Thread: Locking B-tree leafs immediately in exclusive mode
Hi!
Currently _bt_search() always locks leaf buffer in shared mode (aka BT_READ),
while caller can relock it later. However, I don't see what prevents
_bt_search()
from locking leaf immediately in exclusive mode (aka BT_WRITE) when required.
When traversing downlink from non-leaf page of level 1 (lowest level of non-leaf
pages just prior to leaf pages), we know that next page is going to be leaf. In
this case, we can immediately lock next page in exclusive mode if required.
For sure, it might happen that we didn't manage to exclusively lock leaf in this
way when _bt_getroot() points us to leaf page. But this case could be handled
in _bt_search() by relock. Please, find implementation of this approach in the
attached patch.
I've run following simple test of this patch on 72-cores machine.
# postgresql.conf
max_connections = 300
shared_buffers = 32GB
fsync = off
synchronous_commit = off
# DDL:
CREATE UNLOGGED TABLE ordered (id serial primary key, value text not null);
CREATE UNLOGGED TABLE unordered (i integer not null, value text not null);
# script_ordered.sql
INSERT INTO ordered (value) VALUES ('abcdefghijklmnoprsqtuvwxyz');
# script_unordered.sql
\set i random(1, 1000000)
INSERT INTO unordered VALUES (:i, 'abcdefghijklmnoprsqtuvwxyz');
# commands
pgbench -T 60 -P 1 -M prepared -f script_ordered.sql -c 150 -j 150 postgres
pgbench -T 60 -P 1 -M prepared -f script_unordered.sql -c 150 -j 150 postgres
# results
ordered, master: 157473 TPS
ordered, patched 231374 TPS
unordered, master: 232372 TPS
unordered, patched: 232535 TPS
As you can see, difference in unordered case is negligible Due to random
inserts, concurrency for particular leafs is low. But ordered
insertion is almost
50% faster on patched version.
I wonder how could we miss such a simple optimization till now, but I also don't
see this patch to brake anything.
In patched version, it might appear that we have to traverse
rightlinks in exclusive
mode due to splits concurrent to downlink traversal. However, the same might
happen in current master due to splits concurrent to relocks. So, I
don't expect
performance regression to be caused by this patch.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Attachment
On Tue, Jun 5, 2018 at 7:15 PM, Alexander Korotkov
<a.korotkov@postgrespro.ru> wrote:
> Hi!
>
> Currently _bt_search() always locks leaf buffer in shared mode (aka BT_READ),
> while caller can relock it later. However, I don't see what prevents
> _bt_search()
> from locking leaf immediately in exclusive mode (aka BT_WRITE) when required.
> When traversing downlink from non-leaf page of level 1 (lowest level of non-leaf
> pages just prior to leaf pages), we know that next page is going to be leaf. In
> this case, we can immediately lock next page in exclusive mode if required.
> For sure, it might happen that we didn't manage to exclusively lock leaf in this
> way when _bt_getroot() points us to leaf page. But this case could be handled
> in _bt_search() by relock. Please, find implementation of this approach in the
> attached patch.
>
> I've run following simple test of this patch on 72-cores machine.
>
> # postgresql.conf
> max_connections = 300
> shared_buffers = 32GB
> fsync = off
> synchronous_commit = off
>
> # DDL:
> CREATE UNLOGGED TABLE ordered (id serial primary key, value text not null);
> CREATE UNLOGGED TABLE unordered (i integer not null, value text not null);
>
> # script_ordered.sql
> INSERT INTO ordered (value) VALUES ('abcdefghijklmnoprsqtuvwxyz');
>
> # script_unordered.sql
> \set i random(1, 1000000)
> INSERT INTO unordered VALUES (:i, 'abcdefghijklmnoprsqtuvwxyz');
>
> # commands
> pgbench -T 60 -P 1 -M prepared -f script_ordered.sql -c 150 -j 150 postgres
> pgbench -T 60 -P 1 -M prepared -f script_unordered.sql -c 150 -j 150 postgres
>
> # results
> ordered, master: 157473 TPS
> ordered, patched 231374 TPS
> unordered, master: 232372 TPS
> unordered, patched: 232535 TPS
>
> As you can see, difference in unordered case is negligible Due to random
> inserts, concurrency for particular leafs is low. But ordered
> insertion is almost
> 50% faster on patched version.
>
> I wonder how could we miss such a simple optimization till now, but I also don't
> see this patch to brake anything.
>
> In patched version, it might appear that we have to traverse
> rightlinks in exclusive
> mode due to splits concurrent to downlink traversal. However, the same might
> happen in current master due to splits concurrent to relocks. So, I
> don't expect
> performance regression to be caused by this patch.
>
I had a look at this patch and it looks good to me.
With the improvement in performance you mentioned, this optimisation
looks worthy.
--
Regards,
Rafia Sabih
EnterpriseDB: http://www.enterprisedb.com/
On 5 June 2018 at 14:45, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > Currently _bt_search() always locks leaf buffer in shared mode (aka BT_READ), > while caller can relock it later. However, I don't see what prevents > _bt_search() > from locking leaf immediately in exclusive mode (aka BT_WRITE) when required. > When traversing downlink from non-leaf page of level 1 (lowest level of non-leaf > pages just prior to leaf pages), we know that next page is going to be leaf. In > this case, we can immediately lock next page in exclusive mode if required. > For sure, it might happen that we didn't manage to exclusively lock leaf in this > way when _bt_getroot() points us to leaf page. But this case could be handled > in _bt_search() by relock. Please, find implementation of this approach in the > attached patch. It's a good idea. How does it perform with many duplicate entries? -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jun 11, 2018 at 1:06 PM Simon Riggs <simon@2ndquadrant.com> wrote: > On 5 June 2018 at 14:45, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > > Currently _bt_search() always locks leaf buffer in shared mode (aka BT_READ), > > while caller can relock it later. However, I don't see what prevents > > _bt_search() > > from locking leaf immediately in exclusive mode (aka BT_WRITE) when required. > > When traversing downlink from non-leaf page of level 1 (lowest level of non-leaf > > pages just prior to leaf pages), we know that next page is going to be leaf. In > > this case, we can immediately lock next page in exclusive mode if required. > > For sure, it might happen that we didn't manage to exclusively lock leaf in this > > way when _bt_getroot() points us to leaf page. But this case could be handled > > in _bt_search() by relock. Please, find implementation of this approach in the > > attached patch. > > It's a good idea. How does it perform with many duplicate entries? Our B-tree is currently maintaining duplicates unordered. So, during insertion we can traverse rightlinks in order to find page, which would fit new index tuple. However, in this case we're traversing pages in exclusive lock mode, and that happens already after re-lock. _bt_search() doesn't do anything with that. So, I assume there shouldn't be any degradation in the case of many duplicate entries. But this case definitely worth testing, and I'm planning to do it. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Mon, Jun 11, 2018 at 9:30 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > On Mon, Jun 11, 2018 at 1:06 PM Simon Riggs <simon@2ndquadrant.com> wrote: >> It's a good idea. How does it perform with many duplicate entries? I agree that this is a good idea. It independently occurred to me to do this. The L&Y algorithm doesn't take a position on this at all, supposing that *no* locks are needed at all (that's why I recommend people skip L&Y and just read the Lanin & Shasha paper -- L&Y is unnecessarily confusing). This idea seems relatively low risk. > Our B-tree is currently maintaining duplicates unordered. So, during insertion > we can traverse rightlinks in order to find page, which would fit new > index tuple. > However, in this case we're traversing pages in exclusive lock mode, and > that happens already after re-lock. _bt_search() doesn't do anything with that. > So, I assume there shouldn't be any degradation in the case of many > duplicate entries. BTW, I have a prototype patch that makes the keys at the leaf level unique. It is actually an implementation of nbtree suffix truncation that sometimes *adds* a new attribute in pivot tuples, rather than truncating away non-distinguishing attributes -- it adds a special heap TID attribute when it must. The patch typically increases fan-in, of course, but the real goal was to make all entries at the leaf level truly unique, as L&Y intended (we cannot do it without suffix truncation because that will kill fan-in). My prototype has full amcheck coverage, which really helped me gain confidence in my approach. There are still big problems with my patch, though. It seems to hurt performance more often than it helps when there is a lot of contention, so as things stand I don't see a path to making it commitable. I am still going to clean it up some more and post it to -hackers, though. I still think it's quite interesting. I am not pursuing it much further now because it seems like my timing is bad -- not because it seems like a bad idea. I can imagine something like zheap making this patch important again. I can also imagine someone seeing something that I missed. -- Peter Geoghegan
