Thread: Overhead cost of Serializable Snapshot Isolation
I'm looking into upgrading a fairly busy system to 9.1. They use serializable mode for a few certain things, and suffer through some serialization errors as a result. While looking over the new serializable/SSI documentation, one thing that stood out is: http://www.postgresql.org/docs/current/interactive/transaction-iso.html "The monitoring of read/write dependencies has a cost, as does the restart of transactions which are terminated with a serialization failure, but balanced against the cost and blocking involved in use of explicit locks and SELECT FOR UPDATE or SELECT FOR SHARE, Serializable transactions are the best performance choice for some environments." I agree it is better versus SELECT FOR, but what about repeatable read versus the new serializable? How much overhead is there in the 'monitoring of read/write dependencies'? This is my only concern at the moment. Are we talking insignificant overhead? Minor? Is it measurable? Hard to say without knowing the number of txns, number of locks, etc.? -- Greg Sabino Mullane greg@endpoint.com End Point Corporation PGP Key: 0x14964AC8
On 10.10.2011 21:25, Greg Sabino Mullane wrote: > I agree it is better versus SELECT FOR, but what about repeatable read versus > the new serializable? How much overhead is there in the 'monitoring of > read/write dependencies'? This is my only concern at the moment. Are we > talking insignificant overhead? Minor? Is it measurable? Hard to say without > knowing the number of txns, number of locks, etc.? I'm sure it does depend heavily on all of those things, but IIRC Kevin ran some tests earlier in the spring and saw a 5% slowdown. That feels like reasonable initial guess to me. If you can run some tests and measure the overhead in your application, it would be nice to hear about it. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
On Mon, Oct 10, 2011 at 02:25:59PM -0400, Greg Sabino Mullane wrote: > I agree it is better versus SELECT FOR, but what about repeatable read versus > the new serializable? How much overhead is there in the 'monitoring of > read/write dependencies'? This is my only concern at the moment. Are we > talking insignificant overhead? Minor? Is it measurable? Hard to say without > knowing the number of txns, number of locks, etc.? I'd expect that in most cases the main cost is not going to be overhead from the lock manager but rather the cost of having transactions aborted due to conflicts. (But the rollback rate is extremely workload-dependent.) We've seen CPU overhead from the lock manager to be a few percent on a CPU-bound workload (in-memory pgbench). Also, if you're using a system with many cores and a similar workload, SerializableXactHashLock might become a scalability bottleneck. Dan -- Dan R. K. Ports MIT CSAIL http://drkp.net/
Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> wrote: > On 10.10.2011 21:25, Greg Sabino Mullane wrote: >> I agree it is better versus SELECT FOR, but what about repeatable >> read versus the new serializable? How much overhead is there in >> the 'monitoring of read/write dependencies'? This is my only >> concern at the moment. Are we talking insignificant overhead? >> Minor? Is it measurable? Hard to say without knowing the number >> of txns, number of locks, etc.? > > I'm sure it does depend heavily on all of those things, but IIRC > Kevin ran some tests earlier in the spring and saw a 5% slowdown. > That feels like reasonable initial guess to me. If you can run > some tests and measure the overhead in your application, it would > be nice to hear about it. Right: the only real answer is "it depends". At various times I ran different benchmarks where the overhead ranged from "lost in the noise" to about 5% for one variety of "worst case". Dan ran DBT-2, following the instructions on how to measure performance quite rigorously, and came up with a 2% hit versus repeatable read for that workload. I rarely found a benchmark where the hit exceeded 2%, but I have a report of a workload where they hit was 20% -- for constantly overlapping long-running transactions contending for the same table. I do have some concern about whether the performance improvements from reduced LW locking contention elsewhere in the code may (in whack-a-mole fashion) cause the percentages to go higher in SSI. The biggest performance issues in some of the SSI benchmarks were on LW lock contention, so those may become more noticeable as other contention is reduced. I've been trying to follow along on the threads regarding Robert's work in that area, with hopes of applying some of the same techniques to SSI, but it's not clear whether I'll have time to work on that for the 9.2 release. (It's actually looking improbably at this point.) If you give it a try, please optimize using the performance considerations for SSI in the manual. They can make a big difference. -Kevin
On Mon, Oct 10, 2011 at 02:59:04PM -0500, Kevin Grittner wrote: > I do have some concern about whether the performance improvements > from reduced LW locking contention elsewhere in the code may (in > whack-a-mole fashion) cause the percentages to go higher in SSI. > The biggest performance issues in some of the SSI benchmarks were on > LW lock contention, so those may become more noticeable as other > contention is reduced. I've been trying to follow along on the > threads regarding Robert's work in that area, with hopes of applying > some of the same techniques to SSI, but it's not clear whether I'll > have time to work on that for the 9.2 release. (It's actually > looking improbably at this point.) I spent some time thinking about this a while back, but didn't have time to get very far. The problem isn't contention in the predicate lock manager (which is partitioned) but the single lock protecting the active SerializableXact state. It would probably help things a great deal if we could make that lock more fine-grained. However, it's tricky to do this without deadlocking because the serialization failure checks need to examine a node's neighbors in the dependency graph. Dan -- Dan R. K. Ports MIT CSAIL http://drkp.net/
Dan Ports <drkp@csail.mit.edu> wrote: > I spent some time thinking about this a while back, but didn't > have time to get very far. The problem isn't contention in the > predicate lock manager (which is partitioned) but the single lock > protecting the active SerializableXact state. > > It would probably help things a great deal if we could make that > lock more fine-grained. However, it's tricky to do this without > deadlocking because the serialization failure checks need to > examine a node's neighbors in the dependency graph. Did you ever see much contention on SerializablePredicateLockListLock, or was it just SerializableXactHashLock? I think the former might be able to use the non-blocking techniques, but I fear the main issue is with the latter, which seems like a harder problem. -Kevin
On Mon, Oct 10, 2011 at 04:10:18PM -0500, Kevin Grittner wrote: > Did you ever see much contention on > SerializablePredicateLockListLock, or was it just > SerializableXactHashLock? I think the former might be able to use > the non-blocking techniques, but I fear the main issue is with the > latter, which seems like a harder problem. No, not that I recall -- if SerializablePredicateLockListLock was on the list of contended locks, it was pretty far down. SerializableXactHashLock was the main bottleneck, and SerializableXactFinishedListLock was a lesser but still significant one. Dan -- Dan R. K. Ports MIT CSAIL http://drkp.net/
