Thread: Optimize kernel readahead using buffer access strategy
Hi, I create a patch that is improvement of disk-read and OS file caches. It can optimize kernel readahead parameter using buffer access strategy and posix_fadvice() in various disk-read situations. In general OS, readahead parameter was dynamically decided by disk-read situations. If long time disk-read was happened, readahead parameter becomes big. However it is based on experienced or heuristic algorithm, it causes waste disk-read and throws out useful OS file caches in some case. It is bad for disk-read performance a lot. My proposed method is controlling OS readahead parameter by using buffer access strategy in PostgreSQL and posix_fadvice() system call which can control OS readahead parameter. Though, it is a general method in database. For your information of effect of this patch, I got results of pgbench which are in-memory-size database and out-memory-size database, and postgresql.conf settings are always used by us. It seems to improve performance to a better. And I think that this feature is going to be necessary for business intelligence which will be realized at PostgreSQL version 10. I seriously believe Simon's presentation in PostgreSQL conference Europe 2013! It was very exciting!!! PostgreSQL have a lot of kind of disk-read method that are selected by planner, however. I think that we need to discuss more other situations except pgbench, and other cache cold situations. I think that optimizing kernel readahead parameter with considering planner in PostgreSQL seems to be quite difficult, so I seriously recruit co-author in this patch:-) Regards, -- Mitsumasa KONDO NTT Open Source Software Center
Attachment
{kind=link}
{kind=link}
On Thu, Nov 14, 2013 at 9:09 AM, KONDO Mitsumasa
<kondo.mitsumasa@lab.ntt.co.jp> wrote:
> I create a patch that is improvement of disk-read and OS file caches. It can
> optimize kernel readahead parameter using buffer access strategy and
> posix_fadvice() in various disk-read situations.
>
> In general OS, readahead parameter was dynamically decided by disk-read
> situations. If long time disk-read was happened, readahead parameter becomes big.
> However it is based on experienced or heuristic algorithm, it causes waste
> disk-read and throws out useful OS file caches in some case. It is bad for
> disk-read performance a lot.
It would be relevant to know which kernel did you use for those tests.
@@ -677,6 +677,7 @@ mdread(SMgrRelation reln, ForkNumber forknum,
BlockNumber blocknum, errmsg("could not seek to block %u in file \"%s\": %m",
blocknum,FilePathName(v->mdfd_vfd))));
+ BufferHintIOAdvise(v->mdfd_vfd, buffer, BLCKSZ, strategy); nbytes = FileRead(v->mdfd_vfd, buffer, BLCKSZ);
TRACE_POSTGRESQL_SMGR_MD_READ_DONE(forknum, blocknum,
A while back, I tried to use posix_fadvise to prefetch index pages. I
ended up finding out that interleaving posix_fadvise with I/O like
that severly hinders (ie: completely disables) the kernel's read-ahead
algorithm.
How exactly did you set up those benchmarks? pg_bench defaults?
pg_bench does not exercise heavy sequential access patterns, or long
index scans. It performs many single-page index lookups per
transaction and that's it. You may want to try your patch with more
real workloads, and maybe you'll confirm what I found out last time I
messed with posix_fadvise. If my experience is still relevant, those
patterns will have suffered a severe performance penalty with this
patch, because it will disable kernel read-ahead on sequential index
access. It may still work for sequential heap scans, because the
access strategy will tell the kernel to do read-ahead, but many other
access methods will suffer.
Try OLAP-style queries.
On Thu, Nov 14, 2013 at 9:09 PM, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > Hi, > > I create a patch that is improvement of disk-read and OS file caches. It can > optimize kernel readahead parameter using buffer access strategy and > posix_fadvice() in various disk-read situations. When I compiled the HEAD code with this patch on MacOS, I got the following error and warnings. gcc -O0 -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Wendif-labels -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing -fwrapv -g -I../../../../src/include -c -o fd.o fd.c fd.c: In function 'BufferHintIOAdvise': fd.c:1182: error: 'POSIX_FADV_SEQUENTIAL' undeclared (first use in this function) fd.c:1182: error: (Each undeclared identifier is reported only once fd.c:1182: error: for each function it appears in.) fd.c:1185: error: 'POSIX_FADV_RANDOM' undeclared (first use in this function) make[4]: *** [fd.o] Error 1 make[3]: *** [file-recursive] Error 2 make[2]: *** [storage-recursive] Error 2 make[1]: *** [install-backend-recurse] Error 2 make: *** [install-src-recurse] Error 2 tablecmds.c:9120: warning: passing argument 5 of 'smgrread' makes pointer from integer without a cast bufmgr.c:455: warning: passing argument 5 of 'smgrread' from incompatible pointer type Regards, -- Fujii Masao
