Thread: Some interesting results from tweaking spinlocks
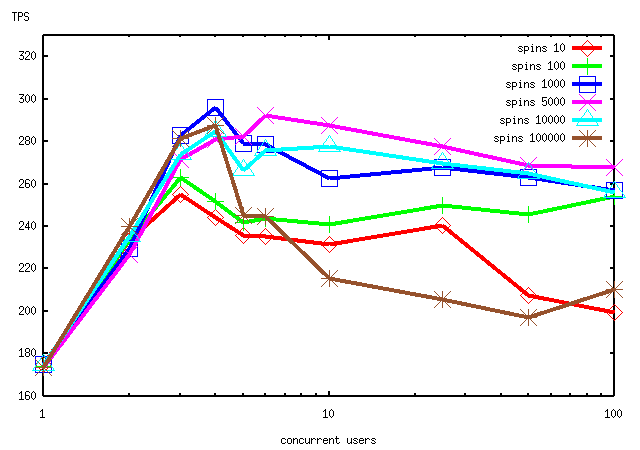
I have been experimenting with altering the SPINS_PER_DELAY number in
src/backend/storage/lmgr/s_lock.c. My results suggest that the current
setting of 100 may be too small.
The attached graph shows pgbench results on the same 4-way Linux box
I described in my last message. (The numbers are not exactly comparable
to the previous graph, because I recompiled with --enable-cassert off
for this set of runs.) All runs use current CVS plus the second LWLock
patch under discussion.
Evidently, on this hardware and test case the optimal SPINS_PER_DELAY
value is somewhere in the low thousands, not 100. I find this rather
surprising given that spinlocks are never held for more than a few
dozen instructions, but the results seem quite stable.
On the other hand, increasing SPINS_PER_DELAY could hardly fail to be
a loser on a single-CPU machine.
Would it be worth making this value a GUC parameter, so that it could
be tuned conveniently on a per-installation basis?
regards, tom lane
Attachment
{kind=link}
Tom Lane wrote: > I have been experimenting with altering the SPINS_PER_DELAY number in > src/backend/storage/lmgr/s_lock.c. My results suggest that the current > setting of 100 may be too small. > > The attached graph shows pgbench results on the same 4-way Linux box > I described in my last message. (The numbers are not exactly comparable > to the previous graph, because I recompiled with --enable-cassert off > for this set of runs.) All runs use current CVS plus the second LWLock > patch under discussion. > > Evidently, on this hardware and test case the optimal SPINS_PER_DELAY > value is somewhere in the low thousands, not 100. I find this rather > surprising given that spinlocks are never held for more than a few > dozen instructions, but the results seem quite stable. > > On the other hand, increasing SPINS_PER_DELAY could hardly fail to be > a loser on a single-CPU machine. > > Would it be worth making this value a GUC parameter, so that it could > be tuned conveniently on a per-installation basis? The difference is small, perhaps 15%. My feeling is that we may want to start configuring whether we are on a multi-cpu machine and handle thing differently. Are there other SMP issues that could be affected by a single boolean setting? Is there a way to detect this on postmaster startup? My offhand opinion is that we should keep what we have now and start to think of a more comprehensive solution for 7.3. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Bruce Momjian <pgman@candle.pha.pa.us> writes:
> The difference is small, perhaps 15%.
The thing that gets my attention is not that it's so small, it's that
it is so large. My expectation was that that code would hardly ever
be executed at all, and even less seldom (on a multiprocessor) need to
block via select(). How is it that *increasing* the delay interval
(which one might reasonably expect to simply waste cycles) can achieve
a 15% improvement in total throughput? That shouldn't be happening.
> My feeling is that we may want to start configuring whether we are on
> a multi-cpu machine and handle thing differently.
