Thread: Postgre Eating Up Too Much RAM
I have been struggling with an issue on our database server lately with Postgres crashing our server by taking up too much RAM. To alleviate this problem, I just upgraded from a 6 GB RAM server to a new 32 GB RAM server. The new server is running Ubuntu 10 with nothing but PostgreSQL 8.4.14 installed.
total used free shared buffers cached
Mem: 30503 20626 9876 0 143 15897
-/+ buffers/cache: 4586 25917
Swap: 1913 0 1913
Total: 32417 20626 11790
Today, after being in use for only 24 hours, it hung the server again. Now, when I run a check on memory usage, I get a quickly growing amount of RAM being used:
free -mt
total used free shared buffers cached
Mem: 30503 20626 9876 0 143 15897
-/+ buffers/cache: 4586 25917
Swap: 1913 0 1913
Total: 32417 20626 11790
Additionally, I see using ps that Postgres is the only process using over 0.1 % of the RAM.
Here is a sample of the PS command for some of the Postgres processes (there are currently a little over 200 active connections to the database):
ps axuf
....
postgres 3523 0.5 1.0 426076 313156 ? Ss 08:44 2:42 \_ postgres: myuser my_db 192.168.1.2(39786) idle
postgres 3820 0.4 0.9 418988 302036 ? Ss 09:04 2:11 \_ postgres: myuser my_db 192.168.1.2(52110) idle
postgres 3821 0.1 0.5 391452 178972 ? Ss 09:04 0:44 \_ postgres: myuser my_db 192.168.1.2(52111) idle
postgres 3822 0.0 0.0 369572 9928 ? Ss 09:04 0:00 \_ postgres: myuser my_db 192.168.1.2(52112) idle
postgres 3823 0.2 0.6 383368 202312 ? Ss 09:04 1:12 \_ postgres: myuser my_db 192.168.1.2(52114) idle
postgres 3824 0.0 0.0 369320 8820 ? Ss 09:04 0:00 \_ postgres: myuser my_db 192.168.1.2(52115) idle
postgres 3825 0.4 0.8 413964 257040 ? Ss 09:04 1:54 \_ postgres: myuser my_db 192.168.1.2(52116) idle
....
Am I reading this right? Are there individual connections using over 300 MB or RAM by themselves? This seems excessive. (Note I am not a system admin exactly so please correct me if I am reading this wrong.)
My postgresql.conf looks like this (I have only included the non-commented lines):
data_directory = '/var/lib/postgresql/8.4/main'
hba_file = '/etc/postgresql/8.4/main/pg_hba.conf'
ident_file = '/etc/postgresql/8.4/main/pg_ident.conf'
external_pid_file = '/var/run/postgresql/8.4-main.pid'
listen_addresses = 'localhost,192.168.1.200'
port = 5432
max_connections = 1000
unix_socket_directory = '/var/run/postgresql'
ssl = true
shared_buffers = 256MB
vacuum_cost_delay = 20ms
default_statistics_target = 100
log_destination = 'stderr'
logging_collector = on
log_directory = '/var/log/postgresql'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_truncate_on_rotation = on
log_rotation_age = 1d
log_rotation_size = 0MB
log_connections = on
log_disconnections = on
log_line_prefix = '<%t %u %h>'
track_activities = on
track_counts = on
datestyle = 'iso, mdy'
lc_messages = 'en_US.UTF-8'
lc_monetary = 'en_US.UTF-8'
lc_numeric = 'en_US.UTF-8'
lc_time = 'en_US.UTF-8'
default_text_search_config = 'pg_catalog.english'
I have read quite a bit over the last couple days and must be missing something as I cannot see why each connection is using so much memory.
Thanks for any help you can provide!
