Thread: how can I fix my accent issues?
hello, I have an ETL process collecting data from a postgresql database and xls files and inserting in a postgresql database that process occurs great in a local DB in postgres 14 with UTF8 codification and Spanish_Cuba.1952 collation but when I execute that process in dev which is in postgres 15 and UTF8 with collation en_US.utf8 the words with accents and ñ looks like an interrogation symbol, what can I do to fix this? thanks in advance
On Fri, 2023-12-08 at 23:58 -0500, Igniris Valdivia Baez wrote: > hello, I have an ETL process collecting data from a postgresql > database and xls files and inserting in a postgresql database that > process occurs great in a local DB in postgres 14 with UTF8 > codification and Spanish_Cuba.1952 collation but when I execute that > process in dev which is in postgres 15 and UTF8 with collation > en_US.utf8 the words with accents and ñ looks like an interrogation > symbol, what can I do to fix this? If the data you are sending are encoded in WINDOWS-1252 (I assume that "1952" is just a typo), you should set the client encoding to WIN1252, so that PostgreSQL knows how to convert the data correctly. You can do that in several ways; the simplest might be to set the environment variable PGCLIENTENCODING to WIN1252. Yours, Laurenz Albe
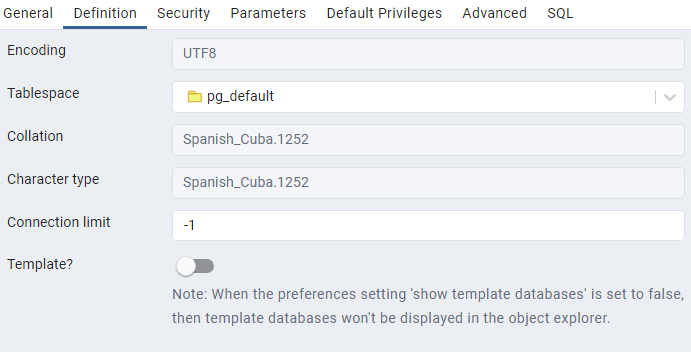
hello, thank you for answering, it's not a typo, in the attachments you can see that this is actually my collation, algo a pic of the problem for more clarification, thank you all best regards El sáb, 9 dic 2023 a las 1:01, Laurenz Albe (<laurenz.albe@cybertec.at>) escribió: > > On Fri, 2023-12-08 at 23:58 -0500, Igniris Valdivia Baez wrote: > > hello, I have an ETL process collecting data from a postgresql > > database and xls files and inserting in a postgresql database that > > process occurs great in a local DB in postgres 14 with UTF8 > > codification and Spanish_Cuba.1952 collation but when I execute that > > process in dev which is in postgres 15 and UTF8 with collation > > en_US.utf8 the words with accents and ñ looks like an interrogation > > symbol, what can I do to fix this? > > If the data you are sending are encoded in WINDOWS-1252 (I assume that > "1952" is just a typo), you should set the client encoding to WIN1252, > so that PostgreSQL knows how to convert the data correctly. > > You can do that in several ways; the simplest might be to set the > environment variable PGCLIENTENCODING to WIN1252. > > Yours, > Laurenz Albe
Attachment
{kind=link}
{kind=link}
On 12/9/23 07:41, Igniris Valdivia Baez wrote: > hello, thank you for answering, it's not a typo, in the attachments > you can see that this is actually my collation, algo a pic of the > problem for more clarification, > thank you all You picture shows the database collation as Spanish_Cuba.1252 not the Spanish_Cuba.1952 you originally indicated. 1) Which is the above for the production database or the dev one? 2) What are the exact settings for the other database? > best regards > > El sáb, 9 dic 2023 a las 1:01, Laurenz Albe > (<laurenz.albe@cybertec.at>) escribió: >> >> On Fri, 2023-12-08 at 23:58 -0500, Igniris Valdivia Baez wrote: >>> hello, I have an ETL process collecting data from a postgresql >>> database and xls files and inserting in a postgresql database that >>> process occurs great in a local DB in postgres 14 with UTF8 >>> codification and Spanish_Cuba.1952 collation but when I execute that >>> process in dev which is in postgres 15 and UTF8 with collation >>> en_US.utf8 the words with accents and ñ looks like an interrogation >>> symbol, what can I do to fix this? >> >> If the data you are sending are encoded in WINDOWS-1252 (I assume that >> "1952" is just a typo), you should set the client encoding to WIN1252, >> so that PostgreSQL knows how to convert the data correctly. >> >> You can do that in several ways; the simplest might be to set the >> environment variable PGCLIENTENCODING to WIN1252. >> >> Yours, >> Laurenz Albe -- Adrian Klaver adrian.klaver@aklaver.com