On Thu, Jun 14, 2018 at 1:01 AM Peter Geoghegan <pg@bowt.ie> wrote: > On Mon, Jun 11, 2018 at 9:30 AM, Alexander Korotkov > <a.korotkov@postgrespro.ru> wrote: > > On Mon, Jun 11, 2018 at 1:06 PM Simon Riggs <simon@2ndquadrant.com> wrote: > >> It's a good idea. How does it perform with many duplicate entries? > > I agree that this is a good idea. It independently occurred to me to > do this. The L&Y algorithm doesn't take a position on this at all, > supposing that *no* locks are needed at all (that's why I recommend > people skip L&Y and just read the Lanin & Shasha paper -- L&Y is > unnecessarily confusing). This idea seems relatively low risk. Great. Unfortunately, we don't have access to 72-cores machine anymore. But I'll do benchmarks on smaller 40-cores machine, which we have access to. I hope there should be some win from this patch too. > > Our B-tree is currently maintaining duplicates unordered. So, during insertion > > we can traverse rightlinks in order to find page, which would fit new > > index tuple. > > However, in this case we're traversing pages in exclusive lock mode, and > > that happens already after re-lock. _bt_search() doesn't do anything with that. > > So, I assume there shouldn't be any degradation in the case of many > > duplicate entries. > > BTW, I have a prototype patch that makes the keys at the leaf level > unique. It is actually an implementation of nbtree suffix truncation > that sometimes *adds* a new attribute in pivot tuples, rather than > truncating away non-distinguishing attributes -- it adds a special > heap TID attribute when it must. The patch typically increases fan-in, > of course, but the real goal was to make all entries at the leaf level > truly unique, as L&Y intended (we cannot do it without suffix > truncation because that will kill fan-in). My prototype has full > amcheck coverage, which really helped me gain confidence in my > approach. Could you, please, clarify what do you mean by "fan-in"? As I understood, higher "fan-in" means more children on single non-leaf page, and in turn "better branching". Is my understanding correct? If my understanding is correct, then making leaf level truly unique without suffix truncation will kill fan-in, because additional heap TID attribute will increase pivot tuple size. However, that doesn't look like inevitable shortcoming, because we could store heap TID in t_tid of pivot index tuples. Yes, we've used t_tid offset for storing number of attributes in truncated tuples. But heap TID is going to be virtually the last attribute of tuple. So, pivot tuples containing heap TID are not going to be suffix-truncated anyway. So, for such tuples we can just don't set INDEX_ALT_TID_MASK, and they would be assumed to have all the attributes. So, my idea that it's not necessary to couple suffix truncation with making leaf tuples unique. Regarding just making leaf tuples unique, I understand that it wouldn't be always win. When we have a lot of duplicates, current implementation searches among the pages containing those duplicates for the first page containing enough of free space. While with unique index, we would have to always insert into particular page. Thus, current implementation gives us better filling of pages, and (probably) faster insertion. But, unique index would give us much better performance of retail tuple delete and update (currently we don't support both). But I believe that future pluggable table access methods will use both. Therefore, my idea is that there is a tradeoff between making btree index unique or non-unique. I think we will need an option for that. I'm not yet sure if this option should be user-visible or auto-decision based on table access method used. > There are still big problems with my patch, though. It seems to hurt > performance more often than it helps when there is a lot of > contention, so as things stand I don't see a path to making it > commitable. I am still going to clean it up some more and post it to > -hackers, though. I still think it's quite interesting. I am not > pursuing it much further now because it seems like my timing is bad -- > not because it seems like a bad idea. I can imagine something like > zheap making this patch important again. I can also imagine someone > seeing something that I missed. I think that joint community efforts are necessary, when single person don't see path to make patch committable. So, I'm looking forward seeing your patch posted. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Thu, Jun 14, 2018 at 9:44 AM Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > > > Our B-tree is currently maintaining duplicates unordered. So, during insertion > > > we can traverse rightlinks in order to find page, which would fit new > > > index tuple. > > > However, in this case we're traversing pages in exclusive lock mode, and > > > that happens already after re-lock. _bt_search() doesn't do anything with that. > > > So, I assume there shouldn't be any degradation in the case of many > > > duplicate entries. > > > > BTW, I have a prototype patch that makes the keys at the leaf level > > unique. It is actually an implementation of nbtree suffix truncation > > that sometimes *adds* a new attribute in pivot tuples, rather than > > truncating away non-distinguishing attributes -- it adds a special > > heap TID attribute when it must. The patch typically increases fan-in, > > of course, but the real goal was to make all entries at the leaf level > > truly unique, as L&Y intended (we cannot do it without suffix > > truncation because that will kill fan-in). My prototype has full > > amcheck coverage, which really helped me gain confidence in my > > approach. > > Could you, please, clarify what do you mean by "fan-in"? As I > understood, higher "fan-in" means more children on single non-leaf > page, and in turn "better branching". Is my understanding correct? > > If my understanding is correct, then making leaf level truly unique > without suffix truncation will kill fan-in, because additional heap > TID attribute will increase pivot tuple size. However, that doesn't > look like inevitable shortcoming, because we could store heap TID in > t_tid of pivot index tuples. Yes, we've used t_tid offset for storing > number of attributes in truncated tuples. But heap TID is going to be > virtually the last attribute of tuple. So, pivot tuples containing > heap TID are not going to be suffix-truncated anyway. So, for such > tuples we can just don't set INDEX_ALT_TID_MASK, and they would be > assumed to have all the attributes. I had a patch[1] that did pretty much just that. I saw no contention issues or adverse effects, but my testing of it was rather limited. The patch has rotted significantly since then, sadly, and it's quite complex. > So, my idea that it's not necessary to couple suffix truncation with > making leaf tuples unique. No, but the work involved for one and the other shares so much that it lends itself to be done in the same patch. > Regarding just making leaf tuples unique, > I understand that it wouldn't be always win. When we have a lot of > duplicates, current implementation searches among the pages containing > those duplicates for the first page containing enough of free space. > While with unique index, we would have to always insert into > particular page. Thus, current implementation gives us better filling > of pages, and (probably) faster insertion. Not at all. Insertion cost in unique indexes with lots of duplicates (happens, dead duplicates) grows quadratically on the number of duplicates, and that's improved by making the index unique and sorted. > Therefore, my idea is that there is a tradeoff between making btree > index unique or non-unique. I think we will need an option for that. We will need a flag somewhere to avoid having to require index rebuilds during pg_upgrade. My old patch maintained backward compatibility, but when using an older version index, the sort order of tids could not be assumed, and thus many optimizations had to be disabled. But it is totally doable, and necessary unless you accept a very painful pg_upgrade. [1] https://www.postgresql.org/message-id/flat/CAGTBQpZ-kTRQiAa13xG1GNe461YOwrA-s-ycCQPtyFrpKTaDBQ%40mail.gmail.com#CAGTBQpZ-kTRQiAa13xG1GNe461YOwrA-s-ycCQPtyFrpKTaDBQ@mail.gmail.com
On Thu, Jun 14, 2018 at 4:56 PM Claudio Freire <klaussfreire@gmail.com> wrote: > Not at all. Insertion cost in unique indexes with lots of duplicates > (happens, dead duplicates) grows quadratically on the number of > duplicates, and that's improved by making the index unique and sorted. Sorry, I've messed up the terms. I did actually compare current non-unique indexes with non-unique indexes keeping duplicate entries ordered by TID (which makes them somewhat unique). I didn't really considered indexes, which forces unique constraints. For them insertion cost grows quadratically (as you mentioned) independently on whether we're keeping duplicates ordered by TID or not. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Thu, Jun 14, 2018 at 5:43 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > Could you, please, clarify what do you mean by "fan-in"? As I > understood, higher "fan-in" means more children on single non-leaf > page, and in turn "better branching". Is my understanding correct? Yes, your understanding is correct. > If my understanding is correct, then making leaf level truly unique > without suffix truncation will kill fan-in, because additional heap > TID attribute will increase pivot tuple size. You're right that that's theoretically possible. However, in practice we can almost always truncate away the heap TID attribute from pivot tuples. We only need the heap TID attribute when there is no other distinguishing attribute. > However, that doesn't > look like inevitable shortcoming, because we could store heap TID in > t_tid of pivot index tuples. But the offset doesn't have enough space for an entire TID. > So, my idea that it's not necessary to couple suffix truncation with > making leaf tuples unique. It seems like by far the simplest way. I don't really care about suffix truncation, though. I care about making the leaf tuples unique. Suffix truncation can help. > Regarding just making leaf tuples unique, > I understand that it wouldn't be always win. When we have a lot of > duplicates, current implementation searches among the pages containing > those duplicates for the first page containing enough of free space. > While with unique index, we would have to always insert into > particular page. Thus, current implementation gives us better filling > of pages, and (probably) faster insertion. You're definitely right that that's the weakness of the design. > But, unique index would > give us much better performance of retail tuple delete and update > (currently we don't support both). But I believe that future > pluggable table access methods will use both. Right. > Therefore, my idea is that there is a tradeoff between making btree > index unique or non-unique. I think we will need an option for that. > I'm not yet sure if this option should be user-visible or > auto-decision based on table access method used. I agree. -- Peter Geoghegan
On Thu, Jun 14, 2018 at 6:32 PM Peter Geoghegan <pg@bowt.ie> wrote: > On Thu, Jun 14, 2018 at 5:43 AM, Alexander Korotkov > <a.korotkov@postgrespro.ru> wrote: > > However, that doesn't > > look like inevitable shortcoming, because we could store heap TID in > > t_tid of pivot index tuples. > > But the offset doesn't have enough space for an entire TID. Sorry, my bad. It slipped my mind that we use t_tid.ip_blkid of pivot tuples to store downlinks :) So, yes, additional attribute is required to store heap TID in pivot tuple. Anyway, I'm looking forward seeing your patch posted, if even it would be not yet perfect shape. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Mon, June 11, 2018 at 4:31 PM, Alexander Korotkov wrote:
> On Mon, Jun 11, 2018 at 1:06 PM Simon Riggs <simon@2ndquadrant.com> wrote:
> > On 5 June 2018 at 14:45, Alexander Korotkov <a.korotkov@postgrespro.ru>
> > wrote:
> > > Currently _bt_search() always locks leaf buffer in shared mode (aka
> > > BT_READ), while caller can relock it later. However, I don't see
> > > what prevents
> > > _bt_search()
> > > from locking leaf immediately in exclusive mode (aka BT_WRITE) when
> > > required.
