Thread: [HACKERS] LWLock optimization for multicore Power machines
Hi everybody!
During FOSDEM/PGDay 2017 developer meeting I said that I have some special assembly optimization for multicore Power machines. From the answers of other hackers I realized following.
- There are some big Power machines with PostgreSQL in production use. Not as many as Intel, but some of them.
- Community could be interested in special assembly optimization for Power machines despite cost of maintaining it.
Power processors use specific implementation of atomic operations. This implementation is some kind of optimistic locking. 'lwarx' instruction 'reserves index', but that reservation could be broken on 'stwcx', and then we have to retry. So, for instance CAS operation on Power processor is a loop. So, loop of CAS operations is two level nested loop. Benchmarks showed that it becomes real problem for LWLockAttemptLock(). However, one actually can put arbitrary logic between 'lwarx' and 'stwcx' and make it a single loop. The downside is that this logic has to be implemented in assembly. See [1] for experiment details.
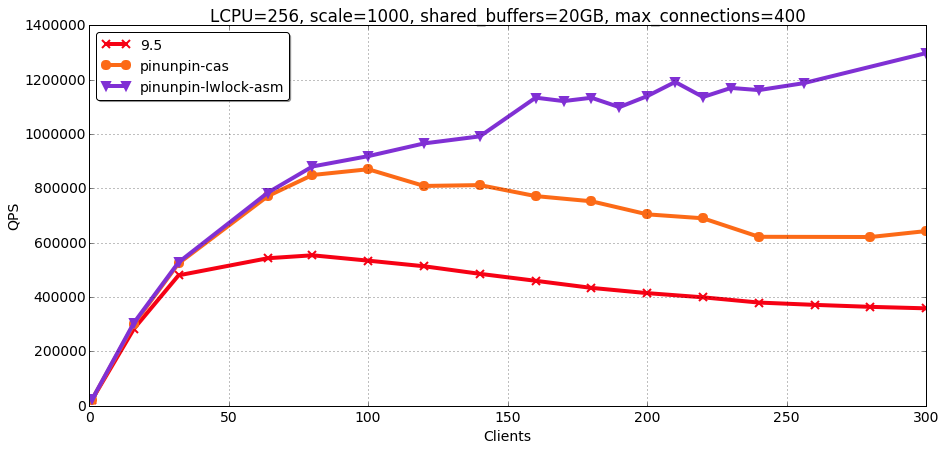
Results in [1] have a lot of junk which isn't relevant anymore. This is why I draw a separate graph.
power8-lwlock-asm-ro.png – results of read-only pgbench test on IBM E880 which have 32 physical cores and 256 virtual thread via SMT. The curves have following meaning.
* 9.5: unpatched PostgreSQL 9.5
* pinunpin-cas: PostgreSQL 9.5 + earlier version of 48354581
* pinunpin-lwlock-asm: PostgreSQL 9.5 + earlier version of 48354581 + LWLock implementation in assembly.
lwlock-power-1.patch – is the patch for assembly implementation of LWLock which I used that time rebased to current master.
Using assembly in lwlock.c looks rough. This is why I refactored it by introducing new atomic operation pg_atomic_fetch_
Unfortunately, I have no big enough Power machine at hand to reproduce that results. Actually, I have no Power machine at hand at all. So, lwlock-power-2.patch was written "blindly". I would very appreciate if someone would help me with testing and benchmarking.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Attachment
{kind=link}
On Fri, Feb 3, 2017 at 8:01 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
Unfortunately, I have no big enough Power machine at hand to reproduce that results. Actually, I have no Power machine at hand at all. So, lwlock-power-2.patch was written "blindly". I would very appreciate if someone would help me with testing and benchmarking.
UPD: It appears that Postgres Pro have access to big Power machine now. So, I can do testing/benchmarking myself.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Fri, 2017-02-03 at 20:11 +0300, Alexander Korotkov wrote: > On Fri, Feb 3, 2017 at 8:01 PM, Alexander Korotkov < > a.korotkov@postgrespro.ru> wrote: > > > Unfortunately, I have no big enough Power machine at hand to > > reproduce > > that results. Actually, I have no Power machine at hand at > > all. So, > > lwlock-power-2.patch was written "blindly". I would very > > appreciate if > > someone would help me with testing and benchmarking. > > > > UPD: It appears that Postgres Pro have access to big Power machine > now. > So, I can do testing/benchmarking myself. > Hi Alexander, We currently also have access to a LPAR on an E850 machine with 4 sockets POWER8 running a Ubuntu 16.04 LTS Server ppc64el OS. I can do some tests next week, if you need to verify your findings. Thanks, Bernd
On Fri, Feb 3, 2017 at 12:01 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > Hi everybody! > > During FOSDEM/PGDay 2017 developer meeting I said that I have some special > assembly optimization for multicore Power machines. From the answers of > other hackers I realized following. > > There are some big Power machines with PostgreSQL in production use. Not as > many as Intel, but some of them. > Community could be interested in special assembly optimization for Power > machines despite cost of maintaining it. > > Power processors use specific implementation of atomic operations. This > implementation is some kind of optimistic locking. 'lwarx' instruction > 'reserves index', but that reservation could be broken on 'stwcx', and then > we have to retry. So, for instance CAS operation on Power processor is a > loop. So, loop of CAS operations is two level nested loop. Benchmarks > showed that it becomes real problem for LWLockAttemptLock(). However, one > actually can put arbitrary logic between 'lwarx' and 'stwcx' and make it a > single loop. The downside is that this logic has to be implemented in > assembly. See [1] for experiment details. > > Results in [1] have a lot of junk which isn't relevant anymore. This is why > I draw a separate graph. > > power8-lwlock-asm-ro.png – results of read-only pgbench test on IBM E880 > which have 32 physical cores and 256 virtual thread via SMT. The curves > have following meaning. > * 9.5: unpatched PostgreSQL 9.5 > * pinunpin-cas: PostgreSQL 9.5 + earlier version of 48354581 > * pinunpin-lwlock-asm: PostgreSQL 9.5 + earlier version of 48354581 + > LWLock implementation in assembly. Cool work. Obviously there's some work to do before we can merge this -- vetting the abstraction, performance testing -- but it seems pretty neat. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Feb 3, 2017 at 11:31 PM, Bernd Helmle <mailings@oopsware.de> wrote:
> UPD: It appears that Postgres Pro have access to big Power machine
> now.
> So, I can do testing/benchmarking myself.
We currently also have access to a LPAR on an E850 machine with 4
sockets POWER8 running a Ubuntu 16.04 LTS Server ppc64el OS. I can do
some tests next week, if you need to verify your findings.
Very good, thank you!
I tried lwlock-power-2.patch on multicore Power machine we have in PostgresPro.
I realized that using labels in assembly isn't safe. Thus, I removed labels and use relative jumps instead (lwlock-power-2.patch).
Unfortunately, I didn't manage to make any reasonable benchmarks. This machine runs AIX, and there are a lot of problems which prevents PostgreSQL to show high TPS. Installing Linux there is not an option too, because that machine is used for tries to make Postgres work properly on AIX.
So, benchmarking help is very relevant. I would very appreciate that.
