Thread: [PATCH] Use 128-bit math to accelerate numeric division, when 8 < divisor digits <= 16
[PATCH] Use 128-bit math to accelerate numeric division, when 8 < divisor digits <= 16
From
"Joel Jacobson"
Date:
Hi,
On platforms where we support 128bit integers, we could accelerate division
when the number of digits in the divisor is larger than 8 and less than or
equal to 16 digits, i.e. when the divisor that fits in a 64-bit integer but would
not fit in a 32-bit integer.
This patch adds div_var_int64(), which is similar to the existing div_var_int(),
but accepts a 64-bit divisor instead of a 32-bit divisor.
The new function is used within div_var() and div_var_fast().
To measure the effect, we need a volatile wrapper function for numeric_div(),
to avoid it being cached since it's immutable:
CREATE OR REPLACE FUNCTION numeric_div_volatile(numeric,numeric)
RETURNS numeric LANGUAGE internal AS 'numeric_div';
We can then use generate_series() to measure the execution time for lots of
executions. This does not account for the overhead of generate_series() and
count(), but that's okay since the overhead is the same in both measurements,
so the relative difference is still correct.
--
-- Division when the divisor is 8 digits should be unchanged:
--
EXPLAIN ANALYZE
SELECT count(numeric_div_volatile(
repeat('1',131071)::numeric,
repeat('3',8)::numeric
)) FROM generate_series(1,1e4);
-- Execution Time: 1633.722 ms (HEAD)
-- Execution Time: 1680.228 ms (div_var_int64.patch)
--
-- Division when the divisor is 9 digits should be faster:
--
EXPLAIN ANALYZE
SELECT count(numeric_div_volatile(
repeat('1',131071)::numeric,
repeat('3',9)::numeric
)) FROM generate_series(1,1e4);
-- Execution Time: 5444.755 ms (HEAD)
-- Execution Time: 1604.967 ms (div_var_int64.patch)
--
-- Division when the divisor is 16 digits should also be faster:
--
EXPLAIN ANALYZE
SELECT count(numeric_div_volatile(
repeat('1',131071)::numeric,
repeat('3',16)::numeric
)) FROM generate_series(1,1e4);
-- Execution Time: 6072.683 ms (HEAD)
-- Execution Time: 3215.686 ms (div_var_int64.patch)
--
-- Division when the divisor is 17 digits should be unchanged:
--
EXPLAIN ANALYZE
SELECT count(numeric_div_volatile(
repeat('1',131071)::numeric,
repeat('3',17)::numeric
)) FROM generate_series(1,1e4);
-- Execution Time: 6948.150 ms (HEAD)
-- Execution Time: 7010.544 ms (div_var_int64.patch)
--
-- Same tests as above, but with a single digit dividend,
-- and 1e7 executions instead of just 1e4.