-Aaron
==================================================================
Aaron Bono
Aranya Software Technologies, Inc.
http://www.aranya.com
http://codeelixir.com
==================================================================
Aaron Bono
Aranya Software Technologies, Inc.
http://www.aranya.com
http://codeelixir.com
==================================================================
On 11/14/2012 06:12 AM, Aaron Bono wrote:
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
....postgres 3523 0.5 1.0 426076 313156 ? Ss 08:44 2:42 \_ postgres: myuser my_db 192.168.1.2(39786) idlepostgres 3820 0.4 0.9 418988 302036 ? Ss 09:04 2:11 \_ postgres: myuser my_db 192.168.1.2(52110) idlepostgres 3821 0.1 0.5 391452 178972 ? Ss 09:04 0:44 \_ postgres: myuser my_db 192.168.1.2(52111) idlepostgres 3822 0.0 0.0 369572 9928 ? Ss 09:04 0:00 \_ postgres: myuser my_db 192.168.1.2(52112) idlepostgres 3823 0.2 0.6 383368 202312 ? Ss 09:04 1:12 \_ postgres: myuser my_db 192.168.1.2(52114) idlepostgres 3824 0.0 0.0 369320 8820 ? Ss 09:04 0:00 \_ postgres: myuser my_db 192.168.1.2(52115) idlepostgres 3825 0.4 0.8 413964 257040 ? Ss 09:04 1:54 \_ postgres: myuser my_db 192.168.1.2(52116) idle
If I recall correctly, RSS is charged against a PostgreSQL back-end when it touches `shared_buffers`. So that doesn't necessarily mean that the back-end is using the full amount of memory listed as RSS.Am I reading this right? Are there individual connections using over 300 MB or RAM by themselves?
Yes, measuring how much memory Pg uses is seriously frustrating because OS accounting for shared memory is so bad.
See http://www.depesz.com/2012/06/09/how-much-ram-is-postgresql-using/
-- Craig Ringer http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
Craig Ringer <craig@2ndQuadrant.com> writes:
> On 11/14/2012 06:12 AM, Aaron Bono wrote:
>> Am I reading this right? Are there individual connections using over
>> 300 MB or RAM by themselves?
> If I recall correctly, RSS is charged against a PostgreSQL back-end when
> it touches `shared_buffers`. So that doesn't necessarily mean that the
> back-end is using the full amount of memory listed as RSS.
Yeah. Since Aaron's got shared_buffers set to 256MB, the shared memory
segment is something more than that (maybe 270-280MB, hard to be sure
without checking). The RSS numbers probably count all or nearly all of
that for each process, but of course there's really only one copy of the
shared memory segment. RSS is likely double-counting the postgres
executable as well, which means that the actual additional memory used
per process is probably just a few meg, which is in line with most
folks' experience with PG.
The "free" stats didn't look like a machine under any sort of memory
pressure --- there's zero swap usage, and nearly half of real RAM is
being used for disk cache, which means the kernel can find no better
use for it than caching copies of disk files. Plus there's still 10G
that's totally free. Maybe things get worse when the machine's been up
longer, but this sure isn't evidence of trouble.
I'm inclined to think that the problem is not RAM consumption at all but
something else. What exactly happens when the server "hangs"?
regards, tom lane
Am 14.11.2012 04:19, schrieb Tom Lane: > Craig Ringer <craig@2ndQuadrant.com> writes: >> On 11/14/2012 06:12 AM, Aaron Bono wrote: >>> Am I reading this right? Are there individual connections using over >>> 300 MB or RAM by themselves? >> If I recall correctly, RSS is charged against a PostgreSQL back-end when >> it touches `shared_buffers`. So that doesn't necessarily mean that the >> back-end is using the full amount of memory listed as RSS. > Yeah. Since Aaron's got shared_buffers set to 256MB, the shared memory > segment is something more than that (maybe 270-280MB, hard to be sure > without checking). The RSS numbers probably count all or nearly all of > that for each process, but of course there's really only one copy of the > shared memory segment. RSS is likely double-counting the postgres > executable as well, which means that the actual additional memory used > per process is probably just a few meg, which is in line with most > folks' experience with PG. > > The "free" stats didn't look like a machine under any sort of memory > pressure --- there's zero swap usage, and nearly half of real RAM is > being used for disk cache, which means the kernel can find no better > use for it than caching copies of disk files. Plus there's still 10G > that's totally free. Maybe things get worse when the machine's been up > longer, but this sure isn't evidence of trouble. Keep in mind though that (SysV) SHM is accounted as "cached" in all Linux tools (I know), thus "free" is never "complete" without "ipcs -m" + "ipcs -mu" outputs. However I second Tom here; your machine looks perfectly healthy. Note that RSS usage of your sessions can quickly "explode" though (due to copy on write) if your clients start creating large return sets (and in the worst case, take a lot of time to "collect" them). You might consider deploying atop (atoptool.nl), which offers to sum up all data based on user and/or process name, and will enable you to track the usage stats to the past. Plus the latest version could already have a seperate display for SHM usage (at least Gerlof promised me to add it ;-). Cheers, -- Gunnar "Nick" Bluth RHCE/SCLA Mobil +49 172 8853339 Email: gunnar.bluth@pro-open.de __________________________________________________________________________ In 1984 mainstream users were choosing VMS over UNIX. Ten years later they are choosing Windows over UNIX. What part of that message aren't you getting? - Tom Payne
Aaron Bono wrote: > (there are currently a little over 200 active connections to the > database): How many cores do you have on the system? What sort of storage systeme? What, exactly, are the symptoms of the problem? Are there 200 active connections when the problem occurs? By "active", do you mean that there is a user connected or that they are actually running something? http://wiki.postgresql.org/wiki/Guide_to_reporting_problems > max_connections = 1000 If you want to handle a large number of clients concurrently, this is probably the wrong way to go about it. You will probably get better performance with a connection pool. http://wiki.postgresql.org/wiki/Number_Of_Database_Connections > shared_buffers = 256MB Depending on your workload, a Linux machine with 32GB RAM should probably have this set somewhere between 1GB and 8GB. > vacuum_cost_delay = 20ms Making VACUUM less aggressive usually backfires and causes unacceptable performance, although that might not happen for days or weeks after you make the configuration change. By the way, the software is called PostgreSQL. It is often shortened to Postgres, but "Postgre" is just wrong. -Kevin
On our old server, our hosting company said the server was running out of RAM and then became unresponsive. I haven't checked about the new server yet.
==================================================================
Aaron Bono
Aranya Software Technologies, Inc.
http://www.aranya.com
http://codeelixir.com
==================================================================
I noticed our problems started about the time when we loaded a new client into the database that had nearly 1 GB of large files stored in BLOBs - PDFs, images, Word docs, etc. We have a daily process that pulls these large files out for search indexing. It is likely the new server crashed at about the time this indexing was taking place.
When we are reading large files out of the BLOBs (upwards of 100 MB a piece), could that cause Postgres to eat up the RAM that remains? With a server having 32 GB RAM I would think only two database connections (that should be all that the processes use for the indexing) would NOT have this effect.
I am glad to see I am not totally missing something obvious but am also a bit flummoxed over this issue. With this server upgrade I changed OS (CentOS to Ubuntu), upgraded Postgres (8.3 to 8.4), increased the RAM (6 GB to 32 GB), increased the hard drive space (1/2 TB to over 1.5 TB on a RAID 10), changed to completely new hardware, removed a ton of stuff on the server we didn't need (like CPanel and its baggage) and even had our daily backups turned off temporarily. In fact, the old server was lasting 2 days or more before having problems and with the new server it went belly up in just a day.
Is there any kind of diagnostics you can think of that would help get to the root of the problem - something I could put in a cron job or a monitor app I could run on the server that would at least tell us what is going on if / when it happens again?
Thanks for all the help!
Aaron
==================================================================
Aaron Bono
Aranya Software Technologies, Inc.
http://www.aranya.com
http://codeelixir.com
==================================================================
On Tue, Nov 13, 2012 at 9:19 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
Craig Ringer <craig@2ndQuadrant.com> writes:
> On 11/14/2012 06:12 AM, Aaron Bono wrote:>> Am I reading this right? Are there individual connections using overYeah. Since Aaron's got shared_buffers set to 256MB, the shared memory
>> 300 MB or RAM by themselves?
> If I recall correctly, RSS is charged against a PostgreSQL back-end when
> it touches `shared_buffers`. So that doesn't necessarily mean that the
> back-end is using the full amount of memory listed as RSS.
segment is something more than that (maybe 270-280MB, hard to be sure
without checking). The RSS numbers probably count all or nearly all of
that for each process, but of course there's really only one copy of the
shared memory segment. RSS is likely double-counting the postgres
executable as well, which means that the actual additional memory used
per process is probably just a few meg, which is in line with most
folks' experience with PG.
The "free" stats didn't look like a machine under any sort of memory
pressure --- there's zero swap usage, and nearly half of real RAM is
being used for disk cache, which means the kernel can find no better
use for it than caching copies of disk files. Plus there's still 10G
that's totally free. Maybe things get worse when the machine's been up
longer, but this sure isn't evidence of trouble.