The Russian Postgres Company
Attachment
Am Montag, den 06.02.2017, 16:45 +0300 schrieb Alexander Korotkov: > I tried lwlock-power-2.patch on multicore Power machine we have in > PostgresPro. > I realized that using labels in assembly isn't safe. Thus, I removed > labels and use relative jumps instead (lwlock-power-2.patch). > Unfortunately, I didn't manage to make any reasonable benchmarks. > This > machine runs AIX, and there are a lot of problems which prevents > PostgreSQL > to show high TPS. Installing Linux there is not an option too, > because > that machine is used for tries to make Postgres work properly on AIX. > So, benchmarking help is very relevant. I would very appreciate > that. Okay, so here are some results. The bench runs against current PostgreSQL master, 24 GByte shared_buffers configured (128 GByte physical RAM), max_wal_size=8GB and effective_cache_size=100GB. I've just discovered that max_connections was accidently set to 601, normally i'd have set something near 110 or so... <master afcb0c97efc58459bcbbe795f42d8b7be414e076> transaction type: <builtin: select only> scaling factor: 1000 query mode: prepared number of clients: 100 number of threads: 100 duration: 30 s number of transactions actually processed: 16910687 latency average = 0.177 ms tps = 563654.968585 (including connections establishing) tps = 563991.459659 (excluding connections establishing) transaction type: <builtin: select only> scaling factor: 1000 query mode: prepared number of clients: 100 number of threads: 100 duration: 30 s number of transactions actually processed: 16523247 latency average = 0.182 ms tps = 550744.748084 (including connections establishing) tps = 552069.267389 (excluding connections establishing) transaction type: <builtin: select only> scaling factor: 1000 query mode: prepared number of clients: 100 number of threads: 100 duration: 30 s number of transactions actually processed: 16796056 latency average = 0.179 ms tps = 559830.986738 (including connections establishing) tps = 560333.682010 (excluding connections establishing) <lw-lock-power-1.patch applied> transaction type: <builtin: select only> scaling factor: 1000 query mode: prepared number of clients: 100 number of threads: 100 duration: 30 s number of transactions actually processed: 14563500 latency average = 0.206 ms tps = 485420.764515 (including connections establishing) tps = 485720.606371 (excluding connections establishing) transaction type: <builtin: select only> scaling factor: 1000 query mode: prepared number of clients: 100 number of threads: 100 duration: 30 s number of transactions actually processed: 14618457 latency average = 0.205 ms tps = 487246.817758 (including connections establishing) tps = 488117.718816 (excluding connections establishing) transaction type: <builtin: select only> scaling factor: 1000 query mode: prepared number of clients: 100 number of threads: 100 duration: 30 s number of transactions actually processed: 14522462 latency average = 0.207 ms tps = 484052.194063 (including connections establishing) tps = 485434.771590 (excluding connections establishing) <lw-lock-power-3.patch applied> transaction type: <builtin: select only> scaling factor: 1000 query mode: prepared number of clients: 100 number of threads: 100 duration: 30 s number of transactions actually processed: 17946058 latency average = 0.167 ms tps = 598164.841490 (including connections establishing) tps = 598582.503248 (excluding connections establishing) transaction type: <builtin: select only> scaling factor: 1000 query mode: prepared number of clients: 100 number of threads: 100 duration: 30 s number of transactions actually processed: 17719648 latency average = 0.169 ms tps = 590621.671588 (including connections establishing) tps = 591093.333153 (excluding connections establishing) transaction type: <builtin: select only> scaling factor: 1000 query mode: prepared number of clients: 100 number of threads: 100 duration: 30 s number of transactions actually processed: 17722941 latency average = 0.169 ms tps = 590728.715465 (including connections establishing) tps = 591619.817043 (excluding connections establishing)
On Mon, Feb 6, 2017 at 8:28 PM, Bernd Helmle <mailings@oopsware.de> wrote:
Thank you very much for testing!
Am Montag, den 06.02.2017, 16:45 +0300 schrieb Alexander Korotkov:
> I tried lwlock-power-2.patch on multicore Power machine we have in
> PostgresPro.
> I realized that using labels in assembly isn't safe. Thus, I removed
> labels and use relative jumps instead (lwlock-power-2.patch).
> Unfortunately, I didn't manage to make any reasonable benchmarks.
> This
> machine runs AIX, and there are a lot of problems which prevents
> PostgreSQL
> to show high TPS. Installing Linux there is not an option too,
> because
> that machine is used for tries to make Postgres work properly on AIX.
> So, benchmarking help is very relevant. I would very appreciate
> that.
Okay, so here are some results. The bench runs against
current PostgreSQL master, 24 GByte shared_buffers configured (128
GByte physical RAM), max_wal_size=8GB and effective_cache_size=100GB.
Results looks strange for me. I wonder why there is difference between lwlock-power-1.patch and lwlock-power-3.patch? From my intuition, it shouldn't be there because it's not much difference between them. Thus, I have following questions.
- Have you warm up database? I.e. could you do "SELECT sum(x.x) FROM (SELECT pg_prewarm(oid) AS x FROM pg_class WHERE relkind IN ('i', 'r') ORDER BY oid) x;" before each run?
- Also could you run each test longer: 3-5 mins, and run them with variety of clients count?
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Hi, On 2017-02-03 20:01:03 +0300, Alexander Korotkov wrote: > Using assembly in lwlock.c looks rough. This is why I refactored it by > introducing new atomic operation pg_atomic_fetch_mask_add_u32 (see > lwlock-power-2.patch). It checks that all masked bits are clear and then > adds to variable. This atomic have special assembly implementation for > Power, and generic implementation for other platforms with loop of CAS. > Probably we would have other implementations for other architectures in > future. This level of abstraction is the best I managed to invent. I think that's a reasonable approach. And I think it might be worth experimenting with a more efficient implementation on x86 too, using hardware lock elision / HLE and/or tsx. Andres
On Mon, 2017-02-06 at 22:44 +0300, Alexander Korotkov wrote:
> Results looks strange for me. I wonder why there is difference
> between
> lwlock-power-1.patch and lwlock-power-3.patch? From my intuition, it
> shouldn't be there because it's not much difference between them.
> Thus, I
> have following questions.
>
>
Yeah, i've realized that as well.
> 1. Have you warm up database? I.e. could you do "SELECT sum(x.x)
> FROM
> (SELECT pg_prewarm(oid) AS x FROM pg_class WHERE relkind IN ('i',
> 'r')
> ORDER BY oid) x;" before each run?
> 2. Also could you run each test longer: 3-5 mins, and run them
> with
> variety of clients count?
The results i've posted were the last 3 run of 9 in summary. I hoped
that should be enough to prewarm the system. I'm going to repeat the
tests with the changes you've requested, though.
Am Montag, den 06.02.2017, 22:44 +0300 schrieb Alexander Korotkov:
2. Also could you run each test longer: 3-5 mins, and run them with
variety of clients count?
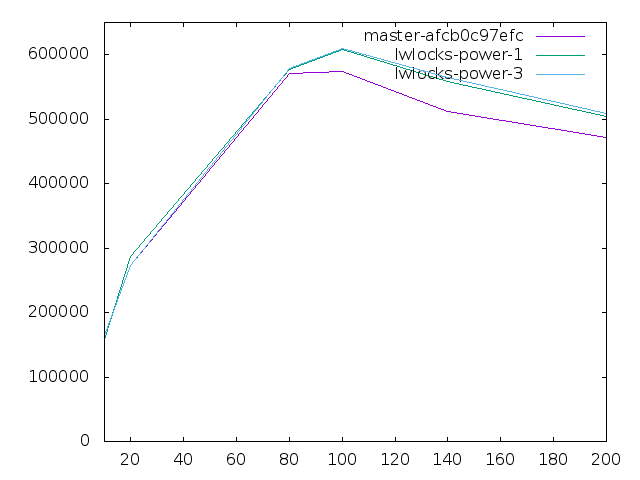
So here are some other results. I've changed max_connections to 300. The bench was prewarmed and run 300s each.
I could run more benches, if necessary.
Attachment
{kind=link}
On Tue, Feb 7, 2017 at 3:16 PM, Bernd Helmle <mailings@oopsware.de> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
Am Montag, den 06.02.2017, 22:44 +0300 schrieb Alexander Korotkov:2. Also could you run each test longer: 3-5 mins, and run them with
variety of clients count?So here are some other results. I've changed max_connections to 300. The bench was prewarmed and run 300s each.I could run more benches, if necessary.
Thank you very much for benchmarks!
There is clear win of both lwlock-power-1.patch and lwlock-power-3.patch in comparison to master. Difference between lwlock-power-1.patch and lwlock-power-3.patch seems to be within the margin of error. But win isn't as high as I observed earlier. And I wonder why absolute numbers are lower than in our earlier experiments. We used IBM E880 which is actually two nodes with interconnect. However interconnect is not fast enough to make one PostgreSQL instance work on both nodes. Thus, used half of IBM E880 which has 4 sockets and 32 physical cores. While you use IBM E850 which is really single node with 4 sockets and 48 physical cores. Thus, it seems that you have lower absolute numbers on more powerful hardware. That makes me uneasy and I think we probably don't get the best from this hardware. Just in case, do you use SMT=8?
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Am Dienstag, den 07.02.2017, 16:48 +0300 schrieb Alexander Korotkov:
> But win isn't
> as high as I observed earlier. And I wonder why absolute numbers are
> lower
> than in our earlier experiments. We used IBM E880 which is actually
> two
Did you run your tests on bare metal or were they also virtualized?