On Mon, Oct 10, 2011 at 8:30 PM, Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> wrote: > On 10.10.2011 21:25, Greg Sabino Mullane wrote: >> >> I agree it is better versus SELECT FOR, but what about repeatable read >> versus >> the new serializable? How much overhead is there in the 'monitoring of >> read/write dependencies'? This is my only concern at the moment. Are we >> talking insignificant overhead? Minor? Is it measurable? Hard to say >> without >> knowing the number of txns, number of locks, etc.? > > I'm sure it does depend heavily on all of those things, but IIRC Kevin ran > some tests earlier in the spring and saw a 5% slowdown. That feels like > reasonable initial guess to me. If you can run some tests and measure the > overhead in your application, it would be nice to hear about it. How do we turn it on/off to allow the overhead to be measured? -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Simon Riggs <simon@2ndQuadrant.com> wrote: > How do we turn it on/off to allow the overhead to be measured? User REPEATABLE READ transactions or SERIALIZABLE transactions. The easiest way, if you're doing it for all transactions (which I recommend) is to set default_transaction_isolation. -Kevin
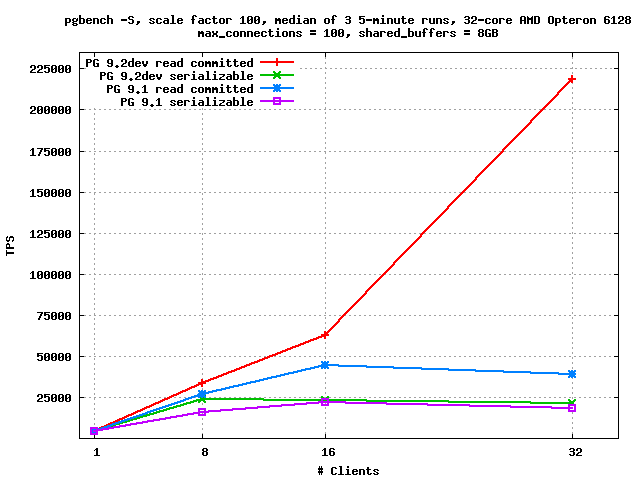
On Mon, Oct 10, 2011 at 3:59 PM, Kevin Grittner <Kevin.Grittner@wicourts.gov> wrote: > I do have some concern about whether the performance improvements > from reduced LW locking contention elsewhere in the code may (in > whack-a-mole fashion) cause the percentages to go higher in SSI. > The biggest performance issues in some of the SSI benchmarks were on > LW lock contention, so those may become more noticeable as other > contention is reduced. I've been trying to follow along on the > threads regarding Robert's work in that area, with hopes of applying > some of the same techniques to SSI, but it's not clear whether I'll > have time to work on that for the 9.2 release. (It's actually > looking improbably at this point.) I ran my good old pgbench -S, scale factor 100, shared_buffers = 8GB test on Nate Boley's box. I ran it on both 9.1 and 9.2dev, and at all three isolation levels. As usual, I took the median of three 5-minute runs, which I've generally found adequate to eliminate the noise. On both 9.1 and 9.2dev, read committed and repeatable read have basically identical performance; if anything, repeatable read may be slightly better - which would make sense, if it cuts down the number of snapshots taken. Serializable mode is much slower on this test, though. On REL9_1_STABLE, it's about 8% slower with a single client. At 8 clients, the difference rises to 43%, and at 32 clients, it's 51% slower. On 9.2devel, raw performance is somewhat higher (e.g. +51% at 8 clients) but the performance when not using SSI has improved so much that the performance gap between serializable and the other two isolation levels is now huge: with 32 clients, in serializable mode, the median result was 21114.577645 tps; in read committed, 218748.929692 tps - that is, read committed is running more than ten times faster than serializable. Data are attached, in text form and as a plot. I excluded the repeatable read results from the plot as they just clutter it up - they're basically on top of the read committed results. I haven't run this with LWLOCK_STATS, but my seat-of-the-pants guess is that there's a single lightweight lock that everything is bottlenecking on. One possible difference between this test case and the ones you may have used is that this case involves lots and lots of really short transactions that don't do much. The effect of anything that only happens once or a few times per transaction is really magnified in this type of workload (which is why the locking changes make so much of a difference here - in a longer or heavier-weight transaction that stuff would be lost in the noise). -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
{kind=link}
Robert Haas <robertmhaas@gmail.com> wrote: > I ran my good old pgbench -S, scale factor 100, shared_buffers = > 8GB test on Nate Boley's box. I ran it on both 9.1 and 9.2dev, > and at all three isolation levels. As usual, I took the median of > three 5-minute runs, which I've generally found adequate to > eliminate the noise. On both 9.1 and 9.2dev, read committed and > repeatable read have basically identical performance; if anything, > repeatable read may be slightly better - which would make sense, > if it cuts down the number of snapshots taken. Right. Thanks for running this. Could you give enough details to allow reproducing on this end (or point to a previous post with the details)? > Serializable mode is much slower on this test, though. On > REL9_1_STABLE, it's about 8% slower with a single client. At 8 > clients, the difference rises to 43%, and at 32 clients, it's 51% > slower. On 9.2devel, raw performance is somewhat higher (e.g. > +51% at 8 clients) but the performance when not using SSI has > improved so much that the performance gap between serializable and > the other two isolation levels is now huge: with 32 clients, in > serializable mode, the median result was 21114.577645 tps; in read > committed, 218748.929692 tps - that is, read committed is running > more than ten times faster than serializable. Yeah. I was very excited to see your numbers as you worked on that, but I've been concerned that with the "Performance Whack A Mole" nature of things (to borrow a term from Josh Berkus), SSI lightweight locks might be popping their heads up. > Data are attached, in text form and as a plot. I excluded the > repeatable read results from the plot as they just clutter it up - > they're basically on top of the read committed results. That was kind, but really the REPEATABLE READ results are probably the more meaningful comparison, even if they are more embarrassing. :-( > I haven't run this with LWLOCK_STATS, but my seat-of-the-pants > guess is that there's a single lightweight lock that everything is > bottlenecking on. The lock in question is SerializableXactHashLock. A secondary problem is SerializableFinishedListLock, which is used for protecting cleanup of old transactions. This is per Dan's reports, who had a better look at in on a 16 core machine, but is consistent with what I saw on fewer cores. Early in development we had a bigger problem with SerializablePredicateLockListLock, but Dan added a local map to eliminate contention during lock promotion decision, and I reworked that lock from the SHARED read and EXCLUSIVE write approach to the SHARED for accessing your own data and EXCLUSIVE for accessing data for another process technique. Combined, that made the problems with that negligible. > One possible difference between this test case and the ones you > may have used is that this case involves lots and lots of really > short transactions that don't do much. I did some tests like that, but not on a box with that many processors, and I probably didn't try using a thread count more than double the core count, so I probably never ran into the level of contention you're seeing. The differences at the low connection counts are surprising to me. Maybe it will make more sense when I see the test case. There's also some chance that late elimination of some race conditions found in testing affected this, and I didn't re-run those tests late enough to see that. Not sure. > The effect of anything that only happens once or a few times per > transaction is really magnified in this type of workload (which is > why the locking changes make so much of a difference here - in a > longer or heavier-weight transaction that stuff would be lost in > the noise). Did these transactions write anything? If not, were they declared to be READ ONLY? If they were, in fact, only reading, it would be interesting to see what the performance looks like if the recommendation to use the READ ONLY attribute is followed. That's at the top of the list of performance tips for SSI at: http://www.postgresql.org/docs/9.1/interactive/transaction-iso.html#XACT-SERIALIZABLE Anyway, this isolates a real issue, even if the tests exaggerate it beyond what anyone is likely to see in production. Once this CF is over, I'll put a review of this at the top of my PG list. -Kevin