this is the settings for my local db which I failed to say is also in Postgres 14, the dev db is in Postgres 15.4 has UTF an en_US.utf8 collation, for the ETL process I'm using Pentaho Data Integration tool, also known as kettle, thanks in advance El sáb, 9 dic 2023 a las 10:50, Adrian Klaver (<adrian.klaver@aklaver.com>) escribió: > > On 12/9/23 07:41, Igniris Valdivia Baez wrote: > > hello, thank you for answering, it's not a typo, in the attachments > > you can see that this is actually my collation, algo a pic of the > > problem for more clarification, > > thank you all > > You picture shows the database collation as Spanish_Cuba.1252 not the > Spanish_Cuba.1952 you originally indicated. > > 1) Which is the above for the production database or the dev one? > > 2) What are the exact settings for the other database? > > > > best regards > > > > El sáb, 9 dic 2023 a las 1:01, Laurenz Albe > > (<laurenz.albe@cybertec.at>) escribió: > >> > >> On Fri, 2023-12-08 at 23:58 -0500, Igniris Valdivia Baez wrote: > >>> hello, I have an ETL process collecting data from a postgresql > >>> database and xls files and inserting in a postgresql database that > >>> process occurs great in a local DB in postgres 14 with UTF8 > >>> codification and Spanish_Cuba.1952 collation but when I execute that > >>> process in dev which is in postgres 15 and UTF8 with collation > >>> en_US.utf8 the words with accents and ñ looks like an interrogation > >>> symbol, what can I do to fix this? > >> > >> If the data you are sending are encoded in WINDOWS-1252 (I assume that > >> "1952" is just a typo), you should set the client encoding to WIN1252, > >> so that PostgreSQL knows how to convert the data correctly. > >> > >> You can do that in several ways; the simplest might be to set the > >> environment variable PGCLIENTENCODING to WIN1252. > >> > >> Yours, > >> Laurenz Albe > > -- > Adrian Klaver > adrian.klaver@aklaver.com >
On 12/9/23 07:54, Igniris Valdivia Baez wrote: > this is the settings for my local db which I failed to say is also in > Postgres 14, the dev db is in Postgres 15.4 has UTF an en_US.utf8 > collation, for the ETL process I'm using Pentaho Data Integration > tool, also known as kettle, thanks in advance The basic issue is that the receiving database(dev/15.4) assumes it is receiving UTF8 when in fact it is receiving Spanish_Cuba.1252. The suggestion from Laurenz Albe was to set PGCLIENTENCODING = WIN1252 to provide the receiving database the information it needed to make the proper conversion. This works for libpq(https://www.postgresql.org/docs/current/libpq-envars.html) based clients or a client that otherwise 'knows' about PGCLIENTENCODING. I have no idea whether Pentaho Kettle would make use of PGCLIENTENCODING. Some searching indicated that you can set character/encoding options in the Pentaho connection dialog. > > El sáb, 9 dic 2023 a las 10:50, Adrian Klaver > (<adrian.klaver@aklaver.com>) escribió: >> >> On 12/9/23 07:41, Igniris Valdivia Baez wrote: >>> hello, thank you for answering, it's not a typo, in the attachments >>> you can see that this is actually my collation, algo a pic of the >>> problem for more clarification, >>> thank you all >> >> You picture shows the database collation as Spanish_Cuba.1252 not the >> Spanish_Cuba.1952 you originally indicated. >> >> 1) Which is the above for the production database or the dev one? >> >> 2) What are the exact settings for the other database? >> >> >>> best regards >>> >>> El sáb, 9 dic 2023 a las 1:01, Laurenz Albe >>> (<laurenz.albe@cybertec.at>) escribió: >>>> >>>> On Fri, 2023-12-08 at 23:58 -0500, Igniris Valdivia Baez wrote: >>>>> hello, I have an ETL process collecting data from a postgresql >>>>> database and xls files and inserting in a postgresql database that >>>>> process occurs great in a local DB in postgres 14 with UTF8 >>>>> codification and Spanish_Cuba.1952 collation but when I execute that >>>>> process in dev which is in postgres 15 and UTF8 with collation >>>>> en_US.utf8 the words with accents and ñ looks like an interrogation >>>>> symbol, what can I do to fix this? >>>> >>>> If the data you are sending are encoded in WINDOWS-1252 (I assume that >>>> "1952" is just a typo), you should set the client encoding to WIN1252, >>>> so that PostgreSQL knows how to convert the data correctly. >>>> >>>> You can do that in several ways; the simplest might be to set the >>>> environment variable PGCLIENTENCODING to WIN1252. >>>> >>>> Yours, >>>> Laurenz Albe >> >> -- >> Adrian Klaver >> adrian.klaver@aklaver.com >> -- Adrian Klaver adrian.klaver@aklaver.com