> nodes with interconnect. However interconnect is not fast enough to
> make
> one PostgreSQL instance work on both nodes. Thus, used half of IBM
> E880
> which has 4 sockets and 32 physical cores. While you use IBM E850
> which is
> really single node with 4 sockets and 48 physical cores. Thus, it
> seems
> that you have lower absolute numbers on more powerful hardware. That
> makes
> me uneasy and I think we probably don't get the best from this
> hardware.
> Just in case, do you use SMT=8?
Yes, SMT=8 was used.
The machine has 4 sockets, 8 Core each, 3.7 GHz clock frequency. The
Ubuntu LPAR running on PowerVM isn't using all physical cores,
currently 28 cores are assigned (=224 SMT Threads). The other cores are
dedicated to the PowerVM hypervisor and a (very) small AIX LPAR.
I've done more pgbenches this morning with SMT-4, too, fastest result
with master was
SMT-4
transaction type: <builtin: select only>
scaling factor: 1000
query mode: prepared
number of clients: 100
number of threads: 100
duration: 300 s
number of transactions actually processed: 167306423
latency average = 0.179 ms
latency stddev = 0.072 ms
tps = 557685.144912 (including connections establishing)
tps = 557835.683204 (excluding connections establishing)
compared with SMT-8:
transaction type: <builtin: select only>
scaling factor: 1000
query mode: prepared
number of clients: 100
number of threads: 100
duration: 300 s
number of transactions actually processed: 173476449
latency average = 0.173 ms
latency stddev = 0.059 ms
tps = 578250.676019 (including connections establishing)
tps = 578412.159601 (excluding connections establishing)
and retried with lwlocks-power-3, SMT-4:
transaction type: <builtin: select only>
scaling factor: 1000
query mode: prepared
number of clients: 100
number of threads: 100
duration: 300 s
number of transactions actually processed: 185991995
latency average = 0.161 ms
latency stddev = 0.059 ms
tps = 619970.030069 (including connections establishing)
tps = 620112.263770 (excluding connections establishing)
credativ@iicl183:~/git/postgres$
...and SMT-8
transaction type: <builtin: select only>
scaling factor: 1000
query mode: prepared
number of clients: 100
number of threads: 100
duration: 300 s
number of transactions actually processed: 185878717
latency average = 0.161 ms
latency stddev = 0.047 ms
tps = 619591.476154 (including connections establishing)
tps = 619655.867280 (excluding connections establishing)
Interestingly the lwlocks patch seems to decrease the SMT influence
factor.
Side note: the system makes around 2 Mio Context Switches during the
benchmarks, e.g.
awk '{print $12;}' /tmp/vmstat.out
cs
10
2153533
2134864
2141623
2126845
2128330
2127454
2145325
2126769
2134492
2130246
2130071
2142660
2136077
2126783
2126107
2125823
2136511
2137752
2146307
2141127
I've also tried a more recent kernel this morning (4.4 vs. 4.8), but
this didn't change the picture. Is there anything more i can do?
On Wed, Feb 8, 2017 at 5:00 PM, Bernd Helmle <mailings@oopsware.de> wrote:
Am Dienstag, den 07.02.2017, 16:48 +0300 schrieb Alexander Korotkov:
> But win isn't
> as high as I observed earlier. And I wonder why absolute numbers are
> lower
> than in our earlier experiments. We used IBM E880 which is actually
> two
Did you run your tests on bare metal or were they also virtualized?
I run tests on bare metal.
> nodes with interconnect. However interconnect is not fast enough to
> make
> one PostgreSQL instance work on both nodes. Thus, used half of IBM
> E880
> which has 4 sockets and 32 physical cores. While you use IBM E850
> which is
> really single node with 4 sockets and 48 physical cores. Thus, it
> seems
> that you have lower absolute numbers on more powerful hardware. That
> makes
> me uneasy and I think we probably don't get the best from this
> hardware.
> Just in case, do you use SMT=8?
Yes, SMT=8 was used.
The machine has 4 sockets, 8 Core each, 3.7 GHz clock frequency. The
Ubuntu LPAR running on PowerVM isn't using all physical cores,
currently 28 cores are assigned (=224 SMT Threads). The other cores are
dedicated to the PowerVM hypervisor and a (very) small AIX LPAR.
Thank you very much for the explanation.
Thus, I see reasons why in your tests absolute results are lower than in my previous tests.
1. You use 28 physical cores while I was using 32 physical cores.
2. You run tests in PowerVM while I was running test on bare metal. PowerVM could have some overhead.
3. I guess you run pgbench on the same machine. While in my tests pgbench was running on another node of IBM E880.
Therefore, having lower absolute numbers in your tests, win of LWLock optimization is also lower. That is understandable. But win of LWLock optimization is clearly visible definitely exceeds variation.
I think it would make sense to run more kinds of tests. Could you try set of tests provided by Tomas Vondra?
If even we wouldn't see win some of the tests, it would be still valuable to see that there is no regression there.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 02/11/2017 01:42 PM, Alexander Korotkov wrote: > > I think it would make sense to run more kinds of tests. Could you try > set of tests provided by Tomas Vondra? > If even we wouldn't see win some of the tests, it would be still > valuable to see that there is no regression there. > FWIW it shouldn't be difficult to tweak my scripts and run them on another machine. You'd have to customize the parameters (scales, client counts, ...) and there are a few hard-coded paths, but that's about it. regards Tomas -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Am Samstag, den 11.02.2017, 15:42 +0300 schrieb Alexander Korotkov: > Thus, I see reasons why in your tests absolute results are lower than > in my > previous tests. > 1. You use 28 physical cores while I was using 32 physical cores. > 2. You run tests in PowerVM while I was running test on bare metal. > PowerVM could have some overhead. > 3. I guess you run pgbench on the same machine. While in my tests > pgbench > was running on another node of IBM E880. > Yeah, pgbench was running locally. Maybe we can get some resources to run them remotely. Interesting side note: If you run a second postgres instance with the same pgbench in parallel, you get nearly the same transaction throughput as a single instance. Short side note: If you run two Postgres instances concurrently with the same pgbench parameters, you get nearly the same transaction throughput for both instances each as when running against a single instance, e.g. - single transaction type: <builtin: select only> scaling factor: 1000 query mode: prepared number of clients: 112 number of threads: 112 duration: 300 s number of transactions actually processed: 121523797 latency average = 0.276 ms latency stddev = 0.096 ms tps = 405075.282309 (including connections establishing) tps = 405114.299174 (excluding connections establishing) instance-1/instance-2 concurrently run: transaction type: <builtin: select only> scaling factor: 1000 query mode: prepared number of clients: 112 number of threads: 56 duration: 300 s number of transactions actually processed: 120645351 latency average = 0.278 ms latency stddev = 0.158 ms tps = 402148.536087 (including connections establishing) tps = 402199.952824 (excluding connections establishing) transaction type: <builtin: select only> scaling factor: 1000 query mode: prepared number of clients: 112 number of threads: 56 duration: 300 s number of transactions actually processed: 121959772 latency average = 0.275 ms latency stddev = 0.110 ms tps = 406530.139080 (including connections establishing) tps = 406556.658638 (excluding connections establishing) So it looks like the machine has plenty of power, but PostgreSQL is limiting somewhere. > Therefore, having lower absolute numbers in your tests, win of LWLock > optimization is also lower. That is understandable. But win of > LWLock > optimization is clearly visible definitely exceeds variation. > > I think it would make sense to run more kinds of tests. Could you > try set > of tests provided by Tomas Vondra? > If even we wouldn't see win some of the tests, it would be still > valuable > to see that there is no regression there. Unfortunately there are some test for AIX scheduled, which will assign resources to that LPAR...i've just talked to the people responsible for the machine and we can get more time for the Linux tests ;)
On 02/13/2017 03:16 PM, Bernd Helmle wrote: > Am Samstag, den 11.02.2017, 15:42 +0300 schrieb Alexander Korotkov: >> Thus, I see reasons why in your tests absolute results are lower than >> in my >> previous tests. >> 1. You use 28 physical cores while I was using 32 physical cores. >> 2. You run tests in PowerVM while I was running test on bare metal. >> PowerVM could have some overhead. >> 3. I guess you run pgbench on the same machine. While in my tests >> pgbench >> was running on another node of IBM E880. >> > > Yeah, pgbench was running locally. Maybe we can get some resources to > run them remotely. Interesting side note: If you run a second postgres > instance with the same pgbench in parallel, you get nearly the same > transaction throughput as a single instance. > > Short side note: > > If you run two Postgres instances concurrently with the same pgbench > parameters, you get nearly the same transaction throughput for both > instances each as when running against a single instance, e.g. > That strongly suggests you're hitting some kind of lock. It'd be good to know which one. I see you're doing "pgbench -S" which also updates branches and other tiny tables - it's possible the sessions are trying to update the same row in those tiny tables. You're running with scale 1000, but with 100 it's still possible thanks to the birthday paradox. Otherwise it might be interesting to look at sampling wait events, which might tell us more about the locks. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Feb 13, 2017 at 10:17 PM, Tomas Vondra <tomas.vondra@2ndquadrant.com> wrote:
On 02/13/2017 03:16 PM, Bernd Helmle wrote:Am Samstag, den 11.02.2017, 15:42 +0300 schrieb Alexander Korotkov:Thus, I see reasons why in your tests absolute results are lower than
in my
previous tests.
