Thread: Block level parallel vacuum WIP
Hi all, I'd like to propose block level parallel VACUUM. This feature makes VACUUM possible to use multiple CPU cores. Vacuum Processing Logic =================== PostgreSQL VACUUM processing logic consists of 2 phases, 1. Collecting dead tuple locations on heap. 2. Reclaiming dead tuples from heap and indexes. These phases 1 and 2 are executed alternately, and once amount of dead tuple location reached maintenance_work_mem in phase 1, phase 2 will be executed. Basic Design ========== As for PoC, I implemented parallel vacuum so that each worker processes both 1 and 2 phases for particular block range. Suppose we vacuum 1000 blocks table with 4 workers, each worker processes 250 consecutive blocks in phase 1 and then reclaims dead tuples from heap and indexes (phase 2). To use visibility map efficiency, each worker scan particular block range of relation and collect dead tuple locations. After each worker finished task, the leader process gathers these vacuum statistics information and update relfrozenxid if possible. I also changed the buffer lock infrastructure so that multiple processes can wait for cleanup lock on a buffer. And the new GUC parameter vacuum_parallel_workers controls the number of vacuum workers. Performance(PoC) ========= I ran parallel vacuum on 13GB table (pgbench scale 1000) with several workers (on my poor virtual machine). The result is, 1. Vacuum whole table without index (disable page skipping) 1 worker : 33 sec 2 workers : 27 sec 3 workers : 23 sec 4 workers : 22 sec 2. Vacuum table and index (after 10000 transaction executed) 1 worker : 12 sec 2 workers : 49 sec 3 workers : 54 sec 4 workers : 53 sec As a result of my test, since multiple process could frequently try to acquire the cleanup lock on same index buffer, execution time of parallel vacuum got worse. And it seems to be effective for only table vacuum so far, but is not improved as expected (maybe disk bottleneck). Another Design ============ ISTM that processing index vacuum by multiple process is not good idea in most cases because many index items can be stored in a page and multiple vacuum worker could try to require the cleanup lock on the same index buffer. It's rather better that multiple workers process particular block range and then multiple workers process each particular block range, and then one worker per index processes index vacuum. Still lots of work to do but attached PoC patch. Feedback and suggestion are very welcome. Regards, -- Masahiko Sawada
Attachment
On Tue, Aug 23, 2016 at 8:02 AM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > 2. Vacuum table and index (after 10000 transaction executed) > 1 worker : 12 sec > 2 workers : 49 sec > 3 workers : 54 sec > 4 workers : 53 sec > > As a result of my test, since multiple process could frequently try to > acquire the cleanup lock on same index buffer, execution time of > parallel vacuum got worse. > And it seems to be effective for only table vacuum so far, but is not > improved as expected (maybe disk bottleneck). Not only that, but from your description (I haven't read the patch, sorry), you'd be scanning the whole index multiple times (one per worker).
I repeat your test on ProLiant DL580 Gen9 with Xeon E7-8890 v3.
pgbench -s 100 and command vacuum pgbench_acounts after 10_000 transactions:
with: alter system set vacuum_cost_delay to DEFAULT;
parallel_vacuum_workers | time
1 | 138.703,263 ms
2 | 83.751,064 ms
4 | 66.105,861 ms
8 | 59.820,171 ms
with: alter system set vacuum_cost_delay to 1;
parallel_vacuum_workers | time
1 | 127.210,896 ms
2 | 75.300,278 ms
4 | 64.253,087 ms
8 | 60.130,953
2016-08-23 14:02 GMT+03:00 Masahiko Sawada <sawada.mshk@gmail.com>:
Hi all,
I'd like to propose block level parallel VACUUM.
This feature makes VACUUM possible to use multiple CPU cores.
Vacuum Processing Logic
===================
PostgreSQL VACUUM processing logic consists of 2 phases,
1. Collecting dead tuple locations on heap.
2. Reclaiming dead tuples from heap and indexes.
These phases 1 and 2 are executed alternately, and once amount of dead
tuple location reached maintenance_work_mem in phase 1, phase 2 will
be executed.
Basic Design
==========
As for PoC, I implemented parallel vacuum so that each worker
processes both 1 and 2 phases for particular block range.
Suppose we vacuum 1000 blocks table with 4 workers, each worker
processes 250 consecutive blocks in phase 1 and then reclaims dead
tuples from heap and indexes (phase 2).
To use visibility map efficiency, each worker scan particular block
range of relation and collect dead tuple locations.
After each worker finished task, the leader process gathers these
vacuum statistics information and update relfrozenxid if possible.
I also changed the buffer lock infrastructure so that multiple
processes can wait for cleanup lock on a buffer.
And the new GUC parameter vacuum_parallel_workers controls the number
of vacuum workers.
Performance(PoC)
=========
I ran parallel vacuum on 13GB table (pgbench scale 1000) with several
workers (on my poor virtual machine).
The result is,
1. Vacuum whole table without index (disable page skipping)
1 worker : 33 sec
2 workers : 27 sec
3 workers : 23 sec
4 workers : 22 sec
2. Vacuum table and index (after 10000 transaction executed)
1 worker : 12 sec
2 workers : 49 sec
3 workers : 54 sec
4 workers : 53 sec
As a result of my test, since multiple process could frequently try to
acquire the cleanup lock on same index buffer, execution time of
parallel vacuum got worse.
And it seems to be effective for only table vacuum so far, but is not
improved as expected (maybe disk bottleneck).
Another Design
============
ISTM that processing index vacuum by multiple process is not good idea
in most cases because many index items can be stored in a page and
multiple vacuum worker could try to require the cleanup lock on the
same index buffer.
It's rather better that multiple workers process particular block
range and then multiple workers process each particular block range,
and then one worker per index processes index vacuum.
Still lots of work to do but attached PoC patch.
Feedback and suggestion are very welcome.
Regards,
--
Masahiko Sawada
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Claudio Freire <klaussfreire@gmail.com> writes:
> Not only that, but from your description (I haven't read the patch,
> sorry), you'd be scanning the whole index multiple times (one per
> worker).
What about pointing each worker at a separate index? Obviously the
degree of concurrency during index cleanup is then limited by the
number of indexes, but that doesn't seem like a fatal problem.
regards, tom lane
On Tue, Aug 23, 2016 at 3:32 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
+1
Claudio Freire <klaussfreire@gmail.com> writes:
> Not only that, but from your description (I haven't read the patch,
> sorry), you'd be scanning the whole index multiple times (one per
> worker).
What about pointing each worker at a separate index? Obviously the
degree of concurrency during index cleanup is then limited by the
number of indexes, but that doesn't seem like a fatal problem.
We could eventually need some effective way of parallelizing vacuum of single index.
But pointing each worker at separate index seems to be fair enough for majority of cases.
The Russian Postgres Company
On Tue, Aug 23, 2016 at 8:02 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > As for PoC, I implemented parallel vacuum so that each worker > processes both 1 and 2 phases for particular block range. > Suppose we vacuum 1000 blocks table with 4 workers, each worker > processes 250 consecutive blocks in phase 1 and then reclaims dead > tuples from heap and indexes (phase 2). So each worker is assigned a range of blocks, and processes them in parallel? This does not sound performance-wise. I recall Robert and Amit emails on the matter for sequential scan that this would suck performance out particularly for rotating disks. -- Michael
On 23.08.2016 15:41, Michael Paquier wrote: > On Tue, Aug 23, 2016 at 8:02 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >> As for PoC, I implemented parallel vacuum so that each worker >> processes both 1 and 2 phases for particular block range. >> Suppose we vacuum 1000 blocks table with 4 workers, each worker >> processes 250 consecutive blocks in phase 1 and then reclaims dead >> tuples from heap and indexes (phase 2). > So each worker is assigned a range of blocks, and processes them in > parallel? This does not sound performance-wise. I recall Robert and > Amit emails on the matter for sequential scan that this would suck > performance out particularly for rotating disks. Rotating disks is not a problem - you can always raid them and etc. 8k allocation per relation once per half an hour that is the problem. Seq scan is this way = random scan... Alex Ignatov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Tue, Aug 23, 2016 at 6:11 PM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Tue, Aug 23, 2016 at 8:02 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >> As for PoC, I implemented parallel vacuum so that each worker >> processes both 1 and 2 phases for particular block range. >> Suppose we vacuum 1000 blocks table with 4 workers, each worker >> processes 250 consecutive blocks in phase 1 and then reclaims dead >> tuples from heap and indexes (phase 2). > > So each worker is assigned a range of blocks, and processes them in > parallel? This does not sound performance-wise. I recall Robert and > Amit emails on the matter for sequential scan that this would suck > performance out particularly for rotating disks. > The implementation in patch is same as we have initially thought for sequential scan, but turned out that it is not good way to do because it can lead to inappropriate balance of work among workers. Suppose one worker is able to finish it's work, it won't be able to do more. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Tue, Aug 23, 2016 at 7:02 AM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > I'd like to propose block level parallel VACUUM. > This feature makes VACUUM possible to use multiple CPU cores. Great. This is something that I have thought about, too. Andres and Heikki recommended it as a project to me a few PGCons ago. > As for PoC, I implemented parallel vacuum so that each worker > processes both 1 and 2 phases for particular block range. > Suppose we vacuum 1000 blocks table with 4 workers, each worker > processes 250 consecutive blocks in phase 1 and then reclaims dead > tuples from heap and indexes (phase 2). > To use visibility map efficiency, each worker scan particular block > range of relation and collect dead tuple locations. > After each worker finished task, the leader process gathers these > vacuum statistics information and update relfrozenxid if possible. This doesn't seem like a good design, because it adds a lot of extra index scanning work. What I think you should do is: 1. Use a parallel heap scan (heap_beginscan_parallel) to let all workers scan in parallel. Allocate a DSM segment to store the control structure for this parallel scan plus an array for the dead tuple IDs and a lock to protect the array. 