hello to all, thanks for your answers i've changed the encoding using this: ALTER DATABASE testdb SET client_encoding = WIN1252; now when we try to select data from a table we get this error: ERROR: character with byte sequence 0xe2 0x80 0x8b in encoding "UTF8" has no equivalent in encoding "WIN1252" SQL state: 22P05ERROR: character with byte sequence 0xe2 0x80 0x8b in encoding "UTF8" has no equivalent in encoding "WIN1252" SQL state: 22P05 i want to clarify that the postgres on dev is in a docker environment that already have databases in it so we can't change encoding for the hole container thanks in advance El sáb, 9 dic 2023 a las 1:01, Laurenz Albe (<laurenz.albe@cybertec.at>) escribió: > > On Fri, 2023-12-08 at 23:58 -0500, Igniris Valdivia Baez wrote: > > hello, I have an ETL process collecting data from a postgresql > > database and xls files and inserting in a postgresql database that > > process occurs great in a local DB in postgres 14 with UTF8 > > codification and Spanish_Cuba.1952 collation but when I execute that > > process in dev which is in postgres 15 and UTF8 with collation > > en_US.utf8 the words with accents and ñ looks like an interrogation > > symbol, what can I do to fix this? > > If the data you are sending are encoded in WINDOWS-1252 (I assume that > "1952" is just a typo), you should set the client encoding to WIN1252, > so that PostgreSQL knows how to convert the data correctly. > > You can do that in several ways; the simplest might be to set the > environment variable PGCLIENTENCODING to WIN1252. > > Yours, > Laurenz Albe
On 12/11/23 10:54 AM, Igniris Valdivia Baez wrote: > hello to all, thanks for your answers i've changed the encoding using this: > ALTER DATABASE testdb > SET client_encoding = WIN1252; > > now when we try to select data from a table we get this error: > > ERROR: character with byte sequence 0xe2 0x80 0x8b in encoding "UTF8" > has no equivalent in encoding "WIN1252" SQL state: 22P05ERROR: > character with byte sequence 0xe2 0x80 0x8b in encoding "UTF8" has no > equivalent in encoding "WIN1252" SQL state: 22P05 That is not surprising as your database has per a previous post from you: "... postgres 15 and UTF8 with collation en_US.utf8 ..." It is entirely possible there are values in the database that have no corresponding sequence in WIN1252. At this point you will need to stick to UTF8. > > i want to clarify that the postgres on dev is in a docker environment > that already have databases in it so we can't change encoding for the > hole container > > thanks in advance > > El sáb, 9 dic 2023 a las 1:01, Laurenz Albe > (<laurenz.albe@cybertec.at>) escribió: >> On Fri, 2023-12-08 at 23:58 -0500, Igniris Valdivia Baez wrote: >>> hello, I have an ETL process collecting data from a postgresql >>> database and xls files and inserting in a postgresql database that >>> process occurs great in a local DB in postgres 14 with UTF8 >>> codification and Spanish_Cuba.1952 collation but when I execute that >>> process in dev which is in postgres 15 and UTF8 with collation >>> en_US.utf8 the words with accents and ñ looks like an interrogation >>> symbol, what can I do to fix this? >> If the data you are sending are encoded in WINDOWS-1252 (I assume that >> "1952" is just a typo), you should set the client encoding to WIN1252, >> so that PostgreSQL knows how to convert the data correctly. >> >> You can do that in several ways; the simplest might be to set the >> environment variable PGCLIENTENCODING to WIN1252. >> >> Yours, >> Laurenz Albe >