On Mon, Oct 10, 2011 at 11:31 PM, Kevin Grittner <Kevin.Grittner@wicourts.gov> wrote: > Simon Riggs <simon@2ndQuadrant.com> wrote: > >> How do we turn it on/off to allow the overhead to be measured? > > User REPEATABLE READ transactions or SERIALIZABLE transactions. The > easiest way, if you're doing it for all transactions (which I > recommend) is to set default_transaction_isolation. Most apps use mixed mode serializable/repeatable read and therefore can't be changed by simple parameter. Rewriting the application isn't a sensible solution. I think it's clear that SSI should have had and still needs an "off switch" for cases that cause performance problems. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Oct 11, 2011 at 12:46 PM, Kevin Grittner <Kevin.Grittner@wicourts.gov> wrote: > Robert Haas <robertmhaas@gmail.com> wrote: >> I ran my good old pgbench -S, scale factor 100, shared_buffers = >> 8GB test on Nate Boley's box. I ran it on both 9.1 and 9.2dev, >> and at all three isolation levels. As usual, I took the median of >> three 5-minute runs, which I've generally found adequate to >> eliminate the noise. On both 9.1 and 9.2dev, read committed and >> repeatable read have basically identical performance; if anything, >> repeatable read may be slightly better - which would make sense, >> if it cuts down the number of snapshots taken. > > Right. Thanks for running this. Could you give enough details to > allow reproducing on this end (or point to a previous post with the > details)? Sure, it's pretty much just a vanilla pgbench -S run, but the scripts I used are attached here. I build the head of each branch using the "test-build" script and then used the "runtestiso" script to drive the test runs. These scripts are throwaway so they're not really documented, but hopefully it's clear enough what it's doing. The server itself is a 32-core AMD 6128. >> Data are attached, in text form and as a plot. I excluded the >> repeatable read results from the plot as they just clutter it up - >> they're basically on top of the read committed results. > > That was kind, but really the REPEATABLE READ results are probably > the more meaningful comparison, even if they are more embarrassing. > :-( They're neither more nor less embarrassing - they're pretty much not different at all. I just didn't see any point in making a graph with 6 lines on it when you could only actually see 4 of them. > Did these transactions write anything? If not, were they declared > to be READ ONLY? If they were, in fact, only reading, it would be > interesting to see what the performance looks like if the > recommendation to use the READ ONLY attribute is followed. pgbench -S doesn't do any writes, or issue any transaction control statements. It just fires off SELECT statements against a single table as fast as it can, retrieving values from rows chosen at random. Each SELECT implicitly begins and ends a transaction. Possibly the system could gaze upon the SELECT statement and infer that the one-statement transaction induced thereby can't possibly write any tuples, and mark it read-only automatically, but I'm actually not that excited about that approach - trying to fix the lwlock contention that's causing the headache in the first place seems like a better use of time, assuming it's possible to make some headway there. My general observation is that, on this machine, a lightweight lock that is taken in exclusive mode by a series of lockers in quick succession seems to max out around 16-20 clients, and the curve starts to bend well before that. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
On Tue, Oct 11, 2011 at 1:11 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > On Mon, Oct 10, 2011 at 11:31 PM, Kevin Grittner > <Kevin.Grittner@wicourts.gov> wrote: >> Simon Riggs <simon@2ndQuadrant.com> wrote: >> >>> How do we turn it on/off to allow the overhead to be measured? >> >> User REPEATABLE READ transactions or SERIALIZABLE transactions. The >> easiest way, if you're doing it for all transactions (which I >> recommend) is to set default_transaction_isolation. > > Most apps use mixed mode serializable/repeatable read and therefore > can't be changed by simple parameter. Rewriting the application isn't > a sensible solution. > > I think it's clear that SSI should have had and still needs an "off > switch" for cases that cause performance problems. Is it possible that you are confusing the default level, which is READ COMMITTED, with REPEATABLE READ? I can't see why anyone would code up their application to use REPEATABLE READ for some things and SERIALIZABLE for other things unless they were explicitly trying to turn SSI off for a subset of their transactions. In all releases prior to 9.0, REPEATABLE READ and SERIALIZABLE behaved identically, so there wouldn't be any reason for a legacy app to mix-and-match between the two. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Oct 11, 2011 at 6:14 PM, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Oct 11, 2011 at 1:11 PM, Simon Riggs <simon@2ndquadrant.com> wrote: >> On Mon, Oct 10, 2011 at 11:31 PM, Kevin Grittner >> <Kevin.Grittner@wicourts.gov> wrote: >>> Simon Riggs <simon@2ndQuadrant.com> wrote: >>> >>>> How do we turn it on/off to allow the overhead to be measured? >>> >>> User REPEATABLE READ transactions or SERIALIZABLE transactions. The >>> easiest way, if you're doing it for all transactions (which I >>> recommend) is to set default_transaction_isolation. >> >> Most apps use mixed mode serializable/repeatable read and therefore >> can't be changed by simple parameter. Rewriting the application isn't >> a sensible solution. >> >> I think it's clear that SSI should have had and still needs an "off >> switch" for cases that cause performance problems. > > Is it possible that you are confusing the default level, which is READ > COMMITTED, with REPEATABLE READ? I can't see why anyone would code up > their application to use REPEATABLE READ for some things and > SERIALIZABLE for other things unless they were explicitly trying to > turn SSI off for a subset of their transactions. In all releases > prior to 9.0, REPEATABLE READ and SERIALIZABLE behaved identically, so > there wouldn't be any reason for a legacy app to mix-and-match between > the two. Yes, I mistyped "read" when I meant "committed". You are right to point out there is no problem if people were using repeatable read and serializable. Let me retype, so there is no confusion: It's common to find applications that have some transactions explicitly coded to use SERIALIZABLE mode, while the rest are in the default mode READ COMMITTED. So common that TPC-E benchmark has been written as a representation of such workloads. The reason this is common is that some transactions require SERIALIZABLE as a "fix" for transaction problems. If you alter the default_transaction_isolation then you will break applications like this, so it is not a valid way to turn off SSI. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Robert Haas <robertmhaas@gmail.com> wrote: > Kevin Grittner <Kevin.Grittner@wicourts.gov> wrote: >> Did these transactions write anything? If not, were they >> declared to be READ ONLY? If they were, in fact, only reading, >> it would be interesting to see what the performance looks like if >> the recommendation to use the READ ONLY attribute is followed. > > pgbench -S doesn't do any writes, or issue any transaction control > statements. It just fires off SELECT statements against a single > table as fast as it can, retrieving values from rows chosen at > random. Each SELECT implicitly begins and ends a transaction. So that test could be accomplished by setting default_transaction_read_only to on. That's actually what we're doing, because we have a lot more of them than of read-write transactions. But, with the scripts I can confirm the performance of that on this end. It should be indistinguishable from the repeatable read line; if not, there's something to look at there. > Possibly the system could gaze upon the SELECT statement and infer > that the one-statement transaction induced thereby can't possibly > write any tuples, and mark it read-only automatically, but I'm > actually not that excited about that approach I wasn't intending to suggest that. In fact I hadn't really thought of it. It might be a fun optimization, although it would be well down my list, and it wouldn't be trivial because you couldn't use if for any statements with volatile functions -- so the statement would need to be planned far enough to know whether that was the case before making this decision. In fact, I'm not sure the community would want to generate an error if a user marked a function other than volatile and ran it in this way. Definitely not something to even look at any time soon. > trying to fix the lwlock contention that's causing the headache in > the first place seems like a better use of time, assuming it's > possible to make some headway there. Absolutely. I just thought the timings with READ ONLY would make for an interesting data point. For one thing, it might reassure people that even this artificial use cases doesn't perform that badly if the advice in the documentation is heeded. For another, a result slower than repeatable read would be a surprise that might point more directly to the problem. > My general observation is that, on this machine, a lightweight > lock that is taken in exclusive mode by a series of lockers in > quick succession seems to max out around 16-20 clients, and the > curve starts to bend well before that. OK, I will keep that in mind. Thanks, -Kevin
Simon Riggs <simon@2ndQuadrant.com> wrote: > It's common to find applications that have some transactions > explicitly coded to use SERIALIZABLE mode, while the rest are in > the default mode READ COMMITTED. So common that TPC-E benchmark > has been written as a representation of such workloads. I would be willing to be that any such implementations assume S2PL, and would not prevent anomalies as expected unless all transactions are serializable. > The reason this is common is that some transactions require > SERIALIZABLE as a "fix" for transaction problems. That is a mode of thinking which doesn't work if you only assume serializable provides the guarantees required by the standard. Many people assume otherwise. It does *not* guarantee blocking on conflicts, and it does not require that transactions appear to have executed in the order of successful commit. It requires only that the result of concurrently running any mix of serializable transactions produce a result consistent with some one-at-a-time execution of those transactions. Rollback of transactions to prevent violations of that guarantee are allowed. I don't see any guarantees about how serializable transactions interact with non-serializable transactions beyond each transaction not seeing any of the phenomena prohibited for its isolation level. > If you alter the default_transaction_isolation then you will break > applications like this, so it is not a valid way to turn off SSI. I don't follow you here. What would break? In what fashion? Since the standard allows any isolation level to provide more strict transaction isolation than required, it would be conforming to *only* support serializable transactions, regardless of the level requested. Not a good idea for some workloads from a performance perspective, but it would be conforming, and any application which doesn't work correctly with that is not written to the standard. -Kevin
On Tue, Oct 11, 2011 at 6:44 PM, Kevin Grittner <Kevin.Grittner@wicourts.gov> wrote: >> If you alter the default_transaction_isolation then you will break >> applications like this, so it is not a valid way to turn off SSI. > > I don't follow you here. What would break? In what fashion? Since > the standard allows any isolation level to provide more strict > transaction isolation than required, it would be conforming to > *only* support serializable transactions, regardless of the level > requested. Not a good idea for some workloads from a performance > perspective, but it would be conforming, and any application which > doesn't work correctly with that is not written to the standard. If the normal default_transaction_isolation = read committed and all transactions that require serializable are explicitly marked in the application then there is no way to turn off SSI without altering the application. That is not acceptable, since it causes changes in application behaviour and possibly also performance issues. We should provide a mechanism to allow people to upgrade to 9.1+ without needing to change the meaning and/or performance of their apps. I strongly support the development of SSI, but I don't support application breakage. We can have SSI without breaking anything for people that can't or don't want to use it. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Robert Haas: > Serializable mode is much slower on this test, though. On > REL9_1_STABLE, it's about 8% slower with a single client. At 8 > clients, the difference rises to 43%, and at 32 clients, it's 51% > slower. Bummer. Thanks for putting some numbers out there; glad I was able to jump start a deeper look at this. Based on this thread so far, I am probably going to avoid serializable in this particular case, and stick to repeatable read. Once things are in place, perhaps I'll be able to try switching to serializable and get some measurements, but I wanted to see if the impact was minor enough to safely start with serializable. Seems not. :) Keep in mind this is not even a formal proposal yet for our client, so any benchmarks from me may be quite a while. Kevin Grittner: > Did these transactions write anything? If not, were they declared > to be READ ONLY? If they were, in fact, only reading, it would be > interesting to see what the performance looks like if the > recommendation to use the READ ONLY attribute is followed. Yes, I'll definitely look into that, but the great majority of the things done in this case are read/write. Simon Riggs: > Most apps use mixed mode serializable/repeatable read and therefore > can't be changed by simple parameter. Rewriting the application isn't > a sensible solution. > > I think it's clear that SSI should have had and still needs an "off > switch" for cases that cause performance problems. Eh? It has an off switch: repeatable read. Thanks for all replying to this thread, it's been very helpful. -- Greg Sabino Mullane greg@endpoint.com End Point Corporation PGP Key: 0x14964AC8
