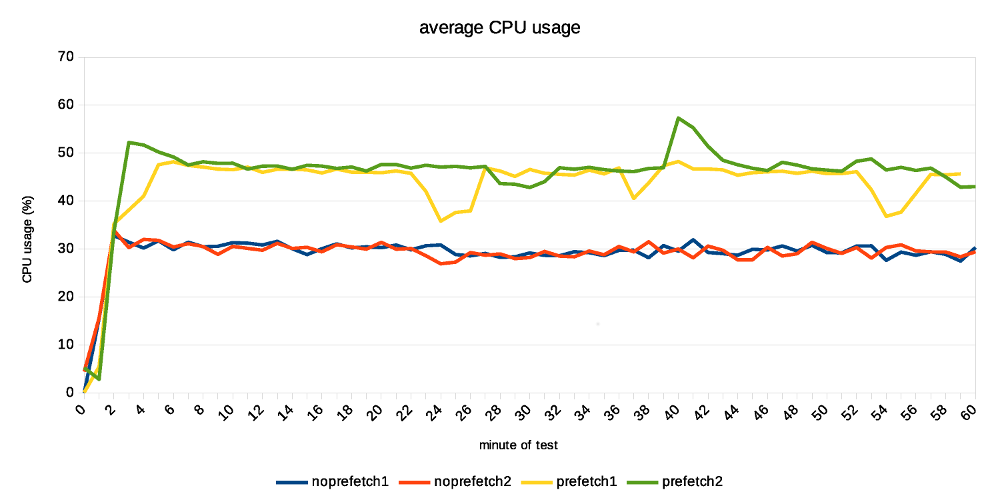{kind=link}
> Without prefetching, it's ~70GB of WAL. With prefetching, it's only about
> 30GB. Considering the 1-hour test generates about 90GB of WAL, this means the
> replay speed grew from 20GB/h to almost 60GB/h. That's rather measurable
> improvement ;-)
Thank you everyone for this reasonably in-depth thread on prefaulting.
Because this was a sprawling thread and I haven't been keeping up with this
discussion until now, let me snag a bunch of points and address them here in one
shot. I've attempted to answer a bunch of questions that appear to have come up
during this thread, as well as provide some clarity where there were unanswered
questions. Apologies in advance for the length.
There are a few points that I want to highlight regarding prefaulting, and I
also want to call out when prefaulting is and isn't useful. But first, let me
introduce three terms that will help characterize this problem:
1. Hot read-modify-write - a PG page that is modified while the page is still
contained within shared_buffers.
2. Warm read-modify-write ("RMW") - a PG page that's in the filesystem cache but
not present in shared_buffers.
3. Cold RMW - a PG page is not in either PG's shared_buffers or the OS'es
filesystem cache.
Prefaulting is only useful in addressing the third situation, the cold
read-modify-write. For fast disks, or systems that have their entire dataset
held in RAM, or whose disk systems can perform a RMW fast enough for the
velocity of incoming writes, there is no benefit of prefaulting (this is why
there is a high and low-watermark in pg_prefaulter). In these situations
prefaulting would potentially be extra constant overhead, especially for DBs
where their workload is ~100% Hot/Warm RMW. Primaries are almost always under
the Hot RMW workload (cold restarts being the exception).
The warm RMW scenario could be solved by prefaulting into shared_buffers, but I
doubt there would be a significant performance benefit because the expense of
PostgreSQL faulting from shared_buffers to the OS cache is relatively small
compared to a disk read. I do think there is something to be gained in the Warm
RMW case, but compared to Cold RMW, this optimization is noise and best left for
a future iteration.
The real importance of prefaulting becomes apparent in the following two
situations:
1. Priming the OS's filesystem cache, notably after an OS restart. This is of
value to all PostgreSQL scenarios, regardless of whether or not it's a
primary or follower. Reducing database startup/recovery times is very
helpful, especially when recovering from an outage or after having performed
planned maintenance. Little in PostgreSQL administration is more infuriating
than watching PostgreSQL recover and seeing the CPU 100% idle and the disk IO
system nearly completely idle (especially during an outage or when recovering
from an outage).
2. When the following two environmental factors are true:
a. the volume of writes to discrete pages is high
b. the interval between subsequent writes to a single page is long enough
that a page is evicted from both shared_buffers and the filesystem cache
Write-heavy workloads tend to see this problem, especially if you're
attempting to provide consistency in your application and do not read from
the followers (thereby priming their OS/shared_buffer cache). If the
workload is continuous, the follower may never be able overcome the write
volume and the database never catches up.
