Thread: Re: BUG #17876: Function width_bucket() for float8 input returns value out of range
Re: BUG #17876: Function width_bucket() for float8 input returns value out of range
From
Mats Kindahl
Date:
Hi all,
Attached is a proposed fix for the issue. It has extended the tests to cover these cases and also some additional tests for values close to DBL_MIN. I compared the old and new version using the attached program with the following result:
DBL_MAX: 1.797693e+308, DBL_MIN: 2.225074e-308
1.04000e+01, low: -1.79769e+308, high: 1.79769e+308, count: 10 --> orig: -2147483648, new: 6
-8.98847e+307, low: -1.79769e+308, high: 1.79769e+308, count: 10 --> orig: -2147483648, new: 3
8.98847e+307, low: -1.79769e+308, high: 1.79769e+308, count: 10 --> orig: -2147483648, new: 8
1.04000e+01, low: -1.79769e+308, high: 1.79769e+308, count: 12 --> orig: -2147483648, new: 7
-8.98847e+307, low: -1.79769e+308, high: 1.79769e+308, count: 12 --> orig: -2147483648, new: 4
8.98847e+307, low: -1.79769e+308, high: 1.79769e+308, count: 12 --> orig: -2147483648, new: 10
1.04000e+01, low: -1.79769e+308, high: 1.79769e+308, count: 1 --> orig: 1, new: 1
-8.98847e+307, low: -1.79769e+308, high: 1.79769e+308, count: 1 --> orig: 1, new: 1
8.98847e+307, low: -1.79769e+308, high: 1.79769e+308, count: 1 --> orig: -2147483648, new: 1
1.04000e+01, low: -1.79769e+308, high: 1.79769e+308, count: 2 --> orig: -2147483648, new: 2
-8.98847e+307, low: -1.79769e+308, high: 1.79769e+308, count: 2 --> orig: 1, new: 1
8.98847e+307, low: -1.79769e+308, high: 1.79769e+308, count: 2 --> orig: -2147483648, new: 2
5.35000e+00, low: 2.40000e-02, high: 1.00600e+01, count: 5 --> orig: 3, new: 3
2.22507e-308, low: -4.45015e-308, high: 4.45015e-308, count: 4 --> orig: 4, new: 4
-2.22507e-308, low: -4.45015e-308, high: 4.45015e-308, count: 4 --> orig: 2, new: 2
2.22507e-308, low: -6.67522e-308, high: 6.67522e-308, count: 4 --> orig: 3, new: 3
-2.22507e-308, low: -6.67522e-308, high: 6.67522e-308, count: 4 --> orig: 2, new: 2
2.22507e-308, low: -6.67522e-308, high: 6.67522e-308, count: 6 --> orig: 5, new: 5
-2.22507e-308, low: -6.67522e-308, high: 6.67522e-308, count: 6 --> orig: 3, new: 3
1.04000e+01, low: -1.79769e+308, high: 1.79769e+308, count: 10 --> orig: -2147483648, new: 6
-8.98847e+307, low: -1.79769e+308, high: 1.79769e+308, count: 10 --> orig: -2147483648, new: 3
8.98847e+307, low: -1.79769e+308, high: 1.79769e+308, count: 10 --> orig: -2147483648, new: 8
1.04000e+01, low: -1.79769e+308, high: 1.79769e+308, count: 12 --> orig: -2147483648, new: 7
-8.98847e+307, low: -1.79769e+308, high: 1.79769e+308, count: 12 --> orig: -2147483648, new: 4
8.98847e+307, low: -1.79769e+308, high: 1.79769e+308, count: 12 --> orig: -2147483648, new: 10
1.04000e+01, low: -1.79769e+308, high: 1.79769e+308, count: 1 --> orig: 1, new: 1
-8.98847e+307, low: -1.79769e+308, high: 1.79769e+308, count: 1 --> orig: 1, new: 1
8.98847e+307, low: -1.79769e+308, high: 1.79769e+308, count: 1 --> orig: -2147483648, new: 1
1.04000e+01, low: -1.79769e+308, high: 1.79769e+308, count: 2 --> orig: -2147483648, new: 2
-8.98847e+307, low: -1.79769e+308, high: 1.79769e+308, count: 2 --> orig: 1, new: 1
8.98847e+307, low: -1.79769e+308, high: 1.79769e+308, count: 2 --> orig: -2147483648, new: 2
5.35000e+00, low: 2.40000e-02, high: 1.00600e+01, count: 5 --> orig: 3, new: 3
2.22507e-308, low: -4.45015e-308, high: 4.45015e-308, count: 4 --> orig: 4, new: 4
-2.22507e-308, low: -4.45015e-308, high: 4.45015e-308, count: 4 --> orig: 2, new: 2
2.22507e-308, low: -6.67522e-308, high: 6.67522e-308, count: 4 --> orig: 3, new: 3
-2.22507e-308, low: -6.67522e-308, high: 6.67522e-308, count: 4 --> orig: 2, new: 2
2.22507e-308, low: -6.67522e-308, high: 6.67522e-308, count: 6 --> orig: 5, new: 5
-2.22507e-308, low: -6.67522e-308, high: 6.67522e-308, count: 6 --> orig: 3, new: 3
As you can see, the old and new computations seem to produce the same values also for values close to DBL_MIN.