1. You use 28 physical cores while I was using 32 physical cores.
2. You run tests in PowerVM while I was running test on bare metal.
PowerVM could have some overhead.
3. I guess you run pgbench on the same machine. While in my tests
pgbench
was running on another node of IBM E880.
Yeah, pgbench was running locally. Maybe we can get some resources to
run them remotely. Interesting side note: If you run a second postgres
instance with the same pgbench in parallel, you get nearly the same
transaction throughput as a single instance.
Short side note:
If you run two Postgres instances concurrently with the same pgbench
parameters, you get nearly the same transaction throughput for both
instances each as when running against a single instance, e.g.
That strongly suggests you're hitting some kind of lock. It'd be good to know which one. I see you're doing "pgbench -S" which also updates branches and other tiny tables - it's possible the sessions are trying to update the same row in those tiny tables. You're running with scale 1000, but with 100 it's still possible thanks to the birthday paradox.
Otherwise it might be interesting to look at sampling wait events, which might tell us more about the locks.
+1
And you could try to use pg_wait_sampling to sampling of wait events.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Am Dienstag, den 14.02.2017, 15:53 +0300 schrieb Alexander Korotkov: > +1 > And you could try to use pg_wait_sampling > <https://github.com/postgrespro/pg_wait_sampling> to sampling of wait > events. Okay, i'm going to try this. Currently Tomas' scripts are still running, i'll provide updates as soon as they are finished.
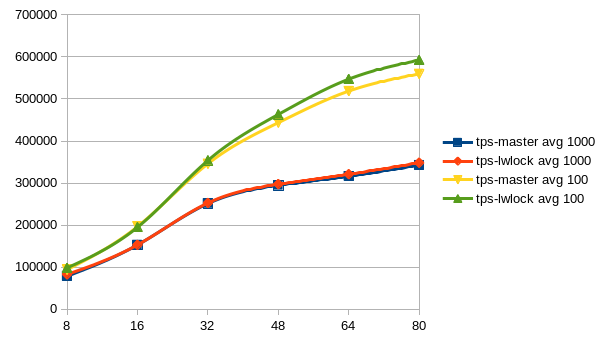
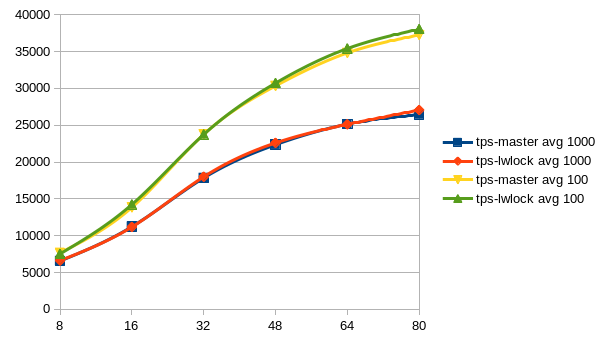
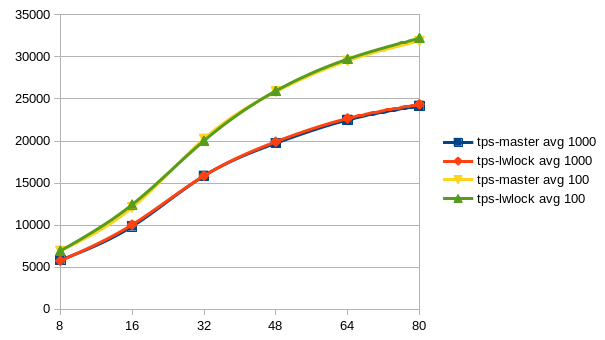
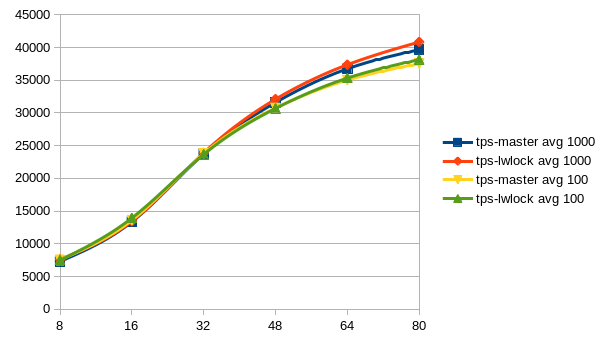
Am Samstag, den 11.02.2017, 15:42 +0300 schrieb Alexander Korotkov: > I think it would make sense to run more kinds of tests. Could you > try set > of tests provided by Tomas Vondra? > If even we wouldn't see win some of the tests, it would be still > valuable > to see that there is no regression there. Sorry for the delay. But here are the results after having run Tomas' benchmarks scripts. The pgbench-ro benchmark shows a clear win of the lwlock-power-3 patch, also you see a slight advantage of this patch in the pgbench-rw graph. At least, i don't see any signifikant regression somewhere. The graphs are showing the average values over all five runs for each client count. -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
On Tue, Feb 21, 2017 at 1:47 PM, Bernd Helmle <mailings@oopsware.de> wrote:
Am Samstag, den 11.02.2017, 15:42 +0300 schrieb Alexander Korotkov:
> I think it would make sense to run more kinds of tests. Could you
> try set
> of tests provided by Tomas Vondra?
> If even we wouldn't see win some of the tests, it would be still
> valuable
> to see that there is no regression there.
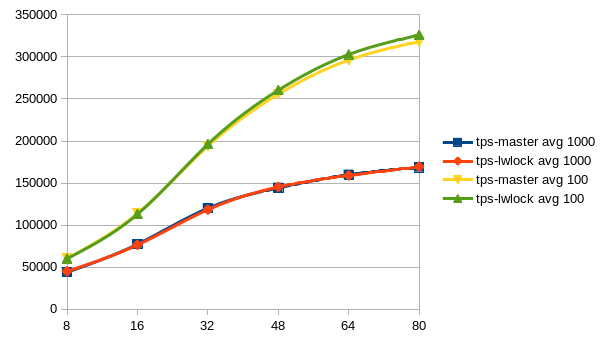
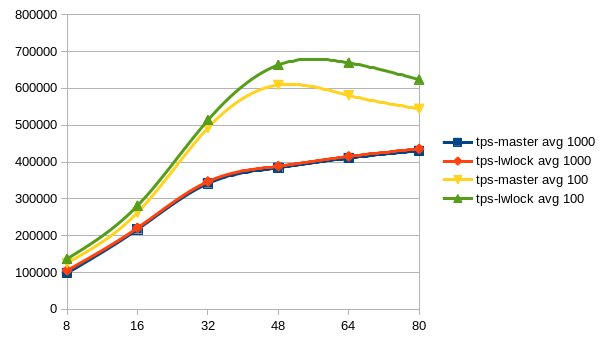
Sorry for the delay.
But here are the results after having run Tomas' benchmarks scripts.
The pgbench-ro benchmark shows a clear win of the lwlock-power-3 patch,
also you see a slight advantage of this patch in the pgbench-rw graph.
At least, i don't see any signifikant regression somewhere.
The graphs are showing the average values over all five runs for each
client count.
Thank you very much for testing, results look good.