> If the normal default_transaction_isolation = read committed and all > transactions that require serializable are explicitly marked in the > application then there is no way to turn off SSI without altering the > application. That is not acceptable, since it causes changes in > application behaviour and possibly also performance issues. Performance, perhaps. What application behavior changes? Less serialization conflicts? > We should provide a mechanism to allow people to upgrade to 9.1+ > without needing to change the meaning and/or performance of their > apps. That ship has sailed. -- Greg Sabino Mullane greg@endpoint.com End Point Corporation PGP Key: 0x14964AC8
On Tue, Oct 11, 2011 at 9:21 PM, Greg Sabino Mullane <greg@endpoint.com> wrote: > Simon Riggs: >> Most apps use mixed mode serializable/repeatable read and therefore >> can't be changed by simple parameter. Rewriting the application isn't >> a sensible solution. >> >> I think it's clear that SSI should have had and still needs an "off >> switch" for cases that cause performance problems. > > Eh? It has an off switch: repeatable read. You mean: if we recode the application and retest it, we can get it to work same way as it used to. To most people that is the same thing as "it doesn't work with this release", ask any application vendor. There is no off switch and there should be. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Greg Sabino Mullane wrote: -- Start of PGP signed section. > > If the normal default_transaction_isolation = read committed and all > > transactions that require serializable are explicitly marked in the > > application then there is no way to turn off SSI without altering the > > application. That is not acceptable, since it causes changes in > > application behaviour and possibly also performance issues. > > Performance, perhaps. What application behavior changes? Less > serialization conflicts? > > > We should provide a mechanism to allow people to upgrade to 9.1+ > > without needing to change the meaning and/or performance of their > > apps. > > That ship has sailed. Simon seems to value backward-compatibility more than the average hackers poster. The lack of complaints about 9.1 I think means that the hackers decision of _not_ providing a swich was the right one. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + It's impossible for everything to be true. +
Simon Riggs wrote: > On Tue, Oct 11, 2011 at 6:44 PM, Kevin Grittner > <Kevin.Grittner@wicourts.gov> wrote: > > >> If you alter the default_transaction_isolation then you will break > >> applications like this, so it is not a valid way to turn off SSI. > > > > I don't follow you here. ?What would break? ?In what fashion? ?Since > > the standard allows any isolation level to provide more strict > > transaction isolation than required, it would be conforming to > > *only* support serializable transactions, regardless of the level > > requested. ?Not a good idea for some workloads from a performance > > perspective, but it would be conforming, and any application which > > doesn't work correctly with that is not written to the standard. > > If the normal default_transaction_isolation = read committed and all > transactions that require serializable are explicitly marked in the > application then there is no way to turn off SSI without altering the > application. That is not acceptable, since it causes changes in > application behaviour and possibly also performance issues. > > We should provide a mechanism to allow people to upgrade to 9.1+ > without needing to change the meaning and/or performance of their > apps. > > I strongly support the development of SSI, but I don't support > application breakage. We can have SSI without breaking anything for > people that can't or don't want to use it. The problem is that all the switches needed to allow for "no application breakage" makes configuration of the server and source code more complicated. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + It's impossible for everything to be true. +
Simon Riggs <simon@2ndQuadrant.com> wrote: > Greg Sabino Mullane <greg@endpoint.com> wrote: >> Eh? It has an off switch: repeatable read. > > You mean: if we recode the application and retest it, we can get > it to work same way as it used to. > > To most people that is the same thing as "it doesn't work with > this release", ask any application vendor. > > There is no off switch and there should be. This was discussed at some length, and nobody seemed to favor a behavior-changing GUC. One example of such a thread is here: http://archives.postgresql.org/pgsql-hackers/2009-05/msg01165.php It came up at least a couple other times, and the outcome was always the same -- after discussion, nobody was in favor of a GUC to make the semantics of these statement variable. I'm sorry if you missed those discussions. It would certainly be a trivial change to implement; the problem is convincing others that it's a good idea. -Kevin
On Tue, Oct 11, 2011 at 04:32:45PM -0400, Bruce Momjian wrote: ... > Simon seems to value backward-compatibility more than the average > hackers poster. The lack of complaints about 9.1 I think means that the > hackers decision of _not_ providing a swich was the right one. I wouldn't go that far: 9.1 is very new. Certainly the release notes do not explain the change enough: part of the reason I wrote: http://blog.endpoint.com/2011/09/postgresql-allows-for-different.html Simon has a point, but I think that having applications switch from serializable to repeatable read is a pain point people should pay when going to 9.1, rather than adding some switch now. -- Greg Sabino Mullane greg@endpoint.com End Point Corporation PGP Key: 0x14964AC8
On Tue, Oct 11, 2011 at 9:32 PM, Bruce Momjian <bruce@momjian.us> wrote: > Greg Sabino Mullane wrote: > -- Start of PGP signed section. >> > If the normal default_transaction_isolation = read committed and all >> > transactions that require serializable are explicitly marked in the >> > application then there is no way to turn off SSI without altering the >> > application. That is not acceptable, since it causes changes in >> > application behaviour and possibly also performance issues. >> >> Performance, perhaps. What application behavior changes? Less >> serialization conflicts? If you change default_transaction_isolation then the behaviour of the application will change. >> > We should provide a mechanism to allow people to upgrade to 9.1+ >> > without needing to change the meaning and/or performance of their >> > apps. >> >> That ship has sailed. > > Simon seems to value backward-compatibility more than the average > hackers poster. The lack of complaints about 9.1 I think means that the > hackers decision of _not_ providing a swich was the right one. So its been out 1 month and you think that is sufficient time for us to decide that there are no user complaints about SSI? I doubt it. Longer term I have every confidence that it will be appreciated. I'm keen to ensure people enjoy the possibility of upgrading to the latest release. The continual need to retest applications mean that very few users upgrade quickly or with anywhere near the frequency with which we put out new releases. What is the point of rushing out software that nobody can use? pg_upgrade doesn't change your applications, so there isn't a fast path to upgrade in the way you seem to think. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Simon Riggs <simon@2ndQuadrant.com> writes:
> There is no off switch and there should be.
