Thread: tweaking NTUP_PER_BUCKET
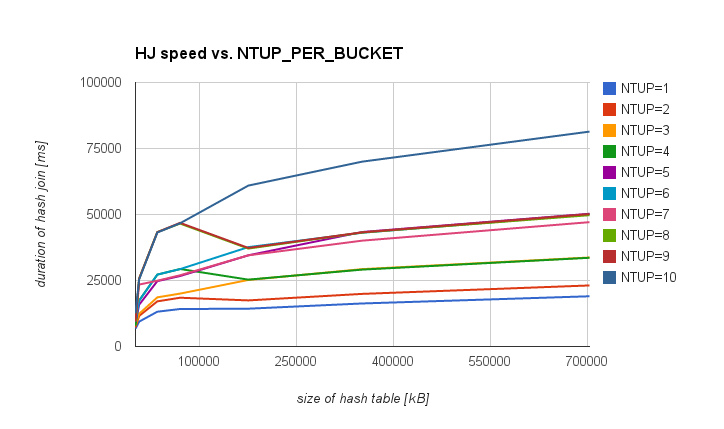
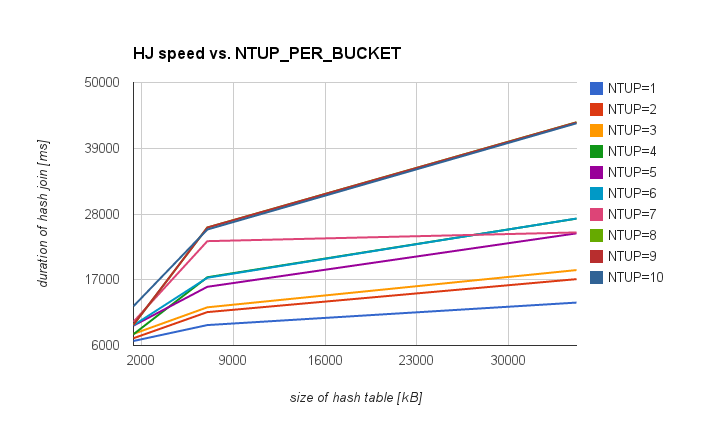
Hi, while hacking on the 'dynamic nbucket' patch, scheduled for the next CF (https://commitfest.postgresql.org/action/patch_view?id=1494) I was repeatedly stumbling over NTUP_PER_BUCKET. I'd like to propose a change in how we handle it. TL;DR; version -------------- I propose dynamic increase of the nbuckets (up to NTUP_PER_BUCKET=1) once the table is built and there's free space in work_mem. The patch mentioned above makes implementing this possible / rather simple. Long version ------------ I've seen discussions in the list in the past, but I don't recall any numbers comparing impact of different values. So I did a simple test, measuring the duration of a simple hashjoin with different hashtable sizes and NTUP_PER_BUCKET values. In short, something like this: CREATE TABLE outer_table (id INT); CREATE TABLE inner_table (id INT, val_int INT, val_txt TEXT); INSERT INTO outer_table SELECT i FROM generate_series(1,50000000) s(i); INSERT INTO inner_table SELECT i, mod(i,10000), md5(i::text) FROM generate_series(1,10000000) s(i); ANALYZE outer_table; ANALYZE inner_table; -- force hash join with a single batch set work_mem = '1GB'; set enable_sort = off; set enable_indexscan = off; set enable_bitmapscan = off; set enable_mergejoin = off; set enable_nestloop = off; -- query with various values in the WHERE condition, determining -- the size of the hash table (single batch, thanks to work_mem) SELECT COUNT(i.val_txt) FROM outer_table o LEFT JOIN inner_table i ON (i.id = o.id) WHERE val_int < 1000; which leads to plans like this: http://explain.depesz.com/s/i7W I've repeated this with with NTUP_PER_BUCKET between 1 and 10, and various values in the WHERE condition, and I got this table, illustrating impact of various NTUP_PER_BUCKET values for various hashtable sizes: kB NTUP=1 NTUP=2 NTUP=4 NTUP=5 NTUP=9 NTUP=10 1407 6753 7218 7890 9324 9488 12574 7032 9417 11586 17417 15820 25732 25402 35157 13179 17101 27225 24763 43323 43175 70313 14203 18475 29354 26690 46840 46676 175782 14319 17458 25325 34542 37342 60949 351563 16297 19928 29124 43364 43232 70014 703125 19027 23125 33610 50283 50165 81398 (I've skipped columns for NTUP values that are almost exactly the same as the adjacent columns due to the fact bucket count grows by doubling). If you prefer charts to tables, attached are two showing the same data (complete and "small hashtables"). Also, attached is a CSV with the results, tracking number of buckets and durations for each hashtable size / NTUP_PER_BUCKET combination. I'm aware that the numbers and exact behaviour depends on the hardware (e.g. L1/L2 cache, RAM etc.), and the query used to get these values is somewhat simple (at least compared to some real-world values). But I believe the general behaviour won't vary too much. The first observation is that for large hashtables the difference between NTUP=1 and NTUP=10 is much larger than for small ones. Not really surprising - probably due to better hit ratios for CPU caches. For the large hashtable the difference is significant, easily beating price for the rebuild of the hashtable (increasing the nbuckets). Therefore I'd like to propose dynamic increase of bucket count. The patch mentioned at the beginning does pretty much exactly this for plans with significantly underestimated cardinality of the hashtable (thus causing inappropriately low bucket count and poor performance of the join). However it allows dynamic approach to NTUP_PER_BUCKET too, so I propose a change along these lines: 1) consider lowering the NTUP_PER_BUCKET (see measurements below) 2) do the initial nbucket/nbatch estimation as today (with whatever NTUP_PER_BUCKET value we end up using) and build the hashtable 3) while building the hashtable, include space for buckets into spaceUsed while deciding whether to increase number of batches (the fact it's not already included seems wrong), but instead of using initial bucket count, do this: if (hashtable->spaceUsed + BUCKET_SPACE(hashtable) > hashtable->spaceAllowed) ExecHashIncreaseNumBatches(hashtable); where BUCKET_SPACE is 'how many buckets would be appropriate, given current tuples per batch'. 4) consider what is the "appropriate" number of buckets and rebuild the table if appropriate This is where the patch fixes the underestimated nbuckets value, but what we can do is look at how much free space remains in work_mem and use as many buckets as fit into work_mem (capped with tuples per batch, of course) if there's free space. Even if the initial cardinality estimate was correct (so we're below NTUP_PER_BUCKET) this may be a significant speedup. Say for example we have 10M tuples in the table - with the default NTUP_PER_BUCKET this means ~1M buckets. But there's significant performance difference between hashtable with 1 or 10 tuples per bucket (see below), and if we have 80MB in work_mem (instead of the default 8MB) this may be a huge gain. Any comments / objections welcome. regards Tomas
Attachment
{kind=link}
{kind=link}
On 3.7.2014 02:13, Tomas Vondra wrote: > Hi, > > while hacking on the 'dynamic nbucket' patch, scheduled for the next CF > (https://commitfest.postgresql.org/action/patch_view?id=1494) I was > repeatedly stumbling over NTUP_PER_BUCKET. I'd like to propose a change > in how we handle it. > > > TL;DR; version > -------------- > > I propose dynamic increase of the nbuckets (up to NTUP_PER_BUCKET=1) > once the table is built and there's free space in work_mem. The patch > mentioned above makes implementing this possible / rather simple. Attached is v1 of this experimental patch. It's supposed to be applied on top of v7 of this patch http://www.postgresql.org/message-id/53B59498.3000800@fuzzy.cz as it shared most of the implementation. So apply it like this: patch -p1 < hashjoin-nbuckets-growth-v7.patch patch -p1 < hashjoin-dynamic-ntup-v1.patch It implements the ideas outlined in the previous message, most importantly: (a) decreases NTUP_PER_BUCKET to 4 (b) checks free work_mem when deciding whether to add batch (c) after building the batches, increases the number of buckets as much as possible, i.e. up to the number of batch tuples, but not exceeding work_mem The improvements for the queries I tried so far are quite significant (partially due to the NTUP_PER_BUCKET decrease, partially due to the additional bucket count increase). The rebuild is quite fast - the patch measures and reports this as a WARNING, and the timings I've seen are ~12ms per 7MB (i.e. ~120ms for 70MB and ~1200ms for 700MB). Of course, this only makes sense when compared to how much time it saved, but for the queries I tested so far this was a good investment. However it's likely there are queries where this may not be the case, i.e. where rebuilding the hash table is not worth it. Let me know if you can construct such query (I wasn't). regards Tomas
Attachment
Tomas,
* Tomas Vondra (tv@fuzzy.cz) wrote:
> However it's likely there are queries where this may not be the case,
> i.e. where rebuilding the hash table is not worth it. Let me know if you
> can construct such query (I wasn't).
Thanks for working on this! I've been thinking on this for a while and
this seems like it may be a good approach. Have you considered a bloom
filter over the buckets..? Also, I'd suggest you check the archives
from about this time last year for test cases that I was using which
showed cases where hashing the larger table was a better choice- those
same cases may also show regression here (or at least would be something
good to test).
Have you tried to work out what a 'worst case' regression for this
change would look like? Also, how does the planning around this change?
Are we more likely now to hash the smaller table (I'd guess 'yes' just
based on the reduction in NTUP_PER_BUCKET, but did you make any changes
due to the rehashing cost?)?
Thanks,
Stephen
On Thu, Jul 3, 2014 at 11:40 PM, Stephen Frost <sfrost@snowman.net> wrote:
Tomas,filter?Thanks for working on this! I've been thinking on this for a while and
* Tomas Vondra (tv@fuzzy.cz) wrote:
> However it's likely there are queries where this may not be the case,
> i.e. where rebuilding the hash table is not worth it. Let me know if you
> can construct such query (I wasn't).
this seems like it may be a good approach. Have you considered a bloom
IIRC, last time when we tried doing bloom filters, I was short of some real world useful hash functions that we could use for building the bloom filter.
If we are restarting experiments on this, I would be glad to assist.