2. When you finish the heap scan, or when the array of dead tuple IDs is full (or very nearly full?), perform a cycle of index vacuuming. For now, have each worker process a separate index; extra workers just wait. Perhaps use the condition variable patch that I posted previously to make the workers wait. Then resume the parallel heap scan, if not yet done. Later, we can try to see if there's a way to have multiple workers work together to vacuum a single index. But the above seems like a good place to start. > I also changed the buffer lock infrastructure so that multiple > processes can wait for cleanup lock on a buffer. You won't need this if you proceed as above, which is probably a good thing. > And the new GUC parameter vacuum_parallel_workers controls the number > of vacuum workers. I suspect that for autovacuum there is little reason to use parallel vacuum, since most of the time we are trying to slow vacuum down, not speed it up. I'd be inclined, for starters, to just add a PARALLEL option to the VACUUM command, for when people want to speed up parallel vacuums. Perhaps VACUUM (PARALLEL 4) relation; ...could mean to vacuum the relation with the given number of workers, and: VACUUM (PARALLEL) relation; ...could mean to vacuum the relation in parallel with the system choosing the number of workers - 1 worker per index is probably a good starting formula, though it might need some refinement. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Aug 23, 2016 at 9:40 PM, Alexander Korotkov <a.korotkov@postgrespro.ru> wrote: > On Tue, Aug 23, 2016 at 3:32 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: >> >> Claudio Freire <klaussfreire@gmail.com> writes: >> > Not only that, but from your description (I haven't read the patch, >> > sorry), you'd be scanning the whole index multiple times (one per >> > worker). >> >> What about pointing each worker at a separate index? Obviously the >> degree of concurrency during index cleanup is then limited by the >> number of indexes, but that doesn't seem like a fatal problem. > > > +1 > We could eventually need some effective way of parallelizing vacuum of > single index. > But pointing each worker at separate index seems to be fair enough for > majority of cases. > Or we can improve vacuum of single index by changing data representation of dead tuple to bitmap.It can reduce the number of index whole scan during vacuum and make comparing the index item to the dead tuples faster. This is a listed on Todo list and I've implemented it. Regards, -- Masahiko Sawada
Robert Haas wrote: > 2. When you finish the heap scan, or when the array of dead tuple IDs > is full (or very nearly full?), perform a cycle of index vacuuming. > For now, have each worker process a separate index; extra workers just > wait. Perhaps use the condition variable patch that I posted > previously to make the workers wait. Then resume the parallel heap > scan, if not yet done. At least btrees should easily be scannable in parallel, given that we process them in physical order rather than logically walk the tree. So if there are more workers than indexes, it's possible to put more than one worker on the same index by carefully indicating each to stop at a predetermined index page number. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Aug 23, 2016 at 10:50 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Aug 23, 2016 at 7:02 AM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >> I'd like to propose block level parallel VACUUM. >> This feature makes VACUUM possible to use multiple CPU cores. > > Great. This is something that I have thought about, too. Andres and > Heikki recommended it as a project to me a few PGCons ago. > >> As for PoC, I implemented parallel vacuum so that each worker >> processes both 1 and 2 phases for particular block range. >> Suppose we vacuum 1000 blocks table with 4 workers, each worker >> processes 250 consecutive blocks in phase 1 and then reclaims dead >> tuples from heap and indexes (phase 2). >> To use visibility map efficiency, each worker scan particular block >> range of relation and collect dead tuple locations. >> After each worker finished task, the leader process gathers these >> vacuum statistics information and update relfrozenxid if possible. > > This doesn't seem like a good design, because it adds a lot of extra > index scanning work. What I think you should do is: > > 1. Use a parallel heap scan (heap_beginscan_parallel) to let all > workers scan in parallel. Allocate a DSM segment to store the control > structure for this parallel scan plus an array for the dead tuple IDs > and a lock to protect the array. > > 2. When you finish the heap scan, or when the array of dead tuple IDs > is full (or very nearly full?), perform a cycle of index vacuuming. > For now, have each worker process a separate index; extra workers just > wait. Perhaps use the condition variable patch that I posted > previously to make the workers wait. Then resume the parallel heap > scan, if not yet done. > > Later, we can try to see if there's a way to have multiple workers > work together to vacuum a single index. But the above seems like a > good place to start. Thank you for the advice. That's a what I thought as an another design, I will change the patch to this design. >> I also changed the buffer lock infrastructure so that multiple >> processes can wait for cleanup lock on a buffer. > > You won't need this if you proceed as above, which is probably a good thing. Right. > >> And the new GUC parameter vacuum_parallel_workers controls the number >> of vacuum workers. > > I suspect that for autovacuum there is little reason to use parallel > vacuum, since most of the time we are trying to slow vacuum down, not > speed it up. I'd be inclined, for starters, to just add a PARALLEL > option to the VACUUM command, for when people want to speed up > parallel vacuums. Perhaps > > VACUUM (PARALLEL 4) relation; > > ...could mean to vacuum the relation with the given number of workers, and: > > VACUUM (PARALLEL) relation; > > ...could mean to vacuum the relation in parallel with the system > choosing the number of workers - 1 worker per index is probably a good > starting formula, though it might need some refinement. It looks convenient. I was thinking that we can manage the number of parallel worker per table using this parameter for autovacuum , like ALTER TABLE relation SET (parallel_vacuum_workers = 2) Regards, -- Masahiko Sawada
On Tue, Aug 23, 2016 at 11:17 AM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > Robert Haas wrote: >> 2. When you finish the heap scan, or when the array of dead tuple IDs >> is full (or very nearly full?), perform a cycle of index vacuuming. >> For now, have each worker process a separate index; extra workers just >> wait. Perhaps use the condition variable patch that I posted >> previously to make the workers wait. Then resume the parallel heap >> scan, if not yet done. > > At least btrees should easily be scannable in parallel, given that we > process them in physical order rather than logically walk the tree. So > if there are more workers than indexes, it's possible to put more than > one worker on the same index by carefully indicating each to stop at a > predetermined index page number. Well that's fine if we figure it out, but I wouldn't try to include it in the first patch. Let's make VACUUM parallel one step at a time. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas wrote: > On Tue, Aug 23, 2016 at 11:17 AM, Alvaro Herrera > <alvherre@2ndquadrant.com> wrote: > > Robert Haas wrote: > >> 2. When you finish the heap scan, or when the array of dead tuple IDs > >> is full (or very nearly full?), perform a cycle of index vacuuming. > >> For now, have each worker process a separate index; extra workers just > >> wait. Perhaps use the condition variable patch that I posted > >> previously to make the workers wait. Then resume the parallel heap > >> scan, if not yet done. > > > > At least btrees should easily be scannable in parallel, given that we > > process them in physical order rather than logically walk the tree. So > > if there are more workers than indexes, it's possible to put more than > > one worker on the same index by carefully indicating each to stop at a > > predetermined index page number. > > Well that's fine if we figure it out, but I wouldn't try to include it > in the first patch. Let's make VACUUM parallel one step at a time. Sure, just putting the idea out there. -- Álvaro Herrera http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 2016-08-23 12:17:30 -0400, Robert Haas wrote: > On Tue, Aug 23, 2016 at 11:17 AM, Alvaro Herrera > <alvherre@2ndquadrant.com> wrote: > > Robert Haas wrote: > >> 2. When you finish the heap scan, or when the array of dead tuple IDs > >> is full (or very nearly full?), perform a cycle of index vacuuming. > >> For now, have each worker process a separate index; extra workers just > >> wait. Perhaps use the condition variable patch that I posted > >> previously to make the workers wait. Then resume the parallel heap > >> scan, if not yet done. > > > > At least btrees should easily be scannable in parallel, given that we > > process them in physical order rather than logically walk the tree. So > > if there are more workers than indexes, it's possible to put more than > > one worker on the same index by carefully indicating each to stop at a > > predetermined index page number. > > Well that's fine if we figure it out, but I wouldn't try to include it > in the first patch. Let's make VACUUM parallel one step at a time. Given that index scan(s) are, in my experience, way more often the bottleneck than the heap-scan(s), I'm not sure that order is the best. The heap-scan benefits from the VM, the index scans don't.
On Tue, Aug 23, 2016 at 10:50 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Tue, Aug 23, 2016 at 6:11 PM, Michael Paquier > <michael.paquier@gmail.com> wrote: >> On Tue, Aug 23, 2016 at 8:02 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>> As for PoC, I implemented parallel vacuum so that each worker >>> processes both 1 and 2 phases for particular block range. >>> Suppose we vacuum 1000 blocks table with 4 workers, each worker >>> processes 250 consecutive blocks in phase 1 and then reclaims dead >>> tuples from heap and indexes (phase 2). >> >> So each worker is assigned a range of blocks, and processes them in >> parallel? This does not sound performance-wise. I recall Robert and >> Amit emails on the matter for sequential scan that this would suck >> performance out particularly for rotating disks. >> > > The implementation in patch is same as we have initially thought for > sequential scan, but turned out that it is not good way to do because > it can lead to inappropriate balance of work among workers. Suppose > one worker is able to finish it's work, it won't be able to do more. Ah, so it was the reason. Thanks for confirming my doubts on what is proposed. -- Michael
On Wed, Aug 24, 2016 at 3:31 AM, Michael Paquier <michael.paquier@gmail.com> wrote:
On Tue, Aug 23, 2016 at 10:50 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Tue, Aug 23, 2016 at 6:11 PM, Michael Paquier
> <michael.paquier@gmail.com> wrote:
>> On Tue, Aug 23, 2016 at 8:02 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>>> As for PoC, I implemented parallel vacuum so that each worker
>>> processes both 1 and 2 phases for particular block range.
>>> Suppose we vacuum 1000 blocks table with 4 workers, each worker
>>> processes 250 consecutive blocks in phase 1 and then reclaims dead
>>> tuples from heap and indexes (phase 2).
>>
>> So each worker is assigned a range of blocks, and processes them in
>> parallel? This does not sound performance-wise. I recall Robert and
>> Amit emails on the matter for sequential scan that this would suck
>> performance out particularly for rotating disks.