As Greg said, that ship has sailed. I believe that we specifically
discussed the notion of an "off switch" via a GUC or similar during
9.1 development, and rejected it on the grounds that GUCs changing
fundamental transactional behavior are dangerous. I don't believe that
you've made a case for changing that decision, and even if you had,
it's too late; 9.1 is what it is. Can we end this subthread please,
and concentrate on something actually useful, like improving SSI's
performance?
regards, tom lane
Greg Sabino Mullane <greg@endpoint.com> wrote: > Kevin Grittner: > >> Did these transactions write anything? If not, were they >> declared to be READ ONLY? If they were, in fact, only reading, >> it would be interesting to see what the performance looks like if >> the recommendation to use the READ ONLY attribute is followed. > > Yes, I'll definitely look into that, but the great majority of > the things done in this case are read/write. But it is precisely *because* those were fully cached read-only transactions that the numbers came out so bad. As Robert pointed out, in other loads the difference in time per transaction could be lost in the noise. Now, I know SSI won't be good fit for all applications, but you might not want to write it off on performance grounds for an application where "the great majority of the things done ... are read/write" based on a test which ran only read-only transactions without declaring them READ ONLY. -Kevin
Simon Riggs wrote: > > Simon seems to value backward-compatibility more than the average > > hackers poster. ?The lack of complaints about 9.1 I think means that the > > hackers decision of _not_ providing a swich was the right one. > > So its been out 1 month and you think that is sufficient time for us > to decide that there are no user complaints about SSI? I doubt it. > Longer term I have every confidence that it will be appreciated. > > I'm keen to ensure people enjoy the possibility of upgrading to the > latest release. The continual need to retest applications mean that > very few users upgrade quickly or with anywhere near the frequency > with which we put out new releases. What is the point of rushing out > software that nobody can use? pg_upgrade doesn't change your > applications, so there isn't a fast path to upgrade in the way you > seem to think. Simon, I basically think you are swimming up-stream on this issue, and on the recovery.conf thread as well. You can keep arguing that backward compatibility warrants more effort, but until there is more general agreement in the group, you are going to lose these arguments, and frankly, the arguments are getting tiring. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + It's impossible for everything to be true. +
Simon Riggs <simon@2ndQuadrant.com> wrote: > "You'll have to retest your apps" just isn't a good answer For which major PostgreSQL releases have you recommended that people deploy their apps without retesting? -Kevin
On Tue, Oct 11, 2011 at 9:37 PM, Kevin Grittner <Kevin.Grittner@wicourts.gov> wrote: > It would certainly be a trivial change to > implement; the problem is convincing others that it's a good idea. I don't want it, I just think we need it now. "You'll have to retest your apps" just isn't a good answer and we should respect the huge cost that causes our users. Probably as a matter of policy all new features that effect semantics should have some kind of compatibility or off switch, if easily possible. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Tue, Oct 11, 2011 at 9:53 PM, Bruce Momjian <bruce@momjian.us> wrote: > Simon Riggs wrote: >> > Simon seems to value backward-compatibility more than the average >> > hackers poster. ?The lack of complaints about 9.1 I think means that the >> > hackers decision of _not_ providing a swich was the right one. >> >> So its been out 1 month and you think that is sufficient time for us >> to decide that there are no user complaints about SSI? I doubt it. >> Longer term I have every confidence that it will be appreciated. >> >> I'm keen to ensure people enjoy the possibility of upgrading to the >> latest release. The continual need to retest applications mean that >> very few users upgrade quickly or with anywhere near the frequency >> with which we put out new releases. What is the point of rushing out >> software that nobody can use? pg_upgrade doesn't change your >> applications, so there isn't a fast path to upgrade in the way you >> seem to think. > > Simon, I basically think you are swimming up-stream on this issue, and > on the recovery.conf thread as well. You can keep arguing that backward > compatibility warrants more effort, but until there is more general > agreement in the group, you are going to lose these arguments, and > frankly, the arguments are getting tiring. I speak when it is important that someone does so, and only on specific, real issues. When I speak, I do so on behalf of my clients and other Postgres users that suffer the problems created by those issues. I've never given a viewpoint on list that I know to be the opposite of the majority of people I represent. How could I change the viewpoint of the group without making rational arguments when it matters? -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Simon Riggs <simon@2ndQuadrant.com> writes:
> How could I change the viewpoint of the group without making rational
> arguments when it matters?
Well, you make your arguments, and you see if you convince anybody.
On these specific points, you've failed to sway the consensus AFAICT,
and at some point you have to accept that you've lost the argument.