Regards,
Atri
Atri
Hi Stephen, On 3.7.2014 20:10, Stephen Frost wrote: > Tomas, > > * Tomas Vondra (tv@fuzzy.cz) wrote: >> However it's likely there are queries where this may not be the case, >> i.e. where rebuilding the hash table is not worth it. Let me know if you >> can construct such query (I wasn't). > > Thanks for working on this! I've been thinking on this for a while > and this seems like it may be a good approach. Have you considered a > bloom filter over the buckets..? Also, I'd suggest you check the I know you've experimented with it, but I haven't looked into that yet. > archives from about this time last year for test cases that I was > using which showed cases where hashing the larger table was a better > choice- those same cases may also show regression here (or at least > would be something good to test). Good idea, I'll look at the test cases - thanks. > Have you tried to work out what a 'worst case' regression for this > change would look like? Also, how does the planning around this > change? Are we more likely now to hash the smaller table (I'd guess > 'yes' just based on the reduction in NTUP_PER_BUCKET, but did you > make any changes due to the rehashing cost?)? The case I was thinking about is underestimated cardinality of the inner table and a small outer table. That'd lead to a large hash table and very few lookups (thus making the rehash inefficient). I.e. something like this: Hash Join Seq Scan on small_table (rows=100) (actual rows=100) Hash Seq Scan on bad_estimate (rows=100) (actualrows=1000000000) Filter: ((a < 100) AND (b < 100)) But I wasn't able to reproduce this reasonably, because in practice that'd lead to a nested loop or something like that (which is a planning issue, impossible to fix in hashjoin code). Tomas
On Thu, Jul 3, 2014 at 11:40 AM, Atri Sharma <atri.jiit@gmail.com> wrote: > IIRC, last time when we tried doing bloom filters, I was short of some real > world useful hash functions that we could use for building the bloom filter. Last time was we wanted to use bloom filters in hash joins to filter out tuples that won't match any of the future hash batches to reduce the amount of tuples that need to be spilled to disk. However the problem was that it was unclear for a given amount of memory usage how to pick the right size bloom filter and how to model how much it would save versus how much it would cost in reduced hash table size. I think it just required some good empirical tests and hash join heavy workloads to come up with some reasonable guesses. We don't need a perfect model just some reasonable bloom filter size that we're pretty sure will usually help more than it hurts. -- greg
On 3.7.2014 20:50, Tomas Vondra wrote: > Hi Stephen, > > On 3.7.2014 20:10, Stephen Frost wrote: >> Tomas, >> >> * Tomas Vondra (tv@fuzzy.cz) wrote: >>> However it's likely there are queries where this may not be the case, >>> i.e. where rebuilding the hash table is not worth it. Let me know if you >>> can construct such query (I wasn't). >> >> Thanks for working on this! I've been thinking on this for a while >> and this seems like it may be a good approach. Have you considered a >> bloom filter over the buckets..? Also, I'd suggest you check the >> archives from about this time last year for test cases that I was >> using which showed cases where hashing the larger table was a better >> choice- those same cases may also show regression here (or at least >> would be something good to test). > > Good idea, I'll look at the test cases - thanks. I can't find the thread / test cases in the archives. I've found this thread in hackers: http://www.postgresql.org/message-id/CAOeZVif-R-iLF966wEipk5By-KhzVLOqpWqurpaK3p5fYw-Rdw@mail.gmail.com Can you point me to the right one, please? regards Tomas
* Greg Stark (stark@mit.edu) wrote:
> On Thu, Jul 3, 2014 at 11:40 AM, Atri Sharma <atri.jiit@gmail.com> wrote:
> > IIRC, last time when we tried doing bloom filters, I was short of some real
> > world useful hash functions that we could use for building the bloom filter.
>
> Last time was we wanted to use bloom filters in hash joins to filter
> out tuples that won't match any of the future hash batches to reduce
> the amount of tuples that need to be spilled to disk. However the
> problem was that it was unclear for a given amount of memory usage how
> to pick the right size bloom filter and how to model how much it would
> save versus how much it would cost in reduced hash table size.
Right. There's only one hash function available, really, (we don't
currently support multiple hash functions..), unless we want to try and
re-hash the 32bit hash value that we get back (not against trying that,
but it isn't what I'd start with) and it would hopefully be sufficient
for this.
> I think it just required some good empirical tests and hash join heavy
> workloads to come up with some reasonable guesses. We don't need a
> perfect model just some reasonable bloom filter size that we're pretty
> sure will usually help more than it hurts.
This would help out a lot of things, really.. Perhaps what Tomas is
developing regarding test cases would help here also.
Thanks,
Stephen
On 6.7.2014 06:47, Stephen Frost wrote: > * Greg Stark (stark@mit.edu) wrote: >> Last time was we wanted to use bloom filters in hash joins to >> filter out tuples that won't match any of the future hash batches >> to reduce the amount of tuples that need to be spilled to disk. >> However the problem was that it was unclear for a given amount of >> memory usage how to pick the right size bloom filter and how to >> model how much it would save versus how much it would cost in >> reduced hash table size. > > Right. There's only one hash function available, really, (we don't > currently support multiple hash functions..), unless we want to try > and re-hash the 32bit hash value that we get back (not against trying > that, but it isn't what I'd start with) and it would hopefully be > sufficient for this. I don't really see a need to add more hashing functions. Use the hash value itself as an input to the bloom filter seems just fine to me. According to [1] the expected number of collisions is n - k + k * math.pow((1 - 1/k), n) where 'k' is the number of possible values (2^32 in our case), and 'n' is the number of inserts (i.e. values inserted into the table). With a 1GB work_mem and ~50B per row, that's ~20M rows. According to the formula, that's ~50k collisions. In other words, 0.25% of false positives. This seems more than sufficient for the bloom filter, and if 0.25% of false positives causes it to be inefficient I'd say the gains are not that great anyway. (Unless my calculations are somehow flawed, of course). [1] https://www.cs.duke.edu/courses/cps102/spring10/Lectures/L-18.pdf >> I think it just required some good empirical tests and hash join >> heavy workloads to come up with some reasonable guesses. We don't >> need a perfect model just some reasonable bloom filter size that >> we're pretty sure will usually help more than it hurts. > > This would help out a lot of things, really.. Perhaps what Tomas is > developing regarding test cases would help here also. The test cases might be reused I guess. However I still don't have a clear idea of how exactly the bloom filter would be implemented. In the threads I found it was suggested to use per-bucket filtersm, which seems really strange to me. I see two options: (a) global filter - bloom filter sized according to estimates from planner - ... so we're screwed if the estimates are significantly wrong - create the filter in ExecHashTableCreate - insert all tuples in ExecHashTableInsert (all batches) (b) per-batch filter - may be built after the batching is completed - we have reliable numbers at this point (not just estimates) - per-batchfilters may be smaller (only fraction of tuples) So the per-batch filter seems to be a better approach. The question is the sizing of the bloom filter. According to [2] there are three rules of thumb for sizing bloom filters: (1) 1B per item, to get 2% error rate (2) 0.7 * bits of hash functions (~5 when using 1B / item) (3) number of hashesdominates the performance (more to compute, more memory accesses) When working with 20M rows, this means ~20MB and 5 hash functions. Not that bad, although we don't know how expensive it's to build the filter. [2] http://corte.si/posts/code/bloom-filter-rules-of-thumb/index.html However this is somewhat flawed because this assumes the 20M hashed values are distinct, so if the inner table contains duplicate keys, we might use smaller bloom filter. But we don't know that value (ndistinct estimates are rather unreliable, but we might use hyperloglog counter to do this). Also, there are cases when we know there will be no misses (e.g. a join on a FK), and in that case it's pointless to build the bloom filter. Would be nice to get some flag from the planner whether to build it, a threshold when to build it (e.g. if rowcount is > 10k, build the filter). Doing something similar for the two patches I posted (tweaking the nbuckets dynamically) might also benefit from such planning information, although it's not that critical for them. regards Tomas
Tomas, * Tomas Vondra (tv@fuzzy.cz) wrote: > I can't find the thread / test cases in the archives. I've found this > thread in hackers: > > http://www.postgresql.org/message-id/CAOeZVif-R-iLF966wEipk5By-KhzVLOqpWqurpaK3p5fYw-Rdw@mail.gmail.com > > Can you point me to the right one, please? This: http://www.postgresql.org/message-id/20130328235627.GV4361@tamriel.snowman.net and I think there may have been other test cases on that thread somewhere... I certainly recall having at least a couple of them that I was playing with. I can probably find them around here somewhere too, if necessary. Thanks, Stephen
On 6.7.2014 17:57, Stephen Frost wrote: > Tomas, > > * Tomas Vondra (tv@fuzzy.cz) wrote: >> I can't find the thread / test cases in the archives. I've found this >> thread in hackers: >> >> http://www.postgresql.org/message-id/CAOeZVif-R-iLF966wEipk5By-KhzVLOqpWqurpaK3p5fYw-Rdw@mail.gmail.com >> >> Can you point me to the right one, please? > > This: > > http://www.postgresql.org/message-id/20130328235627.GV4361@tamriel.snowman.net Sadly, the link to the SQL does not work :-( http://snowman.net/~sfrost/test_case.sql => 404 > and I think there may have been other test cases on that thread > somewhere... I certainly recall having at least a couple of them that I > was playing with. > > I can probably find them around here somewhere too, if necessary. If you could look for them, that'd be great. regards Tomas
On Wed, Jul 2, 2014 at 8:13 PM, Tomas Vondra <tv@fuzzy.cz> wrote: > I propose dynamic increase of the nbuckets (up to NTUP_PER_BUCKET=1) > once the table is built and there's free space in work_mem. The patch > mentioned above makes implementing this possible / rather simple. Another idea would be to start with NTUP_PER_BUCKET=1 and then, if we run out of memory, increase NTUP_PER_BUCKET. I'd like to think that the common case is that work_mem will be large enough that everything fits; and if you do it that way, then you save yourself the trouble of rehashing later, which as you point out might lose if there are only a few probes. If it turns out that you run short of memory, you can merge pairs of buckets up to three times, effectively doubling NTUP_PER_BUCKET each time. Yet another idea is to stick with your scheme, but do the dynamic bucket splits lazily. Set a flag on each bucket indicating whether or not it needs a lazy split. When someone actually probes the hash table, if the flag is set for a particular bucket, move any tuples that don't belong as we scan the bucket. If we reach the end of the bucket chain, clear the flag. Not sure either of these are better (though I kind of like the first one) but I thought I'd throw them out there... -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 8 Červenec 2014, 14:49, Robert Haas wrote: > On Wed, Jul 2, 2014 at 8:13 PM, Tomas Vondra <tv@fuzzy.cz> wrote: >> I propose dynamic increase of the nbuckets (up to NTUP_PER_BUCKET=1) >> once the table is built and there's free space in work_mem. The patch >> mentioned above makes implementing this possible / rather simple. > > Another idea would be to start with NTUP_PER_BUCKET=1 and then, if we > run out of memory, increase NTUP_PER_BUCKET. I'd like to think that > the common case is that work_mem will be large enough that everything > fits; and if you do it that way, then you save yourself the trouble of > rehashing later, which as you point out might lose if there are only a > few probes. If it turns out that you run short of memory, you can > merge pairs of buckets up to three times, effectively doubling > NTUP_PER_BUCKET each time. Maybe. I'm not against setting NTUP_PER_BUCKET=1, but with large outer relations it may be way cheaper to use higher NTUP_PER_BUCKET values instead of increasing the number of batches (resulting in repeated scans of the outer table). I think it's important (but difficult) to keep these things somehow balanced. With large work_mem values the amount of memory for buckets may be quite significant. E.g. 800MB work_mem may easily give ~120MB of memory taken by buckets with NTUP_PER_BUCKET=1. With NTUP_PER_BUCKET=4 it's just ~30MB. > Yet another idea is to stick with your scheme, but do the dynamic > bucket splits lazily. Set a flag on each bucket indicating whether or > not it needs a lazy split. When someone actually probes the hash > table, if the flag is set for a particular bucket, move any tuples > that don't belong as we scan the bucket. If we reach the end of the > bucket chain, clear the flag. I don't think a lazy scheme makes much sense here. There are two clearly separated phases - loading the table and search. Also, it seems to me it can't work as described. Say we build a table and then find out we need a table 4x the size. If I understand your proposal correctly, you'd just resize buckets array, copy the existing buckets (first 1/4 buckets) and set 'needs_split' flags. Correct? Well, the problem is that while scanning a bucket you already need to know which tuples belong there. But with the lazy approach, the tuples might still be in the old (not yet split) buckets. So you'd have to search the current bucket and all buckets that were not split yet. Or did I miss something? Tomas