I'm inclined to think that the problem is not RAM consumption at all but
something else. What exactly happens when the server "hangs"?
regards, tom lane
--
Sent via pgsql-admin mailing list (pgsql-admin@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-admin
On Wed, Nov 14, 2012 at 2:30 AM, Aaron Bono <aaron.bono@aranya.com> wrote:
On our old server, our hosting company said the server was running out of RAM and then became unresponsive. I haven't checked about the new server yet.
Unresponsive how? Can you ssh to it? Can you log to Postgres?
For how long does it happen? Till you reboot?
If it is a server crash then that is not a normal behavior and you should check your hardware. An exhaustive memory test is recommended.
Is there any kind of diagnostics you can think of that would help get to the root of the problem - something I could put in a cron job or a monitor app I could run on the server that would at least tell us what is going on if / when it happens again?
Increase logging on PostgreSQL. Especially log checkpoints and locks.
While experiencing the problem and if you are able to log to the server, a vmstat 1 10 will tell you what is going on with your I/O system in a 10 second span.
Regards,
Fernando.
I replied to this a few days ago but forgot to include the group. It appears that increasing our server swap space has fixed our problems. I will keep my fingers crossed.
> (there are currently a little over 200 active connections to theHow many cores do you have on the system? What sort of storage
> database):
systeme?
Intel Dual Xeon E5606 2133MHz
2 CPU's with 4 Cores each
32GB RAM
Hard Drive: 1.6 TB RAID10
What, exactly, are the symptoms of the problem? Are there
200 active connections when the problem occurs? By "active", do you
mean that there is a user connected or that they are actually running
something?
When the server goes unresponsive I am not sure what the number of connections are. I will do more diagnostic reporting but I suspect the number of connections may be spiking for some reason and / or the usage of the BLOBs in the DB are at the heart of the problem.
http://wiki.postgresql.org/wiki/Guide_to_reporting_problems
> max_connections = 1000
If you want to handle a large number of clients concurrently, this is
probably the wrong way to go about it. You will probably get better
performance with a connection pool.
http://wiki.postgresql.org/wiki/Number_Of_Database_Connections
We already use connection pooling. We are in the process of putting limits on the max open connections and also changing how those connections are used to reduce the number of open connections from any particular application instance.
> shared_buffers = 256MB
Depending on your workload, a Linux machine with 32GB RAM should
probably have this set somewhere between 1GB and 8GB.
I will try increasing the shared_buffers. Thanks.
A few days ago I increased the swap on the machine to 34 GB (it was 2 GB and I added 32 more). The server now appears to be stable. Either this change has been enough to keep things humming along well or whatever the app is doing to cause issues just hasn't occurred in the last few days. I suspect this change is what has stabilized things.
> vacuum_cost_delay = 20ms
Making VACUUM less aggressive usually backfires and causes
unacceptable performance, although that might not happen for days or
weeks after you make the configuration change.
Our databases are mostly heavy reads with not a lot of writes. We almost never do hard deletes. That is why I put the vacuum at this level.
By the way, the software is called PostgreSQL. It is often shortened
to Postgres, but "Postgre" is just wrong.
Yep, my typo.