> > > When traversing downlink from non-leaf page of level 1 (lowest level
> > > of non-leaf pages just prior to leaf pages), we know that next page
> > > is going to be leaf. In this case, we can immediately lock next page
> > > in exclusive mode if required.
> > > For sure, it might happen that we didn't manage to exclusively lock
> > > leaf in this way when _bt_getroot() points us to leaf page. But
> > > this case could be handled in _bt_search() by relock. Please, find
> > > implementation of this approach in the attached patch.
> >
> > It's a good idea. How does it perform with many duplicate entries?
>
> Our B-tree is currently maintaining duplicates unordered. So, during
> insertion we can traverse rightlinks in order to find page, which would
> fit new index tuple.
> However, in this case we're traversing pages in exclusive lock mode, and
> that happens already after re-lock. _bt_search() doesn't do anything
> with that.
> So, I assume there shouldn't be any degradation in the case of many
> duplicate entries.
>
> But this case definitely worth testing, and I'm planning to do it.
>
Hi, I'm reviewing this.
Firstly, I did performance tests on 72-cores machines(AWS c5.18xlarge) same as you did.
> # postgresql.conf
> max_connections = 300
> shared_buffers = 32GB
> fsync = off
> synchronous_commit = off
>
>
>
> # DDL:
> CREATE UNLOGGED TABLE ordered (id serial primary key, value text not null);
> CREATE UNLOGGED TABLE unordered (i integer not null, value text not null);
>
>
>
> # script_ordered.sql
> INSERT INTO ordered (value) VALUES ('abcdefghijklmnoprsqtuvwxyz');
>
>
>
> # script_unordered.sql
> \set i random(1, 1000000)
> INSERT INTO unordered VALUES (:i, 'abcdefghijklmnoprsqtuvwxyz');
>
>
>
> # commands
> pgbench -T 60 -P 1 -M prepared -f script_ordered.sql -c 150 -j 150 postgres
> pgbench -T 60 -P 1 -M prepared -f script_unordered.sql -c 150 -j 150 postgres
>
>
>
> # results
> ordered, master: 157473 TPS
> ordered, patched 231374 TPS
> unordered, master: 232372 TPS
> unordered, patched: 232535 TPS
# my results
ordered, master: 186045 TPS
ordered, patched: 265842 TPS
unordered, master: 313011 TPS
unordered, patched: 309636 TPS
I confirmed that this patch improves ordered insertion.
In addition to your tests, I did the following tests with many duplicate entries
# DDL
CREATE UNLOGGED TABLE duplicated (i integer not null, value text not null);
# script_duplicated.sql
INSERT INTO unordered VALUES (1, 'abcdefghijklmnoprsqtuvwxyz');
# commands
pgbench -T 60 -P 1 -M prepared -f script_duplicated.sql -c 150 -j 150 postgres
# results
duplicated, master: 315450 TPS
duplicated, patched: 311584 TPS
It seems there are almostly no performance degression in case of many duplicated entries.
I'm planning to do code review and send it in the next mail.
Yoshikazu Imai
Hi! On Mon, Jul 9, 2018 at 6:19 AM Imai, Yoshikazu <imai.yoshikazu@jp.fujitsu.com> wrote: > Hi, I'm reviewing this. Great. Thank you for giving attention to this patch. > Firstly, I did performance tests on 72-cores machines(AWS c5.18xlarge) same as you did. OK. But not that c5.18xlarge is 72-VCPU machine, which AFAIK is close to the performance of 36 physical cores. > > # results > > ordered, master: 157473 TPS > > ordered, patched 231374 TPS > > unordered, master: 232372 TPS > > unordered, patched: 232535 TPS > > # my results > ordered, master: 186045 TPS > ordered, patched: 265842 TPS > unordered, master: 313011 TPS > unordered, patched: 309636 TPS > > I confirmed that this patch improves ordered insertion. Good, but it seems like 1% regression in unordered case. > In addition to your tests, I did the following tests with many duplicate entries > > # DDL > CREATE UNLOGGED TABLE duplicated (i integer not null, value text not null); > > # script_duplicated.sql > INSERT INTO unordered VALUES (1, 'abcdefghijklmnoprsqtuvwxyz'); > > # commands > pgbench -T 60 -P 1 -M prepared -f script_duplicated.sql -c 150 -j 150 postgres > > # results > duplicated, master: 315450 TPS > duplicated, patched: 311584 TPS > > It seems there are almostly no performance degression in case of many duplicated entries. In this case it also looks like we observed 1% regression. Despite 1% may seem to be very small, I think we should clarify whether it really exists. I have at least two hypothesis about this. 1) There is no real regression, observed difference of TPS is less than error of measurements. In order to check that we need to retry the experiment multiple times. Also, if you run benchmark on master before patched version (or vice versa) you should also try to swap the order to make sure there is no influence of the order of benchmarks. 2) If we consider relation between TPS and number of clients, TPS is typically growing with increasing number of clients until reach some saturation value. After the saturation value, there is some degradation of TPS. If patch makes some latency lower, that my cause saturation to happen earlier. In order to check that, we need run benchmarks with various number of clients and draw a graph: TPS depending on clients. So, may I ask you to make more experiments in order to clarify the observed regression? ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Mon, Jul 9, 2018 at 9:43 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > In this case it also looks like we observed 1% regression. Despite 1% > may seem to be very small, I think we should clarify whether it really > exists. I have at least two hypothesis about this. > > 1) There is no real regression, observed difference of TPS is less > than error of measurements. In order to check that we need to retry > the experiment multiple times. Also, if you run benchmark on master > before patched version (or vice versa) you should also try to swap the > order to make sure there is no influence of the order of benchmarks. > 2) If we consider relation between TPS and number of clients, TPS is > typically growing with increasing number of clients until reach some > saturation value. After the saturation value, there is some > degradation of TPS. If patch makes some latency lower, that my cause > saturation to happen earlier. In order to check that, we need run > benchmarks with various number of clients and draw a graph: TPS > depending on clients. > > So, may I ask you to make more experiments in order to clarify the > observed regression? It would be nice to actually see script_duplicated.sql. I don't know exactly what the test case was. Here is my wild guess: You may end up moving right more often within _bt_findinsertloc(), which is actually worse than moving right within _bt_moveright(), even when you _bt_moveright() in exclusive mode. _bt_findinsertloc() couples/crabs exclusive buffer locks because the unique case requires it, even when we're not inserting into a unique index. Whereas _bt_moveright() holds at most one buffer lock at a time. -- Peter Geoghegan
On 9 July 2018 at 04:18, Imai, Yoshikazu <imai.yoshikazu@jp.fujitsu.com> wrote:
>> # script_ordered.sql
>> INSERT INTO ordered (value) VALUES ('abcdefghijklmnoprsqtuvwxyz');
>>
>> # script_unordered.sql
>> \set i random(1, 1000000)
>> INSERT INTO unordered VALUES (:i, 'abcdefghijklmnoprsqtuvwxyz');
>> # results
>> ordered, master: 157473 TPS
>> ordered, patched 231374 TPS
>> unordered, master: 232372 TPS
>> unordered, patched: 232535 TPS
>
> # my results
> ordered, master: 186045 TPS
> ordered, patched: 265842 TPS
> unordered, master: 313011 TPS
> unordered, patched: 309636 TPS
>
> I confirmed that this patch improves ordered insertion.