On Tue, Jul 8, 2014 at 9:35 AM, Tomas Vondra <tv@fuzzy.cz> wrote: > On 8 Červenec 2014, 14:49, Robert Haas wrote: >> On Wed, Jul 2, 2014 at 8:13 PM, Tomas Vondra <tv@fuzzy.cz> wrote: >>> I propose dynamic increase of the nbuckets (up to NTUP_PER_BUCKET=1) >>> once the table is built and there's free space in work_mem. The patch >>> mentioned above makes implementing this possible / rather simple. >> >> Another idea would be to start with NTUP_PER_BUCKET=1 and then, if we >> run out of memory, increase NTUP_PER_BUCKET. I'd like to think that >> the common case is that work_mem will be large enough that everything >> fits; and if you do it that way, then you save yourself the trouble of >> rehashing later, which as you point out might lose if there are only a >> few probes. If it turns out that you run short of memory, you can >> merge pairs of buckets up to three times, effectively doubling >> NTUP_PER_BUCKET each time. > > Maybe. I'm not against setting NTUP_PER_BUCKET=1, but with large outer > relations it may be way cheaper to use higher NTUP_PER_BUCKET values > instead of increasing the number of batches (resulting in repeated scans > of the outer table). I think it's important (but difficult) to keep these > things somehow balanced. Right, I think that's clear. I'm just pointing out that you get to decide: you can either start with a larger NTUP_PER_BUCKET and then reduce it if you enough memory left, or you can start with a smaller NTUP_PER_BUCKET and then increase it if you run short of memory. >> Yet another idea is to stick with your scheme, but do the dynamic >> bucket splits lazily. Set a flag on each bucket indicating whether or >> not it needs a lazy split. When someone actually probes the hash >> table, if the flag is set for a particular bucket, move any tuples >> that don't belong as we scan the bucket. If we reach the end of the >> bucket chain, clear the flag. > > I don't think a lazy scheme makes much sense here. There are two clearly > separated phases - loading the table and search. > > Also, it seems to me it can't work as described. Say we build a table and > then find out we need a table 4x the size. If I understand your proposal > correctly, you'd just resize buckets array, copy the existing buckets > (first 1/4 buckets) and set 'needs_split' flags. Correct? > > Well, the problem is that while scanning a bucket you already need to know > which tuples belong there. But with the lazy approach, the tuples might > still be in the old (not yet split) buckets. So you'd have to search the > current bucket and all buckets that were not split yet. Or did I miss > something? If you have, say, bucket 0..63 and you decide to change it to buckets 0..255, then any tuple that isn't in bucket N has to be in bucket N % 64. More generally, any time you expand or contract by a power of two it's pretty easy to figure out where tuples have to go. But even if you do something that's not a power of two, like say a 10x compaction of the buckets, there's still only two buckets that can contain any particular hash value. If the hash value is H, the old number of buckets is O, and the new number of buckets is N, then the tuple has got to be in bucket H % O or bucket H % N. If bucket H % O doesn't have the needs-split flag set, then it must be in H % N (if it exists at all). -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 8 Červenec 2014, 16:16, Robert Haas wrote: > On Tue, Jul 8, 2014 at 9:35 AM, Tomas Vondra <tv@fuzzy.cz> wrote: >> Maybe. I'm not against setting NTUP_PER_BUCKET=1, but with large outer >> relations it may be way cheaper to use higher NTUP_PER_BUCKET values >> instead of increasing the number of batches (resulting in repeated scans >> of the outer table). I think it's important (but difficult) to keep >> these >> things somehow balanced. > > Right, I think that's clear. I'm just pointing out that you get to > decide: you can either start with a larger NTUP_PER_BUCKET and then > reduce it if you enough memory left, or you can start with a smaller > NTUP_PER_BUCKET and then increase it if you run short of memory. I don't think those two approaches are equal. With the approach I took, I can use a compromise value (NTUP=4) initially, and only resize the hash table once at the end (while keeping the amount of memory under work_mem all the time). With the "NTUP=1 and increase in case of memory pressure" you have to shrink the table immediately (to fit into work_mem), and if the hash table gets split into multiple batches you're suddenly in a situation with lower memory pressure and you may need to increase it again. >>> Yet another idea is to stick with your scheme, but do the dynamic >>> bucket splits lazily. Set a flag on each bucket indicating whether or >>> not it needs a lazy split. When someone actually probes the hash >>> table, if the flag is set for a particular bucket, move any tuples >>> that don't belong as we scan the bucket. If we reach the end of the >>> bucket chain, clear the flag. >> >> I don't think a lazy scheme makes much sense here. There are two clearly >> separated phases - loading the table and search. >> >> Also, it seems to me it can't work as described. Say we build a table >> and >> then find out we need a table 4x the size. If I understand your proposal >> correctly, you'd just resize buckets array, copy the existing buckets >> (first 1/4 buckets) and set 'needs_split' flags. Correct? >> >> Well, the problem is that while scanning a bucket you already need to >> know >> which tuples belong there. But with the lazy approach, the tuples might >> still be in the old (not yet split) buckets. So you'd have to search the >> current bucket and all buckets that were not split yet. Or did I miss >> something? > > If you have, say, bucket 0..63 and you decide to change it to buckets > 0..255, then any tuple that isn't in bucket N has to be in bucket N % > 64. More generally, any time you expand or contract by a power of two > it's pretty easy to figure out where tuples have to go. OK. > But even if you do something that's not a power of two, like say a 10x > compaction of the buckets, there's still only two buckets that can > contain any particular hash value. If the hash value is H, the old > number of buckets is O, and the new number of buckets is N, then the > tuple has got to be in bucket H % O or bucket H % N. If bucket H % O > doesn't have the needs-split flag set, then it must be in H % N (if it > exists at all). I wonder if this is really worth the effort - my guess is it's efficient only if large portion of buckets is not visited (and thus does not need to be split) at all. Not sure how common that is (our workloads certainly are not like that). regards Tomas
On Tue, Jul 8, 2014 at 12:06 PM, Tomas Vondra <tv@fuzzy.cz> wrote: > On 8 Červenec 2014, 16:16, Robert Haas wrote: >> On Tue, Jul 8, 2014 at 9:35 AM, Tomas Vondra <tv@fuzzy.cz> wrote: >>> Maybe. I'm not against setting NTUP_PER_BUCKET=1, but with large outer >>> relations it may be way cheaper to use higher NTUP_PER_BUCKET values >>> instead of increasing the number of batches (resulting in repeated scans >>> of the outer table). I think it's important (but difficult) to keep >>> these >>> things somehow balanced. >> >> Right, I think that's clear. I'm just pointing out that you get to >> decide: you can either start with a larger NTUP_PER_BUCKET and then >> reduce it if you enough memory left, or you can start with a smaller >> NTUP_PER_BUCKET and then increase it if you run short of memory. > > I don't think those two approaches are equal. > > With the approach I took, I can use a compromise value (NTUP=4) initially, > and only resize the hash table once at the end (while keeping the amount > of memory under work_mem all the time). > > With the "NTUP=1 and increase in case of memory pressure" you have to > shrink the table immediately (to fit into work_mem), and if the hash table > gets split into multiple batches you're suddenly in a situation with lower > memory pressure and you may need to increase it again. True. On the other hand, this really only comes into play when the estimates are wrong. If you know at the start how many tuples you're going to need to store and how big they are, you determine whether NTUP_PER_BUCKET=1 is going to work before you even start building the hash table. If it isn't, then you use fewer buckets right from the start. If we start by estimating a small value for NTUP_PER_BUCKET and then let it float upward if we turn out to have more tuples than expected, we're optimizing for the case where our statistics are right. If we start by estimating a larger value for NTUP_PER_BUCKET than what we think we need to fit within work_mem, we're basically guessing that our statistics are more likely to be wrong than to be right. I think. > I wonder if this is really worth the effort - my guess is it's efficient > only if large portion of buckets is not visited (and thus does not need to > be split) at all. Not sure how common that is (our workloads certainly are > not like that). Yeah. It may be a bad idea. I threw it out there as a possible way of trying to mitigate the worst case, which is when you trouble to build the hash table and then make very few probes. But that may not be worth the complexity that this would introduce. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 8.7.2014 19:00, Robert Haas wrote: > On Tue, Jul 8, 2014 at 12:06 PM, Tomas Vondra <tv@fuzzy.cz> wrote: >> On 8 Červenec 2014, 16:16, Robert Haas wrote: >> >>> Right, I think that's clear. I'm just pointing out that you get >>> to decide: you can either start with a larger NTUP_PER_BUCKET and >>> then reduce it if you enough memory left, or you can start with a >>> smaller NTUP_PER_BUCKET and then increase it if you run short of >>> memory. >> >> I don't think those two approaches are equal. >> >> With the approach I took, I can use a compromise value (NTUP=4) >> initially, and only resize the hash table once at the end (while >> keeping the amount of memory under work_mem all the time). >> >> With the "NTUP=1 and increase in case of memory pressure" you have >> to shrink the table immediately (to fit into work_mem), and if the >> hash table gets split into multiple batches you're suddenly in a >> situation with lower memory pressure and you may need to increase >> it again. > > True. On the other hand, this really only comes into play when the > estimates are wrong. If you know at the start how many tuples you're > going to need to store and how big they are, you determine whether > NTUP_PER_BUCKET=1 is going to work before you even start building > the hash table. If it isn't, then you use fewer buckets right from > the start. If we start by estimating a small value for > NTUP_PER_BUCKET and then let it float upward if we turn out to have > more tuples than expected, we're optimizing for the case where our > statistics are right. If we start by estimating a larger value for > NTUP_PER_BUCKET than what we think we need to fit within work_mem, > we're basically guessing that our statistics are more likely to be > wrong than to be right. I think. Good point. The fist patch was targetted exactly at the wrongly estimated queries. This patch attempts to apply the rehash to all plans, and maybe there's a better way. If the estimates are correct / not too off, we can use this information to do the sizing 'right' at the beginning (without facing rehashes later). Over-estimates are not a problem, because it won't make the hash table slower (it'll be sized for more tuples) and we can't change the number of batches anyway. With under-estimates we have to decide whether to resize the hash or increase the number of batches. In both cases that matter (correct estimates and under-estimates) we have to decide whether to increase the number of buckets or batches. I'm not sure how to do that. >> I wonder if this is really worth the effort - my guess is it's >> efficient only if large portion of buckets is not visited (and >> thus does not need to be split) at all. Not sure how common that is >> (our workloads certainly are not like that). > > Yeah. It may be a bad idea. I threw it out there as a possible way of > trying to mitigate the worst case, which is when you trouble to build > the hash table and then make very few probes. But that may not be > worth the complexity that this would introduce. Let's keep it simple for now. I think the sizing question (explained above) is more important and needs to be solved first. regards Tomas
On Tue, Jul 8, 2014 at 6:35 AM, Tomas Vondra <tv@fuzzy.cz> wrote:
On 8 Červenec 2014, 14:49, Robert Haas wrote:Maybe. I'm not against setting NTUP_PER_BUCKET=1, but with large outer
> On Wed, Jul 2, 2014 at 8:13 PM, Tomas Vondra <tv@fuzzy.cz> wrote:
>> I propose dynamic increase of the nbuckets (up to NTUP_PER_BUCKET=1)
>> once the table is built and there's free space in work_mem. The patch
>> mentioned above makes implementing this possible / rather simple.
