Thread: PostgreSQL performance problem -> tuning
Hi All!
I have installed PostgreSQL 7.3.2 on FreeBSD 4.7, running on PC with
CPU Pentium II 400MHz and 384Mb RAM.
Problem is that SQL statement (see below) is running too long. With
current WHERE clause 'SUBSTR(2, 2) IN ('NL', 'NM') return 25 records.
With 1 record, SELECT time is about 50 minutes and takes approx. 120Mb
RAM. With 25 records SELECT takes about 600Mb of memory and ends after
about 10 hours with error: "Memory exhausted in AllocSetAlloc(32)".
***
How can I speed up processing? Why query (IMHO not too complex)
executes so long? :(
***
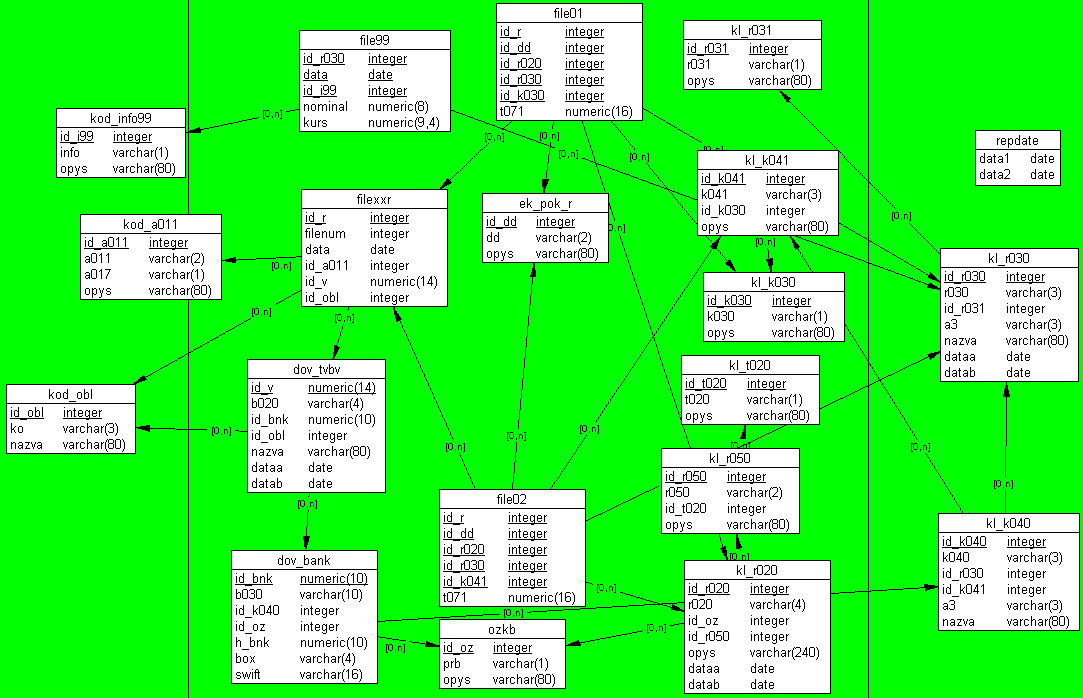
Information about configuration, data structures and table sizes see
below. Model picture attached.
Current postgresql.conf settings (some) are:
=== Cut ===
max_connections = 8
shared_buffers = 8192
max_fsm_relations = 256
max_fsm_pages = 65536
max_locks_per_transaction = 16
wal_buffers = 256
sort_mem = 131072
vacuum_mem = 16384
checkpoint_segments = 4
checkpoint_timeout = 300
commit_delay = 32000
commit_siblings = 4
fsync = false
enable_seqscan = false
effective_cache_size = 65536
=== Cut ===
SELECT statement is:
SELECT showcalc('B00204', dd, r020, t071) AS s04
FROM v_file02wide
WHERE a011 = 3
AND inrepdate(data)
AND SUBSTR(ncks, 2, 2) IN ('NL', 'NM')
AND r030 = 980;
Query plan is:
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=174200202474.99..174200202474.99 rows=1 width=143)
-> Hash Join (cost=174200199883.63..174200202474.89 rows=43 width=143)
Hash Cond: ("outer".id_k041 = "inner".id_k041)
-> Hash Join (cost=174200199880.57..174200202471.07 rows=43
width=139)
Hash Cond: ("outer".id_r030 = "inner".id_r030)
-> Hash Join (cost=174200199865.31..174200202410.31
rows=8992 width=135)
Hash Cond: ("outer".id_r020 = "inner".id_r020)
-> Hash Join
(cost=174200199681.91..174200202069.55 rows=8992 width=124)
Hash Cond: ("outer".id_dd = "inner".id_dd)
-> Merge Join
(cost=174200199676.04..174200201906.32 rows=8992 width=114)
Merge Cond: ("outer".id_v = "inner".id_v)
Join Filter: (("outer".data >= CASE
WHEN ("inner".dataa IS NOT NULL) THEN "inner".dataa WHEN ("outer".data
IS NOT NULL) THEN "outer".data ELSE NULL::date END) AND ("outer".data <=
CASE WHEN ("inner".datab IS NOT NULL) THEN "inner".datab WHEN
("outer".data IS NOT NULL) THEN "outer".data ELSE NULL::date END))
-> Sort (cost=42528.39..42933.04
rows=161858 width=65)
Sort Key: filexxr.id_v
-> Hash Join
(cost=636.25..28524.10 rows=161858 width=65)
Hash Cond: ("outer".id_obl
= "inner".id_obl)
-> Hash Join
(cost=632.67..25687.99 rows=161858 width=61)
Hash Cond:
("outer".id_r = "inner".id_r)
-> Index Scan using
index_file02_k041 on file02 (cost=0.00..18951.63 rows=816093 width=32)
-> Hash
(cost=615.41..615.41 rows=6903 width=29)
-> Index Scan
using index_filexxr_a011 on filexxr (cost=0.00..615.41 rows=6903 width=29)
Index
Cond: (id_a011 = 3)
Filter:
inrepdate(data)
-> Hash (cost=3.47..3.47
rows=43 width=4)
-> Index Scan using
kod_obl_pkey on kod_obl obl (cost=0.00..3.47 rows=43 width=4)
-> Sort
(cost=174200157147.65..174200157150.57 rows=1167 width=49)
Sort Key: dov_tvbv.id_v
-> Merge Join
(cost=0.00..174200157088.20 rows=1167 width=49)
Merge Cond:
("outer".id_bnk = "inner".id_bnk)
-> Index Scan using
dov_bank_pkey on dov_bank (cost=0.00..290100261328.45 rows=1450 width=13)
Filter: (subplan)
SubPlan
-> Materialize
(cost=100000090.02..100000090.02 rows=29 width=11)
-> Seq Scan
on dov_bank (cost=100000000.00..100000090.02 rows=29 width=11)
Filter: ((substr((box)::text, 2, 2) = 'NL'::text) OR
(substr((box)::text, 2, 2) = 'NM'::text))
-> Index Scan using
index_dov_tvbv_bnk on dov_tvbv (cost=0.00..142.42 rows=2334 width=36)
-> Hash (cost=5.83..5.83 rows=16 width=10)
-> Index Scan using ek_pok_r_pkey on
ek_pok_r epr (cost=0.00..5.83 rows=16 width=10)
-> Hash (cost=178.15..178.15 rows=2100 width=11)
-> Index Scan using kl_r020_pkey on kl_r020
(cost=0.00..178.15 rows=2100 width=11)
-> Hash (cost=15.26..15.26 rows=1 width=4)
-> Index Scan using kl_r030_pkey on kl_r030 r030
(cost=0.00..15.26 rows=1 width=4)
Filter: ((r030)::text = '980'::text)
-> Hash (cost=3.04..3.04 rows=4 width=4)
-> Index Scan using kl_k041_pkey on kl_k041
(cost=0.00..3.04 rows=4 width=4)
(45 rows)
Function showcalc definition is:
CREATE OR REPLACE FUNCTION showcalc(VARCHAR(10), VARCHAR(2), VARCHAR(4),
NUMERIC(16)) RETURNS NUMERIC(16)
LANGUAGE SQL AS '
-- Parameters: code, dd, r020, t071
SELECT COALESCE(
(SELECT sc.koef * $4
FROM showing AS s NATURAL JOIN showcomp AS sc
WHERE s.kod LIKE $1
AND NOT SUBSTR(acc_mask, 1, 1) LIKE ''[''
AND SUBSTR(acc_mask, 1, 4) LIKE $3
AND SUBSTR(acc_mask, 5, 1) LIKE SUBSTR($2, 1, 1)),
(SELECT SUM(sc.koef * COALESCE(showcalc(SUBSTR(acc_mask, 2,
LENGTH(acc_mask) - 2), $2, $3, $4), 0))
FROM showing AS s NATURAL JOIN showcomp AS sc
WHERE s.kod LIKE $1
AND SUBSTR(acc_mask, 1, 1) LIKE ''[''),
0) AS showing;
';
View v_file02wide is:
CREATE VIEW v_file02wide AS
SELECT id_a011 AS a011, data, obl.ko, obl.nazva AS oblast, b030,
banx.box AS ncks, banx.nazva AS bank,
epr.dd, r020, r030, a3, r030.nazva AS valuta, k041,
-- Sum equivalent in national currency
t071 * get_kurs(id_r030, data) AS t070,
t071
FROM v_file02 AS vf02
JOIN kod_obl AS obl USING(id_obl)
JOIN (dov_bank NATURAL JOIN dov_tvbv) AS banx
ON banx.id_v = vf02.id_v
AND data BETWEEN COALESCE(banx.dataa, data)
AND COALESCE(banx.datab, data)
JOIN ek_pok_r AS epr USING(id_dd)
JOIN kl_r020 USING(id_r020)
JOIN kl_r030 AS r030 USING(id_r030)
JOIN kl_k041 USING(id_k041);
Function inrepdate is:
CREATE OR REPLACE FUNCTION inrepdate(DATE) RETURNS BOOL
LANGUAGE SQL AS '
-- Returns true if given date is in repdate
SELECT (SELECT COUNT(*) FROM repdate
WHERE $1 BETWEEN COALESCE(data1, CURRENT_DATE)
AND COALESCE(data2, CURRENT_DATE))
> 0;
';
Table sizes (records)
filexxr 34712
file02 816589
v_file02 816589
kod_obl 43
banx 2334
ek_pok_r 16
kl_r020 2100
kl_r030 208
kl_r041 4
v_file02wide
showing 2787
showcomp 13646
repdate 1
Table has indexes almost for all selected fields.
showcalc in this query selects and uses 195 rows.
Total query size is 8066 records (COUNT(*) executes about 33 seconds
and uses 120Mb RAM).
With best regards
Yaroslav Mazurak.
Attachment
{kind=link}
On Wednesday 06 August 2003 08:34, Yaroslav Mazurak wrote:
> Hi All!
>
>
> I have installed PostgreSQL 7.3.2 on FreeBSD 4.7, running on PC with
> CPU Pentium II 400MHz and 384Mb RAM.
Version 7.3.4 is just out - probably worth upgrading as soon as it's
convenient.
> Problem is that SQL statement (see below) is running too long. With
> current WHERE clause 'SUBSTR(2, 2) IN ('NL', 'NM') return 25 records.
> With 1 record, SELECT time is about 50 minutes and takes approx. 120Mb
> RAM. With 25 records SELECT takes about 600Mb of memory and ends after
> about 10 hours with error: "Memory exhausted in AllocSetAlloc(32)".
[snip]
>
> Current postgresql.conf settings (some) are:
>
> === Cut ===
> max_connections = 8
>
> shared_buffers = 8192
> max_fsm_relations = 256
> max_fsm_pages = 65536
> max_locks_per_transaction = 16
> wal_buffers = 256
>
> sort_mem = 131072
This sort_mem value is *very* large - that's 131MB for *each sort* that gets
done. I'd suggest trying something in the range 1,000-10,000. What's probably
happening with the error above is that PG is allocating ridiculous amounts of
memory, the machines going into swap and everything eventually grinds to a
halt.
