Thread: Lockless queue of waiters in LWLock
Hi, hackers!
When we take LWlock, we already use atomic CAS operation to atomically modify the lock state even in the presence of concurrent lock-takers. But if we can not take the lock immediately, we need to put the waiters on a waiting list, and currently, this operation is done not atomically and in a complicated way:
- Parts are done under LWLockWaitListLock, which includes a spin delay to take.
- Also, we need a two-step procedure to immediately dequeue if, after adding a current process into a wait queue, it appears that we don’t need to (and can not!) sleep as the lock is already free.
If the lock state contains references to the queue head and tail, we can implement a lockless queue of waiters for the LWLock. Adding new items to the queue head or tail can be done with a single CAS operation (adding to the tail will also require further setting the reference from the previous tail). Given that there could be only one lock releaser, which wakes up waiters in the queue, we can handle all the concurrency issues with reasonable complexity.
Removing the queue spinlock bit and the corresponding contention should give the performance gain on high concurrent LWLock usage scenarios.
Currently, the maximum size of procarray is 2^18 (as stated in buf_internals.h), so with the use of the 64-bit LWLock state variable, we can store the procarray indexes for both head and tail of the queue, all the existing machinery, and even have some spare bits for future flags.
Thus we almost entirely avoid spinlocks and replace them with repeated try to change the lock state if the CAS operation is unsuccessful due to concurrent state modification.
The attached patch implements described approach. The patch is based on the developments of Alexander Korotkov in the OrioleDB engine. I made further adoption of those ideas with guidance from him.
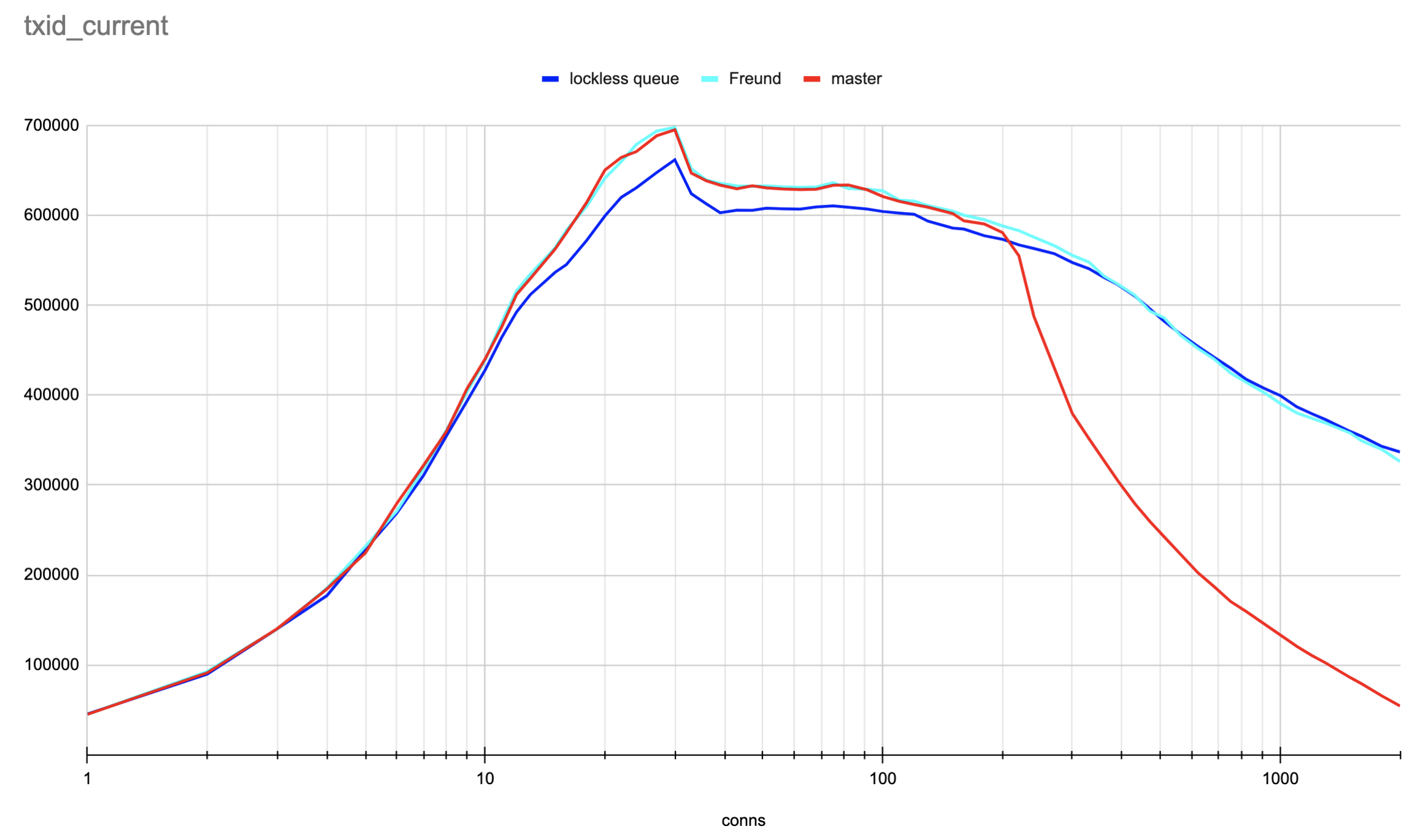
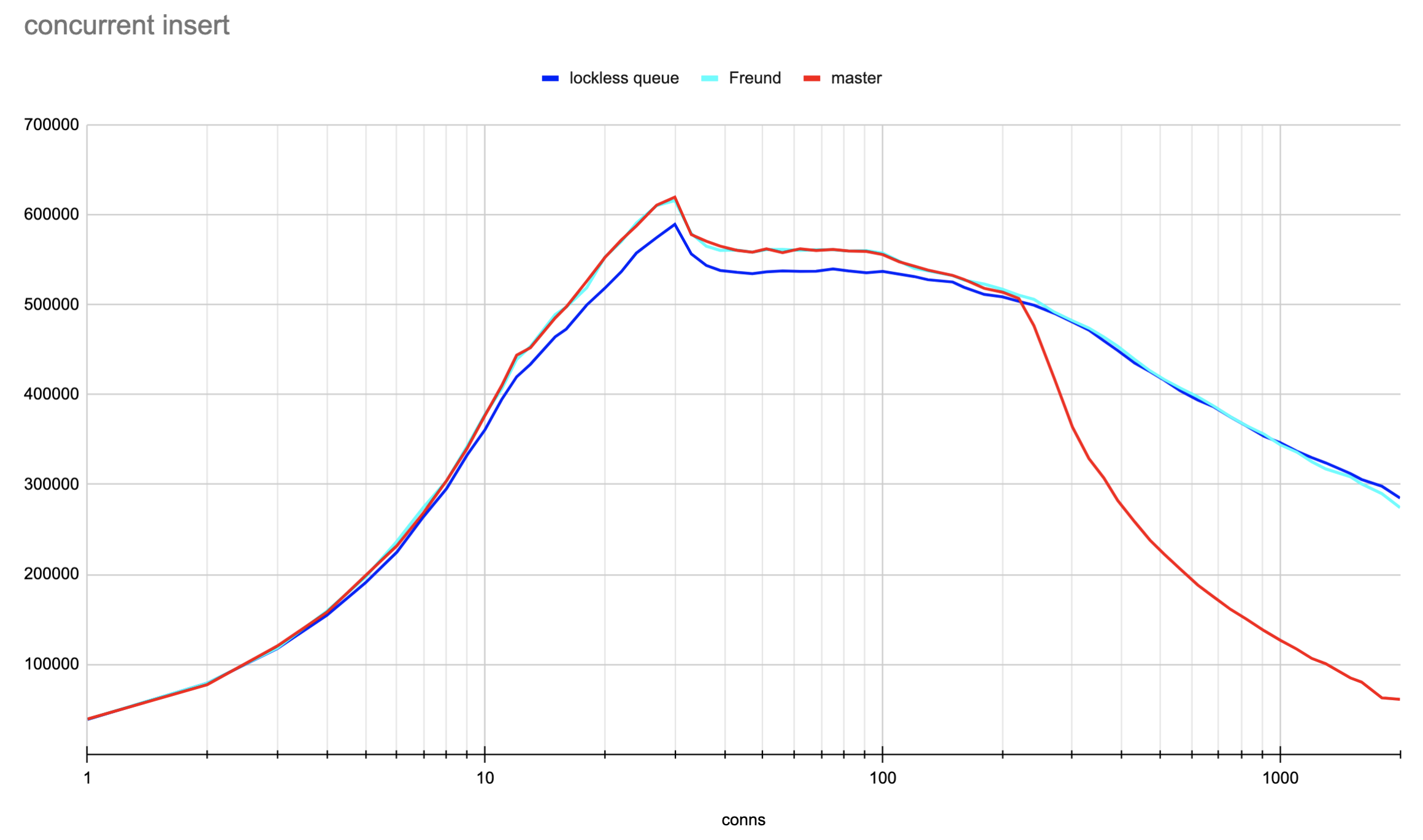
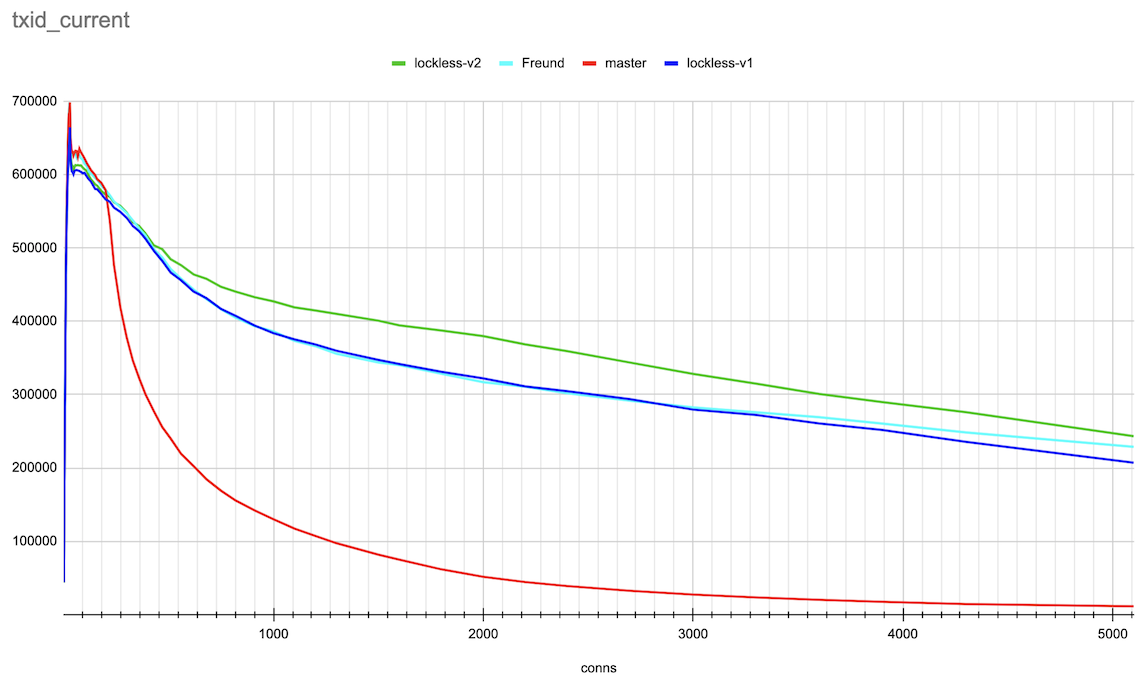
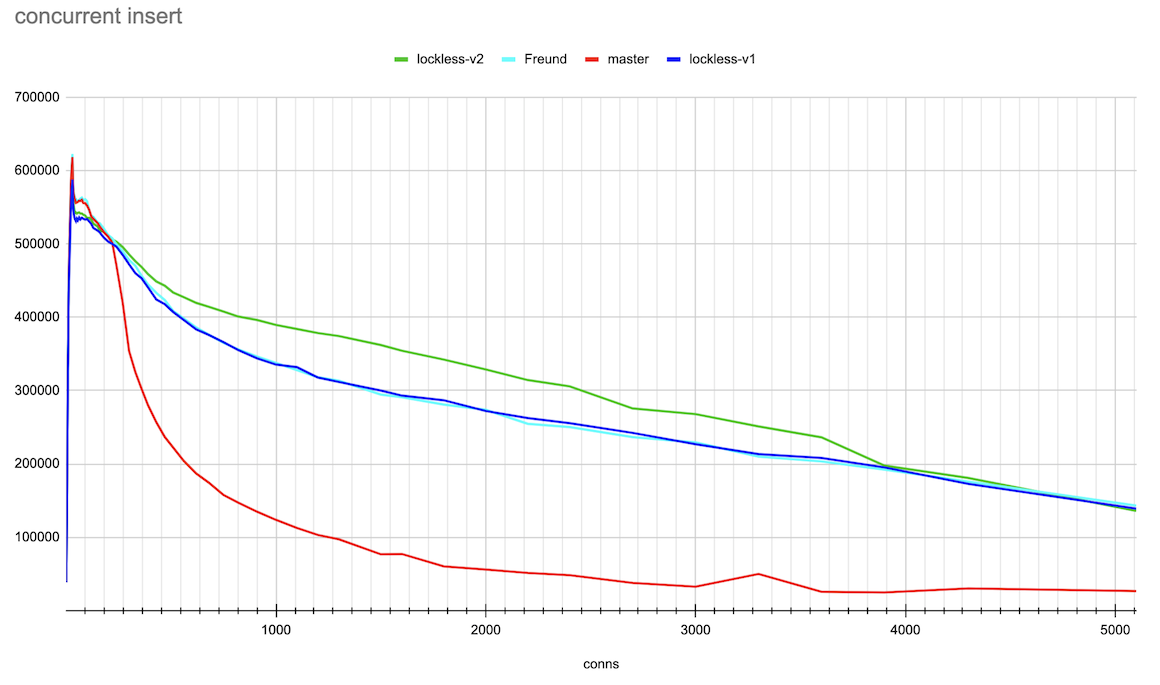
We did some preliminary performance checks and saw that the concurrent insert-only and txid_current tests with ~1000 connections pgbench significantly increase performance. The scripts for testing and results are attached. I’ve done the tests on 32-vcore x86-64 AWS machine using tmpfs as storage for the database to avoid random delays related to disk IO.
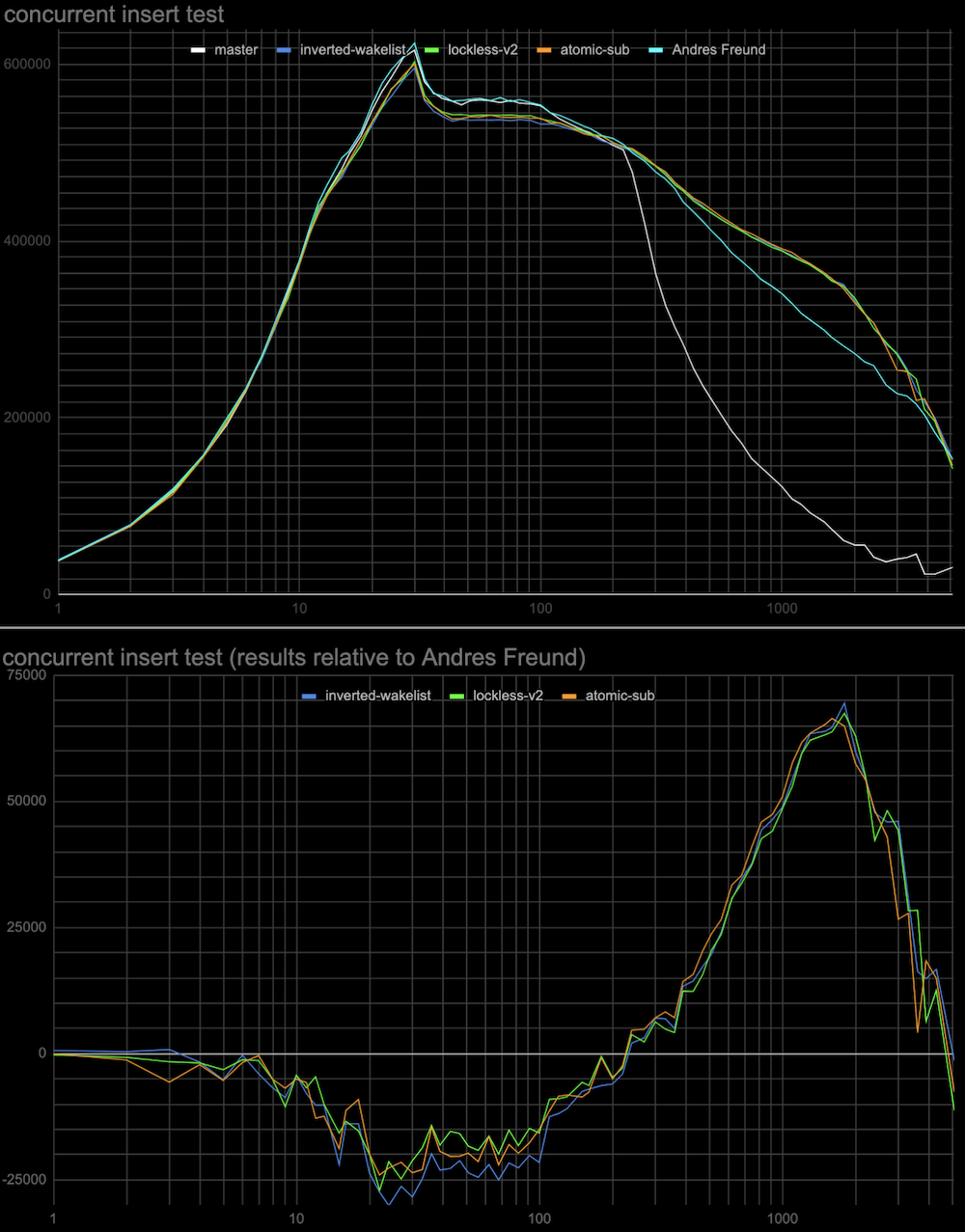