The pg_prefaulter was borne out of the last workload, namely a write-heavy, 24/7
constant load with a large dataset.
What pg_prefaulter does is read in the blocks referenced from the WAL stream
(i.e. PG heap pages) and then load the referenced pages into the OS filesystem
cache (via threaded calls to pread(2)). The WAL apply process has a cache-hit
because the filesystem cache has been primed with the heap page before the apply
process attempted to perform its read-modify-write of the heap.
It is important to highlight that this is a problem because there is only one
synchronous pread(2) call in flight at a time from the apply/recover/startup
process, which effectively acts as the speed limit for PostgreSQL. The physics
of many workloads are such that followers are unable to keep up and are thus
destined to always fall behind (we've all seen this at some point, likely via
apply lag from a VACUUM or pg_repack). The primary can schedule concurrent IO
from multiple client all making independent SELECTS. Contrast that to a replica
who has zero knowledge of the IOs that the primary recently dispatched, and all
IO looks like random read and likely a cache miss. In effect, the pg_prefaulter
raises the speed limit of the WAL apply/recovery process by priming the
filesystem cache by snooping in on the WAL stream.
PostgreSQL's WAL apply and recovery process is only capable of scheduling a
single synchronous pread(2) syscall. As a result, even if you have an RAID10
and a capable IO scheduler in the OS that is able to read form both halves of
each mirror, you're only going to perform ~150-225 pread(2) calls per second.
Despite the entire disk system being able to deliver something closer to
2400-3600 IOPS (~10ms random-read == ~150-225 IOPS * 16x disks), you'll only
observe ~6% utilization of the random read IO capabilities of a server. When
you realize the size of the unapplied WAL entries represents a backlog of queued
or unscheduled IOs, the phrase "suboptimal" doesn't begin to do reality justice.
One or more of the following activities can demonstrate the problem:
* Natural random-write workloads at high velocity
* VACUUM activity
* pg_repack
* slow IO subsystems on followers
* synchronous apply
Regarding the environment where pg_prefaulter was written, the server hardware
was reasonably beefy servers (256GB RAM, 16x 10K SAS disks) and this database
cluster was already in a scale-out configuration. Doubling the number of
database servers would only spread the load out by 2x, but we'd still only be
utilizing ~6% of the IO across the fleet. We needed ~100% IO utilization when
followers were falling behind. In practice we are seeing orders of magnitude
improvement in apply lag.
Other points worth mentioning:
* the checkpoint_interval was set to anywhere between 15s and 300s, it didn't
matter - we did discover a new form of lag, however, checkpoint lag. Pages
were being evicted from cache faster than checkpoints were able to execute,
leading to unbounded checkpoints and WAL growth (i.e. writes were fast enough
that the checkpointer was suffering from Cold RMW). iirc, pg_prefaulter reads
in both WAL pages and WAL files that are about to be used in checkpoints (it's
been a while since I wrote this code).
* The pg_prefaulter saw the best performance when we increased the number of IO
workers to be roughly equal to the available IO commands the OS could schedule
and dispatch (i.e. 16x disks * 150 IOPS == ~2K).
* pg_prefaulter is very aggressive about not performing work twice or reading
the same page multiple times. pg_prefaulter uses a heap page cache to prevent
redundant IOs for the same PG heap page. pg_prefaulter also dedupes IO
requests in case the same page was referenced twice in short succession due to
data locality in the WAL stream. The workload was already under cache
pressure. Artificially promoting a page from the ARC MRU to MFU would result
in potentially useful records in the MFU being evicted from cache.
* During the design phase, I looked into using bgworkers but given the number of
in-flight pread(2) calls required to fully utilize the IO subsystem, I opted
for something threaded (I was also confined to using Solaris which doesn't
support posix_fadvise(2), so I couldn't sequentially dispatch async
posix_fadvise(2) calls and hope for the best).
* In my testing I was successfully using pgbench(1) to simulate the workload.
Increased the checkpoint_interval and segments to a very high number was
sufficient. I could see the improvement for cold-start even with SSDs, but
I'm not sure how big of an impact this would be for NVMe.
* My slides are posted and have graphs of the before and after using the
pg_prefaulter, but I'm happy to provide additional details or answer more Q's.