I'll keep trying to access bigger Power machine where advantage of patch is expected to be larger.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Am Dienstag, den 14.02.2017, 15:53 +0300 schrieb Alexander Korotkov: > +1 > And you could try to use pg_wait_sampling > <https://github.com/postgrespro/pg_wait_sampling> to sampling of wait > events. I've tried this with your example from your blog post[1] and got this: (pgbench scale 1000) pgbench -Mprepared -S -n -c 100 -j 100 -T 300 -P2 pgbench2 SELECT-only: SELECT * FROM profile_log ; ts | event_type | event | count ----------------------------+---------------+---------------+------- 2017-02-21 15:21:52.45719 | LWLockNamed | ProcArrayLock | 8 2017-02-21 15:22:11.19594 | LWLockTranche | lock_manager | 1 2017-02-21 15:22:11.19594 | LWLockNamed | ProcArrayLock | 24 2017-02-21 15:22:31.220803 | LWLockNamed | ProcArrayLock | 1 2017-02-21 15:23:01.255969 | LWLockNamed | ProcArrayLock | 1 2017-02-21 15:23:11.272254 | LWLockNamed | ProcArrayLock | 2 2017-02-21 15:23:41.313069 | LWLockNamed | ProcArrayLock | 1 2017-02-21 15:24:31.37512 | LWLockNamed | ProcArrayLock | 19 2017-02-21 15:24:41.386974 | LWLockNamed | ProcArrayLock | 1 2017-02-21 15:26:41.530399 | LWLockNamed | ProcArrayLock | 1 (10 rows) writes pgbench runs have far more events logged, see the attached text file. Maybe this is of interest... [1] http://akorotkov.github.io/blog/2016/03/25/wait_monitoring_9_6/ -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On 2/21/17 9:54 AM, Bernd Helmle wrote: > Am Dienstag, den 14.02.2017, 15:53 +0300 schrieb Alexander Korotkov: >> +1 >> And you could try to use pg_wait_sampling >> <https://github.com/postgrespro/pg_wait_sampling> to sampling of wait >> events. > > I've tried this with your example from your blog post[1] and got this: > > (pgbench scale 1000) > > pgbench -Mprepared -S -n -c 100 -j 100 -T 300 -P2 pgbench2 > > SELECT-only: > > SELECT * FROM profile_log ; > ts | event_type | event | count > ----------------------------+---------------+---------------+------- > 2017-02-21 15:21:52.45719 | LWLockNamed | ProcArrayLock | 8 > 2017-02-21 15:22:11.19594 | LWLockTranche | lock_manager | 1 > 2017-02-21 15:22:11.19594 | LWLockNamed | ProcArrayLock | 24 > 2017-02-21 15:22:31.220803 | LWLockNamed | ProcArrayLock | 1 > 2017-02-21 15:23:01.255969 | LWLockNamed | ProcArrayLock | 1 > 2017-02-21 15:23:11.272254 | LWLockNamed | ProcArrayLock | 2 > 2017-02-21 15:23:41.313069 | LWLockNamed | ProcArrayLock | 1 > 2017-02-21 15:24:31.37512 | LWLockNamed | ProcArrayLock | 19 > 2017-02-21 15:24:41.386974 | LWLockNamed | ProcArrayLock | 1 > 2017-02-21 15:26:41.530399 | LWLockNamed | ProcArrayLock | 1 > (10 rows) > > writes pgbench runs have far more events logged, see the attached text > file. Maybe this is of interest... > > > [1] http://akorotkov.github.io/blog/2016/03/25/wait_monitoring_9_6/ This patch applies cleanly at cccbdde. It doesn't break compilation on amd64 but I can't test on a Power-based machine Alexander, have you had a chance to look at Bernd's results? -- -David david@pgmasters.net
Hi Alexander, On 3/16/17 1:35 PM, David Steele wrote: > On 2/21/17 9:54 AM, Bernd Helmle wrote: >> Am Dienstag, den 14.02.2017, 15:53 +0300 schrieb Alexander Korotkov: >>> +1 >>> And you could try to use pg_wait_sampling >>> <https://github.com/postgrespro/pg_wait_sampling> to sampling of wait >>> events. >> >> I've tried this with your example from your blog post[1] and got this: >> >> (pgbench scale 1000) >> >> pgbench -Mprepared -S -n -c 100 -j 100 -T 300 -P2 pgbench2 >> >> SELECT-only: >> >> SELECT * FROM profile_log ; >> ts | event_type | event | count >> ----------------------------+---------------+---------------+------- >> 2017-02-21 15:21:52.45719 | LWLockNamed | ProcArrayLock | 8 >> 2017-02-21 15:22:11.19594 | LWLockTranche | lock_manager | 1 >> 2017-02-21 15:22:11.19594 | LWLockNamed | ProcArrayLock | 24 >> 2017-02-21 15:22:31.220803 | LWLockNamed | ProcArrayLock | 1 >> 2017-02-21 15:23:01.255969 | LWLockNamed | ProcArrayLock | 1 >> 2017-02-21 15:23:11.272254 | LWLockNamed | ProcArrayLock | 2 >> 2017-02-21 15:23:41.313069 | LWLockNamed | ProcArrayLock | 1 >> 2017-02-21 15:24:31.37512 | LWLockNamed | ProcArrayLock | 19 >> 2017-02-21 15:24:41.386974 | LWLockNamed | ProcArrayLock | 1 >> 2017-02-21 15:26:41.530399 | LWLockNamed | ProcArrayLock | 1 >> (10 rows) >> >> writes pgbench runs have far more events logged, see the attached text >> file. Maybe this is of interest... >> >> >> [1] http://akorotkov.github.io/blog/2016/03/25/wait_monitoring_9_6/ > > This patch applies cleanly at cccbdde. It doesn't break compilation on > amd64 but I can't test on a Power-based machine > > Alexander, have you had a chance to look at Bernd's results? I'm marking this submission "Waiting for Author" as your input seems to be required. This thread has been idle for a week. Please respond and/or post a new patch by 2017-03-28 00:00 AoE (UTC-12) or this submission will be marked "Returned with Feedback". -- -David david@pgmasters.net
On Thu, Mar 16, 2017 at 8:35 PM, David Steele <david@pgmasters.net> wrote:
This patch applies cleanly at cccbdde. It doesn't break compilation onOn 2/21/17 9:54 AM, Bernd Helmle wrote:
> Am Dienstag, den 14.02.2017, 15:53 +0300 schrieb Alexander Korotkov:
>> +1
>> And you could try to use pg_wait_sampling
>> <https://github.com/postgrespro/pg_wait_sampling> to sampling of wait
>> events.
>
> I've tried this with your example from your blog post[1] and got this:
>
> (pgbench scale 1000)
>
> pgbench -Mprepared -S -n -c 100 -j 100 -T 300 -P2 pgbench2
>
> SELECT-only:
>
> SELECT * FROM profile_log ;
> ts | event_type | event | count
> ----------------------------+---------------+--------------- +-------
> 2017-02-21 15:21:52.45719 | LWLockNamed | ProcArrayLock | 8
> 2017-02-21 15:22:11.19594 | LWLockTranche | lock_manager | 1
> 2017-02-21 15:22:11.19594 | LWLockNamed | ProcArrayLock | 24
> 2017-02-21 15:22:31.220803 | LWLockNamed | ProcArrayLock | 1
> 2017-02-21 15:23:01.255969 | LWLockNamed | ProcArrayLock | 1
> 2017-02-21 15:23:11.272254 | LWLockNamed | ProcArrayLock | 2
> 2017-02-21 15:23:41.313069 | LWLockNamed | ProcArrayLock | 1
> 2017-02-21 15:24:31.37512 | LWLockNamed | ProcArrayLock | 19
> 2017-02-21 15:24:41.386974 | LWLockNamed | ProcArrayLock | 1
> 2017-02-21 15:26:41.530399 | LWLockNamed | ProcArrayLock | 1
> (10 rows)
>
> writes pgbench runs have far more events logged, see the attached text
> file. Maybe this is of interest...
>
>
> [1] http://akorotkov.github.io/blog/2016/03/25/wait_ monitoring_9_6/
amd64 but I can't test on a Power-based machine
Alexander, have you had a chance to look at Bernd's results?
Bernd's results look good. But it seems that his machine is not big enough, so effect of patch isn't huge.