Though recently, Andres proposed a different patch, which just evades O(N) removal from the queue of waiters but improves performance even more [1]. The results of the comparison of the master branch, lockless queue (current) patch, and Andres’ patch are below. Please, take into account that the horizontal axis uses a log scale.
---------------------------------------
cat insert.sql
\set aid random(1, 10 * :scale)
\set delta random(1, 100000 * :scale)
INSERT INTO pgbench_accounts (aid, bid, abalance) VALUES (:aid, :aid, :delta);
pgbench -d postgres -i -s 1 --unlogged-tables
echo -e "max_connections=2500\nmax_wal_senders=0\nwal_level=minimal\nmax_wal_size = 10GB\nshared_buffers = 20000MB\nautovacuum = off\nfsync = off\nfull_page_writes = off\nmax_worker_processes = 1024\nmax_parallel_workers = 1024\n" > ./pgdata$v/postgresql.auto.conf
psql -dpostgres -c "ALTER TABLE pgbench_accounts DROP CONSTRAINT pgbench_accounts_pkey;
for conns in 1 2 3 4 5 6 7 8 9 10 11 12 13 15 16 18 20 22 24 27 30 33 36 39 43 47 51 56 62 68 75 82 91 100 110 120 130 150 160 180 200 220 240 270 300 330 360 390 430 470 510 560 620 680 750 820 910 1000 1100 1200 1300 1500 1600 1800 2000
do
psql -dpostgres -c "truncate pgbench_accounts;"
psql -dpostgres -c "vacuum full pgbench_accounts;"
pgbench postgres -f insert.sql -s 1 -P20 -M prepared -T 10 -j 5 -c $conns --no-vacuum | grep tps
done

Are there some scenarios where the lockless queue approach is superior? I expected they should be, at least in theory. Probably, there is a way to improve the attached patch further to achieve that superiority.
Best regards,
Pavel Borisov,
Supabase.
[1] https://www.postgresql.org/message-id/20221027165914.2hofzp4cvutj6gin@awork3.anarazel.de
When we take LWlock, we already use atomic CAS operation to atomically modify the lock state even in the presence of concurrent lock-takers. But if we can not take the lock immediately, we need to put the waiters on a waiting list, and currently, this operation is done not atomically and in a complicated way:
- Parts are done under LWLockWaitListLock, which includes a spin delay to take.
- Also, we need a two-step procedure to immediately dequeue if, after adding a current process into a wait queue, it appears that we don’t need to (and can not!) sleep as the lock is already free.
If the lock state contains references to the queue head and tail, we can implement a lockless queue of waiters for the LWLock. Adding new items to the queue head or tail can be done with a single CAS operation (adding to the tail will also require further setting the reference from the previous tail). Given that there could be only one lock releaser, which wakes up waiters in the queue, we can handle all the concurrency issues with reasonable complexity.
