Thread: [GENERAL] How well does PostgreSQL 9.6.1 support unicode?
Unicode has evolved from version 1.0 with 7,161 characters released in 1991 to version 9.0 with 128,172 characters released in June 2016. My questions are
- which version of Unicode is supported by PostgreSQL 9.6.1?
- what does "supported" exactly mean? simply store it? comparison? sorting? substring? etc.
Below is a test I did which reveals some unexpected behaviors.
My test database 'gsdb' is using UTF8 encoding, confirmed by
select datname, datcollate, datctype, pg_encoding_to_char(encoding)
from pg_database
where datname = 'gsdb';
which returned UTF8.
Here is a simple test table:
create table unicode (id int, string varchar(100));
Then I insert some unicode characters by referencing their code points in hexadecimal:
/* characters from BMP, 0000 - FFFF */
insert into unicode(id, string) values(1, U&'\0041'); -- 'A'
insert into unicode(id, string) values(2, U&'\00C4'); -- 'A' with umlaut, German
insert into unicode(id, string) values(3, U&'\03B1'); -- Greek letter alpha
insert into unicode(id, string) values(4, U&'\6211'); -- a Chinese character, https://unicodelookup.com/#0x6211/1
insert into unicode(id, string) values(5, U&'\6211\4EEC'); -- a string of two Chinese characters
insert into unicode(id, string) values(6, U&'\30CF'); -- a Japanese character
insert into unicode(id, string) values(7, U&'\306F'); -- a Japanese character
insert into unicode(id, string) values(8, U&'\2B41'); -- https://unicodelookup.com/#0x2b41/1
insert into unicode(id, string) values(9, U&'\2B44'); -- https://unicodelookup.com/#0x2b44/1
insert into unicode(id, string) values(10, U&'\2B50'); -- https://unicodelookup.com/#0x2b50/1
/* Below are unicode characters with code points beyond FFFF, aka planes 1 - F */
insert into unicode(id, string) values(100, U&'\1F478'); -- a mojo character, https://unicodelookup.com/#0x1f478/1
insert into unicode(id, string) values(101, U&'\1F479'); -- another mojo
insert into unicode(id, string) values(102, U&'\1D11F'); -- musical symbol g clef ottava alta
insert into unicode(id, string) values(103, U&'\26000'); -- a very infrequently used Chinese character
insert into unicode(id, string) values(104, U&'\26001'); -- another very infrequently used Chinese character
insert into unicode(id, string) values(105, U&'\26000\26001'); -- a string with 2 Chinese characters in the plane 2
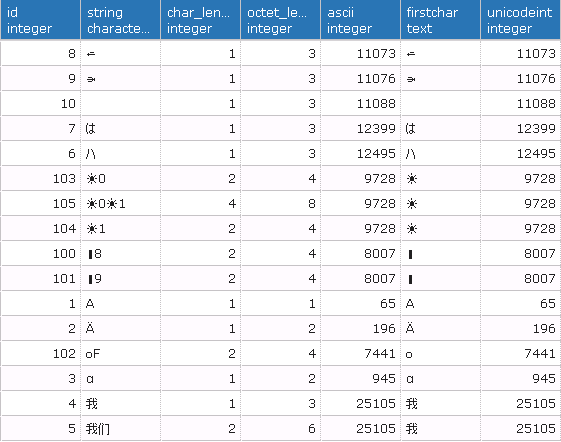
The SELECT below shows what PostgreSQL has recorded:
select id, string,
char_length(string),
octet_length(string),
ascii(string),
substring(string, 1, 1) as firstChar,
ascii(substring(string, 1, 1)) as unicodeInt
from unicode
order by string;
Here are the results:
Observations
- BMP characters (id <= 10)
- they are stored and fetched correctly.
- their lengths in char are correct, although some of them take 3 bytes (id = 4, 6, 7)
- But their sorting order seems to be undefined. Can anyone comment the sorting rules?
- Non-BMP characters (id >= 100)
- they take 2 - 4 bytes.
- Their lengths in character are not correct
- they are not retrieved correctly, judged by the their fetched ascii value (column 5 in the table above)
- substring is not correct
Specifically, the lack of support for emojo characters 0x1F478, 0x1F479 is causing a problem in my application.
My conclusion:
- PostgreSQL 9.6.1 only supports a subset of unicode characters in BMP. Is there any documents defining which subset is fully supported?
Are any configuration I can change so that more unicode characters are supported?