I will get access to big enough Power8 machine in Monday 27 March. I will run benchmarks there and post results immediately.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov <a.korotkov@postgrespro.ru> writes:
> [ lwlock-power-3.patch ]
I experimented with this patch a bit. I can't offer help on testing it
on large PPC machines, but I can report that it breaks the build on
Apple PPC machines, apparently because of nonstandard assembly syntax.
I get "Parameter syntax error" on these four lines of assembly:
and 3,r0,r4 cmpwi 3,0 add 3,r0,r5 stwcx. 3,0,r2
I am not sure what the "3"s are meant to be --- if that's a hard-coded
register number, then it's unacceptable code to begin with, IMO.
You should be able to get gcc to give you a scratch register of its
choosing via appropriate use of the register assignment part of the
asm syntax. I think there are examples in s_lock.h.
I'm also unhappy that this patch changes the generic implementation of
LWLockAttemptLock. That means that we'd need to do benchmarking on *every*
machine type to see what we're paying elsewhere for the benefit of PPC.
It seems unlikely that putting an extra level of function call into that
hot-spot is zero cost.
Lastly, putting machine-specific code into atomics.c is a really bad idea.
We have a convention for where to put such code, and that is not it.
You could address both the second and third concerns, I think, by putting
the PPC asm function into port/atomics/arch-ppc.h (which is where it
belongs anyway) and making the generic implementation be a "static inline"
function in port/atomics/fallback.h. In that way, at least with compilers
that do inlines sanely, we could expect that this patch doesn't change the
generated code for LWLockAttemptLock at all on machines other than PPC.
regards, tom lane
On Sat, Mar 25, 2017 at 8:44 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
Alexander Korotkov <a.korotkov@postgrespro.ru> writes:
> [ lwlock-power-3.patch ]
I experimented with this patch a bit. I can't offer help on testing it
on large PPC machines, but I can report that it breaks the build on
Apple PPC machines, apparently because of nonstandard assembly syntax.
I get "Parameter syntax error" on these four lines of assembly:
and 3,r0,r4
cmpwi 3,0
add 3,r0,r5
stwcx. 3,0,r2
I am not sure what the "3"s are meant to be --- if that's a hard-coded
register number, then it's unacceptable code to begin with, IMO.
You should be able to get gcc to give you a scratch register of its
choosing via appropriate use of the register assignment part of the
asm syntax. I think there are examples in s_lock.h.
Right. Now I use variable bind to register instead of hard-coded register for that purpose.
I'm also unhappy that this patch changes the generic implementation of
LWLockAttemptLock. That means that we'd need to do benchmarking on *every*
machine type to see what we're paying elsewhere for the benefit of PPC.
It seems unlikely that putting an extra level of function call into that
hot-spot is zero cost.
Lastly, putting machine-specific code into atomics.c is a really bad idea.
We have a convention for where to put such code, and that is not it.
You could address both the second and third concerns, I think, by putting
the PPC asm function into port/atomics/arch-ppc.h (which is where it
belongs anyway) and making the generic implementation be a "static inline"
function in port/atomics/fallback.h. In that way, at least with compilers
that do inlines sanely, we could expect that this patch doesn't change the
generated code for LWLockAttemptLock at all on machines other than PPC.
I moved PPC implementation of pg_atomic_fetch_mask_add_u32() into port/atomics/arch-ppc.h. I also had to declare pg_atomic_uint32 there to satisfy usage of this type as argument of pg_atomic_fetch_mask_add_u32_impl().
I moved generic implementation of pg_atomic_fetch_mask_add_u32() into port/atomics/generic.h. That seems to be more appropriate place for that than fallback.h. Because fallback.h has definitions for cases when we don't have atomic for this platform at all. generic.h has definitions of lacking atomics using defined atomics.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Attachment
Alexander Korotkov <a.korotkov@postgrespro.ru> writes:
> I moved PPC implementation of pg_atomic_fetch_mask_add_u32() into
> port/atomics/arch-ppc.h. I also had to declare pg_atomic_uint32 there to
> satisfy usage of this type as argument
> of pg_atomic_fetch_mask_add_u32_impl().
Hm, you did something wrong there, because now I get a bunch of failures:
ccache gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels
-Wmissing-format-attribute-Wformat-security -fno-strict-aliasing -fwrapv -g -O2 -I../../../../src/include -c -o
brin.obrin.c
In file included from ../../../../src/include/port/atomics.h:123, from
../../../../src/include/utils/dsa.h:17, from ../../../../src/include/nodes/tidbitmap.h:26,
from../../../../src/include/access/genam.h:19, from ../../../../src/include/nodes/execnodes.h:17,
from ../../../../src/include/access/brin.h:14, from brin.c:18:
../../../../src/include/port/atomics/generic.h:154:3: error: #error "No pg_atomic_test_and_set provided"
../../../../src/include/port/atomics.h: In function 'pg_atomic_init_flag':
../../../../src/include/port/atomics.h:178: warning: implicit declaration of function 'pg_atomic_init_flag_impl'
../../../../src/include/port/atomics.h: In function 'pg_atomic_test_set_flag':
../../../../src/include/port/atomics.h:193: warning: implicit declaration of function 'pg_atomic_test_set_flag_impl'
../../../../src/include/port/atomics.h: In function 'pg_atomic_unlocked_test_flag':
../../../../src/include/port/atomics.h:208: warning: implicit declaration of function
'pg_atomic_unlocked_test_flag_impl'
... and so on.
I'm not entirely sure what the intended structure of these header files
is. Maybe Andres can comment.
regards, tom lane
On Sat, Mar 25, 2017 at 11:32 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
Alexander Korotkov <a.korotkov@postgrespro.ru> writes:
> I moved PPC implementation of pg_atomic_fetch_mask_add_u32() into
> port/atomics/arch-ppc.h. I also had to declare pg_atomic_uint32 there to
> satisfy usage of this type as argument
> of pg_atomic_fetch_mask_add_u32_impl().
Hm, you did something wrong there, because now I get a bunch of failures:
ccache gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -g -O2 -I../../../../src/include -c -o brin.o brin.c
In file included from ../../../../src/include/port/atomics.h:123,
from ../../../../src/include/utils/dsa.h:17,
from ../../../../src/include/nodes/tidbitmap.h:26,
from ../../../../src/include/access/genam.h:19,
from ../../../../src/include/nodes/execnodes.h:17,
from ../../../../src/include/access/brin.h:14,
from brin.c:18:
../../../../src/include/port/atomics/generic.h:154:3: error: #error "No pg_atomic_test_and_set provided"
../../../../src/include/port/atomics.h: In function 'pg_atomic_init_flag':
../../../../src/include/port/atomics.h:178: warning: implicit declaration of function 'pg_atomic_init_flag_impl'
../../../../src/include/port/atomics.h: In function 'pg_atomic_test_set_flag':
../../../../src/include/port/atomics.h:193: warning: implicit declaration of function 'pg_atomic_test_set_flag_impl'
../../../../src/include/port/atomics.h: In function 'pg_atomic_unlocked_test_flag' :
../../../../src/include/port/atomics.h:208: warning: implicit declaration of function 'pg_atomic_unlocked_test_flag_ impl'
... and so on.
I'm not entirely sure what the intended structure of these header files
is. Maybe Andres can comment.
It seems that on this platform definition of atomics should be provided by fallback.h. But it doesn't because I already defined PG_HAVE_ATOMIC_U32_SUPPORT in arch-ppc.h. I think in this case we shouldn't provide ppc-specific implementation of pg_atomic_fetch_mask_add_u32(). However, I don't know how to do this assuming arch-ppc.h is included before compiler-specific headers. Thus, in arch-ppc.h we don't know yet if we would find implementation of atomics for this platform. One possible solution is to provide assembly implementation for all atomics in arch-ppc.h.
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Sun, Mar 26, 2017 at 12:29 AM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Sat, Mar 25, 2017 at 11:32 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:Alexander Korotkov <a.korotkov@postgrespro.ru> writes:
> I moved PPC implementation of pg_atomic_fetch_mask_add_u32() into
> port/atomics/arch-ppc.h. I also had to declare pg_atomic_uint32 there to
> satisfy usage of this type as argument
> of pg_atomic_fetch_mask_add_u32_impl().