On Mon, 2023-12-11 at 13:54 -0500, Igniris Valdivia Baez wrote: > El sáb, 9 dic 2023 a las 1:01, Laurenz Albe (<laurenz.albe@cybertec.at>) escribió: > > > > On Fri, 2023-12-08 at 23:58 -0500, Igniris Valdivia Baez wrote: > > > hello, I have an ETL process collecting data from a postgresql > > > database and xls files and inserting in a postgresql database that > > > process occurs great in a local DB in postgres 14 with UTF8 > > > codification and Spanish_Cuba.1952 collation but when I execute that > > > process in dev which is in postgres 15 and UTF8 with collation > > > en_US.utf8 the words with accents and ñ looks like an interrogation > > > symbol, what can I do to fix this? > > > > If the data you are sending are encoded in WINDOWS-1252 (I assume that > > "1952" is just a typo), you should set the client encoding to WIN1252, > > so that PostgreSQL knows how to convert the data correctly. > > > > You can do that in several ways; the simplest might be to set the > > environment variable PGCLIENTENCODING to WIN1252. > > hello to all, thanks for your answers i've changed the encoding using this: > ALTER DATABASE testdb > SET client_encoding = WIN1252; > > now when we try to select data from a table we get this error: > > ERROR: character with byte sequence 0xe2 0x80 0x8b in encoding "UTF8" > has no equivalent in encoding "WIN1252" SQL state: 22P05ERROR: > character with byte sequence 0xe2 0x80 0x8b in encoding "UTF8" has no > equivalent in encoding "WIN1252" SQL state: 22P05 So that was not the correct encoding. Unfortunately your problem description lacks the precision required to give a certain answer. You'll have to figure out what encoding the application data have and how the client encoding is set in the case where the non-ASCII characters look right and when the don't. You should also investigate what bytes are actually stored in the database in both cases. Yours, Laurenz Albe
Igniris Valdivia Baez wrote: > hello, thank you for answering, it's not a typo, in the attachments > you can see that this is actually my collation, algo a pic of the > problem for more clarification, This character is meant to replace undisplayable characters: From https://en.wikipedia.org/wiki/Specials_(Unicode_block): U+FFFD � REPLACEMENT CHARACTER used to replace an unknown, unrecognised, or unrepresentable character It would useful to know whether: - this code point U+FFFD is in the database contents in places where accented characters should be. In this case the SQL client is just faithfully displaying it and the problem is not on its side. - or whether the database contains the accented characters normally encoded in UTF8. In this case there's a configuration mismatch on the SQL client side when reading. To break down a string into code points to examine it, a query like the following can be used, where you replace SELECT 'somefield' with a query that selects a suspicious string from your actual table: WITH string(x) AS ( SELECT 'somefield' ) SELECT c, to_hex(ascii(c)) AS codepoint FROM string CROSS JOIN LATERAL regexp_split_to_table(x, '') AS c ; Best regards, -- Daniel Vérité https://postgresql.verite.pro/ Twitter: @DanielVerite
this is the result I got, now I have to figure it out how to solve it, thank you so much El mar, 12 dic 2023 a las 14:42, Daniel Verite (<daniel@manitou-mail.org>) escribió: > > Igniris Valdivia Baez wrote: > > > hello, thank you for answering, it's not a typo, in the attachments > > you can see that this is actually my collation, algo a pic of the > > problem for more clarification, > > This character is meant to replace undisplayable characters: > > From https://en.wikipedia.org/wiki/Specials_(Unicode_block): > > U+FFFD � REPLACEMENT CHARACTER used to replace an unknown, > unrecognised, or unrepresentable character > > It would useful to know whether: > > - this code point U+FFFD is in the database contents in places > where accented characters should be. In this case the SQL client is > just faithfully displaying it and the problem is not on its side. > > - or whether the database contains the accented characters normally > encoded in UTF8. In this case there's a configuration mismatch on the > SQL client side when reading. > > To break down a string into code points to examine it, a query like > the following can be used, where you replace SELECT 'somefield' > with a query that selects a suspicious string from your actual table: > > WITH string(x) AS ( > SELECT 'somefield' > ) > SELECT > c, > to_hex(ascii(c)) AS codepoint > FROM > string CROSS JOIN LATERAL regexp_split_to_table(x, '') AS c > ; > > > Best regards, > -- > Daniel Vérité > https://postgresql.verite.pro/ > Twitter: @DanielVerite
Attachment
{kind=link}
