Thread: PostgreSQL Tuning Results
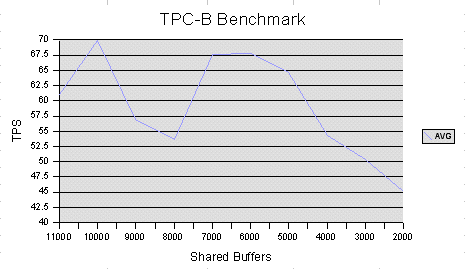
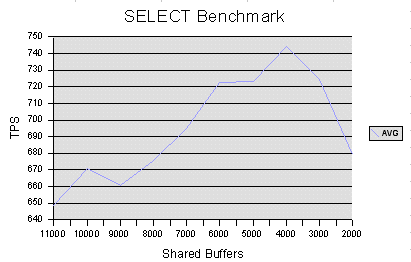
Hi Everyone, I have just completed a basic set of benchmarking on our new database server. I wanted to figure out a good value for shared_buffers before we go live. We are a busy ecommerce-style website and so we probably get 10 or 20 to 1 read transactions vs. write transactions. We also don't have particularly large tables. Attached are the charts for select only and tpc-b runs. Also attached is an OpenOffice.org spreadsheet with all the results, averages and charts. I place all these attachments in the public domain, so you guys can use them how you wish. I installed pgbench, and set up a pgbench database with scale factor 1. I then set shared_buffers to all the values between 2000 and 11000 and tested select and tcp-b with each. I ran each test 3 times and averaged the values. TPC-B was run after select so had advantages due to the buffers already being filled, but I was consistent with this. Machine: 256MB RAM, FreeBSD 4.7, EIDE HDD, > 1 Ghz TPC-B config: pgbench -c 64 -t 100 pgbench (Note: only 64 users here) SELECT config: pgbench -c 128 -t 100 -S pgbench (Note: full 128 users here) I'm not sure why 8000 and 9000 are low on tpc-b, it's odd. Anyway, from the attached results you can see that 4000 buffers gave the best SELECT only performance, whereas the TPC-B stuff seemed to max out way up at 10000 or so. Since there is a 20% gain in performance on TPC-B going from 4000 buffers to 5000 buffers and only a 2% loss in performance for SELECTs, I have configured my server to use 5000 shared buffers, eg. 45MB RAM. I am now going to leave it on 5000 and play with wal_buffers. Is there anything else people are interested in me trying? Later on, I'll run pg_autotune to see how its recommendation matches my findings. Chris
Attachment
{kind=link}
{kind=link}
Hi Chris, On Wed, 12 Feb 2003, Christopher Kings-Lynne wrote: > Machine: > 256MB RAM, FreeBSD 4.7, EIDE HDD, > 1 Ghz Seems like a small amount of memory to be memory based tests with. What about testing sort_mem as well. It would system to me that there would be no negative to having infinite sort_mem given infinite memory, though. Gavin
> > Machine: > > 256MB RAM, FreeBSD 4.7, EIDE HDD, > 1 Ghz > > Seems like a small amount of memory to be memory based tests with. Perhaps, but I'm benchmarking for that machine, not for any other. The results have to include the 256MB spec. Also, the peak was 25MB of SHM, which still leave 231MB for the rest of the system, so surely RAM is not the bottleneck here? > What about testing sort_mem as well. It would system to me that there > would be no negative to having infinite sort_mem given infinite memory, > though. Yeah, however I'm pretty sure that pgbench doesn't perform any sorts. I reckon that sort_mem is the hardest thing to optimise1 Chris
Gavin Sherry wrote:
>Hi Chris,
>
>On Wed, 12 Feb 2003, Christopher Kings-Lynne wrote:
>
>
>
>>Machine:
>>256MB RAM, FreeBSD 4.7, EIDE HDD, > 1 Ghz
>>
>>
>
>Seems like a small amount of memory to be memory based tests with.
>
>What about testing sort_mem as well. It would system to me that there
>would be no negative to having infinite sort_mem given infinite memory,
>though.
>
>Gavin
>
>
>---------------------------(end of broadcast)---------------------------
>TIP 1: subscribe and unsubscribe commands go to majordomo@postgresql.org
>
>
Be careful with sort_mem - this might lead to VERY unexpected results. I
did some testing on my good old Athlon 500 with a brand new IBM 120 Gigs
HDD. Reducing the sort_mem gave me significantly faster results when
sorting/indexing 20.000.000 randon rows.
However, it would be nice to see the results of concurrent sorts.
Hans
--
*Cybertec Geschwinde u Schoenig*
Ludo-Hartmannplatz 1/14, A-1160 Vienna, Austria
Tel: +43/1/913 68 09; +43/664/233 90 75
www.postgresql.at <http://www.postgresql.at>, cluster.postgresql.at
<http://cluster.postgresql.at>, www.cybertec.at
<http://www.cybertec.at>, kernel.cybertec.at <http://kernel.cybertec.at>
On Wed, 12 Feb 2003, [ISO-8859-1] Hans-J\xFCrgen Sch\xF6nig wrote: > Be careful with sort_mem - this might lead to VERY unexpected results. I > did some testing on my good old Athlon 500 with a brand new IBM 120 Gigs > HDD. Reducing the sort_mem gave me significantly faster results when > sorting/indexing 20.000.000 randon rows. Actually, the results are completely expected once you know what's exactly is going on. I found it weird that my sorts were also slowing down with more sort memory until Tom or Bruce or someone pointed out to me that my stats said my sorts were swapping. If I'm understanding this correctly, this basically meant that my sort results would start hitting disk becuase they were being paged out to swap space, but then once the block was sorted, it would be read in again from disk, and then written out to disk again (in a different place), creating a lot more I/O than was really necessary. This strikes me, too, as another area where mmap might allow the system to do a better job with less tuning. Basically, the sort is getting split into a bunch of smaller chunks, each of which is individually sorted, and then you merge at the end, right? So if all those individual chunks were mmaped, the system could deal with paging them out if and when necessary, and for the sorts you do before the merge, you could mlock() the area that you're currently sorting to make sure that it doesn't thrash. If the VM system accepts hints, you might also get some further optimizations because you can tell it (using madvise()) when you're doing random versus sequential access on a chunk of memory. cjs -- Curt Sampson <cjs@cynic.net> +81 90 7737 2974 http://www.netbsd.org Don't you know, in this new Dark Age, we're all light. --XTC
> > >Actually, the results are completely expected once you know what's >exactly is going on. I found it weird that my sorts were also slowing >down with more sort memory until Tom or Bruce or someone pointed out to >me that my stats said my sorts were swapping. > > this way my first expectation but since the machine was newly booted and had 1/2 gig of ram (nothing running but PostgreSQL) I couldn't believe in that theory ... Maybe but I couldn't verify that ... Of course swapping is worse than anything else. >This strikes me, too, as another area where mmap might allow the system >to do a better job with less tuning. Basically, the sort is getting >split into a bunch of smaller chunks, each of which is individually >sorted, and then you merge at the end, right? So if all those individual >chunks were mmaped, the system could deal with paging them out if and >when necessary, and for the sorts you do before the merge, you could >mlock() the area that you're currently sorting to make sure that it >doesn't thrash. > As far as I have seen in the source code they use Knuth's tape algorithm. It is based on dividing, sorting, and merging together. >If the VM system accepts hints, you might also get some further >optimizations because you can tell it (using madvise()) when you're >doing random versus sequential access on a chunk of memory. > >cj > it is an interesting topic. the result of the benchmark is very clock speed depedent (at least in case my of my data structure). Hans -- Cybertec Geschwinde &. Schoenig Ludo-Hartmannplatz 1/14; A-1160 Wien Tel.: +43/1/913 68 09 oder +43/664/233 90 75 URL: www.postgresql.at, www.cybertec.at, www.python.co.at, www.openldap.at