That would be more palatable if there were some portable way of
detecting it. But maybe we'll be forced into an "is_smp" GUC switch.
regards, tom lane
Tom Lane wrote: > Bruce Momjian <pgman@candle.pha.pa.us> writes: > > OK, I am a little confused now. I thought the spinlock was only done a > > few times if we couldn't get a lock, and if we don't we go to sleep, and > > the count determines how many times we try. Isn't that expected to > > affect SMP machines? > > Yeah, but if the spinlock is only held for a few dozen instructions, > one would think that the max useful delay is also a few dozen > instructions (or maybe a few times that, allowing for the possibility > that other processors might claim the lock before we can get it). > If we spin for longer than that, the obvious conclusion is that the > spinlock is held by a process that's lost the CPU, and we should > ourselves yield the CPU so that it can run again. Further spinning > just wastes CPU time that might be used elsewhere. > > These measurements seem to say there's a flaw in that reasoning. > What is the flaw? My guess is that the lock is held for more than a few instructions, at least in some cases. Spin/increment is a pretty fast operation with no access of RAM. Could the overhead of the few instructions be more than the spin time, or perhaps there is a stall in the cpu cache, requiring slower RAM access while the spin counter is incrementing rapidly? -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Tom Lane wrote: > Bruce Momjian <pgman@candle.pha.pa.us> writes: > > The difference is small, perhaps 15%. > > The thing that gets my attention is not that it's so small, it's that > it is so large. My expectation was that that code would hardly ever > be executed at all, and even less seldom (on a multiprocessor) need to > block via select(). How is it that *increasing* the delay interval > (which one might reasonably expect to simply waste cycles) can achieve > a 15% improvement in total throughput? That shouldn't be happening. OK, I am a little confused now. I thought the spinlock was only done a few times if we couldn't get a lock, and if we don't we go to sleep, and the count determines how many times we try. Isn't that expected to affect SMP machines? > > > My feeling is that we may want to start configuring whether we are on > > a multi-cpu machine and handle thing differently. > > That would be more palatable if there were some portable way of > detecting it. But maybe we'll be forced into an "is_smp" GUC switch. Yes, that is what I was thinking, but frankly, I am not going to give up on SMP auto-detection until I am convinced it can't be done portably. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Bruce Momjian <pgman@candle.pha.pa.us> writes:
> OK, I am a little confused now. I thought the spinlock was only done a
> few times if we couldn't get a lock, and if we don't we go to sleep, and
> the count determines how many times we try. Isn't that expected to
> affect SMP machines?
Yeah, but if the spinlock is only held for a few dozen instructions,
one would think that the max useful delay is also a few dozen
instructions (or maybe a few times that, allowing for the possibility
that other processors might claim the lock before we can get it).
If we spin for longer than that, the obvious conclusion is that the
spinlock is held by a process that's lost the CPU, and we should
ourselves yield the CPU so that it can run again. Further spinning
just wastes CPU time that might be used elsewhere.
These measurements seem to say there's a flaw in that reasoning.
What is the flaw?
regards, tom lane
Bruce Momjian <pgman@candle.pha.pa.us> writes:
> My guess is that the lock is held for more than a few instructions, at
> least in some cases.
It is not. LWLock and a couple of other places are the only direct uses
of spinlocks, and none of them execute more than a few lines of C code
while holding a spinlock. Nor do they touch any wide range of memory
while doing so; your thought about cache stalls is a good one, but I
don't buy it.
