[GENERAL] How well does PostgreSQL 9.6.1 support unicode? - Mailing list pgsql-general
| From | James Zhou |
|---|---|
| Subject | [GENERAL] How well does PostgreSQL 9.6.1 support unicode? |
| Date | |
| Msg-id | CAGuREpPHJmoHe_5+P25UCosRvqQpbhPF_0LGFbJ+xYgUKndydg@mail.gmail.com Whole thread |
| Responses |
Re: [GENERAL] How well does PostgreSQL 9.6.1 support unicode?
Re: [GENERAL] How well does PostgreSQL 9.6.1 support unicode? Re: [GENERAL] How well does PostgreSQL 9.6.1 support unicode? |
| List | pgsql-general |
Unicode has evolved from version 1.0 with 7,161 characters released in 1991 to version 9.0 with 128,172 characters released in June 2016. My questions are
- which version of Unicode is supported by PostgreSQL 9.6.1?
- what does "supported" exactly mean? simply store it? comparison? sorting? substring? etc.
Below is a test I did which reveals some unexpected behaviors.
My test database 'gsdb' is using UTF8 encoding, confirmed by
select datname, datcollate, datctype, pg_encoding_to_char(encoding)
from pg_database
where datname = 'gsdb';
which returned UTF8.
Here is a simple test table:
create table unicode (id int, string varchar(100));
Then I insert some unicode characters by referencing their code points in hexadecimal:
/* characters from BMP, 0000 - FFFF */
insert into unicode(id, string) values(1, U&'\0041'); -- 'A'
insert into unicode(id, string) values(2, U&'\00C4'); -- 'A' with umlaut, German
insert into unicode(id, string) values(3, U&'\03B1'); -- Greek letter alpha
insert into unicode(id, string) values(4, U&'\6211'); -- a Chinese character, https://unicodelookup.com/#0x6211/1
insert into unicode(id, string) values(5, U&'\6211\4EEC'); -- a string of two Chinese characters
insert into unicode(id, string) values(6, U&'\30CF'); -- a Japanese character
insert into unicode(id, string) values(7, U&'\306F'); -- a Japanese character
insert into unicode(id, string) values(8, U&'\2B41'); -- https://unicodelookup.com/#0x2b41/1
insert into unicode(id, string) values(9, U&'\2B44'); -- https://unicodelookup.com/#0x2b44/1
insert into unicode(id, string) values(10, U&'\2B50'); -- https://unicodelookup.com/#0x2b50/1
/* Below are unicode characters with code points beyond FFFF, aka planes 1 - F */
insert into unicode(id, string) values(100, U&'\1F478'); -- a mojo character, https://unicodelookup.com/#0x1f478/1
insert into unicode(id, string) values(101, U&'\1F479'); -- another mojo
insert into unicode(id, string) values(102, U&'\1D11F'); -- musical symbol g clef ottava alta
insert into unicode(id, string) values(103, U&'\26000'); -- a very infrequently used Chinese character
insert into unicode(id, string) values(104, U&'\26001'); -- another very infrequently used Chinese character
insert into unicode(id, string) values(105, U&'\26000\26001'); -- a string with 2 Chinese characters in the plane 2
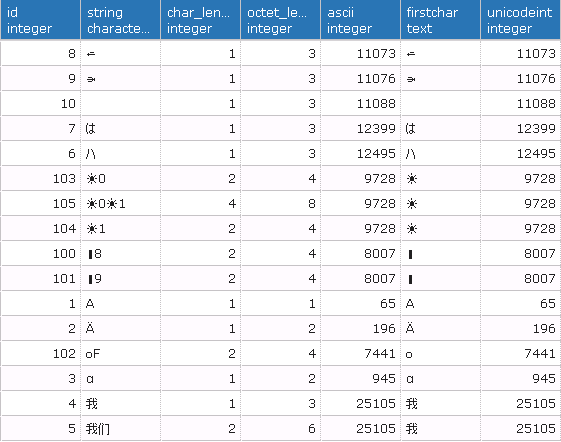
The SELECT below shows what PostgreSQL has recorded:
select id, string,
char_length(string),
octet_length(string),
ascii(string),
substring(string, 1, 1) as firstChar,
ascii(substring(string, 1, 1)) as unicodeInt
from unicode
order by string;
Here are the results:
Observations
- BMP characters (id <= 10)
- they are stored and fetched correctly.
- their lengths in char are correct, although some of them take 3 bytes (id = 4, 6, 7)
- But their sorting order seems to be undefined. Can anyone comment the sorting rules?
- Non-BMP characters (id >= 100)
- they take 2 - 4 bytes.
- Their lengths in character are not correct
- they are not retrieved correctly, judged by the their fetched ascii value (column 5 in the table above)
- substring is not correct
Specifically, the lack of support for emojo characters 0x1F478, 0x1F479 is causing a problem in my application.
My conclusion:
- PostgreSQL 9.6.1 only supports a subset of unicode characters in BMP. Is there any documents defining which subset is fully supported?
Are any configuration I can change so that more unicode characters are supported?
Thanks
James
Attachment
pgsql-general by date: