Thread: Sort functions with specialized comparators
Hi!
In a thread about sorting comparators[0] Andres noted that we have infrastructure to help compiler optimize sorting.
PFAattached PoC implementation. I've checked that it indeed works on the benchmark from that thread.
postgres=# CREATE TABLE arrays_to_sort AS
SELECT array_shuffle(a) arr
FROM
(SELECT ARRAY(SELECT generate_series(1, 1000000)) a),
generate_series(1, 10);
postgres=# SELECT (sort(arr))[1] FROM arrays_to_sort; -- original
Time: 990.199 ms
postgres=# SELECT (sort(arr))[1] FROM arrays_to_sort; -- patched
Time: 696.156 ms
The benefit seems to be on the order of magnitude with 30% speedup.
There's plenty of sorting by TransactionId, BlockNumber, OffsetNumber, Oid etc. But this sorting routines never show up
inperf top or something like that.
Seems like in most cases we do not spend much time in sorting. But specialization does not cost us much too, only some
CPUcycles of a compiler. I think we can further improve speedup by converting inline comparator to value extractor:
morecompilers will see what is actually going on. But I have no proofs for this reasoning.
What do you think?
Best regards, Andrey Borodin.
[0]
https://www.postgresql.org/message-id/flat/20240209184014.sobshkcsfjix6u4r%40awork3.anarazel.de#fc23df2cf314bef35095b632380b4a59
Attachment
Hi!
In a thread about sorting comparators[0] Andres noted that we have infrastructure to help compiler optimize sorting. PFA attached PoC implementation. I've checked that it indeed works on the benchmark from that thread.
postgres=# CREATE TABLE arrays_to_sort AS
SELECT array_shuffle(a) arr
FROM
(SELECT ARRAY(SELECT generate_series(1, 1000000)) a),
generate_series(1, 10);
postgres=# SELECT (sort(arr))[1] FROM arrays_to_sort; -- original
Time: 990.199 ms
postgres=# SELECT (sort(arr))[1] FROM arrays_to_sort; -- patched
Time: 696.156 ms
The benefit seems to be on the order of magnitude with 30% speedup.
There's plenty of sorting by TransactionId, BlockNumber, OffsetNumber, Oid etc. But this sorting routines never show up in perf top or something like that.
Seems like in most cases we do not spend much time in sorting. But specialization does not cost us much too, only some CPU cycles of a compiler. I think we can further improve speedup by converting inline comparator to value extractor: more compilers will see what is actually going on. But I have no proofs for this reasoning.
What do you think?
You could change the style to:
bench_oid_sort
----------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 116990848 ns, Time taken by list_oid_sort: 80446640 ns, Percentage difference: 31.24%
(1 row)
postgres=# SELECT bench_int_sort(1000000);
bench_int_sort
----------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 118168506 ns, Time taken by list_int_sort: 80523373 ns, Percentage difference: 31.86%
(1 row)
Hi!
In a thread about sorting comparators[0] Andres noted that we have infrastructure to help compiler optimize sorting. PFA attached PoC implementation. I've checked that it indeed works on the benchmark from that thread.
postgres=# CREATE TABLE arrays_to_sort AS
SELECT array_shuffle(a) arr
FROM
(SELECT ARRAY(SELECT generate_series(1, 1000000)) a),
generate_series(1, 10);
postgres=# SELECT (sort(arr))[1] FROM arrays_to_sort; -- original
Time: 990.199 ms
postgres=# SELECT (sort(arr))[1] FROM arrays_to_sort; -- patched
Time: 696.156 ms
The benefit seems to be on the order of magnitude with 30% speedup.
There's plenty of sorting by TransactionId, BlockNumber, OffsetNumber, Oid etc. But this sorting routines never show up in perf top or something like that.
Seems like in most cases we do not spend much time in sorting. But specialization does not cost us much too, only some CPU cycles of a compiler. I think we can further improve speedup by converting inline comparator to value extractor: more compilers will see what is actually going on. But I have no proofs for this reasoning.
What do you think?
Best regards, Andrey Borodin.
[0] https://www.postgresql.org/message-id/flat/20240209184014.sobshkcsfjix6u4r%40awork3.anarazel.de#fc23df2cf314bef35095b632380b4a59
Attachment
- v42-0006-Implemented-benchmarking-for-optimized-sorting.patch
- v42-0002-Optimized-Oid-List-Sorting-by-using-template-sor.patch
- v42-0004-Optimized-Int-List-Sorting-by-using-template-sor.patch
- v42-0005-Enhanced-Sorting-Efficiency-for-Integer-Lists.patch
- v42-0003-Enhanced-Sorting-Efficiency-for-Oid-Lists.patch
- v42-0001-Use-specialized-sort-facilities.patch
Hello all.I am interested in the proposed patch and would like to propose some additional changes that would complement it. My changes would introduce similar optimizations when working with a list of integers or object identifiers. Additionally, my patch includes an extension for benchmarking, which shows an average speedup of 30-40%.postgres=# SELECT bench_oid_sort(1000000);
bench_oid_sort
----------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 116990848 ns, Time taken by list_oid_sort: 80446640 ns, Percentage difference: 31.24%
(1 row)
postgres=# SELECT bench_int_sort(1000000);
bench_int_sort
----------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 118168506 ns, Time taken by list_int_sort: 80523373 ns, Percentage difference: 31.86%
(1 row)What do you think about these changes?Best regards, Stepan Neretin.On Fri, Jun 7, 2024 at 11:08 PM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote:Hi!
In a thread about sorting comparators[0] Andres noted that we have infrastructure to help compiler optimize sorting. PFA attached PoC implementation. I've checked that it indeed works on the benchmark from that thread.
postgres=# CREATE TABLE arrays_to_sort AS
SELECT array_shuffle(a) arr
FROM
(SELECT ARRAY(SELECT generate_series(1, 1000000)) a),
generate_series(1, 10);
postgres=# SELECT (sort(arr))[1] FROM arrays_to_sort; -- original
Time: 990.199 ms
postgres=# SELECT (sort(arr))[1] FROM arrays_to_sort; -- patched
Time: 696.156 ms
The benefit seems to be on the order of magnitude with 30% speedup.
There's plenty of sorting by TransactionId, BlockNumber, OffsetNumber, Oid etc. But this sorting routines never show up in perf top or something like that.
Seems like in most cases we do not spend much time in sorting. But specialization does not cost us much too, only some CPU cycles of a compiler. I think we can further improve speedup by converting inline comparator to value extractor: more compilers will see what is actually going on. But I have no proofs for this reasoning.
What do you think?
Best regards, Andrey Borodin.
[0] https://www.postgresql.org/message-id/flat/20240209184014.sobshkcsfjix6u4r%40awork3.anarazel.de#fc23df2cf314bef35095b632380b4a59
bench_int16_sort
-----------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 66354981 ns, Time taken by optimized sort: 52151523 ns, Percentage difference: 21.41%
(1 row)
postgres=# select bench_float8_sort(1000000);
bench_float8_sort
------------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 121475231 ns, Time taken by optimized sort: 74458545 ns, Percentage difference: 38.70%
(1 row)
postgres=#
Attachment
- v42-0008-Refactor-sorting-of-attribute-numbers-in-pg_publ.patch
- v42-0009-Introduce-benchmarking-function-for-int16-array-.patch
- v42-0010-Implement-Sorting-Template-for-float8-Arrays.patch
- v42-0012-Add-benchmark-comparing-float8-sorting-methods.patch
- v42-0011-Optimize-box-quad-picksplit-with-float8-array-so.patch
- v42-0005-Enhanced-Sorting-Efficiency-for-Integer-Lists.patch
- v42-0007-Consolidate-and-optimize-int16-array-sorting.patch
- v42-0004-Optimized-Int-List-Sorting-by-using-template-sor.patch
- v42-0006-Implemented-benchmarking-for-optimized-sorting.patch
- v42-0003-Enhanced-Sorting-Efficiency-for-Oid-Lists.patch
- v42-0001-Use-specialized-sort-facilities.patch
- v42-0002-Optimized-Oid-List-Sorting-by-using-template-sor.patch
Hello all.
