Thread: moving pg_xlog -- yeah, it's worth it!
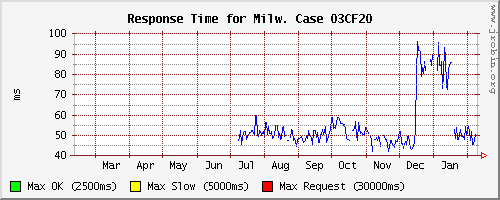
Due to an error during an update to the system kernel on a database server backing a web application, we ran for a month (mid-December to mid-January) with the WAL files in the pg_xlog subdirectory on the same 40-spindle array as the data -- only the OS was on a separate mirrored pair of drives. When we found the problem, we moved the pg_xlog directory back to its own mirrored pair of drives and symlinked to it. It's a pretty dramatic difference. Graph attached, this is response time for a URL request (like what a user from the Internet would issue) which runs 15 queries and formats the results. Response time is 85 ms without putting WAL on its own RAID; 50 ms with it on its own RAID. This is a real-world, production web site with 1.3 TB data, millions of hits per day, and it's an active replication target 24/7. Frankly, I was quite surprised by this, since some of the benchmarks people have published on the effects of using a separate RAID for the WAL files have only shown a one or two percent difference when using a hardware RAID controller with BBU cache configured for write-back. No assistance needed; just posting a performance data point. -Kevin
Attachment
{kind=link}
> > Frankly, I was quite surprised by this, since some of the benchmarks > people have published on the effects of using a separate RAID for > the WAL files have only shown a one or two percent difference when > using a hardware RAID controller with BBU cache configured for > write-back. Hi Kevin. Nice report, but just a few questions. Sorry if it is obvious.. but what filesystem/OS are you using and do you have BBU-writeback on the main data catalog also? Jesper
Jesper Krogh <jesper@krogh.cc> wrote: > Sorry if it is obvious.. but what filesystem/OS are you using and > do you have BBU-writeback on the main data catalog also? Sorry for not providing more context. ATHENA:/var/pgsql/data # uname -a Linux ATHENA 2.6.16.60-0.39.3-smp #1 SMP Mon May 11 11:46:34 UTC 2009 x86_64 x86_64 x86_64 GNU/Linux ATHENA:/var/pgsql/data # cat /etc/SuSE-release SUSE Linux Enterprise Server 10 (x86_64) VERSION = 10 PATCHLEVEL = 2 File system is xfs noatime,nobarrier for all data; OS is on ext3. I *think* the pg_xlog mirrored pair is hanging off the same BBU-writeback controller as the big RAID, but I'd have to track down the hardware tech to confirm, and he's out today. System has 16 Xeon CPUs and 64 GB RAM. -Kevin
On Tue, Feb 9, 2010 at 10:03 PM, Kevin Grittner <Kevin.Grittner@wicourts.gov> wrote:
Jesper Krogh <jesper@krogh.cc> wrote:*think* the pg_xlog mirrored pair is hanging off the same
File system is xfs noatime,nobarrier for all data; OS is on ext3. I
BBU-writeback controller as the big RAID, but I'd have to track down
the hardware tech to confirm, and he's out today. System has 16
Xeon CPUs and 64 GB RAM.
-Kevin
Hi Kevin
Just curious if you have a 16 physical CPU's or 16 cores on 4 CPU/8 cores over 2 CPU with HT.