* It would be interesting to see if posix_fadvise(2) is actually harming
performance. For example, spinning off a throw-away implementation that uses
aio or a pthread worker pool + pread(2). I do remember seeing some mailing
list blurbs from Mozilla where they were attempting to use posix_fadvise(2)
and were seeing a slow down in performance on Linux (I believe this has since
been fixed, but it wouldn't surprise me if there were still unintended
consequences from this syscall).
* I have a port of pg_prefaulter that supports PostgreSQL >= 9 ~complete, but
not pushed. I'll see if I can get to that this week. For "reasons" this
isn't a high priority for me at the moment, but I'm happy to help out and see
this move forward.
* Tomas, feel free to contact me offline to discuss why the pg_prefault isn't
working for you. I have it running on Linux, FreeBSD, illumos, and macOS.
* In the graph from Tomas (nice work, btw), it's clear that the bandwidth is the
same. The way that we verified this earlier was to run ~10-15min traces and
capture the file and offset of every read of PostgreSQL and pg_prefaulter. We
saw pg_prefaulter IOs be ~100% cache miss. For PostgreSQL, we could observe
that ~99% of its IO was cache hit. We also verified that pg_prefaulter wasn't
doing any IO that wasn't eventually performed by PostgreSQL by comparing the
IOs performed against each heap segment.
* Drop a VACUUM FULL FREEZE into any pgbench testing (or a pg_repack) and it's
trivial to see the effects, even on SSD. Similarly, performing a fast
shutdown of a replica and amassing a large backlog of unrecieved, unapplied
WAL pages is pretty demonstrative.
* "In this case I see that without prefetching, the replay process uses about
20% of a CPU. With prefetching increases this to ~60%, which is nice." With
the pg_prefaulter, the IO should hit 100% utilization. Like I mentioned
above, Tomas, I'd like to make sure you get this working so you can compare
and improve as necessary. :~] I never got CPU utilization to 100%, but I did
get disk IO utilization to 100%, and that to me was the definition of success.
CPU utilization of the apply process could become 100% utilized with fast
enough disks but in production I didn't have anything that wasn't spinning
rust.
* It looks like we're still trying to figure out the nature of this problem and
the cost of various approaches. From a rapid prototyping perspective, feel
free to suggest changes to the Go pg_prefaulter and toss the various
experiments behind a feature flag.
* "> But it is implemented in GO and using pg_waldump.
Yeah, that's not too good if we want it in core."
I fail to see the problem with a side-car in Go. *checks calendar* :~]
* In pg_prefaulter all IOs are converted into full-page reads.
* pg_prefaulter will not activate if the number of unapplied WAL pages is less
than the size of 1 WAL segment (i.e. 16MB). This could be tuned further, but
this low-water mark seems to work well.
* pg_prefaulter won't read-ahead more than 100x WAL segments into the future. I
made the unverified assumption that PostgreSQL could not process more than
1.6GB of WAL (~1/2 of the memory bandwidth available for a single process) in
less than the rotational latency of a random IO (i.e. ~10ms), and that
pg_prefaulter could in theory stay ahead of PG. PostgreSQL normally overtakes
pg_prefaulter's ability to fault in random pages due to disk IO limitations
(PostgreSQL's cache hit rate is ~99.9%, not 100% for this very reason). In
practice this has worked out, but I'm sure there's room for improvement with
regards to setting the high-watermark and reducing this value. #yoloconstants
* I contemplated not reading in FPW but this would have been detrimental on ZFS
because ZFS is a copy-on-write filesystem (vs block filesystem). For ZFS, we
are using a 16K record size, compressed down to ~8K. We have to read the
entire record in before we can modify half of the page. I suspect eliding
prefaulting FPWs will always be a performance loss for nearly all hardware.
* If there is sufficient interest in these experiences, contact me offline (or
via PostgreSQL Slack) and I can setup a call to answer questions in a
higher-bandwidth setting such as Zoom or Google Hangouts.
I'm sorry for being late to the reply party, I've been watching posts in this
thread accumulate for a while and haven't had time to respond until now.