I have decided to explore more areas in which I can optimize and have added
two new benchmarks. Do you have any thoughts on this?postgres=# select bench_int16_sort(1000000);
bench_int16_sort-----------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 66354981 ns, Time taken by optimized sort:
52151523 ns, Percentage difference: 21.41%
(1 row)postgres=# select bench_float8_sort(1000000);
bench_float8_sort------------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 121475231 ns, Time taken by optimized sort:
74458545 ns, Percentage difference: 38.70%
(1 row)
postgres=#
On Sat, Jun 8, 2024 at 1:50 AM Stepan Neretin <sncfmgg@gmail.com> wrote:Hello all.I am interested in the proposed patch and would like to propose some additional changes that would complement it. My changes would introduce similar optimizations when working with a list of integers or object identifiers. Additionally, my patch includes an extension for benchmarking, which shows an average speedup of 30-40%.postgres=# SELECT bench_oid_sort(1000000);
bench_oid_sort
----------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 116990848 ns, Time taken by list_oid_sort: 80446640 ns, Percentage difference: 31.24%
(1 row)
postgres=# SELECT bench_int_sort(1000000);
bench_int_sort
----------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 118168506 ns, Time taken by list_int_sort: 80523373 ns, Percentage difference: 31.86%
(1 row)What do you think about these changes?Best regards, Stepan Neretin.On Fri, Jun 7, 2024 at 11:08 PM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote:Hi!
In a thread about sorting comparators[0] Andres noted that we have infrastructure to help compiler optimize sorting. PFA attached PoC implementation. I've checked that it indeed works on the benchmark from that thread.
postgres=# CREATE TABLE arrays_to_sort AS
SELECT array_shuffle(a) arr
FROM
(SELECT ARRAY(SELECT generate_series(1, 1000000)) a),
generate_series(1, 10);
postgres=# SELECT (sort(arr))[1] FROM arrays_to_sort; -- original
Time: 990.199 ms
postgres=# SELECT (sort(arr))[1] FROM arrays_to_sort; -- patched
Time: 696.156 ms
The benefit seems to be on the order of magnitude with 30% speedup.
There's plenty of sorting by TransactionId, BlockNumber, OffsetNumber, Oid etc. But this sorting routines never show up in perf top or something like that.
Seems like in most cases we do not spend much time in sorting. But specialization does not cost us much too, only some CPU cycles of a compiler. I think we can further improve speedup by converting inline comparator to value extractor: more compilers will see what is actually going on. But I have no proofs for this reasoning.
What do you think?
Best regards, Andrey Borodin.
[0] https://www.postgresql.org/message-id/flat/20240209184014.sobshkcsfjix6u4r%40awork3.anarazel.de#fc23df2cf314bef35095b632380b4a59Hello all.I have decided to explore more areas in which I can optimize and have added two new benchmarks. Do you have any thoughts on this?postgres=# select bench_int16_sort(1000000);
bench_int16_sort
-----------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 66354981 ns, Time taken by optimized sort: 52151523 ns, Percentage difference: 21.41%
(1 row)
postgres=# select bench_float8_sort(1000000);
bench_float8_sort
------------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 121475231 ns, Time taken by optimized sort: 74458545 ns, Percentage difference: 38.70%
(1 row)
postgres=#
Best regards, Stepan Neretin.
Hello all.
I have decided to explore more areas in which I can optimize and have added
two new benchmarks. Do you have any thoughts on this?postgres=# select bench_int16_sort(1000000);
bench_int16_sort-----------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 66354981 ns, Time taken by optimized sort:
52151523 ns, Percentage difference: 21.41%
(1 row)postgres=# select bench_float8_sort(1000000);
bench_float8_sort------------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 121475231 ns, Time taken by optimized sort:
74458545 ns, Percentage difference: 38.70%
(1 row)Hello allWe would like to see the relationship between the length of the sorted array and the performance gain, perhaps some graphs. We also want to see to set a "worst case" test, sorting the array in ascending order when it is initially descendingBest, regards, Antoine Violinpostgres=#
On Mon, Jul 15, 2024 at 10:32 AM Stepan Neretin <sncfmgg@gmail.com> wrote:On Sat, Jun 8, 2024 at 1:50 AM Stepan Neretin <sncfmgg@gmail.com> wrote:Hello all.I am interested in the proposed patch and would like to propose some additional changes that would complement it. My changes would introduce similar optimizations when working with a list of integers or object identifiers. Additionally, my patch includes an extension for benchmarking, which shows an average speedup of 30-40%.postgres=# SELECT bench_oid_sort(1000000);
bench_oid_sort
----------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 116990848 ns, Time taken by list_oid_sort: 80446640 ns, Percentage difference: 31.24%
(1 row)
postgres=# SELECT bench_int_sort(1000000);
bench_int_sort
----------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 118168506 ns, Time taken by list_int_sort: 80523373 ns, Percentage difference: 31.86%
(1 row)What do you think about these changes?Best regards, Stepan Neretin.On Fri, Jun 7, 2024 at 11:08 PM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote:Hi!
In a thread about sorting comparators[0] Andres noted that we have infrastructure to help compiler optimize sorting. PFA attached PoC implementation. I've checked that it indeed works on the benchmark from that thread.
postgres=# CREATE TABLE arrays_to_sort AS
SELECT array_shuffle(a) arr
FROM
(SELECT ARRAY(SELECT generate_series(1, 1000000)) a),
generate_series(1, 10);
postgres=# SELECT (sort(arr))[1] FROM arrays_to_sort; -- original
Time: 990.199 ms
postgres=# SELECT (sort(arr))[1] FROM arrays_to_sort; -- patched
Time: 696.156 ms
The benefit seems to be on the order of magnitude with 30% speedup.
There's plenty of sorting by TransactionId, BlockNumber, OffsetNumber, Oid etc. But this sorting routines never show up in perf top or something like that.
Seems like in most cases we do not spend much time in sorting. But specialization does not cost us much too, only some CPU cycles of a compiler. I think we can further improve speedup by converting inline comparator to value extractor: more compilers will see what is actually going on. But I have no proofs for this reasoning.
What do you think?
Best regards, Andrey Borodin.
[0] https://www.postgresql.org/message-id/flat/20240209184014.sobshkcsfjix6u4r%40awork3.anarazel.de#fc23df2cf314bef35095b632380b4a59Hello all.I have decided to explore more areas in which I can optimize and have added two new benchmarks. Do you have any thoughts on this?postgres=# select bench_int16_sort(1000000);
bench_int16_sort
-----------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 66354981 ns, Time taken by optimized sort: 52151523 ns, Percentage difference: 21.41%
(1 row)
postgres=# select bench_float8_sort(1000000);
bench_float8_sort
------------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 121475231 ns, Time taken by optimized sort: 74458545 ns, Percentage difference: 38.70%
(1 row)
postgres=#
Best regards, Stepan Neretin.
./pgbench -c 10 -j2 -t1000 -d postgres
pgbench (18devel)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10
query mode: simple
number of clients: 10
number of threads: 2
maximum number of tries: 1
number of transactions per client: 1000
number of transactions actually processed: 10000/10000
number of failed transactions: 0 (0.000%)
latency average = 1.609 ms
initial connection time = 24.080 ms
tps = 6214.244789 (without initial connection time)
./pgbench -c 10 -j2 -t1000 -d postgres
pgbench (18devel)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10
query mode: simple
number of clients: 10
number of threads: 2
maximum number of tries: 1
number of transactions per client: 1000
number of transactions actually processed: 10000/10000
number of failed transactions: 0 (0.000%)
latency average = 1.731 ms
initial connection time = 15.177 ms
tps = 5776.173285 (without initial connection time)
Best regards, Stepan Neretin.
On Mon, Jul 15, 2024 at 12:23 PM Антуан Виолин <violin.antuan@gmail.com> wrote:Hello all.