With regards
Amitabh Kant
Amitabh Kant <amitabhkant@gmail.com> wrote: > Just curious if you have a 16 physical CPU's or 16 cores on 4 > CPU/8 cores over 2 CPU with HT. Four quad core CPUs: vendor_id : GenuineIntel cpu family : 6 model : 15 model name : Intel(R) Xeon(R) CPU X7350 @ 2.93GHz stepping : 11 cpu MHz : 2931.978 cache size : 4096 KB physical id : 3 siblings : 4 core id : 0 cpu cores : 4 -Kevin
Kevin Grittner wrote: > Jesper Krogh <jesper@krogh.cc> wrote: > > > Sorry if it is obvious.. but what filesystem/OS are you using and > > do you have BBU-writeback on the main data catalog also? > > Sorry for not providing more context. > > ATHENA:/var/pgsql/data # uname -a > Linux ATHENA 2.6.16.60-0.39.3-smp #1 SMP Mon May 11 11:46:34 UTC > 2009 x86_64 x86_64 x86_64 GNU/Linux > ATHENA:/var/pgsql/data # cat /etc/SuSE-release > SUSE Linux Enterprise Server 10 (x86_64) > VERSION = 10 > PATCHLEVEL = 2 > > File system is xfs noatime,nobarrier for all data; OS is on ext3. I > *think* the pg_xlog mirrored pair is hanging off the same > BBU-writeback controller as the big RAID, but I'd have to track down > the hardware tech to confirm, and he's out today. System has 16 > Xeon CPUs and 64 GB RAM. I would be surprised if the RAID controller had a BBU-writeback cache. I don't think having xlog share a BBU-writeback makes things slower, and if it does, I would love for someone to explain why. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + If your life is a hard drive, Christ can be your backup. +
On Thu, Feb 11, 2010 at 4:29 AM, Bruce Momjian <bruce@momjian.us> wrote: > Kevin Grittner wrote: >> Jesper Krogh <jesper@krogh.cc> wrote: >> >> > Sorry if it is obvious.. but what filesystem/OS are you using and >> > do you have BBU-writeback on the main data catalog also? >> >> Sorry for not providing more context. >> >> ATHENA:/var/pgsql/data # uname -a >> Linux ATHENA 2.6.16.60-0.39.3-smp #1 SMP Mon May 11 11:46:34 UTC >> 2009 x86_64 x86_64 x86_64 GNU/Linux >> ATHENA:/var/pgsql/data # cat /etc/SuSE-release >> SUSE Linux Enterprise Server 10 (x86_64) >> VERSION = 10 >> PATCHLEVEL = 2 >> >> File system is xfs noatime,nobarrier for all data; OS is on ext3. I >> *think* the pg_xlog mirrored pair is hanging off the same >> BBU-writeback controller as the big RAID, but I'd have to track down >> the hardware tech to confirm, and he's out today. System has 16 >> Xeon CPUs and 64 GB RAM. > > I would be surprised if the RAID controller had a BBU-writeback cache. > I don't think having xlog share a BBU-writeback makes things slower, and > if it does, I would love for someone to explain why. I believe in the past when this discussion showed up it was mainly due to them being on the same file system (and then not with pg_xlog separate) that made the biggest difference. I recall there being a noticeable performance gain from having two file systems on the same logical RAID device even.
"Kevin Grittner" <Kevin.Grittner@wicourts.gov> wrote: > Jesper Krogh <jesper@krogh.cc> wrote: > >> Sorry if it is obvious.. but what filesystem/OS are you using and >> do you have BBU-writeback on the main data catalog also? > File system is xfs noatime,nobarrier for all data; OS is on ext3. > I *think* the pg_xlog mirrored pair is hanging off the same > BBU-writeback controller as the big RAID, but I'd have to track > down the hardware tech to confirm Another example of why I shouldn't trust my memory. Per the hardware tech: OS: /dev/sda is RAID1 - 2 x 2.5" 15k SAS disk pg_xlog: /dev/sdb is RAID1 - 2 x 2.5" 15k SAS disk These reside on a ServeRAID-MR10k controller with 256MB BB cache. data: /dev/sdc is RAID5 - 30 x 3.5" 15k SAS disk These reside on the DS3200 disk subsystem with 512MB BB cache per controller and redundant drive loops. At least I had the file systems and options right. ;-) -Kevin
Kevin Grittner wrote: > Another example of why I shouldn't trust my memory. Per the > hardware tech: > > > OS: /dev/sda is RAID1 - 2 x 2.5" 15k SAS disk > pg_xlog: /dev/sdb is RAID1 - 2 x 2.5" 15k SAS disk > > These reside on a ServeRAID-MR10k controller with 256MB BB cache. > > > data: /dev/sdc is RAID5 - 30 x 3.5" 15k SAS disk > > These reside on the DS3200 disk subsystem with 512MB BB cache per > controller and redundant drive loops. Hmm, so maybe the performance benefit is not from it being on a separate array, but from it being RAID1 instead of RAID5? -- Alvaro Herrera http://www.CommandPrompt.com/ PostgreSQL Replication, Consulting, Custom Development, 24x7 support
* Alvaro Herrera <alvherre@commandprompt.com> [100211 12:58]: > Hmm, so maybe the performance benefit is not from it being on a separate > array, but from it being RAID1 instead of RAID5? Or the cumulative effects of: 1) Dedicated spindles/Raid1 2) More BBU cache available (I can't imagine the OS pair writing much) 3) not being queued behind data writes before getting to controller 3) Not waiting for BBU cache to be available (which is shared with all data writes) which requires RAID5 writes to complete... Really, there's *lots* of variables here. The basics being that WAL on the same FS as data, on a RAID5, even with BBU is worse than WAL on a dedicated set of RAID1 spindles with it's own BBU. Wow! ;-) -- Aidan Van Dyk Create like a god, aidan@highrise.ca command like a king, http://www.highrise.ca/ work like a slave.