Removing the queue spinlock bit and the corresponding contention should give the performance gain on high concurrent LWLock usage scenarios.
Currently, the maximum size of procarray is 2^18 (as stated in buf_internals.h), so with the use of the 64-bit LWLock state variable, we can store the procarray indexes for both head and tail of the queue, all the existing machinery, and even have some spare bits for future flags.
Thus we almost entirely avoid spinlocks and replace them with repeated try to change the lock state if the CAS operation is unsuccessful due to concurrent state modification.
The attached patch implements described approach. The patch is based on the developments of Alexander Korotkov in the OrioleDB engine. I made further adoption of those ideas with guidance from him.
We did some preliminary performance checks and saw that the concurrent insert-only and txid_current tests with ~1000 connections pgbench significantly increase performance. The scripts for testing and results are attached. I’ve done the tests on 32-vcore x86-64 AWS machine using tmpfs as storage for the database to avoid random delays related to disk IO.
Though recently, Andres proposed a different patch, which just evades O(N) removal from the queue of waiters but improves performance even more [1]. The results of the comparison of the master branch, lockless queue (current) patch, and Andres’ patch are below. Please, take into account that the horizontal axis uses a log scale.
---------------------------------------
cat insert.sql
\set aid random(1, 10 * :scale)
\set delta random(1, 100000 * :scale)
INSERT INTO pgbench_accounts (aid, bid, abalance) VALUES (:aid, :aid, :delta);
pgbench -d postgres -i -s 1 --unlogged-tables
echo -e "max_connections=2500\nmax_wal_senders=0\nwal_level=minimal\nmax_wal_size = 10GB\nshared_buffers = 20000MB\nautovacuum = off\nfsync = off\nfull_page_writes = off\nmax_worker_processes = 1024\nmax_parallel_workers = 1024\n" > ./pgdata$v/postgresql.auto.conf
psql -dpostgres -c "ALTER TABLE pgbench_accounts DROP CONSTRAINT pgbench_accounts_pkey;
for conns in 1 2 3 4 5 6 7 8 9 10 11 12 13 15 16 18 20 22 24 27 30 33 36 39 43 47 51 56 62 68 75 82 91 100 110 120 130 150 160 180 200 220 240 270 300 330 360 390 430 470 510 560 620 680 750 820 910 1000 1100 1200 1300 1500 1600 1800 2000
do
psql -dpostgres -c "truncate pgbench_accounts;"
psql -dpostgres -c "vacuum full pgbench_accounts;"
pgbench postgres -f insert.sql -s 1 -P20 -M prepared -T 10 -j 5 -c $conns --no-vacuum | grep tps
done
--------------------------------------------------
cat txid.sql
select txid_current();
for conns in 1 2 3 4 5 6 7 8 9 10 11 12 13 15 16 18 20 22 24 27 30 33 36 39 43 47 51 56 62 68 75 82 91 100 110 120 130 150 160 180 200 220 240 270 300 330 360 390 430 470 510 560 620 680 750 820 910 1000 1100 1200 1300 1500 1600 1800 2000
do
pgbench postgres -f txid.sql -s 1 -P20 -M prepared -T 10 -j 5 -c $conns --no-vacuum | grep tps
done
I can not understand why the performance of a lockless queue patch has a minor regression in the region of around 20 connections, even when compared to the current master branch.cat txid.sql
select txid_current();
for conns in 1 2 3 4 5 6 7 8 9 10 11 12 13 15 16 18 20 22 24 27 30 33 36 39 43 47 51 56 62 68 75 82 91 100 110 120 130 150 160 180 200 220 240 270 300 330 360 390 430 470 510 560 620 680 750 820 910 1000 1100 1200 1300 1500 1600 1800 2000
do
pgbench postgres -f txid.sql -s 1 -P20 -M prepared -T 10 -j 5 -c $conns --no-vacuum | grep tps
done

Are there some scenarios where the lockless queue approach is superior? I expected they should be, at least in theory. Probably, there is a way to improve the attached patch further to achieve that superiority.
Best regards,
Pavel Borisov,
Supabase.
[1] https://www.postgresql.org/message-id/20221027165914.2hofzp4cvutj6gin@awork3.anarazel.de
Attachment
It seems that test results pictures failed to attach in the original email. I add them here. Pavel Borisov
Attachment
{kind=link}
{kind=link}
Hi, Thanks for working on this - I think it's something we need to improve. On 2022-10-31 14:38:23 +0400, Pavel Borisov wrote: > If the lock state contains references to the queue head and tail, we can > implement a lockless queue of waiters for the LWLock. Adding new items to > the queue head or tail can be done with a single CAS operation (adding to > the tail will also require further setting the reference from the previous > tail). Given that there could be only one lock releaser, which wakes up > waiters in the queue, we can handle all the concurrency issues with > reasonable complexity. Right now lock releases happen *after* the lock is released. I suspect that is at least part of the reason for the regression you're seeing. It also looks like you're going to need a substantially higher number of atomic operations - right now the queue processing needs O(1) atomic ops, but your approach ends up with O(waiters) atomic ops. I suspect it might be worth going halfway, i.e. put the list head/tail in the atomic variable, but process the list with a lock held, after the lock is released. > Removing the queue spinlock bit and the corresponding contention should > give the performance gain on high concurrent LWLock usage scenarios. > Currently, the maximum size of procarray is 2^18 (as stated in > buf_internals.h), so with the use of the 64-bit LWLock state variable, we > can store the procarray indexes for both head and tail of the queue, all > the existing machinery, and even have some spare bits for future flags. Another advantage: It shrinks the LWLock struct, which makes it cheaper to make locks more granular... > I can not understand why the performance of a lockless queue patch has a > minor regression in the region of around 20 connections, even when compared > to the current master branch. I suspect that's the point where the additional atomic operations hurt the most, while not yet providing a substantial gain. Greetings, Andres Freund