Hi Claudio, (2013/11/14 22:53), Claudio Freire wrote: > On Thu, Nov 14, 2013 at 9:09 AM, KONDO Mitsumasa > <kondo.mitsumasa@lab.ntt.co.jp> wrote: >> I create a patch that is improvement of disk-read and OS file caches. It can >> optimize kernel readahead parameter using buffer access strategy and >> posix_fadvice() in various disk-read situations. >> >> In general OS, readahead parameter was dynamically decided by disk-read >> situations. If long time disk-read was happened, readahead parameter becomes big. >> However it is based on experienced or heuristic algorithm, it causes waste >> disk-read and throws out useful OS file caches in some case. It is bad for >> disk-read performance a lot. > > It would be relevant to know which kernel did you use for those tests. I use CentOS 6.4 which kernel version is 2.6.32-358.23.2.el6.x86_64 in this test. > A while back, I tried to use posix_fadvise to prefetch index pages. I search your past work. Do you talk about this ML-thread? Or is there another latest discussion? I see your patch is interesting, but it wasn't submitted to CF and stopping discussions. http://www.postgresql.org/message-id/CAGTBQpZzf70n0PYJ=VQLd+jb3wJGo=2TXmY+SkJD6G_vjC5QNg@mail.gmail.com >I ended up finding out that interleaving posix_fadvise with I/O like > that severly hinders (ie: completely disables) the kernel's read-ahead > algorithm. Your patch becomes maximum readahead, when a sql is selected index range scan. Is it right? I think that your patch assumes that pages are ordered by index-data. This assumption is partially wrong. If your assumption is true, we don't need CLUSTER command. In actuary, CLUSTER command becomes better performance than nothing. > How exactly did you set up those benchmarks? pg_bench defaults? My detail test setting is under following, * Server info CPU: Intel(R) Xeon(R) CPU E5645 @ 2.40GHz (2U/12C) RAM: 6GB -> I reduced it intentionally in OS paraemter,because large memory tests have long time. HDD: SEAGATE Model: ST2000NM0001 @ 7200rpm * 1 RAID: none. * postgresql.conf(summarized) shared_buffers = 600MB (10% of RAM = 6GB) work_mem = 1MB maintenance_work_mem = 64MB wal_level= archive fsync = on archive_mode = on checkpoint_segments = 300 checkpoint_timeout = 15min checkpoint_completion_target= 0.7 * pgbench settings pgbench -j 4 -c 32 -T 600 pgbench > pg_bench does not exercise heavy sequential access patterns, or long > index scans. It performs many single-page index lookups per > transaction and that's it. Yes, your argument is right. And it is also a fact that performance becomes better in these situations. > You may want to try your patch with more > real workloads, and maybe you'll confirm what I found out last time I > messed with posix_fadvise. If my experience is still relevant, those > patterns will have suffered a severe performance penalty with this > patch, because it will disable kernel read-ahead on sequential index > access. It may still work for sequential heap scans, because the > access strategy will tell the kernel to do read-ahead, but many other > access methods will suffer. The decisive difference with your patch is that my patch uses buffer hint control architecture, so it can control readahaed smarter in some cases. However, my patch is on the way and needed to more improvement. I am going to add method of controlling readahead by GUC, for user can freely select readahed parameter in their transactions. > Try OLAP-style queries. I have DBT-3(TPC-H) benchmark tools. If you don't like TPC-H, could you tell me good OLAP benchmark tools? Regards, -- Mitsumasa KONDO NTT Open Source Software
(2013/11/15 2:03), Fujii Masao wrote: > On Thu, Nov 14, 2013 at 9:09 PM, KONDO Mitsumasa > <kondo.mitsumasa@lab.ntt.co.jp> wrote: >> Hi, >> >> I create a patch that is improvement of disk-read and OS file caches. It can >> optimize kernel readahead parameter using buffer access strategy and >> posix_fadvice() in various disk-read situations. > > When I compiled the HEAD code with this patch on MacOS, I got the following > error and warnings. > > gcc -O0 -Wall -Wmissing-prototypes -Wpointer-arith > -Wdeclaration-after-statement -Wendif-labels > -Wmissing-format-attribute -Wformat-security -fno-strict-aliasing > -fwrapv -g -I../../../../src/include -c -o fd.o fd.c > fd.c: In function 'BufferHintIOAdvise': > fd.c:1182: error: 'POSIX_FADV_SEQUENTIAL' undeclared (first use in > this function) > fd.c:1182: error: (Each undeclared identifier is reported only once > fd.c:1182: error: for each function it appears in.) > fd.c:1185: error: 'POSIX_FADV_RANDOM' undeclared (first use in this function) > make[4]: *** [fd.o] Error 1 > make[3]: *** [file-recursive] Error 2 > make[2]: *** [storage-recursive] Error 2 > make[1]: *** [install-backend-recurse] Error 2 > make: *** [install-src-recurse] Error 2 > > tablecmds.c:9120: warning: passing argument 5 of 'smgrread' makes > pointer from integer without a cast > bufmgr.c:455: warning: passing argument 5 of 'smgrread' from > incompatible pointer type Thanks you for your report! I will fix it. Could you tell me your Mac OS version and gcc version? I have only mac book air with Maverick OS(10.9). Regards, -- Mitsumasa KONDO NTT Open Source Software Center