Attachment
Aidan Van Dyk <aidan@highrise.ca> wrote: > Alvaro Herrera <alvherre@commandprompt.com> wrote: >> Hmm, so maybe the performance benefit is not from it being on a >> separate array, but from it being RAID1 instead of RAID5? > > Or the cumulative effects of: > 1) Dedicated spindles/Raid1 > 2) More BBU cache available (I can't imagine the OS pair writing > much) > 3) not being queued behind data writes before getting to > controller > 3) Not waiting for BBU cache to be available (which is shared with > all data writes) which requires RAID5 writes to complete... > > Really, there's *lots* of variables here. The basics being that > WAL on the same FS as data, on a RAID5, even with BBU is worse > than WAL on a dedicated set of RAID1 spindles with it's own BBU. > > Wow! Sure, OK, but what surprised me was that a set of 15 read-only queries (with pretty random reads) took almost twice as long when the WAL files were on the same file system. That's with OS writes being only about 10% of reads, and *that's* with 128 GB of RAM which keeps a lot of the reads from having to go to the disk. I would not have expected that a read-mostly environment like this would be that sensitive to the WAL file placement. (OK, I *did* request the separate file system for them anyway, but I thought it was going to be a marginal benefit, not something this big.) -Kevin
Hannu Krosing wrote: > Can it be, that each request does at least 1 write op (update > session or log something) ? Well, the web application connects through a login which only has SELECT rights; but, in discussing a previous issue we've pretty well established that it's not unusual for a read to force a dirty buffer to write to the OS. Perhaps this is the issue here again. Nothing is logged on the database server for every request. > If you can, set > > synchronous_commit = off; > > and see if it further increases performance. I wonder if it might also pay to make the background writer even more aggressive than we have, so that SELECT-only queries don't spend so much time writing pages. Anyway, given that these are replication targets, and aren't the "database of origin" for any data of their own, I guess there's no reason not to try asynchronous commit. Thanks for the suggestion. -Kevin
Kevin Grittner wrote: > Hannu Krosing wrote: > > > Can it be, that each request does at least 1 write op (update > > session or log something) ? > > Well, the web application connects through a login which only has > SELECT rights; but, in discussing a previous issue we've pretty well > established that it's not unusual for a read to force a dirty buffer > to write to the OS. Perhaps this is the issue here again. Nothing > is logged on the database server for every request. I don't think it explains it, because dirty buffers are obviously written to the data area, not pg_xlog. > I wonder if it might also pay to make the background writer even more > aggressive than we have, so that SELECT-only queries don't spend so > much time writing pages. That's worth trying. > Anyway, given that these are replication > targets, and aren't the "database of origin" for any data of their > own, I guess there's no reason not to try asynchronous commit. Yeah; since the transactions only ever write commit records to WAL, it wouldn't matter a bit that they are lost on crash. And you should see an improvement, because they wouldn't have to flush at all. -- Alvaro Herrera http://www.CommandPrompt.com/ PostgreSQL Replication, Consulting, Custom Development, 24x7 support
Alvaro Herrera wrote: > Kevin Grittner wrote: > > Anyway, given that these are replication > > targets, and aren't the "database of origin" for any data of their > > own, I guess there's no reason not to try asynchronous commit. > > Yeah; since the transactions only ever write commit records to WAL, it > wouldn't matter a bit that they are lost on crash. And you should see > an improvement, because they wouldn't have to flush at all. Actually, a transaction that performed no writes doesn't get a commit WAL record written, so it shouldn't make any difference at all. -- Alvaro Herrera http://www.CommandPrompt.com/ PostgreSQL Replication, Consulting, Custom Development, 24x7 support
Alvaro Herrera <alvherre@commandprompt.com> wrote: > Alvaro Herrera wrote: >> Kevin Grittner wrote: > >> > Anyway, given that these are replication targets, and aren't >> > the "database of origin" for any data of their own, I guess >> > there's no reason not to try asynchronous commit. >> >> Yeah; since the transactions only ever write commit records to >> WAL, it wouldn't matter a bit that they are lost on crash. And >> you should see an improvement, because they wouldn't have to >> flush at all. > > Actually, a transaction that performed no writes doesn't get a > commit WAL record written, so it shouldn't make any difference at > all. Well, concurrent to the web application is the replication. Would asynchronous commit of that potentially alter the pattern of writes such that it had less impact on the reads? I'm thinking, again, of why the placement of the pg_xlog on a separate file system made such a dramatic difference to the read-only response time -- might it make less difference if the replication was using asynchronous commit? By the way, the way our replication system works is that each target keeps track of how far it has replicated in the transaction stream of each source, so as long as a *later* transaction from a source is never persisted before an *earlier* one, there's no risk of data loss; it's strictly a performance issue. It will be able to catch up from wherever it is in the transaction stream when it comes back up after any down time (planned or otherwise). By the way, I have no complaints about the performance with the pg_xlog directory on its own file system (although if it could be *even faster* with a configuration change I will certainly take advantage of that). I do like to understand the dynamics of these things when I can, though. -Kevin
Kevin Grittner wrote: > Alvaro Herrera <alvherre@commandprompt.com> wrote: > > Actually, a transaction that performed no writes doesn't get a > > commit WAL record written, so it shouldn't make any difference at > > all. > > Well, concurrent to the web application is the replication. Would > asynchronous commit of that potentially alter the pattern of writes > such that it had less impact on the reads? Well, certainly async commit would completely change the pattern of writes: it would give the controller an opportunity to reorder them according to some scheduler. Otherwise they are strictly serialized. > I'm thinking, again, of > why the placement of the pg_xlog on a separate file system made such > a dramatic difference to the read-only response time -- might it > make less difference if the replication was using asynchronous > commit? Yeah, I think it would have been less notorious, but this is all theoretical. -- Alvaro Herrera http://www.CommandPrompt.com/ The PostgreSQL Company - Command Prompt, Inc.
