Thread: Tuplesort merge pre-reading
While reviewing Peter's latest round of sorting patches, and trying to
understand the new "batch allocation" mechanism, I started to wonder how
useful the pre-reading in the merge stage is in the first place.
I'm talking about the code that reads a bunch of from each tape, loading
them into the memtuples array. That code was added by Tom Lane, back in
1999:
commit cf627ab41ab9f6038a29ddd04dd0ff0ccdca714e
Author: Tom Lane <tgl@sss.pgh.pa.us>
Date: Sat Oct 30 17:27:15 1999 +0000
Further performance improvements in sorting: reduce number of
comparisons
during initial run formation by keeping both current run and next-run
tuples in the same heap (yup, Knuth is smarter than I am). And, during
merge passes, make use of available sort memory to load multiple tuples
from any one input 'tape' at a time, thereby improving locality of
access to the temp file.
So apparently there was a benefit back then, but is it still worthwhile?
The LogicalTape buffers one block at a time, anyway, how much gain are
we getting from parsing the tuples into SortTuple format in batches?
I wrote a quick patch to test that, attached. It seems to improve
performance, at least in this small test case:
create table lotsofints(i integer);
insert into lotsofints select random() * 1000000000.0 from
generate_series(1, 10000000);
vacuum freeze;
select count(*) FROM (select * from lotsofints order by i) t;
On my laptop, with default work_mem=4MB, that select takes 7.8 s on
unpatched master, and 6.2 s with the attached patch.
So, at least in some cases, the pre-loading hurts. I think we should get
rid of it. This patch probably needs some polishing: I replaced the
batch allocations with a simpler scheme with a buffer to hold just a
single tuple for each tape, and that might need some more work to allow
downsizing those buffers if you have a few very large tuples in an
otherwise narrow table. And perhaps we should free and reallocate a
smaller memtuples array for the merging, now that we're not making use
of the whole of it. And perhaps we should teach LogicalTape to use
larger buffers, if we can't rely on the OS to do the buffering for us.
But overall, this seems to make the code both simpler and faster.
Am I missing something?
- Heikki
Attachment
On Tue, Sep 6, 2016 at 5:20 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > I wrote a quick patch to test that, attached. It seems to improve > performance, at least in this small test case: > > create table lotsofints(i integer); > insert into lotsofints select random() * 1000000000.0 from > generate_series(1, 10000000); > vacuum freeze; > > select count(*) FROM (select * from lotsofints order by i) t; > > On my laptop, with default work_mem=4MB, that select takes 7.8 s on > unpatched master, and 6.2 s with the attached patch. The benefits have a lot to do with OS read-ahead, and efficient use of memory bandwidth during the merge, where we want to access the caller tuples sequentially per tape (i.e. that's what the batch memory stuff added -- it also made much better use of available memory). Note that I've been benchmarking the parallel CREATE INDEX patch on a server with many HDDs, since sequential performance is mostly all that matters. I think that in 1999, the preloading had a lot more to do with logtape.c's ability to aggressively recycle blocks during merges, such that the total storage overhead does not exceed the original size of the caller tuples (plus what it calls "trivial bookkeeping overhead" IIRC). That's less important these days, but still matters some (it's more of an issue when you can't complete the sort in one pass, which is rare these days). Offhand, I would think that taken together this is very important. I'd certainly want to see cases in the hundreds of megabytes or gigabytes of work_mem alongside your 4MB case, even just to be able to talk informally about this. As you know, the default work_mem value is very conservative. -- Peter Geoghegan
On Tue, Sep 6, 2016 at 12:08 PM, Peter Geoghegan <pg@heroku.com> wrote: > Offhand, I would think that taken together this is very important. I'd > certainly want to see cases in the hundreds of megabytes or gigabytes > of work_mem alongside your 4MB case, even just to be able to talk > informally about this. As you know, the default work_mem value is very > conservative. It looks like your benchmark relies on multiple passes, which can be misleading. I bet it suffers some amount of problems from palloc() fragmentation. When very memory constrained, that can get really bad. Non-final merge passes (merges with more than one run -- real or dummy -- on any given tape) can have uneven numbers of runs on each tape. So, tuplesort.c needs to be prepared to doll out memory among tapes *unevenly* there (same applies to memtuples "slots"). This is why batch memory support is so hard for those cases (the fact that they're so rare anyway also puts me off it). As you know, I wrote a patch that adds batch memory support to cases that require randomAccess (final output on a materialized tape), for their final merge. These final merges happen to not be a final on-the-fly merge only due to this randomAccess requirement from caller. It's possible to support these cases in the future, with that patch, only because I am safe to assume that each run/tape is the same size there (well, the assumption is exactly as safe as it was for the 9.6 final on-the-fly merge, at least). My point about non-final merges is that you have to be very careful that you're comparing apples to apples, memory accounting wise, when looking into something like this. I'm not saying that you didn't, but it's worth considering. FWIW, I did try an increase in the buffer size in LogicalTape at one time several months back, and so no benefit there (at least, with no other changes). -- Peter Geoghegan
On 09/06/2016 10:26 PM, Peter Geoghegan wrote: > On Tue, Sep 6, 2016 at 12:08 PM, Peter Geoghegan <pg@heroku.com> wrote: >> Offhand, I would think that taken together this is very important. I'd >> certainly want to see cases in the hundreds of megabytes or gigabytes >> of work_mem alongside your 4MB case, even just to be able to talk >> informally about this. As you know, the default work_mem value is very >> conservative. I spent some more time polishing this up, and also added some code to logtape.c, to use larger read buffers, to compensate for the fact that we don't do pre-reading from tuplesort.c anymore. That should trigger the OS read-ahead, and make the I/O more sequential, like was the purpose of the old pre-reading code. But simpler. I haven't tested that part much yet, but I plan to run some tests on larger data sets that don't fit in RAM, to make the I/O effects visible. I wrote a little testing toolkit, see third patch. I'm not proposing to commit that, but that's what I used for testing. It creates four tables, about 1GB in size each (it also creates smaller and larger tables, but I used the "medium" sized ones for these tests). Two of the tables contain integers, and two contain text strings. Two of the tables are completely ordered, two are in random order. To measure, it runs ORDER BY queries on the tables, with different work_mem settings. Attached are the full results. In summary, these patches improve performance in some of the tests, and are a wash on others. The patches help in particular in the randomly ordered cases, with up to 512 MB of work_mem. For example, with work_mem=256MB, which is enough to get a single merge pass: with patches: ordered_ints: 7078 ms, 6910 ms, 6849 ms random_ints: 15639 ms, 15575 ms, 15625 ms ordered_text: 11121 ms, 12318 ms, 10824 ms random_text: 53462 ms, 53420 ms, 52949 ms unpatched master: ordered_ints: 6961 ms, 7040 ms, 7044 ms random_ints: 19205 ms, 18797 ms, 18955 ms ordered_text: 11045 ms, 11377 ms, 11203 ms random_text: 57117 ms, 54489 ms, 54806 ms (The same queries were run three times in a row, that's what the three numbers on each row mean. I.e. the differences between the numbers on same row are noise) > It looks like your benchmark relies on multiple passes, which can be > misleading. I bet it suffers some amount of problems from palloc() > fragmentation. When very memory constrained, that can get really bad. > > Non-final merge passes (merges with more than one run -- real or dummy > -- on any given tape) can have uneven numbers of runs on each tape. > So, tuplesort.c needs to be prepared to doll out memory among tapes > *unevenly* there (same applies to memtuples "slots"). This is why > batch memory support is so hard for those cases (the fact that they're > so rare anyway also puts me off it). As you know, I wrote a patch that > adds batch memory support to cases that require randomAccess (final > output on a materialized tape), for their final merge. These final > merges happen to not be a final on-the-fly merge only due to this > randomAccess requirement from caller. It's possible to support these > cases in the future, with that patch, only because I am safe to assume > that each run/tape is the same size there (well, the assumption is > exactly as safe as it was for the 9.6 final on-the-fly merge, at > least). > > My point about non-final merges is that you have to be very careful > that you're comparing apples to apples, memory accounting wise, when > looking into something like this. I'm not saying that you didn't, but > it's worth considering. I'm not 100% sure I'm accounting for all the memory correctly. But I didn't touch the way the initial quicksort works, nor the way the runs are built. And the merge passes don't actually need or benefit from a lot of memory, so I doubt it's very sensitive to that. In this patch, the memory available for the read buffers is just divided evenly across maxTapes. The buffers for the tapes that are not currently active are wasted. It could be made smarter, by freeing all the currently-unused buffers for tapes that are not active at the moment. Might do that later, but this is what I'm going to benchmark for now. I don't think adding buffers is helpful beyond a certain point, so this is probably good enough in practice. Although it would be nice to free the memory we don't need earlier, in case there are other processes that could make use of it. > FWIW, I did try an increase in the buffer size in LogicalTape at one > time several months back, and so no benefit there (at least, with no > other changes). Yeah, unless you get rid of the pre-reading in tuplesort.c, you're just double-buffering. - Heikki
Attachment
On 09/08/2016 09:59 PM, Heikki Linnakangas wrote: > On 09/06/2016 10:26 PM, Peter Geoghegan wrote: >> On Tue, Sep 6, 2016 at 12:08 PM, Peter Geoghegan <pg@heroku.com> wrote: >>> Offhand, I would think that taken together this is very important. I'd >>> certainly want to see cases in the hundreds of megabytes or gigabytes >>> of work_mem alongside your 4MB case, even just to be able to talk >>> informally about this. As you know, the default work_mem value is very >>> conservative. > > I spent some more time polishing this up, and also added some code to > logtape.c, to use larger read buffers, to compensate for the fact that > we don't do pre-reading from tuplesort.c anymore. That should trigger > the OS read-ahead, and make the I/O more sequential, like was the > purpose of the old pre-reading code. But simpler. I haven't tested that > part much yet, but I plan to run some tests on larger data sets that > don't fit in RAM, to make the I/O effects visible. Ok, I ran a few tests with 20 GB tables. I thought this would show any differences in I/O behaviour, but in fact it was still completely CPU bound, like the tests on smaller tables I posted yesterday. I guess I need to point temp_tablespaces to a USB drive or something. But here we go. It looks like there was a regression when sorting random text, with 256 MB work_mem. I suspect that was a fluke - I only ran these tests once because they took so long. But I don't know for sure. Claudio, if you could also repeat the tests you ran on Peter's patch set on the other thread, with these patches, that'd be nice. These patches are effectively a replacement for 0002-Use-tuplesort-batch-memory-for-randomAccess-sorts.patch. And review would be much appreciated too, of course. Attached are new versions. Compared to last set, they contain a few comment fixes, and a change to the 2nd patch to not allocate tape buffers for tapes that were completely unused. - Heikki