On Wed, Mar 29, 2023 at 10:12 AM PG Bug reporting form <noreply@postgresql.org> wrote:
The following bug has been logged on the website:
Bug reference: 17876
Logged by: Mats Kindahl
Email address: mats@timescale.com
PostgreSQL version: 15.2
Operating system: All
Description:
On 64-bit platforms, the existing width_bucket() computation can
result in a NaN (0x8000000) if the difference between the `operand`,
`low`, or `high` parameters exceeds DBL_MAX. This is then cast to the
value -2147483648.
mats=# WITH sample(operand, low, high, cnt) AS (
VALUES
(10.5::float8, -1.797e+308::float8, 1.797e+308::float8, 1::int4),
(10.5::float8, -1.797e+308::float8, 1.797e+308::float8, 2),
(10.5::float8, -1.797e+308::float8, 1.797e+308::float8, 3),
(1.797e+308::float8 / 2, -1.797e+308::float8, 1.797e+308::float8, 10),
(-1.797e+308::float8 / 2, -1.797e+308::float8, 1.797e+308::float8, 10),
(1.797e+308::float8 / 2, -1.797e+308::float8, 1.797e+308::float8, 16),
(-1.797e+308::float8 / 2, -1.797e+308::float8, 1.797e+308::float8, 16),
(1.797e+308::float8, -1.797e+308::float8 / 2, 1.797e+308::float8 / 2,
10),
(-1.797e+308::float8, -1.797e+308::float8 / 2, 1.797e+308::float8 / 2,
10)
) SELECT width_bucket(operand, low, high, cnt) FROM sample;
width_bucket
--------------
1
-2147483648
-2147483648
-2147483648
-2147483648
-2147483648
-2147483648
11
0
(9 rows)
Attachment
Re: BUG #17876: Function width_bucket() for float8 input returns value out of range
From
Tom Lane
Date:
Mats Kindahl <mats@timescale.com> writes:
> Attached is a proposed fix for the issue.
Hm. Aren't you replacing a risk of overflow with a risk of underflow?
I'd be happier about doing this only if isinf(bound2 - bound1), or
the reverse for the other path. (Seems like we shouldn't need to
check the operand diff separately.)
regards, tom lane
Re: BUG #17876: Function width_bucket() for float8 input returns value out of range
From
Mats Kindahl
Date:
On Wed, Mar 29, 2023 at 2:33 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
Mats Kindahl <mats@timescale.com> writes:
> Attached is a proposed fix for the issue.
Hm. Aren't you replacing a risk of overflow with a risk of underflow?
I'd be happier about doing this only if isinf(bound2 - bound1), or
the reverse for the other path. (Seems like we shouldn't need to
check the operand diff separately.)
Yes, I was wondering the same which is why I was adding these tests as a separate file to see if I could force a bad bucket. It seems to be hard to construct a case where the underflow would cause a change in the result.
However, better safe than sorry, so I modified the patch to include the check. And yes, you're right in that there is no need to check for the operand diff since the previous checks guarantee that the operand is between the bounds, and since the diff between the bounds is not infinite, the diff between the operand and any of the bounds cannot be infinite. Added a comment to that effect to the patch as well.
Best wishes,
Mats Kindahl, Timescale
regards, tom lane
Attachment
Re: BUG #17876: Function width_bucket() for float8 input returns value out of range
From
Tom Lane
Date:
Mats Kindahl <mats@timescale.com> writes:
> However, better safe than sorry, so I modified the patch to include the
> check. And yes, you're right in that there is no need to check for the
> operand diff since the previous checks guarantee that the operand is
> between the bounds, and since the diff between the bounds is not infinite,
> the diff between the operand and any of the bounds cannot be infinite.
> Added a comment to that effect to the patch as well.
I looked this over and noted two problems:
* You missed fixing the mirror code path (bound1 > bound2).
* It seems at least possible that, for an operand just slightly less
than bound2, the quotient ((operand - bound1) / (bound2 - bound1))
could round to exactly 1, even though it should theoretically always
be in [0, 1). If that did happen, and count is INT_MAX, then the final
addition of 1 would create its own possibility of integer overflow.
We have code to check that but it's only applied in the operand >= bound2
case. I fixed that by moving the overflow-aware addition of 1 to the
bottom of the function so it's done in all cases, and adjusting the other
code paths to account for that.
Pushed with those changes and some cosmetic tweaking.
regards, tom lane
Re: BUG #17876: Function width_bucket() for float8 input returns value out of range
From
Mats Kindahl
Date:
On Thu, Mar 30, 2023 at 5:35 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
Mats Kindahl <mats@timescale.com> writes:
> However, better safe than sorry, so I modified the patch to include the
> check. And yes, you're right in that there is no need to check for the
> operand diff since the previous checks guarantee that the operand is
> between the bounds, and since the diff between the bounds is not infinite,
> the diff between the operand and any of the bounds cannot be infinite.
> Added a comment to that effect to the patch as well.
I looked this over and noted two problems:
* You missed fixing the mirror code path (bound1 > bound2).
* It seems at least possible that, for an operand just slightly less
than bound2, the quotient ((operand - bound1) / (bound2 - bound1))
could round to exactly 1, even though it should theoretically always
be in [0, 1). If that did happen, and count is INT_MAX, then the final
addition of 1 would create its own possibility of integer overflow.
We have code to check that but it's only applied in the operand >= bound2
case. I fixed that by moving the overflow-aware addition of 1 to the
bottom of the function so it's done in all cases, and adjusting the other
code paths to account for that.
Pushed with those changes and some cosmetic tweaking.
Thanks Tom!
regards, tom lane
Re: BUG #17876: Function width_bucket() for float8 input returns value out of range
From
Tom Lane
Date:
Mats Kindahl <mats@timescale.com> writes:
> On Thu, Mar 30, 2023 at 5:35 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> * It seems at least possible that, for an operand just slightly less
>> than bound2, the quotient ((operand - bound1) / (bound2 - bound1))
>> could round to exactly 1, even though it should theoretically always
>> be in [0, 1). If that did happen, and count is INT_MAX, then the final
>> addition of 1 would create its own possibility of integer overflow.
>> We have code to check that but it's only applied in the operand >= bound2
>> case. I fixed that by moving the overflow-aware addition of 1 to the
>> bottom of the function so it's done in all cases, and adjusting the other
>> code paths to account for that.
I realized that it's actually not too hard to make that happen:
regression=# select width_bucket(0, -1e100::float8, 1, 10);
width_bucket
--------------
11
(1 row)
While I'm not bothered too much if rounding affects which internal
bucket a value lands in, it's a bit more annoying if that causes
it to be reported as being in the end bucket, when we know positively
that the value is less than bound2. Is it worth expending more
cycles to prevent this? It'd need to be something like
/* Result of division is surely in [0,1], so this can't overflow */
result = count * ((operand - bound1) / (bound2 - bound1));
+ /* ... but the quotient could round to 1, which would be a lie */
+ if (result >= count)
+ result = count - 1;
and we'd need two or four copies of that depending on whether we want
to refactor some more.
