Thread: Backport of fsync queue compaction
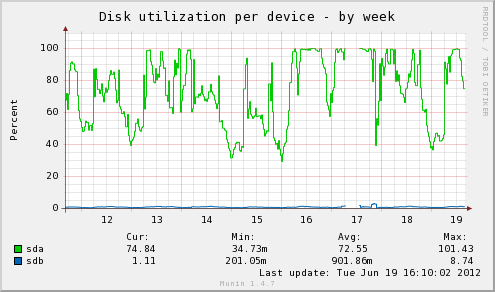
In January of 2011 Robert committed 7f242d880b5b5d9642675517466d31373961cf98 to try and compact the fsync queue when clients find it full. There's no visible behavior change, just a substantial performance boost possible in the rare but extremely bad situations where the background writer stops doing fsync absorption. I've been running that in production at multiple locations since practically the day it hit this mailing list, with backports all the way to 8.3 being common (and straightforward to construct). I've never seen a hint of a problem with this new code. I'm running into this more lately, in even worse forms than the report that kicked that investigation off. I wanted to share two of those, and raise the idea of backporting this fix to an uncommon but very bad situation. I see this as similar to the O(n^2) DROP issues. Not that many people will run into the issue, but the systems impacted really suffer from it. And this one can result in significant downtime for the server. The attached graphs show how bad the latest example I ran into was. The holes were effectively downtime even though the server stayed running, because performance was too slow to be useful. Sample bad checkpoint from the downtime on the 17th: 2012-06-17 14:48:13 EDT LOG: checkpoint complete: wrote 90 buffers (0.1%); 0 transaction log file(s) added, 0 removed, 14 recycled; write=26.531 s, sync=4371.513 s, total=4461.058 s That's over an hour for a checkpoint that only wrote out 720K of buffers! I used to think this was a terabyte scale problem--first three instances I saw were that size--and therefore not worth worrying too much about. This latest example happened with only a 200GB database though, on a server with 96GB of RAM. That's the reason I think this is a big enough risk to consider a mitigation backport now. The chance of running into this is much higher than I originally pegged it at. At the terabyte level, though, this can turn extremely nasty. Here's my worst example yet, from a different system altogether than any I've mentioned yet (I don't have graphs for this one I can share, just the quite anonymous log data): 2011-07-12 09:02:18.875 BST LOG: checkpoint complete: wrote 98888 buffers (9.4%); 0 transaction log file(s) added, 510 removed, 257 recycled; write=385.612 s, sync=9852.170 s, total=10246.452 s 2011-07-12 14:48:51.762 BST 30673 LOG: checkpoint complete: wrote 73101 buffers (7.0%); 0 transaction log file(s) added, 479 removed, 257 recycled; write=1789.793 s, sync=18994.602 s, total=20792.612 s 2011-07-12 18:02:25.722 BST 30673 LOG: checkpoint complete: wrote 141563 buffers (13.5%); 0 transaction log file(s) added, 1109 removed, 257 recycled; write=944.601 s, sync=10635.130 s, total=11613.953 s That site was effectively down an entire day while stuck in just these three checkpoints, with the middle one taking 5 hours to complete. The spike in pg_xlog disk usage was pretty nasty as well. It seems pretty possible for any site with the following characteristics to run into this at some point: -Either heavy writes or autovacuum can pump lots into the OS write cache. In the example with the graphs, the worst periods involved >4GB of dirty memory in the OS cache. That's how the setup for this type of failure starts, with lots of random writes queued up. -Periods where disk I/O can hit 100% on the database drive. Oon the disk utilization graph, you can see that's the case on the main database drive (sda); it's stuck at 100% busy doing I/O during the downtime. -Constant stream of incoming requests, such that a significant slowdown in query processing will lead to a negative feedback loop on the number of active queries. Connection graph attached showing how that plays out, the large number of idle connections are coming from Tomcat/JDBC pooling. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
Attachment
{kind=link}
{kind=link}
On Tue, Jun 19, 2012 at 5:33 PM, Greg Smith <greg@2ndquadrant.com> wrote: > In January of 2011 Robert committed 7f242d880b5b5d9642675517466d31373961cf98 > to try and compact the fsync queue when clients find it full. There's no > visible behavior change, just a substantial performance boost possible in > the rare but extremely bad situations where the background writer stops > doing fsync absorption. I've been running that in production at multiple > locations since practically the day it hit this mailing list, with backports > all the way to 8.3 being common (and straightforward to construct). I've > never seen a hint of a problem with this new code. I've been in favor of back-porting this for a while, so you'll get no argument from me. Anyone disagree? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Jun 19, 2012 at 5:39 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Jun 19, 2012 at 5:33 PM, Greg Smith <greg@2ndquadrant.com> wrote: >> In January of 2011 Robert committed 7f242d880b5b5d9642675517466d31373961cf98 >> to try and compact the fsync queue when clients find it full. There's no >> visible behavior change, just a substantial performance boost possible in >> the rare but extremely bad situations where the background writer stops >> doing fsync absorption. I've been running that in production at multiple >> locations since practically the day it hit this mailing list, with backports >> all the way to 8.3 being common (and straightforward to construct). I've >> never seen a hint of a problem with this new code. > > I've been in favor of back-porting this for a while, so you'll get no > argument from me. > > Anyone disagree? I recall reviewing that; it seemed like quite a good change. Me likes. -- When confronted by a difficult problem, solve it by reducing it to the question, "How would the Lone Ranger handle this?"