Cheers. -sc
--
Sean Chittenden
Attachment
On 07/09/2018 02:26 AM, Sean Chittenden wrote: > > ... snip ... > > The real importance of prefaulting becomes apparent in the following two > situations: > > 1. Priming the OS's filesystem cache, notably after an OS restart. This is of > value to all PostgreSQL scenarios, regardless of whether or not it's a > primary or follower. Reducing database startup/recovery times is very > helpful, especially when recovering from an outage or after having performed > planned maintenance. Little in PostgreSQL administration is more infuriating > than watching PostgreSQL recover and seeing the CPU 100% idle and the disk IO > system nearly completely idle (especially during an outage or when recovering > from an outage). > 2. When the following two environmental factors are true: > a. the volume of writes to discrete pages is high > b. the interval between subsequent writes to a single page is long enough > that a page is evicted from both shared_buffers and the filesystem cache > > Write-heavy workloads tend to see this problem, especially if you're > attempting to provide consistency in your application and do not read from > the followers (thereby priming their OS/shared_buffer cache). If the > workload is continuous, the follower may never be able overcome the write > volume and the database never catches up. > > The pg_prefaulter was borne out of the last workload, namely a write-heavy, 24/7 > constant load with a large dataset. > Good, that generally matches the workload I've been using for testing. > > What pg_prefaulter does is read in the blocks referenced from the WAL stream > (i.e. PG heap pages) and then load the referenced pages into the OS filesystem > cache (via threaded calls to pread(2)). The WAL apply process has a cache-hit > because the filesystem cache has been primed with the heap page before the apply > process attempted to perform its read-modify-write of the heap. > > It is important to highlight that this is a problem because there is only one > synchronous pread(2) call in flight at a time from the apply/recover/startup > process, which effectively acts as the speed limit for PostgreSQL. The physics > of many workloads are such that followers are unable to keep up and are thus > destined to always fall behind (we've all seen this at some point, likely via > apply lag from a VACUUM or pg_repack). The primary can schedule concurrent IO > from multiple client all making independent SELECTS. Contrast that to a replica > who has zero knowledge of the IOs that the primary recently dispatched, and all > IO looks like random read and likely a cache miss. In effect, the pg_prefaulter > raises the speed limit of the WAL apply/recovery process by priming the > filesystem cache by snooping in on the WAL stream. > > PostgreSQL's WAL apply and recovery process is only capable of scheduling a > single synchronous pread(2) syscall. As a result, even if you have an RAID10 > and a capable IO scheduler in the OS that is able to read form both halves of > each mirror, you're only going to perform ~150-225 pread(2) calls per second. > Despite the entire disk system being able to deliver something closer to > 2400-3600 IOPS (~10ms random-read == ~150-225 IOPS * 16x disks), you'll only > observe ~6% utilization of the random read IO capabilities of a server. When > you realize the size of the unapplied WAL entries represents a backlog of queued > or unscheduled IOs, the phrase "suboptimal" doesn't begin to do reality justice. > > One or more of the following activities can demonstrate the problem: > > * Natural random-write workloads at high velocity > * VACUUM activity > * pg_repack > * slow IO subsystems on followers > * synchronous apply > > Regarding the environment where pg_prefaulter was written, the server hardware > was reasonably beefy servers (256GB RAM, 16x 10K SAS disks) and this database > cluster was already in a scale-out configuration. Doubling the number of > database servers would only spread the load out by 2x, but we'd still only be > utilizing ~6% of the IO across the fleet. We needed ~100% IO utilization when > followers were falling behind. In practice we are seeing orders of magnitude > improvement in apply lag. > Yeah, the poor I/O utilization is annoying. Considering the storage is often the most expensive part of the database system, it's a bit like throwing money out of the window :-/ > > Other points worth mentioning: > > * the checkpoint_interval was set to anywhere between 15s and 300s, it didn't > matter - we did discover a new form of lag, however, checkpoint lag. Pages > were being evicted from cache faster than checkpoints were able to execute, > leading to unbounded checkpoints and WAL growth (i.e. writes were fast enough > that the checkpointer was suffering from Cold RMW). iirc, pg_prefaulter reads > in both WAL pages and WAL files that are about to be used in checkpoints (it's > been a while since I wrote this code). > Hmmm, I'm not sure how a checkpointer could hit a cold RMW, considering it merely writes out dirty pages