> vacuum_mem = 16384
>
> checkpoint_segments = 4
> checkpoint_timeout = 300
> commit_delay = 32000
> commit_siblings = 4
> fsync = false
I'd turn fsync back on - unless you don't mind losing your data after a crash.
> enable_seqscan = false
Don't tinker with these in a live system, they're only really for
testing/debugging.
> effective_cache_size = 65536
So you typically get about 256MB cache usage in top/free?
> === Cut ===
>
> SELECT statement is:
>
> SELECT showcalc('B00204', dd, r020, t071) AS s04
> FROM v_file02wide
> WHERE a011 = 3
> AND inrepdate(data)
> AND SUBSTR(ncks, 2, 2) IN ('NL', 'NM')
> AND r030 = 980;
Hmm - mostly views and function calls, OK - I'll read on.
> (cost=174200202474.99..174200202474.99 rows=1 width=143) -> Hash Join
^^^^^^^
This is a BIG cost estimate and you've got lots more like them. I'm guessing
it's because of the sort_mem / enable_seqscan settings you have. The numbers
don't make sense to me - it sounds like you've pushed the cost estimator into
a very strange corner.
> Function showcalc definition is:
>
> CREATE OR REPLACE FUNCTION showcalc(VARCHAR(10), VARCHAR(2), VARCHAR(4),
> NUMERIC(16)) RETURNS NUMERIC(16)
> LANGUAGE SQL AS '
> -- Parameters: code, dd, r020, t071
> SELECT COALESCE(
> (SELECT sc.koef * $4
> FROM showing AS s NATURAL JOIN showcomp AS sc
> WHERE s.kod LIKE $1
> AND NOT SUBSTR(acc_mask, 1, 1) LIKE ''[''
> AND SUBSTR(acc_mask, 1, 4) LIKE $3
> AND SUBSTR(acc_mask, 5, 1) LIKE SUBSTR($2, 1, 1)),
Obviously, you could use = for these 3 rather than LIKE ^^^
Same below too.
> (SELECT SUM(sc.koef * COALESCE(showcalc(SUBSTR(acc_mask, 2,
> LENGTH(acc_mask) - 2), $2, $3, $4), 0))
> FROM showing AS s NATURAL JOIN showcomp AS sc
> WHERE s.kod LIKE $1
> AND SUBSTR(acc_mask, 1, 1) LIKE ''[''),
> 0) AS showing;
> ';
>
> View v_file02wide is:
>
> CREATE VIEW v_file02wide AS
> SELECT id_a011 AS a011, data, obl.ko, obl.nazva AS oblast, b030,
> banx.box AS ncks, banx.nazva AS bank,
> epr.dd, r020, r030, a3, r030.nazva AS valuta, k041,
> -- Sum equivalent in national currency
> t071 * get_kurs(id_r030, data) AS t070,
> t071
> FROM v_file02 AS vf02
> JOIN kod_obl AS obl USING(id_obl)
> JOIN (dov_bank NATURAL JOIN dov_tvbv) AS banx
> ON banx.id_v = vf02.id_v
> AND data BETWEEN COALESCE(banx.dataa, data)
> AND COALESCE(banx.datab, data)
> JOIN ek_pok_r AS epr USING(id_dd)
> JOIN kl_r020 USING(id_r020)
> JOIN kl_r030 AS r030 USING(id_r030)
> JOIN kl_k041 USING(id_k041);
You might want to rewrite the view so it doesn't use explicit JOIN statements,
i.e FROM a,b WHERE a.id=b.ref rather than FROM a JOIN b ON id=ref
At the moment, this will force PG into making the joins in the order you write
them (I think this is changed in v7.4)
> Function inrepdate is:
>
> CREATE OR REPLACE FUNCTION inrepdate(DATE) RETURNS BOOL
> LANGUAGE SQL AS '
> -- Returns true if given date is in repdate
> SELECT (SELECT COUNT(*) FROM repdate
> WHERE $1 BETWEEN COALESCE(data1, CURRENT_DATE)
> AND COALESCE(data2, CURRENT_DATE))
>
> > 0;
You can probably replace this with:
SELECT true FROM repdate WHERE $1 ...
You'll need to look at where it's used though.
[snip table sizes]
> Table has indexes almost for all selected fields.
That's not going to help you for the SUBSTR(...) stuff, although you could use
functional indexes (see manuals/list archives for details).
First thing is to get those two configuration settings somewhere sane, then we
can tune properly. You might like the document at:
http://www.varlena.com/varlena/GeneralBits/Tidbits/perf.html
--
Richard Huxton
Archonet Ltd
"Yaroslav Mazurak" <yamazurak@Lviv.Bank.Gov.UA>
> Problem is that SQL statement (see below) is running too long. With
> current WHERE clause 'SUBSTR(2, 2) IN ('NL', 'NM') return 25 records.
> With 1 record, SELECT time is about 50 minutes and takes approx. 120Mb
> RAM. With 25 records SELECT takes about 600Mb of memory and ends after
> about 10 hours with error: "Memory exhausted in AllocSetAlloc(32)".
Did you try to use a functional index on that field ?
create or replace function my_substr(varchar)
returns varchar AS'
begin
return substr($1,2,2);
end;
' language 'plpgsql'
IMMUTABLE;
create index idx on <table> ( my_substr(<field>) );
and after you should use in your where:
where my_substr(<field>) = 'NL'
Hi All!
First, thanks for answers.
Richard Huxton wrote:
> On Wednesday 06 August 2003 08:34, Yaroslav Mazurak wrote:
> Version 7.3.4 is just out - probably worth upgrading as soon as it's
> convenient.
Has version 7.3.4 significant performance upgrade relative to 7.3.2?
I've downloaded version 7.3.4, but not installed yet.
>>sort_mem = 131072
> This sort_mem value is *very* large - that's 131MB for *each sort* that gets
> done. I'd suggest trying something in the range 1,000-10,000. What's probably
> happening with the error above is that PG is allocating ridiculous amounts of
> memory, the machines going into swap and everything eventually grinds to a
> halt.
What mean "each sort"? Each query with SORT clause or some internal
(invisible to user) sorts too (I can't imagine: indexed search or
whatever else)?
I'm reduced sort_mem to 16M.
>>fsync = false
> I'd turn fsync back on - unless you don't mind losing your data after a crash.
This is temporary performance solution - I want get SELECT query result
first, but current performance is too low.
>>enable_seqscan = false
> Don't tinker with these in a live system, they're only really for
> testing/debugging.
This is another strange behavior of PostgreSQL - he don't use some
created indexes (seq_scan only) after ANALYZE too. OK, I'm turned on
this option back.
>>effective_cache_size = 65536
> So you typically get about 256MB cache usage in top/free?
No, top shows 12-20Mb.
I'm reduced effective_cache_size to 4K blocks (16M?).
>> SELECT statement is:
>>
>>SELECT showcalc('B00204', dd, r020, t071) AS s04
>>FROM v_file02wide
>>WHERE a011 = 3
>> AND inrepdate(data)
>> AND SUBSTR(ncks, 2, 2) IN ('NL', 'NM')
>> AND r030 = 980;
> Hmm - mostly views and function calls, OK - I'll read on.
My data are distributed accross multiple tables to integrity and avoid
redundancy. During SELECT query these data rejoined to be presented in
"human-readable" form. :)
"SUBSTR" returns about 25 records, I'm too lazy for write 25 numbers.
:) I'm also worried for errors.
>>(cost=174200202474.99..174200202474.99 rows=1 width=143) -> Hash Join
> ^^^^^^^
> This is a BIG cost estimate and you've got lots more like them. I'm guessing
> it's because of the sort_mem / enable_seqscan settings you have. The numbers
> don't make sense to me - it sounds like you've pushed the cost estimator into
> a very strange corner.
I think that cost estimator "pushed into very strange corner" by himself.
>> Function showcalc definition is:
>>CREATE OR REPLACE FUNCTION showcalc(VARCHAR(10), VARCHAR(2), VARCHAR(4),
>>NUMERIC(16)) RETURNS NUMERIC(16)
>>LANGUAGE SQL AS '
>>-- Parameters: code, dd, r020, t071
>> SELECT COALESCE(
>> (SELECT sc.koef * $4
>> FROM showing AS s NATURAL JOIN showcomp AS sc
>> WHERE s.kod LIKE $1
>> AND NOT SUBSTR(acc_mask, 1, 1) LIKE ''[''
>> AND SUBSTR(acc_mask, 1, 4) LIKE $3
>> AND SUBSTR(acc_mask, 5, 1) LIKE SUBSTR($2, 1, 1)),
> Obviously, you could use = for these 3 rather than LIKE ^^^
> Same below too.
>> (SELECT SUM(sc.koef * COALESCE(showcalc(SUBSTR(acc_mask, 2,
>>LENGTH(acc_mask) - 2), $2, $3, $4), 0))
>> FROM showing AS s NATURAL JOIN showcomp AS sc
>> WHERE s.kod LIKE $1
>> AND SUBSTR(acc_mask, 1, 1) LIKE ''[''),
>> 0) AS showing;
>>';
OK, all unnecessary "LIKEs" replaced by "=", JOIN removed too:
CREATE OR REPLACE FUNCTION showcalc(VARCHAR(10), VARCHAR(2), VARCHAR(4),
NUMERIC(16)) RETURNS NUMERIC(16)
LANGUAGE SQL AS '
-- Parameters: code, dd, r020, t071
SELECT COALESCE(
(SELECT sc.koef * $4
FROM showing AS s, showcomp AS sc
WHERE sc.kod = s.kod
AND s.kod LIKE $1
AND NOT SUBSTR(acc_mask, 1, 1) = ''[''
AND SUBSTR(acc_mask, 1, 4) = $3
AND SUBSTR(acc_mask, 5, 1) = SUBSTR($2, 1, 1)),
(SELECT SUM(sc.koef * COALESCE(showcalc(SUBSTR(acc_mask, 2,
LENGTH(acc_mask) - 2), $2, $3, $4), 0))
FROM showing AS s, showcomp AS sc
WHERE sc.kod = s.kod
AND s.kod = $1
AND SUBSTR(acc_mask, 1, 1) = ''[''),
0) AS showing;
';
>> View v_file02wide is:
>>CREATE VIEW v_file02wide AS
>>SELECT id_a011 AS a011, data, obl.ko, obl.nazva AS oblast, b030,
>>banx.box AS ncks, banx.nazva AS bank,
>> epr.dd, r020, r030, a3, r030.nazva AS valuta, k041,
>> -- Sum equivalent in national currency
>> t071 * get_kurs(id_r030, data) AS t070,
>> t071
>>FROM v_file02 AS vf02
>> JOIN kod_obl AS obl USING(id_obl)
>> JOIN (dov_bank NATURAL JOIN dov_tvbv) AS banx
>> ON banx.id_v = vf02.id_v
>> AND data BETWEEN COALESCE(banx.dataa, data)
>> AND COALESCE(banx.datab, data)
>> JOIN ek_pok_r AS epr USING(id_dd)
>> JOIN kl_r020 USING(id_r020)
>> JOIN kl_r030 AS r030 USING(id_r030)
>> JOIN kl_k041 USING(id_k041);
> You might want to rewrite the view so it doesn't use explicit JOIN statements,
> i.e FROM a,b WHERE a.id=b.ref rather than FROM a JOIN b ON id=ref
> At the moment, this will force PG into making the joins in the order you write
> them (I think this is changed in v7.4)
I think this is a important remark. Can "JOIN" significantly reduce
performance of SELECT statement relative to ", WHERE"?