--
--
-- Division when the divisor is 8 digits should be unchanged:
--
EXPLAIN ANALYZE
SELECT count(numeric_div_volatile(
1,
repeat('3',8)::numeric
)) FROM generate_series(1,1e7);
-- Execution Time: 1827.567 ms (HEAD)
-- Execution Time: 1828.029 ms (div_var_int64.patch)
--
-- Division when the divisor is 9 digits should be faster:
--
EXPLAIN ANALYZE
SELECT count(numeric_div_volatile(
1,
repeat('3',9)::numeric
)) FROM generate_series(1,1e7);
-- Execution Time: 2314.851 ms (HEAD)
-- Execution Time: 1886.170 ms (div_var_int64.patch)
--
-- Division when the divisor is 16 digits should also be faster:
--
EXPLAIN ANALYZE
SELECT count(numeric_div_volatile(
1,
repeat('3',16)::numeric
)) FROM generate_series(1,1e7);
-- Execution Time: 2244.009 ms (HEAD)
-- Execution Time: 1968.148 ms (div_var_int64.patch)
--
-- Division when the divisor is 17 digits should be unchanged:
--
EXPLAIN ANALYZE
SELECT count(numeric_div_volatile(
1,
repeat('3',17)::numeric
)) FROM generate_series(1,1e7);
-- Execution Time: 2334.896 ms (HEAD)
-- Execution Time: 2338.141 ms (div_var_int64.patch)
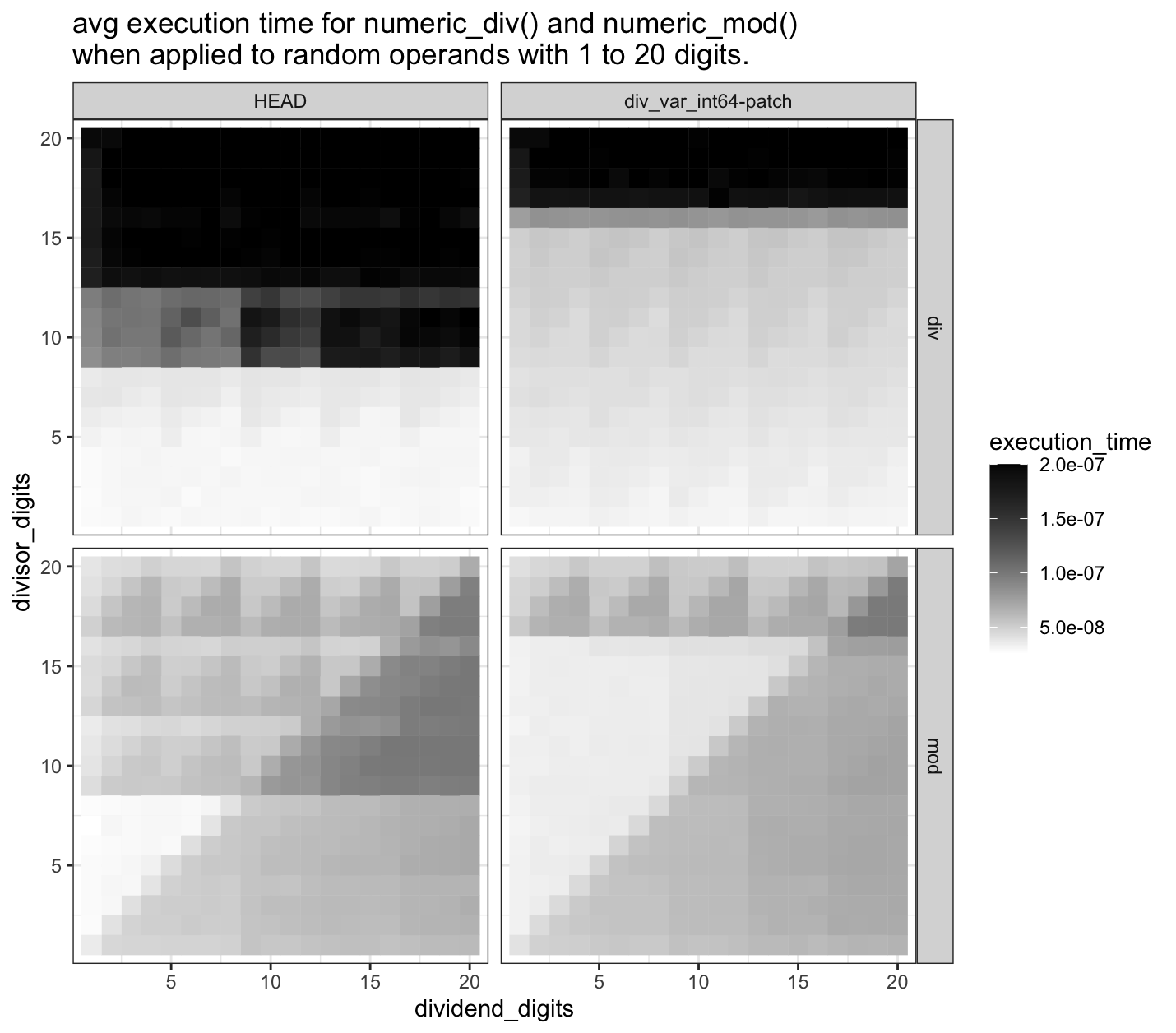
The graph below shows the effect on execution time for numeric_div(),
and also looks at numeric_mod() since it's a heavy user of numeric_div().