Looks good
Please can you check insertion with the index on 2 keys
1st key has 10,000 values
2nd key has monotonically increasing value from last 1st key value
So each session picks one 1st key value
Then each new INSERTion is a higher value of 2nd key
so 1,1, then 1,2 then 1,3 etc
Probably easier to do this with a table like this
CREATE UNLOGGED TABLE ordered2 (id integer, logdate timestamp default
now(), value text not null, primary key (id, logdate));
# script_ordered2.sql
\set i random(1, 10000)
INSERT INTO ordered2 (id, value) VALUES (:i, 'abcdefghijklmnoprsqtuvwxyz');
Thanks
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jul 9, 2018 at 8:18 PM Peter Geoghegan <pg@bowt.ie> wrote: > On Mon, Jul 9, 2018 at 9:43 AM, Alexander Korotkov > <a.korotkov@postgrespro.ru> wrote: > > In this case it also looks like we observed 1% regression. Despite 1% > > may seem to be very small, I think we should clarify whether it really > > exists. I have at least two hypothesis about this. > > > > 1) There is no real regression, observed difference of TPS is less > > than error of measurements. In order to check that we need to retry > > the experiment multiple times. Also, if you run benchmark on master > > before patched version (or vice versa) you should also try to swap the > > order to make sure there is no influence of the order of benchmarks. > > 2) If we consider relation between TPS and number of clients, TPS is > > typically growing with increasing number of clients until reach some > > saturation value. After the saturation value, there is some > > degradation of TPS. If patch makes some latency lower, that my cause > > saturation to happen earlier. In order to check that, we need run > > benchmarks with various number of clients and draw a graph: TPS > > depending on clients. > > > > So, may I ask you to make more experiments in order to clarify the > > observed regression? > > It would be nice to actually see script_duplicated.sql. I don't know > exactly what the test case was. > > Here is my wild guess: You may end up moving right more often within > _bt_findinsertloc(), which is actually worse than moving right within > _bt_moveright(), even when you _bt_moveright() in exclusive mode. > _bt_findinsertloc() couples/crabs exclusive buffer locks because the > unique case requires it, even when we're not inserting into a unique > index. Whereas _bt_moveright() holds at most one buffer lock at a > time. I'm sorry, but I didn't understand this guess. I agree that moving right within _bt_findinsertloc() might be worse than moving right within _bt_moveright(). But why should it happen more often, if both with and without patch that happens only after _bt_moveright() in exclusive mode (with patch _bt_search() calls _bt_moveright() in exclusive mode)? ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Mon, Jul 9, 2018 at 3:23 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > I'm sorry, but I didn't understand this guess. I agree that moving > right within _bt_findinsertloc() might be worse than moving right > within _bt_moveright(). But why should it happen more often, if both > with and without patch that happens only after _bt_moveright() in > exclusive mode (with patch _bt_search() calls _bt_moveright() in > exclusive mode)? _bt_moveright() doesn't serialize access, because it doesn't couple buffer locks. I think that it's possible that it's slower for that reason -- not because it moves right more often. "The Convoy Phenomenon" research report may be worth a read sometime, though it's very old. It's co-authored by Jim Gray. As they put it, sometimes "a non-FIFO strategy" can be faster. In simple terms, sometimes it can be faster to randomly grant a lock, since in practice nobody gets starved out. I'm guessing (and it is very much a guess) that it could be something like that, since the behavior of _bt_findinsertloc() can be FIFO-like, whereas the behavior of _bt_moveright() may not be. Again, the actual queries would help a lot. It's just a guess. -- Peter Geoghegan
On Mon, July 9, 2018 at 4:44 PM, Alexander Korotkov wrote:
> > Firstly, I did performance tests on 72-cores machines(AWS c5.18xlarge) same as you did.
>
> OK. But not that c5.18xlarge is 72-VCPU machine, which AFAIK is
> close to the performance of 36 physical cores.
Thanks for pointing that. I referred to /proc/cpuinfo and understood there are 36 physical cores.
> In this case it also looks like we observed 1% regression. Despite 1%
> may seem to be very small, I think we should clarify whether it really
> exists. I have at least two hypothesis about this.
>
> 1) There is no real regression, observed difference of TPS is less
> than error of measurements. In order to check that we need to retry
> the experiment multiple times. Also, if you run benchmark on master
> before patched version (or vice versa) you should also try to swap the
> order to make sure there is no influence of the order of benchmarks.
> 2) If we consider relation between TPS and number of clients, TPS is
> typically growing with increasing number of clients until reach some
> saturation value. After the saturation value, there is some
> degradation of TPS. If patch makes some latency lower, that my cause
> saturation to happen earlier. In order to check that, we need run
> benchmarks with various number of clients and draw a graph: TPS
> depending on clients.
>
> So, may I ask you to make more experiments in order to clarify the
> observed regression?
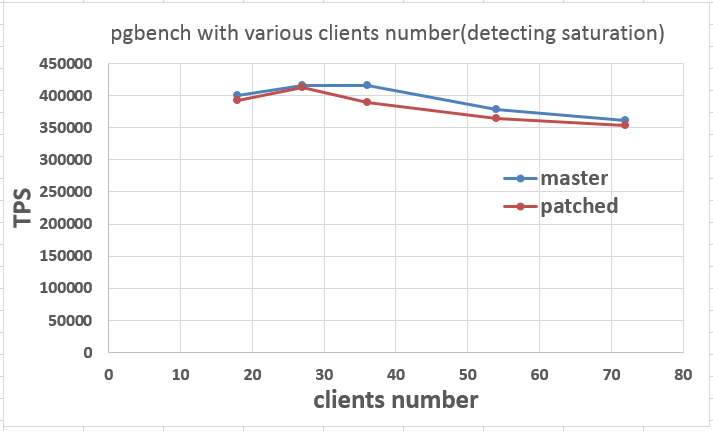
I experimented 2) with changing clients parameter with 18, 36, 54, 72.
While doing experiment, I realized that results of pgbench with 36 clients improve after executing pgbench with 72
clients.
I don't know why this occurs, but anyway, in this experiment, I executed pgbench with 72 clients before executing other
pgbenchs.(e.g. -c 72, -c 18, -c 36, -c 54, -c 72)
I tested experiments to master and patched unorderly(e.g. master, patched, patched, master, master, patched, patched,
master)
# results of changing clients(18, 36, 54, 72 clients)
master, -c 18 -j 18: Ave 400410 TPS (407615,393942,401845,398241)
master, -c 36 -j 36: Ave 415616 TPS (411939,400742,424855,424926)
master, -c 54 -j 54: Ave 378734 TPS (401646,354084,408044,351163)
master, -c 72 -j 72: Ave 360864 TPS (367718,360029,366432,349277)
patched, -c 18 -j 18: Ave 393115 TPS (382854,396396,395530,397678)
patched, -c 36 -j 36: Ave 390328 TPS (376100,404873,383498,396840)
patched, -c 54 -j 54: Ave 364894 TPS (365533,373064,354250,366727)
patched, -c 72 -j 72: Ave 353982 TPS (355237,357601,345536,357553)
It may seem saturation is between 18 and 36 clients, so I also experimented with 27 clients.