Hi Andres, Thank you for your feedback. On Tue, Nov 1, 2022 at 2:15 AM Andres Freund <andres@anarazel.de> wrote: > On 2022-10-31 14:38:23 +0400, Pavel Borisov wrote: > > If the lock state contains references to the queue head and tail, we can > > implement a lockless queue of waiters for the LWLock. Adding new items to > > the queue head or tail can be done with a single CAS operation (adding to > > the tail will also require further setting the reference from the previous > > tail). Given that there could be only one lock releaser, which wakes up > > waiters in the queue, we can handle all the concurrency issues with > > reasonable complexity. > > Right now lock releases happen *after* the lock is released. That makes sense. The patch makes the locker hold the lock, which it's processing the queue. So, the lock is held for a longer time. > I suspect that is > at least part of the reason for the regression you're seeing. It also looks > like you're going to need a substantially higher number of atomic operations - > right now the queue processing needs O(1) atomic ops, but your approach ends > up with O(waiters) atomic ops. Hmm... In the patch, queue processing calls CAS once after processing the queue. There could be retries to process the queue parts, which were added concurrently. But I doubt it ends up with O(waiters) atomic ops. Pavel, I think we could gather some statistics to check how many retries we have on average. > I suspect it might be worth going halfway, i.e. put the list head/tail in the > atomic variable, but process the list with a lock held, after the lock is > released. Good idea. We, anyway, only allow one locker at a time to process the queue. ------ Regards, Alexander Korotkov
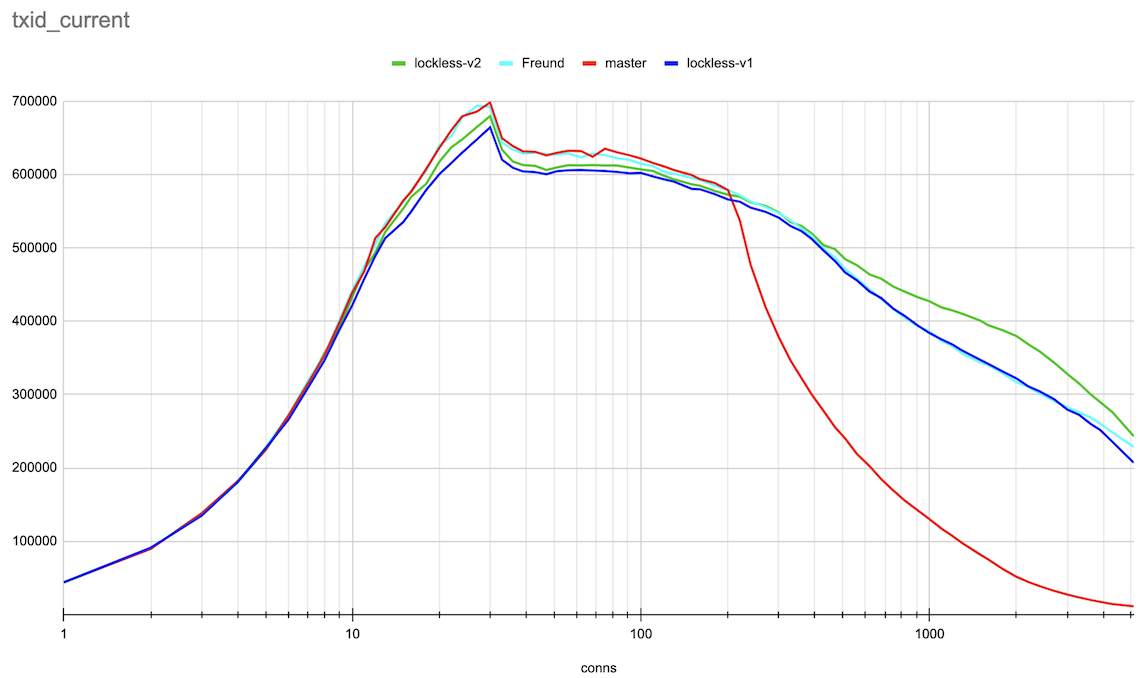
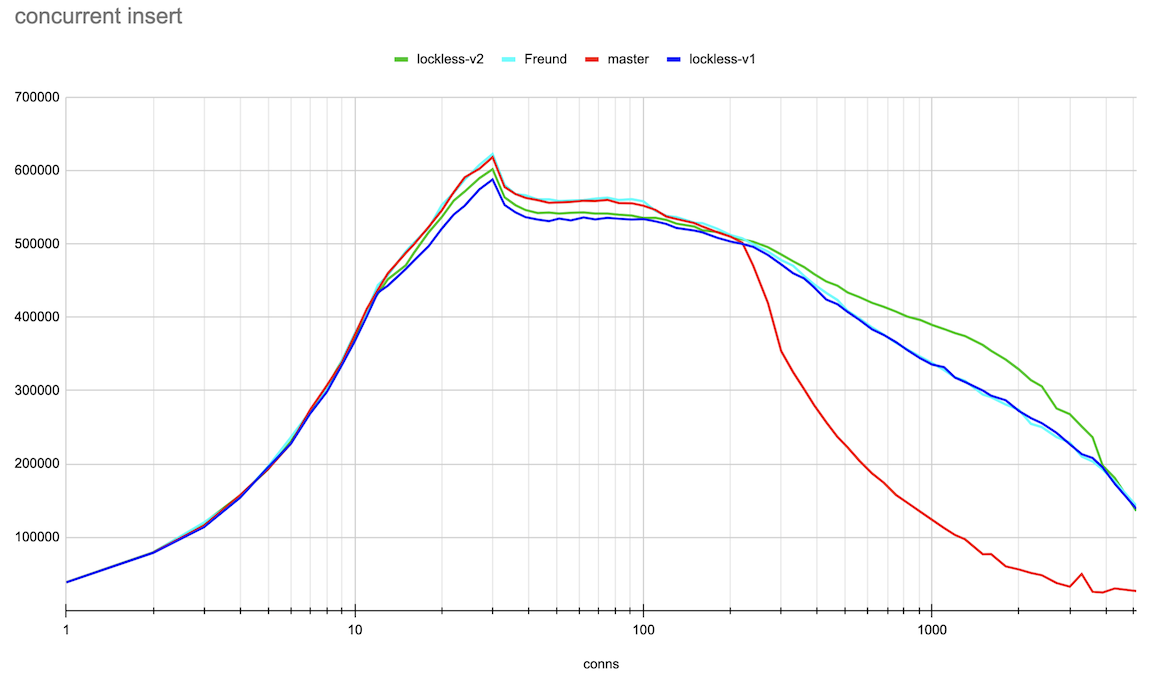
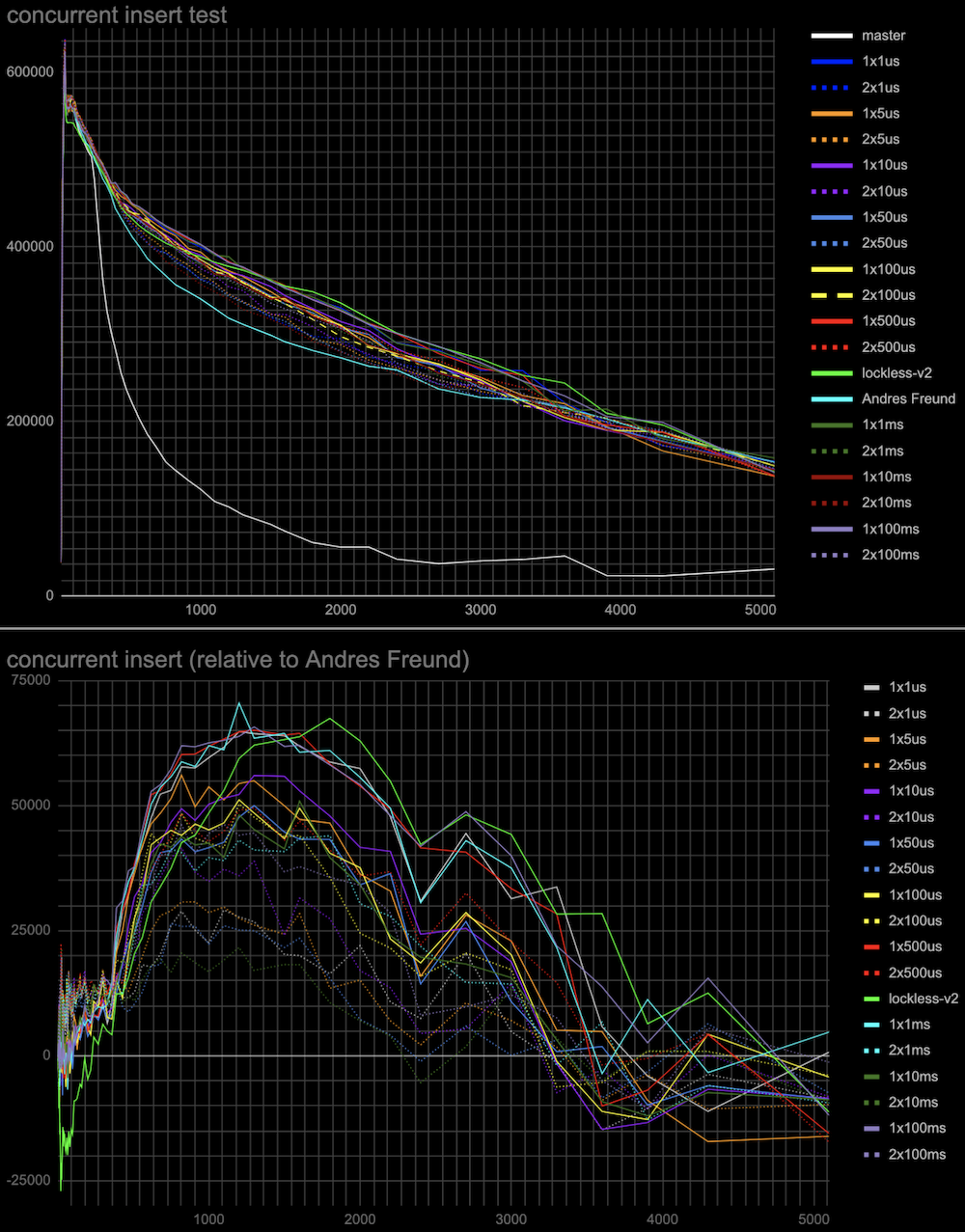
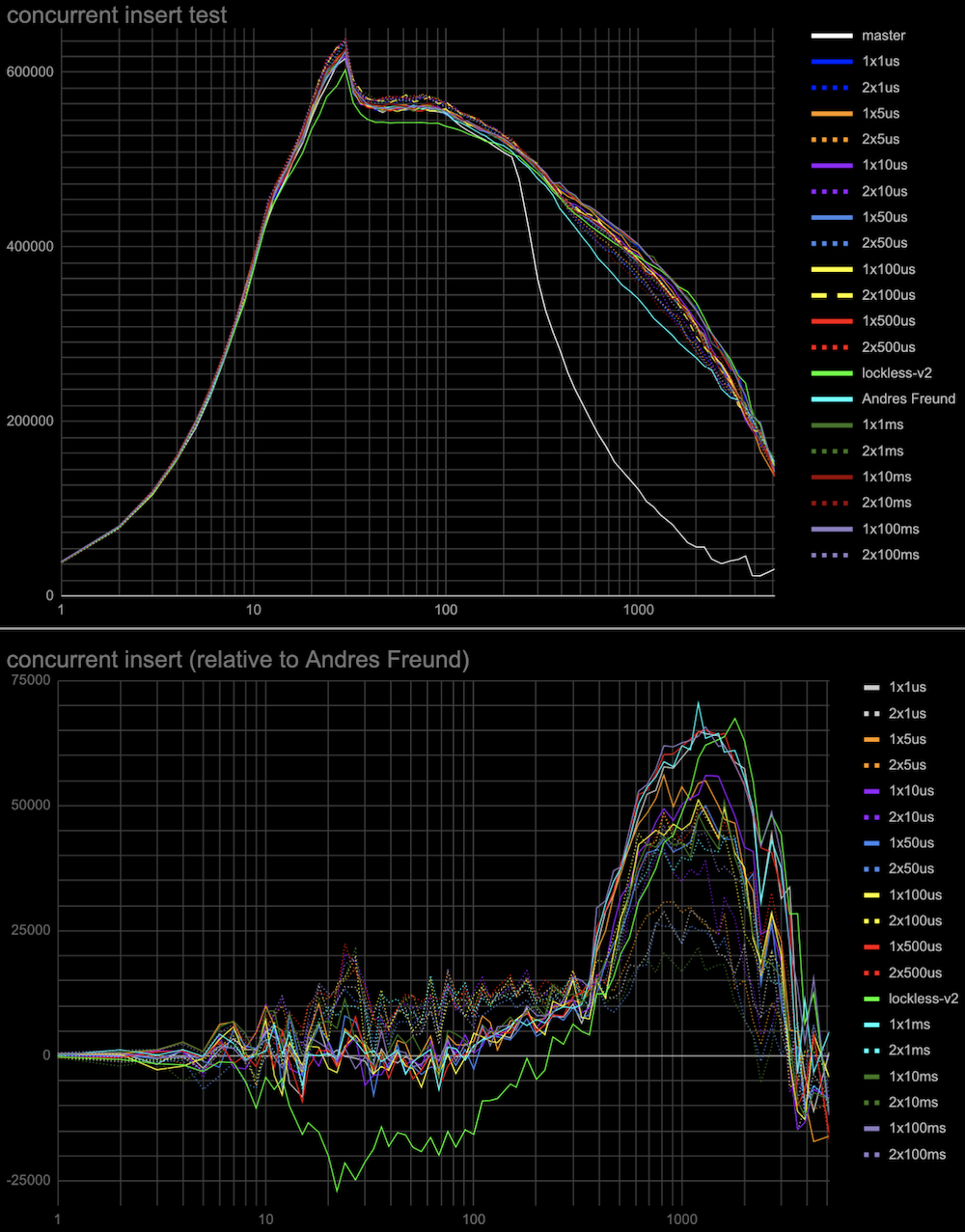
Hi, Andres, Thank you very much for the ideas on this topic! > > > If the lock state contains references to the queue head and tail, we can > > > implement a lockless queue of waiters for the LWLock. Adding new items to > > > the queue head or tail can be done with a single CAS operation (adding to > > > the tail will also require further setting the reference from the previous > > > tail). Given that there could be only one lock releaser, which wakes up > > > waiters in the queue, we can handle all the concurrency issues with > > > reasonable complexity. > > > > Right now lock releases happen *after* the lock is released. > > That makes sense. The patch makes the locker hold the lock, which it's > processing the queue. So, the lock is held for a longer time. > > > I suspect that is > > at least part of the reason for the regression you're seeing. It also looks > > like you're going to need a substantially higher number of atomic operations - > > right now the queue processing needs O(1) atomic ops, but your approach ends > > up with O(waiters) atomic ops. > > Hmm... In the patch, queue processing calls CAS once after processing > the queue. There could be retries to process the queue parts, which > were added concurrently. But I doubt it ends up with O(waiters) atomic > ops. Pavel, I think we could gather some statistics to check how many > retries we have on average. > I've made some measurements on the number of repeated CAS operations on lock acquire and release. (For this I applied Print-lwlock-stats-on-CAS-repeats.patch onto the previous patch v1 in this thread) The results when running the same insert test, that produced the results in the original post on 20 connections are as follows: lwlock ProcArray: -------------| locks acquired | CAS repeats to acquire | CAS repeats to release shared | 493187 | 57310 | 12049 exclusive | 46816 | 42329 | 8816 wait-until-free | - | 0 | 76124 blk 79473 > > I suspect it might be worth going halfway, i.e. put the list head/tail in the > > atomic variable, but process the list with a lock held, after the lock is > > released. > > Good idea. We, anyway, only allow one locker at a time to process the queue. Alexander added these changes in v2 of a patch. The results of the same benchmarking master vs Andres' patch vs lockless queue patch v1 and v2 are attached. They are done in the same way as in the original post. The small difference is that I've gone further until 5000 connections and also produced both log and linear scale connections axis plots for the more clear demonstration. Around 20 connections TPS increased though not yet to the same value the master and Andres' patches has. And in a range 300-3000 connections the v2 patch demonstrated clear gain. I'm planning to gather more detailed statistics on different LWLockAcquire calls soon to understand prospects for further optimizations. Best regards, Pavel Borisov