Hm, you did something wrong there, because now I get a bunch of failures:
ccache gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -g -O2 -I../../../../src/include -c -o brin.o brin.c
In file included from ../../../../src/include/port/atomics.h:123,
from ../../../../src/include/utils/dsa.h:17,
from ../../../../src/include/nodes/tidbitmap.h:26,
from ../../../../src/include/access/genam.h:19,
from ../../../../src/include/nodes/execnodes.h:17,
from ../../../../src/include/access/brin.h:14,
from brin.c:18:
../../../../src/include/port/atomics/generic.h:154:3: error: #error "No pg_atomic_test_and_set provided"
../../../../src/include/port/atomics.h: In function 'pg_atomic_init_flag':
../../../../src/include/port/atomics.h:178: warning: implicit declaration of function 'pg_atomic_init_flag_impl'
../../../../src/include/port/atomics.h: In function 'pg_atomic_test_set_flag':
../../../../src/include/port/atomics.h:193: warning: implicit declaration of function 'pg_atomic_test_set_flag_impl'
../../../../src/include/port/atomics.h: In function 'pg_atomic_unlocked_test_flag' :
../../../../src/include/port/atomics.h:208: warning: implicit declaration of function 'pg_atomic_unlocked_test_flag_ impl'
... and so on.
I'm not entirely sure what the intended structure of these header files
is. Maybe Andres can comment.It seems that on this platform definition of atomics should be provided by fallback.h. But it doesn't because I already defined PG_HAVE_ATOMIC_U32_SUPPORT in arch-ppc.h. I think in this case we shouldn't provide ppc-specific implementation of pg_atomic_fetch_mask_add_ u32(). However, I don't know how to do this assuming arch-ppc.h is included before compiler-specific headers. Thus, in arch-ppc.h we don't know yet if we would find implementation of atomics for this platform. One possible solution is to provide assembly implementation for all atomics in arch-ppc.h.
BTW, implementation for all atomics in arch-ppc.h would be too invasive and shouldn't be considered for v10.
However, I made following workaround: declare pg_atomic_uint32 and pg_atomic_fetch_mask_add_u32_impl() only when we know that generic-gcc.h would declare gcc-based atomics.
Could you, please, check it on Apple PPC?
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Attachment
Alexander Korotkov <a.korotkov@postgrespro.ru> writes:
>> It seems that on this platform definition of atomics should be provided by
>> fallback.h. But it doesn't because I already defined PG_HAVE_ATOMIC_U32_SUPPORT
>> in arch-ppc.h. I think in this case we shouldn't provide ppc-specific
>> implementation of pg_atomic_fetch_mask_add_u32(). However, I don't know
>> how to do this assuming arch-ppc.h is included before compiler-specific
>> headers. Thus, in arch-ppc.h we don't know yet if we would find
>> implementation of atomics for this platform. One possible solution is to
>> provide assembly implementation for all atomics in arch-ppc.h.
> BTW, implementation for all atomics in arch-ppc.h would be too invasive and
> shouldn't be considered for v10.
> However, I made following workaround: declare pg_atomic_uint32 and
> pg_atomic_fetch_mask_add_u32_impl() only when we know that generic-gcc.h
> would declare gcc-based atomics.
I don't have a well-informed opinion on whether this is a reasonable thing
to do, but I imagine Andres does.
> Could you, please, check it on Apple PPC?
It does compile and pass "make check" on prairiedog.
regards, tom lane
Hi,
On 2017-03-31 13:38:31 +0300, Alexander Korotkov wrote:
> > It seems that on this platform definition of atomics should be provided by
> > fallback.h. But it doesn't because I already defined PG_HAVE_ATOMIC_U32_SUPPORT
> > in arch-ppc.h. I think in this case we shouldn't provide ppc-specific
> > implementation of pg_atomic_fetch_mask_add_u32(). However, I don't know
> > how to do this assuming arch-ppc.h is included before compiler-specific
> > headers. Thus, in arch-ppc.h we don't know yet if we would find
> > implementation of atomics for this platform. One possible solution is to
> > provide assembly implementation for all atomics in arch-ppc.h.
That'd probably not be good use of effort.
> BTW, implementation for all atomics in arch-ppc.h would be too invasive and
> shouldn't be considered for v10.
> However, I made following workaround: declare pg_atomic_uint32 and
> pg_atomic_fetch_mask_add_u32_impl() only when we know that generic-gcc.h
> would declare gcc-based atomics.
> Could you, please, check it on Apple PPC?
That doesn't sound crazy to me.
> +/*
> + * pg_atomic_fetch_mask_add_u32 - atomically check that masked bits in variable
> + * and if they are clear then add to variable.
Hm, expanding on this wouldn't hurt.
> + * Returns the value of ptr before the atomic operation.
Sounds a bit like it'd return the pointer itself, not what it points to...
> + * Full barrier semantics.
Does it actually have full barrier semantics? Based on a quick skim I
don't think the ppc implementation doesn't?
> +#if defined(HAVE_ATOMICS) \
> + && (defined(HAVE_GCC__ATOMIC_INT32_CAS) || defined(HAVE_GCC__SYNC_INT32_CAS))
> +
> +/*
> + * Declare pg_atomic_uint32 structure before generic-gcc.h does it in order to
> + * use it in function arguments.
> + */
If we do this, then the other side needs a pointer to keep this up2date.
> +#define PG_HAVE_ATOMIC_U32_SUPPORT
> +typedef struct pg_atomic_uint32
> +{
> + volatile uint32 value;
> +} pg_atomic_uint32;
> +
> +/*
> + * Optimized implementation of pg_atomic_fetch_mask_add_u32() for Power
> + * processors. Atomic operations on Power processors are implemented using
> + * optimistic locking. 'lwarx' instruction 'reserves index', but that
> + * reservation could be broken on 'stwcx.' and then we have to retry. Thus,
> + * each CAS operation is a loop. But loop of CAS operation is two level nested
> + * loop. Experiments on multicore Power machines shows that we can have huge
> + * benefit from having this operation done using single loop in assembly.
> + */
> +#define PG_HAVE_ATOMIC_FETCH_MASK_ADD_U32
> +static inline uint32
> +pg_atomic_fetch_mask_add_u32_impl(volatile pg_atomic_uint32 *ptr,
> + uint32 mask, uint32 increment)
> +{
> + uint32 result,
> + tmp;
> +
> + __asm__ __volatile__(
> + /* read *ptr and reserve index */
> +#ifdef USE_PPC_LWARX_MUTEX_HINT
> + " lwarx %0,0,%5,1 \n"
> +#else
> + " lwarx %0,0,%5 \n"
> +#endif
Hm, we should remove that hint bit stuff at some point...
> + " and %1,%0,%3 \n" /* calculate '*ptr & mask" */
> + " cmpwi %1,0 \n" /* compare '*ptr & mark' vs 0 */
> + " bne- $+16 \n" /* exit on '*ptr & mark != 0' */
> + " add %1,%0,%4 \n" /* calculate '*ptr + increment' */
> + " stwcx. %1,0,%5 \n" /* try to store '*ptr + increment' into *ptr */
> + " bne- $-24 \n" /* retry if index reservation is broken */
> +#ifdef USE_PPC_LWSYNC
> + " lwsync \n"
> +#else
> + " isync \n"
> +#endif
> + : "=&r"(result), "=&r"(tmp), "+m"(*ptr)
> + : "r"(mask), "r"(increment), "r"(ptr)
> + : "memory", "cc");
> + return result;
> +}
I'm not sure that the barrier semantics here are sufficient.
> +/*
> + * Generic implementation of pg_atomic_fetch_mask_add_u32() via loop
> + * of compare & exchange.
> + */
> +static inline uint32
> +pg_atomic_fetch_mask_add_u32_impl(volatile pg_atomic_uint32 *ptr,
> + uint32 mask_, uint32 add_)
> +{
> + uint32 old_value;
> +
> + /*
> + * Read once outside the loop, later iterations will get the newer value
> + * via compare & exchange.
> + */
> + old_value = pg_atomic_read_u32_impl(ptr);
> +
> + /* loop until we've determined whether we could make an increment or not */
> + while (true)
> + {
> + uint32 desired_value;
> + bool free;
> +
> + desired_value = old_value;
> + free = (old_value & mask_) == 0;
> + if (free)
> + desired_value += add_;
> +
> + /*
> + * Attempt to swap in the value we are expecting. If we didn't see
> + * masked bits to be clear, that's just the old value. If we saw them
> + * as clear, we'll attempt to make an increment. The reason that we
> + * always swap in the value is that this doubles as a memory barrier.