The graph was produced by generating 100 random numeric integer values
for each combination of number of dividend/divisor digits between 1 to 20.
In total, that's 20*20*100*2=80000 test values.
As expected, the ceiling for the fast short division is lifted from 8 to 16 divisor digits,
and speedups for modulus is noticed in the same region.
The graph was produced using results from pg-timeit [1] and R for the plotting.
/Joel
Attachment
Re: [PATCH] Use 128-bit math to accelerate numeric division, when 8 < divisor digits <= 16
From
Dean Rasheed
Date:
On Sun, 22 Jan 2023 at 13:42, Joel Jacobson <joel@compiler.org> wrote: > > Hi, > > On platforms where we support 128bit integers, we could accelerate division > when the number of digits in the divisor is larger than 8 and less than or > equal to 16 digits, i.e. when the divisor that fits in a 64-bit integer but would > not fit in a 32-bit integer. > Seems like a reasonable idea, with some pretty decent gains. Note, however, that for a divisor having fewer than 5 or 6 digits, it's now significantly slower because it's forced to go through div_var_int64() instead of div_var_int() for all small divisors. So the var2ndigits <= 2 case needs to come first. The implementation of div_var_int64() should be in an #ifdef HAVE_INT128 block. In div_var_int64(), s/ULONG_MAX/PG_UINT64_MAX/ Regards, Dean
Re: [PATCH] Use 128-bit math to accelerate numeric division, when 8 < divisor digits <= 16
From
"Joel Jacobson"
Date:
On Sun, Jan 22, 2023, at 11:06, Dean Rasheed wrote: > Seems like a reasonable idea, with some pretty decent gains. > > Note, however, that for a divisor having fewer than 5 or 6 digits, > it's now significantly slower because it's forced to go through > div_var_int64() instead of div_var_int() for all small divisors. So > the var2ndigits <= 2 case needs to come first. Can you give a measurable example of when the patch the way it's written is significantly slower for a divisor having fewer than 5 or 6 digits, on some platform? I can't detect any difference at all at my MacBook Pro M1 Max for this example: EXPLAIN ANALYZE SELECT count(numeric_div_volatile(1,3333)) FROM generate_series(1,1e8); I did write the code like you suggest first, but changed it, since I realised the extra "else if" needed could be eliminated, and thought div_var_int64() wouldn't be slower than div_var_int() since I thought 64-bit instructions in general are as fast as 32-bit instructions, on 64-bit platforms. I'm not suggesting your claim is incorrect, I'm just trying to understand and verify it experimentally. > The implementation of div_var_int64() should be in an #ifdef HAVE_INT128 block. > > In div_var_int64(), s/ULONG_MAX/PG_UINT64_MAX/ OK, thanks, I'll fix, but I'll await your feedback first on the above. /Joel
Re: [PATCH] Use 128-bit math to accelerate numeric division, when 8 < divisor digits <= 16
From
Dean Rasheed
Date:
On Sun, 22 Jan 2023 at 15:41, Joel Jacobson <joel@compiler.org> wrote: > > On Sun, Jan 22, 2023, at 11:06, Dean Rasheed wrote: > > Seems like a reasonable idea, with some pretty decent gains. > > > > Note, however, that for a divisor having fewer than 5 or 6 digits, > > it's now significantly slower because it's forced to go through > > div_var_int64() instead of div_var_int() for all small divisors. So > > the var2ndigits <= 2 case needs to come first. > > Can you give a measurable example of when the patch > the way it's written is significantly slower for a divisor having > fewer than 5 or 6 digits, on some platform? > I just modified the previous test you posted: \timing on SELECT count(numeric_div_volatile(1e131071,123456)) FROM