>
> Another idea would be to start with NTUP_PER_BUCKET=1 and then, if we
> run out of memory, increase NTUP_PER_BUCKET. I'd like to think that
> the common case is that work_mem will be large enough that everything
> fits; and if you do it that way, then you save yourself the trouble of
> rehashing later, which as you point out might lose if there are only a
> few probes. If it turns out that you run short of memory, you can
> merge pairs of buckets up to three times, effectively doubling
> NTUP_PER_BUCKET each time.
relations it may be way cheaper to use higher NTUP_PER_BUCKET values
instead of increasing the number of batches (resulting in repeated scans
of the outer table). I think it's important (but difficult) to keep these
things somehow balanced.
With large work_mem values the amount of memory for buckets may be quite
significant. E.g. 800MB work_mem may easily give ~120MB of memory taken by
buckets with NTUP_PER_BUCKET=1. With NTUP_PER_BUCKET=4 it's just ~30MB.
That extra 90MB is memory well spent, in my book. Versus having to walk a 4-deep linked list which is scattered all over main memory just to find one entry we care about in it.
It might cause some things that were very close to the edge to tip over into multi-pass hash joins, but even that is not necessarily a bad thing. (When I test with work_mem in the 20 to 50 MB range, I often find batches=2 be ~30% faster than batches=1, I think because partitioning into main memory using sequential writes is not much of a burden, and building and walking two hash tables that both fit in L3 cache is much faster than building 1 hash table in main memory, and more than makes up for the work of partitioning. Presumably that situation doesn't apply to work_mem 900MB, but isn't NUMA about the same thing as L4 cache, in effect?).
And if someone had a whole bunch of hash joins which were right in that anti-sweet spot, all they have to do is increase work_mem by (at most) 15% to get out of it. work_mem is basically impossible to tune, so I doubt anyone exists who has a reasonable setting for it which can' be increased by 15% and still be reasonable. And if someone does have it tuned so tightly, they probably won't be upgrading to new major versions without expecting to do some re-tuning.
Cheers,
Jeff
On 8.7.2014 21:53, Jeff Janes wrote: > On Tue, Jul 8, 2014 at 6:35 AM, Tomas Vondra <tv@fuzzy.cz> wrote: >> >> Maybe. I'm not against setting NTUP_PER_BUCKET=1, but with large >> outer relations it may be way cheaper to use higher NTUP_PER_BUCKET >> values instead of increasing the number of batches (resulting in >> repeated scans of the outer table). I think it's important (but >> difficult) to keep these things somehow balanced. >> >> With large work_mem values the amount of memory for buckets may be >> quite significant. E.g. 800MB work_mem may easily give ~120MB of >> memory taken by buckets with NTUP_PER_BUCKET=1. With >> NTUP_PER_BUCKET=4 it's just ~30MB. > > > That extra 90MB is memory well spent, in my book. Versus having to > walk a 4-deep linked list which is scattered all over main memory > just to find one entry we care about in it. Yes, I share this view, although it really depends on how expensive it's to rescan the outer relation (due to more batches) vs. lookup in a "deeper" hash table. The other thing is that this memory is currently unaccounted for, i.e. the space for buckets is not counted within the work_mem limit (unless I'm missing something in the code). I'm not sure why, and I believe it should be, so I changer this in the patch. > It might cause some things that were very close to the edge to tip > over into multi-pass hash joins, but even that is not necessarily a > bad thing. (When I test with work_mem in the 20 to 50 MB range, I > often find batches=2 be ~30% faster than batches=1, I think because > partitioning into main memory using sequential writes is not much of > a burden, and building and walking two hash tables that both fit in > L3 cache is much faster than building 1 hash table in main memory, > and more than makes up for the work of partitioning. Presumably that > situation doesn't apply to work_mem 900MB, but isn't NUMA about the > same thing as L4 cache, in effect?). Yes, I've seen cases where plans with (nbatch>1) were faster than a plan with (nbatch=1). I'm not entirely sure why :-( but I have two hypotheses so far: (a) Caching within CPU (current CPUs have multiple MBs of L2 cache), which may make a difference, especially in the sizerange you've mentioned. (b) Lower tuple/bucket ratio - this may easily happen for example if the estimates are slighly lower than reality (eitherrow count or row width) and narrowly exceed work_mem, thus forcing batching. The resulting hash table has ~50%tuple/bucket on average, and thus is faster. > And if someone had a whole bunch of hash joins which were right in > that anti-sweet spot, all they have to do is increase work_mem by (at > most) 15% to get out of it. work_mem is basically impossible to tune, > so I doubt anyone exists who has a reasonable setting for it which > can' be increased by 15% and still be reasonable. And if someone does > have it tuned so tightly, they probably won't be upgrading to new > major versions without expecting to do some re-tuning. Right. Still, it's not really nice to get slower hash joins after upgrading to a new version - I somehow expect to get the same or better performance, if possible. So I'd like to make it as efficient as possible, within the given memory limit. Sadly, the increase may be needed anyway because of counting the bucket memory into work_mem, as mentioned above. If committed, this should be probably mentioned in release notes or something. regards Tomas
Hi, Thinking about this a bit more, do we really need to build the hash table on the first pass? Why not to do this: (1) batching - read the tuples, stuff them into a simple list - don't build the hash table yet (2) building the hash table - we have all the tuples in a simple list, batching is done - we know exact row count, cansize the table properly - build the table Also, maybe we could use a regular linear hash table [1], instead of using the current implementation with NTUP_PER_BUCKET=1. (Although, that'd be absolutely awful with duplicates.) regards Tomas [1] http://en.wikipedia.org/wiki/Linear_probing
On Tue, Jul 8, 2014 at 5:16 PM, Tomas Vondra <tv@fuzzy.cz> wrote: > Thinking about this a bit more, do we really need to build the hash > table on the first pass? Why not to do this: > > (1) batching > - read the tuples, stuff them into a simple list > - don't build the hash table yet > > (2) building the hash table > - we have all the tuples in a simple list, batching is done > - we know exact row count, can size the table properly > - build the table We could do this, and in fact we could save quite a bit of memory if we allocated say 1MB chunks and packed the tuples in tightly instead of palloc-ing each one separately. But I worry that rescanning the data to build the hash table would slow things down too much. > Also, maybe we could use a regular linear hash table [1], instead of > using the current implementation with NTUP_PER_BUCKET=1. (Although, > that'd be absolutely awful with duplicates.) Linear probing is pretty awful unless your load factor is << 1. You'd probably want NTUP_PER_BUCKET=0.25, or something like that, which would eat up a lot of memory. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 9.7.2014 16:07, Robert Haas wrote: > On Tue, Jul 8, 2014 at 5:16 PM, Tomas Vondra <tv@fuzzy.cz> wrote: >> Thinking about this a bit more, do we really need to build the >> hash table on the first pass? Why not to do this: >> >> (1) batching - read the tuples, stuff them into a simple list - >> don't build the hash table yet >> >> (2) building the hash table - we have all the tuples in a simple >> list, batching is done - we know exact row count, can size the >> table properly - build the table > > We could do this, and in fact we could save quite a bit of memory if > we allocated say 1MB chunks and packed the tuples in tightly instead > of palloc-ing each one separately. But I worry that rescanning the > data to build the hash table would slow things down too much. OK. I think we should shoot for no negative impact on well estimated plans, and the rescans might violate that. I need to think about this for some time, but my current plan is this: (1) size the buckets for NTUP_PER_BUCKET=1 (and use whatever number of batches this requires) (2) build the batches as in the current patch (3) if the hash table is too small, resize it Which is not really different from the current patch. >> Also, maybe we could use a regular linear hash table [1], instead >> of using the current implementation with NTUP_PER_BUCKET=1. >> (Although, that'd be absolutely awful with duplicates.) > > Linear probing is pretty awful unless your load factor is << 1. > You'd probably want NTUP_PER_BUCKET=0.25, or something like that, > which would eat up a lot of memory. My experience is that 0.5-0.75 load factor is quite OK, and NTUP_PER_BUCKET=1 gives you ~0.75 load on average, so it's not that different. Anyway, the inability to handle duplicies reasonably is probably a show-stopper. Tomas
On 9.7.2014 16:07, Robert Haas wrote:
> On Tue, Jul 8, 2014 at 5:16 PM, Tomas Vondra <tv@fuzzy.cz> wrote:
>> Thinking about this a bit more, do we really need to build the hash
>> table on the first pass? Why not to do this:
>>
>> (1) batching
>> - read the tuples, stuff them into a simple list
>> - don't build the hash table yet
>>
>> (2) building the hash table
>> - we have all the tuples in a simple list, batching is done
>> - we know exact row count, can size the table properly
>> - build the table
>
> We could do this, and in fact we could save quite a bit of memory if
> we allocated say 1MB chunks and packed the tuples in tightly instead
> of palloc-ing each one separately. But I worry that rescanning the
> data to build the hash table would slow things down too much.