On Thu, Nov 14, 2013 at 6:18 PM, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > I will fix it. Could you tell me your Mac OS version and gcc version? I have > only mac book air with Maverick OS(10.9). I have an idea that Mac OSX doesn't have posix_fadvise at all. Didn't you use the relevant macros so that the code at least builds on those platforms? -- Peter Geoghegan
(2013/11/15 11:17), Peter Geoghegan wrote: > On Thu, Nov 14, 2013 at 6:18 PM, KONDO Mitsumasa > <kondo.mitsumasa@lab.ntt.co.jp> wrote: >> I will fix it. Could you tell me your Mac OS version and gcc version? I have >> only mac book air with Maverick OS(10.9). > > I have an idea that Mac OSX doesn't have posix_fadvise at all. Didn't > you use the relevant macros so that the code at least builds on those > platforms? Thank you for your nice advice, too. I try to fix macro program. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
On Thu, Nov 14, 2013 at 11:13 PM, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > Hi Claudio, > > > (2013/11/14 22:53), Claudio Freire wrote: >> >> On Thu, Nov 14, 2013 at 9:09 AM, KONDO Mitsumasa >> <kondo.mitsumasa@lab.ntt.co.jp> wrote: >>> >>> I create a patch that is improvement of disk-read and OS file caches. It >>> can >>> optimize kernel readahead parameter using buffer access strategy and >>> posix_fadvice() in various disk-read situations. >>> >>> In general OS, readahead parameter was dynamically decided by disk-read >>> situations. If long time disk-read was happened, readahead parameter >>> becomes big. >>> However it is based on experienced or heuristic algorithm, it causes >>> waste >>> disk-read and throws out useful OS file caches in some case. It is bad >>> for >>> disk-read performance a lot. >> >> >> It would be relevant to know which kernel did you use for those tests. > > I use CentOS 6.4 which kernel version is 2.6.32-358.23.2.el6.x86_64 in this > test. That's close to the kernel version I was using, so you should see the same effect. >> A while back, I tried to use posix_fadvise to prefetch index pages. > > I search your past work. Do you talk about this ML-thread? Or is there > another latest discussion? I see your patch is interesting, but it wasn't > submitted to CF and stopping discussions. > http://www.postgresql.org/message-id/CAGTBQpZzf70n0PYJ=VQLd+jb3wJGo=2TXmY+SkJD6G_vjC5QNg@mail.gmail.com Yes, I didn't, exactly because of that bad interaction with the kernel. It needs either more smarts to only do fadvise on known-random patterns (what you did mostly), or an accompanying kernel patch (which I was working on, but ran out of test machines). >> I ended up finding out that interleaving posix_fadvise with I/O like >> that severly hinders (ie: completely disables) the kernel's read-ahead >> algorithm. > > Your patch becomes maximum readahead, when a sql is selected index range > scan. Is it right? Ehm... sorta. > I think that your patch assumes that pages are ordered by > index-data. No. It just knows which pages will be needed, and fadvises them. No guessing involved, except the guess that the scan will not be aborted. There's a heuristic to stop limited scans from attempting to fadvise, and that's that prefetch strategy is applied only from the Nth+ page walk. It improves index-only scans the most, but I also attempted to handle heap prefetches. That's where the kernel started conspiring against me, because I used many naturally-clustered indexes, and THERE performance was adversely affected because of that kernel bug. >> You may want to try your patch with more >> real workloads, and maybe you'll confirm what I found out last time I >> messed with posix_fadvise. If my experience is still relevant, those >> patterns will have suffered a severe performance penalty with this >> patch, because it will disable kernel read-ahead on sequential index >> access. It may still work for sequential heap scans, because the >> access strategy will tell the kernel to do read-ahead, but many other >> access methods will suffer. > > The decisive difference with your patch is that my patch uses buffer hint > control architecture, so it can control readahaed smarter in some cases. Indeed, but it's not enough. See my above comment about naturally clustered indexes. The planner expects that, and plans accordingly. It will notice correlation between a PK and physical location, and will treat an index scan over PK to be almost sequential. With your patch, that assumption will be broken I believe. > However, my patch is on the way and needed to more improvement. I am going > to add method of controlling readahead by GUC, for user can freely select > readahed parameter in their transactions. Rather, I'd try to avoid fadvising consecutive or almost-consecutive blocks. Detecting that is hard at the block level, but maybe you can tie that detection into the planner, and specify a sequential strategy when the planner expects index-heap correlation? >> Try OLAP-style queries. > > I have DBT-3(TPC-H) benchmark tools. If you don't like TPC-H, could you tell > me good OLAP benchmark tools? I don't really know. Skimming the specs, I'm not sure if those queries generate large index range queries. You could try, maybe with autoexplain?