>>
>
> The implementation in patch is same as we have initially thought for
> sequential scan, but turned out that it is not good way to do because
> it can lead to inappropriate balance of work among workers. Suppose
> one worker is able to finish it's work, it won't be able to do more.
Ah, so it was the reason. Thanks for confirming my doubts on what is proposed.
--
I believe Sawada-san has got enough feedback on the design to work out the next steps. It seems natural that the vacuum workers are assigned a portion of the heap to scan and collect dead tuples (similar to what patch does) and the same workers to be responsible for the second phase of heap scan.
But as far as index scans are concerned, I agree with Tom that the best strategy is to assign a different index to each worker process and let them vacuum indexes in parallel. That way the work for each worker process is clearly cut out and they don't contend for the same resources, which means the first patch to allow multiple backends to wait for a cleanup buffer is not required. Later we could extend it further such multiple workers can vacuum a single index by splitting the work on physical boundaries, but even that will ensure clear demarkation of work and hence no contention on index blocks.
ISTM this will require further work and it probably makes sense to mark the patch as "Returned with feedback" for now.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Sat, Sep 10, 2016 at 7:44 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > > > On Wed, Aug 24, 2016 at 3:31 AM, Michael Paquier <michael.paquier@gmail.com> > wrote: >> >> On Tue, Aug 23, 2016 at 10:50 PM, Amit Kapila <amit.kapila16@gmail.com> >> wrote: >> > On Tue, Aug 23, 2016 at 6:11 PM, Michael Paquier >> > <michael.paquier@gmail.com> wrote: >> >> On Tue, Aug 23, 2016 at 8:02 PM, Masahiko Sawada >> >> <sawada.mshk@gmail.com> wrote: >> >>> As for PoC, I implemented parallel vacuum so that each worker >> >>> processes both 1 and 2 phases for particular block range. >> >>> Suppose we vacuum 1000 blocks table with 4 workers, each worker >> >>> processes 250 consecutive blocks in phase 1 and then reclaims dead >> >>> tuples from heap and indexes (phase 2). >> >> >> >> So each worker is assigned a range of blocks, and processes them in >> >> parallel? This does not sound performance-wise. I recall Robert and >> >> Amit emails on the matter for sequential scan that this would suck >> >> performance out particularly for rotating disks. >> >> >> > >> > The implementation in patch is same as we have initially thought for >> > sequential scan, but turned out that it is not good way to do because >> > it can lead to inappropriate balance of work among workers. Suppose >> > one worker is able to finish it's work, it won't be able to do more. >> >> Ah, so it was the reason. Thanks for confirming my doubts on what is >> proposed. >> -- > > > I believe Sawada-san has got enough feedback on the design to work out the > next steps. It seems natural that the vacuum workers are assigned a portion > of the heap to scan and collect dead tuples (similar to what patch does) and > the same workers to be responsible for the second phase of heap scan. Yeah, thank you for the feedback. > But as far as index scans are concerned, I agree with Tom that the best > strategy is to assign a different index to each worker process and let them > vacuum indexes in parallel. > That way the work for each worker process is > clearly cut out and they don't contend for the same resources, which means > the first patch to allow multiple backends to wait for a cleanup buffer is > not required. Later we could extend it further such multiple workers can > vacuum a single index by splitting the work on physical boundaries, but even > that will ensure clear demarkation of work and hence no contention on index > blocks. I also agree with this idea. Each worker vacuums different indexes and then the leader process should update all index statistics after parallel mode exited. I'm implementing this patch but I need to resolve the problem regarding lock for extension by multiple parallel workers. In parallel vacuum, multiple workers could try to acquire the exclusive lock for extension on same relation. Since acquiring the exclusive lock for extension by multiple workers is regarded as locking from same locking group, multiple workers extend fsm or vm at the same time and end up with error. I thought that it might be involved with parallel update operation, so I'd like to discuss about this in advance. Regards, -- Masahiko Sawada NIPPON TELEGRAPH AND TELEPHONE CORPORATION NTT Open Source Software Center
On Thu, Sep 15, 2016 at 7:21 AM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > I'm implementing this patch but I need to resolve the problem > regarding lock for extension by multiple parallel workers. > In parallel vacuum, multiple workers could try to acquire the > exclusive lock for extension on same relation. > Since acquiring the exclusive lock for extension by multiple workers > is regarded as locking from same locking group, multiple workers > extend fsm or vm at the same time and end up with error. > I thought that it might be involved with parallel update operation, so > I'd like to discuss about this in advance. Hmm, yeah. This is one of the reasons why parallel queries currently need to be entirely read-only. I think there's a decent argument that the relation extension lock mechanism should be entirely redesigned: the current system is neither particularly fast nor particularly elegant, and some of the services that the heavyweight lock manager provides, such as deadlock detection, are not relevant for relation extension locks. I'm not sure if we should try to fix that right away or come up with some special-purpose hack for vacuum, such as having backends use condition variables to take turns calling visibilitymap_set(). -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Sep 15, 2016 at 11:44 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, Sep 15, 2016 at 7:21 AM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >> I'm implementing this patch but I need to resolve the problem >> regarding lock for extension by multiple parallel workers. >> In parallel vacuum, multiple workers could try to acquire the >> exclusive lock for extension on same relation. >> Since acquiring the exclusive lock for extension by multiple workers >> is regarded as locking from same locking group, multiple workers >> extend fsm or vm at the same time and end up with error. >> I thought that it might be involved with parallel update operation, so >> I'd like to discuss about this in advance. > > Hmm, yeah. This is one of the reasons why parallel queries currently > need to be entirely read-only. I think there's a decent argument that > the relation extension lock mechanism should be entirely redesigned: > the current system is neither particularly fast nor particularly > elegant, and some of the services that the heavyweight lock manager > provides, such as deadlock detection, are not relevant for relation > extension locks. I'm not sure if we should try to fix that right away > or come up with some special-purpose hack for vacuum, such as having > backends use condition variables to take turns calling > visibilitymap_set(). > Yeah, I don't have a good solution for this problem so far. We might need to improve group locking mechanism for the updating operation or came up with another approach to resolve this problem. For example, one possible idea is that the launcher process allocates vm and fsm enough in advance in order to avoid extending fork relation by parallel workers, but it's not resolve fundamental problem. Regards, -- Masahiko Sawada NIPPON TELEGRAPH AND TELEPHONE CORPORATION NTT Open Source Software Center
On Fri, Sep 16, 2016 at 6:56 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > Yeah, I don't have a good solution for this problem so far. > We might need to improve group locking mechanism for the updating > operation or came up with another approach to resolve this problem. > For example, one possible idea is that the launcher process allocates > vm and fsm enough in advance in order to avoid extending fork relation > by parallel workers, but it's not resolve fundamental problem. Marked as returned with feedback because of lack of activity and... Feedback provided. -- Michael
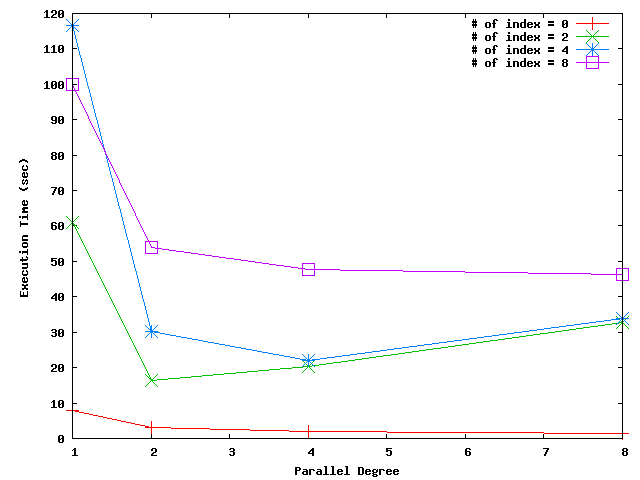
On Mon, Oct 3, 2016 at 11:00 AM, Michael Paquier <michael.paquier@gmail.com> wrote: > On Fri, Sep 16, 2016 at 6:56 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >> Yeah, I don't have a good solution for this problem so far. >> We might need to improve group locking mechanism for the updating >> operation or came up with another approach to resolve this problem. >> For example, one possible idea is that the launcher process allocates >> vm and fsm enough in advance in order to avoid extending fork relation >> by parallel workers, but it's not resolve fundamental problem. > I got some advices at PGConf.ASIA 2016 and started to work on this again. The most big problem so far is the group locking. As I mentioned before, parallel vacuum worker could try to extend the same visibility map page at the same time. So we need to make group locking conflict in some cases, or need to eliminate the necessity of acquiring extension lock. Attached 000 patch uses former idea, which makes the group locking conflict between parallel workers when parallel worker tries to acquire extension lock on same page. I'm not sure this is the best idea but it's very simple and enough to support parallel vacuum. More smart idea could be needed when we want to support parallel DML and so on. 001 patch adds parallel option to VACUUM command. As Robert suggested before, parallel option is set with parallel degree. =# VACUUM (PARALLEL 4) table_name; ..means 4 background processes are launched and background process executes lazy_scan_heap while the launcher (leader) process waits for all vacuum workers finish. If N = 1 or without parallel option, leader process itself executes lazy_scan_heap. Internal Design ============= I changed the parallel