Thanks
James
Attachment
On 12/20/2016 4:41 PM, James Zhou wrote:
- PostgreSQL 9.6.1 only supports a subset of unicode characters in BMP. Is there any documents defining which subset is fully supported?
I believve its support is based on what the OS native runtime libraries support.
-- john r pierce, recycling bits in santa cruz
The comments in here may be of help: https://github.com/postgres/postgres/blob/master/src/include/mb/pg_wchar.h Kind regards Peter
James Zhou <james@360data.ca> writes:
> - *But their sorting order seems to be undefined. Can anyone comment
> the sorting rules?*
Well, it would depend on lc_collate, which you have not told us, and
it would also depend on how well your platform's strcoll() function
implements that collation; but you have not told us what platform this
is running on.
Most of the other behaviors you mention are also partly or wholly
dependent on which software you use with Postgres and whether you've
correctly configured that software. So it's pretty hard to answer
this usefully with only this much info.
regards, tom lane
both lc_type and lc_collate are en_US.UTF-8. Sorry for missing them in the original post.
I understand that collate has impact on sorting order, but the fact that char_length() is not returning the correct length in char for certain characters (non-BMP) is an indication that unicode is not fully supported. If char_length() is not working properly, I'd expect that substring() won't work either.
The PostgreSQL I am using is an AWS PostgreSQL RDS. I can check with AWS, but presumably that they are running PostgreSQL RDS on some flavor of lunix.
My client is PgAdmin 4 running on a Windows 7 machine. I understand that some client tools may not be able to display all unicode chars, but I do expect that the function ascii() return correct values of the stored chars.
For me the primary requirement is storing and retrieving all unicode characters as they are, and char_length() returns the correct values for all supported unicode chars. Correct sorting is nice-to-have.
Any help to get unicode chars, particularly the mojos (0x1F478, 0x1F479), in and out of pg correctly is much appreciated. Thank you!
James
On Tue, Dec 20, 2016 at 9:24 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
James Zhou <james@360data.ca> writes:
> - *But their sorting order seems to be undefined. Can anyone comment
> the sorting rules?*
Well, it would depend on lc_collate, which you have not told us, and
it would also depend on how well your platform's strcoll() function
implements that collation; but you have not told us what platform this
is running on.
Most of the other behaviors you mention are also partly or wholly
dependent on which software you use with Postgres and whether you've
correctly configured that software. So it's pretty hard to answer
this usefully with only this much info.
regards, tom lane
Hello, At Tue, 20 Dec 2016 16:41:51 -0800, James Zhou <james@360data.ca> wrote in <CAGuREpPHJmoHe_5+P25UCosRvqQpbhPF_0LGFbJ+xYgUKndydg@mail.gmail.com> > Unicode has evolved from version 1.0 with 7,161 characters released in 1991 > to version 9.0 with 128,172 characters released in June 2016. My questions > are > - which version of Unicode is supported by PostgreSQL 9.6.1? > - what does "supported" exactly mean? simply store it? comparison? sorting? > substring? etc. ... > /* characters from BMP, 0000 - FFFF */ > insert into unicode(id, string) values(1, U&'\0041'); -- 'A' ... > insert into unicode(id, string) values(5, U&'\6211\4EEC'); -- a string of two Chinese characters These shouldn't be a problem. > /* Below are unicode characters with code points beyond FFFF, aka planes 1 - F */ > insert into unicode(id, string) values(100, U&'\1F478'); -- a mojo character, https://unicodelookup.com/#0x1f478/1 https://www.postgresql.org/docs/9.6/static/sql-syntax-lexical.html > Unicode characters can be specified in escaped form by writing a > backslash followed by the four-digit hexadecimal code point > number or alternatively a backslash followed by a plus sign > followed by a six-digit hexadecimal code point number. So this is parsed as U+1f47 + '8' as you seen. This should be as the following. '+' is needed just after the backslash. insert into unicode(id, string) values(100, U&'\+01F478'); The six-digit form accepts up to U+10FFFF so the whole space in Unicode is usable. > Observations > > - BMP characters (id <= 10) > - they are stored and fetched correctly. > - their lengths in char are correct, although some of them take 3 > bytes (id = 4, 6, 7) > - *But their sorting order seems to be undefined. Can anyone comment > the sorting rules?* > - Non-BMP characters (id >= 100) > - they take 2 - 4 bytes. > - Their lengths in character are not correct > - they are not retrieved correctly, judged by the their fetched ascii > value (column 5 in the table above) > - substring is not correct > > Specifically, the lack of support for emojo characters 0x1F478, 0x1F479 is > causing a problem in my application. '+' would resolve the problem. > My conclusion: > - PostgreSQL 9.6.1 only supports a subset of unicode characters in BMP. Is > there any documents defining which subset is fully supported? A PostgreSQL database with encoding=UTF8 just accepts the whole range of Unicode, regardless that a character is defined for the code or not. > Are any configuration I can change so that more unicode characters are > supported? For the discussion on sorting, categorize is described in Tom's mail. -- Kyotaro Horiguchi NTT Open Source Software Center