Attachment
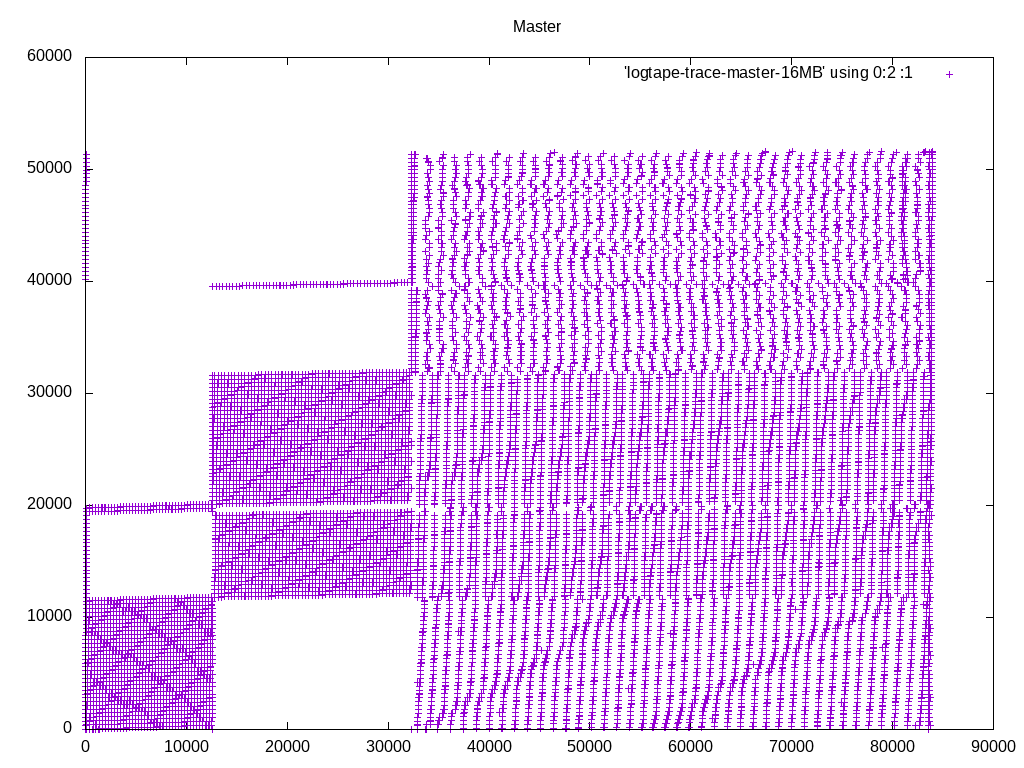
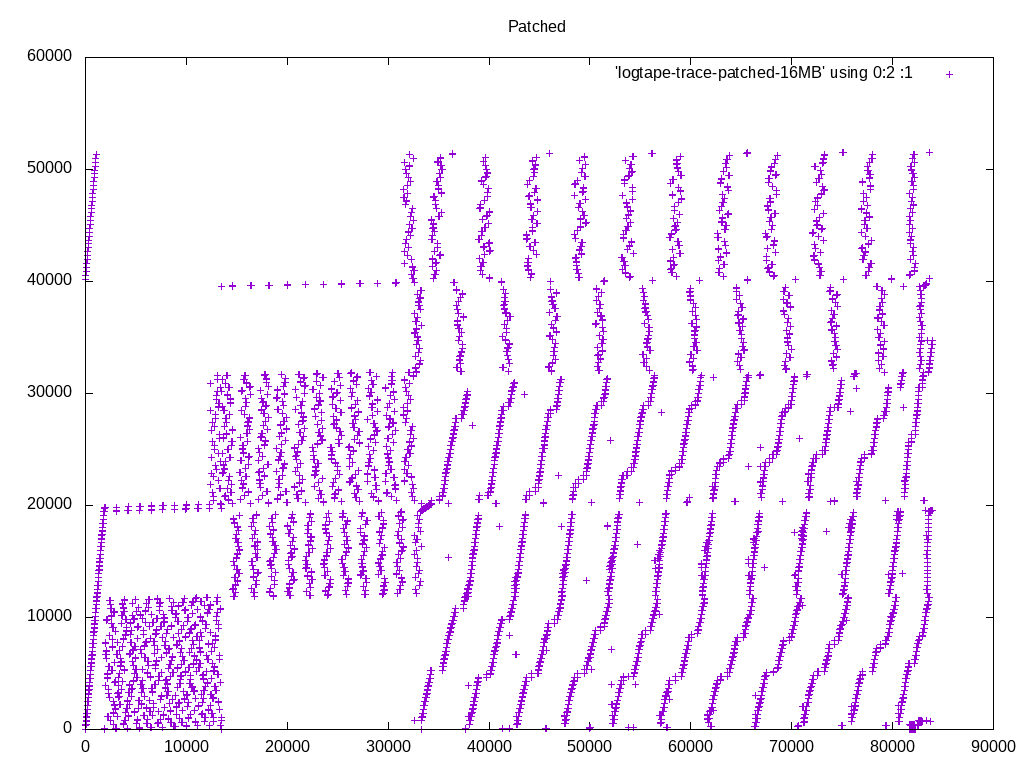
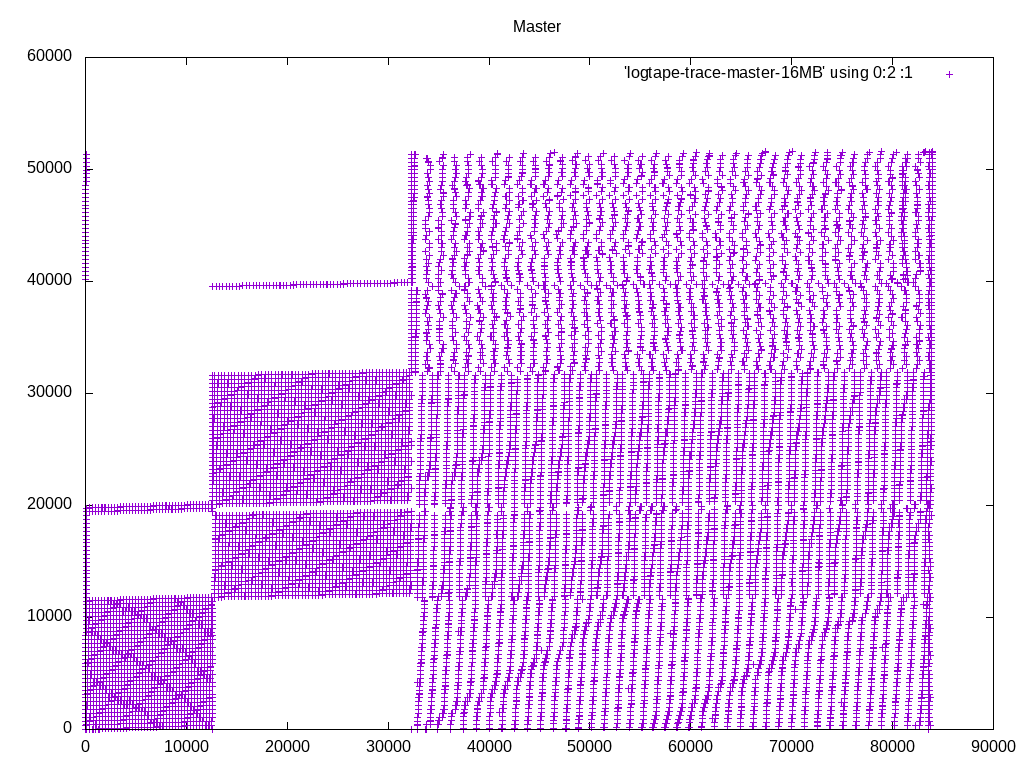
(Resending with compressed files, to get below the message size limit of the list) On 09/09/2016 02:13 PM, Heikki Linnakangas wrote: > On 09/08/2016 09:59 PM, Heikki Linnakangas wrote: >> On 09/06/2016 10:26 PM, Peter Geoghegan wrote: >>> On Tue, Sep 6, 2016 at 12:08 PM, Peter Geoghegan <pg@heroku.com> wrote: >>>> Offhand, I would think that taken together this is very important. I'd >>>> certainly want to see cases in the hundreds of megabytes or gigabytes >>>> of work_mem alongside your 4MB case, even just to be able to talk >>>> informally about this. As you know, the default work_mem value is very >>>> conservative. >> >> I spent some more time polishing this up, and also added some code to >> logtape.c, to use larger read buffers, to compensate for the fact that >> we don't do pre-reading from tuplesort.c anymore. That should trigger >> the OS read-ahead, and make the I/O more sequential, like was the >> purpose of the old pre-reading code. But simpler. I haven't tested that >> part much yet, but I plan to run some tests on larger data sets that >> don't fit in RAM, to make the I/O effects visible. > > Ok, I ran a few tests with 20 GB tables. I thought this would show any > differences in I/O behaviour, but in fact it was still completely CPU > bound, like the tests on smaller tables I posted yesterday. I guess I > need to point temp_tablespaces to a USB drive or something. But here we go. I took a different tact at demonstrating the I/O pattern effects. I added some instrumentation code to logtape.c, that prints a line to a file whenever it reads a block, with the block number. I ran the same query with master and with these patches, and plotted the access pattern with gnuplot. I'm happy with what it looks like. We are in fact getting a more sequential access pattern with these patches, because we're not expanding the pre-read tuples into SortTuples. Keeping densely-packed blocks in memory, instead of SortTuples, allows caching more data overall. Attached is the patch I used to generate these traces, the gnuplot script, and traces from I got from sorting a 1 GB table of random integers, with work_mem=16MB. Note that in the big picture, what appear to be individual dots, are actually clusters of a bunch of dots. So the access pattern is a lot more sequential than it looks like at first glance, with or without these patches. The zoomed-in pictures show that. If you want to inspect these in more detail, I recommend running gnuplot in interactive mode, so that you can zoom in and out easily. I'm happy with the amount of testing I've done now, and the results. Does anyone want to throw out any more test cases where there might be a regression? If not, let's get these reviewed and committed. - Heikki
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
On Fri, Sep 9, 2016 at 1:01 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > I'm happy with what it looks like. We are in fact getting a more sequential > access pattern with these patches, because we're not expanding the pre-read > tuples into SortTuples. Keeping densely-packed blocks in memory, instead of > SortTuples, allows caching more data overall. Wow, this is really cool. We should do something like this for query execution too. I still didn't follow exactly why removing the prefetching allows more sequential i/o. I thought the whole point of prefetching was to reduce the random i/o from switching tapes. -- greg
On 09/09/2016 03:25 PM, Greg Stark wrote: > On Fri, Sep 9, 2016 at 1:01 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> I'm happy with what it looks like. We are in fact getting a more sequential >> access pattern with these patches, because we're not expanding the pre-read >> tuples into SortTuples. Keeping densely-packed blocks in memory, instead of >> SortTuples, allows caching more data overall. > > > Wow, this is really cool. We should do something like this for query > execution too. > > I still didn't follow exactly why removing the prefetching allows more > sequential i/o. I thought the whole point of prefetching was to reduce > the random i/o from switching tapes. The first patch removed prefetching, but the second patch re-introduced it, in a different form. The prefetching is now done in logtape.c, by reading multiple pages at a time. The on-tape representation of tuples is more compact than having them in memory as SortTuples, so you can fit more data in memory overall, which makes the access pattern more sequential. There's one difference between these approaches that I didn't point out earlier: We used to prefetch tuples from each *run*, and stopped pre-reading when we reached the end of the run. Now that we're doing the prefetching as raw tape blocks, we don't stop at run boundaries. I don't think that makes any big difference one way or another, but I thought I'd mention it. - Heikki
On 09/09/2016 02:13 PM, Heikki Linnakangas wrote: > On 09/08/2016 09:59 PM, Heikki Linnakangas wrote: >> On 09/06/2016 10:26 PM, Peter Geoghegan wrote: >>> On Tue, Sep 6, 2016 at 12:08 PM, Peter Geoghegan <pg@heroku.com> wrote: >>>> Offhand, I would think that taken together this is very important. I'd >>>> certainly want to see cases in the hundreds of megabytes or gigabytes >>>> of work_mem alongside your 4MB case, even just to be able to talk >>>> informally about this. As you know, the default work_mem value is very >>>> conservative. >> >> I spent some more time polishing this up, and also added some code to >> logtape.c, to use larger read buffers, to compensate for the fact that >> we don't do pre-reading from tuplesort.c anymore. That should trigger >> the OS read-ahead, and make the I/O more sequential, like was the >> purpose of the old pre-reading code. But simpler. I haven't tested that >> part much yet, but I plan to run some tests on larger data sets that >> don't fit in RAM, to make the I/O effects visible. > > Ok, I ran a few tests with 20 GB tables. I thought this would show any > differences in I/O behaviour, but in fact it was still completely CPU > bound, like the tests on smaller tables I posted yesterday. I guess I > need to point temp_tablespaces to a USB drive or something. But here we go. I took a different tact at demonstrating the I/O pattern effects. I added some instrumentation code to logtape.c, that prints a line to a file whenever it reads a block, with the block number. I ran the same query with master and with these patches, and plotted the access pattern with gnuplot. I'm happy with what it looks like. We are in fact getting a more sequential access pattern with these patches, because we're not expanding the pre-read tuples into SortTuples. Keeping densely-packed blocks in memory, instead of SortTuples, allows caching more data overall. Attached is the patch I used to generate these traces, the gnuplot script, and traces from I got from sorting a 1 GB table of random integers, with work_mem=16MB. Note that in the big picture, what appear to be individual dots, are actually clusters of a bunch of dots. So the access pattern is a lot more sequential than it looks like at first glance, with or without these patches. The zoomed-in pictures show that. If you want to inspect these in more detail, I recommend running gnuplot in interactive mode, so that you can zoom in and out easily. I'm happy with the amount of testing I've done now, and the results. Does anyone want to throw out any more test cases where there might be a regression? If not, let's get these reviewed and committed. - Heikki
Attachment
{kind=link}
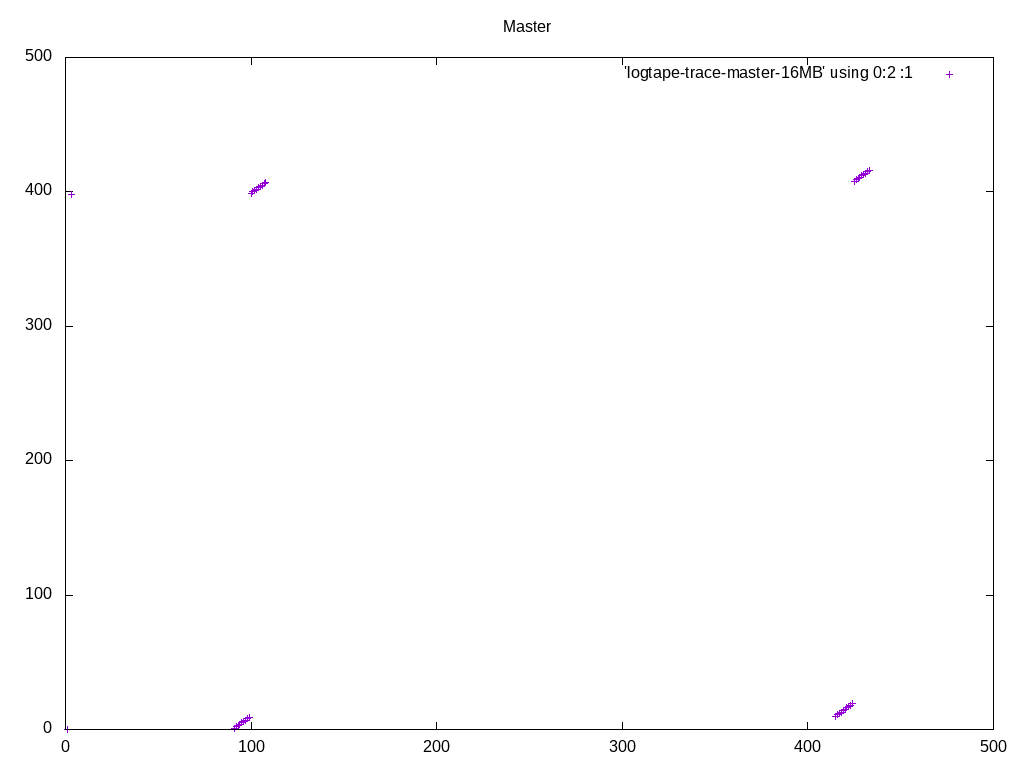{kind=link}
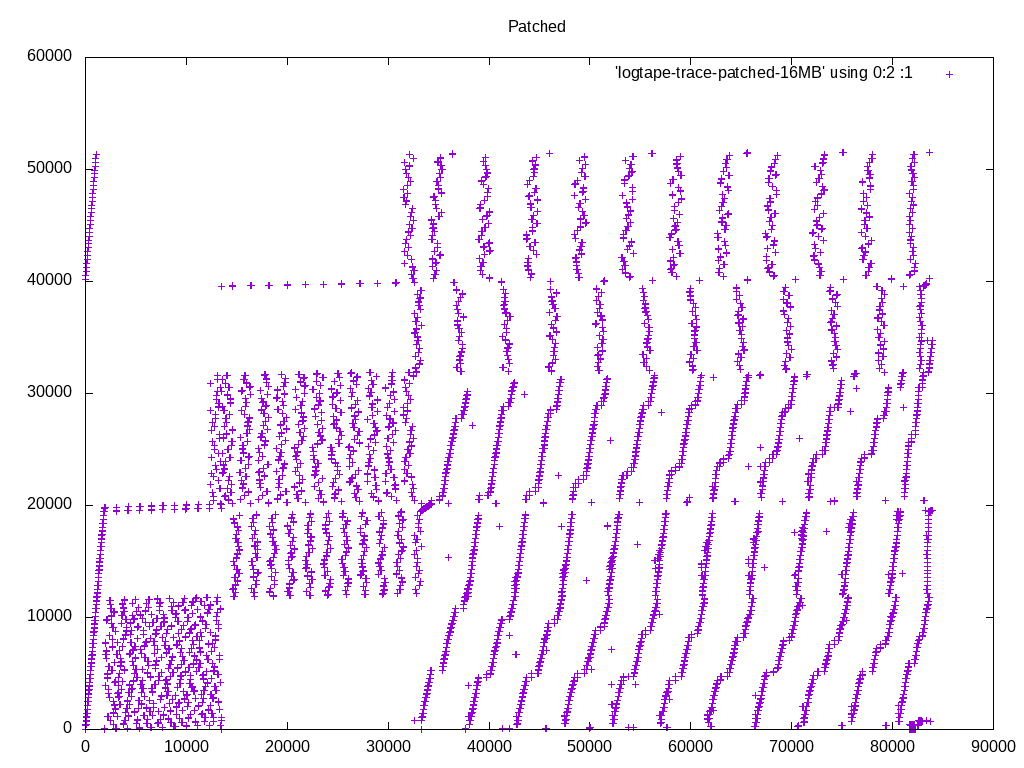{kind=link}
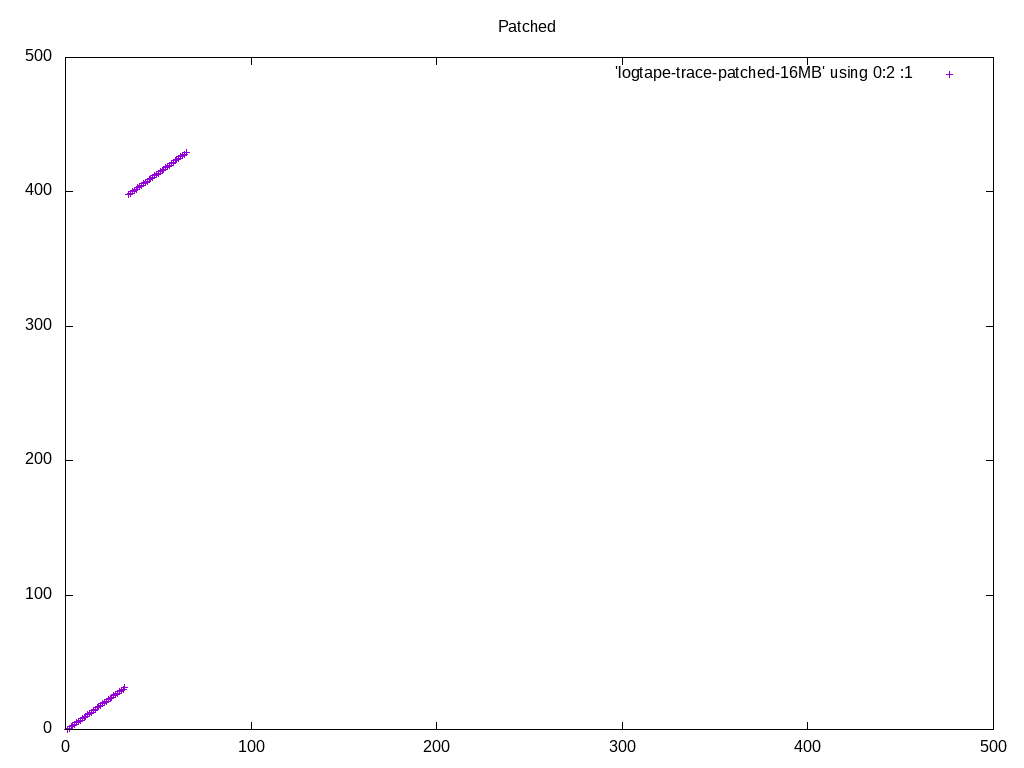{kind=link}
On Fri, Sep 9, 2016 at 4:55 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > I'm happy with the amount of testing I've done now, and the results. Does > anyone want to throw out any more test cases where there might be a > regression? If not, let's get these reviewed and committed. I'll try to look at this properly tomorrow. Currently still working away at creating a new revision of my sorting patchset. Obviously this is interesting, but it raises certain questions for the parallel CREATE INDEX patch in particular that I'd like to get straight, aside from everything else. I've been using an AWS d2.4xlarge instance for testing all my recent sort patches, with 16 vCPUs, 122 GiB RAM, 12 x 2 TB disks. It worked well to emphasize I/O throughput and parallelism over latency. I'd like to investigate how this pre-reading stuff does there. I recall that for one very large case, it took a full minute to do just the first round of preloading during the leader's final merge (this was with something like 50GB of maintenance_work_mem). So, it will be interesting. BTW, noticed a typo here: > + * track memory usage of indivitual tuples. -- Peter Geoghegan
On Fri, Sep 9, 2016 at 5:25 AM, Greg Stark <stark@mit.edu> wrote: > Wow, this is really cool. We should do something like this for query > execution too. We should certainly do this for tuplestore.c, too. I've been meaning to adopt it to use batch memory. I did look at it briefly, and recall that it was surprisingly awkward because a surprisingly large number of callers want to have memory that they can manage independently of the lifetime of their tuplestore. -- Peter Geoghegan
On Fri, Sep 9, 2016 at 8:13 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > > Claudio, if you could also repeat the tests you ran on Peter's patch set on > the other thread, with these patches, that'd be nice. These patches are > effectively a replacement for > 0002-Use-tuplesort-batch-memory-for-randomAccess-sorts.patch. And review > would be much appreciated too, of course. > > Attached are new versions. Compared to last set, they contain a few comment > fixes, and a change to the 2nd patch to not allocate tape buffers for tapes > that were completely unused. Will do so
On Fri, Sep 9, 2016 at 9:51 PM, Claudio Freire <klaussfreire@gmail.com> wrote: > On Fri, Sep 9, 2016 at 8:13 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> >> Claudio, if you could also repeat the tests you ran on Peter's patch set on >> the other thread, with these patches, that'd be nice. These patches are >> effectively a replacement for >> 0002-Use-tuplesort-batch-memory-for-randomAccess-sorts.patch. And review >> would be much appreciated too, of course. >> >> Attached are new versions. Compared to last set, they contain a few comment >> fixes, and a change to the 2nd patch to not allocate tape buffers for tapes >> that were completely unused. > > > Will do so It seems both 1 and 1+2 break make check. Did I misunderstand something? I'm applying the first patch of Peter's series (cap number of tapes), then your first one (remove prefetch) and second one (use larger read buffers). Peter's patch needs some rebasing on top of those but nothing major.