I did a quick test of how much memory we could save by this. The
attached patch densely packs the tuples into 32kB chunks (1MB seems way
too much because of small work_mem values, but I guess this might be
tuned based on number of tuples / work_mem size ...).
Tested on query like this (see the first message in this thread how to
generate the tables):
QUERY PLAN
-----------------------------------------------------------------------
Aggregate (cost=2014697.64..2014697.65 rows=1 width=33) (actual
time=63796.270..63796.271 rows=1 loops=1)
-> Hash Left Join (cost=318458.14..1889697.60 rows=50000016
width=33) (actual time=2865.656..61778.592 rows=50000000 loops=1)
Hash Cond: (o.id = i.id)
-> Seq Scan on outer_table o (cost=0.00..721239.16
rows=50000016 width=4) (actual time=0.033..2676.234 rows=50000000 loops=1)
-> Hash (cost=193458.06..193458.06 rows=10000006 width=37)
(actual time=2855.408..2855.408 rows=10000000 loops=1)
Buckets: 1048576 Batches: 1 Memory Usage: 703125kB
-> Seq Scan on inner_table i (cost=0.00..193458.06
rows=10000006 width=37) (actual time=0.044..952.802 rows=10000000 loops=1)
Planning time: 1.139 ms
Execution time: 63889.056 ms
(9 rows)
I.e. it creates a single batch with ~700 MB of tuples. Without the
patch, top shows this:
VIRT RES SHR S %CPU %MEM COMMAND
2540356 1,356g 5936 R 100,0 17,6 postgres: EXPLAIN
and the MemoryContextStats added to MultiExecHash shows this:
HashBatchContext: 1451221040 total in 182 blocks; 2826592 free (11
chunks); 1448394448 used
So yeah, the overhead is pretty huge in this case - basicaly 100%
overhead, because the inner table row width is only ~40B. With wider
rows the overhead will be lower.
Now, with the patch it looks like this:
VIRT RES SHR S %CPU %MEM COMMAND
1835332 720200 6096 R 100,0 8,9 postgres: EXPLAIN
HashBatchContext: 729651520 total in 21980 blocks; 0 free (0 chunks);
729651520 used
So, pretty much no overhead at all. It was slightly faster too (~5%) but
I haven't done much testing so it might be measurement error.
This patch is pretty independent of the other changes discussed here
(tweaking NTUP_PER_BUCKET / nbuckets) so I'll keep it separate.
regards
Tomas
Attachment
On 9 July 2014 18:54, Tomas Vondra <tv@fuzzy.cz> wrote: > (1) size the buckets for NTUP_PER_BUCKET=1 (and use whatever number > of batches this requires) If we start off by assuming NTUP_PER_BUCKET = 1, how much memory does it save to recalculate the hash bucket at 10 instead? Resizing sounds like it will only be useful of we only just overflow our limit. If we release next version with this as a hardcoded change, my understanding is that memory usage for hash joins will leap upwards, even if the run time of queries reduces. It sounds like we need some kind of parameter to control this. "We made it faster" might not be true if we run this on servers that are already experiencing high memory pressure. -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 11 Červenec 2014, 9:27, Simon Riggs wrote:
> On 9 July 2014 18:54, Tomas Vondra <tv@fuzzy.cz> wrote:
>
>> (1) size the buckets for NTUP_PER_BUCKET=1 (and use whatever number
>> of batches this requires)
>
> If we start off by assuming NTUP_PER_BUCKET = 1, how much memory does
> it save to recalculate the hash bucket at 10 instead?
> Resizing sounds like it will only be useful of we only just overflow our
> limit.
>
> If we release next version with this as a hardcoded change, my
> understanding is that memory usage for hash joins will leap upwards,
> even if the run time of queries reduces. It sounds like we need some
> kind of parameter to control this. "We made it faster" might not be
> true if we run this on servers that are already experiencing high
> memory pressure.
Sure. We certainly don't want to make things worse for environments with
memory pressure.
The current implementation has two issues regarding memory:
(1) It does not include buckets into used memory, i.e. it's not included
into work_mem (so we may overflow work_mem). I plan to fix this, to make
work_mem a bit more correct, as it's important for cases with
NTUP_PER_BUCKET=1.
(2) There's a significant palloc overhead, because of allocating each
tuple separately - see my message from yesterday, where I observed the
batch memory context to get 1.4GB memory for 700MB of tuple data. By
densely packing the tuples, I got down to ~700MB (i.e. pretty much no
overhead).
The palloc overhead seems to be 20B (on x86_64) per tuple, and eliminating
this it more than compensates for ~8B per tuple, required for
NTUP_PER_BUCKET=1. And fixing (1) makes it more correct / predictable.
It also improves the issue that palloc overhead is not counted into
work_mem at all (that's why I got ~1.4GB batch context with work_mem=1GB).
So in the end this should give us much lower memory usage for hash joins,
even if we switch to NTUP_PER_BUCKET=1 (although that's pretty much
independent change). Does that seem reasonable?
Regarding the tunable to control this - I certainly don't want another GUC
no one really knows how to set right. And I think it's unnecessary thanks
to the palloc overhead / work_mem accounting fix, described above.
The one thing I'm not sure about is what to do in case of reaching the
work_mem limit (which should only happen with underestimated row count /
row width) - how to decide whether to shrink the hash table or increment
the number of batches. But this is not exclusive to NTUP_PER_BUCKET=1, it
may happen with whatever NTUP_PER_BUCKET value you choose.
The current code does not support resizing at all, so it always increments
the number of batches, but I feel an "interleaved" approach might be more
appropriate (nbuckets/2, nbatches*2, nbuckets/2, nbatches*2, ...). It'd be
nice to have some cost estimates ('how expensive is a rescan' vs. 'how
expensive is a resize'), but I'm not sure how to get that.
regards
Tomas
On 11 July 2014 10:23, Tomas Vondra <tv@fuzzy.cz> wrote:
> On 11 Červenec 2014, 9:27, Simon Riggs wrote:
>> On 9 July 2014 18:54, Tomas Vondra <tv@fuzzy.cz> wrote:
>>
>>> (1) size the buckets for NTUP_PER_BUCKET=1 (and use whatever number
>>> of batches this requires)
>>
>> If we start off by assuming NTUP_PER_BUCKET = 1, how much memory does
>> it save to recalculate the hash bucket at 10 instead?
>> Resizing sounds like it will only be useful of we only just overflow our
>> limit.
>>
>> If we release next version with this as a hardcoded change, my
>> understanding is that memory usage for hash joins will leap upwards,
>> even if the run time of queries reduces. It sounds like we need some
>> kind of parameter to control this. "We made it faster" might not be
>> true if we run this on servers that are already experiencing high
>> memory pressure.
>
> Sure. We certainly don't want to make things worse for environments with
> memory pressure.
>
> The current implementation has two issues regarding memory:
>
> (1) It does not include buckets into used memory, i.e. it's not included
> into work_mem (so we may overflow work_mem). I plan to fix this, to make
> work_mem a bit more correct, as it's important for cases with
> NTUP_PER_BUCKET=1.
>
> (2) There's a significant palloc overhead, because of allocating each
> tuple separately - see my message from yesterday, where I observed the
> batch memory context to get 1.4GB memory for 700MB of tuple data. By
> densely packing the tuples, I got down to ~700MB (i.e. pretty much no
> overhead).
>
> The palloc overhead seems to be 20B (on x86_64) per tuple, and eliminating
> this it more than compensates for ~8B per tuple, required for
> NTUP_PER_BUCKET=1. And fixing (1) makes it more correct / predictable.
>
> It also improves the issue that palloc overhead is not counted into
> work_mem at all (that's why I got ~1.4GB batch context with work_mem=1GB).
>
> So in the end this should give us much lower memory usage for hash joins,
> even if we switch to NTUP_PER_BUCKET=1 (although that's pretty much
> independent change). Does that seem reasonable?
Yes, that alleviates my concern. Thanks.
> Regarding the tunable to control this - I certainly don't want another GUC
> no one really knows how to set right. And I think it's unnecessary thanks
> to the palloc overhead / work_mem accounting fix, described above.
Agreed, nor does anyone.
> The one thing I'm not sure about is what to do in case of reaching the
> work_mem limit (which should only happen with underestimated row count /
> row width) - how to decide whether to shrink the hash table or increment
> the number of batches. But this is not exclusive to NTUP_PER_BUCKET=1, it
> may happen with whatever NTUP_PER_BUCKET value you choose.
>
> The current code does not support resizing at all, so it always increments
> the number of batches, but I feel an "interleaved" approach might be more
> appropriate (nbuckets/2, nbatches*2, nbuckets/2, nbatches*2, ...). It'd be
> nice to have some cost estimates ('how expensive is a rescan' vs. 'how
> expensive is a resize'), but I'm not sure how to get that.
-- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 10.7.2014 21:33, Tomas Vondra wrote: > On 9.7.2014 16:07, Robert Haas wrote: >> On Tue, Jul 8, 2014 at 5:16 PM, Tomas Vondra <tv@fuzzy.cz> wrote: >>> Thinking about this a bit more, do we really need to build the hash >>> table on the first pass? Why not to do this: >>> >>> (1) batching >>> - read the tuples, stuff them into a simple list >>> - don't build the hash table yet >>> >>> (2) building the hash table >>> - we have all the tuples in a simple list, batching is done >>> - we know exact row count, can size the table properly >>> - build the table >> >> We could do this, and in fact we could save quite a bit of memory if >> we allocated say 1MB chunks and packed the tuples in tightly instead >> of palloc-ing each one separately. But I worry that rescanning the >> data to build the hash table would slow things down too much. > > I did a quick test of how much memory we could save by this. The > attached patch densely packs the tuples into 32kB chunks (1MB seems > way too much because of small work_mem values, but I guess this might > be tuned based on number of tuples / work_mem size ...). Turns out getting this working properly will quite complicated. The patch was only a quick attempt to see how much overhead there is, and didn't solve one important details - batching. The problem is that when increasing the number of batches, we need to get rid of the tuples from one of them. Which means calling pfree() on the tuples written to a temporary file, and that's not possible with the dense allocation. 1) copy into new chunks (dead end) ---------------------------------- The first idea I had was to just "copy" everything into new chunks and then throw away the old ones, but this way we might end up using 150% of work_mem on average (when the two batches are about 1/2 the data each), and in an extreme case up to 200% of work_mem (all tuples having the same key and thus falling into the same batch). So I don't think that's really a good approach. 2) walking through the tuples sequentially ------------------------------------------ The other option is not to walk the tuples through buckets, but by walking throught the chunks - we know the tuples are stored as HashJoinTuple/MinimalTuple, so it shouldn't be that difficult. And by walking the tuples in the order they're stored, we may just rearrange the tuples in already allocated memory. And maybe it could be even faster than the current code, because of the sequential access to the memory (as opposed to the random access through buckets) and CPU caches. So I like this approach - it's simple, clean and shouldn't add any overhead (memory or CPU). 3) batch-aware chunks --------------------- I also think a "batch-aware" chunks might work. Say we're starting with nbatch=N. Instead of allocating everything in a single chunk, we'll allocate the tuples from the chunks according to a "hypothetical batch number" - what batch would the tuple belong to if we had (nbatch=N*2). So we'd have two chunks (or sequences of chunks), and we'd allocate the tuples into them. Then if we actually need to increase the number of batches, we know we can just free one of the chunks, because all of the tuples are from the 'wrong' batche, and redistribute the remaining tuples into the new chunks (according to the new hypothetical batch numbers). I'm not sure how much overhead this would be, though. I think it can be done quite efficiently, though, and it shouldn't have any impact at all, if we don't do any additional batching (i.e. if the initial estimates are ok). Any other ideas how to tackle this? regards Tomas
On 11 July 2014 18:25, Tomas Vondra <tv@fuzzy.cz> wrote: > Turns out getting this working properly will quite complicated. Lets keep this patch simple then. Later research can be another patch. In terms of memory pressure, having larger joins go x4 faster has a much more significant reducing effect on memory pressure than anything else. So my earlier concerns seem less of a concern. So lets just this change done and then do more later. -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 12.7.2014 11:39, Simon Riggs wrote: > On 11 July 2014 18:25, Tomas Vondra <tv@fuzzy.cz> wrote: > >> Turns out getting this working properly will quite complicated. > > Lets keep this patch simple then. Later research can be another patch. Well, the dense allocation is independent to the NTUP_PER_BUCKET changes, and only happened to be discussed here because it's related to hash joins. My plan was to keep it as a separate patch, thus not making the NTUP patch any more complex. > In terms of memory pressure, having larger joins go x4 faster has a > much more significant reducing effect on memory pressure than > anything else. So my earlier concerns seem less of a concern. OK. > So lets just this change done and then do more later. There's no way back, sadly. The dense allocation turned into a challenge. I like challenges. I have to solve it or I won't be able to sleep. regards Tomas
On 12 July 2014 12:43, Tomas Vondra <tv@fuzzy.cz> wrote: >> So lets just this change done and then do more later. > > There's no way back, sadly. The dense allocation turned into a > challenge. I like challenges. I have to solve it or I won't be able to > sleep. I admire your tenacity, but how about we solve the first challenge first and the second one second? -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 13.7.2014 12:27, Simon Riggs wrote: > On 12 July 2014 12:43, Tomas Vondra <tv@fuzzy.cz> wrote: > >>> So lets just this change done and then do more later. >> >> There's no way back, sadly. The dense allocation turned into a >> challenge. I like challenges. I have to solve it or I won't be able >> to sleep. > > I admire your tenacity, but how about we solve the first challenge > first and the second one second? Yeah, I know. However the two patches deal with the same part of the code, so it feels natural to work on both at the same time. And I already had a solution in my head, and "only" needed to code it. Also, I think the question of allocated memory / memory pressure is important, and I'd like to avoid "this will be solved by the other patch" only to find out that the other patch does not work. regards Tomas
On 11.7.2014 19:25, Tomas Vondra wrote:
> 2) walking through the tuples sequentially
> ------------------------------------------
>
> The other option is not to walk the tuples through buckets, but by
> walking throught the chunks - we know the tuples are stored as
> HashJoinTuple/MinimalTuple, so it shouldn't be that difficult. And by
> walking the tuples in the order they're stored, we may just rearrange
> the tuples in already allocated memory. And maybe it could be even
> faster than the current code, because of the sequential access to the
> memory (as opposed to the random access through buckets) and CPU caches.
> So I like this approach - it's simple, clean and shouldn't add any
> overhead (memory or CPU).
So, attached is a patch that implements this. It's not very complicated
and the resulting code is surprisingly readable (IMHO comprable to the
previous code).
Basics of the patch:
(1) adds HashChunkData structure - a buffer used for dense allocation
of tuples, 16kB by default
(2) adds 'chunks_batch' into HashJoinTableData, which is a linked list
of HashChunkData
(3) the allocation itself is done in chunk_alloc - in short it either
allocates the tuple in the current chunk, or adds a new one if
needed
(4) ExecHashTableInsert calls chunk_alloc (instead of the regular
MemoryContextAlloc)
(5) the main change is in ExecHashIncreaseNumBatches, which now can't
do pfree (does not work with dense allocation), so it reads the
tuples from chunks directly and simply rebuilds the buckets
from scratch (thanks to this we only need one more chunk of memory,
not a complete copy, and we don't need to duplicate buckets at all)
>From the tests I've done so far this seems to work perfectly - it still
saves the memory overhead, and I've seen no difference in performance.
The current patch only implemnents this for tuples in the main hash
table, not for skew buckets. I plan to do that, but it will require
separate chunks for each skew bucket (so we can remove it without
messing with all of them). The chunks for skew buckets should be smaller
(I'm thinking about ~4kB), because there'll be more of them, but OTOH
those buckets are for frequent values so the chunks should not remain empty.
But let's see if the current patch misses something important first.
regards
Tomas
Attachment
Tomas, * Tomas Vondra (tv@fuzzy.cz) wrote: > On 6.7.2014 17:57, Stephen Frost wrote: > > * Tomas Vondra (tv@fuzzy.cz) wrote: > >> I can't find the thread / test cases in the archives. I've found this > >> thread in hackers: > >> > >> http://www.postgresql.org/message-id/CAOeZVif-R-iLF966wEipk5By-KhzVLOqpWqurpaK3p5fYw-Rdw@mail.gmail.com > >> > >> Can you point me to the right one, please? > > > > This: > > > > http://www.postgresql.org/message-id/20130328235627.GV4361@tamriel.snowman.net > > Sadly, the link to the SQL does not work :-( > > http://snowman.net/~sfrost/test_case.sql => 404 > > > and I think there may have been other test cases on that thread > > somewhere... I certainly recall having at least a couple of them that I > > was playing with. > > > > I can probably find them around here somewhere too, if necessary. > > If you could look for them, that'd be great. cc'ing me directly helps me notice these... I've added back test_case.sql and test_case2.sql. Please check them out and let me know- they're real-world cases we've run into. Thanks! Stephen
On 14.7.2014 06:29, Stephen Frost wrote: > Tomas, > > * Tomas Vondra (tv@fuzzy.cz) wrote: >> On 6.7.2014 17:57, Stephen Frost wrote: >>> * Tomas Vondra (tv@fuzzy.cz) wrote: >>>> I can't find the thread / test cases in the archives. I've found this >>>> thread in hackers: >>>> >>>> http://www.postgresql.org/message-id/CAOeZVif-R-iLF966wEipk5By-KhzVLOqpWqurpaK3p5fYw-Rdw@mail.gmail.com >>>> >>>> Can you point me to the right one, please? >>> >>> This: >>> >>> http://www.postgresql.org/message-id/20130328235627.GV4361@tamriel.snowman.net >> >> Sadly, the link to the SQL does not work :-( >> >> http://snowman.net/~sfrost/test_case.sql => 404 >> >>> and I think there may have been other test cases on that thread >>> somewhere... I certainly recall having at least a couple of them that I >>> was playing with. >>> >>> I can probably find them around here somewhere too, if necessary. >> >> If you could look for them, that'd be great. > > cc'ing me directly helps me notice these... > > I've added back test_case.sql and test_case2.sql. Please check them out > and let me know- they're real-world cases we've run into. Hi Stephen, I've reviewed the two test cases mentioned here, and sadly there's nothing that can be 'fixed' by this patch. The problem here lies in the planning stage, which decides to hash the large table - we can't fix that in the executor. I did three runs - with master, with the 'dense allocation' patch applied, and with 'dense allocation + ntup patch' applied. As the estimates are pretty exact here, the ntup patch effectively only sets NTUP_PER_BUCKET=1 (and does not do any dynamic resize or so). For the first testcase, it behaves like this: ####### master (no patches) ######## QUERY PLAN -------------------------------------------------------------------------Hash Join (cost=115030.10..116671.32 rows=41176width=24) (actual time=980.363..1015.623 rows=13731 loops=1) Hash Cond: (small_table.id_short = big_table.id_short) -> Seq Scan on small_table (cost=0.00..714.76 rows=41176 width=24) (actual time=0.015..2.563 rows=41176 loops=1) -> Hash (cost=61626.71..61626.71 rows=4272271 width=4) (actual time=979.399..979.399 rows=4272271 loops=1) Buckets: 524288 Batches: 1 Memory Usage: 150198kB -> Seq Scanon big_table (cost=0.00..61626.71 rows=4272271 width=4) (actual time=0.026..281.151 rows=4272271 loops=1)Planning time: 0.196 msExecution time: 1034.931 ms (8 rows) # without explain analyze Time: 841,198 ms Time: 825,000 ms ####### master + dense allocation ######## QUERY PLAN -------------------------------------------------------------------------Hash Join (cost=115030.10..116671.32 rows=41176width=24) (actual time=778.116..815.254 rows=13731 loops=1) Hash Cond: (small_table.id_short = big_table.id_short) -> Seq Scan on small_table (cost=0.00..714.76 rows=41176 width=24) (actual time=0.006..2.423 rows=41176 loops=1) -> Hash (cost=61626.71..61626.71 rows=4272271 width=4) (actual time=775.803..775.803 rows=4272271 loops=1) Buckets: 524288 Batches: 1 Memory Usage: 150198kB -> Seq Scanon big_table (cost=0.00..61626.71 rows=4272271 width=4) (actual time=0.005..227.274 rows=4272271 loops=1)Planning time: 0.061 msExecution time: 826.346 ms (8 rows) # without explain analyze Time: 758,393 ms Time: 734,329 ms ####### master + dense allocation + ntup=1 patch ######## QUERY PLAN -------------------------------------------------------------------------Hash Join (cost=115030.10..116465.44 rows=41176width=24) (actual time=1020.288..1033.539 rows=13731 loops=1) Hash Cond: (small_table.id_short = big_table.id_short) -> Seq Scan on small_table (cost=0.00..714.76 rows=41176 width=24) (actual time=0.015..2.214 rows=41176 loops=1) -> Hash (cost=61626.71..61626.71 rows=4272271 width=4) (actual time=953.890..953.890 rows=4272271 loops=1) Buckets: 8388608 Batches: 1 Memory Usage: 215734kB -> Seq Scanon big_table (cost=0.00..61626.71 rows=4272271 width=4) (actual time=0.014..241.223 rows=4272271 loops=1)Planning time: 0.193 msExecution time: 1055.351 ms (8 rows) # without explain analyze Time: 836,050 ms Time: 822,818 ms ######################################################### For the second test case, the times are like this: # master Time: 2326,579 ms Time: 2320,232 ms # master + dense allocation Time: 2207,254 ms Time: 2251,691 ms # master + dense allocation + ntup=1 Time: 2374,278 ms Time: 2377,409 ms So while the dense allocation shaves off ~5%, the time with both patches is slightly higher (again, ~5% difference). After spending some time by profiling the code, I believe it's because of worse cache hit ratio when accessing the buckets. By decreasing NTUP_PER_BUCKET the second test case now uses ~130MB of buckets, while originally it used only ~16MB). That means slightly lower cache hit ratio when accessing hashtable->buckets (e.g. in ExecHashTableInsert). The resulting hash table should be much faster when doing lookups, however the main issue illustrated by the test cases is that we're hashing large table and scanning the small one, which means relatively small amount of lookups. Which pretty much prevents getting anything from the better lookup performance. So, I think we need to fix the planning problem here, if possible. I might try doing that, but if someone with better knowledge of the planner could do that, that'd be great. regards Tomas
Tomas Vondra <tv@fuzzy.cz> writes:
> I've reviewed the two test cases mentioned here, and sadly there's
> nothing that can be 'fixed' by this patch. The problem here lies in the
> planning stage, which decides to hash the large table - we can't fix
> that in the executor.