generate_series(1,1e4); Time: 2048.060 ms (00:02.048) -- HEAD Time: 2422.720 ms (00:02.423) -- With patch > I did write the code like you suggest first, but changed it, > since I realised the extra "else if" needed could be eliminated, > and thought div_var_int64() wouldn't be slower than div_var_int() since > I thought 64-bit instructions in general are as fast as 32-bit instructions, > on 64-bit platforms. > Apparently it can make a difference. Probably something to do with having less data to move around. I remember noticing that when I wrote div_var_int(), which is why I split it into 2 branches in that way. Regards, Dean
Re: [PATCH] Use 128-bit math to accelerate numeric division, when 8 < divisor digits <= 16
From
"Joel Jacobson"
Date:
On Sun, Jan 22, 2023, at 14:25, Dean Rasheed wrote: > I just modified the previous test you posted: > > \timing on > SELECT count(numeric_div_volatile(1e131071,123456)) FROM generate_series(1,1e4); > > Time: 2048.060 ms (00:02.048) -- HEAD > Time: 2422.720 ms (00:02.423) -- With patch > ... > > Apparently it can make a difference. Probably something to do with > having less data to move around. I remember noticing that when I wrote > div_var_int(), which is why I split it into 2 branches in that way. Many thanks for feedback. Nice catch! New patch attached. Interesting, I'm not able to reproduce this on my MacBook Pro M1 Max: SELECT version; PostgreSQL 16devel on aarch64-apple-darwin22.2.0, compiled by Apple clang version 14.0.0 (clang-1400.0.29.202), 64-bit SELECT count(numeric_div_volatile(1e131071,123456)) FROM generate_series(1,1e 4); Time: 1569.730 ms (00:01.570) - HEAD Time: 1569.918 ms (00:01.570) -- div_var_int64.patch Time: 1569.038 ms (00:01.569) -- div_var_int64-2.patch Just curious, what platform are you on? /Joel
Attachment
Re: [PATCH] Use 128-bit math to accelerate numeric division, when 8 < divisor digits <= 16
From
John Naylor
Date:
On Sun, Jan 22, 2023 at 10:42 PM Joel Jacobson <joel@compiler.org> wrote:
> I did write the code like you suggest first, but changed it,
> since I realised the extra "else if" needed could be eliminated,
> and thought div_var_int64() wouldn't be slower than div_var_int() since
> I thought 64-bit instructions in general are as fast as 32-bit instructions,
> on 64-bit platforms.
According to Agner's instruction tables [1], integer division on Skylake (for example) has a latency of 26 cycles for 32-bit operands, and 42-95 cycles for 64-bit.
[1] https://www.agner.org/optimize/instruction_tables.pdf
Re: [PATCH] Use 128-bit math to accelerate numeric division, when 8 < divisor digits <= 16
From
Dean Rasheed
Date:
On Mon, 23 Jan 2023 at 05:06, John Naylor <john.naylor@enterprisedb.com> wrote: > > According to Agner's instruction tables [1], integer division on Skylake (for example) has a latency of 26 cycles for 32-bitoperands, and 42-95 cycles for 64-bit. > > [1] https://www.agner.org/optimize/instruction_tables.pdf > Thanks, that's a very useful reference. (And I do indeed have one of those CPUs, which explains what I was seeing.) Regards, Dean
Re: [PATCH] Use 128-bit math to accelerate numeric division, when 8 < divisor digits <= 16
From
Dean Rasheed
Date:
On Sun, 22 Jan 2023 at 22:49, Joel Jacobson <joel@compiler.org> wrote: > > Many thanks for feedback. Nice catch! New patch attached. > Cool, that resolves the performance issues I was seeing for smaller divisors (which also had a noticeable impact on the numeric_big regression test). After some more testing, the gains look good to me, and I wasn't able to find any cases where it made things slower, so I've gone ahead and pushed it. Regards, Dean