On 09/10/2016 04:21 AM, Claudio Freire wrote: > On Fri, Sep 9, 2016 at 9:51 PM, Claudio Freire <klaussfreire@gmail.com> wrote: >> On Fri, Sep 9, 2016 at 8:13 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >>> >>> Claudio, if you could also repeat the tests you ran on Peter's patch set on >>> the other thread, with these patches, that'd be nice. These patches are >>> effectively a replacement for >>> 0002-Use-tuplesort-batch-memory-for-randomAccess-sorts.patch. And review >>> would be much appreciated too, of course. >>> >>> Attached are new versions. Compared to last set, they contain a few comment >>> fixes, and a change to the 2nd patch to not allocate tape buffers for tapes >>> that were completely unused. >> >> Will do so Thanks! > It seems both 1 and 1+2 break make check. Oh. Works for me. What's the failure you're getting? > Did I misunderstand something? I'm applying the first patch of Peter's > series (cap number of tapes), then your first one (remove prefetch) > and second one (use larger read buffers). Yes. I have been testing without Peter's first patch, with just the two patches I posted. But it should work together (and does, I just tested) with that one as well. - Heikki
On Sat, Sep 10, 2016 at 12:04 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> Did I misunderstand something? I'm applying the first patch of Peter's >> series (cap number of tapes), then your first one (remove prefetch) >> and second one (use larger read buffers). > > > Yes. I have been testing without Peter's first patch, with just the two > patches I posted. But it should work together (and does, I just tested) with > that one as well. You're going to need to rebase, since the root displace patch is based on top of my patch 0002-*, not Heikki's alternative. But, that should be very straightforward. -- Peter Geoghegan
Here's a new version of these patches, rebased over current master. I squashed the two patches into one, there's not much point to keep them separate. - Heikki
Attachment
On Sun, Sep 11, 2016 at 8:47 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote:
> Here's a new version of these patches, rebased over current master. I
> squashed the two patches into one, there's not much point to keep them
> separate.
I think I have my head fully around this now. For some reason, I
initially thought that this patch was a great deal more radical than
it actually is. (Like Greg, I somehow initially thought that you were
rejecting the idea of batch memory in general, and somehow (over)
leveraging the filesystem cache. I think I misunderstood your remarks
when we talked on IM about it early on.)
I don't know what the difference is between accessing 10 pages
randomly, and accessing a random set of 10 single pages sequentially,
in close succession. As Tom would say, that's above my pay grade. I
suppose it comes down to how close "close" actually is (but in any
case, it's all very fudged).
I mention this because I think that cost_sort() should be updated to
consider sequential I/O the norm, alongside this patch of yours (your
patch strengthens the argument [1] for that general idea). The reason
that this new approach produces more sequential I/O, apart from the
simple fact that you effectively have much more memory available and
so fewer rounds of preloading, is that the indirection block stuff can
make I/O less sequential in order to support eager reclamation of
space. For example, maybe there is interleaving of blocks as logtape.c
manages to reclaim blocks in the event of multiple merge steps. I care
about that second factor a lot more now than I would have a year ago,
when a final on-the-fly merge generally avoids multiple passes (and
associated logtape.c block fragmentation), because parallel CREATE
INDEX is usually affected by that (workers will often want to do their
own merge ahead of the leader's final merge), and because I want to
cap the number of tapes used, which will make multiple passes a bit
more common in practice.
I was always suspicious of the fact that memtuples is so large during
merging, and had a vague plan to fix that (although I was the one
responsible for growing memtuples even more for the merge in 9.6, that
was just because under the status quo of having many memtuples during
the merge, the size of memtuples should at least be in balance with
remaining memory for caller tuples -- it wasn't an endorsement of the
status quo). However, it never occurred to me to do that by pushing
batch memory into the head of logtape.c, which now seems like an
excellent idea.
To summarize my understanding of this patch: If it wasn't for my work
on parallel CREATE INDEX, I would consider this patch to give us only
a moderate improvement to user-visible performance, since it doesn't
really help memory rich cases very much (cases that are not likely to
have much random I/O anyway). In that universe, I'd be more
appreciative of the patch as a simplifying exercise, since while
refactoring. It's nice to get a boost for more memory constrained
cases, it's not a huge win. However, that's not the universe we live
in -- I *am* working on parallel CREATE INDEX, of course. And so, I
really am very excited about this patch, because it really helps with
the particular challenges I have there, even though it's fair to
assume that we have a reasonable amount of memory available when
parallelism is used. If workers are going to do their own merges, as
they often will, then multiple merge pass cases become far more
important, and any additional I/O is a real concern, *especially*
additional random I/O (say from logtape.c fragmentation). The patch
directly addresses that, which is great. Your patch, alongside my
just-committed patch concerning how we maintain the heap invariant,
together attack the merge bottleneck from two different directions:
they address I/O costs, and CPU costs, respectively.
Other things I noticed:
* You should probably point out that typically, access to batch memory
will still be sequential, despite your block-based scheme. The
preloading will now more or less make that the normal case. Any
fragmentation will now be essentially in memory, not on disk, which is
a big win.
* I think that logtape.c header comments are needed for this. Maybe
that's where you should point out that memory access is largely
sequential. But it's surely true that logtape.c needs to take
responsibility for being the place where the vast majority of memory
is allocated during merging.
* i think you should move "bool *mergeactive; /* active input run
source? */" within Tuplesortstate to be next to the other batch memory
stuff. No point in having separate merge and batch "sections" there
anymore.
* You didn't carry over my 0002-* batch memory patch modifications to
comments, even though you should have in a few cases. There remains
some references in comments to batch memory, as a thing exclusively
usable by final on-the-fly merges. That's not true anymore -- it's
usable by final merges, too. For example, readtup_alloc() still
references the final on-the-fly merge.
* You also fail to take credit in the commit message for making batch
memory usable when returning caller tuples to callers that happen to
request "randomAccess" (So, I guess the aforementioned comments above
routines like readtup_alloc() shouldn't even refer to merging, unless
it's to say that non-final merges are not supported due to their
unusual requirements). My patch didn't go that far (I only addressed
the final merge itself, not the subsequent access to tuples when
reading from that materialized final output tape by TSS_SORTEDONTAPE
case). But, that's actually really useful for randomAccess callers,
above and beyond what I proposed (which in any case was mostly written
with parallel workers in mind, which never do TSS_SORTEDONTAPE
processing).
* Furthermore, readtup_alloc() will not just be called in WRITETUP()
routines -- please update comments.
* There is a very subtle issue here:
> + /*
> + * We no longer need a large memtuples array, only one slot per tape. Shrink
> + * it, to make the memory available for other use. We only need one slot per
> + * tape.
> + */
> + pfree(state->memtuples);
> + FREEMEM(state, state->memtupsize * sizeof(SortTuple));
> + state->memtupsize = state->maxTapes;
> + state->memtuples = (SortTuple *) palloc(state->maxTapes * sizeof(SortTuple));
> + USEMEM(state, state->memtupsize * sizeof(SortTuple));
The FREEMEM() call needs to count the chunk overhead in both cases. In
short, I think you need to copy the GetMemoryChunkSpace() stuff that
you see within grow_memtuples().
* Whitespace issue here:
> @@ -2334,7 +2349,8 @@ inittapes(Tuplesortstate *state)
> #endif
>
> /*
> - * Decrease availMem to reflect the space needed for tape buffers; but
> + * Decrease availMem to reflect the space needed for tape buffers, when
> + * writing the initial runs; but
> * don't decrease it to the point that we have no room for tuples. (That
> * case is only likely to occur if sorting pass-by-value Datums; in all
> * other scenarios the memtuples[] array is unlikely to occupy more than
> @@ -2359,14 +2375,6 @@ inittapes(Tuplesortstate *state)
> state->tapeset = LogicalTapeSetCreate(maxTapes);
* I think that you need to comment on why state->tuplecontext is not
used for batch memory now. It is still useful, for multiple merge
passes, but the situation has notably changed for it.
* Doesn't this code need to call MemoryContextAllocHuge() rather than palloc()?:
> @@ -709,18 +765,19 @@ LogicalTapeRewind(LogicalTapeSet *lts, int tapenum, bool forWrite)
> Assert(lt->frozen);
> datablocknum = ltsRewindFrozenIndirectBlock(lts, lt->indirect);
> }
> +
> + /* Allocate a read buffer */
> + if (lt->buffer)
> + pfree(lt->buffer);
> + lt->buffer = palloc(lt->read_buffer_size);
> + lt->buffer_size = lt->read_buffer_size;
* Typo:
> +
> + /*
> + * from this point on, we no longer use the usemem()/lackmem() mechanism to
> + * track memory usage of indivitual tuples.
> + */
> + state->batchused = true;
* Please make this use the ".., + 1023" natural rounding trick that is
used in the similar traces that are removed:
> +#ifdef TRACE_SORT
> + if (trace_sort)
> + elog(LOG, "using %d kB of memory for read buffers in %d tapes, %d kB per tape",
> + (int) (state->availMem / 1024), maxTapes, (int) (per_tape * BLCKSZ) / 1024);
> +#endif
* It couldn't hurt to make this code paranoid about LACKMEM() becoming
true, which will cause havoc (we saw this recently in 9.6; a patch of
mine to fix that just went in):
> + /*
> + * Use all the spare memory we have available for read buffers. Divide it
> + * memory evenly among all the tapes.
> + */
> + avail_blocks = state->availMem / BLCKSZ;
> + per_tape = avail_blocks / maxTapes;
> + cutoff = avail_blocks % maxTapes;
> + if (per_tape == 0)
> + {
> + per_tape = 1;
> + cutoff = 0;
> + }
> + for (tapenum = 0; tapenum < maxTapes; tapenum++)
> + {
> + LogicalTapeAssignReadBufferSize(state->tapeset, tapenum,
> + (per_tape + (tapenum < cutoff ? 1 : 0)) * BLCKSZ);
> + }
In other words, we really don't want availMem to become < 0, since
it's int64, but a derived value is passed to
LogicalTapeAssignReadBufferSize() as an argument of type "Size". Now,
if LACKMEM() did happen it would be a bug anyway, but I recommend
defensive code also be added. Per grow_memtuples(), "We need to be
sure that we do not cause LACKMEM to become true, else the space
management algorithm will go nuts". Let's be sure that we get that
right, since, as we saw recently, especially since grow_memtuples()
will not actually have the chance to save us here (if there is a bug
along these lines, let's at least make the right "can't happen error"
complaint to user when it pops up).
* It looks like your patch makes us less eager about freeing per-tape
batch memory, now held as preload buffer space within logtape.c.
ISTM that there should be some way to have the "tape exhausted" code
path within tuplesort_gettuple_common() (as well as the similar spot
within mergeonerun()) instruct logtape.c that we're done with that
tape. In other words, when mergeprereadone() (now renamed to
mergereadnext()) detects the tape is exhausted, it should have
logtape.c free its huge tape buffer immediately. Think about cases
where input is presorted, and earlier tapes can be freed quite early
on. It's worth keeping that around, (you removed the old way that this
happened, through mergebatchfreetape()).
That's all I have right now. I like the direction this is going in,
but I think this needs more polishing.