On Tue, 2023-12-12 at 15:44 -0500, Igniris Valdivia Baez wrote: > this is the result I got, now I have to figure it out how to solve it, Since you already have a replacement character in the database, the software that stores the data in the database must be responsible. PostgreSQL doesn't convert characters to replacement characters. Yours, Laurenz Albe
On 12/12/23 12:44, Igniris Valdivia Baez wrote: > this is the result I got, now I have to figure it out how to solve it, > thank you so much In what client are you viewing the data? -- Adrian Klaver adrian.klaver@aklaver.com
On 12/11/23 10:54, Igniris Valdivia Baez wrote: > hello to all, thanks for your answers i've changed the encoding using this: > ALTER DATABASE testdb > SET client_encoding = WIN1252; > > now when we try to select data from a table we get this error: > > ERROR: character with byte sequence 0xe2 0x80 0x8b in encoding "UTF8" > has no equivalent in encoding "WIN1252" SQL state: 22P05ERROR: > character with byte sequence 0xe2 0x80 0x8b in encoding "UTF8" has no > equivalent in encoding "WIN1252" SQL state: 22P05 > > i want to clarify that the postgres on dev is in a docker environment > that already have databases in it so we can't change encoding for the > hole container You don't have to: https://www.postgresql.org/docs/current/manage-ag-templatedbs.html Another common reason for copying template0 instead of template1 is that new encoding and locale settings can be specified when copying template0, whereas a copy of template1 must use the same settings it does. This is because template1 might contain encoding-specific or locale-specific data, while template0 is known not to. > > thanks in advance > > El sáb, 9 dic 2023 a las 1:01, Laurenz Albe > (<laurenz.albe@cybertec.at>) escribió: >> >> On Fri, 2023-12-08 at 23:58 -0500, Igniris Valdivia Baez wrote: >>> hello, I have an ETL process collecting data from a postgresql >>> database and xls files and inserting in a postgresql database that >>> process occurs great in a local DB in postgres 14 with UTF8 >>> codification and Spanish_Cuba.1952 collation but when I execute that >>> process in dev which is in postgres 15 and UTF8 with collation >>> en_US.utf8 the words with accents and ñ looks like an interrogation >>> symbol, what can I do to fix this? >> >> If the data you are sending are encoded in WINDOWS-1252 (I assume that >> "1952" is just a typo), you should set the client encoding to WIN1252, >> so that PostgreSQL knows how to convert the data correctly. >> >> You can do that in several ways; the simplest might be to set the >> environment variable PGCLIENTENCODING to WIN1252. >> >> Yours, >> Laurenz Albe > > -- Adrian Klaver adrian.klaver@aklaver.com
On 12/12/23 15:54, Igniris Valdivia Baez wrote: Please use Reply All to reply to list also Ccing list > PgAdmin 4 but it looks the same in the console and from postman. > I believe that the problem is the xls that is generated from a postgres > database opened in Windows to fulfill a review requirement and imported > again using Pentaho, because I'm moving another data using the same > environment and it's fine the difference is the review xls Huh, where did that come from? At no point previously have you indicated xls(Excel?) was involved. Provide a more detailed explanation that the route the data is taking to get to the database. > Thank you > > El mar., 12 de diciembre de 2023 6:04 p. m., Adrian Klaver > <adrian.klaver@aklaver.com <mailto:adrian.klaver@aklaver.com>> escribió: > > On 12/12/23 12:44, Igniris Valdivia Baez wrote: > > this is the result I got, now I have to figure it out how to > solve it, > > thank you so much > > In what client are you viewing the data? > > > -- > Adrian Klaver > adrian.klaver@aklaver.com <mailto:adrian.klaver@aklaver.com> > -- Adrian Klaver adrian.klaver@aklaver.com
Hello to all, to clarify the data is moving this way:
1. The data is extracted from a database in postgres using Pentaho(Kettle)
2. Here is there is a bifurcation some data is loaded into the destiny database and behaves fine the other scenario the data is saved in xls files to be reviewed
3. After the revision the data is loaded to the destiny database and here is were I believe the issue is, because the data is reviewed in Windows and somehow Pentaho is not understanding correctly the interaction between both operating systems.