We've heard a couple reports before of the planner deciding to hash a
larger table rather than a smaller one. The only reason I can think of
for that is if the smaller table has many more duplicates, so that the
planner thinks the executor might end up traversing long hash chains.
The planner's estimates could easily be off in this area, of course.
estimate_hash_bucketsize() is the likely culprit if it's wrong.
Which test case are you seeing this in, exactly?
regards, tom lane
On 13.7.2014 21:32, Tomas Vondra wrote: > The current patch only implemnents this for tuples in the main hash > table, not for skew buckets. I plan to do that, but it will require > separate chunks for each skew bucket (so we can remove it without > messing with all of them). The chunks for skew buckets should be > smaller (I'm thinking about ~4kB), because there'll be more of them, > but OTOH those buckets are for frequent values so the chunks should > not remain empty. I've looked into extending the dense allocation to the skew buckets, and I think we shouldn't do that. I got about 50% of the changes and then just threw it out because it turned out quite pointless. The amount of memory for skew buckets is limited to 2% of work mem, so even with 100% overhead it'll use ~4% of work mem. So there's pretty much nothing to gain here. So the additional complexity introduced by the dense allocation seems pretty pointless. I'm not entirely happy with the code allocating some memory densely and some using traditional palloc, but it certainly seems cleaner than the code I had. So I think the patch is mostly OK as is. regards Tomas
On 19.7.2014 20:24, Tom Lane wrote: > Tomas Vondra <tv@fuzzy.cz> writes: >> I've reviewed the two test cases mentioned here, and sadly there's >> nothing that can be 'fixed' by this patch. The problem here lies in the >> planning stage, which decides to hash the large table - we can't fix >> that in the executor. > > We've heard a couple reports before of the planner deciding to hash a > larger table rather than a smaller one. The only reason I can think of > for that is if the smaller table has many more duplicates, so that the > planner thinks the executor might end up traversing long hash chains. > The planner's estimates could easily be off in this area, of course. > estimate_hash_bucketsize() is the likely culprit if it's wrong. > > Which test case are you seeing this in, exactly? The two reported by Stephen here: http://www.postgresql.org/message-id/20130328235627.GV4361@tamriel.snowman.net Just download this (I had to gunzip it): http://snowman.net/~sfrost/test_case.sql http://snowman.net/~sfrost/test_case2.sql regards Tomas
On 19.7.2014 20:28, Tomas Vondra wrote: > On 19.7.2014 20:24, Tom Lane wrote: >> Tomas Vondra <tv@fuzzy.cz> writes: >>> I've reviewed the two test cases mentioned here, and sadly there's >>> nothing that can be 'fixed' by this patch. The problem here lies in the >>> planning stage, which decides to hash the large table - we can't fix >>> that in the executor. >> >> We've heard a couple reports before of the planner deciding to hash a >> larger table rather than a smaller one. The only reason I can think of >> for that is if the smaller table has many more duplicates, so that the >> planner thinks the executor might end up traversing long hash chains. >> The planner's estimates could easily be off in this area, of course. >> estimate_hash_bucketsize() is the likely culprit if it's wrong. >> >> Which test case are you seeing this in, exactly? > > The two reported by Stephen here: > > > http://www.postgresql.org/message-id/20130328235627.GV4361@tamriel.snowman.net > > Just download this (I had to gunzip it): > > http://snowman.net/~sfrost/test_case.sql > http://snowman.net/~sfrost/test_case2.sql Anyway, looking a bit at the distributions, I don't think the distributions are significantly skewed. In the first testscase, I get this test=# select cnt, count(*) from (select id_short, count(*) AS cnt from small_table group by 1) foo group by cnt order by cnt;cnt | count -----+------- 1 | 23 2 | 18795 3 | 13 4 | 726 5 | 4 6 | 93 8 | 4 10 | 1 (8 rows) and in the second one I get this: test=# select cnt, count(*) from (select id_short, count(*) AS cnt from small_table group by 1) foo group by cnt order by cnt;cnt | count -----+-------- 1 | 182161 2 | 5582 3 | 371 4 | 28 5 | 2 6 | 3 9 | 1 (7 rows) So while #1 contains most values twice, #2 is almost perfectly distinct. In the big_table, the values are unique. For the first case, a WARNING at the end of estimate_hash_bucketsize says this: WARNING: nbuckets=8388608.00 estfract=0.000001 WARNING: nbuckets=65536.00 estfract=0.000267 There are 4.3M rows in the big_table, so it says ~4 tuples (selectivity >= 1e-6), and ~10 tuples/bucket for the small_table (42k rows). For the second case, I get this: WARNING: nbuckets=16777216.00 estfract=0.000001 WARNING: nbuckets=262144.00 estfract=0.000100 i.e. ~11 tuples/bucket for big_table and ~20 tuples for small_table. That sounds really strange, because small_table in the second test case is almost perfectly unique. And in the first test case, there are only very few keys with >2 occurences. By explicitly setting the selectivity in estimate_hash_bucketsize to 1e-6, I got these plans: Test case #1 QUERY PLAN ---------------------------------------------------------------------Hash Join (cost=1229.46..79288.95 rows=41176 width=24)(actual time=50.397..634.986 rows=13731 loops=1) Hash Cond: (big_table.id_short = small_table.id_short) -> Seq Scan on big_table (cost=0.00..61626.71 rows=4272271 width=4) (actual time=0.018..229.597 rows=4272271 loops=1) -> Hash (cost=714.76..714.76 rows=41176 width=24) (actual time=31.653..31.653 rows=41176 loops=1) Buckets: 65536 Batches: 1 Memory Usage: 3086kB -> Seq Scan on small_table (cost=0.00..714.76 rows=41176 width=24) (actual time=0.012..13.341 rows=41176 loops=1)Planning time: 0.597 msExecution time: 635.498 ms (8 rows) Without explain analyze: 486 ms (original plan: >850ms). Test case #2 QUERY PLAN ---------------------------------------------------------------------Hash Join (cost=5240.21..220838.44 rows=194587 width=4)(actual time=88.252..2143.457 rows=149540 loops=1) Hash Cond: (big_table.id_short = small_table.id_short) -> Seq Scan on big_table (cost=0.00..169569.72 rows=11755372 width=4) (actual time=0.018..533.955 rows=11755475 loops=1) -> Hash (cost=2807.87..2807.87 rows=194587 width=4) (actual time=87.548..87.548 rows=194587 loops=1) Buckets: 262144 Batches: 1 Memory Usage: 8889kB -> Seq Scan onsmall_table (cost=0.00..2807.87 rows=194587 width=4) (actual time=0.012..29.929 rows=194587 loops=1)Planning time: 0.438 msExecution time: 2146.818 ms (8 rows) Without explain analyze: 1600 ms (original plan: >2300ms) The differences are fairly small - well, it's 30-40% faster, but it's less than 1s in both cases. I'm wondering whether we could get into similar problems with much longer queries and still get 30-40% improvement. Tomas
On 19.7.2014 23:07, Tomas Vondra wrote:
> On 19.7.2014 20:28, Tomas Vondra wrote:
> For the first case, a WARNING at the end of estimate_hash_bucketsize
> says this:
>
> WARNING: nbuckets=8388608.00 estfract=0.000001
> WARNING: nbuckets=65536.00 estfract=0.000267
>
> There are 4.3M rows in the big_table, so it says ~4 tuples (selectivity
>> = 1e-6), and ~10 tuples/bucket for the small_table (42k rows).
>
> For the second case, I get this:
>
> WARNING: nbuckets=16777216.00 estfract=0.000001
> WARNING: nbuckets=262144.00 estfract=0.000100
>
> i.e. ~11 tuples/bucket for big_table and ~20 tuples for small_table.
>
> That sounds really strange, because small_table in the second test case
> is almost perfectly unique. And in the first test case, there are only
> very few keys with >2 occurences.
FWIW, the "problem" seems to be this:
/* * Adjust estimated bucketsize upward to account for skewed * distribution. */
if (avgfreq > 0.0 && mcvfreq > avgfreq) estfract *= mcvfreq / avgfreq;
Which is explained like in the estimate_hash_bucketsize comment like this:
* be nonuniformly occupied. If the other relation in the join has a key
* distribution similar to this one's, then the most-loaded buckets are
* exactly those that will be probed most often. Therefore, the "average"
* bucket size for costing purposes should really be taken as something *
close to the "worst case" bucket size. We try to estimate this by
* adjusting the fraction if there are too few distinct data values, and
* then scaling up by the ratio of the most common value's frequency to
* the average frequency.
The problem is that the two testcases don't behave like this, i.e. the
other relation does not have similar distribution (because there the
join key is unique). Actually, I wonder how frequently that happens and
I wouldn't be surprised if it was quite rare.
So maybe we shouldn't scale it the way we scale it now. For example we
could do this:
if (avgfreq > 0.0 && mcvfreq > avgfreq) estfract *= sqrt(mcvfreq / avgfreq);
Or instead of using the first MCV frequency (i.e. the frequency of the
most common value, which causes the unexpectedly hight tuple/bucket
values), use an average or median of the MCV frequenfies.
Either of these three changes "fixed" the first test case, some fixed
the second one. However it's pure guesswork, and I have how many plans
will be hit negatively by these changes.