vacuum internal design. Collecting garbage on table is processed in block-level parallel. For tables with indexes, each index on table is assigned to each vacuum worker and all garbage on a index are processed by particular assigned vacuum worker. The all spaces for the array of dead tuple TIDs used by vacuum worker are allocated in dynamic shared memory by launcher process. Vacuum worker process stores dead tuple location into its dead tuple array without lock, the TIDs in a dead tuple array are ordered by TID. Note that entire space for dead tuple, that is a bunch of dead tuple array, are not ordered. If table has index, all dead tuple TIDs needs to be shared with all vacuum workers before actual reclaiming dead tuples starts and these data should be cleared after all vacuum worker finished to use them. So I put two synchronization points at where before reclaiming dead tuples and where after finished to reclaim them. At these points, parallel vacuum worker waits for all other workers to reach to the same point. Once all vacuum workers reached to same point, vacuum worker resumes next operation. For example, If a table has five indexes and we execute parallel lazy vacuum on that table with three vacuum workers, two of three vacuum workers are assigned two indexes and another one vacuum worker is assigned to one indexes. After the amount of dead tuple of all vacuum worker reached to maintenance_work_mem size vacuum worker starts to reclaim dead tuple on table and index. A vacuum worker that is assigned to one index finishes (probably first) and sleeps until other two vacuum workers finish to vacuum. If table has no index then each parallel vacuum worker vacuums each page as we go. Performance =========== I measured the execution time of vacuum on dirty table with several parallel degree in my poor environment. table_size | indexes | parallel_degree | time ------------+---------+-----------------+---------- 6.5GB | 0 | 1 | 00:00:14 6.5GB | 0 | 2 | 00:00:02 6.5GB | 0 | 4 | 00:00:02 6.5GB | 1 | 1 | 00:00:13 6.5GB | 1 | 2 | 00:00:15 6.5GB | 1 | 4 | 00:00:18 6.5GB | 2 | 1 | 00:02:18 6.5GB | 2 | 2 | 00:00:38 6.5GB | 2 | 4 | 00:00:46 13GB | 0 | 1 | 00:03:52 13GB | 0 | 2 | 00:00:49 13GB | 0 | 4 | 00:00:50 13GB | 1 | 1 | 00:01:41 13GB | 1 | 2 | 00:01:59 13GB | 1 | 4 | 00:01:24 13GB | 2 | 1 | 00:12:42 13GB | 2 | 2 | 00:01:17 13GB | 2 | 4 | 00:02:12 In result of my measurement, vacuum execution time got better in some cases but didn't improve in case where index = 1. I'll investigate the cause. ToDo ====== * Vacuum progress support. * Storage parameter support, perhaps parallel_vacuum_workers parameter which allows autovacuum to use parallel vacuum on specified table. I register this to next CF. Regards, -- Masahiko Sawada NIPPON TELEGRAPH AND TELEPHONE CORPORATION NTT Open Source Software Center -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Fri, Jan 6, 2017 at 2:38 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > table_size | indexes | parallel_degree | time > ------------+---------+-----------------+---------- > 6.5GB | 0 | 1 | 00:00:14 > 6.5GB | 0 | 2 | 00:00:02 > 6.5GB | 0 | 4 | 00:00:02 Those numbers look highly suspect. Are you sure you're not experiencing caching effects? (ie: maybe you ran the second and third vacuums after the first, and didn't flush the page cache, so the table was cached) > 6.5GB | 2 | 1 | 00:02:18 > 6.5GB | 2 | 2 | 00:00:38 > 6.5GB | 2 | 4 | 00:00:46 ... > 13GB | 0 | 1 | 00:03:52 > 13GB | 0 | 2 | 00:00:49 > 13GB | 0 | 4 | 00:00:50 .. > 13GB | 2 | 1 | 00:12:42 > 13GB | 2 | 2 | 00:01:17 > 13GB | 2 | 4 | 00:02:12 These would also be consistent with caching effects
On Fri, Jan 6, 2017 at 11:08 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > On Mon, Oct 3, 2016 at 11:00 AM, Michael Paquier > <michael.paquier@gmail.com> wrote: >> On Fri, Sep 16, 2016 at 6:56 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>> Yeah, I don't have a good solution for this problem so far. >>> We might need to improve group locking mechanism for the updating >>> operation or came up with another approach to resolve this problem. >>> For example, one possible idea is that the launcher process allocates >>> vm and fsm enough in advance in order to avoid extending fork relation >>> by parallel workers, but it's not resolve fundamental problem. >> > > I got some advices at PGConf.ASIA 2016 and started to work on this again. > > The most big problem so far is the group locking. As I mentioned > before, parallel vacuum worker could try to extend the same visibility > map page at the same time. So we need to make group locking conflict > in some cases, or need to eliminate the necessity of acquiring > extension lock. Attached 000 patch uses former idea, which makes the > group locking conflict between parallel workers when parallel worker > tries to acquire extension lock on same page. > How are planning to ensure the same in deadlock detector? Currently, deadlock detector considers members from same lock group as non-blocking. If you think we don't need to make any changes in deadlock detector, then explain why so? -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Sat, Jan 7, 2017 at 2:47 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Fri, Jan 6, 2017 at 11:08 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >> On Mon, Oct 3, 2016 at 11:00 AM, Michael Paquier >> <michael.paquier@gmail.com> wrote: >>> On Fri, Sep 16, 2016 at 6:56 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>>> Yeah, I don't have a good solution for this problem so far. >>>> We might need to improve group locking mechanism for the updating >>>> operation or came up with another approach to resolve this problem. >>>> For example, one possible idea is that the launcher process allocates >>>> vm and fsm enough in advance in order to avoid extending fork relation >>>> by parallel workers, but it's not resolve fundamental problem. >>> >> >> I got some advices at PGConf.ASIA 2016 and started to work on this again. >> >> The most big problem so far is the group locking. As I mentioned >> before, parallel vacuum worker could try to extend the same visibility >> map page at the same time. So we need to make group locking conflict >> in some cases, or need to eliminate the necessity of acquiring >> extension lock. Attached 000 patch uses former idea, which makes the >> group locking conflict between parallel workers when parallel worker >> tries to acquire extension lock on same page. >> > > How are planning to ensure the same in deadlock detector? Currently, > deadlock detector considers members from same lock group as > non-blocking. If you think we don't need to make any changes in > deadlock detector, then explain why so? > Thank you for comment. I had not considered necessity of dead lock detection support. But because lazy_scan_heap actquires the relation extension lock and release it before acquiring another extension lock, I guess we don't need that changes for parallel lazy vacuum. Thought? Regards, -- Masahiko Sawada NIPPON TELEGRAPH AND TELEPHONE CORPORATION NTT Open Source Software Center
On 9 January 2017 at 08:48, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > I had not considered necessity of dead lock detection support. It seems like a big potential win to scan multiple indexes in parallel. What do we actually gain from having the other parts of VACUUM execute in parallel? Does truncation happen faster in parallel? ISTM we might reduce the complexity of this if there is no substantial gain. Can you give us some timings for performance of the different phases, with varying levels of parallelism? Does the design for collecting dead TIDs use a variable amount of memory? Does this work negate the other work to allow VACUUM to use > 1GB memory? -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sat, Jan 7, 2017 at 7:18 AM, Claudio Freire <klaussfreire@gmail.com> wrote: > On Fri, Jan 6, 2017 at 2:38 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >> table_size | indexes | parallel_degree | time >> ------------+---------+-----------------+---------- >> 6.5GB | 0 | 1 | 00:00:14 >> 6.5GB | 0 | 2 | 00:00:02 >> 6.5GB | 0 | 4 | 00:00:02 > > Those numbers look highly suspect. > > Are you sure you're not experiencing caching effects? (ie: maybe you > ran the second and third vacuums after the first, and didn't flush the > page cache, so the table was cached) > >> 6.5GB | 2 | 1 | 00:02:18 >> 6.5GB | 2 | 2 | 00:00:38 >> 6.5GB | 2 | 4 | 00:00:46 > ... >> 13GB | 0 | 1 | 00:03:52 >> 13GB | 0 | 2 | 00:00:49 >> 13GB | 0 | 4 | 00:00:50 > .. >> 13GB | 2 | 1 | 00:12:42 >> 13GB | 2 | 2 | 00:01:17 >> 13GB | 2 | 4 | 00:02:12 > > These would also be consistent with caching effects Since I ran vacuum after updated all pages on table, I thought that all data are in either shared buffer or OS cache. But anyway, I measured it at only one time so this result is not accurate. I'll test again and measure it at some times. Regards, -- Masahiko Sawada NIPPON TELEGRAPH AND TELEPHONE CORPORATION NTT Open Source Software Center