Hi, On Tue, 13 Nov 2012, Aaron Bono wrote: > I have been struggling with an issue on our database server lately with > Postgres crashing our server by taking up too much RAM. To alleviate this > problem, I just upgraded from a 6 GB RAM server to a new 32 GB RAM server. > The new server is running Ubuntu 10 with nothing but PostgreSQL 8.4.14 > installed. > > Today, after being in use for only 24 hours, it hung the server again. > Now, when I run a check on memory usage, I get a quickly growing amount of > RAM being used: > > free -mt > > total used free shared buffers cached > Mem: 30503 20626 9876 0 143 15897 > -/+ buffers/cache: 4586 25917 > Swap: 1913 0 1913 > Total: 32417 20626 11790 just in case nobody has noticed yet: Above free output is linux telling you that use processes are using 4586 KB of ram wheres 25917 KB is free. PostgreSQL is not hogging up you RAM. Linux is using unused ram for buffers and cache. This is an ancient linux FAQ. Whatever amount of ram you put into a linux box free will show it used shortly after. Checkthe -/+ buffers line for the values you are looking for. Greetings Christian -- Christian Kratzer CK Software GmbH Email: ck@cksoft.de Wildberger Weg 24/2 Phone: +49 7032 893 997 - 0 D-71126 Gaeufelden Fax: +49 7032 893 997 - 9 HRB 245288, Amtsgericht Stuttgart Web: http://www.cksoft.de/ Geschaeftsfuehrer: Christian Kratzer
On Wed, Nov 14, 2012 at 3:51 PM, Fernando Hevia <fhevia@gmail.com> wrote: > > > > On Wed, Nov 14, 2012 at 2:30 AM, Aaron Bono <aaron.bono@aranya.com> wrote: >> >> On our old server, our hosting company said the server was running out of >> RAM and then became unresponsive. I haven't checked about the new server >> yet. > > > Unresponsive how? Can you ssh to it? Can you log to Postgres? > For how long does it happen? Till you reboot? > If it is a server crash then that is not a normal behavior and you should > check your hardware. An exhaustive memory test is recommended. > >> >> Is there any kind of diagnostics you can think of that would help get to >> the root of the problem - something I could put in a cron job or a monitor >> app I could run on the server that would at least tell us what is going on >> if / when it happens again? >> > > Increase logging on PostgreSQL. Especially log checkpoints and locks. > While experiencing the problem and if you are able to log to the server, a > vmstat 1 10 will tell you what is going on with your I/O system in a 10 > second span. also turning on sysstat / sar processes is a good idea. On linux boxen go to /etc/default and edit the sysstat file and change the line ENABLED="false" to ENABLED="true" then start sysstat collection with "sudo /etc/init.d/sysstat start" then read them with sar. Sar's a great post-mortem analysis tool.
Sorry, I forgot to mail to the list. ---------- Forwarded message ---------- From: Aaron Bono <aaron.bono@gmail.com> Date: Sun, Nov 18, 2012 at 3:24 AM Subject: Fwd: [ADMIN] Postgre Eating Up Too Much RAM To: Postgres <pgsql-admin@postgresql.org> I replied to this a few days ago but forgot to include the group. It appears that increasing our server swap space has fixed our problems. I will keep my fingers crossed. > > > (there are currently a little over 200 active connections to the > > database): > > How many cores do you have on the system? What sort of storage > systeme? Intel Dual Xeon E5606 2133MHz 2 CPU's with 4 Cores each 32GB RAM Hard Drive: 1.6 TB RAID10 > > What, exactly, are the symptoms of the problem? Are there > > 200 active connections when the problem occurs? By "active", do you > mean that there is a user connected or that they are actually running > something? When the server goes unresponsive I am not sure what the number of connections are. I will do more diagnostic reporting but I suspect the number of connections may be spiking for some reason and / or the usage of the BLOBs in the DB are at the heart of the problem. > > > http://wiki.postgresql.org/wiki/Guide_to_reporting_problems > > > max_connections = 1000 > > If you want to handle a large number of clients concurrently, this is > probably the wrong way to go about it. You will probably get better > performance with a connection pool. > > http://wiki.postgresql.org/wiki/Number_Of_Database_Connections We already use connection pooling. We are in the process of putting limits on the max open connections and also changing how those connections are used to reduce the number of open connections from any particular application instance. > > > shared_buffers = 256MB > > > Depending on your workload, a Linux machine with 32GB RAM should > probably have this set somewhere between 1GB and 8GB. I will try increasing the shared_buffers. Thanks. A few days ago I increased the swap on the machine to 34 GB (it was 2 GB and I added 32 more). The server now appears to be stable. Either this change has been enough to keep things humming along well or whatever the app is doing to cause issues just hasn't occurred in the last few days. I suspect this change is what has stabilized things. > > > vacuum_cost_delay = 20ms > > Making VACUUM less aggressive usually backfires and causes > unacceptable performance, although that might not happen for days or > weeks after you make the configuration change. Our databases are mostly heavy reads with not a lot of writes. We almost never do hard deletes. That is why I put the vacuum at this level. > > > By the way, the software is called PostgreSQL. It is often shortened > to Postgres, but "Postgre" is just wrong. Yep, my typo.
I replied to this a few days ago but forgot to include the group. It appears that increasing our server swap space has fixed our problems. I will keep my fingers crossed.