regards, tom lane
On Tue, Oct 11, 2011 at 10:00 PM, Kevin Grittner <Kevin.Grittner@wicourts.gov> wrote: > Simon Riggs <simon@2ndQuadrant.com> wrote: > >> "You'll have to retest your apps" just isn't a good answer > > For which major PostgreSQL releases have you recommended that people > deploy their apps without retesting? None. People don't always follow my advice, regrettably. They ask comparative questions like "What is the risk of upgrade?", "How much testing is required?" I never met a customer yet that has an automated test suite designed to stress the accuracy of results under concurrent workloads, so the inability to control the way a new feature operates makes such questions more likely to be given an answer that indicates greater effort and higher risk. That is exactly what I personally would wish to avoid. An off switch encourages people to use new features. It is not a punishment or an admonition to the developer. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Oct11, 2011, at 22:55 , Simon Riggs wrote: > Probably as a matter of policy all new features that effect semantics > should have some kind of compatibility or off switch, if easily > possible. There's a huge downside to that, though. After a while, you end up with a gazillion settings, each influencing behaviour in non-obvious, subtle ways. Plus, every new code we add would have to be tested against *all* combinations of these switches. Or, maybe, we'd punt and make some features work only with "reasonable" settings. And by doing so cause much frustration of the kind "I need to set X to Y to use feature Z, but I can't because our app requires X to be set to Y2". I've recently had to use Microsoft SQL Server for a project, and they fell into *precisely* this trap. Nearly *everything* is a setting there, like whether various things follow the ANSI standard (NULLS, CHAR types, one setting for each), whether identifiers are double-quoted or put between square brackets, whether loss of precision is an error, ... And, some of their very own features depend on specific combination of these settings. Sometimes on the values in effect when the object was created, sometimes when it's used. For example, their flavour of materialized views (called "indexed views") requires a bunch of options to be set correctly to be able to create such an object. Some of these must even be in effect to update the view's base tables, once the view is created... That experience has taught me that backwards compatibility, while very important in a lot of cases, has the potential to do just as much harm if overdone. best regards, Florian Pflug
On Tue, Oct 11, 2011 at 10:22 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Simon Riggs <simon@2ndQuadrant.com> writes: >> How could I change the viewpoint of the group without making rational >> arguments when it matters? > > Well, you make your arguments, and you see if you convince anybody. > On these specific points, you've failed to sway the consensus AFAICT, > and at some point you have to accept that you've lost the argument. I'm happy to wait more than 4 hours before trying to judge any meaningful consensus. Rushing judgement on such points is hardly likely to encourage people to speak up, even assuming they have the opportunity. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Simon Riggs <simon@2ndQuadrant.com> wrote: > They ask comparative questions like "What is the risk of > upgrade?", "How much testing is required?" > I never met a customer yet that has an automated test suite > designed to stress the accuracy of results under concurrent > workloads I'll try to provide some information here to help you answer those questions. I hope it is helpful. The only behavioral difference an unchanged application could see (short of some as-yet-undiscovered bug) is that they could get more serialization failures when using serializable isolation level than they previously got, and that there could be a performance impact. It really does nothing except run exactly what serializable mode was before, while monitoring for conditions which are present when a race condition between transactions might cause odd results, and generate a serialization failure as needed to prevent that. It kind of "hangs off the side" of legacy behavior and watches things. No new blocking. No new deadlocks. No chance of results you didn't get before. It might also be worth reviewing this page: http://www.postgresql.org/docs/9.1/interactive/transaction-iso.html -Kevin
On Tue, Oct 11, 2011 at 10:30 PM, Florian Pflug <fgp@phlo.org> wrote: > That experience has taught me that backwards compatibility, while very > important in a lot of cases, has the potential to do just as much harm > if overdone. Agreed. Does my suggestion represent overdoing it? I ask for balance, not an extreme. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Simon Riggs wrote: > On Tue, Oct 11, 2011 at 10:22 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Simon Riggs <simon@2ndQuadrant.com> writes: > >> How could I change the viewpoint of the group without making rational > >> arguments when it matters? > > > > Well, you make your arguments, and you see if you convince anybody. > > On these specific points, you've failed to sway the consensus AFAICT, > > and at some point you have to accept that you've lost the argument. > > I'm happy to wait more than 4 hours before trying to judge any > meaningful consensus. > > Rushing judgement on such points is hardly likely to encourage people > to speak up, even assuming they have the opportunity. This is an issue you have been pushing for a very long time on many fronts --- four hours is not going to change anything. Have you considered developing a super-backward-compatible version of Postgres, or a patch set which does this, and seeing if there is any interest from users? If you could get major uptake, it would certainly bolster your argument. But, until I see that, I am unlikely to listen to further protestations. I am much more likely to just ignore your suggestions as "Oh, it is just Simon on the backward-compatibility bandwagon again", and it causes me to just mentally filter your ideas, which isn't productive, and I am sure others will do the same. Read the MS-SQL post about backward compatibility knobs as proof that many of us know the risks of too much backward compatibility. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + It's impossible for everything to be true. +
Simon Riggs wrote: > On Tue, Oct 11, 2011 at 10:30 PM, Florian Pflug <fgp@phlo.org> wrote: > > > That experience has taught me that backwards compatibility, while very > > important in a lot of cases, has the potential to do just as much harm > > if overdone. > > Agreed. Does my suggestion represent overdoing it? I ask for balance, > not an extreme. Well, balance is looking at what everyone else in the group is suggesting, and realizing you might not have all the answers, and listening. As far as I can see, you are the _only_ one who thinks it needs an option. In that light, your suggestion seems extreme, not balanced. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + It's impossible for everything to be true. +
On 11.10.2011 23:21, Simon Riggs wrote: > If the normal default_transaction_isolation = read committed and all > transactions that require serializable are explicitly marked in the > application then there is no way to turn off SSI without altering the > application. That is not acceptable, since it causes changes in > application behaviour and possibly also performance issues. I don't get that. If all the transactions that require serializability are marked as such, why would you disable SSI for them? That would just break the application, since the transactions would no longer be serializable. If they don't actually need serializability, but repeatable read is enough, then mark them that way. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
On tis, 2011-10-11 at 21:50 +0100, Simon Riggs wrote: > I'm keen to ensure people enjoy the possibility of upgrading to the > latest release. The continual need to retest applications mean that > very few users upgrade quickly or with anywhere near the frequency > with which we put out new releases. What is the point of rushing out > software that nobody can use? pg_upgrade doesn't change your > applications, so there isn't a fast path to upgrade in the way you > seem to think. This is a valid concern, which I share, but I think adding a few configuration parameters of the nature, "this setting really means what this setting meant in the old release" is only the tip of the iceberg. Ensuring full compatibility between major releases would require an extraordinary amount of effort, including a regression test suite that would be orders of magnitude larger than what we currently have. I frankly don't see the resources to do that. The workaround strategy is that we maintain backbranches, so that users are not forced to upgrade to incompatible releases. Actually, I'm currently personally more concerned about the breakage we introduce in minor releases. We'd need to solve that problem before we can even begin to think about dealing with the major release issue.