On 21/12/16 05:24, Tom Lane wrote: > James Zhou <james@360data.ca> writes: >> - *But their sorting order seems to be undefined. Can anyone comment >> the sorting rules?* > > Well, it would depend on lc_collate, which you have not told us, and > it would also depend on how well your platform's strcoll() function > implements that collation; but you have not told us what platform this > is running on. As I understand it, when you first initialise pg with initdb, it inherits the collation of the process that runs the initdb. Having said that see: https://www.postgresql.org/docs/9.6/static/collation.html "If the operating system provides support for using multiple locales within a single program (newlocale and related functions), then when a database cluster is initialized, initdb populates the system catalog pg_collation with collations based on all the locales it finds on the operating system at the time." So the pg is capable, in principle at least, of using any of the locales available at the time that initdb is run. > > Most of the other behaviors you mention are also partly or wholly > dependent on which software you use with Postgres and whether you've > correctly configured that software. So it's pretty hard to answer > this usefully with only this much info. > The more recent versions of perl (see http://perldoc.perl.org/perlunicode.htm - maybe other languages) knows, not only about code points, but also "graphemes", so in the appropriate context "LATIN CAPITAL LETTER E WITH ACUTE" can be considered to be "equal" to "LATIN CAPITAL LETTER E" together with "COMBINING ACUTE ACCENT", although they are 1 and 2 unicode characters respectively so this effects notions of equality as well as collation. This has implications for pg varchar(N) fields etc. I would be interest to know what support pg has/will have for graphemes. Steve
On Wed, Dec 21, 2016 at 2:56 AM, Kyotaro HORIGUCHI <horiguchi.kyotaro@lab.ntt.co.jp> wrote:
> A PostgreSQL database with encoding=UTF8 just accepts the whole
> range of Unicode, regardless that a character is defined for the
> code or not.
Interesting... when I converted my application and database to utf8 encoding, I discovered that Postgres is picky about UTF-8. Specifically the UTF-8 code point 0xed 0xa0 0x8d which maps to UNICODE code point 0xd80d. This looks like a proper character but in fact is not a defined character code point.
Given the above unicode table:
insert into unicode(id, string) values(1, E'\xed\xa0\x8d');
ERROR: invalid byte sequence for encoding "UTF8": 0xed 0xa0 0x8d
So I think when you present an actual string of UTF8 encoded characters, Postgres does refuse characters unknown. However, as you observe, inserting the unicode code point directly does not produce an error:
insert into unicode(id, string) values(1, U&'\d80d');
INSERT 0 1
I discovered this when that specific byte sequence was found in my database during the conversion. I have no idea what my customer entered in the form to make that sequence, but it was part of the Vietnamese spelling of Ho Chi Minh City as best I could figure.
Vick Khera <vivek@khera.org> writes: > On Wed, Dec 21, 2016 at 2:56 AM, Kyotaro HORIGUCHI < > horiguchi.kyotaro@lab.ntt.co.jp> wrote: >> A PostgreSQL database with encoding=UTF8 just accepts the whole >> range of Unicode, regardless that a character is defined for the >> code or not. > Interesting... when I converted my application and database to utf8 > encoding, I discovered that Postgres is picky about UTF-8. Specifically the > UTF-8 code point 0xed 0xa0 0x8d which maps to UNICODE code point 0xd80d. > This looks like a proper character but in fact is not a defined character > code point. Well, we're picky to the extent that RFC 3629 tells us to be picky: http://www.faqs.org/rfcs/rfc3629.html The case you mention is rejected because it would be half of a UTF16 "surrogate pair", which should not be used in any Unicode representation other than UTF16; if we allowed it then there would be more than one way to represent the same Unicode code point, which is undesirable for a lot of reasons. > So I think when you present an actual string of UTF8 encoded characters, > Postgres does refuse characters unknown. However, as you observe, inserting > the unicode code point directly does not produce an error: > insert into unicode(id, string) values(1, U&'\d80d'); > INSERT 0 1 Hm. I think that's a bug. The lexer does know that \d80d is half of a surrogate pair, and it expects the second half to come next. If you supply something that isn't the second half of a surrogate pair, you get an error as expected: u8=# insert into unicode(id, string) values(1, U&'\d80dfoo'); ERROR: invalid Unicode surrogate pair at or near "foo'" LINE 1: insert into unicode(id, string) values(1, U&'\d80dfoo'); ^ But it looks like if you just end the string after the first half of a surrogate, it just drops the character without complaint. Notice that what got inserted was a zero-length string, not U+D08D: u8=# select *, length(string) from unicode; id | string | length ----+--------+-------- 1 | | 0 (1 row) I'd have expected a syntax error along the line of "incomplete Unicode surrogate pair". Peter, I think this was your code to begin with --- was it intentional to not raise error here, or is that an oversight? regards, tom lane
I figured out that I need to use the function CHR to enter supplementary unicode characters (code points > FFFF, i.e. planes 1 - F), e.g.