OK, I'm changed VIEW to this text:
CREATE VIEW v_file02 AS
SELECT filenum, data, id_a011, id_v, id_obl, id_dd, id_r020, id_r030,
id_k041, t071
FROM filexxr, file02
WHERE file02.id_r = filexxr.id_r;
CREATE VIEW v_file02wide AS
SELECT id_a011 AS a011, data, obl.ko, obl.nazva AS oblast, b030,
banx.box AS ncks, banx.nazva AS bank,
epr.dd, r020, vf02.id_r030 AS r030, a3, kl_r030.nazva AS valuta, k041,
-- Sum equivalent in national currency
t071 * get_kurs(vf02.id_r030, data) AS t070, t071
FROM v_file02 AS vf02, kod_obl AS obl, v_banx AS banx,
ek_pok_r AS epr, kl_r020, kl_r030, kl_k041
WHERE obl.id_obl = vf02.id_obl
AND banx.id_v = vf02.id_v
AND data BETWEEN COALESCE(banx.dataa, data)
AND COALESCE(banx.datab, data)
AND epr.id_dd = vf02.id_dd
AND kl_r020.id_r020 = vf02.id_r020
AND kl_r030.id_r030 = vf02.id_r030
AND kl_k041.id_k041 = vf02.id_k041;
Now (with configuration and view definition changed) "SELECT COUNT(*)
FROM v_file02wide;" executes about 6 minutes and 45 seconds instead of
30 seconds (previous).
Another annoying "feature" is impossibility writing "SELECT * FROM..."
- duplicate column names error. In NATURAL JOIN joined columns hiding
automatically. :-|
>> Function inrepdate is:
>>CREATE OR REPLACE FUNCTION inrepdate(DATE) RETURNS BOOL
>>LANGUAGE SQL AS '
>> -- Returns true if given date is in repdate
>> SELECT (SELECT COUNT(*) FROM repdate
>> WHERE $1 BETWEEN COALESCE(data1, CURRENT_DATE)
>> AND COALESCE(data2, CURRENT_DATE))
>>
>> > 0;
> You can probably replace this with:
> SELECT true FROM repdate WHERE $1 ...
> You'll need to look at where it's used though.
Hmm... table repdate contain date intervals. For example:
data1 data2
2003-01-01 2003-01-10
2003-05-07 2003-05-24
...
I need single value (true or false) about given date as parameter -
report includes given date or not. COUNT used as aggregate function for
this. Can you write this function more simpler?
BTW, I prefer SQL language if possible, then PL/pgSQL. This may be mistake?
>> Table has indexes almost for all selected fields.
> That's not going to help you for the SUBSTR(...) stuff, although you could use
> functional indexes (see manuals/list archives for details).
Yes, I'm using functional indexes, but not in this case... now in this
case too! :)
> First thing is to get those two configuration settings somewhere sane, then we
> can tune properly. You might like the document at:
> http://www.varlena.com/varlena/GeneralBits/Tidbits/perf.html
Thanks, it's interesting.
Current query plan:
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=188411.98..188411.98 rows=1 width=151)
-> Hash Join (cost=186572.19..188398.39 rows=5437 width=151)
Hash Cond: ("outer".id_obl = "inner".id_obl)
-> Hash Join (cost=186570.65..188301.70 rows=5437 width=147)
Hash Cond: ("outer".id_dd = "inner".id_dd)
-> Hash Join (cost=186569.45..188205.34 rows=5437
width=137)
Hash Cond: ("outer".id_k041 = "inner".id_k041)
-> Hash Join (cost=186568.40..188109.14
rows=5437 width=133)
Hash Cond: ("outer".id_r020 = "inner".id_r020)
-> Hash Join (cost=186499.15..187944.74
rows=5437 width=122)
Hash Cond: ("outer".id_r030 =
"inner".id_r030)
-> Merge Join
(cost=186493.55..187843.99 rows=5437 width=118)
Merge Cond: ("outer".id_v =
"inner".id_v)
Join Filter: (("outer".data >=
CASE WHEN ("inner".dataa IS NOT NULL) THEN "inner".dataa WHEN
("outer".data IS NOT NULL) THEN "outer".data ELSE NULL::date END) AND
("outer".data <= CASE WHEN ("inner".datab IS NOT NULL) THEN
"inner".datab WHEN ("outer".data IS NOT NULL) THEN "outer".data ELSE
NULL::date END))
-> Sort
(cost=29324.30..29568.97 rows=97870 width=61)
Sort Key: filexxr.id_v
-> Hash Join
(cost=632.67..21211.53 rows=97870 width=61)
Hash Cond:
("outer".id_r = "inner".id_r)
-> Seq Scan on
file02 (cost=0.00..16888.16 rows=493464 width=32)
Filter:
(id_r030 = 980)
-> Hash
(cost=615.41..615.41 rows=6903 width=29)
-> Index Scan
using index_filexxr_a011 on filexxr (cost=0.00..615.41 rows=6903 width=29)
Index
Cond: (id_a011 = 3)
Filter:
inrepdate(data)
-> Sort
(cost=157169.25..157172.17 rows=1167 width=57)
Sort Key: v.id_v
-> Hash Join
(cost=1.18..157109.80 rows=1167 width=57)
Hash Cond:
("outer".id_oz = "inner".id_oz)
-> Merge Join
(cost=0.00..157088.20 rows=1167 width=53)
Merge Cond:
("outer".id_bnk = "inner".id_bnk)
-> Index Scan
using dov_bank_pkey on dov_bank b (cost=0.00..261328.45 rows=1450 width=17)
Filter:
(subplan)
SubPlan
->
Materialize (cost=90.02..90.02 rows=29 width=11)
-> Seq Scan on dov_bank (cost=0.00..90.02 rows=29 width=11)
Filter: ((dov_bank_box_22(box) = 'NL'::character varying) OR
(dov_bank_box_22(box) = 'NM'::character varying))
-> Index Scan
using index_dov_tvbv_bnk on dov_tvbv v (cost=0.00..142.42 rows=2334
width=36)
-> Hash
(cost=1.14..1.14 rows=14 width=4)
-> Seq Scan
on ozkb o (cost=0.00..1.14 rows=14 width=4)
-> Hash (cost=5.08..5.08 rows=208
width=4)
-> Seq Scan on kl_r030
(cost=0.00..5.08 rows=208 width=4)
-> Hash (cost=64.00..64.00 rows=2100 width=11)
-> Seq Scan on kl_r020
(cost=0.00..64.00 rows=2100 width=11)
-> Hash (cost=1.04..1.04 rows=4 width=4)
-> Seq Scan on kl_k041 (cost=0.00..1.04
rows=4 width=4)
-> Hash (cost=1.16..1.16 rows=16 width=10)
-> Seq Scan on ek_pok_r epr (cost=0.00..1.16
rows=16 width=10)
-> Hash (cost=1.43..1.43 rows=43 width=4)
-> Seq Scan on kod_obl obl (cost=0.00..1.43 rows=43
width=4)
(49 rows)
Now (2K shared_buffers blocks, 16K effective_cache_size blocks, 16Mb
sort_mem) PostgreSQL uses much less memory, about 64M... it's not good,
I want using all available RAM if possible - PostgreSQL is the main task
on this PC.
May set effective_cache_size to 192M (48K blocks) be better? I don't
understand exactly: effective_cache_size tells PostgreSQL about OS cache
size or about available free RAM?
With best regards
Yaroslav Mazurak.
Attachment
On 6 Aug 2003 at 15:42, Yaroslav Mazurak wrote: > >>sort_mem = 131072 > > This sort_mem value is *very* large - that's 131MB for *each sort* that gets > > done. I'd suggest trying something in the range 1,000-10,000. What's probably > > happening with the error above is that PG is allocating ridiculous amounts of > > memory, the machines going into swap and everything eventually grinds to a > > halt. > > What mean "each sort"? Each query with SORT clause or some internal > (invisible to user) sorts too (I can't imagine: indexed search or > whatever else)? > I'm reduced sort_mem to 16M. Good call. I would say start with 4M if you time to experiment. > >>enable_seqscan = false > > > Don't tinker with these in a live system, they're only really for > > testing/debugging. > > This is another strange behavior of PostgreSQL - he don't use some > created indexes (seq_scan only) after ANALYZE too. OK, I'm turned on > this option back. At times it thinks correct as well. An index scan might be costly. It does not hurt leaving this option on. If your performance improves by turning off this option, usually the problem is somewhere else.. > > >>effective_cache_size = 65536 > > > So you typically get about 256MB cache usage in top/free? > > No, top shows 12-20Mb. > I'm reduced effective_cache_size to 4K blocks (16M?). Are you on linux?( I lost OP). Don't trust top. Use free to find out how much true free memory you have.. Look at second line of free.. HTH Bye Shridhar -- millihelen, n.: The amount of beauty required to launch one ship.
>> On Wednesday 06 August 2003 08:34, Yaroslav Mazurak wrote:
>
>> Version 7.3.4 is just out - probably worth upgrading as soon as it's
>> convenient.
>
> Has version 7.3.4 significant performance upgrade relative to 7.3.2?
> I've downloaded version 7.3.4, but not installed yet.
No, but there are some bug fixes.
>>>sort_mem = 131072
>
>> This sort_mem value is *very* large - that's 131MB for *each sort* that
> What mean "each sort"? Each query with SORT clause or some internal
> (invisible to user) sorts too (I can't imagine: indexed search or
> whatever else)?
> I'm reduced sort_mem to 16M.
It means each sort - if you look at your query plan and see three "sort"
clauses that means that query might allocate 48MB to sorting. Now, that's
good because sorting items on disk is much slower. It's bad because that's
48MB less for everything else that's happening.
>>>fsync = false
>
>> I'd turn fsync back on - unless you don't mind losing your data after a
>> crash.
>
> This is temporary performance solution - I want get SELECT query result
> first, but current performance is too low.
>
>>>enable_seqscan = false
>
>> Don't tinker with these in a live system, they're only really for
>> testing/debugging.
>
> This is another strange behavior of PostgreSQL - he don't use some
> created indexes (seq_scan only) after ANALYZE too. OK, I'm turned on
> this option back.
Fair enough, we can work on those. With 7.3.x you can tell PG to examine
some tables more thouroughly to get better plans.
>>>effective_cache_size = 65536
>
>> So you typically get about 256MB cache usage in top/free?
>
> No, top shows 12-20Mb.
> I'm reduced effective_cache_size to 4K blocks (16M?).
Cache size is in blocks of 8KB (usually) - it's a way of telling PG what
the chances are of disk blocks being already cached by Linux.
>>> SELECT statement is:
>>>
>>>SELECT showcalc('B00204', dd, r020, t071) AS s04
>>>FROM v_file02wide
>>>WHERE a011 = 3
>>> AND inrepdate(data)
>>> AND SUBSTR(ncks, 2, 2) IN ('NL', 'NM')
>>> AND r030 = 980;
>
>> Hmm - mostly views and function calls, OK - I'll read on.
>
> My data are distributed accross multiple tables to integrity and avoid
> redundancy. During SELECT query these data rejoined to be presented in
> "human-readable" form. :)
> "SUBSTR" returns about 25 records, I'm too lazy for write 25 numbers.
> :) I'm also worried for errors.
Sounds like good policy.
>
>>>(cost=174200202474.99..174200202474.99 rows=1 width=143) -> Hash Join
>
>> ^^^^^^^
>> This is a BIG cost estimate and you've got lots more like them. I'm
>> guessing
>> it's because of the sort_mem / enable_seqscan settings you have. The
>> numbers
>> don't make sense to me - it sounds like you've pushed the cost estimator
>> into
>> a very strange corner.
>
> I think that cost estimator "pushed into very strange corner" by himself.
>
>>> Function showcalc definition is:
>
>>>CREATE OR REPLACE FUNCTION showcalc(VARCHAR(10), VARCHAR(2), VARCHAR(4),
>>>NUMERIC(16)) RETURNS NUMERIC(16)
>>>LANGUAGE SQL AS '
>>>-- Parameters: code, dd, r020, t071
>>> SELECT COALESCE(
>>> (SELECT sc.koef * $4
>>> FROM showing AS s NATURAL JOIN showcomp AS sc
>>> WHERE s.kod LIKE $1
>>> AND NOT SUBSTR(acc_mask, 1, 1) LIKE ''[''
>>> AND SUBSTR(acc_mask, 1, 4) LIKE $3
>>> AND SUBSTR(acc_mask, 5, 1) LIKE SUBSTR($2, 1, 1)),
>
>> Obviously, you could use = for these 3 rather than LIKE ^^^
>> Same below too.