[1] https://www.postgresql.org/message-id/CAM3SWZQLP6e=1si1NcQjYft7R-VYpprrf_i59tZOZX5m7VFK-w@mail.gmail.com
--
Peter Geoghegan
On Sun, Sep 11, 2016 at 3:13 PM, Peter Geoghegan <pg@heroku.com> wrote: > * Please make this use the ".., + 1023" natural rounding trick that is > used in the similar traces that are removed: > >> +#ifdef TRACE_SORT >> + if (trace_sort) >> + elog(LOG, "using %d kB of memory for read buffers in %d tapes, %d kB per tape", >> + (int) (state->availMem / 1024), maxTapes, (int) (per_tape * BLCKSZ) / 1024); >> +#endif Also, please remove the int cast, and use INT64_FORMAT. Again, this should match existing trace_sort traces concerning batch memory. -- Peter Geoghegan
On Sun, Sep 11, 2016 at 3:13 PM, Peter Geoghegan <pg@heroku.com> wrote: > * Doesn't this code need to call MemoryContextAllocHuge() rather than palloc()?: > >> @@ -709,18 +765,19 @@ LogicalTapeRewind(LogicalTapeSet *lts, int tapenum, bool forWrite) >> Assert(lt->frozen); >> datablocknum = ltsRewindFrozenIndirectBlock(lts, lt->indirect); >> } >> + >> + /* Allocate a read buffer */ >> + if (lt->buffer) >> + pfree(lt->buffer); >> + lt->buffer = palloc(lt->read_buffer_size); >> + lt->buffer_size = lt->read_buffer_size; Of course, when you do that you're going to have to make the new "buffer_size" and "read_buffer_size" fields of type "Size" (or, possibly, "int64", to match tuplesort.c's own buffer sizing variables ever since Noah added MaxAllocSizeHuge). Ditto for the existing "pos" and "nbytes" fields next to "buffer_size" within the struct LogicalTape, I think. ISTM that logtape.c blocknums can remain of type "long", though, since that reflects an existing hardly-relevant limitation that you're not making any worse. More generally, I think you also need to explain in comments why there is a "read_buffer_size" field in addition to the "buffer_size" field. -- Peter Geoghegan
On Sun, Sep 11, 2016 at 3:13 PM, Peter Geoghegan <pg@heroku.com> wrote:
>> + for (tapenum = 0; tapenum < maxTapes; tapenum++)
>> + {
>> + LogicalTapeAssignReadBufferSize(state->tapeset, tapenum,
>> + (per_tape + (tapenum < cutoff ? 1 : 0)) * BLCKSZ);
>> + }
Spotted another issue with this code just now. Shouldn't it be based
on state->tapeRange? You don't want the destTape to get memory, since
you don't use batch memory for tapes that are written to (and final
on-the-fly merges don't use their destTape at all).
(Looks again...)
Wait, you're using a local variable maxTapes here, which potentially
differs from state->maxTapes:
> + /*
> + * If we had fewer runs than tapes, refund buffers for tapes that were never
> + * allocated.
> + */
> + maxTapes = state->maxTapes;
> + if (state->currentRun < maxTapes)
> + {
> + FREEMEM(state, (maxTapes - state->currentRun) * TAPE_BUFFER_OVERHEAD);
> + maxTapes = state->currentRun;
> + }
I find this confusing, and think it's probably buggy. I don't think
you should have a local variable called maxTapes that you modify at
all, since state->maxTapes is supposed to not change once established.
You can't use state->currentRun like that, either, I think, because
it's the high watermark number of runs (quicksorted runs), not runs
after any particular merge phase, where we end up with fewer runs as
they're merged (we must also consider dummy runs to get this) -- we
want something like activeTapes. cf. the code you removed for the
beginmerge() finalMergeBatch case. Of course, activeTapes will vary if
there are multiple merge passes, which suggests all this code really
has no business being in mergeruns() (it should instead be in
beginmerge(), or code that beginmerge() reliably calls).
Immediately afterwards, you do this:
> + /* Initialize the merge tuple buffer arena. */
> + state->batchMemoryBegin = palloc((maxTapes + 1) * MERGETUPLEBUFFER_SIZE);
> + state->batchMemoryEnd = state->batchMemoryBegin + (maxTapes + 1) * MERGETUPLEBUFFER_SIZE;
> + state->freeBufferHead = (MergeTupleBuffer *) state->batchMemoryBegin;
> + USEMEM(state, (maxTapes + 1) * MERGETUPLEBUFFER_SIZE);
The fact that you size the buffer based on "maxTapes + 1" also
suggests a problem. I think that the code looks like this because it
must instruct logtape.c that the destTape tape requires some buffer
(iff there is to be a non-final merge). Is that right? I hope that you
don't give the typically unused destTape tape a full share of batch
memory all the time (the same applies to any other
inactive-at-final-merge tapes).
--
Peter Geoghegan
On 12/09/16 10:13, Peter Geoghegan wrote: > On Sun, Sep 11, 2016 at 8:47 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: [...] > I don't know what the difference is between accessing 10 pages > randomly, and accessing a random set of 10 single pages sequentially, > in close succession. As Tom would say, that's above my pay grade. I > suppose it comes down to how close "close" actually is (but in any > case, it's all very fudged). If you select ten pages at random and sort them, then consecutive reads of the sorted list are more likely to access pages in the same block or closely adjacent (is my understanding). eg blocks: XXXX XXXX XXXX XXXX XXXX pages: 0 1 2 3 4 5 6 7 8 9 if the ten 'random pages' were selected in the random order: 6 1 7 8 4 2 9 3 0 Consecutive reads would always read new blocks, but the sorted list would have blocks read sequentially. In practice, it would be rarely this simple. However, if any of the random pages where in the same block, then that block would only need to be fetched once - similarly if 2 of the random pages where in consecutive blocks, then the two blocks would be logically adjacent (which means they are likely to be physically close together, but not guaranteed!). [...] Cheers, Gavin
On 12/09/16 12:16, Gavin Flower wrote: [...] > two blocks would be logically adjacent (which means they are likely > to be physically close together, but not guaranteed!). > [...] Actual disk layouts are quite complicated, the above is an over simplification, but the message is still valid. There are various tricks of disc layout ( & low level handling) that can be used to minimise the time taken to read 2 blocks that are logically adjacent. I had to know this stuff for discs that MainFrame computers used in the 1980's - modern disk systems are way more complicated, but the conclusions are still valid. I am extremely glad that I no longer have to concern myself with understanding the precise low stuff on discs these days - there is no longer a one-to-one correspondence of what the O/S thinks is a disk block, with how the data is physically recorded on the disc. Cheers, Gavin
On Sun, Sep 11, 2016 at 12:47 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > Here's a new version of these patches, rebased over current master. I > squashed the two patches into one, there's not much point to keep them > separate. I don't know what was up with the other ones, but this one works fine. Benchmarking now.
On Mon, Sep 12, 2016 at 12:02 PM, Claudio Freire <klaussfreire@gmail.com> wrote: > On Sun, Sep 11, 2016 at 12:47 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> Here's a new version of these patches, rebased over current master. I >> squashed the two patches into one, there's not much point to keep them >> separate. > > > I don't know what was up with the other ones, but this one works fine. > > Benchmarking now. I spoke too soon, git AM had failed and I didn't notice. regression.diffs attached Built with ./configure --enable-debug --enable-cassert && make clean && make -j7 && make check
Attachment
On Mon, Sep 12, 2016 at 8:47 AM, Claudio Freire <klaussfreire@gmail.com> wrote: > I spoke too soon, git AM had failed and I didn't notice. I wrote the regression test that causes Postgres to crash with the patch applied. It tests, among other things, that CLUSTER tuples are fixed-up by a routine like the current MOVETUP(), which is removed in Heikki's patch. (There was a 9.6 bug where CLUSTER was broken due to that.) It shouldn't be too difficult for Heikki to fix this. -- Peter Geoghegan
On 09/12/2016 06:47 PM, Claudio Freire wrote: > On Mon, Sep 12, 2016 at 12:02 PM, Claudio Freire <klaussfreire@gmail.com> wrote: >> On Sun, Sep 11, 2016 at 12:47 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >>> Here's a new version of these patches, rebased over current master. I >>> squashed the two patches into one, there's not much point to keep them >>> separate. >> >> I don't know what was up with the other ones, but this one works fine. >> >> Benchmarking now. > > I spoke too soon, git AM had failed and I didn't notice. > > regression.diffs attached > > Built with > > ./configure --enable-debug --enable-cassert && make clean && make -j7 > && make check Ah, of course! I had been building without assertions, as I was doing performance testing. With --enable-cassert, it failed for me as well (and there was even a compiler warning pointing out one of the issues). Sorry about that. Here's a fixed version. I'll go through Peter's comments and address those, but I don't think there was anything there that should affect performance much, so I think you can proceed with your benchmarking with this version. (You'll also need to turn off assertions for that!) - Heikki
Attachment
On Mon, Sep 12, 2016 at 12:07 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > Here's a fixed version. I'll go through Peter's comments and address those, > but I don't think there was anything there that should affect performance > much, so I think you can proceed with your benchmarking with this version. > (You'll also need to turn off assertions for that!) I agree that it's unlikely that addressing any of my feedback will result in any major change to performance. -- Peter Geoghegan
Addressed all your comments one way or another, new patch attached.
Comments on some specific points below:
On 09/12/2016 01:13 AM, Peter Geoghegan wrote:
> Other things I noticed:
>
> * You should probably point out that typically, access to batch memory
> will still be sequential, despite your block-based scheme. The
> preloading will now more or less make that the normal case. Any
> fragmentation will now be essentially in memory, not on disk, which is
> a big win.
That's not true, the "buffers" in batch memory are not accessed
sequentially. When we pull the next tuple from a tape, we store it in
the next free buffer. Usually, that buffer was used to hold the previous
tuple that was returned from gettuple(), and was just added to the free
list.
It's still quite cache-friendly, though, because we only need a small
number of slots (one for each tape).
> * i think you should move "bool *mergeactive; /* active input run
> source? */" within Tuplesortstate to be next to the other batch memory
> stuff. No point in having separate merge and batch "sections" there
> anymore.
Hmm. I think I prefer to keep the memory management stuff in a separate
section. While it's true that it's currently only used during merging,
it's not hard to imagine using it when building the initial runs, for
example. Except for replacement selection, the pattern for building the
runs is: add a bunch of tuples, sort, flush them out. It would be
straightforward to use one large chunk of memory to hold all the tuples.
I'm not going to do that now, but I think keeping the memory management
stuff separate from merge-related state makes sense.
> * I think that you need to comment on why state->tuplecontext is not
> used for batch memory now. It is still useful, for multiple merge
> passes, but the situation has notably changed for it.
Hmm. We don't actually use it after the initial runs at all anymore. I
added a call to destroy it in mergeruns().
Now that we use the batch memory buffers for allocations < 1 kB (I
pulled that number out of a hat, BTW), and we only need one allocation
per tape (plus one), there's not much risk of fragmentation.
> On Sun, Sep 11, 2016 at 3:13 PM, Peter Geoghegan <pg@heroku.com> wrote:
>> * Doesn't this code need to call MemoryContextAllocHuge() rather than palloc()?:
>>
>>> @@ -709,18 +765,19 @@ LogicalTapeRewind(LogicalTapeSet *lts, int tapenum, bool forWrite)
>>> Assert(lt->frozen);
>>> datablocknum = ltsRewindFrozenIndirectBlock(lts, lt->indirect);
>>> }
>>> +
>>> + /* Allocate a read buffer */
>>> + if (lt->buffer)
>>> + pfree(lt->buffer);
>>> + lt->buffer = palloc(lt->read_buffer_size);
>>> + lt->buffer_size = lt->read_buffer_size;
>
> Of course, when you do that you're going to have to make the new
> "buffer_size" and "read_buffer_size" fields of type "Size" (or,
> possibly, "int64", to match tuplesort.c's own buffer sizing variables
> ever since Noah added MaxAllocSizeHuge). Ditto for the existing "pos"
> and "nbytes" fields next to "buffer_size" within the struct
> LogicalTape, I think. ISTM that logtape.c blocknums can remain of type
> "long", though, since that reflects an existing hardly-relevant
> limitation that you're not making any worse.
True. I fixed that by putting a MaxAllocSize cap on the buffer size
instead. I doubt that doing > 1 GB of read-ahead of a single tape will
do any good.
I wonder if we should actually have a smaller cap there. Even 1 GB seems
excessive. Might be better to start the merging sooner, rather than wait
for the read of 1 GB to complete. The point of the OS readahead is that
the OS will do that for us, in the background. And other processes might
have better use for the memory anyway.
> * It couldn't hurt to make this code paranoid about LACKMEM() becoming
> true, which will cause havoc (we saw this recently in 9.6; a patch of
> mine to fix that just went in):
>
>> + /*
>> + * Use all the spare memory we have available for read buffers. Divide it
>> + * memory evenly among all the tapes.
>> + */
>> + avail_blocks = state->availMem / BLCKSZ;
>> + per_tape = avail_blocks / maxTapes;
>> + cutoff = avail_blocks % maxTapes;
>> + if (per_tape == 0)
>> + {
>> + per_tape = 1;
>> + cutoff = 0;
>> + }
>> + for (tapenum = 0; tapenum < maxTapes; tapenum++)
>> + {
>> + LogicalTapeAssignReadBufferSize(state->tapeset, tapenum,
>> + (per_tape + (tapenum < cutoff ? 1 : 0)) * BLCKSZ);
>> + }
>
> In other words, we really don't want availMem to become < 0, since
> it's int64, but a derived value is passed to
> LogicalTapeAssignReadBufferSize() as an argument of type "Size". Now,
> if LACKMEM() did happen it would be a bug anyway, but I recommend
> defensive code also be added. Per grow_memtuples(), "We need to be
> sure that we do not cause LACKMEM to become true, else the space
> management algorithm will go nuts". Let's be sure that we get that
> right, since, as we saw recently, especially since grow_memtuples()
> will not actually have the chance to save us here (if there is a bug
> along these lines, let's at least make the right "can't happen error"
> complaint to user when it pops up).
Hmm. We don't really need the availMem accounting at all, after we have
started merging. There is nothing we can do to free memory if we run
out, and we use fairly little memory anyway. But yes, better safe than
sorry. I tried to clarify the comments on that.
> * It looks like your patch makes us less eager about freeing per-tape
> batch memory, now held as preload buffer space within logtape.c.
>
> ISTM that there should be some way to have the "tape exhausted" code
> path within tuplesort_gettuple_common() (as well as the similar spot
> within mergeonerun()) instruct logtape.c that we're done with that
> tape. In other words, when mergeprereadone() (now renamed to
> mergereadnext()) detects the tape is exhausted, it should have
> logtape.c free its huge tape buffer immediately. Think about cases
> where input is presorted, and earlier tapes can be freed quite early
> on. It's worth keeping that around, (you removed the old way that this
> happened, through mergebatchfreetape()).
OK. I solved that by calling LogicalTapeRewind(), when we're done
reading a tape. Rewinding a tape has the side-effect of freeing the
buffer. I was going to put that into mergereadnext(), but it turns out
that it's tricky to figure out if there are any more runs on the same
tape, because we have the "actual" tape number there, but the tp_runs is
indexed by "logical" tape number. So I put the rewind calls at the end
of mergeruns(), and in TSS_FINALMERGE processing, instead. It means that
we don't free the buffers quite as early as we could, but I think this
is good enough.
> On Sun, Sep 11, 2016 at 3:13 PM, Peter Geoghegan <pg@heroku.com> wrote:
>>> + for (tapenum = 0; tapenum < maxTapes; tapenum++)
>>> + {
>>> + LogicalTapeAssignReadBufferSize(state->tapeset, tapenum,
>>> + (per_tape + (tapenum < cutoff ? 1 : 0)) * BLCKSZ);
>>> + }
>
> Spotted another issue with this code just now. Shouldn't it be based
> on state->tapeRange? You don't want the destTape to get memory, since
> you don't use batch memory for tapes that are written to (and final
> on-the-fly merges don't use their destTape at all).
logtape.c will only actually allocate the memory when reading.
> (Looks again...)
>
> Wait, you're using a local variable maxTapes here, which potentially
> differs from state->maxTapes:
>
>> + /*
>> + * If we had fewer runs than tapes, refund buffers for tapes that were never
>> + * allocated.