On 11/14/13, 7:09 AM, KONDO Mitsumasa wrote: > I create a patch that is improvement of disk-read and OS file caches. It can > optimize kernel readahead parameter using buffer access strategy and > posix_fadvice() in various disk-read situations. Various compiler warnings: tablecmds.c: In function ‘copy_relation_data’: tablecmds.c:9120:3: warning: passing argument 5 of ‘smgrread’ makes pointer from integer without a cast [enabled by default] In file included from tablecmds.c:79:0: ../../../src/include/storage/smgr.h:94:13: note: expected ‘char *’ but argument is of type ‘int’ bufmgr.c: In function ‘ReadBuffer_common’: bufmgr.c:455:4: warning: passing argument 5 of ‘smgrread’ from incompatible pointer type [enabled by default] In file included from ../../../../src/include/storage/buf_internals.h:22:0, from bufmgr.c:45: ../../../../src/include/storage/smgr.h:94:13: note: expected ‘char *’ but argument is of type ‘BufferAccessStrategy’ md.c: In function ‘mdread’: md.c:680:2: warning: passing argument 2 of ‘BufferHintIOAdvise’ makes integer from pointer without a cast [enabled by default] In file included from md.c:34:0: ../../../../src/include/storage/fd.h:79:12: note: expected ‘off_t’ but argument is of type ‘char *’
(2013/11/15 13:48), Claudio Freire wrote: > On Thu, Nov 14, 2013 at 11:13 PM, KONDO Mitsumasa >> I use CentOS 6.4 which kernel version is 2.6.32-358.23.2.el6.x86_64 in this >> test. > > That's close to the kernel version I was using, so you should see the > same effect. OK. You proposed readahead maximum patch, I think it seems to get benefit for perofomance and your part of argument is really true. >> Your patch becomes maximum readahead, when a sql is selected index range >> scan. Is it right? > > Ehm... sorta. > >> I think that your patch assumes that pages are ordered by >> index-data. > > No. It just knows which pages will be needed, and fadvises them. No > guessing involved, except the guess that the scan will not be aborted. > There's a heuristic to stop limited scans from attempting to fadvise, > and that's that prefetch strategy is applied only from the Nth+ page > walk. We may completely optimize kernel readahead in PostgreSQL in the future, however it is very difficult and takes long time that it completely comes true from a beginning. So I propose GUC switch that can use in their transactions.(I will create this patch in this CF.). If someone off readahed for using file cache more efficient in his transactions, he can set "SET readahead = off". PostgreSQL is open source, and I think that it becomes clear which case it is effective for, by using many people. > It improves index-only scans the most, but I also attempted to handle > heap prefetches. That's where the kernel started conspiring against > me, because I used many naturally-clustered indexes, and THERE > performance was adversely affected because of that kernel bug. I also create gaussinan-distributed pgbench now and submit this CF. It can clear which situasion is effective, partially we will know. >>> You may want to try your patch with more >>> real workloads, and maybe you'll confirm what I found out last time I >>> messed with posix_fadvise. If my experience is still relevant, those >>> patterns will have suffered a severe performance penalty with this >>> patch, because it will disable kernel read-ahead on sequential index >>> access. It may still work for sequential heap scans, because the >>> access strategy will tell the kernel to do read-ahead, but many other >>> access methods will suffer. >> >> The decisive difference with your patch is that my patch uses buffer hint >> control architecture, so it can control readahaed smarter in some cases. > > Indeed, but it's not enough. See my above comment about naturally > clustered indexes. The planner expects that, and plans accordingly. It > will notice correlation between a PK and physical location, and will > treat an index scan over PK to be almost sequential. With your patch, > that assumption will be broken I believe. ~ >> However, my patch is on the way and needed to more improvement. I am going >> to add method of controlling readahead by GUC, for user can freely select >> readahed parameter in their transactions. > > Rather, I'd try to avoid fadvising consecutive or almost-consecutive > blocks. Detecting that is hard at the block level, but maybe you can > tie that detection into the planner, and specify a sequential strategy > when the planner expects index-heap correlation? I think we had better to develop these patches in step by step each patches, because it is difficult that readahead optimizetion is completely come true from a beginning of one patch. We need flame-work in these patches, first. >>> Try OLAP-style queries. >> >> I have DBT-3(TPC-H) benchmark tools. If you don't like TPC-H, could you tell >> me good OLAP benchmark tools? > > I don't really know. Skimming the specs, I'm not sure if those queries > generate large index range queries. You could try, maybe with > autoexplain? OK, I do. And, I will use simple large index range queries with explain command. Regards, -- Mitsuamsa KONDO NTT Open Source Software Center
On Sun, Nov 17, 2013 at 11:02 PM, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: >>> However, my patch is on the way and needed to more improvement. I am >>> going >>> to add method of controlling readahead by GUC, for user can freely select >>> readahed parameter in their transactions. >> >> >> Rather, I'd try to avoid fadvising consecutive or almost-consecutive >> blocks. Detecting that is hard at the block level, but maybe you can >> tie that detection into the planner, and specify a sequential strategy >> when the planner expects index-heap correlation? > > I think we had better to develop these patches in step by step each patches, > because it is difficult that readahead optimizetion is completely come true > from a beginning of one patch. We need flame-work in these patches, first. Well, problem is, that without those smarts, I don't think this patch can be enabled by default. It will considerably hurt common use cases for postgres. But I guess we'll have a better idea about that when we see how much of a performance impact it makes when you run those tests, so no need to guess in the dark.