Kevin Grittner wrote: > I wonder if it might also pay to make the background writer even more > aggressive than we have, so that SELECT-only queries don't spend so > much time writing pages. You can easily quantify if the BGW is aggressive enough. Buffers leave the cache three ways, and they each show up as separate counts in pg_stat_bgwriter: buffers_checkpoint, buffers_clean (the BGW), and buffers_backend (the queries). Cranking it up further tends to shift writes out of buffers_backend, which are the ones you want to avoid, toward buffers_clean instead. If buffers_backend is already low on a percentage basis compared to the other two, there's little benefit in trying to make the BGW do more. -- Greg Smith 2ndQuadrant Baltimore, MD PostgreSQL Training, Services and Support greg@2ndQuadrant.com www.2ndQuadrant.com
Greg Smith <greg@2ndquadrant.com> wrote: > You can easily quantify if the BGW is aggressive enough. Buffers > leave the cache three ways, and they each show up as separate > counts in pg_stat_bgwriter: buffers_checkpoint, buffers_clean > (the BGW), and buffers_backend (the queries). Cranking it up > further tends to shift writes out of buffers_backend, which are > the ones you want to avoid, toward buffers_clean instead. If > buffers_backend is already low on a percentage basis compared to > the other two, there's little benefit in trying to make the BGW do > more. Here are the values from our two largest and busiest systems (where we found the pg_xlog placement to matter so much). It looks to me like a more aggressive bgwriter would help, yes? cir=> select * from pg_stat_bgwriter ; -[ RECORD 1 ]------+------------ checkpoints_timed | 125996 checkpoints_req | 16932 buffers_checkpoint | 342972024 buffers_clean | 343634920 maxwritten_clean | 9928 buffers_backend | 575589056 buffers_alloc | 52397855471 cir=> select * from pg_stat_bgwriter ; -[ RECORD 1 ]------+------------ checkpoints_timed | 125992 checkpoints_req | 16840 buffers_checkpoint | 260358442 buffers_clean | 474768152 maxwritten_clean | 9778 buffers_backend | 565837397 buffers_alloc | 71463873477 Current settings: bgwriter_delay = '200ms' bgwriter_lru_maxpages = 1000 bgwriter_lru_multiplier = 4 Any suggestions on how far to push it? -Kevin
On Feb 23, 2010, at 2:23 PM, Kevin Grittner wrote:
Here are the values from our two largest and busiest systems (where
we found the pg_xlog placement to matter so much). It looks to me
like a more aggressive bgwriter would help, yes?
cir=> select * from pg_stat_bgwriter ;
-[ RECORD 1 ]------+------------
checkpoints_timed | 125996
checkpoints_req | 16932
buffers_checkpoint | 342972024
buffers_clean | 343634920
maxwritten_clean | 9928
buffers_backend | 575589056
buffers_alloc | 52397855471
cir=> select * from pg_stat_bgwriter ;
-[ RECORD 1 ]------+------------
checkpoints_timed | 125992
checkpoints_req | 16840
buffers_checkpoint | 260358442
buffers_clean | 474768152
maxwritten_clean | 9778
buffers_backend | 565837397
buffers_alloc | 71463873477
Current settings:
bgwriter_delay = '200ms'
bgwriter_lru_maxpages = 1000
bgwriter_lru_multiplier = 4
Any suggestions on how far to push it?
I don't know how far to push it, but you could start by reducing the delay time and observe how that affects performance.