>
>>> (SELECT SUM(sc.koef * COALESCE(showcalc(SUBSTR(acc_mask, 2,
>>>LENGTH(acc_mask) - 2), $2, $3, $4), 0))
>>> FROM showing AS s NATURAL JOIN showcomp AS sc
>>> WHERE s.kod LIKE $1
>>> AND SUBSTR(acc_mask, 1, 1) LIKE ''[''),
>>> 0) AS showing;
>>>';
>
> OK, all unnecessary "LIKEs" replaced by "=", JOIN removed too:
> CREATE OR REPLACE FUNCTION showcalc(VARCHAR(10), VARCHAR(2), VARCHAR(4),
> NUMERIC(16)) RETURNS NUMERIC(16)
> LANGUAGE SQL AS '
> -- Parameters: code, dd, r020, t071
> SELECT COALESCE(
> (SELECT sc.koef * $4
> FROM showing AS s, showcomp AS sc
> WHERE sc.kod = s.kod
> AND s.kod LIKE $1
> AND NOT SUBSTR(acc_mask, 1, 1) = ''[''
> AND SUBSTR(acc_mask, 1, 4) = $3
> AND SUBSTR(acc_mask, 5, 1) = SUBSTR($2, 1, 1)),
> (SELECT SUM(sc.koef * COALESCE(showcalc(SUBSTR(acc_mask, 2,
> LENGTH(acc_mask) - 2), $2, $3, $4), 0))
> FROM showing AS s, showcomp AS sc
> WHERE sc.kod = s.kod
> AND s.kod = $1
> AND SUBSTR(acc_mask, 1, 1) = ''[''),
> 0) AS showing;
> ';
>
>>> View v_file02wide is:
>
>>>CREATE VIEW v_file02wide AS
>>>SELECT id_a011 AS a011, data, obl.ko, obl.nazva AS oblast, b030,
>>>banx.box AS ncks, banx.nazva AS bank,
>>> epr.dd, r020, r030, a3, r030.nazva AS valuta, k041,
>>> -- Sum equivalent in national currency
>>> t071 * get_kurs(id_r030, data) AS t070,
>>> t071
>>>FROM v_file02 AS vf02
>>> JOIN kod_obl AS obl USING(id_obl)
>>> JOIN (dov_bank NATURAL JOIN dov_tvbv) AS banx
>>> ON banx.id_v = vf02.id_v
>>> AND data BETWEEN COALESCE(banx.dataa, data)
>>> AND COALESCE(banx.datab, data)
>>> JOIN ek_pok_r AS epr USING(id_dd)
>>> JOIN kl_r020 USING(id_r020)
>>> JOIN kl_r030 AS r030 USING(id_r030)
>>> JOIN kl_k041 USING(id_k041);
>
>> You might want to rewrite the view so it doesn't use explicit JOIN
>> statements,
>> i.e FROM a,b WHERE a.id=b.ref rather than FROM a JOIN b ON id=ref
>> At the moment, this will force PG into making the joins in the order you
>> write
>> them (I think this is changed in v7.4)
>
> I think this is a important remark. Can "JOIN" significantly reduce
> performance of SELECT statement relative to ", WHERE"?
> OK, I'm changed VIEW to this text:
It can sometimes. What it means is that PG will follow whatever order you
write the joins in. If you know joining a to b to c is the best order,
that can be a good thing. Unfortunately, it means the planner can't make a
better guess based on its statistics.
> CREATE VIEW v_file02 AS
> SELECT filenum, data, id_a011, id_v, id_obl, id_dd, id_r020, id_r030,
> id_k041, t071
> FROM filexxr, file02
> WHERE file02.id_r = filexxr.id_r;
>
> CREATE VIEW v_file02wide AS
> SELECT id_a011 AS a011, data, obl.ko, obl.nazva AS oblast, b030,
> banx.box AS ncks, banx.nazva AS bank,
> epr.dd, r020, vf02.id_r030 AS r030, a3, kl_r030.nazva AS valuta, k041,
> -- Sum equivalent in national currency
> t071 * get_kurs(vf02.id_r030, data) AS t070, t071
> FROM v_file02 AS vf02, kod_obl AS obl, v_banx AS banx,
> ek_pok_r AS epr, kl_r020, kl_r030, kl_k041
> WHERE obl.id_obl = vf02.id_obl
> AND banx.id_v = vf02.id_v
> AND data BETWEEN COALESCE(banx.dataa, data)
> AND COALESCE(banx.datab, data)
> AND epr.id_dd = vf02.id_dd
> AND kl_r020.id_r020 = vf02.id_r020
> AND kl_r030.id_r030 = vf02.id_r030
> AND kl_k041.id_k041 = vf02.id_k041;
>
> Now (with configuration and view definition changed) "SELECT COUNT(*)
> FROM v_file02wide;" executes about 6 minutes and 45 seconds instead of
> 30 seconds (previous).
OK - don't worry if it looks like we're going backwards, we should be able
to get everything running nicely soon.
> Another annoying "feature" is impossibility writing "SELECT * FROM..."
> - duplicate column names error. In NATURAL JOIN joined columns hiding
> automatically. :-|
>
>>> Function inrepdate is:
>
>>>CREATE OR REPLACE FUNCTION inrepdate(DATE) RETURNS BOOL
>>>LANGUAGE SQL AS '
>>> -- Returns true if given date is in repdate
>>> SELECT (SELECT COUNT(*) FROM repdate
>>> WHERE $1 BETWEEN COALESCE(data1, CURRENT_DATE)
>>> AND COALESCE(data2, CURRENT_DATE))
>>>
>>> > 0;
>
>> You can probably replace this with:
>> SELECT true FROM repdate WHERE $1 ...
>> You'll need to look at where it's used though.
>
> Hmm... table repdate contain date intervals. For example:
> data1 data2
> 2003-01-01 2003-01-10
> 2003-05-07 2003-05-24
> ...
> I need single value (true or false) about given date as parameter -
> report includes given date or not. COUNT used as aggregate function for
> this. Can you write this function more simpler?
> BTW, I prefer SQL language if possible, then PL/pgSQL. This may be
> mistake?
No - not really. You can do things in plpgsql that you can't in sql, but I
use both depending on the situation.
>>> Table has indexes almost for all selected fields.
>
>> That's not going to help you for the SUBSTR(...) stuff, although you
>> could use
>> functional indexes (see manuals/list archives for details).
>
> Yes, I'm using functional indexes, but not in this case... now in this
> case too! :)
>
>> First thing is to get those two configuration settings somewhere sane,
>> then we
>> can tune properly. You might like the document at:
>
>> http://www.varlena.com/varlena/GeneralBits/Tidbits/perf.html
>
> Thanks, it's interesting.
>
> Current query plan:
>
>
> QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
> Aggregate (cost=188411.98..188411.98 rows=1 width=151)
> -> Hash Join (cost=186572.19..188398.39 rows=5437 width=151)
> Hash Cond: ("outer".id_obl = "inner".id_obl)
> -> Hash Join (cost=186570.65..188301.70 rows=5437 width=147)
[snip]
Well the cost estimates look much more plausible. You couldn't post
EXPLAIN ANALYSE could you? That actually runs the query.
> Now (2K shared_buffers blocks, 16K effective_cache_size blocks, 16Mb
> sort_mem) PostgreSQL uses much less memory, about 64M... it's not good,
> I want using all available RAM if possible - PostgreSQL is the main task
> on this PC.
Don't forget that any memory PG is using the operating-system can't. The
OS will cache frequently accessed disk blocks for you, so it's a question
of finding the right balance.
> May set effective_cache_size to 192M (48K blocks) be better? I don't
> understand exactly: effective_cache_size tells PostgreSQL about OS cache
> size or about available free RAM?
It needs to reflect how much cache the system is using - try the "free"
command to see figures.
If you could post the output of EXPLAIN ANALYSE rather than EXPLAIN, I'll
take a look at it this evening (London time). There's also plenty of other
people on this list who can help too.
HTH
- Richard Huxton
Yaroslav Mazurak <yamazurak@Lviv.Bank.Gov.UA> writes:
>>> fsync = false
>> I'd turn fsync back on - unless you don't mind losing your data after a crash.
> This is temporary performance solution - I want get SELECT query result
> first, but current performance is too low.
Disabling fsync will not help SELECT performance one bit. It would only
affect transactions that modify the database.
regards, tom lane
Yaroslav Mazurak <yamazurak@Lviv.Bank.Gov.UA> writes:
> Current postgresql.conf settings (some) are:
> max_locks_per_transaction = 16
This strikes me as a really bad idea --- you save little space by
reducing it from the default, and open yourself up to unexpected failures.
> wal_buffers = 256
That is almost certainly way more than you need.
> sort_mem = 131072
People have already told you that one's a bad idea.
> commit_delay = 32000
I'm unconvinced that setting this nonzero is a good idea. Have you done
experiments to prove that you get a benefit?
> enable_seqscan = false
This is the cause of the bizarre-looking cost estimates. I don't
recommend setting it false as a system-wide setting. If you want
to nudge the planner towards indexscans, reducing random_page_cost
a little is probably a better way.
regards, tom lane
Hi All!
Richard Huxton wrote:
>>>On Wednesday 06 August 2003 08:34, Yaroslav Mazurak wrote:
>>>>sort_mem = 131072
>>>This sort_mem value is *very* large - that's 131MB for *each sort* that
It's not TOO large *for PostgreSQL*. When I'm inserting a large amount
of data into tables, sort_mem helps. Value of 192M speeds up inserting
significantly (verified :))!
>> What mean "each sort"? Each query with SORT clause or some internal
>>(invisible to user) sorts too (I can't imagine: indexed search or
>>whatever else)?
>> I'm reduced sort_mem to 16M.
> It means each sort - if you look at your query plan and see three "sort"
> clauses that means that query might allocate 48MB to sorting. Now, that's
> good because sorting items on disk is much slower. It's bad because that's
> 48MB less for everything else that's happening.
OK, I'm preparing to fix this value. :)
IMHO this is PostgreSQL's lack of memory management. I think that
PostgreSQL can finally allocate enough memory by himself! :-E
>> This is another strange behavior of PostgreSQL - he don't use some
>>created indexes (seq_scan only) after ANALYZE too. OK, I'm turned on
>>this option back.
> Fair enough, we can work on those. With 7.3.x you can tell PG to examine
> some tables more thouroughly to get better plans.
You might EXPLAIN ANALYZE?
>>>>effective_cache_size = 65536
>>>So you typically get about 256MB cache usage in top/free?
>> No, top shows 12-20Mb.
>> I'm reduced effective_cache_size to 4K blocks (16M?).
> Cache size is in blocks of 8KB (usually) - it's a way of telling PG what
> the chances are of disk blocks being already cached by Linux.
PostgreSQL is running on FreeBSD, memory block actually is 4Kb, but in
most cases documentation says about 8Kb... I don't know exactly about
real disk block size, but suspect that it's 4Kb. :)
>> I think this is a important remark. Can "JOIN" significantly reduce
>>performance of SELECT statement relative to ", WHERE"?
>> OK, I'm changed VIEW to this text:
> It can sometimes. What it means is that PG will follow whatever order you
> write the joins in. If you know joining a to b to c is the best order,
> that can be a good thing. Unfortunately, it means the planner can't make a
> better guess based on its statistics.
At this moment this don't helps. :(
> Well the cost estimates look much more plausible. You couldn't post
> EXPLAIN ANALYSE could you? That actually runs the query.
>> Now (2K shared_buffers blocks, 16K effective_cache_size blocks, 16Mb
>>sort_mem) PostgreSQL uses much less memory, about 64M... it's not good,
>>I want using all available RAM if possible - PostgreSQL is the main task
>>on this PC.