from shared buffers. Although, perhaps it's specific to ZFS setups with 16kB record sizes? > * The pg_prefaulter saw the best performance when we increased the number of IO > workers to be roughly equal to the available IO commands the OS could schedule > and dispatch (i.e. 16x disks * 150 IOPS == ~2K). > Yeah. I wonder how would this work for flash-based storage that can achieve much higher IOPS values. > * pg_prefaulter is very aggressive about not performing work twice or reading > the same page multiple times. pg_prefaulter uses a heap page cache to prevent > redundant IOs for the same PG heap page. pg_prefaulter also dedupes IO > requests in case the same page was referenced twice in short succession due to > data locality in the WAL stream. The workload was already under cache > pressure. Artificially promoting a page from the ARC MRU to MFU would result > in potentially useful records in the MFU being evicted from cache. > Makes sense. I think the patch does that too, by keeping a cache of recently prefetched blocks. > * During the design phase, I looked into using bgworkers but given the number of > in-flight pread(2) calls required to fully utilize the IO subsystem, I opted > for something threaded (I was also confined to using Solaris which doesn't > support posix_fadvise(2), so I couldn't sequentially dispatch async > posix_fadvise(2) calls and hope for the best). > Hmm, yeah. I'm not sure what to do with this. Using many (thousands?) of prefetch processes seems like a bad idea - we surely can't make them regular bgworkers. Perhaps we could use one process with many threads? Presumably if we knew about a better way to do prefetching without posix_fadvise, we'd have implemented it in FilePrefetch(). But we just error out instead :-( > * In my testing I was successfully using pgbench(1) to simulate the workload. > Increased the checkpoint_interval and segments to a very high number was > sufficient. I could see the improvement for cold-start even with SSDs, but > I'm not sure how big of an impact this would be for NVMe. > I think the impact on NVMe (particularly Optane) will be smaller, because the devices handle low queue depths better, particularly for reads. AFAIK it's the opposite for writes (higher queue depths are needed), but writes are kinda throttled by reads (faster recovery means more write requests). But then again, if you have multiple NVMe devices in a RAID, that means non-trivial number of requests is needed. > * My slides are posted and have graphs of the before and after using the > pg_prefaulter, but I'm happy to provide additional details or answer more Q's. > > * It would be interesting to see if posix_fadvise(2) is actually harming > performance. For example, spinning off a throw-away implementation that uses > aio or a pthread worker pool + pread(2). I do remember seeing some mailing > list blurbs from Mozilla where they were attempting to use posix_fadvise(2) > and were seeing a slow down in performance on Linux (I believe this has since > been fixed, but it wouldn't surprise me if there were still unintended > consequences from this syscall). > Not sure, but in this case we can demonstrate it clearly helps. Maybe there's an alternative way to do async prefetching, performing better (say, aio or whatever), but I've seen plenty of issues with those too. > * I have a port of pg_prefaulter that supports PostgreSQL >= 9 ~complete, but > not pushed. I'll see if I can get to that this week. For "reasons" this > isn't a high priority for me at the moment, but I'm happy to help out and see > this move forward. > Good to hear that. > * Tomas, feel free to contact me offline to discuss why the pg_prefault isn't > working for you. I have it running on Linux, FreeBSD, illumos, and macOS. > Will do. It can easily be due to my lack of golang knowledge, or something similarly silly. > * In the graph from Tomas (nice work, btw), it's clear that the bandwidth is the > same. The way that we verified this earlier was to run ~10-15min traces and > capture the file and offset of every read of PostgreSQL and pg_prefaulter. We > saw pg_prefaulter IOs be ~100% cache miss. For PostgreSQL, we could observe > that ~99% of its IO was cache hit. We also verified that pg_prefaulter wasn't > doing any IO that wasn't eventually performed by PostgreSQL by comparing the > IOs performed against each heap segment. > I'm not sure what bandwidth? > > * "In this case I see that without prefetching, the replay process uses about > 20% of a CPU. With prefetching increases this to ~60%, which is nice." With > the pg_prefaulter, the IO should hit 100% utilization. Like I mentioned > above, Tomas, I'd like to make sure you get this working so you can compare > and improve as necessary. :~] I never got CPU utilization to 100%, but I did > get disk IO utilization to 100%, and that to me was the definition of success. > CPU utilization of the apply process could become 100% utilized with fast > enough disks but in production I didn't have anything that wasn't spinning > rust. > Not sure 100% is really achievable, but