Thread: [RFC] Enhance scalability of TPCC performance on HCC (high-core-count) systems
[RFC] Enhance scalability of TPCC performance on HCC (high-core-count) systems
From
"Zhou, Zhiguo"
Date:
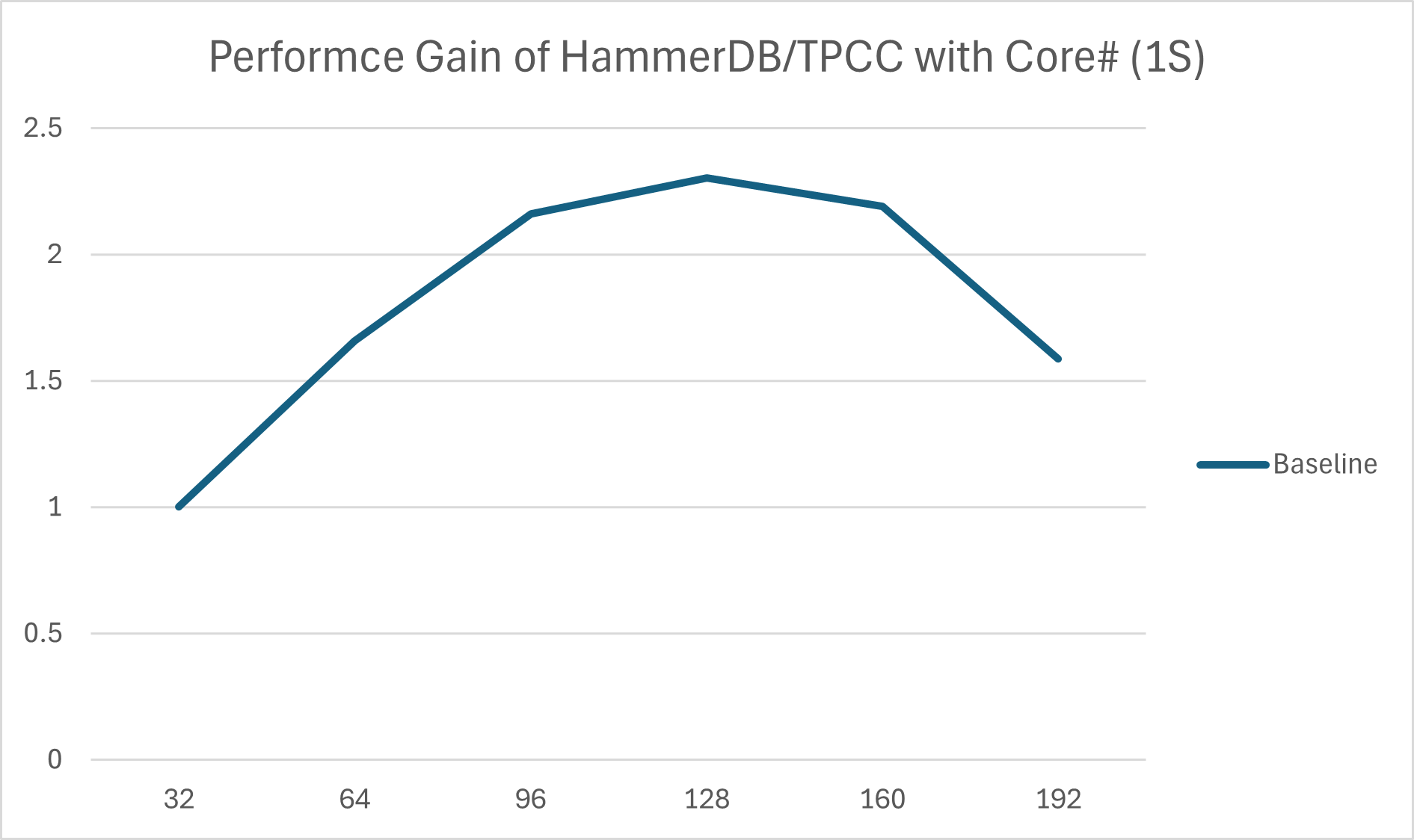
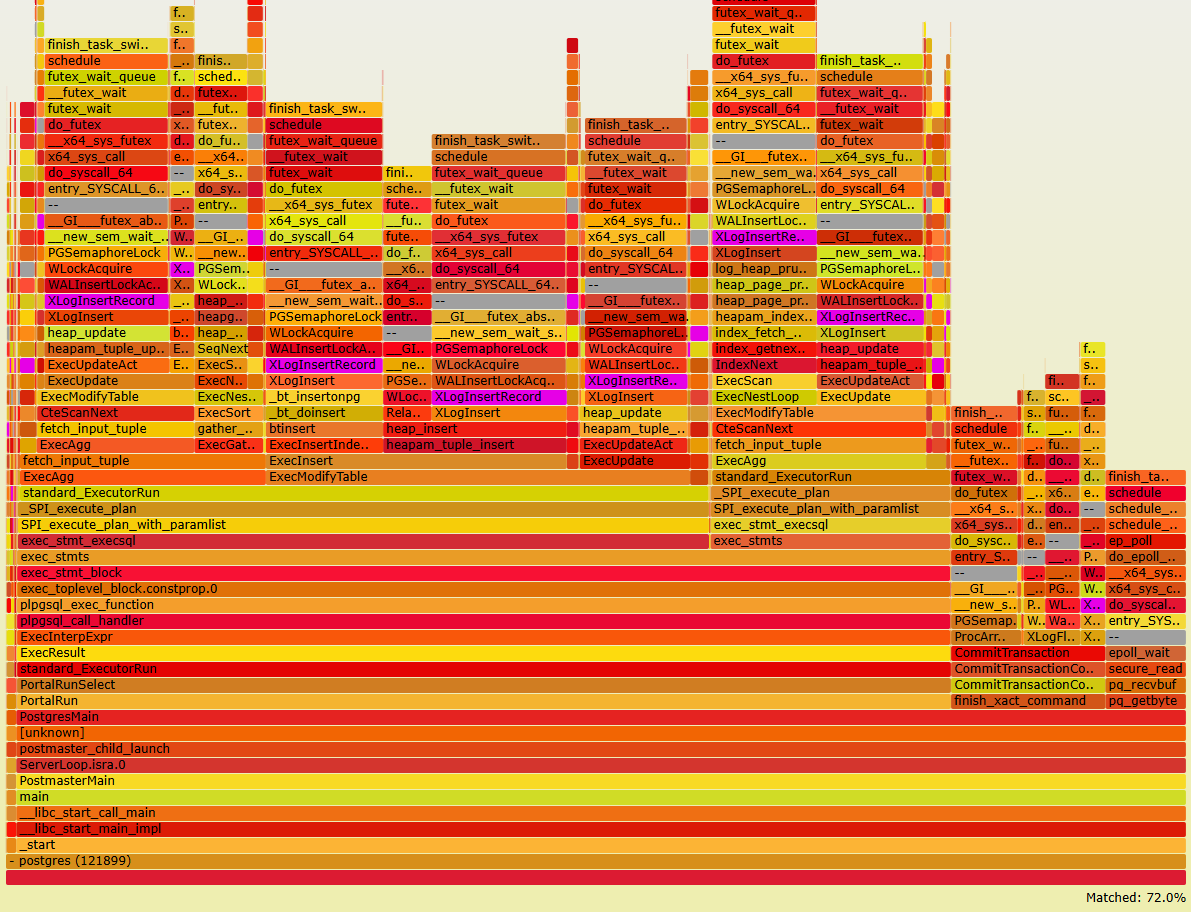
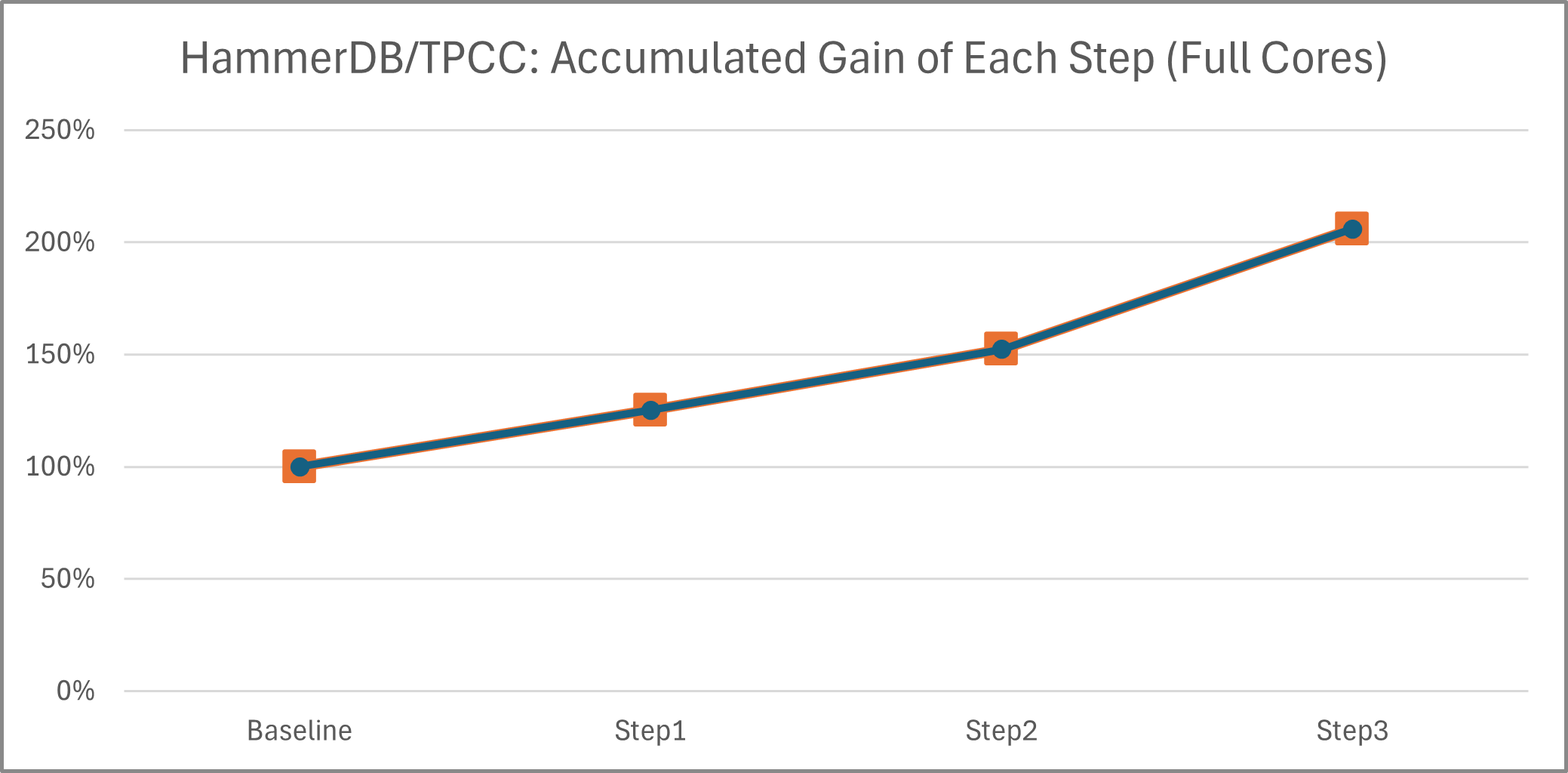
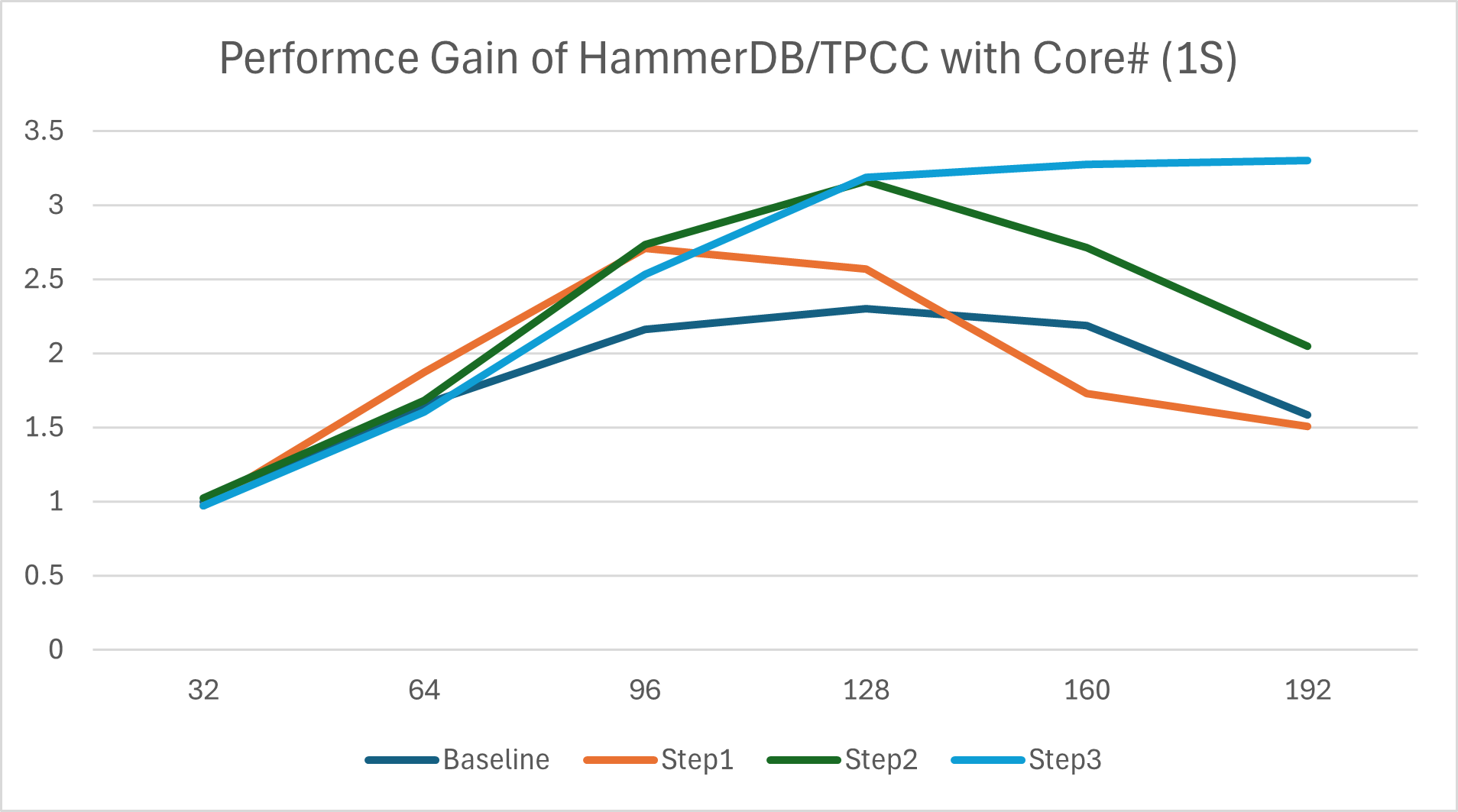
Dear PostgreSQL Community, Over recent months, we've submitted several patches ([1][2][3][4]) targeting performance bottlenecks in HammerDB/TPROC-C scalability on high-core-count (HCC) systems. Recognizing these optimizations form a dependent chain (later patches build upon earlier ones), we’d like to present a holistic overview of our findings and proposals to accelerate review and gather community feedback. --- ### Why HCC and TPROC-C Matter Modern servers now routinely