I've performed some profiling on that 4-way SMP machine, and it might
be useful to look at the call patterns for LWLock, which is certainly
the main use of spinlocks. This is an extract from gprof for one
backend process in a 25-client pgbench run, using CVS + second version
of LWLock patch:
----------------------------------------------- 0.00 0.00 1/420232 ExtendCLOG [475]
0.00 0.00 1/420232 InitBufferPool [517] 0.00 0.00 1/420232
InitBackendSharedInvalidationState[539] 0.00 0.00 1/420232 CleanupInvalidationState [547]
0.00 0.00 1/420232 LockMethodTableInit [511] 0.00 0.00 4/420232
GetPageWithFreeSpace[516] 0.00 0.00 8/420232 WaitIO [523] 0.00 0.00
8/420232 RecordAndGetPageWithFreeSpace [501] 0.00 0.00 10/420232 ReleaseAndReadBuffer
[513] 0.00 0.00 11/420232 XLogWrite [266] 0.00 0.00 12/420232
ShmemInitStruct[494] 0.00 0.00 14/420232 SetBufferCommitInfoNeedsSave [509]
0.00 0.00 128/420232 ProcSleep [450] 0.00 0.00 289/420232 BufferReplace [304]
0.00 0.00 400/420232 TransactionIdSetStatus [263] 0.00 0.00 400/420232
GetNewObjectId[449] 0.00 0.00 400/420232 XLogFlush [215] 0.00 0.00
401/420232 GetNewTransactionId [448] 0.00 0.00 401/420232 CommitTransaction [47]
0.00 0.00 403/420232 LockReleaseAll [345] 0.00 0.00 762/420232 StartBufferIO
[439] 0.00 0.00 1460/420232 TransactionIdGetStatus [192] 0.00 0.00
2000/420232 ReadNewTransactionId [388] 0.00 0.00 2000/420232 GetSnapshotData [334]
0.00 0.00 2870/420232 WriteBuffer [346] 0.00 0.00 3204/420232 XLogInsert [43]
0.00 0.00 9499/420232 LockRelease [107] 0.01 0.00 18827/420232
LockAcquire[66] 0.01 0.00 30871/420232 ReceiveSharedInvalidMessages [196] 0.03
0.01 76888/420232 ReleaseBuffer [80] 0.04 0.01 110970/420232 ReadBufferInternal [31]
0.06 0.01 157987/420232 LockBuffer [55]
[44] 5.4 0.15 0.04 420232 LWLockAcquire [44] 0.04 0.00 29912/30040
IpcSemaphoreLock[144] 0.00 0.00 4376/7985 s_lock [596]
----------------------------------------------- 0.00 0.00 1/420708 InitBufferPool [517]
0.00 0.00 1/420708 shmem_exit [554] 0.00 0.00 1/420708
InitShmemIndex[524] 0.00 0.00 1/420708 InitBackendSharedInvalidationState [539]
0.00 0.00 1/420708 LockMethodTableInit [511] 0.00 0.00 4/420708
GetPageWithFreeSpace[516] 0.00 0.00 8/420708 WaitIO [523] 0.00 0.00
8/420708 RecordAndGetPageWithFreeSpace [501] 0.00 0.00 11/420708 ShmemInitStruct [494]
0.00 0.00 11/420708 XLogWrite [266] 0.00 0.00 14/420708
SetBufferCommitInfoNeedsSave[509] 0.00 0.00 128/420708 ProcSleep [450] 0.00
0.00 289/420708 BufferReplace [304] 0.00 0.00 400/420708 TransactionLogUpdate [260]
0.00 0.00 400/420708 GetNewObjectId [449] 0.00 0.00 401/420708
CommitTransaction[47] 0.00 0.00 402/420708 GetNewTransactionId [448] 0.00
0.00 403/420708 LockReleaseAll [345] 0.00 0.00 762/420708 ReadBufferInternal [31]
0.00 0.00 762/420708 TerminateBufferIO [455] 0.00 0.00 800/420708
XLogFlush[215] 0.00 0.00 1460/420708 TransactionIdGetStatus [192] 0.00 0.00
2000/420708 ReadNewTransactionId [388] 0.00 0.00 2000/420708 GetSnapshotData [334]
0.00 0.00 2870/420708 WriteBuffer [346] 0.00 0.00 3280/420708 XLogInsert [43]
0.00 0.00 9499/420708 LockRelease [107] 0.00 0.00 18827/420708
LockAcquire[66] 0.01 0.00 30871/420708 ReceiveSharedInvalidMessages [196] 0.02
0.00 76888/420708 ReleaseBuffer [80] 0.02 0.00 110218/420708 BufferAlloc [42]
0.03 0.00 157987/420708 LockBuffer [55]
[70] 2.6 0.09 0.00 420708 LWLockRelease [70] 0.00 0.00 29982/30112
IpcSemaphoreUnlock[571] 0.00 0.00 3604/7985 s_lock [596]
What I draw from this is:
1. The BufMgrLock is the principal source of LWLock contention, since it
is locked more than anything else. (The ReleaseBuffer,
ReadBufferInternal, and BufferAlloc calls are all to acquire/release
BufMgrLock. Although LockBuffer appears to numerically exceed these
calls, the LockBuffer operations are spread out over all the per-buffer
context locks, so it's unlikely that there's much contention for any one
buffer context lock.) It's too late in the 7.2 cycle to think about
redesigning bufmgr's interlocking but this ought to be high priority for
future work.