On Wed, Oct 12, 2011 at 6:34 AM, Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> wrote: > On 11.10.2011 23:21, Simon Riggs wrote: >> >> If the normal default_transaction_isolation = read committed and all >> transactions that require serializable are explicitly marked in the >> application then there is no way to turn off SSI without altering the >> application. That is not acceptable, since it causes changes in >> application behaviour and possibly also performance issues. > > I don't get that. If all the transactions that require serializability are > marked as such, why would you disable SSI for them? That would just break > the application, since the transactions would no longer be serializable. > > If they don't actually need serializability, but repeatable read is enough, > then mark them that way. Obviously, if apps require serializability then turning serializability off would break them. That is not what I have said, nor clearly not what I would mean by "turning off SSI". The type of serializability we had in the past is now the same as repeatable read. So the request is for a parameter that changes a request for serializable into a request for repeatable read, so that applications are provided with exactly what they had before, in 9.0 and earlier. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Oct 12, 2011 at 8:50 AM, Peter Eisentraut <peter_e@gmx.net> wrote: > On tis, 2011-10-11 at 21:50 +0100, Simon Riggs wrote: >> I'm keen to ensure people enjoy the possibility of upgrading to the >> latest release. The continual need to retest applications mean that >> very few users upgrade quickly or with anywhere near the frequency >> with which we put out new releases. What is the point of rushing out >> software that nobody can use? pg_upgrade doesn't change your >> applications, so there isn't a fast path to upgrade in the way you >> seem to think. > > This is a valid concern, which I share, but I think adding a few > configuration parameters of the nature, "this setting really means what > this setting meant in the old release" is only the tip of the iceberg. > Ensuring full compatibility between major releases would require an > extraordinary amount of effort, including a regression test suite that > would be orders of magnitude larger than what we currently have. I > frankly don't see the resources to do that. > > The workaround strategy is that we maintain backbranches, so that users > are not forced to upgrade to incompatible releases. > > Actually, I'm currently personally more concerned about the breakage we > introduce in minor releases. We'd need to solve that problem before we > can even begin to think about dealing with the major release issue. Thanks, these look like reasonable discussion points with no personal comments added. I agree that config parameters don't solve the whole problem, though much of the iceberg is already covered with them. Currently about half of our parameters are either on/off behaviour switches. Right now we are inconsistent about whether we add a parameter for major features: sync_scans, hot_standby, partial vacuum all had ways of disabling them if required - virtually all features can be disabled, bgwriter, autovacuum etc even though it is almost never a recommendation to do so. I can't see a good argument for including some switches, but not others. SSI is a complex new feature and really should have an off switch. Right now, we've had one report and a benchmark that show severe performance degradation and that might have benefited from turning it off. That is not sufficient at this point to convince some people, so I am happy to wait to see if further reports emerge. SSI doesn't affect everybody. Yes, I agree that the only really good answer in the general case is to maintain back branches, or provide enhanced versions as some vendors choose to do. That is not my first thought, and try quite hard to put my (/our) best work into mainline Postgres. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Oct11, 2011, at 23:35 , Simon Riggs wrote: > On Tue, Oct 11, 2011 at 10:30 PM, Florian Pflug <fgp@phlo.org> wrote: > >> That experience has taught me that backwards compatibility, while very >> important in a lot of cases, has the potential to do just as much harm >> if overdone. > > Agreed. Does my suggestion represent overdoing it? I ask for balance, > not an extreme. It's my belief that an "off" switch for true serializability is overdoing it, yes. With such a switch, every application that relies on true serializability for correctness would be prone to silent data corruption should the switch ever get set to "off" accidentally. Without such a switch, OTOH, all that will happen are a few more aborts due to serialization errors in application who request SERIALIZABLE when they really only need REPEATABLE READ. Which, in the worst case, is a performance issue, but never an issue of correctness. best regards, Florian Pflug
On Wed, Oct 12, 2011 at 8:44 AM, Florian Pflug <fgp@phlo.org> wrote: > With such a switch, every application that relies on true serializability for > correctness would be prone to silent data corruption should the switch ever > get set to "off" accidentally. Agreed. > Without such a switch, OTOH, all that will happen are a few more aborts due to > serialization errors in application who request SERIALIZABLE when they really > only need REPEATABLE READ. Which, in the worst case, is a performance issue, > but never an issue of correctness. Right. And, in fairness: 1. The benchmark that I did was probably close to a worst-case scenario for SSI. Since there are no actual writes, there is no possibility of serialization conflicts, but the system must still be prepared for the possibility of a write (and, thus, potentially, a conflict) at any time. In addition, all of the transactions are very short, magnifying the effect of transaction start and cleanup overhead. In real life, people who have this workload are unlikely to use serializable mode in the first place. The whole point of serializability (not just SSI) is that it helps prevent anomalies when you have complex transactions that could allow subtle serialization anomalies to creep in. Single-statement transactions that read (or write) values based on a primary key are not the workload where you have that problem. You'd probably be happy to turn off MVCC altogether if we had an option for that. 2. Our old SERIALIZABLE behavior (now REPEATABLE READ) is a pile of garbage. Since Kevin started beating the drum about SSI, I've come across (and posted about) situations where REPEATABLE READ read causes serialization anomalies that don't exist at the READ COMMITTED level (which is exactly the opposite of what is really supposed to happen - REPEATABLE READ is supposed to provide more isolation, not less); and Kevin's pointed out many situations where REPEATABLE READ utterly fails to deliver serializable behavior. I'm not exactly thrilled with these benchmark results, but going back to a technology that doesn't work is not better. If individual users want to request that defective behavior for their applications, I am fine with giving them that option, and we have. But if people actually want serializability and we given them REPEATABLE READ, then they're going to get wrong behavior. The fact that we've been shipping that wrong behavior for years and years for lack of anything better is not a reason to continue doing it. I agree with Tom's comment upthread that the best thing to do here is put some effort into improving SSI. I think it's probably going to perform adequately for the workloads where people actually need it, but I'd certainly like to see us make it better. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Oct 12, 2011 at 1:44 PM, Florian Pflug <fgp@phlo.org> wrote: > On Oct11, 2011, at 23:35 , Simon Riggs wrote: >> On Tue, Oct 11, 2011 at 10:30 PM, Florian Pflug <fgp@phlo.org> wrote: >> >>> That experience has taught me that backwards compatibility, while very >>> important in a lot of cases, has the potential to do just as much harm >>> if overdone. >> >> Agreed. Does my suggestion represent overdoing it? I ask for balance, >> not an extreme. > > It's my belief that an "off" switch for true serializability is overdoing > it, yes. > > With such a switch, every application that relies on true serializability > for > correctness would be prone to silent data corruption should the switch ever > get set to "off" accidentally. > > Without such a switch, OTOH, all that will happen are a few more aborts due > to > serialization errors in application who request SERIALIZABLE when they > really > only need REPEATABLE READ. Which, in the worst case, is a performance issue, > but never an issue of correctness. That's a good argument and I accept it. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Oct 12, 2011 at 10:50:13AM +0300, Peter Eisentraut wrote: .... > Actually, I'm currently personally more concerned about the breakage we > introduce in minor releases. We'd need to solve that problem before we > can even begin to think about dealing with the major release issue. +1 This bit me the other day. -- Greg Sabino Mullane greg@endpoint.com End Point Corporation PGP Key: 0x14964AC8