> (there are currently a little over 200 active connections to theHow many cores do you have on the system? What sort of storage
> database):
systeme?
2 CPU's with 4 Cores each
32GB RAM
Hard Drive: 1.6 TB RAID10
What, exactly, are the symptoms of the problem? Are there
200 active connections when the problem occurs? By "active", do you
mean that there is a user connected or that they are actually running
something?
When the server goes unresponsive I am not sure what the number of connections are. I will do more diagnostic reporting but I suspect the number of connections may be spiking for some reason and / or the usage of the BLOBs in the DB are at the heart of the problem.
http://wiki.postgresql.org/wiki/Guide_to_reporting_problems
> max_connections = 1000
If you want to handle a large number of clients concurrently, this is
probably the wrong way to go about it. You will probably get better
performance with a connection pool.
http://wiki.postgresql.org/wiki/Number_Of_Database_Connections
We already use connection pooling. We are in the process of putting limits on the max open connections and also changing how those connections are used to reduce the number of open connections from any particular application instance.
> shared_buffers = 256MB
Depending on your workload, a Linux machine with 32GB RAM should
probably have this set somewhere between 1GB and 8GB.
I will try increasing the shared_buffers. Thanks.
A few days ago I increased the swap on the machine to 34 GB (it was 2 GB and I added 32 more). The server now appears to be stable. Either this change has been enough to keep things humming along well or whatever the app is doing to cause issues just hasn't occurred in the last few days. I suspect this change is what has stabilized things.
> vacuum_cost_delay = 20ms
Making VACUUM less aggressive usually backfires and causes
unacceptable performance, although that might not happen for days or
weeks after you make the configuration change.
Our databases are mostly heavy reads with not a lot of writes. We almost never do hard deletes. That is why I put the vacuum at this level.
By the way, the software is called PostgreSQL. It is often shortened
to Postgres, but "Postgre" is just wrong.
Yep, my typo.
Just putting a follow up on this issue as it is still unresolved.
I worked with a PostgreSQL sys admin and they could not find anything amiss with the server or configuration.Then I talked to the hosting company (Liquid Web) and they said the parent (it is on a Bare Metal Storm server) had a hardware problem. Last week I moved to a new server (did a clone) and it went to a new parent as well as new hardware.
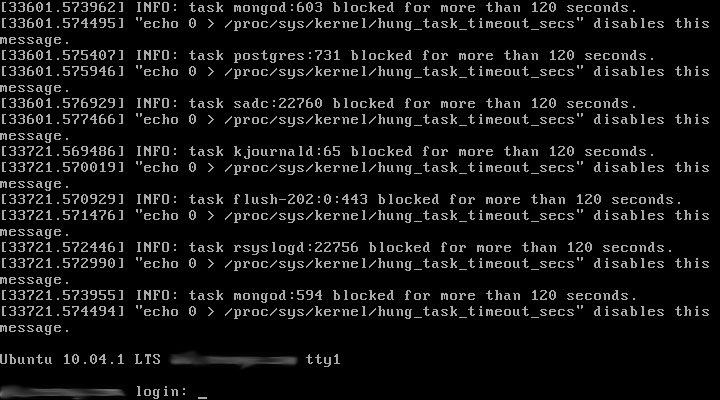
Aaron
==================================================================
Aaron Bono
Aranya Software Technologies, Inc.
http://www.aranya.com
http://codeelixir.com
==================================================================
Aaron Bono
Aranya Software Technologies, Inc.