2. In this example, almost one in ten LWLockAcquire calls results in
blocking (calling IpcSemaphoreLock). That seems like a lot. I was
seeing much better results on a uniprocessor under essentially the
same test: one in a thousand LWLockAcquire calls blocked, not one in
ten. What's causing that discrepancy?
3. The amount of spinlock-level contention seems too high too. We
are calling s_lock about one out of every hundred LWLockAcquire or
LWLockRelease calls; the equivalent figure from a uniprocessor profile
is one in five thousand. Given the narrow window in which the spinlock
is held, how can the contention rate be so high?
Anyone see an explanation for these last two observations?
regards, tom lane
Thanks. Looks good to me. --------------------------------------------------------------------------- Rod Taylor wrote: > The number of CPUs on a system should be fairly straight forward to > find out. Distributed.net source code has some good examples. > > What I'm not sure of is how well this stuff reacts to CPUs being > software disabled (Solaris has such a feature). > > ftp://ftp.distributed.net/pub/dcti/source/pub-20010416.tgz > > first function of client/common/cpucheck.cpp > > Each OS gets its own implementation, but they've got all the ones > Postgresql uses covered off. > -- > Rod Taylor > > This message represents the official view of the voices in my head > > ----- Original Message ----- > From: "Tom Lane" <tgl@sss.pgh.pa.us> > To: "Bruce Momjian" <pgman@candle.pha.pa.us> > Cc: <pgsql-hackers@postgresql.org> > Sent: Friday, January 04, 2002 11:49 PM > Subject: Re: [HACKERS] Some interesting results from tweaking > spinlocks > > > > Bruce Momjian <pgman@candle.pha.pa.us> writes: > > > The difference is small, perhaps 15%. > > > > The thing that gets my attention is not that it's so small, it's > that > > it is so large. My expectation was that that code would hardly ever > > be executed at all, and even less seldom (on a multiprocessor) need > to > > block via select(). How is it that *increasing* the delay interval > > (which one might reasonably expect to simply waste cycles) can > achieve > > a 15% improvement in total throughput? That shouldn't be happening. > > > > > My feeling is that we may want to start configuring whether we are > on > > > a multi-cpu machine and handle thing differently. > > > > That would be more palatable if there were some portable way of > > detecting it. But maybe we'll be forced into an "is_smp" GUC > switch. > > > > regards, tom lane > > > > ---------------------------(end of > broadcast)--------------------------- > > TIP 1: subscribe and unsubscribe commands go to > majordomo@postgresql.org > > > > -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
> 2. In this example, almost one in ten LWLockAcquire calls results in > blocking (calling IpcSemaphoreLock). That seems like a lot. I was > seeing much better results on a uniprocessor under essentially the > same test: one in a thousand LWLockAcquire calls blocked, not one in > ten. What's causing that discrepancy? > > 3. The amount of spinlock-level contention seems too high too. We > are calling s_lock about one out of every hundred LWLockAcquire or > LWLockRelease calls; the equivalent figure from a uniprocessor profile > is one in five thousand. Given the narrow window in which the spinlock > is held, how can the contention rate be so high? > > Anyone see an explanation for these last two observations? Isn't there tons more lock contention on an SMP machine. I don't see the surprise. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Tom Lane wrote: > Bruce Momjian <pgman@candle.pha.pa.us> writes: > > Isn't there tons more lock contention on an SMP machine. > > No, one would hope not. If you can't get the various processes to > run without much interference, you're wasting your time dealing > with multiple CPUs. There is hope and reality. :-) > In a uniprocessor, we'll suffer from lock contention if one process > happens to lose the CPU while holding a lock, and one of the other > processes that gets to run meanwhile tries to acquire that same lock. > In SMP this gets folded down: the lock holder might not lose its CPU > at all, but some other CPU could be running a process that tries to > acquire the lock meanwhile. It's not apparent to me why that should > increase the chance of lock contention, however. The percentage of > a process' runtime in which it is holding a lock should be the same > either way, so the probability that another process fails to acquire > the lock when it wants shouldn't change either. Where is the flaw > in this analysis? At the risk of sounding stupid because I am missing something: On a single CPU system, one process is grabbing-releasing the lock while it has the CPU, and sometimes it loses the CPU while it has the lock. On an SMP machine, all the backends are contending for the lock at the _same_ time. That is why SMP kernel coding is so hard, and they usually get around it by having one master kernel lock, which seems to be exactly what our mega-lock is doing; not a pretty picture. On a single CPU machine, you fail to get the lock only if another process has gone to sleep while holding the lock. With a multi-cpu machine, especially a 4-way, you can have up to three processes (excluding your own) holding that lock, and if that happens, you can't get it. Think of it this way, on a single-cpu machine, only one process can go to sleep waiting on the lock. Any others will fail to get the lock and go back to sleep. On a 4-way (which is what I think you said you were one), you have three possible processes holding that lock, plus processes that have gone to sleep holding the lock. Does that make any sense? -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Bruce Momjian <pgman@candle.pha.pa.us> writes:
> Isn't there tons more lock contention on an SMP machine.