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hi, hackers! > I'm planning to gather more detailed statistics on different > LWLockAcquire calls soon to understand prospects for further > optimizations. So, I've made more measurements. 1. Applied measuring patch 0001 to a patch with lockless queue optimization (v2) from [0] in this thread and run the same concurrent insert test described in [1] on 20 pgbench connections. The new results for ProcArray lwlock are as follows: exacq 45132 // Overall number of exclusive locks taken ex_attempt[0] 20755 // Exclusive locks taken immediately ex_attempt[1] 18800 // Exclusive locks taken after one waiting on semaphore ex_attempt[2] 5577 // Exclusive locks taken after two or more waiting on semaphore shacq 494871 // .. same stats for shared locks sh_attempt[0] 463211 // .. sh_attempt[1] 29767 // .. sh_attempt[2] 1893 // .. same stats for shared locks sh_wake_calls 31070 // Number of calls to wake up shared waiters sh_wakes 36190 // Number of shared waiters woken up. GroupClearXid 55300 // Number of calls of ProcArrayGroupClearXid EndTransactionInternal: 236193 // Number of calls ProcArrayEndTransactionInternal 2. Applied measuring patch 0002 to a Andres Freund's patch v3 from [2] and run the same concurrent insert test described in [1] on 20 pgbench connections. The results for ProcArray lwlock are as follows: exacq 49300 // Overall number of exclusive locks taken ex_attempt1[0] 18353 // Exclusive locks taken immediately by first call of LWLockAttemptLock in LWLockAcquire loop ex_attempt2[0] 18144. // Exclusive locks taken immediately by second call of LWLockAttemptLock in LWLockAcquire loop ex_attempt1[1] 9985 // Exclusive locks taken after one waiting on semaphore by first call of LWLockAttemptLock in LWLockAcquire loop ex_attempt2[1] 1838. // Exclusive locks taken after one waiting on semaphore by second call of LWLockAttemptLock in LWLockAcquire loop ex_attempt1[2] 823. // Exclusive locks taken after two or more waiting on semaphore by first call of LWLockAttemptLock in LWLockAcquire loop ex_attempt2[2] 157. // Exclusive locks taken after two or more waiting on semaphore by second call of LWLockAttemptLock in LWLockAcquire loop shacq 508131 // .. same stats for shared locks sh_attempt1[0] 469410 //.. sh_attempt2[0] 27858. //.. sh_attempt1[1] 10309. //.. sh_attempt2[1] 460. //.. sh_attempt1[2] 90. //.. sh_attempt2[2] 4. // .. same stats for shared locks dequeue self 48461 // Number of dequeue_self calls sh_wake_calls 27560 // Number of calls to wake up shared waiters sh_wakes 19408 // Number of shared waiters woken up. GroupClearXid 65021. // Number of calls of ProcArrayGroupClearXid EndTransactionInternal: 249003 // Number of calls ProcArrayEndTransactionInternal It seems that two calls in each look in Andres's (and master) code help evade semaphore-waiting loops that may be relatively expensive. The probable reason for this is that the small delay between these two calls is sometimes enough for concurrent takers to free spinlock for the queue modification. Could we get even more performance if we do three or more tries to take the lock in the queue? Will this degrade performance in some other cases? Or maybe there is another explanation for now small performance difference around 20 connections described in [0]? Thoughts? Regards, Pavel Borisov [0] https://www.postgresql.org/message-id/CALT9ZEF7q%2BSarz1MjrX-fM7OsoU7CK16%3DONoGCOkY3Efj%2BGrnw%40mail.gmail.com [1] https://www.postgresql.org/message-id/CALT9ZEEz%2B%3DNepc5eti6x531q64Z6%2BDxtP3h-h_8O5HDdtkJcPw%40mail.gmail.com [2] https://www.postgresql.org/message-id/20221031235114.ftjkife57zil7ryw%40awork3.anarazel.de
Attachment
Hi, Pavel! On Thu, Nov 3, 2022 at 1:51 PM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > > I'm planning to gather more detailed statistics on different > > LWLockAcquire calls soon to understand prospects for further > > optimizations. > > So, I've made more measurements. > > 1. Applied measuring patch 0001 to a patch with lockless queue > optimization (v2) from [0] in this thread and run the same concurrent > insert test described in [1] on 20 pgbench connections. > The new results for ProcArray lwlock are as follows: > exacq 45132 // Overall number of exclusive locks taken > ex_attempt[0] 20755 // Exclusive locks taken immediately > ex_attempt[1] 18800 // Exclusive locks taken after one waiting on semaphore > ex_attempt[2] 5577 // Exclusive locks taken after two or more > waiting on semaphore > shacq 494871 // .. same stats for shared locks > sh_attempt[0] 463211 // .. > sh_attempt[1] 29767 // .. > sh_attempt[2] 1893 // .. same stats for shared locks > sh_wake_calls 31070 // Number of calls to wake up shared waiters > sh_wakes 36190 // Number of shared waiters woken up. > GroupClearXid 55300 // Number of calls of ProcArrayGroupClearXid > EndTransactionInternal: 236193 // Number of calls > ProcArrayEndTransactionInternal > > 2. Applied measuring patch 0002 to a Andres Freund's patch v3 from [2] > and run the same concurrent insert test described in [1] on 20 pgbench > connections. > The results for ProcArray lwlock are as follows: > exacq 49300 // Overall number of exclusive locks taken > ex_attempt1[0] 18353 // Exclusive locks taken immediately by first > call of LWLockAttemptLock in LWLockAcquire loop > ex_attempt2[0] 18144. // Exclusive locks taken immediately by second > call of LWLockAttemptLock in LWLockAcquire loop > ex_attempt1[1] 9985 // Exclusive locks taken after one waiting on > semaphore by first call of LWLockAttemptLock in LWLockAcquire loop > ex_attempt2[1] 1838. // Exclusive locks taken after one waiting on > semaphore by second call of LWLockAttemptLock in LWLockAcquire loop > ex_attempt1[2] 823. // Exclusive locks taken after two or more > waiting