> Don't forget that any memory PG is using the operating-system can't. The
> OS will cache frequently accessed disk blocks for you, so it's a question
> of finding the right balance.
PostgreSQL is the primary task for me on this PC - I don't worry about
other tasks except OS. ;)
>> May set effective_cache_size to 192M (48K blocks) be better? I don't
>>understand exactly: effective_cache_size tells PostgreSQL about OS cache
>>size or about available free RAM?
> It needs to reflect how much cache the system is using - try the "free"
> command to see figures.
I'm not found "free" utility on FreeBSD 4.7. :(
> If you could post the output of EXPLAIN ANALYSE rather than EXPLAIN, I'll
> take a look at it this evening (London time). There's also plenty of other
> people on this list who can help too.
I'm afraid that this may be too long. :-(((
Yesterday I'm re-execute my query with all changes... after 700 (!)
minutes query failed with: "ERROR: Memory exhausted in AllocSetAlloc(104)".
I don't understand: result is actually 8K rows long only, but
PostgreSQL failed! Why?!! Function showcalc is recursive, but in my
query used with level 1 depth only (I know exactly).
Again: I think that this is PostgreSQL's lack of quality memory
management. :-(
> - Richard Huxton
With best regards
Yaroslav Mazurak.
On 7 Aug 2003 at 10:05, Yaroslav Mazurak wrote: > > It needs to reflect how much cache the system is using - try the "free" > > command to see figures. > > I'm not found "free" utility on FreeBSD 4.7. :( <rant> Grr.. I don't like freeBSD for it's top output.Active/inactive/Wired.. Grr.. why can't it be shared buffered and cached? Same goes for HP-UX top. Looking at it one gets hardly any real information.. Anyway that's just me.. </rant> Top on freeBSD seems pretty unintuituive em but if you find any documentation on that, that would help you. ( Haven't booted in freeBSD in ages so no data out of my head..) You can try various sysctls on freeBSD. Basicalyl idea is to find out how much of memory is used and how much is cached. FreeBSD must be providing that one in some form.. IIRC there is a limit on filesystem cache on freeBSD. 300MB by default. If that is the case, you might have to raise it to make effective_cache_size really effective.. HTH Bye Shridhar -- Another war ... must it always be so? How many comrades have we lostin this way? ... Obedience. Duty. Death, and more death ... -- Romulan Commander, "Balance of Terror", stardate 1709.2
Hi All!
Tom Lane wrote:
> Yaroslav Mazurak <yamazurak@Lviv.Bank.Gov.UA> writes:
>>>>fsync = false
>>>I'd turn fsync back on - unless you don't mind losing your data after a crash.
>> This is temporary performance solution - I want get SELECT query result
>>first, but current performance is too low.
> Disabling fsync will not help SELECT performance one bit. It would only
> affect transactions that modify the database.
Fixed. But at this moment primary tasks are *get result* (1st) from
SELECT in *reasonable* time (2nd). :)
> regards, tom lane
With best regards
Yaroslav Mazurak.
On Thursday 07 August 2003 08:05, Yaroslav Mazurak wrote: > Hi All! > > Richard Huxton wrote: > >>>On Wednesday 06 August 2003 08:34, Yaroslav Mazurak wrote: > >>>>sort_mem = 131072 > >>> > >>>This sort_mem value is *very* large - that's 131MB for *each sort* that > > It's not TOO large *for PostgreSQL*. When I'm inserting a large amount > of data into tables, sort_mem helps. Value of 192M speeds up inserting > significantly (verified :))! And what about every other operation? > >> What mean "each sort"? Each query with SORT clause or some internal > >>(invisible to user) sorts too (I can't imagine: indexed search or > >>whatever else)? > >> > >> I'm reduced sort_mem to 16M. > > > > It means each sort - if you look at your query plan and see three "sort" > > clauses that means that query might allocate 48MB to sorting. Now, that's > > good because sorting items on disk is much slower. It's bad because > > that's 48MB less for everything else that's happening. > > OK, I'm preparing to fix this value. :) > IMHO this is PostgreSQL's lack of memory management. I think that > PostgreSQL can finally allocate enough memory by himself! :-E But this parameter controls how much memory can be allocated to sorts - I don't see how PG can figure out a reasonable maximum by itself. > >> This is another strange behavior of PostgreSQL - he don't use some > >>created indexes (seq_scan only) after ANALYZE too. OK, I'm turned on > >>this option back. > > > > Fair enough, we can work on those. With 7.3.x you can tell PG to examine > > some tables more thouroughly to get better plans. > > You might EXPLAIN ANALYZE? No - I meant altering the number of rows used to gather stats (ALTER TABLE...SET STATISTICS) - this controls how many rows PG looks at when deciding the "shape" of the data in the table. [snip] > > Don't forget that any memory PG is using the operating-system can't. The > > OS will cache frequently accessed disk blocks for you, so it's a question > > of finding the right balance. > > PostgreSQL is the primary task for me on this PC - I don't worry about > other tasks except OS. ;) You still want the OS to cache your database files. If you try and allocate too much memory to PG you will only hurt performance. > >> May set effective_cache_size to 192M (48K blocks) be better? I don't > >>understand exactly: effective_cache_size tells PostgreSQL about OS cache > >>size or about available free RAM? > > > > It needs to reflect how much cache the system is using - try the "free" > > command to see figures. > > I'm not found "free" utility on FreeBSD 4.7. :( Sorry - I don't know what the equivalent is in FreeBSD. > > If you could post the output of EXPLAIN ANALYSE rather than EXPLAIN, I'll > > take a look at it this evening (London time). There's also plenty of > > other people on this list who can help too. > > I'm afraid that this may be too long. :-((( > Yesterday I'm re-execute my query with all changes... after 700 (!) > minutes query failed with: "ERROR: Memory exhausted in > AllocSetAlloc(104)". I don't understand: result is actually 8K rows long > only, but > PostgreSQL failed! Why?!! Function showcalc is recursive, but in my > query used with level 1 depth only (I know exactly). I must say I'm puzzled as to how this can happen. In fact, if the last EXPLAIN output was accurate, it couldn't run out of memory, not with the settings you've got now. > Again: I think that this is PostgreSQL's lack of quality memory > management. :-( If it's allocating all that memory (do you see the memory usage going up in top) then there's something funny going on now. Well sir, I can only think of two options now: 1. simplify the query until it works and then build it back up again - that should identify where the problem is. 2. If you can put together a pg_dump with a small amount of sample data, I can take a look at it here. -- Richard Huxton Archonet Ltd
On Thu, 7 Aug 2003, Richard Huxton wrote: > But this parameter controls how much memory can be allocated to sorts - I > don't see how PG can figure out a reasonable maximum by itself. One could have one setting for the total memory usage and pg could use statistics or some heuristics to use the memory for different things in a good way. Then that setting could have an auto setting so it uses 40% of all memory or something like that. Not perfect but okay for most people. -- /Dennis
Hi All!
Shridhar Daithankar wrote:
> On 7 Aug 2003 at 10:05, Yaroslav Mazurak wrote:
>>>It needs to reflect how much cache the system is using - try the "free"
>>>command to see figures.
>> I'm not found "free" utility on FreeBSD 4.7. :(
> <rant>
> Grr.. I don't like freeBSD for it's top output.Active/inactive/Wired.. Grr..
> why can't it be shared buffered and cached? Same goes for HP-UX top. Looking at
> it one gets hardly any real information.. Anyway that's just me..
> </rant>
Grr... I don't like PostgreSQL for it's memory usage parameters. In
Sybase ASA, I say for example: "use 64Mb RAM for cache". I don't worry
about data in this cache - this may be queries, sort areas, results etc.
I think that server know better about it's memory requirements. I know
that Sybase *use*, and use *only this* memory and don't trap with
"Memory exhausted" error.
I'm not remember 700 minutes queries (more complex that my query),
following with "memory exhausted" error, on Sybase.
Advertising, he? :(
> Top on freeBSD seems pretty unintuituive em but if you find any documentation
> on that, that would help you. (Haven't booted in freeBSD in ages so no data
> out of my head..)
> You can try various sysctls on freeBSD. Basicalyl idea is to find out how much
> of memory is used and how much is cached. FreeBSD must be providing that one in
> some form..
> IIRC there is a limit on filesystem cache on freeBSD. 300MB by default. If that
> is the case, you might have to raise it to make effective_cache_size really
> effective..
"Try various sysctls" says nothing for me. I want use *all available
RAM* (of course, without needed for OS use) for PostgreSQL.
While idle time top says:
Mem: 14M Active, 1944K Inact, 28M Wired, 436K Cache, 48M Buf, 331M Free
Swap: 368M Total, 17M Used, 352M Free, 4% Inuse
After 1 minute of "EXPLAIN ANALYZE SELECT SUM(showcalc('B00204', dd,
r020, t071)) FROM v_file02wide WHERE a011 = 3 AND inrepdate(data) AND
b030 IN (SELECT b030 FROM dov_bank WHERE dov_bank_box_22(box) IN ('NL',
'NM')) AND r030 = 980;" executing:
Mem: 64M Active, 17M Inact, 72M Wired, 436K Cache, 48M Buf, 221M Free
Swap: 368M Total, 3192K Used, 365M Free
PID USERNAME PRI NICE SIZE RES STATE TIME WCPU CPU COMMAND
59063 postgres 49 0 65560K 55492K RUN 1:06 94.93% 94.63% postgres
After 12 minutes of query executing:
Mem: 71M Active, 17M Inact, 72M Wired, 436K Cache, 48M Buf, 214M Free
Swap: 368M Total, 3192K Used, 365M Free
PID USERNAME PRI NICE SIZE RES STATE TIME WCPU CPU COMMAND
59063 postgres 56 0 73752K 62996K RUN 12:01 99.02% 99.02% postgres
I suspect that swap-file size is too small for my query... but query
isn't too large, about 8K rows only. :-|
> Shridhar
With best regards
Yaroslav Mazurak.
On Thursday 07 August 2003 09:24, Yaroslav Mazurak wrote:
> > IIRC there is a limit on filesystem cache on freeBSD. 300MB by default.
> > If that is the case, you might have to raise it to make
> > effective_cache_size really effective..
>
> "Try various sysctls" says nothing for me. I want use *all available
> RAM* (of course, without needed for OS use) for PostgreSQL.
PG will be using the OS' disk caching.
> While idle time top says:
>
> Mem: 14M Active, 1944K Inact, 28M Wired, 436K Cache, 48M Buf, 331M Free
> Swap: 368M Total, 17M Used, 352M Free, 4% Inuse
>
> After 1 minute of "EXPLAIN ANALYZE SELECT SUM(showcalc('B00204', dd,
> r020, t071)) FROM v_file02wide WHERE a011 = 3 AND inrepdate(data) AND
> b030 IN (SELECT b030 FROM dov_bank WHERE dov_bank_box_22(box) IN ('NL',
> 'NM')) AND r030 = 980;" executing:
>
> Mem: 64M Active, 17M Inact, 72M Wired, 436K Cache, 48M Buf, 221M Free
> Swap: 368M Total, 3192K Used, 365M Free
>
> PID USERNAME PRI NICE SIZE RES STATE TIME WCPU CPU
> COMMAND 59063 postgres 49 0 65560K 55492K RUN 1:06 94.93% 94.63%
> postgres
>
> After 12 minutes of query executing:
>
> Mem: 71M Active, 17M Inact, 72M Wired, 436K Cache, 48M Buf, 214M Free
> Swap: 368M Total, 3192K Used, 365M Free
>
> PID USERNAME PRI NICE SIZE RES STATE TIME WCPU CPU
> COMMAND 59063 postgres 56 0 73752K 62996K RUN 12:01 99.02% 99.02%
> postgres
>
> I suspect that swap-file size is too small for my query... but query
> isn't too large, about 8K rows only. :-|
Looks fine - PG isn't growing too large and your swap usage seems steady. We
can try upping the sort memory later, but given the amount of data you're
dealing with I'd guess 64MB should be fine.