No, one would hope not. If you can't get the various processes to
run without much interference, you're wasting your time dealing
with multiple CPUs.
In a uniprocessor, we'll suffer from lock contention if one process
happens to lose the CPU while holding a lock, and one of the other
processes that gets to run meanwhile tries to acquire that same lock.
In SMP this gets folded down: the lock holder might not lose its CPU
at all, but some other CPU could be running a process that tries to
acquire the lock meanwhile. It's not apparent to me why that should
increase the chance of lock contention, however. The percentage of
a process' runtime in which it is holding a lock should be the same
either way, so the probability that another process fails to acquire
the lock when it wants shouldn't change either. Where is the flaw
in this analysis?
regards, tom lane
[2002-01-05 00:00] Tom Lane said: | Bruce Momjian <pgman@candle.pha.pa.us> writes: | > OK, I am a little confused now. I thought the spinlock was only done a | > few times if we couldn't get a lock, and if we don't we go to sleep, and | > the count determines how many times we try. Isn't that expected to | > affect SMP machines? | | Yeah, but if the spinlock is only held for a few dozen instructions, | one would think that the max useful delay is also a few dozen | instructions (or maybe a few times that, allowing for the possibility | that other processors might claim the lock before we can get it). | If we spin for longer than that, the obvious conclusion is that the | spinlock is held by a process that's lost the CPU, and we should | ourselves yield the CPU so that it can run again. Further spinning | just wastes CPU time that might be used elsewhere. | | These measurements seem to say there's a flaw in that reasoning. | What is the flaw? Knowing very little of SMP, it looks like the spinning is parallelizing as expected, getting to select() faster, then serializing on the select() call. I suspect using usleep() instead of select() might relieve the serialization. I'm aware that usleep(10) will actually yield between 10 and 20us due to the kernel's scheduler. b -- "Develop your talent, man, and leave the world something. Records are really gifts from people. To think that an artist would love you enough to share his music with anyone is a beautiful thing." -- Duane Allman
Your observation that spinning instead of sleeping being faster on SMP makes
sense.
On a single processor system, if you don't have the lock, you should call
select() as soon as possible (never spin). This will allow the OS (presumably)
to switch to the process who does. You will never get the lock unless your
process loses the CPU because some other process MUST get CPU time in order to
release the lock.
On an SMP machine, this is different, other processes can run truly
simultaneously to the process spinning. Then you have the trade-off of wasting
CPU cycles vs sleeping.
A better lock system could know how many CPUs are in a system, and how many
processes are waiting for the lock. Use this information to manage who sleeps
and who spins.
For instance, if you have a 2 CPU SMP box, the first process to get the lock
gets it. The next process to try for the lock should spin. The third process
waiting should sleep.