On Mon, Jan 9, 2017 at 2:18 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > On Sat, Jan 7, 2017 at 2:47 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> On Fri, Jan 6, 2017 at 11:08 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>> On Mon, Oct 3, 2016 at 11:00 AM, Michael Paquier >>> <michael.paquier@gmail.com> wrote: >>>> On Fri, Sep 16, 2016 at 6:56 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>>>> Yeah, I don't have a good solution for this problem so far. >>>>> We might need to improve group locking mechanism for the updating >>>>> operation or came up with another approach to resolve this problem. >>>>> For example, one possible idea is that the launcher process allocates >>>>> vm and fsm enough in advance in order to avoid extending fork relation >>>>> by parallel workers, but it's not resolve fundamental problem. >>>> >>> >>> I got some advices at PGConf.ASIA 2016 and started to work on this again. >>> >>> The most big problem so far is the group locking. As I mentioned >>> before, parallel vacuum worker could try to extend the same visibility >>> map page at the same time. So we need to make group locking conflict >>> in some cases, or need to eliminate the necessity of acquiring >>> extension lock. Attached 000 patch uses former idea, which makes the >>> group locking conflict between parallel workers when parallel worker >>> tries to acquire extension lock on same page. >>> >> >> How are planning to ensure the same in deadlock detector? Currently, >> deadlock detector considers members from same lock group as >> non-blocking. If you think we don't need to make any changes in >> deadlock detector, then explain why so? >> > > Thank you for comment. > I had not considered necessity of dead lock detection support. But > because lazy_scan_heap actquires the relation extension lock and > release it before acquiring another extension lock, I guess we don't > need that changes for parallel lazy vacuum. Thought? > Okay, but it is quite possible that lazy_scan_heap is not able to acquire the required lock as that is already acquired by another process (which is not part of group performing Vacuum), then all the processes in a group might need to run deadlock detector code wherein multiple places, it has been assumed that group members won't conflict. As an example, refer code in TopoSort where it is trying to emit all groupmates together and IIRC, the basis of that part of the code is groupmates won't conflict with each other and this patch will break that assumption. I have not looked into the parallel vacuum patch, but changes in 000_make_group_locking_conflict_extend_lock_v2 doesn't appear to be safe. Even if your parallel vacuum patch doesn't need any change in deadlock detector, then also as proposed it appears that changes in locking will behave same for any of the operations performing relation extension. So in future any parallel operation (say parallel copy/insert) which involves relation extension lock will behave similary. Is that okay or are you assuming that the next person developing any such feature should rethink about this problem and extends your solution to match his requirement. > What do we actually gain from having the other parts of VACUUM execute > in parallel? Does truncation happen faster in parallel? > I think all CPU intensive operations for heap (like checking of dead/live rows, processing of dead tuples, etc.) can be faster. > Can you give us some timings for performance of the different phases, > with varying levels of parallelism? I feel timings depend on the kind of test we perform, for example if there are many dead rows in heap and there are few indexes on a table, we might see that the gain for doing parallel heap scan is substantial. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Tue, Jan 10, 2017 at 3:46 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Mon, Jan 9, 2017 at 2:18 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >> On Sat, Jan 7, 2017 at 2:47 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>> On Fri, Jan 6, 2017 at 11:08 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>>> On Mon, Oct 3, 2016 at 11:00 AM, Michael Paquier >>>> <michael.paquier@gmail.com> wrote: >>>>> On Fri, Sep 16, 2016 at 6:56 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>>>>> Yeah, I don't have a good solution for this problem so far. >>>>>> We might need to improve group locking mechanism for the updating >>>>>> operation or came up with another approach to resolve this problem. >>>>>> For example, one possible idea is that the launcher process allocates >>>>>> vm and fsm enough in advance in order to avoid extending fork relation >>>>>> by parallel workers, but it's not resolve fundamental problem. >>>>> >>>> >>>> I got some advices at PGConf.ASIA 2016 and started to work on this again. >>>> >>>> The most big problem so far is the group locking. As I mentioned >>>> before, parallel vacuum worker could try to extend the same visibility >>>> map page at the same time. So we need to make group locking conflict >>>> in some cases, or need to eliminate the necessity of acquiring >>>> extension lock. Attached 000 patch uses former idea, which makes the >>>> group locking conflict between parallel workers when parallel worker >>>> tries to acquire extension lock on same page. >>>> >>> >>> How are planning to ensure the same in deadlock detector? Currently, >>> deadlock detector considers members from same lock group as >>> non-blocking. If you think we don't need to make any changes in >>> deadlock detector, then explain why so? >>> >> >> Thank you for comment. >> I had not considered necessity of dead lock detection support. But >> because lazy_scan_heap actquires the relation extension lock and >> release it before acquiring another extension lock, I guess we don't >> need that changes for parallel lazy vacuum. Thought? >> > > Okay, but it is quite possible that lazy_scan_heap is not able to > acquire the required lock as that is already acquired by another > process (which is not part of group performing Vacuum), then all the > processes in a group might need to run deadlock detector code wherein > multiple places, it has been assumed that group members won't > conflict. As an example, refer code in TopoSort where it is trying to > emit all groupmates together and IIRC, the basis of that part of the > code is groupmates won't conflict with each other and this patch will > break that assumption. I have not looked into the parallel vacuum > patch, but changes in 000_make_group_locking_conflict_extend_lock_v2 > doesn't appear to be safe. Even if your parallel vacuum patch doesn't > need any change in deadlock detector, then also as proposed it appears > that changes in locking will behave same for any of the operations > performing relation extension. So in future any parallel operation > (say parallel copy/insert) which involves relation extension lock will > behave similary. Is that okay or are you assuming that the next > person developing any such feature should rethink about this problem > and extends your solution to match his requirement. Thank you for expatiation. I agree that we should support dead lock detection as well in this patch even if this feature doesn't need that actually. I'm going to extend 000 patch to support dead lock detection. > > >> What do we actually gain from having the other parts of VACUUM execute >> in parallel? Does truncation happen faster in parallel? >> > > I think all CPU intensive operations for heap (like checking of > dead/live rows, processing of dead tuples, etc.) can be faster. Vacuum on table with no index can be faster as well. Regards, -- Masahiko Sawada NIPPON TELEGRAPH AND TELEPHONE CORPORATION NTT Open Source Software Center
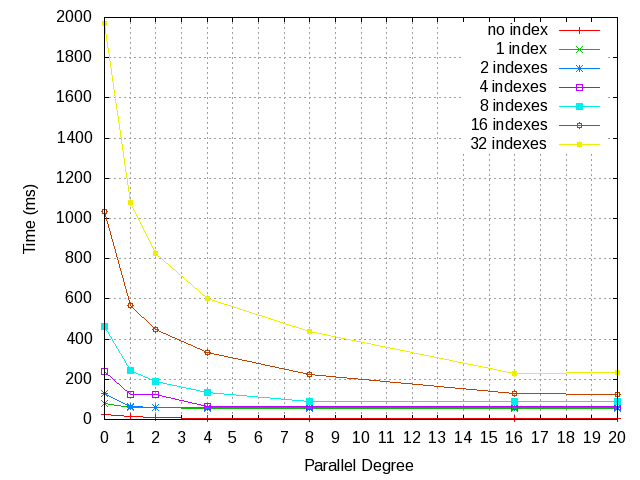
On Mon, Jan 9, 2017 at 6:01 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > On 9 January 2017 at 08:48, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > >> I had not considered necessity of dead lock detection support. > > It seems like a big potential win to scan multiple indexes in parallel. > > Does the design for collecting dead TIDs use a variable amount of > memory? No. Collecting dead TIDs and calculation for max dead tuples are same as current lazy vacuum. That is, the memory space for dead TIDs is allocated with fixed size. If parallel lazy vacuum that memory space is allocated in dynamic shared memory, else is allocated in local memory. > Does this work negate the other work to allow VACUUM to use > > 1GB memory? Partly yes. Because memory space for dead TIDs needs to be allocated in DSM before vacuum worker launches, parallel lazy vacuum cannot use such a variable amount of memory as that work does. But in non-parallel lazy vacuum, that work would be effective. We might be able to do similar thing using DSA but I'm not sure that is better. Attached result of performance test with scale factor = 500 and the test script I used. I measured each test at four times and plot average of last three execution times to sf_500.png file. When table has index, vacuum execution time is smallest when number of index and parallel degree is same. Regards, -- Masahiko Sawada NIPPON TELEGRAPH AND TELEPHONE CORPORATION NTT Open Source Software Center -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
{kind=link}
On Tue, Jan 10, 2017 at 6:42 AM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > Attached result of performance test with scale factor = 500 and the > test script I used. I measured each test at four times and plot > average of last three execution times to sf_500.png file. When table > has index, vacuum execution time is smallest when number of index and > parallel degree is same. It does seem from those results that parallel heap scans aren't paying off, and in fact are hurting. It could be your I/O that's at odds with the parallel degree settings rather than the approach (ie: your I/O system can't handle that many parallel scans), but in any case it does warrant a few more tests. I'd suggest you try to: 1. Disable parallel lazy vacuum, leave parallel index scans 2. Limit parallel degree to number of indexes, leaving parallel lazy vacuum enabled 3. Cap lazy vacuum parallel degree by effective_io_concurrency, and index scan parallel degree to number of indexes And compare against your earlier test results. I suspect 1 could be the winner, but 3 has a chance too (if e_i_c is properly set up for your I/O system).
On Tue, Jan 10, 2017 at 6:42 AM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >> Does this work negate the other work to allow VACUUM to use > >> 1GB memory? > > Partly yes. Because memory space for dead TIDs needs to be allocated > in DSM before vacuum worker launches, parallel lazy vacuum cannot use > such a variable amount of memory as that work does. But in > non-parallel lazy vacuum, that work would be effective. We might be > able to do similar thing using DSA but I'm not sure that is better. I think it would work well with DSA as well. Just instead of having a single segment list, you'd have one per worker. Since workers work on disjoint tid sets, that shouldn't pose a problem. The segment list can be joined together later rather efficiently (simple logical joining of the segment pointer arrays) for the index scan phases.