I think we're going to have to break the query down a little and see where the
issue is.
What's the situation with:
EXPLAIN ANALYZE SELECT <some_field> FROM v_file02wide WHERE a011 = 3 AND
inrepdate(data) AND b030 IN (SELECT b030 FROM dov_bank WHERE
dov_bank_box_22(box) IN ('NL', 'NM')) AND r030 = 980;
and:
EXPLAIN ANALYZE SELECT SUM(showcalc(<parameters>)) FROM <something simple>
Hopefully one of these will run in a reasonable time, and the other will not.
Then we can examine the slow query in more detail. Nothing from your previous
EXPLAIN (email of yesterday 13:42) looks unreasonable but something must be
going wild in the heart of the query, otherwise you wouldn't be here.
--
Richard Huxton
Archonet Ltd
On Thu, 7 Aug 2003, Yaroslav Mazurak wrote: > Hi All! > > Shridhar Daithankar wrote: > > > On 7 Aug 2003 at 10:05, Yaroslav Mazurak wrote: > > >>>It needs to reflect how much cache the system is using - try the "free" > >>>command to see figures. > > >> I'm not found "free" utility on FreeBSD 4.7. :( > > > <rant> > > Grr.. I don't like freeBSD for it's top output.Active/inactive/Wired.. Grr.. > > why can't it be shared buffered and cached? Same goes for HP-UX top. Looking at > > it one gets hardly any real information.. Anyway that's just me.. > > </rant> > > Grr... I don't like PostgreSQL for it's memory usage parameters. In > Sybase ASA, I say for example: "use 64Mb RAM for cache". I don't worry > about data in this cache - this may be queries, sort areas, results etc. > I think that server know better about it's memory requirements. I know > that Sybase *use*, and use *only this* memory and don't trap with > "Memory exhausted" error. > I'm not remember 700 minutes queries (more complex that my query), > following with "memory exhausted" error, on Sybase. > Advertising, he? :( > > > Top on freeBSD seems pretty unintuituive em but if you find any documentation > > on that, that would help you. (Haven't booted in freeBSD in ages so no data > > out of my head..) > > > You can try various sysctls on freeBSD. Basicalyl idea is to find out how much > > of memory is used and how much is cached. FreeBSD must be providing that one in > > some form.. > > > IIRC there is a limit on filesystem cache on freeBSD. 300MB by default. If that > > is the case, you might have to raise it to make effective_cache_size really > > effective.. > > "Try various sysctls" says nothing for me. I want use *all available > RAM* (of course, without needed for OS use) for PostgreSQL. That's a nice theory, but it doesn't work out that way. About every two months someone shows up wanting postgresql to use all the memory in their box for caching and we wind up explaining that the kernel is better at caching than postgresql is, and how it's better not to push the usage of the memory right up to the limit. The reason you don't want to use every bit for postgresql is that, if you use add load after that you may make the machine start to swap out and slow down considerably. My guess is that this is exactly what's happening to you, you're using so much memory that the machine is running out and slowing down. Drop shared_buffers to 1000 to 4000, sort_mem to 8192 and start over from there. Then, increase them each one at a time until there's no increase in speed, or stop if it starts getting slower and back off. bigger is NOT always better.
Hi All!
First, thanks for answers!
Richard Huxton wrote:
> On Thursday 07 August 2003 09:24, Yaroslav Mazurak wrote:
>>>IIRC there is a limit on filesystem cache on freeBSD. 300MB by default.
>>>If that is the case, you might have to raise it to make
>>>effective_cache_size really effective..
>> "Try various sysctls" says nothing for me. I want use *all available
>>RAM* (of course, without needed for OS use) for PostgreSQL.
> PG will be using the OS' disk caching.
I think all applications using OS disk caching. ;)
Or you want to say that PostgreSQL tuned for using OS-specific cache
implementation?
Do you know method for examining real size of OS filesystem cache? If I
understood right, PostgreSQL dynamically use all available RAM minus
shared_buffers minus k * sort_mem minus effective_cache_size?
I want configure PostgreSQL for using _maximum_ of available RAM.
> Looks fine - PG isn't growing too large and your swap usage seems steady. We
> can try upping the sort memory later, but given the amount of data you're
> dealing with I'd guess 64MB should be fine.
> I think we're going to have to break the query down a little and see where the
> issue is.
> What's the situation with:
> EXPLAIN ANALYZE SELECT <some_field> FROM v_file02wide WHERE a011 = 3 AND
> inrepdate(data) AND b030 IN (SELECT b030 FROM dov_bank WHERE
> dov_bank_box_22(box) IN ('NL', 'NM')) AND r030 = 980;
> and:
> EXPLAIN ANALYZE SELECT SUM(showcalc(<parameters>)) FROM <something simple>
> Hopefully one of these will run in a reasonable time, and the other will not.
> Then we can examine the slow query in more detail. Nothing from your previous
> EXPLAIN (email of yesterday 13:42) looks unreasonable but something must be
> going wild in the heart of the query, otherwise you wouldn't be here.
Yes, you're right. I've tested a few statements and obtain interesting
results.
SELECT * FROM v_file02wide WHERE... executes about 34 seconds.
SELECT showcalc(...); executes from 0.7 seconds (without recursion) up
to 6.3 seconds if recursion is used! :(
This mean, that approximate execute time for fully qualified SELECT
with about 8K rows is... about 13 hours! :-O
Hence, problem is in my function showcalc:
CREATE OR REPLACE FUNCTION showcalc(VARCHAR(10), VARCHAR(2), VARCHAR(4),
NUMERIC(16)) RETURNS NUMERIC(16)
LANGUAGE SQL STABLE AS '
-- Parameters: code, dd, r020, t071
SELECT COALESCE(
(SELECT sc.koef * $4
FROM showing AS s NATURAL JOIN showcomp AS sc
WHERE s.kod = $1
AND NOT SUBSTR(acc_mask, 1, 1) = ''[''
AND SUBSTR(acc_mask, 1, 4) = $3
AND SUBSTR(acc_mask, 5, 1) = SUBSTR($2, 1, 1)),
(SELECT SUM(sc.koef * COALESCE(showcalc(SUBSTR(acc_mask, 2,
LENGTH(acc_mask) - 2), $2, $3, $4), 0))
FROM showing AS s NATURAL JOIN showcomp AS sc
WHERE s.kod = $1
AND SUBSTR(acc_mask, 1, 1) = ''[''),
0) AS showing;
';
BTW, cross join "," with WHERE clause don't improve performance
relative to NATURAL JOIN.
Additionally, with user-defined function beginchar (SUBSTR(..., 1, 1)),
used for indexing, showcalc executes about 16 seconds. With function
SUBSTR the same showcalc executes 6 seconds.
Table showing contain information about showing: showing id (id_show),
code (kod) and description (opys). Table showcomp contain information
about showing components (accounts): showing id (id_show), coefficient
(koef) and account_mask (acc_mask). Account mask is 4-char balance
account mask || 1-char account characteristics or another showing in
square bracket.
Example:
showing
=========+==========+===========
id_show | kod | opys
=========+==========+===========
1 | 'A00101' | 'Received'
2 | 'A00102' | 'Sent'
3 | 'A00103' | 'Total'
=========+==========+===========
showcomp
=========+======+===========
id_show | koef | acc_mask
=========+======+===========
1 | 1.0 | '60102'
1 | 1.0 | '60112'
2 | 1.0 | '70011'
2 | 1.0 | '70021'
3 | 1.0 | '[A00101]'
3 | -1.0 | '[A00102]'
=========+======+===========
This mean that: A00101 includes accounts 6010 and 6011 with
characteristics 2, A00102 includes accounts 7001 and 7002 with
characteristics 1, and A00103 = A00102 - A00101. In almost all cases
recursion depth not exceed 1 level, but I'm not sure. :)
View v_file02wide contain account (r020) and 2-char characteristics
(dd). Using showcalc I want to sum numbers (t071) on accounts included
in appropriate showings. I.e SELECT SUM(showcalc('A00101', dd, r020,
t071)) FROM ... must return sum on accounts 6010 and 6011 with
characteristics 2 etc.
Now I think about change function showcalc or/and this data
structures... :)
Anyway, 600Mb is too low for PostgreSQL for executing my query - DBMS
raise error after 11.5 hours (of estimated 13?). :(
With best regards
Yaroslav Mazurak.
On Thu, 7 Aug 2003, Yaroslav Mazurak wrote: > Hi All! > > > Richard Huxton wrote: > > >>>On Wednesday 06 August 2003 08:34, Yaroslav Mazurak wrote: > > >>>>sort_mem = 131072 > > >>>This sort_mem value is *very* large - that's 131MB for *each sort* that > > It's not TOO large *for PostgreSQL*. When I'm inserting a large amount > of data into tables, sort_mem helps. Value of 192M speeds up inserting > significantly (verified :))! If I remember right, this is on a PII-400 with 384 Megs of RAM. On a machine that small, 128Meg is probably too big for ensuring there are no swap storms. Once you force the box to swap you loose. > >>>>effective_cache_size = 65536 > > >>>So you typically get about 256MB cache usage in top/free? > > >> No, top shows 12-20Mb. > >> I'm reduced effective_cache_size to 4K blocks (16M?). > > > Cache size is in blocks of 8KB (usually) - it's a way of telling PG what > > the chances are of disk blocks being already cached by Linux. > > PostgreSQL is running on FreeBSD, memory block actually is 4Kb, but in > most cases documentation says about 8Kb... I don't know exactly about > real disk block size, but suspect that it's 4Kb. :) FYI effective cache size and shared_buffers are both measured in Postgresql sized blocks, which default to 8k but can be changed upon compile. So, effective_cache size for a machine that shows 128 Meg kernel cache and 20 meg buffers would be (138*2^20)/(8*2^10) -> (138*2^10)/8 -> 17664. > I'm afraid that this may be too long. :-((( > Yesterday I'm re-execute my query with all changes... after 700 (!) > minutes query failed with: "ERROR: Memory exhausted in AllocSetAlloc(104)". > I don't understand: result is actually 8K rows long only, but > PostgreSQL failed! Why?!! Function showcalc is recursive, but in my > query used with level 1 depth only (I know exactly). > Again: I think that this is PostgreSQL's lack of quality memory > management. :-( Can you run top while this is happening and see postgresql's memory usage climb or df the disks to see if they're filling up? could be swap is filling even. How much swap space do you have allocated, by the way? Also, you have to restart postgresql to get the changes to postgresql.conf to take effect. Just in case you haven't. Do a show all; in psql to see if the settings are what they should be.
scott.marlowe wrote:
> On Thu, 7 Aug 2003, Yaroslav Mazurak wrote:
>>Shridhar Daithankar wrote:
> That's a nice theory, but it doesn't work out that way. About every two
> months someone shows up wanting postgresql to use all the memory in their
> box for caching and we wind up explaining that the kernel is better at
> caching than postgresql is, and how it's better not to push the usage of
> the memory right up to the limit.
I'm reading this mailing list just few days. :)))
> The reason you don't want to use every bit for postgresql is that, if you
> use add load after that you may make the machine start to swap out and
> slow down considerably.
What kind of load? PostgreSQL or another? I say that for this PC
primary task and critical goal is DBMS and it's performance.
> My guess is that this is exactly what's happening to you, you're using so
> much memory that the machine is running out and slowing down.
> Drop shared_buffers to 1000 to 4000, sort_mem to 8192 and start over from
> there. Then, increase them each one at a time until there's no increase
> in speed, or stop if it starts getting slower and back off.
> bigger is NOT always better.
Let I want to use all available RAM with PostgreSQL.
Without executing query (PostgreSQL is running) top say now:
Mem: 71M Active, 23M Inact, 72M Wired, 436K Cache, 48M Buf, 208M Free
Swap: 368M Total, 2852K Used, 366M Free
It's right that I can figure that I can use 384M (total RAM) - 72M
(wired) - 48M (buf) = 264M for PostgreSQL.