ATOMIC_INC(lock->waiters);
while(TAS(lock))
{if (++delays > (TIMEOUT_MSEC / DELAY_MSEC)) s_lock_stuck(lock, file, line);if(lock->waiters >= num_cpus){
delay.tv_sec= 0; delay.tv_usec = DELAY_MSEC * 1000; (void) select(0, NULL, NULL, NULL, &delay);}
}
ATOMIC_DEC(lock->waiters);
The above code is probably wrong, but something like it may improve performance
on SMP and uniprocessor boxes. On a uniprocessor box, the CPU is released right
away on contention. On an SMP box light contention allows some spinning, but on
heavy contention the CPUs aren't wasting a lot of time spinning.
mlw wrote:
[snip]
#define SPINS_PER_DELAY 2000
#define DELAY_MSEC 10
#define TIMEOUT_MSEC (60 * 1000)
ATOMIC_INC(lock->waiters);
while (TAS(lock)) { if ( (++spins > SPINS_PER_DELAY) || (lock->waiters >= CPUS) )
{ if (++delays > (TIMEOUT_MSEC / DELAY_MSEC)) s_lock_stuck(lock,
file,line);
delay.tv_sec = 0; delay.tv_usec = DELAY_MSEC * 1000;
(void)select(0, NULL, NULL, NULL, &delay);
spins = 0; } } ATOMIC_DEC(lock->waiters);
This is better function, the one in my previous post was non-sense, I should
have coffee BEFORE I post.
mlw <markw@mohawksoft.com> writes:
> A better lock system could know how many CPUs are in a system, and how many
> processes are waiting for the lock. Use this information to manage who sleeps
> and who spins.
> For instance, if you have a 2 CPU SMP box, the first process to get the lock
> gets it. The next process to try for the lock should spin. The third process
> waiting should sleep.
Actually, the thing you want to know before deciding whether to spin is
whether the current lock holder is running (presumably on some other
CPU) or is waiting to run. If he is waiting then it makes sense to
yield your CPU so he can run. If he is running then you should just
spin for the presumably short time before he frees the spinlock.
On a single-CPU system this decision rule obviously reduces to "always
yield".
Unfortunately, while we could store the PID of the current lock holder
in the data structure, I can't think of any adequately portable way to
do anything with the information :-(. AFAIK there's no portable kernel
call that asks "is this PID currently running on another CPU?"
regards, tom lane
Brent Verner <brent@rcfile.org> writes:
> I suspect using usleep() instead of select() might
> relieve the serialization.
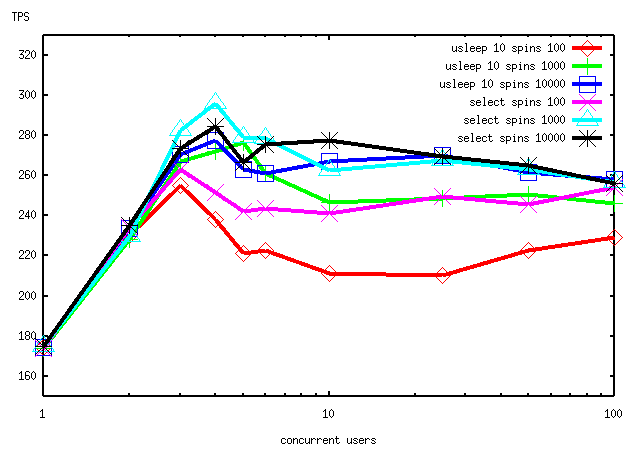
A number of people have suggested that reducing the sleep interval would
improve matters. I tried that just now, again on RedHat's 4-way box,
and was mildly astonished to find that it makes things worse. The graph
below shows pgbench results for both the current code (10 millisec delay
using select()) and a 10-microsec delay using usleep(), with several
different SPINS_PER_DELAY values. Test conditions are otherwise the
same as in my last message (in particular, LWLock patch version 2).
At any given SPINS_PER_DELAY, the 10msec sleep beats the 10usec sleep
handily. I wonder if this indicates a problem with Linux'
implementation of usleep?