(2013/11/18 11:25), Claudio Freire wrote: > On Sun, Nov 17, 2013 at 11:02 PM, KONDO Mitsumasa > <kondo.mitsumasa@lab.ntt.co.jp> wrote: >>>> However, my patch is on the way and needed to more improvement. I am >>>> going >>>> to add method of controlling readahead by GUC, for user can freely select >>>> readahed parameter in their transactions. >>> >>> >>> Rather, I'd try to avoid fadvising consecutive or almost-consecutive >>> blocks. Detecting that is hard at the block level, but maybe you can >>> tie that detection into the planner, and specify a sequential strategy >>> when the planner expects index-heap correlation? >> >> I think we had better to develop these patches in step by step each patches, >> because it is difficult that readahead optimizetion is completely come true >> from a beginning of one patch. We need flame-work in these patches, first. > > Well, problem is, that without those smarts, I don't think this patch > can be enabled by default. It will considerably hurt common use cases > for postgres. Yes. I have thought as much you that defalut setting is false. (use normal readahead as before). Next version of my patch will become these. > But I guess we'll have a better idea about that when we see how much > of a performance impact it makes when you run those tests, so no need > to guess in the dark. Yes, sure. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
Hi,
I revise this patch and re-run performance test, it can work collectry in Linux
and no complile wanings. I add GUC about enable_kernel_readahead option in new
version. When this GUC is on(default), it works in POSIX_FADV_NORMAL which is
general readahead in OS. And when it is off, it works in POSXI_FADV_RANDOM or
POSIX_FADV_SEQUENTIAL which is judged by buffer hint in Postgres, readahead
parameter is optimized by postgres. We can change this parameter in their
transactions everywhere and everytime.
* Test server
Server: HP Proliant DL360 G7
CPU: Xeon E5640 2.66GHz (1P/4C)
Memory: 18GB(PC3-10600R-9)
Disk: 146GB(15k)*4 RAID1+0
RAID controller: P410i/256MB
OS: RHEL 6.4(x86_64)
FS: Ext4
* Test setting
I use "pgbench -c 8 -j 4 -T 2400 -S -P 10 -a"
I also use my accurate patch in this test. So I exexuted under following
command before each benchmark.
1. cluster all database
2. truncate pgbench_history
3. checkpoint
4. sync
5. checkpoint
* postresql.conf
shared_buffers = 2048MB
maintenance_work_mem = 64MB
wal_level = minimal
checkpoint_segments = 300
checkpoint_timeout = 15min
checkpoint_completion_target = 0.7
* Performance test result
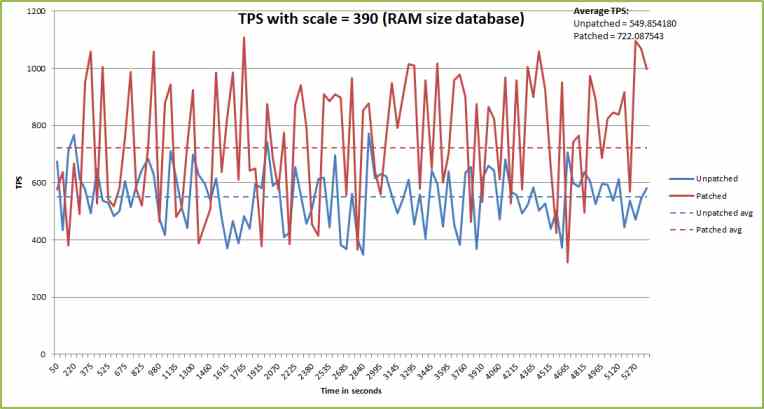
** In memory database size
s=1000 | 1 | 2 | 3 | avg
---------------------------------------------
readahead=on | 39836 | 40229 | 40055 | 40040
readahead=off | 31259 | 29656 | 30693 | 30536
ratio | 78% | 74% | 77% | 76%
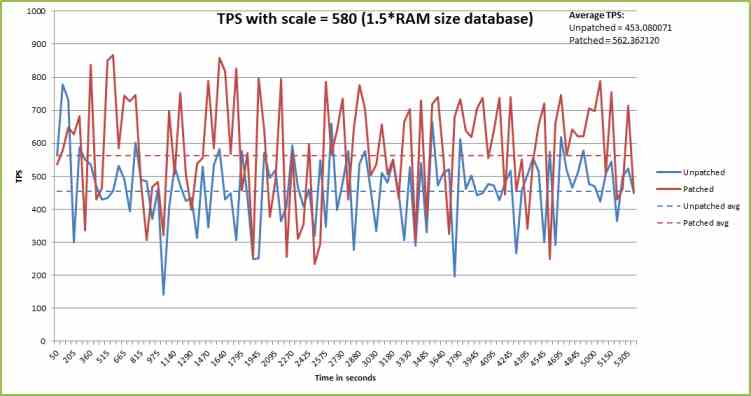
** Over memory database size
s=2000 | 1 | 2 | 3 | avg
---------------------------------------------
readahead=on | 1288 | 1370 | 1367 | 1341
readahead=off | 1683 | 1688 | 1395 | 1589
ratio | 131% | 123% | 102% | 118%
s=3000 | 1 | 2 | 3 | avg
---------------------------------------------
readahead=on | 965 | 862 | 993 | 940
readahead=off | 1113 | 1098 | 935 | 1049
ratio | 115% | 127% | 94% | 112%
It seems good performance expect scale factor=1000. When readahead parameter is
off, disk IO keep to a minimum or necessary, therefore it is faster than
"readahead=on". "readahead=on" uses useless diskIO. For example, which is faster
8KB random read or 12KB random read from disks in many times transactions? It is
self-evident that the former is faster.