Hence, if I set effective_cache_size to 24M (3072 8K blocks),
reasonable value (less than 240M, say 48M) for sort_mem, some value for
shared_buffers (i.e. 24M, or 6144 4K blocks (FreeBSD), or 3072 8K blocks
(PostgreSQL)), and rest of RAM 264M (total free with OS cache) - 24M
(reserved for OS cache) - 48M (sort) - 24M (shared) = 168M PostgreSQL
allocate dynamically by himself?
With best regards
Yaroslav Mazurak.
> Mem: 71M Active, 23M Inact, 72M Wired, 436K Cache, 48M Buf, 208M Free > Swap: 368M Total, 2852K Used, 366M Free > > It's right that I can figure that I can use 384M (total RAM) - 72M > (wired) - 48M (buf) = 264M for PostgreSQL. > Hence, if I set effective_cache_size to 24M (3072 8K blocks), > reasonable value (less than 240M, say 48M) for sort_mem, some value for > shared_buffers (i.e. 24M, or 6144 4K blocks (FreeBSD), or 3072 8K blocks > (PostgreSQL)), and rest of RAM 264M (total free with OS cache) - 24M > (reserved for OS cache) - 48M (sort) - 24M (shared) = 168M PostgreSQL > allocate dynamically by himself? Totally, utterly the wrong way around. Start with 384M, subtract whatever is in use by other processes, excepting kernel disk cache, subtract your PG shared buffers, subtract (PG proc size + PG sort mem)*(max number of PG processes you need to run - should be same as max_connections if thinking conservatively), leave some spare room so you can ssh in without swapping, and *the remainder* is what you should set effective_cache_size to. This is all in the docs. The key thing is: set effective_cache_size *last*. Note that Postgres assumes your OS is effective at caching disk blocks, so if that assumption is wrong you lose performance. Also, why on _earth_ would you need 48MB for sort memory? Are you seriously going to run a query that returns 48M of data and then sort it, on a machine with 384M of RAM? M
On Thursday 07 August 2003 17:30, Yaroslav Mazurak wrote: > Hi All! > > > First, thanks for answers! > > Richard Huxton wrote: > > On Thursday 07 August 2003 09:24, Yaroslav Mazurak wrote: > >>>IIRC there is a limit on filesystem cache on freeBSD. 300MB by default. > >>>If that is the case, you might have to raise it to make > >>>effective_cache_size really effective.. > >> > >> "Try various sysctls" says nothing for me. I want use *all available > >>RAM* (of course, without needed for OS use) for PostgreSQL. > > > > PG will be using the OS' disk caching. > > I think all applications using OS disk caching. ;) > Or you want to say that PostgreSQL tuned for using OS-specific cache > implementation? > Do you know method for examining real size of OS filesystem cache? If I > understood right, PostgreSQL dynamically use all available RAM minus > shared_buffers minus k * sort_mem minus effective_cache_size? > I want configure PostgreSQL for using _maximum_ of available RAM. PG's memory use can be split into four areas (note - I'm not a developer so this could be wrong). 1. Shared memory - vital so that different connections can communicate with each other. Shouldn't be too large, otherwise PG spends too long managing its shared memory rather than working on your queries. 2. Sort memory - If you have to sort results during a query it will use up to the amount you define in sort_mem and then use disk if it needs any more. This is for each sort. 3. Results memory - If you're returning 8000 rows then PG will assemble these and send them to the client which also needs space to store the 8000 rows. 4. Working memory - to actually run the queries - stack and heap space to keep track of its calculations etc. Your best bet is to start off with some smallish reasonable values and step them up gradually until you don't see any improvement. What is vital is that the OS can cache enough disk-space to keep all your commonly used tables and indexes in memory - if it can't then you'll see performance drop rapidly as PG has to keep accessing the disk. For the moment, I'd leave the settings roughly where they are while we look at the query, then once that's out of the way we can fine-tune the settings. [snip suggestion to break the query down] > Yes, you're right. I've tested a few statements and obtain interesting > results. > SELECT * FROM v_file02wide WHERE... executes about 34 seconds. > SELECT showcalc(...); executes from 0.7 seconds (without recursion) up > to 6.3 seconds if recursion is used! :( > This mean, that approximate execute time for fully qualified SELECT > with about 8K rows is... about 13 hours! :-O Hmm - not good. > Hence, problem is in my function showcalc: That's certainly the place to start, although we might be able to do something with v_file02wide later. > CREATE OR REPLACE FUNCTION showcalc(VARCHAR(10), VARCHAR(2), VARCHAR(4), > NUMERIC(16)) RETURNS NUMERIC(16) > LANGUAGE SQL STABLE AS ' > -- Parameters: code, dd, r020, t071 > SELECT COALESCE( > (SELECT sc.koef * $4 > FROM showing AS s NATURAL JOIN showcomp AS sc > WHERE s.kod = $1 > AND NOT SUBSTR(acc_mask, 1, 1) = ''['' > AND SUBSTR(acc_mask, 1, 4) = $3 > AND SUBSTR(acc_mask, 5, 1) = SUBSTR($2, 1, 1)), > (SELECT SUM(sc.koef * COALESCE(showcalc(SUBSTR(acc_mask, 2, > LENGTH(acc_mask) - 2), $2, $3, $4), 0)) > FROM showing AS s NATURAL JOIN showcomp AS sc > WHERE s.kod = $1 > AND SUBSTR(acc_mask, 1, 1) = ''[''), > 0) AS showing; > '; > > BTW, cross join "," with WHERE clause don't improve performance > relative to NATURAL JOIN. > Additionally, with user-defined function beginchar (SUBSTR(..., 1, 1)), > used for indexing, showcalc executes about 16 seconds. With function > SUBSTR the same showcalc executes 6 seconds. Fair enough - substr should be fairly efficient. [snip explanation of table structures and usage] I'm not going to claim I understood everything in your explanation, but there are a couple of things I can suggest. However, before you go and do any of that, can I ask you to post an EXPLAIN ANALYSE of two calls to your showcalc() function (once for a simple account, once for one with recursion)? You'll need to cut and paste the query as standard SQL since the explain won't look inside the function body. OK - bear in mind that these suggestions are made without the benefit of the explain analyse: 1. You could try splitting out the various tags of your mask into different fields - that will instantly eliminate all the substr() calls and might make a difference. If you want to keep the mask for display purposes, we could build a trigger to keep it in sync with the separate flags. 2. Use a "calculations" table and build your results step by step. So - calculate all the simple accounts, then calculate the ones that contain the simple accounts. 3. You could keep a separate "account_contains" table that might look like: acc_id | contains A001 | A001 A002 | A002 A003 | A003 A003 | A001 A004 | A004 A004 | A003 A004 | A001 So here A001/A002 are simple accounts but A003 contains A001 too. A004 contains A003 and A001. The table can be kept up to date automatically using some triggers. This should make it simple to pick up all the accounts contained within the target account and might mean you can eliminate the recursion. > Now I think about change function showcalc or/and this data > structures... :) Post the EXPLAIN ANALYSE first - maybe someone smarter than me will have an idea. > Anyway, 600Mb is too low for PostgreSQL for executing my query - DBMS > raise error after 11.5 hours (of estimated 13?). :( I think the problem is the 13 hours, not the 600MB. Once we've got the query running in a reasonable length of time (seconds) then the memory requirements will go down, I'm sure. -- Richard Huxton Archonet Ltd
On Thu, 2003-08-07 at 12:04, Yaroslav Mazurak wrote: > scott.marlowe wrote: > > > On Thu, 7 Aug 2003, Yaroslav Mazurak wrote: > > >>Shridhar Daithankar wrote: > [snip] > > My guess is that this is exactly what's happening to you, you're using so > > much memory that the machine is running out and slowing down. > > > Drop shared_buffers to 1000 to 4000, sort_mem to 8192 and start over from > > there. Then, increase them each one at a time until there's no increase > > in speed, or stop if it starts getting slower and back off. > > > bigger is NOT always better. > > Let I want to use all available RAM with PostgreSQL. > Without executing query (PostgreSQL is running) top say now: You're missing the point. PostgreSQL is not designed like Oracle, Sybase, etc. They say, "Give me all the RAM; I will cache everything myself." PostgreSQL says "The kernel programmers have worked very hard on disk caching. Why should I duplicate their efforts?" Thus, give PG only a "little" RAM, and let the OS' disk cache hold the rest. -- +---------------------------------------------------------------+ | Ron Johnson, Jr. Home: ron.l.johnson@cox.net | | Jefferson, LA USA | | | | "Man, I'm pretty. Hoo Hah!" | | Johnny Bravo | +---------------------------------------------------------------+
On Thu, 7 Aug 2003, Yaroslav Mazurak wrote: > scott.marlowe wrote: > > > On Thu, 7 Aug 2003, Yaroslav Mazurak wrote: > > >>Shridhar Daithankar wrote: > > > That's a nice theory, but it doesn't work out that way. About every two > > months someone shows up wanting postgresql to use all the memory in their > > box for caching and we wind up explaining that the kernel is better at > > caching than postgresql is, and how it's better not to push the usage of > > the memory right up to the limit. > > I'm reading this mailing list just few days. :))) We all get started somewhere. Glad to have you on the list. > > The reason you don't want to use every bit for postgresql is that, if you > > use add load after that you may make the machine start to swap out and > > slow down considerably. > > What kind of load? PostgreSQL or another? I say that for this PC > primary task and critical goal is DBMS and it's performance. Just Postgresql. Imagine that you set up the machine with 64 Meg sort_mem setting, and it has only two or three users right now. If the number of users jumps up to 16 or 32, then it's quite possible that all those connections can each spawn a sort or two, and if they are large sorts, then poof, all your memory is gone and your box is swapping out like mad. > > My guess is that this is exactly what's happening to you, you're using so > > much memory that the machine is running out and slowing down. > > > Drop shared_buffers to 1000 to 4000, sort_mem to 8192 and start over from > > there. Then, increase them each one at a time until there's no increase > > in speed, or stop if it starts getting slower and back off. > > > bigger is NOT always better. > > Let I want to use all available RAM with PostgreSQL. > Without executing query (PostgreSQL is running) top say now: > > Mem: 71M Active, 23M Inact, 72M Wired, 436K Cache, 48M Buf, 208M Free > Swap: 368M Total, 2852K Used, 366M Free > > It's right that I can figure that I can use 384M (total RAM) - 72M > (wired) - 48M (buf) = 264M for PostgreSQL. > Hence, if I set effective_cache_size to 24M (3072 8K blocks), > reasonable value (less than 240M, say 48M) for sort_mem, some value for > shared_buffers (i.e. 24M, or 6144 4K blocks (FreeBSD), or 3072 8K blocks > (PostgreSQL)), and rest of RAM 264M (total free with OS cache) - 24M > (reserved for OS cache) - 48M (sort) - 24M (shared) = 168M PostgreSQL > allocate dynamically by himself? It's important to understand that effective_cache_size is simply a number that tells the query planner about how big the kernel cache is for postgresql. Note that in your top output, it shows 48 M buffer, and 208M free, and 436k cache. Adding those up comes to about 256 Megs of available cache to the OS. But that's assuming postgresql isn't gonna use some of that for sorts or buffers, so assuming some of the memory will get used for that, then it's likely that effective_cache_size will really be about 100 to 150 Meg. Like someone else said, you set effective cache size last. First set buffers to a few thousand (1000 to 5000 is usually a good number) and set sort_mem to 8 to 32 meg to start, and adjust it as you test the database under parallel load. Then, take the numbers you get for free/buffer/cache from top to figure out effective_cache_size. Again, I'll repeat what I said in an earlier post on this, the size of buffers and effective_cache_size are set in POSTGRESQL blocks. i.e. your kernel page block size is meaningless here. If you have 100 Meg left over, then you need to do the math as: 100*2^20 --------- 8*2^10 becomes 100*2^10 --------- 8 becomes 12800 (8k blocks.) Reading your other response I got the feeling you may have been under the impression that this is set in OS blocks, so I just wanted to make sure it was clear it's not.