regards, tom lane
Attachment
{kind=link}
Tom Lane wrote: >Unfortunately, while we could store the PID of the current lock holder >in the data structure, I can't think of any adequately portable way to >do anything with the information :-(. AFAIK there's no portable kernel >call that asks "is this PID currently running on another CPU?" > But do all performance tweaks need to be portable ? >regards, tom lane > >---------------------------(end of broadcast)--------------------------- >TIP 6: Have you searched our list archives? > >http://archives.postgresql.org >
[2002-01-05 14:01] Tom Lane said: | Brent Verner <brent@rcfile.org> writes: | > I suspect using usleep() instead of select() might | > relieve the serialization. | | A number of people have suggested that reducing the sleep interval would | improve matters. Using a single-processor machine, we're not going to get any lower sleep times than ~10ms from either usleep or select on linux, and usleep is always longer. brent$ ./s_lock 1 0 usleep = 0.007130 s select = 0.000007 s nanosleep = 0.013286 s brent$ ./s_lock 1 10 usleep = 0.013465 s select = 0.009879 s nanosleep = 0.019924 s On FBSD, the shortest sleep is ~20ms, but is the same for usleep and select. | I tried that just now, again on RedHat's 4-way box, | and was mildly astonished to find that it makes things worse. The graph | below shows pgbench results for both the current code (10 millisec delay | using select()) and a 10-microsec delay using usleep(), with several | different SPINS_PER_DELAY values. Test conditions are otherwise the | same as in my last message (in particular, LWLock patch version 2). Ah, now this is very interesting. Looks like increasing spins allows the process to get the lock before the usleep/select is run -- based on the fact the that "usleep 10 spins 100" is markedly lower than the select version. This is in keeping with observation mentioned above where usleep sleeps longer than select() on linux. It would be interesting to count the number of times this select() is called on the SMP machines at various spin counts. | At any given SPINS_PER_DELAY, the 10msec sleep beats the 10usec sleep | handily. I wonder if this indicates a problem with Linux' | implementation of usleep? I don't think so, but it does disprove my original suspicion. Given the significant performance gap, I'd vote to add a configurable parameter for the spin counter. thanks. brent -- "Develop your talent, man, and leave the world something. Records are really gifts from people. To think that an artist would love you enough to share his music with anyone is a beautiful thing." -- Duane Allman
Brent Verner <brent@rcfile.org> writes:
> Using a single-processor machine, we're not going to get any lower
> sleep times than ~10ms from either usleep or select on linux, and
> usleep is always longer.
Ah, so usleep is just being stricter about rounding up the requested
delay? That would explain the results all right.
> Looks like increasing spins allows
> the process to get the lock before the usleep/select is run
Right. Up to a point, increasing spins improves the odds of acquiring
the lock without having to release the processor.
What I should've thought of is to try sched_yield() as well, which is
the operation we *really* want here, and it is available on this version
of Linux. Off to run another batch of tests ...
regards, tom lane
[2002-01-05 17:04] Tom Lane said: | Brent Verner <brent@rcfile.org> writes: | > Using a single-processor machine, we're not going to get any lower | > sleep times than ~10ms from either usleep or select on linux, and | > usleep is always longer. | | Ah, so usleep is just being stricter about rounding up the requested | delay? That would explain the results all right. The only difference I see is that sys_nanosleep gets its actual timeout value using timespec_to_jiffies(), and do_select leaves the specified delay untouched. | > Looks like increasing spins allows | > the process to get the lock before the usleep/select is run | | Right. Up to a point, increasing spins improves the odds of acquiring | the lock without having to release the processor. | | What I should've thought of is to try sched_yield() as well, which is | the operation we *really* want here, and it is available on this version | of Linux. Off to run another batch of tests ... yes. using just sched_yield() inside the TAS loop appears to give better performance on both freebsd and linux (single-proc); in particular, it _looks_ like there is a 8-10% performance gain at 32 clients. btw, what are y'all using to generate these nifty graphs? thanks. brent -- "Develop your talent, man, and leave the world something. Records are really gifts from people. To think that an artist would love you enough to share his music with anyone is a beautiful thing." -- Duane Allman
> btw, what are y'all using to generate these nifty graphs? > gnuplot. -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 853-3000+ If your life is a hard drive, | 830 Blythe Avenue + Christ can be your backup. | Drexel Hill, Pennsylvania19026
Bruce Momjian <pgman@candle.pha.pa.us> writes:
>> btw, what are y'all using to generate these nifty graphs?
> gnuplot.