on semaphore by first call of LWLockAttemptLock in > LWLockAcquire loop > ex_attempt2[2] 157. // Exclusive locks taken after two or more > waiting on semaphore by second call of LWLockAttemptLock in > LWLockAcquire loop > shacq 508131 // .. same stats for shared locks > sh_attempt1[0] 469410 //.. > sh_attempt2[0] 27858. //.. > sh_attempt1[1] 10309. //.. > sh_attempt2[1] 460. //.. > sh_attempt1[2] 90. //.. > sh_attempt2[2] 4. // .. same stats for shared locks > dequeue self 48461 // Number of dequeue_self calls > sh_wake_calls 27560 // Number of calls to wake up > shared waiters > sh_wakes 19408 // Number of shared waiters woken up. > GroupClearXid 65021. // Number of calls of > ProcArrayGroupClearXid > EndTransactionInternal: 249003 // Number of calls > ProcArrayEndTransactionInternal > > It seems that two calls in each look in Andres's (and master) code > help evade semaphore-waiting loops that may be relatively expensive. > The probable reason for this is that the small delay between these two > calls is sometimes enough for concurrent takers to free spinlock for > the queue modification. Could we get even more performance if we do > three or more tries to take the lock in the queue? Will this degrade > performance in some other cases? Thank you for gathering the statistics. Let me do some relative analysis of that. *Lockless queue patch* 1. Shared lockers 1.1. 93.60% of them acquire lock without sleeping on semaphore 1.2. 6.02% of them acquire lock after sleeping on semaphore 1 time 1.3. 0.38% of them acquire lock after sleeping on semaphore 2 or more times 2. Exclusive lockers 2.1. 45.99% of them acquire lock without sleeping on semaphore 2.2. 41.66% of them acquire lock after sleeping on semaphore 1 time 2.3. 12.36% of them acquire lock after sleeping on semaphore 2 or more times In general, about 10% of lockers sleep on the semaphore. *Andres's patch* 1. Shared lockers 1.1. 97.86% of them acquire lock without sleeping on the semaphore (92.38% do this immediately and 5.48% after queuing) 1.2. 2.12% of them acquire lock after sleeping on semaphore 1 time (2.03% do this immediately and 0.09% after queuing) 1.3. 0.02% of them acquire lock after sleeping on semaphore 2 or more times (0.02% do this immediately and 0.00% after queuing) 2. Exclusive lockers 2.1. 74.03% of them acquire lock without sleeping on the semaphore (37.23% do this immediately and 36.80% after queuing) 2.2. 23.98% of them acquire lock after sleeping on semaphore 1 time (20.25% do this immediately and 3.73% after queuing) 2.3. 1.99% of them acquire lock after sleeping on semaphore 2 or more times (1.67% do this immediately and 0.32% after queuing) In general, about 4% of lockers sleep on the semaphore. I agree with Pavel that the reason for the regression of the lockless queue patch seems to be sleeping on semaphores. The lockless queue patch seems to give only one chance to the lockers to acquire the lock without such sleeping. But the current LWLock code gives two such chances: before queuing and after queuing. LWLockWaitListLock() includes perform_spin_delay(), which may call pg_usleep(). So, the second attempt to acquire the lock may have significant changes (we see almost the same percentage for exclusive lockers!). Pavel, could you also measure the average time LWLockWaitListLock() spends with pg_usleep()? It's a bit discouraging that sleeping on semaphores is so slow that even manual fixed-time sleeping is faster. I'm not sure if this is the issue of semaphores or the multi-process model. If we don't change this, then let's try with multiple lock tries as Pavel proposed. ------ Regards, Alexander Korotkov
Hi, On 2022-11-03 14:50:11 +0400, Pavel Borisov wrote: > Or maybe there is another explanation for now small performance > difference around 20 connections described in [0]? > Thoughts? Using xadd is quite a bit cheaper than cmpxchg, and now every lock release uses a compare-exchange, I think. In the past I had a more complicated version of LWLockAcquire which tried to use an xadd to acquire locks. IIRC (and this is long enough ago that I might not) that proved to be a benefit, but I was worried about the complexity. And just getting in the version that didn't always use a spinlock was the higher priority. The use of cmpxchg vs lock inc/lock add/xadd is one of the major reasons why lwlocks are slower than a spinlock (but obviously are better under contention nonetheless). I have a benchmark program that starts a thread for each physical core and just increments a counter on an atomic value. On my dual Xeon Gold 5215 workstation: cmpxchg: 32: throughput per thread: 0.55M/s, total: 11.02M/s 64: throughput per thread: 0.63M/s, total: 12.68M/s lock add: 32: throughput per thread: 2.10M/s, total: 41.98M/s 64: throughput per thread: 2.12M/s, total: 42.40M/s xadd: 32: throughput per thread: 2.10M/s, total: 41.91M/s 64: throughput per thread: 2.04M/s, total: 40.71M/s and even when there's no contention, every thread just updating its own cacheline: cmpxchg: 32: throughput per thread: 88.83M/s, total: 1776.51M/s 64: throughput per thread: 96.46M/s, total: 1929.11M/s lock add: 32: throughput per thread: 166.07M/s, total: 3321.31M/s 64: throughput per thread: 165.86M/s, total: 3317.22M/s add (no lock): 32: throughput per thread: 530.78M/s, total: 10615.62M/s 64: throughput per thread: 531.22M/s, total: 10624.35M/s xadd: 32: throughput per thread: 165.88M/s, total: 3317.51M/s 64: throughput per thread: 165.93M/s, total: 3318.53M/s Greetings, Andres Freund