Hi, All!
Richard Huxton wrote:
> On Thursday 07 August 2003 17:30, Yaroslav Mazurak wrote:
>>Richard Huxton wrote:
>>>On Thursday 07 August 2003 09:24, Yaroslav Mazurak wrote:
> PG's memory use can be split into four areas (note - I'm not a developer so
> this could be wrong).
> 1. Shared memory - vital so that different connections can communicate with
> each other. Shouldn't be too large, otherwise PG spends too long managing its
> shared memory rather than working on your queries.
> 2. Sort memory - If you have to sort results during a query it will use up to
> the amount you define in sort_mem and then use disk if it needs any more.
> This is for each sort.
> 3. Results memory - If you're returning 8000 rows then PG will assemble these
> and send them to the client which also needs space to store the 8000 rows.
> 4. Working memory - to actually run the queries - stack and heap space to keep
> track of its calculations etc.
Hence, total free RAM - shared_buffers - k * sort_mem -
effective_cache_size == (results memory + working memory)?
> For the moment, I'd leave the settings roughly where they are while we look at
> the query, then once that's out of the way we can fine-tune the settings.
OK.
>> Additionally, with user-defined function beginchar (SUBSTR(..., 1, 1)),
>>used for indexing, showcalc executes about 16 seconds. With function
>>SUBSTR the same showcalc executes 6 seconds.
> Fair enough - substr should be fairly efficient.
Cost of user-defined SQL function call in PostgreSQL is high?
> OK - bear in mind that these suggestions are made without the benefit of the
> explain analyse:
> 1. You could try splitting out the various tags of your mask into different
> fields - that will instantly eliminate all the substr() calls and might make
> a difference. If you want to keep the mask for display purposes, we could
> build a trigger to keep it in sync with the separate flags.
This will be next step. :)
> 2. Use a "calculations" table and build your results step by step. So -
> calculate all the simple accounts, then calculate the ones that contain the
> simple accounts.
I give to SQL to user and few helper functions. Therefore single step
is required for building results.
> 3. You could keep a separate "account_contains" table that might look like:
> acc_id | contains
> A001 | A001
> A002 | A002
> A003 | A003
> A003 | A001
> A004 | A004
> A004 | A003
> A004 | A001
> So here A001/A002 are simple accounts but A003 contains A001 too. A004
> contains A003 and A001. The table can be kept up to date automatically using
> some triggers.
> This should make it simple to pick up all the accounts contained within the
> target account and might mean you can eliminate the recursion.
Thanks, sounds not so bad, but I suspect that this method don't improve
performance essentially.
I think about another secondary table for showcomp (compshow :)) with
showings "compiled" into account numbers and characteritics. After
inserting or updating new or old showing this showing will be
"recompiled" by explicit function call or trigger into atomary account
numbers and characteristics.
> Post the EXPLAIN ANALYSE first - maybe someone smarter than me will have an
> idea.
First result - simple showing 'B00202' (without recursion).
Second result - complex showing 'B00204' with recursion (1 level depth).
Showing 'B00202' contains 85 accounts, 'B00203' - 108 accounts, and
'B00204' = 'B00202' - 'B00203'.
Query text:
EXPLAIN ANALYZE SELECT COALESCE(
(SELECT sc.koef * 100
FROM showing AS s NATURAL JOIN showcomp AS sc
WHERE s.kod = 'B00202'
AND NOT SUBSTR(acc_mask, 1, 1) = '['
AND SUBSTR(acc_mask, 1, 4) = '6010'
AND SUBSTR(acc_mask, 5, 1) = SUBSTR('20', 1, 1)),
(SELECT SUM(sc.koef * COALESCE(showcalc(SUBSTR(acc_mask, 2,
LENGTH(acc_mask) - 2), '20', '6010', 100), 0))
FROM showing AS s NATURAL JOIN showcomp AS sc
WHERE s.kod = 'B00202'
AND SUBSTR(acc_mask, 1, 1) = '['),
0) AS showing;
EXPLAIN ANALYZE SELECT COALESCE(
(SELECT sc.koef * 100
FROM showing AS s NATURAL JOIN showcomp AS sc
WHERE s.kod = 'B00204'
AND NOT SUBSTR(acc_mask, 1, 1) = '['
AND SUBSTR(acc_mask, 1, 4) = '6010'
AND SUBSTR(acc_mask, 5, 1) = SUBSTR('20', 1, 1)),
(SELECT SUM(sc.koef * COALESCE(showcalc(SUBSTR(acc_mask, 2,
LENGTH(acc_mask) - 2), '20', '6010', 100), 0))
FROM showing AS s NATURAL JOIN showcomp AS sc
WHERE s.kod = 'B00204'
AND SUBSTR(acc_mask, 1, 1) = '['),
0) AS showing;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Result (cost=0.00..0.01 rows=1 width=0) (actual time=704.39..704.39
rows=1 loops=1)
InitPlan
-> Hash Join (cost=5.22..449.63 rows=1 width=19) (actual
time=167.28..352.90 rows=1 loops=1)
Hash Cond: ("outer".id_show = "inner".id_show)
-> Seq Scan on showcomp sc (cost=0.00..444.40 rows=1
width=15) (actual time=23.29..350.17 rows=32 loops=1)
Filter: ((substr((acc_mask)::text, 1, 1) <> '['::text)
AND (substr((acc_mask)::text, 1, 4) = '6010'::text) AND
(substr((acc_mask)::text, 5, 1) = '2'::text))
-> Hash (cost=5.22..5.22 rows=1 width=4) (actual
time=0.67..0.67 rows=0 loops=1)
-> Index Scan using index_showing_kod on showing s
(cost=0.00..5.22 rows=1 width=4) (actual time=0.61..0.64 rows=1 loops=1)
Index Cond: (kod = 'B00202'::character varying)
-> Hash Join (cost=5.22..449.63 rows=1 width=19) (actual
time=166.20..351.28 rows=1 loops=1)
Hash Cond: ("outer".id_show = "inner".id_show)
-> Seq Scan on showcomp sc (cost=0.00..444.40 rows=1
width=15) (actual time=23.36..349.24 rows=32 loops=1)
Filter: ((substr((acc_mask)::text, 1, 1) <> '['::text)
AND (substr((acc_mask)::text, 1, 4) = '6010'::text) AND
(substr((acc_mask)::text, 5, 1) = '2'::text))
-> Hash (cost=5.22..5.22 rows=1 width=4) (actual
time=0.17..0.17 rows=0 loops=1)
-> Index Scan using index_showing_kod on showing s
(cost=0.00..5.22 rows=1 width=4) (actual time=0.12..0.14 rows=1 loops=1)
Index Cond: (kod = 'B00202'::character varying)
-> Aggregate (cost=312.61..312.61 rows=1 width=28) (never executed)
-> Hash Join (cost=5.22..312.61 rows=1 width=28) (never
executed)
Hash Cond: ("outer".id_show = "inner".id_show)
-> Seq Scan on showcomp sc (cost=0.00..307.04
rows=69 width=24) (never executed)
Filter: (substr((acc_mask)::text, 1, 1) = '['::text)
-> Hash (cost=5.22..5.22 rows=1 width=4) (never
executed)
-> Index Scan using index_showing_kod on
showing s (cost=0.00..5.22 rows=1 width=4) (never executed)
Index Cond: (kod = 'B00202'::character
varying)
-> Aggregate (cost=312.61..312.61 rows=1 width=28) (never executed)
-> Hash Join (cost=5.22..312.61 rows=1 width=28) (never
executed)
Hash Cond: ("outer".id_show = "inner".id_show)
-> Seq Scan on showcomp sc (cost=0.00..307.04
rows=69 width=24) (never executed)
Filter: (substr((acc_mask)::text, 1, 1) = '['::text)
-> Hash (cost=5.22..5.22 rows=1 width=4) (never
executed)
-> Index Scan using index_showing_kod on
showing s (cost=0.00..5.22 rows=1 width=4) (never executed)
Index Cond: (kod = 'B00202'::character
varying)
Total runtime: 706.82 msec
(33 rows)
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Result (cost=0.00..0.01 rows=1 width=0) (actual time=6256.20..6256.21
rows=1 loops=1)
InitPlan
-> Hash Join (cost=5.22..449.63 rows=1 width=19) (actual
time=357.43..357.43 rows=0 loops=1)
Hash Cond: ("outer".id_show = "inner".id_show)
-> Seq Scan on showcomp sc (cost=0.00..444.40 rows=1
width=15) (actual time=23.29..355.41 rows=32 loops=1)
Filter: ((substr((acc_mask)::text, 1, 1) <> '['::text)
AND (substr((acc_mask)::text, 1, 4) = '6010'::text) AND
(substr((acc_mask)::text, 5, 1) = '2'::text))
-> Hash (cost=5.22..5.22 rows=1 width=4) (actual
time=0.22..0.22 rows=0 loops=1)
-> Index Scan using index_showing_kod on showing s
(cost=0.00..5.22 rows=1 width=4) (actual time=0.16..0.19 rows=1 loops=1)
Index Cond: (kod = 'B00204'::character varying)
-> Hash Join (cost=5.22..449.63 rows=1 width=19) (never executed)
Hash Cond: ("outer".id_show = "inner".id_show)
-> Seq Scan on showcomp sc (cost=0.00..444.40 rows=1
width=15) (never executed)
Filter: ((substr((acc_mask)::text, 1, 1) <> '['::text)
AND (substr((acc_mask)::text, 1, 4) = '6010'::text) AND
(substr((acc_mask)::text, 5, 1) = '2'::text))
-> Hash (cost=5.22..5.22 rows=1 width=4) (never executed)
-> Index Scan using index_showing_kod on showing s
(cost=0.00..5.22 rows=1 width=4) (never executed)
Index Cond: (kod = 'B00204'::character varying)
-> Aggregate (cost=312.61..312.61 rows=1 width=28) (actual
time=2952.69..2952.69 rows=1 loops=1)
-> Hash Join (cost=5.22..312.61 rows=1 width=28) (actual
time=12.59..264.69 rows=2 loops=1)
Hash Cond: ("outer".id_show = "inner".id_show)
-> Seq Scan on showcomp sc (cost=0.00..307.04
rows=69 width=24) (actual time=0.09..251.52 rows=1035 loops=1)
Filter: (substr((acc_mask)::text, 1, 1) = '['::text)
-> Hash (cost=5.22..5.22 rows=1 width=4) (actual
time=0.17..0.17 rows=0 loops=1)
-> Index Scan using index_showing_kod on
showing s (cost=0.00..5.22 rows=1 width=4) (actual time=0.12..0.14
rows=1 loops=1)
Index Cond: (kod = 'B00204'::character
varying)
-> Aggregate (cost=312.61..312.61 rows=1 width=28) (actual
time=2945.79..2945.80 rows=1 loops=1)
-> Hash Join (cost=5.22..312.61 rows=1 width=28) (actual
time=12.02..263.63 rows=2 loops=1)
Hash Cond: ("outer".id_show = "inner".id_show)
-> Seq Scan on showcomp sc (cost=0.00..307.04
rows=69 width=24) (actual time=0.09..251.09 rows=1035 loops=1)
Filter: (substr((acc_mask)::text, 1, 1) = '['::text)
-> Hash (cost=5.22..5.22 rows=1 width=4) (actual
time=0.17..0.17 rows=0 loops=1)
-> Index Scan using index_showing_kod on
showing s (cost=0.00..5.22 rows=1 width=4) (actual time=0.12..0.14
rows=1 loops=1)
Index Cond: (kod = 'B00204'::character
varying)
Total runtime: 6257.35 msec
(33 rows)
>> Anyway, 600Mb is too low for PostgreSQL for executing my query - DBMS
>>raise error after 11.5 hours (of estimated 13?). :(
> I think the problem is the 13 hours, not the 600MB. Once we've got the query
> running in a reasonable length of time (seconds) then the memory requirements
> will go down, I'm sure.
OK, that's right.
With best regards
Yaroslav Mazurak.