What I think might work better is lowering the cost of searching small
hash tables, when the hash table fits into L1/L2... caches. The table I
posted in the first message in this thread illustrates that:
kB NTUP=1 NTUP=2 NTUP=4 NTUP=5 NTUP=9 NTUP=10 1407 6753 7218 7890 9324 9488 12574 7032
9417 11586 17417 15820 25732 25402 35157 13179 17101 27225 24763 43323 43175 70313 14203
18475 29354 26690 46840 46676 175782 14319 17458 25325 34542 37342 60949 351563 16297 19928
29124 43364 43232 70014 703125 19027 23125 33610 50283 50165 81398
So a small hash table (~1.4MB), fitting into L2 (measured on CPU with
~4MB cache) is influenced much less than large tables. I don't know
whether we should detect the CPU cache size somehow, or whether we
should assume some conservative size (say, 4MB sounds OK), or what. But
I think something like this might work
if (hash_size < 4MB) { /* take in only 10% of the difference */ estfract += (mcvfreq / avgfreq) * estfract *
0.1;} else if (hash_size > 16MB) { estfract *= (mcvfreq / avgfreq); } else { /* linear approximation between 10
and100% */ estfract += (mcvfreq / avgfreq) * estfract * (0.1 + 0.9 * (hash_size - 4MB) / 12MB); }
Or maybe not, I'm not really sure. The problem is that the two test
cases really don't match the assumption that the outer relation has the
same distribution.
regards
Tomas
On 20.7.2014 00:12, Tomas Vondra wrote: > On 19.7.2014 23:07, Tomas Vondra wrote: >> On 19.7.2014 20:28, Tomas Vondra wrote: >> For the first case, a WARNING at the end of estimate_hash_bucketsize >> says this: >> >> WARNING: nbuckets=8388608.00 estfract=0.000001 >> WARNING: nbuckets=65536.00 estfract=0.000267 >> >> There are 4.3M rows in the big_table, so it says ~4 tuples (selectivity >>> = 1e-6), and ~10 tuples/bucket for the small_table (42k rows). >> >> For the second case, I get this: >> >> WARNING: nbuckets=16777216.00 estfract=0.000001 >> WARNING: nbuckets=262144.00 estfract=0.000100 >> >> i.e. ~11 tuples/bucket for big_table and ~20 tuples for small_table. >> >> That sounds really strange, because small_table in the second test case >> is almost perfectly unique. And in the first test case, there are only >> very few keys with >2 occurences. > > FWIW, the "problem" seems to be this: > > /* > * Adjust estimated bucketsize upward to account for skewed > * distribution. */ > > if (avgfreq > 0.0 && mcvfreq > avgfreq) > estfract *= mcvfreq / avgfreq; > > Which is explained like in the estimate_hash_bucketsize comment like this: > > * be nonuniformly occupied. If the other relation in the join has a key > * distribution similar to this one's, then the most-loaded buckets are > * exactly those that will be probed most often. Therefore, the "average" > * bucket size for costing purposes should really be taken as something * > close to the "worst case" bucket size. We try to estimate this by > * adjusting the fraction if there are too few distinct data values, and > * then scaling up by the ratio of the most common value's frequency to > * the average frequency. After thinking about this a bit more, I'm starting to question the logic behind the adjustment. The thing is, with NTUP_PER_BUCKET=1, all the tuples in a bucket should have the same hash value and (hash collisions aside) the same join key value. That means we're not really searching through the bucket, we're merely iterating and returning all the tuples. With NTUP_PER_BUCKET=10 it maybe made sense, because it was expected to see multiple hash values in a single bucket. With NTUP_PER_BUCKET=1 we shouldn't really expect that. So I think we should rip the MCV adjustment out ouf estimate_hash_bucketsize (and indeed, it fixed both the test cases). The only case where I think this might play role is when we can't use the optimal number of buckets (achieving NTUP_PER_BUCKET=1), but in that case the patched ExecChooseHashTableSize prefers to increase number of batches. So that seems safe to me. Or in what scenario (with NTUP_PER_BUCKET=1) does this still make sense? Two more comments: (a) Isn't the minimum selectivity enforced in estimate_hash_bucketsize (1.0e-6) too high? I mean, With 1GB work_mem I canget ~20M tuples into the hash table, and in that case it's off by an order of magnitude. Maybe 1e-9 would be moreappropriate? (b) Currently, ExecChooseHashTableSize sizes the hash table (nbuckets) using ntuples, but maybe ndistinct (if available)would be better? It's tricky, though, because while both values are initially estimates, ndistinct is notoriouslyless reliable. Also, we currently don't have means to count ndistinct while building the table (as opposedto ntuples, which is trivial), which is needed when resizing the hash table in case the initial estimate was off. So currently the code optimizes for "ndistinct==ntuples" which may produce larger nbuckets values, but ISTM it'sthe right choice. regards Tomas
On 19.7.2014 20:24, Tomas Vondra wrote: > On 13.7.2014 21:32, Tomas Vondra wrote: >> The current patch only implemnents this for tuples in the main >> hash table, not for skew buckets. I plan to do that, but it will >> require separate chunks for each skew bucket (so we can remove it >> without messing with all of them). The chunks for skew buckets >> should be smaller (I'm thinking about ~4kB), because there'll be >> more of them, but OTOH those buckets are for frequent values so the >> chunks should not remain empty. > > I've looked into extending the dense allocation to the skew buckets, > and I think we shouldn't do that. I got about 50% of the changes and > then just threw it out because it turned out quite pointless. > > The amount of memory for skew buckets is limited to 2% of work mem, > so even with 100% overhead it'll use ~4% of work mem. So there's > pretty much nothing to gain here. So the additional complexity > introduced by the dense allocation seems pretty pointless. > > I'm not entirely happy with the code allocating some memory densely > and some using traditional palloc, but it certainly seems cleaner > than the code I had. > > So I think the patch is mostly OK as is. Attached is v4 of the patch, mostly with minor improvements and cleanups (removed MemoryContextStats, code related to skew buckets). regards Tomas
Attachment
On 07/20/2014 07:17 PM, Tomas Vondra wrote: > On 19.7.2014 20:24, Tomas Vondra wrote: >> On 13.7.2014 21:32, Tomas Vondra wrote: >>> The current patch only implemnents this for tuples in the main >>> hash table, not for skew buckets. I plan to do that, but it will >>> require separate chunks for each skew bucket (so we can remove it >>> without messing with all of them). The chunks for skew buckets >>> should be smaller (I'm thinking about ~4kB), because there'll be >>> more of them, but OTOH those buckets are for frequent values so the >>> chunks should not remain empty. >> >> I've looked into extending the dense allocation to the skew buckets, >> and I think we shouldn't do that. I got about 50% of the changes and >> then just threw it out because it turned out quite pointless. >> >> The amount of memory for skew buckets is limited to 2% of work mem, >> so even with 100% overhead it'll use ~4% of work mem. So there's >> pretty much nothing to gain here. So the additional complexity >> introduced by the dense allocation seems pretty pointless. >> >> I'm not entirely happy with the code allocating some memory densely >> and some using traditional palloc, but it certainly seems cleaner >> than the code I had. >> >> So I think the patch is mostly OK as is. > > Attached is v4 of the patch, mostly with minor improvements and cleanups > (removed MemoryContextStats, code related to skew buckets). Can you remind me what kind of queries this is supposed to help with? Could you do some performance testing to demonstrate the effect? And also a worst-case scenario. At a quick glance, I think you're missing a fairly obvious trick in ExecHashIncreaseNumBatches: if a chunk contains only a single tuple, you can avoid copying it to a new chunk and just link the old chunk to the new list instead. Not sure if ExecHashIncreaseNumBatches is called often enough for that to be noticeable, but at least it should help in extreme cases where you push around huge > 100MB tuples. - Heikki
On 20 Srpen 2014, 14:05, Heikki Linnakangas wrote: > On 07/20/2014 07:17 PM, Tomas Vondra wrote: >> On 19.7.2014 20:24, Tomas Vondra wrote: >>> On 13.7.2014 21:32, Tomas Vondra wrote: >>>> The current patch only implemnents this for tuples in the main >>>> hash table, not for skew buckets. I plan to do that, but it will >>>> require separate chunks for each skew bucket (so we can remove it >>>> without messing with all of them). The chunks for skew buckets >>>> should be smaller (I'm thinking about ~4kB), because there'll be >>>> more of them, but OTOH those buckets are for frequent values so the >>>> chunks should not remain empty. >>> >>> I've looked into extending the dense allocation to the skew buckets, >>> and I think we shouldn't do that. I got about 50% of the changes and >>> then just threw it out because it turned out quite pointless. >>> >>> The amount of memory for skew buckets is limited to 2% of work mem, >>> so even with 100% overhead it'll use ~4% of work mem. So there's >>> pretty much nothing to gain here. So the additional complexity >>> introduced by the dense allocation seems pretty pointless. >>> >>> I'm not entirely happy with the code allocating some memory densely >>> and some using traditional palloc, but it certainly seems cleaner >>> than the code I had. >>> >>> So I think the patch is mostly OK as is. >> >> Attached is v4 of the patch, mostly with minor improvements and cleanups >> (removed MemoryContextStats, code related to skew buckets). > > Can you remind me what kind of queries this is supposed to help with? > Could you do some performance testing to demonstrate the effect? And > also a worst-case scenario. The dense allocation? That was not really directed at any specific queries, it was about lowering hashjoin memory requirements in general. First to make it more correct with respect to work_mem (hashjoin does not account for the palloc overhead, so the actual memory consumption might be much higher than work_mem). Second to compensate for the memory for more buckets due to NTUP_PER_BUCKET, which is tweaked in the 'hashjoin dynamic nbuckets' patch. There are some numbers / more detailed analysis in http://www.postgresql.org/message-id/a17d6217fe0c9e459cb45cb764ad727c.squirrel@sq.gransy.com > > At a quick glance, I think you're missing a fairly obvious trick in > ExecHashIncreaseNumBatches: if a chunk contains only a single tuple, you > can avoid copying it to a new chunk and just link the old chunk to the > new list instead. Not sure if ExecHashIncreaseNumBatches is called often > enough for that to be noticeable, but at least it should help in extreme > cases where you push around huge > 100MB tuples. Yeah, I thought about that too, but it seemed like a rare corner case. But maybe you're right - it will also eliminate the 'fluctuation' (allocating 100MB chunk, which might get us over work_mem, ...). Not sure if this is going to help, but it's easy enough to fix I guess. The other optimization I'm thinking about is that when increasing number of batches, the expectation is only about 1/2 the chunks will be necessary. So instead of freeing the chunk, we might keep it and reuse it later. That might lower the palloc overhead a bit (but it's already very low, so I don't think that's measurable difference). regards Tomas