Hi,
I revise this patch and re-run performance test, it can work collectry in Linux
and no complile wanings. I add GUC about enable_kernel_readahead option in new
version. When this GUC is on(default), it works in POSIX_FADV_NORMAL which is
general readahead in OS. And when it is off, it works in POSXI_FADV_RANDOM or
POSIX_FADV_SEQUENTIAL which is judged by buffer hint in Postgres, readahead
parameter is optimized by postgres. We can change this parameter in their
transactions everywhere and everytime.
* Test server
Server: HP Proliant DL360 G7
CPU: Xeon E5640 2.66GHz (1P/4C)
Memory: 18GB(PC3-10600R-9)
Disk: 146GB(15k)*4 RAID1+0
RAID controller: P410i/256MB
OS: RHEL 6.4(x86_64)
FS: Ext4
* Test setting
I use "pgbench -c 8 -j 4 -T 2400 -S -P 10 -a"
I also use my accurate patch in this test. So I exexuted under following
command before each benchmark.
1. cluster all database
2. truncate pgbench_history
3. checkpoint
4. sync
5. checkpoint
* postresql.conf
shared_buffers = 2048MB
maintenance_work_mem = 64MB
wal_level = minimal
checkpoint_segments = 300
checkpoint_timeout = 15min
checkpoint_completion_target = 0.7
* Performance test result
** In memory database size
s=1000 | 1 | 2 | 3 | avg
---------------------------------------------
readahead=on | 39836 | 40229 | 40055 | 40040
readahead=off | 31259 | 29656 | 30693 | 30536
ratio | 78% | 74% | 77% | 76%
** Over memory database size
s=2000 | 1 | 2 | 3 | avg
---------------------------------------------
readahead=on | 1288 | 1370 | 1367 | 1341
readahead=off | 1683 | 1688 | 1395 | 1589
ratio | 131% | 123% | 102% | 118%
s=3000 | 1 | 2 | 3 | avg
---------------------------------------------
readahead=on | 965 | 862 | 993 | 940
readahead=off | 1113 | 1098 | 935 | 1049
ratio | 115% | 127% | 94% | 112%
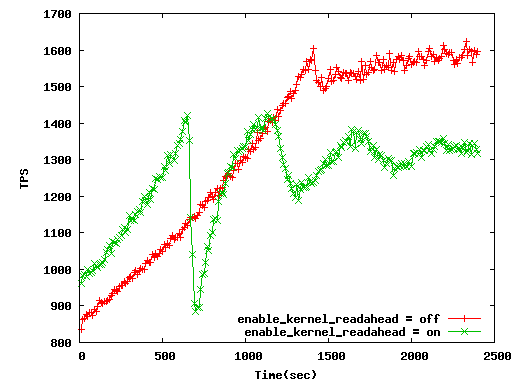
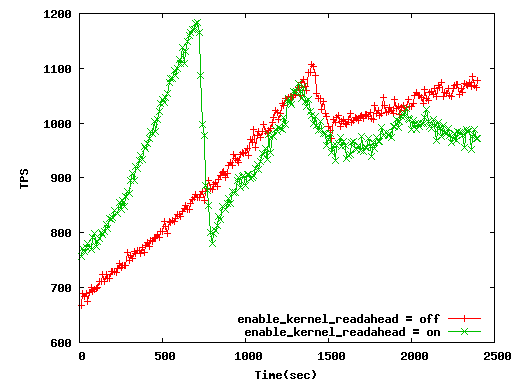
It seems good performance expect scale factor=1000. When readahead parameter is
off, disk IO keep to a minimum or necessary, therefore it is faster than
"readahead=on". "readahead=on" uses useless diskIO. For example, which is faster
8KB random read or 12KB random read from disks in many times transactions? It is
self-evident that the former is faster.
In scale factor 1000, it becomes to slower buffer-is-hot than "readahead=on". So
it seems to less performance. But it is essence in measuring perfomance. And you
can confirm it by attached benchmark graphs. We can use this parameter when
buffer is reratively hot. If you want to see other trial graphs, I will send.
And I will support to MacOS and create document about this patch in this week.
#MacOS is in my house.
Regards,
--
Mitsumasa KONDO
NTT Open Source Software Center
{kind=link}
{kind=link}
{kind=link}