>> + */
>> + maxTapes = state->maxTapes;
>> + if (state->currentRun < maxTapes)
>> + {
>> + FREEMEM(state, (maxTapes - state->currentRun) * TAPE_BUFFER_OVERHEAD);
>> + maxTapes = state->currentRun;
>> + }
>
> I find this confusing, and think it's probably buggy. I don't think
> you should have a local variable called maxTapes that you modify at
> all, since state->maxTapes is supposed to not change once established.
I changed that so that it does actually change state->maxTapes. I
considered having a separate numTapes field, that can be smaller than
maxTapes, but we don't need the original maxTapes value after that point
anymore, so it would've been just pro forma to track them separately. I
hope the comment now explains that better.
> You can't use state->currentRun like that, either, I think, because
> it's the high watermark number of runs (quicksorted runs), not runs
> after any particular merge phase, where we end up with fewer runs as
> they're merged (we must also consider dummy runs to get this) -- we
> want something like activeTapes. cf. the code you removed for the
> beginmerge() finalMergeBatch case. Of course, activeTapes will vary if
> there are multiple merge passes, which suggests all this code really
> has no business being in mergeruns() (it should instead be in
> beginmerge(), or code that beginmerge() reliably calls).
Hmm, yes, using currentRun here is wrong. It needs to be "currentRun +
1", because we need one more tape than there are runs, to hold the output.
Note that I'm not re-allocating the read buffers depending on which
tapes are used in the current merge pass. I'm just dividing up the
memory among all tapes. Now that the pre-reading is done in logtape.c,
when we reach the end of a run on a tape, we will already have data from
the next run on the same tape in the read buffer.
> Immediately afterwards, you do this:
>
>> + /* Initialize the merge tuple buffer arena. */
>> + state->batchMemoryBegin = palloc((maxTapes + 1) * MERGETUPLEBUFFER_SIZE);
>> + state->batchMemoryEnd = state->batchMemoryBegin + (maxTapes + 1) * MERGETUPLEBUFFER_SIZE;
>> + state->freeBufferHead = (MergeTupleBuffer *) state->batchMemoryBegin;
>> + USEMEM(state, (maxTapes + 1) * MERGETUPLEBUFFER_SIZE);
>
> The fact that you size the buffer based on "maxTapes + 1" also
> suggests a problem. I think that the code looks like this because it
> must instruct logtape.c that the destTape tape requires some buffer
> (iff there is to be a non-final merge). Is that right? I hope that you
> don't give the typically unused destTape tape a full share of batch
> memory all the time (the same applies to any other
> inactive-at-final-merge tapes).
Ah, no, the "+ 1" comes from the need to hold the tuple that we last
returned to the caller in tuplesort_gettuple, until the next call. See
lastReturnedTuple. I tried to clarify the comments on that.
Thanks for the thorough review! Let me know how this looks now.
- Heikki
Attachment
On Wed, Sep 14, 2016 at 10:43 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > Addressed all your comments one way or another, new patch attached. Comments > on some specific points below: Cool. My response here is written under time pressure, which is not ideal. I think it's still useful, though. >> * You should probably point out that typically, access to batch memory >> will still be sequential, despite your block-based scheme. > That's not true, the "buffers" in batch memory are not accessed > sequentially. When we pull the next tuple from a tape, we store it in the > next free buffer. Usually, that buffer was used to hold the previous tuple > that was returned from gettuple(), and was just added to the free list. > > It's still quite cache-friendly, though, because we only need a small number > of slots (one for each tape). That's kind of what I meant, I think -- it's more or less sequential. Especially in the common case where there is only one merge pass. > True. I fixed that by putting a MaxAllocSize cap on the buffer size instead. > I doubt that doing > 1 GB of read-ahead of a single tape will do any good. You may well be right about that, but ideally that could be verified. I think that the tuplesort is entitled to have whatever memory the user makes available, unless that's almost certainly useless. It doesn't seem like our job to judge that it's always wrong to use extra memory with only a small expected benefit. If it's actually a microscopic expected benefit, or just as often negative to the sort operation's performance, then I'd say it's okay to cap it at MaxAllocSize. But it's not obvious to me that this is true; not yet, anyway. > Hmm. We don't really need the availMem accounting at all, after we have > started merging. There is nothing we can do to free memory if we run out, > and we use fairly little memory anyway. But yes, better safe than sorry. I > tried to clarify the comments on that. It is true that we don't really care about the accounting at all. But, the same applies to the existing grow_memtuples() case at the beginning of merging. The point is, we *do* care about availMem, this one last time. We must at least produce a sane (i.e. >= 0) number in any calculation. (I think you understand this already -- just saying.) > OK. I solved that by calling LogicalTapeRewind(), when we're done reading a > tape. Rewinding a tape has the side-effect of freeing the buffer. I was > going to put that into mergereadnext(), but it turns out that it's tricky to > figure out if there are any more runs on the same tape, because we have the > "actual" tape number there, but the tp_runs is indexed by "logical" tape > number. So I put the rewind calls at the end of mergeruns(), and in > TSS_FINALMERGE processing, instead. It means that we don't free the buffers > quite as early as we could, but I think this is good enough. That seems adequate. >> Spotted another issue with this code just now. Shouldn't it be based >> on state->tapeRange? You don't want the destTape to get memory, since >> you don't use batch memory for tapes that are written to (and final >> on-the-fly merges don't use their destTape at all). >> Wait, you're using a local variable maxTapes here, which potentially >> differs from state->maxTapes: > I changed that so that it does actually change state->maxTapes. I considered > having a separate numTapes field, that can be smaller than maxTapes, but we > don't need the original maxTapes value after that point anymore, so it > would've been just pro forma to track them separately. I hope the comment > now explains that better. I still don't get why you're doing all of this within mergeruns() (the beginning of when we start merging -- we merge all quicksorted runs), rather than within beginmerge() (the beginning of one particular merge pass, of which there are potentially more than one). As runs are merged in a non-final merge pass, fewer tapes will remain active for the next merge pass. It doesn't do to do all that up-front when we have multiple merge passes, which will happen from time to time. Correct me if I'm wrong, but I think that you're more skeptical of the need for polyphase merge than I am. I at least see no reason to not keep it around. I also think it has some value. It doesn't make this optimization any harder, really. > Hmm, yes, using currentRun here is wrong. It needs to be "currentRun + 1", > because we need one more tape than there are runs, to hold the output. As I said, I think it should be the number of active tapes, as you see today within beginmerge() + mergebatch(). Why not do it that way? If you don't get the distinction, see my remarks below on final merges always using batch memory, even when there are to be multiple merge passes (no reason to add that restriction here). More generally, I really don't want to mess with the long standing definition of maxTapes and things like that, because I see no advantage. > Ah, no, the "+ 1" comes from the need to hold the tuple that we last > returned to the caller in tuplesort_gettuple, until the next call. See > lastReturnedTuple. I tried to clarify the comments on that. I see. I don't think that you need to do any of that. Just have the sizing be based on an even share among activeTapes on final merges (not necessarily final on-the-fly merges, per my 0002-* patch -- you've done that here, it looks like). However, It looks like you're doing the wrong thing by only having the check at the top of beginmerge() -- "if (state->Level == 1)". You're not going to use batch memory for the final merge just because there happened to be multiple merges, that way. Sure, you shouldn't be using batch memory for non-final merges (due to their need for an uneven amount of memory per active tape), which you're not doing, but the mere fact that you had a non-final merge should not affect the final merge at all. Which is the kind of thing I'm concerned about when I talk about beginmerge() being the right place for all that new code (not mergeruns()). Even if you can make it work, it fits a lot better to put it in beginmerge() -- that's the existing flow of things, which should be preserved. I don't think you need to examine "state->Level" or "state->currentRun" at all. Did you do it this way to make the "replacement selection best case" stuff within mergeruns() catch on, so it does the right thing during its TSS_SORTEDONTAPE processing? Thanks -- Peter Geoghegan
On 09/15/2016 10:12 PM, Peter Geoghegan wrote: > On Wed, Sep 14, 2016 at 10:43 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >>> Spotted another issue with this code just now. Shouldn't it be based >>> on state->tapeRange? You don't want the destTape to get memory, since >>> you don't use batch memory for tapes that are written to (and final >>> on-the-fly merges don't use their destTape at all). > >>> Wait, you're using a local variable maxTapes here, which potentially >>> differs from state->maxTapes: > >> I changed that so that it does actually change state->maxTapes. I considered >> having a separate numTapes field, that can be smaller than maxTapes, but we >> don't need the original maxTapes value after that point anymore, so it >> would've been just pro forma to track them separately. I hope the comment >> now explains that better. > > I still don't get why you're doing all of this within mergeruns() (the > beginning of when we start merging -- we merge all quicksorted runs), > rather than within beginmerge() (the beginning of one particular merge > pass, of which there are potentially more than one). As runs are > merged in a non-final merge pass, fewer tapes will remain active for > the next merge pass. It doesn't do to do all that up-front when we > have multiple merge passes, which will happen from time to time. Now that the pre-reading is done in logtape.c, it doesn't stop at a run boundary. For example, when we read the last 1 MB of the first run on a tape, and we're using a 10 MB read buffer, we will merrily also read the first 9 MB from the next run. You cannot un-read that data, even if the tape is inactive in the next merge pass. I don't think it makes much difference in practice, because most merge passes use all, or almost all, of the available tapes. BTW, I think the polyphase algorithm prefers to do all the merges that don't use all tapes upfront, so that the last final merge always uses all the tapes. I'm not 100% sure about that, but that's my understanding of the algorithm, and that's what I've seen in my testing. > Correct me if I'm wrong, but I think that you're more skeptical of the > need for polyphase merge than I am. I at least see no reason to not > keep it around. I also think it has some value. It doesn't make this > optimization any harder, really. We certainly still need multi-pass merges. BTW, does a 1-way merge make any sense? I was surprised to see this in the log, even without this patch: LOG: finished 1-way merge step: CPU 0.62s/7.22u sec elapsed 8.43 sec STATEMENT: SELECT COUNT(*) FROM (SELECT * FROM medium.random_ints ORDER BY i) t; LOG: finished 1-way merge step: CPU 0.62s/7.22u sec elapsed 8.43 sec STATEMENT: SELECT COUNT(*) FROM (SELECT * FROM medium.random_ints ORDER BY i) t; LOG: finished 1-way merge step: CPU 0.62s/7.22u sec elapsed 8.43 sec STATEMENT: SELECT COUNT(*) FROM (SELECT * FROM medium.random_ints ORDER BY i) t; LOG: finished 1-way merge step: CPU 0.62s/7.22u sec elapsed 8.43 sec STATEMENT: SELECT COUNT(*) FROM (SELECT * FROM medium.random_ints ORDER BY i) t; LOG: finished 3-way merge step: CPU 0.62s/7.23u sec elapsed 8.44 sec STATEMENT: SELECT COUNT(*) FROM (SELECT * FROM medium.random_ints ORDER BY i) t; LOG: finished 6-way merge step: CPU 0.62s/7.24u sec elapsed 8.44 sec STATEMENT: SELECT COUNT(*) FROM (SELECT * FROM medium.random_ints ORDER BY i) t; LOG: finished 6-way merge step: CPU 0.62s/7.24u sec elapsed 8.45 sec STATEMENT: SELECT COUNT(*) FROM (SELECT * FROM medium.random_ints ORDER BY i) t; - Heikki
On Thu, Sep 15, 2016 at 1:51 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> I still don't get why you're doing all of this within mergeruns() (the >> beginning of when we start merging -- we merge all quicksorted runs), >> rather than within beginmerge() (the beginning of one particular merge >> pass, of which there are potentially more than one). As runs are >> merged in a non-final merge pass, fewer tapes will remain active for >> the next merge pass. It doesn't do to do all that up-front when we >> have multiple merge passes, which will happen from time to time. > > > Now that the pre-reading is done in logtape.c, it doesn't stop at a run > boundary. For example, when we read the last 1 MB of the first run on a > tape, and we're using a 10 MB read buffer, we will merrily also read the > first 9 MB from the next run. You cannot un-read that data, even if the tape > is inactive in the next merge pass. I'm not sure that I like that approach. At the very least, it seems to not be a good fit with the existing structure of things. I need to think about it some more, and study how that plays out in practice. > BTW, does a 1-way merge make any sense? Not really, no, but it's something that I've seen plenty of times. This is seen when runs are distributed such that mergeonerun() only finds one real run on all active tapes, with all other active tapes having only dummy runs. In general, dummy runs are "logically merged" (decremented) in preference to any real runs on the same tape (that's the reason why they exist), so you end up with what we call a "1-way merge" when you see one real one on one active tape only. You never see something like "0-way merge" within trace_sort output, though, because that case is optimized to be almost a no-op. It's almost a no-op because when it happens then mergeruns() knows to itself directly decrement the number of dummy runs once for each active tape, making that "logical merge" completed with only that simple change in metadata (that is, the "merge" completes by just decrementing dummy run counts -- no actual call to mergeonerun()). We could optimize away "1-way merge" cases, perhaps, so that tuples don't have to be spilt out one at a time (there could perhaps instead be just some localized change to metadata, a bit like the all-dummy case). That doesn't seem worth bothering with, especially with this new approach of yours. I prefer to avoid special cases like that. -- Peter Geoghegan
On Thu, Sep 15, 2016 at 1:51 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > BTW, does a 1-way merge make any sense? I was surprised to see this in the > log, even without this patch: > > LOG: finished 1-way merge step: CPU 0.62s/7.22u sec elapsed 8.43 sec > STATEMENT: SELECT COUNT(*) FROM (SELECT * FROM medium.random_ints ORDER BY > i) t; > LOG: finished 1-way merge step: CPU 0.62s/7.22u sec elapsed 8.43 sec > STATEMENT: SELECT COUNT(*) FROM (SELECT * FROM medium.random_ints ORDER BY > i) t; > LOG: finished 1-way merge step: CPU 0.62s/7.22u sec elapsed 8.43 sec > STATEMENT: SELECT COUNT(*) FROM (SELECT * FROM medium.random_ints ORDER BY > i) t; > LOG: finished 1-way merge step: CPU 0.62s/7.22u sec elapsed 8.43 sec > STATEMENT: SELECT COUNT(*) FROM (SELECT * FROM medium.random_ints ORDER BY > i) t; > LOG: finished 3-way merge step: CPU 0.62s/7.23u sec elapsed 8.44 sec > STATEMENT: SELECT COUNT(*) FROM (SELECT * FROM medium.random_ints ORDER BY > i) t; > LOG: finished 6-way merge step: CPU 0.62s/7.24u sec elapsed 8.44 sec > STATEMENT: SELECT COUNT(*) FROM (SELECT * FROM medium.random_ints ORDER BY > i) t; > LOG: finished 6-way merge step: CPU 0.62s/7.24u sec elapsed 8.45 sec > STATEMENT: SELECT COUNT(*) FROM (SELECT * FROM medium.random_ints ORDER BY > i) t; Another thing that I think it worth pointing out here is that the number of merge passes shown is excessive, practically speaking. I suggested that we have something like checkpoint_warning for this last year, which Greg Stark eventually got behind, but Robert Haas didn't seem to like. Maybe this idea should be revisited. What do you think? There is no neat explanation for why it's considered excessive to checkpoint every 10 seconds, but not every 2 minutes. But, we warn about the former case by default, and not the latter. It's hard to know exactly where to draw the line, but that isn't a great reason to not do it (maybe one extra merge pass is a good threshold -- that's what I suggested once). I think that other database systems similarly surface multiple merge passes. It's just inefficient to ever do multiple merge passes, even if you're very frugal with memory. Certainly, it's almost impossible to defend doing 3+ passes these days. -- Peter Geoghegan
On Wed, Sep 14, 2016 at 10:43 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > Addressed all your comments one way or another, new patch attached. So, it's clear that this isn't ready today. As I mentioned, I'm going away for a week now. I ask that you hold off on committing this until I return, and have a better opportunity to review the performance characteristics of this latest revision, for one thing. Thanks -- Peter Geoghegan
On 09/17/2016 07:27 PM, Peter Geoghegan wrote: > On Wed, Sep 14, 2016 at 10:43 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> Addressed all your comments one way or another, new patch attached. > > So, it's clear that this isn't ready today. As I mentioned, I'm going > away for a week now. I ask that you hold off on committing this until > I return, and have a better opportunity to review the performance > characteristics of this latest revision, for one thing. Ok. I'll probably read through it myself once more some time next week, and also have a first look at your actual parallel sorting patch. Have a good trip! - Heikki
On Sat, Sep 17, 2016 at 9:41 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > Ok. I'll probably read through it myself once more some time next week, and > also have a first look at your actual parallel sorting patch. Have a good > trip! Thanks! It will be good to get away for a while. I'd be delighted to recruit you to work on the parallel CREATE INDEX patch. I've already explained how I think this preread patch of yours works well with parallel tuplesort (as proposed) in particular. To reiterate: while what you've come up with here is technically an independent improvement to merging, it's much more valuable in the overall context of parallel sort, where disproportionate wall clock time is spent merging, and where multiple passes are the norm (one pass in each worker, plus one big final pass in the leader process alone -- logtape.c fragmentation becomes a real issue). The situation is actually similar to the original batch memory preloading patch that went into 9.6 (which your new patch supersedes), and the subsequently committed quicksort for external sort patch (which my new patch extends to work in parallel). Because I think of your preload patch as a part of the overall parallel CREATE INDEX effort, if that was the limit of your involvement then I'd still think it fair to credit you as my co-author. I hope it isn't the limit of your involvement, though, because it seems likely that the final result will be better still if you get involved with the big patch that formally introduces parallel CREATE INDEX. -- Peter Geoghegan
On Fri, Sep 9, 2016 at 9:51 PM, Claudio Freire <klaussfreire@gmail.com> wrote: > On Fri, Sep 9, 2016 at 8:13 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> >> Claudio, if you could also repeat the tests you ran on Peter's patch set on >> the other thread, with these patches, that'd be nice. These patches are >> effectively a replacement for >> 0002-Use-tuplesort-batch-memory-for-randomAccess-sorts.patch. And review >> would be much appreciated too, of course. >> >> Attached are new versions. Compared to last set, they contain a few comment >> fixes, and a change to the 2nd patch to not allocate tape buffers for tapes >> that were completely unused. > > > Will do so Well, here they are, the results. ODS format only (unless you've got issues opening the ODS). The results seem all over the map. Some regressions seem significant (both in the amount of performance lost and their significance, since all 4 runs show a similar regression). The worst being "CREATE INDEX ix_lotsofitext_zz2ijw ON lotsofitext (z, z2, i, j, w);" with 4GB work_mem, which should be an in-memory sort, which makes it odd. I will re-run it overnight just in case to confirm the outcome.