Excerpts from Robert Haas's message of mar jun 19 17:39:46 -0400 2012: > On Tue, Jun 19, 2012 at 5:33 PM, Greg Smith <greg@2ndquadrant.com> wrote: > > In January of 2011 Robert committed 7f242d880b5b5d9642675517466d31373961cf98 > > to try and compact the fsync queue when clients find it full. There's no > > visible behavior change, just a substantial performance boost possible in > > the rare but extremely bad situations where the background writer stops > > doing fsync absorption. I've been running that in production at multiple > > locations since practically the day it hit this mailing list, with backports > > all the way to 8.3 being common (and straightforward to construct). I've > > never seen a hint of a problem with this new code. > > I've been in favor of back-porting this for a while, so you'll get no > argument from me. +1. I even thought we had already backported it and was surprised to discover we hadn't, when we had this problem at a customer, not long ago. -- Álvaro Herrera <alvherre@commandprompt.com> The PostgreSQL Company - Command Prompt, Inc. PostgreSQL Replication, Consulting, Custom Development, 24x7 support
On Tuesday, June 19, 2012 11:39:46 PM Robert Haas wrote: > On Tue, Jun 19, 2012 at 5:33 PM, Greg Smith <greg@2ndquadrant.com> wrote: > > In January of 2011 Robert committed > > 7f242d880b5b5d9642675517466d31373961cf98 to try and compact the fsync > > queue when clients find it full. There's no visible behavior change, > > just a substantial performance boost possible in the rare but extremely > > bad situations where the background writer stops doing fsync absorption. > > I've been running that in production at multiple locations since > > practically the day it hit this mailing list, with backports all the way > > to 8.3 being common (and straightforward to construct). I've never seen > > a hint of a problem with this new code. > > I've been in favor of back-porting this for a while, so you'll get no > argument from me. > > Anyone disagree? Not me, I have seen several sites having problems as well. +1 Andres -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
To what version will we backport it? -- Josh Berkus PostgreSQL Experts Inc. http://pgexperts.com
On Tue, Jun 19, 2012 at 7:33 PM, Josh Berkus <josh@agliodbs.com> wrote: > To what version will we backport it? All supported branches, I would think. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 06/19/2012 08:41 PM, Robert Haas wrote: > On Tue, Jun 19, 2012 at 7:33 PM, Josh Berkus<josh@agliodbs.com> wrote: >> To what version will we backport it? > > All supported branches, I would think. Yeah, I would feel a lot better if this was improved in 8.3 and up. I didn't bother trying to push it before now because I wanted both more bad examples and some miles on 9.1 without the new code triggering any problems from the field. Seems we're at that point now. I fear a lot of people are going to stay on 8.3 for a long time even after it's officially unsupported. It's been hard enough to move some people off of 8.1 and 8.2 even with the carrot of "8.3 will be much faster at everything". I fear 8.3 is going to end up like 7.4, where a 7 year long support window passes and people are still using it years later. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
I don't want to take a bunch of time away from the active CF talking about this, just wanted to pass along some notes: -Back branch release just happening a few weeks ago. Happy to have this dropped until the CF is over. -Attached is a working backport of this to 8.4, with standard git comments in the header. I think this one will backport happily with git cherrypick. Example provided mainly to prove that; not intended to be a patch submission. -It is still possible to get extremely long running sync times with the improvement applied. Since I had a 8.4 server manifesting this problem where I could just try this one change, I did that. Before we had this: > 2012-06-17 14:48:13 EDT LOG: checkpoint complete: wrote 90 buffers > (0.1%); 0 transaction log file(s) added, 0 removed, 14 recycled; > write=26.531 s, sync=4371.513 s, total=4461.058 s After the compaction code was working (also backported the extra logging here) I got this instead: 2012-06-20 23:10:36 EDT LOG: checkpoint complete: wrote 188 buffers (0.1%); 0 transaction log file(s) added, 0 removed, 7 recycled; write=31.975 s, sync=3064.270 s, total=3096.263 s; sync files=308, longest=482.200 s, average=9.948 s So the background writer still took a long time due to starvation from clients. But the backend side latency impact wasn't nearly as bad though. The peak load average didn't jump into the hundreds, it only got 10 to 20 clients behind on things. Anyway, larger discussion around this and related OS tuning is a better topic for pgsql-performance, will raise this there when I've sorted that out a bit more clearly. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
Attachment
On Tue, Jun 19, 2012 at 5:39 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Jun 19, 2012 at 5:33 PM, Greg Smith <greg@2ndquadrant.com> wrote: >> In January of 2011 Robert committed 7f242d880b5b5d9642675517466d31373961cf98 >> to try and compact the fsync queue when clients find it full. There's no >> visible behavior change, just a substantial performance boost possible in >> the rare but extremely bad situations where the background writer stops >> doing fsync absorption. I've been running that in production at multiple >> locations since practically the day it hit this mailing list, with backports >> all the way to 8.3 being common (and straightforward to construct). I've >> never seen a hint of a problem with this new code. > > I've been in favor of back-porting this for a while, so you'll get no > argument from me. > > Anyone disagree? Hearing no disagreement, I went ahead and did this. I didn't take Greg Smith's suggestion of adding a log message when/if the fsync compaction logic fails to make any headway, because (1) the proposed message didn't follow message style guidelines and I couldn't think of a better one that did and (2) I'm not sure it's worth creating extra translation work in the back-branches for such a marginal case. We can revisit this if people feel strongly about it. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company