Tatsuo Ishii <t-ishii@sra.co.jp> writes:
>> Now that's a close to linear as you are going to get. Pretty good I think:
>> a sort of one billion rows in half an hour.
> Oops! It's not one billion but 10 millions. Sorry.
Actually, the behavior ought to be O(N log N) not O(N).
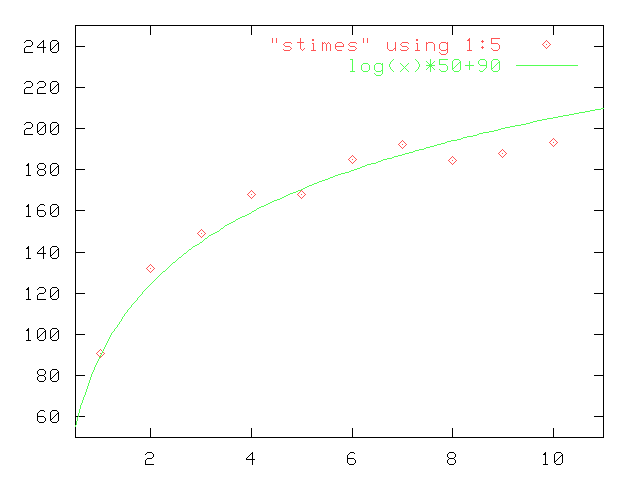
With a little bit of arithmetic, we get
MTuples Time Sec Delta Sec/ MTuple/sec
sec MTuple
1 1:31 91 91 91 0.010989
2 4:24 264 173 132 0.00757576
3 7:27 447 183 149 0.00671141
4 11:11 671 224 167.75 0.00596125
5 14:01 841 170 168.2 0.0059453
6 18:31 1111 270 185.167 0.00540054
7 22:24 1344 233 192 0.00520833
8 24:36 1476 132 184.5 0.00542005
9 28:12 1692 216 188 0.00531915
10 32:14 1934 242 193.4 0.00517063
which is obviously nonlinear. Column 5 should theoretically be a log(N)
curve, and it's not too hard to draw one that matches it pretty well
(see attached plot).
It's pretty clear that we don't have any specific problem with the
one-versus-two-segment issue, which is good (I looked again at the code
and couldn't see any reason for such a problem to exist). But there's
still the question of whether the old code is faster.
Tatsuo, could you run another set of numbers using 6.5.* and the same
test conditions, as far up as you can get with 6.5? (I think you ought
to be able to reach 2Gb, though not pass it, so most of this curve
can be compared to 6.5.)
regards, tom lane
{kind=link}