Attachment
On Tue, Sep 20, 2016 at 3:34 PM, Claudio Freire <klaussfreire@gmail.com> wrote: > On Fri, Sep 9, 2016 at 9:51 PM, Claudio Freire <klaussfreire@gmail.com> wrote: >> On Fri, Sep 9, 2016 at 8:13 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >>> >>> Claudio, if you could also repeat the tests you ran on Peter's patch set on >>> the other thread, with these patches, that'd be nice. These patches are >>> effectively a replacement for >>> 0002-Use-tuplesort-batch-memory-for-randomAccess-sorts.patch. And review >>> would be much appreciated too, of course. >>> >>> Attached are new versions. Compared to last set, they contain a few comment >>> fixes, and a change to the 2nd patch to not allocate tape buffers for tapes >>> that were completely unused. >> >> >> Will do so > > Well, here they are, the results. > > ODS format only (unless you've got issues opening the ODS). > > The results seem all over the map. Some regressions seem significant > (both in the amount of performance lost and their significance, since > all 4 runs show a similar regression). The worst being "CREATE INDEX > ix_lotsofitext_zz2ijw ON lotsofitext (z, z2, i, j, w);" with 4GB > work_mem, which should be an in-memory sort, which makes it odd. > > I will re-run it overnight just in case to confirm the outcome. A new run for "patched" gives better results, it seems it was some kind of glitch in the run (maybe some cron decided to do something while running those queries). Attached In essence, it doesn't look like it's harmfully affecting CPU efficiency. Results seem neutral on the CPU front.
Attachment
On 09/22/2016 03:40 AM, Claudio Freire wrote: > On Tue, Sep 20, 2016 at 3:34 PM, Claudio Freire <klaussfreire@gmail.com> wrote: >> The results seem all over the map. Some regressions seem significant >> (both in the amount of performance lost and their significance, since >> all 4 runs show a similar regression). The worst being "CREATE INDEX >> ix_lotsofitext_zz2ijw ON lotsofitext (z, z2, i, j, w);" with 4GB >> work_mem, which should be an in-memory sort, which makes it odd. >> >> I will re-run it overnight just in case to confirm the outcome. > > A new run for "patched" gives better results, it seems it was some > kind of glitch in the run (maybe some cron decided to do something > while running those queries). > > Attached > > In essence, it doesn't look like it's harmfully affecting CPU > efficiency. Results seem neutral on the CPU front. Looking at the spreadsheet, there is a 40% slowdown in the "slow" "CREATE INDEX ix_lotsofitext_zz2ijw ON lotsofitext (z, z2, i, j, w);" test with 4GB of work_mem. I can't reproduce that on my laptop, though. Got any clue what's going on there? - Heikki
On Thu, Sep 22, 2016 at 4:17 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > On 09/22/2016 03:40 AM, Claudio Freire wrote: >> >> On Tue, Sep 20, 2016 at 3:34 PM, Claudio Freire <klaussfreire@gmail.com> >> wrote: >>> >>> The results seem all over the map. Some regressions seem significant >>> (both in the amount of performance lost and their significance, since >>> all 4 runs show a similar regression). The worst being "CREATE INDEX >>> ix_lotsofitext_zz2ijw ON lotsofitext (z, z2, i, j, w);" with 4GB >>> work_mem, which should be an in-memory sort, which makes it odd. >>> >>> I will re-run it overnight just in case to confirm the outcome. >> >> >> A new run for "patched" gives better results, it seems it was some >> kind of glitch in the run (maybe some cron decided to do something >> while running those queries). >> >> Attached >> >> In essence, it doesn't look like it's harmfully affecting CPU >> efficiency. Results seem neutral on the CPU front. > > > Looking at the spreadsheet, there is a 40% slowdown in the "slow" "CREATE > INDEX ix_lotsofitext_zz2ijw ON lotsofitext (z, z2, i, j, w);" test with 4GB > of work_mem. I can't reproduce that on my laptop, though. Got any clue > what's going on there? It's not present in other runs, so I think it's a fluke the spreadsheet isn't filtering out. Especially considering that one should be a fully in-memory fast sort and thus unaffected by the current patch (z and z2 being integers, IIRC, most comparisons should be about comparing the first columns and thus rarely involve the big strings). I'll try to confirm that's the case though.
On Thu, Sep 15, 2016 at 9:51 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote:
>> I still don't get why you're doing all of this within mergeruns() (the
>> beginning of when we start merging -- we merge all quicksorted runs),
>> rather than within beginmerge() (the beginning of one particular merge
>> pass, of which there are potentially more than one). As runs are
>> merged in a non-final merge pass, fewer tapes will remain active for
>> the next merge pass. It doesn't do to do all that up-front when we
>> have multiple merge passes, which will happen from time to time.
>
>
> Now that the pre-reading is done in logtape.c, it doesn't stop at a run
> boundary. For example, when we read the last 1 MB of the first run on a
> tape, and we're using a 10 MB read buffer, we will merrily also read the
> first 9 MB from the next run. You cannot un-read that data, even if the tape
> is inactive in the next merge pass.
I've had a chance to think about this some more. I did a flying review
of the same revision that I talk about here, but realized some more
things. First, I will do a recap.
> I don't think it makes much difference in practice, because most merge
> passes use all, or almost all, of the available tapes. BTW, I think the
> polyphase algorithm prefers to do all the merges that don't use all tapes
> upfront, so that the last final merge always uses all the tapes. I'm not
> 100% sure about that, but that's my understanding of the algorithm, and
> that's what I've seen in my testing.
Not sure that I understand. I agree that each merge pass tends to use
roughly the same number of tapes, but the distribution of real runs on
tapes is quite unbalanced in earlier merge passes (due to dummy runs).
It looks like you're always using batch memory, even for non-final
merges. Won't that fail to be in balance much of the time because of
the lopsided distribution of runs? Tapes have an uneven amount of real
data in earlier merge passes.
FWIW, polyphase merge actually doesn't distribute runs based on the
Fibonacci sequence (at least in Postgres). It uses a generalization of
the Fibonacci numbers [1] -- *which* generalization varies according
to merge order/maxTapes. IIRC, with Knuth's P == 6 (i.e. merge order
== 6), it's the "hexanacci" sequence.
The following code is from your latest version, posted on 2016-09-14,
within the high-level mergeruns() function (the function that takes
quicksorted runs, and produces final output following 1 or more merge
passes):
> + usedBlocks = 0;
> + for (tapenum = 0; tapenum < state->maxTapes; tapenum++)
> + {
> + int64 numBlocks = blocksPerTape + (tapenum < remainder ? 1 : 0);
> +
> + if (numBlocks > MaxAllocSize / BLCKSZ)
> + numBlocks = MaxAllocSize / BLCKSZ;
> + LogicalTapeAssignReadBufferSize(state->tapeset, tapenum,
> + numBlocks * BLCKSZ);
> + usedBlocks += numBlocks;
> + }
> + USEMEM(state, usedBlocks * BLCKSZ);
I'm basically repeating myself here, but: I think it's incorrect that
LogicalTapeAssignReadBufferSize() is called so indiscriminately (more
generally, it is questionable that it is called in such a high level
routine, rather than the start of a specific merge pass -- I said so a
couple of times already).
It's weird that you change the meaning of maxTapes by reassigning in
advance of iterating through maxTapes like this. I should point out
again that the master branch mergebatch() function does roughly the
same thing as you're doing here as follows:
static void
mergebatch(Tuplesortstate *state, int64 spacePerTape)
{ int srcTape;
Assert(state->activeTapes > 0); Assert(state->tuples);
/* * For the purposes of tuplesort's memory accounting, the batch allocation * is special, and regular memory
accountingthrough USEMEM() calls is * abandoned (see mergeprereadone()). */ for (srcTape = 0; srcTape <
state->maxTapes;srcTape++) { char *mergetuples;
if (!state->mergeactive[srcTape]) continue;
/* Allocate buffer for each active tape */ mergetuples = MemoryContextAllocHuge(state->tuplecontext,
spacePerTape);
/* Initialize state for tape */ state->mergetuples[srcTape] = mergetuples;
state->mergecurrent[srcTape]= mergetuples; state->mergetail[srcTape] = mergetuples;
state->mergeoverflow[srcTape]= NULL; }
state->batchUsed = true; state->spacePerTape = spacePerTape;
}
Notably, this function:
* Works without altering the meaning of maxTapes. state->maxTapes is
Knuth's T, which is established very early and doesn't change with
polyphase merge (same applies to state->tapeRange). What does change
across merge passes is the number of *active* tapes. I don't think
it's necessary to change that in any way. I find it very confusing.
(Also, that you're using state->currentRun here at all seems bad, for
more or less the same reason -- that's the number of quicksorted
runs.)
* Does allocation for the final merge (that's the only point that it's
called), and so is not based on the number of active tapes that happen
to be in play when merging begins at a high level (i.e., when
mergeruns() is first called). Many tapes will be totally inactive by
the final merge, so this seems completely necessary for multiple merge
pass cases.
End of recap. Here is some new information:
I was previously confused on this last point, because I thought that
logtape.c might be able to do something smart to recycle memory that
is bound per-tape by calls to LogicalTapeAssignReadBufferSize() in
your patch. But it doesn't: all the recycling stuff only happens for
the much smaller buffers that are juggled and reused to pass tuples
back to caller within tuplesort_gettuple_common(), etc -- not the
logtape.c managed buffers. So, AFAICT there is no justification that I
can see for not adopting these notable properties of mergebatch() for
some analogous point in this patch. Actually, you should probably not
get rid of mergebatch(), but instead call
LogicalTapeAssignReadBufferSize() there. This change would mean that
the big per-tape memory allocations would happen in the same place as
before -- you'd just be asking logtape.c to do it for you, instead of
allocating directly.
Perhaps the practical consequences of not doing something closer to
mergebatch() are debatable, but I suspect that there is little point
in actually debating it. I think you might as well do it that way. No?
[1] http://mathworld.wolfram.com/Fibonaccin-StepNumber.html
--
Peter Geoghegan
On 09/28/2016 06:05 PM, Peter Geoghegan wrote:
> On Thu, Sep 15, 2016 at 9:51 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote:
>> I don't think it makes much difference in practice, because most merge
>> passes use all, or almost all, of the available tapes. BTW, I think the
>> polyphase algorithm prefers to do all the merges that don't use all tapes
>> upfront, so that the last final merge always uses all the tapes. I'm not
>> 100% sure about that, but that's my understanding of the algorithm, and
>> that's what I've seen in my testing.
>
> Not sure that I understand. I agree that each merge pass tends to use
> roughly the same number of tapes, but the distribution of real runs on
> tapes is quite unbalanced in earlier merge passes (due to dummy runs).
> It looks like you're always using batch memory, even for non-final
> merges. Won't that fail to be in balance much of the time because of
> the lopsided distribution of runs? Tapes have an uneven amount of real
> data in earlier merge passes.
How does the distribution of the runs on the tapes matter?
>> + usedBlocks = 0;
>> + for (tapenum = 0; tapenum < state->maxTapes; tapenum++)
>> + {
>> + int64 numBlocks = blocksPerTape + (tapenum < remainder ? 1 : 0);
>> +
>> + if (numBlocks > MaxAllocSize / BLCKSZ)
>> + numBlocks = MaxAllocSize / BLCKSZ;
>> + LogicalTapeAssignReadBufferSize(state->tapeset, tapenum,
>> + numBlocks * BLCKSZ);
>> + usedBlocks += numBlocks;
>> + }
>> + USEMEM(state, usedBlocks * BLCKSZ);
>
> I'm basically repeating myself here, but: I think it's incorrect that
> LogicalTapeAssignReadBufferSize() is called so indiscriminately (more
> generally, it is questionable that it is called in such a high level
> routine, rather than the start of a specific merge pass -- I said so a
> couple of times already).
You can't release the tape buffer at the end of a pass, because the
buffer of a tape will already be filled with data from the next run on
the same tape.