insert into unicode(id, string) values(100, CHR(128120)); -- a mojo character, https://unicodelookup.com/#0x1f478/1
insert into unicode(id, string) values(101, CHR(128121)); -- another mojo
insert into unicode(id, string) values(102, CHR(119071)); -- musical symbol g clef ottava alta
insert into unicode(id, string) values(103, CHR(155648)); -- a very infrequently used Chinese character
insert into unicode(id, string) values(104, CHR(155649)); -- another very infrequently used Chinese character
the parameters are decimal representation of the code point values, e.g. 128120 is the decimal value of 1f478
The format U&'\03B1' only works for chars between 0000 - FFFF
When entered with CHR(), PostgreSQL gets their char_length() correctly, so does substring() function.
Thank you all for help.
James
On Wed, Dec 21, 2016 at 8:31 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
Vick Khera <vivek@khera.org> writes:
> On Wed, Dec 21, 2016 at 2:56 AM, Kyotaro HORIGUCHI <
> horiguchi.kyotaro@lab.ntt.co.jp> wrote:
>> A PostgreSQL database with encoding=UTF8 just accepts the whole
>> range of Unicode, regardless that a character is defined for the
>> code or not.
> Interesting... when I converted my application and database to utf8
> encoding, I discovered that Postgres is picky about UTF-8. Specifically the
> UTF-8 code point 0xed 0xa0 0x8d which maps to UNICODE code point 0xd80d.
> This looks like a proper character but in fact is not a defined character
> code point.
Well, we're picky to the extent that RFC 3629 tells us to be picky:
http://www.faqs.org/rfcs/rfc3629.html
The case you mention is rejected because it would be half of a UTF16
"surrogate pair", which should not be used in any Unicode representation
other than UTF16; if we allowed it then there would be more than one way
to represent the same Unicode code point, which is undesirable for a lot
of reasons.
> So I think when you present an actual string of UTF8 encoded characters,
> Postgres does refuse characters unknown. However, as you observe, inserting
> the unicode code point directly does not produce an error:
> insert into unicode(id, string) values(1, U&'\d80d');
> INSERT 0 1
Hm. I think that's a bug. The lexer does know that \d80d is half of a
surrogate pair, and it expects the second half to come next. If you
supply something that isn't the second half of a surrogate pair, you
get an error as expected:
u8=# insert into unicode(id, string) values(1, U&'\d80dfoo');
ERROR: invalid Unicode surrogate pair at or near "foo'"
LINE 1: insert into unicode(id, string) values(1, U&'\d80dfoo');
^
But it looks like if you just end the string after the first half of a
surrogate, it just drops the character without complaint. Notice that
what got inserted was a zero-length string, not U+D08D:
u8=# select *, length(string) from unicode;
id | string | length
----+--------+--------
1 | | 0
(1 row)
I'd have expected a syntax error along the line of "incomplete Unicode
surrogate pair". Peter, I think this was your code to begin with ---
was it intentional to not raise error here, or is that an oversight?
regards, tom lane
--
Sent via pgsql-general mailing list (pgsql-general@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-general
James Zhou <james@360data.ca> writes:
> The format U&'\03B1' only works for chars between 0000 - FFFF
Kyotaro-san already pointed you to the right answer on that:
you have to use "\+nnnnnn" for six-digit code points in the U&
string syntax.
regards, tom lane
On Wed, Dec 21, 2016 at 11:31 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
Well, we're picky to the extent that RFC 3629 tells us to be picky:
http://www.faqs.org/rfcs/rfc3629.html
And I'm *GLAD* it is that way. Who wants garbage in their database? :)