On 1/10/17 11:23 AM, Claudio Freire wrote: > On Tue, Jan 10, 2017 at 6:42 AM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>> Does this work negate the other work to allow VACUUM to use > >>> 1GB memory? >> >> Partly yes. Because memory space for dead TIDs needs to be allocated >> in DSM before vacuum worker launches, parallel lazy vacuum cannot use >> such a variable amount of memory as that work does. But in >> non-parallel lazy vacuum, that work would be effective. We might be >> able to do similar thing using DSA but I'm not sure that is better. > > I think it would work well with DSA as well. > > Just instead of having a single segment list, you'd have one per worker. > > Since workers work on disjoint tid sets, that shouldn't pose a problem. > > The segment list can be joined together later rather efficiently > (simple logical joining of the segment pointer arrays) for the index > scan phases. It's been a while since there was any movement on this patch and quite a few issues have been raised. Have you tried the approaches that Claudio suggested? -- -David david@pgmasters.net
On Fri, Mar 3, 2017 at 11:01 PM, David Steele <david@pgmasters.net> wrote: > On 1/10/17 11:23 AM, Claudio Freire wrote: >> On Tue, Jan 10, 2017 at 6:42 AM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>>> Does this work negate the other work to allow VACUUM to use > >>>> 1GB memory? >>> >>> Partly yes. Because memory space for dead TIDs needs to be allocated >>> in DSM before vacuum worker launches, parallel lazy vacuum cannot use >>> such a variable amount of memory as that work does. But in >>> non-parallel lazy vacuum, that work would be effective. We might be >>> able to do similar thing using DSA but I'm not sure that is better. >> >> I think it would work well with DSA as well. >> >> Just instead of having a single segment list, you'd have one per worker. >> >> Since workers work on disjoint tid sets, that shouldn't pose a problem. >> >> The segment list can be joined together later rather efficiently >> (simple logical joining of the segment pointer arrays) for the index >> scan phases. > > It's been a while since there was any movement on this patch and quite a > few issues have been raised. > > Have you tried the approaches that Claudio suggested? > Yes, it's taking a time to update logic and measurement but it's coming along. Also I'm working on changing deadlock detection. Will post new patch and measurement result. Regards, -- Masahiko Sawada NIPPON TELEGRAPH AND TELEPHONE CORPORATION NTT Open Source Software Center
On Fri, Mar 3, 2017 at 9:50 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > Yes, it's taking a time to update logic and measurement but it's > coming along. Also I'm working on changing deadlock detection. Will > post new patch and measurement result. I think that we should push this patch out to v11. I think there are too many issues here to address in the limited time we have remaining this cycle, and I believe that if we try to get them all solved in the next few weeks we're likely to end up getting backed into some choices by time pressure that we may later regret bitterly. Since I created the deadlock issues that this patch is facing, I'm willing to try to help solve them, but I think it's going to require considerable and delicate surgery, and I don't think doing that under time pressure is a good idea. From a fairness point of view, a patch that's not in reviewable shape on March 1st should really be pushed out, and we're several days past that. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Mar 4, 2017 at 5:47 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Fri, Mar 3, 2017 at 9:50 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >> Yes, it's taking a time to update logic and measurement but it's >> coming along. Also I'm working on changing deadlock detection. Will >> post new patch and measurement result. > > I think that we should push this patch out to v11. I think there are > too many issues here to address in the limited time we have remaining > this cycle, and I believe that if we try to get them all solved in the > next few weeks we're likely to end up getting backed into some choices > by time pressure that we may later regret bitterly. Since I created > the deadlock issues that this patch is facing, I'm willing to try to > help solve them, but I think it's going to require considerable and > delicate surgery, and I don't think doing that under time pressure is > a good idea. > > From a fairness point of view, a patch that's not in reviewable shape > on March 1st should really be pushed out, and we're several days past > that. > Agreed. There are surely some rooms to discuss about the design yet, and it will take long time. it's good to push this out to CF2017-07. Thank you for the comment. Regards, -- Masahiko Sawada NIPPON TELEGRAPH AND TELEPHONE CORPORATION NTT Open Source Software Center
On 3/4/17 9:08 PM, Masahiko Sawada wrote: > On Sat, Mar 4, 2017 at 5:47 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Fri, Mar 3, 2017 at 9:50 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>> Yes, it's taking a time to update logic and measurement but it's >>> coming along. Also I'm working on changing deadlock detection. Will >>> post new patch and measurement result. >> >> I think that we should push this patch out to v11. I think there are >> too many issues here to address in the limited time we have remaining >> this cycle, and I believe that if we try to get them all solved in the >> next few weeks we're likely to end up getting backed into some choices >> by time pressure that we may later regret bitterly. Since I created >> the deadlock issues that this patch is facing, I'm willing to try to >> help solve them, but I think it's going to require considerable and >> delicate surgery, and I don't think doing that under time pressure is >> a good idea. >> >> From a fairness point of view, a patch that's not in reviewable shape >> on March 1st should really be pushed out, and we're several days past >> that. >> > > Agreed. There are surely some rooms to discuss about the design yet, > and it will take long time. it's good to push this out to CF2017-07. > Thank you for the comment. I have marked this patch "Returned with Feedback." Of course you are welcome to submit this patch to the 2017-07 CF, or whenever you feel it is ready. -- -David david@pgmasters.net
On Sun, Mar 5, 2017 at 12:14 PM, David Steele <david@pgmasters.net> wrote: > On 3/4/17 9:08 PM, Masahiko Sawada wrote: >> On Sat, Mar 4, 2017 at 5:47 PM, Robert Haas <robertmhaas@gmail.com> wrote: >>> On Fri, Mar 3, 2017 at 9:50 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>>> Yes, it's taking a time to update logic and measurement but it's >>>> coming along. Also I'm working on changing deadlock detection. Will >>>> post new patch and measurement result. >>> >>> I think that we should push this patch out to v11. I think there are >>> too many issues here to address in the limited time we have remaining >>> this cycle, and I believe that if we try to get them all solved in the >>> next few weeks we're likely to end up getting backed into some choices >>> by time pressure that we may later regret bitterly. Since I created >>> the deadlock issues that this patch is facing, I'm willing to try to >>> help solve them, but I think it's going to require considerable and >>> delicate surgery, and I don't think doing that under time pressure is >>> a good idea. >>> >>> From a fairness point of view, a patch that's not in reviewable shape >>> on March 1st should really be pushed out, and we're several days past >>> that. >>> >> >> Agreed. There are surely some rooms to discuss about the design yet, >> and it will take long time. it's good to push this out to CF2017-07. >> Thank you for the comment. > > I have marked this patch "Returned with Feedback." Of course you are > welcome to submit this patch to the 2017-07 CF, or whenever you feel it > is ready. Thank you! Regards, -- Masahiko Sawada NIPPON TELEGRAPH AND TELEPHONE CORPORATION NTT Open Source Software Center
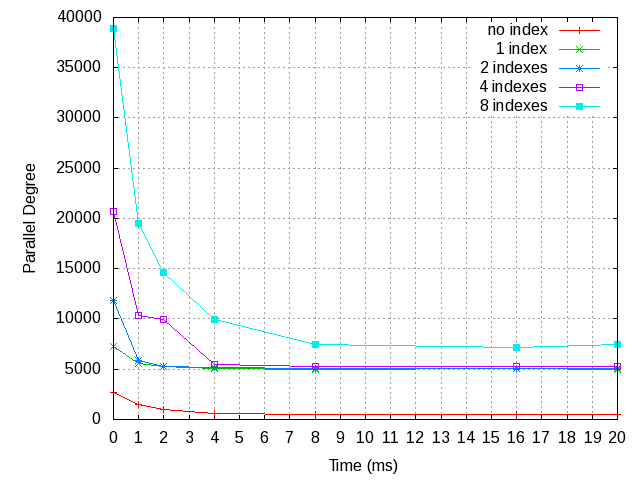
On Sun, Mar 5, 2017 at 4:09 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > On Sun, Mar 5, 2017 at 12:14 PM, David Steele <david@pgmasters.net> wrote: >> On 3/4/17 9:08 PM, Masahiko Sawada wrote: >>> On Sat, Mar 4, 2017 at 5:47 PM, Robert Haas <robertmhaas@gmail.com> wrote: >>>> On Fri, Mar 3, 2017 at 9:50 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>>>> Yes, it's taking a time to update logic and measurement but it's >>>>> coming along. Also I'm working on changing deadlock detection. Will >>>>> post new patch and measurement result. >>>> >>>> I think that we should push this patch out to v11. I think there are >>>> too many issues here to address in the limited time we have remaining >>>> this cycle, and I believe that if we try to get them all solved in the >>>> next few weeks we're likely to end up getting backed into some choices >>>> by time pressure that we may later regret bitterly. Since I created >>>> the deadlock issues that this patch is facing, I'm willing to try to >>>> help solve them, but I think it's going to require considerable and >>>> delicate surgery, and I don't think doing that under time pressure is >>>> a good idea. >>>> >>>> From a fairness point of view, a patch that's not in reviewable shape >>>> on March 1st should really be pushed out, and we're several days past >>>> that. >>>> >>> >>> Agreed. There are surely some rooms to discuss about the design yet, >>> and it will take long time. it's good to push this out to CF2017-07. >>> Thank you for the comment. >> >> I have marked this patch "Returned with Feedback." Of course you are >> welcome to submit this patch to the 2017-07 CF, or whenever you feel it >> is ready. > > Thank you! > I re-considered the basic design of parallel lazy vacuum. I didn't change the basic concept of this feature and usage, the lazy vacuum still executes with some parallel workers. In current design, dead tuple TIDs are shared with all vacuum workers including leader process when table has index. If we share dead tuple TIDs, we have to make two synchronization points: before starting vacuum and before clearing dead tuple TIDs. Before starting vacuum we have to make sure that the dead tuple TIDs are not added no more. And before clearing dead tuple TIDs we have to make sure that it's used no more. For index vacuum, each indexes is assigned to a vacuum workers based on ParallelWorkerNumber. For example, if a table has 5 indexes and vacuum with 2 workers, the leader process and one vacuum worker are assigned to 2 indexes, and another vacuum process is assigned the remaining one. The following steps are how the parallel vacuum processes if table has indexes. 