- Heikki
On Wed, Sep 28, 2016 at 5:04 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> Not sure that I understand. I agree that each merge pass tends to use >> roughly the same number of tapes, but the distribution of real runs on >> tapes is quite unbalanced in earlier merge passes (due to dummy runs). >> It looks like you're always using batch memory, even for non-final >> merges. Won't that fail to be in balance much of the time because of >> the lopsided distribution of runs? Tapes have an uneven amount of real >> data in earlier merge passes. > > > How does the distribution of the runs on the tapes matter? The exact details are not really relevant to this discussion (I think it's confusing that we simply say "Target Fibonacci run counts", FWIW), but the simple fact that it can be quite uneven is. This is why I never pursued batch memory for non-final merges. Isn't that what you're doing here? You're pretty much always setting "state->batchUsed = true". >> I'm basically repeating myself here, but: I think it's incorrect that >> LogicalTapeAssignReadBufferSize() is called so indiscriminately (more >> generally, it is questionable that it is called in such a high level >> routine, rather than the start of a specific merge pass -- I said so a >> couple of times already). > > > You can't release the tape buffer at the end of a pass, because the buffer > of a tape will already be filled with data from the next run on the same > tape. Okay, but can't you just not use batch memory for non-final merges, per my initial approach? That seems far cleaner. -- Peter Geoghegan
On Wed, Sep 28, 2016 at 5:11 PM, Peter Geoghegan <pg@heroku.com> wrote: > This is why I never pursued batch memory for non-final merges. Isn't > that what you're doing here? You're pretty much always setting > "state->batchUsed = true". Wait. I guess you feel you have to, since it wouldn't be okay to use almost no memory per tape on non-final merges. You're able to throw out so much code here in large part because you give almost all memory over to logtape.c (e.g., you don't manage each tape's share of "slots" anymore -- better to give everything to logtape.c). So, with your patch, you would actually only have one caller tuple in memory at once per tape for a merge that doesn't use batch memory (if you made it so that a merge *could* avoid the use of batch memory, as I suggest). In summary, under your scheme, the "batchUsed" variable contains a tautological value, since you cannot sensibly not use batch memory. (This is even true with !state->tuples callers). Do I have that right? If so, this seems rather awkward. Hmm. -- Peter Geoghegan
On 09/28/2016 07:11 PM, Peter Geoghegan wrote: > On Wed, Sep 28, 2016 at 5:04 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >>> Not sure that I understand. I agree that each merge pass tends to use >>> roughly the same number of tapes, but the distribution of real runs on >>> tapes is quite unbalanced in earlier merge passes (due to dummy runs). >>> It looks like you're always using batch memory, even for non-final >>> merges. Won't that fail to be in balance much of the time because of >>> the lopsided distribution of runs? Tapes have an uneven amount of real >>> data in earlier merge passes. >> >> >> How does the distribution of the runs on the tapes matter? > > The exact details are not really relevant to this discussion (I think > it's confusing that we simply say "Target Fibonacci run counts", > FWIW), but the simple fact that it can be quite uneven is. Well, I claim that the fact that the distribution of runs is uneven, does not matter. Can you explain why you think it does? > This is why I never pursued batch memory for non-final merges. Isn't > that what you're doing here? You're pretty much always setting > "state->batchUsed = true". Yep. As the patch stands, we wouldn't really need batchUsed, as we know that it's always true when merging, and false otherwise. But I kept it, as it seems like that might not always be true - we might use batch memory when building the initial runs, for example - and because it seems nice to have an explicit flag for it, for readability and debugging purposes. >>> I'm basically repeating myself here, but: I think it's incorrect that >>> LogicalTapeAssignReadBufferSize() is called so indiscriminately (more >>> generally, it is questionable that it is called in such a high level >>> routine, rather than the start of a specific merge pass -- I said so a >>> couple of times already). >> >> >> You can't release the tape buffer at the end of a pass, because the buffer >> of a tape will already be filled with data from the next run on the same >> tape. > > Okay, but can't you just not use batch memory for non-final merges, > per my initial approach? That seems far cleaner. Why? I don't see why the final merge should behave differently from the non-final ones. - Heikki
On 09/28/2016 07:20 PM, Peter Geoghegan wrote: > On Wed, Sep 28, 2016 at 5:11 PM, Peter Geoghegan <pg@heroku.com> wrote: >> This is why I never pursued batch memory for non-final merges. Isn't >> that what you're doing here? You're pretty much always setting >> "state->batchUsed = true". > > Wait. I guess you feel you have to, since it wouldn't be okay to use > almost no memory per tape on non-final merges. > > You're able to throw out so much code here in large part because you > give almost all memory over to logtape.c (e.g., you don't manage each > tape's share of "slots" anymore -- better to give everything to > logtape.c). So, with your patch, you would actually only have one > caller tuple in memory at once per tape for a merge that doesn't use > batch memory (if you made it so that a merge *could* avoid the use of > batch memory, as I suggest). Correct. > In summary, under your scheme, the "batchUsed" variable contains a > tautological value, since you cannot sensibly not use batch memory. > (This is even true with !state->tuples callers). I suppose. > Do I have that right? If so, this seems rather awkward. Hmm. How is it awkward? - Heikki
On Thu, Sep 29, 2016 at 10:49 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote:
>> Do I have that right? If so, this seems rather awkward. Hmm.
>
>
> How is it awkward?
Maybe that was the wrong choice of words. What I mean is that it seems
somewhat unprincipled to give over an equal share of memory to each
active-at-least-once tape, regardless of how much that matters in
practice. One tape could have several runs in memory at once, while
another only has a fraction of a single much larger run. Maybe this is
just the first time that I find myself on the *other* side of a
discussion about an algorithm that seems brute-force compared to what
it might replace, but is actually better overall. :-)
Now, that could be something that I just need to get over. In any
case, I still think:
* Variables like maxTapes have a meaning that is directly traceable
back to Knuth's description of polyphase merge. I don't think that you
should do anything to them, on general principle.
* Everything or almost everything that you've added to mergeruns()
should probably be in its own dedicated function. This function can
have a comment where you acknowledge that it's not perfectly okay that
you claim memory per-tape, but it's simpler and faster overall.
* I think you should be looking at the number of active tapes, and not
state->Level or state->currentRun in this new function. Actually,
maybe this wouldn't be the exact definition of an active tape that we
establish at the beginning of beginmerge() (this considers tapes with
dummy runs to be inactive for that merge), but it would look similar.
The general concern I have here is that you shouldn't rely on
state->Level or state->currentRun from a distance for the purposes of
determining which tapes need some batch memory. This is also where you
might say something like: "we don't bother with shifting memory around
tapes for each merge step, even though that would be fairer. That's
why we don't use the beginmerge() definition of activeTapes --
instead, we use our own broader definition of the number of active
tapes that doesn't exclude dummy-run-tapes with real runs, making the
allocation reasonably sensible for every merge pass".
* The "batchUsed" terminology really isn't working here, AFAICT. For
one thing, you have two separate areas where caller tuples might
reside: The small per-tape buffers (sized MERGETUPLEBUFFER_SIZE per
tape), and the logtape.c controlled preread buffers (sized up to
MaxAllocSize per tape). Which of these two things is batch memory? I
think it might just be the first one, but KiBs of memory do not
suggest "batch" to me. Isn't that really more like what you might call
double buffer memory, used not to save overhead from palloc (having
many palloc headers in memory), but rather to recycle memory
efficiently? So, these two things should have two new names of their
own, I think, and neither should be called "batch memory" IMV. I see
several assertions remain here and there that were written with my
original definition of batch memory in mind -- assertions like:
case TSS_SORTEDONTAPE: Assert(forward || state->randomAccess); Assert(!state->batchUsed);
(Isn't state->batchUsed always true now?)
And:
case TSS_FINALMERGE: Assert(forward); Assert(state->batchUsed || !state->tuples);
(Isn't state->tuples only really of interest to datum-tuple-case
routines, now that you've made everything use large logtape.c preread
buffers?)
* Is is really necessary for !state->tuples cases to do that
MERGETUPLEBUFFER_SIZE-based allocation? In other words, what need is
there for pass-by-value datum cases to have this scratch/double buffer
memory at all, since the value is returned to caller by-value, not
by-reference? This is related to the problem of it not being entirely
clear what batch memory now is, I think.
--
Peter Geoghegan
On Thu, Sep 29, 2016 at 6:52 AM, Peter Geoghegan <pg@heroku.com> wrote: >> How is it awkward? > > Maybe that was the wrong choice of words. What I mean is that it seems > somewhat unprincipled to give over an equal share of memory to each > active-at-least-once tape, ... I don't get it. If the memory is being used for prereading, then the point is just to avoid doing many small I/Os instead of one big I/O, and that goal will be accomplished whether the memory is equally distributed or not; indeed, it's likely to be accomplished BETTER if the memory is equally distributed than if it isn't. I can imagine that there might be a situation in which it makes sense to give a bigger tape more resources than a smaller one; for example, if one were going to divide N tapes across K worker processess and make individual workers or groups of workers responsible for sorting particular tapes, one would of course want to divide up the data across the available processes relatively evenly, rather than having some workers responsible for only a small amount of data and others for a very large amount of data. But such considerations are irrelevant here. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 09/29/2016 01:52 PM, Peter Geoghegan wrote: > * Variables like maxTapes have a meaning that is directly traceable > back to Knuth's description of polyphase merge. I don't think that you > should do anything to them, on general principle. Ok. I still think that changing maxTapes would make sense, when there are fewer runs than tapes, but that is actually orthogonal to the rest of the patch, so let's discuss that separately. I've changed the patch to not do that. > * Everything or almost everything that you've added to mergeruns() > should probably be in its own dedicated function. This function can > have a comment where you acknowledge that it's not perfectly okay that > you claim memory per-tape, but it's simpler and faster overall. Ok. > * I think you should be looking at the number of active tapes, and not > state->Level or state->currentRun in this new function. Actually, > maybe this wouldn't be the exact definition of an active tape that we > establish at the beginning of beginmerge() (this considers tapes with > dummy runs to be inactive for that merge), but it would look similar. > The general concern I have here is that you shouldn't rely on > state->Level or state->currentRun from a distance for the purposes of > determining which tapes need some batch memory. This is also where you > might say something like: "we don't bother with shifting memory around > tapes for each merge step, even though that would be fairer. That's > why we don't use the beginmerge() definition of activeTapes -- > instead, we use our own broader definition of the number of active > tapes that doesn't exclude dummy-run-tapes with real runs, making the > allocation reasonably sensible for every merge pass". I'm not sure I understood what your concern was, but please have a look at this new version, if the comments in initTapeBuffers() explain that well enough. > * The "batchUsed" terminology really isn't working here, AFAICT. For > one thing, you have two separate areas where caller tuples might > reside: The small per-tape buffers (sized MERGETUPLEBUFFER_SIZE per > tape), and the logtape.c controlled preread buffers (sized up to > MaxAllocSize per tape). Which of these two things is batch memory? I > think it might just be the first one, but KiBs of memory do not > suggest "batch" to me. Isn't that really more like what you might call > double buffer memory, used not to save overhead from palloc (having > many palloc headers in memory), but rather to recycle memory > efficiently? So, these two things should have two new names of their > own, I think, and neither should be called "batch memory" IMV. I see > several assertions remain here and there that were written with my > original definition of batch memory in mind -- assertions like: Ok. I replaced "batch" terminology with "slab allocator" and "slab slots", I hope this is less confusing. This isn't exactly like e.g. the slab allocator in the Linux kernel, as it has a fixed number of slots, so perhaps an "object pool" might be more accurate. But I like "slab" because it's not used elsewhere in the system. I also didn't use the term "cache" for the "slots", as might be typical for slab allocators, because "cache" is such an overloaded term. > case TSS_SORTEDONTAPE: > Assert(forward || state->randomAccess); > Assert(!state->batchUsed); > > (Isn't state->batchUsed always true now?) Good catch. It wasn't, because mergeruns() set batchUsed only after checking for the TSS_SORTEDONTAPE case, even though it set up the batch memory arena before it. So if replacement selection was able to produce a single run batchUsed was false. Fixed, the slab allocator (as it's now called) is now always used in TSS_SORTEDONTAPE case. > And: > > case TSS_FINALMERGE: > Assert(forward); > Assert(state->batchUsed || !state->tuples); > > (Isn't state->tuples only really of interest to datum-tuple-case > routines, now that you've made everything use large logtape.c preread > buffers?) Yeah, fixed. > * Is is really necessary for !state->tuples cases to do that > MERGETUPLEBUFFER_SIZE-based allocation? In other words, what need is > there for pass-by-value datum cases to have this scratch/double buffer > memory at all, since the value is returned to caller by-value, not > by-reference? This is related to the problem of it not being entirely > clear what batch memory now is, I think. True, fixed. I still set slabAllocatorUsed (was batchUsed), but it's initialized as a dummy 0-slot arena when !state->tuples. Here's a new patch version, addressing the points you made. Please have a look! - Heikki
Attachment
On 09/29/2016 05:41 PM, Heikki Linnakangas wrote: > Here's a new patch version, addressing the points you made. Please have > a look! Bah, I fumbled the initSlabAllocator() function, attached is a fixed version. - Heikki
Attachment
On Thu, Sep 29, 2016 at 2:59 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> Maybe that was the wrong choice of words. What I mean is that it seems >> somewhat unprincipled to give over an equal share of memory to each >> active-at-least-once tape, ... > > I don't get it. If the memory is being used for prereading, then the > point is just to avoid doing many small I/Os instead of one big I/O, > and that goal will be accomplished whether the memory is equally > distributed or not; indeed, it's likely to be accomplished BETTER if > the memory is equally distributed than if it isn't. I think it could hurt performance if preloading loads runs on a tape that won't be needed until some subsequent merge pass, in preference to using that memory proportionately, giving more to larger input runs for *each* merge pass (giving memory proportionate to the size of each run to be merged from each tape). For tapes with a dummy run, the appropriate amount of memory for there next merge pass is zero. I'm not arguing that it would be worth it to do that, but I do think that that's the sensible way of framing the idea of using a uniform amount of memory to every maybe-active tape up front. I'm not too concerned about this because I'm never too concerned about multiple merge pass cases, which are relatively rare and relatively unimportant. Let's just get our story straight. -- Peter Geoghegan
On Thu, Sep 29, 2016 at 11:38 AM, Peter Geoghegan <pg@heroku.com> wrote: > On Thu, Sep 29, 2016 at 2:59 PM, Robert Haas <robertmhaas@gmail.com> wrote: >>> Maybe that was the wrong choice of words. What I mean is that it seems >>> somewhat unprincipled to give over an equal share of memory to each >>> active-at-least-once tape, ... >> >> I don't get it. If the memory is being used for prereading, then the >> point is just to avoid doing many small I/Os instead of one big I/O, >> and that goal will be accomplished whether the memory is equally >> distributed or not; indeed, it's likely to be accomplished BETTER if >> the memory is equally distributed than if it isn't. > > I think it could hurt performance if preloading loads runs on a tape > that won't be needed until some subsequent merge pass, in preference > to using that memory proportionately, giving more to larger input runs > for *each* merge pass (giving memory proportionate to the size of each > run to be merged from each tape). For tapes with a dummy run, the > appropriate amount of memory for there next merge pass is zero. OK, true. But I still suspect that unless the amount of data you need to read from a tape is zero or very small, the size of the buffer doesn't matter. For example, if you have a 1GB tape and a 10GB tape, I doubt there's any benefit in making the buffer for the 10GB tape 10x larger. They can probably be the same. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Sep 29, 2016 at 4:10 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote:
> Bah, I fumbled the initSlabAllocator() function, attached is a fixed
> version.
This looks much better. It's definitely getting close. Thanks for
being considerate of my more marginal concerns. More feedback:
* Should say "fixed number of...":
> + * we start merging. Merging only needs to keep a small, fixed number tuples
* Minor concern about these new macros:
> +#define IS_SLAB_SLOT(state, tuple) \
> + ((char *) tuple >= state->slabMemoryBegin && \
> + (char *) tuple < state->slabMemoryEnd)
> +
> +/*
> + * Return the given tuple to the slab memory free list, or free it
> + * if it was palloc'd.
> + */
> +#define RELEASE_SLAB_SLOT(state, tuple) \
> + do { \
> + SlabSlot *buf = (SlabSlot *) tuple; \
> + \
> + if (IS_SLAB_SLOT(state, tuple)) \
> + { \
> + buf->nextfree = state->slabFreeHead; \
> + state->slabFreeHead = buf; \
> + } else \
> + pfree(tuple); \
> + } while(0)
I suggest duplicating the paranoia seen elsewhere around what "state"
macro argument could expand to. You know, by surrounding "state" with
parenthesis each time it is used. This is what we see with existing,
similar macros.