I have decided to explore more areas in which I can optimize and have added
two new benchmarks. Do you have any thoughts on this?postgres=# select bench_int16_sort(1000000);
bench_int16_sort-----------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 66354981 ns, Time taken by optimized sort:
52151523 ns, Percentage difference: 21.41%
(1 row)postgres=# select bench_float8_sort(1000000);
bench_float8_sort------------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 121475231 ns, Time taken by optimized sort:
74458545 ns, Percentage difference: 38.70%
(1 row)Hello allWe would like to see the relationship between the length of the sorted array and the performance gain, perhaps some graphs. We also want to see to set a "worst case" test, sorting the array in ascending order when it is initially descendingBest, regards, Antoine Violinpostgres=#
On Mon, Jul 15, 2024 at 10:32 AM Stepan Neretin <sncfmgg@gmail.com> wrote:On Sat, Jun 8, 2024 at 1:50 AM Stepan Neretin <sncfmgg@gmail.com> wrote:Hello all.I am interested in the proposed patch and would like to propose some additional changes that would complement it. My changes would introduce similar optimizations when working with a list of integers or object identifiers. Additionally, my patch includes an extension for benchmarking, which shows an average speedup of 30-40%.postgres=# SELECT bench_oid_sort(1000000);
bench_oid_sort
----------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 116990848 ns, Time taken by list_oid_sort: 80446640 ns, Percentage difference: 31.24%
(1 row)
postgres=# SELECT bench_int_sort(1000000);
bench_int_sort
----------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 118168506 ns, Time taken by list_int_sort: 80523373 ns, Percentage difference: 31.86%
(1 row)What do you think about these changes?Best regards, Stepan Neretin.On Fri, Jun 7, 2024 at 11:08 PM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote:Hi!
In a thread about sorting comparators[0] Andres noted that we have infrastructure to help compiler optimize sorting. PFA attached PoC implementation. I've checked that it indeed works on the benchmark from that thread.
postgres=# CREATE TABLE arrays_to_sort AS
SELECT array_shuffle(a) arr
FROM
(SELECT ARRAY(SELECT generate_series(1, 1000000)) a),
generate_series(1, 10);
postgres=# SELECT (sort(arr))[1] FROM arrays_to_sort; -- original
Time: 990.199 ms
postgres=# SELECT (sort(arr))[1] FROM arrays_to_sort; -- patched
Time: 696.156 ms
The benefit seems to be on the order of magnitude with 30% speedup.
There's plenty of sorting by TransactionId, BlockNumber, OffsetNumber, Oid etc. But this sorting routines never show up in perf top or something like that.
Seems like in most cases we do not spend much time in sorting. But specialization does not cost us much too, only some CPU cycles of a compiler. I think we can further improve speedup by converting inline comparator to value extractor: more compilers will see what is actually going on. But I have no proofs for this reasoning.
What do you think?
Best regards, Andrey Borodin.
[0] https://www.postgresql.org/message-id/flat/20240209184014.sobshkcsfjix6u4r%40awork3.anarazel.de#fc23df2cf314bef35095b632380b4a59Hello all.I have decided to explore more areas in which I can optimize and have added two new benchmarks. Do you have any thoughts on this?postgres=# select bench_int16_sort(1000000);
bench_int16_sort
-----------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 66354981 ns, Time taken by optimized sort: 52151523 ns, Percentage difference: 21.41%
(1 row)
postgres=# select bench_float8_sort(1000000);
bench_float8_sort
------------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 121475231 ns, Time taken by optimized sort: 74458545 ns, Percentage difference: 38.70%
(1 row)
postgres=#
Best regards, Stepan Neretin.I run benchmark with my patches:
./pgbench -c 10 -j2 -t1000 -d postgres
pgbench (18devel)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10
query mode: simple
number of clients: 10
number of threads: 2
maximum number of tries: 1
number of transactions per client: 1000
number of transactions actually processed: 10000/10000
number of failed transactions: 0 (0.000%)
latency average = 1.609 ms
initial connection time = 24.080 ms
tps = 6214.244789 (without initial connection time)and without:
./pgbench -c 10 -j2 -t1000 -d postgres
pgbench (18devel)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10
query mode: simple
number of clients: 10
number of threads: 2
maximum number of tries: 1
number of transactions per client: 1000
number of transactions actually processed: 10000/10000
number of failed transactions: 0 (0.000%)
latency average = 1.731 ms
initial connection time = 15.177 ms
tps = 5776.173285 (without initial connection time)tps with my patches increase. What do you think?
Best regards, Stepan Neretin.
bench_oid_reverse_sort
----------------------------------------------------------------------------------------------------------
Time taken by list_sort: 182557 ns, Time taken by list_oid_sort: 85864 ns, Percentage difference: 52.97%
(1 row)
Time: 2,291 ms
postgres=# SELECT bench_oid_reverse_sort(100000);
bench_oid_reverse_sort
-------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 9064163 ns, Time taken by list_oid_sort: 4313448 ns, Percentage difference: 52.41%
(1 row)
Time: 17,146 ms
postgres=# SELECT bench_oid_reverse_sort(1000000);
bench_oid_reverse_sort
---------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 61990395 ns, Time taken by list_oid_sort: 23703380 ns, Percentage difference: 61.76%
(1 row)
postgres=# SELECT bench_int_reverse_sort(1000000);
bench_int_reverse_sort
---------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 50712416 ns, Time taken by list_int_sort: 24120417 ns, Percentage difference: 52.44%
(1 row)
Time: 89,359 ms
postgres=# SELECT bench_float8_reverse_sort(1000000);
bench_float8_reverse_sort
-----------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 57447775 ns, Time taken by optimized sort: 25214023 ns, Percentage difference: 56.11%
(1 row)
Time: 92,308 ms
Best regards, Stepan Neretin.
Attachment
{kind=link}
{kind=link}
On Mon, Jul 15, 2024 at 4:52 PM Stepan Neretin <sncfmgg@gmail.com> wrote:On Mon, Jul 15, 2024 at 12:23 PM Антуан Виолин <violin.antuan@gmail.com> wrote:Hello all.
I have decided to explore more areas in which I can optimize and have added
two new benchmarks. Do you have any thoughts on this?postgres=# select bench_int16_sort(1000000);
bench_int16_sort-----------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 66354981 ns, Time taken by optimized sort:
52151523 ns, Percentage difference: 21.41%
(1 row)postgres=# select bench_float8_sort(1000000);
bench_float8_sort------------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 121475231 ns, Time taken by optimized sort:
74458545 ns, Percentage difference: 38.70%
(1 row)Hello allWe would like to see the relationship between the length of the sorted array and the performance gain, perhaps some graphs. We also want to see to set a "worst case" test, sorting the array in ascending order when it is initially descendingBest, regards, Antoine Violinpostgres=#
On Mon, Jul 15, 2024 at 10:32 AM Stepan Neretin <sncfmgg@gmail.com> wrote:On Sat, Jun 8, 2024 at 1:50 AM Stepan Neretin <sncfmgg@gmail.com> wrote:Hello all.I am interested in the proposed patch and would like to propose some additional changes that would complement it. My changes would introduce similar optimizations when working with a list of integers or object identifiers. Additionally, my patch includes an extension for benchmarking, which shows an average speedup of 30-40%.postgres=# SELECT bench_oid_sort(1000000);
bench_oid_sort
----------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 116990848 ns, Time taken by list_oid_sort: 80446640 ns, Percentage difference: 31.24%
(1 row)
postgres=# SELECT bench_int_sort(1000000);
bench_int_sort
----------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 118168506 ns, Time taken by list_int_sort: 80523373 ns, Percentage difference: 31.86%
(1 row)What do you think about these changes?Best regards, Stepan Neretin.On Fri, Jun 7, 2024 at 11:08 PM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote:Hi!
In a thread about sorting comparators[0] Andres noted that we have infrastructure to help compiler optimize sorting. PFA attached PoC implementation. I've checked that it indeed works on the benchmark from that thread.
postgres=# CREATE TABLE arrays_to_sort AS
SELECT array_shuffle(a) arr
FROM
(SELECT ARRAY(SELECT generate_series(1, 1000000)) a),
generate_series(1, 10);
postgres=# SELECT (sort(arr))[1] FROM arrays_to_sort; -- original
Time: 990.199 ms
postgres=# SELECT (sort(arr))[1] FROM arrays_to_sort; -- patched
Time: 696.156 ms
The benefit seems to be on the order of magnitude with 30% speedup.
There's plenty of sorting by TransactionId, BlockNumber, OffsetNumber, Oid etc. But this sorting routines never show up in perf top or something like that.
Seems like in most cases we do not spend much time in sorting. But specialization does not cost us much too, only some CPU cycles of a compiler. I think we can further improve speedup by converting inline comparator to value extractor: more compilers will see what is actually going on. But I have no proofs for this reasoning.
What do you think?
Best regards, Andrey Borodin.
