On Tue, Feb 21, 2017 at 6:21 PM, Simon Riggs <simon@2ndquadrant.com> wrote:
> I think what we need to show some test results with the graph of lag
> over time for these cases:
> 1. steady state - pgbench on master, so we can see how that responds
> 2. blocked apply on standby - so we can see how the lag increases but
> also how the accuracy goes down as the lag increases and whether the
> reported value changes (depending upon algo)
> 3. burst mode - where we go from not moving to moving at high speed
> and then stop again quickly
> +other use cases you or others add
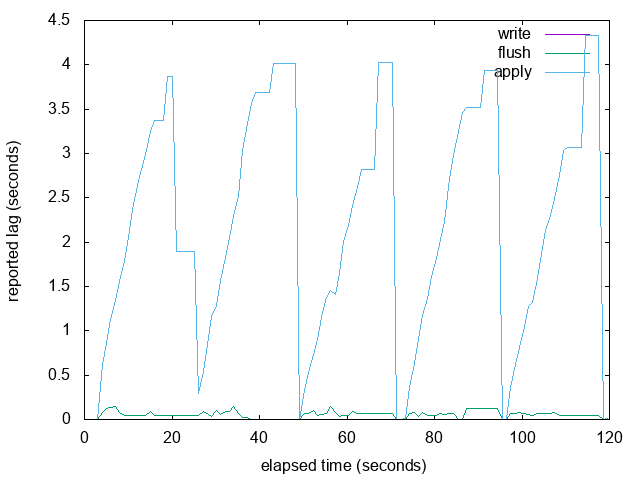
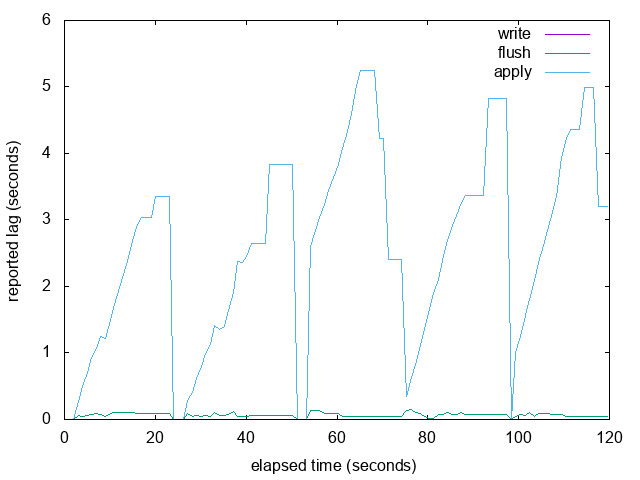
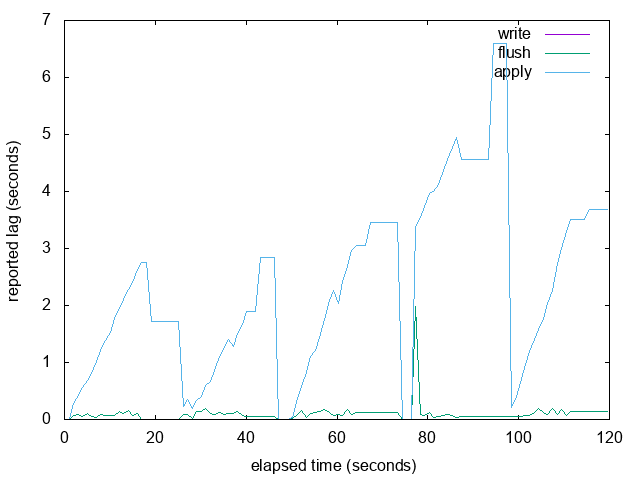
Here are graphs of the 'burst' example from my previous email, with
LAG_TRACKER_BUFFER_SIZE set to 4 (really small so that it fills up)
and 8192 (the size I'm proposing in this patch). It looks like the
resampling and interpolation work pretty well to me when the buffer is
full.
The overall graph looks pretty similar, but it is more likely to short
hiccups caused by occasional slow WAL fsyncs in walreceiver. See the
attached graphs with 'spike' in the name: in the large buffer version
we see a short spike in write/flush lag and that results in apply
falling behind, but in the small buffer version we can only guess that
that might have happened because apply fell behind during the 3rd and
4th write bursts. We don't know exactly why because we didn't have
sufficient samples to detect a short lived write/flush delay.
The workload just does this in a loop:
DROP TABLE IF EXISTS foo;
CREATE TABLE foo AS SELECT generate_series(1, 10000000);
SELECT pg_sleep(10);
While testing with a small buffer I found a thinko when write_head is
moved back, fixed in the attached.
--
Thomas Munro
http://www.enterprisedb.com
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
{kind=link}
{kind=link}
{kind=link}
{kind=link}