In scale factor 1000, it becomes to slower buffer-is-hot than "readahead=on". So
it seems to less performance. But it is essence in measuring perfomance. And you
can confirm it by attached benchmark graphs. We can use this parameter when
buffer is reratively hot. If you want to see other trial graphs, I will send.
And I will support to MacOS and create document about this patch in this week.
#MacOS is in my house.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
Attachment
{kind=link}
{kind=link}
{kind=link}
On Tue, Dec 10, 2013 at 5:03 AM, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > I revise this patch and re-run performance test, it can work collectry in > Linux and no complile wanings. I add GUC about enable_kernel_readahead > option in new version. When this GUC is on(default), it works in > POSIX_FADV_NORMAL which is general readahead in OS. And when it is off, it > works in POSXI_FADV_RANDOM or POSIX_FADV_SEQUENTIAL which is judged by > buffer hint in Postgres, readahead parameter is optimized by postgres. We > can change this parameter in their transactions everywhere and everytime. I'd change the naming to enable_readahead=os|fadvise with os = on, fadvise = off And, if you want to keep the on/off values, I'd reverse them. Because off reads more like "I don't do anything special", and in your patch it's quite the opposite.
(2013/12/10 22:55), Claudio Freire wrote: > On Tue, Dec 10, 2013 at 5:03 AM, KONDO Mitsumasa > <kondo.mitsumasa@lab.ntt.co.jp> wrote: >> I revise this patch and re-run performance test, it can work collectry in >> Linux and no complile wanings. I add GUC about enable_kernel_readahead >> option in new version. When this GUC is on(default), it works in >> POSIX_FADV_NORMAL which is general readahead in OS. And when it is off, it >> works in POSXI_FADV_RANDOM or POSIX_FADV_SEQUENTIAL which is judged by >> buffer hint in Postgres, readahead parameter is optimized by postgres. We >> can change this parameter in their transactions everywhere and everytime. > > I'd change the naming to OK. I think "on" or "off" naming is not good, too. > enable_readahead=os|fadvise > > with os = on, fadvise = off Hmm. fadvise is method and is not a purpose. So I consider another idea of this GUC. 1)readahead_strategy=os|pg This naming is good for future another implements. If we will want to set maximum readaheadparaemeter which is always use POSIX_FADV_SEQUENTIAL, we can set "max". 2)readahead_optimizer=os|pg or readahaed_strategist=os|pg This naming is easy to understand to who is opitimized readahead. But it isn't extensibility for future another implements. > And, if you want to keep the on/off values, I'd reverse them. Because > off reads more like "I don't do anything special", and in your patch > it's quite the opposite. I understand your feeling. If we adopt "on|off" setting, I would like to set GUC optimized_readahead=off|on. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
On Wed, Dec 11, 2013 at 3:14 AM, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > >> enable_readahead=os|fadvise >> >> with os = on, fadvise = off > > Hmm. fadvise is method and is not a purpose. So I consider another idea of > this GUC. Yeah, I was thinking of opening the door for readahead=aio, but whatever clearer than on-off would work ;)
(2013/12/12 9:30), Claudio Freire wrote: > On Wed, Dec 11, 2013 at 3:14 AM, KONDO Mitsumasa > <kondo.mitsumasa@lab.ntt.co.jp> wrote: >> >>> enable_readahead=os|fadvise >>> >>> with os = on, fadvise = off >> >> Hmm. fadvise is method and is not a purpose. So I consider another idea of >> this GUC. > > Yeah, I was thinking of opening the door for readahead=aio, but > whatever clearer than on-off would work ;) I'm very interested in Postgres with libaio, and I'd like to see the perfomance improvements. I'm not sure about libaio, however, it will face exclusive-buffer-lock problem in asynchronous IO. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
On 14 November 2013 12:09, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > For your information of effect of this patch, I got results of pgbench which are > in-memory-size database and out-memory-size database, and postgresql.conf > settings are always used by us. It seems to improve performance to a better. And > I think that this feature is going to be necessary for business intelligence > which will be realized at PostgreSQL version 10. I seriously believe Simon's > presentation in PostgreSQL conference Europe 2013! It was very exciting!!! Thank you. I like the sound of this patch, sorry I've not been able to help as yet. Your tests seem to relate to pgbench. Do we have tests on more BI related tasks? -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
2013/12/12 Simon Riggs <simon@2ndquadrant.com>
On 14 November 2013 12:09, KONDO Mitsumasa<kondo.mitsumasa@lab.ntt.co.jp> wrote:Thank you.
> For your information of effect of this patch, I got results of pgbench which are
> in-memory-size database and out-memory-size database, and postgresql.conf
> settings are always used by us. It seems to improve performance to a better. And
> I think that this feature is going to be necessary for business intelligence
> which will be realized at PostgreSQL version 10. I seriously believe Simon's
> presentation in PostgreSQL conference Europe 2013! It was very exciting!!!
I like the sound of this patch, sorry I've not been able to help as yet.
Your tests seem to relate to pgbench. Do we have tests on more BI related tasks?
Yes, off-course! We will need another benchmark test before conclusion of this patch.