Tatsuo previously posted a script to extract a gnuplot-ready data file
from a transcript of a set of pgbench runs. I've been using that, plus
gnuplot scripts like the following (slightly tweaked from Tatsuo's
example):
set xlabel "concurrent users"
set ylabel "TPS"
set yrange [150:330]
set logscale x
set key width 5
set key right
plot \
'bench.try2-noassert.data' title 'select spins 100' with linespoint lw 4 pt 1 ps 4, \
'bench.try2-na-s1000.data' title 'select spins 1000' with linespoint lw 4 pt 2 ps 4, \
'bench.try2-na-s10000-2.data' title 'select spins 10000' with linespoint lw 4 pt 3 ps 4, \
'bench.yield-s100-2.data' title 'yield spins 100' with linespoint lw 4 pt 4 ps 4, \
'bench.yield-s1000-2.data' title 'yield spins 1000' with linespoint lw 4 pt 5 ps 4
regards, tom lane
Brent Verner <brent@rcfile.org> writes:
> | What I should've thought of is to try sched_yield() as well, which is
> | the operation we *really* want here, and it is available on this version
> | of Linux. Off to run another batch of tests ...
> yes. using just sched_yield() inside the TAS loop appears to give
> better performance on both freebsd and linux (single-proc); in
> particular, it _looks_ like there is a 8-10% performance gain at
> 32 clients.
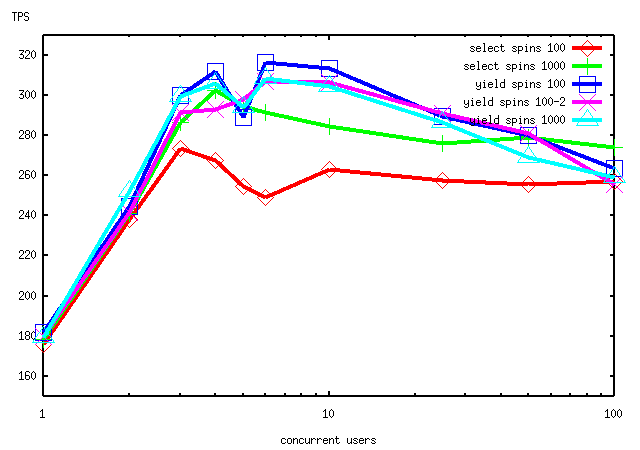
I'm noticing more variability in the results today than I got yesterday;
this is odd, since the only change in the system environment is that we
cleaned off some more free space on the disk drive array in preparation
for running larger benchmarks. An example of the variability can be
seen by comparing the two "yield spins 100" curves below, which should
be identical circumstances. Still, it's clear that using sched_yield
is a win.
Also note that spins=1000 seems to be a loser compared to spins=100 when
using sched_yield, while it is not with either select or usleep. This
makes sense, since the reason for not wanting to yield the processor
is the large delay till we can run again. With sched_yield that penalty
is eliminated.
regards, tom lane
Attachment
{kind=link}
The number of CPUs on a system should be fairly straight forward to find out. Distributed.net source code has some good examples. What I'm not sure of is how well this stuff reacts to CPUs being software disabled (Solaris has such a feature). ftp://ftp.distributed.net/pub/dcti/source/pub-20010416.tgz first function of client/common/cpucheck.cpp Each OS gets its own implementation, but they've got all the ones Postgresql uses covered off. -- Rod Taylor This message represents the official view of the voices in my head ----- Original Message ----- From: "Tom Lane" <tgl@sss.pgh.pa.us> To: "Bruce Momjian" <pgman@candle.pha.pa.us> Cc: <pgsql-hackers@postgresql.org> Sent: Friday, January 04, 2002 11:49 PM Subject: Re: [HACKERS] Some interesting results from tweaking spinlocks > Bruce Momjian <pgman@candle.pha.pa.us> writes: > > The difference is small, perhaps 15%. > > The thing that gets my attention is not that it's so small, it's that > it is so large. My expectation was that that code would hardly ever > be executed at all, and even less seldom (on a multiprocessor) need to > block via select(). How is it that *increasing* the delay interval > (which one might reasonably expect to simply waste cycles) can achieve > a 15% improvement in total throughput? That shouldn't be happening. > > > My feeling is that we may want to start configuring whether we are on > > a multi-cpu machine and handle thing differently. > > That would be more palatable if there were some portable way of > detecting it. But maybe we'll be forced into an "is_smp" GUC switch. > > regards, tom lane > > ---------------------------(end of broadcast)--------------------------- > TIP 1: subscribe and unsubscribe commands go to majordomo@postgresql.org >