> + * We could try to be smarter and only swap in values if we saw the
> + * maked bits as clear, but benchmark haven't shown it as beneficial
> + * so far.
> + *
> + * Retry if the value changed since we last looked at it.
> + */
> + if (pg_atomic_compare_exchange_u32_impl(ptr, &old_value, desired_value))
> + return old_value;
> + }
> + pg_unreachable();
> +}
> +#endif
Have you done x86 benchmarking?
Greetings,
Andres Freund
Hi,
On 2017-04-03 11:56:13 -0700, Andres Freund wrote:
>
> > +/*
> > + * Generic implementation of pg_atomic_fetch_mask_add_u32() via loop
> > + * of compare & exchange.
> > + */
> > +static inline uint32
> > +pg_atomic_fetch_mask_add_u32_impl(volatile pg_atomic_uint32 *ptr,
> > + uint32 mask_, uint32 add_)
> > +{
> > + uint32 old_value;
> > +
> > + /*
> > + * Read once outside the loop, later iterations will get the newer value
> > + * via compare & exchange.
> > + */
> > + old_value = pg_atomic_read_u32_impl(ptr);
> > +
> > + /* loop until we've determined whether we could make an increment or not */
> > + while (true)
> > + {
> > + uint32 desired_value;
> > + bool free;
> > +
> > + desired_value = old_value;
> > + free = (old_value & mask_) == 0;
> > + if (free)
> > + desired_value += add_;
> > +
> > + /*
> > + * Attempt to swap in the value we are expecting. If we didn't see
> > + * masked bits to be clear, that's just the old value. If we saw them
> > + * as clear, we'll attempt to make an increment. The reason that we
> > + * always swap in the value is that this doubles as a memory barrier.
> > + * We could try to be smarter and only swap in values if we saw the
> > + * maked bits as clear, but benchmark haven't shown it as beneficial
> > + * so far.
> > + *
> > + * Retry if the value changed since we last looked at it.
> > + */
> > + if (pg_atomic_compare_exchange_u32_impl(ptr, &old_value, desired_value))
> > + return old_value;
> > + }
> > + pg_unreachable();
> > +}
> > +#endif
>
> Have you done x86 benchmarking?
I think unless such benchmarking is done in the next 24h we need to move
this patch to the next CF...
Greetings,
Andres Freund
Andres Freund <andres@anarazel.de> writes:
> On 2017-04-03 11:56:13 -0700, Andres Freund wrote:
>> Have you done x86 benchmarking?
> I think unless such benchmarking is done in the next 24h we need to move
> this patch to the next CF...
In theory, inlining the _impl function should lead to exactly the same
assembly code as before, on all non-PPC platforms. Confirming that would
be a good substitute for benchmarking.
Having said that, I'm not sure this patch is solid enough to push in
right now, and would be happy with seeing it pushed to v11.
regards, tom lane
On Thu, Apr 6, 2017 at 2:16 AM, Andres Freund <andres@anarazel.de> wrote:
I think unless such benchmarking is done in the next 24h we need to moveOn 2017-04-03 11:56:13 -0700, Andres Freund wrote:
>
> > +/*
> > + * Generic implementation of pg_atomic_fetch_mask_add_u32() via loop
> > + * of compare & exchange.
> > + */
> > +static inline uint32
> > +pg_atomic_fetch_mask_add_u32_impl(volatile pg_atomic_uint32 *ptr,
> > + uint32 mask_, uint32 add_)
> > +{
> > + uint32 old_value;
> > +
> > + /*
> > + * Read once outside the loop, later iterations will get the newer value
> > + * via compare & exchange.
> > + */
> > + old_value = pg_atomic_read_u32_impl(ptr);
> > +
> > + /* loop until we've determined whether we could make an increment or not */
> > + while (true)
> > + {
> > + uint32 desired_value;
> > + bool free;
> > +
> > + desired_value = old_value;
> > + free = (old_value & mask_) == 0;
> > + if (free)
> > + desired_value += add_;
> > +
> > + /*
> > + * Attempt to swap in the value we are expecting. If we didn't see
> > + * masked bits to be clear, that's just the old value. If we saw them
> > + * as clear, we'll attempt to make an increment. The reason that we
> > + * always swap in the value is that this doubles as a memory barrier.
> > + * We could try to be smarter and only swap in values if we saw the
> > + * maked bits as clear, but benchmark haven't shown it as beneficial
> > + * so far.
> > + *
> > + * Retry if the value changed since we last looked at it.
> > + */
> > + if (pg_atomic_compare_exchange_u32_impl(ptr, &old_value, desired_value))
> > + return old_value;
> > + }
> > + pg_unreachable();
> > +}
> > +#endif
>
> Have you done x86 benchmarking?
this patch to the next CF...
Thank you for your comments.
I didn't x86 benchmarking. I even didn't manage to reproduce previous results on Power8.
Presumably, it's because previous benchmarks were done on bare metal, while now I have to some kind of virtual machine on IBM E880 where I can't reproduce any win of Power8 LWLock optimization. But probably there is another reason.
Thus, I'm moving this patch to the next CF.
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Thu, Apr 6, 2017 at 5:37 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
On Thu, Apr 6, 2017 at 2:16 AM, Andres Freund <andres@anarazel.de> wrote:I think unless such benchmarking is done in the next 24h we need to moveOn 2017-04-03 11:56:13 -0700, Andres Freund wrote:
> Have you done x86 benchmarking?
this patch to the next CF...Thank you for your comments.I didn't x86 benchmarking. I even didn't manage to reproduce previous results on Power8.Presumably, it's because previous benchmarks were done on bare metal, while now I have to some kind of virtual machine on IBM E880 where I can't reproduce any win of Power8 LWLock optimization. But probably there is another reason.Thus, I'm moving this patch to the next CF.
I see it's already moved. OK!
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Thu, Apr 6, 2017 at 5:38 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:
It doesn't seems to make sense to consider this patch unless we get access to suitable Power machine to reproduce benefits.
On Thu, Apr 6, 2017 at 5:37 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote:On Thu, Apr 6, 2017 at 2:16 AM, Andres Freund <andres@anarazel.de> wrote:I think unless such benchmarking is done in the next 24h we need to moveOn 2017-04-03 11:56:13 -0700, Andres Freund wrote:
> Have you done x86 benchmarking?
this patch to the next CF...Thank you for your comments.I didn't x86 benchmarking. I even didn't manage to reproduce previous results on Power8.Presumably, it's because previous benchmarks were done on bare metal, while now I have to some kind of virtual machine on IBM E880 where I can't reproduce any win of Power8 LWLock optimization. But probably there is another reason.Thus, I'm moving this patch to the next CF.I see it's already moved. OK!
This is why I'm going to mark this patch "Returned with feedback".
Once we would get access to the appropriate machine, I will resubmit this patch.
The Russian Postgres Company
Alexander Korotkov <a.korotkov@postgrespro.ru> writes:
> It doesn't seems to make sense to consider this patch unless we get access
> to suitable Power machine to reproduce benefits.
> This is why I'm going to mark this patch "Returned with feedback".
> Once we would get access to the appropriate machine, I will resubmit this
> patch.
What about hydra (that 60-core POWER7 machine we have community
access to)?
regards, tom lane
On 2017-08-30 16:24, Tom Lane wrote: > Alexander Korotkov <a.korotkov@postgrespro.ru> writes: >> It doesn't seems to make sense to consider this patch unless we get >> access >> to suitable Power machine to reproduce benefits. >> This is why I'm going to mark this patch "Returned with feedback". >> Once we would get access to the appropriate machine, I will resubmit >> this >> patch. > > What about hydra (that 60-core POWER7 machine we have community > access to)? > > regards, tom lane Anyway, I encourage to consider first another LWLock patch: https://commitfest.postgresql.org/14/1166/ It positively affects performance on any platform (I've tested it on Power as well). And I have prototype of further adaptation of that patch for POWER platform (ie using inline assembly) (not published yet). -- Sokolov Yura Postgres Professional: https://postgrespro.ru The Russian Postgres Company