# results of changing clients(27 clients)
master, -c 27 -j 27: Ave 416756 (423512,424241,399241,420030) TPS
patched, -c 27 -j 27: Ave 413568 (410187,404291,420152,419640) TPS
I created a graph and attached in this mail("detecting saturation.png").
Referring to a graph, patched version's saturation happens earlier than master's one as you expected.
But even the patched version's nearly saturated TPS value has small regression from the master's one, I think.
Is there another experiments to do about this?
Yoshikazu Imai
Attachment
{kind=link}
On Mon, Jul 9, 2018 at 8:18 PM Peter Geoghegan <pg@bowt.ie> wrote: > On Mon, Jul 9, 2018 at 9:43 AM, Alexander Korotkov > <a.korotkov@postgrespro.ru> wrote: > > In this case it also looks like we observed 1% regression. Despite 1% > > may seem to be very small, I think we should clarify whether it really > > exists. I have at least two hypothesis about this. > > > > 1) There is no real regression, observed difference of TPS is less > > than error of measurements. In order to check that we need to retry > > the experiment multiple times. Also, if you run benchmark on master > > before patched version (or vice versa) you should also try to swap the > > order to make sure there is no influence of the order of benchmarks. > > 2) If we consider relation between TPS and number of clients, TPS is > > typically growing with increasing number of clients until reach some > > saturation value. After the saturation value, there is some > > degradation of TPS. If patch makes some latency lower, that my cause > > saturation to happen earlier. In order to check that, we need run > > benchmarks with various number of clients and draw a graph: TPS > > depending on clients. > > > > So, may I ask you to make more experiments in order to clarify the > > observed regression? > > It would be nice to actually see script_duplicated.sql. I don't know > exactly what the test case was. BTW, contents of script_duplicated.sql was posted by Imai, Yoshikazu in the message body: > # script_duplicated.sql > INSERT INTO unordered VALUES (1, 'abcdefghijklmnoprsqtuvwxyz'); ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Tue, Jul 10, 2018 at 2:19 PM Imai, Yoshikazu
<imai.yoshikazu@jp.fujitsu.com> wrote:
> On Mon, July 9, 2018 at 4:44 PM, Alexander Korotkov wrote:
> > > Firstly, I did performance tests on 72-cores machines(AWS c5.18xlarge) same as you did.
> >
> > OK. But not that c5.18xlarge is 72-VCPU machine, which AFAIK is
> > close to the performance of 36 physical cores.
>
> Thanks for pointing that. I referred to /proc/cpuinfo and understood there are 36 physical cores.
>
> > In this case it also looks like we observed 1% regression. Despite 1%
> > may seem to be very small, I think we should clarify whether it really
> > exists. I have at least two hypothesis about this.
> >
> > 1) There is no real regression, observed difference of TPS is less
> > than error of measurements. In order to check that we need to retry
> > the experiment multiple times. Also, if you run benchmark on master
> > before patched version (or vice versa) you should also try to swap the
> > order to make sure there is no influence of the order of benchmarks.
> > 2) If we consider relation between TPS and number of clients, TPS is
> > typically growing with increasing number of clients until reach some
> > saturation value. After the saturation value, there is some
> > degradation of TPS. If patch makes some latency lower, that my cause
> > saturation to happen earlier. In order to check that, we need run
> > benchmarks with various number of clients and draw a graph: TPS
> > depending on clients.
> >
> > So, may I ask you to make more experiments in order to clarify the
> > observed regression?
>
> I experimented 2) with changing clients parameter with 18, 36, 54, 72.
> While doing experiment, I realized that results of pgbench with 36 clients improve after executing pgbench with 72
clients.
> I don't know why this occurs, but anyway, in this experiment, I executed pgbench with 72 clients before executing
otherpgbenchs. (e.g. -c 72, -c 18, -c 36, -c 54, -c 72)
> I tested experiments to master and patched unorderly(e.g. master, patched, patched, master, master, patched, patched,
master)
>
> # results of changing clients(18, 36, 54, 72 clients)
> master, -c 18 -j 18: Ave 400410 TPS (407615,393942,401845,398241)
> master, -c 36 -j 36: Ave 415616 TPS (411939,400742,424855,424926)
> master, -c 54 -j 54: Ave 378734 TPS (401646,354084,408044,351163)
> master, -c 72 -j 72: Ave 360864 TPS (367718,360029,366432,349277)
> patched, -c 18 -j 18: Ave 393115 TPS (382854,396396,395530,397678)
> patched, -c 36 -j 36: Ave 390328 TPS (376100,404873,383498,396840)
> patched, -c 54 -j 54: Ave 364894 TPS (365533,373064,354250,366727)
> patched, -c 72 -j 72: Ave 353982 TPS (355237,357601,345536,357553)
>
> It may seem saturation is between 18 and 36 clients, so I also experimented with 27 clients.
>
> # results of changing clients(27 clients)
> master, -c 27 -j 27: Ave 416756 (423512,424241,399241,420030) TPS
> patched, -c 27 -j 27: Ave 413568 (410187,404291,420152,419640) TPS
>
> I created a graph and attached in this mail("detecting saturation.png").
> Referring to a graph, patched version's saturation happens earlier than master's one as you expected.
> But even the patched version's nearly saturated TPS value has small regression from the master's one, I think.
>
> Is there another experiments to do about this?
Thank you for the experiments! It seems that there is real regression
here... BTW, which script were you using in this benchmark:
script_unordered.sql or script_duplicated.sql?
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 2018/07/10 20:36, Alexander Korotkov wrote:
> On Tue, Jul 10, 2018 at 2:19 PM Imai, Yoshikazu
> <imai.yoshikazu@jp.fujitsu.com> wrote:
>> On Mon, July 9, 2018 at 4:44 PM, Alexander Korotkov wrote:
>>>> Firstly, I did performance tests on 72-cores machines(AWS c5.18xlarge) same as you did.
>>>
>>> OK. But not that c5.18xlarge is 72-VCPU machine, which AFAIK is
>>> close to the performance of 36 physical cores.
>>
>> Thanks for pointing that. I referred to /proc/cpuinfo and understood there are 36 physical cores.
>>
>>> In this case it also looks like we observed 1% regression. Despite 1%
>>> may seem to be very small, I think we should clarify whether it really
>>> exists. I have at least two hypothesis about this.
>>>
>>> 1) There is no real regression, observed difference of TPS is less
>>> than error of measurements. In order to check that we need to retry
>>> the experiment multiple times. Also, if you run benchmark on master
>>> before patched version (or vice versa) you should also try to swap the
>>> order to make sure there is no influence of the order of benchmarks.
>>> 2) If we consider relation between TPS and number of clients, TPS is
>>> typically growing with increasing number of clients until reach some
>>> saturation value. After the saturation value, there is some
>>> degradation of TPS. If patch makes some latency lower, that my cause
>>> saturation to happen earlier. In order to check that, we need run
>>> benchmarks with various number of clients and draw a graph: TPS
>>> depending on clients.
>>>
>>> So, may I ask you to make more experiments in order to clarify the
>>> observed regression?
>>
>> I experimented 2) with changing clients parameter with 18, 36, 54, 72.
>> While doing experiment, I realized that results of pgbench with 36 clients improve after executing pgbench with 72
clients.
>> I don't know why this occurs, but anyway, in this experiment, I executed pgbench with 72 clients before executing
otherpgbenchs. (e.g. -c 72, -c 18, -c 36, -c 54, -c 72)
>> I tested experiments to master and patched unorderly(e.g. master, patched, patched, master, master, patched,
patched,master)
>>
>> # results of changing clients(18, 36, 54, 72 clients)
>> master, -c 18 -j 18: Ave 400410 TPS (407615,393942,401845,398241)
>> master, -c 36 -j 36: Ave 415616 TPS (411939,400742,424855,424926)
>> master, -c 54 -j 54: Ave 378734 TPS (401646,354084,408044,351163)
>> master, -c 72 -j 72: Ave 360864 TPS (367718,360029,366432,349277)
>> patched, -c 18 -j 18: Ave 393115 TPS (382854,396396,395530,397678)
>> patched, -c 36 -j 36: Ave 390328 TPS (376100,404873,383498,396840)
>> patched, -c 54 -j 54: Ave 364894 TPS (365533,373064,354250,366727)
>> patched, -c 72 -j 72: Ave 353982 TPS (355237,357601,345536,357553)
>>
>> It may seem saturation is between 18 and 36 clients, so I also experimented with 27 clients.