PD: when the hole operation is executed in Windows it never fails
Thank you all
El mar., 12 de diciembre de 2023 7:00 p. m., Adrian Klaver <adrian.klaver@aklaver.com> escribió:
On 12/12/23 15:54, Igniris Valdivia Baez wrote:
Please use Reply All to reply to list also
Ccing list
> PgAdmin 4 but it looks the same in the console and from postman.
> I believe that the problem is the xls that is generated from a postgres
> database opened in Windows to fulfill a review requirement and imported
> again using Pentaho, because I'm moving another data using the same
> environment and it's fine the difference is the review xls
Huh, where did that come from?
At no point previously have you indicated xls(Excel?) was involved.
Provide a more detailed explanation that the route the data is taking to
get to the database.
> Thank you
>
> El mar., 12 de diciembre de 2023 6:04 p. m., Adrian Klaver
> <adrian.klaver@aklaver.com <mailto:adrian.klaver@aklaver.com>> escribió:
>
> On 12/12/23 12:44, Igniris Valdivia Baez wrote:
> > this is the result I got, now I have to figure it out how to
> solve it,
> > thank you so much
>
> In what client are you viewing the data?
>
>
> --
> Adrian Klaver
> adrian.klaver@aklaver.com <mailto:adrian.klaver@aklaver.com>
>
--
Adrian Klaver
adrian.klaver@aklaver.com
On 12/12/23 16:09, Igniris Valdivia Baez wrote: > Hello to all, to clarify the data is moving this way: > 1. The data is extracted from a database in postgres using Pentaho(Kettle) > 2. Here is there is a bifurcation some data is loaded into the destiny > database and behaves fine the other scenario the data is saved in xls > files to be reviewed How is saved to xls files? > 3. After the revision the data is loaded to the destiny database and > here is were I believe the issue is, because the data is reviewed in > Windows and somehow Pentaho is not understanding correctly the > interaction between both operating systems. Defined reviewed, on particular is the data changed? How is transferred from xls to to the database? Is the data reviewed in Excel only on one machine or many? What the locales/encodings/character sets involved? > > PD: when the hole operation is executed in Windows it never fails Define what you mean by whole operation done in Windows. > Thank you all -- Adrian Klaver adrian.klaver@aklaver.com
Hello, How is saved to xls files? --- using pentaho there is a tool there to output data in different formats in this case xls Defined reviewed, on particular is the data changed? ---Yes, some descriptions are changed How is transferred from xls to to the database? --- Using pentaho there is a tool there to load the data in different formats in this case xls Is the data reviewed in Excel only on one machine or many? ---only in one machine What the locales/encodings/character sets involved? ---UTF 8 location spanish_Cuba.1252 Define what you mean by whole operation done in Windows.--- When the process is executed in my local machine which is in windows there are no issues, when it move to dev environment which is in linux but the xls is still reviewed in windows the load throws data with the U+FFFD � REPLACEMENT CHARACTER. best regards El mié, 13 dic 2023 a las 0:19, Adrian Klaver (<adrian.klaver@aklaver.com>) escribió: > > On 12/12/23 16:09, Igniris Valdivia Baez wrote: > > Hello to all, to clarify the data is moving this way: > > 1. The data is extracted from a database in postgres using Pentaho(Kettle) > > 2. Here is there is a bifurcation some data is loaded into the destiny > > database and behaves fine the other scenario the data is saved in xls > > files to be reviewed > > How is saved to xls files? > > > 3. After the revision the data is loaded to the destiny database and > > here is were I believe the issue is, because the data is reviewed in > > Windows and somehow Pentaho is not understanding correctly the > > interaction between both operating systems. > > Defined reviewed, on particular is the data changed? > > How is transferred from xls to to the database? > > Is the data reviewed in Excel only on one machine or many? > > What the locales/encodings/character sets involved? > > > > > PD: when the hole operation is executed in Windows it never fails > > Define what you mean by whole operation done in Windows. > > > Thank you all > > > -- > Adrian Klaver > adrian.klaver@aklaver.com >
