CREATE STATISTICS st_simrun_component_metadata (dependencies) ON sim_run_id, key FROM sim_run_component_metadata;
ANALYZE sim_run_component_metadata;
When I run this query, no statistics are returned:
SELECT m.* FROM pg_statistic_ext join pg_statistic_ext_data on (oid = stxoid),
pg_mcv_list_items(stxdmcv) m WHERE stxname = 'st_simrun_component_metadata';
Is there something I might have missed?
It looks like you created "dependencies" statistics, but then searched for "mcv" statistics. To test if mcv helps, you could drop and recreate as: CREATE STATISTICS st_simrun_component_metadata (mcv) ...
oh, right. Thank you. However, I increased the statistics target to 10000, and there are some statistics in pg_statistics_ext. But I am not allowed to access pg_statistics_ext_data.
The fetch from the table is rather fast. some milliseconds. But a subsequent sort operations takes very long time, for the amount of records fetched.
This does not seem to be the case for the slow cases you shared (those are dominated by several millisecond index scans that are looped over 32k times). So I assume you're talking about the fast case? If so, there is a Sort that takes a couple of hundred milliseconds being done on disk (~15MB) so you might also want to look into how fast that would be in memory (via work_mem).
What I see in the plan is, that there is a CTE scan with 512.960.256 rows, consuming 30 seconds. The CTE result set has ~12.632 rows. I do not understand what makes the CTE scan explode so drastically.
When I look at this, considering 12632 rows in the CTE:
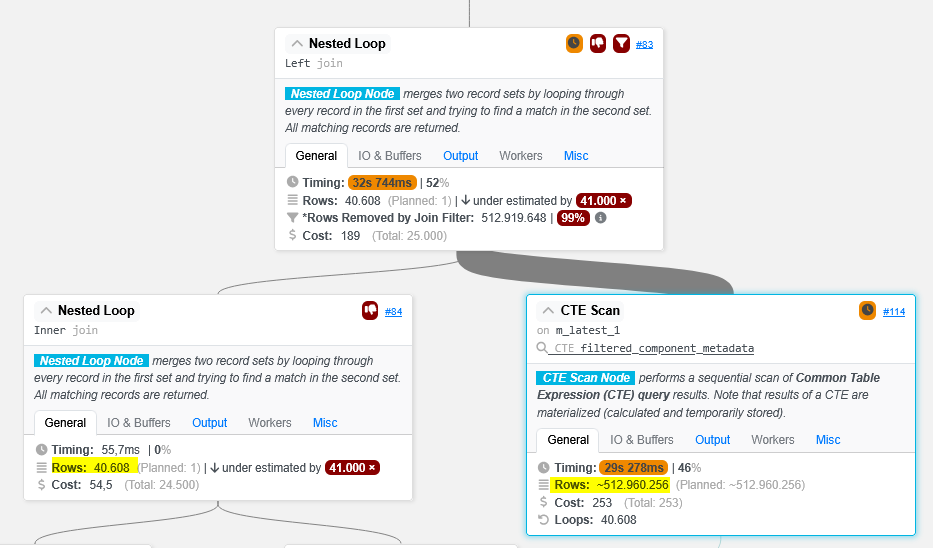
the left join is accessing / scanning the CTE result 40.608 times, and thus reads 512.960.256 rows from the CTE. On the CTE there is no index and thus a scan is needed.
When I remove that CTE and go with the real table on the join, the index is used and thus its way faster.
My naive assumption was that using CTEs in queries when their result is needed multiple times will speed up queries. But this is not the case when as this example shows. Maybe in smaller CTEs result sets, but CTEs will most likely be used in joins, and thus lead to CTE scans which have the potential to explode.
Or are there approaches to address such situations? I can not assume that the row distribution is like I face now, the query might have to deal with even larger sub result sets and way smaller ones as well.
KR
Chris