>>
>> # results of changing clients(27 clients)
>> master, -c 27 -j 27: Ave 416756 (423512,424241,399241,420030) TPS
>> patched, -c 27 -j 27: Ave 413568 (410187,404291,420152,419640) TPS
>>
>> I created a graph and attached in this mail("detecting saturation.png").
>> Referring to a graph, patched version's saturation happens earlier than master's one as you expected.
>> But even the patched version's nearly saturated TPS value has small regression from the master's one, I think.
>>
>> Is there another experiments to do about this?
>
> Thank you for the experiments! It seems that there is real regression
> here... BTW, which script were you using in this benchmark:
> script_unordered.sql or script_duplicated.sql?
Sorry, I forgot to write that. I used script_unordered.sql.
Yoshikazu Imai
On Mon, July 9, 2018 at 5:25 PM, Simon Riggs wrote:
> Please can you check insertion with the index on 2 keys
> 1st key has 10,000 values
> 2nd key has monotonically increasing value from last 1st key value
>
> So each session picks one 1st key value
> Then each new INSERTion is a higher value of 2nd key
> so 1,1, then 1,2 then 1,3 etc
>
> Probably easier to do this with a table like this
>
> CREATE UNLOGGED TABLE ordered2 (id integer, logdate timestamp default
> now(), value text not null, primary key (id, logdate));
>
> # script_ordered2.sql
> \set i random(1, 10000)
> INSERT INTO ordered2 (id, value) VALUES (:i, 'abcdefghijklmnoprsqtuvwxyz');
>
> Thanks
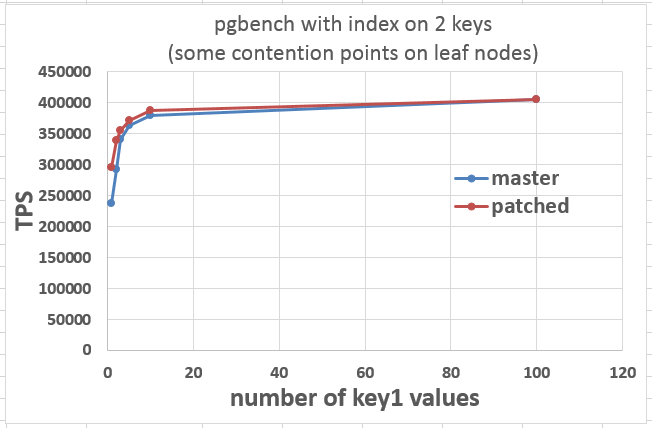
I tried to do this, but I might be mistaken your intention, so please specify if I am wrong.
While script_ordered.sql supposes that there is one contention point on the most right leaf node,
script_ordered2.sql supposes that there are some contention points on some leaf nodes, is it right?
I experimented with key1 having 10000 values, but there are no difference in the results compared to unordered.sql one,
soI experimented with key1 having 1, 2, 3, 5, 10, and 100 values.
Also, If I created primary key, "ERROR: duplicate key value violates unique constraint "ordered2_pkey" happened, so I
creatednon-unique key.
#DDL
CREATE UNLOGGED TABLE ordered2 (id integer, logdate timestamp default now(), value text not null);
CREATE INDEX ordered2_key ON ordered2 (id, logdate);
# script_ordered2.sql
\set i random(1, 100) #second value is 1, 2, 3, 5, 10, or 100
INSERT INTO ordered2 (id, value) VALUES (:i, 'abcdefghijklmnoprsqtuvwxyz');
# ordered2 results, key1 having 1, 2, 3, 5, 10, and 100 values
master, key1 with 1 values: 236428
master, key1 with 2 values: 292248
master, key1 with 3 values: 340980
master, key1 with 5 values: 362808
master, key1 with 10 values: 379525
master, key1 with 100 values: 405265
patched, key1 with 1 values: 295862
patched, key1 with 2 values: 339538
patched, key1 with 3 values: 355793
patched, key1 with 5 values: 371332
patched, key1 with 10 values: 387731
patched, key1 with 100 values: 405115
From an attached graph("some_contention_points_on_leaf_nodes.png"), as contention points dispersed, we can see that TPS
isincreased and TPS difference between master and patched version becomes smaller.
Yoshikazu Imai
Attachment
{kind=link}
On Mon, July 9, 2018 at 3:19 AM, Imai, Yoshikazu wrote:
> I'm planning to do code review and send it in the next mail.
Sorry for delaying the code review.
I did the code review, and I think there are no logical wrongs
with B-Tree.
I tested integrity of B-Tree with amcheck just in case.
I execute this test on 16-cores machine with 64GB mem.
I run B-Tree insertion and deletion simultaneously and execute
'bt_index_parent_check' periodically.
I also run B-Tree insertion and update simultaneously and execute
'bt_index_parent_check' periodically.
## DDL
create table mytab (val1 int, val2 int);
create index mytabidx on mytab (val1, val2);
## script_integrity_check_insert.sql
\set i random(1, 100)
\set j random(1, 100)
insert into mytab values (:i, :j);
## script_integrity_check_delete.sql
\set i random(1, 100)
\set j random(1, 100)
delete from mytab where val1 = :i and val2 = :j
## script_integrity_check_update.sql
\set i random(1, 100)
\set j random(1, 100)
\set k random(1, 100)
\set l random(1, 100)
update mytab set val1 = :k, val2 = :l where val1 = :i and val2 = :j
## commands(insert, delete, simultaneously executed)
pgbench -T 60 -P 1 -M prepared -f script_integrity_check_insert.sql -c 2 postgres
pgbench -T 60 -P 1 -M prepared -f script_integrity_check_delete.sql -c 2 postgres
## commands(insert, update, simultaneously executed)
pgbench -T 60 -P 1 -M prepared -f script_integrity_check_insert.sql -c 2 postgres
pgbench -T 60 -P 1 -M prepared -f script_integrity_check_update.sql -c 2 postgres
## commands(executed during above insert, delete, update)
(psql) select bt_index_parent_check('mytabidx');
Finally, I confirmed there are no integrity problems during B-Tree operation.
Lefted tasks in my review is doing the regression tests.
Yoshikazu Imai
On 13 July 2018 at 03:14, Imai, Yoshikazu <imai.yoshikazu@jp.fujitsu.com> wrote:
> On Mon, July 9, 2018 at 5:25 PM, Simon Riggs wrote:
>> Please can you check insertion with the index on 2 keys
>> 1st key has 10,000 values
>> 2nd key has monotonically increasing value from last 1st key value
>>
>> So each session picks one 1st key value
>> Then each new INSERTion is a higher value of 2nd key
>> so 1,1, then 1,2 then 1,3 etc
>>
>> Probably easier to do this with a table like this
>>
>> CREATE UNLOGGED TABLE ordered2 (id integer, logdate timestamp default
>> now(), value text not null, primary key (id, logdate));
>>
>> # script_ordered2.sql
>> \set i random(1, 10000)
>> INSERT INTO ordered2 (id, value) VALUES (:i, 'abcdefghijklmnoprsqtuvwxyz');
>>
>> Thanks
> I tried to do this, but I might be mistaken your intention, so please specify if I am wrong.
>
> While script_ordered.sql supposes that there is one contention point on the most right leaf node,
> script_ordered2.sql supposes that there are some contention points on some leaf nodes, is it right?
Yes, that is right, thank you for testing.
> I experimented with key1 having 10000 values, but there are no difference in the results compared to unordered.sql
one
That is an important result, thanks
> so I experimented with key1 having 1, 2, 3, 5, 10, and 100 values.
OK, good
> From an attached graph("some_contention_points_on_leaf_nodes.png"), as contention points dispersed, we can see that
TPSis increased and TPS difference between master and patched version becomes smaller.
So I think this clearly shows the drop in throughput when we have
index contention and that this patch improves on that situation.
In cases where we don't have contention, the patch doesn't cause a
negative effect.
So +1 from me!
--
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi! On Tue, Jul 10, 2018 at 4:39 PM 今井 良一 <yoshikazu_i443@live.jp> wrote: > On 2018/07/10 20:36, Alexander Korotkov wrote: > > Thank you for the experiments! It seems that there is real regression > > here... BTW, which script were you using in this benchmark: > > script_unordered.sql or script_duplicated.sql? > > Sorry, I forgot to write that. I used script_unordered.sql. I've reread the thread. And I found that in my initial letter [1] I forget to include index definition. CREATE INDEX unordered_i_idx ON unordered (i); So, when you did experiments [2], did you define any index on unordered table? If not, then it's curious why there is any performance difference at all. 1. https://www.postgresql.org/message-id/CAPpHfduAMDFMNYTCN7VMBsFg_hsf0GqiqXnt%2BbSeaJworwFoig%40mail.gmail.com 2. https://www.postgresql.org/message-id/0F97FA9ABBDBE54F91744A9B37151A51189451%40g01jpexmbkw24 ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Hi!