Igniris Valdivia Baez wrote: > 3. After the revision the data is loaded to the destiny database and > here is were I believe the issue is, because the data is reviewed in > Windows and somehow Pentaho is not understanding correctly the > interaction between both operating systems. On Windows, a system in spanish would plausibly use https://en.wikipedia.org/wiki/Windows-1252 as the default codepage. On Unix, it might use UTF-8, with a locale like maybe es_CU.UTF-8. Now if a certain component of your data pipeline assumes that the input data is in the default encoding of the system, and the input data appears to be always encoded with Windows-1252, then only the version running on Windows will have it right. The one that runs on Unix might translate the bytes that do not meet its encoding expectations into the U+FFFD code point. At least that's a plausible explanation for the result you're seeing in the Postgres database. A robust solution is to not use defaults for encodings and explicitly declare the encoding of every input throughout the data pipeline. Best regards, -- Daniel Vérité https://postgresql.verite.pro/ Twitter: @DanielVerite
On 12/13/23 06:42, Igniris Valdivia Baez wrote: > Hello, > How is saved to xls files? --- using pentaho there is a tool there to > output data in different formats in this case xls > Defined reviewed, on particular is the data changed? ---Yes, some > descriptions are changed > How is transferred from xls to to the database? --- Using pentaho > there is a tool there to load the data in different formats in this > case xls > Is the data reviewed in Excel only on one machine or many? ---only in > one machine > What the locales/encodings/character sets involved? ---UTF 8 location > spanish_Cuba.1252 > Define what you mean by whole operation done in Windows.--- When the > process is executed in my local machine which is in windows there are > no issues, when it move to dev environment which is in linux but the > xls is still reviewed in windows the load throws data with the U+FFFD As Daniel Vérité pointed out the above is moving through many steps across multiple systems. The fact that you see the issue when moving the data from Windows --> Linux indicates this is the point of concern. In other words you need to determine what locale/character set you are working in on the Windows machine and what you are transferring it to on the Linux machine. Then make the appropriate adjustments. This is sort of generic answer as it is still not clear to me what the exact settings are in Windows(xls) and Linux(Postgres). As a side note and possible alternative, why not just move the data(via Pentaho) into the dev database into a staging table. Then have a form that the reviewer can use to correct the data, after which it can be moved into the final table. This cuts out an OS transfer. > � REPLACEMENT CHARACTER. > best regards > -- Adrian Klaver adrian.klaver@aklaver.com
Hello to all, we have found the solution to our accents problem, a colleague of mine got the idea to use xlsx instead of xls and the magic happened, thanks to all for your support best regards El mié, 13 dic 2023 a las 0:19, Adrian Klaver (<adrian.klaver@aklaver.com>) escribió: > > On 12/12/23 16:09, Igniris Valdivia Baez wrote: > > Hello to all, to clarify the data is moving this way: > > 1. The data is extracted from a database in postgres using Pentaho(Kettle) > > 2. Here is there is a bifurcation some data is loaded into the destiny > > database and behaves fine the other scenario the data is saved in xls > > files to be reviewed > > How is saved to xls files? > > > 3. After the revision the data is loaded to the destiny database and > > here is were I believe the issue is, because the data is reviewed in > > Windows and somehow Pentaho is not understanding correctly the > > interaction between both operating systems. > > Defined reviewed, on particular is the data changed? > > How is transferred from xls to to the database? > > Is the data reviewed in Excel only on one machine or many? > > What the locales/encodings/character sets involved? > > > > > PD: when the hole operation is executed in Windows it never fails > > Define what you mean by whole operation done in Windows. > > > Thank you all > > > -- > Adrian Klaver > adrian.klaver@aklaver.com >