[0] https://www.postgresql.org/message-id/flat/20240209184014.sobshkcsfjix6u4r%40awork3.anarazel.de#fc23df2cf314bef35095b632380b4a59Hello all.I have decided to explore more areas in which I can optimize and have added two new benchmarks. Do you have any thoughts on this?postgres=# select bench_int16_sort(1000000);
bench_int16_sort
-----------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 66354981 ns, Time taken by optimized sort: 52151523 ns, Percentage difference: 21.41%
(1 row)
postgres=# select bench_float8_sort(1000000);
bench_float8_sort
------------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 121475231 ns, Time taken by optimized sort: 74458545 ns, Percentage difference: 38.70%
(1 row)
postgres=#
Best regards, Stepan Neretin.I run benchmark with my patches:
./pgbench -c 10 -j2 -t1000 -d postgres
pgbench (18devel)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10
query mode: simple
number of clients: 10
number of threads: 2
maximum number of tries: 1
number of transactions per client: 1000
number of transactions actually processed: 10000/10000
number of failed transactions: 0 (0.000%)
latency average = 1.609 ms
initial connection time = 24.080 ms
tps = 6214.244789 (without initial connection time)and without:
./pgbench -c 10 -j2 -t1000 -d postgres
pgbench (18devel)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10
query mode: simple
number of clients: 10
number of threads: 2
maximum number of tries: 1
number of transactions per client: 1000
number of transactions actually processed: 10000/10000
number of failed transactions: 0 (0.000%)
latency average = 1.731 ms
initial connection time = 15.177 ms
tps = 5776.173285 (without initial connection time)tps with my patches increase. What do you think?
Best regards, Stepan Neretin.I implement reverse benchmarks:postgres=# SELECT bench_oid_reverse_sort(1000);