Curiously, width_bucket_numeric has this problem too:
regression=# select width_bucket(0, -1e100::numeric, 1, 10);
width_bucket
--------------
11
(1 row)
I suppose it's also rounding somewhere in there.
regards, tom lane
Re: BUG #17876: Function width_bucket() for float8 input returns value out of range
From
Mats Kindahl
Date:
On Fri, Mar 31, 2023 at 3:14 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
Mats Kindahl <mats@timescale.com> writes:
> On Thu, Mar 30, 2023 at 5:35 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> * It seems at least possible that, for an operand just slightly less
>> than bound2, the quotient ((operand - bound1) / (bound2 - bound1))
>> could round to exactly 1, even though it should theoretically always
>> be in [0, 1). If that did happen, and count is INT_MAX, then the final
>> addition of 1 would create its own possibility of integer overflow.
>> We have code to check that but it's only applied in the operand >= bound2
>> case. I fixed that by moving the overflow-aware addition of 1 to the
>> bottom of the function so it's done in all cases, and adjusting the other
>> code paths to account for that.
I realized that it's actually not too hard to make that happen:
regression=# select width_bucket(0, -1e100::float8, 1, 10);
width_bucket
--------------
11
(1 row)
While I'm not bothered too much if rounding affects which internal
bucket a value lands in, it's a bit more annoying if that causes
it to be reported as being in the end bucket, when we know positively
that the value is less than bound2. Is it worth expending more
cycles to prevent this?
I think it could be. I agree that it does not make sense to select the end bucket when the value is in range, even if just.
It'd need to be something like
/* Result of division is surely in [0,1], so this can't overflow */
result = count * ((operand - bound1) / (bound2 - bound1));
+ /* ... but the quotient could round to 1, which would be a lie */
+ if (result >= count)
+ result = count - 1;
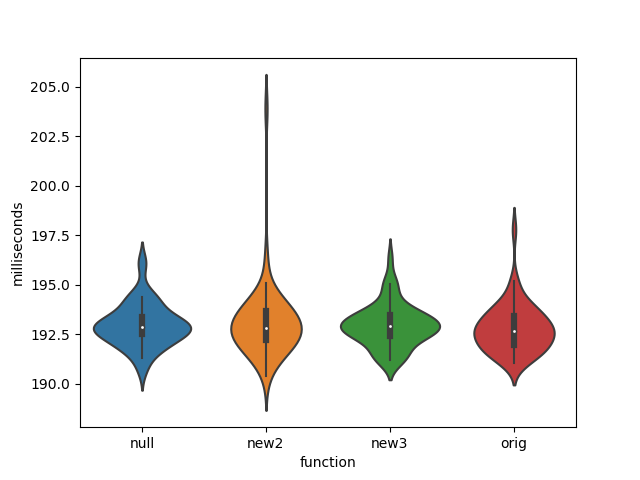
Just doing some quick measurements on the different alternatives, I do not see a big difference in performance between doing this additional check. Have a look at the attached files. You can probably add a few other alternatives to see if it can be improved further. Compiled at -O2.
and we'd need two or four copies of that depending on whether we want
to refactor some more.
Curiously, width_bucket_numeric has this problem too:
regression=# select width_bucket(0, -1e100::numeric, 1, 10);
width_bucket
--------------
11
(1 row)
I suppose it's also rounding somewhere in there.
Best wishes,
Mats Kindahl
regards, tom lane
Attachment
{kind=link}
Re: BUG #17876: Function width_bucket() for float8 input returns value out of range
From
Tom Lane
Date:
Mats Kindahl <mats@timescale.com> writes:
> On Fri, Mar 31, 2023 at 3:14 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> While I'm not bothered too much if rounding affects which internal
>> bucket a value lands in, it's a bit more annoying if that causes
>> it to be reported as being in the end bucket, when we know positively
>> that the value is less than bound2. Is it worth expending more
>> cycles to prevent this?
> I think it could be. I agree that it does not make sense to select the end
> bucket when the value is in range, even if just.
Yeah. I did that already at a2a0c7c29, sorry for not circling back
to this thread.
regards, tom lane