1. The leader process and workers scan the table in parallel using ParallelHeapScanDesc, and collect dead tuple TIDs to shared memory. 2. Before vacuum on table, the leader process sort the dead tuple TIDs in physical order once all workers completes to scan the table. 3. In vacuum on table, the leader process and workers reclaim garbage on table in block-level parallel. 4. In vacuum on indexes, the indexes on table is assigned to particular parallel worker or leader process. The process assigned to a index vacuums on the index. 5. Before back to scanning the table, the leader process clears the dead tuple TIDs once all workers completes to vacuum on table and indexes. Attached the latest patch but it's still PoC version patch and contains some debug codes. Note that this patch still requires another patch which moves the relation extension lock out of heavy-weight lock[1]. The parallel lazy vacuum patch could work even without [1] patch but could fail during vacuum in some cases. Also, I attached the result of performance evaluation. The table size is approximately 300MB ( > shared_buffers) and I deleted tuples on every blocks before execute vacuum so that vacuum visits every blocks. The server spec is * Intel Xeon E5620 @ 2.4Ghz (8cores) * 32GB RAM * ioDrive According to the result of table with indexes, performance of lazy vacuum improved up to a point where the number of indexes and parallel degree are the same. If a table has 16 indexes and vacuum with 16 workers, parallel vacuum is 10x faster than single process execution. Also according to the result of table with no indexes, the parallel vacuum is 5x faster than single process execution at 8 parallel degree. Of course we can vacuum only for indexes I'm planning to work on that in PG11, will register it to next CF. Comment and feedback are very welcome. [1] https://www.postgresql.org/message-id/CAD21AoAmdW7eWKi28FkXXd_4fjSdzVDpeH1xYVX7qx%3DSyqYyJA%40mail.gmail.com Regards, -- Masahiko Sawada NIPPON TELEGRAPH AND TELEPHONE CORPORATION NTT Open Source Software Center -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
{kind=link}
{kind=link}
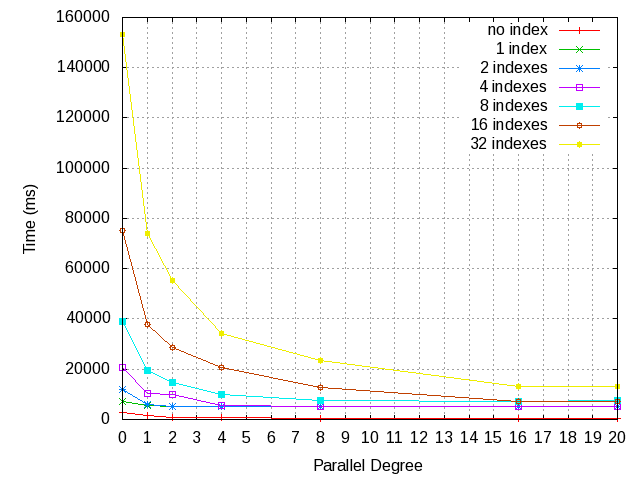
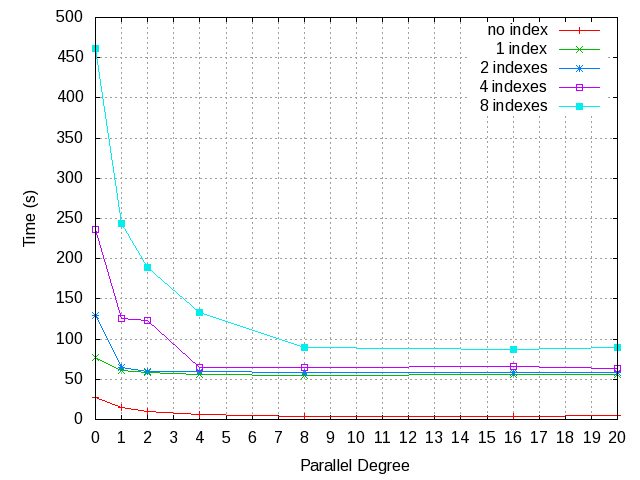
On Wed, Jul 26, 2017 at 5:38 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > On Sun, Mar 5, 2017 at 4:09 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >> On Sun, Mar 5, 2017 at 12:14 PM, David Steele <david@pgmasters.net> wrote: >>> On 3/4/17 9:08 PM, Masahiko Sawada wrote: >>>> On Sat, Mar 4, 2017 at 5:47 PM, Robert Haas <robertmhaas@gmail.com> wrote: >>>>> On Fri, Mar 3, 2017 at 9:50 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>>>>> Yes, it's taking a time to update logic and measurement but it's >>>>>> coming along. Also I'm working on changing deadlock detection. Will >>>>>> post new patch and measurement result. >>>>> >>>>> I think that we should push this patch out to v11. I think there are >>>>> too many issues here to address in the limited time we have remaining >>>>> this cycle, and I believe that if we try to get them all solved in the >>>>> next few weeks we're likely to end up getting backed into some choices >>>>> by time pressure that we may later regret bitterly. Since I created >>>>> the deadlock issues that this patch is facing, I'm willing to try to >>>>> help solve them, but I think it's going to require considerable and >>>>> delicate surgery, and I don't think doing that under time pressure is >>>>> a good idea. >>>>> >>>>> From a fairness point of view, a patch that's not in reviewable shape >>>>> on March 1st should really be pushed out, and we're several days past >>>>> that. >>>>> >>>> >>>> Agreed. There are surely some rooms to discuss about the design yet, >>>> and it will take long time. it's good to push this out to CF2017-07. >>>> Thank you for the comment. >>> >>> I have marked this patch "Returned with Feedback." Of course you are >>> welcome to submit this patch to the 2017-07 CF, or whenever you feel it >>> is ready. >> >> Thank you! >> > > I re-considered the basic design of parallel lazy vacuum. I didn't > change the basic concept of this feature and usage, the lazy vacuum > still executes with some parallel workers. In current design, dead > tuple TIDs are shared with all vacuum workers including leader process > when table has index. If we share dead tuple TIDs, we have to make two > synchronization points: before starting vacuum and before clearing > dead tuple TIDs. Before starting vacuum we have to make sure that the > dead tuple TIDs are not added no more. And before clearing dead tuple > TIDs we have to make sure that it's used no more. > > For index vacuum, each indexes is assigned to a vacuum workers based > on ParallelWorkerNumber. For example, if a table has 5 indexes and > vacuum with 2 workers, the leader process and one vacuum worker are > assigned to 2 indexes, and another vacuum process is assigned the > remaining one. The following steps are how the parallel vacuum > processes if table has indexes. > > 1. The leader process and workers scan the table in parallel using > ParallelHeapScanDesc, and collect dead tuple TIDs to shared memory. > 2. Before vacuum on table, the leader process sort the dead tuple TIDs > in physical order once all workers completes to scan the table. > 3. In vacuum on table, the leader process and workers reclaim garbage > on table in block-level parallel. > 4. In vacuum on indexes, the indexes on table is assigned to > particular parallel worker or leader process. The process assigned to > a index vacuums on the index. > 5. Before back to scanning the table, the leader process clears the > dead tuple TIDs once all workers completes to vacuum on table and > indexes. > > Attached the latest patch but it's still PoC version patch and > contains some debug codes. Note that this patch still requires another > patch which moves the relation extension lock out of heavy-weight > lock[1]. The parallel lazy vacuum patch could work even without [1] > patch but could fail during vacuum in some cases. > > Also, I attached the result of performance evaluation. The table size > is approximately 300MB ( > shared_buffers) and I deleted tuples on > every blocks before execute vacuum so that vacuum visits every blocks. > The server spec is > * Intel Xeon E5620 @ 2.4Ghz (8cores) > * 32GB RAM > * ioDrive > > According to the result of table with indexes, performance of lazy > vacuum improved up to a point where the number of indexes and parallel > degree are the same. If a table has 16 indexes and vacuum with 16 > workers, parallel vacuum is 10x faster than single process execution. > Also according to the result of table with no indexes, the parallel > vacuum is 5x faster than single process execution at 8 parallel > degree. Of course we can vacuum only for indexes > > I'm planning to work on that in PG11, will register it to next CF. > Comment and feedback are very welcome. > Since the previous patch conflicts with current HEAD I attached the latest version patch. Also, I measured performance benefit with more large 4GB table and indexes and attached the result. Regards, -- Masahiko Sawada NIPPON TELEGRAPH AND TELEPHONE CORPORATION NTT Open Source Software Center -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
{kind=link}
{kind=link}
On Tue, Aug 15, 2017 at 10:13 AM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > On Wed, Jul 26, 2017 at 5:38 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >> On Sun, Mar 5, 2017 at 4:09 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>> On Sun, Mar 5, 2017 at 12:14 PM, David Steele <david@pgmasters.net> wrote: >>>> On 3/4/17 9:08 PM, Masahiko Sawada wrote: >>>>> On Sat, Mar 4, 2017 at 5:47 PM, Robert Haas <robertmhaas@gmail.com> wrote: >>>>>> On Fri, Mar 3, 2017 at 9:50 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>>>>>> Yes, it's taking a time to update logic and measurement but it's >>>>>>> coming along. Also I'm working on changing deadlock detection. Will >>>>>>> post new patch and measurement result. >>>>>> >>>>>> I think that we should push this patch out to v11. I think there are >>>>>> too many issues here to address in the limited time we have remaining >>>>>> this cycle, and I believe that if we try to get them all solved in the >>>>>> next few weeks we're likely to end up getting backed into some choices >>>>>> by time pressure that we may later regret bitterly. Since I created >>>>>> the deadlock issues that this patch is facing, I'm willing to try to >>>>>> help solve them, but I think it's going to require considerable and >>>>>> delicate surgery, and I don't think doing that under time pressure is >>>>>> a good idea. >>>>>> >>>>>> From a fairness point of view, a patch that's not in reviewable shape >>>>>> on March 1st should really be pushed out, and we're several days past >>>>>> that. >>>>>> >>>>> >>>>> Agreed. There are surely some rooms to discuss about the design yet, >>>>> and it will take long time. it's good to push this out to CF2017-07. >>>>> Thank you for the comment. >>>> >>>> I have marked this patch "Returned with Feedback." Of course you are >>>> welcome to submit this patch to the 2017-07 CF, or whenever you feel it >>>> is ready. >>> >>> Thank you! >>> >> >> I re-considered the basic design of parallel lazy vacuum. I didn't >> change the basic concept of this feature and usage, the lazy vacuum >> still executes with some parallel workers. In current design, dead >> tuple TIDs are shared with all vacuum workers including leader process >> when table has index. If we share dead tuple TIDs, we have to make two >> synchronization points: before starting vacuum and before clearing >> dead tuple TIDs. Before starting vacuum we have to make sure that the >> dead tuple TIDs are not added no more. And before clearing dead tuple >> TIDs we have to make sure that it's used no more. >> >> For index vacuum, each indexes is assigned to a vacuum workers based >> on ParallelWorkerNumber. For example, if a table has 5 indexes and >> vacuum with 2 workers, the leader process and one vacuum worker are >> assigned to 2 indexes, and another vacuum process is assigned the >> remaining one. The following steps are how the parallel vacuum >> processes if table has indexes. >> >> 1. The leader process and workers scan the table in parallel using >> ParallelHeapScanDesc, and collect dead tuple TIDs to shared memory. >> 2. Before vacuum on table, the leader process sort the dead tuple TIDs >> in physical order once all workers completes to scan the table. >> 3. In vacuum on table, the leader process and workers reclaim garbage >> on table in block-level parallel. >> 4. In vacuum on indexes, the indexes on table is assigned to >> particular parallel worker or leader process. The process assigned to >> a index vacuums on the index. >> 5. Before back to scanning the table, the