What kind of benchmark do you have?
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
On 12 December 2013 13:43, Mitsumasa KONDO <kondo.mitsumasa@gmail.com> wrote: >> Your tests seem to relate to pgbench. Do we have tests on more BI related >> tasks? > > Yes, off-course! We will need another benchmark test before conclusion of > this patch. > What kind of benchmark do you have? I suggest isolating SeqScan and IndexScan and BitmapIndex/HeapScan examples, as well as some of the simpler TPC-H queries. But start with some SeqScan and VACUUM cases. -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
Hi,
I fixed the patch to improve followings.
- Can compile in MacOS.
- Change GUC name enable_kernel_readahead to readahead_strategy.
- Change POSIX_FADV_SEQUNENTIAL to POISX_FADV_NORMAL when we select sequential
access strategy, this reason is later...
I tested simple two access paterns which are followings in pgbench tables scale
size is 1000.
A) SELECT count(bid) FROM pgbench_accounts; (Index only scan)
B) SELECT count(bid) FROM pgbench_accounts; (Seq scan)
In each test, I restart postgres and drop file cache before each test.
Unpatched PG is faster than patched in A and B query. It was about 1.3 times
faster. Result of A query as expected, because patched PG cannot execute
readahead at all. So cache cold situation is bad for patched PG. However, it
might good for cache hot situation, because it doesn't read disk IO at all and
can calculate file cache usage and know which cache is important.
However, result of B query as unexpected, because my patch select
POSIX_FADV_SEQUNENTIAL collectry, but it slow. I cannot understand that,
nevertheless I read kernel source code... Next, I change POSIX_FADV_SEQUNENTIAL
to POISX_FADV_NORMAL in my patch. B query was faster as unpatched PG.
In heavily random access benchmark tests which are pgbench and DBT-2, my patched
PG is about 1.1 - 1.3 times faster than unpatched PG. But postgres buffer hint
strategy algorithm have not optimized for readahead strategy yet, and I don't fix
it. It is still only for ring buffer algorithm in shared_buffer.
Attached printf-debug patch will show you inside postgres buffer strategy. When
you see "S" it selects sequential access strategy, on the other hands, when you
see "R" it selects random access strategy. It might interesting for you. It's
very visual.
Example output is here.
> [mitsu-ko@localhost postgresql]$ bin/vacuumdb
> SSSSSSSSSSSSSSSSSSSSSSSSSSS~~SSSSSSSSSSSSSSSSSSSSSSSSSSSSSS
> [mitsu-ko@localhost postgresql]$ bin/psql -c "EXPLAIN ANALYZE SELECT count(aid) FROM pgbench_accounts"
> QUERY PLAN
>
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
> Aggregate (cost=2854.29..2854.30 rows=1 width=4) (actual time=33.438..33.438 rows=1 loops=1)
> -> Index Only Scan using pgbench_accounts_pkey on pgbench_accounts (cost=0.29..2604.29 rows=100000 width=4)
(actualtime=0.072..20.912 rows=100000 loops=1)
> Heap Fetches: 0
> Total runtime: 33.552 ms
> (4 rows)
>
> RRRRRRRRRRRRRRRRRRRRRRRRRRR~~RRRRRRRRRRRRRRRRRRRRRRRRRRRRRR
> [mitsu-ko@localhost postgresql]$ bin/psql -c "EXPLAIN ANALYZE SELECT count(bid) FROM pgbench_accounts"
> SSSSSSSSSSSSSSSSSSSSSSSSSSS~~SSSSSSSSSSSSSSSSSSSSSSSSSSSSSS
>
------------------------------------------------------------------------------------------------------------------------------
> Aggregate (cost=2890.00..2890.01 rows=1 width=4) (actual time=40.315..40.315 rows=1 loops=1)
> -> Seq Scan on pgbench_accounts (cost=0.00..2640.00 rows=100000 width=4) (actual time=0.112..23.001 rows=100000
loops=1)
> Total runtime: 40.472 ms
> (3 rows)
Thats's all now.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
Attachment
On 17 December 2013 11:50, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > Unpatched PG is faster than patched in A and B query. It was about 1.3 times > faster. Result of A query as expected, because patched PG cannot execute > readahead at all. So cache cold situation is bad for patched PG. However, it > might good for cache hot situation, because it doesn't read disk IO at all > and can calculate file cache usage and know which cache is important. > > However, result of B query as unexpected, because my patch select > POSIX_FADV_SEQUNENTIAL collectry, but it slow. I cannot understand that, > nevertheless I read kernel source code... Next, I change > POSIX_FADV_SEQUNENTIAL to POISX_FADV_NORMAL in my patch. B query was faster > as unpatched PG. > > In heavily random access benchmark tests which are pgbench and DBT-2, my > patched PG is about 1.1 - 1.3 times faster than unpatched PG. But postgres > buffer hint strategy algorithm have not optimized for readahead strategy > yet, and I don't fix it. It is still only for ring buffer algorithm in > shared_buffer. These are interesting results. Good research. They also show that the benefit of this is very specific to the exact task being performed. I can't see any future for a setting that applies to everything or nothing. We must be more selective. We also need much better benchmark results, clearly laid out, so they can be reproduced and discussed. Please keep working on this. -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