deploy 100s of cores (approaching 1,000+), introducing hardware challenges like NUMA latency and cache coherency overheads. For Cloud Service Providers (CSPs) offering managed Postgres, scalable HCC performance is critical to maximize hardware ROI. HammerDB/TPROC-C—a practical, industry-standard OLTP benchmark—exposes critical scalability roadblocks under high concurrency, making it essential for real-world performance validation. --- ### The Problem: Scalability Collapse Our analysis on a 384-vCPU Intel system revealed severe scalability collapse: HammerDB’s NOPM metric regressed as core counts increased (Fig 1). We identified three chained bottlenecks: 1. Limited WALInsertLocks parallelism, starving CPU utilization (only 17.4% observed). 2. Acute contention on insertpos_lck when #1 was mitigated. 3. LWLock shared acquisition overhead becoming dominant after #1–#2 were resolved. --- ### Proposed Optimization Steps Our three-step approach tackles these dependencies systematically: Step 1: Unlock Parallel WAL Insertion Patch [1]: Increase NUM_XLOGINSERT_LOCKS (allowing more concurrent XLog inserters) as bcc/offcputime flamegraph in Fig 2 shows the cause is low CPU utilization is the low NUM_XLOGINSERT_LOCKS restricts the current XLog inserters. Patch [2]: Replace insertpos_lck spinlock with lock-free XLog reservation via atomic operations. This reduces the critical section to a single pg_atomic_fetch_add_u64(), cutting severe lock contention when reserving WAL space. (Kudos to Yura Sokolov for enhancing robustness with a Murmur-hash table!) Result: [1]+[2] 1.25x NOPM gains. (Note: To avoid confusion with data in [1], the other device achieving ~1.8x improvement has 480 vCPUs) Step 2 & 3: Optimize LWLock Scalability Patch [3]: Merge LWLock shared-state updates into a single atomic add (replacing read-modify-write loops). This reduces cache coherence overhead under contention. Result: [1]+[2]+[3] 1.52x NOPM gains. Patch [4]: Introduce ReadBiasedLWLock for heavily shared Locks (e.g., ProcArrayLock). Partitions reader lock states across 16 cache lines, mitigating readers’ atomic contention. Result: [1]+[2]+[3]+[4] 2.10x NOPM improvement. --- ### Overall Impact With all patches applied, we observe: - 2.06x NOPM improvement vs. upstream (384-vCPU, HammerDB: 192 VU, 757 warehouse). - Accumulated gains for each optimization step (Fig 3) - Enhanced performance scalability with core count (Fig 4) --- ### Figures & Patch Links Fig 1: TPROC-C scalability regression (1 socket view) Fig 2: offcputime flamegraph (pre-optimization) Fig 3: Accumulated gains (full cores) Fig 4: Accumulated gains vs core count (1 socket view) [1] Increase NUM_XLOGINSERT_LOCKS: https://www.postgresql.org/message-id/flat/3b11fdc2-9793-403d-b3d4-67ff9a00d447@postgrespro.ru [2] Lock-free XLog Reservation from WAL: https://www.postgresql.org/message-id/flat/PH7PR11MB5796659F654F9BE983F3AD97EF142%40PH7PR11MB5796.namprd11.prod.outlook.com [3] Optimize shared LWLock acquisition for high-core-count systems: https://www.postgresql.org/message-id/flat/73d53acf-4f66-41df-b438-5c2e6115d4de%40intel.com [4] Optimize LWLock scalability via ReadBiasedLWLock for heavily-shared locks: https://www.postgresql.org/message-id/e7d50174-fbf8-4a82-a4cd-1c4018595d1b@intel.com Best regards, Zhiguo
{kind=link}
{kind=link}
{kind=link}
{kind=link}