leader process clears the >> dead tuple TIDs once all workers completes to vacuum on table and >> indexes. >> >> Attached the latest patch but it's still PoC version patch and >> contains some debug codes. Note that this patch still requires another >> patch which moves the relation extension lock out of heavy-weight >> lock[1]. The parallel lazy vacuum patch could work even without [1] >> patch but could fail during vacuum in some cases. >> >> Also, I attached the result of performance evaluation. The table size >> is approximately 300MB ( > shared_buffers) and I deleted tuples on >> every blocks before execute vacuum so that vacuum visits every blocks. >> The server spec is >> * Intel Xeon E5620 @ 2.4Ghz (8cores) >> * 32GB RAM >> * ioDrive >> >> According to the result of table with indexes, performance of lazy >> vacuum improved up to a point where the number of indexes and parallel >> degree are the same. If a table has 16 indexes and vacuum with 16 >> workers, parallel vacuum is 10x faster than single process execution. >> Also according to the result of table with no indexes, the parallel >> vacuum is 5x faster than single process execution at 8 parallel >> degree. Of course we can vacuum only for indexes >> >> I'm planning to work on that in PG11, will register it to next CF. >> Comment and feedback are very welcome. >> > > Since the previous patch conflicts with current HEAD I attached the > latest version patch. Also, I measured performance benefit with more > large 4GB table and indexes and attached the result. > Since v4 patch conflicts with current HEAD I attached the latest version patch. Regards, -- Masahiko Sawada NIPPON TELEGRAPH AND TELEPHONE CORPORATION NTT Open Source Software Center -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Fri, Sep 8, 2017 at 10:37 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > Since v4 patch conflicts with current HEAD I attached the latest version patch. Hi Sawada-san, Here is an interesting failure with this patch: test rowsecurity ... FAILED test rules ... FAILED Down at the bottom of the build log in the regression diffs file you can see: ! ERROR: cache lookup failed for relation 32893 https://travis-ci.org/postgresql-cfbot/postgresql/builds/277165907 -- Thomas Munro http://www.enterprisedb.com -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Tue, Sep 19, 2017 at 3:33 PM, Thomas Munro <thomas.munro@enterprisedb.com> wrote: > On Fri, Sep 8, 2017 at 10:37 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >> Since v4 patch conflicts with current HEAD I attached the latest version patch. > > Hi Sawada-san, > > Here is an interesting failure with this patch: > > test rowsecurity ... FAILED > test rules ... FAILED > > Down at the bottom of the build log in the regression diffs file you can see: > > ! ERROR: cache lookup failed for relation 32893 > > https://travis-ci.org/postgresql-cfbot/postgresql/builds/277165907 > Thank you for letting me know. Hmm, it's an interesting failure. I'll investigate it and post the new patch. Regards, -- Masahiko Sawada NIPPON TELEGRAPH AND TELEPHONE CORPORATION NTT Open Source Software Center -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Tue, Sep 19, 2017 at 4:31 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > On Tue, Sep 19, 2017 at 3:33 PM, Thomas Munro > <thomas.munro@enterprisedb.com> wrote: >> On Fri, Sep 8, 2017 at 10:37 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>> Since v4 patch conflicts with current HEAD I attached the latest version patch. >> >> Hi Sawada-san, >> >> Here is an interesting failure with this patch: >> >> test rowsecurity ... FAILED >> test rules ... FAILED >> >> Down at the bottom of the build log in the regression diffs file you can see: >> >> ! ERROR: cache lookup failed for relation 32893 >> >> https://travis-ci.org/postgresql-cfbot/postgresql/builds/277165907 >> > > Thank you for letting me know. > > Hmm, it's an interesting failure. I'll investigate it and post the new patch. > Since the patch conflicts with current HEAD, I've rebased the patch and fixed a bug. Please review it. Regards, -- Masahiko Sawada NIPPON TELEGRAPH AND TELEPHONE CORPORATION NTT Open Source Software Center -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Thu, Oct 5, 2017 at 10:50 AM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > On Tue, Sep 19, 2017 at 4:31 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >> On Tue, Sep 19, 2017 at 3:33 PM, Thomas Munro >> <thomas.munro@enterprisedb.com> wrote: >>> On Fri, Sep 8, 2017 at 10:37 PM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>>> Since v4 patch conflicts with current HEAD I attached the latest version patch. >>> >>> Hi Sawada-san, >>> >>> Here is an interesting failure with this patch: >>> >>> test rowsecurity ... FAILED >>> test rules ... FAILED >>> >>> Down at the bottom of the build log in the regression diffs file you can see: >>> >>> ! ERROR: cache lookup failed for relation 32893 >>> >>> https://travis-ci.org/postgresql-cfbot/postgresql/builds/277165907 >>> >> >> Thank you for letting me know. >> >> Hmm, it's an interesting failure. I'll investigate it and post the new patch. >> > > Since the patch conflicts with current HEAD, I've rebased the patch > and fixed a bug. Please review it. > Attached latest version patch. I updated the followings since the previous version. * Support vacuum progress reporting. * Enable to set the parallel vacuum degree per table for autovacuum (0 by default) * Fix bugs I've done implementation of all parts that I attempted to support, so this patch now is no longer WIP patch. Please review it. Regards, -- Masahiko Sawada NIPPON TELEGRAPH AND TELEPHONE CORPORATION NTT Open Source Software Center -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On Tue, Sep 19, 2017 at 3:31 AM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >> Down at the bottom of the build log in the regression diffs file you can see: >> >> ! ERROR: cache lookup failed for relation 32893 >> >> https://travis-ci.org/postgresql-cfbot/postgresql/builds/277165907 > > Thank you for letting me know. > > Hmm, it's an interesting failure. I'll investigate it and post the new patch. Did you ever find out what the cause of this problem was? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Sun, Oct 22, 2017 at 5:09 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Sep 19, 2017 at 3:31 AM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>> Down at the bottom of the build log in the regression diffs file you can see: >>> >>> ! ERROR: cache lookup failed for relation 32893 >>> >>> https://travis-ci.org/postgresql-cfbot/postgresql/builds/277165907 >> >> Thank you for letting me know. >> >> Hmm, it's an interesting failure. I'll investigate it and post the new patch. > > Did you ever find out what the cause of this problem was? I wonder if it might have been the same issue that commit 19de0ab23ccba12567c18640f00b49f01471018d fixed a week or so later. -- Thomas Munro http://www.enterprisedb.com -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On 2017/10/22 5:25, Thomas Munro wrote: > On Sun, Oct 22, 2017 at 5:09 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Tue, Sep 19, 2017 at 3:31 AM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>>> Down at the bottom of the build log in the regression diffs file you can see: >>>> >>>> ! ERROR: cache lookup failed for relation 32893 >>>> >>>> https://travis-ci.org/postgresql-cfbot/postgresql/builds/277165907 >>> >>> Thank you for letting me know. >>> >>> Hmm, it's an interesting failure. I'll investigate it and post the new patch. >> >> Did you ever find out what the cause of this problem was? > > I wonder if it might have been the same issue that commit > 19de0ab23ccba12567c18640f00b49f01471018d fixed a week or so later. Hmm, 19de0ab23ccba seems to prevent the "cache lookup failed for relation XXX" error in a different code path though (the code path handling manual vacuum). Not sure if the commit could have prevented that error being emitted by DROP SCHEMA ... CASCADE, which seems to be what produced it in this case. Maybe I'm missing something though. Thanks, Amit -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Mon, Oct 23, 2017 at 10:43 AM, Amit Langote <Langote_Amit_f8@lab.ntt.co.jp> wrote: > On 2017/10/22 5:25, Thomas Munro wrote: >> On Sun, Oct 22, 2017 at 5:09 AM, Robert Haas <robertmhaas@gmail.com> wrote: >>> On Tue, Sep 19, 2017 at 3:31 AM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: >>>>> Down at the bottom of the build log in the regression diffs file you can see: >>>>> >>>>> ! ERROR: cache lookup failed for relation 32893 >>>>> >>>>> https://travis-ci.org/postgresql-cfbot/postgresql/builds/277165907 >>>> >>>> Thank you for letting me know. >>>> >>>> Hmm, it's an interesting failure. I'll investigate it and post the new patch. >>> >>> Did you ever find out what the cause of this problem was? >> >> I wonder if it might have been the same issue that commit >> 19de0ab23ccba12567c18640f00b49f01471018d fixed a week or so later. > > Hmm, 19de0ab23ccba seems to prevent the "cache lookup failed for relation > XXX" error in a different code path though (the code path handling manual > vacuum). Not sure if the commit could have prevented that error being > emitted by DROP SCHEMA ... CASCADE, which seems to be what produced it in > this case. Maybe I'm missing something though. > Yeah, I was thinking the commit is relevant with this issue but as Amit mentioned this error is emitted by DROP SCHEMA CASCASE. I don't find out the cause of this issue yet. With the previous version patch, autovacuum workers were woking with one parallel worker but it never drops relations. So it's possible that the error might not have been relevant with the patch but anywayI'll continue to work on that. Regards, -- Masahiko Sawada NIPPON TELEGRAPH AND TELEPHONE CORPORATION NTT Open Source Software Center -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On Tue, Oct 24, 2017 at 5:54 AM, Masahiko Sawada <sawada.mshk@gmail.com> wrote: > Yeah, I was thinking the commit is relevant with this issue but as > Amit mentioned this error is emitted by DROP SCHEMA CASCASE. > I don't find out the cause of this issue yet. With the previous > version patch, autovacuum workers were woking with one parallel worker > but it never drops relations. So it's possible that the error might > not have been relevant with the patch but anywayI'll continue to work > on that. This depends on the extension lock patch from https://www.postgresql.org/message-id/flat/CAD21AoCmT3cFQUN4aVvzy5chw7DuzXrJCbrjTU05B+Ss=Gn1LA@mail.gmail.com/ if I am following correctly. So I propose to mark this patch as returned with feedback for now, and come back to it once the root problems are addressed. Feel free to correct me if you think that's not adapted. -- Michael