(2013/12/17 21:29), Simon Riggs wrote: > These are interesting results. Good research. Thanks! > They also show that the benefit of this is very specific to the exact > task being performed. I can't see any future for a setting that > applies to everything or nothing. We must be more selective. This patch is still needed some human judgement whether readahead is on or off. But it might have been already useful for clever users. However, I'd like to implement adding more the minimum optimization. > We also need much better benchmark results, clearly laid out, so they > can be reproduced and discussed. I think this feature is big benefit for OLTP, and it might useful for BI now. BI queries are mostly compicated, so we will need to test more in some situations. Printf debug is very useful for debugging my patch, and it will accelerate the optimization. > Please keep working on this. OK. I do it patiently. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
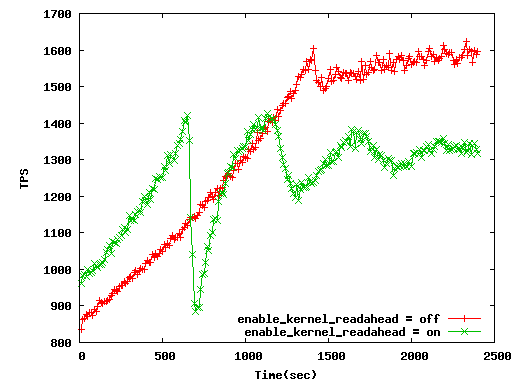
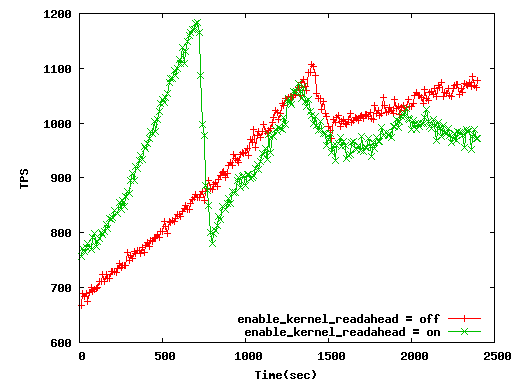
Hi, I fix and submit this patch in CF4. In my past patch, it is significant bug which is mistaken caluculation of offset in posix_fadvise():-( However it works well without problem in pgbench. Because pgbench transactions are always random access... And I test my patch in DBT-2 benchmark. Results are under following. * Test server Server: HP Proliant DL360 G7 CPU: Xeon E5640 2.66GHz (1P/4C) Memory: 18GB(PC3-10600R-9) Disk: 146GB(15k)*4 RAID1+0 RAID controller: P410i/256MB OS: RHEL 6.4(x86_64) FS: Ext4 * DBT-2 result(WH400, SESSION=100, ideal_score=5160) Method | score | average | 90%tile | Maximum ------------------------------------------------ plain | 3589 | 9.751 | 33.680 | 87.8036 option=off | 3670 | 9.107 | 34.267 | 79.3773 option=on | 4222 | 5.140 | 7.619 | 102.473 "option" is "readahead_strategy" option, and "on" is my proposed. "average", "90%tile", and Maximum represent latency. Average_latency is 2 times faster than plain! * Detail results (uploading now. please wait for a hour...) [plain] http://pgstatsinfo.projects.pgfoundry.org/readahead_dbt2/normal_20140109/HTML/index_thput.html [option=off] http://pgstatsinfo.projects.pgfoundry.org/readahead_dbt2/readahead_off_20140109/HTML/index_thput.html [option=on] http://pgstatsinfo.projects.pgfoundry.org/readahead_dbt2/readahead_on_20140109/HTML/index_thput.html We can see part of super slow latency in my proposed method test. Part of transaction active is 20%, and part of slow transactions is 80%. It might be Pareto principle in CHECKPOINT;-) #It's joke. I will test some join sqls performance and TPC-3 benchmark in this or next week. Regards, -- Mitsumasa KONDO NTT Open Source Software Center
Attachment
On Tue, Jan 14, 2014 at 8:58 AM, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > > In my past patch, it is significant bug which is mistaken caluculation of > offset in posix_fadvise():-( However it works well without problem in > pgbench. > Because pgbench transactions are always random access... Did you notice any difference? AFAIK, when specifying read patterns (ie, RANDOM, SEQUENTIAL and stuff like that), the offset doesn't matter. At least in linux.
On Tue, Jan 14, 2014 at 8:58 AM, KONDO Mitsumasa <kondo.mitsumasa@lab.ntt.co.jp> wrote: > > In my past patch, it is significant bug which is mistaken caluculation of > offset in posix_fadvise():-( However it works well without problem in > pgbench. > Because pgbench transactions are always random access... Did you notice any difference? AFAIK, when specifying read patterns (ie, RANDOM, SEQUENTIAL and stuff like that), the offset doesn't matter. At least in linux.
Hi, On 2014-01-14 20:58:20 +0900, KONDO Mitsumasa wrote: > I will test some join sqls performance and TPC-3 benchmark in this or next week. This patch has been marked as "Waiting For Author" for nearly two months now. Marked as "Returned with Feedback". Greetings, Andres Freund