bench_oid_reverse_sort
----------------------------------------------------------------------------------------------------------
Time taken by list_sort: 182557 ns, Time taken by list_oid_sort: 85864 ns, Percentage difference: 52.97%
(1 row)
Time: 2,291 ms
postgres=# SELECT bench_oid_reverse_sort(100000);
bench_oid_reverse_sort
-------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 9064163 ns, Time taken by list_oid_sort: 4313448 ns, Percentage difference: 52.41%
(1 row)
Time: 17,146 ms
postgres=# SELECT bench_oid_reverse_sort(1000000);
bench_oid_reverse_sort
---------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 61990395 ns, Time taken by list_oid_sort: 23703380 ns, Percentage difference: 61.76%
(1 row)
postgres=# SELECT bench_int_reverse_sort(1000000);
bench_int_reverse_sort
---------------------------------------------------------------------------------------------------------------
Time taken by list_sort: 50712416 ns, Time taken by list_int_sort: 24120417 ns, Percentage difference: 52.44%
(1 row)
Time: 89,359 ms
postgres=# SELECT bench_float8_reverse_sort(1000000);
bench_float8_reverse_sort
-----------------------------------------------------------------------------------------------------------------
Time taken by usual sort: 57447775 ns, Time taken by optimized sort: 25214023 ns, Percentage difference: 56.11%
(1 row)
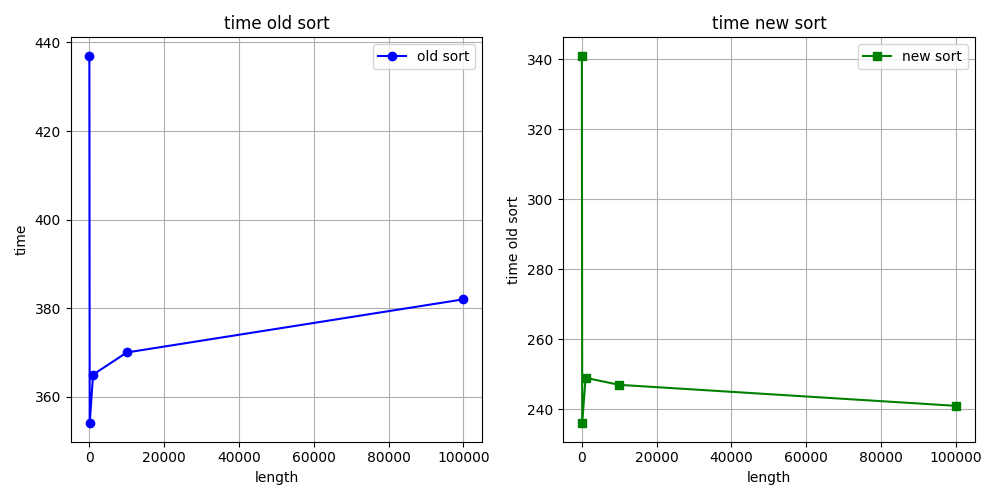
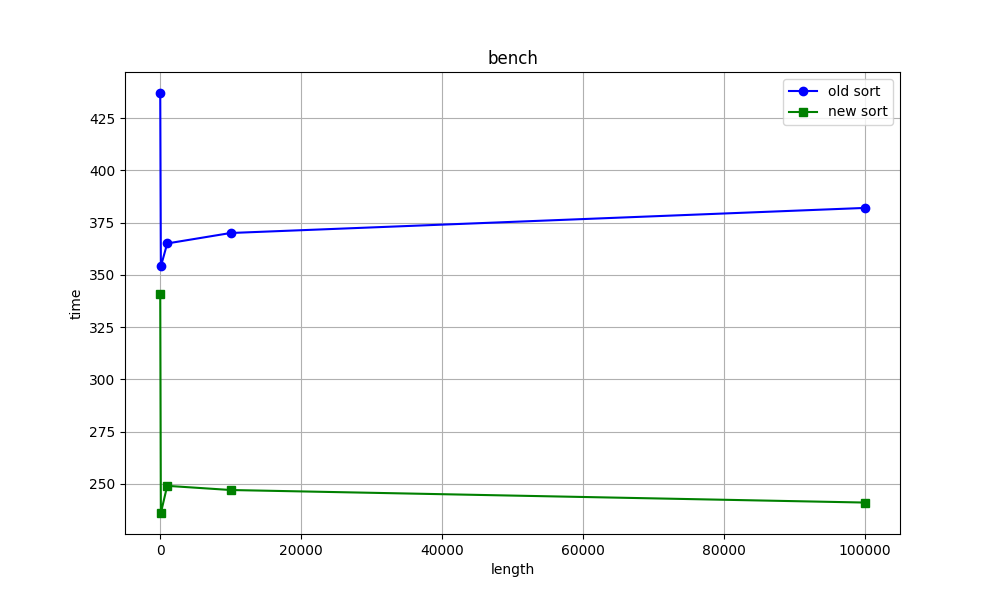
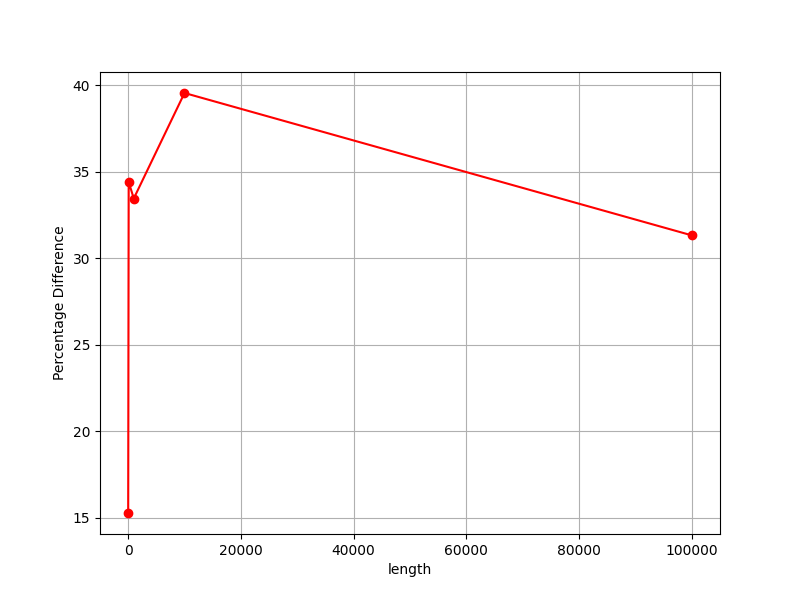
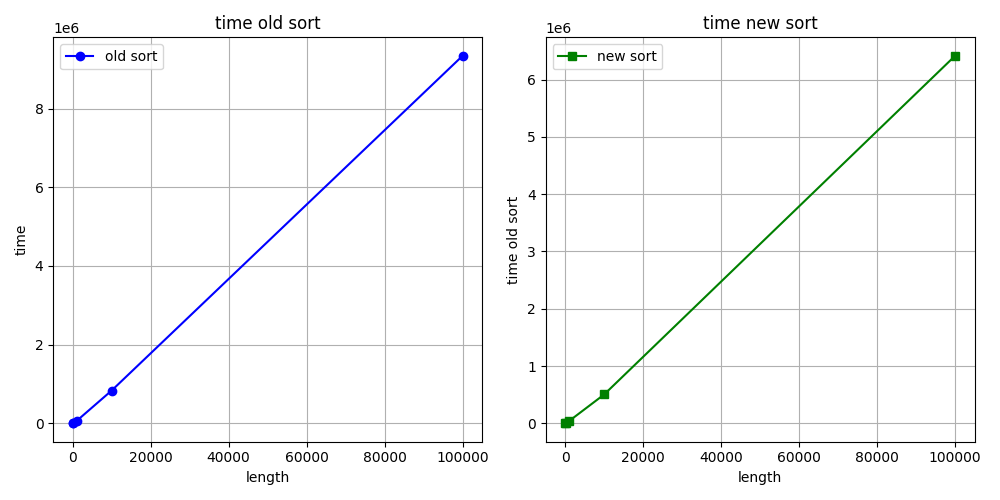
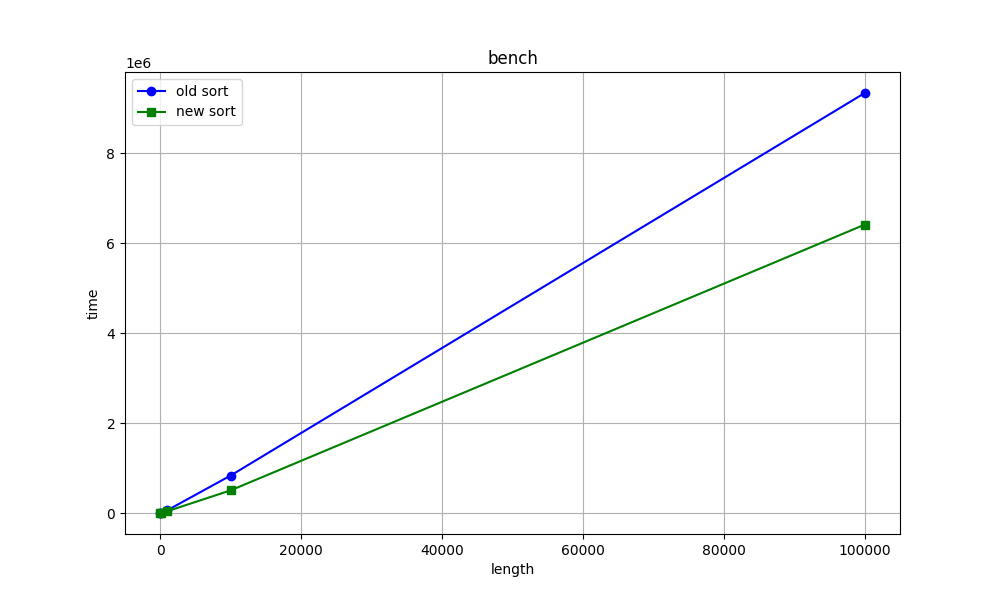
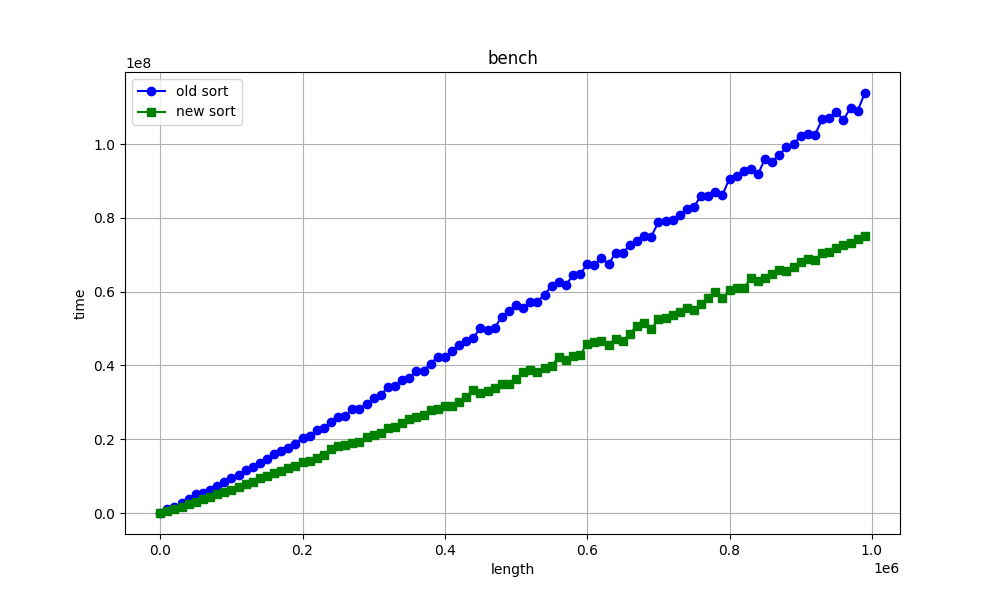
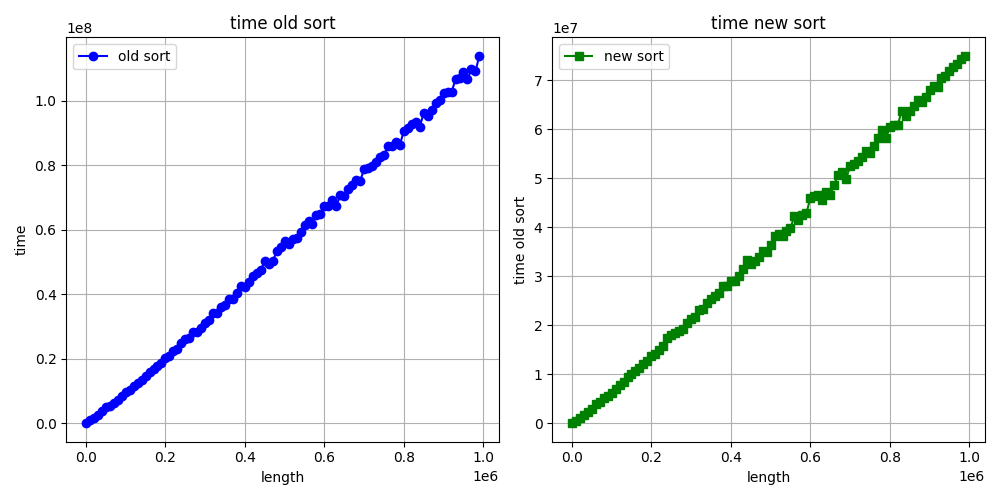
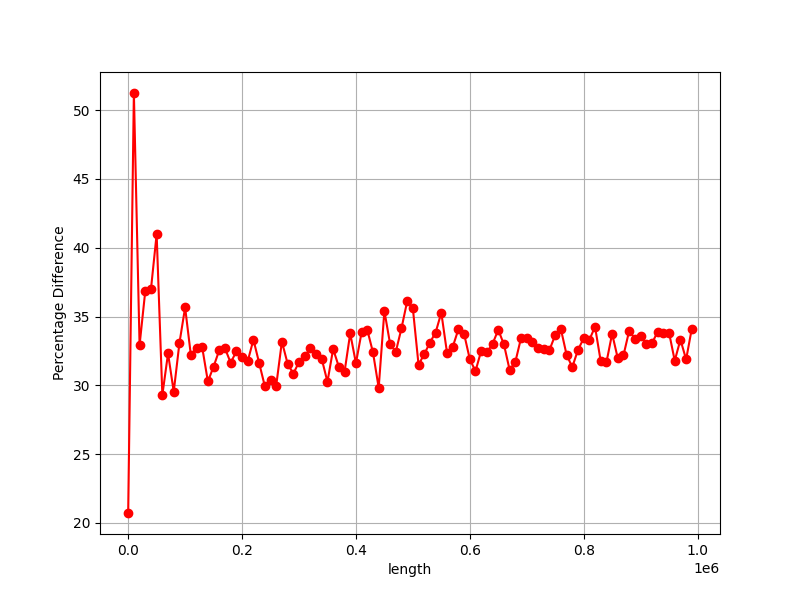
Time: 92,308 msHello again. I want to show you the graphs of when we increase the length vector/array sorting time (ns). What do you think about graphs?