http://www.aranya.com
http://codeelixir.com
==================================================================
On Tue, Nov 13, 2012 at 4:12 PM, Aaron Bono <aaron.bono@aranya.com> wrote:
I have been struggling with an issue on our database server lately with Postgres crashing our server by taking up too much RAM. To alleviate this problem, I just upgraded from a 6 GB RAM server to a new 32 GB RAM server. The new server is running Ubuntu 10 with nothing but PostgreSQL 8.4.14 installed.Today, after being in use for only 24 hours, it hung the server again. Now, when I run a check on memory usage, I get a quickly growing amount of RAM being used:free -mt
total used free shared buffers cached
Mem: 30503 20626 9876 0 143 15897
-/+ buffers/cache: 4586 25917
Swap: 1913 0 1913
Total: 32417 20626 11790Additionally, I see using ps that Postgres is the only process using over 0.1 % of the RAM.Here is a sample of the PS command for some of the Postgres processes (there are currently a little over 200 active connections to the database):ps axuf....postgres 3523 0.5 1.0 426076 313156 ? Ss 08:44 2:42 \_ postgres: myuser my_db 192.168.1.2(39786) idlepostgres 3820 0.4 0.9 418988 302036 ? Ss 09:04 2:11 \_ postgres: myuser my_db 192.168.1.2(52110) idlepostgres 3821 0.1 0.5 391452 178972 ? Ss 09:04 0:44 \_ postgres: myuser my_db 192.168.1.2(52111) idlepostgres 3822 0.0 0.0 369572 9928 ? Ss 09:04 0:00 \_ postgres: myuser my_db 192.168.1.2(52112) idlepostgres 3823 0.2 0.6 383368 202312 ? Ss 09:04 1:12 \_ postgres: myuser my_db 192.168.1.2(52114) idlepostgres 3824 0.0 0.0 369320 8820 ? Ss 09:04 0:00 \_ postgres: myuser my_db 192.168.1.2(52115) idlepostgres 3825 0.4 0.8 413964 257040 ? Ss 09:04 1:54 \_ postgres: myuser my_db 192.168.1.2(52116) idle....Am I reading this right? Are there individual connections using over 300 MB or RAM by themselves? This seems excessive. (Note I am not a system admin exactly so please correct me if I am reading this wrong.)My postgresql.conf looks like this (I have only included the non-commented lines):data_directory = '/var/lib/postgresql/8.4/main'hba_file = '/etc/postgresql/8.4/main/pg_hba.conf'ident_file = '/etc/postgresql/8.4/main/pg_ident.conf'external_pid_file = '/var/run/postgresql/8.4-main.pid'listen_addresses = 'localhost,192.168.1.200'port = 5432max_connections = 1000unix_socket_directory = '/var/run/postgresql'ssl = trueshared_buffers = 256MBvacuum_cost_delay = 20msdefault_statistics_target = 100log_destination = 'stderr'logging_collector = onlog_directory = '/var/log/postgresql'log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'log_truncate_on_rotation = onlog_rotation_age = 1dlog_rotation_size = 0MBlog_connections = onlog_disconnections = onlog_line_prefix = '<%t %u %h>'track_activities = ontrack_counts = ondatestyle = 'iso, mdy'lc_messages = 'en_US.UTF-8'lc_monetary = 'en_US.UTF-8'lc_numeric = 'en_US.UTF-8'lc_time = 'en_US.UTF-8'default_text_search_config = 'pg_catalog.english'I have read quite a bit over the last couple days and must be missing something as I cannot see why each connection is using so much memory.Thanks for any help you can provide!-Aaron==================================================================
Aaron Bono
Aranya Software Technologies, Inc.
http://www.aranya.com
http://codeelixir.com
==================================================================
Attachment
On Wed, Jan 2, 2013 at 1:38 AM, Jesper Krogh <jesper@krogh.cc> wrote:
I do suspect you have too much IO going on for the hardware.
I would trim down. /proc/sys/vm/dirty_ratio and dirty_background_ratio to 2 and 1 and see if the problem goes away.
And establish graphing of the io-wait numbers if you dont have that allready.
I didn't know about this setting, thanks for the information.
I have been doing some reading on these settings and hope I am coming to an understanding. Can you help clarify whether I am understanding this properly?
So this setting is the amount of disk writes, as a percentage of the RAM both physical and virtual available, that will be held before writing to the disk? Which then would mean that the more RAM you have the more will build up before a write? So at some point there would be some trigger to fire off the write and since we have so much RAM it could take quite some time to finish the write causing the server to appear to become unresponsive?
If my understanding of this is correct and it will block all processes while until it falls under the dirty_background_ratio then the bigger the difference between the dirty_ratio and dirty_background_ratio and the more RAM and swap you have the longer it will block all processes (causing the server to appear to lock up?). That would definitely lead the the problems I am experiencing.
The odd thing is that the articles I am reading suggest increasing the dirty_ratio and decreasing the dirty_background_ratio which is the opposite of what you are suggesting.
Though I think these suggest lowering the ratios:
and
I just want to make sure I understand this setting before making the change.
Thank you very much for your help!
-Aaron