On Wed, Jul 25, 2018 at 1:19 PM Simon Riggs <simon@2ndquadrant.com> wrote:
> On 13 July 2018 at 03:14, Imai, Yoshikazu <imai.yoshikazu@jp.fujitsu.com> wrote:
> > From an attached graph("some_contention_points_on_leaf_nodes.png"), as contention points dispersed, we can see that
TPSis increased and TPS difference between master and patched version becomes smaller.
>
> So I think this clearly shows the drop in throughput when we have
> index contention and that this patch improves on that situation.
>
> In cases where we don't have contention, the patch doesn't cause a
> negative effect.
>
> So +1 from me!
Thank you, but Imai found another case [1], where patch causes a small
regression. For now, it's not completely clear for me what test case
was used, because I forgot to add any indexes to initial specification
of this test case [2]. If regression will be confirmed, then it would
be nice to mitigate that. And even if we wouldn't manage to mitigate
that and consider that as acceptable trade-off, then it would be nice
to at least explain it...
1. https://www.postgresql.org/message-id/0F97FA9ABBDBE54F91744A9B37151A51189451%40g01jpexmbkw24
2.
https://www.postgresql.org/message-id/CAPpHfds%3DWmjv%2Bu7S0peHN2zRrw4C%3DYySn-ZKddp4E7q8KQ18hQ%40mail.gmail.com------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Wed, Jul 25, 2018 at 5:54 AM Imai, Yoshikazu
<imai.yoshikazu@jp.fujitsu.com> wrote:
> On Mon, July 9, 2018 at 3:19 AM, Imai, Yoshikazu wrote:
> > I'm planning to do code review and send it in the next mail.
>
> Sorry for delaying the code review.
>
> I did the code review, and I think there are no logical wrongs
> with B-Tree.
>
> I tested integrity of B-Tree with amcheck just in case.
> I execute this test on 16-cores machine with 64GB mem.
>
> I run B-Tree insertion and deletion simultaneously and execute
> 'bt_index_parent_check' periodically.
> I also run B-Tree insertion and update simultaneously and execute
> 'bt_index_parent_check' periodically.
>
> ## DDL
> create table mytab (val1 int, val2 int);
> create index mytabidx on mytab (val1, val2);
>
> ## script_integrity_check_insert.sql
> \set i random(1, 100)
> \set j random(1, 100)
> insert into mytab values (:i, :j);
>
> ## script_integrity_check_delete.sql
> \set i random(1, 100)
> \set j random(1, 100)
> delete from mytab where val1 = :i and val2 = :j
>
> ## script_integrity_check_update.sql
> \set i random(1, 100)
> \set j random(1, 100)
> \set k random(1, 100)
> \set l random(1, 100)
> update mytab set val1 = :k, val2 = :l where val1 = :i and val2 = :j
>
> ## commands(insert, delete, simultaneously executed)
> pgbench -T 60 -P 1 -M prepared -f script_integrity_check_insert.sql -c 2 postgres
> pgbench -T 60 -P 1 -M prepared -f script_integrity_check_delete.sql -c 2 postgres
>
> ## commands(insert, update, simultaneously executed)
> pgbench -T 60 -P 1 -M prepared -f script_integrity_check_insert.sql -c 2 postgres
> pgbench -T 60 -P 1 -M prepared -f script_integrity_check_update.sql -c 2 postgres
>
> ## commands(executed during above insert, delete, update)
> (psql) select bt_index_parent_check('mytabidx');
>
>
> Finally, I confirmed there are no integrity problems during B-Tree operation.
>
> Lefted tasks in my review is doing the regression tests.
Cool, thank you for review!
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Hi. On Wed, July 25, 2018 at 0:28 AM, Alexander Korotkov wrote: > Hi! > > On Tue, Jul 10, 2018 at 4:39 PM 今井 良一 <yoshikazu_i443(at)live(dot)jp> wrote: > > On 2018/07/10 20:36, Alexander Korotkov wrote: > > > Thank you for the experiments! It seems that there is real regression > > > here... BTW, which script were you using in this benchmark: > > > script_unordered.sql or script_duplicated.sql? > > > > Sorry, I forgot to write that. I used script_unordered.sql. > > I've reread the thread. And I found that in my initial letter [1] I > forget to include index definition. > CREATE INDEX unordered_i_idx ON unordered (i); > > So, when you did experiments [2], did you define any index on > unordered table? If not, then it's curious why there is any > performance difference at all. > > 1. https://www.postgresql.org/message-id/CAPpHfduAMDFMNYTCN7VMBsFg_hsf0GqiqXnt%2BbSeaJworwFoig%40mail.gmail.com > 2. https://www.postgresql.org/message-id/0F97FA9ABBDBE54F91744A9B37151A51189451%40g01jpexmbkw24 My experiment[1][2] was totally wrong that I didn't create index in unordered and duplicated case. On Mon, July 9, 2018 at 3:19 AM, I wrote: > # script_duplicated.sql > INSERT INTO unordered VALUES (1, 'abcdefghijklmnoprsqtuvwxyz'); I also made mistake in duplicated.sql that I used unordered table in duplicated experiment... I re-run the experiments. This time, I created indexes on unordered and duplicated table, and confirmed indexes are created in both master and patched by using \d commands in psql. I used AWS c5.18xlarge, and executed pgbench with 36 clients. # results with indexes created master, ordered, Ave 252796 TPS (253122,252469) patched, ordered, Ave 314541 TPS (314011,315070) master, unordered, Ave 409591 TPS (413901,412010,404912,404607,416494,405619) patched, unordered, Ave 412765 TPS (409626,408578,416900,415955) master, duplicated, Ave 44811 TPS (45139,44482) patched, duplicated, Ave 202325 TPS (201519,203130) The TPS of "master, ordered" and "patched, ordered" is similar to the TPS of "master, key1 with 1 values" in previous experiment[3] (contention is concentrated), the TPS of "master, unordered" and "patched, unordered" is similar to the TPS of "master, key1 with 100 values" in previous experiment[3] (contention is dispersed). Therefore this experiment and previous experiment[3] asked for from Simon is correct I think. The TPS of "patched, duplicated" was almost 4.5 times bigger than "master, duplicated" one. About a small performance regression in previous experiments[1], I think it is because of machine's performance. I don't have rational reason nor evidence, so I only describe what I thought and did (TL;DR:). In this experiments, in order to increase machine's performance, I did something like "machine warm" as below batch. ## DDL CREATE UNLOGGED TABLE improve_performance (i integer not null, value text not null); CREATE INDEX improve_i_idx on improve_performance (i); ## improve_performance.sql \set i random(1, 1000000) INSERT INTO improve_performance VALUES (:i, 'abcdefghijklmnopqrstuvwxyz'); ## test batch port=$1 client=$2 j=$3 tablenames_all=(ordered unordered duplicated ordered2) tablenames=(unordered) function cleaning() { for tablename_ in ${tablenames_all[@]}; do psql -p ${port} -c "truncate table ${tablename_};" done psql -p ${port} -c "vacuum full analyze;" } pgbench -p ${port} -T 60 -P 1 -M prepared -f improve_performance.sql -c 72 -j 36 postgres # do for warm cleaning for tablename in ${tablenames[@]}; do for i in `seq 0 1`; do pgbench -p ${port} -T 60 -P 1 -M prepared -f script_${tablename}.sql -c ${client} -j ${j} postgres` cleaning done done When I created index on improve_performance table and executed test batch against unordered table in patched version three times, results are below. 1. 379644,381409 2. 391089,391741 3. 383141,367851 These results are little decreased compared to "patched, key1 with 100 values: 405115" (unordered) in my previous experiments[3]. I thought if I execute pgbench for warm against table with index created, warm hasn't be completely done. Because in experiments[3], I executed pgbench for warm against table without index created. So I dropped index from improve_performance table and executed test batch against patched two times, results are below. 1. 409626,408578, 2. 416900,415955, Even in the same test, performance differs largely, so a small regression can be ignored I think. Of course, I wonder there were regressions in all cases at the experiments[2]. [1] https://www.postgresql.org/message-id/0F97FA9ABBDBE54F91744A9B37151A51186E9D%40g01jpexmbkw24 [2] https://www.postgresql.org/message-id/0F97FA9ABBDBE54F91744A9B37151A51189451@g01jpexmbkw24 [3] https://www.postgresql.org/message-id/0F97FA9ABBDBE54F91744A9B37151A5118C7C3%40g01jpexmbkw24 Yoshikazu Imai
On Wed, July 25, 2018 at 0:30 AM, Alexander Korotkov wrote: > > Lefted tasks in my review is doing the regression tests. > > Cool, thank you for review! > I did "make check-world" in patched version and all tests were passed successfully! Yoshikazu Imai