Best regards, Stepan Neretin.Hello again :) I made a mistake in the benchmarks code. I am attaching new corrected benchmarks for int sorting as example. And my stupid, simple python script for making benchs and draw graphs. What do you think about this graphs?
Best regards, Stepan Neretin.
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
> On 15 Jul 2024, at 12:52, Stepan Neretin <sncfmgg@gmail.com> wrote: > > > I run benchmark with my patches: > ./pgbench -c 10 -j2 -t1000 -d postgres > > pgbench (18devel) > starting vacuum...end. > transaction type: <builtin: TPC-B (sort of)> > scaling factor: 10 > query mode: simple > number of clients: 10 > number of threads: 2 > maximum number of tries: 1 > number of transactions per client: 1000 > number of transactions actually processed: 10000/10000 > number of failed transactions: 0 (0.000%) > latency average = 1.609 ms > initial connection time = 24.080 ms > tps = 6214.244789 (without initial connection time) > > and without: > ./pgbench -c 10 -j2 -t1000 -d postgres > > pgbench (18devel) > starting vacuum...end. > transaction type: <builtin: TPC-B (sort of)> > scaling factor: 10 > query mode: simple > number of clients: 10 > number of threads: 2 > maximum number of tries: 1 > number of transactions per client: 1000 > number of transactions actually processed: 10000/10000 > number of failed transactions: 0 (0.000%) > latency average = 1.731 ms > initial connection time = 15.177 ms > tps = 5776.173285 (without initial connection time) > > tps with my patches increase. What do you think? Hi Stepan! Thank you for implementing specialized sorting and doing this benchmarks. I believe it's a possible direction for good improvement. However, I doubt in correctness of your benchmarks. Increasing TPC-B performance from 5776 TPS to 6214 TPS seems too good to be true. Best regards, Andrey Borodin.
> On 15 Jul 2024, at 12:52, Stepan Neretin <sncfmgg@gmail.com> wrote:
>
>
> I run benchmark with my patches:
> ./pgbench -c 10 -j2 -t1000 -d postgres
>
> pgbench (18devel)
> starting vacuum...end.
> transaction type: <builtin: TPC-B (sort of)>
> scaling factor: 10
> query mode: simple
> number of clients: 10
> number of threads: 2
> maximum number of tries: 1
> number of transactions per client: 1000
> number of transactions actually processed: 10000/10000
> number of failed transactions: 0 (0.000%)
> latency average = 1.609 ms
> initial connection time = 24.080 ms
> tps = 6214.244789 (without initial connection time)
>
> and without:
> ./pgbench -c 10 -j2 -t1000 -d postgres
>
> pgbench (18devel)
> starting vacuum...end.
> transaction type: <builtin: TPC-B (sort of)>
> scaling factor: 10
> query mode: simple
> number of clients: 10
> number of threads: 2
> maximum number of tries: 1
> number of transactions per client: 1000
> number of transactions actually processed: 10000/10000
> number of failed transactions: 0 (0.000%)
> latency average = 1.731 ms
> initial connection time = 15.177 ms
> tps = 5776.173285 (without initial connection time)
>
> tps with my patches increase. What do you think?
Hi Stepan!
Thank you for implementing specialized sorting and doing this benchmarks.
I believe it's a possible direction for good improvement.
However, I doubt in correctness of your benchmarks.
Increasing TPC-B performance from 5776 TPS to 6214 TPS seems too good to be true.
Best regards, Andrey Borodin.
Yes... I agree.. Very strange.. I restarted the tps measurement and see this:
tps = 14669.624075 (without initial connection time) patched
Best regards, Stepan Neretin.
On Sun, 8 Sept 2024 at 20:51, Stepan Neretin <sndcppg@gmail.com> wrote: > Hi! I rebase, clean and some refactor my patches. I'm unsure what exactly is going on with this thread. It started with Andrey proposing a patch to speed up intarray sorting and now it's turned into you proposing 10 patches which implement a series of sort specialisation functions without any justification as to why the change is useful. If you want to have a performance patch accepted, then you'll need to show your test case and the performance results before and after. What this patch series looks like to me is that you've just searched the code base for qsort and just implemented a specialised qsort version without any regard as to whether the change is useful or not. For example, looking at v2-0006, you've added a specialisation to sort the columns which are specified in the CREATE STATISTICS command. This seems highly unlikely to be useful. The number of elements in this array is limited by STATS_MAX_DIMENSIONS, which is 8. Are you claiming the sort specialisation you've added makes a meaningful performance improvement to sorting an 8 element array? It looks to me like you've just derailed Andrey's proposal. I suggest you validate which ones of these patches you can demonstrate produce a meaningful performance improvement, ditch the remainder, and then start your own thread showing your test case and results. David
On Mon, 9 Sept 2024 at 01:00, Stepan Neretin <sndcppg@gmail.com> wrote: > Hi, why do you think that I rejected Andrey's offer? I included his patch first in my own. Yes, patch 2-0006 is the onlypatch to which I have not attached any statistics and it looks really dubious. But the rest seem useful. Above, I attacheda speed graph for one of the patches and tps(pgbench) The difference with your patches and Andrey's patch is that he included a benchmark which is targeted to the code he changed and his results show a speed-up. What it appears that you've done is made an assortment of changes and picked the least effort thing that tests performance of something. You by chance saw a performance increase so assumed it was due to your changes. > What do you think is the format in which to make benchmarks for my patches? You'll need a benchmark that exercises the code you've changed to some degree where it has a positive impact on performance. As far as I can see, you've not done that yet. Just to give you the benefit of the doubt, I applied all 10 v2 patches and adjusted the call sites to add a NOTICE to include the size of the array being sorted. Here is the result of running your benchmark: $ pgbench -t1000 -d postgres pgbench (18devel) NOTICE: RelationGetIndexList 1 NOTICE: RelationGetStatExtList 0 NOTICE: RelationGetIndexList 3 NOTICE: RelationGetStatExtList 0 NOTICE: RelationGetIndexList 2 NOTICE: RelationGetStatExtList 0 NOTICE: RelationGetIndexList 1 NOTICE: RelationGetStatExtList 0 NOTICE: RelationGetIndexList 2 NOTICE: RelationGetStatExtList 0 starting vacuum...NOTICE: RelationGetIndexList 1 NOTICE: RelationGetIndexList 0 end. NOTICE: RelationGetIndexList 1 NOTICE: RelationGetStatExtList 0 NOTICE: RelationGetIndexList 1 NOTICE: RelationGetStatExtList 0 NOTICE: RelationGetIndexList 1 NOTICE: RelationGetStatExtList 0 transaction type: <builtin: TPC-B (sort of)> scaling factor: 1 query mode: simple number of clients: 1 number of threads: 1 maximum number of tries: 1 number of transactions per client: 1000 number of transactions actually processed: 1000/1000 number of failed transactions: 0 (0.000%) latency average = 0.915 ms initial connection time = 23.443 ms tps = 1092.326732 (without initial connection time) Note that -t1000 shows the same number of notices as -t1. So, it seems everything you've changed that runs in your benchmark is RelationGetIndexList() and RelationGetStatExtList(). In one of the calls to RelationGetIndexList() we're sorting up to a maximum of 3 elements. Just to be clear, I'm not stating that I think all of your changes are useless. If you want these patches accepted, then you're going to need to prove they're useful and you've not done that. Also, unless Andrey is happy for you to tag onto the work he's doing, I'd suggest another thread for that work. I don't think there's any good reason for that work to delay Andrey's work. David
> On 9 Sep 2024, at 02:31, David Rowley <dgrowleyml@gmail.com> wrote: > > Also, unless Andrey is happy for you to tag onto the work he's doing, > I'd suggest another thread for that work. I don't think there's any > good reason for that work to delay Andrey's work. Stepan asked for mentoring project, so I handed him this patch set. We are working together, but the main goal is integratingStepan into dev process. Well, the summer was really hot and we somehow were not advancing the project… So yourthread bump is very timely! Many thanks for your input about benchmarks! We will focus on measuring impact of changes. I totally share your concernsabout optimization of sorts that are not used frequently. Best regards, Andrey Borodin.