we can try. There's room for improvement, that's for sure. > * It looks like we're still trying to figure out the nature of this problem and > the cost of various approaches. From a rapid prototyping perspective, feel > free to suggest changes to the Go pg_prefaulter and toss the various > experiments behind a feature flag. > > * "> But it is implemented in GO and using pg_waldump. > Yeah, that's not too good if we want it in core." > I fail to see the problem with a side-car in Go. *checks calendar* :~] > I think there's a couple of valid reasons for that. It's not that we're somehow against Go in principle, but adding languages into a code base makes it more difficult to maintain it. Also, if we want to integrate it with core (start it automatically on replicas, make it access internal state etc.) it's just easier to do that from C. It can be done from a standalone tool (say, an extension written in Go). But then why make it part of core at all? That has disadvantages too, like coupling the release cycle etc. > * pg_prefaulter will not activate if the number of unapplied WAL pages is less > than the size of 1 WAL segment (i.e. 16MB). This could be tuned further, but > this low-water mark seems to work well. > > * pg_prefaulter won't read-ahead more than 100x WAL segments into the future. I > made the unverified assumption that PostgreSQL could not process more than > 1.6GB of WAL (~1/2 of the memory bandwidth available for a single process) in > less than the rotational latency of a random IO (i.e. ~10ms), and that > pg_prefaulter could in theory stay ahead of PG. PostgreSQL normally overtakes > pg_prefaulter's ability to fault in random pages due to disk IO limitations > (PostgreSQL's cache hit rate is ~99.9%, not 100% for this very reason). In > practice this has worked out, but I'm sure there's room for improvement with > regards to setting the high-watermark and reducing this value. #yoloconstants > I think there's a stable state where the recovery reaches maximum performance and we don't prefetch pages too far ahead (at some point the recovery speed will stop improving, and eventually start decreasing because we'll end up pushing out pages we've prefetched). I wonder how we could auto-tune this. > * I contemplated not reading in FPW but this would have been detrimental on ZFS > because ZFS is a copy-on-write filesystem (vs block filesystem). For ZFS, we > are using a 16K record size, compressed down to ~8K. We have to read the > entire record in before we can modify half of the page. I suspect eliding > prefaulting FPWs will always be a performance loss for nearly all hardware. > That's a good point - on regular filesystems with small pages we can just skip FPW (in fact, we should treat them as prefetched), while on ZFS we need to prefetch them. We probably need to make this configurable. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi, On 2018-07-09 11:59:06 +0200, Tomas Vondra wrote: > > * During the design phase, I looked into using bgworkers but given the number of > > in-flight pread(2) calls required to fully utilize the IO subsystem, I opted > > for something threaded (I was also confined to using Solaris which doesn't > > support posix_fadvise(2), so I couldn't sequentially dispatch async > > posix_fadvise(2) calls and hope for the best). > > > > Hmm, yeah. I'm not sure what to do with this. Using many (thousands?) of > prefetch processes seems like a bad idea - we surely can't make them regular > bgworkers. Perhaps we could use one process with many threads? > Presumably if we knew about a better way to do prefetching without > posix_fadvise, we'd have implemented it in FilePrefetch(). But we just error > out instead :-( Solaris is dead. We shouldn't design for it... I think there's decent reasons to go for a non fadvise approach, but solaris imo isn't one of them. Greetings, Andres Freund
On 08.07.2018 00:47, Tomas Vondra wrote: > Hi, > > I've done a bit of testing on the current patch, mostly to see how much > the prefetching can help (if at all). While the patch is still in early > WIP stages (at least that's my assessment, YMMV), the improvement are > already quite significant. > > I've also planned to compare it to the pg_prefaulter [1] which kinda > started this all, but I've been unable to get it working with my very > limited knowledge of golang. I've fixed the simple stuff (references to > renamed PostgreSQL functions etc.) but then it does not do anything :-( > I wonder if it's working on FreeBSD only, or something like that ... > > So this compares only master with and without WAL prefetching. > > Instead of killing the server and measuring local recovery (which is > what Konstantin did before), I've decided to use replication. That is, > setup a replica, run pgbench on the master and see how much apply lag we > end up with over time. I find this much easier to reproduce, monitor > over time, do longer runs, ... > > master > ------ > * 32 cores (2x E5-2620v4) > * 32GB of RAM > * Intel Optane SSD 280GB > * shared_buffers=4GB > * max_wal_size=128GB > * checkpoint_timeout=30min > > replica > ------- > * 4 cores (i5-2500k) > * 8GB RAM > * 6x Intel S3700 SSD (RAID0) > * shared_buffers=512MB > * effective_cache_size=256MB > > I've also decided to use pgbench scale 1000 (~16GB) which fits into RAM > on the master but not the replica. This may seem like a bit strange > choice, but I think it's not entirely crazy, for a couple of reasons: > > * It's not entirely uncommon to have replicas with different hardware > condiguration. For HA it's a bad idea, but there are valid use cases. > > * Even with the same hardware config, you may have very different > workload on the replica, accessing very different subset of the data. > Consider master doing OLTP on small active set, while replica runs BI > queries on almost all data, pushing everything else from RAM. > > * It amplifies the effect of prefetching, which is nice for testing. > > * I don't have two machines with exactly the same config anyway ;-) > > The pgbench test is then executed on master like this: > > pgbench -c 32 -j 8 -T 3600 -l --aggregate-interval=1 test > > The replica is unlikely to keep up with the master, so the question is > how much apply lag we end up with at the end. > > Without prefetching, it's ~70GB of WAL. With prefetching, it's only > about 30GB. Considering the 1-hour test generates about 90GB of WAL, > this means the replay speed grew from 20GB/h to almost 60GB/h. That's > rather measurable improvement ;-) > > The attached replication-lag.png chart, showing how the lag grows over > time. The "bumps" after ~30 minutes coincide with a checkpoint, > triggering FPIs for a short while. The record-size.png and fpi-size.png > come from pg_waldump and show what part of WAL consists of regular > records and FPIs. > > Note: I've done two runs with each configuration, so there are four data > series on all charts. > > With prefetching the lag drops down a bit after a while (by about the > same amount of WAL), while without prefetch it does not. My explanation > is that the replay is so slow it does not get to the FPIs until after > the test - so it happens, but we don't see it here. > > Now, how does this look on system metrics? Without prefetching we see > low CPU usage, because the process is waiting for I/O. And the I/O is > under-utilized, because we only issue one request at a time (which means > short I/O queues, low utilization of individual devices in the RAID). > > In this case I see that without prefetching, the replay process uses > about 20% of a CPU. With prefetching increases this to ~60%, which is nice. > > At the storage level, the utilization for each device in the RAID0 array > is ~20%, and with prefetching enabled this jumps up to ~40%. If you look > at IOPS instead, that jumps from ~2000 to ~6500, so about 3x. How is > this possible when the utilization grew only ~2x? We're generating > longer I/O queues (20 requests instead of 3), and the devices can > optimize it quite a bit. > > > I think there's a room for additional improvement. We probably can't get > the CPU usage to 100%, but 60% is still quite low. The storage can > certainly handle more requests, the devices are doing something only > about 40% of the time. > > But overall it looks quite nice, and I think it's worth to keep working > on it. > > BTW to make this work, I had to tweak NUM_AUXILIARY_PROCS (increase it > from 4 to 5), otherwise InitAuxiliaryProcess() fails because there's not > room for additional process. I assume it works with local recovery, but > once you need to start walreceiver it fails. > > regards > Thank you very much for such precise and detailed investigation of my patch. Right now I am in vacation, but I am going to continue work on it. Any advice of what else can be improved or refactored inn this patch is welcome.
On 09.07.2018 21:28, Andres Freund wrote: > Hi, > > On 2018-07-09 11:59:06 +0200, Tomas Vondra wrote: >>> * During the design phase, I looked into using bgworkers but given the number of >>> in-flight pread(2) calls required to fully utilize the IO subsystem, I opted >>> for something threaded (I was also confined to using Solaris which doesn't >>> support posix_fadvise(2), so I couldn't sequentially dispatch async >>> posix_fadvise(2) calls and hope for the best). >>> >> Hmm, yeah. I'm not sure what to do with this. Using many (thousands?) of >> prefetch processes seems like a bad idea - we surely can't make them regular >> bgworkers. Perhaps we could use one process with many threads? >> Presumably if we knew about a better way to do prefetching without >> posix_fadvise, we'd have implemented it in FilePrefetch(). But we just error >> out instead :-( > Solaris is dead. We shouldn't design for it... I think there's decent > reasons to go for a non fadvise approach, but solaris imo isn't one of > them. > > Greetings, > > Andres Freund I have attached to the first my mail in this thread small utility for measuring effect of data prefetch for random reads. At my desktop posix_fadvise performed in one thread demostrated the best results, comparing with pread in any number of threads.