Hi! On Thu, Jul 26, 2018 at 1:31 PM Imai, Yoshikazu <imai.yoshikazu@jp.fujitsu.com> wrote: > On Wed, July 25, 2018 at 0:28 AM, Alexander Korotkov wrote:> > On Tue, Jul 10, 2018 at 4:39 PM 今井 良一 <yoshikazu_i443(at)live(dot)jp>wrote: > > I've reread the thread. And I found that in my initial letter [1] I > > forget to include index definition. > > CREATE INDEX unordered_i_idx ON unordered (i); > > > > So, when you did experiments [2], did you define any index on > > unordered table? If not, then it's curious why there is any > > performance difference at all. > > > > 1. https://www.postgresql.org/message-id/CAPpHfduAMDFMNYTCN7VMBsFg_hsf0GqiqXnt%2BbSeaJworwFoig%40mail.gmail.com > > 2. https://www.postgresql.org/message-id/0F97FA9ABBDBE54F91744A9B37151A51189451%40g01jpexmbkw24 > > My experiment[1][2] was totally wrong that I didn't create index in unordered and duplicated case. > > On Mon, July 9, 2018 at 3:19 AM, I wrote: > > # script_duplicated.sql > > INSERT INTO unordered VALUES (1, 'abcdefghijklmnoprsqtuvwxyz'); > I also made mistake in duplicated.sql that I used unordered table in duplicated experiment... > > I re-run the experiments. > This time, I created indexes on unordered and duplicated table, and confirmed > indexes are created in both master and patched by using \d commands in psql. > I used AWS c5.18xlarge, and executed pgbench with 36 clients. > > # results with indexes created > master, ordered, Ave 252796 TPS (253122,252469) > patched, ordered, Ave 314541 TPS (314011,315070) > master, unordered, Ave 409591 TPS (413901,412010,404912,404607,416494,405619) > patched, unordered, Ave 412765 TPS (409626,408578,416900,415955) > master, duplicated, Ave 44811 TPS (45139,44482) > patched, duplicated, Ave 202325 TPS (201519,203130) > > The TPS of "master, ordered" and "patched, ordered" is similar to the TPS of "master, key1 with 1 values" > in previous experiment[3] (contention is concentrated), the TPS of "master, unordered" and "patched, unordered" > is similar to the TPS of "master, key1 with 100 values" in previous experiment[3] (contention is dispersed). > Therefore this experiment and previous experiment[3] asked for from Simon is correct I think. > > The TPS of "patched, duplicated" was almost 4.5 times bigger than "master, duplicated" one. > > > About a small performance regression in previous experiments[1], I think it is because of machine's performance. > I don't have rational reason nor evidence, so I only describe what I thought and did (TL;DR:). > > In this experiments, in order to increase machine's performance, I did something like "machine warm" as below batch. > > ## DDL > CREATE UNLOGGED TABLE improve_performance (i integer not null, value text not null); > CREATE INDEX improve_i_idx on improve_performance (i); > > ## improve_performance.sql > \set i random(1, 1000000) > INSERT INTO improve_performance VALUES (:i, 'abcdefghijklmnopqrstuvwxyz'); > > ## test batch > port=$1 > client=$2 > j=$3 > tablenames_all=(ordered unordered duplicated ordered2) > tablenames=(unordered) > > function cleaning() { > for tablename_ in ${tablenames_all[@]}; do > psql -p ${port} -c "truncate table ${tablename_};" > done > > psql -p ${port} -c "vacuum full analyze;" > } > > > pgbench -p ${port} -T 60 -P 1 -M prepared -f improve_performance.sql -c 72 -j 36 postgres # do for warm > cleaning > > for tablename in ${tablenames[@]}; do > for i in `seq 0 1`; do > pgbench -p ${port} -T 60 -P 1 -M prepared -f script_${tablename}.sql -c ${client} -j ${j} postgres` > cleaning > done > done > > > When I created index on improve_performance table and executed test batch against unordered table > in patched version three times, results are below. > 1. 379644,381409 > 2. 391089,391741 > 3. 383141,367851 > > These results are little decreased compared to "patched, key1 with 100 values: 405115" (unordered) > in my previous experiments[3]. > > I thought if I execute pgbench for warm against table with index created, warm hasn't be completely done. > Because in experiments[3], I executed pgbench for warm against table without index created. > > So I dropped index from improve_performance table and executed test batch against patched two times, results are below. > 1. 409626,408578, > 2. 416900,415955, > > Even in the same test, performance differs largely, so a small regression can be ignored I think. > Of course, I wonder there were regressions in all cases at the experiments[2]. > > > [1] https://www.postgresql.org/message-id/0F97FA9ABBDBE54F91744A9B37151A51186E9D%40g01jpexmbkw24 > [2] https://www.postgresql.org/message-id/0F97FA9ABBDBE54F91744A9B37151A51189451@g01jpexmbkw24 > [3] https://www.postgresql.org/message-id/0F97FA9ABBDBE54F91744A9B37151A5118C7C3%40g01jpexmbkw24 Great, thank you! So, I think the regression is demystified. We can now conclude that on our benchmarks this patch doesn't cause performance regression larger than measurement error. But in some cases it shows huge performance benefit. So, I'm going to commit this, if no objections. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 26 July 2018 at 20:59, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > Great, thank you! So, I think the regression is demystified. We can > now conclude that on our benchmarks this patch doesn't cause > performance regression larger than measurement error. But in some > cases it shows huge performance benefit. > > So, I'm going to commit this, if no objections. +1 to commit. What will the commit message be? For me, this is about reducing contention on index leaf page hotspots, while at the same time reducing the path length of lock acquisition on leaf pages -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Fri, Jul 27, 2018 at 12:30 AM Simon Riggs <simon@2ndquadrant.com> wrote: > On 26 July 2018 at 20:59, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > > > Great, thank you! So, I think the regression is demystified. We can > > now conclude that on our benchmarks this patch doesn't cause > > performance regression larger than measurement error. But in some > > cases it shows huge performance benefit. > > > > So, I'm going to commit this, if no objections. > > +1 to commit. > > What will the commit message be? > > For me, this is about reducing contention on index leaf page hotspots, > while at the same time reducing the path length of lock acquisition on > leaf pages So, reducing path length of lock acquisition is particular technical change made, while reducing contention on index leaf pages is a result. I think that reducing path length of lock acquisition should be mentioned in title of commit message, while contention reduction should be mentioned in the body of commit message, because it's motivation of this commit. If we would have release notes item for this commit, it should also mention contention reduction, because it's a user-visible effect of this commit. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Fri, Jul 27, 2018 at 6:11 PM Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > On Fri, Jul 27, 2018 at 12:30 AM Simon Riggs <simon@2ndquadrant.com> wrote: > > On 26 July 2018 at 20:59, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > > > > > Great, thank you! So, I think the regression is demystified. We can > > > now conclude that on our benchmarks this patch doesn't cause > > > performance regression larger than measurement error. But in some > > > cases it shows huge performance benefit. > > > > > > So, I'm going to commit this, if no objections. > > > > +1 to commit. > > > > What will the commit message be? > > > > For me, this is about reducing contention on index leaf page hotspots, > > while at the same time reducing the path length of lock acquisition on > > leaf pages > > So, reducing path length of lock acquisition is particular technical > change made, while reducing contention on index leaf pages is a > result. I think that reducing path length of lock acquisition should > be mentioned in title of commit message, while contention reduction > should be mentioned in the body of commit message, because it's > motivation of this commit. If we would have release notes item for > this commit, it should also mention contention reduction, because it's > a user-visible effect of this commit. So, I've pushed it. Thanks to everybody for review. ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company