Hi, Andres! On Fri, Nov 4, 2022 at 10:07 PM Andres Freund <andres@anarazel.de> wrote: > The use of cmpxchg vs lock inc/lock add/xadd is one of the major reasons why > lwlocks are slower than a spinlock (but obviously are better under contention > nonetheless). > > > I have a benchmark program that starts a thread for each physical core and > just increments a counter on an atomic value. Thank you for this insight! I didn't know xadd is much cheaper than cmpxchg unless there are retries. I also wonder how cmpxchg becomes faster with higher concurrency. ------ Regards, Alexander Korotkov
Hi, On 2022-11-05 12:05:43 +0300, Alexander Korotkov wrote: > On Fri, Nov 4, 2022 at 10:07 PM Andres Freund <andres@anarazel.de> wrote: > > The use of cmpxchg vs lock inc/lock add/xadd is one of the major reasons why > > lwlocks are slower than a spinlock (but obviously are better under contention > > nonetheless). > > > > > > I have a benchmark program that starts a thread for each physical core and > > just increments a counter on an atomic value. > > Thank you for this insight! I didn't know xadd is much cheaper than > cmpxchg unless there are retries. The magnitude of the effect is somewhat surprising, I agree. Some difference makes sense to me, but... > I also wonder how cmpxchg becomes faster with higher concurrency. If you're referring to the leading 32/64 that's not concurrency, that's 32/64bit values. Sorry for not being clearer on that. Greetings, Andres Freund
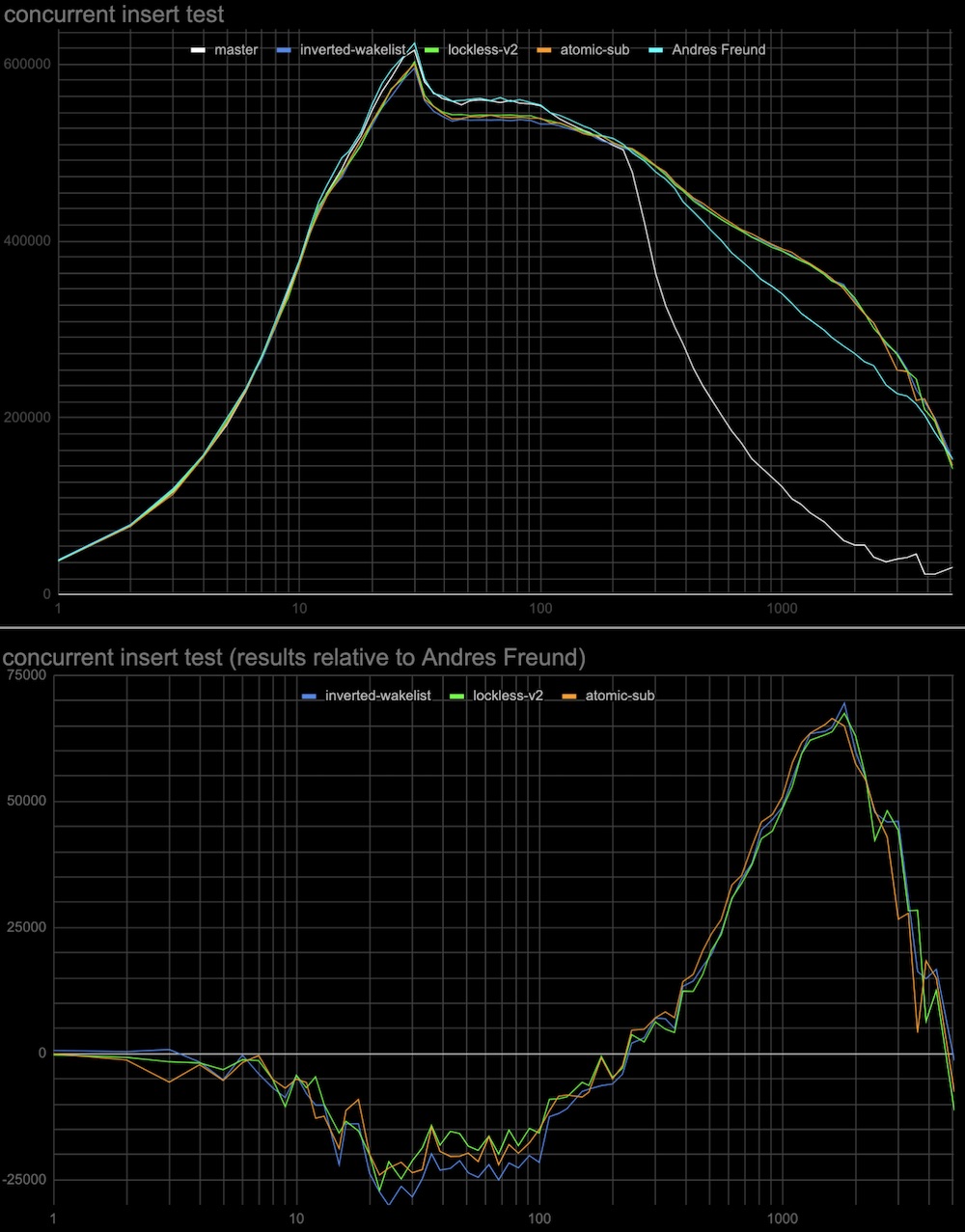
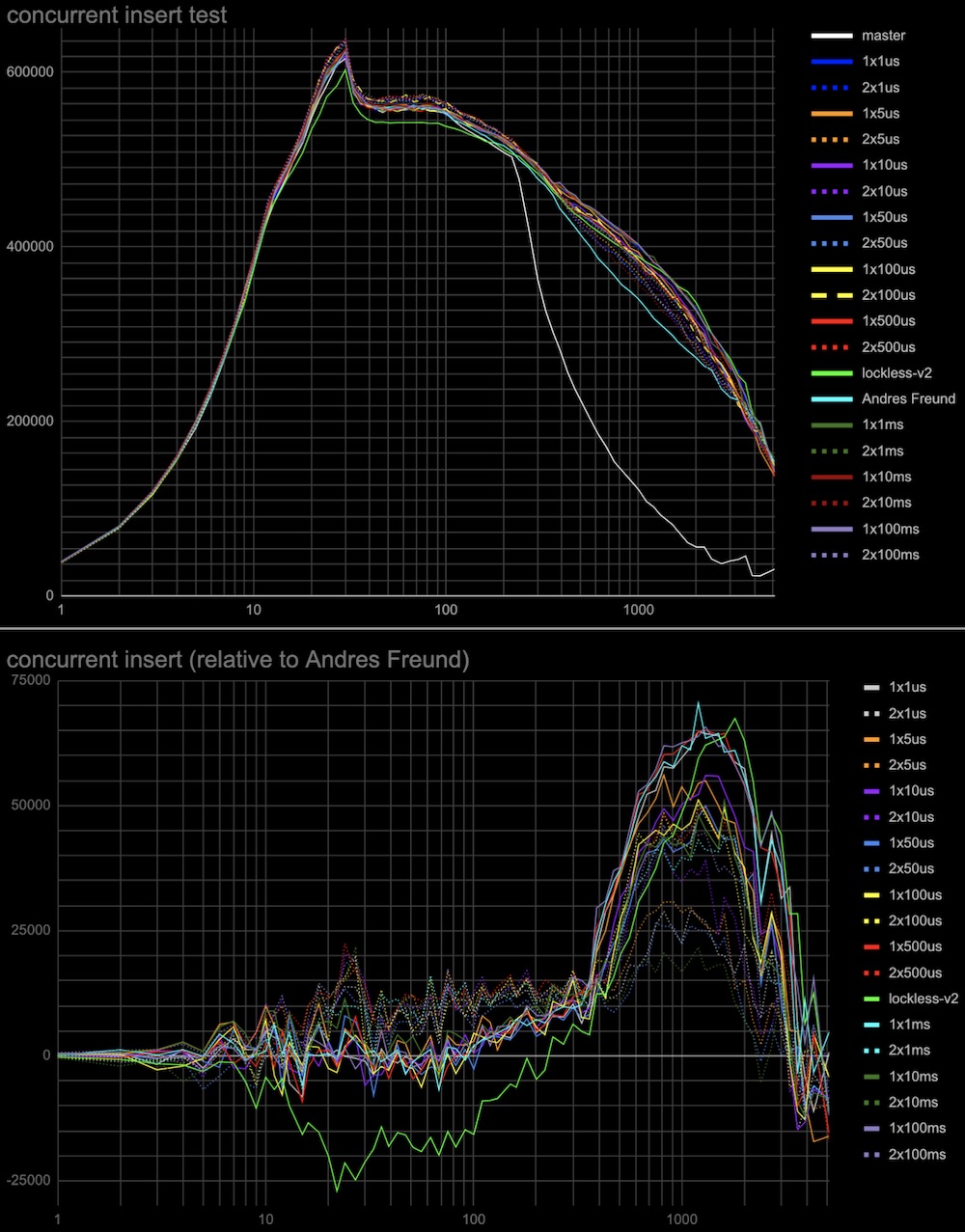
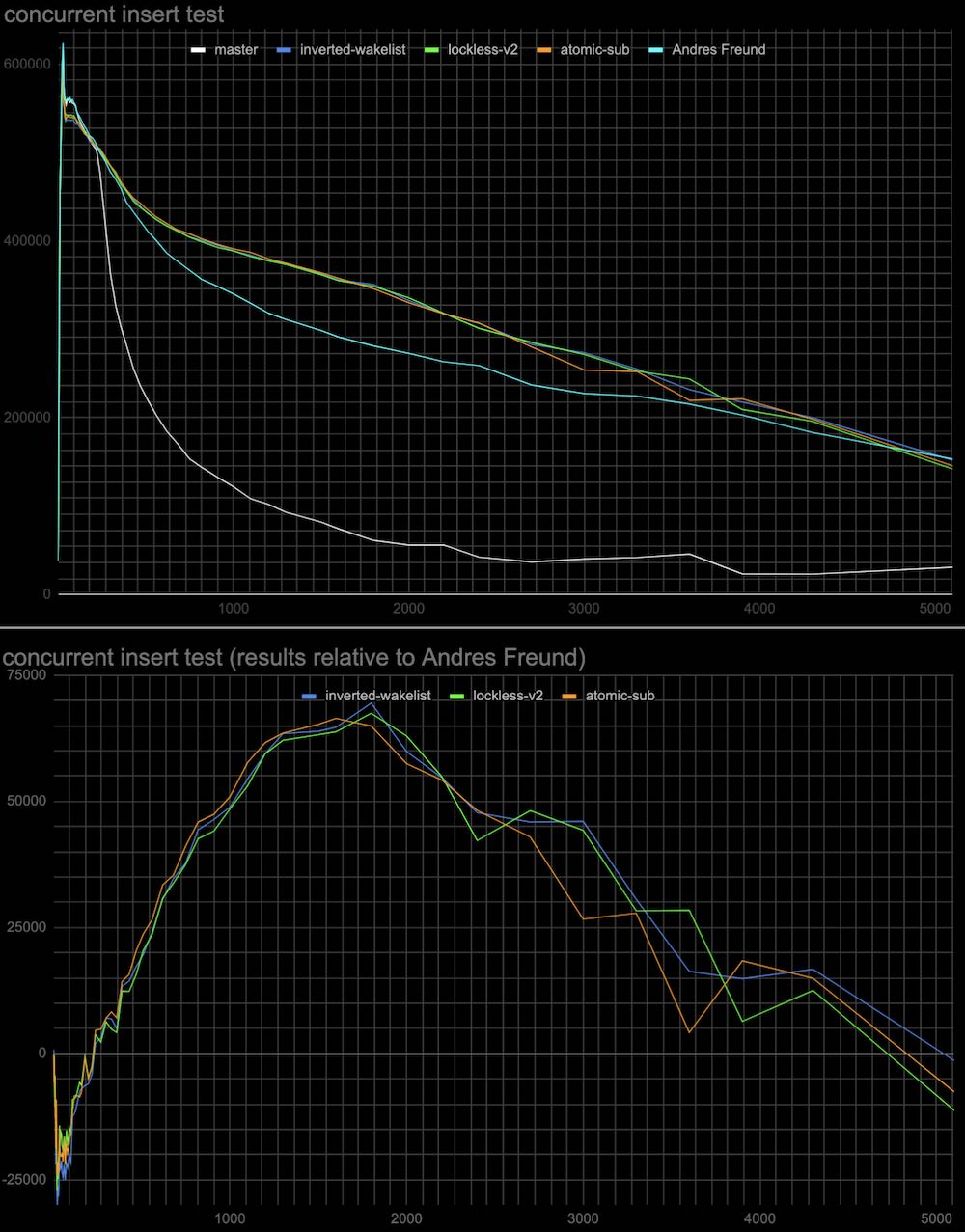
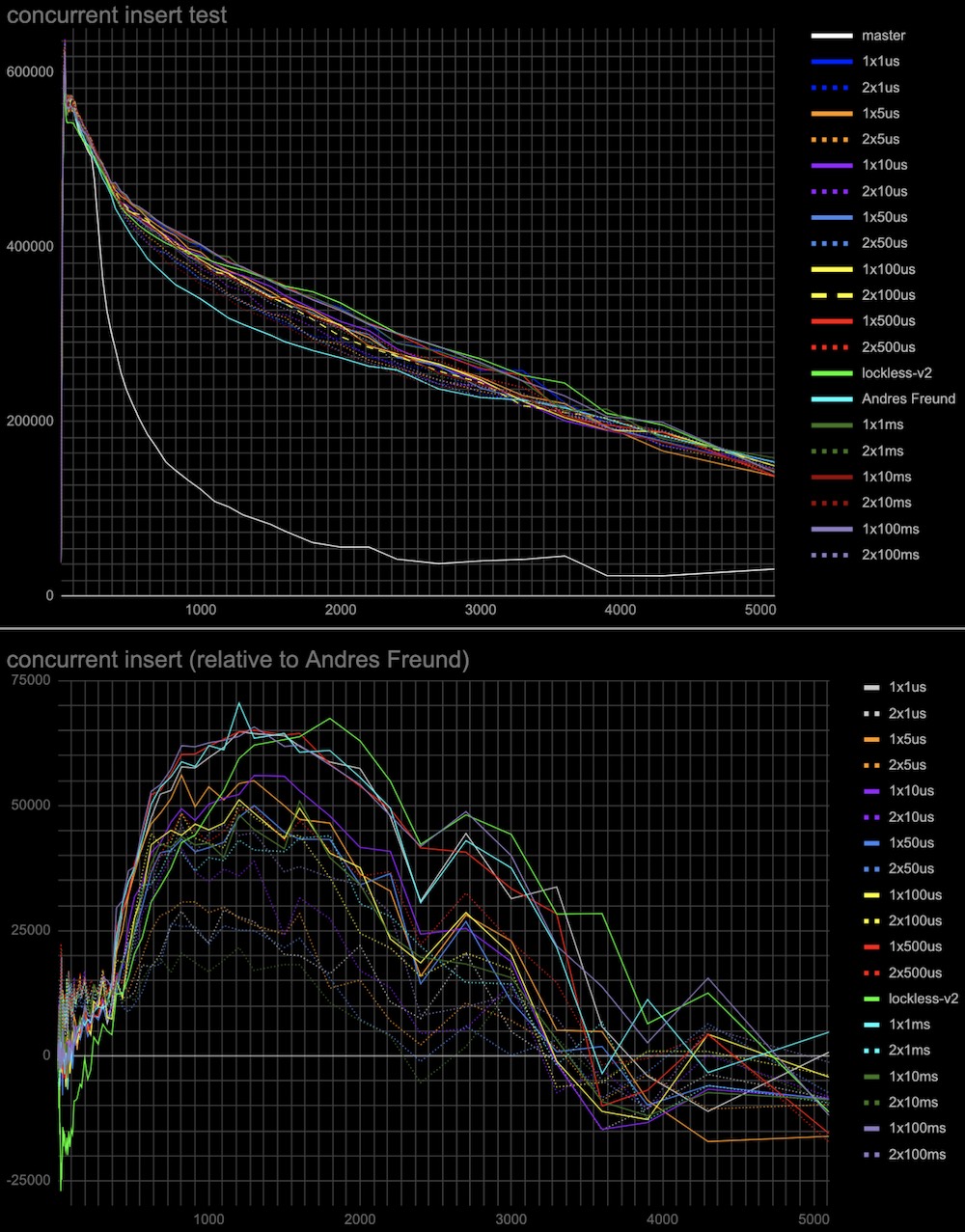
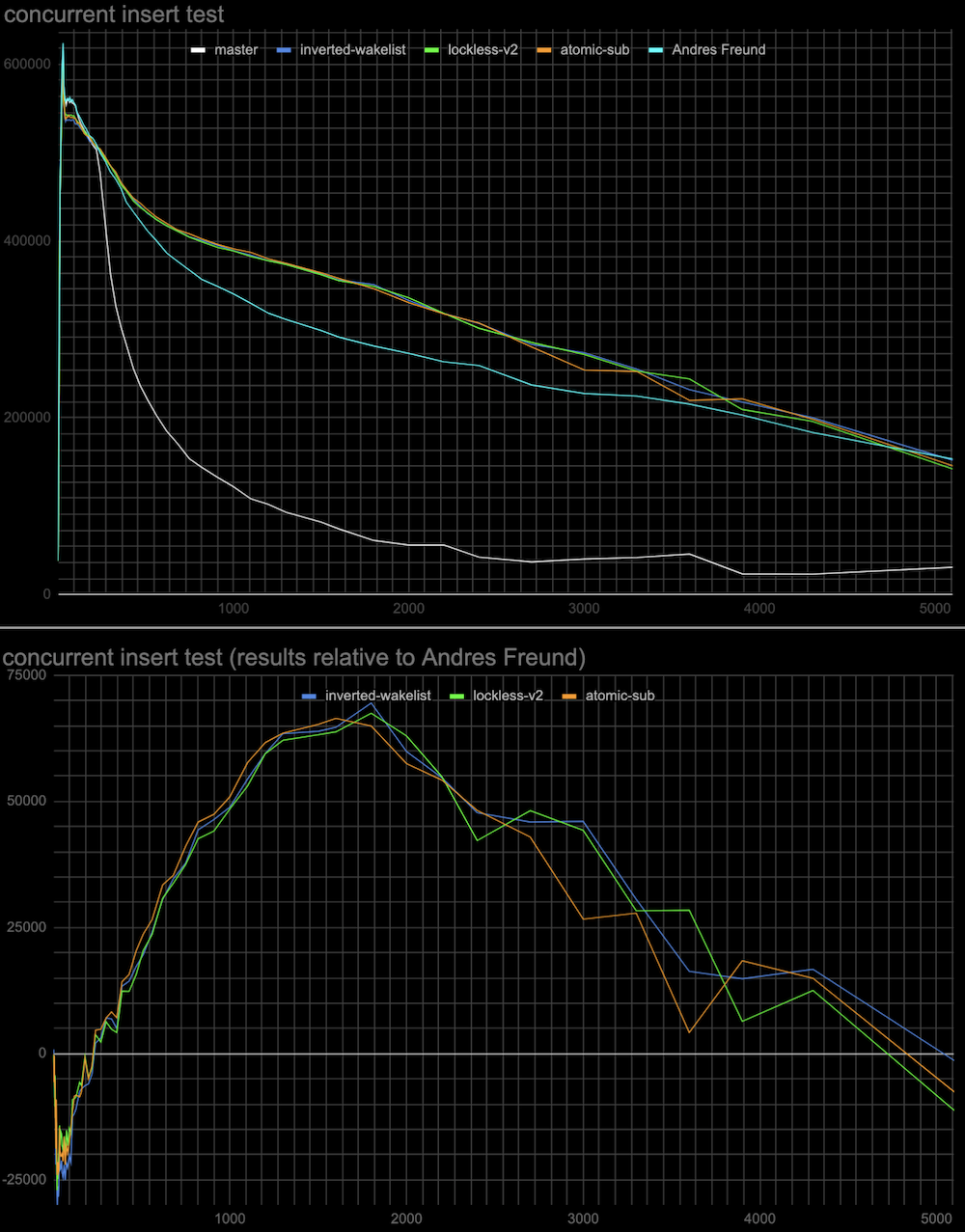
Hi, Andres, and Alexander! I've done some more measurements to check the hypotheses regarding the performance of a previous patch v2, and explain the results of tests in [1]. The results below are the same (tps vs connections) plots as in [1], and the test is identical to the insert test in this thread [2]. Additionally, in each case, there is a plot with results relative to Andres Freund's patch [3]. Log plots are good for seeing details in the range of 20-30 connections, but they somewhat hide the fact that the effect in the range of 500+ connections is much more significant overall, so I'd recommend looking at the linear plots as well. The particular tests: 1. Whether CAS operation cost in comparison to the atomic-sub affects performance. The patch (see attached atomic-sub-instead-of-CAS-for-shared-lockers-without.patch) uses atomic-sub to change LWlock state variable for releasing a shared lock that doesn't have a waiting queue. The results are attached (see atomic-sub-inverted-queue-*.jpg) 2. Whether sending wake signals in inverted order affects performance. In patch v2 the most recent shared lockers taken are woken up first (but anyway they all get wake signals at the same wake pass). The patch (see attached Invert-wakeup-queue-order.patch) inverts the wake queue of lockers so the last lockers come first to wake. The results are attached to the same plot as the previous test (see atomic-sub-inverted-queue-*.jpg) It seems that 1 and 2 don't have a visible effect on performance. 3. In the original master patch lock taking is tried twice separated by the cheap spin delay before waiting on a more expensive semaphore. This might explain why the proposed lockless queue patch [1] has a little performance degradation around 20-30 connections. While we don't need two-step lock-taking anymore I've tried to add it to see whether it can improve performance. I've tried different initial spinlock delays from 1 microsecond to 100 milliseconds and 1 or 2 retries (in case the lock is still busy in each case. (see the attached: Extra-spin-waits-for-the-lock-to-be-freed-by-concurr.patch) The results attached (see add-spin-delays-*.jpg) are interesting. Indeed second attempt to take lock after the spin delay will increase performance in any combinations of delays and retries. Also, the delay and the number of retries act in opposite directions to the regions of 20-30 connections and 500+ connections. So we can choose to have a more even performance gain at any number of connections (e.g. 2 retries x 500 microseconds) or better performance at 500+ connections and the same performance as in Andres's patch around 20-30 connections (e.g. 1 retry x 100 milliseconds). 4. I've also collected some statistics for the overall (sum for all backends) number and duration of spin-delays in the same test in Andres Freund's patch gathered using a slightly modified LWLOCK_STATS mechanism. conns / overall spin delays, s / overall number of spin delays / average time of spin delay, ms 20 / 0 / 0 / 0 100 / 1.9 / 1177 / 1.6 200 / 21.9 / 14833 / 1.5 1000 / 12.9 / 11909 / 1.1 2000 / 3.2 / 2297 / 1.4 I've attached v3 of the lockless queue patch with added 2 retries x 500 microseconds spin delay which makes the test results superior to the existing patch, leaves no performance degradation, and with steady performance gain in the whole range of connections. But it's surely worth discussing which parameters we want to have in the production patch. I'm also planning to do the same tests on an ARM server when the free one comes available to me. Thoughts? Regards, Pavel Borisov. [1] https://www.postgresql.org/message-id/CALT9ZEF7q%2BSarz1MjrX-fM7OsoU7CK16%3DONoGCOkY3Efj%2BGrnw%40mail.gmail.com [2] https://www.postgresql.org/message-id/CALT9ZEEz%2B%3DNepc5eti6x531q64Z6%2BDxtP3h-h_8O5HDdtkJcPw%40mail.gmail.com [3] https://www.postgresql.org/message-id/20221031235114.ftjkife57zil7ryw%40awork3.anarazel.de