On Wed, Dec 4, 2024 at 2:47 PM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote: > sort_int32_cmp Time: 543.690 ms > sort_int32_cmp_2 Time: 609.019 ms > sort_int32_cmp_4 Time: 612.219 ms > > So, I'd stick with sort_int32_cmp. But, perhaps, on Intel we might have different results. I tried on an older Intel chip and got similar results, so we'll go with your original comparator: master: latency average = 1867.878 ms cmp1: latency average = 1189.225 ms cmp2: latency average = 1341.153 ms cmp3: latency average = 1270.053 ms I believe src/port/qsort.c was meant to be just for the standard sort interface as found in a C library. We do have one globally visible special sort here: src/backend/utils/sort/qsort_interruptible.c ...so that directory seems a better fit. The declaration is in src/include/port.h, though. Note: that one doesn't have a global wrapper around a static function -- it's declared global since ST_SCOPE is not defined. And one more bikeshedding bit that might get noticed: tuplesorts express their boolean as "reversed". We don't necessarily need to follow that, but consistency is good for readability. -- John Naylor Amazon Web Services
On Fri, Dec 6, 2024 at 1:32 AM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote: > > > On 5 Dec 2024, at 15:16, John Naylor <johncnaylorls@gmail.com> wrote: > > I believe src/port/qsort.c was meant to be just for the standard sort > > interface as found in a C library. We do have one globally visible > > special sort here: > > src/backend/utils/sort/qsort_interruptible.c > > ...so that directory seems a better fit. > OK. BTW do we need ST_CHECK_FOR_INTERRUPTS? That's a good thing to raise right now -- intarray currently doesn't have one, and we haven't gotten complaints from people trying to sort large arrays and cancel the query. This extension is not commonly used, so that's not surprising. It could be that large arrays are even less common, or no one bothered to report it. What's the largest size that your customers use? If we do need a check for interrupts, then this whole thing must remain private to intarray. From reading e64cdab0030 , it's not safe to interrupt in general. > > And one more bikeshedding bit that might get noticed: tuplesorts > > express their boolean as "reversed". We don't necessarily need to > > follow that, but consistency is good for readability. > > I do not know if "reversed sorting order" is more idiomatic than "ascending sorting order". If you think it is - let'sswitch argument's name to "reversed". After sleeping on it, I actually think it's mildly ridiculous for this module to force the comparator to know about the sort direction. Tuplesorts must do that because each sort key could have a different sort order. There is only one place in intarray that wants reversed order -- maybe that place should reverse elements itself? It's fine to keep thing as they are if the sort function stays private to intarray, but this patch creates a global function, where the "ascending" parameter is just noise. And if we don't have large int32 sorts outside of intarray, then the path of least resistance may be to keep it private. I had a look at the files touched by this patch and noticed that there is another sort used for making arrays unique. Were you going to look at that as well? That reminded me of a patchset from Thomas Munro that added bsearch and unique macros to the sort template -- see 0001-0003 in the link below. (That also includes a proposal to have a specialization for uint32 -- I'm still not sure if that would have a performance benefit for real workloads, but I believe the motivation was mostly cosmetic): https://www.postgresql.org/message-id/CA%2BhUKGKztHEWm676csTFjYzortziWmOcf8HDss2Zr0muZ2xfEg%40mail.gmail.com -- John Naylor Amazon Web Services
On Mon, Dec 9, 2024 at 8:02 PM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote: > > > On 6 Dec 2024, at 08:49, John Naylor <johncnaylorls@gmail.com> wrote: > > That's a good thing to raise right now -- intarray currently doesn't > > have one, and we haven't gotten complaints from people trying to sort > > large arrays and cancel the query. This extension is not commonly > > used, so that's not surprising. It could be that large arrays are even > > less common, or no one bothered to report it. What's the largest size > > that your customers use? > > > > If we do need a check for interrupts, then this whole thing must > > remain private to intarray. From reading e64cdab0030 , it's not safe > > to interrupt in general. > > I think commit message states that it's better to opt-in for interruptible sort. So I do not think making sort interruptibleis a blocker for making global specialized sorting routines. There is a difference, though -- that commit had a number of uses for it immediately. In my view, there is no reason to have a global interruptible sort that's only used by one contrib module. YAGNI Also, I was hoping get an answer for how this would actually affect intarray use you've seen in the wild. If the answer is "I don't know of any one who uses this either", then I'm actually starting to wonder if the speed matters at all. Maybe all uses are for a few hundred or thousand integers, in which case the sort time is trivial anyway? > We could use global function for oid lists which may be arbitrary large. BTW, oids are unsigned. (See the 0002 patch from Thomas M. I linked to earlier) -- John Naylor Amazon Web Services
> On 11 Dec 2024, at 11:39, John Naylor <johncnaylorls@gmail.com> wrote: > > On Mon, Dec 9, 2024 at 8:02 PM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote: >> >> I think commit message states that it's better to opt-in for interruptible sort. So I do not think making sort interruptibleis a blocker for making global specialized sorting routines. > > There is a difference, though -- that commit had a number of uses for > it immediately. In my view, there is no reason to have a global > interruptible sort that's only used by one contrib module. YAGNI > > Also, I was hoping get an answer for how this would actually affect > intarray use you've seen in the wild. If the answer is "I don't know > of any one who uses this either", then I'm actually starting to wonder > if the speed matters at all. Maybe all uses are for a few hundred or > thousand integers, in which case the sort time is trivial anyway? I do not have access to user data in most clusters... I remember only one particular case: tags and folders applied to mailmessages are represented by int array. Mostly for GIN search. In that case vast majority of these arrays are 0-10 elements,some hot-acceses fraction of 10-1000. Only robots (service accounts) can have millions, and in their case latencyhave no impact at all. But this particular case also does not trigger sorting much: arrays are stored sorted and modifications are infrequent. Inmost cases sorting is invoked for already sorted or almost sorted input. So yeah, from practical point of view cosmetic reasons seems to be most important :) >> We could use global function for oid lists which may be arbitrary large. > > BTW, oids are unsigned. (See the 0002 patch from Thomas M. I linked to earlier) Seems like we cannot reuse same function... So, let's do the function private for intarray and try to remove as much code as possible? Best regards, Andrey Borodin.
On Mon, Dec 16, 2024 at 12:58 AM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote: > > > On 11 Dec 2024, at 11:39, John Naylor <johncnaylorls@gmail.com> wrote: > > Also, I was hoping get an answer for how this would actually affect > > intarray use you've seen in the wild. If the answer is "I don't know > > of any one who uses this either", then I'm actually starting to wonder > > if the speed matters at all. Maybe all uses are for a few hundred or > > thousand integers, in which case the sort time is trivial anyway? > > I do not have access to user data in most clusters... I remember only one particular case: tags and folders applied tomail messages are represented by int array. Mostly for GIN search. In that case vast majority of these arrays are 0-10elements, some hot-acceses fraction of 10-1000. Only robots (service accounts) can have millions, and in their case latencyhave no impact at all. > But this particular case also does not trigger sorting much: arrays are stored sorted and modifications are infrequent.In most cases sorting is invoked for already sorted or almost sorted input. Okay, if one case uses millions, than surely others also do so. > So yeah, from practical point of view cosmetic reasons seems to be most important :) Seems worth doing. -- John Naylor Amazon Web Services
On Mon, Dec 16, 2024 at 12:58 AM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote: > So, let's do the function private for intarray and try to remove as much code as possible? Sorry, I forgot this part earlier. Yes, let's have the private function. -- John Naylor Amazon Web Services
On Sat, Dec 21, 2024 at 12:16 AM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote:
>
>
>
> > On 16 Dec 2024, at 14:02, John Naylor <johncnaylorls@gmail.com> wrote:
> >
> > Sorry, I forgot this part earlier. Yes, let's have the private function.
>
> PFA v6.
v6-0001:
+static int
+unique_cmp(const void *a, const void *b)
+{
+ int32 aval = *((const int32 *) a);
+ int32 bval = *((const int32 *) b);
+
+ return pg_cmp_s32(aval, bval);
+}
I'm not sure it makes sense to create a whole new function for this,
when the same patch removed:
-int
-compASC(const void *a, const void *b)
-{
- return pg_cmp_s32(*(const int32 *) a, *(const int32 *) b);
-}
...which in effect the exact same thing.
Otherwise seems close to committable.
v6-0002: Seems like a good idea to be more consistent, but I admit I'm
not much a fan of little indirection macros like this. It makes the
code less readable in my view.
v6-0003: I didn't feel like digging further. It's interesting that
inner_int_inter() takes care to detect the zero-length case and free
the old array to avoid resizing.