* Should cast to int64 here (for the benefit of win64):
> + elog(LOG, "using " INT64_FORMAT " KB of memory for read buffers among %d input tapes",
> + (long) (availBlocks * BLCKSZ) / 1024, numInputTapes);
* FWIW, I still don't love this bit:
> + * numTapes and numInputTapes reflect the actual number of tapes we will
> + * use. Note that the output tape's tape number is maxTapes - 1, so the
> + * tape numbers of the used tapes are not consecutive, so you cannot
> + * just loop from 0 to numTapes to visit all used tapes!
> + */
> + if (state->Level == 1)
> + {
> + numInputTapes = state->currentRun;
> + numTapes = numInputTapes + 1;
> + FREEMEM(state, (state->maxTapes - numTapes) * TAPE_BUFFER_OVERHEAD);
> + }
But I can see how the verbosity of almost-duplicating the activeTapes
stuff seems unappealing. That said, I think that you should point out
in comments that you're calculating the number of
maybe-active-in-some-merge tapes. They're maybe-active in that they
have some number of real tapes. Not going to insist on that, but
something to think about.
* Shouldn't this use state->tapeRange?:
> + else
> + {
> + numInputTapes = state->maxTapes - 1;
> + numTapes = state->maxTapes;
> + }
* Doesn't it also set numTapes without it being used? Maybe that
variable can be declared within "if (state->Level == 1)" block.
* Minor issues with initSlabAllocator():
You call the new function initSlabAllocator() as follows:
> + if (state->tuples)
> + initSlabAllocator(state, numInputTapes + 1);
> + else
> + initSlabAllocator(state, 0);
Isn't the number of slots (the second argument to initSlabAllocator())
actually just numInputTapes when we're "state->tuples"? And so,
shouldn't the "+ 1" bit happen within initSlabAllocator() itself? It
can just inspect "state->tuples" itself. In short, maybe push a bit
more into initSlabAllocator(). Making the arguments match those passed
to initTapeBuffers() a bit later would be nice, perhaps.
* This could be simpler, I think:
> + /* Release the read buffers on all the other tapes, by rewinding them. */
> + for (tapenum = 0; tapenum < state->maxTapes; tapenum++)
> + {
> + if (tapenum == state->result_tape)
> + continue;
> + LogicalTapeRewind(state->tapeset, tapenum, true);
> + }
Can't you just use state->tapeRange, and remove the "continue"? I
recommend referring to "now-exhausted input tapes" here, too.
* I'm not completely prepared to give up on using
MemoryContextAllocHuge() within logtape.c just yet. Maybe you're right
that it couldn't possibly matter that we impose a MaxAllocSize cap
within logtape.c (per tape), but I have slight reservations that I
need to address. Maybe a better way of putting it would be that I have
some reservations about possible regressions at the very high end,
with very large workMem. Any thoughts on that?
--
Peter Geoghegan
On 09/30/2016 04:08 PM, Peter Geoghegan wrote:
> On Thu, Sep 29, 2016 at 4:10 PM, Heikki Linnakangas <hlinnaka@iki.fi> wrote:
>> Bah, I fumbled the initSlabAllocator() function, attached is a fixed
>> version.
>
> This looks much better. It's definitely getting close. Thanks for
> being considerate of my more marginal concerns. More feedback:
Fixed most of the things you pointed out, thanks.
> * Minor issues with initSlabAllocator():
>
> You call the new function initSlabAllocator() as follows:
>
>> + if (state->tuples)
>> + initSlabAllocator(state, numInputTapes + 1);
>> + else
>> + initSlabAllocator(state, 0);
>
> Isn't the number of slots (the second argument to initSlabAllocator())
> actually just numInputTapes when we're "state->tuples"? And so,
> shouldn't the "+ 1" bit happen within initSlabAllocator() itself? It
> can just inspect "state->tuples" itself. In short, maybe push a bit
> more into initSlabAllocator(). Making the arguments match those passed
> to initTapeBuffers() a bit later would be nice, perhaps.
The comment above that explains the "+ 1". init_slab_allocator allocates
the number of slots that was requested, and the caller is responsible
for deciding how many slots are needed. Yeah, we could remove the
argument and move the logic altogether into init_slab_allocator(), but I
think it's clearer this way. Matter of taste, I guess.
> * This could be simpler, I think:
>
>> + /* Release the read buffers on all the other tapes, by rewinding them. */
>> + for (tapenum = 0; tapenum < state->maxTapes; tapenum++)
>> + {
>> + if (tapenum == state->result_tape)
>> + continue;
>> + LogicalTapeRewind(state->tapeset, tapenum, true);
>> + }
>
> Can't you just use state->tapeRange, and remove the "continue"? I
> recommend referring to "now-exhausted input tapes" here, too.
Don't think so. result_tape == tapeRange only when the merge was done in
a single pass (or you're otherwise lucky).
> * I'm not completely prepared to give up on using
> MemoryContextAllocHuge() within logtape.c just yet. Maybe you're right
> that it couldn't possibly matter that we impose a MaxAllocSize cap
> within logtape.c (per tape), but I have slight reservations that I
> need to address. Maybe a better way of putting it would be that I have
> some reservations about possible regressions at the very high end,
> with very large workMem. Any thoughts on that?
Meh, I can't imagine that using more than 1 GB for a read-ahead buffer
could make any difference in practice. If you have a very large
work_mem, you'll surely get away with a single merge pass, and
fragmentation won't become an issue. And 1GB should be more than enough
to trigger OS read-ahead.
Committed with some final kibitzing. Thanks for the review!
PS. This patch didn't fix bug #14344, the premature reuse of memory with
tuplesort_gettupleslot. We'll still need to come up with 1. a
backportable fix for that, and 2. perhaps a different fix for master.
- Heikki
On Mon, Oct 3, 2016 at 3:39 AM, Heikki Linnakangas <hlinnaka@iki.fi> wrote: >> Can't you just use state->tapeRange, and remove the "continue"? I >> recommend referring to "now-exhausted input tapes" here, too. > > > Don't think so. result_tape == tapeRange only when the merge was done in a > single pass (or you're otherwise lucky). Ah, yes. Logical tape assignment/physical tape number confusion on my part here. >> * I'm not completely prepared to give up on using >> MemoryContextAllocHuge() within logtape.c just yet. Maybe you're right >> that it couldn't possibly matter that we impose a MaxAllocSize cap >> within logtape.c (per tape), but I have slight reservations that I >> need to address. Maybe a better way of putting it would be that I have >> some reservations about possible regressions at the very high end, >> with very large workMem. Any thoughts on that? > > > Meh, I can't imagine that using more than 1 GB for a read-ahead buffer could > make any difference in practice. If you have a very large work_mem, you'll > surely get away with a single merge pass, and fragmentation won't become an > issue. And 1GB should be more than enough to trigger OS read-ahead. I had a non-specific concern, not an intuition of suspicion about this. I think that I'll figure it out when I rebase the parallel CREATE INDEX patch on top of this and test that. > Committed with some final kibitzing. Thanks for the review! Thanks for working on this! > PS. This patch didn't fix bug #14344, the premature reuse of memory with > tuplesort_gettupleslot. We'll still need to come up with 1. a backportable > fix for that, and 2. perhaps a different fix for master. Agreed. It seemed like you favor not changing memory ownership semantics for 9.6. I'm not sure that that's the easiest approach for 9.6, but let's discuss that over on the dedicated thread soon. -- Peter Geoghegan
Heikki Linnakangas <hlinnaka@iki.fi> writes: > I'm talking about the code that reads a bunch of from each tape, loading > them into the memtuples array. That code was added by Tom Lane, back in > 1999: > commit cf627ab41ab9f6038a29ddd04dd0ff0ccdca714e > Author: Tom Lane <tgl@sss.pgh.pa.us> > Date: Sat Oct 30 17:27:15 1999 +0000 > Further performance improvements in sorting: reduce number of comparisons > during initial run formation by keeping both current run and next-run > tuples in the same heap (yup, Knuth is smarter than I am). And, during > merge passes, make use of available sort memory to load multiple tuples > from any one input 'tape' at a time, thereby improving locality of > access to the temp file. > So apparently there was a benefit back then, but is it still worthwhile? I'm fairly sure that the point was exactly what it said, ie improve locality of access within the temp file by sequentially reading as many tuples in a row as we could, rather than grabbing one here and one there. It may be that the work you and Peter G. have been doing have rendered that question moot. But I'm a bit worried that the reason you're not seeing any effect is that you're only testing situations with zero seek penalty (ie your laptop's disk is an SSD). Back then I would certainly have been testing with temp files on spinning rust, and I fear that this may still be an issue in that sort of environment. The relevant mailing list thread seems to be "sort on huge table" in pgsql-hackers in October/November 1999. The archives don't seem to have threaded that too successfully, but here's a message specifically describing the commit you mention: https://www.postgresql.org/message-id/2726.941493808%40sss.pgh.pa.us and you can find the rest by looking through the archive summary pages for that interval. The larger picture to be drawn from that thread is that we were seeing very different performance characteristics on different platforms. The specific issue that Tatsuo-san reported seemed like it might be down to weird read-ahead behavior in a 90s-vintage Linux kernel ... but the point that this stuff can be environment-dependent is still something to take to heart. regards, tom lane
I wrote:
> Heikki Linnakangas <hlinnaka@iki.fi> writes:
>> I'm talking about the code that reads a bunch of from each tape, loading
>> them into the memtuples array. That code was added by Tom Lane, back in
>> 1999:
>> So apparently there was a benefit back then, but is it still worthwhile?
> I'm fairly sure that the point was exactly what it said, ie improve
> locality of access within the temp file by sequentially reading as many
> tuples in a row as we could, rather than grabbing one here and one there.
[ blink... ] Somehow, my mail reader popped up a message from 2016
as current, and I spent some time researching and answering it without
noticing the message date.
Never mind, nothing to see here ...
regards, tom lane
On Thu, Apr 13, 2017 at 9:51 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > I'm fairly sure that the point was exactly what it said, ie improve > locality of access within the temp file by sequentially reading as many > tuples in a row as we could, rather than grabbing one here and one there. > > It may be that the work you and Peter G. have been doing have rendered > that question moot. But I'm a bit worried that the reason you're not > seeing any effect is that you're only testing situations with zero seek > penalty (ie your laptop's disk is an SSD). Back then I would certainly > have been testing with temp files on spinning rust, and I fear that this > may still be an issue in that sort of environment. I actually think Heikki's work here would particularly help on spinning rust, especially when less memory is available. He specifically justified it on the basis of it resulting in a more sequential read pattern, particularly when multiple passes are required. > The larger picture to be drawn from that thread is that we were seeing > very different performance characteristics on different platforms. > The specific issue that Tatsuo-san reported seemed like it might be > down to weird read-ahead behavior in a 90s-vintage Linux kernel ... > but the point that this stuff can be environment-dependent is still > something to take to heart. BTW, I'm skeptical of the idea of Heikki's around killing polyphase merge itself at this point. I think that keeping most tapes active per pass is useful now that our memory accounting involves handing over an even share to each maybe-active tape for every merge pass, something established by Heikki's work on external sorting. Interestingly enough, I think that Knuth was pretty much spot on with his "sweet spot" of 7 tapes, even if you have modern hardware. Commit df700e6 (where the sweet spot of merge order 7 was no longer always used) was effective because it masked certain overheads that we experience when doing multiple passes, overheads that Heikki and I mostly removed. This was confirmed by Robert's testing of my merge order cap work for commit fc19c18, where he found that using 7 tapes was only slightly worse than using many hundreds of tapes. If we could somehow be completely effective in making access to logical tapes perfectly sequential, then 7 tapes would probably be noticeably *faster*, due to CPU caching effects. Knuth was completely correct to say that it basically made no difference once more than 7 tapes are used to merge, because he didn't have logtape.c fragmentation to worry about. -- Peter Geoghegan VMware vCenter Server https://www.vmware.com/
On Thu, Apr 13, 2017 at 10:19 PM, Peter Geoghegan <pg@bowt.ie> wrote: > I actually think Heikki's work here would particularly help on > spinning rust, especially when less memory is available. He > specifically justified it on the basis of it resulting in a more > sequential read pattern, particularly when multiple passes are > required. BTW, what you might have missed is that Heikki did end up using a significant amount of memory in the committed version. It just ended up being managed by logtape.c, which now does the prereading instead of tuplesort.c, but at a lower level. There is only one tuple in the merge heap, but there is still up to 1GB of memory per tape, containing raw preread tuples mixed with integers that demarcate tape contents. -- Peter Geoghegan VMware vCenter Server https://www.vmware.com/
On Fri, Apr 14, 2017 at 1:19 AM, Peter Geoghegan <pg@bowt.ie> wrote: > Interestingly enough, I think that Knuth was pretty much spot on with > his "sweet spot" of 7 tapes, even if you have modern hardware. Commit > df700e6 (where the sweet spot of merge order 7 was no longer always > used) was effective because it masked certain overheads that we > experience when doing multiple passes, overheads that Heikki and I > mostly removed. This was confirmed by Robert's testing of my merge > order cap work for commit fc19c18, where he found that using 7 tapes > was only slightly worse than using many hundreds of tapes. If we could > somehow be completely effective in making access to logical tapes > perfectly sequential, then 7 tapes would probably be noticeably > *faster*, due to CPU caching effects. I don't think there's any one fixed answer, because increasing the number of tapes reduces I/O by adding CPU cost, and visca versa. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, Apr 14, 2017 at 5:57 AM, Robert Haas <robertmhaas@gmail.com> wrote: > I don't think there's any one fixed answer, because increasing the > number of tapes reduces I/O by adding CPU cost, and visca versa. Sort of, but if you have to merge hundreds of runs (a situation that should be quite rare), then you should be concerned about being CPU bound first, as Knuth was. Besides, on modern hardware, read-ahead can be more effective if you have more merge passes, to a point, which might also make it worth it -- using hundreds of tapes results in plenty of *random* I/O. Plus, most of the time you only do a second pass over a subset of initial quicksorted runs -- not all of them. Probably the main complicating factor that Knuth doesn't care about is time to return the first tuple -- startup cost. That was a big advantage for commit df700e6 that I should have mentioned. I'm not seriously suggesting that we should prefer multiple passes in the vast majority of real world cases, nor am I suggesting that we should go out of our way to help cases that need to do that. I just find all this interesting. -- Peter Geoghegan VMware vCenter Server https://www.vmware.com/
On 04/14/2017 08:19 AM, Peter Geoghegan wrote: > BTW, I'm skeptical of the idea of Heikki's around killing polyphase > merge itself at this point. I think that keeping most tapes active per > pass is useful now that our memory accounting involves handing over an > even share to each maybe-active tape for every merge pass, something > established by Heikki's work on external sorting. The pre-read buffers are only needed for input tapes; the total number of tapes doesn't matter. For comparison, imagine that you want to perform a merge, such that you always merge 7 runs into one. With polyphase merge, you would need 8 tapes, so that you always read from 7 of them, and write onto one. With balanced merge, you would need 14 tapes: you always read from 7 tapes, and you would need up to 7 output tapes, of which one would be active at any given time. Those extra idle output tapes are practically free in our implementation. The "pre-read buffers" are only needed for input tapes, the number of output tapes doesn't matter. Likewise, maintaining the heap is cheaper if you only merge a small number of tapes at a time, but that's also dependent on the number of *input* tapes, not the total number of tapes. - Heikki