Attachment
- atomic-sub-inverted-queue-log.jpg
- add-spin-delays-log.jpg
- atomic-sub-inverted-queue-linear.jpg
- add-spin-delays-linear.jpg
- v3-0001-Lockless-queue-of-LWLock-waiters.patch
- Extra-spin-waits-for-the-lock-to-be-freed-by-concurr.patch
- Invert-wakeup-queue-order.patch
- atomic-sub-instead-of-CAS-for-shared-lockers-without.patch
{kind=link}
{kind=link}
{kind=link}
{kind=link}
CFbot isn't happy because of additional patches in the previous message, so here I attach v3 patch alone. Regards, Pavel
Attachment
Hi, Pavel! On Fri, Nov 11, 2022 at 2:40 PM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > I've done some more measurements to check the hypotheses regarding the > performance of a previous patch v2, and explain the results of tests > in [1]. > > The results below are the same (tps vs connections) plots as in [1], > and the test is identical to the insert test in this thread [2]. > Additionally, in each case, there is a plot with results relative to > Andres Freund's patch [3]. Log plots are good for seeing details in > the range of 20-30 connections, but they somewhat hide the fact that > the effect in the range of 500+ connections is much more significant > overall, so I'd recommend looking at the linear plots as well. Thank you for doing all the experiments! BTW, sometimes it's hard to distinguish so many lines on a jpg picture. Could I ask you to post the same graphs in png and also post raw data in csv format? > I'm also planning to do the same tests on an ARM server when the free > one comes available to me. > Thoughts? ARM tests should be great. We definitely need to check this on more than just one architecture. Please, check with and without LSE instructions. They could lead to dramatic speedup [1]. Although, most of precompiled binaries are distributed without them. So, both cases seems important to me so far. From what we have so far, I think we could try combine the multiple strategies to achieve the best result. 2x1ms is one of the leaders before ~200 connections, and 1x1ms is once of the leaders after. We could implement simple heuristics to switch between 1 and 2 retries similar to what we have to spin delays. But let's have ARM results first. Links 1. https://akorotkov.github.io/blog/2021/04/30/arm/ ------ Regards, Alexander Korotkov
Hi, Alexander! > BTW, sometimes it's hard to distinguish so many lines on a jpg > picture. Could I ask you to post the same graphs in png and also post > raw data in csv format? Here are the same pictures in png format and raw data attached. Regards, Pavel.
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hi, hackers! I've noticed that alignment requirements for using pg_atomic_init_u64() for LWlock state (there's an assertion that it's aligned at 8 bytes) do not correspond to the code in SimpleLruInit() on 32-bit arch when MAXIMUM_ALIGNOF = 4. Fixed this in v4 patch (PFA). Regards, Pavel.
Attachment
Hi, hackers! Andres Freund recently committed his nice LWLock optimization a4adc31f6902f6f. So I've rebased the patch on top of the current master (PFA v5). Regards, Pavel Borisov, Supabase.
Attachment
Hi, hackers! In the measurements above in the thread, I've been using LIFO wake queue in a primary lockless patch (and it was attached as the previous versions of a patch) and an "inverted wake queue" (in faсt FIFO) as the alternative benchmarking option. I think using the latter is more fair and natural and provided they show no difference in the speed, I'd make the main patch using it (attached as v6). No other changes from v5, though. Regards, Pavel.
Attachment
On Sat, 26 Nov 2022 at 00:24, Pavel Borisov <pashkin.elfe@gmail.com> wrote: > > Hi, hackers! > In the measurements above in the thread, I've been using LIFO wake > queue in a primary lockless patch (and it was attached as the previous > versions of a patch) and an "inverted wake queue" (in faсt FIFO) as > the alternative benchmarking option. I think using the latter is more > fair and natural and provided they show no difference in the speed, > I'd make the main patch using it (attached as v6). No other changes > from v5, though. There has not been much interest on this as the thread has been idle for more than a year now. I'm not sure if we should take it forward or not. I would prefer to close this in the current commitfest unless someone wants to take it further. Regards, Vignesh
On Sat, 20 Jan 2024 at 07:28, vignesh C <vignesh21@gmail.com> wrote: > > On Sat, 26 Nov 2022 at 00:24, Pavel Borisov <pashkin.elfe@gmail.com> wrote: > > > > Hi, hackers! > > In the measurements above in the thread, I've been using LIFO wake > > queue in a primary lockless patch (and it was attached as the previous > > versions of a patch) and an "inverted wake queue" (in faсt FIFO) as > > the alternative benchmarking option. I think using the latter is more > > fair and natural and provided they show no difference in the speed, > > I'd make the main patch using it (attached as v6). No other changes > > from v5, though. > > There has not been much interest on this as the thread has been idle > for more than a year now. I'm not sure if we should take it forward or > not. I would prefer to close this in the current commitfest unless > someone wants to take it further. I have returned this patch in commitfest as nobody had shown any interest in pursuing it. Feel free to add a new entry when someone wants to work on this more actively. Regards, Vignesh