--
John Naylor
Amazon Web Services
> On 6 Jan 2025, at 15:54, John Naylor <johncnaylorls@gmail.com> wrote: >> >> I thought about it, but decided to rename the routine. >> Here's a version 7 with compASC(). > > I had the right idea, but the wrong function -- HEAD already had a > suitable comp function, and one that works well with inlined > specialized sorts: isort_cmp(). We just need to remove the extra > argument. Like some other patches in this series, this does have the > side effect of removing the ability to skip quinique(), so that should > be benchmarked (I can do that this week unless you beat me to it). With the same setup as in the first message of this thread we can do: postgres=# SELECT _int_contains(arr,ARRAY[1]) FROM arrays_to_sort; before patch patch Time: 567.928 ms after patch Time: 890.297 ms timing of this function is dominated by PREPAREARR(a); What bothers me is that PREPAREARR(a); is returning new array in case of empty input. That's why I considered little refactoringof resize_intArrayType(): reorder cases so that if (num == ARRNELEMS(a)) was first. > We > can specialize quinique too, as mentioned upthread, but I'm not sure > we need to. > >> And, just in case, if we already have ASC, why not keep DESC too instead of newly invented cmp function :) PFA v8. > > Those functions from common/int.h are probably not good when inlined > (see comment there). If we really want to keep the branch for asc/desc > out of the comparison, it makes more sense to add a function to > reverse the elements after sorting. That allows using the same cmp > function for everything, thus removing the apparent need for a global > wrapper around the static sort function. > > I've done both ideas in v9, which also tries to improve patch > legibility by keeping things in the same place they were before. It > also removes the internal "n > 1" checks that you mentioned earlier -- > after thinking about it that seems better than adding braces to one > macro to keep it functional. LGTM. Thanks! Best regards, Andrey Borodin.
On Mon, Jan 06, 2025 at 05:54:29PM +0700, John Naylor wrote: > Those functions from common/int.h are probably not good when inlined > (see comment there). +1. In fact, I think this comment was added because of the ST_MED3() function in sort_template.h [0]. IIRC clang handles this just fine, but gcc does not. [0] https://postgr.es/m/20240212230423.GA3519%40nathanxps13 -- nathan
On Mon, Jan 6, 2025 at 10:51 PM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote:
>
> > On 6 Jan 2025, at 15:54, John Naylor <johncnaylorls@gmail.com> wrote:
> > argument. Like some other patches in this series, this does have the
> > side effect of removing the ability to skip quinique(), so that should
> > be benchmarked (I can do that this week unless you beat me to it).
>
> With the same setup as in the first message of this thread we can do:
>
> postgres=# SELECT _int_contains(arr,ARRAY[1]) FROM arrays_to_sort;
>
> before patch patch
> Time: 567.928 ms
> after patch
> Time: 890.297 ms
> timing of this function is dominated by PREPAREARR(a);
>
> What bothers me is that PREPAREARR(a); is returning new array in case of empty input. That's why I considered little
refactoringof resize_intArrayType(): reorder cases so that if (num == ARRNELEMS(a)) was first.
Hmm, I'm confused. First, none of the arrays are empty that I can see
-- am I missing something?
Then, the first message setup is
CREATE TABLE arrays_to_sort AS
SELECT array_shuffle(a) arr
FROM
(SELECT ARRAY(SELECT generate_series(1, 1000000)) a),
generate_series(1, 10);
...so most of the time is in sorting the big array, and I don't see a
regression, the opposite in fact:
SELECT _int_contains(arr,ARRAY[1]) FROM arrays_to_sort;
master:
1492.552 ms
v9:
873.697 ms
The case I was concerned about was if the big array was already sorted
and unique. Then, it's conceivable that unnecessarily running qunique
would make things slower, but I don't see that either:
--ordered
CREATE TABLE arrays_sorted AS
SELECT a arr
FROM
(SELECT ARRAY(SELECT generate_series(1, 1000000)) a),
generate_series(1, 10);
SELECT _int_contains(arr,ARRAY[1]) FROM arrays_sorted;
master:
31.388
v9:
28.247
--
John Naylor
Amazon Web Services
On Tue, Jan 7, 2025 at 12:47 AM Nathan Bossart <nathandbossart@gmail.com> wrote: > > On Mon, Jan 06, 2025 at 05:54:29PM +0700, John Naylor wrote: > > Those functions from common/int.h are probably not good when inlined > > (see comment there). > > +1. In fact, I think this comment was added because of the ST_MED3() > function in sort_template.h [0]. IIRC clang handles this just fine, but > gcc does not. > > [0] https://postgr.es/m/20240212230423.GA3519%40nathanxps13 Yeah. If it were just med3, it would probably be okay, but I remember earlier experiments (also gcc) where branch-free comparators seemed to not work well with our partitioning scheme. -- John Naylor Amazon Web Services
> On 7 Jan 2025, at 09:43, John Naylor <johncnaylorls@gmail.com> wrote:
>
>> With the same setup as in the first message of this thread we can do:
>>
>> postgres=# SELECT _int_contains(arr,ARRAY[1]) FROM arrays_to_sort;
>>
>> before patch patch
>> Time: 567.928 ms
>> after patch
>> Time: 890.297 ms
>> timing of this function is dominated by PREPAREARR(a);
>>
>> What bothers me is that PREPAREARR(a); is returning new array in case of empty input. That's why I considered little
refactoringof resize_intArrayType(): reorder cases so that if (num == ARRNELEMS(a)) was first.
>
> Hmm, I'm confused. First, none of the arrays are empty that I can see
> -- am I missing something?
Ugh...sorry, I posted very confusing results. For starters, I swapped "patched" and "unpatched" results. So results
showclear improvement in default case.
I'm worried about another case that we cannot measure: PREPAREARR(a) on empty array will return new array.
And one more case.
BTW for pre-sorted desc arrays desc sorting is slower:
postgres=# CREATE TABLE arrays_sorted_desc AS
SELECT a arr
FROM
(SELECT ARRAY(SELECT -i from generate_series(1, 1000000)i) a),
generate_series(1, 10);
SELECT 10
Time: 707.016 ms
postgres=# SELECT (sort_desc(arr))[0] FROM arrays_sorted_desc;
Time: 41.874 ms
but with a patch
postgres=# SELECT (sort_desc(arr))[0] FROM arrays_sorted_desc;
Time: 166.837 ms
Best regards, Andrey Borodin.
On Tue, Jan 7, 2025 at 12:59 PM Andrey M. Borodin <x4mmm@yandex-team.ru> wrote:
>
> I'm worried about another case that we cannot measure: PREPAREARR(a) on empty array will return new array.
In theory, yes, but it doesn't happen in our regression tests, so it might be worth looking into making that happen before worrying about it further.
https://coverage.postgresql.
> And one more case.
> BTW for pre-sorted desc arrays desc sorting is slower:
Right, that's because the sort template special-cases pre-sorted input, and that only works for descending input if the comparator is wired for descending output. I'm still not in favor of having two separate specializations because that's kind of a brute force approach, and even if that's okay this is a strange place to set that precedent [*]. The principled way to avoid this regression is to add a one-time check for descending input in the template, which would be more widely beneficial. I suspect (and I think the archives show others wondering the same) we could make the ascending pre-check a one-time operation as well, but I'd need to test.
[*] It's interesting to note that not terribly long ago isort was an insertion sort, hence the name:
commit 8d1f239003d0245dda636dfa6cf0ad
Author: Tom Lane <tgl@sss.pgh.pa.us>
Date: Sun Mar 15 23:22:03 2015 -0400
Replace insertion sort in contrib/intarray with qsort().
--
John Naylor
Amazon Web Services
--
On Wed, Feb 5, 2025 at 8:34 PM John Naylor <johncnaylorls@gmail.com> wrote: > > > On Tue, Jan 14, 2025 at 4:22 PM Andrey Borodin <x4mmm@yandex-team.ru> wrote: > > > > Looks good to me. > > Nice stats for some cleaning up 34 insertions(+), 48 deletions(-). > > Great, I've attached v11 with a draft commit message. It also adds a comment for the comparator arg and removes ST_DECLAREsince we have a hand-written declaration in the header. I plan to commit this next week unless there are objections. Committed, with just one small change of "_asc" to "_ascending" for readability. -- John Naylor Amazon Web Services